Subject (SRCs) and object relative clauses (ORCs) such as (1a) and (1b) are instances of filler–gap dependencies involving movement of a noun (NP) from a canonical thematic position to a higher position in the structure. Even though both (1a) and (1b) include a displaced NP, the two structures differ crucially in the position of the extraction site (indicated by __). In SRCs such as (1a), the extracted NP moves from the subject of the relative clause position (o majiras esprokse ton servitoro, ’the cook pushed the waiter‘) to the left periphery, whereas in ORCs such as (1b) the extracted NP moves from the direct object of the verb to the left periphery (o servitoros esprokse ton majira, ’the waiter pushed the cook’).
1.1. Relative Clause Processing in Adults
One of the main foci of the sentence processing research in the past thirty years has been to investigate the extent to which parsing strategies are universal, and at the same time to identify language-specific properties that actively contribute to the real-time parsing of complex structures. The investigation of relative clause processing, and more specifically the potential differences in processing difficulty between SRCs and ORCs, gives us the opportunity to explore these questions. One of the first studies that discussed the processing asymmetry between SRCs and ORCs is the study by
King and Just (
1991). In this study,
King and Just (
1991) investigated structures such as those in (2).
| 2. | a. | The reporter that attacked the senator admitted the error. (SRC) |
| | b. | The reporter that the senator attacked admitted the error. (ORC) |
In the examples from
King and Just (
1991) in (2a) and (2b), both sentences include an extracted noun phrase (NP) (the reporter) which must be maintained in working memory (WM) until the moment that it is integrated in the structure.
King and Just (
1991) showed that ORCs caused substantial processing difficulty, especially in participants with a low WM span. A large amount of experimental research in adult populations has subsequently revealed that ORCs (such as 2b) are processed more slowly and are thus harder to comprehend than SRCs (2a) (e.g.,
Bates and MacWhinney 1982;
Gibson 1998;
Gordon et al. 2001;
King and Just 1991;
Mak et al. 2002,
2006;
Traxler et al. 2002;
Warren and Gibson 2002). The main hypotheses that have been put forward to account for this processing discrepancy have been based on perspective shifting (e.g.,
Bever 1970;
MacWhinney and Pléh 1988), syntactic and discourse factors (e.g.,
Clifton and Frazier 1989;
Frazier and Clifton 1989;
Frazier and Flores d’Arcais 1989), working memory limitations (e.g.,
Gibson 1998), and expectation-based processing (e.g.,
Levy 2008). We broadly divide these accounts into two categories: universal complexity accounts, which assume similar parsing strategies cross-linguistically, and parametric differences accounts, which hypothesize that RC parsing complexity depends to a large extent on language-specific morphosyntactic features and probabilistic constraints.
The main claim of universal complexity accounts is that SRCs should always be easier to comprehend than ORCs because subjects are inherently more salient than objects. Two prominent approaches that can be characterized as universal complexity accounts are the Accessibility Hierarchy (e.g.,
Keenan and Comrie 1977;
Keenan and Hawkins 1987) and the Perspective Shift Hypothesis (e.g.,
Bever 1970;
MacWhinney and Pléh 1988). The Accessibility Hierarchy claims that certain NPs are hierarchically more accessible than others when they act as antecedents of relative clauses. In this hierarchy, subjects are more accessible than objects and thus SRCs should always be easier to process than ORCs. The Perspective Shift Hypothesis claims that SRCs should always be favored, because they do not involve any change in perspective shift (i.e., the subject of the main clause is also the subject of the relative clause). In contrast, the difficulty of ORCs stems from switching perspectives (from subject of the main clause to object of the relative clause) and this requires additional cognitive resources. Although the predictions of universal complexity accounts are verified for SVO languages such as English and French, they do not seem to hold for head-final and ergative languages (e.g., Chinese:
Hsiao and Gibson (
2003) and Basque:
Carreiras et al. (
2010)).
Accounts positing that the processing of SRCs and ORCs may vary depending on cross-linguistic or parametric differences among languages can be broadly categorized into two distinct groups: memory limitation theories and expectation-based theories. Theories that assume that working memory limitations play an important role in the processing of relative clauses include the Active Filler Strategy (
Clifton and Frazier 1989;
Frazier and Flores d’Arcais 1989), the Minimal Chain Principle (
De Vincenzi 1991), the Decay/Reactivation/Retrieval–Interference Theory (
Lewis and Vasishth 2005), the Similarity-based Interference Model (e.g.,
Gordon et al. 2001;
Lewis and Vasishth 2005;
McElree et al. 2003), the Self-Organized Sentence Processing Model (SOSP) (e.g.,
Tabor and Hutchins 2004), and the Dependency Locality Theory (DLT:
Gibson 1998,
2000). The DLT (
Gibson 1998,
2000), for example, predicts that the most integration-intensive word should be the verb of the ORC (
attacked in (2b)), as it is the point at which both the preceding subject and object NPs must simultaneously be integrated in the structure, whereas this is not the case in SRCs (such as (2a)). The DLT thus places considerable importance on the linear distance of the retrieved element from the integration site. In other words, the greater the linear distance between the retrieved element and the integration site, the larger the processing difficulty. A very important advantage of the DLT is that it makes clear predictions concerning the exact point of parsing difficulty during on-line processing, and thus makes it easier to test experimentally. Several studies (e.g.,
Grodner and Gibson 2005;
Hsiao and Gibson 2003;
Traxler et al. 2002,
2005;
Vasishth et al. 2013;) have provided experimental support for the DLT from data in English and Chinese (cf.
Xiaoxia et al. 2016 for Chinese). Experimental support for working memory limitation theories has also been provided from French (e.g.,
Cohen and Mehler 1996).
The second main group of accounts that take into consideration possible parametric differences across languages are expectation-based theories. Expectation-based theories include word-order frequency theories (e.g.,
Bever 1970;
MacDonald and Christiansen 2002), which assume that surface word orders with higher frequency in a language are easier to process than orders with lower frequency (e.g.,
Reali 2014), and syntactic surprisal accounts (e.g.,
Gennari and MacDonald 2008;
Hale 2001;
Levy 2008), which predict difficulty in processing for less frequent structures on the assumption that the parser takes longer to integrate less expected input in an incremental structure. More specifically, Surprisal (
Hale 2001;
Levy 2008;
Smith and Levy 2013) predicts that the parser creates and updates fine-grained expectations for the upcoming input at multiple levels of the linguistic structure. This means that structural frequencies have a direct relation to comprehenders’ moment-to-moment parsing decisions. For example, under the Verb Predictability Hypothesis (
Levy 2008) pre-verbal RC NPs such as
the senator in (2b) are expected to be harder to process because NP Comp NP structures are less frequent and thus less expected. In contrast, the verb of the ORC (
attacked in (2b)) is expected to be easier to process than the verb in the SRC because in the ORC the occurrence of a verb after an NP is more probable. This prediction directly contrasts with the prediction of the DLT, under which the ORC verb is expected to be the hardest to process. Experimental support for expectation-based theories comes from languages that are predominantly verb-final, have a relatively high flexibility in scrambling nominal constituents, and have rich morphological systems, such as Hindi (
Vasishth and Lewis 2006), German (
Konieczny 2000;
Konieczny and Döring 2003), and Japanese (e.g.,
Miyamoto and Nakamura 2003;
Nakatani and Gibson 2009).
Parametric difference hypotheses, such as the DLT and Surprisal, have been tested in studies that include data from free word order languages, such as Russian and Hungarian. In Russian,
Levy et al. (
2013) and
Price and Witzel (
2017) examined the on-line processing of SRCs and ORCs introduced by the case-marked relative pronoun
kotoryj ‘who’ /
kotorogo ‘whom‘ and the case-syncretized relative pronoun
chto ‘who’, ‘whom‘. Levy et al.’s study found support for the DLT (e.g.,
Gibson 1998) in the case-marked relative pronoun condition, but also partial evidence for expectation-based processing (
Levy 2008) in the syncretized pronoun condition. More specifically,
Levy et al. (
2013) investigated structures such as (1a) and (1b) in Russian, manipulating RC word order (either RC verb or RC NP immediately following the relative pronoun) and case (the relative pronoun was in nominative case in SRCs and accusative case in ORCs). This case manipulation did not of course apply in the case-syncretized relative pronoun condition with
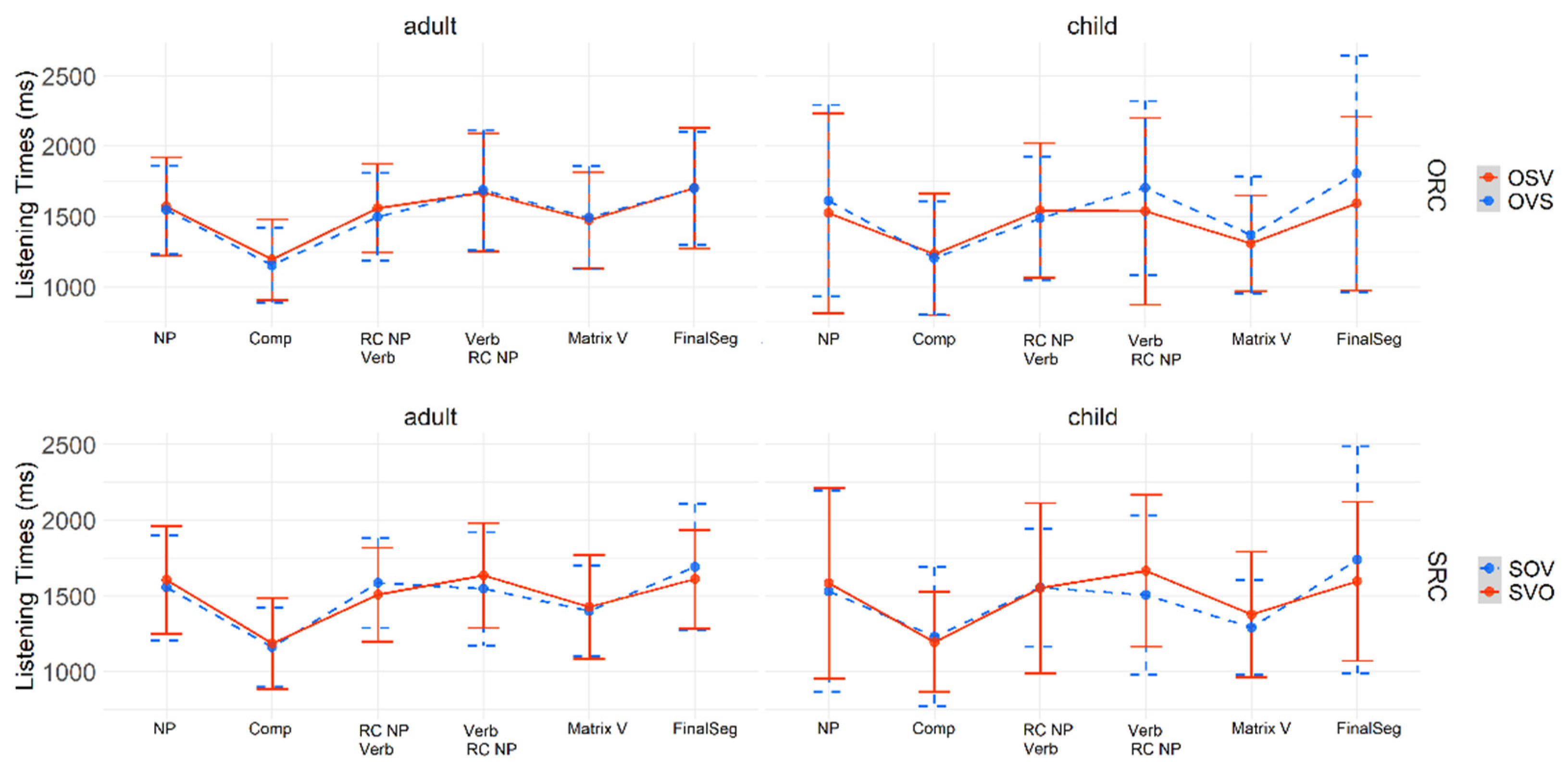
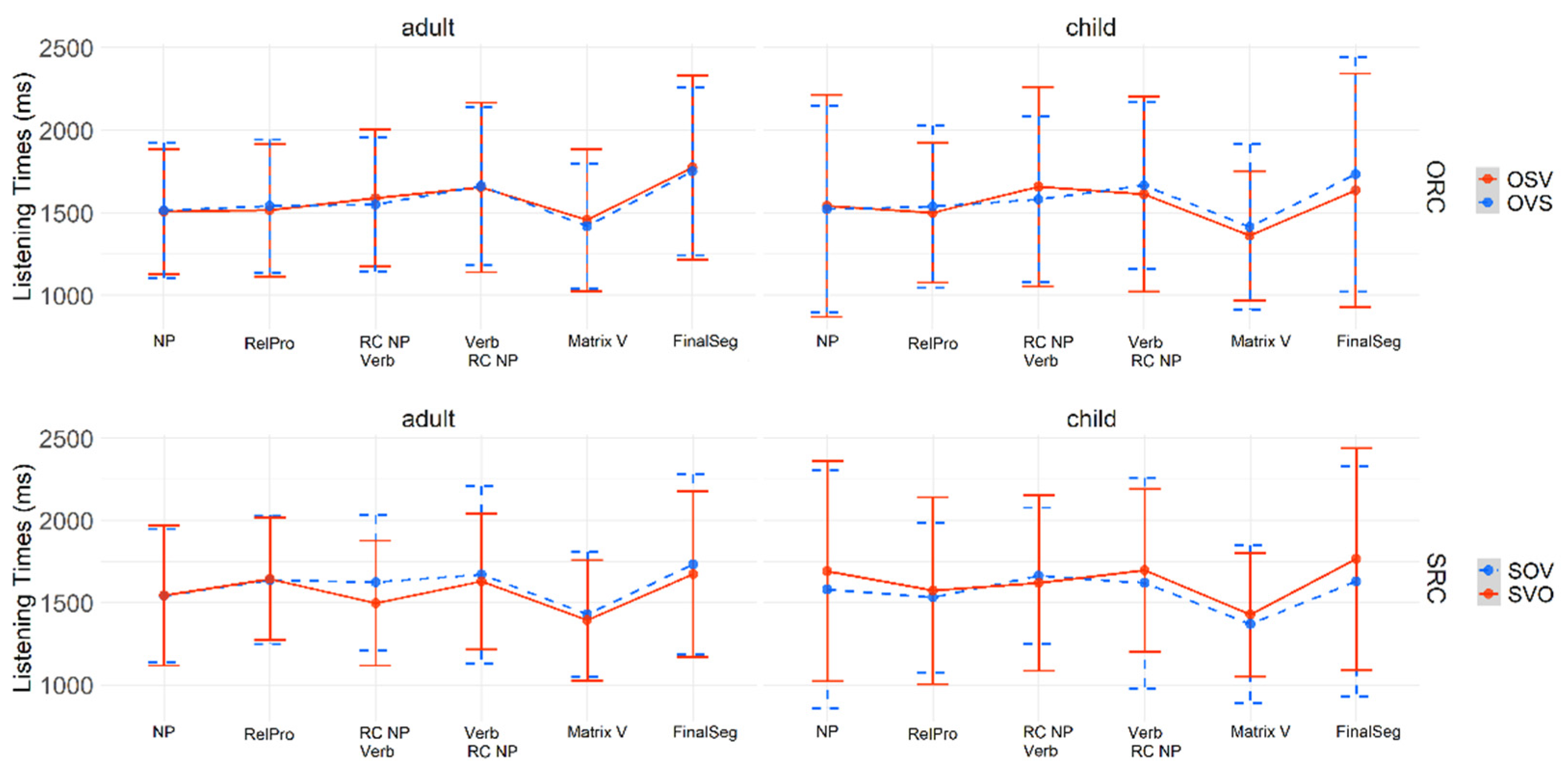
chto, in which only word order was manipulated. In total, there were four experimental conditions: SRC canonical (SVO), SRC scrambled (SOV), ORC canonical (OSV), and ORC scrambled (OVS), as in (3).
| 3. | a. | Elektrik, kotoryj udaril slesarja so vsego rasmaxa… (SRC, default/SVO) |
| | | Electrician, who.NOM hit repairman.ACC with all strength |
| | b. | Elektrik, kotoryj slesarja udaril so vsego rasmaxa… (SRC, Scrambled/SOV) |
| | | Electrician, who.NOM repairman.ACC hit with all strength |
| | | ’The electrician, who hit the repairman with all his strength…’ |
| | c. | Elektrik, kotorogo slesar’ udaril so vsego rasmaxa… (ORC, default/OSV) |
| | | Electrician, whom.ACC repairman.NOM hit with all strength |
| | d. | Elektrik, kotorogo udaril slesar’ so vsego rasmaxa…(ORC, scrambled/OVS) |
| | | Electrician, whom.ACC hit repairman.NOM with all strength |
| | | ’The electrician, whom the repairman hit with all his strength…’ |
After conducting a self-paced reading task,
Levy et al. (
2013) found no statistically significant difference between SRCs and ORCs in the inflected relative pronoun condition, but a statistically significant time penalty for the two conditions in which the RC verb was linearly distant from the relative pronoun (i.e., SRC scrambled and ORC canonical).
Levy et al. (
2013) thus argued in favor of the DLT in the inflected relative pronoun condition. In the case-syncretized pronoun condition, however, there was an overall time advantage for SRCs, which is the most frequent word order in Russian. Thus, contrary to the inflected relative pronoun condition, the syncretized pronoun condition provided evidence for expectation-based accounts. It should be noted here that the DLT does not make any specific predictions for case-inflected vs. case-syncretized relative pronouns. Accordingly,
Levy et al. (
2013) originally predicted a time penalty on the RC verb in non-local conditions (RC verb not adjacent to relative pronoun), independently of the properties of the relative pronoun. In addition, in a study including self-paced reading and eye-tracking data in Russian SRCs and ORCs with full and pronominal NPs,
Price and Witzel (
2017) also found mixed evidence for working memory limitation and expectation-based theories. In Hungarian,
Kovács and Vasishth’s (
2013) study on SRCs and ORCs introduced by the case-marked relative pronoun
aki ‘who’ /
akit ‘whom‘ provided support for the DLT. As we can see, the very limited number of previous studies does not help us to reach clear conclusions on the real-time processing strategies of speakers of free word order/rich morphology languages. We thus hope that by providing data from Greek we can shed more light onto the real-time processing of complex structures in adults and 11- to 12-year-old children, as well as contribute to the understanding of the role that certain language-specific morphosyntactic cues play in the on-line processing of complex structures in Greek.
In the current study, we present relative clause processing data in Greek. Greek is traditionally classified as an SVO language, although it allows all possible word order combinations (e.g.,
Catsimali 1990;
Horrocks 1994;
Tsimpli 1990;
Tzanidaki 1998). In addition, Greek has a rich nominal inflectional system, with a three-partite gender system and a four-partite case system. Although Greek has a certain degree of case syncretism (mainly involving the neuter gender), syntactic relations can most of the time be identified no matter in which position of the clause an element occurs. Relative clauses in Greek are post-nominal and are introduced with either the complementizer
pu ‘that‘ or the inflected relative pronoun
o opios / i opia / to opio ‘who
-MASC-FEM-NEU‘ (
Alexiadou 1997;
Holton et al. 2012;
Joseph 1983;
Mackridge 1992). Under the hypothesis, then, that specific morphosyntactic characteristics of a language play an active role in on-line processing, we can broadly categorize Greek into a group of languages with free word order and rich morphology. In contrast to languages with rigid word order such as English, on-line relative clause studies in free word order languages in adults are very limited and, to our knowledge, there is no previous study examining on-line RC processing in a free word order language in children
Following the word order manipulation of the above-mentioned free word order language studies, our study also manipulates word order so as to include an SRC and an ORC condition in which the RC verb is adjacent to the relative pronoun, and an SRC and ORC condition in which the RC verb is linearly distant from the relative pronoun. In addition, similar to
Levy et al. (
2013),
Price and Witzel (
2017) and
Kovács and Vasishth (
2013), the RCs in our experimental sentences were headed by the inflected relative pronoun o
opios ‘who’ /
ton opio ‘whom‘, and parallel to
Levy et al. (
2013), our RCs were also headed by a non-inflected relativizer, namely the complementizer
pu ‘that‘. Thus, on the basis of previous evidence from free word order languages, we predict that monolingually raised Greek speakers follow the DLT strategy in the case-inflected pronoun condition. This means that local structures (RC verb adjacent to relative pronoun) are expected to be processed faster than non-local ones, independently of whether or not the RC is subject- or object-modifying. This strategy is not expected to hold for RCs introduced by the complementizer, as in this case we expect frequency to take precedence over locality. In other words, the fact that canonical word order SRCs introduced by the complementizer
pu ‘that’ in Greek are much more frequent than any of the other SRC or ORC, word order configuration is expected to facilitate SVO SRCs. These predictions may or may not hold in the case of 11- to 12-year-old children. We discuss this issue in more detail in the next section after we first provide an overview of previous relative clause studies in children.
1.2. Relative Clause Processing in Children
The timing of information processing and cue integration during real-time processing has been widely investigated in adults across different languages. There are, however, to date very few studies focusing on the moment-to-moment structural processing in children. When it comes to morphosyntax, for example, a number of studies investigate the comprehension and production of filler–gap dependencies such as relative clauses in children (e.g.,
Guasti et al. 2012;
Arosio et al. 2009;
Friedmann et al. 2009;
Stavrakaki et al. 2015;
Varlokosta et al. 2015). In comparison, however, very few studies have used temporally sensitive measures to study the comprehension of complex structures in children (for a review, see
Sekerina et al. 2008). The main reason for this is that it is quite challenging to apply on-line methods (e.g., self-paced reading, eye tracking) that are used in the adult population to children, especially when dealing with filler–gap structures which are cognitively demanding. Nonetheless, such studies are crucial. On the one hand, the investigation of children’s comprehension and production skills in their early stages of linguistic development provides us with valuable insight into children’s linguistic knowledge, and on the other hand, the study of children’s real-time processing can inform us about how children apply their linguistic knowledge in the moment-to-moment parsing of linguistic structures. Studying real-time processing in children can also inform us whether children’s sentence-parsing mechanisms are similar to or different from those of adults.
The idea of continuity in language processing (
Crain and Thornton 1998;
Crain and Wexler 1999;
Fodor 1998) was incorporated into Clahsen and Felser’s Continuity of Parsing Hypothesis (
Clahsen and Felser 2006b; see also
Felser et al. 2003), which predicts no qualitative differences between child and adult parsing strategies.
Felser et al. (
2003) provide experimental support for the continuity of parsing hypothesis in a study on 6- to 7-year-old English children and adults processing temporarily ambiguous RC structures in English. Their experimental material included sentences such as those in (4).
| 4. | a. | The doctor recognized the nurse of the pupil who was feeling very tired. |
| | b. | The doctor recognized the nurse with the pupil who was feeling very tired. |
Structures such as (4a) and (4b) are ambiguous in that the RC can either modify the immediately preceding NP
the pupil (low attachment) or the complex NP
the nurse of (with) the pupil (high attachment). After conducting a self-paced listening task,
Felser et al. (
2003) found a significant interaction between type of preposition (
of vs.
with) and attachment type (high vs. low) only in the adult group. This means that adult English speakers preferred high attachment in structures including the preposition
of and low attachment in structures including the preposition
with. Therefore, the lexical choice of preposition affected adults’—but not children’s—RC attachments. Children showed a preference for high attachment irrespective of preposition, but an additional short-term memory span test indicated that 6- to 7-year-old children’s attachment preferences significantly interacted with their listening span; low-span children showed an overall preference for low RC attachment, while high-span children showed a preference for high attachment irrespective of preposition.
Felser et al. (
2003) thus argue that, depending on their listening span, children apply one of two locality principles during on-line ambiguous RC attachment; similar to adults, high-span children follow the “predicate proximity” principle (
Gibson et al. 1996), whereas low-span children apply a linear locality strategy by associating the RC to the most recently processed NP. Thus, contrary to adults whose on-line parsing is affected by the semantics of the preposition (
of vs.
with), younger children’s on-line parsing is based on the semantic associations between NPs. Older children follow a more structural-based strategy (predicate proximity), which favors RC attachment to the NP that is closest to the IP node (
Gibson et al. 1996). Overall,
Felser et al. (
2003) claim that their study provides evidence for the continuity of parsing hypothesis, as it shows that although the high-span children’s self-paced listening pattern differed from that of adults (evidenced by children’s lack of significant time difference between the processing of structures with the two types of preposition), the pattern in the grammaticality judgment task that immediately followed the on-line task was the same. Felser et al.’s interpretation of this result is that children’s use of semantic and contextual information is not yet fully developed and automatized (
Felser et al. 2003 provide similar evidence from 10- to 11-year-old children) for effects to appear on-line. The fact, however, that children and adults have the same pattern of results in the grammaticality judgment task that immediately followed the on-line task shows that children may simply need more time to integrate lexicosemantic and contextual information.
Children’s on-line RC processing has also been investigated within the scope of structural complexity processing.
Booth et al. (
2000) examined 8- to 11-year-old children’s SRC and ORC processing in a self-paced reading and a self-paced listening task.
Booth et al.’s (
2000) materials included structures such as those in (5).
| 5. | a. | The principal that tripped the janitor used the phone to call home. (SRC) |
| | b. | The man that the captain invited built the stage for the band. (ORC) |
On the basis of the Perspective Shift hypothesis (e.g.,
MacWhinney and Pléh 1988),
Booth et al. (
2000) predict that children have more difficulty with ORCs, which require two perspective shifts (shifting from the subject of the main clause
the man in (5b) to the subject of the RC
the captain and then back to the subject of the main clause), than with SRCs in which no perspective shift is required.
Booth et al. (
2000) also administered measures of working memory and short-term memory span. The self-paced reading and the self-paced listening tasks yielded similar results; children were significantly slower in the transition from main to relative clause in ORCs than in SRCs. Interestingly, the short-term memory digit span task showed that high-digit-span/older children slowed down more often than low-digit-span/younger children in the transition from the main to the relative clause.
Booth et al. (
2000) account for this result by claiming that high-digit-span children process cognitively demanding structures such as ORCs (5b) through storing each word in their short-term memory, allowing them to be more accurate than low-span children in answering comprehension questions. In contrast, low-digit-span/younger children do not (yet) have that option and this leads them to faster on-line RC processing but lower comprehension question accuracy compared to high-span children. Irrespective of the differences in processing speed between high- and low-span children, children’s overall pattern of results (ORCs harder to process than SRCs) was similar to adults, and thus Booth et al. argue in favor of continuity in parsing.
In a recent study,
Guasti et al. (
2018) also provide evidence for continuity in sentence comprehension from a referent selection task and self-paced reading task including SRCs and ORCs in 5- to 7-year-old children and adults in French and Italian.
Guasti et al. (
2018) replicate the well-known SRC/ORC asymmetry and argue that structures that are first acquired by children (such as SRCs) are the easiest for adults to process (see
Phillips and Ehrenhofer 2015). Interestingly,
Guasti et al.’s (
2018) materials in French and Italian also include a word order manipulation in the ORC condition, as shown in (6).
| 6. | a. | Montre-moi [le lion qui mord les chameaux] (SRC, SVO) |
| | | ‘Show me the lion that bites the camels.’ |
| | b. | Montre-moi [l’oie que les lapins poursuivent] (ORC, OSV) |
| | | ‘Show me the goose that the rabbits chase.’ |
| | c. | Montre-moi [les lions que bat le cheval] (ORC, OVS) |
| | | show me the lions that hits the horse |
| | | ‘Show me the lions that the horse hits.’ |
Schelstraete and Degand (
1998) previously showed that OVS structures were easier to process than OSV structures in self-paced reading in French-speaking adults.
Schelstraete and Degand (
1998) interpret these results on the grounds of the Competition Model (e.g.,
MacWhinney and Pléh 1988), according to which grammatical role assignment of NPs in a sentence is based on the competition of cues such as frequency, case marking, and agreement, etc. The competition of NP cues, the weight of which may vary across different languages, starts as soon as the verb is encountered. Before encountering the verb, NPs are assumed to remain unbounded, thus causing working memory load. Thus, according to
Schelstraete and Degand (
1998), French OSV structures were read more slowly than OVS structures because OSV structures such as (6b) involve NP cue competition and working memory load, whereas OVS structures such as (6c) only involve competition
2. In contrast,
Guasti et al. (
2018) provide evidence from French and Italian adults and children that pre-verbal subject OSV structures are actually easier to process than post-verbal subject OVS structures.
Guasti et al. (
2018) explain this result on the grounds of
Fodor and Inoue’s (
2000) Diagnosis and Repair Model, according to which the parser resorts to a re-analysis of the initial structure. This process involves the revising or repairing of an existing analysis rather than building a new one. In OSV relatives, the parser receives information from two NPs that the preferred SRC interpretation is not correct and on the basis of these two NPs re-analyzes the structure and achieves the correct analysis upon reaching the verb. In OVS relatives, however, the parser sees the object NP and then the verb, and up to this point it still analyzes the structure as an SRC. Upon reaching the post-verbal subject, it has to reanalyze and repair on the basis of negative input, indicating that this is not an SRC, which in the end is a more costly procedure. Thus, the prediction and subsequent evidence of
Guasti et al. (
2018) is that pre-verbal NPs and RC verbs in OSV ORCs should be processed faster than post-verbal NPs in OVS ORCs because in OSV structures the parser receives more evidence that the upcoming structure is an ORC and not an SRC. This prediction is similar to the prediction made by Surprisal (e.g.,
Levy 2008), according to which the occurrence of two NPs in OSV structures makes the probability of the verb very high. In contrast, the DLT (
Gibson 1998,
2000) predicts, on the one hand, faster processing of pre-verbal NPs in comparison to post-verbal NPs in general (due to post-verbal NPs having to be immediately integrated to the preceding verb), but, on the other hand, the verb in OSV ORCs is expected to be processed very slowly because the parser has to simultaneously integrate the two preceding NPs.
Overall, it should be noted that both
Schelstraete and Degand (
1998) and
Guasti et al. (
2018) found an overall SRC preference, with SRCs being processed faster than both ORC configurations. In contrast to French and Italian which do not allow word order scrambling in SRCs, Greek allows different word order configurations both in SRCs and ORCs. Thus, the word order manipulation in our study allows us not only to shed more light on the previous conflicting evidence on the processing of different word order configurations in ORCs coming from French and Italian, but also to provide additional evidence on the processing of distinct word order configurations in SRCs. In terms of continuity,
Guasti et al. (
2018) found no main differences between adult and children’s RC processing in Italian and French. In our study, we examine the extent to which children follow adult processing patterns by including data from 11- to 12-year-old children. We thus investigate the Continuity of Parsing Hypothesis (
Clahsen and Felser 2006b). At the same time, we examine possible parsing effects that may stem from language-specific properties of Greek, such as free word order and morphological richness. In terms of linguistic knowledge, studies on languages with head-initial relative clauses show that SRCs are produced relatively early, and that children may struggle with the comprehension of ORCs in later stages of acquisition (see, e.g.,
Friedmann et al. 2009;
Guasti et al. 2018;
Guasti and Cardinaletti 2003). In Greek, it seems that children have fewer problems comprehending and producing relative clauses because case marking on NPs provides an extra cue for thematic role assignment and object relative clause comprehension (e.g.,
Guasti et al. 2012;
Stathopoulou 2007;
Stavrakaki 2001;
Varlokosta 1997). In the absence of case as a disambiguating cue, Greek-speaking children perform similarly to Italian-speaking children, with higher scores in SRCs than ORCs (
Guasti et al. 2012,
2008). More specifically,
Guasti et al. (
2012) investigated the role that number and case may play in the comprehension of relative clauses in 4.5- to 6.5-year-old Greek and Italian children. They conducted two picture selection tasks including Greek SRCs and ORCs, such as in (7) and (8).
| 7. | a. | Dhikse mou to alogo pou kiniga ta liontaria. (SRC) |
| | | ‘Show me the horse that chases the lions.’ |
| | b. | Dhikse mou to alogo pou kinigoun ta liontaria. (ORC) |
| | | show me the horse that chase the lions. |
| | | ‘Show me the horse that the lions chase’ |
| 8. | a. | Dhikse mou ti maimou pou pleni tin arkouda. (SRC) |
| | | ‘Show me the monkey that is washing the.ACC bear’ |
| | b. | Dhikse mou ti maimou pou pleni i arkouda. (ORC) |
| | | show me the monkey that is washing the.NOM bear |
| | | ‘Show me the monkey that the bear is washing’ |
In examples (7a) and (7b), the disambiguation towards an SRC or ORC interpretation takes place on the verb. When the verb is in the singular
kiniga ‘chases’, then it is the horse that chases the lions, thus a SRC. When the verb is in the plural
kinigun ‘chase’, then it is the lions that chase the horse, thus an ORC. In examples (8a) and (8b),
Guasti et al. (
2012) use feminine (and masculine, in the experiment) NPs which inflect distinctly for nominative and accusative case. Thus, in this case, the RC verb is always in the singular and the disambiguation takes place after the verb on the determiner of the RC NP, which either has accusative case in SRCs or nominative case (post-verbal subject) in ORCs. The results show that the comprehension of ORCs significantly improved when the disambiguation was achieved through case (8b), whereas there was no significant difference in the comprehension of SRCs between the number and case condition. Thus, Greek-speaking children performed similarly to Italian-speaking children in the number disambiguation condition. In the case disambiguation condition, which could only be applied to Greek, however, Greek-speaking children showed an improved performance. According to
Guasti et al. (
2012), the boost in Greek-speaking children’s performance in the case disambiguation condition suggests that specific morphosyntactic characteristics of a language (such as overt case marking) affect children’s acquisition of complex structures such as RCs.
In addition,
Stavrakaki (
2001) reports that overt case marking contributes to children’s better performance in ORCs with the object NP head in the accusative and the RC subject in the nominative, in comparison to ORCs that are not marked for case. Additional evidence on the facilitatory role of overt case marking in the comprehension of ORCs is provided in
Stavrakaki et al. (
2015) and in
Varlokosta et al. (
2015), who investigated Greek-speaking 4- to 6.5-year-old children’s comprehension of wh-questions, relative clauses, and free relatives.
Based on the results of previous real-time studies on RC processing in children, we hypothesized that the children would have a similar pattern of results as the adults. This means that locality effects that have been found in free word order languages in the relative pronoun condition (e.g.,
Levy et al. 2013) are also expected to be found in Greek-speaking children and adults in the current study.
Levy et al. (
2013) found an SRC preference in the syncretized pronoun condition, which was attributed to the SRC structure’s high frequency of occurrence. Similarly, we expect frequency to play a role in both children’s and adults’ listening times. In terms of case marking, although previous results in French and Italian regarding the preference for pre-verbal vs. post-verbal subjects in ORCs are conflicting and do not allow us to form a robust prediction, we follow
Guasti et al. (
2018) in predicting that children and adults have an overall similar pattern of results.
Due to working memory limitations, we believe that children take longer to process RCs and this may result in significant effects and interactions in post-critical segments in the child group. According to
Felser et al. (
2003), 10- to 11-year-old English children-speaking do not process ambiguous RCs similarly to adults on-line, but they do so in the subsequent off-line grammaticality judgment task (see analysis of
Felser et al.’s (
2003) study above). The different processing pattern between children and adults in the on-line task was attributed by
Felser et al. (
2003) to 10- to 11-year-old children’s still developing ability for automated use of lexicosemantic and textual cues. Our study includes a group of 11- to 12-year-old children. The main reason why we chose to include 11- to 12-year-old children in our study was to examine if children in that age group are actually able to successfully integrate all different types of cues (e.g., morphosyntactic, semantic, contextual) during on-line sentence complex RC processing.





{kind=link}
{kind=link}
{kind=link}


