
Parallel Corpus Research and Target Language Representativeness: The Contrastive, Typological, and Translation Mining Traditions

 ,
,  , , and
, , and 
Abstract
:1. Introduction
1.1. Early Skepticism
1.2. Parallel Corpus Traditions
1.3. Roadmap
2. The Contrastive Tradition
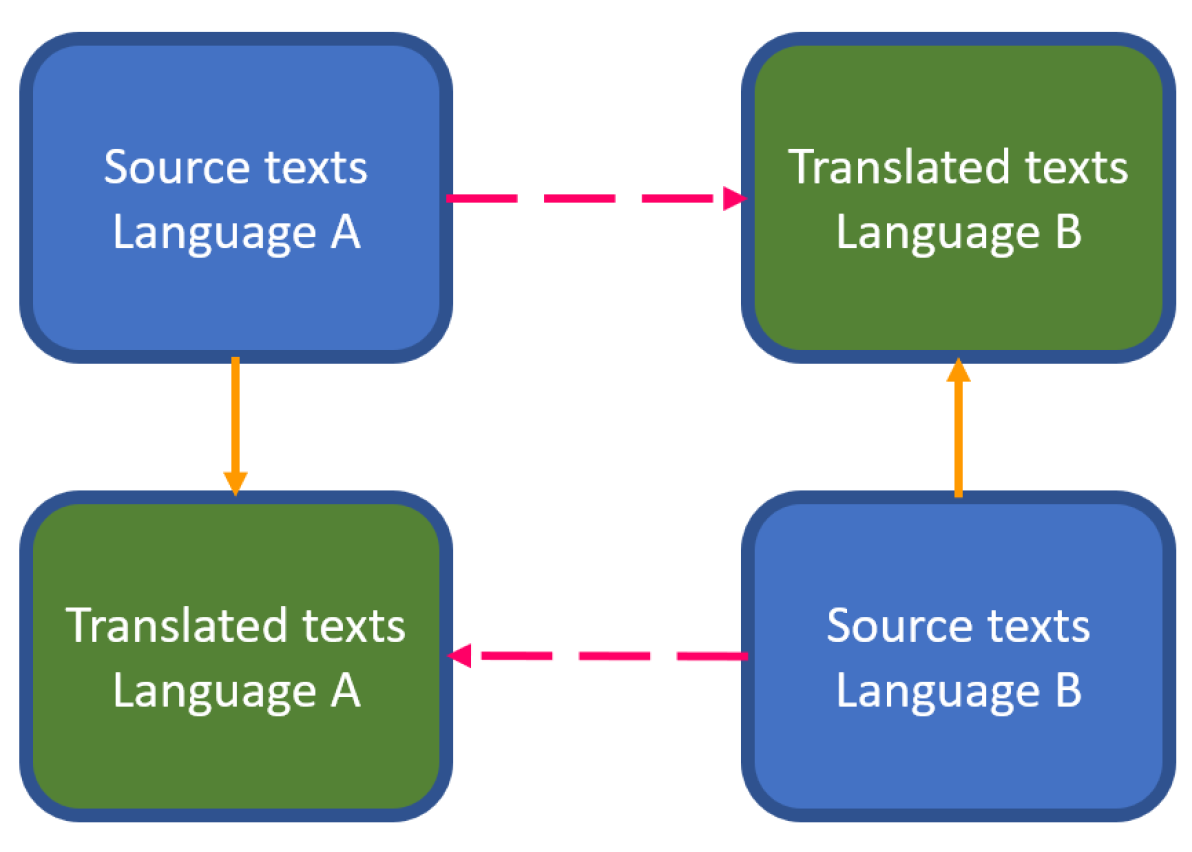
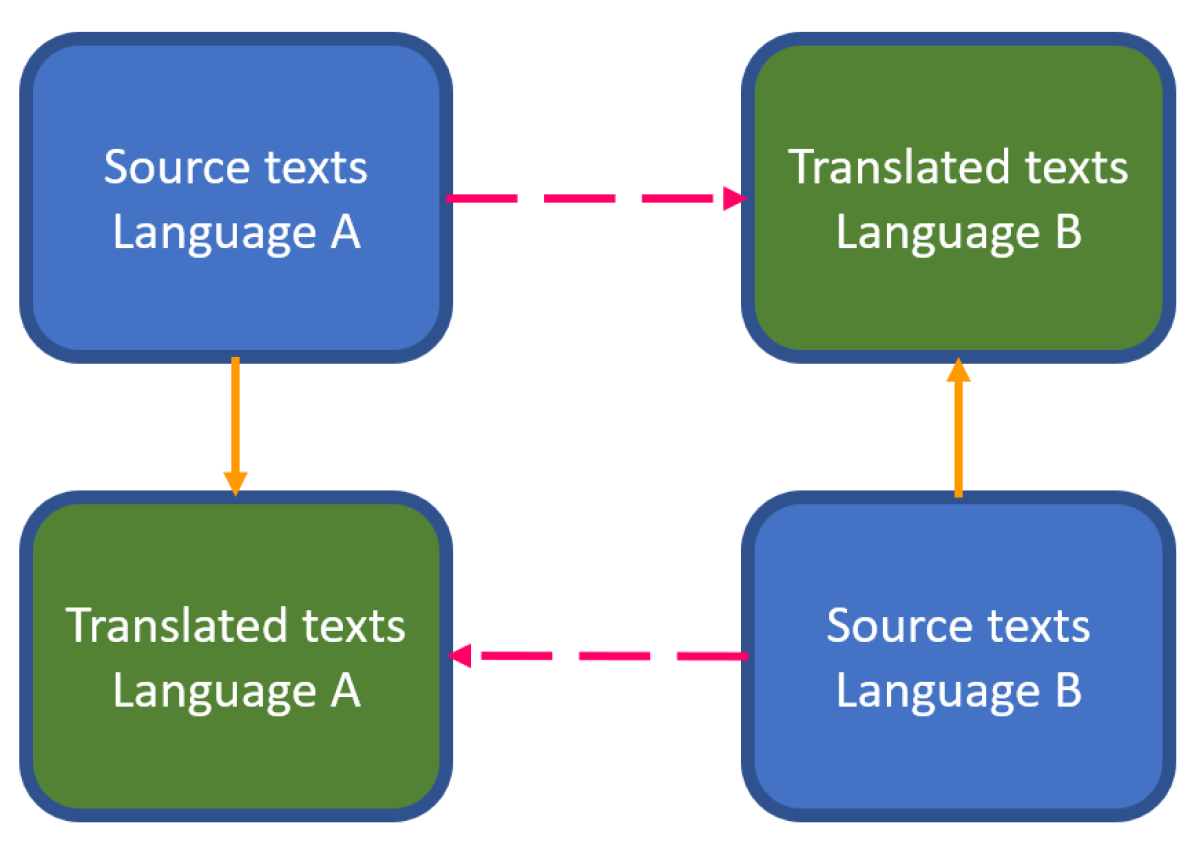
2.1. The Contrastive Parallel Corpus Architecture
2.2. Putting the Contrastive Parallel Corpus Architecture to Use
2.2.1. Comparisons between Languages

where CSα/β stands for the number of times a construction C occurs in Source Texts in language α/β, and C’Tα/β stands for the number of times construction C’ occurs in Translated Texts in language α/β as the translation of construction C.
2.2.2. From Comparisons between Languages to Comparisons within Each Language
2.3. The Contrastive Tradition: Conclusion
3. The Typological Tradition
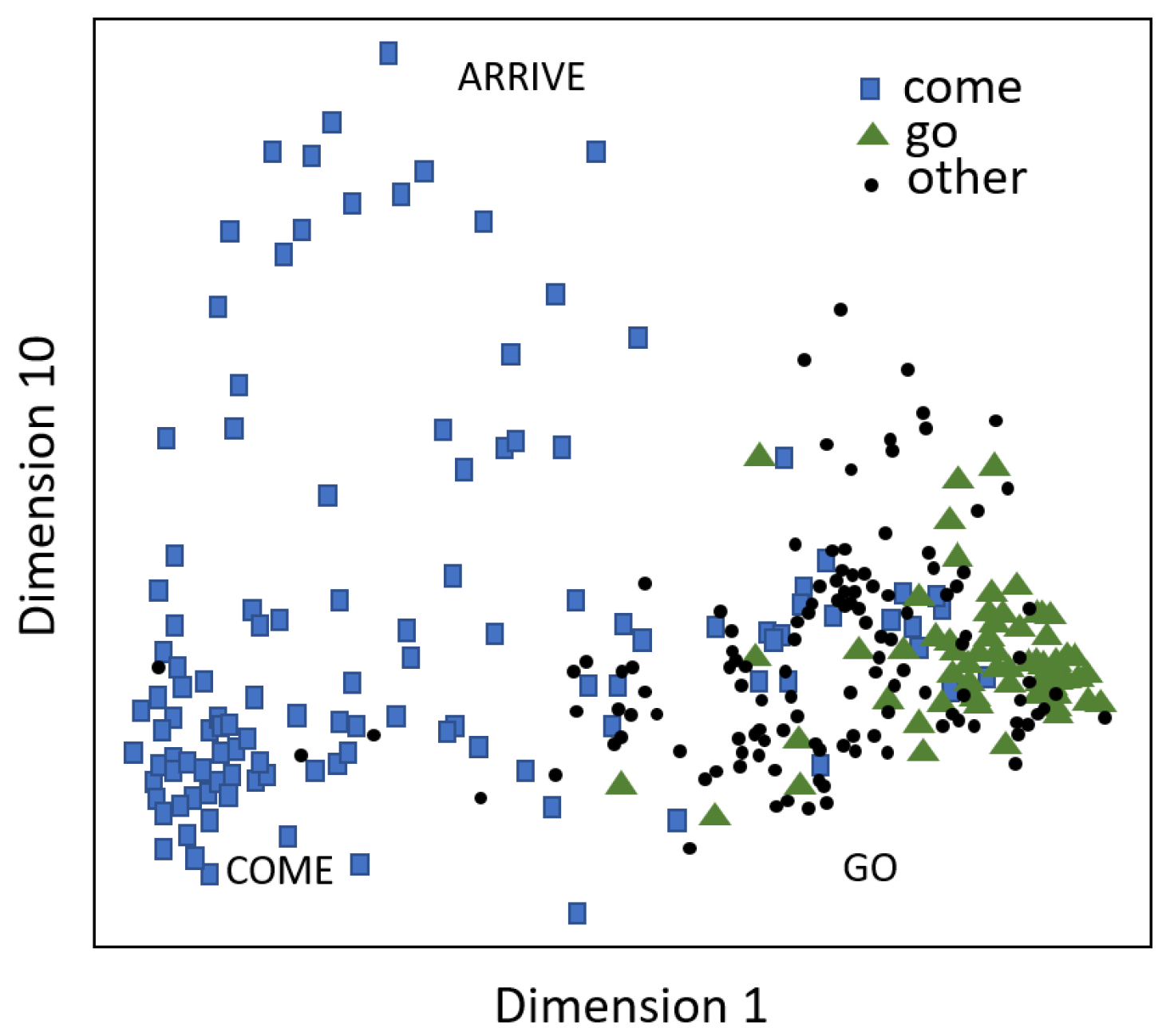
3.1. A Specific Study in the Typological Tradition
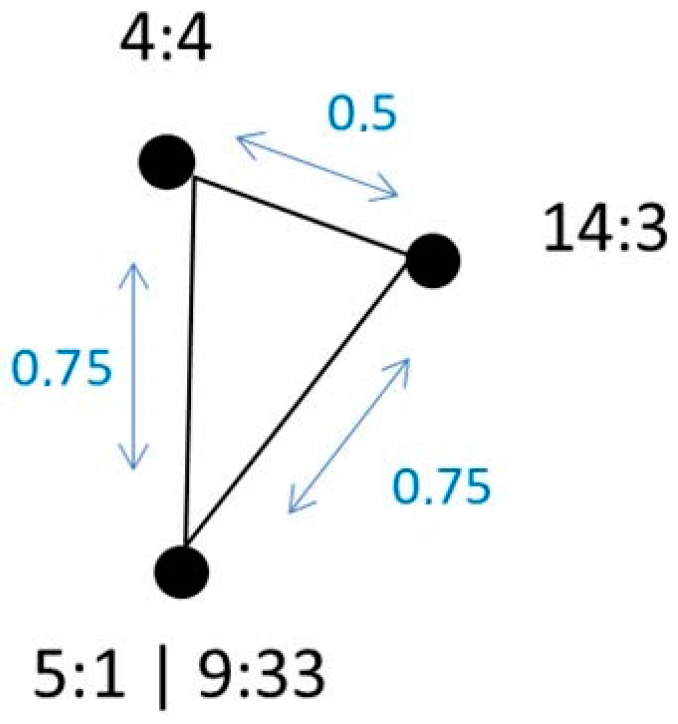
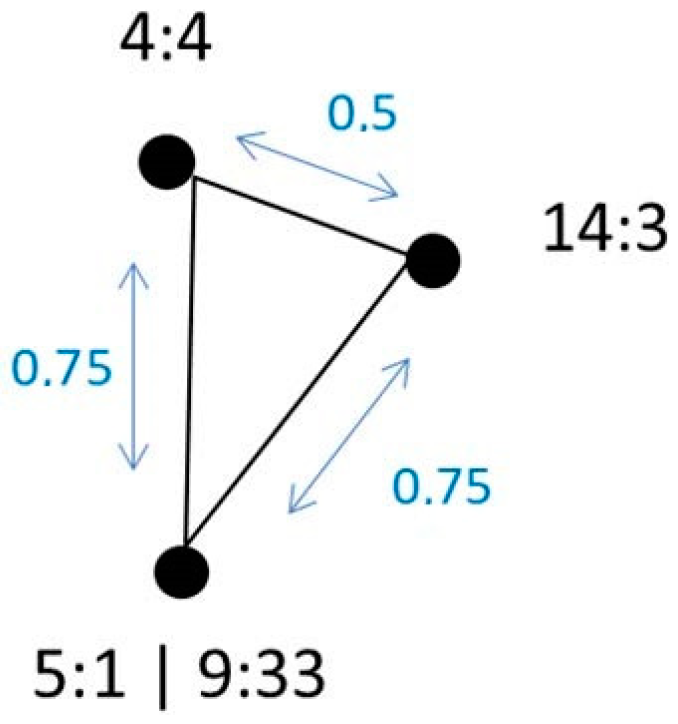
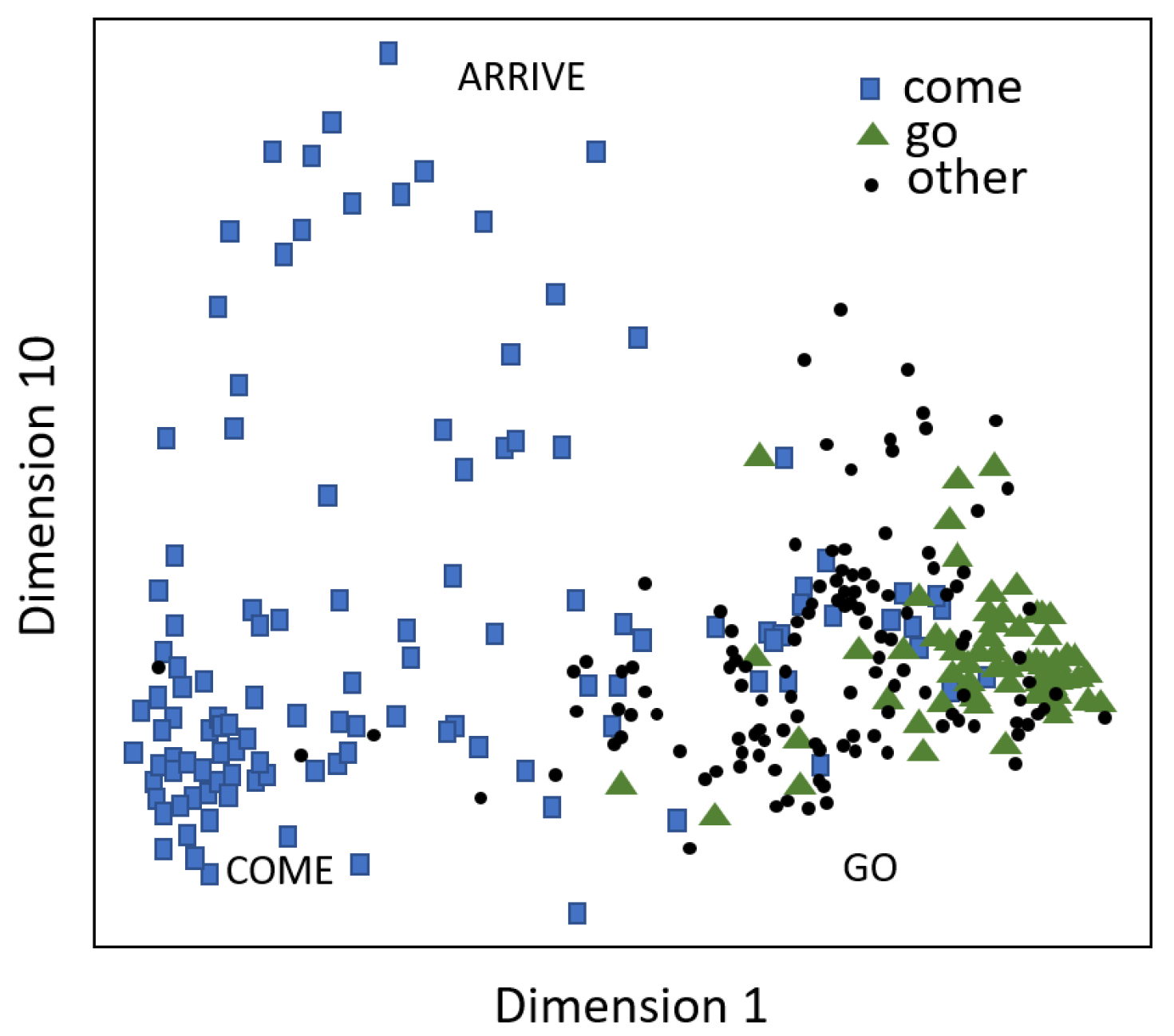
3.1.1. The Dissimilarity Matrix
3.1.2. Interpreting the Dissimilarity Matrix and MDS
| (5) | 1:31 | <come, s’approcher, megy, fülkon> |
3.1.3. Summary
3.2. The Typological Parallel Corpus Architecture
3.3. Putting the Typological Parallel Corpus Architecture to Use
3.4. The Typological Tradition: Conclusion
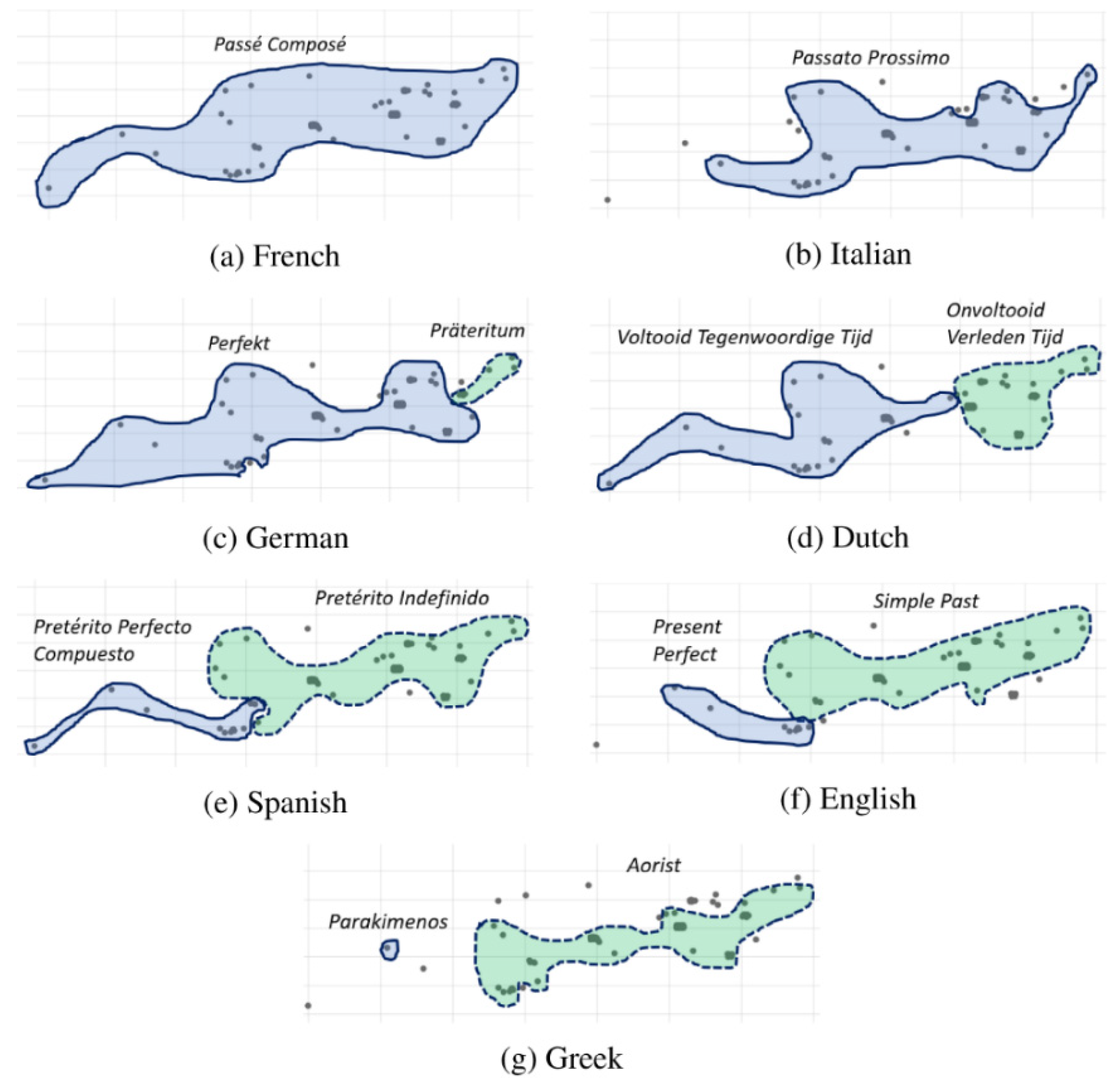
4. The Translation Mining Tradition
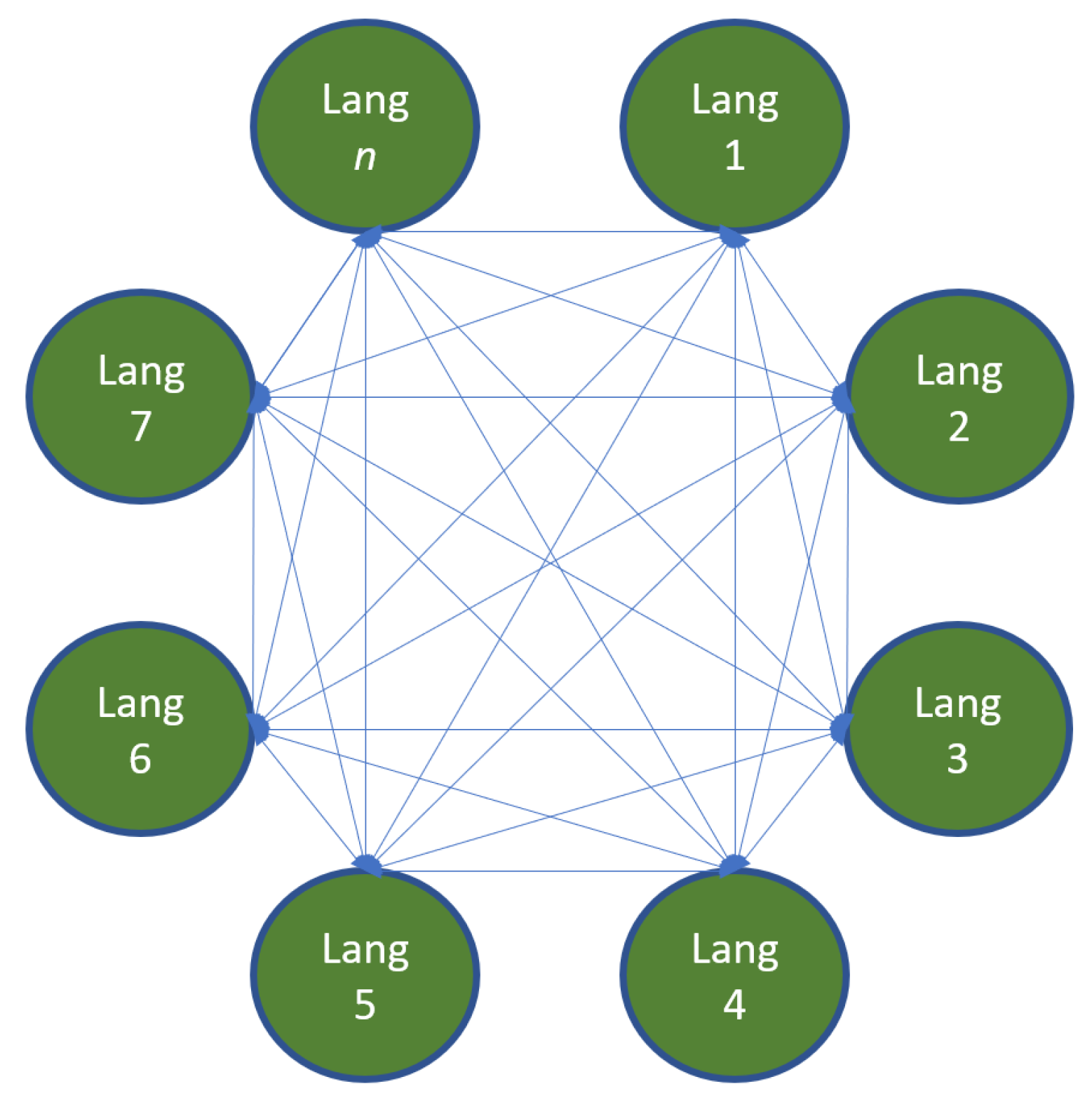
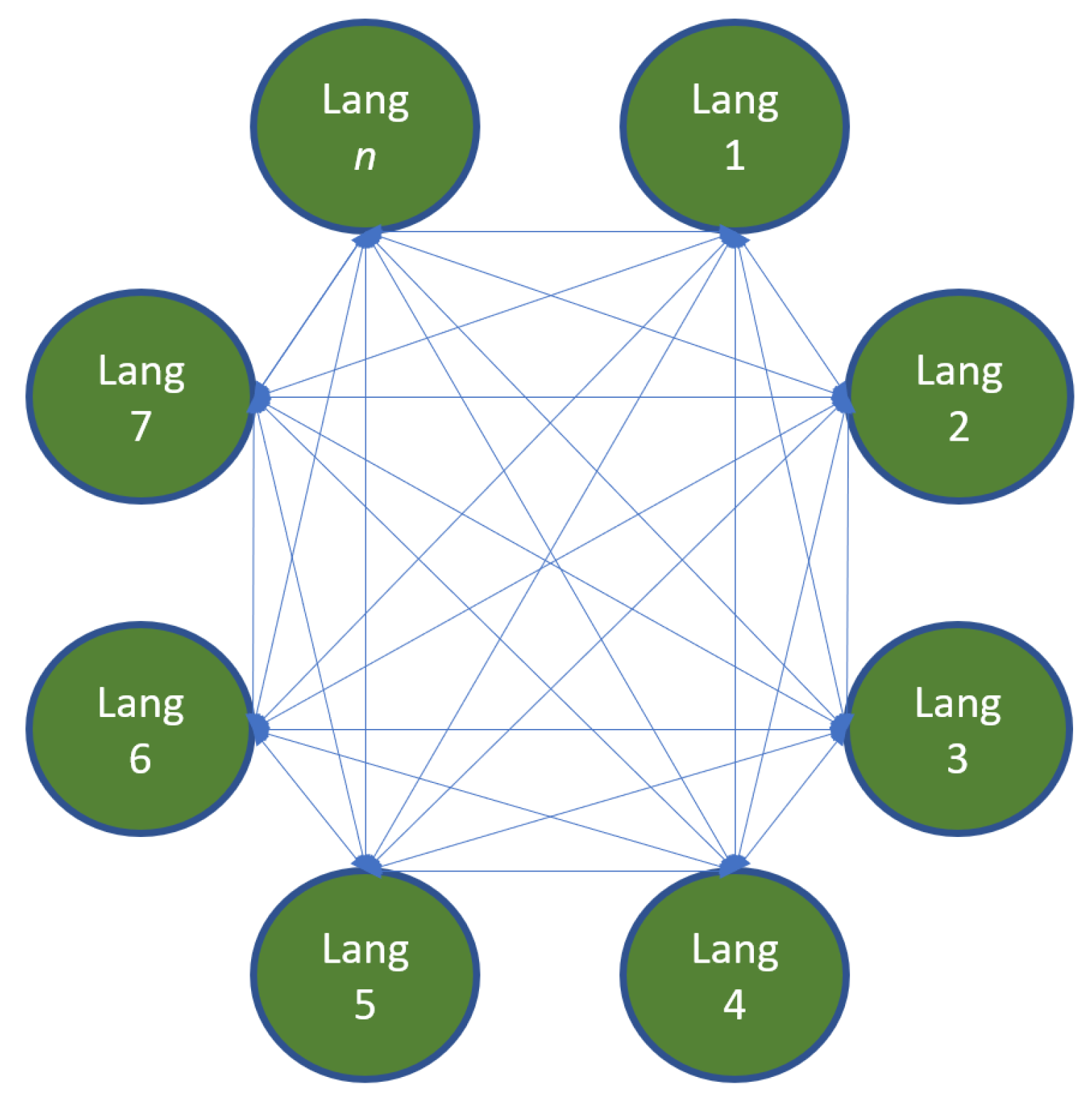
4.1. The Translation Mining Parallel Corpus Architecture
| (6) | Implicational hierarchy ofhave-perfect use in past contexts |
| French|Italian > German > Dutch > Spanish > English > Greek |
4.2. The Translation Mining Interpretation of the Typological Corpus Architecture
4.3. The Translation Mining Tradition: Conclusion
5. Choosing a Strategy: Some Preliminaries
5.1. Generalizing Mutual Correspondence
5.2. Assumptions of the Contrastive Tradition and Corpus Size
5.3. Corpus Size and Choosing a Representativeness Strategy
6. General Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | We note that there is also a vibrant literature on the use of parallel corpora in natural language processing and translation studies. Working out how these literatures relate to the different traditions that are more geared towards linguistic analysis lies beyond the scope of this paper, though. |
| 2 | A reviewer correctly points out that the existence of multiple source texts for the different translations included in Wälchli and Cysouw (2012) complicates the interpretation of the data. We leave this complication aside as it is connected to the bible corpus Wälchli & Cysouw use and not to the overall parallel corpus architecture of the Typological tradition. |
| 3 | We thank Bernhard Wälchli for providing us with the data from Wälchli and Cysouw (2012). |
| 4 | We computed eigenvalues in R with the function cmdscale() and the parameter eig set to TRUE. |
| 5 | We use the term group of contexts deliberately here as van der Klis et al. do not run cluster analyses on their data. We refer to van der Klis and Tellings (2022) for an overview of the different ways of running cluster analyses independently or alongside MDS. |
References
- Altenberg, Bengt. 1999. Adverbial Connectors in English and Swedish: Semantic and Lexical Correspondences. Language and Computers 26: 249–68. [Google Scholar]
- Altenberg, Bengt, and Karin Aijmer. 2000. The English-Swedish Parallel Corpus: A resource for contrastive research and translation studies. In Corpus Linguistics and Linguistic Theory Papers from the Twentieth International Conference on English Language Research on Computerized Corpora (ICAME 20) Freiburg im Breisgau 1999. Edited by Christian Mair and Marianne Hundt. Amsterdam: Brill, pp. 15–33. [Google Scholar]
- Beekhuizen, Barend, Julia Watson, and Suzanne Stevenson. 2017. Semantic Typology and Parallel Corpora: Something about Indefinite Pronouns. In Proceedings of the 39th Annual Conference of the Cognitive Science Society. Edited by Glenn Gunzelmann, Andrew Howes, Thora Tenbrink and Eddy Davelaar. Austin: Cognitive Science Society, pp. 112–7. [Google Scholar]
- Bogaards, Maarten. 2019. A Mandarin map for Dutch durativity: Parallel text analysis as a heuristic for investigating aspectuality. Nederlandse Taalkunde 24: 157–93. [Google Scholar] [CrossRef]
- Bogaards, Maarten. 2022. The Discovery of Aspect: A heuristic parallel corpus study of ingressive, continuative and resumptive viewpoint aspect. Languages 7: 158. [Google Scholar] [CrossRef]
- Bogaart, Jade, and Heleen Jager. 2020. La variation Étrange Dans L’Étranger. La Competition du Parfait et du Passé Dans les Traductions Néerlandaises de L’Étranger. Bachelor’s thesis, Utrecht University, Utrecht, The Netherlands. [Google Scholar]
- Bouma, Gerlof. 2009. Normalized (pointwise) mutual information in collocation extraction. Proceedings of GSCL 30: 31–40. [Google Scholar]
- Bremmers, David, Jianan Liu, Martijn van der Klis, and Bert Le Bruyn. 2021. Translation Mining: Definiteness across Languages—A Reply to Jenks (2018). Linguistic Inquiry, 1–18. [Google Scholar] [CrossRef]
- Chang, Vincent Wu. 1986. The Particle LE in Chinese Narrative Discourse: An Investigative Description. Ph.D. thesis, University of Florida, Gainsville, FL, USA. [Google Scholar]
- Chu, Chauncey. 1987. The semantics, syntax, and pragmatics of the verbal suffix zhe. Journal of Chinese Language Teachers Association 22: 1–41. [Google Scholar]
- Corre, Eric. 2022. Perfective marking in the Breton tense-aspect system. Languages, 7. [Google Scholar]
- Dahl, Östen, and Viveka Velupillai. 2013. The Perfect. In The World Atlas of Language Structures Online. Edited by Matthew S. Dryer and Martin Haspelmath. Leipzig: Max Planck Institute for Evolutionary Anthropology, Chapter 68. [Google Scholar]
- Dahl, Östen, and Bernhard Wälchli. 2016. Perfects and iamitives: Two gram types in one grammatical space. Letras de Hoje 51: 325–48. [Google Scholar] [CrossRef] [Green Version]
- Davies, Mark. 2008. The Corpus of Contemporary American English (COCA). Available online: https://www.english-corpora.org/coca/ (accessed on 30 June 2022).
- de Swart, Henriëtte, Jos Tellings, and Bernhard Wälchli. 2022. Not… Until across European Languages. Languages 7: 56. [Google Scholar] [CrossRef]
- Frankenberg-Garcia, Ana, and Diana Santos. 2003. Introducing COMPARA, the Portuguese-English parallel corpus. In Corpora in Translator Education. Edited by Federico Zanettin, Silvia Bernardini and Dominic Stewart. Manchester: Routledge, pp. 71–87. [Google Scholar]
- Fuchs, Martín, and Paz González. 2022. Perfect-Perfective Variation across Spanish Dialects: A Parallel Corpus Study. Languages 7: 166. [Google Scholar] [CrossRef]
- Gehrke, Berit. 2022. Differences between Russian and Czech in the Use of Aspect in Narrative Discourse and Factual Contexts. Languages 7: 155. [Google Scholar] [CrossRef]
- Gellerstam, Martin. 1996. Translations as a source for cross-linguistic studies. Lund Studies in English 88: 53–62. [Google Scholar]
- Granger, Sylviane, and Marie-Aude Lefer. 2020. Introduction: A two-pronged approach to corpus-based crosslinguistic studies. Languages in Contrast 20: 167–83. [Google Scholar] [CrossRef]
- Grønn, Atle, and Arnim von Stechow. 2020. The Perfect. In The Wiley Blackwell Companion to Semantics. Edited by Daniel Gutzmann, Lisa Matthewson, Cécile Meier, Hotze Rullmann and Thomas Ede Zimmermann. Hoboken: John Wiley & Sons, Inc. [Google Scholar] [CrossRef]
- Hansen-Schirra, Silvia, Stella Neumann, and Erich Steiner. 2013. Cross-Linguistic Corpora for the Study of Translations. Berlin: De Gruyter. [Google Scholar]
- Hasselgård, Hilde. 2020. Corpus-based contrastive studies: Beginnings, developments and directions. Languages in Contrast 20: 184–208. [Google Scholar] [CrossRef]
- Johansson, Stig. 1998a. On the role of corpora in cross-linguistic research. In Corpora and Cross-Linguistic Research: Theory, Method, and Case Studies. Edited by Stig Johansson and Signe Oksefjell. Amsterdam: Rodopi, pp. 93–103. [Google Scholar]
- Johansson, Stig. 1998b. Loving and hating in English and Norwegian: A corpus-based contrastive study. In Perspectives on Foreign and Second Language Pedagogy. Essays presented to Kirsten Haastrup on the Occasion of Her Sixtieth Birthday. Edited by Dorte Albrechtsen, Birgit Henriksen, Inger M. Mees and Erik Poulsen. Odense: Odense University Press, pp. 93–103. [Google Scholar]
- Johansson, Stig. 2007. Seeing through Multilingual Corpora. Amsterdam: John Benjamins. [Google Scholar]
- Lauridsen, Karen. 1996. Text corpora and contrastive linguistics: Which type of corpus for which type of analysis? Lund Studies in English 88: 63–72. [Google Scholar]
- Le Bruyn, Bert, Martijn van der Klis, and Henriëtte de Swart. 2019. The Perfect in dialogue: Evidence from Dutch. Linguistics in the Netherlands 36: 162–75. [Google Scholar] [CrossRef]
- Le Bruyn, Bert, Martijn van der Klis, and Henriëtte de Swart. 2022. Variation and stability: The present perfect and the tense-aspect grammar of western European languages. In Beyond Time 2. Edited by Astrid De Wit, Frank Brisard, Carol Madden-Lombardi, Michael Meeuwis and Adeline Patar. Oxford: Oxford University Press. [Google Scholar]
- Lehmann, Christian. 1990. Towards lexical typology. In Studies in Typology and Diachrony: Papers Presented to Joseph H. Greenberg on His 75th Birthday. Edited by William A. Croft, Suzanne Kemmer and Keith Denning. Amsterdam: John Benjamins, pp. 161–85. [Google Scholar]
- Levshina, Natalia. 2022. Semantic maps of causation: New hybrid approaches based on corpora and grammar descriptions. Zeitschrift für Sprachwissenschaft 41: 179–205. [Google Scholar] [CrossRef]
- Lu, Wei-Lun, and Arie Verhagen. 2016. Shifting viewpoints: How does that actually work across languages? An exercise in parallel text analysis. In Viewpoint and the Fabric of Meaning. Edited by Barbara Dancygier, Wei-lun Lu and Arie Verhagen. Boston/Berlin: De Gruyter Mouton, pp. 169–90. [Google Scholar]
- Lu, Wei-Lun, Arie Verhagen, and I-Wen Su. 2018. A Multiple-Parallel-Text Approach for Viewpoint Research Across Languages. In Expressive Minds and Artistic Creations: Studies in Cognitive Poetics. Edited by S. Csábi. Oxford: Oxford University Press, pp. 131–57. [Google Scholar]
- Macken, Lieve, Orphée De Clercq, and Hans Paulussen. 2011. Dutch parallel corpus: A balanced copyright-cleared parallel corpus. Meta: Journal des Traducteurs/Meta: Translators’ Journal 56: 374–90. [Google Scholar] [CrossRef] [Green Version]
- McEnery, Tony, and Richard Xiao. 1999. Domains, text types, aspect marking and English-Chinese translation. Languages in Contrast 2: 211–29. [Google Scholar] [CrossRef] [Green Version]
- McEnery, Tony, Richard Xiao, and Yukio Tono. 2006. Corpus-Based Language Studies: An Advanced Resource Book. London and New York: Routledge. [Google Scholar]
- Mulder, Gijs, Gert-Jan Schoenmakers, Olaf Hoenselaar, and Helen de Hoop. 2022. Tense and aspect in a Spanish literary work and its translations. Languages 7. [Google Scholar]
- Tellings, Jos, and Martín Fuchs. 2021. Sluicing and Temporal Definiteness. Manuscript. Utrecht: Utrecht University. [Google Scholar]
- van der Klis, Martijn, Bert Le Bruyn, and Henriëtte de Swart. 2017. Mapping the Perfect via Translation Mining. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2—Short Papers. Edited by Mirella Lapata, Phil Blunsom and Alexander Koller. Valencia: Association for Computational Linguistics, pp. 497–502. [Google Scholar]
- van der Klis, Martijn, Bert Le Bruyn, and Henriëtte de Swart. 2021a. A multilingual corpus study of the competition between past and perfect in narrative discourse. Journal of Linguistics 58: 423–57. [Google Scholar] [CrossRef]
- van der Klis, Martijn, Bert Le Bruyn, and Henriëtte de Swart. 2021b. Reproducing the Implicational Hierarchy of Perfect Use. Manuscript. Utrecht: Utrecht University. [Google Scholar]
- van der Klis, Martijn, and Jos Tellings. 2022. Multidimensional scaling and linguistic theory. Corpus Linguistics and Linguistic Theory, Advance online publication. [Google Scholar] [CrossRef]
- Wälchli, Bernhard. 2010. Similarity semantics and building probabilistic semantic maps from parallel texts. Linguistic Discovery 8: 331–71. [Google Scholar] [CrossRef] [Green Version]
- Wälchli, Bernhard, and Michael Cysouw. 2012. Lexical typology through similarity semantics: Toward a semantic map of motion verbs. Linguistics 50: 671–710. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Richard. 2002. A Corpus-Based Study of Aspect in Mandarin Chinese. Ph.D. thesis, Lancaster University, Lancaster, UK. [Google Scholar]
- Xiao, Richard, and Xianyao Hu. 2015. Corpus-Based Studies of Translational Chinese in English-Chinese Translation. Berlin/Heidelberg: Springer. [Google Scholar]
- Xiao, Richard, and Tony McEnery. 2004. Aspect in Mandarin Chinese. Amsterdam: John Benjamins. [Google Scholar]
- Yang, Suying. 1995. The Aspectual System of Chinese. Ph.D. thesis, University of Victoria, Victoria, BC, Canada. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English > | Norwegian | Norwegian > | English | ||
|---|---|---|---|---|---|
| talk | snakke | 204 | snakke | talk | 313 |
| prate | 14 | left | 80 | ||
| fortelle | 4 | say | 13 | ||
| si | 3 | mention | 9 | ||
| other | 34 | other | 61 | ||
| Ø | 9 | Ø | 8 | ||
| total | 268 | total | 484 |
| Source Texts | Translated Texts | |
|---|---|---|
| Norwegian | ||
| hate | 23 | 34 |
| elske | 36 | 90 |
| English | ||
| hate | 67 | 25 |
| love | 100 | 62 |
| Motion Verb Context (Verse). | English | French | Hungarian | Mapudungun |
|---|---|---|---|---|
| 4:4 | come | venir | jön | aku |
| 5:1 | come | arriver | ér | puw |
| 9:33 | come | arriver | ér | puw |
| 14:3 | come | entrer | lép | aku |
| 4:4 | 5:1 | 9:33 | 14:3 | |
| 4:4 | 0 | 0.75 | 0.75 | 0.50 |
| 5:1 | 0.75 | 0 | 0 | 0.75 |
| 9:33 | 0.75 | 0 | 0 | 0.75 |
| 14:3 | 0.50 | 0.75 | 0.75 | 0 |
| Hate | Love | |
|---|---|---|
| 1992 | 1374 (57) | 4671 (196) |
| 1993 | 1762 (72) | 5430 (221) |
| Hate | Love | |
|---|---|---|
| 1990–1994 | 7671 (55) | 24,656 (177) |
| 1995–1999 | 8377 (56) | 31,979 (216) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le Bruyn, B.; Fuchs, M.; van der Klis, M.; Liu, J.; Mo, C.; Tellings, J.; de Swart, H. Parallel Corpus Research and Target Language Representativeness: The Contrastive, Typological, and Translation Mining Traditions. Languages 2022, 7, 176. https://doi.org/10.3390/languages7030176
Le Bruyn B, Fuchs M, van der Klis M, Liu J, Mo C, Tellings J, de Swart H. Parallel Corpus Research and Target Language Representativeness: The Contrastive, Typological, and Translation Mining Traditions. Languages. 2022; 7(3):176. https://doi.org/10.3390/languages7030176
Chicago/Turabian StyleLe Bruyn, Bert, Martín Fuchs, Martijn van der Klis, Jianan Liu, Chou Mo, Jos Tellings, and Henriëtte de Swart. 2022. "Parallel Corpus Research and Target Language Representativeness: The Contrastive, Typological, and Translation Mining Traditions" Languages 7, no. 3: 176. https://doi.org/10.3390/languages7030176
APA StyleLe Bruyn, B., Fuchs, M., van der Klis, M., Liu, J., Mo, C., Tellings, J., & de Swart, H. (2022). Parallel Corpus Research and Target Language Representativeness: The Contrastive, Typological, and Translation Mining Traditions. Languages, 7(3), 176. https://doi.org/10.3390/languages7030176