The Effect of Silence and Distance: Evidence from Recomplementation in US Heritage Spanish

Abstract
1. Introduction
- Morphology (e.g., agreement and marking)
- Distance (i.e., dependency relations at a distance)
- Silence (i.e., the interpretation of null elements)
- Ambiguity (i.e., one-to-many mappings between form and meaning)
| 1. | Me | dice | que | por | suerte | que | va | a | tener | suficiente | tiempo |
| CL.DAT | says | that | for | luck | that | go | to | have | enough | time | |
| ‘S/he says that luckily s/he is going to have enough time.’ | |||||||||||
- An initial investigation of the acquisition of recomplementation structures in a heritage language population
- Novel data in support of the growing literature arguing that the left periphery is a “vulnerable” domain
- Evidence in support of the Model of Divergent Attainment in heritage grammar.
1.1. Linguistic Phenomenon
| 2. | Me | dijo | que | esa | guitarra | vieja | que | cuándo | la | iba | a | tocar |
| CL.DAT | said | that | that | guitar | old | that | when | CL.ACC | go | to | play | |
| ‘S/He asked me when I was going to play that old guitar.’ | ||||||||||||
| 3. | Me | dijo | que | esa | guitarra | vieja | que | la | iba | a | tocar |
| CL.DAT | said | that | that | guitar | old | that | CL.ACC | go | to | play | |
| ‘S/He told me that s/he was going to play that old guitar.’ | |||||||||||
| 4. | [ForceP [Force’ que [TopicP esa guitarra vieja [Top’ que … [FocusP cuándo [FinitenessP [Fin’…]]]]]] |
| 5. | [ForceP [Force’ que [TopicP esa guitarra vieja [Top’ [(Doubled)ForceP [(Doubled)Force’ que [FocusP cuándo |
| [FinitenessP [Fin’…]]]]]]. |
| 6. | John reminded Mary that after he was finished with his meeting (that) his |
| brother would be ready to leave. |
| 7. | John reminded Mary that soon (that) his brother would be ready to leave. |
| 8. | Me | dijo | que | ese | dibujo | bonito | que | dónde | iba | a | colgarlo |
| CL.DAT | said | that | that | painting | beautiful | that | where | go | to | hang-CL.ACC | |
| ‘S/he asked me where I was going to hang that beautiful painting.’ | |||||||||||
| 9. | Me | dijo | que | ese | traje | formal | que | iba | a | pedirlo |
| CL.DAT | said | that | that | suit | formal | that | go | to | order-CL.ACC | |
| ‘S/he told me that s/he was going to order that formal suit.’ | ||||||||||
| 10. | que algunos otros Ø non ayan envidia dellos |
| ‘that some others don’t envy them’ |
| 11. | entendiendo que pues todo fincava en su poder, que podría obrar en ello como quisiese |
| ‘understanding that because everything laid in his power, that he could act in it as he wished’ |
1.2. Divergent Attainment in US Heritage Spanish
| 12. | Yo creo Ø inventaron el nombre. |
| ‘I think (that) they invented the name.’ |
| 13. | Me dijo (que)* cuándo iban a salir. |
| ‘He asked when they were going to leave.’ |
1.3. Research Questions and Predictions
- Do advanced heritage speakers accept the null C2 construction at a higher rate than the overt C2 option? Does language use or proficiency predict this outcome?
- Do advanced heritage speakers prefer the null C2 construction at a higher rate than the overt C2 option? Does language use or proficiency predict this outcome?
- With respect to (1) and (2), do advanced heritage speakers diverge from the baseline group?
2. Materials and Methods
2.1. Participants
2.2. Experimental Tasks
| 14. | Preamble: | Ese dibujo bonito, ¿dónde vas a colgarlo? |
| ‘Where are you going to hang that beautiful picture?’ | ||
| Question: | ¿Qué te dijo Susana? | |
| ‘What did Susana ask you?’ | ||
| Response: | Me dijo que ese dibujo bonito (que) dónde iba a colgarlo. | |
| ‘She asked me where I was going to hang that beautiful picture.’ |
| 15. | Preamble: | Ese traje formal, voy a pedirlo. |
| ‘I am going to order that formal suite.’ | ||
| Question: | ¿Qué te dijo Susana? | |
| ‘What did Susana tell you?’ | ||
| Response: | Me dijo que ese traje formal (que) iba a pedirlo. | |
| ‘She told me that she was going to order that formal suite.’ |
| 16. | Preamble: | Ayer Miguel tuvo que recordarme de la chaqueta que habíamos visto. |
| ‘Yesterday Miguel reminded me about the jacket that we had seen.’ | ||
| ________ | Miguel me repitió que esa chaqueta, que cuándo iba a comprarla. | |
| ________ | Miguel me repitió que esa chaqueta, cuándo iba a comprarla. | |
| ‘Miguel asked me again when I was going to buy that jacket.’ |
| 17. | Preamble: | Ayer Leonardo tuvo que recordarme del folleto que creamos la semana pasada. |
| ‘Yesterday Leonardo reminded me of the flyer that we created last week. | ||
| ________ | Leonardo me dijo que ese folleto, iba a distribuirlo en el centro. | |
| ________ | Leonardo me dijo que ese folleto, que iba a distribuirlo en el centro. | |
| ‘Leonardo told me that he was going to distribute that flyer downtown.’ |
3. Results
3.1. Acceptability Judgment Task
3.2. Preference Task
4. Discussion
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Item | Sentence Type | C2 | Stimuli |
|---|---|---|---|
| 1 | statement | que | Preamble: Esa casita antigua, voy a pintarla. “I will paint the old house.” Response: Me dijo que esa casita antigua que iba a pintarla. “S/he told me s/he was going to paint the old house.” |
| 2 | statement | que | Preamble: Esas joyas elegantes, voy a llevarlas. “I will wear the elegant jewels.” Response: Me dijo que esas joyas elegantes que iba a llevarlas. “S/he told me s/he was going to wear the elegant jewels.” |
| 3 | statement | que | Preamble: Esa motocicleta clásica, voy a montarla. “I will ride the classic motorcycle.” Response: Me dijo que esa motocicleta clásica que iba a montarla. “S/he told me s/he was going to ride the classic motorcycle.” |
| 4 | statement | que | Preamble: Esa guitarra eléctrica, voy a venderla. “I will sell the electric guitar.” Response: Me dijo que esa guitarra eléctrica que iba a venderla. “S/he told me s/he was going to sell the electric guitar.” |
| 5 | statement | que | Preamble: Ese coche deportivo, voy a comprarlo. “I will buy the sports car.” Response: Me dijo que ese coche deportivo que iba a comprarlo. “S/he told me s/he was going to buy the sports car.” |
| 6 | statement | que | Preamble: Esa camisa rota, voy a coserla. “I will sew the torn shirt.” Response: Me dijo que esa camisa rota que iba a coserla. “S/he told me s/he was going to sew the torn shirt.” |
| 7 | statement | no que | Preamble: Ese traje formal, voy a pedirlo. “I will order the formal suit.” Response: Me dijo que ese traje formal iba a pedirlo. “S/he told me s/he was going to order the formal suit.” |
| 8 | statement | no que | Preamble: Ese folleto informativo, voy a distribuirlo. “I will distribute the informational flier.” Response: Me dijo que ese folleto informativo iba a distribuirlo. “S/he told me s/he was going to distribute the informational flier.” |
| 9 | statement | no que | Preamble: Ese libro clásico, voy a leerlo. “I will read the classic book.” Response: Me dijo que ese libro clásico iba a leerlo. “S/he told me s/he was going to read the classic book.” |
| 10 | statement | no que | Preamble: Esa canción popular, voy a buscarla. “I will search for the popular song.” Response: Me dijo que esa canción popular iba a buscarla. “S/he told me s/he was going to search for the popular song.” |
| 11 | statement | no que | Preamble: Esa clase nocturna, voy a tomarla. “I will take the night class.” Response: Me dijo que esa clase nocturna iba a tomarla. “S/he told me s/he was going to take the night class.” |
| 12 | statement | no que | Preamble: Esa planta seca, voy a regarla. “I will water the dry plant.” Response: Me dijo que esa planta seca iba a regarla. “S/he told me s/he was going to water the dry plant.” |
| 13 | question | que | Preamble: Ese postre dulce, ¿dónde vas a guardarlo? “Where will you store the sweet dessert?” Response: Me dijo que ese postre dulce que dónde iba a guardarlo. “S/he asked me where I was going to store the sweet dessert.” |
| 14 | question | que | Preamble: Ese teléfono viejo, ¿cuándo vas a cambiarlo? “When will you change the old telephone?” Response: Me dijo que ese teléfono viejo que cuándo iba a cambiarlo. “S/he asked me when I was going to change the old telephone.” |
| 15 | question | que | Preamble: Ese pescado frito, ¿cuándo vas a cocinarlo? “When will you cook the fried fish?” Response: Me dijo que ese pescado frito que cuándo iba a cocinarlo. “S/he asked me when I was going to cook the fried fish.” |
| 16 | question | que | Preamble: Esa bicicleta nueva, ¿cuándo vas a montarla? “When will you ride the new bicycle?” Response: Me dijo que esa bicicleta nueva que cuándo iba a montarla. “S/he asked me when I was going to ride the new bicycle.” |
| 17 | question | que | Preamble: Ese uniforme colombiano, ¿dónde vas a encontrarlo? “Where will you find the Colombian uniform?” Response: Me dijo que ese uniforme colombiano que dónde iba a encontrarlo. “S/he asked me where I was going to find the Colombian uniform.” |
| 18 | question | que | Preamble: Esa camisa fea, ¿cuándo vas a devolverla? “When will you return the ugly shirt?” Response: Me dijo que esa camisa fea que cuándo iba a devolverla. “S/he asked me when I was going to return the ugle shirt.” |
| 19 | question | no que | Preamble: Esa flor morada, ¿dónde vas a sembrarla? “Where will you plant the purple flower?” Response: Me dijo que esa flor morada dónde iba a sembrarla. “S/he asked me where I was going to plant the purple flower.” |
| 20 | question | no que | Preamble: Ese dibujo bonito, ¿dónde vas a colgarlo? “Where will you hang the beautiful drawing?” Response: Me dijo que ese dibujo bonito dónde iba a colgarlo. “S/he asked me where I was going to hang the beautiful drawing.” |
| 21 | question | no que | Preamble: Ese dinero estadounidense, ¿dónde vas a cambiarlo? “Where will you exchange the US currency?” Response: Me dijo que ese dinero estadounidense dónde iba a cambiarlo. “S/he asked me where I was going to exchange the US currency.” |
| 22 | question | no que | Preamble: Esa mesa pesada, ¿cómo vas a moverla? “How will you move the heavy table?” Response: Me dijo que esa mesa pesada cómo iba a moverla. “S/he asked me how I was going to move the heavy table.” |
| 23 | question | no que | Preamble: Esa chaqueta roja, ¿cuándo vas a comprarla? “When will you buy the red jacket?” Response: Me dijo que esa chaqueta roja cuándo iba a comprarla. “S/he asked me when I was going to buy the red jacket.” |
| 24 | question | no que | Preamble: Ese museo privado, ¿cuándo vas a visitarlo? “When will you visit the private museum?” Response: Me dijo que ese museo privado cuándo iba a visitarlo. “S/he asked me when I was going to visit the private museum.” |
| Item | Sentence Type | Stimuli |
|---|---|---|
| 1 | Statement | Preamble: Ayer Leonardo tuvo que recordarme del folleto que creamos la semana pasada. “Yesterday Leo reminded me about the flyer that we created last week.” Option 1: Leonardo me dijo que ese folleto, iba a distribuirlo en el centro. Option 2: Leonardo me dijo que ese folleto, que iba a distribuirlo en el centro. “Leo told me that he was going to distribute the flyer downtown.” |
| 2 | Statement | Preamble: Ayer tuve que recordarle a Natalia de los conciertos que el músico iba a presentar esta semana. “Yesterday I reminded Natalie of the concerts that the musician was going to present this week.” Option 1: Yo le dije que ese concierto, iba a asistirlo este viernes. Option 2: Yo le dije que ese concierto, que iba a asistirlo este viernes. “I told him that I was going to attend the concert this Friday.” |
| 3 | Statement | Preamble: Ayer Pablo tuvo que recordarme de la opción de alquilar la computadora de la biblioteca. “Yesterday Pablo reminded me of the option of renting a computer from the library.” Option 1: Pablo me dijo que esa computadora, que iba a alquilarla toda la semana. Option 2: Pablo me dijo que esa computadora, iba a alquilarla toda la semana. “Pablo told me that he was going to rent the computer for the entire week.” |
| 4 | Statement | Preamble: Ayer Raúl tuvo que recordarme de su sombrero que no había llevado por mucho tiempo. “Yesterday Raul reminded me about his hat which he hadn’t worn for a while.” Option 1: Raúl me dijo que ese sombrero, iba a llevarlo por la tarde. Option 2: Raúl me dijo que ese sombrero, que iba a llevarlo por la tarde. “Raul told me that he was going to wear the hat in the afternoon.” |
| 5 | Statement | Preamble: Ayer, como la semana pasada, Miguel tuvo que recordarme del anillo que había visto en la joyería. “Yesterday, like last week, Miguel reminded me of the ring that he had seen in the jewelry store.” Option 1: Miguel me repitió que ese anillo, que iba a comprarlo un día pronto. Option 2: Miguel me repitió que ese anillo, iba a comprarlo un día pronto. “Miguel told me again that he was going to buy the ring one day soon.” |
| 6 | Statement | Preamble: Ayer, como la semana pasada, tuve que recordarle a Alfredo de lo que iba a hacer con la camisa fea. “Yesterday, like last week, I reminded Alfredo what I was going to do with the ugly shirt” Option 1: Yo le repetí que esa camisa, que iba a llevarla al cumpleaños. Option 2: Yo le repetí que esa camisa, iba a llevarla al cumpleaños. “I told him again that I was going to wear the shirt for the birthday party.” |
| 7 | Statement | Preamble: Ayer, como la semana pasada, tuve que recordarle a Javier de la hora que iba a tomar la clase. “Yesterday, like last week, I had to remind Javier of the time that I was going to take the class.” Option 1: Yo le repetí que esa clase, iba a tomarla por la tarde. Option 2: Yo le repetí que esa clase, que iba a tomarla por la tarde. “I told him again that I was going to take the class in the afternoon.” |
| 8 | Statement | Preamble: Ayer, como la semana pasado, tuve que recordarle a Ramón de la cama. “Yesterday, like last week, I reminded Ramon about the bed.” Option 1: Yo le repetí que esa cama, iba a comprarla pronto. Option 2: Yo le repetí que esa cama, que iba a comprarla pronto. “I told him again that I was going to buy the bed soon.” |
| 9 | question | Preamble: Ayer, Felipe tuvo que recordarme de la renovación de la casa. “Yesterday, Philip reminded me about the home renovation.” Option 1: Felipe me preguntó que esa casa, que cuándo iba a renovarla. Option 2: Felipe me preguntó que esa casa, cuándo iba a renovarla. “Philip asked me when I was going to renovate the home.” |
| 10 | question | Preamble: Ayer, tuve que recordarle a Mario de la colección de joyería. “Yesterday I reminded Mario of the jewelry collection.” Option 1: Yo le pregunté que esa joyería, adónde iba a llevarla. Option 2: Yo le pregunté que esa joyería, que adónde iba a llevarla. “I asked him where he was going to take the jewelry.” |
| 11 | question | Preamble: Ayer, como la semana pasada, tuve que recordarle a Ramón del teléfono antiguo. “Yesterday, like last week, I reminded Ramon about the old telephone.” Option 1: Yo le pregunté que ese teléfono, que cuándo iba a cambiarlo. Option 2: Yo le pregunté que ese teléfono, cuándo iba a cambiarlo. “I asked him when he was going to exchange the telephone.” |
| 12 | question | Preamble: Ayer, como la semana pasada, Rodrigo tuvo que recordarme del tamaño del árbol. “Yesterday, like last week, Rodrigo reminded me of the size of the tree.” Option 1: Rodrigo me preguntó que ese árbol, dónde iba a sembrarlo. Option 2: Rodrigo me preguntó que ese árbol, que dónde iba a sembrarlo. “Rodrigo asked me where I was going to plant the tree.” |
| 13 | question | Preamble: Ayer, Carlos tuvo que recordarme que no íbamos a dejar el postre en la mesa. “Yesterday, Carlos reminded me that we weren’t going to leave the dessert on the table.” Option 1: Carlos me dijo que ese postre, que adónde iba a guardarlo. Option 2: Carlos me dijo que ese postre, adónde iba a guardarlo. “Carlos asked me where I was going to leave the dessert.” |
| 14 | question | Preamble: Ayer, como la semana pasada, tuve que recordarle a Emilia de la bicicleta en nuestro garaje. “Yesterday, like last week, I reminded Emilia about the bicycle in our garage.” Option 1: Yo le dije que esa bicicleta, que cuándo iba a montarla. Option 2: Yo le dije que esa bicicleta, cuándo iba a montarla. “I asked her when she was going to ride the bicycle.” |
| 15 | question | Preamble: Ayer, como la semana pasada, Miguel tuvo que recordarme de la chaqueta que habíamos visto. “Yesterday, like last week, Miguel reminded me about the jacket that we had seen.” Option 1: Miguel me repitió que esa chaqueta, cuándo iba a comprarla. Option 2: Miguel me repitió que esa chaqueta, que cuándo iba a comprarla. “Miguel asked me again when I was going to buy the jacket.” |
| 16 | question | Preamble: Ayer, como la semana pasada, tuve que recordarle a María del dibujo en el suelo. “Yesterday, like last week, I reminded Maria of the picture on the floor.” Option 1: Yo le repetí que ese dibujo, dónde iba a colgarlo. Option 2: Yo le repetí que ese dibujo, que dónde iba a colgarlo. “I asked her again where she was going to hang the painting.” |
References
- Alarcón, Irma. 2011. Spanish gender agreement under complete and incomplete acquisition: Early and late bilinguals’ linguistic behavior within the noun phrase. Bilingualism: Language and Cognition 14: 332–50. [Google Scholar] [CrossRef]
- Audacity Team. 2019. Audacity®: Free Audio Editor and Recorder. Version 2.0.3. Available online: https://audacityteam.org/ (accessed on 15 August 2014).
- Bailey, Karl, and Fernanda Ferreira. 2003. Disfluencies affect the parsing of garden-path sentences. Journal of Memory and Language 49: 183–200. [Google Scholar] [CrossRef]
- Bowles, Melissa. 2011. Exploring the role of modality: L2-heritage learner interactions in the Spanish language classroom. Heritage Language Journal 8: 30–65. [Google Scholar]
- Brovetto, Claudia. 2002. Spanish clauses without complementizer. In Current Issues in Romance Languages: Selected Proceedings of the 29th Linguistic Symposium on Romance Languages. Edited by Teresa Satterfield, Christina Tortora and Diana Cresti. Amsterdam and Philadelphia: John Benjamins, pp. 33–46. [Google Scholar]
- Bruhn de Garavito, Joyce. 2002. Verb Raising in Spanish: A Comparison of Early and Late Bilinguals. In Proceedings of the 26th Annual Boston University Conference on Language Development. Edited by Barbora Skarabela, Sarah Fish and Anna Do. Somerville: Cascadilla Press, pp. 84–94. [Google Scholar]
- Casasanto, Laura, and Ivan Sag. 2008. The Advantage of the Ungrammatical. In Proceedings of the 30th Annual Conference of the Cognitive Science Society. Edited by Bradley Love, Ken McRae and Vladimir Sloutsky. Austin: Cognitive Science Society, pp. 601–6. [Google Scholar]
- Christensen, Rune Haubo. 2015. Analysis of Ordinal Data with Cumulative Link Models—Estimation with the R-Package Ordinal. R-Version 3.6.3. pp. 1–31. Available online: https://mran.microsoft.com/snapshot/2015-03-12/web/packages/ordinal/vignettes/clm_intro.pdf (accessed on 1 April 2020).
- Cuza, Alejandro, Ana Teresa Pérez-Leroux, and Liliana Sánchez. 2013. The role of semantic transfer in clitic drop among simultaneous and sequential Chinese-Spanish bilinguals. Studies in Second Language Acquisition 35: 93–125. [Google Scholar] [CrossRef]
- Cuza, Alejandro, and Joshua Frank. 2011. Transfer effects at the syntax-semantics interface: The case of double-que questions in heritage Spanish. The Heritage Language Journal 8: 66–89. [Google Scholar]
- Cuza, Alejandro, and Joshua Frank. 2015. On the Role of Experience and Age-Related Effects: Evidence from the Spanish CP. Second Language Research 31: 3–28. [Google Scholar] [CrossRef]
- Cuza, Alejandro, and Rocío Pérez-Tattam. 2016. Grammatical gender selection and phrasal word order in child heritage Spanish: A feature re-assembly approach. Bilingualism: Language and Cognition 19: 50–68. [Google Scholar] [CrossRef]
- Cuza, Alejandro, Lauren Miller, Rocío Pérez-Tattam, and Mariluz Ortiz Vergara. 2019. Structure complexity effects in child heritage Spanish: The case of the Spanish personal a. International Journal of Bilingualism 23: 1333–57. [Google Scholar] [CrossRef]
- Cuza, Alejandro. 2013. Crosslinguistic influence at the syntax proper: Interrogative subject–verb inversion in heritage Spanish. International Journal of Bilingualism 17: 71–96. [Google Scholar] [CrossRef]
- Cuza, Alejandro. 2016. The status of interrogative subject–verb inversion in Spanish-English bilingual children. Lingua 180: 124–38. [Google Scholar] [CrossRef]
- Dąbrowska, Ewa. 2012. Different speakers, different grammars: Individual differences in native language attainment. Linguistic Approaches to Bilingualism 2: 219–53. [Google Scholar] [CrossRef]
- de Prada Pérez, Ana. 2009. Subject Expression in Minorcan Spanish: Consequences of Contact with Catalan. Ph.D. dissertation, Pennsylvania State University, State College, PA, USA. [Google Scholar]
- Demonte, Violeta, and Olga Fernández-Soriano. 2009. Force and finiteness in the Spanish complementizer system. Probus 21: 23–49. [Google Scholar] [CrossRef]
- Demonte, Violeta, and Olga Fernández-Soriano. 2014. Evidentiality and illocutionary force: Spanish matrix que at the syntax-pragmatics interface. In Left Sentence Peripheries in Spanish: Diachronic, Variationist, and Typological Perspectives. Edited by Andreas Dufter. Amsterdam: John Benjamins, pp. 217–52. [Google Scholar]
- Echeverría, Carlos, and Javier López Seoane. 2019. Recomplementation as constrained CP resetting. Paper presented at the Association of Linguistics and Philology of Latin America (Alfalito), Queens College, City University of New York, New York, NY, USA, September 20. [Google Scholar]
- Fontana, Josep. 1993. Phrase Structure and the Syntax of Clitics in the History of Spanish. Ph.D. dissertation, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Frank, Joshua, and Almeida Jacqueline Toribio. 2017. Recomplementation as an unexplored locus of dialectal variation: The status of reduplicative que in Cuban Spanish. In Cuban Spanish Dialectology: Variation, Contact, and Change. Edited by Alejandro Cuza. Washington: Georgetown University Press, pp. 119–33. [Google Scholar]
- Frank, Joshua. 2013. Derivational complexity effects in bilingual adults: Instances of interrogative inversion in Spanish. In Selected Proceedings of the 16th Hispanic Linguistics Symposium. Edited by Jennifer Cabrelli, Gillian Lord, Ana de Prada Pérez and Jessi Aaron. Somerville: Cascadilla Proceedings Project, pp. 143–55. [Google Scholar]
- Frank, Joshua. 2016. On the grammaticality of recomplementation in Spanish. In Inquiries in Hispanic Linguistics: From Theory to Empirical Evidence. Edited by Alejandro Cuza, Lori Czerwionka and Daniel Olson. Amsterdam: John Benjamins, pp. 39–52. [Google Scholar]
- Giancaspro, David. 2017. Heritage Speakers’ Production and Comprehension of Lexically- and Contextually-Selected Subjunctive Mood Morphology. Ph.D. dissertation, Rutgers University, New Brunswick, NJ, USA. [Google Scholar]
- Gibson, Edward. 1998. Linguistic complexity: Locality of syntactic dependencies. Cognition 68: 1–76. [Google Scholar] [CrossRef]
- Gibson, Edward. 2000. The dependency locality theory: A distance-based theory of linguistic complexity. In Image, Language, Brain. Edited by Alec Marantz, Yasushi Miyashita and Wayne O’Neil. Cambridge: MIT Press, pp. 95–126. [Google Scholar]
- González i Planas, Francesc. 2014. On quotative recomplementation: Between pragmatics and morphosyntax. Lingua 146: 39–74. [Google Scholar] [CrossRef]
- Gupton, Timothy. 2010. The Syntax Information Structure Interface: Subjects and Clausal Word Order in Galician. Ph.D. dissertation, University of Iowa, Iowa City, IA, USA. [Google Scholar]
- Hale, John. 2001. A probabilistic early parser as a psycholinguistic model. In Proceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, pp. 159–66. [Google Scholar]
- Keating, Gregory, Jill Jegerski, and Bill VanPatten. 2016. Online processing of subject pronouns in monolingual and heritage bilingual speakers of Mexican Spanish. Bilingualism: Language and Cognition 19: 36–49. [Google Scholar] [CrossRef]
- Kim, Ji-Hye, Silvina Montrul, and James Yoon. 2010. Dominant language influence in acquisition and attrition of binding: Interpretation of the Korean reflexive caki. Bilingualism: Language and Cognition 13: 73–84. [Google Scholar] [CrossRef]
- Ledgeway, Adam. 2000. A Comparative Syntax of the Dialects of Southern Italy. A Minimalist Approach. Boston: Blackwell. [Google Scholar]
- Levy, Roger. 2008. Expectation-based syntactic comprehension. Cognition 106: 1126–77. [Google Scholar] [CrossRef]
- Martín-González, Javier. 2002. The Syntax of Sentential Negation in Spanish. Ph.D. dissertation, Harvard University, Cambridge, MA, USA. [Google Scholar]
- Mascarenhas, Salvador. 2007. Complementizer Doubling in European Portuguese. Amsterdam and New York: ILLC/NYU. [Google Scholar]
- Montrul, Silvina, and Roumyana Slabakova. 2003. Competence similarities between native and near-native speakers: An investigation of the Preterite/Imperfect contrast in Spanish. Studies in Second Language Acquisition 25: 351–98. [Google Scholar] [CrossRef]
- Montrul, Silvina, Rebecca Foote, and Silvia Perpiñán. 2008. Knowledge of Wh-movement in Spanish L2 learners and heritage speakers. In Selected Proceedings of the 10th Hispanics Linguistics Symposium. Edited by Joyce Bruhn de Garavito and Elena Valenzuela. Somerville: Cascadilla Proceedings Project, pp. 93–106. [Google Scholar]
- Montrul, Silvina. 2002. Incomplete acquisition and attrition of Spanish tense/aspect distinctions in adult bilinguals. Bilingualism: Language and Cognition 5: 39–68. [Google Scholar] [CrossRef]
- Montrul, Silvina. 2004. Subject and object expression in Spanish heritage speakers: A case of morphosyntactic convergence. Bilingualism: Language and Cognition 7: 125–42. [Google Scholar] [CrossRef]
- Montrul, Silvina. 2008. Incomplete Acquisition in Bilingualism: Re-Examining the Age Factor. Amsterdam: John Benjamins. [Google Scholar]
- Montrul, Silvina. 2010. How similar are L2 learners and heritage speakers? Spanish clitics and word order. Applied Psycholinguistics 31: 167–207. [Google Scholar] [CrossRef]
- Montrul, Silvina. 2011. Morphological errors in Spanish second language learners and heritage speakers. Studies in Second Language Acquisition 33: 155–61. [Google Scholar] [CrossRef]
- Montrul, Silvina. 2016. The Acquisition of Heritage Languages. Cambridge: Cambridge University Press. [Google Scholar]
- Müller, Natascha, and Aafke Hulk. 2001. Crosslinguistic influence in bilingual language acquisition: Italian and French as recipient languages. Bilingualism: Language and Cognition 4: 1–21. [Google Scholar] [CrossRef]
- Otheguy, Ricardo, Ana Celia Zentella, and David Livert. 2007. Language and dialect contact in Spanish in New York: Toward the formation of a speech community. Language 83: 770–802. [Google Scholar] [CrossRef]
- Otheguy, Ricardo, and Ana Celia Zentella. 2012. Spanish in New York: Language Contact, Dialect Leveling, and Structural Continuity. New York: Oxford University Press. [Google Scholar]
- Paoli, Sandra. 2006. The fine structure of the left periphery: COMPs and subjects: Evidence from Romance. Lingua 117: 1057–79. [Google Scholar] [CrossRef]
- Pascual y Cabo, Diego, and Jason Rothman. 2012. The (il) logical problem of heritage speaker bilingualism and incomplete acquisition. Applied Linguistics 33: 450–55. [Google Scholar] [CrossRef]
- Perez-Cortes, Silvia. 2016. Acquiring Obligatory and Variable Mood Selection: Spanish Heritage Speakers and L2 Learners’ Performance in Desideratives and Reported Speech Contexts. Ph.D. dissertation, Rutgers University, New Brunswick, NJ, USA. [Google Scholar]
- Polinsky, Maria, and Gregory Scontras. 2019. Understanding heritage languages. Bilingualism: Language and Cognition 23: 4–20. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2011. Reanalysis in adult heritage language: A case for attrition. Studies in Second Language Acquisition 33: 305–28. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press. [Google Scholar]
- Potowski, Kim, Jill Jegerski, and Kara Morgan-Short. 2009. The effects of instruction on linguistic development in Spanish heritage language speakers. Language Learning 59: 537–79. [Google Scholar] [CrossRef]
- R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 1 April 2020).
- Radford, Andrew. 2013. The complementiser system in spoken English. In Information Structure and Agreement. Edited by Victoria Camacho-Taboada, Ángel Jiménez-Fernández, Javier Martín-González and Mariano Reyes-Tejedor. Amsterdam: John Benjamins, pp. 11–54. [Google Scholar]
- Radford, Andrew. 2018. Colloquial English: Structure and Variation. Cambridge: Cambridge University Press. [Google Scholar]
- Rizzi, Luigi. 1997. The fine structure of the left periphery. In Elements of Grammar. Edited by Liliane Haegeman. Dordrecht: Kluwer Academic Publishers, pp. 281–337. [Google Scholar]
- Rizzi, Luigi. 2013. Notes on cartography and further explanation. Probus 25: 197–226. [Google Scholar] [CrossRef]
- Rodríguez-Ramalle, Teresa. 2003. La Gramática de los Adverbios en -mente o Cómo Expresar Maneras, Opiniones y Actitudes a Través de la Lengua. Madrid: Ediciones de la Universidad Autónoma de Madrid. [Google Scholar]
- Sánchez, Liliana. 2019. Bilingual Alignments. Languages 4: 82. [Google Scholar] [CrossRef]
- Scontras, Gregory, Maria Polinsky, C. Y. Edwin Tsai, and Kenneth Mai. 2017. Cross-linguistic scope ambiguity: When two systems meet. Glossa: A Journal of General Linguistics 2: 1–28. [Google Scholar] [CrossRef]
- Scontras, Gregory, Maria Polinsky, and Zuzanna Fuchs. 2018. In support of representational economy: Agreement in heritage Spanish. Glossa: A Journal of General Linguistics 3: 1. [Google Scholar] [CrossRef]
- Silva-Corvalán, Carmen. 1993. On the permeability of grammars: Evidence from Spanish and English contact. In Linguistic Perspectives on Romance Languages. Edited by William Ashby, Marianne Mithun and Giorgio Perissinotto. Amsterdam: John Benjamins, pp. 19–43. [Google Scholar]
- Silva-Corvalán, Carmen. 1994. Language Contact and Change. Spanish in Los Angeles. Oxford: Oxford University Press. [Google Scholar]
- Sorace, Antonella. 2004. Native language attrition and developmental instability at the syntax-discourse interface: Data, interpretations and methods. Bilingualism: Language and Cognition 7: 143–45. [Google Scholar] [CrossRef]
- Sorace, Antonella. 2011. Pinning down the concept of “interface” in bilingualism. Linguistic Approaches to Bilingualism 1: 1–33. [Google Scholar] [CrossRef]
- Suñer, Margarita. 1993. About indirect questions and semi-questions. Linguistics and Philosophy 16: 45–77. [Google Scholar] [CrossRef]
- Unsworth, Sharon. 2016. Quantity and quality of language input in bilingual language development. In Lifespan Perspectives on Bilingualism. Edited by Elena Nicoladis and Simona Montanari. Berlin: Mouton de Gruyter, pp. 136–96. [Google Scholar]
- Villa-García, Julio. 2012. Recomplementation and locality of movement in Spanish. Probus 24: 257–314. [Google Scholar] [CrossRef]
- Villa-García, Julio. 2015. The Syntax of Multiple-Que Sentences in Spanish: Along the Left Periphery. Amsterdam: John Benjamins. [Google Scholar]
- Villa-García, Julio. 2019. Recomplementation in English and Spanish: Delineating the CP space. Glossa: A Journal of General Linguistics 4: 56. [Google Scholar] [CrossRef]
- Yip, Virginia, and Stephen Matthews. 2009. Conditions on cross-linguistic influence in bilingual acquisition: The case of wh-interrogatives. Paper presented at the 7th International Symposium on Bilingualism, Utrecht, The Netherlands, July 8–11. [Google Scholar]
- Zapata, Gabriela, Liliana Sánchez, and Almeida Jacqueline Toribio. 2005. Contact and contracting Spanish. International Journal of Bilingualism 9: 377–95. [Google Scholar] [CrossRef]



| Selected Information | Baseline Group | Test Group |
|---|---|---|
| Birthplace | Colombia | USA (1 MEX) |
| Gender | 7 male, 5 female | 9 male, 6 female |
| Age at testing | M = 22, SD = 5.4 | M = 20, SD = 1.5 |
| Level of Education | 8 college, 4 high school | College |
| Language Spoken as a Child | SPAN | 8 SPAN, 7 Both |
| Primary Language of Instruction | SPAN | ENG |
| SPAN Proficiency (DELE out of 50) | M = 43, SD = 2.7, R: 39–47 | M = 37, SD = 4.9, R: 30–44 |
| SPAN/ENG Self-Reported Proficiency (1-basic to 4-excellent) | SPAN: M = 3.79, SD = 0.35 ENG: M = 1.79, SD = 0.60 | SPAN: M = 2.97, SD = 0.27 ENG: M = 3.83, SD = 0.28 |
| Dominant Language | SPAN | ENG (1 balanced) |
| More Comfortable Language | SPAN | 9 ENG, 6 Both |
| Spanish Use | Proportion | Interpretation |
|---|---|---|
| at school | M = 0.10, SD = 0.11 | Mainly ENG |
| at home | M = 0.47, SD = 0.32 | SPAN and ENG equally |
| at work | M = 0.18, SD = 0.18 | Mainly ENG |
| in social situations | M = 0.23, SD = 0.15 | Mainly ENG |
| overall | M = 0.24, SD = 0.13 | Mainly ENG |
| Null C2 Question | Null C2 Statement | Overt C2 Question | Overt C2 Statement | |
|---|---|---|---|---|
| Baseline group | 1.96 (SE = 0.15) | 1.65 (SE = 0.12) | 2.82 (SE = 0.21) | 2.99 (SE = 0.21) |
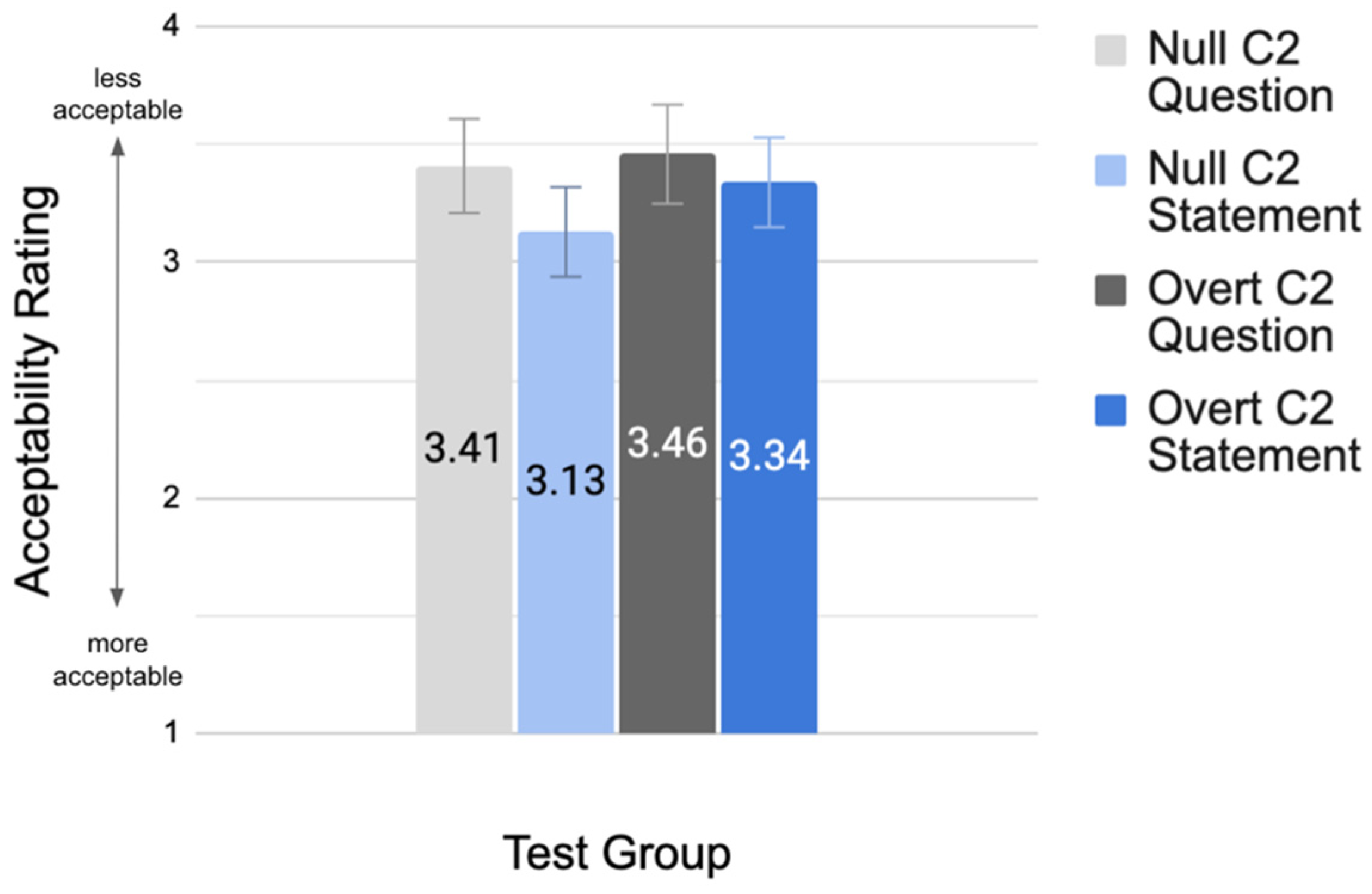
| Test group | 3.41 (SE = 0.20) | 3.13 (SE = 0.19) | 3.46 (SE = 0.21) | 3.34 (SE = 0.19) |
| Null | Overt | Equal | |||
|---|---|---|---|---|---|
| Low (<1) | High (>1) | Low (<1) | High (>1) | ||
| Baseline group | 2/12 (17%) | 6/12 (50%) | 2/12 (17%) | 0/12 (0%) | 2/12 (17%) |
| Test group | 7/15 (47%) | 1/15 (7%) | 6/15 (40%) | 0/15 (0%) | 1/15 (7%) |
| Question | Statement | |
|---|---|---|
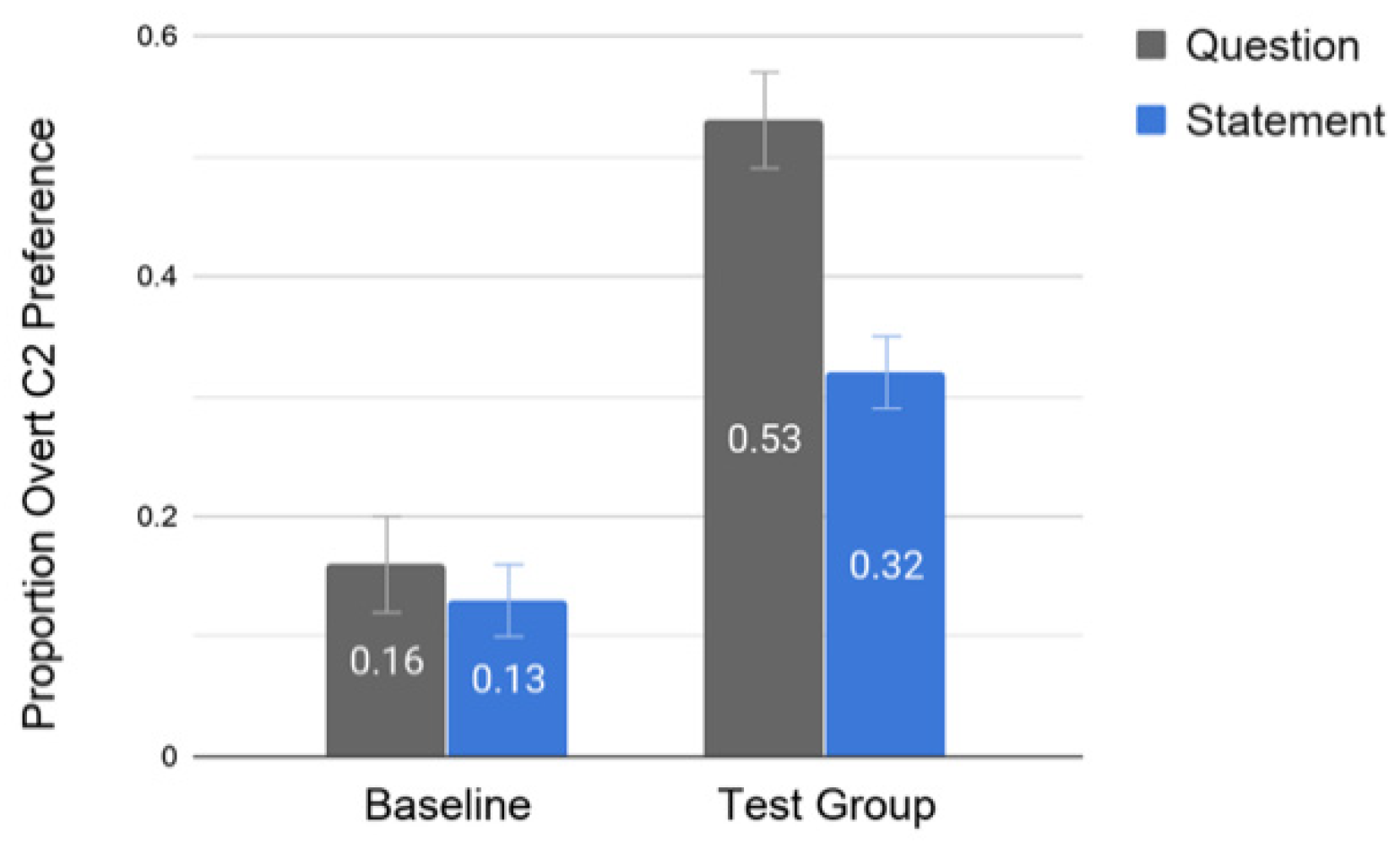
| Baseline group | 0.16 (SE = 0.04) | 0.13 (SE = 0.03) |
| Test group | 0.53 (SE = 0.05) | 0.32 (SE = 0.04) |
| Type | Null | Overt | Equal | |
|---|---|---|---|---|
| Baseline group | Question | 10/12 (83%) | 1/12 (8%) | 1/12 (8%) |
| Statement | 12/12 (100%) | 0/12 (0%) | 0/12 (0%) | |
| Test group | Question | 5/15 (33%) | 7/15 (47%) | 3/15 (20%) |
| Statement | 11/15 (73%) | 4/15 (27%) | 0/15 (0%) |
| Baseline Group | Heritage Speaker Group | |
|---|---|---|
| Source of complexity | overt C2 | silence and distance problems |
| Trigger | principle of economy | processing complexity |
| Grammatical representation | TopicP | Doubled-ForceP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frank, J. The Effect of Silence and Distance: Evidence from Recomplementation in US Heritage Spanish. Languages 2020, 5, 66. https://doi.org/10.3390/languages5040066
Frank J. The Effect of Silence and Distance: Evidence from Recomplementation in US Heritage Spanish. Languages. 2020; 5(4):66. https://doi.org/10.3390/languages5040066
Chicago/Turabian StyleFrank, Joshua. 2020. "The Effect of Silence and Distance: Evidence from Recomplementation in US Heritage Spanish" Languages 5, no. 4: 66. https://doi.org/10.3390/languages5040066
APA StyleFrank, J. (2020). The Effect of Silence and Distance: Evidence from Recomplementation in US Heritage Spanish. Languages, 5(4), 66. https://doi.org/10.3390/languages5040066