A Corpus-Assisted Discourse Study of Attitudes toward Spanish as a Heritage Language in Florida



Abstract
1. Introduction
2. Theory
3. Methodology
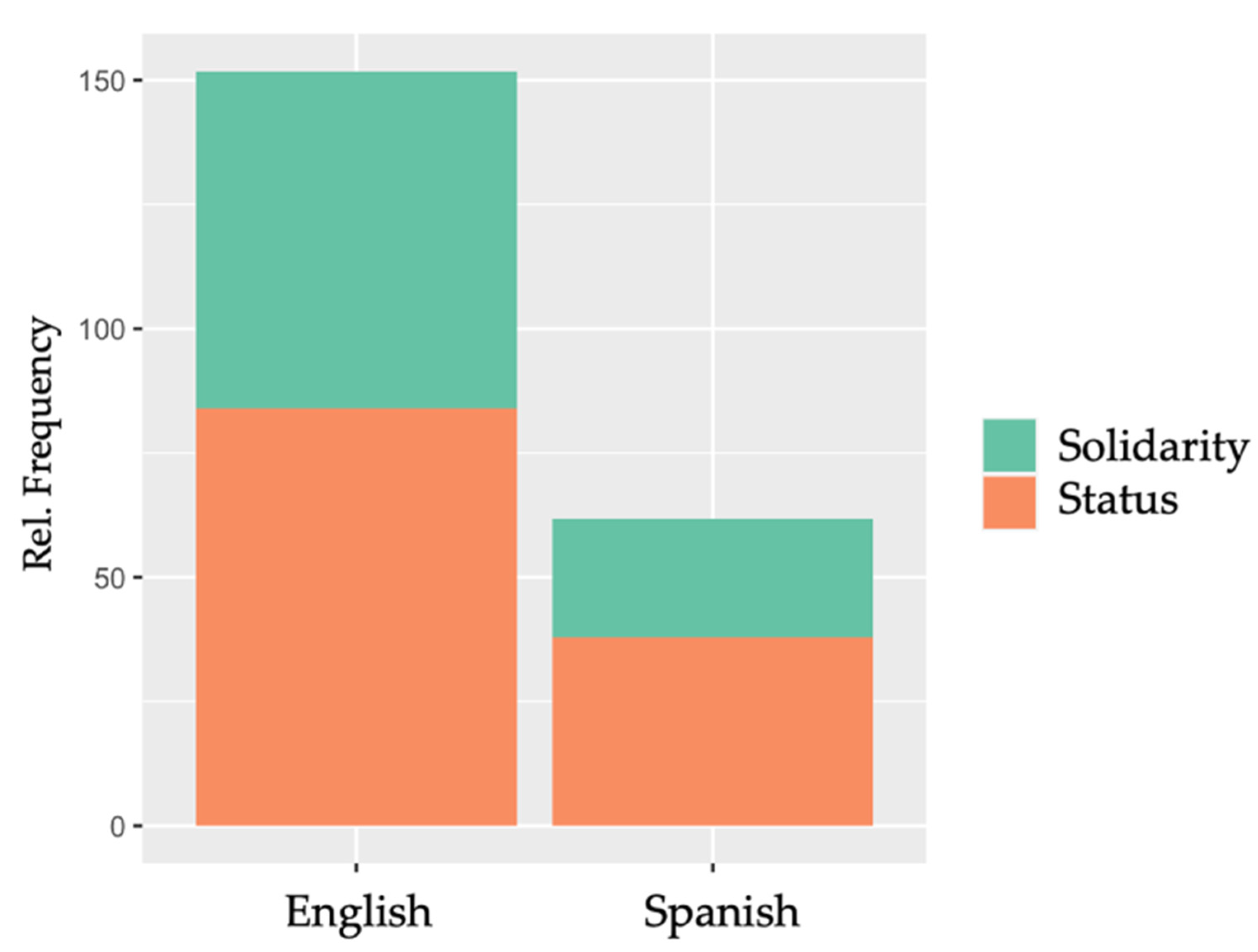
- Q1: Do the data reveal attitudinal differences with regard to the status and the solidarity dimension?
- Q2: Are attitudes expressed differently in the English and the Spanish corpus?
- Q3: Do the data provide possible explanations for the low vitality of Spanish in Florida?
3.1. Data Collection
3.2. Data Analysis
4. Results
4.1. Attitudes on the Status Dimension
“In April, national unemployment for Latinos peaked at 18.5%. For Latina women, it was even higher, at 20.”
“Because Trump is beating Biden with the Hispanic vote and 3/4 with Spanish speaking voters (did the poll in Spanish) Democrats made another stupid move and made Bush Republican Anna Navarro their Latino outreach. Democrats need to do better if they want to win.”
“Trump se encuentra en el sur de Florida en busca del voto latino, uno de los bloques de votantes más importantes del estado https …” (Trump finds himself in South Florida looking for the Latin vote, one of the most important blocks of voters in the state https …)
“Telemundo seems to want their Spanish speaking audience to vote for Trump. Remember this is one of only two Spanish networks in America. They have a lot of power.”
4.2. Attitudes on the Solidarity Dimension
“It is important speaking with them one on one (in Spanish) and connecting to the community in Spanish. When I was a kid, this was the only way for me to connect with my people.”
“I am half Colombian half Mexican. I start speaking Spanish and they’re like, where’d you learn that. It’s always so nice to see that your community and friends appreciate your language. This is my city, I belong here.”
“Speaking Spanish is my heritage. It is what makes me who I am.”
“My miami family made me embrace more my Spanish side and I realized how much I’ve been missing out.”
“I remember in elementary school being forbidden from speaking Spanish with my mom. They actually threatened to send child services to accuse my mom of leaving me unequipped to deal with American society for speaking Spanish to me.”6
“My mom encouraged me to speak English at home to avoid an accent.”
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Translations of the Concordance Lines in Figure 4, Figure 5 and Figure 7



References
- Anthony, Laurence. 2019. AntConc (Version 3.5.8) [Computer Software]. Tokyo: Waseda University. Available online: https://www.laurenceanthony.net/software (accessed on 20 February 2021).
- Baker, Colin. 1992. Attitudes and Language. Clevedon: Multilingual Matters. [Google Scholar]
- Baker, Paul. 2006. Using Corpora in Discourse Analysis. London: Continuum. [Google Scholar]
- Baker, Paul. 2010. Sociolinguistics and Corpus Linguistics. Edinburgh: Edinburgh University Press. [Google Scholar]
- Baker, Paul, Andrew Hardie, and Tony McEnery. 2006. Glossary of Corpus Linguistics. Edinburgh: Edinburgh University Press. [Google Scholar]
- Benmamoun, Elabbas, Silvina Montrul, and Maria Polinsky. 2013. Heritage languages and their speakers: Opportunities and Challenges for linguistics. Theoretical Linguistics 39: 129–81. [Google Scholar] [CrossRef]
- Bohner, Gerd. 2001. Attitudes. In Introduction to Social Psychology. Edited by Miles Hewstone and Wolfgang Stroebe. Oxford: Blackwell, pp. 239–82. [Google Scholar]
- Bourhis, Richard Y., and Anne Maass. 2005. Linguistic prejudice and stereotypes. In Sociolinguistics: An International Handbook of the Science of Language and Society. Edited by Ulrich Ammon, Norbert Dittmar, Klaus J. Mattheier and Peter Trudgill. Berlin: Walter de Gruyter, pp. 1587–601. [Google Scholar]
- Brezina, Vaclav. 2018. Statistics in Corpus Linguistics: A Practical Guide. Cambridge: Cambridge University Press. [Google Scholar]
- Brown, Anna, and Mark Hugo Lopez. 2013. Mapping the Latino population, by state, county and city. Pew Hispanic Center 202: 17. [Google Scholar]
- Buchstaller, Isabelle. 2006. Social stereotypes, personality traits and regional perception displaced: Attitudes towards the “new” quotatives in the U.K. Journal of Sociolinguistics 10: 362–81. [Google Scholar] [CrossRef]
- Callesano, Salvatore, and Phillip M. Carter. 2019. Latinx perceptions of Spanish in Miami: Dialect variation, personality attributes and language use. Language and Communication 67: 84–98. [Google Scholar] [CrossRef]
- Campbell-Montalvo, Rebecca. 2020. Linguistic Re-Formation in Florida Heartland Schools: School Erasures of Indigenous Latino Languages. American Educational Research Journal, 1–36. [Google Scholar] [CrossRef]
- Cargile, Aaron Castelan, and Howard Giles. 1997. Understanding language attitudes: Exploring listener affect and identity. Language & Communication 17: 195–217. [Google Scholar]
- Cargile, Aaron Castelan, Howard Giles, Ellen B. Ryan, and James J. Bradac. 1994. Language attitudes as a social process: A conceptual model and new directions. Language and Communication 14: 211–36. [Google Scholar] [CrossRef]
- Carter, Phillip. M., and Andrew Lynch. 2015. Multilingual Miami: Current Trends in Sociolinguistic Research. Language and Linguistics Compass 9: 369–85. [Google Scholar] [CrossRef]
- De Houwer, Annick. 1999. Environmental factors in early bilingual development: The role of parental beliefs and attitudes. In Bilingualism and Migration. Edited by Guus Extra and Ludo Verhoeven. Berlin: Mouton de Gruyter, pp. 75–96. [Google Scholar] [CrossRef]
- De Houwer, Annick. 2015. Harmonious bilingual development: Young families’ well-being in language contact situations. International Journal of Bilingualism 19: 169–84. [Google Scholar] [CrossRef]
- De Houwer, Annick. 2017. Minority language parenting in Europe and children’s well-being. In Handbook on Positive Development of Minority Children and Youth. Edited by Natasha J. Cabrera and Birgit Leyendecker. New York: Springer, pp. 231–46. [Google Scholar]
- Díaz-campos, Manuel, and Jason Killam. 2012. Assessing Language Attitudes through a Matched-guise Experiment: The Case of Consonantal Deletion in Venezuelan Spanish. Hispania 95: 83–102. [Google Scholar]
- Durham, Mercedes. Forthcoming. Content analysis of social media data. In Research Methods in Language Attitudes. Edited by Ruth Kircher and Lena Zipp. Cambridge: Cambridge University Press.
- Fishman, Joshua A. 1991. Reversing Language Shift: Theoretical and Empirical Foundations of Assistance to Threatened Languages. Bristol: Multilingual Matters, vol. 76. [Google Scholar]
- Fishman, Joshua A. 2001. 300-plus years of heritage language education in the United States. In Heritage languages in America: Preserving a National Resource. Edited by Joy Kreeft Peyton, Donald A. Ranard and Scott McGinnis. Washington, DC and McHenry: Center for Applied Linguistics & Delta Systems, pp. 81–98. [Google Scholar]
- Flores, Nelson, and Jonathan Rosa. 2015. Undoing appropriateness: Raciolinguistic ideologies and language diversity in education. Harvard Educational Review 85: 149–71. [Google Scholar] [CrossRef]
- Gablasova, Dana, Vaclav Brezina, and Tony McEnery. 2017. Collocations in corpus-based language learning research: Identifying, comparing, and interpreting the evidence. Language Learning 67: 155–79. [Google Scholar] [CrossRef]
- Gardner, Robert C., and Wallace E. Lambert. 1972. Attitudes and Motivation in Second-Language Learning. Rowley: Newbury House. [Google Scholar]
- Garrett, Peter, Nikolas Coupland, and Angie Williams. 2003. Investigating Language Attitudes: Social Meanings of Dialect, Ethnicity and Performance. Cardiff: University of Wales Press. [Google Scholar]
- Giles, Howard, and Bernadette M. Watson. 2013. The Social Meanings of Language, Dialect and Accent: International Perspectives on Speech Styles. New York: Peter Lang. [Google Scholar]
- Grosjean, François. 1982. Life with Two Languages: An Introduction to Bilingualism. London: Harvard University Press. [Google Scholar]
- Hunston, Susan, and Geoff Thompson. 2006. System and corpus: Two traditions with a common ground. In System and Corpus: Exploring Connections. Edited by Geoff Thompson and Susan Hunston. London: Equinox, pp. 1–14. [Google Scholar]
- Jaworska, Sylvia, and Christiana Themistocleous. 2018. Public discourses on multilingualism in the UK: Triangulating a corpus study with a sociolinguistic attitude survey. Language in Society, 47. [Google Scholar] [CrossRef]
- Kearney, Michael W. 2019. rtweet: Collecting and analyzing Twitter data. Journal of Open Source Software 4: 1829. [Google Scholar] [CrossRef]
- Kelleher, Ann. 2010. Who Is a Heritage Language Learner. Heritage Briefs. Washington, DC: Center for Applied Linguistics and Delta Systems, pp. 1–3. [Google Scholar]
- Kircher, Ruth. 2016. Montreal’s multilingual migrants: Social identities and language attitudes after the proposition of the Quebec Charter of Values. In Language, Identity and Migration: Voices from Transnational Speakers and Communities. Edited by Vera Regan, Chloe Diskin and Jennifer Martyn. Bern: Peter Lang, pp. 217–47. [Google Scholar]
- Kircher, Ruth. 2019. Intergenerational language transmission in Quebec: Patterns and predictors in the light of provincial language planning. International Journal of Bilingual Education and Bilingualism. [Google Scholar] [CrossRef]
- Kircher, Ruth, and Sue Fox. 2019. Multicultural London English and its speakers: A corpus-informed discourse study of standard language ideology and social stereotypes. Journal of Multilingual and Multicultural Development, 1–19. [Google Scholar] [CrossRef]
- Kircher, Ruth, and James Hawkey. Forthcoming. Mixed-methods approaches to the study of language attitudes. In Research Methods in Language Attitudes. Edited by Ruth Kircher and Lena Zipp. Cambridge: Cambridge University Press.
- Kircher, Ruth, and Lena Zipp, eds. Forthcoming. An introduction to language attitudes research. In Research Methods in Language Attitudes. Cambridge: Cambridge University Press.
- Kutlu, Ethan. 2020. Now You See Me, Now You Mishear Me: Raciolinguistic accounts of speech perception in different English varieties. Journal of Multilingual and Multicultural Development, 1–15. [Google Scholar] [CrossRef]
- Kutlu, Ethan, Mehrgol Tiv, Stefanie Wulff, and Debra Titone. Forthcoming. The Impact of Race on Speech Perception and Accentedness Judgments in Racially Diverse and Non-Diverse Groups. [CrossRef]
- Lee, Carmen. 2016. Multilingualism Online. New York: Taylor & Francis. [Google Scholar]
- Lopez, Mark Hugo, Ana Gonzalez-Barrera, and Danielle Cuddington. 2013. Diverse Origins: The Nation’s 14 Largest Hispanic-Origin Groups. Washington, DC: Pew Hispanic Center. [Google Scholar]
- Martinez, Danny C., Javier Rojo, and Rubén A. González. 2019. Speaking Spanish in white public spaces: Implications for literacy classrooms. Journal of Adolescent & Adult Literacy 62: 451–54. [Google Scholar]
- Moyna, María Irene, and Verónica Loureiro-Rodríguez. 2017. La técnica de máscaras emparejadas para evaluar actitudes hacia formas de tratamiento en el español de Montevideo. Revista Internacional de Lingüística Iberoamericana 15: 47–82. [Google Scholar]
- Orpin, Debbie. 2005. Corpus linguistics and critical discourse analysis: Examining the ideology of sleaze. International Journal of Corpus Linguistics 10: 37–61. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2011. Reanalysis in adult heritage language: New evidence in support of attrition. Studies in Second Language Acquisition 33: 305–28. [Google Scholar] [CrossRef]
- Potowski, Kim, and Maria Carreira. 2010. Spanish in the USA. In Language Diversity in the USA. Cambridge: Cambridge University Press, pp. 66–80. [Google Scholar] [CrossRef]
- Rivera-Mills, Susana V. 2012. Spanish heritage language maintenance. In Spanish as a Heritage Language in the United States: The State of the Field. Washington, DC: Georgetown University Press, pp. 21–42. [Google Scholar]
- Rothman, Jason. 2009. Understanding the nature and outcomes of early bilingualism: Romance languages as heritage languages. International Journal of Bilingualism 13: 155–63. [Google Scholar] [CrossRef]
- Ryan, Ellen Bouchard, Howard Giles, and Richard J. Sebastian. 1982. An integrative perspective for the study of attitudes toward language variation. In Attitudes towards Language Variation: Social and Applied Contexts. Edited by Ellen Bouchard Ryan and Howard Giles. London: Edward Arnold, pp. 1–19. [Google Scholar]
- Sallabank, Julia. 2013. Attitudes to Endangered Languages: Identities and Policies. Cambridge: Cambridge University Press. [Google Scholar]
- Sherkina-Lieber, Marina. 2020. A classification of receptive bilinguals: Why we need to distinguish them, and what they have in common. Linguistic Approaches to Bilingualism 10: 3. [Google Scholar] [CrossRef]
- Spilioti, Tereza, and Caroline Tagg. 2017. The ethics of online research methods in applied linguistics: Challenges, opportunities, and directions in ethical decision-making. Applied Linguistics Review 8: 163–67. [Google Scholar] [CrossRef]
- Stavans, Anat, and Maya Ashkenazi. 2020. Heritage language maintenance and management across three generations: The case of Spanish-speakers in Israel. International Journal of Bilingual Education and Bilingualism, 1–21. [Google Scholar] [CrossRef]
- Surrain, Sarah. 2018. ‘Spanish at home, English at school’: How perceptions of bilingualism shape family language policies among Spanish-speaking parents of preschoolers. International Journal of Bilingual Education and Bilingualism, 1–15. [Google Scholar] [CrossRef]
- Tajfel, Henri, and John C. Turner. 1986. The social identity theory of intergroup behavior. In Psychology of Intergroup Relations. Edited by Stephen Worchel and William G. Austin. Chicago: Nelson-Hall, pp. 7–24. [Google Scholar]
- The Associated Press. 2019. Florida Nurses: Clinic Warns Only Speak English or Be Fired. Latino Rebels. Available online: https://www.latinorebels.com/2019/08/20/floridanurses/ (accessed on 20 February 2021).
- U.S. Census Bureau. 2019a. Hispanic or Latino Origin by Specific Origin, 2019 American Community Survey 1-Year Estimates. Available online: https://data.census.gov/cedsci/table?q=hispanic&g=0400000US12&tid=ACSDT1Y2019.B03001&hidePreview=false (accessed on 20 February 2021).
- U.S. Census Bureau. 2019b. Language Spoken at Home, 2019 American Community Survey 1-Year Estiamates. Available online: https://data.census.gov/cedsci/table?q=spanish&tid=ACSST1Y2019.S1601&hidePreview=false (accessed on 20 February 2021).
- United Nations (ND). n.d. Department of Economic and Social Affairs. Available online: http://www.un.org/en/development/desa/population/theme/international-migration/ (accessed on 20 February 2021).
- Valdés, Guadalupe. 2001. Learning and Not Learning English: Latino Students in American Schools. New York: Teachers College Press. [Google Scholar]
- Vessey, Rachelle. 2015. Corpus approaches to language ideology. Applied Linguistics 38: 277–96. [Google Scholar] [CrossRef]
- Vessey, Rachelle. 2016a. Language ideologies in social media: The case of Pastagate. Journal of Language and Politics 15: 1–24. [Google Scholar] [CrossRef]
- Vessey, Rachelle. 2016b. Language and Canadian Media: Representations, Ideologies, Policies. London: Palgrave Macmillan. [Google Scholar]
- Vessey, Rachelle. 2021. Nationalist language ideologies in tweets about the 2019 Canadian general election. Discourse, Context & Media 39: 100447. [Google Scholar]
- Yuasa, Ikuko Patricia. 2010. Creaky voice: A new feminine voice quality for young urban-oriented upwardly mobile American women? American Speech 85: 315–37. [Google Scholar] [CrossRef]
| 1 | While this definition only makes reference to attitudes toward entire varieties (i.e., languages, dialects, accents), there is in fact also a growing body of research toward particular linguistic features and phenomena, including attitudes toward quotatives (Buchstaller 2006), vocal fry (e.g., Yuasa 2010), phonetic variables (e.g., Díaz-Campos and Killam 2012), and forms of address (e.g., Moyna and Loureiro-Rodríguez 2017). However, this article focuses exclusively on attitudes toward the Spanish language. |
| 2 | They investigated representations of multilingualism as a metalinguistic construct in traditional media and then compared these with survey-based attitudinal data. |
| 3 | As these numbers indicate, there was an average of 29 words per tweet in the English corpus, compared to an average of 25 words per tweet in the Spanish corpus. There are several possible reasons for this difference, including the fact that Spanish is a pro-drop language (i.e., certain classes of pronouns can be omitted in contexts where they are grammatically and/or pragmatically inferable). It is also possible that the lower average word count per tweet in the Spanish corpus is a result of the fact that many Spanish tweets included links, as we will discuss below. Links count as one word but take up many character spaces. In any case, it is very unlikely that the different averages of words per tweet affected our overall findings. |
| 4 | Another common procedure is the investigation of keywords—that is, words which are unusually frequent when one’s own corpus is compared to a larger reference corpus (see, e.g., Vessey 2016b). However, for reasons of space, this procedure is not discussed here. |
| 5 | This means that we investigated not only the infinitive “hablar” (“to speak”) itself but also all conjugated forms of this verb. |
| 6 | Evidently, we cannot know whether the tweeter and their mother were actually in Florida at the time of this occurrence. In fact, the tendency for Latinx parents to use English with their children is not an uncommon one in the US (see, e.g., Martinez et al. 2019). Nevertheless, given that there is much evidence of language-based discrimination of Florida’s Spanish-speaking population (see, e.g., The Associated Press 2019), we consider this tweeter’s recollection of their mother’s behaviour meaningful in the present context. |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | ENGLISH | SPANISH | ||||
|---|---|---|---|---|---|---|
| Word | Abs. freq. | Rel. freq. | Word | Abs. freq. | Rel. freq. | |
| Directly | unemployment | 1386 | 2.56 | desempleo | 48 | 0.91 |
| negative | Category total | 1386 | 2.56 wptt | Category total | 48 | 0.91 wptt |
| Negative and positive | work | 2853 | 5.27 | trabajo | 217 | 4.12 |
| school | 2155 | 3.98 | escuela | 50 | 0.95 | |
| job | 1507 | 2.78 | ||||
| working | 1489 | 2.75 | trabajando | 25 | 0.47 | |
| college | 877 | 1.62 | universidad | 52 | 0.98 | |
| education | 740 | 1.36 | educación | 76 | 1.44 | |
| Category total | 9621 | 17.76 wptt | Category total | 420 | 7.96 wptt | |
| Indirectly positive | vote | 9979 | 18.4 | voto | 348 | 6.62 |
| voters | 5466 | 10.1 | votantes | 56 | 1.06 | |
| president | 4573 | 8.45 | presidente | 321 | 6.10 | |
| democrats | 2652 | 4.90 | demócratas | 74 | 1.40 | |
| voting | 2644 | 4.89 | votación | 10 | 0.19 | |
| leader | 2036 | 3.76 | líder | 48 | 0.91 | |
| election | 1826 | 3.37 | elecciones | 261 | 4.96 | |
| republican | 1708 | 3.15 | republicano/a | 22/11 | 0.41/0.20 | |
| government | 1442 | 2.66 | gobierno | 273 | 5.19 | |
| campaign | 1215 | 2.24 | campaña | 78 | 1.48 | |
| office | 910 | 1.68 | oficina | 23 | 0.43 | |
| Category total | 34,451 | 63.6 wptt | Category total | 1252 | 28.95 wptt | |
| Overall total | 45,458 | 83.92 wptt | Overall total | 1720 | 37.82 wptt | |
| ENGLISH | SPANISH | |||||
|---|---|---|---|---|---|---|
| Category | Word | Abs. Freq. | Rel. Freq. | Word | Abs. Freq. | Rel. Freq. |
| Community | immigrants | 1855 | 3.43 | inmigrante | 18 | 0.34 |
| immigrant | 1662 | 3.07 | inmigrantes | 46 | 0.87 | |
| community | 8610 | 15.9 | comunidad | 311 | 5.91 | |
| communities | 2276 | 4.21 | comunidades | 33 | 0.62 | |
| culture | 2563 | 4.74 | cultura | 130 | 2.47 | |
| members | 1635 | 3.02 | miembros | 26 | 0.49 | |
| friends | 2417 | 4.47 | amigos/as | 144/7 | 2.74/0.13 | |
| history | 2099 | 3.88 | historia | 228 | 4.33 | |
| Category total | 23,117 | 42.72 wptt | Category total | 943 | 17.9 wptt | |
| Family | heritage | 4372 | 8.08 | patrimonio | 12 | 0.22 |
| parents | 2195 | 4.06 | padres | 74 | 1.40 | |
| mom | 2089 | 3.86 | mamá | 49 | 0.93 | |
| families | 1544 | 2.85 | familias | 67 | 1.27 | |
| generation | 738 | 1.36 | generacion | 2 | 0.03 | |
| children | 2641 | 4.88 | niñas/os | 16/98 | 0.30/1.86 | |
| Category total | 13,579 | 25.09 wptt | Category total | 318 | 6.01 wptt | |
| Overall total | 36,696 | 67.81 wptt | Overall total | 1261 | 23.91 wptt | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kutlu, E.; Kircher, R. A Corpus-Assisted Discourse Study of Attitudes toward Spanish as a Heritage Language in Florida. Languages 2021, 6, 38. https://doi.org/10.3390/languages6010038
Kutlu E, Kircher R. A Corpus-Assisted Discourse Study of Attitudes toward Spanish as a Heritage Language in Florida. Languages. 2021; 6(1):38. https://doi.org/10.3390/languages6010038
Chicago/Turabian StyleKutlu, Ethan, and Ruth Kircher. 2021. "A Corpus-Assisted Discourse Study of Attitudes toward Spanish as a Heritage Language in Florida" Languages 6, no. 1: 38. https://doi.org/10.3390/languages6010038
APA StyleKutlu, E., & Kircher, R. (2021). A Corpus-Assisted Discourse Study of Attitudes toward Spanish as a Heritage Language in Florida. Languages, 6(1), 38. https://doi.org/10.3390/languages6010038