1. Introduction
Usage-based approaches have been hugely prominent in research on language acquisition, and recently have also begun to be applied to bilingual first language acquisition (e.g.,
Backus 2021). The hallmark of usage-based work is that it puts center stage the continuous influence of linguistic experience (‘usage’) on speakers’ linguistic knowledge, or mental representation. It posits a continuously operating learning mechanism through which speakers cannot help but constantly update their knowledge on the basis of their never-ending language use. This puts it at odds with formalist and theoretical views on language, which have been prominent in the study of bilingual acquisition. A usage-based approach to language learning claims that children learn language in a piecemeal way, starting with specific words and lexically fixed combinations
and this, moving on to frame-and-slot patterns [I want X] and eventually forming abstract patterns on the basis of their linguistic experience. Learning syntax is a matter of increasing productivity and increasing schematicity of these frame-and-slot patterns, also referred to as ‘partially schematic constructions’. Given the intense interest in linguistics in the acquisition of grammatical knowledge, a crucial question is then, how to account for the emergence of patterns in mental representation. In research on first language acquisition, the traceback method has been developed to document this, and to test the hypothesis that children’s utterances can be accounted for on the basis of a limited inventory of patterns and frame-and-slot patterns (e.g.,
Lieven et al. 2009). The traceback method fits a usage-based perspective as it is strictly bottom-up, only looking at the child’s own output, and avoids the need to assume any pre-existing morphosyntactic and lexical categories: it accounts for the composition of utterances only by relying on previously acquired material.
Recently, some studies have applied the traceback method to bilingual acquisition, and specifically to utterances containing material from both languages, thus exhibiting code-mixing (CM)
1, as produced by children who are growing up with two languages (e.g.,
Vihman 2018;
Quick et al. 2021a,
2021b). As has been found for monolingual acquisition, most of the CMed utterances seem to be constructed around lexically fixed multi-word units and frame-and-slot patterns. This suggests that the same fundamental cognitive processes are at work that we find in all language use by young children. Entrenchment levels, for example, help explain why we find certain patterns in CMed utterances.
Quick et al. (
2018b), for example, analyzed the German–English code-mixing of a German-English-Spanish trilingual child and found that the majority of CMed utterances were structured around a frame-and-slot pattern in which the open slot is filled by a word from the other language, e.g., [this is X] as in
this is kaputt ‘this is broken’. This is reminiscent, of course, to what the well-known models of adult CM say about prototypical ‘insertion’, one of two main sub-types of CM (the other one being ‘alternation’, in which utterances in the two languages alternate): in insertion, a content word from an Embedded Language is inserted into a grammatical frame from the Matrix Language (
Myers-Scotton 1997). However, it is important to point out that in contrast to such CM models, traceback studies do not presuppose any grammatical structure: fixed frames are solely based on previously experienced co-occurrence between lexical items. In another study,
Quick et al. (
2021a) applied the traceback method to the CMed output of three German-English bilingual children to investigate whether differences in their input situations could account for the frame-and-slot patterns that were productive in the language use of each of the two-to-four year old children. Results showed, again, that each child’s CM drew heavily on lexically fixed combinations and frame-and-slot patterns, and that these were in turn strongly dependent on the children’s language input situations.
These findings support the idea that lexically specific multiword units and partially schematic frame-and-slot patterns are integral building blocks for language use by children in the early phases of acquisition, including when they are learning two languages simultaneously, and mixing them. Note that, compared to classic work on CM, the usage-based perspective does not presuppose fixed switch conventions or constraints. Instead, the units of selection are words, multiword units, and partially schematic frame-and-slot patterns. This does not mean, though, that the patterns that can be derived from children’s bilingual speech are necessarily different from what such constraints would predict. They may or may not be similar; the main differences between the usage-based and the classic approach lie in the way in which they account for the acquisition process and for language use. In this paper we want to present what light the empirical use of the traceback method, and the general adoption of a usage-based theoretical perspective, can shed on the study of bilingual acquisition in general, and specifically on code-mixing in the speech of young children.
1.1. Code-Mixing Research—Bringing Two Literatures Together
While bilingualism is extremely common around the world, most theorizing about language acquisition is performed on the basis of observations in monolingual settings. Findings from studies on bilingual acquisition rarely take a prominent position in this field. Yet, one might argue that the circumstances under which much of the language acquisition in this world takes place should also figure prominently in our theories of language acquisition. It is beyond the scope of this paper to bring the literatures on monolingual and bilingual language acquisition together, but we do hope to convince the reader that there is much to learn from bilingual acquisition that will help us understand more fully how language acquisition works in general.
What is inside the scope of the paper, however, is another attempt to merge two research traditions: those on bilingual acquisition and those about bilingual language use in general. They have in common, of course, that they deal with populations who use two languages, and our focus is on one aspect of bilingual language use studied in both traditions: the mixing of two languages in the same speech event, known as ‘code-mixing’ (CM). The study of bilingual children’s CM during acquisition sheds light on how they learn to recognize that there are two languages in their lives, which they, moreover, often need to keep separate. It also shows that they learn that there are situations in which there is no norm that one should stick to monolingual speech. The question then is to what degree their mixing aligns with how adults in their community practice CM. More generally, studying bilingual children’s CM can help us understand how children become communicatively competent in the communicative repertoire of the community they are born into, to what degree they achieve this by imitating input, and to what degree by productively building their skills.
Bilingual children’s CM has been studied mainly through observation and has a long history. There have been some celebrated case studies in which linguists studied the bilingual development of one child, often their own son or daughter. Such case studies have been conducted right up to the present, and often involve the detailed recording of a child’s output, or that of a small number of children. In many cases, speech directed at the child is recorded too. The resulting databases are sets of transcripts containing output and often also input over a critical time span, usually somewhere between the ages 1 and 5, during which the children are acquiring two or more languages (e.g.,
Deuchar 1999;
Vihman 1985,
2018;
Genesee et al. 1995). It has been clear from the start that young children’s CM is similar to adult CM in some ways but also differs from it. The similarities suggest either universal factors governing language mixing or the learning of community norms, or both, while the differences may tell us something interesting about language acquisition. Either way, of course, the analysis of such data first involves a basic description of the patterns. The most remarkable finding, perhaps, has been that bilingual children will CM even when growing up in families in which there is strict adherence to the so-called One Parent One Language mode of language choice (in which each parent speaks his or her own mother tongue at all times). Furthermore, as has been shown for adult CM, the way in which children mix their languages is not random. As in adult CM, children produce alternation between utterances in the two languages, and ‘insertional CM’, in which words from one language are inserted into utterances from the other. However, the actual patterns in children’s CM show some unique characteristics: as utterances are very short in the speech of young children, it is not always so clear what the status is of, for example, a one-word utterance, and, more importantly, analyses from various language pairs have shown that children will CM to use a function word from the other language. In adult CM, this is very rare. While in the case studies of bilingual children such observations are based on obviously provide valuable insights, they are difficult to generalize to entire communities, and to connect with the literature on adult CM, which is often based on more large-scale investigations of language choice by a fairly large range of participants. In addition, the bilingual communities in which adult CM is studied tend not to be the bilingual settings from which data on bilingual acquisition are drawn.
Recently, two research traditions have developed that have stimulated methodological and theoretical innovation. First, some studies aim to bridge the gap between case and community studies, using larger samples of bilingual child participants from whom output data are collected. We will refer to this research tradition as Quantitative Structural Analysis (QSA), as it makes use of the affordances of larger corpora and adopt traditional structural categories as the main units of analysis, especially insertion and alternation (or inter- and intrasentential CM), and content and function words (e.g.,
Montanari et al. 2019). The second set of studies are the ones we ourselves have been involved in and which we will focus on in this paper. We will refer to this tradition as ‘Usage-Based Analysis’, and it usually involves multiple case studies and applies methods and insights from usage-based linguistics. This entails the use of large dense corpora and an innovative look at the categories mentioned above. In what follows, we will briefly describe some of the findings obtained by the QSA studies and interpret these in the light of a usage-based perspective, before summarizing our own studies. Throughout, issues will be highlighted for which the two approaches are both insightful and provide overlapping or complementary perspectives, and these will be further discussed in the final section.
1.2. Quantitative Structural Analysis
A prominent example of a study in the tradition identified above as Quantitative Structural Analysis is
Montanari et al. (
2019). Data were collected in monolingual contexts from 26 Spanish-English bilingual children in the US at ages 3;6 and 4;5. The authors established the frequency of CM in the children’s output, checked how this CM behavior correlated with proficiency measures, and examined whether the participants clustered around certain prototypes, defined in terms of profiles combining proficiency profiles and preferred types of mixing. Proficiency was measured in two ways, corresponding to syntactic and lexical proficiency. MLU, claimed by
Bedore et al. (
2010) to be the best measurement, and a lexical diversity score were used as measurements of these two subtypes of language skill. Mixing type was predominantly an issue of directionality: switching to Spanish or to English. Results are presented in terms of CM rates in both directions and at both ages. Confirming what seems to be a general trend (see
Gutiérrez-Clellen et al. 2009;
Paradis and Nicoladis 2007), CM rates are fairly low (at 10–16%, but recall that the data are recorded in sessions that are supposed to be monolingual). Mixing rates are the same in both languages at 3;6, but differ at 4;5: basically, CM disappears in the English output but remains in the Spanish output. Interestingly, at 3;6 CM seems related to low lexical proficiency, as children who had lower proficiency in Language X produced more CM from Language X, but at 4;5 CM rates seemed not related to proficiency measures anymore. The authors conclude that at this point the children have started acquiring sociolinguistic community norms: community Spanish includes CM to English, while community English is monolingual. This is supported by a convergent trend among the children: at 4;5 no clusters of different types of speakers were found while there were three clear clusters at 3;6: (1) low proficiency scores in both languages but dominant in Spanish and producing CM to Spanish (at 4;5, even while dominant in Spanish, they still produce little CM to Spanish when speaking English); (2) high proficiency scores in both languages and producing little CM; and (3) dominant in English and CM mostly to English. A final result worth mentioning is that mixing at 3;6 mostly concerned ‘whole utterances’. We will discuss the implications of this finding later.
A second relevant example is
Smolak et al. (
2020), which compares similar data in two bilingual settings: 29 child participants are Spanish-English bilinguals from San Diego, CA and 24 French-English bilinguals from Montreal. The age range is 2;7–3;3, the data are longitudinal, and the recordings are again conducted in monolingual sessions. The analysis of CS types includes whether intrasentential CM is for content or function words. These authors, too, find evidence for sociolinguistic awareness, and they find it at an early age: Spanish-English children switch more to English in the Spanish data than to Spanish in the English data, and CM to Spanish decreases with age, echoing what
Montanari et al. (
2019) found. In addition, CM to English is more pronounced in children of high SES background, which is interpreted as an effect of exposure, since high SES children are exposed to Spanish less than low SES children are, and therefore experience a bigger need to use English words. In fact, the main determinant of the rate of CM was found to be exposure to the two languages in the Spanish-English data, but proficiency in the French-English data. French-English children also increased their rate of CM to English as they grew older, apparently reflecting community patterns. Here, lower proficiency in French (more specifically, lower word knowledge, not lower syntactic knowledge) appeared to stimulate CM to English at the early age, echoing the important role claimed for proficiency in determining child CM in earlier studies, e.g.,
Genesee et al. (
1995).
Smolak et al. (
2020) found, similar to
Montanari et al. (
2019), that there was more intersentential than intrasentential CM (though note that MLU is very low at this young age), and that the proportion of intrasentential CM goes up as children grow older (and MLU goes up). As is to be expected given what we know about the phenomenon of CM, there was more CM for content words than for function words. There is an interesting difference between the communities, however. In the French-English data, CM for function words decreased, confirming the generalizations made earlier by e.g.,
Greene et al. (
2013): as children acquire more of the language, they rely less and less on the grammar of the other language. This suggests that children need to borrow grammar from their dominant language, just as they borrow words from it: as long as they have not acquired a particular structure in their weaker language, it is a syntactic gap. However, in the Spanish-English CM data, there is an increase in CM for function words. The authors suggest that this reflects a ‘lack of maturation’ of their Spanish morphosyntactic skills, or the impact of increasing English proficiency, or both. The authors think it is mostly the increasing English proficiency and find that their data support
Lindholm and Padilla (
1978), but not
Vihman (
1985), who found a propensity for CM to function words overall.
In conclusion, studies, such as
Montanari et al. (
2019) and
Smolak et al. (
2020), improve on earlier work on bilingual language acquisition by moving beyond the case study, investigating CM in larger samples.
Montanari et al. (
2019) indeed claim to be building a bridge between the qualitatively rich case studies and the quantitatively rich surveys by checking for CM, categorized as either inter- or intrasentential, in a large number of participants. The picture that arises concerning CM is that it occurs in conversational settings intended to be monolingual, though at fairly low rates. The sociolinguistic asymmetry that characterizes many bilingual settings is reflected in CM development as the child grows older: CM disappears from the language that tends to be used in monolingual mode only (English in the case of
Montanari et al. 2019) but remains in the language that tends to be used in bilingual mode (Spanish, in their case). These findings show an additional important factor; namely, the effect of bilingual language use in the input (see also
Phillips and Deuchar 2022). The fact that children CM in both languages at the younger age suggests that it is used to compensate for lexical gaps (see
Genesee and Nicoladis 2007 for a review of this phenomenon).
Montanari et al. (
2019) call for studies of children at younger ages, for the inclusion of naturalistic conversational data, for more longitudinal data, and for data collected in bilingual mode (see also
Smolak et al. 2020), referring to
Yow et al. (
2018), who found that habitual code-switchers indeed switched a whole lot more, and to
Comeau et al. (
2003) who showed that children do adapt their CM rate to the bilingual habits of their interlocutors. We will see that in the studies we report on below, the first three of these issues are addressed.
1.3. Usage-Based Approach to Language
The usage-based approach (UB) is based on the assumption that speakers acquire their linguistic knowledge based on their experiences with language (e.g.,
Tomasello 2003;
Bybee 2010). Rejecting the assumption that linguistic knowledge is innate, UB approaches instead claim that language is a dynamic system which is acquired with the help of the general learning and storing mechanisms of the human mind. As such, UB approaches are broadly aligned with cognitive-functional approaches in linguistics, which see a speaker’s language as grounded in ‘usage events’. Language is conceptualized as an inventory of constructions (form-meaning pairings) and these constructions can be situated along a continuum of abstraction from completely lexically fixed expressions (I don’t know) via partially schematic constructions (Can I have X) to presumably completely abstract patterns (Subject Verb Object). Children’s early language is generally low in complexity and characterized by a high number of lexically fixed expressions and partially schematic (‘frame-and-slot’) patterns. Many of these can be related back to already acquired patterns (e.g.,
Lieven et al. 2009,
1997), suggesting that children’s linguistic output is often produced by re-using a limited number of patterns with various slot fillers. Over time, children exhibit increasing productivity and creativity. Since linguistic knowledge is acquired based on the language children hear, input plays an important role in acquisition scenarios. Children may learn patterns directly from the input (e.g.,
Cameron-Faulkner et al. 2003). Pattern acquisition and activation is related to the notion of frequency and subsequently entrenchment. Frequency plays a crucial role in UB approaches: the more frequently a particular construction is encountered the earlier it is acquired. Similarly, the more often these constructions are used the better they become entrenched in the minds of individual children, where entrenchment refers to consolidation in memory. The better entrenched a pattern is, the more easily accessible it is for future language use; consequently, it is more likely to be repeated again (see
Schmid 2020).
Schmid (
2016) refers to this as “[…] a feedback loop in which frequency comes to serve as both a cause and an effect of entrenchment.” (p. 21).
A wealth of studies has demonstrated that young children’s early utterances are less complex and abstract than those of adults and often contain patterns which are reused again and again. This observed patterning gave rise to the idea that children’s early utterances are constructed around low-scope formulae or frames.
Braine and Bowerman (
1976) conceived of these frames as a pivot grammar in which children use so-called ‘pivot’ words and combine these with a range of other words to create lexical frames, such as more X. Later studies have shown that a large proportion of children’s early utterances can be accounted for by a limited number of high-frequency frames, for example I want X (
Lieven et al. 1997;
Pine et al. 1998;
Tomasello 2003). Often these frames contained multiword chunks which at least initially go unanalyzed. Research has further shown that there is relatively little overlap in the content of these frames which supported the idea that children individually learn these frames from the input (e.g.,
Pine et al. 1998). No two children live the same life, so individual differences in the input and, consequently, in children’s output are predicted given the complex interplay of cognition and environment. These individual differences are relatively unimportant for structurally oriented approaches because their focus is on the abstract patterns only. The individual differences in linguistic experience that we find absolutely normal for adult speakers also hold, up to a point, for young children: they have, for example, different language experience concerning the frequency with which words and constructions appear in their input, the types of interlocutors they interact with, and the socio-economic (SES) background in which they grow up: this implies differences in the quality and quantity of their linguistic experiences. This then leads to different inventories. More important for our concerns, it also triggers different routes to productivity (e.g.,
Dąbrowska 2012). Since all speakers have their own inventories, which moreover are constantly changing, the question arises how to account for potential patterns in the data. To verify that language knowledge is built up in this bottom-up way, we need a method that can tap into this process during language acquisition. One such method is the ‘Traceback Method’, and it has been used in many studies to investigate how closely children’s novel utterances are tied to their previous utterances (e.g.,
Lieven et al. 2009,
2003). By identifying patterns only on the basis of what is in the data, the traceback method avoids having to assume a priori categories, or constraints on what is possible.
The basic idea of the traceback method is to identify patterns and frame-and-slot patterns only if they had been uttered before, and thus can be traced back to previous utterances in the corpus. In order to be able to trace back utterances a corpus is divided into a short test corpus (usually the last recording(s)) and a target corpus (the remaining recordings). Patterns in the test corpus are only identified if they can be related back to utterances in the target corpus. If they match verbatim, a lexically fixed pattern/unit/chunk is established, such as
I want it. If the match is only partially, a so-called frame-and-slot pattern is identified, e.g., [I want X].
Lieven et al. (
2009) applied the method to the speech of four English-speaking two-year-old children and were able to show that between 58–78% of the utterances in the test corpus contained either verbatim repetitions or a frame-and-slot pattern. These results support UB ideas in that children acquire their language in a piecemeal way and that utterances are very closely related to what the children had said previously.
In UB account it is assumed that output is closely tied to the input children receive and that children are able to extract linguistic knowledge from the language they hear. Following up on this,
Cameron-Faulkner et al. (
2003) conducted “a construction based analysis of child directed speech” to investigate how repetitive caretakers are and if children are able to pick up the constructions used by the caretakers. The authors found that many of the input utterances contained an utterance-initial frame, such as [Are you X], [I think X], [Let’s X] and that children’s use of these frames correlated highly with their caretaker’s frequency of use. Thus, these findings support the idea that children can infer language from what they hear and that the input children receive is far from being impoverished and chaotic. Most studies that used the traceback method applied it to monolingual data but recently a variant of the traceback method was also applied to bilingual data, specifically to account for CM in German-English bilingual children (e.g.,
Quick et al. 2018a,
2018b;
Gaskins et al. 2019;
Quick and Hartmann 2021).
2. Code-Mixing Meets the Traceback Method
The dynamic view of linguistic structure that is characteristic of the usage-based approach provides a new perspective for analyzing bilingual utterances. Rather than identifying the positions in fully abstract grammatical patterns at which CM is possible (as structuralist approaches do), CM is analyzed in terms of the activation of frames or patterns from two languages. Obviously, many empirical observations remain the same no matter how they are theoretically accounted for: bilingual children often fill slots in an activated pattern with language material from the other language, e.g., [this is X] as in
this is ein Baum ‘this is a tree’. Compared to traditional applications of the traceback method, the studies by Quick and colleagues carve up their data set in a different way: they use the children’s utterances that contain CM as their test corpus, and all the preceding utterances as their target corpus. Each CMed utterance is first traced back to all the preceding utterances as a whole. If the traceback yields a match, a chunk is established, e.g., the combination
und this ‘and this’ was used many times by one of the German-English bilingual children and thus qualified as a lexically fully specific pattern, i.e., a chunk (and one that happens to be bilingual). If a bilingual utterance was matched only partially, a partially schematic unit (frame-and-slot pattern) was established (and claimed to exist in that speaker’s mind at the time the utterance was produced). For example, the utterance
und dann magic air ‘and then magic air’ was not uttered in this way before and, therefore, does not classify as a chunk. However, there are preceding utterances which contain the pattern [und dann X] ‘and then X’ as in und
dann tauchen die ‘and then they dive’ and therefore, the codemixed utterance
und dann magic air yields a frame-and-slot pattern that contains the German pattern [und dann X] with the open slot X, in this case filled with English
magic air and thus producing a bilingual utterance.
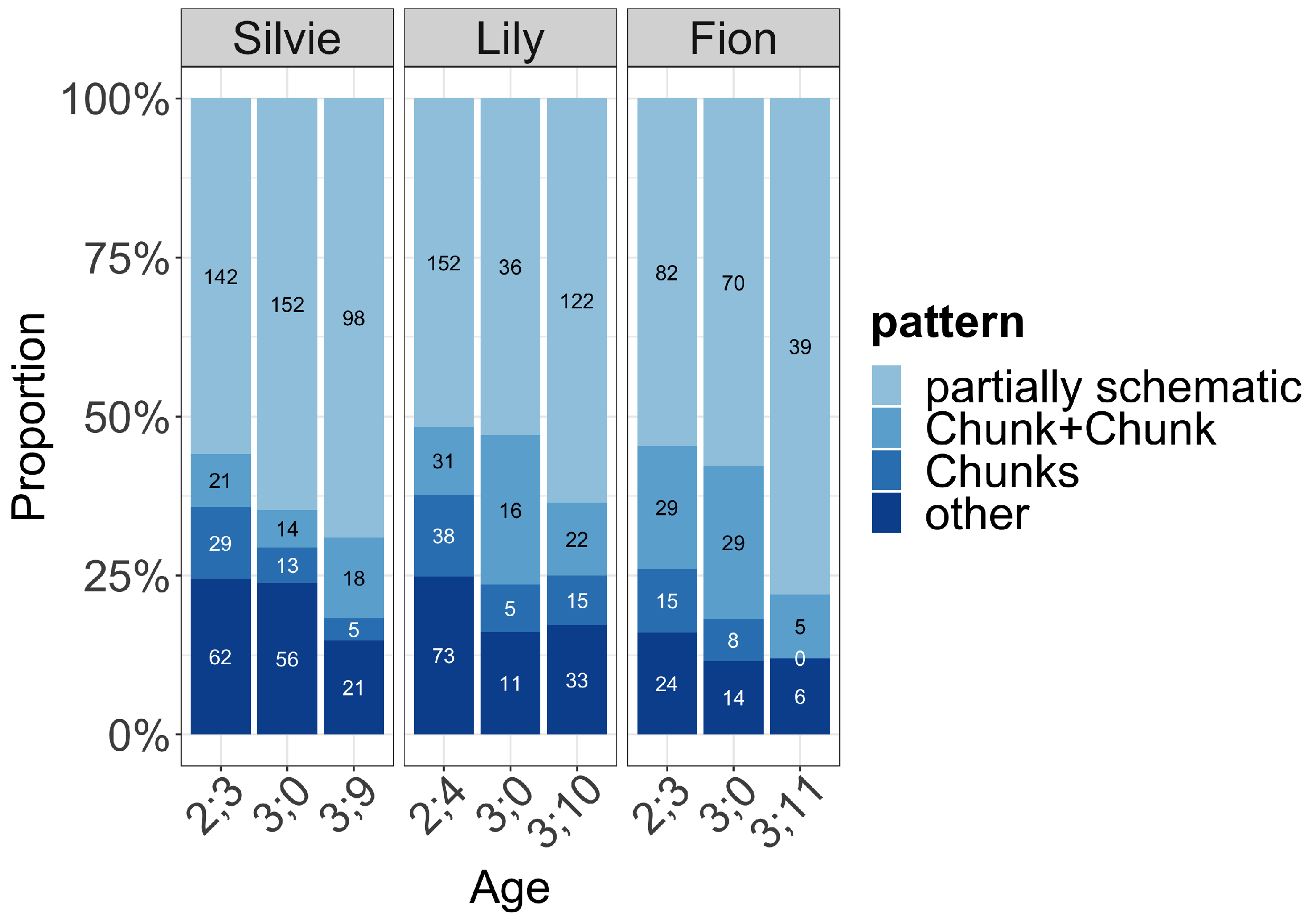
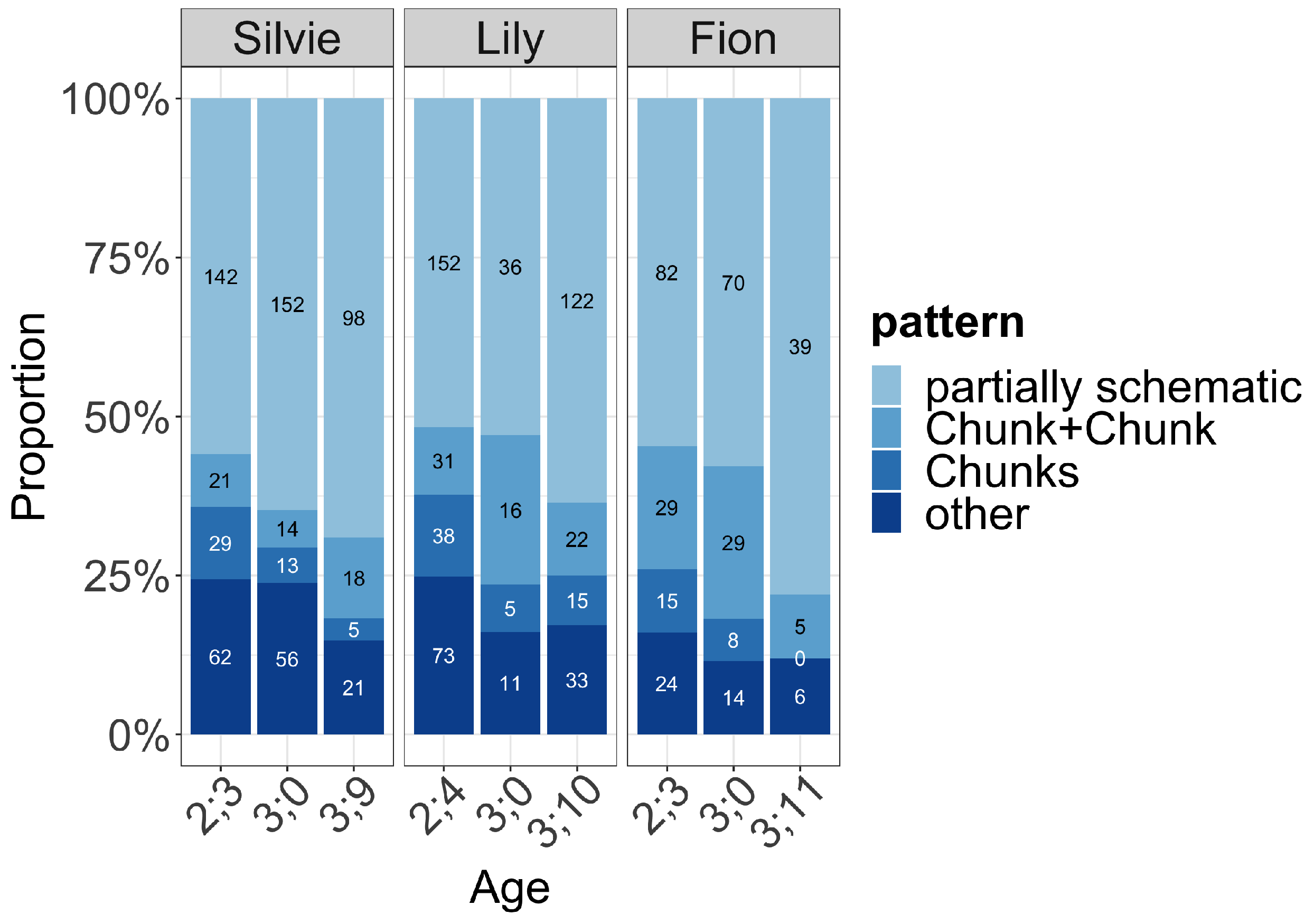
Quick et al. (
2021a) analyzed three German-English bilingual children’s code-mixing aged from 2;3 to 3;11 and showed that with the operationalization described above more than 50% of the bilingual utterances were constructed around such frame-and-slot patterns (more than 70% in fact contained a lexically specific pattern, see
Figure 1).
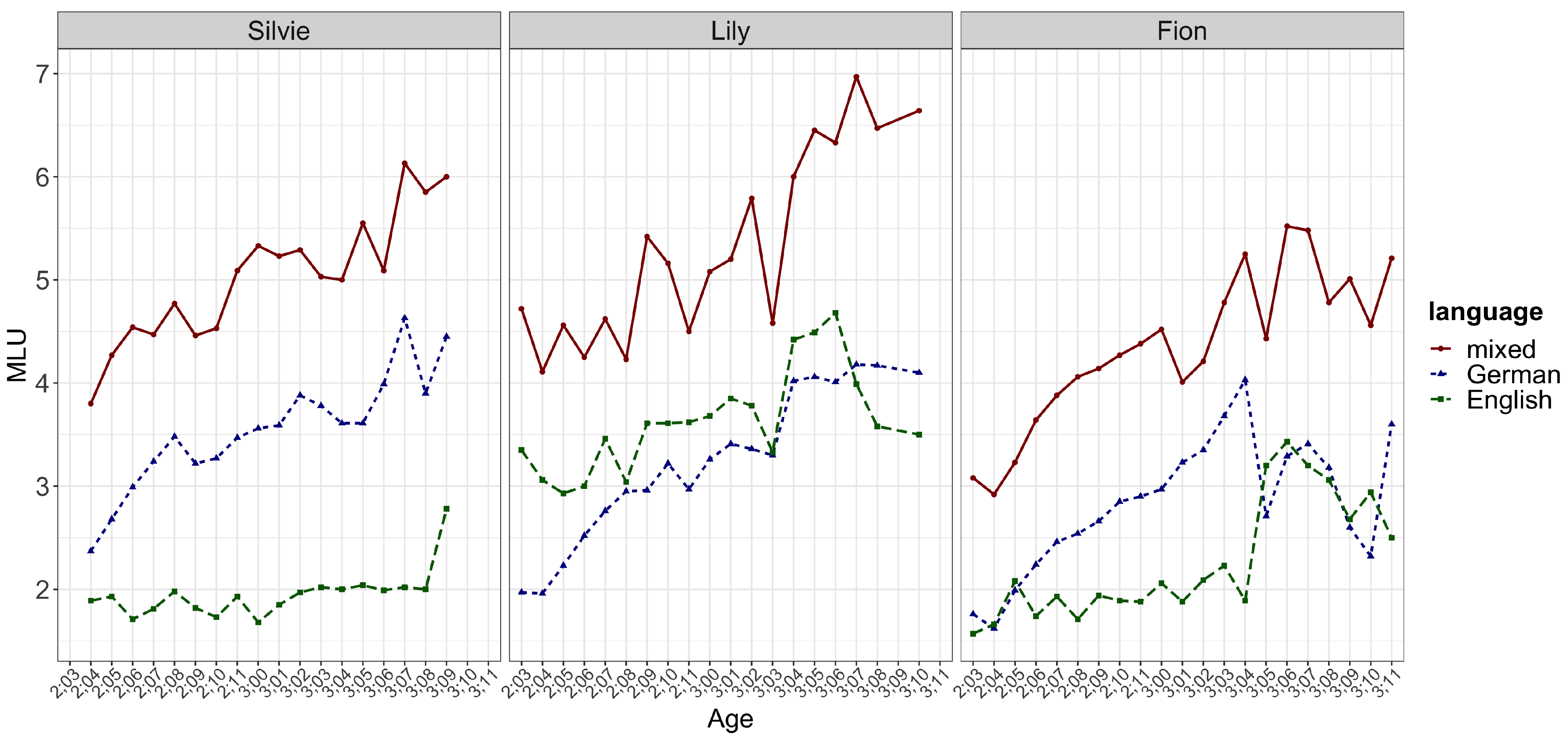
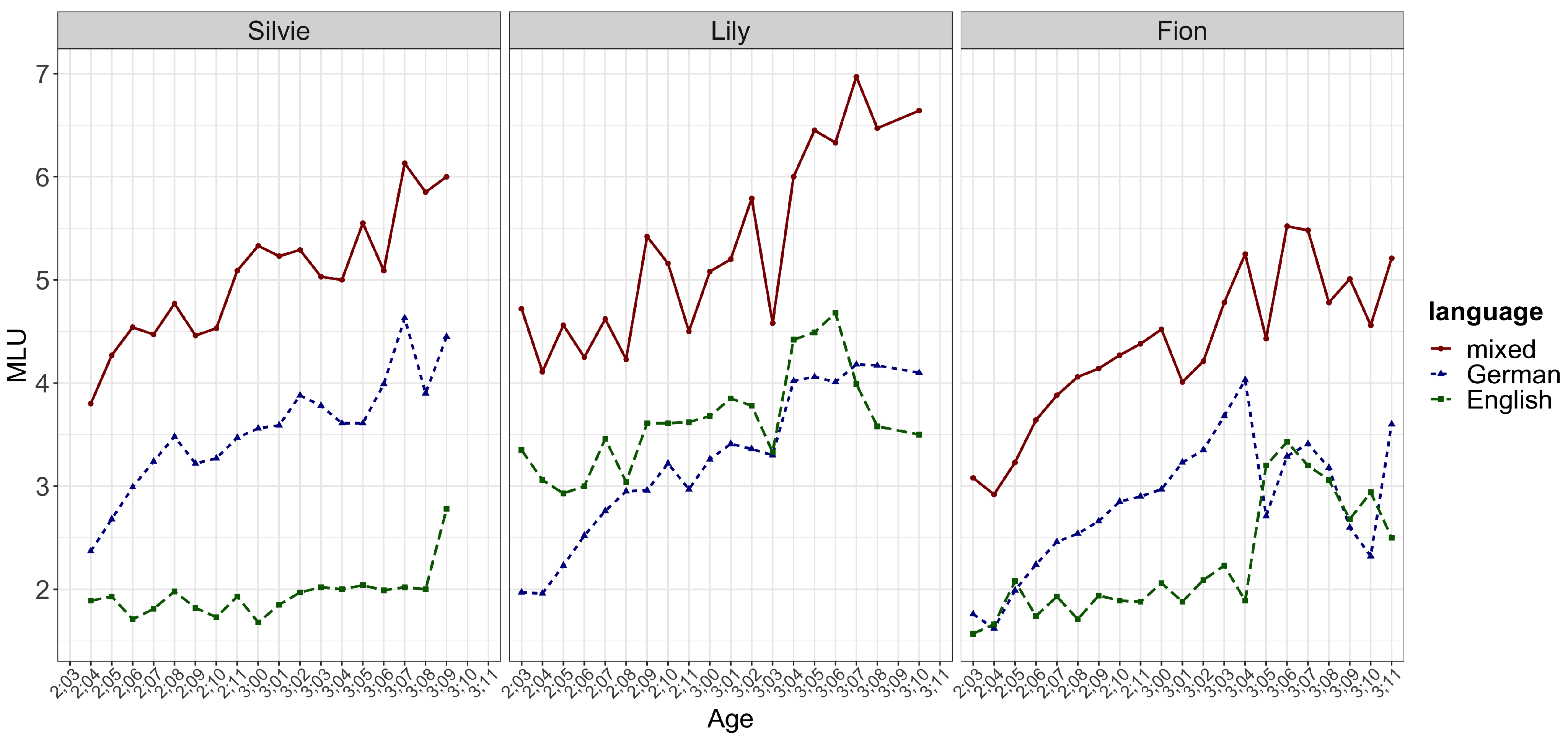
Most of the time, the chunks as well as the lexically specific parts in the frame-and-slot patterns (often analyzable as the ‘grammatical morphemes’ or ‘function words’) were from what should be seen as the language the child was more proficient in, as determined by their Mean Length of Utterance (MLU) and the analysis of her bilingual speech showed that in her frame-and-slot patterns most of the lexically specific parts were realized in German, e.g., [ich will jetzt X machen] ‘I want to make X’ in ich will jetzt the boat machen. Lily, on the other hand, was a balanced bilingual, as her monolingual MLUs were very similar to each other. Interestingly, there was no clear language preference in her frame-and-slot patterns for the lexically-specific parts, with some in German and others in English. Fion’s data showed this connection between input and output more spectacularly. Initially, he was classified as more proficient in German and indeed most of his patterns had German lexically-specific material. However, during the recording period his exposure to English went up (after his third birthday), and this change is reflected in his MLUs: his English MLU caught up with his German MLU. In his CM patterns, there was a change from mostly German-based to mostly English-based frames.
The MLU results yielded some other interesting results. For the monolingual as well as the bilingual utterances,
Quick et al. (
2021a) found that, while the language which was more frequently found in the input had, as expected, a longer MLU than the other language, the bilingual utterances were significantly longer and more complex throughout the period of recording (see
Figure 2 from
Quick et al. 2021a).
In another study,
Gaskins et al. (
2019) extended the traceback method to other language combinations (English–Polish, English–German and English–Finnish) and also found that much of the CMed utterances are constructed around already acquired patterns. These results show that CM can be analyzed as the combined production of lexically fixed chunks and emerging frame-and-slot patterns, e.g., resulting in creative utterances, such as
und dann magic air.
In UB accounts input and output are inextricably linked to each other. Children extract linguistic knowledge from the input they receive to build up their language. Studies on child-directed-speech produced evidence for the repetitive nature of input and that children are able to pick up on these patterns (e.g.,
Cameron-Faulkner et al. 2003;
Stoll et al. 2009;
Kirjavainen et al. 2009). For example,
Stoll et al. (
2009) analyzed the input of German and Russian children and found that caregivers often used lexically-initial frames, such as [Are you X] which were subsequently picked up by their children. The impact of input is not only limited to slowly accumulating build-up and processing of memory traces: direct discourse situations also have their impact.
Kirjavainen et al. (
2009) showed, for example, that certain errors children make, such as the ‘me-for-I error’ in me do it, are direct uptake effects from the discourse, since children had heard utterances such as
Let me do it just before. The question arises whether this combination from long-term and short-term input effects can also account for certain CM patterns. In order to investigate whether CMed utterances were determined by input as well as immediately previous usage,
Quick et al. (
2021b) extended the traceback method and related patterns found in the CM back to the input. Applying an automatic traceback using n-grams, the authors were able to trace back a large proportion of the patterns found in the CM to the input data (75%). For example, patterns such as [ich bin X] ‘I am X’ as in
ich bin die cat ‘ I am the cat’ could be traced back to input utterances such as
ich bin dran ‘it is my turn’. This suggests that children are able to extract patterns from the input to use it in their CM. In another study (
Quick et al. 2018a) direct discourse priming effects were investigated, to see whether mixed utterances or parts of mixed utterances were repeated from the immediate discourse. The authors checked up to 20 prior utterances for each code-mixed utterance to analyze if there were any precedents. Results showed that very often children pick up bits and pieces from the immediately preceding discourse, and they do so to a greater extent at an earlier age. This suggests that the reliance on input is greater at a younger age, when proficiency is lower. Note that, while these findings confirm that input in general and the immediately preceding discourse in particular help bilingual children to construct their utterances, just as is the case with monolingual children, the specific utterances analyzed here were CMed utterances, which in that form did not occur in the input as the parents did not code-mix. Language production on the basis of the concrete lexical chunks and the frame-and-slot patterns the children had heard before in both languages was enough to lead them to the production of mixed utterances.
Finally, since each child lives a different life it stands to reason that no child will have the same set of patterns. Individual differences are at the core of a UB approach and are even predicted. Each set of patterns, and, consequently, each CMed utterance will depend on individual usage and input. This issue was tackled in
Quick and Hartmann (
2021). They compared two German-English bilingual children’s sets of patterns using the traceback method within one child’s data and across their data sets. Results showed that tracing back patterns within each child (the classic traceback approach) was more successful than tracing back to the other child’s corpus, indicating that each child has their own set of patterns which depends very much on their individual input. As such, these findings mirror what previous studies have shown before, that children’s early language as well as their bilingual utterances are constructed around chunks and frame-and-slot patterns with relatively little overlap in the content of these chunks and frames.
3. Discussion
In our final discussion we first want to highlight similarities and differences between the quantitative structural approaches and usage-based approaches to CM before we turn to future directions a UB account has to offer for contact phenomena.
Comparing Quantitative Structural Analysis and Usage-Based Analysis
If we compare the two approaches and how they conduct studies we can observe similarities but also substantial differences, both methodological and theoretical. Let us first turn towards the similarities. All studies collect data in settings intended to be monolingual, and perhaps for that reason yield relatively low mixing rates, even when participants are from communities in which codeswitching is common. All studies find a relationship between CM rates and proficiency, but also signal a reduction of this importance as the child grows older, and the adherence to community norms regarding CM takes over. Children stop CM in languages that are supposed to be used in a monolingual mode: English in the case of the bilingual communities in North America and both German and English in the case of the children we studied. Recall, however, that our studies stopped data collection before the age at which children start developing such sociolinguistic awareness. All studies report individual differences, which surface as different clusters of children that show similar CM behavior in
Montanari et al. (
2019), and as individual children’s CM profiles in our data. Some aspects remain hard to compare in any detail, however, complicating the consideration of implications for linguistic theory. While MLU rates are used in all studies as a measurement for syntactic proficiency, studies differ in how they apply it.
Montanari et al. (
2019), for example, did not count MLU of mixed utterances separately, and discarded switched words (a three-word English utterance with a Spanish word in it counted as a two-word English utterance). In our studies, on the other hand, we counted the MLUs of German, English and mixed utterances separately. More generally, it remains somewhat uncertain how we should perceive ‘dominance’: it is clear that it is a major factor in determining CM direction, as all studies, regardless of theoretical framework, show, but how it relates to exposure and proficiency remains a tricky issue (cf.
Silva-Corvalán and Treffers-Daller 2016 for a state-of-the-art review of the concept). A second, and perhaps more important issue, is that our analysis of the role of constructional productivity in determining CM patterns cannot be directly compared to anything in the other studies. This is because the traceback method forces the focus on individual constructions rather than on the grammars of the two languages involved. Nevertheless, all studies support the generalization that there is greater constructional productivity for constructions that ‘belong to’ the language that is overall the dominant language for the child at that particular moment in time, to the extent that dominance of one of the languages can be established.
Whereas structuralist accounts focus on form and the kinds of switches that are possible or not, a UB approach sees all structure as emergent. This means that it cannot a priori distinguish between, for example, lexical and functional words, and predict whether or not they can be inserted. Rather, speakers are assumed to select particular form-meaning units because they are easiest to activate, which then often will be because they are best entrenched for that speaker. These units may be completely lexically fixed frames, such as
I don’t know, or consist of a frame and an open slot, e.g., [I want X]. In our studies, we found that very often the frames and their lexically fixed components are in the language the child is more proficient in. This is similar to one of the main findings about adult CM, as amply documented in the literature: one of the languages often functions as the so-called matrix language that provides the grammar, whereas the embedded language is only allowed to contribute lexical items (e.g.,
Myers-Scotton 1997). However, just as adult CM often manifests other configurations, CM in young children too cannot easily be captured through just this simple opposition. Consequently, a UB perspective views the ‘matrix language effect’ in code-mixing simply as a side-effect of the entrenchment of partially schematic constructions, constructions that are used often are better entrenched and therefore more easily activated. This frequency of use itself is driven by language choice: constructions in a language used more often by a speaker are more frequent in that speaker’s usage than constructions in the language used less often.
From a UB perspective, the division between functional and lexical items successfully employed in other frameworks needs to be accounted for in other ways. The units of selection may be words, multiword frames, or frame-and-slot patterns, and most utterances contain units of all three types, and they overlap. Very frequently, these units are constructed around both lexical and functional items, such as [I want X] exemplifying the continuum that UB linguists assume between lexicon and grammar. The question is not which items (lexical or functional) are activated and used in CMed utterances, but UB linguistics offers an explanation that goes deeper into the linguistic status of functional elements. Specifically, functional items together with lexical items form the fixed elements in frame-and-slot patterns. These patterns are the target of ‘lexical’ selection, for independent reasons related to usage frequency and psycholinguistic entrenchment; the functional elements are simply necessary parts of the frame. The units of selection are not grammatical patterns and individual lexemes, but, as mentioned above, words, multiword units and frame-and-slot patterns. Which units are activated is a question of storage and processing characteristics, applied to the communicative needs of the current conversation. Since language is seen as a dynamic system, fully schematic units develop in the minds of speakers over time as an abstraction over lexically fixed chunks that exhibit the same structure; often, this process will proceed through the intermediate stage of frame-and-slot patterns. These partially schematic units are claimed to remain in speakers’ grammars even if fully schematic units also develop on the basis of similarities they share (it is a matter of debate to what extent fully schematic units actually exist in people’s minds). These processes play out in the minds of each individual speaker, and since they are based on usage, individual differences are predicted by the UB account. The task for the analyst is to establish which patterns are part of a child’s inventory. The traceback method has been developed in the context of UB linguistics to test whether and to what extent children’s utterances can be accounted for by recurring chunks and patterns the children already have in their inventory. Being a purely data-driven approach, the traceback method only detects patterns explicitly present in the data. Our results showed that CMed utterances are constructed around chunks and frame-and-slot patterns, just as monolingual utterances are. Despite the absence of such mixing in the input, the patterns we found in the data correlate heavily with the input children receive. Very often, CM reflected creativity, in the form of frame-and-slot patterns with in one language in which the open slot was filled in with a lexeme from the other language, or in the form of juxtaposed chunks from both languages.
Of course, several questions relating to the traceback method and its outcome need further development. One that is important for our present concerns is threshold levels built into the model; another one is the cognitive plausibility of the attested patterns. The question of when a pattern is considered entrenched is operationalized through an arbitrary threshold: the traceback method thus merely shows that children recycle their units when forming an utterance, reusing bits and pieces they have uttered before. However, whether these bits and pieces actually constitute cognitively entrenched patterns cannot be proven this way. Nevertheless, the incontrovertible fact established through the traceback method is that “what children say is closely related to what they have said previously […]” also in the bilingual utterances (
Lieven et al. 2009, p. 502). Another issue is the status of the precise measurements the traceback method returns for how many of the cases of CM can be traced back to previous language experience. These figures are as precise as the data allow: the corpora we have will, however, always be but a fraction of any child’s language experience. This may explain why not 100% of the cases can be traced back; on the other hand, one would never expect the figure to reach that high, given that creativity in verbalization is a design feature of language. Locating exactly where linguistic creativity resides and accounting for how it is accomplished remains a challenging task for linguistics.
4. Conclusions
A number of issues are left that need to be addressed in future research. First, the monolingual bias in the design of most studies needs to be balanced out with observations of how children CM when in bilingual mode. Of course, most societies exhibit a monolingual bias, and it is clear that children growing up in such societies need to learn to keep their languages separate, but that does not mean we should lose sight of the fact that apparently mixing languages is the natural thing to do if you are bilingual, and that at least one of the languages of a bilingual may habitually be used in bilingual mode (such as Spanish in the case of Spanish-English in the US, or Turkish in the case of Turkish-German bilingualism in Germany). The studies we reviewed suggest that sociolinguistic norms take over from proficiency as the main determinant of the child’s CM behavior as the child grows older. The question is often asked whether CM is the result of a lack of proficiency or of the application of communicative competence, and the evidence suggests that proficiency is not an important factor at later ages (see
Ribot and Hoff 2014 for insights into how children acquire community norms). Is CM for young children really to be seen as a case of compensating for lexical gaps or more as simply reflecting lexical competence (and relative absence of metalinguistic knowledge)? The findings of
Smolak et al. (
2020) show that children as young as 2;7 have already learned that English is more prominent than Spanish in their community. As for proficiency, it is important to find out more about the degree to which exposure and proficiency can really be differentiated all that easily.
Bedore et al. (
2010) show there is not a one-to-one relationship, if ‘exposure’ is equaled to input and ‘proficiency’ to acquisition and ‘usage’ (
Smolak et al. 2020, p. 501), although obviously the two concepts are very much related. In fact, this relationship is the cornerstone of the usage-based approach. The quantitative studies distinguish between inter- versus intrasentential CM, and between CM for content words and function words. These categories reflect earlier work on CM, both in adults and in children, but these categorizations make direct comparison with our usage-based analyses difficult. The increase in CM for function words
Smolak et al. (
2020) report for the Spanish-English data suggests ongoing ‘interference’ from English, but without further details about the instances we cannot be sure. How does ‘CM for function word’ compare with our categorizations of CS within frame-and-slot patterns (also see
Deuchar 1999)? And how does this compare to the earlier literature demonstrating the relevance of constraints (e.g.,
Genesee and Nicoladis 2007)? These questions are difficult to solve, partly also because QSA and input-driven approaches ask different questions. For example, the distinction between lexical and functional items and their role in CMed utterances does not play a role in UB approaches as these items are often both parts of multiword units. Concerning the role of constraints, UB theories do not propose fixed switching points simply because the focus is on units/patterns and which units are common and why.
To conclude, both QSA and UB studies on bilingualism show that CM is a natural outcome of bilingual acquisition, which can give us valuable insights about (constructional) productivity and creativity, as well as the important impact of the implicit and explicit social surroundings.



{kind=link}
{kind=link}