1. Introduction
One of the key characteristics of the computational brain is its ability to encode, retrieve, and communicate information, while learning from experience the expected value range of certain variables (e.g., the distance between two places) and continuously updating memory resources accordingly (
Gallistel and King 2009). Another important characteristic is its tendency toward radical contextualization which, among other things, entails a propensity to (i) adhere to Grice’s four maxims of co-operation,
1 even when the communicative context lacks the conversational features that call for the application of these maxims, and (ii) contextualize incoming stimuli by drawing on those memory resources that are most readily accessible (
Kahneman and Tversky 1982;
Hilton 1995;
Stanovich and West 2000). To illustrate how these tendencies may lead to judgmental errors,
Kahneman and Tversky (
1982) introduced the Linda problem (1).
- (1)
Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Asking for judgments of probability,
Kahneman and Tversky (
1982) presented participants with different options: A. Linda is a bank teller, and B. Linda is a bank teller and is active in the feminist movement. The results showed that people perceived Linda as a very good fit for a feminist activist. Yet, there is an often unnoticed logical relation between A and B: the set of feminist bank tellers is included in the set of bank tellers; thus, the probability of B cannot be higher than the probability of A (see (
Kahneman 2011, pp. 156–65) for a detailed discussion of the Linda problem). This error in judgment boils down to the human tendency toward contextualization, and more specifically, to an application of Grice’s maxim of relation: (1) involves information about Linda that participants take to be
relevant—even though they do not encounter this information in a setting that calls for application of conversational maxims, because they are biased towards contextualizing information this way. As
Adler (
1984, p. 175) puts it, “[a]ssuming that Linda is a feminist provides the only explanatory path to the contents of the sketch of her”.
The appeal to such tendencies and processing heuristics has been explained in terms of the brain employing a dual-process theory of reasoning: System 1 is automatic, largely unconscious, and operates in a computationally undemanding way, while System 2 is responsible for effortful computations that are typical of analytic intelligence (
Stanovich and West 2000 and references therein). Giving the incorrect response to the Linda problem is the result of a failure of System 2 to intervene, check, and override the wrong response provided automatically by System 1. It is the latter that employs judgment heuristics and biases of various types (
Kahneman 2000).
The Linda problem brings forward the question of whether naïve participants are good intuitive statisticians. While different answers to this question exist in the literature (cf.
Cosmides and Tooby 1996;
Anderson 1998), it seems that certain domains of cognition have been linked more heavily than others to intuitive answers that demonstrate biased or faulty reasoning. Put differently, although the appeal to processing heuristics is a general property of cognition—and as such, relevant to all cognitive domains—certain domains have been associated to more robust judgments than others. Language is one such domain.
Intuitive judgments about what forms part of one’s linguistic repertoire are highly reliable and consistent (
Sprouse and Almeida 2012), and this is important because such a degree of accuracy and stability does not characterize all types of judgments that are related to some aspect of human perception. For example, in the viral ‘The Dress’ photograph, judgments of color perception were found to differ both across participants (i.e., the dress was seen as blue/black, blue/brown or white/gold) and across testing sessions (
Lafer-Sousa et al. 2015). To continue the analogy with statistics, naïve participants may not always be intuitively good statisticians, but there is little debate over the fact that they are intuitively good linguists. This exceptionality of language was grasped even in the early work of Amos Tversky and Daniel Kahneman on judgment and decision making in the 1960s:
“Amos told the class about an ongoing program of research at the University of Michigan that sought to answer this question: Are people good intuitive statisticians? We already knew that people are good intuitive grammarians: at age four a child effortlessly conforms to the rules of grammar as she speaks, although she has no idea that such rules exist. Do people have a similar intuitive feel for the basic principles of statistics? Amos reported that the answer was a qualified yes. We had a lively debate in the seminar and ultimately concluded that a qualified no was a better answer”.
Although acceptability judgments in linguistic tasks are robust and reliable, human cognition is fallible to illusions of all types. In the domain of language processing, several types of illusions have been shown to trick the cognitive parser into giving them a high acceptability judgment despite the fact that they are grammatically ill-formed (see
Phillips et al. 2011 for discussion of various examples). One of the most powerful grammatical illusions is the so-called comparative illusion (2).
Native speakers of English give sentences like (2) a mean rating of 3.7 (
Wellwood et al. 2018) or 4.3–4.63 (
O’Connor 2015) on a 7-point Likert scale where 7 is the maximum rating of well-formedness. However, when speakers that gave (2) a high acceptability rating are asked to provide its meaning, they often stop perplexed. This happens because the well-formedness of (2) is an
illusion. The meaning of (2) cannot be that the number of the people that have been to Russia exceeds the number of me, similar to how ‘More people have been to Tromsø than penguins have’ means that the number of people that have been to Tromsø exceeds the number of penguins that have been to Tromsø. In linguistic terms, (2) is ill-formed because the main clause subject calls for a comparison of cardinalities of sets of individuals, but in the absence of a bare plural in the embedded clause subject, there is no appropriate constituent to host the degree variable after Verb Phrase ellipsis is resolved (
Phillips et al. 2011;
O’Connor 2015). Pronouns, proper names, and definite descriptions are not appropriate hosts, only a bare plural would be a legit correlate in the embedded clause (
Bresnan 1973;
De Dios-Flores 2016;
Wellwood et al. 2018), as (3) shows.
Why is (2) acceptable though? It was argued earlier that naïve participants stop perplexed when asked to spell out the meaning they have assigned to the sentence upon accepting it as well-formed. Although this is sometimes the case, not everybody is unable to provide a meaning. Some people do it effortlessly by offering one of the following two interpretations (4a–b).
- (4a)
More people than just me have been to Russia.
- (4b)
People have been to Russia more times than I have.
- (5)
Helen ate four ice creams last weekend.
Comparative: Today she ate more (= a new set of ice creams that is bigger than four, e.g., five, six, etc.).
Additive: Today she ate more (= at least one more, but not necessarily five more).
Both readings of (5) involve some kind of comparison of sets, which is why I use the term “set comparison re-analysis” for them. More specifically, in (5a) the set of ice creams that Helen ate last weekend is compared to the set of ice creams she ate today, while in (5b) the set of ice creams that Helen ate last weekend is compared to a proper superset that involves both the ice creams of last weekend and the one(s) she ate today. These are the possible interpretations behind (4a).
The meaning of (4b) is different, because here we are dealing with a comparison of events, not a comparison of sets. Thus, (4b) can be read as saying something about the number of times that Russia has been visited, similar to how (6b) says something about the times the event of walking through the turnstile occurred.
- (6)
Object-related reading: 12,000 different persons.
Event comparison reading: 12,000 events of walking (but the persons may be fewer than 12,000).
To sum up, according to the literature, (2) can be interpreted by naïve participants as denoting a set comparison (i.e., along the lines of (5)) or an event comparison (as in (6b)).
I propose a third possibility. Upon judging (2) as highly acceptable, naïve participants assign a meaning to it that is related to some aspect of comparison, without necessarily settling in an unambiguous way on either the set comparison or the event comparison interpretation. Under this scenario, participants may not be ready to put their finger on a single, full-fledged, and fully coherent interpretation, but they have parsed the sentence, such that their parser has reached a potentially ambiguous and vague interpretation. Let us call this the “shallow comparison re-analysis”.
Crucially, the three re-analyses make very different empirical predictions, and these predictions will be relevant for the design of the present experiment. The set comparison scenario presupposes that the subject of the embedded clause can be included in the denotation of the matrix subject (
Wellwood et al. 2018). For example, in (2), the pronoun
I denotes an entity that belongs to the set of
people. In (7), however, this relation does not hold. Under the predictions of the set comparison scenario, (7) will not induce the illusion under this re-analysis.
- (7)
More boys have visited Tromsø than she has.
In addition, if
more is substituted with
fewer, the additive reading of the set comparison is not possible (
Wellwood et al. 2018). The prediction is that (8) will not induce the illusion under this reading.
- (8)
Fewer boys have visited Tromsø than he has.
The event comparison re-analysis makes a different prediction. The comparison of events in (6b) entails that if the persons are fewer than 12,000, each event of walking through the turnstile must be carried out multiple times by the same person. In other words, the event comparison scenario entails that the action denoted by the predicate must be repeatedly carried out by the same entity (
Krifka 1990). In this sense, the repeatability of the predicate is crucial in obtaining the illusion under this meaning. Further, (2) features a repeatable predicate (i.e., one can visit Russia as many times as one likes), but (9) does not (i.e., people graduate high school once). The prediction thus is that (9) will not induce the illusion under the event comparison interpretation.
- (9)
More people have graduated high school than I have.
Having presented the different interpretations that may justify a high acceptability rating, the second important question to be asked is what exactly makes the illusion go unnoticed. Why is the parser tricked in constructing an interpretation for (2) instead of noticing outright its incoherence? Again, different explanations exist in the literature. One of them is that (2) shows a blend of two perfectly coherent—at a local level—templates (
Townsend and Bever 2001). Comparison of events is very frequent in language and so is comparison of individuals. By blending the two templates in one sentence, the parser sees two chunks that it frequently encounters, without any
marked deviation from the patterns it anticipates (i.e., what was earlier described as the brain’s tendency to learn from experience and update the expected range of values accordingly). Put another way, by the time the deviation kicks in when the embedded clause subject is reached in (2), the parser is already into the process of constructing a meaning and actively anticipates a range of values. The pronoun ‘I’ is sufficiently close to this expected range of values for the parser to be tricked into not noticing the deviation. Had the illusion in (2) been completed as in (10), the parser would immediately notice the marked distortion, the process of assigning meaning would have failed, the sentence would not have been accepted as well-formed, and no illusion would arise.
- (10)
More people have visited Tromsø than *beautifully.
Another view is presented in
Phillips et al. (
2011), who suggest that the experimental results that show sensitivity to the semantics of the predicate (i.e., its repeatability) suggest that Townsend and Bever’s explanation is not fully satisfactory in the following sense: The illusions seem robust only with repeatable predicates. Given that the blend of locally coherent templates is there regardless of the semantics of the predicate, what can account for this difference in robustness?
O’Connor (
2015) summarizes these two different views in the following way: “Note that the event comparison and shallow processing accounts stand at different ends of the spectrum in their explanation of the acceptability of the illusion: whereas the event comparison hypothesis posits immediate, exhaustive and grammar-based interpretation with localized changes to fix targeted problems, the uninterpreted heuristics approach of
Townsend and Bever (
2001) posits no grammatical analysis at all at the time the illusion is first judged acceptable” (p. 74). It should be noted, however, that these two explanations do not really answer the same question. The emphasis of the event comparison explanation is on
how the meaning is construed (possible answer: by resorting to a grammar-based interpretation that facilitates the event comparison re-analysis) and not on
why the parser fails to spot the illusion
in the first place (possible answer: because it operates by making use of processing heuristics).
Last, a third explanation that integrates assumptions from both previous ones suggests that syntactic parsing occurs both algorithmically and heuristically such that processing is shallow, partial, or simply “good enough” (
Ferreira et al. 2002;
Ferreira 2003;
Ferreira and Patson 2007). Under this account, grammatical illusions are the outcome of a partial-match strategy that is operative during processing (
Reder and Kusbit 1991;
Kamas et al. 1996). Upon receiving a linguistic stimulus, its parts are matched to stored knowledge, so that an output is produced. However, the parser matches the stimulus to stored information only up to a point. In other words, a processing threshold is set, and the stimulus is checked up to this threshold, hence the notion of partial matching. The notion of processing threshold can be understood as the tipping point of the process of mental engaging with the received stimulus, that suffices to elicit an interpretation that the parser deems good enough.
Do all people set the threshold at the same level? There is no answer to this question, because to this day, comparative illusions have been tested mainly with monolingual, neurotypical speakers of English. It was found that English speakers spot the comparative illusion to varying degrees (
Wellwood et al. 2018 and references therein). The cross-linguistic robustness of the illusion has been experimentally confirmed with speakers of Danish, and anecdotally confirmed with speakers of Swedish, Faroese, German, Icelandic, Polish, and Swedish (
Christensen 2016). Given that some variation is observed even among people that speak the same language and fit the same behavioral profile, one expects that people with different profiles will show even greater differences. In other words, it is possible that people with pronounced differences in cognitive aptitude—the latter being defined as the combined outcome of mental abilities such as speed of computation, attention orienting, task-switching efficiency, etc. (
Kahneman 2011;
Stanovich 2011)—will perform differently in tasks that involve demanding processing over tricky patterns of superficial well-formedness. This prediction is grounded on an observation made by Kahneman in the context of a different stimulus (11), albeit one that tricks the parser too.
- (11)
A chocolate bar and a candy cost €1.10. The chocolate bar costs €1 more than the candy. How much does the candy cost? (adapted from
Kahneman 2011, p. 44)
Presenting this as a tricky stimulus already provides a very strong cue that the obvious answer to the question is wrong. Despite the salience of this cue, an ‘obvious’, intuitive answer did come to your mind, and this was 10 cents. If this intuitive answer is suppressed and checked for accuracy, the correct answer is easy to find; the correct answer is 5 cents. How often is the intuitive answer suppressed though? Kahneman used puzzles like (11) to show how our ‘lazy’ System 2 is not always checking intuitive answers. In his words, “the results are shocking. More than 50% of students at Harvard, MIT, and Princeton, gave the intuitive—incorrect—answer. At less selective universities, the rate of demonstrable failure to check was in excess of 80%” (
Kahneman 2011, p. 45). The observation that students from universities that differ in their selectivity perform differently in the chocolate-and-candy problem suggests that it is indeed possible that different people are fallible to illusions to different degrees. The reasons for this are largely unknown: the difference could be plausibly attributed both to variable socio-economic background, to enhanced cognitive abilities, or to both, with an unknown nature-to-nurture ratio. Previous research on comparative illusions has not addressed the topic from this perspective and the factors that may lead to robust differences—if any—are also unknown.
In this context, the present research aims to broaden our knowledge about language processing in comparative illusions, by putting this phenomenon to test through comparing two populations that differ in one crucial factor: the number of languages they use on a daily basis. The aim is to investigate all the factors that, according to the literature, play a role in inducing the illusion (i.e., the repeatability of the predicate, the ability of the embedded clause subject to be included in the matrix clause subject, the role of fewer) plus an additional factor: the impact of having a different developmental trajectory on the processing of grammatical illusions.
In a nutshell, the questions that the present research aims to address are the following:
Research question 1: Are the factors that have been linked to inducing the illusion at its strongest equally robust in languages other than English?
Research question 2: Are people with different developmental trajectories fallible to comparative illusions to different degrees?
3. Results
As often happens in experiments that collect reaction times, this measure did not show a normal distribution due to a skewed right tail. The standard logarithm () was used to normalize the data and a classical ±3 SD filter was applied to detect outliers. Only four reaction times were removed (for consistency the acceptability judgments linked to them were also removed), which led to the elimination of 0.33% of the data.
With respect to the acceptability judgments, the results revealed that the illusory effect reported for English speakers also holds in Greek.
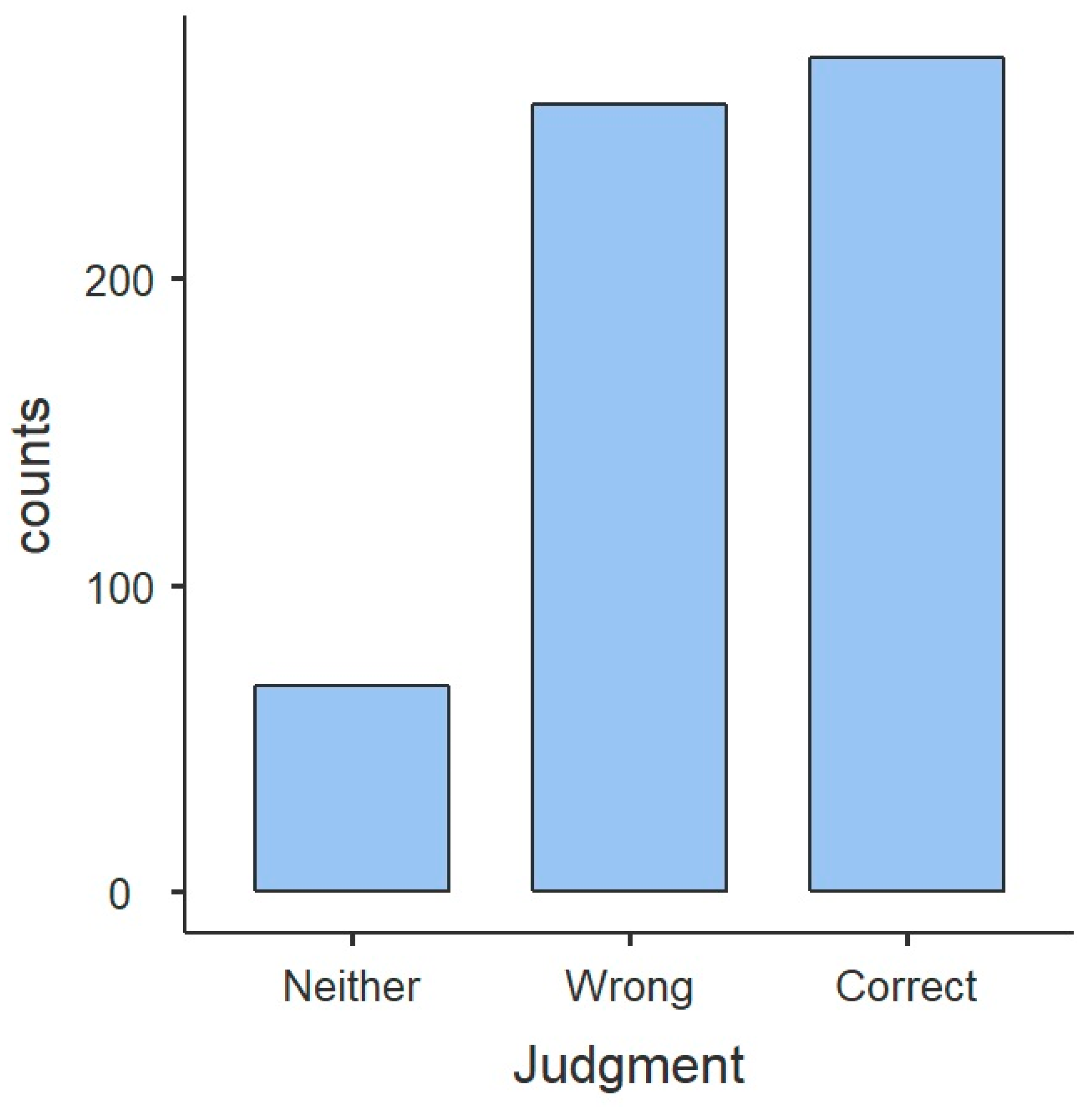
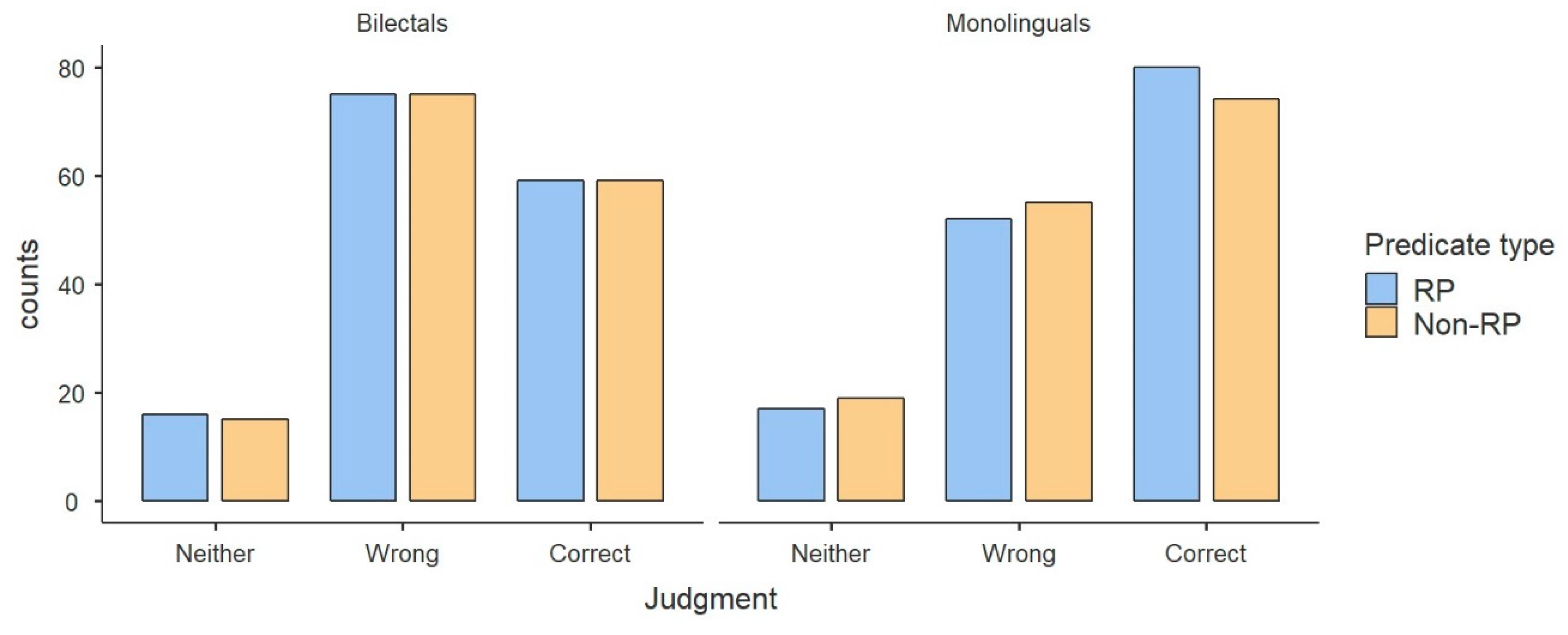
Figure 1 shows that the predominant judgment is ‘correct’, meaning that the deviation was not spotted, and participants were largely tricked into accepting the illusions as well-formed sentences. At the same time, the results appear quite balanced, as
Figure 1 shows that a big number of participants fully rejected the sentences as ‘wrong’. By comparison, the ‘neither’ responses are relatively few. This suggests that the sentences were either parsed successfully such that an interpretation was reached, in which case they were given the judgment ‘correct’, or that parsing failed to yield any interpretation, such that the illusion was spotted, and rejected as ‘wrong’.
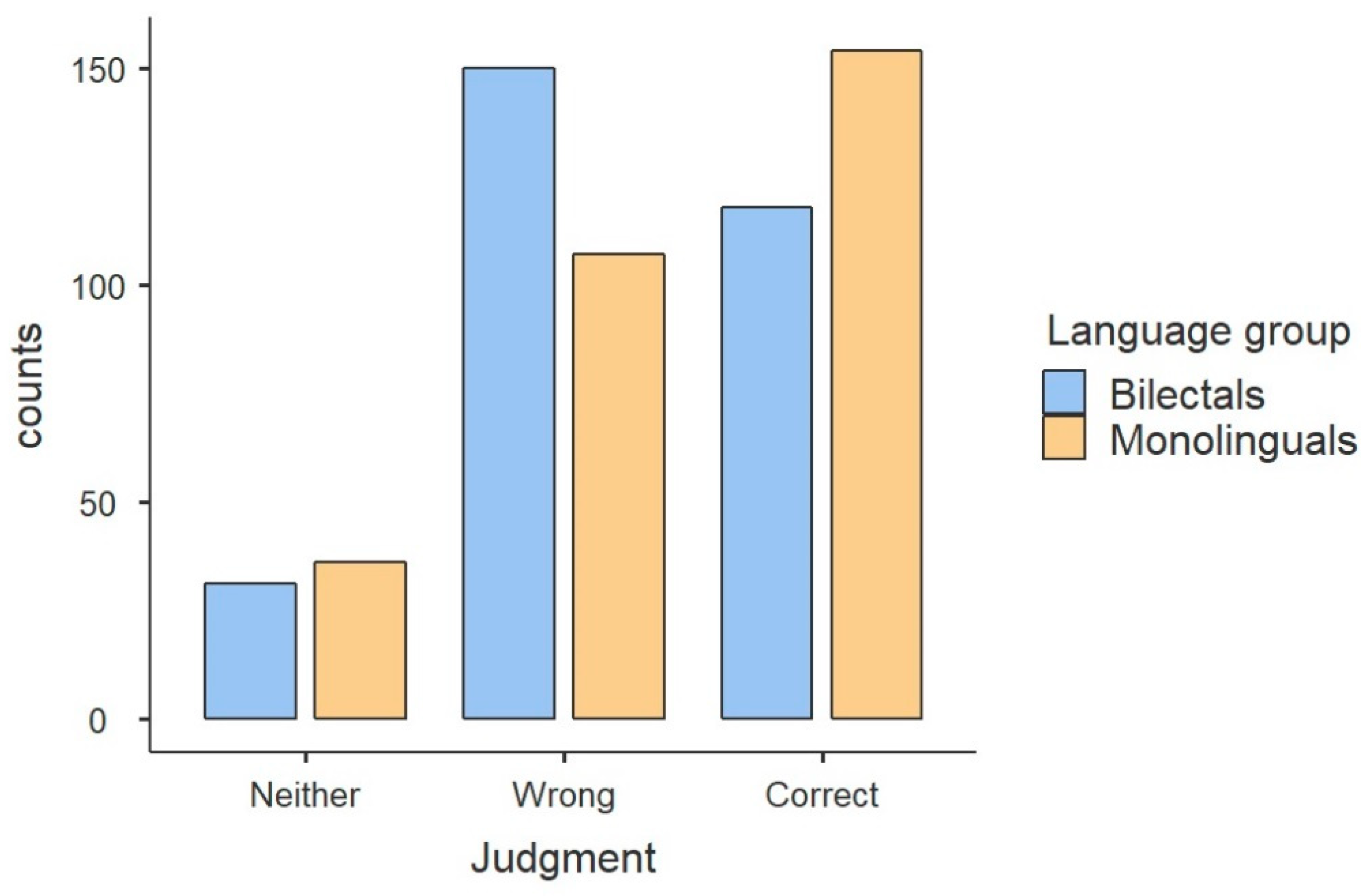
Upon splitting participants into two groups, monolinguals and bilectals, an interesting picture emerges. As shown in
Figure 2, the two groups differ in their performance: the predominant answer for the monolinguals is ‘correct’, similar to what was observed in
Figure 1. The predominant answer for the bilectals is ‘wrong’, meaning that the deviation was spotted and rejected more times. The two groups performed alike in terms of how often they chose the middle, ‘neither’ option. Using JAMOVI, a generalized linear model showed the difference in acceptability judgments between the two groups to be moderately significant, treating the dependent variable as multinomial (χ
2 = 2.4,
p = 0.002).
Turning to the online measure, the analysis of reaction times did not reveal evidence for a statistically significant difference between the two groups (χ
2 = 0.0279,
p = 0.867). Importantly, the interaction between judgment and reaction times was found to be highly significant both in the entire group of participants (χ
2 = 42.4,
p < 0.001) and after splitting for group (monolinguals: χ
2 = 16.8,
p < 0.001; bilectals: χ
2 = 30.3,
p < 0.001). As
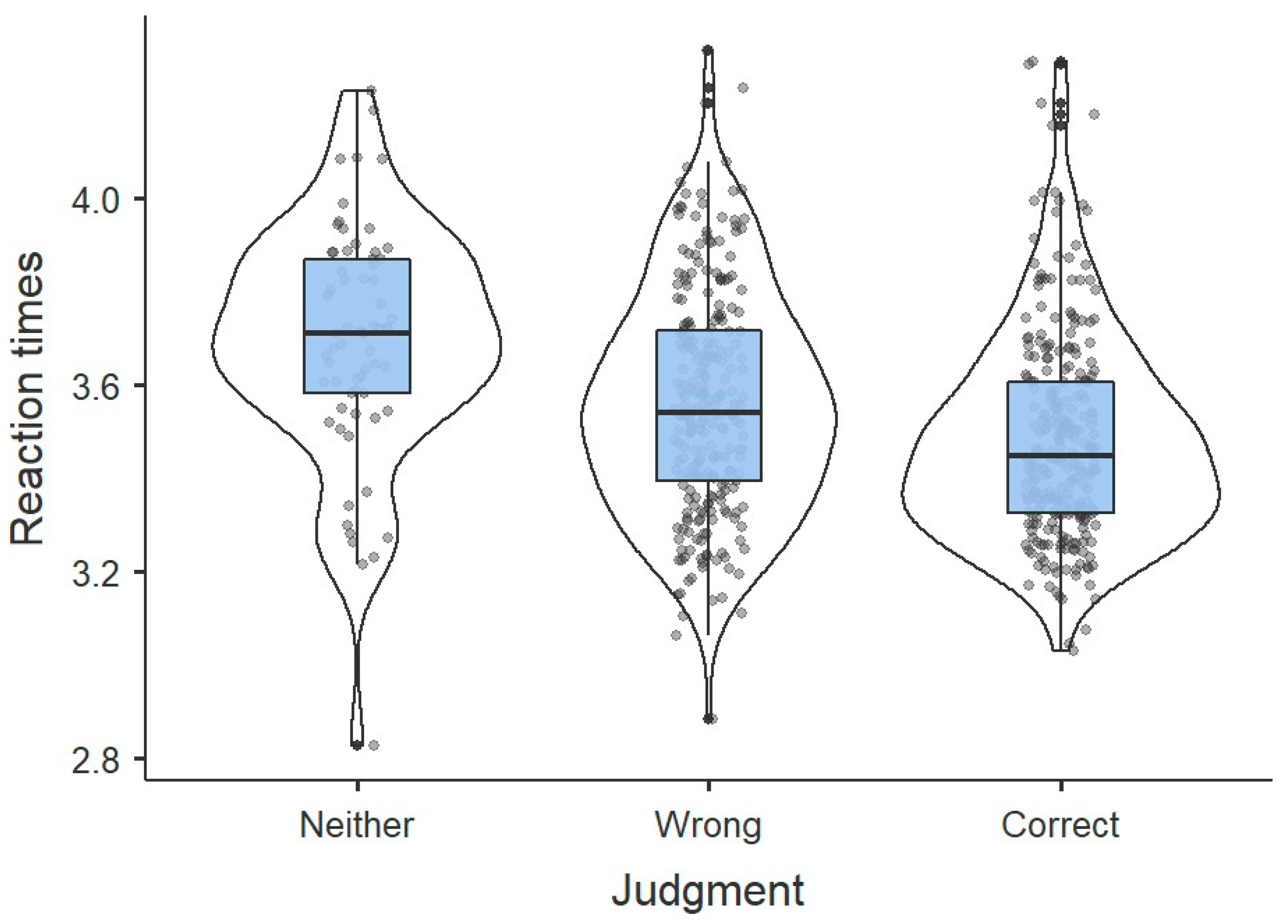
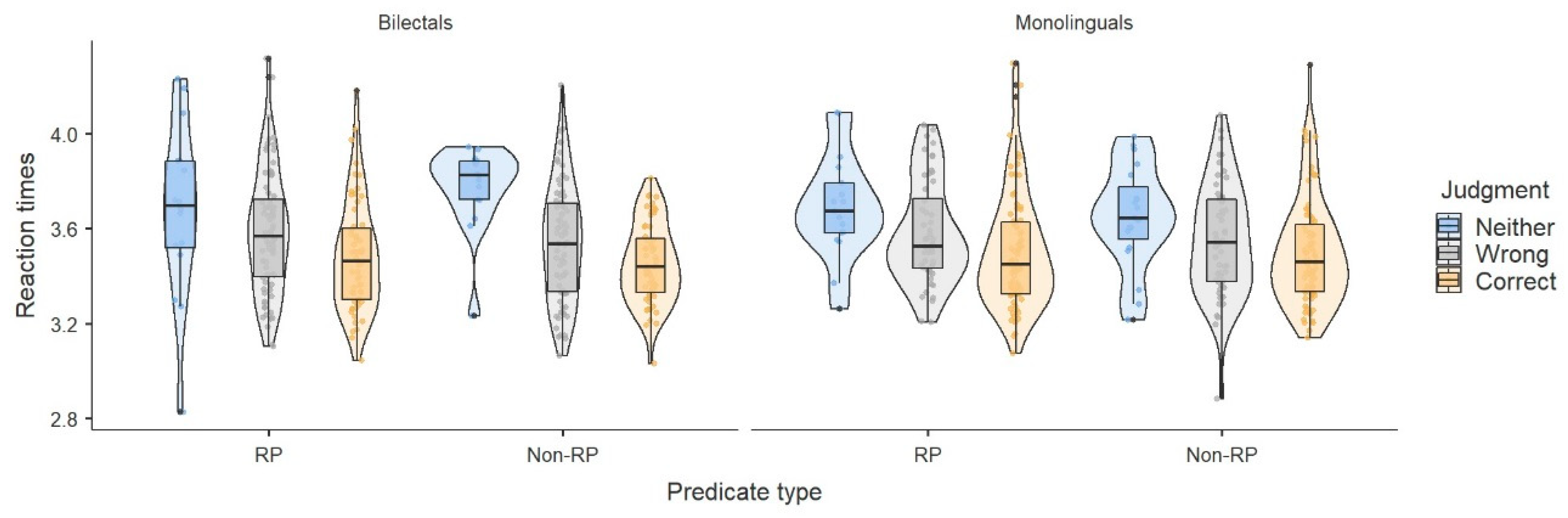
Figure 3 shows, the judgment ‘correct’ had the shortest decision time (agreeing with the results of
Christensen (
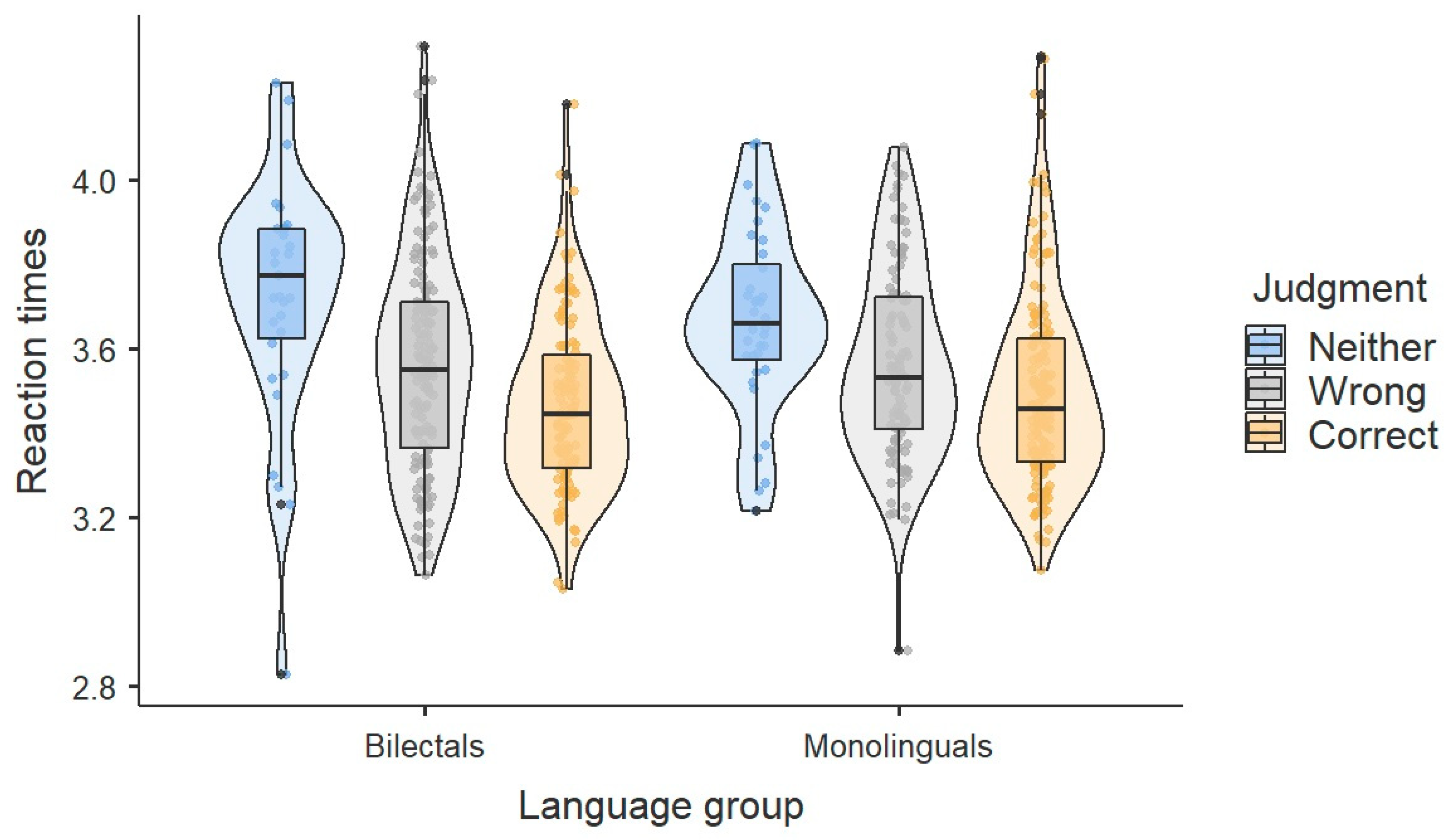
2016)), followed by ‘wrong’, and then ‘neither’. This picture remains unaltered after splitting for group (
Figure 4).
Contrary to what was expected on the basis of the results obtained from testing speakers of English (
O’Connor et al. 2012;
O’Connor 2015;
De Dios-Flores 2016;
Wellwood et al. 2018), repeatable predicates are not linked to a more robust illusion effect, that is, to higher acceptability judgments, corroborating the finding of
Christensen (
2016). When taking the two groups of participants together, the difference between the two conditions (i.e., repeatable vs. non-repeatable predicate, see
Table 1) fails to reach statistical significance in relation to either measure (acceptability judgments: χ
2 = 0.176,
p = 0.916; reaction times: χ
2 = 1.06,
p = 0.304). Splitting for group, the impact of condition remains non-significant (monolinguals, acceptability judgments: χ
2 = 0.426,
p = 0.808; monolinguals, reaction times: χ
2 = 0.292,
p = 0.589; bilectals, acceptability judgments: χ
2 = 0.028,
p = 0.986; bilectals, reaction times: χ
2 = 0.811,
p = 0.368). As
Figure 5 shows, bilectals have a remarkably uniform performance in terms of judgments across the two conditions. On the other hand, monolinguals show a very slight increase in their acceptability ratings in the repeatable condition, something that is in line with the results from English speakers. With respect to the reaction times, the pattern that was shown in
Figure 3 and
Figure 4 remains the same after splitting for condition; in both conditions, the judgment ‘neither’ is accompanied by the longest reaction times (
Figure 6).
The type of test item (see ‘tested feature’ in
Table 1) was not found to have a statistically significant effect on either the acceptability judgments or the reaction times, meaning that it was not the case that one type of illusion was accepted/rejected significantly more than others or that one type of illusion took significantly longer to process (effect of test item in both groups together, acceptability judgments: χ
2 = 13.6,
p = 0.753; both groups together, reaction times: χ
2 = 6.92,
p = 0.646; monolinguals, acceptability judgments: χ
2 =10.0,
p = 0.930; monolinguals, reaction times: χ
2 = 7.78,
p = 0.557; bilectals, acceptability judgments: χ
2 =13.3,
p = 0.771; bilectals, reaction times: χ
2 = 6.09,
p = 0.731).
Seeing the picture that
Figure 3,
Figure 4 and
Figure 6 paint, one may wonder whether the aforementioned highly significant effect of judgment on reaction times is a true effect or whether it is induced by the ‘neither’ responses, which consistently show up as being associated with longer processing times. Put more clearly, the question is the following: If one views the ‘neither’ responses not as a real, spontaneous preference, but as a case of ‘last resort’ answer due to time pressure, will discarding them nullify the claimed effect? To answer this, the interaction between reaction times and acceptability judgments was re-analyzed after removing the ‘neither’ responses from the sample. The results affirm the robustness of the effect, which remains stable. The difference between the two remaining judgments, ‘correct’ and ‘wrong’, in terms of their associated decision times is statistically significant in monolinguals (χ
2 = 4.75,
p = 0.029), bilectals (χ
2 = 10.8,
p = 0.001), and when taking both groups together (χ
2 = 14.3,
p < 0.001).
4. Discussion
As mentioned in
Section 1, the aim of this study is to address the following two questions:
Research question 1: Are the factors that have been linked to inducing the illusion at its strongest equally robust in languages other than English?
Research question 2: Are people with different developmental trajectories fallible to comparative illusions to different degrees?
Starting off from the first question, the answer is negative. If it is the case that speakers settle on either the event comparison or the set comparison re-analysis when they accept the illusion, how is it possible that they do either with a sentence that allows neither, by not permitting subject-inclusion and not involving a repeatable predicate? Let us demonstrate this problem with a concrete example. As
Table 1 shows, there are sentences in the present study that do not involve a repeatable predicate. Among them, there are two that also disallow subject-inclusion, repeated below as (12) and (13):
- (12)
More men have finished high school than she has.
- (13)
Fewer people have finished high school than I have.
Thus, (12) does not permit an event comparison reading. As various studies on the acceptability of comparative illusions in English-speaking populations have repeatedly argued (
O’Connor et al. 2012;
O’Connor 2015;
De Dios-Flores 2016;
Wellwood et al. 2018), the event comparison interpretation is only possible if the semantic properties of the predicate express a repeatable action, and this is not the case here. Furthermore, (12) does not permit a set comparison reading, because the subject of the embedded clause cannot be included in the denotation of the matrix clause subject. Similarly, (13) does not permit an event comparison reading and the additive/set comparison reading is also ruled out. It is hard to even construct an interpretation of (13) that goes along the lines of (4a) and (5) for the set comparison reading, as shown in (14a) below. Equally strange is the event comparison reading, along the lines of (4b) and (6), given in (14b):
- (14a)
The set of people that have finished high school involves fewer members than the set of just me.
- (14b)
People have finished high school fewer times than I have finished high school.
Under these assumptions, we would expect a sharp decrease in the acceptability of these two test items, compared to the other test items given in
Table 1, simply because no re-analysis—from the ones proposed in the literature—is possible for them. Recall that the effect of test item on acceptability judgments was not found to be significant. However, let us further analyze this finding by examining how (13) fares in comparison with the other test items.
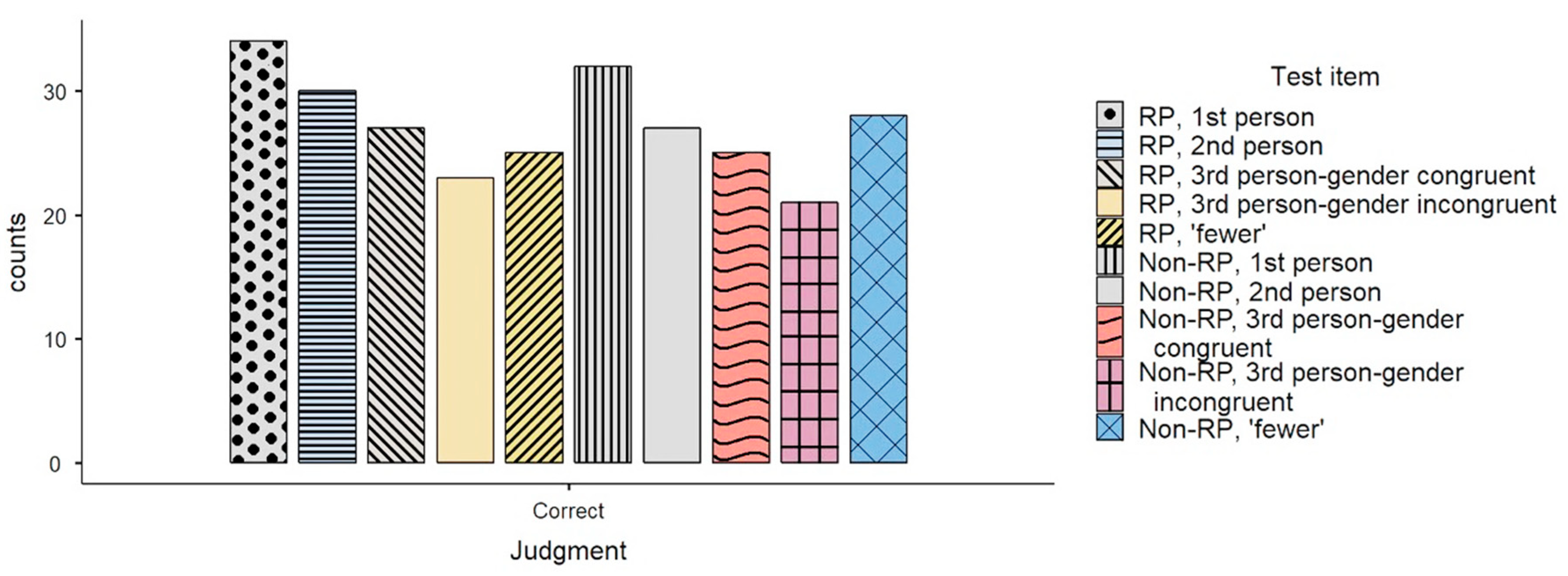
Figure 7 shows how many times a test item received the judgment ‘correct’, meaning that the illusion was not detected. The maximum possible number for each test item is 60. (13) received the judgment ‘correct’ 28 times. This is one time
more than the test item marked in
Figure 7 as ‘RP, 3rd person gender congruent’, which features both a repeatable predicate and permits subject inclusion. This finding is hard to explain under any of the two re-analyses of the illusion that were proposed for English.
Giving a negative answer to research question 1 does not undermine the credibility of the re-analyses proposed in the literature. In fact, I argue that drawing insights from these re-analyses can provide useful answers with respect to the what, why, and how questions that surround the phenomenon of comparative illusions.
Beginning with
why, it was argued in
Section 1 that the event comparison hypothesis focuses on how meaning is construed (its answer: by resorting to a grammar-based interpretation that facilitates the event comparison re-analysis;
Wellwood et al. 2018), but it does not explain equally clearly why the parser fails to spot the illusion in the first place. Under the shallow comparison scenario that I propose here, the answer to
‘why does the parser fail to spot the illusion in the first place?’ is because it encounters values that are pretty close to the predictions it forms on the basis of previous experience. To explain this further, the parser is oblivious to the manipulative context that induces the illusion, therefore it contextualizes a sentence like (13), by treating templates it has previously encountered (i.e., comparison of events and comparison of individuals) and knows to be meaningful as such. Put differently, given the tendency for radical contextualization, when the parser is dealing with a sentence that is largely syntactically correct, it seeks to assign a meaning to it, because it
presupposes that the sentence
has a meaning. For the same reason, people can easily assign structure to semantically anomalous sentences, such as
Chomsky’s (
1957) famous example “colorless green idea sleep furiously”. If the parser resorts to a System 1 heuristic, it legitimizes this presupposition by constructing an interpretation (along the lines of the
what question discussed below). If, on the other hand, System 2 intervenes and challenges this presupposition, the parser may spot the illusion. Both systems operate in tandem and this explains why there is variation in spotting the illusion even across individuals that fit the same behavioral profile (
Wellwood et al. 2018). Overall, this answer to the
why question fits theories that assume a complex interplay between heuristic processing and deep syntactic parsing (
Karimi and Ferreira 2016). Evidence in favor of the deep grammar-based parsing account comes from
Figure 7, which shows that people are sensitive to grammatical cues such as gender incongruency, but not to a degree that would lead to a statistically significant effect of test item.
Turning to the
how question (i.e.,
‘how is the meaning of the illusion construed?’), the explanation I propose partly agrees with the one presented in
Phillips et al. (
2011) and
Wellwood et al. (
2018): by positing grammar-based interpretations. Evidence for this claim comes from the finding that certain judgments are associated with longer reaction times, as shown in
Figure 3,
Figure 4 and
Figure 6. The parser is actively engaged in grammatical processing, construing, evaluating, and discarding different interpretations, which is why the ‘neither’ and ‘wrong’ responses consistently take longer to form. In other words, it is not the case that most of the people who spotted the illusion did so immediately. This explanation parts company with the one by
Phillips et al. (
2011) and
Wellwood et al. (
2018) in accepting that deep grammatical processing occurs, but until a System 1 heuristic takes over. For some people, this happens early, and the illusion is accepted as well-formed straight away. For some people, the heuristic kicks in later, and the illusion may be spotted or not.
Finally, the speculative answer to the
what question (i.e., ‘
what is the interpretation that the illusion finally gets?’) is that there is not one. The acceptability of (13) is not predicted by either the set comparison or the event comparison re-analysis. Thus, (13) should not be acceptable, and yet it is. Under the shallow comparison scenario that I propose, (13) is acceptable because people do not settle on one full-fledged interpretation. They have parsed the sentence, such that their parser has constructed a potentially ambiguous and vague interpretation, and this is enough to render a high acceptability rating. This approach is in line with
Christensen’s (
2010) claim that comparative illusions are “semantic dead ends” in the sense that they cannot be assigned a full semantic interpretation. Perhaps the strongest argument in favor of the proposal I put forth here comes from a crucial observation made by
Wellwood et al. (
2018): “
O’Connor’s (
2015) results are suggestive here: she found that participants’ reading times were slower following the ellipsis site for C[omparative] I[llusion]-type sentences as compared to controls, and that the reaction times correlated with acceptability ratings for controls but not for illusions. If shallow processing was behind high acceptability ratings for CIs,
we would expect to see no slowdown when participants eventually gave a high rating” (p. 577; emphasis added). This is exactly what we see in the results of the present experiment: the highest rating (i.e., the response ‘correct’) shows no slowdown in reaction times, unlike the other two ratings (
Figure 3,
Figure 4 and
Figure 6). Put more succinctly, slower reaction times do seem to go hand-in-hand with spotting the illusion.
With respect to the second research question and to whether people with different developmental trajectories are fallible to comparative illusions to different degrees, the answer seems to be a tentative yes. Given that variation in spotting the illusion was observed among speakers of the same language and even fit the same behavioral profile (
Wellwood et al. 2018), it is perhaps unsurprising that such interspeaker differences show up as more pronounced when one compares individuals from different behavioral profiles/developmental trajectories. The obtained results provide tentative evidence for a significantly better ability of bilectals to spot and reject the illusions as ill-formed. In relation to why this happens, only speculations can be offered at this point, because many factors can be identified as possible culprits behind this finding.
First, the difference could be due to some grammar-specific particularities of Cypriot Greek. Although all participants were tested in Standard Greek, the bilectal speakers also use a second variety in their daily life: Cypriot Greek. More specifically, the issue could be that the tested illusions involve predicates in present perfect, which is arguably a novel development in Cypriot Greek, and absent from older forms of this variety (see
Melissaropoulou et al. 2013 for an overview). Under this explanation, the fact that bilectals reject more than monolinguals the comparative illusions may have nothing to do with spotting the illusions themselves. Instead, it could be the result of cross-linguistic interference from their home-variety, in which this tense is absent and thus may sound alien to them. Overall, this seems to be a weak explanation, because the possibility of such interference is low for two reasons. First, recent studies demonstrate the existence of present perfect in contemporary Cypriot Greek (
Melissaropoulou et al. 2013;
Tsiplakou et al. 2016;
Tsiplakou et al. 2019) and the tested participants are quite young (mean age in bilectals: 30.2, SD: 7.6). Second, it should not be overlooked that the language of testing is Standard Greek, a variety of Greek to which the bilectals definitely have exposure as it is one of the official languages of the state. In this sense, the use of present perfect should not cause any interference.
Another culprit behind this better performance of bilectals boils down to the fact that unlike their monolingual peers, they have at least two grammars (Standard and Cypriot Greek), which they use almost on a daily basis. To spell out the idea more clearly, if bilectals have frequent opportunities to code-switch, perhaps this constant engagement of top-down control processes, which has been explicitly linked to stimulus-driven code-switching (
Blanco-Elorrieta and Pylkkänen 2018;
Leivada et al. 2020), is responsible for their better performance in this task. It can be hypothesized that code-switching may facilitate the setting of a higher processing threshold through sharpened top-down control processes, something that would entail decreased fallibility to grammatical illusions. Setting a higher processing threshold could mean better matching to retrieval cues together with a superior ability to attend selectively to various aspects of the stimuli, (dis)engaging attentional resources accordingly. In the literature, partial matching to retrieval cues has been already linked to agreement illusions (
Phillips et al. 2011;
Phillips 2013), and it is not implausible that it plays a role in comparative illusions as well. This interpretation of the results is in agreement with many behavioral studies that report an enhanced ability of bilinguals to make accurate acceptability judgments in the context of misleading sentences that feature semantic deviations (
Galambos and Hakuta 1988;
Bialystok 1988;
Ricciardelli 1992;
Cromdal 1999). Bilingual children have been also found to have a heightened pragmatic sensitivity (
Groba et al. 2018). Viewing grammatical illusions as semantico-pragmatic constructs that arise within a manipulative context (
Maillat and Oswald 2009), the enhanced ability of bilinguals to provide selective attention to specific aspects of a linguistic representation may be the key to explain what lead to the successful identification of these illusions as ill-formed sentences in one of the two tested groups.
A third hypothesis is that bilectals are anxious to prove that they can speak Standard Greek, hence they sometimes tend to hyper-correct and reject ill-formed sentences that are perfectly acceptable in Standard Greek. This (meta)linguistic insecurity is well-documented for both child and adult populations in Cyprus (
Grohmann and Leivada 2012;
Leivada et al. 2017) and has to do with the complex dynamics that underlie the standard-dialect continuum. If this hypothesis holds, the difference in the performance between monolinguals and bilectals does not have a cognitive background as the previous hypothesis posits, but a sociolinguistic one. To evaluate this hypothesis, it seems that it suffers from one major problem. If the source of the low acceptability ratings in bilectals was due to their tendency to hyper-correct, the grammatical fillers should also show this effect; they do not. In raw numbers, the performance of the two groups in the grammatical fillers amounts to 4/150 counts of ‘wrong’ for monolinguals and 3/150 for bilectals. In other words, both groups correctly accepted the grammatical fillers as ‘correct’. To put these numbers in perspective, the equivalent number of ‘wrong’ judgments in the illusions (i.e., which means that the illusion was spotted and correctly rejected as wrong) is 109/300 for monolinguals vs. 150/300 for bilectals. It can thus be concluded that since the grammatical fillers do not show the slightest evidence of hyper-correction, this hypothesis lacks empirical support.
A fourth explanation could be the interaction of the two previous ones: setting a higher processing threshold makes bilectals less fallible to illusions, but at the same time, their performance is driven by linguistic insecurity, hence they also pay more attention to the stimuli. This is a valid hypothesis, but then one should account for the fact that the reaction times were not found to be significantly different between the two groups. If bilectals paid more attention and processed the stimuli more, the reaction times should have reflected this, because they are sensitive to the number of operations and alternative meanings that are computed (
Bates et al. 1982). In order to evaluate the strength of this explanation, let us observe again the obtained reaction times. Indeed, the statistical analysis did not reveal a difference between the two groups (χ2 = 0.0279, p = 0.867). In addition, the interaction between the type of judgment and reaction times was highly significant in both groups alike (monolinguals: χ
2 = 16.8,
p < 0.001; bilectals: χ
2 = 30.3,
p < 0.001). Recall, however, that after the ‘neither’ responses were removed from the sample, the difference between the two remaining judgments, ‘correct’ and ‘wrong’ in terms of their associated decision times, is
differentially significant in the two groups (monolinguals: χ
2 = 4.75,
p = 0.029; bilectals: χ
2 = 10.8,
p = 0.001). Evidently, the result is only marginally significant in monolinguals (and if it is corrected for multiple comparisons this significance would disappear), while it is strong in bilectals. Put another way, there is evidence that the reaction times in bilectals
are more sensitive to the given acceptability judgment in the sense that spotting illusion and rejecting it as ‘wrong’ is indeed associated with longer processing time. The ‘wrong’ responses in monolinguals are also linked with longer processing times (
Figure 4), but the difference is not as strong as the one observed for bilectals. Overall, this explanation can be neither accepted nor rejected at present. On the one hand, it is possible that failing to find evidence for an overall group difference in reaction times is due to the small number of participants in each group and the big number of ‘correct’ responses in both groups in the following sense: the judgment ‘correct’ is the one associated with faster reaction times in both groups and it is sufficiently plentiful in each group to mask an overall group difference. On the other hand, the fact remains that the two groups were not found to differ in terms of their overall reaction times. Crucially, removing the ‘neither’ responses from the sample is perhaps informative and helpful in order to discern subtler patterns of variation, but the results of such a move should be interpreted with caution. Excluding a portion of the obtained data for an analysis brings along the danger of data mining, by looking at too many possible associations at a subset level.
The last explanation that will be contemplated is that the difference between monolinguals and bilectals is an accidental one; a difference of the sort one can find any time two groups of people are compared. Given that there is no literature on the topic of grammatical illusions in Greek speaking populations, the obtained results cannot be interpreted in comparison with other studies from the same population. Until they are replicated, the possibility that this is an accidental difference cannot be discarded.
Overall, the results together with the above evaluation of each hypothesis seem to support the second explanation, lending support to the idea that the mental juggling involved in using two or more languages on a daily basis may play a role in establishing a higher processing threshold. However, more research is needed in order to evaluate the effect and the robustness of this result.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}