


Exploring the Accent Mix Perceptually and Automatically: French Learners of English and the RP–GA Divide




Abstract
1. Introduction
2. Materials and Methods
2.1. Audio Recordings
2.2. Auditory Assessment
2.3. Automatic Speech Recognition
2.4. Automatic Accent Identification
3. Results
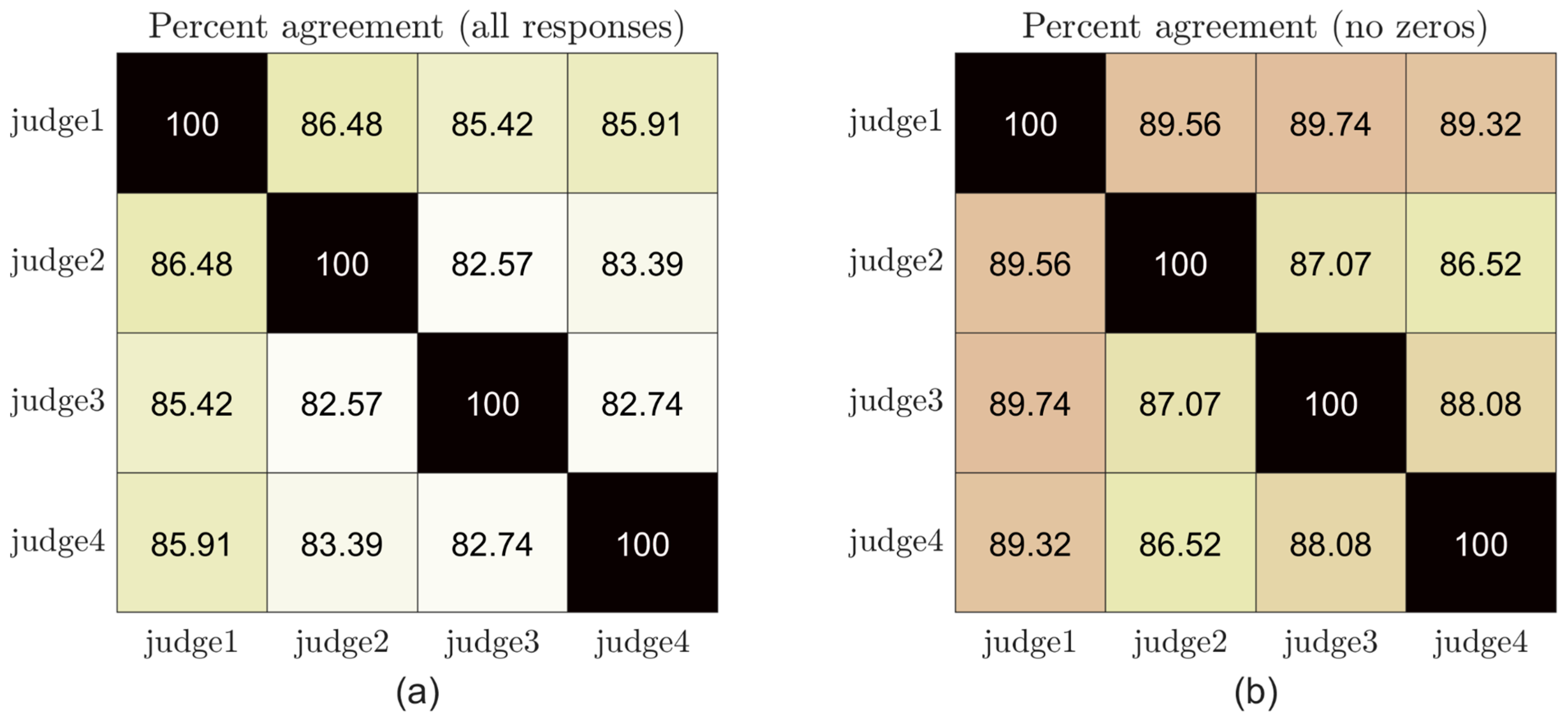
3.1. Auditory Assessment
3.1.1. Four Phonological Features
3.1.2. Accent Profiles
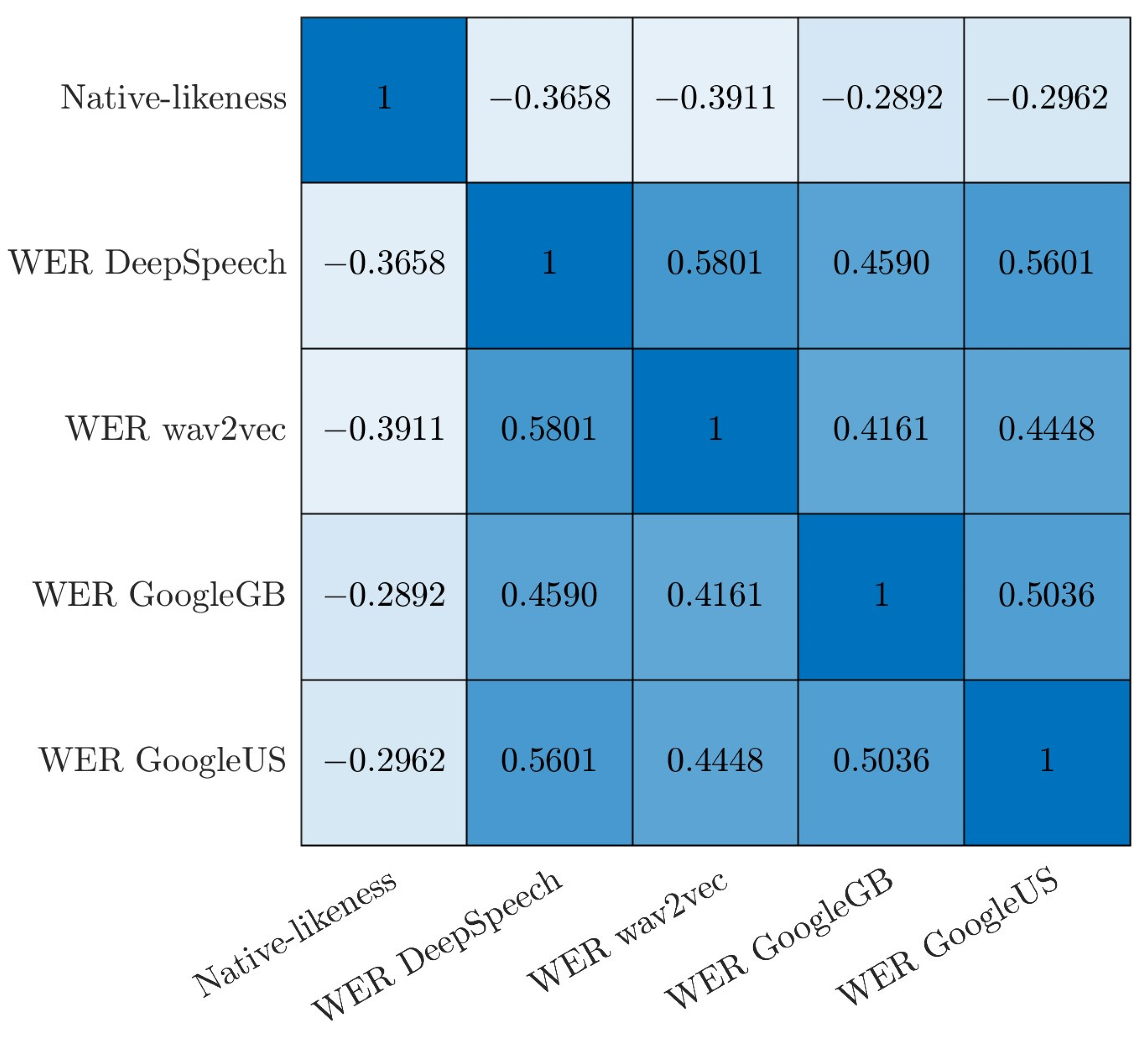
3.1.3. Native-Likeness
3.2. Automatic Speech Recognition
3.2.1. ASR: Results by Model
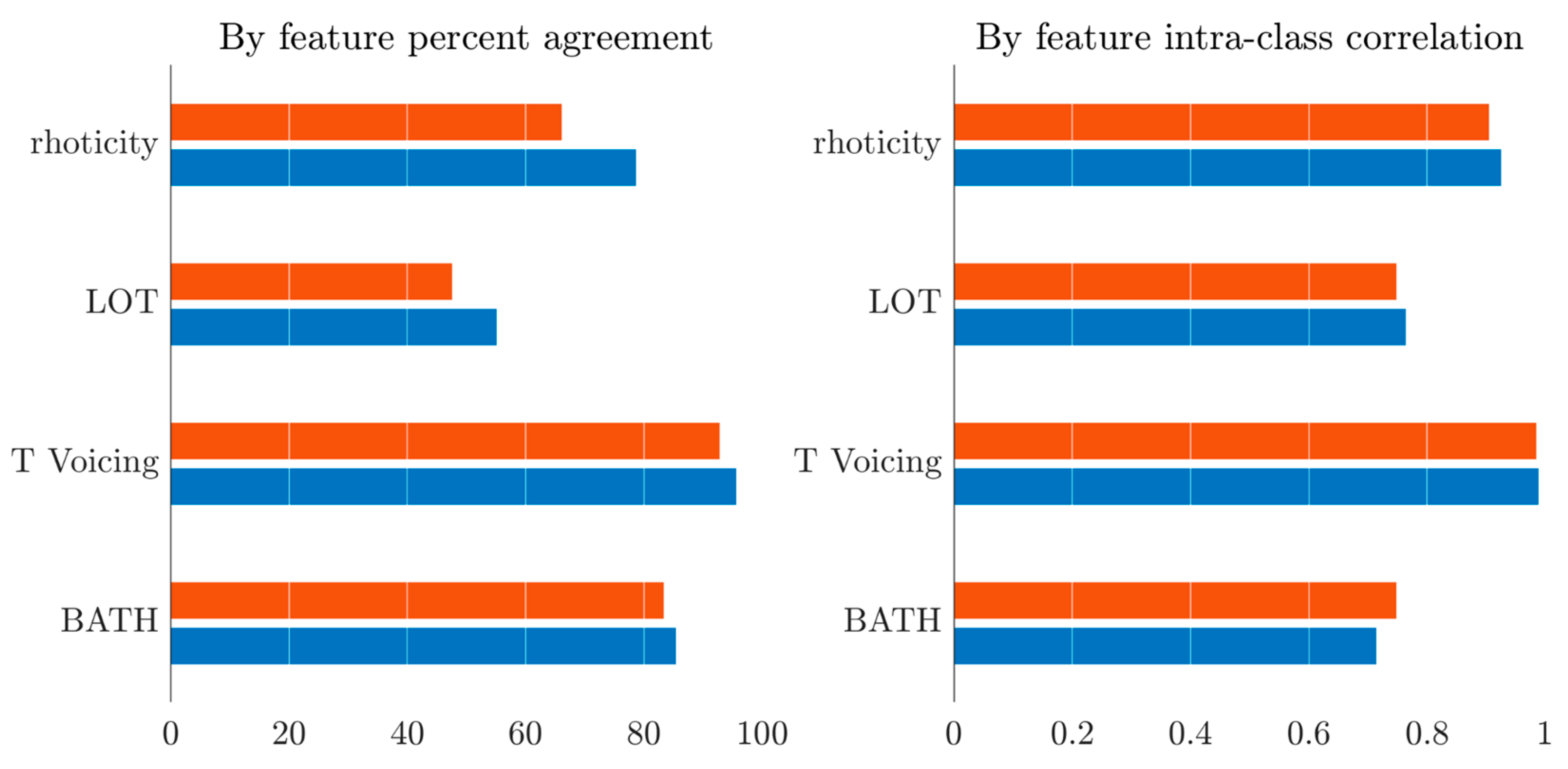
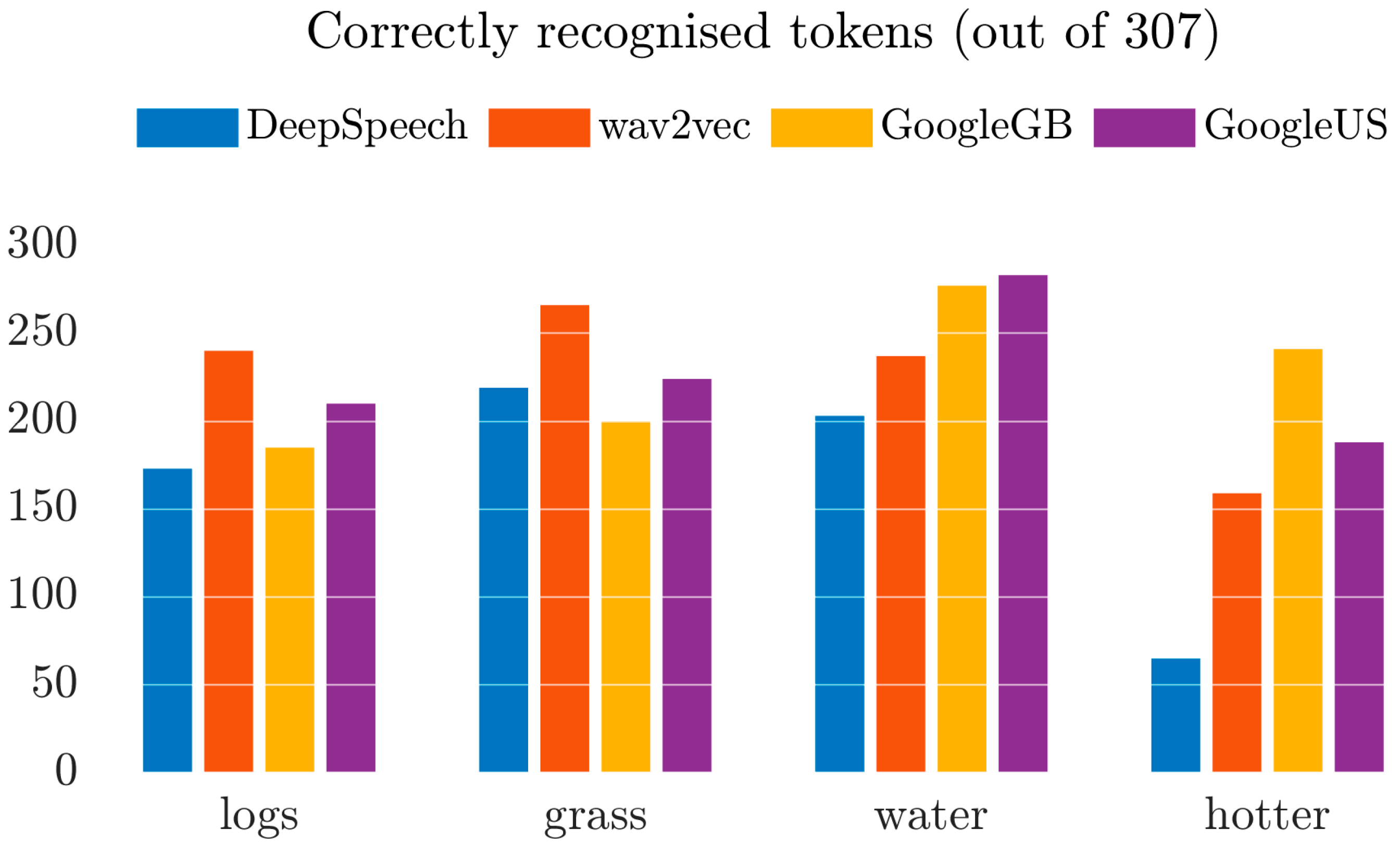
3.2.2. ASR: Results by Feature
3.2.3. ASR: Results by Accent
3.3. Automatic Accent Identification
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- (1)
- I knew I ought to have asked google dot com. It’s better and faster than a secretary.
- (2)
- I have the last-minute pleasure to introduce that new volatile character from Marge Butterfly’s novel.
- (3)
- Who cared when the Duke got shot at in a bitter blast up in North New Jersey last January.
- (4)
- Are you sure grasping Harry Potter will turn you into an extraordinary futile sorceress?
- (5)
- Authorities came to the realisation that it was customary for new fragile rappers to snitch in order to better their chances in court.
- (6)
- A lot of producers use samples to enhance their creativity but the generalisation of autotuning now seems mandatory.
- (7)
- The loss of twenty odd ductile brass boxes was reported by security.
- (8)
- A fire with thirty logs and a little grass will make your water hotter.
- (9)
- I’m not hostile to new civilizations; past societies were vastly overrated.
- (10)
- A broad example of Americanization is the nutrition pattern of resorting to fertile brands like McDonalds.
- (11)
- The organization demanded that its staff exercise caution when talking about the missile inventory.
- (12)
- Their daughter thought a depilatory bath was more suitable than is often assumed.
| 1 | We stick to the historical label, although alternatives such as Southern Standard British English (International Phonetic Association 1999) or General British (Cruttenden and Gimson 2014) would more accurately portray what we are referring to here. However, the term RP is deeply entrenched in the field of English as a Foreign Language. |
| 2 | Standard lexical sets are “a set of keywords, each of which […] stands for a large number of words which behave in the same way in respect of the incidence of vowels in different accents”. (Wells 1982, pp. 119–20). |
| 3 | Intraclass correlations are used here to evaluate the reliability of ratings between judges, or between automatic models. ICC2k is also known as the two-way random effects model measuring absolute agreement between multiple raters or measurements; equations are available in Koo and Li (2016). |
| 4 | https://github.com/mozilla/DeepSpeech/releases/tag/v0.7.1, accessed on 23 January 2024. |
| 5 | The pretrained model we used is available here: https://fr.mathworks.com/matlabcentral/fileexchange/103525-wav2vec-2-0, accessed on 23 January 2024. |
References
- Ahn, Tae Youn, and Sangmin-Michelle Lee. 2016. User experience of a mobile speaking application with automatic speech recognition for EFL learning: Speaking app with ASR. British Journal of Educational Technology 47: 778–86. [Google Scholar] [CrossRef]
- Ardila, Rosana, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. 2019. Common Voice: A Massively-Multilingual Speech Corpus. arXiv arXiv:1912.06670. [Google Scholar]
- Armstrong, Nigel, and Jennifer Low. 2008. C’est encœur plus jeuli, le Mareuc: Some evidence for the spread of/ɔ/-fronting in French. Transactions of the Philological Society 106: 432–55. [Google Scholar] [CrossRef]
- Baevski, Alexei, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv arXiv:2006.11477. [Google Scholar]
- Baratta, Alex. 2017. Accent and Linguistic Prejudice within British Teacher Training. Journal of Language, Identity & Education 16: 416–23. [Google Scholar] [CrossRef]
- Carrie, Erin. 2017. ‘British is professional, American is urban’: Attitudes towards English reference accents in Spain. International Journal of Applied Linguistics 27: 427–47. [Google Scholar] [CrossRef]
- Cruttenden, Alan, and Alfred Charles Gimson. 2014. Gimson’s Pronunciation of English, 8th ed. London: Routledge. [Google Scholar]
- Cucchiarini, Catia, and Helmer Strik. 2017. Automatic speech recognition for second language pronunciation training. In The Routledge Handbook of Contemporary English Pronunciation. Edited by Okim Kang, Ron I. Thomson and John M. Murphy. London: Routledge, pp. 556–69. [Google Scholar]
- de Wet, Febe, Christa Van der Walt, and Thomas R. Niesler. 2009. Automatic assessment of oral language proficiency and listening comprehension. Speech Communication 51: 864–74. [Google Scholar] [CrossRef]
- Derwing, Tracey M., and Murray J. Munro. 1997. Accent, Intelligibility, and Comprehensibility: Evidence from FourL1s. Studies in Second Language Acquisition 19: 1–16. [Google Scholar] [CrossRef]
- Deschamps, Alain, Jean-Michel Fournier, Jean-Louis Duchet, and Michael O’Neil. 2004. English Phonology and Graphophonemics. Paris: Editions Ophrys. [Google Scholar]
- DiChristofano, Alex, Henry Shuster, Shefali Chandra, and Neal Patwari. 2022. Global Performance Disparities Between English-Language Accents in Automatic Speech Recognition. arXiv arXiv:2208.01157. [Google Scholar]
- Dubravac, Vildana, Amna Brdarević-Čeljo, and Senad Bećirović. 2018. The English of Bosnia and Herzegovina. World Englishes 37: 635–52. [Google Scholar] [CrossRef]
- Ferragne, Emmanuel, Sébastien Flavier, and Christian Fressard. 2013. ROCme! Software for the recording and management of speech corpora. Paper presented at Interspeech, Lyon, France, August 25–29; pp. 1864–65. [Google Scholar]
- Frumkin, Lara A., and Anna Stone. 2020. Not all eyewitnesses are equal: Accent status, race and age interact to influence evaluations of testimony. Journal of Ethnicity in Criminal Justice 18: 123–45. [Google Scholar] [CrossRef]
- Golonka, Ewa M., Anita R. Bowles, Victor M. Frank, Dorna L. Richardson, and Suzanne Freynik. 2014. Technologies for foreign language learning: A review of technology types and their effectiveness. Computer Assisted Language Learning 27: 70–105. [Google Scholar] [CrossRef]
- Hannun, Awni, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and et al. 2014. Deep Speech: Scaling up end-to-end speech recognition. arXiv arXiv:1412.5567. [Google Scholar]
- Henderson, Alice, Dan Frost, Elina Tergujeff, Alexander Kautzsch, Deirdre Murphy, Anastazija Kirkova-Naskova, Ewa Waniek-Klimczak, David Levey, Una Cunnigham, and Lesley Curnick. 2012. The English Pronunciation Teaching in Europe Survey: Selected results. Research in Language 10: 5–27. [Google Scholar] [CrossRef]
- International Phonetic Association, ed. 1999. Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet. Cambridge: Cambridge University Press. [Google Scholar]
- Jakšič, Jan, and Pavel Šturm. 2017. Accents of English at Czech Schools: Students’ Attitudes and Recognition Skills. Research in Language 15: 353–69. [Google Scholar] [CrossRef]
- Jenkins, Jennifer. 2006. Current Perspectives on Teaching World Englishes and English as a Lingua Franca. TESOL Quarterly 40: 157. [Google Scholar] [CrossRef]
- Kachru, Braj. 1985. Standards, codification and sociolinguistic realism: The English language in the outer circle. In English in the World: Teaching and Learning the Language and Literatures. Edited by Randolph Quirk and Henry G. Widdowson. Cambridge: Cambridge University Press, pp. 11–30. [Google Scholar]
- Kang, Okim. 2015. Learners’ Perceptions toward Pronunciation Instruction in Three Circles of World Englishes. TESOL Journal 6: 59–80. [Google Scholar] [CrossRef]
- Koo, Terry K., and Mae Y. Li. 2016. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. Journal of Chiropractic Medicine 15: 155–63. [Google Scholar] [CrossRef]
- Labov, William, Sharon Ash, and Charles Boberg. 2006. The Atlas of North American English: Phonetics, Phonology and Sound Change. Berlin: Mouton de Gruyter. [Google Scholar] [CrossRef]
- Levis, John M. 2005. Changing contexts and shifting paradigms in pronunciation teaching. TESOL Quarterly 39: 369–77. [Google Scholar] [CrossRef]
- Marian, Viorica, Henrike K. Blumenfeld, and Margarita Kaushanskaya. 2007. The Language Experience and Proficiency Questionnaire (LEAP-Q): Assessing Language Profiles in Bilinguals and Multilinguals. Journal of Speech, Language, and Hearing Research 50: 940–67. [Google Scholar] [CrossRef]
- Markl, Nina. 2022. Language variation and algorithmic bias: Understanding algorithmic bias in British English automatic speech recognition. Paper presented at 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21–24; pp. 521–34. [Google Scholar] [CrossRef]
- McCrocklin, Shannon. 2015. Automatic Speech Recognition: Making It Work for Your Pronunciation Class. Pronunciation in Second Language Learning and Teaching Proceedings 6: 126–33. Available online: https://www.iastatedigitalpress.com/psllt/article/id/15254/ (accessed on 23 January 2024).
- McKenzie, Robert M., and Erin Carrie. 2018. Implicit–explicit attitudinal discrepancy and the investigation of language attitude change in progress. Journal of Multilingual and Multicultural Development 39: 830–44. [Google Scholar] [CrossRef]
- Meer, Philipp, Johanna Hartmann, and Dominik Rumlich. 2022. Attitudes of German high school students toward different varieties of English. Applied Linguistics 43: 538–62. [Google Scholar] [CrossRef]
- Mering, Andy. 2022. Mid-Atlantic English in the EFL Context. Baden-Baden: Tectum—Ein Verlag in der Nomos Verlagsgesellschaft mbH & Co. KG. [Google Scholar] [CrossRef]
- Modiano, Marko. 1996. The Americanization of Euro-English. World Englishes 15: 207–15. [Google Scholar] [CrossRef]
- Ngo, Thuy Thi-Nhu, Howard Hao-Jan Chen, and Kyle Kuo-Wei Lai. 2023. The effectiveness of automatic speech recognition in ESL/EFL pronunciation: A meta-analysis. ReCALL 36: 4–21. [Google Scholar] [CrossRef]
- Panayotov, Vassil, Guoguo Chen, Daneil Povey, and Sanjeev Khudanpur. 2015. Librispeech: An ASR corpus based on public domain audio books. Paper presented at 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, April 19–24; pp. 5206–10. [Google Scholar] [CrossRef]
- Pantos, Andrew J., and Andrew W. Perkins. 2013. Measuring Implicit and Explicit Attitudes Toward Foreign Accented Speech. Journal of Language and Social Psychology 32: 3–20. [Google Scholar] [CrossRef]
- Pennington, Martha C., and Pamela Rogerson-Revell. 2019. English Pronunciation Teaching and Research: Contemporary Perspectives, 1st ed. London: Palgrave Macmillan. [Google Scholar] [CrossRef]
- Pélissier, Maud, and Emmanuel Ferragne. 2022. The N400 reveals implicit accent-induced prejudice. Speech Communication 137: 114–26. [Google Scholar] [CrossRef]
- Phan, Huong Le Thu. 2020. Vietnamese learners’ attitudes towards American and British accents. European Journal of English Language Teaching 6: 97–117. [Google Scholar] [CrossRef]
- Rindal, Ulrikke. 2010. Constructing identity with L2: Pronunciation and attitudes among Norwegian learners of English. Journal of Sociolinguistics 14: 240–61. [Google Scholar] [CrossRef]
- Roach, Peter. 2009. English Phonetics and Phonology: A Practical Course, 4th ed. Cambridge: Cambridge University Press. [Google Scholar]
- Roberts, Gillian. 2020. Language attitudes and L2 pronunciation: An experimental study with Flemish adolescent learners of English. English Text Construction 13: 178–211. [Google Scholar] [CrossRef]
- Ryan, Spring, and Tabuchi Ryuji. 2021. Assessing the Practicality of Using an Automatic Speech Recognition Tool to Teach English Pronunciation Online. STEM Journal 22: 93–104. [Google Scholar] [CrossRef]
- Sharma, Devyani, Erez Levon, and Yang Ye. 2022. 50 years of British accent bias: Stability and lifespan change in attitudes to accents. English World-Wide 43: 135–66. [Google Scholar] [CrossRef]
- Tatman, Rachael. 2017. Gender and Dialect Bias in YouTube’s Automatic Captions. Paper presented at the First ACL Workshop on Ethics in Natural Language Processing, Valencia, Spain, April 4; pp. 53–59. [Google Scholar] [CrossRef]
- Tejedor-García, Cristian, David Escudero-Mancebo, Enrique Cámara-Arenas, César González-Ferreras, and Valentín Cardeñoso-Payo. 2020. Assessing Pronunciation Improvement in Students of English Using a Controlled Computer-Assisted Pronunciation Tool. IEEE Transactions on Learning Technologies 13: 269–82. [Google Scholar] [CrossRef]
- Thomson, Ron I., and Tracey M. Derwing. 2015. The Effectiveness of L2 Pronunciation Instruction: A Narrative Review. Applied Linguistics 36: 326–44. [Google Scholar] [CrossRef]
- Toffoli, Denyze, and Geoff Sockett. 2015. L’apprentissage informel de l’anglais en ligne (AIAL): Quelles conséquences pour les centres de ressources en langues? Recherche et Pratiques Pédagogiques En Langues de Spécialité—Cahiers de l’APLIUT 34: 147–65. [Google Scholar] [CrossRef]
- Torrent, Mélanie. 2022. Rapport du Jury de l’agrégation Externe d’anglais. Ministère de l’Education Nationale et de la Jeunesse: Available online: https://media.devenirenseignant.gouv.fr/file/agreg_externe/39/5/rj-2022-agregation-externe-lve-anglais_1428395.pdf (accessed on 23 January 2024).
- Trofimovich, Pavel, and Talia Isaacs. 2012. Disentangling accent from comprehensibility. Bilingualism: Language and Cognition 15: 905–16. [Google Scholar] [CrossRef]
- Tsang, Art. 2020. Are learners ready for Englishes in the EFL classroom? A large-scale survey of learners’ views of non-standard accents and teachers’ accents. System 94: 102298. [Google Scholar] [CrossRef]
- Walker, Robin. 2010. Teaching the Pronunciation of English as a Lingua Franca. Oxford: Oxford University Press. [Google Scholar]
- Wells, John C. 1982. Accents of English. Cambridge: Cambridge University Press. [Google Scholar]
- Xiao, Wenqi, and Moonyoung Park. 2021. Using Automatic Speech Recognition to Facilitate English Pronunciation Assessment and Learning in an EFL Context: Pronunciation Error Diagnosis and Pedagogical Implications. International Journal of Computer-Assisted Language Learning and Teaching 11: 74–91. [Google Scholar] [CrossRef]
- Yibokou, Kossi Seto, Denyze Toffoli, and Béatrice Vaxelaire. 2019. Variabilité inter-individuelle et intra-individuelle dans la prononciation d’étudiants français qui pratiquent l’Apprentissage informel de l’anglais en ligne. Lidil 59. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, Juan, Sara Ahmed, Danielius Visockas, and Cem Subakan. 2023. CommonAccent: Exploring Large Acoustic Pretrained Models for Accent Classification Based on Common Voice. arXiv arXiv:2305.18283. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Word: LOGS | DeepSpeech | wav2vec | GoogleGB | GoogleUS |
|---|---|---|---|---|
| strut items (e.g., lugs) | 29 | 36 | 14 | 30 |
| dogs | 0 | 0 | 40 | 9 |
| Correct identification of logs | 173 | 240 | 185 | 210 |
| Target Word: GRASS | DeepSpeech | wav2vec | GoogleGB | GoogleUS |
|---|---|---|---|---|
| dress items (e.g., dress) | 22 | 4 | 40 | 20 |
| lot items (e.g., cross) | 18 | 4 | 12 | 30 |
| Correct identification of grass | 219 | 266 | 200 | 224 |
| Target Word: Hotter | DeepSpeech | wav2vec | GoogleGB | GoogleUS |
|---|---|---|---|---|
| Monosyllabic items (e.g., hot) | 17 | 6 | 9 | 6 |
| Two word items (e.g., hot tub) | 17 | 1 | 5 | 8 |
| Disyllabic item with final <r> (e.g., holder) | 189 | 122 | 29 | 81 |
| Disyllabic item without final <r> (e.g., hotel) | 16 | 14 | 14 | 17 |
| Correct identification of hotter | 65 | 159 | 241 | 188 |
| GoogleGB | GoogleUS | ||||
|---|---|---|---|---|---|
| Sentence Number | Target Word | Correct Identification Out of 11 | Output Errors | Correct Identification Out of 11 | Output Errors |
| 8 | thirty | 10 | thirteen | 2 | that he, their two, that she, search, certain, such a, cutting, the two, turkey |
| 11 | staff | 10 | does | 2 | stuff (3), tough (6) |
| 12 | daughter | 11 | _ | 5 | Delta (2), adults with (1), doctors (1), deuce (1), doses (1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferragne, E.; Guyot Talbot, A.; King, H.; Navarro, S. Exploring the Accent Mix Perceptually and Automatically: French Learners of English and the RP–GA Divide. Languages 2024, 9, 50. https://doi.org/10.3390/languages9020050
Ferragne E, Guyot Talbot A, King H, Navarro S. Exploring the Accent Mix Perceptually and Automatically: French Learners of English and the RP–GA Divide. Languages. 2024; 9(2):50. https://doi.org/10.3390/languages9020050
Chicago/Turabian StyleFerragne, Emmanuel, Anne Guyot Talbot, Hannah King, and Sylvain Navarro. 2024. "Exploring the Accent Mix Perceptually and Automatically: French Learners of English and the RP–GA Divide" Languages 9, no. 2: 50. https://doi.org/10.3390/languages9020050
APA StyleFerragne, E., Guyot Talbot, A., King, H., & Navarro, S. (2024). Exploring the Accent Mix Perceptually and Automatically: French Learners of English and the RP–GA Divide. Languages, 9(2), 50. https://doi.org/10.3390/languages9020050