

Exploring the Onset of Phonetic Drift in Voice Onset Time Perception


Abstract
1. Introduction
2. Background
2.1. Phonetic Drift in Perception
2.2. The Present Study
- Q1.
- What is the smallest amount of FL exposure leading to detectable perceptual drift?
- Q2.
- Under what FL exposure circumstances does perceptual drift first arise? That is, what is the weakest condition of FL exposure leading to early perceptual drift?
- Q3.
- Is early perceptual drift assimilatory or dissimilatory with respect to the FL?
- Q4.
- How durable is perceptual drift following recent FL exposure?
- Q5.
- How generalizable is perceptual drift beyond the specific details of FL exposure?
3. Materials and Methods
3.1. Participants
3.2. Procedure and Stimuli
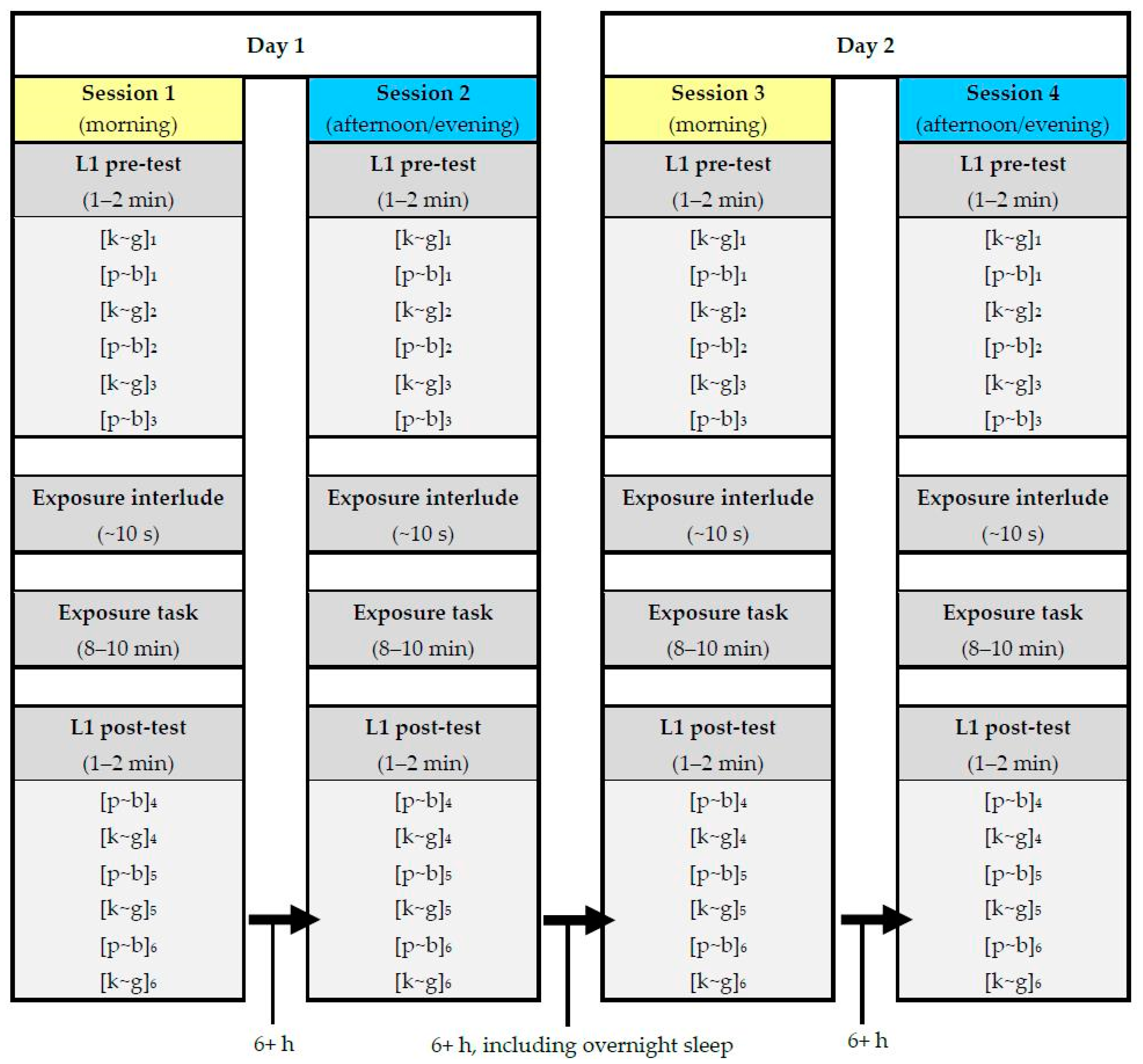
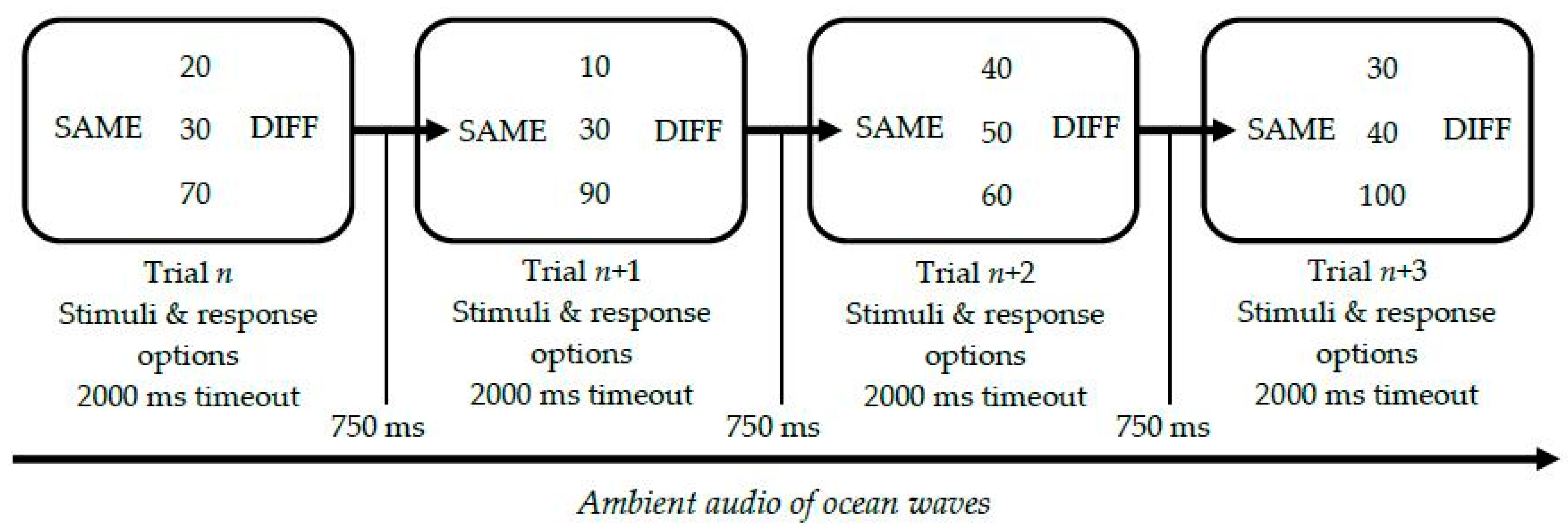
3.2.1. Study Design
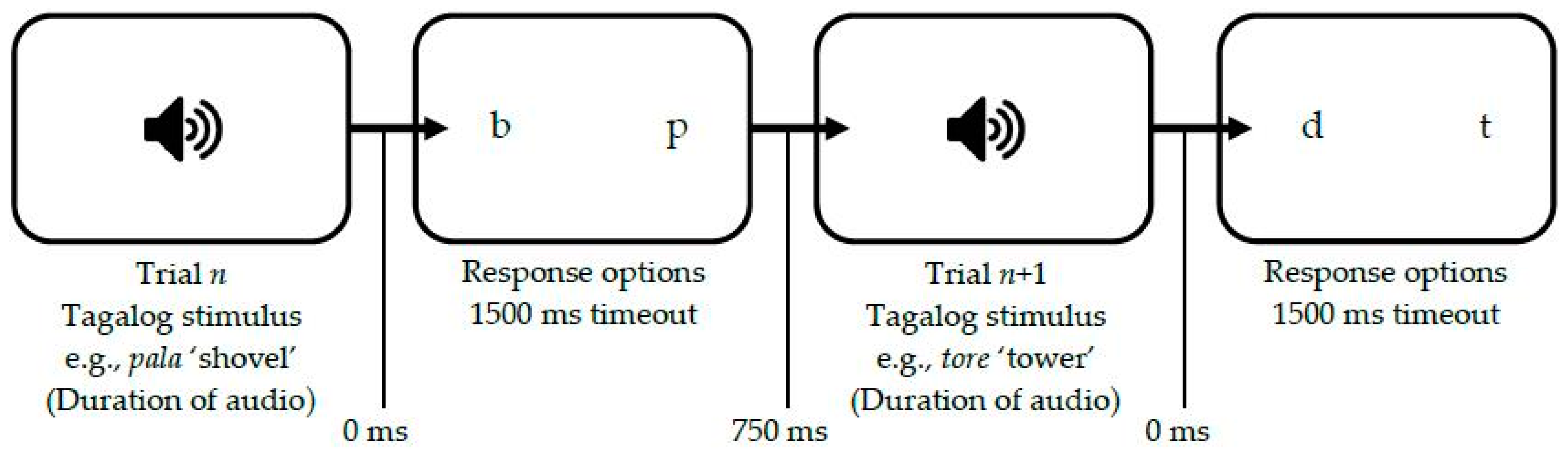
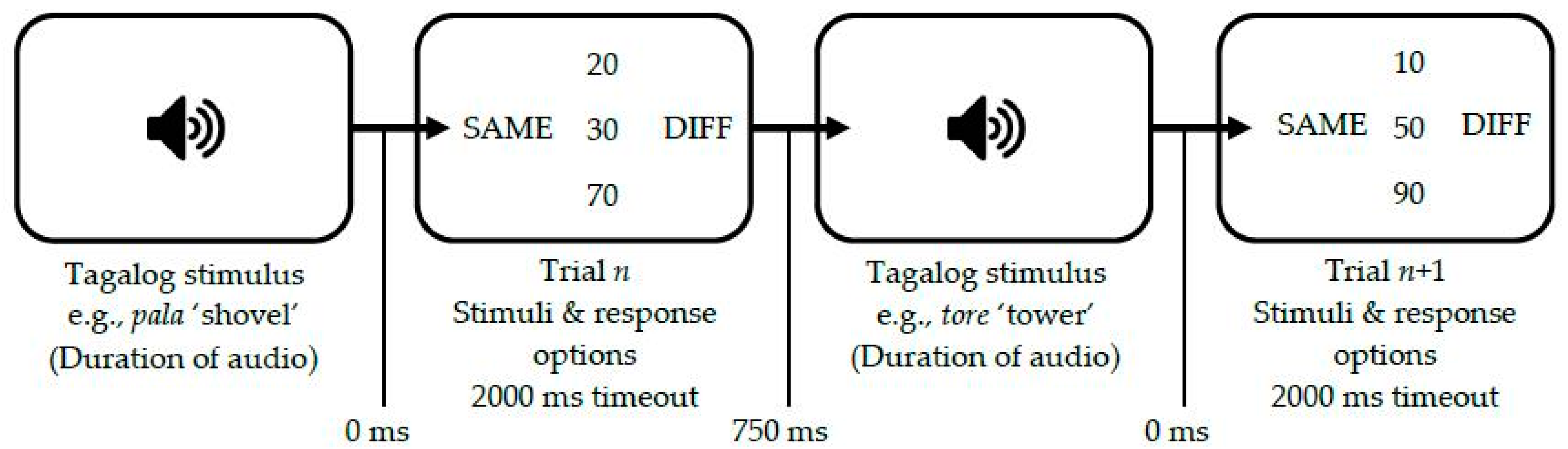
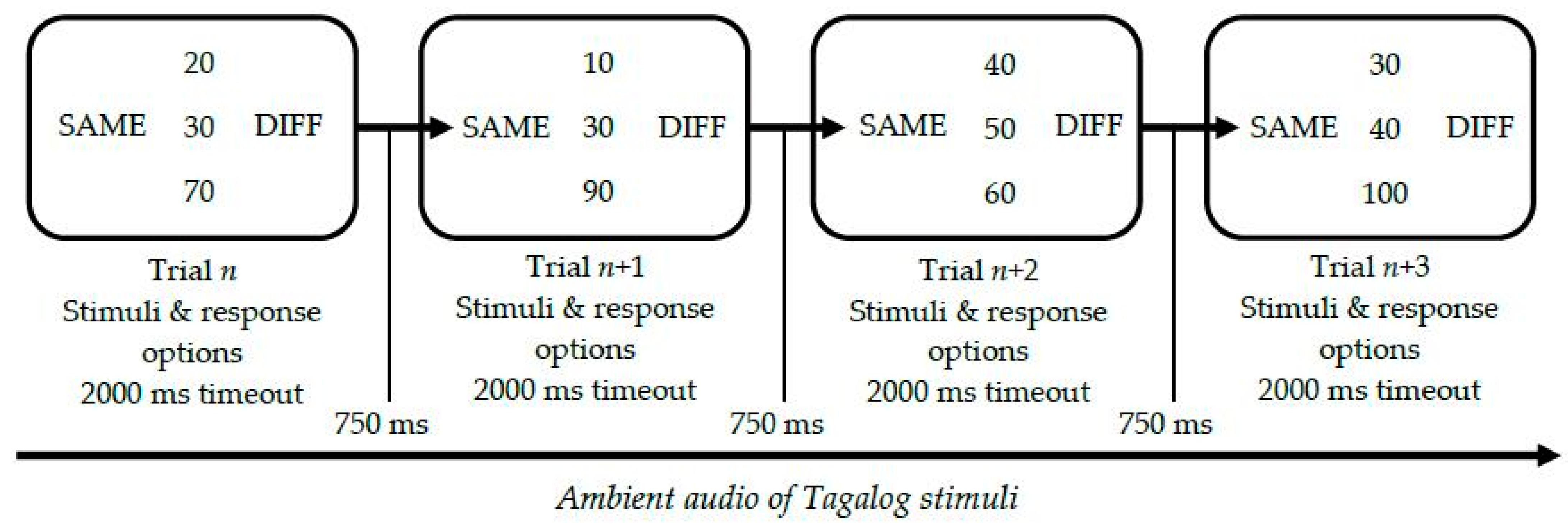
3.2.2. Task Conditions
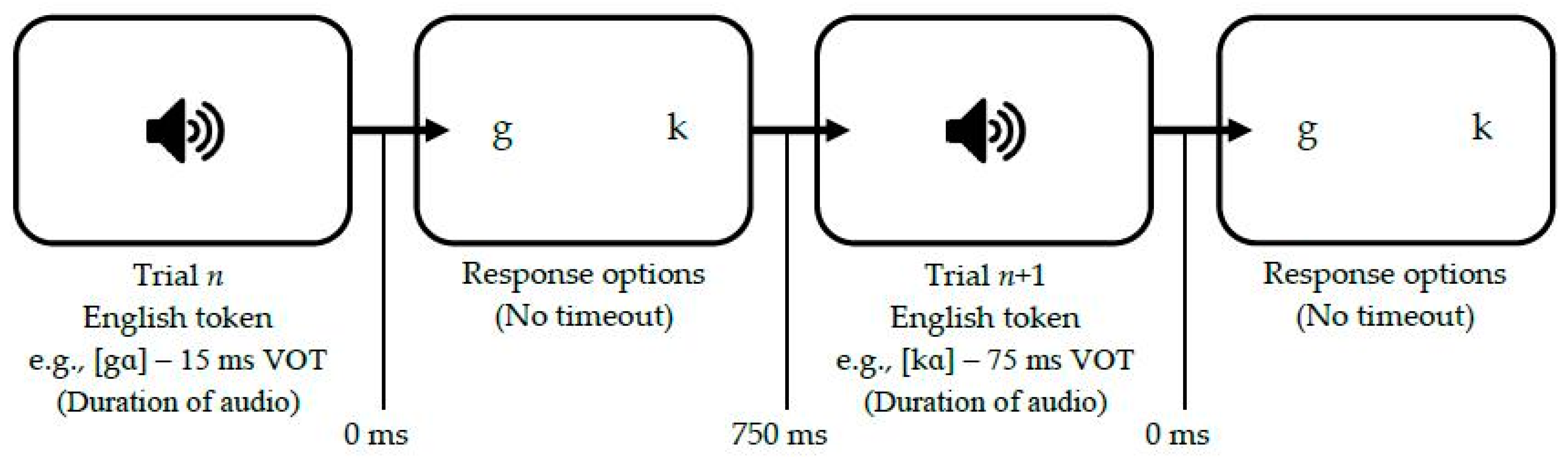
3.2.3. L1 Identification Experiments
4. Results
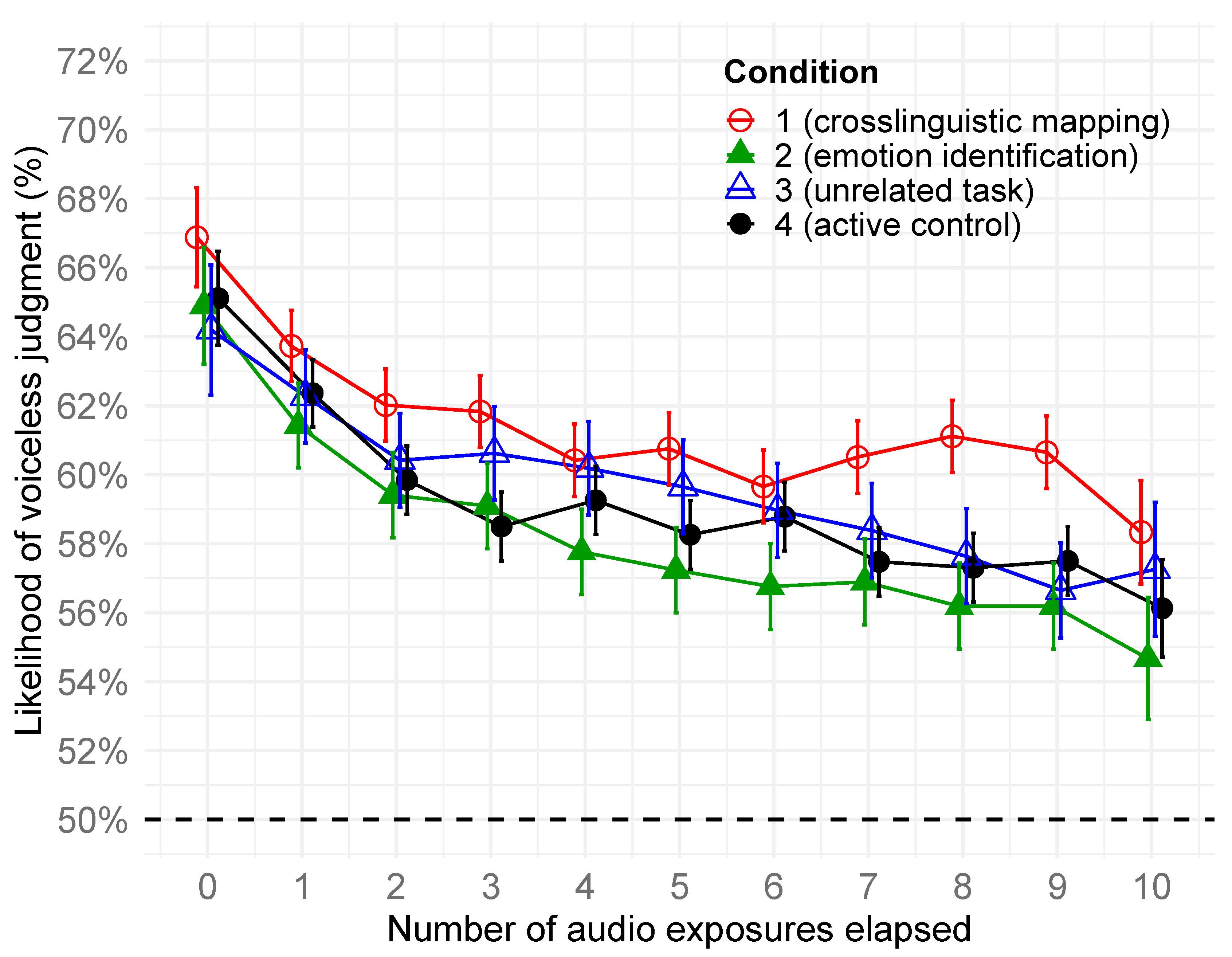
4.1. H1–H3: Effects of Exposure and Task Condition
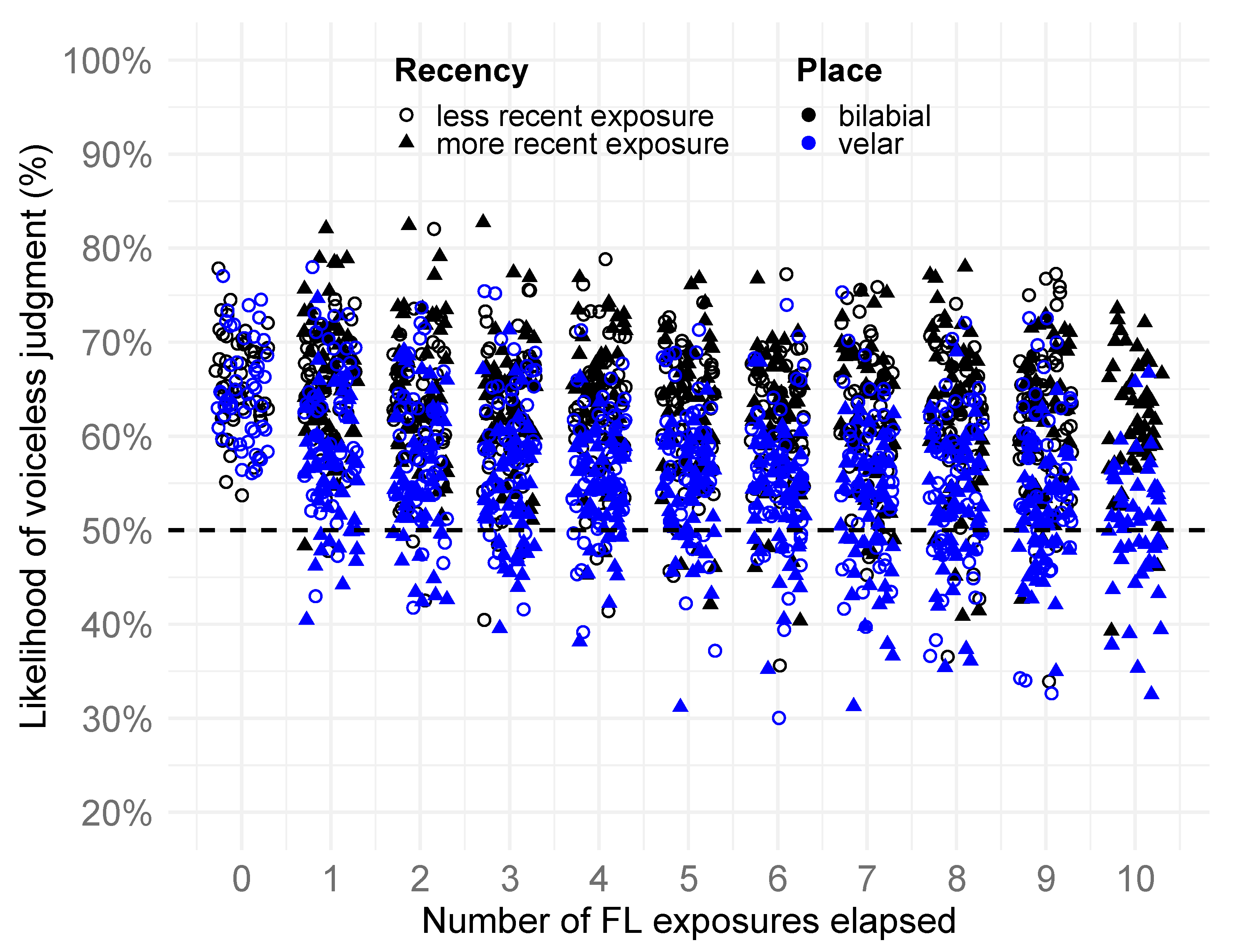
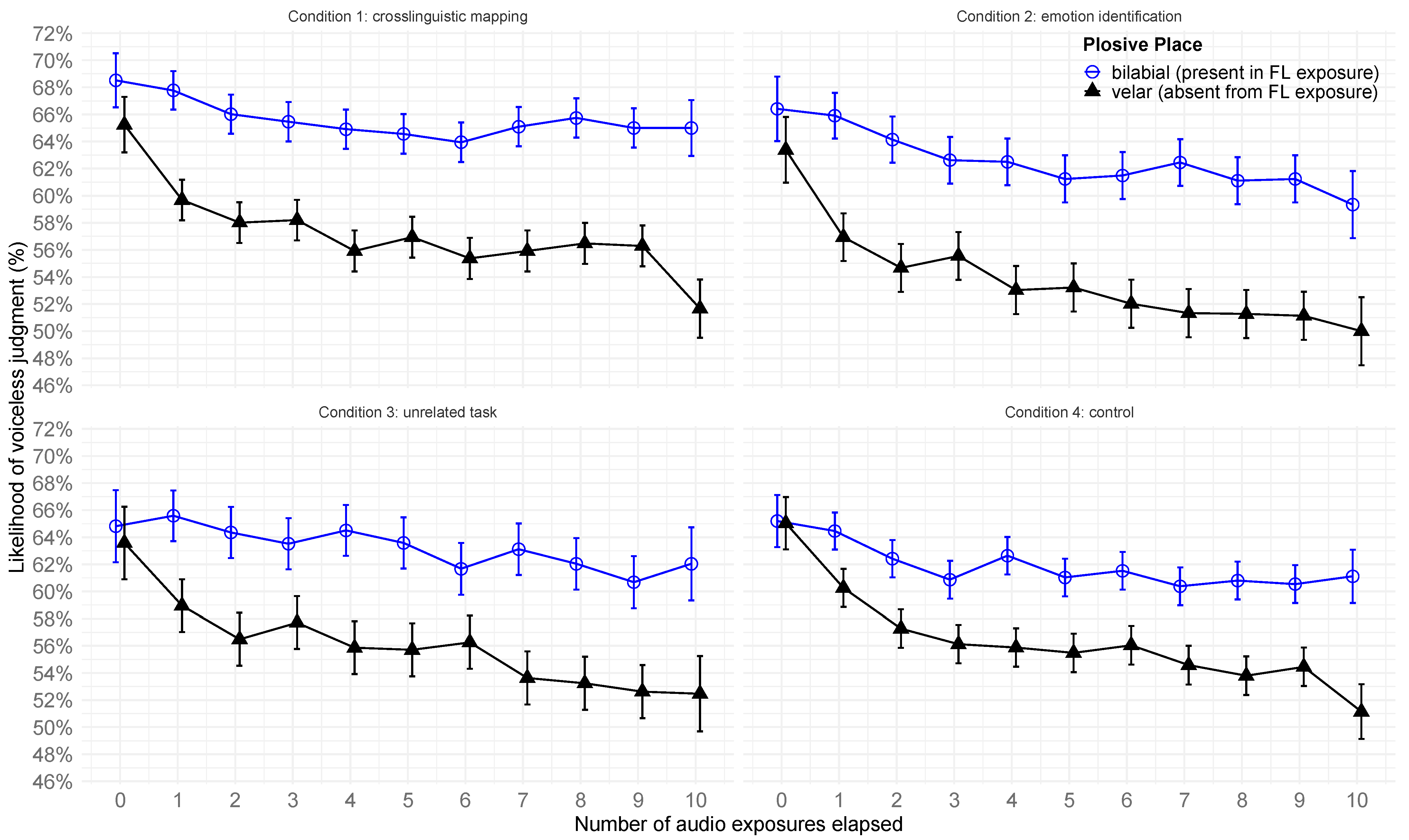
4.2. H5: Generalization of Perceptual Drift (Place Effects)
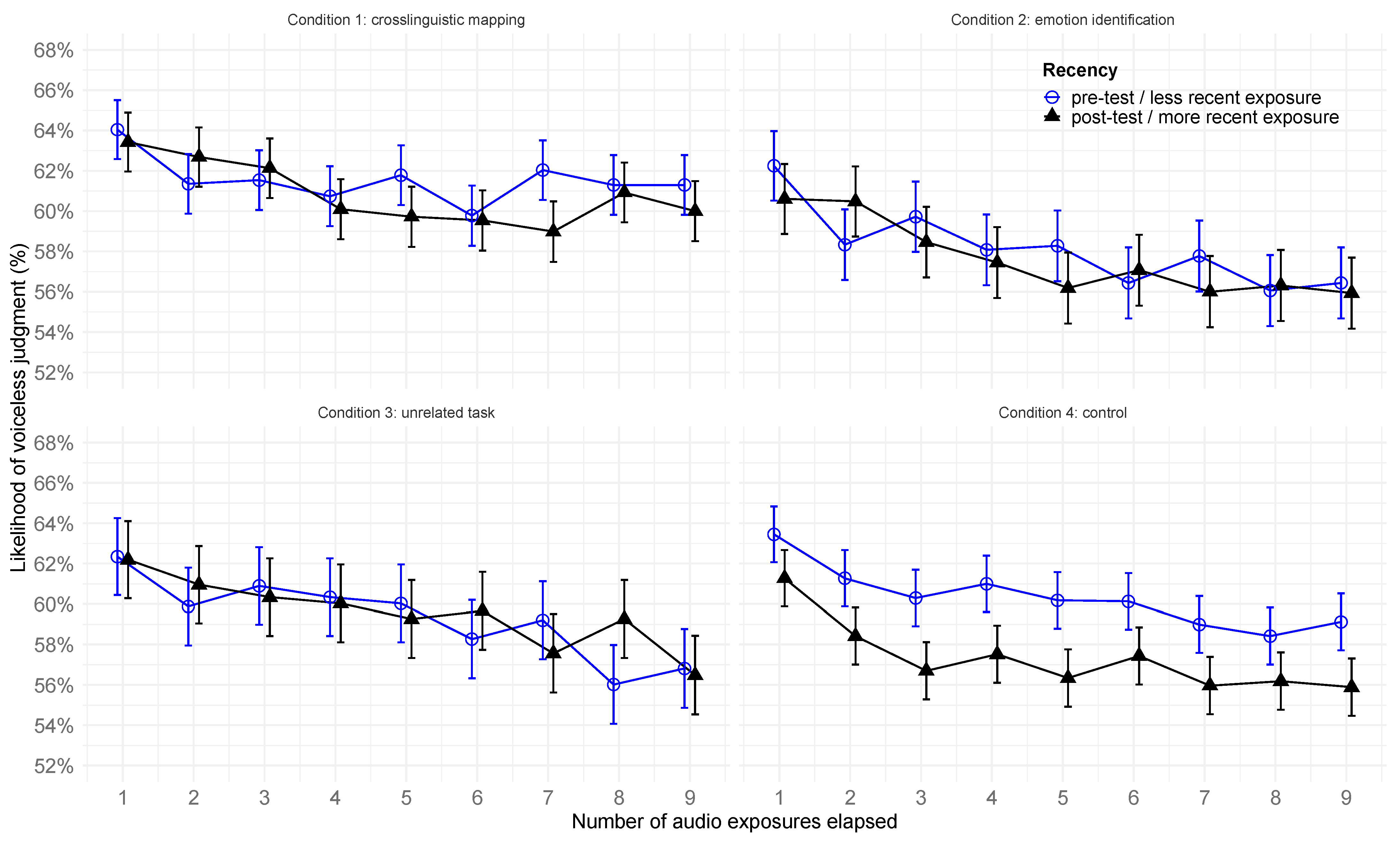
4.3. H4: Durability of Perceptual Drift (Recency Effects)
4.4. H1: Onset of Perceptual Drift
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Condition 1 (crosslinguistic mapping) as reference level: | ||||
| β | SE | z-value | p-value | |
| (Intercept) | 0.646 | 0.052 | 12.533 | <0.001 |
| Exposure | −0.012 | 0.007 | −1.685 | 0.091 |
| Condition: 2 | −0.128 | 0.079 | −1.616 | 0.106 |
| Condition: 3 | −0.099 | 0.084 | −1.169 | 0.242 |
| Condition: 4 | −0.160 | 0.071 | −2.270 | 0.023 |
| Place: velar | −0.357 | 0.028 | −12.666 | <0.001 |
| Exposure × Condition: 2 | −0.012 | 0.011 | −1.132 | 0.257 |
| Exposure × Condition: 3 | −0.007 | 0.011 | −0.636 | 0.525 |
| Exposure × Condition: 4 | −0.005 | 0.009 | −0.508 | 0.612 |
| Exposure × Place: velar | −0.016 | 0.010 | −1.645 | 0.100 |
| Condition: 2 × Place: velar | −0.017 | 0.043 | −0.385 | 0.700 |
| Condition: 3 × Place: velar | 0.047 | 0.046 | 1.020 | 0.308 |
| Condition: 4 × Place: velar | 0.123 | 0.038 | 3.209 | 0.001 |
| Exposure × Condition: 2 × Place: velar | 0.003 | 0.015 | 0.210 | 0.833 |
| Exposure × Condition: 3 × Place: velar | 0.001 | 0.016 | 0.053 | 0.958 |
| Exposure × Condition: 4 × Place: velar | −0.002 | 0.013 | −0.157 | 0.875 |
| (b) Condition 2 (emotion identification) as reference level: | ||||
| β | SE | z-value | p-value | |
| (Intercept) | 0.518 | 0.060 | 8.637 | <0.001 |
| Exposure | −0.024 | 0.008 | −2.964 | 0.003 |
| Condition: 1 | 0.128 | 0.079 | 1.616 | 0.106 |
| Condition: 3 | 0.030 | 0.089 | 0.331 | 0.741 |
| Condition: 4 | −0.032 | 0.077 | −0.422 | 0.673 |
| Place: velar | −0.373 | 0.033 | −11.465 | <0.001 |
| Exposure × Condition: 1 | 0.012 | 0.011 | 1.130 | 0.258 |
| Exposure × Condition: 3 | 0.005 | 0.012 | 0.403 | 0.687 |
| Exposure × Condition: 4 | 0.007 | 0.010 | 0.701 | 0.483 |
| Exposure × Place: velar | −0.013 | 0.011 | −1.145 | 0.252 |
| Condition: 1 × Place: velar | 0.017 | 0.043 | 0.385 | 0.700 |
| Condition: 3 × Place: velar | 0.063 | 0.049 | 1.301 | 0.193 |
| Condition: 4 × Place: velar | 0.140 | 0.042 | 3.350 | <0.001 |
| Exposure × Condition: 1 × Place: velar | −0.003 | 0.015 | −0.209 | 0.834 |
| Exposure × Condition: 3 × Place: velar | −0.002 | 0.017 | −0.136 | 0.892 |
| Exposure × Condition: 4 × Place: velar | −0.005 | 0.014 | −0.361 | 0.718 |
| (c) Condition 3 (unrelated task) as reference level: | ||||
| β | SE | z-value | p-value | |
| (Intercept) | 0.547 | 0.066 | 8.288 | <0.001 |
| Exposure | −0.019 | 0.009 | −2.130 | 0.033 |
| Condition: 1 | 0.098 | 0.084 | 1.173 | 0.241 |
| Condition: 2 | −0.030 | 0.089 | −0.331 | 0.740 |
| Condition: 4 | −0.062 | 0.082 | −0.760 | 0.447 |
| Place: velar | −0.310 | 0.036 | −8.601 | <0.001 |
| Exposure × Condition: 1 | 0.007 | 0.011 | 0.636 | 0.525 |
| Exposure × Condition: 2 | −0.005 | 0.012 | −0.404 | 0.686 |
| Exposure × Condition: 4 | 0.002 | 0.011 | 0.217 | 0.829 |
| Exposure × Place: velar | −0.015 | 0.012 | −1.216 | 0.224 |
| Condition: 1 × Place: velar | −0.047 | 0.046 | −1.020 | 0.308 |
| Condition: 2 × Place: velar | −0.063 | 0.049 | −1.303 | 0.193 |
| Condition: 4 × Place: velar | 0.077 | 0.045 | 1.724 | 0.085 |
| Exposure × Condition: 1 × Place: velar | −0.001 | 0.016 | −0.052 | 0.958 |
| Exposure × Condition: 2 × Place: velar | 0.002 | 0.017 | 0.136 | 0.892 |
| Exposure × Condition: 4 × Place: velar | −0.003 | 0.015 | −0.190 | 0.849 |
| (d) Condition 4 (active control) as reference level: | ||||
| β | SE | z-value | p-value | |
| (Intercept) | 0.485 | 0.048 | 10.068 | <0.001 |
| Exposure | −0.017 | 0.006 | −2.577 | 0.01 |
| Condition: 1 | 0.160 | 0.071 | 2.272 | 0.023 |
| Condition: 2 | 0.033 | 0.077 | 0.423 | 0.673 |
| Condition: 3 | 0.062 | 0.082 | 0.757 | 0.449 |
| Place: velar | −0.233 | 0.026 | −8.897 | <0.001 |
| Exposure × Condition: 1 | 0.005 | 0.009 | 0.507 | 0.612 |
| Exposure × Condition: 2 | −0.007 | 0.010 | −0.702 | 0.483 |
| Exposure × Condition: 3 | −0.002 | 0.011 | −0.217 | 0.829 |
| Exposure × Place: velar | −0.018 | 0.009 | −1.997 | 0.046 |
| Condition: 1 × Place: velar | −0.123 | 0.038 | −3.209 | 0.001 |
| Condition: 2 × Place: velar | −0.140 | 0.042 | −3.351 | <0.001 |
| Condition: 3 × Place: velar | −0.077 | 0.045 | −1.722 | 0.085 |
| Exposure × Condition: 1 × Place: velar | 0.002 | 0.013 | 0.158 | 0.875 |
| Exposure × Condition: 2 × Place: velar | 0.005 | 0.014 | 0.361 | 0.718 |
| Exposure × Condition: 3 × Place: velar | 0.003 | 0.015 | 0.19 | 0.849 |
| 1 | The duration of L2 sessions in Gong et al. (2016) was provided via personal correspondence with Jian Gong (September 2021). |
| 2 | This would mirror other U-shaped patterns in acquisition, such as the development of the English past tense in both L1 learners (Jackson and Cottrell 1997) and late sequential L2 learners (Williams et al. 2022). |
| 3 | An anonymous reviewer asked whether the emotionality of the speech tokens had been validated (e.g., by having a separate group of listeners rate the emotion they thought a given token conveyed). In short, we did not separately measure the perceptibility of the emotional states produced by the Tagalog speakers, because this was tangential to our research questions. Although the speakers were instructed to pronounce each word four times, with varying affect (happy, then angry, then sad, then neutral), this instruction was intended simply to produce a range of different speech qualities for the emotion identification condition, and the response options in this condition were not made to match the list of target emotional states. Speakers may have been inconsistent in how they interpreted this instruction, and the details of each speaker’s specific performance of the target emotional states—including, for example, whether their ‘happy’ voice may have been ‘misclassified’ as ‘negative’—were not our concern. |
References
- Bissiri, Maria Paola, Maria Luisa Lecumberri, Martin Cooke, and Jan Volín. 2011. The role of word-initial glottal stops in recognizing English words. In Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH 2011). Edited by Piero Cosi, Renato De Mori, Giuseppe Di Fabbrizio and Roberto Pieraccini. Bonn: ISCA Archive, pp. 165–68. [Google Scholar]
- Boersma, Paul, and David Weenink. 2021. Praat: Doing Phonetics by Computer, Version 6.2.09; Available online: http://www.praat.org/ (accessed on 2 March 2023).
- Böttcher-Gandor, C., and Peter Ullsperger. 1992. Mismatch negativity in event-related potentials to auditory stimuli as a function of varying interstimulus interval. Psychophysiology 29: 546–50. [Google Scholar] [CrossRef] [PubMed]
- Cabrelli, Jennifer, Alicia Luque, and Irene Finestrat-Martínez. 2019. Influence of L2 English phonotactics in L1 Brazilian Portuguese illusory vowel perception. Journal of Phonetics 73: 55–69. [Google Scholar] [CrossRef]
- Chang, Charles B. 2012. Rapid and multifaceted effects of second-language learning on first-language speech production. Journal of Phonetics 40: 249–68. [Google Scholar] [CrossRef]
- Chang, Charles B. 2013. A novelty effect in phonetic drift of the native language. Journal of Phonetics 41: 520–33. [Google Scholar] [CrossRef]
- Chang, Charles B. 2019a. Language change and linguistic inquiry in a world of multicompetence: Sustained phonetic drift and its implications for behavioral linguistic research. Journal of Phonetics 74: 96–113. [Google Scholar] [CrossRef]
- Chang, Charles B. 2019b. Phonetic drift. In The Oxford Handbook of Language Attrition. Edited by Monika S. Schmid and Barbara Köpke. Oxford: Oxford University Press, pp. 191–203. [Google Scholar] [CrossRef]
- Christensen, Jens B. 1984. The perception of voice onset time: A cross language study of American English and Danish. Annual Report of the Institute of Phonetics University of Copenhagen 18: 163–84. [Google Scholar] [CrossRef]
- Cooper, William E. 1974. Selective adaptation for acoustic cues of voicing in initial stops. Journal of Phonetics 2: 303–13. [Google Scholar] [CrossRef]
- de Leeuw, Esther, and Charles B. Chang. 2023. Phonetic and phonological L1 attrition and drift in bilingual speech. In The Cambridge Handbook of Bilingual Phonetics and Phonology. Edited by Mark Amengual. Cambridge: Cambridge University Press, under review. [Google Scholar]
- de Leeuw, Esther, and Chiara Celata. 2019. Plasticity of native phonetic and phonological domains in the context of bilingualism. Journal of Phonetics 75: 88–93. [Google Scholar] [CrossRef]
- Dmitrieva, Olga. 2019. Transferring perceptual cue-weighting from second language into first language: Cues to voicing in Russian speakers of English. Journal of Phonetics 73: 128–43. [Google Scholar] [CrossRef]
- Dmitrieva, Olga, and Alexis N. Tews. 2018. First language phonetic drift in second language instructional environment. Journal of the Acoustical Society of America 143: 1952. [Google Scholar] [CrossRef]
- Dmitrieva, Olga, Allard Jongman, and Joan A. Sereno. 2020. The effect of instructed second language learning on the acoustic properties of first language speech. Languages 5: 44. [Google Scholar] [CrossRef]
- Eimas, Peter D., and John D. Corbit. 1973. Selective adaptation of linguistic feature detectors. Cognitive Psychology 4: 99–109. [Google Scholar] [CrossRef]
- Eimas, Peter D., William E. Cooper, and John D. Corbit. 1973. Some properties of linguistic feature detectors. Perception & Psychophysics 13: 247–52. [Google Scholar] [CrossRef]
- Fenn, Kimberly M., Howard C. Nusbaum, and Daniel Margoliash. 2003. Consolidation during sleep of perceptual learning of spoken language. Nature 425: 614–16. [Google Scholar] [CrossRef] [PubMed]
- Flege, James Emil. 1987. The production of ‘new’ and ‘similar’ phones in a foreign language: Evidence for the effect of equivalence classification. Journal of Phonetics 15: 47–65. [Google Scholar] [CrossRef]
- Flege, James Emil. 1995. Second language speech learning: Theory, findings, and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winfred Strange. Timonium: York Press, pp. 223–72. [Google Scholar]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The Revised Speech Learning Model (SLM-r). In Second Language Speech Learning: Theoretical and Empirical Progress. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar] [CrossRef]
- Fox, John, and Sanford Weisberg. 2019. An R Companion to Applied Regression, 3rd ed. Thousand Oaks: Sage Publications. [Google Scholar]
- Goldinger, Stephen D. 1998. Echoes of echoes? An episodic theory of lexical access. Psychological Review 105: 251–79. [Google Scholar] [CrossRef]
- Gong, Jian, María Luisa García Lecumberri, and Martin Cooke. 2016. Can intensive exposure to foreign language sounds affect the perception of native sounds? In Proceedings of Interspeech 2016. Edited by Nelson Morgan, Panayiotis Georgiou, Shrikanth S. Narayanan and Florian Metze. Adelaide: Casual Productions, pp. 883–87. [Google Scholar] [CrossRef]
- Gorba, Celia. 2018. The effect of L2 experience on the categorization of native and non-native stops by Spanish learners of English. In Persistence and Resistance in English Studies: New Research. Edited by Sara Martin, Owen David and Elisabet Pladevall-Ballester. Newcastle upon Tyne: Cambridge Scholars Publishing, pp. 164–73. [Google Scholar]
- Gorba, Celia. 2019. Bidirectional influence on L1 Spanish and L2 English stop perception: The role of L2 experience. Journal of the Acoustical Society of America 145: EL587–92. [Google Scholar] [CrossRef]
- Gordon, Peter C., Jennifer L. Eberhardt, and Jay G. Rueckl. 1993. Attentional modulation of the phonetic significance of acoustic cues. Cognitive Psychology 25: 1–42. [Google Scholar] [CrossRef]
- Huffman, Marie K., and Katharina S. Schuhmann. 2015a. Effect of early L2 learning on L1 stop voicing. Proceedings of Meetings on Acoustics 23: 060007. [Google Scholar] [CrossRef]
- Huffman, Marie K., and Katharina S. Schuhmann. 2015b. Individual differences in phonetic drift by English-speaking learners of Spanish. Journal of the Acoustical Society of America 137: 2268. [Google Scholar] [CrossRef]
- Huffman, Marie K., Katharina S. Schuhmann, Kayla Keller, and Chanda Chen. 2017. Interaction of drift and distinctiveness in L1 English-L2 Japanese learners. Journal of the Acoustical Society of America 141: 3517. [Google Scholar] [CrossRef]
- Jackson, Dan, and Garrison W. Cottrell. 1997. Attention and U-shaped learning in the acquisition of the past tense. In Proceedings of the Nineteenth Annual Conference of the Cognitive Science Society. Edited by Michael G. Shafto and Pat Langley. Mahwah: Lawrence Erlbaum Associates, pp. 325–30. [Google Scholar]
- Kang, Yoonjung, Sneha George, and Rachel Soo. 2016. Cross-language influence in the stop voicing contrast in heritage Tagalog. Heritage Language Journal 13: 184–218. [Google Scholar] [CrossRef]
- Kartushina, Natalia, Alexis Hervais-Adelman, Ulrich Hans Frauenfelder, and Narly Golestani. 2016. Mutual influences between native and non-native vowels in production: Evidence from short-term visual articulatory feedback training. Journal of Phonetics 57: 21–39. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Lein, Tatjana, Tanja Kupisch, and Joost van de Weijer. 2016. Voice onset time and global foreign accent in German–French simultaneous bilinguals during adulthood. International Journal of Bilingualism 20: 732–49. [Google Scholar] [CrossRef]
- Lenth, Russell V., Paul Buerkner, Maxime Herve, Jonathon Love, Hannes Riebl, and Henrik Singmann. 2021. emmeans: Estimated marginal means, aka least-squares means [R package], Version 1.7.0. Available online: https://cran.r-project.org/web/packages/emmeans/index.html (accessed on 2 March 2023).
- Lev-Ari, Shiri, and Sharon Peperkamp. 2013. Low inhibitory skill leads to non-native perception and production in bilinguals’ native language. Journal of Phonetics 41: 320–31. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1964. A cross-language study of voicing in initial stops: Acoustical measurements. Word 20: 384–422. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1967. Some effects of context on voice onset time in English stops. Language and Speech 10: 1–28. [Google Scholar] [CrossRef] [PubMed]
- Lisker, Leigh, and Arthur S. Abramson. 1970. The voicing dimension: Some experiments in comparative phonetics. In Proceedings of the 6th International Congress of Phonetic Sciences. Edited by Bohuslav Hála, Milan Romportl and Přmysl Janota. Prague: Academia, pp. 563–67. [Google Scholar]
- Major, Roy C. 1992. Losing English as a first language. The Modern Language Journal 76: 190–208. [Google Scholar] [CrossRef]
- Mathôt, Sebastiaan, Daniel Schreij, and Jan Theeuwes. 2012. OpenSesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods 44: 314–24. [Google Scholar] [CrossRef]
- Mora, Joan C., and Marianna Nadeu. 2012. L2 effects on the perception and production of a native vowel contrast in early bilinguals. International Journal of Bilingualism 16: 484–500. [Google Scholar] [CrossRef]
- Namjoshi, Jui, Annie Tremblay, Elsa Spinelli, Mirjam Broersma, Maria Teresa Martínez-García, Katrina Connell, Taehong Cho, and Sahyang Kim. 2015. Speech segmentation is adaptive even in adulthood: Role of the linguistic environment. In Proceedings of the 18th International Conference on Phonetic Sciences. Edited by The Scottish Consortium for ICPhS 2015. Glasgow: University of Glasgow, p. 0676. [Google Scholar]
- Nearey, Terrance M., and Bernard L. Rochet. 1994. Effects of place of articulation and vowel context on VOT production and perception for French and English stops. Journal of the International Phonetic Association 24: 1–18. [Google Scholar] [CrossRef]
- Nielsen, Kuniko. 2011. Specificity and abstractness of VOT imitation. Journal of Phonetics 39: 132–42. [Google Scholar] [CrossRef]
- Plomp, Reiner, and A. M. Mimpen. 1979. Improving the reliability of testing the speech reception threshold for sentences. International Journal of Audiology 18: 43–52. [Google Scholar] [CrossRef]
- R Development Core Team. 2022. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Sams, Mikko, Riitta Hari, Josi Rif, and Jukka Knuutila. 1993. The human auditory sensory memory trace persists about 10 sec: Neuromagnetic evidence. Journal of Cognitive Neuroscience 5: 363–70. [Google Scholar] [CrossRef]
- Sancier, Michele L., and Carol A. Fowler. 1997. Gestural drift in a bilingual speaker of Brazilian Portuguese and English. Journal of Phonetics 27: 421–36. [Google Scholar] [CrossRef]
- Sypiańska, Jolanta, and Zuzanna Cal. 2022. Perceptual drift in L1 phonetic categories in multilinguals. In Theoretical and Practical Developments in English Speech Assessment, Research, and Training: Studies in Honour of Ewa Waniek-Klimczak. Edited by Veronica G. Sardegna and Anna Jarosz. Cham: Springer, pp. 299–313. [Google Scholar] [CrossRef]
- Takahashi, Chikako. 2020. The Interaction Between L1 and L2 Phonetic Learning. Ph.D. thesis, Stony Brook University, Stony Brook, NY, USA. [Google Scholar]
- Tice, Marisa, and Melinda Woodley. 2012. Paguettes and bastries: Novice French learners show shifts in native phoneme boundaries. UC Berkeley Phonology Lab Annual Report 8: 72–75. [Google Scholar] [CrossRef]
- Wickham, Hadley. 2016. ggplot2: Elegant Graphics for Data Analysis. New York: Springer. Available online: https://ggplot2.tidyverse.org (accessed on 12 May 2022).
- Williams, Stefan, Pedro Guijarro-Fuentes, and Mila Vulchanova. 2022. U-shaped trajectories in an L2 context: Evidence from the acquisition of verb morphology. Vigo International Journal of Applied Linguistics 19: 223–66. [Google Scholar] [CrossRef]
- Winn, Matthew B. 2020. Manipulation of voice onset time in speech stimuli: A tutorial and flexible Praat script. Journal of the Acoustical Society of America 147: 852–66. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kellogg, J.; Chang, C.B. Exploring the Onset of Phonetic Drift in Voice Onset Time Perception. Languages 2023, 8, 78. https://doi.org/10.3390/languages8010078
Kellogg J, Chang CB. Exploring the Onset of Phonetic Drift in Voice Onset Time Perception. Languages. 2023; 8(1):78. https://doi.org/10.3390/languages8010078
Chicago/Turabian StyleKellogg, Jackson, and Charles B. Chang. 2023. "Exploring the Onset of Phonetic Drift in Voice Onset Time Perception" Languages 8, no. 1: 78. https://doi.org/10.3390/languages8010078
APA StyleKellogg, J., & Chang, C. B. (2023). Exploring the Onset of Phonetic Drift in Voice Onset Time Perception. Languages, 8(1), 78. https://doi.org/10.3390/languages8010078