

Operation LiLi: Using Crowd-Sourced Data and Automatic Alignment to Investigate the Phonetics and Phonology of Less-Resourced Languages


Abstract
:1. Introduction
2. Materials and Methods
- German (deu): German is a Germanic language mostly spoken in Germany, Austria and Switzerland. It displays 14 vocalic timbres: /i, y, ɪ, ʏ, e, ø, ɛ, œ, a, ə, ɔ, o, ʊ, u/.
- Afrikaans (afr): Afrikaans is a Germanic language mostly spoken in South Africa. It displays 18 vowels: 12 oral /i, y, e, ø, ɛ, œ, a, ɑ, ə, ɔ, o, u/ and 6 nasal /, ũ, , , , /, i.e., 12 vocalic timbres.
- French (fre): French is a Romance language mostly spoken in Europe, Northern America and Africa. Standard French displays 16 vowels: 12 oral /i, y, e, ø, ɛ, œ, a, ɑ, ə, ɔ, o, u/ and 4 nasal /, , , /, i.e., 12 vocalic timbres.
- Catalan (cat): Catalan is a Romance language mostly spoken in Northern Spain. Central Catalan displays 8 vocalic timbres: /i, e, ɛ, a, ə, ɔ, o, u/.
- Italian (ita): Italian is a Romance language mostly spoken in Italy. It displays 7 vocalic timbres: /i, e, ɛ, a, ɔ, o, u/.
- Romanian (ron): Romanian is a Romance language mostly spoken in Romania. It displays 7 vocalic timbres: /i, ɨ, e, ə, a, o, u/.
- Polish (pol): Polish is a Slavic language mostly spoken in Poland. It displays 6 oral vocalic timbres: /i, ɪ, ɛ, a, ɔ, u/ and 2 nasals /ẽ, õ/.
- Russian (rus): Russian is a Slavic language mostly spoken in Russia. It displays 6 vocalic timbres: /i, ɪ, e, a, o, u/.
- Spanish (spa): Spanish is a Romance language mostly spoken in Europe and Latin America. It displays 5 vocalic timbres: /i, e, a, o, u/.
- Basque (eus): Basque is an isolate mostly spoken in Northern Spain and South-Western France. It displays 5 vocalic timbres: /i, e, a, o, u/.
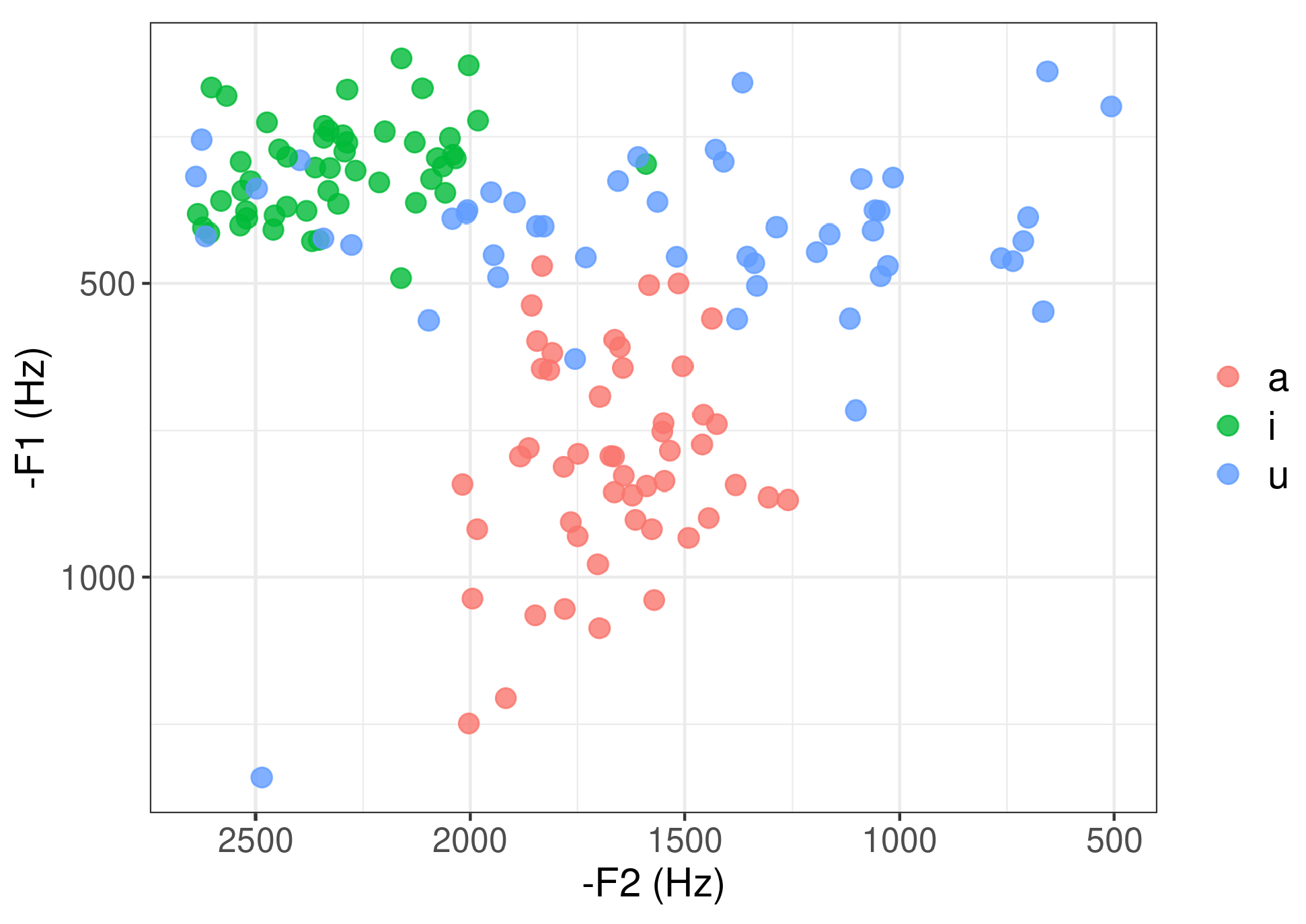
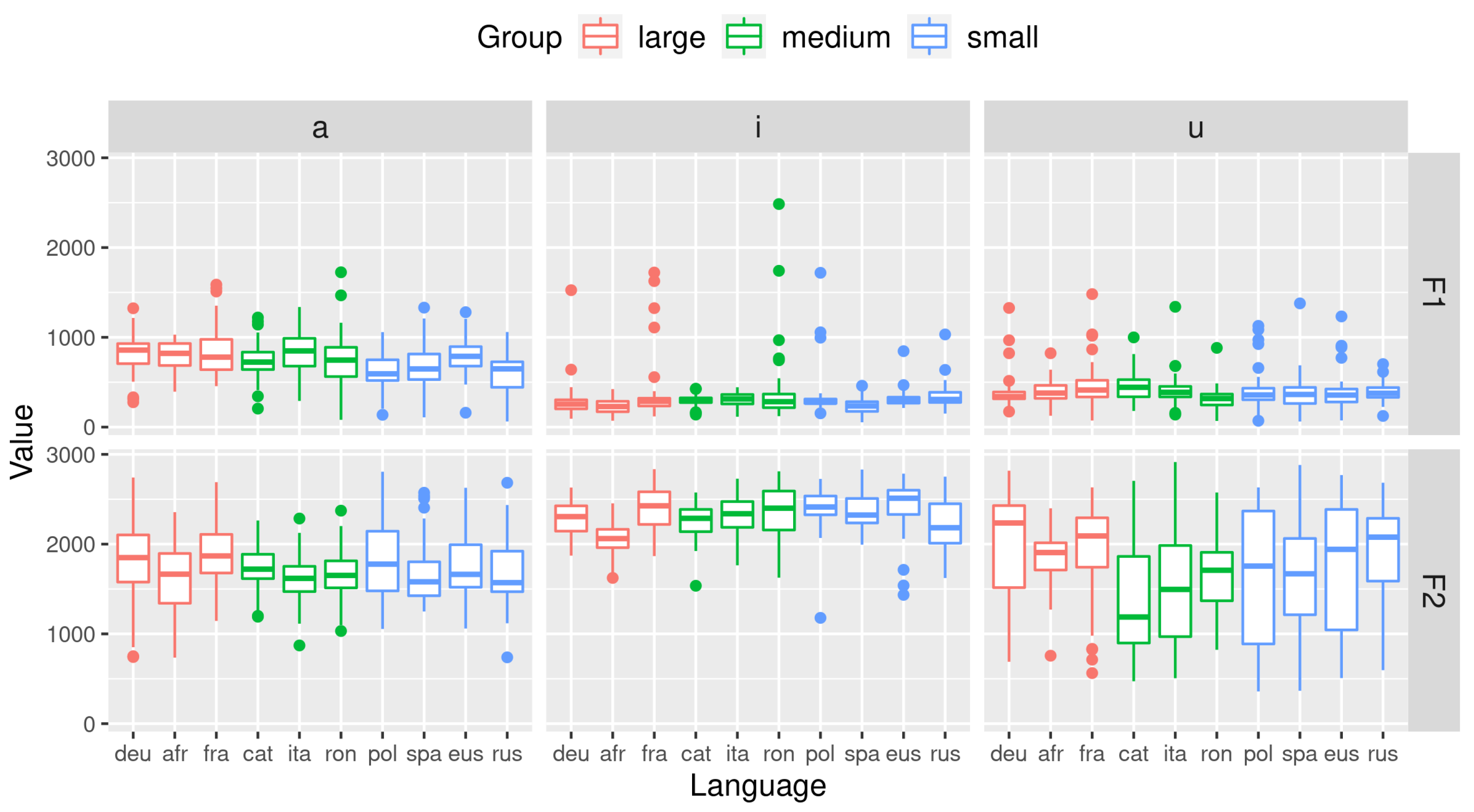
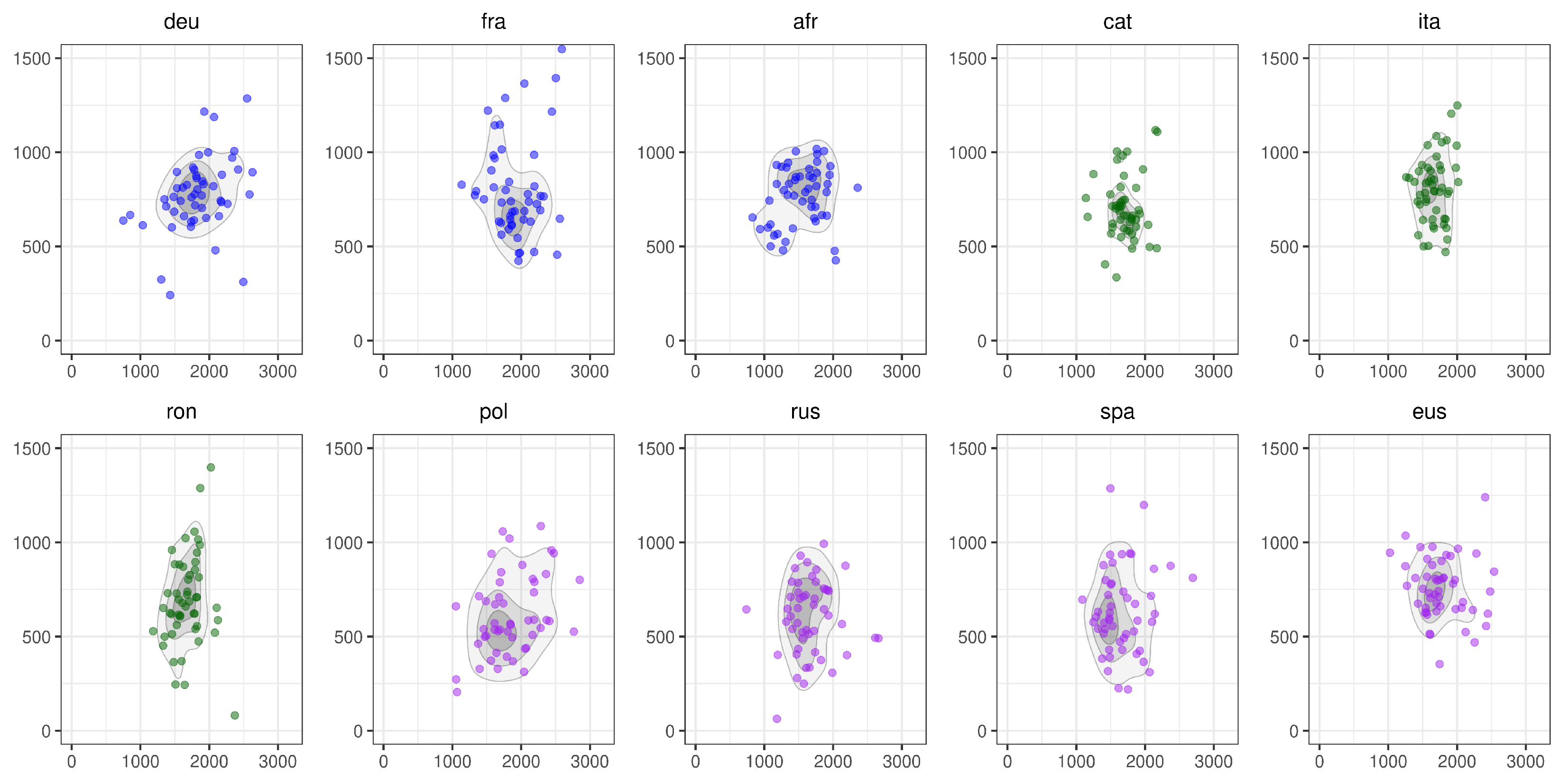
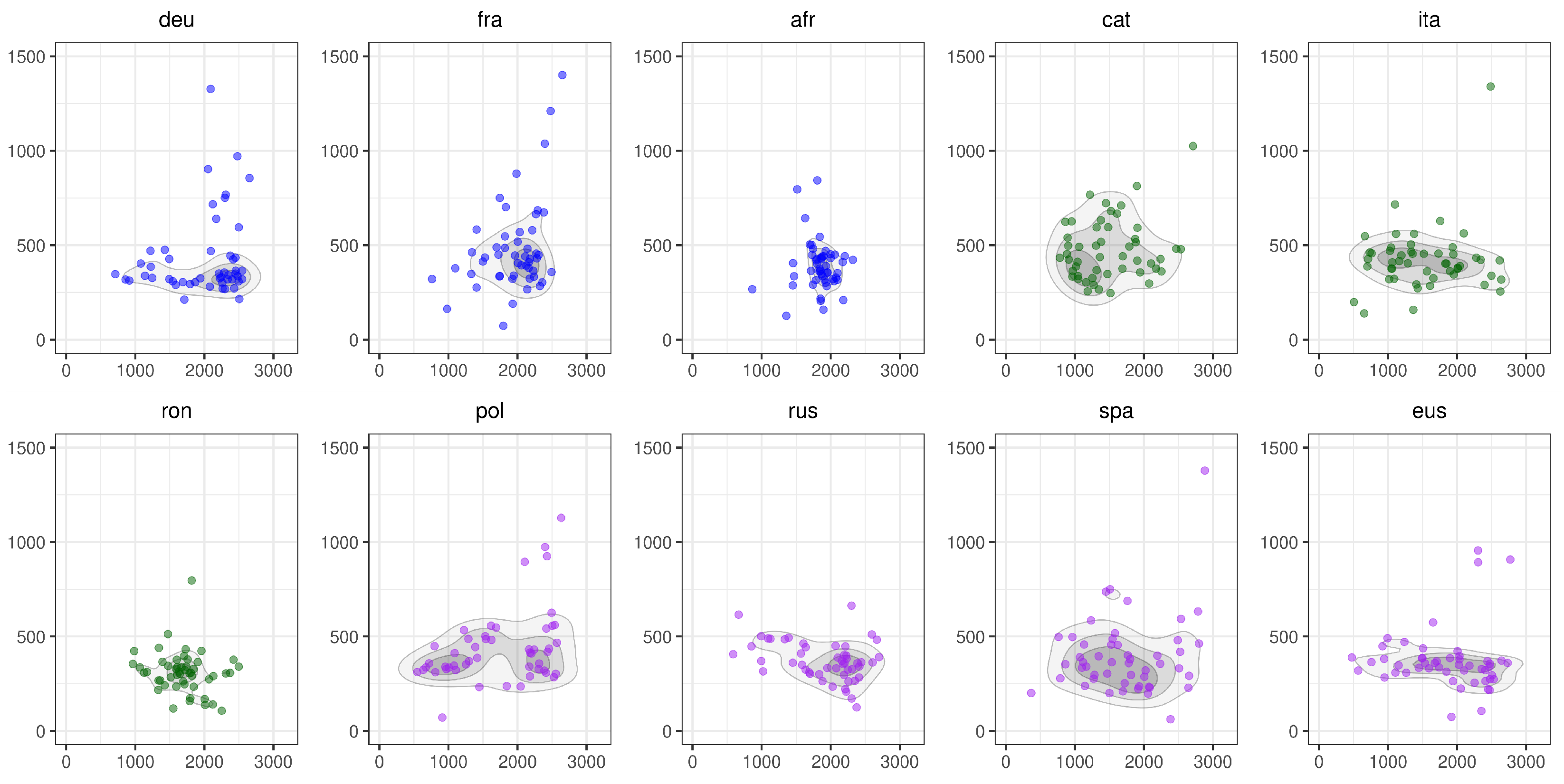
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VDT | Vowel Dispersion Theory |
| ISH | Inventory Size Hypothesis |
| MAUS | Munich Automatic Segmentation System |
| SAMPA | Speech Assessment Methods Phonetic Alphabet |
| 1 | The data of Lingua Libre can be downloaded directly at https://lingualibre.org/datasets/, accessed on 30 August 2022. |
| 2 | Since schwa is by definition the central vowel in inventories, it is expected, if the ISH is valid, to repel other vowels to the periphery of the acoustic space. |
References
- Ahn, Emily P., and Eleanor Chodroff. 2022. Voxcommunis: A corpus for cross-linguistic phonetic analysis. Paper presented at the 12th International Conference on Language Resources and Evaluation Conference (LREC 2022), Marseille, France, May 13–15. [Google Scholar]
- Al-Tamimi, Jalal-Eddin, and Emmanuel Ferragne. 2005. Does vowel space size depend on language vowel inventories? Evidence from two Arabic dialects and French. Paper presented at the Interspeech Eurospeech 2005, Lisbonne, Portugal, September 4–8; pp. 2465–68. [Google Scholar]
- Albin, Aaron. 2014. Praatr: An architecture for controlling the phonetics software “praat” with the r programming language. Journal of the Acoustical Society of America 135: 2198. [Google Scholar] [CrossRef]
- Ardila, Rosana, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. 2020. Common voice: A massively-multilingual speech corpus. arXiv arXiv:1912.06670. [Google Scholar]
- Bentz, Christian, and Bodo Winter. 2013. Languages with More Second Language Learners Tend to Lose Nominal Case. Language Dynamics and Change 3: 1–27. [Google Scholar] [CrossRef]
- Black, Alan W. 2019. Cmu wilderness multilingual speech dataset. Paper presented at the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, May 12–17; pp. 5971–75. [Google Scholar] [CrossRef]
- Bradlow, Ann R. 1995. A comparative acoustic study of english and spanish vowels. The Journal of the Acoustical Society of America 97: 1916–24. [Google Scholar] [CrossRef] [PubMed]
- Branco, António, Amália Mendes, Sílvia Pereira, Paulo Henriques, Thomas Pellegrini, Hugo Meinedo, Isabel Trancoso, Paulo Quaresma, Vera Lúcia Strube de Lima, and Fernanda Bacelar. 2012. A Língua Portuguesa na era Digital—The Portuguese Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Burchardt, Aljoscha, Markus Egg, Kathrin Eichler, Brigitte Krenn, Jörn Kreutel, Annette Leßmöllmann, Georg Rehm, Manfred Stede, Hans Uszkoreit, and Martin Volk. 2012. Die Deutsche Sprache im Digitalen Zeitalter—The German Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Calzolari, Nicoletta, Bernardo Magnini, Claudia Soria, and Manuela Speranza. 2012. La Lingua Italiana nell’Era Digitale—The Italian Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Dunbar, Ewan, Julien Karadayi, Mathieu Bernard, Xuan-Nga Cao, Robin Algayres, Lucas Ondel, Laurent Besacier, Sakriani Sakti, and Emmanuel Dupoux. 2020. The Zero Resource Speech Challenge 2020: Discovering Discrete Subword and Word Units. Paper presented at Interspeech 2020, Shanghai, China, October 25–29; pp. 4831–35. [Google Scholar] [CrossRef]
- Dunbar, Ewan, Robin Algayres, Julien Karadayi, Mathieu Bernard, Juan Benjumea, Xuan-Nga Cao, Lucie Miskic, Charlotte Dugrain, Lucas Ondel, Alan W. Black, and et al. 2019. The Zero Resource Speech Challenge 2019: TTS Without T. Paper presented at the Interspeech 2019, Graz, Austria, September 15–19; pp. 1088–92. [Google Scholar] [CrossRef]
- Dunbar, Ewan, Xuan Nga Cao, Juan Benjumea, Julien Karadayi, Mathieu Bernard, Laurent Besacier, Xavier Anguera, and Emmanuel Dupoux. 2017. The zero resource speech challenge 2017. Paper presented at 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, December 16–20. [Google Scholar]
- Engstrand, Olle, and D. Krull. 1991. Effects of inventory size on the distribution of vowels in the formant space: Preliminary data from seven languages. PERILUS 13: 15–18. [Google Scholar]
- Gendrot, Cédric, and Martine Adda-Decker. 2007. Impact of duration and vowel inventory on formant values of oral vowels: An automated formant analysis from eight languages. Paper presented at International Conference on Phonetics Sciences, Saarbrücken, Germany, August 6–10; pp. 1417–20. [Google Scholar]
- Heeringa, Wilbert, Heike Schoormann, and Jörg Peters. 2015. Cross-linguistic vowel variation in saterland: Saterland frisian, low german, and high german. The Journal of the Acoustical Society of America 137: 25–29. [Google Scholar] [CrossRef]
- Hernáez, Inmaculada, Eva Navas, Igor Odriozola, Kepa Sarasola, Arantza Diaz de Ilarraza, Igor Leturia, Araceli Diaz de Lezana, Beñat Oihartzabal, and Jasone Salaberria. 2012. Euskara Aro Digitalean—The Basque Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Hutin, Mathilde, and Marc Allassonnière-Tang. 2022a. Crowd-sourcing for less-resourced languages: Lingua libre for Polish. Paper presented at Language Resources and Evaluation Conference (LREC 2022), Marseille, France, June 20–25; pp. 41–47. [Google Scholar]
- Hutin, Mathilde, and Marc Allassonnière-Tang. 2022b. Investigating Phonological Theories with Crowd-Sourced Data: The Inventory Size Hypothesis in the Light of Lingua Libre. Seattle: Association for Computational Linguistics, pp. 23–28. [Google Scholar]
- Jongman, Allard, Marios Fourakis, and Joan A. Sereno. 1989. The Acoustic Vowel Space of Modern Greek and German. Language and Speech 32: 221–48. [Google Scholar] [CrossRef] [PubMed]
- Kipp, Andreas, Maria-Barbara Wesenick, and Florian Schiel. 1997. Pronuncation modeling applied to automatic segmentation of spontaneous speech. Paper presented at 5th European Conference on Speech Communication and Technology (Eurospeech 1997), Rhodes, Greece, September 22–25; pp. 1023–26. [Google Scholar]
- Kisler, Thomas, Uwe Reichel, and Florian Schiel. 2017. Multilingual processing of speech via web services. Computer Speech & Language 45: 326–47. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef] [Green Version]
- Ladd, D. Robert, Seán G. Roberts, and Dan Dediu. 2015. Correlational Studies in Typological and Historical Linguistics. Annual Review of Linguistics 1: 221–41. [Google Scholar] [CrossRef]
- Larouche, Chloé, and François Steffann. 2018. Vowel space of french and inuktitut: An exploratory study of the effect of vowel density on vowel dispersion. In Proceedings of the Workshop on the Structure and Constituency of Languages of the Americas. U. of British Columbia Working Papers in Linguistics 46. Vancouver: University of British Columbia, vol. 21. [Google Scholar]
- Lee, Wai-Sum. 2012. A cross-dialect comparison of vowel dispersion and vowel variability. Paper presented at 2012 8th International Symposium on Chinese Spoken Language Processing, Hong Kong, China, December 5–8; pp. 25–29. [Google Scholar]
- Liljencrants, Johan, and Björn Lindblom. 1972. Numerical simulation of vowel quality systems: The role of perceptual contrast. Language 48: 839–62. [Google Scholar] [CrossRef]
- Lindblom, Björn. 1986. Phonetic universals in vowel systems. In Experimental Phonology. Edited by John Ohala and Jeri Jaeger. Orlando: Academic Press, pp. 13–44. [Google Scholar]
- Lindblom, Björn. 1990. Explaining phonetic variation: A sketch of the h&h theory. In Speech Production and Speech Modelling. Edited by William Hardcastle and Alain Marchal. Dordrecht: Springer, pp. 403–39. [Google Scholar] [CrossRef]
- Livijn, Peter. 2000. Acoustic distribution of vowels in differently sized inventories—Hot spots or adaptive dispersion? PERILUS 23: 93–96. [Google Scholar]
- Mariani, Joseph, Patrick Paroubek, Gil Francopoulo, Aurélien Max, François Yvon, and Pierre Zweigenbaum. 2012. La Langue Française à l’ Ère du Numérique—The French Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Marjou, Xavier. 2021. Oteann: Estimating the Transparency of Orthographies with an Artificial Neural Network. Stroudsburg: Association for Computational Linguistics. [Google Scholar] [CrossRef]
- Melero, Maite, Toni Badia, and Asunción Moreno. 2012. La Lengua Española en la era Digital—The Spanish Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Meunier, Christine, Cheryl Frenck-Mestre, Taissia Lelekov-Boissard, and Martine Le Besnerais. 2003. Production and perception of vowels: Does the density of the system play a role? Paper presented at 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; pp. 723–26. [Google Scholar]
- Miłkowski, Marcin. 2012. Język Polski w erze Cyfrowej—The Polish Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Moran, Steven, and Daniel McCloy, eds. 2019. PHOIBLE 2.0. Jena: Max Planck Institute for the Science of Human History. [Google Scholar]
- Moreno, Asunción, Núria Bel, Eva Revilla, Emília Garcia, and Sisco Vallverdú. 2012. La Llengua Catalana a l’era Digital—The Catalan Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Peters, Jörg, Wilbert J. Heeringa, and Heike E. Schoormann. 2017. Cross-linguistic vowel variation in trilingual speakers of saterland frisian, low german, and high german. The Journal of the Acoustical Society of America 142: 991–1005. [Google Scholar] [CrossRef]
- Recasens, Daniel, and Aina Espinosa. 2009. Dispersion and variability in catalan five and six peripheral vowel systems. Speech Communication 51: 240–58. [Google Scholar] [CrossRef]
- Salesky, Elizabeth, Eleanor Chodroff, Tiago Pimentel, Matthew Wiesner, Ryan Cotterell, Alan W. Black, and Jason Eisner. 2020. A corpus for large-scale phonetic typology. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, July 5–10. Stroudsburg: Association for Computational Linguistics, pp. 4526–46. [Google Scholar] [CrossRef]
- Schiel, Florian. 1999. Automatic phonetic transcription of non-prompted speech. Paper presented at the XIVth International Congress of Phonetic Sciences: ICPhS 99, San Francisco, CA, USA, August 1–7; pp. 607–10. [Google Scholar]
- Schwartz, Jean-Luc, Louis-Jean Boë, Nathalie Vallée, and Christian Abry. 1997. The dispersion-focalization theory of vowel systems. Journal of Phonetics 25: 255–86. [Google Scholar] [CrossRef]
- Sinnemäki, Kaius, and Francesca Di Garbo. 2018. Language structures may adapt to the sociolinguistic environment, but it matters what and how you count: A typological study of verbal and nominal complexity. Frontiers in Psychology 9: 1141. [Google Scholar] [CrossRef]
- Trandabăț, Diana, Elena Irimia, Verginica Barbu Mititelu, Dan Cristea, and Dan Tufiș. 2012. Limba Română în era Digitală—The Romanian Language in the Digital Age. META-NET White Paper Series; Edited by Georg Rehm and Hans Uszkoreit. Berlin: Springer. Available online: http://www.meta-net.eu/whitepapers (accessed on 30 August 2022).
- Vaux, Bert, and Bridget Samuels. 2015. Explaining vowel systems: Dispersion theory vs natural selection. The Linguistic Review 32: 573–99. [Google Scholar] [CrossRef]
- Venables, Bill, Brian D. Ripley, and Bill Venables. 2002. Modern Applied Statistics with S, 4th ed. Statistics and Computing. New York: Springer. [Google Scholar]
- Versteegh, Maarten, Roland Thiollière, Thomas Schatz, Xuan Nga Cao, Xavier Anguera, Aren Jansen, and Emmanuel Dupoux. 2015. The zero resource speech challenge 2015. Paper presented at Interspeech 2015, Dresden, Germany, September 4–5; pp. 3169–73. [Google Scholar] [CrossRef]
- Wells, John. 1997. SAMPA Computer Readable Phonetic Alphabet. Volume Part IV. Berlin: Mouton de Gruyter. [Google Scholar]
- Wickham, Hadley. 2017. tidyverse: Easily Install and Load the Tidyverse. R Package Version 1.2.1. Vienna: The R Foundation for Statistical Computing. [Google Scholar]
- Winkelmann, Raphael, Jonathan Harrington, and Klaus Jänsch. 2017. EMU-SDMS: Advanced Speech Database Management and Analysis in R. R Package Version 2.3.0. Vienna: The R Foundation for Statistical Computing. [Google Scholar]
- Zhang, Menghan, and Tao Gong. 2022. Structural variability shows power-law based organization of vowel systems. Frontiers in Psychology 13: 801908. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | iso | Vowel Inventory | [a] | [i] | [u] | Speaker Count |
|---|---|---|---|---|---|---|
| German | deu | 14 | 551 | 225 | 70 | 9 |
| Afrikaans | afr | 12 | 228 | 249 | 87 | 3 |
| French | fra | 12 | 408 | 285 | 56 | 13 |
| Catalan | cat | 8 | 398 | 478 | 325 | 4 |
| Italian | ita | 7 | 969 | 538 | 104 | 4 |
| Romanian | ron | 7 | 794 | 524 | 377 | 4 |
| Polish | pol | 6 | 936 | 347 | 162 | 8 |
| Russian | rus | 6 | 951 | 560 | 199 | 10 |
| Spanish | spa | 5 | 1087 | 413 | 139 | 13 |
| Basque | eus | 5 | 1376 | 542 | 253 | 6 |
| Vowel | ID | iso | F1 | F2 | Speaker | Item |
|---|---|---|---|---|---|---|
| i | 5460 | fra | 430 | 2588 | 0x010C | rime |
| i | 6547 | fra | 315 | 2394 | WikiLucas00 | décider |
| u | 6546 | fra | 356 | 1995 | WikiLucas00 | debout |
| u | 6648 | fra | 323 | 2024 | WikiLucas00 | pelouses |
| a | 5536 | fra | 641 | 2575 | DenisdeShawi | accourent |
| Dependent Variable | Predictor | Estimate | df | t Value | p Value |
|---|---|---|---|---|---|
| Area | nb_of_timbres | 0.002 | 5 | 0.038 | 0.972 |
| Area | vowel_i | −0.064 | 288 | −1.437 | 0.152 |
| Area | vowel_u | −0.077 | 288 | −1.731 | 0.085 |
| Area | Group_medium | 0.040 | 5 | 0.154 | 0.883 |
| Area | Group_small | 0.084 | 5 | 0.243 | 0.818 |
| Area | with_schwa | −0.007 | 5 | −0.057 | 0.957 |
| sd F1 | nb_of_timbres | −20.387 | 5 | −0.732 | 0.497 |
| sd F1 | vowel_i | −61.511 | 288 | −7.385 | 0.000 *** |
| sd F1 | vowel_u | −50.488 | 288 | −6.062 | 0.000 *** |
| sd F1 | Group_medium | −99.208 | 5 | −0.648 | 0.545 |
| sd F1 | Group_small | −112.119 | 5 | −0.552 | 0.605 |
| sd F1 | with_schwa | 57.125 | 5 | 0.804 | 0.458 |
| sd F2 | nb_of_timbres | 40.694 | 5 | 3.197 | 0.024 * |
| sd F2 | vowel_i | −114.216 | 288 | −11.013 | 0.000 *** |
| sd F2 | vowel_u | 225.373 | 288 | 21.731 | 0.000 *** |
| sd F2 | Group_medium | 191.031 | 5 | 2.732 | 0.041 * |
| sd F2 | Group_small | 329.166 | 5 | 3.548 | 0.016 * |
| sd F2 | with_schwa | −51.890 | 5 | −1.599 | 0.171 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hutin, M.; Allassonnière-Tang, M. Operation LiLi: Using Crowd-Sourced Data and Automatic Alignment to Investigate the Phonetics and Phonology of Less-Resourced Languages. Languages 2022, 7, 234. https://doi.org/10.3390/languages7030234
Hutin M, Allassonnière-Tang M. Operation LiLi: Using Crowd-Sourced Data and Automatic Alignment to Investigate the Phonetics and Phonology of Less-Resourced Languages. Languages. 2022; 7(3):234. https://doi.org/10.3390/languages7030234
Chicago/Turabian StyleHutin, Mathilde, and Marc Allassonnière-Tang. 2022. "Operation LiLi: Using Crowd-Sourced Data and Automatic Alignment to Investigate the Phonetics and Phonology of Less-Resourced Languages" Languages 7, no. 3: 234. https://doi.org/10.3390/languages7030234
APA StyleHutin, M., & Allassonnière-Tang, M. (2022). Operation LiLi: Using Crowd-Sourced Data and Automatic Alignment to Investigate the Phonetics and Phonology of Less-Resourced Languages. Languages, 7(3), 234. https://doi.org/10.3390/languages7030234