1. Introduction
Depicting exists alongside indexing and describing as basic communicative tools used by human beings to relay information about people, places, things, and events. Clark describes this tripartite communicative strategy as follows, “In describing, people use arbitrary symbols (e.g., words, phrases, nods, and thumbs-up) to denote things categorically, and in indicating, they use pointing, placing, and other indexes to locate things in time and space. In depicting, people create one physical scene to represent another” (
Clark 2016, p. 324). Clark suggests that both indexing and describing have received the lion’s share of attention, while depiction has escaped the gaze of many researchers operating within mainstream linguistic theory. This is an unfortunate oversight, due to, as Clark notes, a false assumption that depiction does not participate in the complex semantic and syntactic calculations made by language users.
Signed language and gesture researchers have not been fooled by these base assumptions regarding the seemingly elementary nature of depiction. When looking at language use in the visual modality, depiction is an undeniable feature which requires careful consideration and theoretical attention. Both signers and gesturers utilize a range of multimodal semiotic resources, requiring researchers, who focus their efforts on understanding the complexities of languages in the visual modality, to account for these ubiquitous constructions. Gesturers have been shown to deploy depiction in constructions like “like this”, where ‘like-this’ functions to introduce the depiction which can simply be a gesture (
Fillmore 1997). Similarly, constructed speech is also recognized as a type of depiction (
Partee 1973) in which direct quotations are an enactment of a speech act. Signers can use ‘constructed action’ to encode different perspectives, either simultaneously or sequentially relaying information about referents by pivoting their gaze, shoulders, or bodies or by changing facial markers.
The use of constructed action in deaf signers has been well documented across a variety of signed languages including Danish Sign Language (
Engberg-Pedersen 1993), American Sign Language (
Metzger 1995;
Janzen 2004;
Dudis 2004), French Sign Language (
Cuxac 2000), South African Sign Language (
Aarons and Morgan 2003), German Sign Language (
Perniss 2007), Icelandic Sign Language (
Thorvaldsdottir 2008), Mexican Sign Language (
Quinto-Pozos et al. 2009), Swedish Sign Language (
Nilsson 2010), Irish Sign Language (
Leeson and Saeed 2012), British Sign Language (
Cormier et al. 2013), Auslan (
Ferrara and Johnston 2014), Austrian Sign Language (
Lackner 2017), and Finnish Sign Language (
Jantunen 2017). To give an approximation of how pervasive ‘constructed action’ can be in a stretch of signed discourse,
Thumann (
2013) found that, in 160 min of recorded video presentations in ASL, presenters averaged 20 “depictions” per minute
1. Constructed action is so prevalent it has led researchers to question why it seems to be obligatory in signed languages (
Quinto-Pozos 2007). Given the frequency of occurrence and the existence of constructed action cross-linguistically, it does seem to be a ubiquitous strategy for reporting narratives and for general event enactment.
First language acquisition studies suggest that children use constructed action in signed language productions as young as 2–3 years of age, but have yet to master these constructions even at age 8 (
Schick 1987;
Slobin et al. 2003). Previous studies with adult signers have suggested that Deaf signers have the ability to use constructed actions to switch seamlessly between perspectives during the telling or retelling of stories (
Cormier et al. 2013). Central to the effective use of constructed action is the ability of the signer to use space to assign viewpoints belonging to different actors in the narrative thereby maintaining consistent reference tracking to rapidly switch between participants in the narrative discourse (
Metzger 1995;
Janzen 2017,
2019).
Unfortunately, little is known about the acquisition or use of constructed action among sequential bimodal bilinguals, or signers who learn American Sign Language (ASL) much later than their first spoken language. Signers who learn a signed language as their second language, in a second modality are often referred to as M2L2 (second language-second modality) signers. However, some have used M2L2 to refer to signers more generally with two modalities, including simultaneous bilinguals who are CODAs (children of deaf adults) who learn a signed language alongside a spoken language, from birth (
Reynolds 2016). We restrict our use of M2L2 to these college-aged adults, learning a second language in a second modality with a large gap between first and second language acquisition.
M2L2 studies on this population are still in their infancy. Most publications have focused on controlled lab experiments rather than on natural language acquisition trajectories or natural language use (but see
Ferrara and Nilsson 2017 for Norwegian M2L2 signers). Luckily researchers in Norway, Germany, Ireland, and the United States have all taken steps toward creating corpora of M2L2 language use and more research in the acquisition of M2L2 signers will be forthcoming. We have based our research questions on what is known about constructed action and the use of viewpoint constructions in Deaf adult signers. We wondered for example, about the acquisition trajectory and use of character, observer, and blended viewpoint in new hearing signers acquiring ASL as a second language in a second modality.
In the next section we give a brief introduction to constructed action, and more specifically on viewpoint constructions in signed languages. We then explain the methods used to investigate constructed action acquisition in hearing M2L2 signers. We will report on our preliminary findings with regards to constructed action, discuss possible interpretations of the data, and conclude with some remarks about the role of gesture on the acquisition of M2L2 constructions.
Depiction, to the extent that it has been researched, is generally tackled by cognitive-functional linguists working on multimodal aspects of spoken languages, or sign language linguists (both formally and functionally oriented) who are forced to confront depiction in the grammars of the world’s signed languages. This in turn has led to a proliferation of terminology as researchers from different theoretical camps continue to reinvent the wheel in their discussions of frequent and well-attested perspective-taking functions in spoken and signed languages. Debates on how best to split these complex constructions into cohesive linguistic groupings vary greatly depending on whether one attempts to describe functional or formal similarities. Within sign language linguistics and gesture studies, ‘depiction’ is often used interchangeably with ‘constructed action’, both as umbrella terms for various depicting constructions which themselves are categorized using varying terminologies, e.g., role-shift (
Padden 1986), imagistic gesture (
McNeill 1992), constructed speech, enactment, referential shift (
Engberg-Pedersen 1993), surrogate blends (
Liddell 1995), and personal transfer (
Cuxac 2000), just to name a few
2. For the purposes of our analysis, ‘constructed action’ serves as a macro-category which includes ‘depictive/classifier’ constructions as well as more canonical examples of ‘constructed action’ which encode viewpoint and perspective through articulations of the hands, face, and body (
Metzger 1995;
Janzen 2004;
Quinto-Pozos and Parrill 2015)
3.
But even across the varied approaches to constructed action and depiction, researchers seem to agree that one of the major functions instantiated by the use of constructed action is encoding viewpoint or perspective-taking. Perspective-taking is a complex cognitive task that involves the construction of the conceptualizer’s point-of-view relative to the object of conception (be it an object or event). Perspective-taking in signed languages requires the ability to map the physical articulatory space surrounding the signer onto various referential frameworks which are part of sign language grammars. That is, there is a ‘right way’ and a ‘wrong way’ to effectively use constructed action to convey viewpoints. In this sense, signers can make grammaticality judgements about the use or obligatoriness of constructed action (
Quinto-Pozos 2007).
While researchers have developed many terms for referring to the semantic mapping of space onto articulatory space, i.e., surrogate space, token space, depicting space, referential space, it is clear from the list in
Table 1 that most have identified two distinct types of perspective construction. For the purposes of our analysis, we adopt the terms ‘observer’ and ‘character viewpoint’ to refer to these two different vantage points. In the following section we describe how character and observer viewpoint differ with regard to how articulatory space and semantic space are structured.
The space around the signer is referred to as signing space or articulatory space more generally. Articulatory space is ‘where the articulation occurs.’ At the same time, it is clear that this space is also semantically structured. The space around the signer can also encode semantic relationships that are set up during the discourse space of the narrative space. In this sense, space is dynamically organized during a given discourse context into semantically significant space with grammatical meaning (
Liddell 1990;
Engberg-Pedersen 1993). ‘Semantic space’ which can also be considered ‘grammatical space’, encodes where referents are positioned during an event as well as how they move and interact. Thus, the space around the signer is both comprised of forms (the articulations) and meanings (the who’s, how’s, and what’s). In the retelling of a narrative, the relationship between the physical articulatory space and structure of semantic space is dynamically negotiated within that narrative space. Form-meaning relationships can be temporarily used to encode various viewpoints either in sequence or simultaneously.
The relationship between articulatory space and semantic space is a key determiner when deciding whether a signer is using character or observer viewpoint constructions. Perniss and Özyürek have discussed this relationship between articulatory space and narrative space as ‘projection.’ Using Perniss and Özyürek’s term, narrative space is thus “projected” onto articulatory space to create a temporary form-meaning relationship for the purposes of discourse cohesion. Below,
Table 2 outlines the main differences between how observer and character viewpoints are mapped, or projected from ‘event space’ to ‘sign space’, or using our terminology, ‘narrative space’ and ‘articulatory space’, respectively.
Observer perspective encodes a point-of-view in which the signer takes a global view of the event, looking at the event from an external point of view, not as a participant in the event itself. Importantly, the narrative space during observer viewpoint is reduced in size relative to the real space occupied by the signer. This is what gives the sense of a ‘bird’s-eye-view’, because the space in front of the signer is of a reduced size, where large objects like buildings and streets, or humans and animals, can be set in space to create a map-like reference between fixed or moving entities. When a signer is occupying an observer viewpoint, the signer is likely to use ‘classifier constructions’ to depict the placement of objects in the scene, as seen below in
Figure 1. When using observer viewpoint, the narrator does not put themselves ‘on-stage’ by using first person referring constructions such as ‘I’ and does not convey their own feelings, thoughts, or inner-states. In observer viewpoint the signer describes the scene by showing how objects move, what they look like, or how they are positioned relative to one another. Because of the descriptive off-stage presence of the signer, this viewpoint has sometimes been referred to as ‘narrator viewpoint’ (
Slobin et al. 2003).
The character viewpoint construction, on the other hand, describes a perspective in which the signer represents the narrative event space to depict a participant within the story (
Slobin et al. 2003). The semantic space is ‘projected’ onto articulatory space. One way to conceptualize this relationship is as a one-to-one mapping between the signer’s body and the character’s body they are depicting. Notably, in character viewpoint, the size of the narrative space (or projected space) is life-sized (
Perniss and Özyürek 2008). To the untrained eye, character viewpoint may look like charades, because the body of the signer ‘becomes’ the body of the character they are depicting. When the signer’s body, head, and face move, the referent’s body, head, and face move. An example of character viewpoint can be seen in
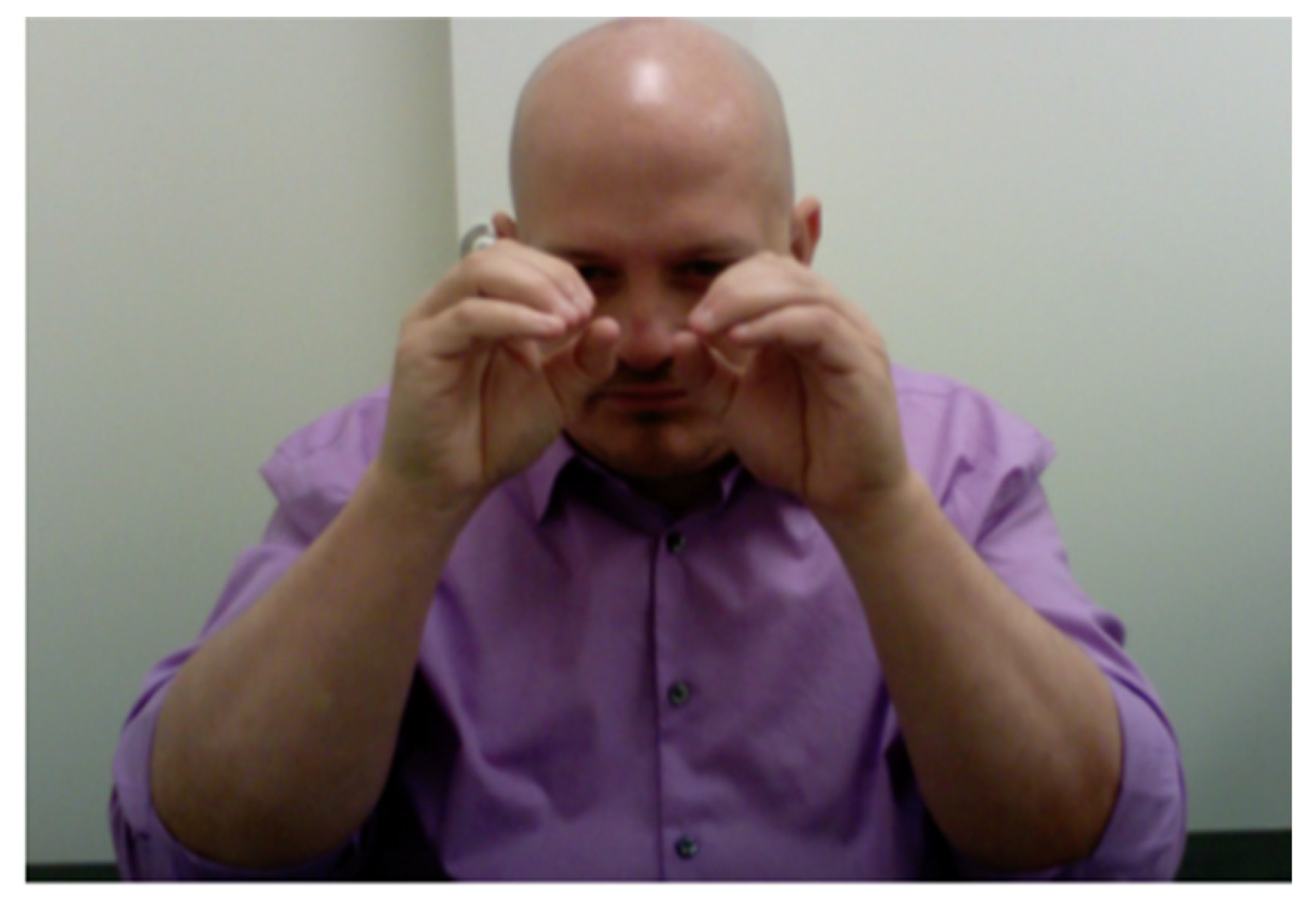
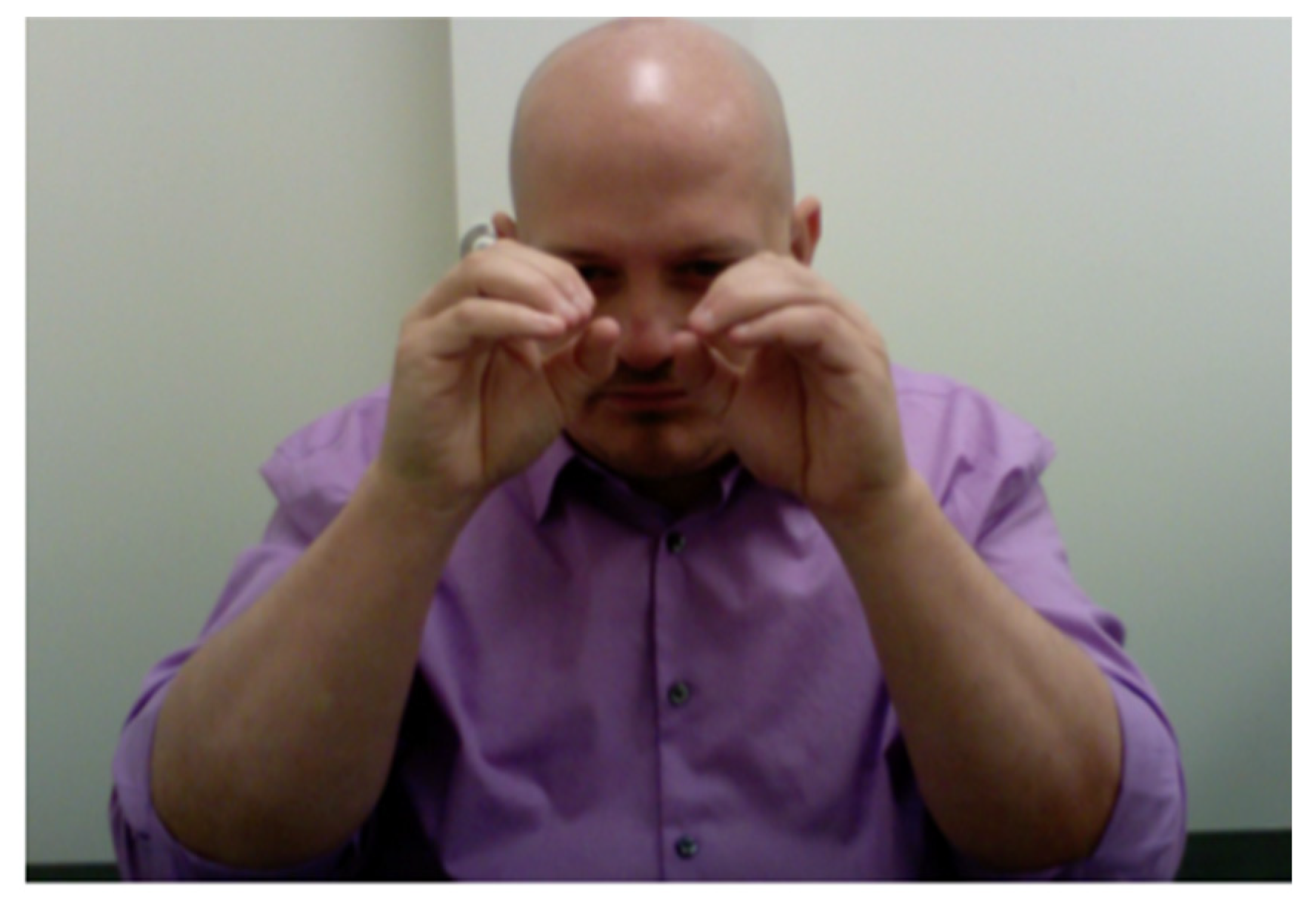
Figure 2, where the signer is looking through the binoculars at the cat (from the perspective of Tweety).
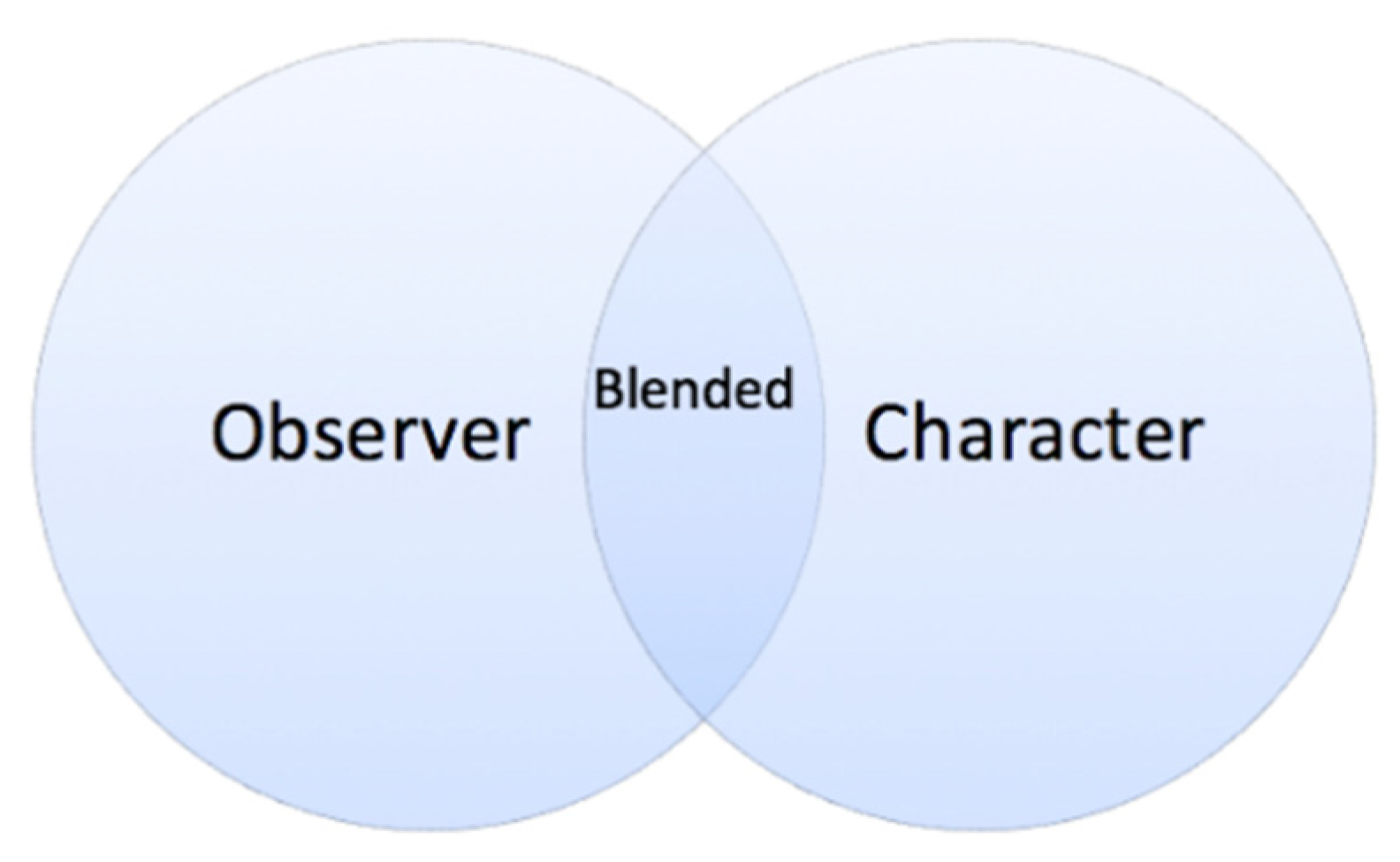
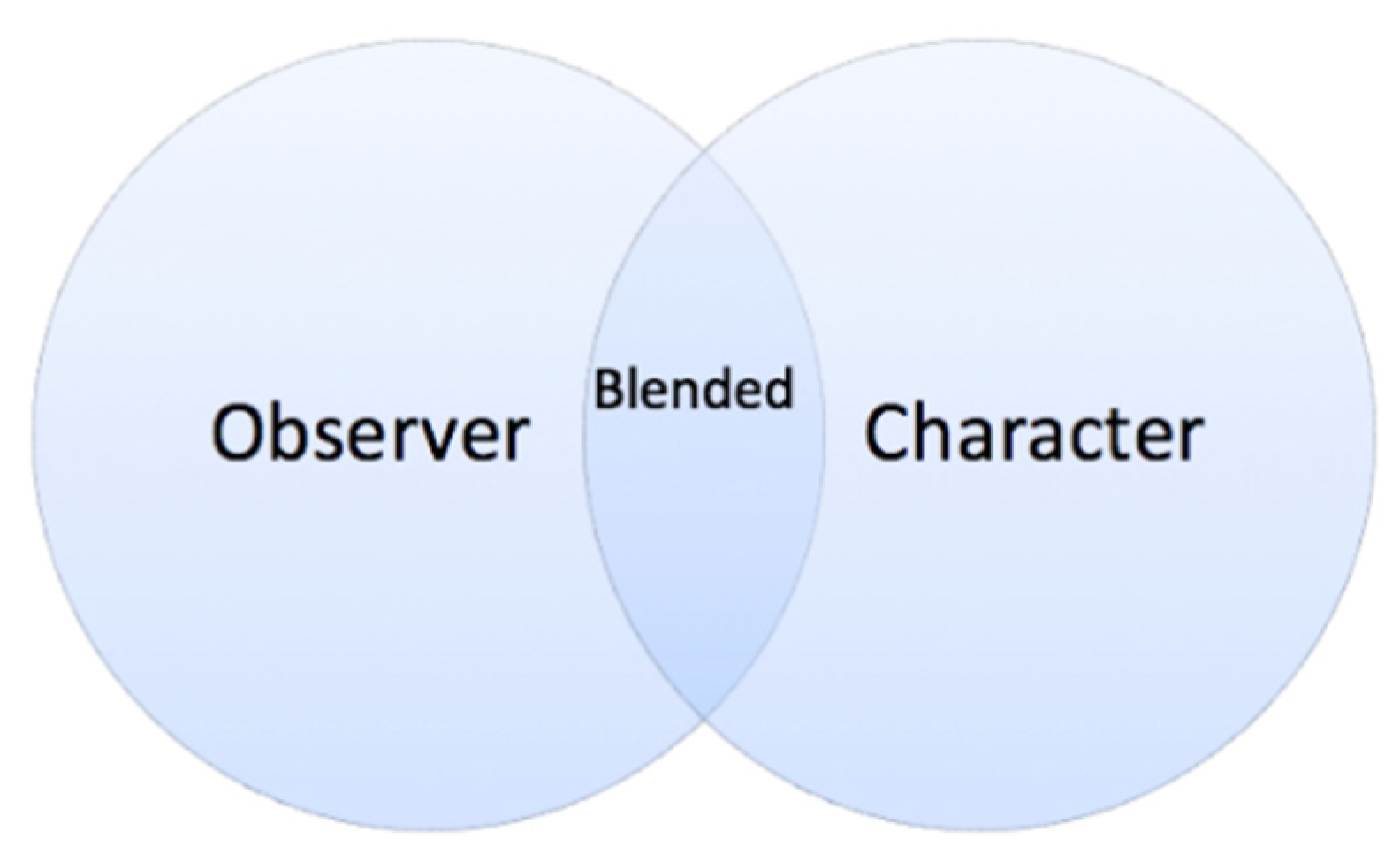
In addition to character and observer viewpoint constructions, we also analyzed a third viewpoint type, a combination of character and observer viewpoints produced simultaneously. This dual viewpoint construction (
McNeill 1992;
Parrill 2009) consists of the features of both character and observer viewpoints and is often referred to as ‘blended viewpoint’ (
Dudis 2004;
Wulf and Dudis 2005). Blended viewpoint is produced by using different articulators to encode different viewpoints, for example, the hands and body, may encode character viewpoint, while the face encodes observer viewpoint. During blended viewpoint the signer simultaneously enacts characteristics of both the character and the observer perspectives, simultaneously (
Figure 3).
To give an example of blended viewpoint,
Figure 4 shows a signer who is simultaneously producing a character viewpoint, depicting the life-sized element of |cat|, and a much smaller scale, ‘bird’s-eye’ articulation of an entity classifier signifying |cat| simultaneously combining these two elements into a single blended viewpoint construction. Note that neither of these articulations on their own means CAT, but within the blended viewpoint construction embedded within the larger narrative discourse space which is constructed for the retelling of the narrative, the meaning of |cat| is clearly evoked.
Clark (
2016) notes that multimodal co-speech gesture productions can also consist of what he calls, ‘hybrid depictions’, which correspond to blended viewpoint discussed in signed language literature on depiction constructions.
3. Results
Participants’ videos were qualitatively analyzed for evidence of each of the three viewpoints characteristics based on prototypical articulations seen in native-like ASL use. Analysis particularly centered on the participants’ ability to adopt character or blended viewpoints when producing verbs, as the event-internal vantage point which is required to produce these narration styles is a feature of constructed action. The
Canary Row clips repeatedly elicited the concept of Sylvester the cat looking at, or searching for, Tweety Bird, with and without explicit mention of a pair of binoculars. The verbs produced to convey this concept were most frequently HOLDING-BINOCULARS, LOOK and SEARCH, or similar variations (see
Table 4 for individual analyses).
Figure 5 illustrates a single participant utilizing two different constructions in session one and session two, however each is an instantiation of the character viewpoint. At time one, the participant depicts the character looking through binoculars while at time two, the participant signs the lexical sign LOOK paired with a constructed action, with their eyes wide, eyebrows raised, and mouth slightly open, to show the character looking straight ahead, mildly astonished at the scene.
Figure 6 illustrates a participant using a different lexical sign, in a different construal of the same situation, choosing instead the sign SEARCH with widened eyes and mouth slightly agape. Note that the use of different lexical signs LOOK-AT used by participant 1: time two, or SEARCH used by participant 11: time 2, does not indicate that the depiction is ‘wrong’ but simply that the two participants offer different construals or different ways of conveying the same part of the story where the character is looking for/searching for the antagonist.
Participants’ productions of each of these verbs can also be categorized as successful and unsuccessful attempts at deploying constructed action. An unsuccessful production of constructed action can be seen when the signer does not adequately depict the referent on their body. For example, the participant’s eye gaze, facial expression, head movement, and body movement may not align with the gaze and posture that would be present if they were participating in the narrative from an internal point of view. As a result, the interlocutor does not receive the impression that the participant has fully enacted the perspective of the referent in their narrative. In successful character or blended viewpoint production, the participant adequately enacts characteristics of the referent. Incorporated eye gaze, facial expression, head and body movements are accurate and projected to the relative space an internal participant in the narrative might occupy.
The resulting enactment gives the impression that the participant is telling the story as a character actively experiencing the narrative, not merely as an external narrator. Successful and unsuccessful deployment of character viewpoint constructions can be seen in
Figure 7 and
Figure 8, both showing the same signer, during the same session. In
Figure 7, at the beginning of the narration, the signer does not successfully implement the character viewpoint construction because the straightforward eye gaze and lack of head movement are not modified to match the perspective of a character that is looking around for something.
However, we see that only a little later in this same session, this participant successfully employs the use of the same HOLDING-BINOCULARS construction with the addition of the appropriate head movement (sweeping motion) and eye-gaze because the rotation of the head and hands mimics the movement of a character that is looking around the space for something, shown in
Figure 8.
We might take this variable implementation and use of a fully instantiated character viewpoint as evidence that the student is aware of, but has not yet fully acquired, the appropriate formal elements of this construction. However, we might assume that when testing at a later time that this participant might more systematically represent the character viewpoint in their signing. In
Figure 9, we see that at time 2, this participant still does not achieve successful character viewpoint because the straightforward eye gaze and lack of head movement do not enact the expressions or movements of character that is searching for something. This is akin to the original production of the sign HOLDING-BINOCULARS except the lexical item is replaced by the sign SEARCH (
Figure 7) though neither is an example of successful deployment of constructed action.
In contrast to the unsuccessful deployment of the character viewpoint construction with the lexical item SEARCH in
Figure 9, we can see that in
Figure 10, Participant 1, at time 2, successfully deploys the character viewpoint construction using SEARCH accompanied by the appropriate formal elements of eye-gaze, and head/body movement. Notice that in
Figure 10, the eye gaze moves about the space, and the head moves with the hands/body, enacting the movement of the character that is searching the premises for something in their vicinity.
The following
Table 5,
Table 6 and
Table 7 outline the number of times each predication involving the signs: HOLDING-BINOCULARS, LOOK-AT, and SEARCH were successfully or unsuccessfully produced using the character or blended viewpoint constructions. In other words, only signers who produced the prediction using one of these three lexical signs, at least one time (whether successfully or unsuccessfully), are shown, thus not every participant is represented in each table. If the participant is not included in the table, they did not produce the viewpoint construction in during time 1 or time 2.
This data shows that eight of the eleven participants decreased production of the s HOLDING-BINOCULARS and/or the sign production of LOOK from T1 to T2 (1–4, 6–7, 9, 10). Three of these eight participants introduced the verb SEARCH in T2 (1, 6–7). The verb SEARCH never appeared in any participant’s data in T1. Participant 11 consistently used LOOK successfully across T1 and T2, and later successfully implemented the use of SEARCH, suggesting that they have learned to use these verbs in predication with constructed action to enact perspectives other than their own. It should be noted that all of the participants completed at least Beginning ASL I at RIT during T1 and prior to T2. The verb SEARCH is part of the ASL I curriculum at RIT and is typically introduced during the fifth unit at approximately Week 7 of the semester. While six of the participants would not have been introduced to the sign SEARCH prior to time one testing, the other participants may not have acquired the use of SEARCH, despite having been introduced to it, prior to T1 testing. As such, SEARCH only begins to appear during the T2 testing session and is used to a much lesser extent than LOOK.
Additionally, the viewpoint constructions paired with the verbs HOLDING-BINOCULARS and LOOK were more often successfully implemented with character or blended viewpoints. However, the verb SEARCH was only successfully modified two of the five times it appears in its uses by the four participants in time two. It is possible that because HOLDING-BINOCULARS and LOOK are articulated with static hand shape and position, that the participants are more successful at integrating these verbs with the movement of the head and body within the viewpoint construction. SEARCH is not articulated with a static hand configuration but instead requires the movement of the hand circling the face. This may prove to be articulatorily more difficult for novice signers.
Some participants, such as number 7 (as seen in
Figure 7,
Figure 8 and
Figure 9) used viewpoint constructions both successfully and unsuccessfully at T1 and T2, indicating that while they have knowledge of how to produce viewpoint constructions, they are not able to consistently implement them. Other signers, such as number 3 were unsuccessful in all T1 attempts and successful in al T2 attempts, suggesting that they may have acquired the use of viewpoint constructions. However, signer 3 did not produce many viewpoint constructions at T2, suggesting they are still unconfident of unsure of where exactly they should occur.
4. Discussion
We were interested to see whether the data collected from the M2L2 students revealed qualitative information related to common patterns. The initial hypothesis focused on the search for quantitative similarities and differences among students across times 1 (T1) and 2 (T2). It was hypothesized that students would exhibit similar patterns, revealing a common acquisition trajectory for constructed action in new signers, specifically exhibiting an increase in the presence of character and blended viewpoints due to the acquisition of grammar skills key to proficiency in ASL.
A common acquisition trajectory for constructed action across sessions was not seen in this population. It is possible that we did not have a large enough sample to make generalizations but it seems that students varied in their use of viewpoint types at T1 and T2. Because we were unable to make any quantitative claims about the data, the scope of our analysis shifted to qualitative description of the observed language production to discern the nature of variation among participants. We did not find a general increase in the use of all types of constructed action over time, but in fact that many showed a decrease in character use between T1 and T2. We found instead that the acquisition trajectory varied greatly across individuals and that the details of how individuals acquire constructed action constructions is more variable than previously thought.
We hypothesized that students would exhibit similar patterns across T1 and T2, revealing a common acquisition trajectory for constructed action in new signers, and that students would exhibit a higher number of character viewpoints during the narratives due to the mimetic nature of the task. We found instead that signers were variable both within and across participants in their use and consistency in using these viewpoint constructions.
It is very possible that the students felt more comfortable using their natural co-speech gesture inclinations to depict character viewpoint early-on in their learning trajectory, as they were not familiar with the patterns or rules associated with the appropriate use of character viewpoint constructions in ASL structure. Hearing students’ experience with games such as Charades, which encourage character viewpoint depictions, gives students prior scripts for moving their body in ways which embody a character. However, analyzing whether a given articulation in the visual modality is a sign or a gesture is an impossible judgement, based on formal properties alone. Only a speaker or signer knows whether the articulation they produced was intended to be a sign or gesture, and in some cases, in spontaneous conversation they may not have the metalinguistic awareness to know the difference. To further complicate the matter, regardless of the intent of the speaker/signer, the interlocutor may categorize an articulation as a sign or gesture differently, based on their linguistic experience. As Occhino and Wilcox have stated previously, traditional assumptions about gradience, deciding whether or not something is a sign or a gesture, is a categorization task that is influenced by the linguistic experience of the interlocutors (
Occhino and Wilcox 2017).
What does seem clear is that as the students progress through their ASL education, they are exposed to new vocabulary and learn more prescriptive rules of ASL in the formal classroom setting. Over time, the students may have become more sensitive to the formal rules, thus biasing a slight increase in the production of observer viewpoint constructions, which may feel “more like ASL” due to the overt rule-based instruction students receive for classifier-handshapes involved in the production of observer viewpoint constructions. On the other hand, the use of character viewpoint constructions requires the task of mapping the body of the character onto the body of the signer, which is not taught as a rule-based one-to-one mapping between a form and a function. This is a more general schematization of the body that signers need to acquire as a skill required for specific discourse genres which are not necessarily needed for every day, face-to-face communication.
It should be mentioned that this preliminary analysis is a small sample from a much larger longitudinal study of ASL M2L2 acquisition and as such this study is limited in scope. First, due to the small sample size collected during this first round of data collection, our results are not easily generalizable. Upon analyzing more data and expanding beyond our first 11 participants, we hope to gain a better understanding of norms for ASL M2L2 acquisition outcomes for college students.
A second limitation is the high percentage deaf and hard-of-hearing students at Rochester Institute of Technology. The university has approximately 20,000 hearing students and 1200 deaf and hard-of-hearing students, which means that many of the hearing students have regular contact with deaf and signing peers. Although we screened participants to be sure they did not have prior training in ASL and were not enrolled in other language courses prior to beginning our study, it is still possible that these students received minimal exposure to deaf and hard-of-hearing students who use ASL on campus in shared classroom, dorm, dining hall, and other social environments. It is possible that RIT M2L2 students do not represent the ‘average’ M2L2 signer who do not have the same socio-culture exposure to signers and Deaf culture outside of the classroom. Studies should be carried out at other institutions of higher education which have ASL programs to test whether there are unseen benefits outside of the classroom which affect in the M2L2 population at RIT.
Another consideration is that while we controlled for ASL courses, we did not control for courses outside of the ASL curriculum or foreign language classes. What about those signers who take a course such as an acting class, or Visual Gestural Communication class where they are strongly encouraged to use as much visual gestures as possible as part of developing communication strategies? What are the non-linguistic factors such as aptitude, motivation, and learning styles that exert influence on the degree of M2L2 (as suggested by
Chen Pichler and Koulidobrova 2015)?
With regards to the sign versus gesture question. The only foreseeable solution to determine to what extent these students relied on gestural repertoire from their L1 English would be to conduct a round of follow-up interviews with students where we watch their story-telling videos with them and ask them a round of meta-linguistic questions regarding their choice of constructions and whether or not they thought they were using ASL or whether they did not know the appropriate construction at the time and instead substituted gestures. This would require an extension of our IRB as well as more funding but it is definitely something to consider if we are to better understand the role of what is traditionally considered “transfer” from L1 to L2 which could be found in the extension of articulatory gestures from multimodal use of English to ASL.
Whether or not new M2L2 signers can try to capitalize on their gestural repertoire as a way to bootstrap learning a language in a visual modality has yet to be seen. Recent research has shown that hearing signers “generate expectations about the form of iconic signs never seen before based on their implicit knowledge of gestures” (
Ortega et al. 2019). It is still unclear whether ASL teachers could somehow leverage the knowledge of a gestural repertoire to teach constructed action or viewpoint constructions. To be sure, this would involve making explicit the implicit and of course would vary by individual.
While we have made some preliminary observations, we uncovered many more questions than we found answers. Future studies should include whether new signers require explicit instruction on the use of constructed action or whether they begin to use constructed action during ASL 1 with only minimal exposure from seeing instructors use it in their own dialogues? It is still unclear at what level of instruction are new signers able to use a combination of observer viewpoint and character viewpoint, also known as blended viewpoint constructions. We failed to observe any regularized use of M2L2 signers encoding simultaneous information about the observer and character through the use of body partitioning. The lack of robust use of blended viewpoint suggests it arises later on in the M2L2 acquisition trajectory, but exactly when and how remains to be seen.
Further longitudinal studies are needed to analyze the later stages of acquisition of constructed action, and to measure the amount of improvement at each level of ASL. In future studies, we wish to correlate our findings with the ASL curriculum used at the university to track how long after specific constructions are introduced, do the constructions consistently, and correctly, manifest in the signed productions of M2L2 students. Further analysis of our data will also reveal whether ASL students who take ASL as part of a foreign language requirement, differ from those students majoring in ASL interpreting, with the intention of becoming sign language interpreters. It is possible that different curricula and different emphases during classroom contact hours may accelerate or inhibit the acquisition of these complex constructions. Furthermore, studies are needed to compare the acquisition trajectories of constructed action in M2L2 ASL users with other global signed languages in other countries.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}