

Online Assessment of Cross-Linguistic Similarity as a Measure of L2 Perceptual Categorization Accuracy



Abstract
1. Introduction
2. Background
2.1. Measuring Cross-Language Similarity
2.2. Cross-Language Lexical Competition
2.3. Asymmetrical Lexical Access
2.4. The Current Study
RQ1: Do Catalan learners of English exhibit asymmetric levels of cross-language lexical competition between the dominant and the non-dominant L2 vowel categories in the confusable English vowel pairs /iː/-/ɪ/ and /æ/-/ʌ/ and their corresponding L1 vowel categories /i/ and /a/?
RQ2: To what extent are asymmetries in the strength of cross-language lexical competition related to differences in cross-linguistic perceptual similarity?
3. Experiment 1: Perceived Similarity between English and Catalan Vowels
3.1. Methods and Materials
3.1.1. Participants
3.1.2. Target Sounds
3.1.3. Stimuli
3.1.4. Procedure
3.2. Results
3.3. Interim Discussion
4. Experiment 2: Cross-Language Lexical Competition
4.1. Methods and Materials
4.1.1. Participants
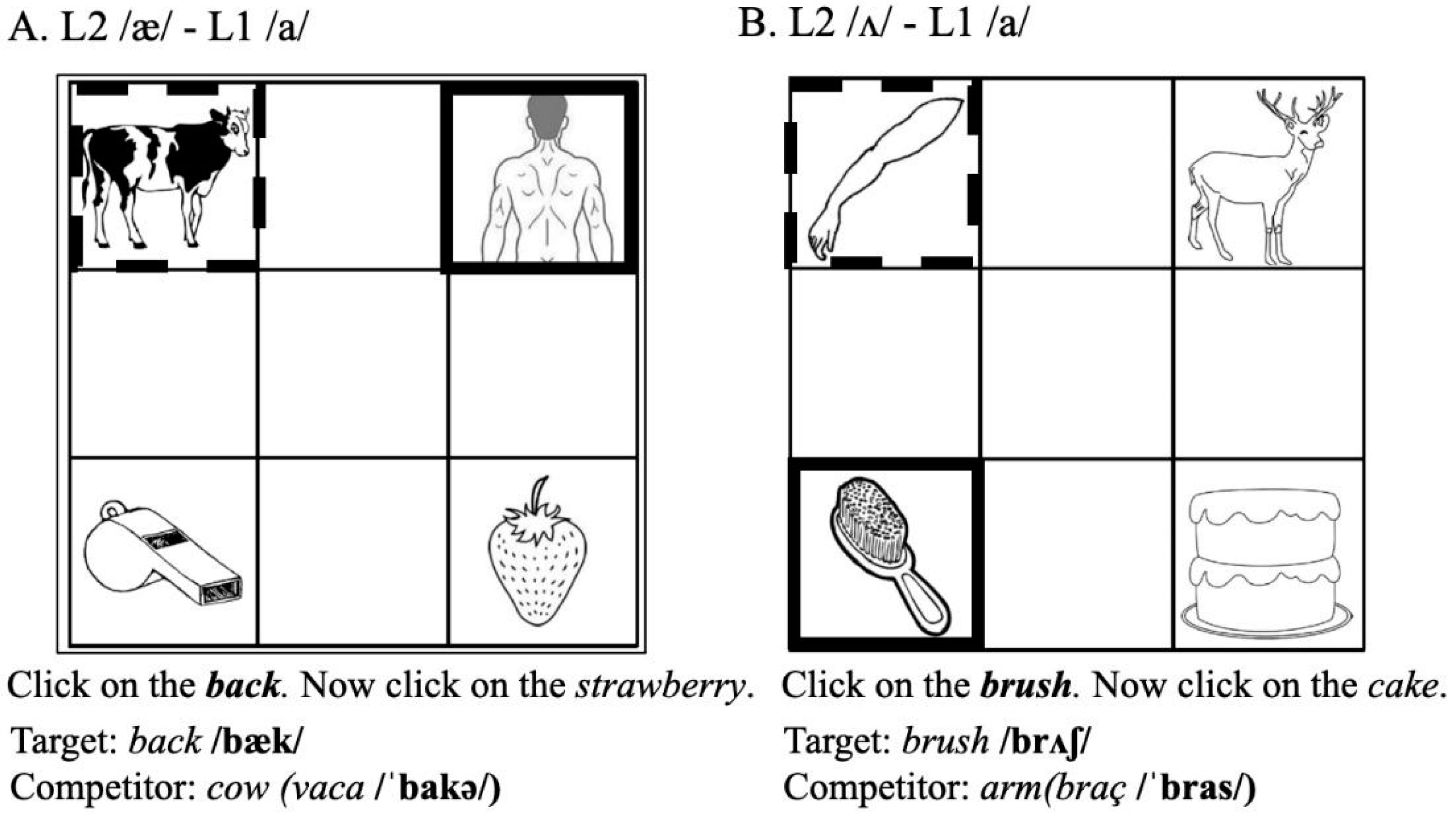
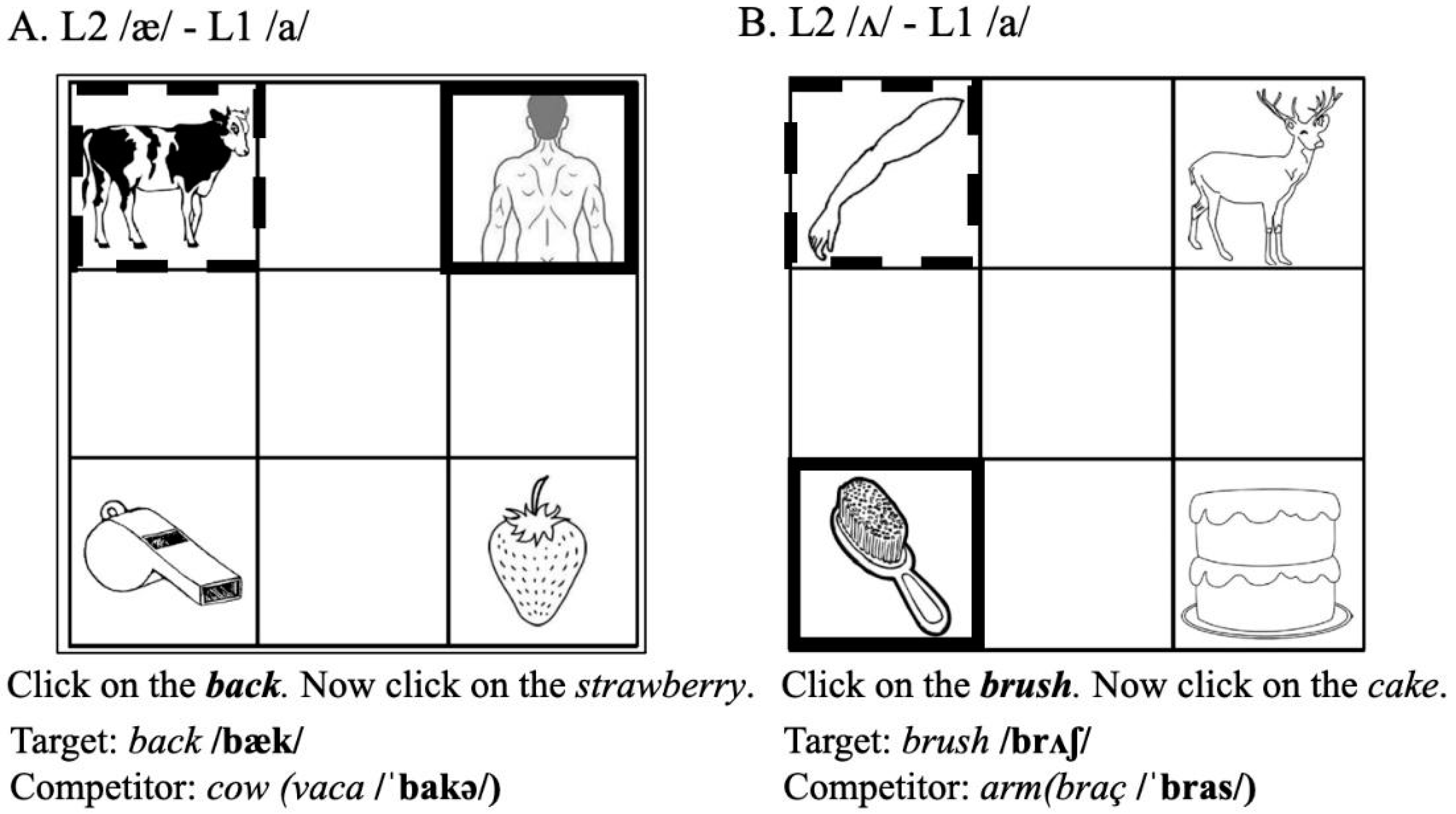
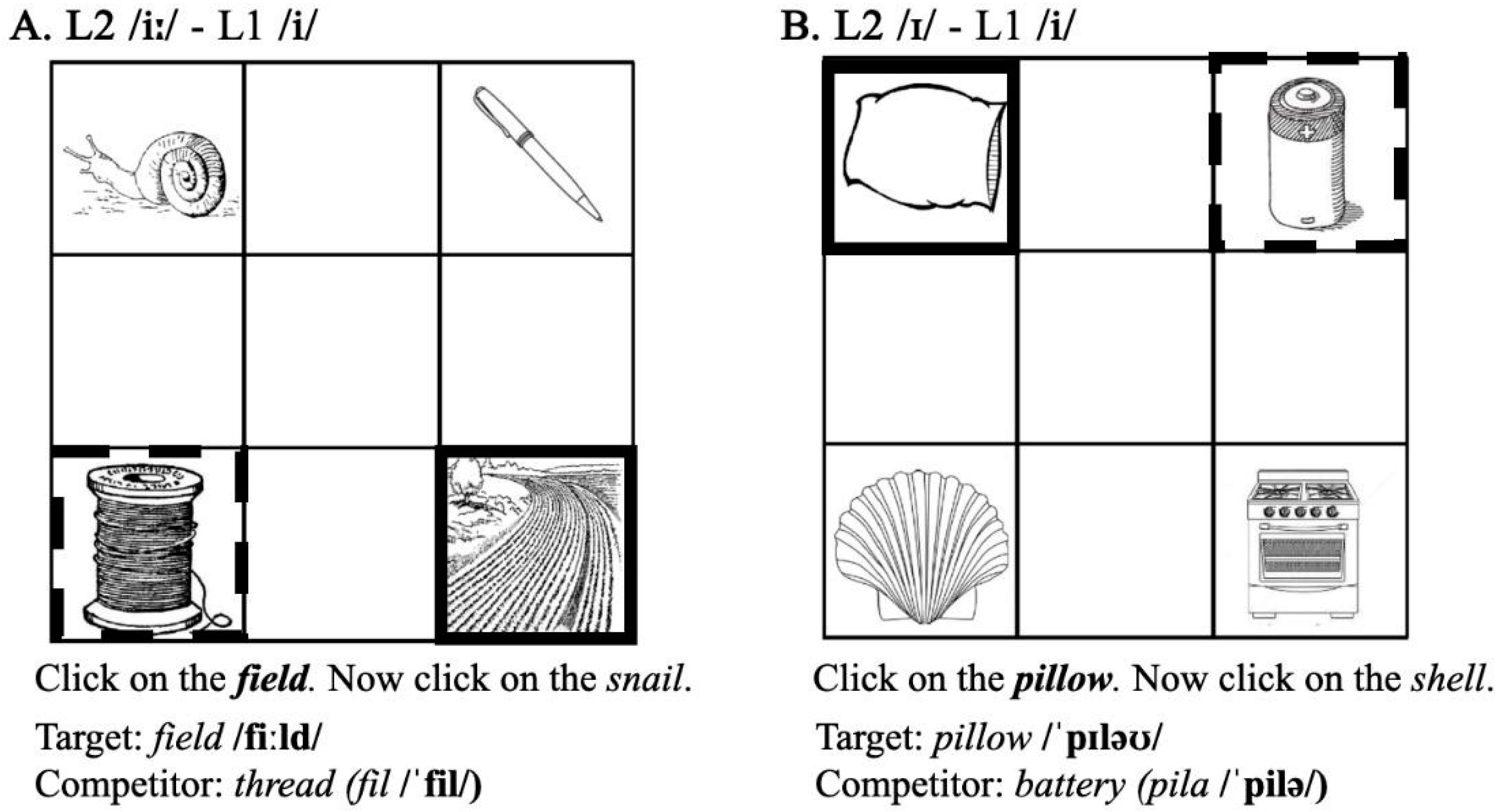
4.1.2. Cross-Language Lexical Competition Task
4.1.3. Stimuli and Task Design
4.1.4. Procedures
4.1.5. Data Analysis
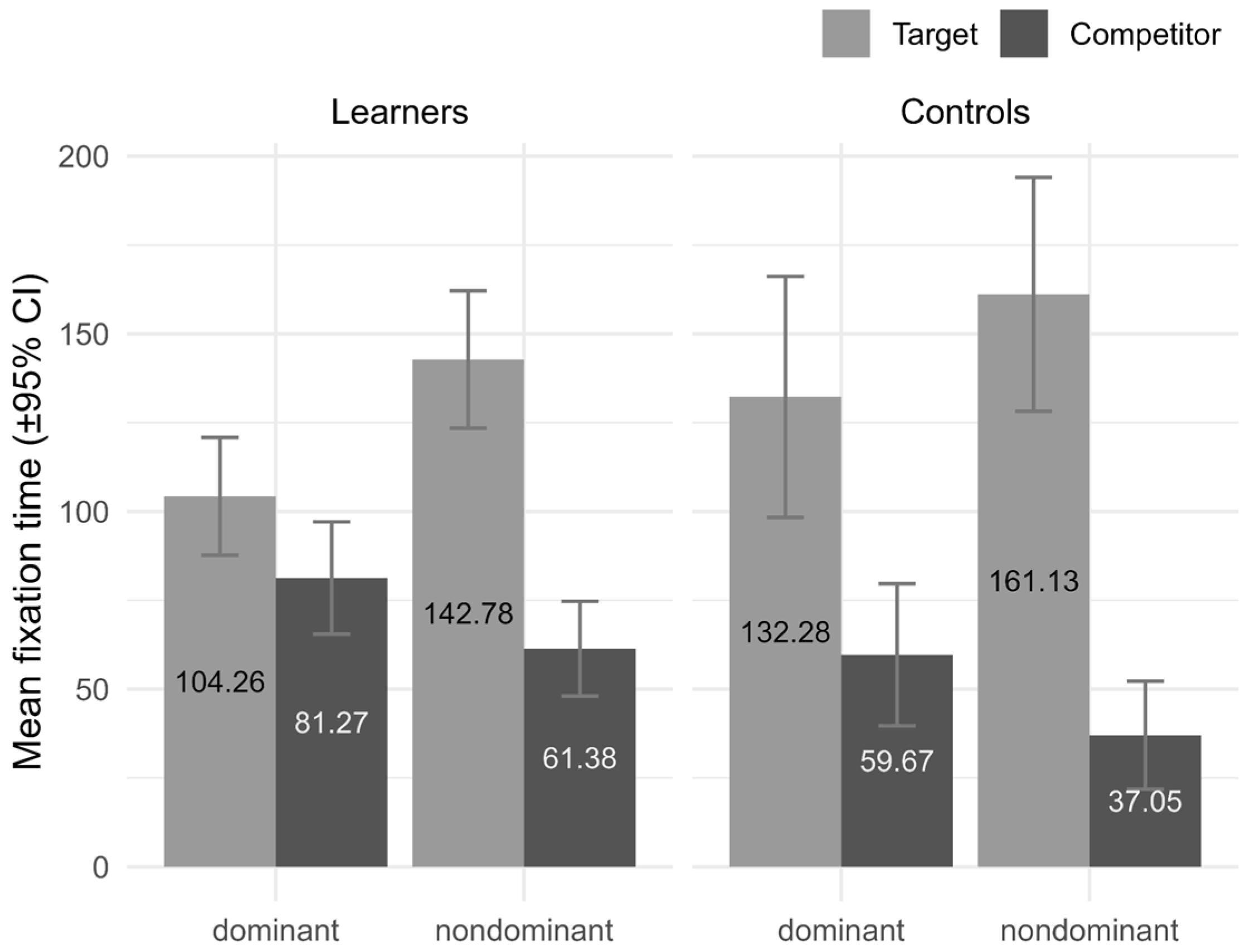
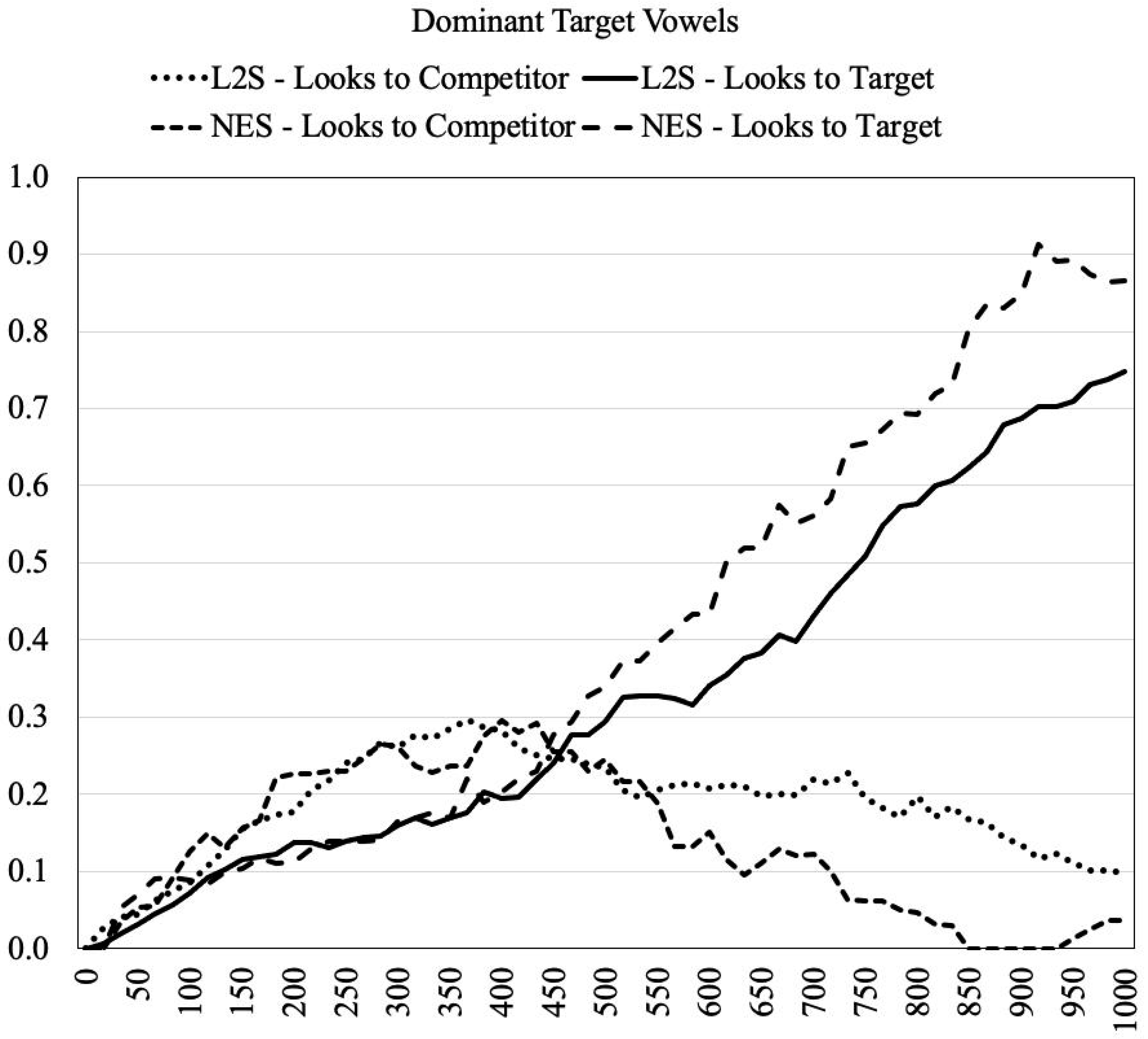
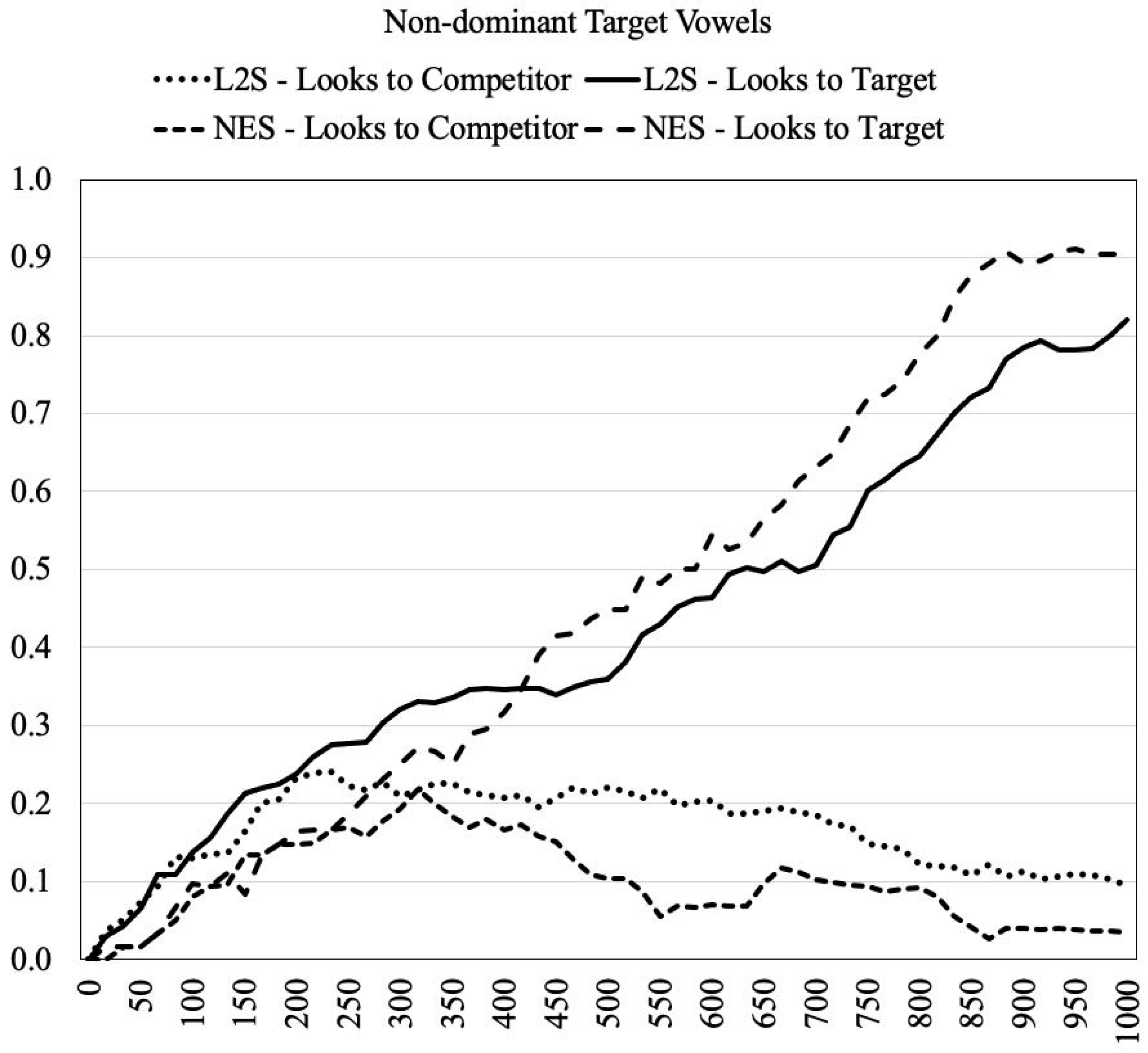
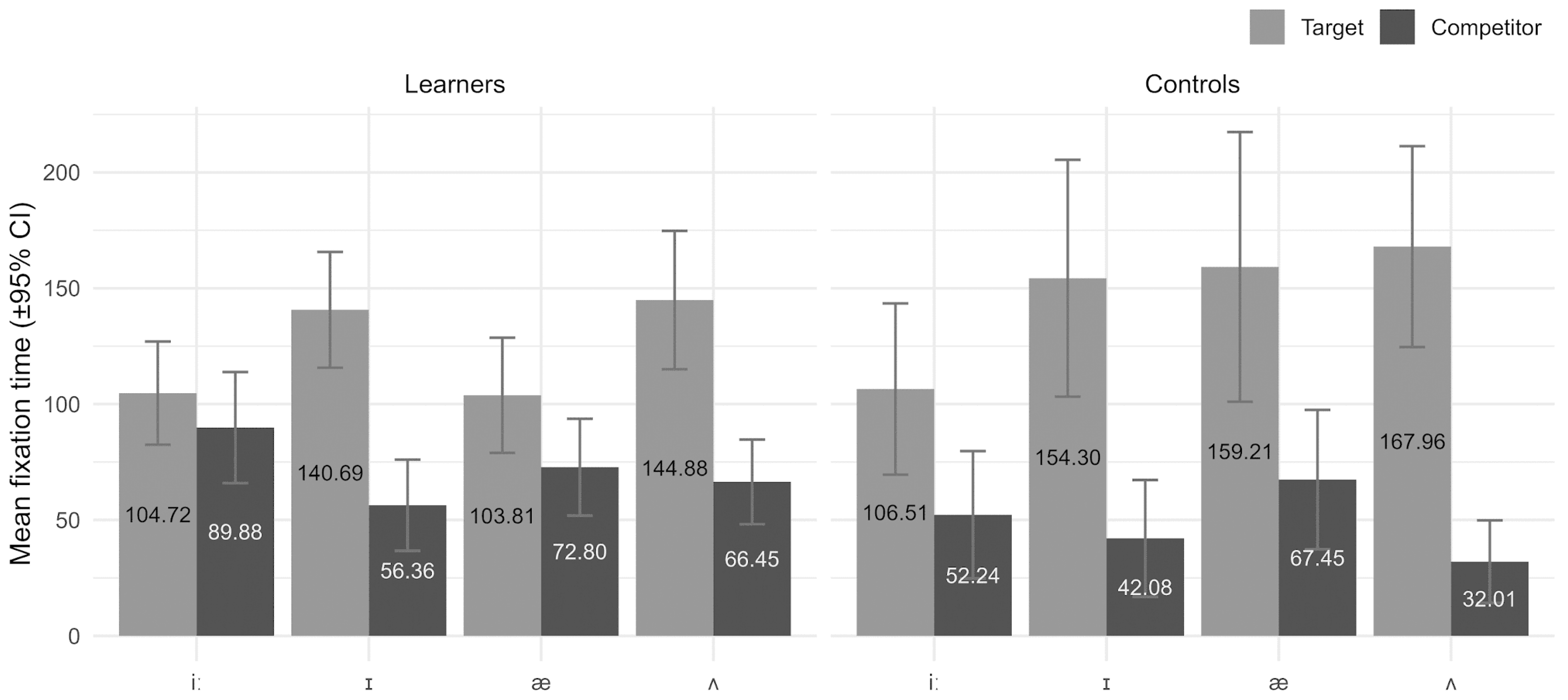
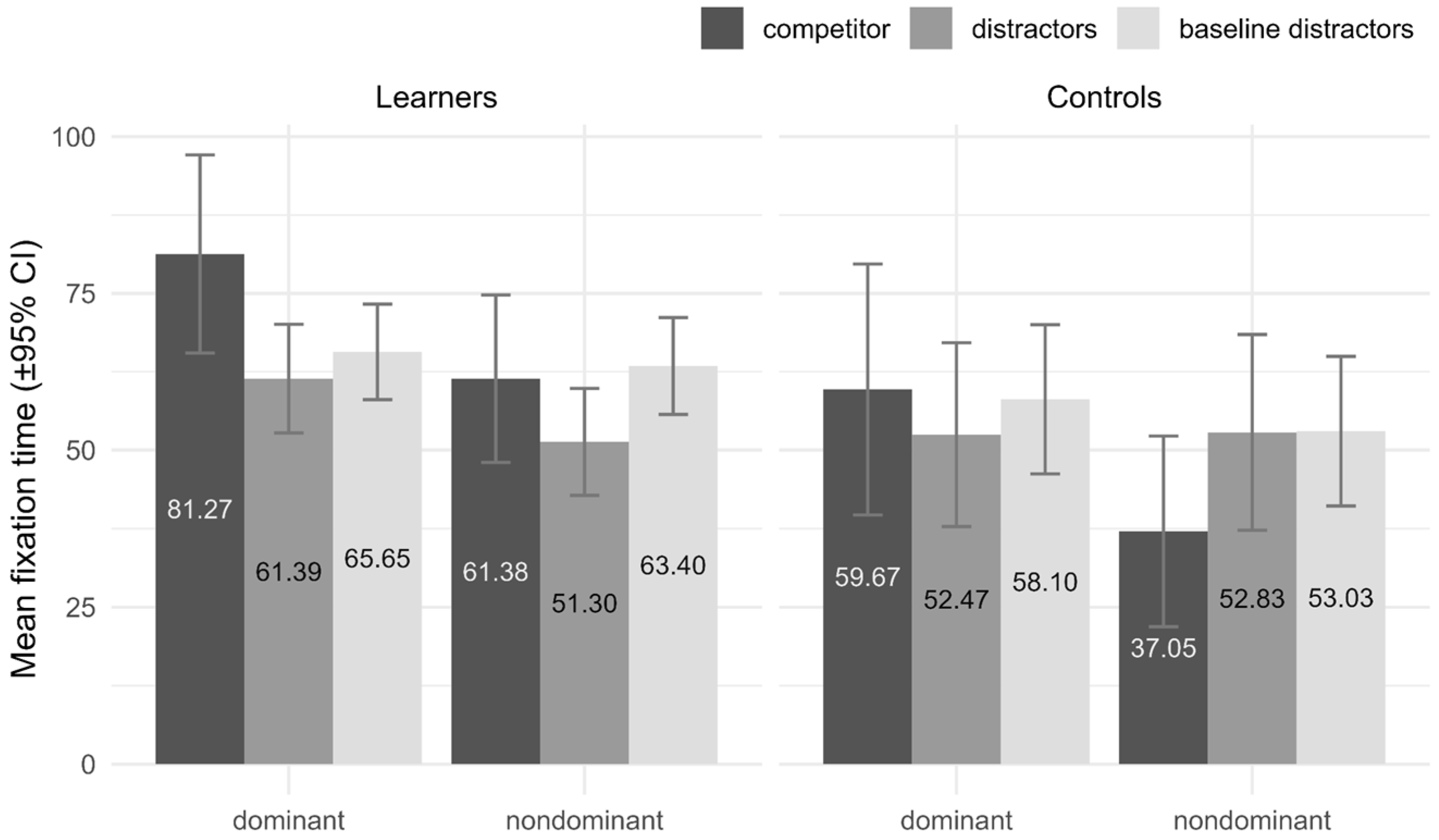
4.2. Results
4.3. Interim Discussion
5. Relationship between Perceptual Assimilation and Lexical Competition Measures
6. General Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| glmmTMB (fixdur_norm~group * dominance * contrast * aoi + (1|subject) + (1|item), data). | |||||
| Predictors | β | SE | CI | t | p |
| Intercept | 0.161 | 0.097 | −0.029–0.350 | 1.664 | 0.096 |
| group [NES] | −0.257 | 0.144 | −0.540–0.025 | −1.788 | 0.074 |
| dominance [non-dominant] | −0.25 | 0.137 | −0.518–0.018 | −1.828 | 0.068 |
| height [low] | −0.096 | 0.136 | −0.363–0.172 | −0.702 | 0.483 |
| aoi [target] | 0.134 | 0.107 | −0.075–0.343 | 1.258 | 0.208 |
| group [NES] × dominance [non-dominant] | 0.132 | 0.202 | −0.264–0.528 | 0.653 | 0.514 |
| group [NES] × height [low] | 0.197 | 0.205 | −0.205–0.599 | 0.959 | 0.338 |
| dominance [non-dominant] × height [low] | 0.18 | 0.193 | −0.199–0.558 | 0.93 | 0.352 |
| group [NES] × aoi [target] | 0.272 | 0.204 | −0.127–0.671 | 1.334 | 0.182 |
| dominance [non-dominant] × aoi [target] | 0.502 | 0.151 | 0.207–0.797 | 3.333 | 0.001 |
| height [low] × aoi [target] | 0.052 | 0.15 | −0.242–0.346 | 0.344 | 0.731 |
| group [NES] × dominance [non-dominant]) × height [low] | −0.302 | 0.287 | −0.864–0.260 | −1.052 | 0.293 |
| group [NES] × dominance [non-dominant]) × aoi [target] | −0.128 | 0.286 | −0.688–0.432 | −0.449 | 0.654 |
| group [NES] × height [low]) × aoi [target] | 0.159 | 0.29 | −0.409–0.727 | 0.548 | 0.584 |
| dominance [non-dominant] × height [low]) × aoi [target] | −0.158 | 0.213 | −0.576–0.259 | −0.744 | 0.457 |
| group [NES] × dominance [non-dominant] × height [low]) × aoi [target] | 0.161 | 0.406 | −0.635–0.956 | 0.396 | 0.692 |
| Random Effects | |||||
| σ2 | 0.69 | ||||
| τ00 subject | 0 | ||||
| τ00 item | 0.01 | ||||
| N subject | 61 | ||||
| N item | 12 | ||||
| Observations | 1350 | ||||
| Marginal R2/Conditional R2 | 0.096/NA | ||||
| glmmTMB (fixdur_norm~group * dominance * aoi + (1|subject) + (1|item), data). | |||||
| Predictors | β | SE | CI | t | p |
| Intercept | 0.113 | 0.068 | −0.021–0.246 | 1.651 | 0.099 |
| group [NES] | −0.16 | 0.103 | −0.361–0.042 | −1.556 | 0.120 |
| dominance [non-dominant] | −0.16 | 0.097 | −0.349–0.030 | −1.654 | 0.098 |
| aoi [target] | 0.16 | 0.075 | 0.013–0.307 | 2.129 | 0.033 |
| group [NES] × dominance [non-dominant] | −0.018 | 0.144 | −0.300–0.264 | −0.126 | 0.900 |
| group [NES] × aoi [target] | 0.349 | 0.145 | 0.064–0.633 | 2.399 | 0.016 |
| dominance [non-dominant] × aoi [target] | 0.423 | 0.107 | 0.214–0.632 | 3.966 | <0.001 |
| group [NES] × dominance [non-dominant]) × aoi [target] | −0.046 | 0.203 | −0.444–0.353 | −0.224 | 0.823 |
| Random Effects | |||||
| σ2 | 0.7 | ||||
| τ00 subject | 0 | ||||
| τ00 item | 0.01 | ||||
| N subject | 61 | ||||
| N item | 12 | ||||
| Observations | 1350 | ||||
| Marginal R2/Conditional R2 | 0.091/NA | ||||
| glmmTMB (fixdur_norm~group * dominance * aoi + (1|subject) + (1|item), data). | |||||
| Predictors | β | SE | CI | t | p |
| Intercept | 0.112 | 0.045 | 0.023–0.200 | 2.472 | 0.013 |
| group [NES] | −0.161 | 0.078 | −0.313–−0.008 | −2.065 | 0.039 |
| dominance [non-dominant] | −0.158 | 0.064 | −0.284–−0.033 | −2.471 | 0.013 |
| aoi [dist] | −0.138 | 0.057 | −0.250–−0.026 | −2.423 | 0.015 |
| group [NES] × dominance [non-dominant] | −0.017 | 0.109 | −0.231–0.196 | −0.159 | 0.873 |
| group [NES] × aoi [dist] | 0.091 | 0.11 | −0.125–0.307 | 0.824 | 0.410 |
| dominance [non-dominant] × aoi [dist] | 0.066 | 0.081 | −0.093–0.224 | 0.816 | 0.415 |
| group [NES] × dominance [non-dominant]) × aoi [dist] | 0.071 | 0.154 | −0.231–0.373 | 0.461 | 0.645 |
| Random Effects | |||||
| σ2 | 0.40 | ||||
| τ00 subject | 0.00 | ||||
| τ00 item | 0.00 | ||||
| N subject | 61 | ||||
| N item | 12 | ||||
| Observations | 1350 | ||||
| Marginal R2/Conditional R2 | 0.021/NA | ||||
| 1 | The same pattern of cross-linguistic perceived assimilation is observed for English /æ ʌ ɑː/ with respect to Catalan /a/ (Cebrian 2021). |
| 2 | The results for the remaining vowels were the following: SSBE /e/ 76% as Catalan /ɛ/ (GR: 5.6 out of 7) and 24% as /e/ (GR: 4.5); SSBE /eɪ/ 92% as Catalan /ei/ (GR: 4.8) and 7% as /ai/ (GR: 3.4); SSBE /aɪ/ 98% as Catalan /ai/ (GR: 4.5). These results are in line with previous findings (e.g., Cebrian 2021). |
| 3 | The lexical frequency indices were obtained from the SUBTLEXus resource for English (Brysbaert and New 2009) and the SUBTLEXcat resource for Catalan (NIM, Guasch et al. 2013), which indicate the relative frequency of a word per one million words. |
References
- Alario, F-Xavier, and Ludovic Ferrand. 1999. A set of 400 pictures standardized for French: Norms for name agreement, image agreement, familiarity, visual complexity, image variability, and age of acquisition. Behavior Research Methods, Instruments, & Computers 31: 531–52. [Google Scholar] [CrossRef]
- Allopenna, Paul D., James S. Magnuson, and Michael K. Tanenhaus. 1998. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language 38: 419–39. [Google Scholar] [CrossRef]
- Best, Catherine T. 1995. A direct realist view of cross-language speech perception. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues. Edited by Winifred Strange. Timonium: York Press, pp. 171–204. [Google Scholar]
- Best, Catherine T., and Michael D. Tyler. 2007. Non-native and second language speech perception. In Language Experience in Second Language Speech Learning. In Honor of James Emil Flege. Edited by Ocke-Schewn Bohn and Murray J. Munro. Amsterdam: John Benjamins, pp. 15–34. [Google Scholar] [CrossRef]
- Birdsong, David, Libby M. Gertken, and Mark Amengual. 2012. Bilingual Language Profile: An Easy-to-Use Instrument to Assess Bilingualism. COERLL, University of Texas at Austin. Web. Available online: https://sites.la.utexas.edu/bilingual/ (accessed on 20 January 2012).
- Bohn, Ocke-Schewn. 2002. On phonetic similarity. In An Integrated View of Language Development: Papers in Honor of Henning Wode. Edited by Petra Burmeister, Thorsten Piske and Andreas Rohde. Trier: Wissenschaftlicher Verlag, pp. 191–216. [Google Scholar]
- Bohn, Ocke-Schewn. 2017. Cross-language and second language speech perception. In The Handbook of Psycholinguistics. Edited by Eva M. Fernández and Helen Smith Cairns. Chichester: Wiley-Blackwell, pp. 213–39. [Google Scholar]
- Bonin, Patrick, Ronald Peereman, Nathalie Malardier, Alain Méot, and Marylène Chalard. 2003. A new set of 299 pictures for psycholinguistic studies: French norms for name agreement, image agreement, conceptual familiarity, visual complexity, image variability, age of acquisition, and naming latencies. Behavior Research Methods, Instruments, & Computers 35: 158–67. [Google Scholar] [CrossRef]
- Brooks, Mollie E., Kasper Kristensen, Koen J. Van Benthem, Arni Magnusson, Casper W. Berg, Anders Nielsen, Hans J. Skaug, Martin Machler, and Benjamin M. Bolker. 2017. GlmmTMB balances speed and flexibility among packages for zero-inflated generalized linear mixed modelling. The R Journal 9: 378–400. [Google Scholar] [CrossRef]
- Brysbaert, Marc, and Boris New. 2009. Moving beyond Kucera and Francis: A Critical Evaluation of Current Word Frequency Norms and the Introduction of a New and Improved Word Frequency Measure for American English. Behavior Research Methods 41: 977–90. [Google Scholar] [CrossRef]
- Cebrian, Juli. 2006. Experience and the use of non-native duration in L2 vowel categorization. Journal of Phonetics 34: 372–87. [Google Scholar] [CrossRef]
- Cebrian, Juli. 2019. Perceptual assimilation of British English vowels to Spanish monophthongs and diphthongs. Journal of the Acoustical Society of America 145: EL52–EL58. [Google Scholar] [CrossRef]
- Cebrian, Juli. 2021. Perception of English and Catalan vowels by English and Catalan listeners: A study of reciprocal cross-linguistic similarity. Journal of the Acoustical Society of America 149: 2671–85. [Google Scholar] [CrossRef]
- Cebrian, Juli. 2022. Perception of English and Catalan vowels by English and Catalan listeners. Part II. Perceptual vs ecphoric similarity. Journal of the Acoustical Society of America 152: 2781–93. [Google Scholar] [CrossRef] [PubMed]
- Cebrian, Juli, Joan C. Mora, and Cristina Aliaga García. 2011. Assessing cross-linguistic similarity by means of rated discrimination and perceptual assimilation tasks. In Achievements and Perspectives in the Acquisition of Second Language Speech: New Sounds 2010. Edited by Magdalena Wrembel, Małgorzata Kul and Katarzyna Dziubalska-Kołaczyk. Frankfurt am Main: Peter Lang, vol. I, pp. 41–52. [Google Scholar]
- Chambers, Craig G., and Hilary Cooke. 2009. Lexical competition during second-language listening: Sentence context, but not proficiency, constrains interference from the native lexicon. Journal of Experimental Psychology: Learning Memory and Cognition 35: 1029–40. [Google Scholar] [CrossRef] [PubMed]
- Cutler, Anne, Andrea Weber, and Takashi Otake. 2006. Asymmetric mapping from phonetic to lexical representations in second-language listening. Journal of Phonetics 34: 269–84. [Google Scholar] [CrossRef]
- Dahan, Delphine, and Michael K. Tanenhaus. 2005. Looking at the rope when looking for the snake: Conceptually mediated eye movements during spoken-word recognition. Psychonomic Bulletin & Review 12: 453–59. [Google Scholar] [CrossRef]
- Dahan, Delphine, James S. Magnuson, and Michael K. Tanenhaus. 2001. Time course of frequency effects in spoken-word recognition in French. Cognitive Psychology 42: 317–67. [Google Scholar] [CrossRef] [PubMed]
- Escudero, Paola, Rachel Hayes-Harb, and Holger Mitterer. 2008. Novel second-language words and asymmetric lexical access. Journal of Phonetics 36: 345–60. [Google Scholar] [CrossRef]
- Faris, Mona M., Catherine T. Best, and Michael D. Tyler. 2018. Discrimination of uncategorised non-native vowel contrasts is modulated by perceived overlap with native phonological categories. Journal of Phonetics 70: 1–19. [Google Scholar] [CrossRef]
- Flege, James Emil. 1995. Second-language Speech Learning: Theory, Findings, and Problems. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues. Edited by Winifred Strange. Timonium: York Press, pp. 229–73. [Google Scholar]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The revised speech learning model (SLM-r). In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by R. Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar] [CrossRef]
- Flege, James Emil, Murray J. Munro, and Robert Allen Fox. 1994. Auditory and categorical effects on cross-language vowel perception. The Journal of the Acoustical Society of America 95: 3623–41. [Google Scholar] [CrossRef] [PubMed]
- Guasch, Marc, Roger Boada, Pilar Ferré, and Rosa Sánchez-Casas. 2013. NIM: A Web-based Swiss Army knife to select stimuli for psycholinguistic studies. Behavior Research Methods 45: 765–71. [Google Scholar] [CrossRef] [PubMed]
- Guion, Susan G., James Emile Flege, Reiko Akahane-Yamada, and Jesica C. Pruitt. 2000. An investigation of current models of second language speech perception: The case of Japanese adults’ perception of English consonants. Journal of the Acoustical Society of America 107: 2711–24. [Google Scholar] [CrossRef]
- Iverson, Paul, Patricia K. Kuhl, Reiko Akahane-Yamada, Eugen Diesch, Andreas Kettermann, and Claudia Siebert. 2003. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition 87: B47–B57. [Google Scholar] [CrossRef]
- Ju, Min, and Paul A. Luce. 2004. Falling on sensitive ears: Constraints on bilingual lexical activation. Psychological Science 15: 314–18. [Google Scholar] [CrossRef]
- Kuhl, Patricia K., Barbara T. Conboy, Sharon Coffey-Corina, Denise Padden, Maritza Rivera-Gaxiola, and Tobey Nelson. 2008. Phonetic learning as a pathway to language: New data and native language magnet theory expanded (NLM-e). Philosophical Transactions of the Royal Society B 363: 979–1000. [Google Scholar] [CrossRef]
- Levy, Erika S. 2009. Language experience and consonantal context effects on perceptual assimilation of French vowels by American-English learners of French. Journal of the Acoustical Society of America 125: 1138–52. [Google Scholar] [CrossRef]
- Marian, Viorica, and Michael Spivey. 2003. Competing activation in bilingual language processing. Bilingualism: Language and Cognition 6: 97–115. [Google Scholar] [CrossRef]
- Meara, Paul M., and James Milton. 2003. X-lex: The Swansea Levels Test. Berkshire: Express Publishing. [Google Scholar]
- Mora, Joan C., and Ingrid Mora-Plaza. 2019. Contributions of cognitive attention control to L2 speech learning. In A Sound Approach to Language Matters—In Honor of Ocke-Schwen Bohn. Edited by Anne Mette Nyvad, Michaela Hejná, Anders Højen, Anna Bothe Jespersen and Mette Hjortshøj Sørensen. Aarhus: Department of English, School of Communication & Culture, Aarhus University, pp. 477–99. [Google Scholar]
- Peterson, Ryan A. 2021. Finding optimal normalizing transformations via bestNormalize. The R Journal 13: 310–29. [Google Scholar] [CrossRef]
- Peterson, Ryan A., and Joseph E. Cavanaugh. 2020. Ordered quantile normalization: A semiparametric transformation built for the cross-validation era. Journal of Applied Statistics 47: 2312–27. [Google Scholar] [CrossRef]
- Rallo Fabra, Lucrècia. 2005. Predicting ease of acquisition of L2 speech sounds: A perceived dissimilarity test. Vigo International Journal of Applied Linguistics 2: 75–92. [Google Scholar]
- Snodgrass, Joan G., and Mary Vanderwart. 1980. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory 6: 174–215. [Google Scholar] [CrossRef]
- Spivey, Michael J., and Viorica Marian. 1999. Cross talk between native and second languages: Partial activation of an irrelevant lexicon. Psychological Science 10: 281–84. [Google Scholar] [CrossRef]
- Strange, Winifred. 2007. Cross-language similarity of vowels. Theoretical and methodological issues. In Language Experience in Second Language Speech Learning. Edited by Ocke-Schewn Bohn and Murray J. Munro. Amsterdam: John Benjamins, pp. 35–55. [Google Scholar] [CrossRef]
- Strange, Winifred, Erika S. Levy, and Franzo F. Law. 2009. Cross-language categorization of French and German vowels by naïve American listeners. The Journal of the Acoustical Society of America 126: 1461–76. [Google Scholar] [CrossRef]
- Tanenhaus, Michael K., Michael J. Spivey-Knowlton, Kathleen M. Eberhard, and Julie C. Sedivy. 1995. Integration of visual and linguistic information in spoken language comprehension. Science 268: 1632–34. [Google Scholar] [CrossRef]
- Tsang, Cara, and Craig G. Chambers. 2011. Appearances aren’t everything: Shape classifiers and referential processing in Cantonese. Journal of Experimental Psychology: Learning, Memory, and Cognition 37: 1065–80. [Google Scholar] [CrossRef] [PubMed]
- Tyler, Michael D. 2021. Phonetic and phonological influences on the discrimination of non-native phones. In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 157–74. [Google Scholar] [CrossRef]
- Tyler, Michael D., Catherine T. Best, Alice Faber, and Andrea G. Levitt. 2014. Perceptual assimilation and discrimination of non-native vowel contrasts. Phonetica 71: 4–21. [Google Scholar] [CrossRef] [PubMed]
- Weber, Andrea, and Anne Cutler. 2004. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language 50: 1–25. [Google Scholar] [CrossRef]

| SSBE Vowel | L1 Vowel | % Assimilation | GR (Out of 7) | Fit Index (Max 7) |
|---|---|---|---|---|
| /æ/ | /a/ | 100 | 5.4 | 5.4 |
| /ʌ/ | /a/ | 97.5 | 4.5 | 4.4 |
| /iː/ | /i/ | 96 | 5.5 | 5.3 |
| /ɪ/ | /i/ | 46.2 | 4.5 | 2.1 |
| /e/ | 46.6 | 5.2 | 2.4 |
| English Vowel | Target Word | Competitor Object | Catalan Word |
|---|---|---|---|
| /æ/ | back | cow | vaca /ˈbakə/ |
| /æ/ | carrot | face | cara /ˈkaɾə/ |
| /æ/ | man | sleeve | màniga /ˈmanigə/ |
| /ʌ/ | brush | arm | braç /bɾas/ |
| /ʌ/ | money | blanket | manta /ˈmantə/ |
| /ʌ/ | nuts | whipped cream | nata /ˈnatə/ |
| /iː/ | field | thread | fil /fil/ |
| /iː/ | bee | wine | vi /bi/ |
| /iː/ | beetle | glass | vidre /ˈbiðɾə/ |
| /ɪ/ | pillow | battery | pila /ˈpilə/ |
| /ɪ/ | sink | five | cinc /siŋ/ |
| /ɪ/ | fish | poker chips | fitxa /ˈfitʃə/ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cebrian, J.; Mora, J.C. Online Assessment of Cross-Linguistic Similarity as a Measure of L2 Perceptual Categorization Accuracy. Languages 2024, 9, 152. https://doi.org/10.3390/languages9050152
Cebrian J, Mora JC. Online Assessment of Cross-Linguistic Similarity as a Measure of L2 Perceptual Categorization Accuracy. Languages. 2024; 9(5):152. https://doi.org/10.3390/languages9050152
Chicago/Turabian StyleCebrian, Juli, and Joan C. Mora. 2024. "Online Assessment of Cross-Linguistic Similarity as a Measure of L2 Perceptual Categorization Accuracy" Languages 9, no. 5: 152. https://doi.org/10.3390/languages9050152
APA StyleCebrian, J., & Mora, J. C. (2024). Online Assessment of Cross-Linguistic Similarity as a Measure of L2 Perceptual Categorization Accuracy. Languages, 9(5), 152. https://doi.org/10.3390/languages9050152