Tonal Proximity Relationship in the Spanish of the Canary Islands in the Light of Dialectometry


Abstract
1. Introduction
2. Methodology
2.1. Informants
2.2. Corpus Data
2.3. Collecting the Data
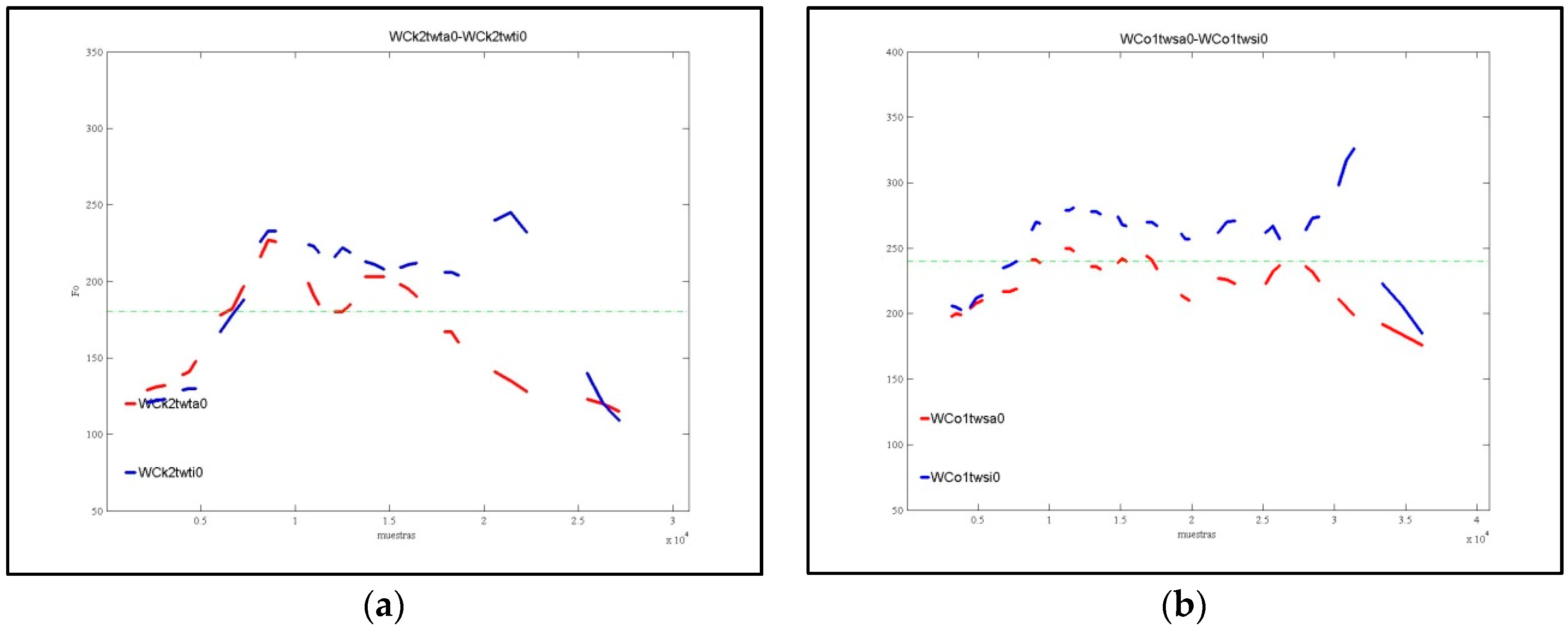
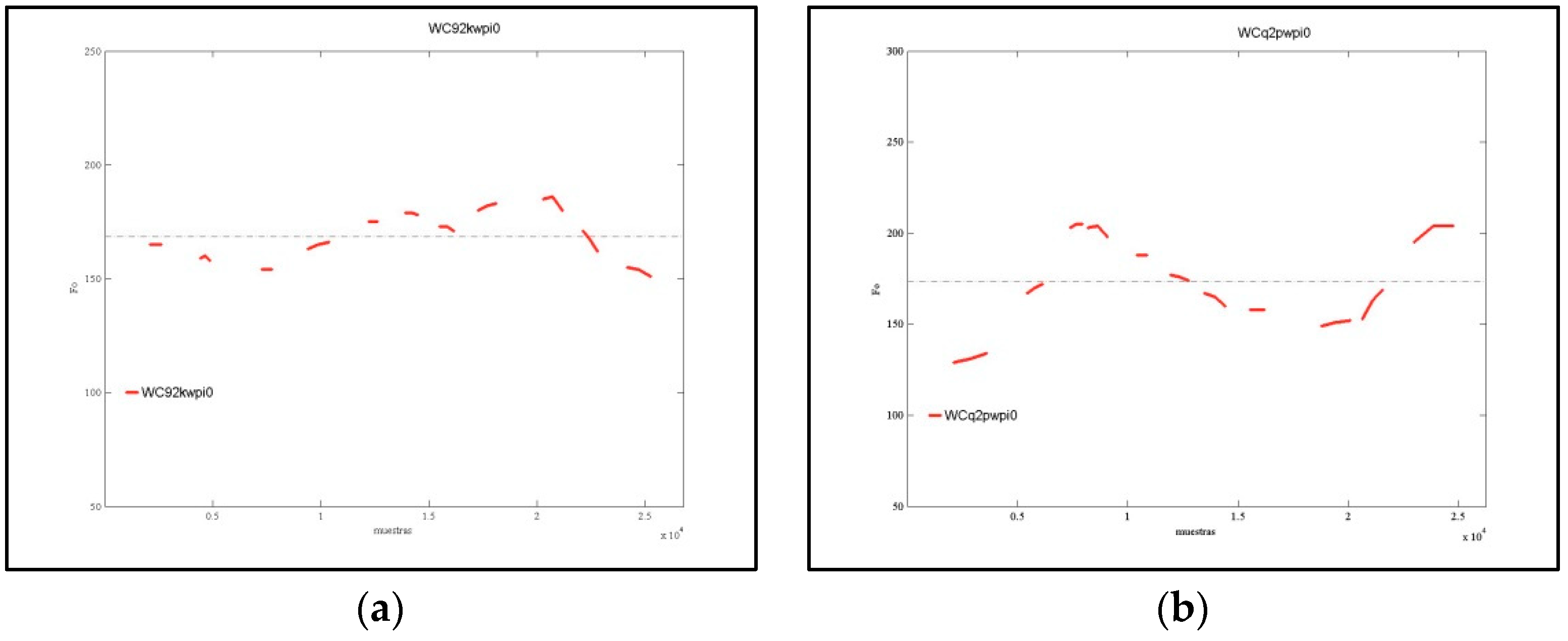
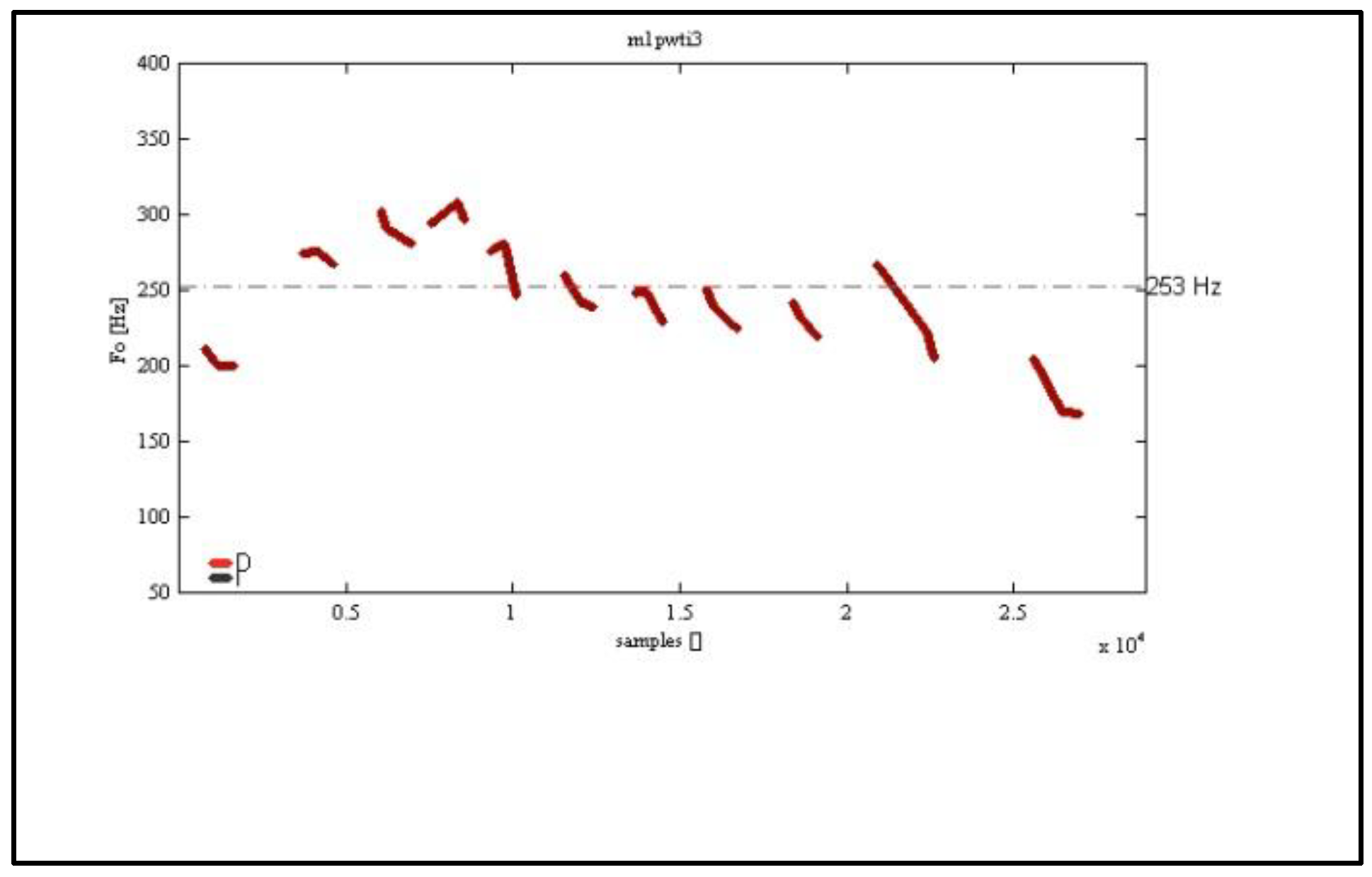
2.4. Acoustic Data Processing with ProDis
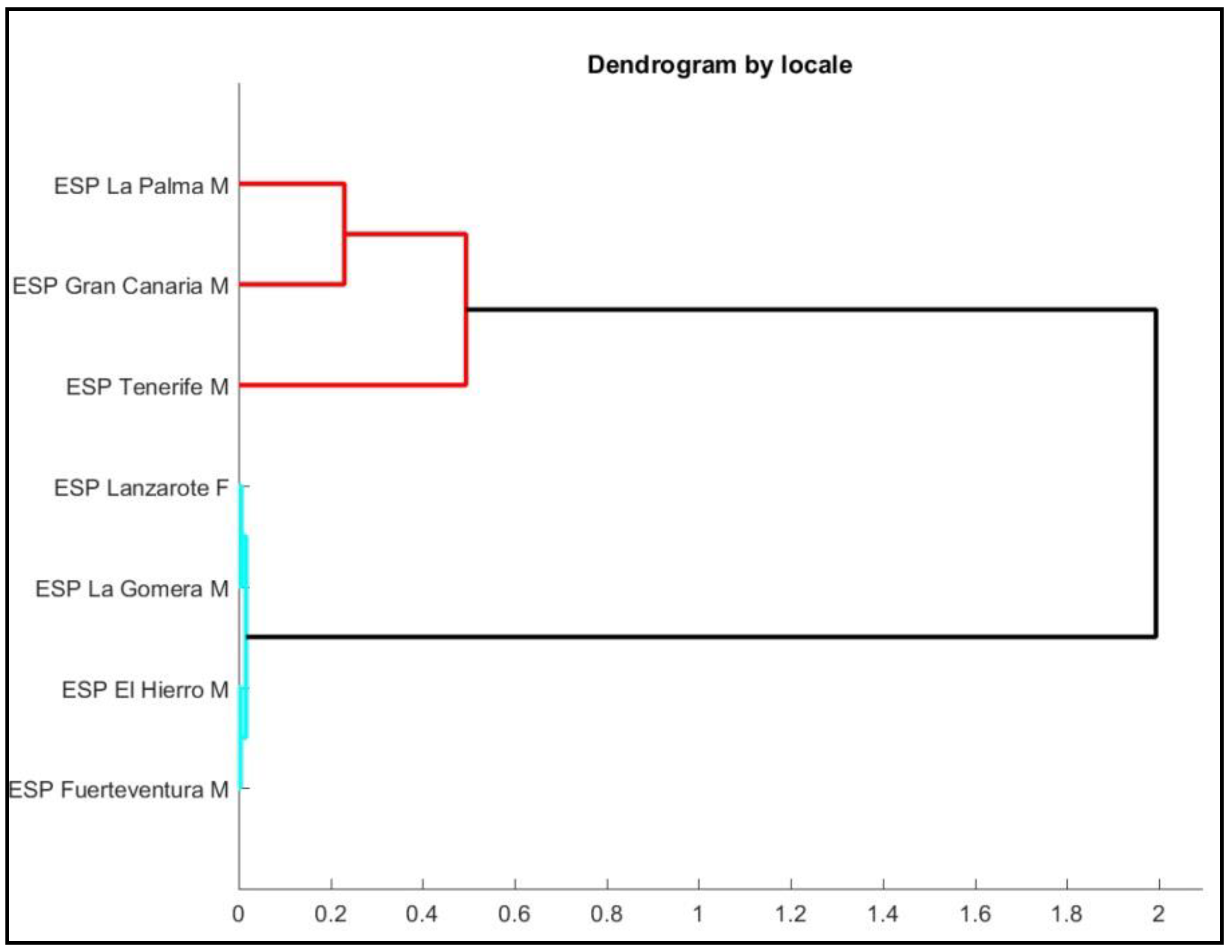
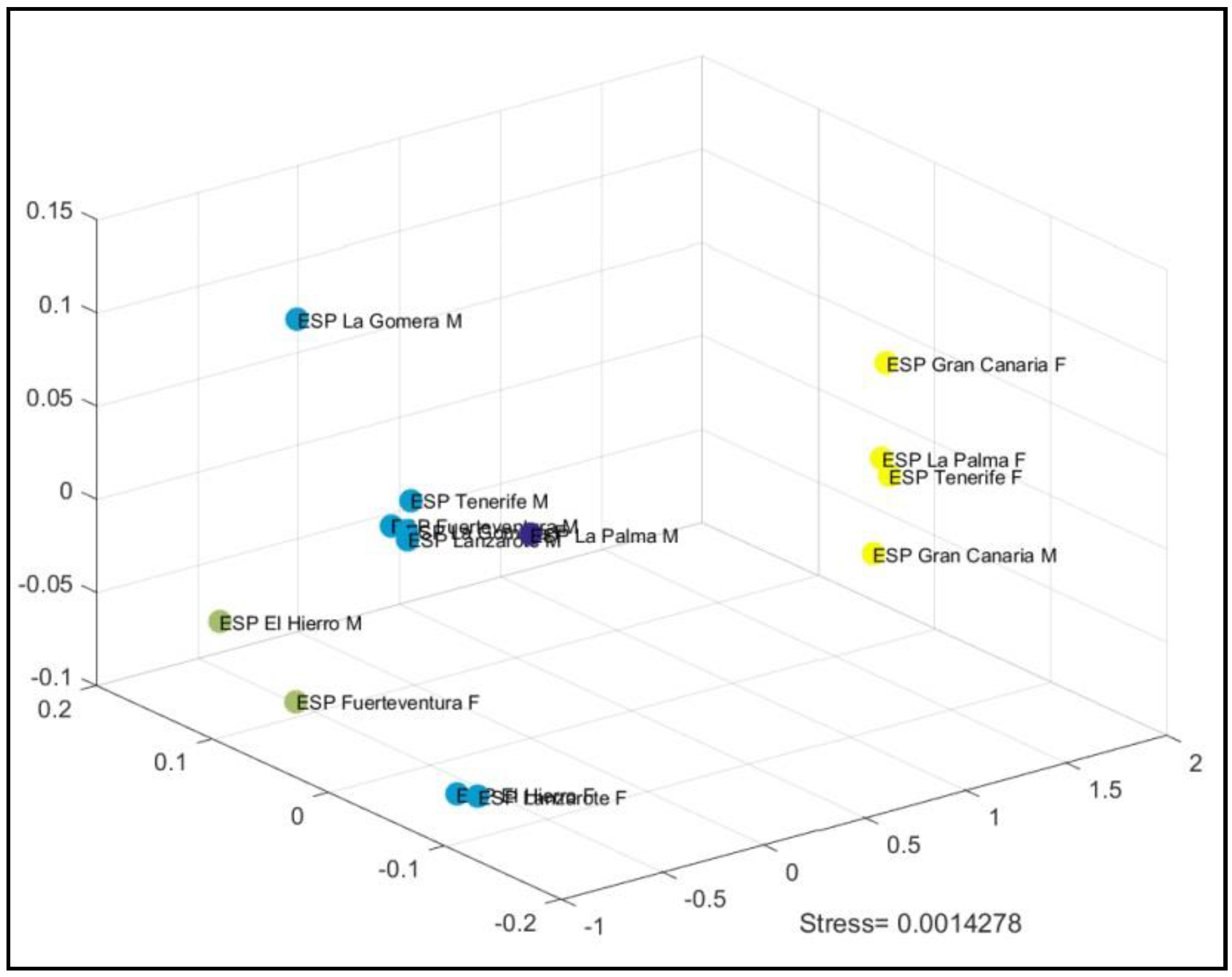
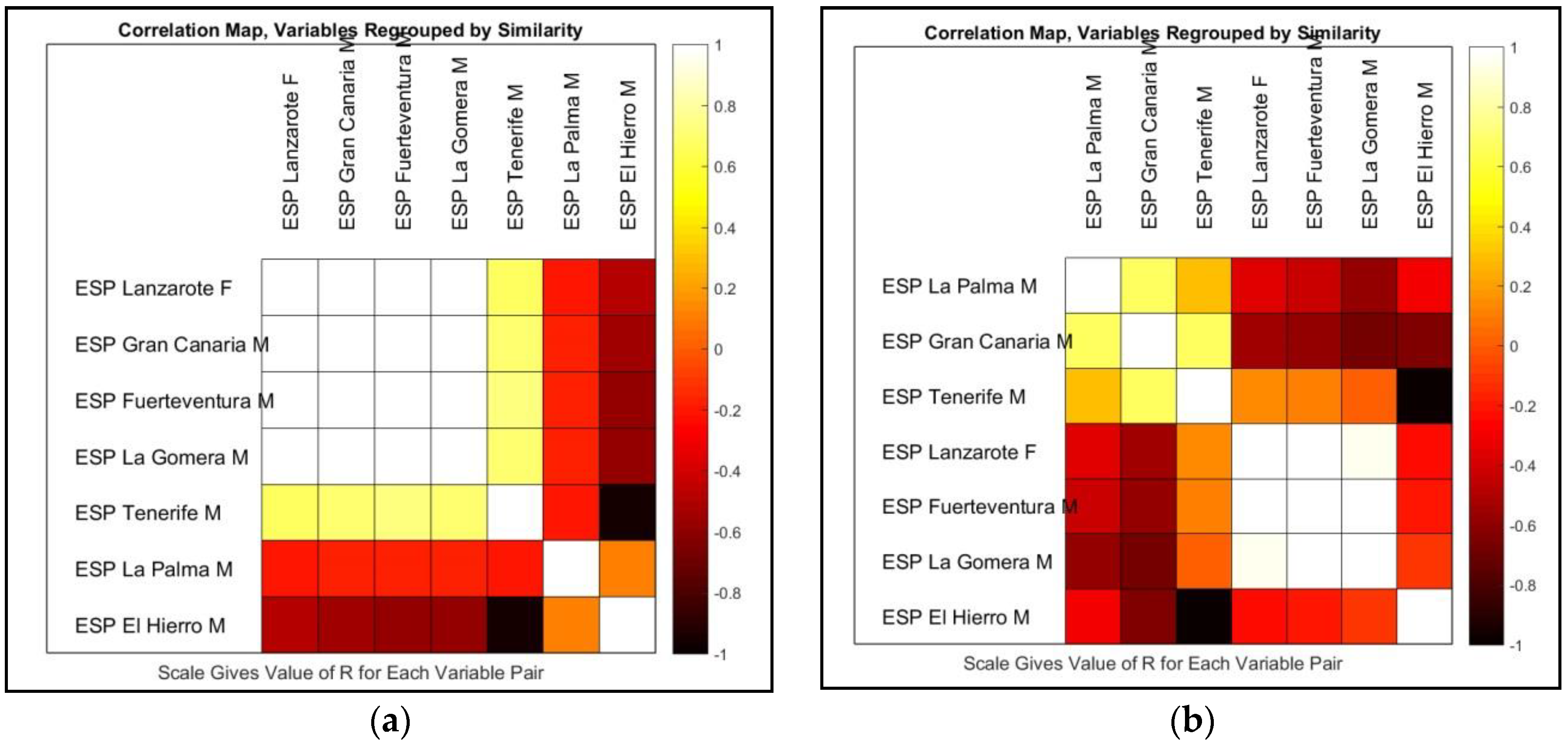
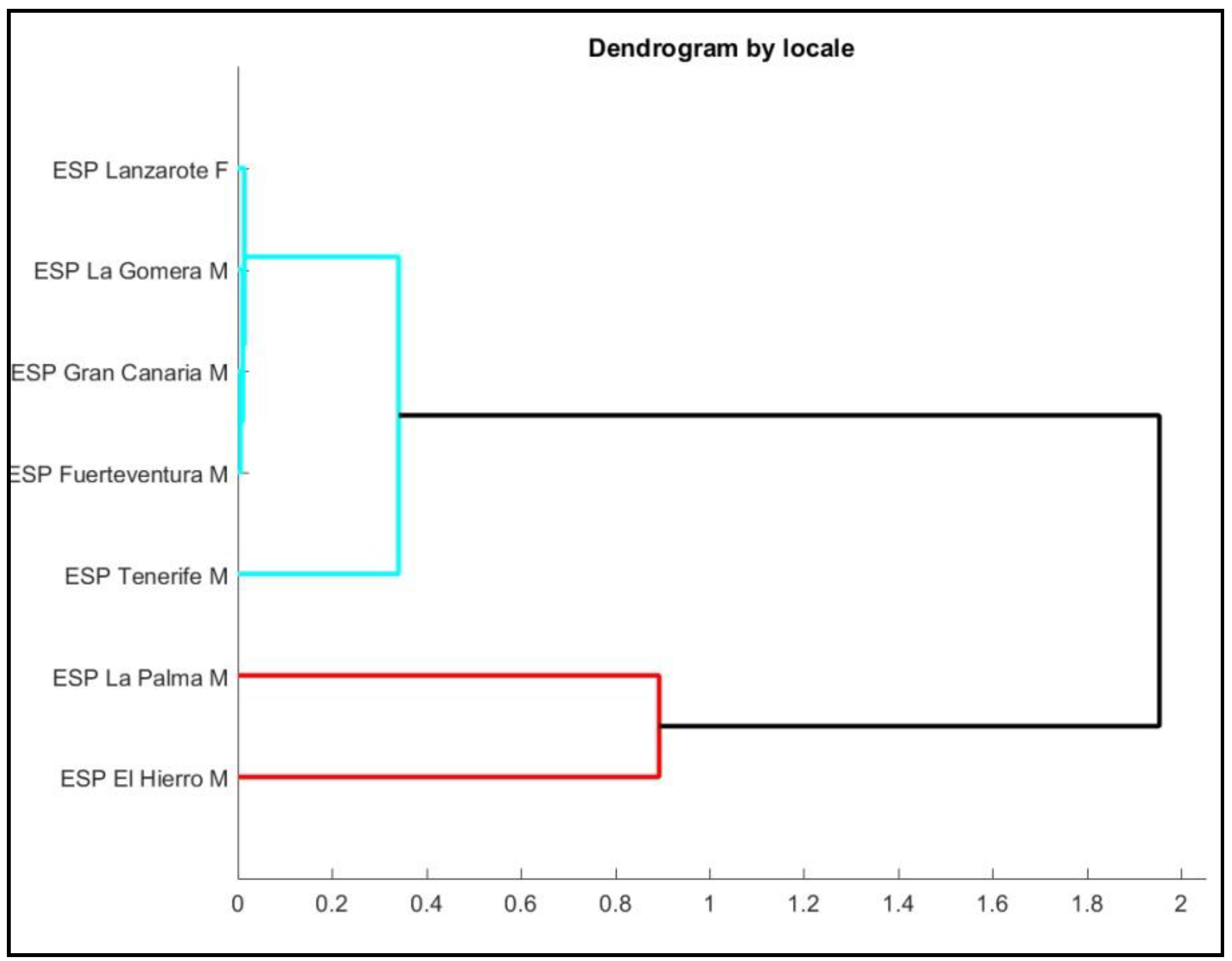
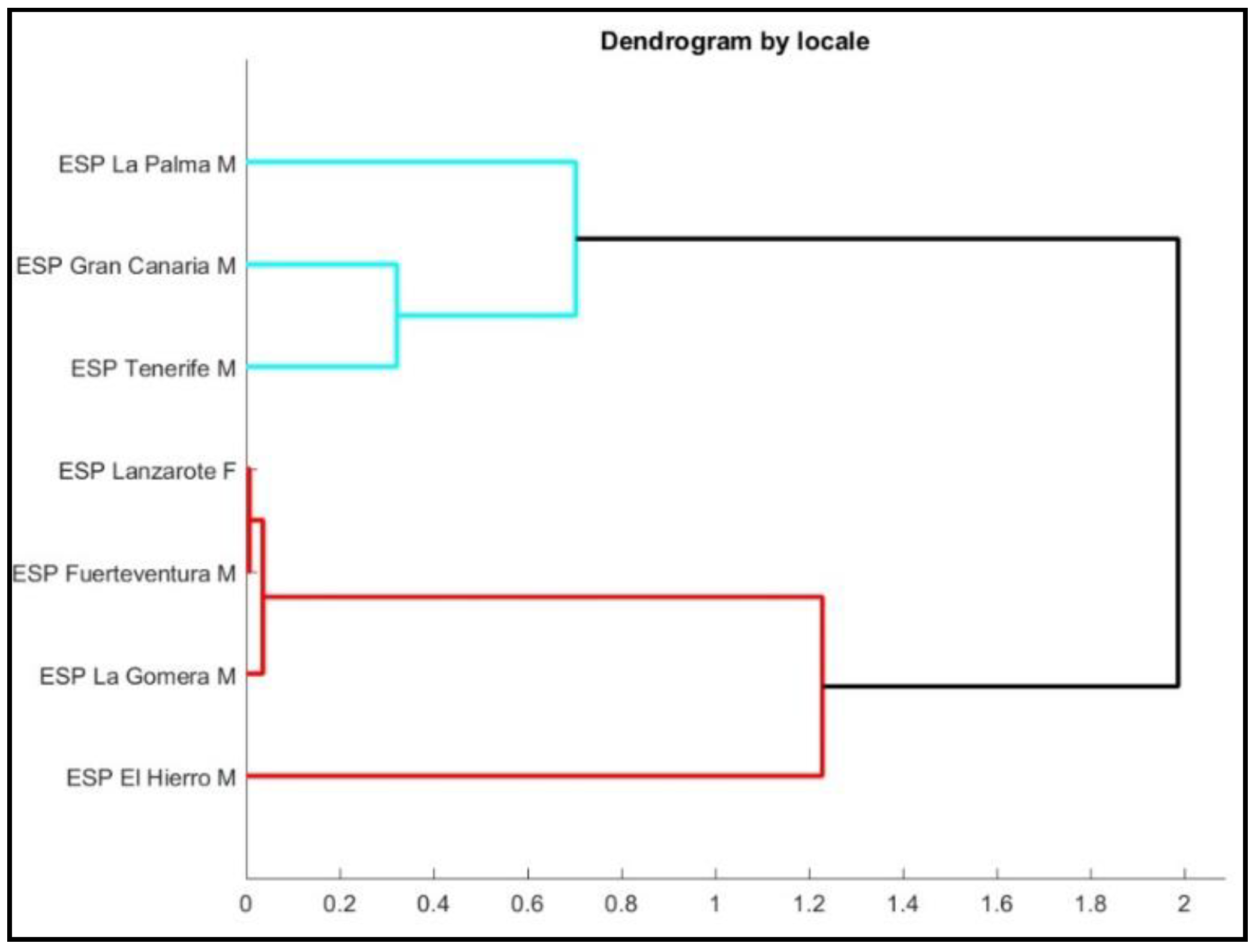
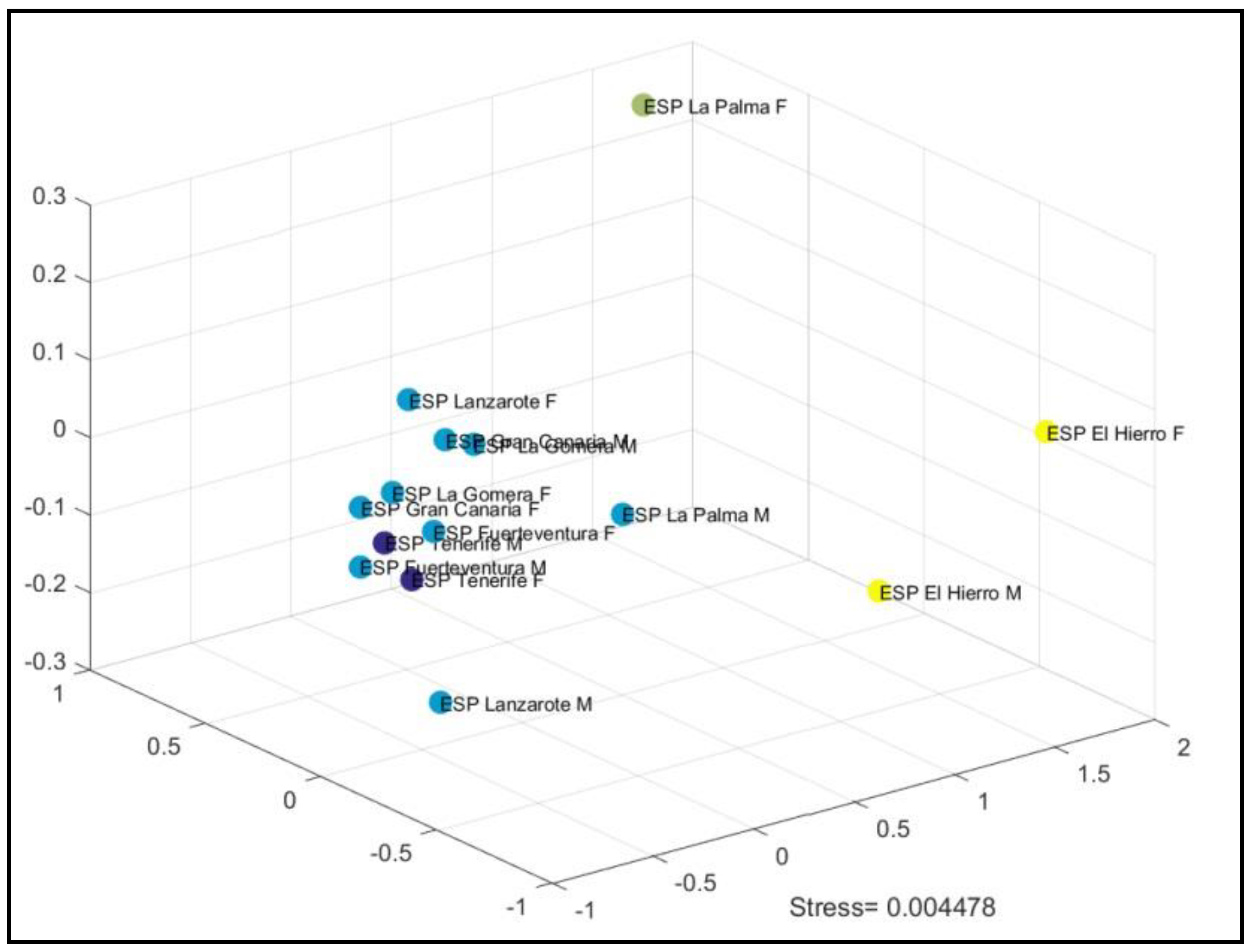
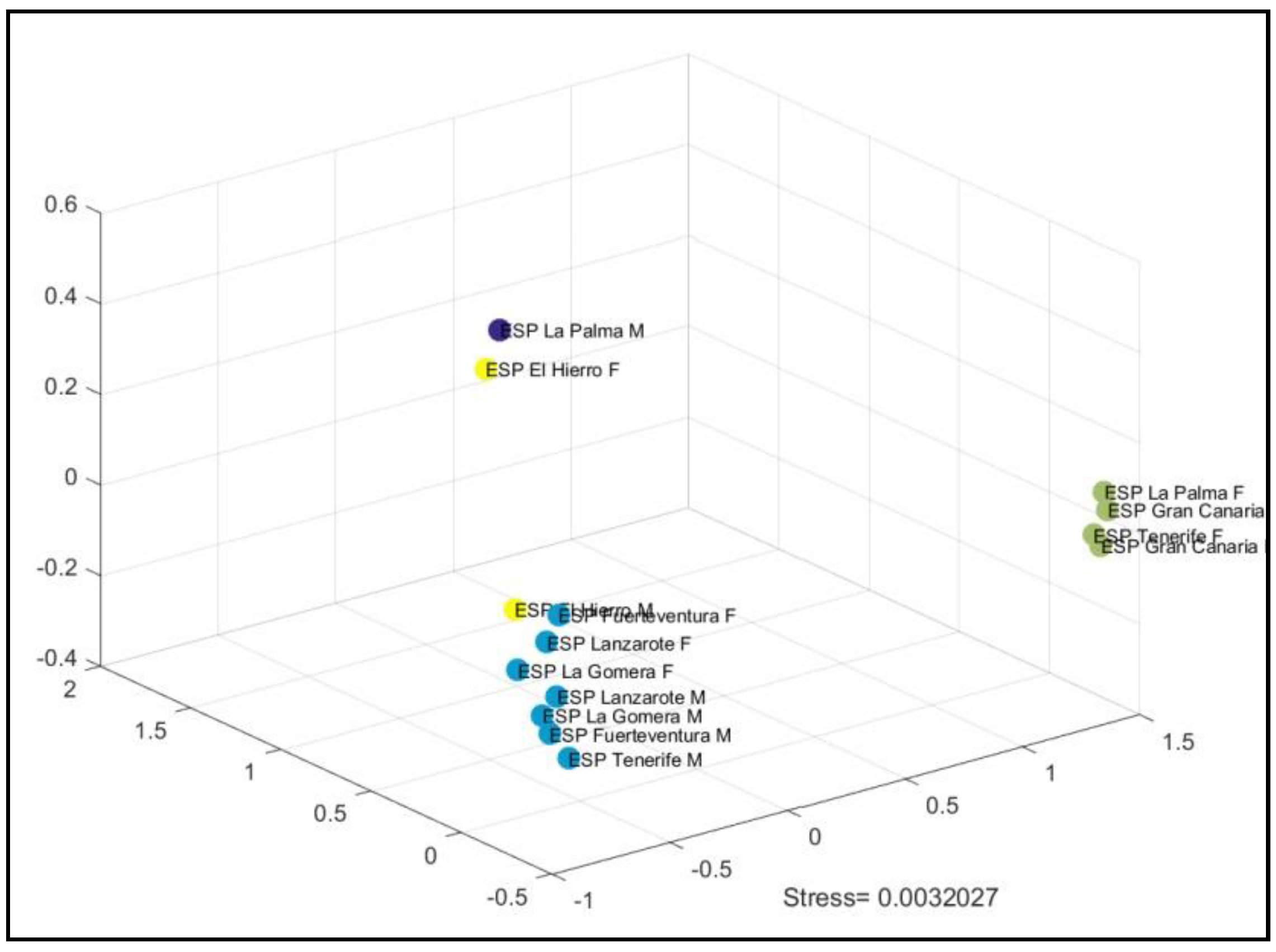
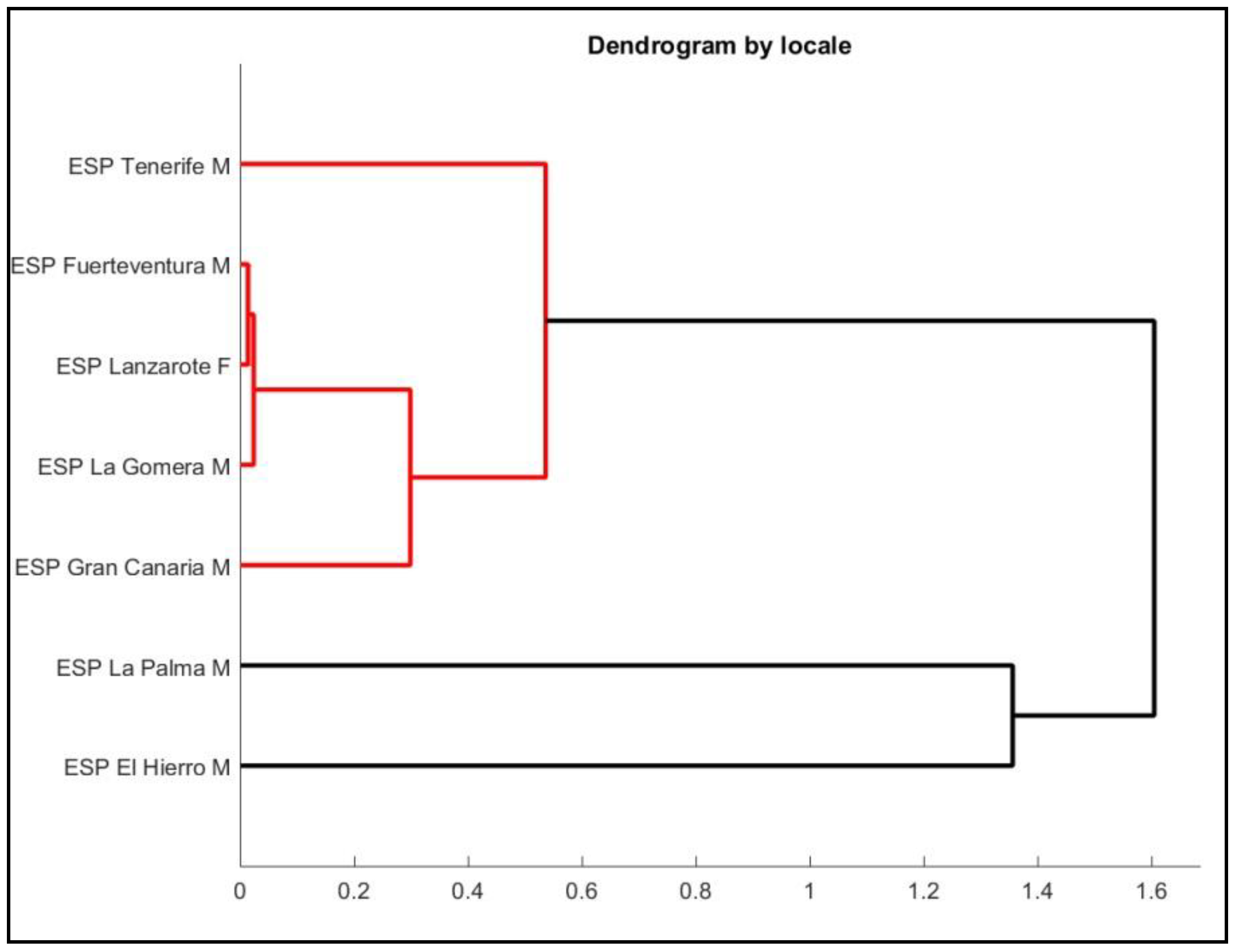
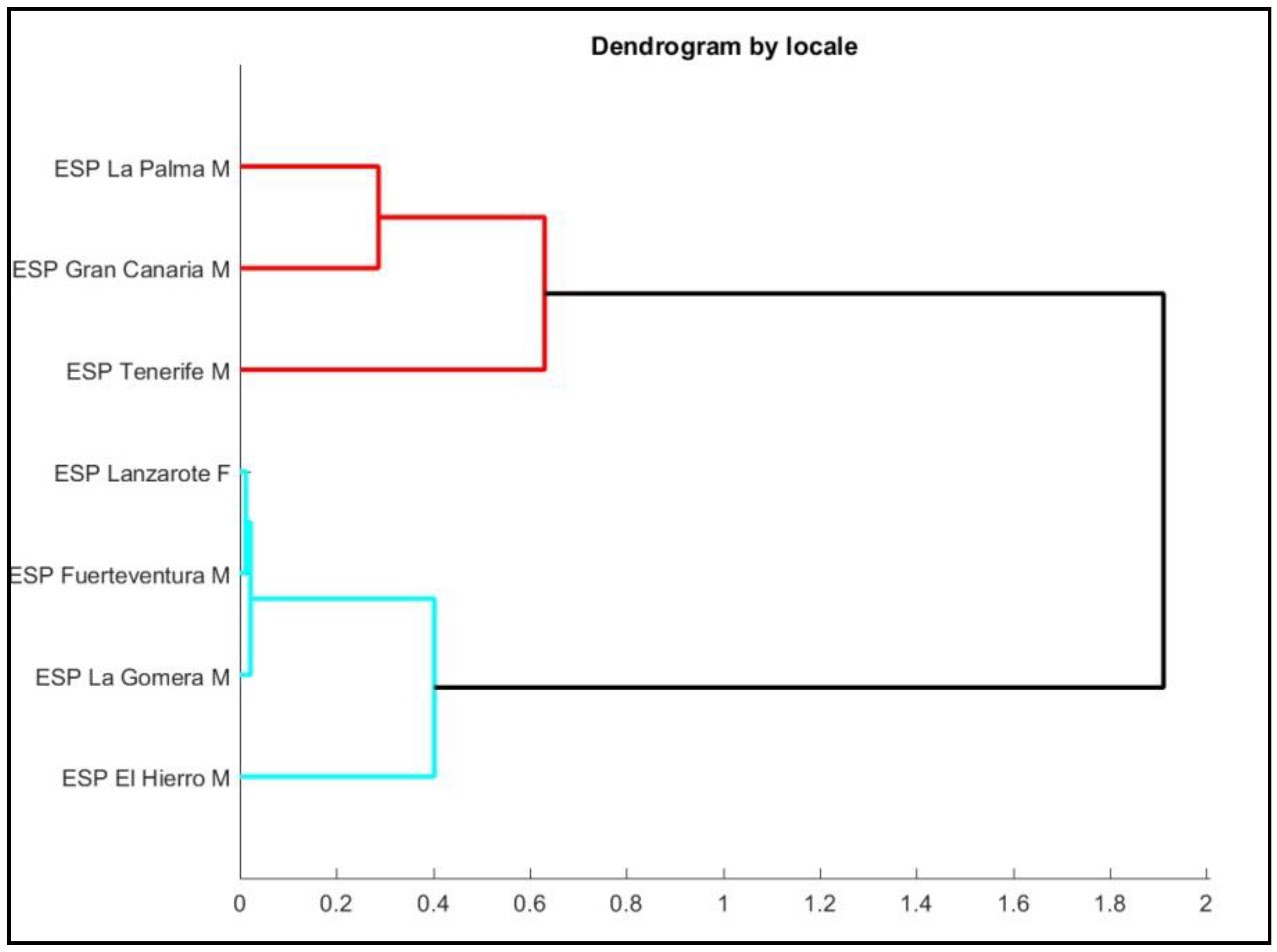
3. Results
3.1. Declarative Sentences
3.2. Interrogative Sentences
3.3. Declarative Sentences vs. Interrogative Sentences
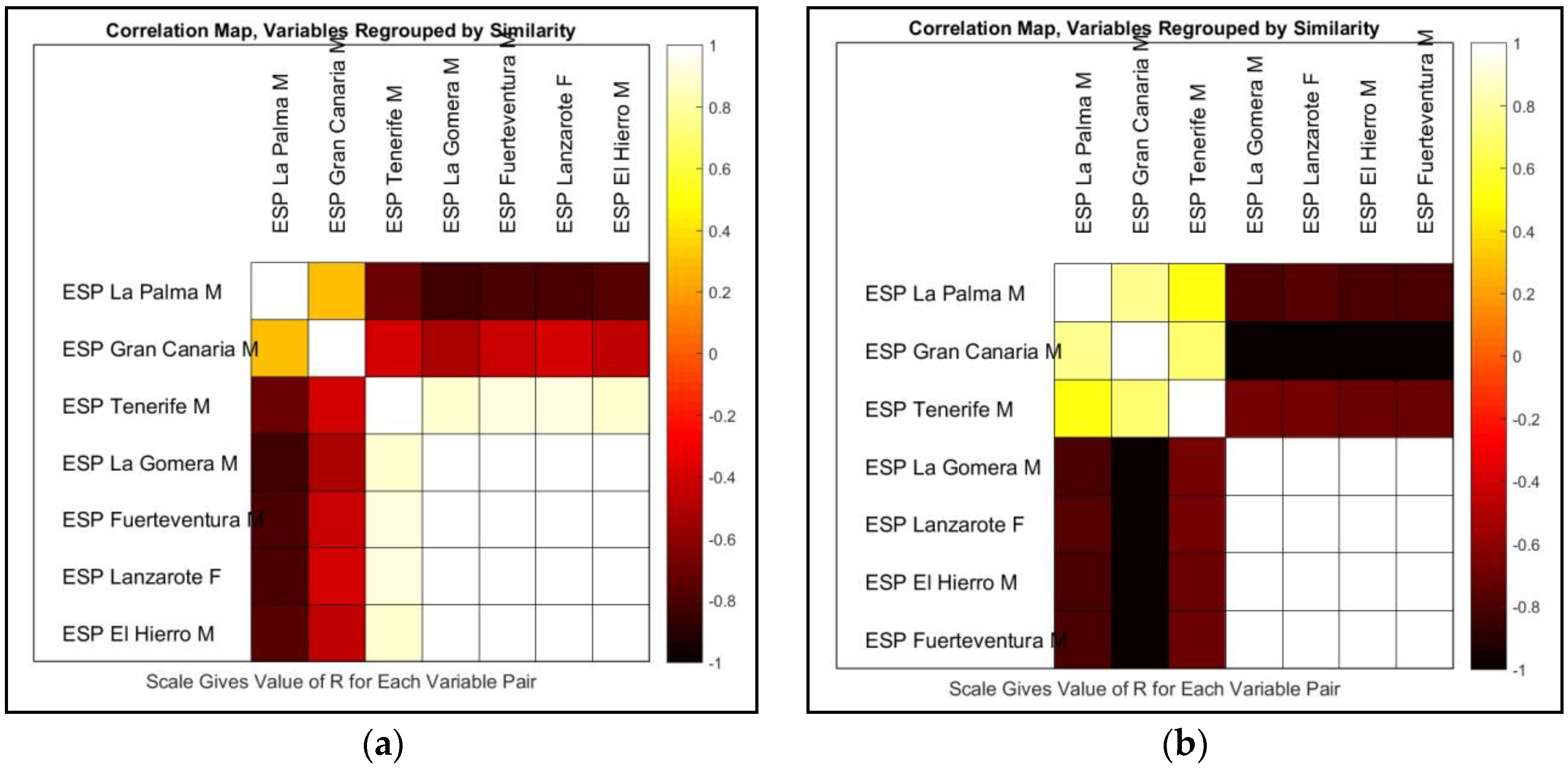
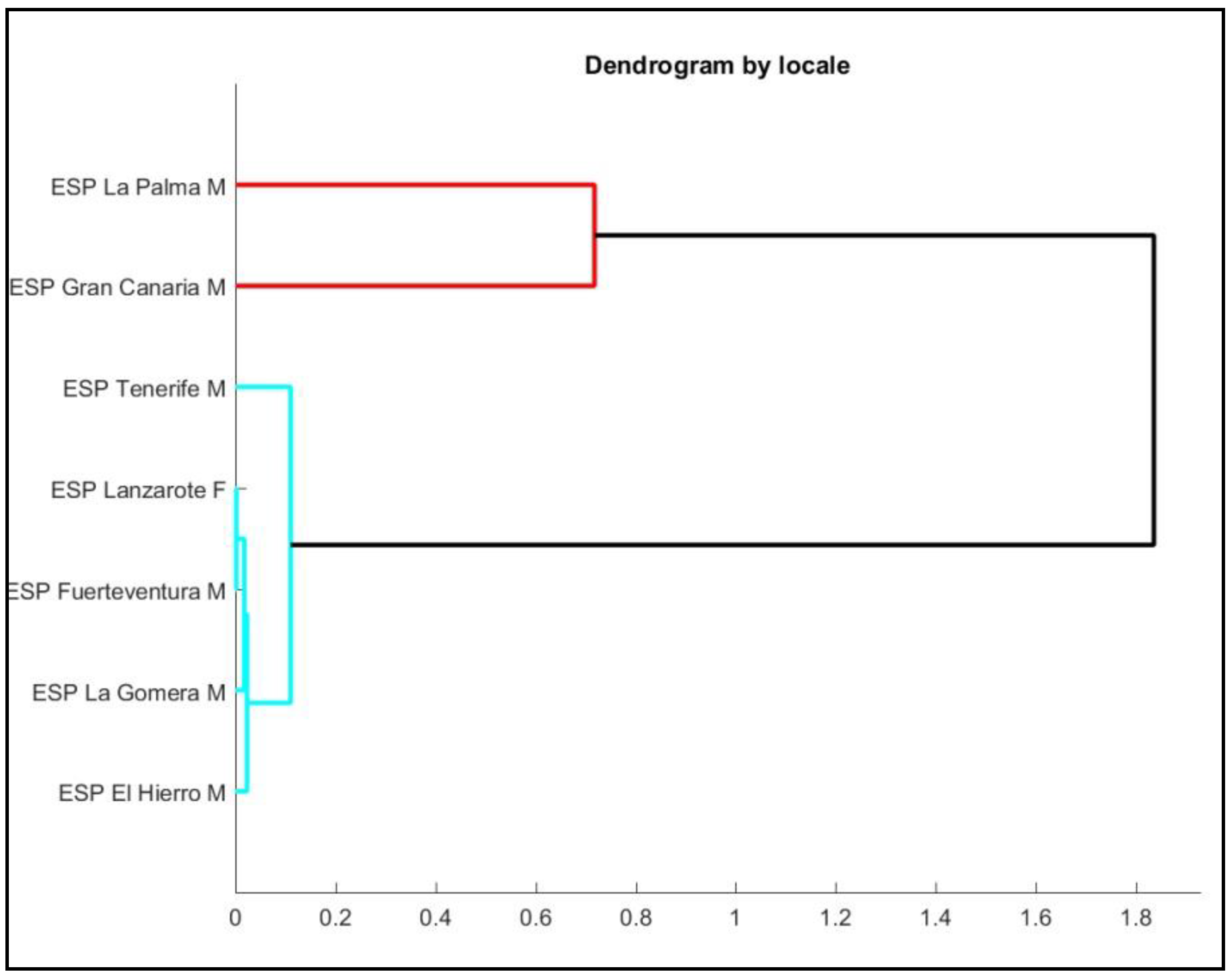
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alvar, Manuel. 1975. Atlas Lingüístico y Etnográfico de las Islas Canarias I–III. Las Palmas de Gran Canaria: Cabildo Insular. [Google Scholar]
- Álvarez, Rosario, Francisco Dubert García, and Xulio Sousa Fernández. 2006. Aplicación da análise dialectométrica aos datos do Atlas Lingüístico Galego. In Lingua e Territorio. Edited by Rosario Álvarez, Francisco Dubert and Xulio Sousa. Santiago de Compostela: Consello da Cultura Galega- Instituto da Lingua Galega, pp. 461–93. [Google Scholar]
- Aurrekoetxea, Gotzon, Karmele Fernández-Aguirre, Jesús Rubio, Borja Ruiz, and Jon Sánchez. 2013. DiaTech: A new tool for dialectology. Literary and Linguistic Computing 28: 23–30. [Google Scholar] [CrossRef][Green Version]
- Bauer, Roland. 2003. Sguardo dialettometrico apoyo alcune zone di transizione dell’Italia norte-orientale (lombardo vs. Trentino vs. Veneto). Parallel X. Sguardi reciprocidad. Vicende linguistiche e cultural dell’area italofona e germanófona. In Atti del Decimo Incontro italo-austriaco dei lingüista. Edited by Raffaella Bombi and Fabiana Fusco. Italia: Forum Editrice, pp. 93–119. [Google Scholar]
- Brezmes-Alonso, David. 2007. Desarrollo de una aplicación software para el análisis de características fundamentales de la voz. Proyecto de fin de carrera. Oviedo: Universidad de Oviedo. [Google Scholar]
- Clua, Esteve. 2004. El método dialectomètric: aplicación del análisis multivariante a la clasificación de las variedades del catalán. In Dialectología y recursos informáticos. Edited by María Pilar Perea. Barcelona: Universitat de Barcelona, pp. 59–88. [Google Scholar]
- D’Andrés Díaz, Ramón, Fernando Álvarez-Balbuena García, and Xosé Miguel Suárez Fernández. 2007. Proxecto ETLEN para o estudio dialectográfico e dialectométrico da zona Eo-Navia, Asturias: fundamentos teóricos. In Actas VII Congreso Internacional de Estudos Galegos: mulleres en Galicia: Galicia e os outros pobas da península. A Coruña: Ediciós do Castro, pp. 749–59. [Google Scholar]
- De Castro Moutinho, Lourdes, Rosa Lidia Coimbra, Albert Rilliard, and Antonio Romano. 2011. Mesure de la variation prosodique diatopique en portugais européen. Estudios de Fonética Experimental XX: 33–55. [Google Scholar]
- Díaz, Chaxiraxi. 2013. Contribución al atlas prosódico de Canarias (AMPER–Can): Declarativas e interrogativas de La Gomera (Islas Canarias). Ph.D. thesis, Universidad de La Laguna, San Cristóbal de La Laguna, Spain. [Google Scholar]
- Díaz, Chaxiraxi, and Josefa Dorta. 2015. ¿Coexistencia de configuraciones tonales en la variedad de español de La Gomera? Cuadernos de Investigación 41: 77–101. [Google Scholar] [CrossRef]
- Díaz, Chaxiraxi, and Josefa Dorta. 2016. Estudio de la entonación en voz masculina en la zona occidental del archipiélago canario. Estudios de Lingüística Aplicada 64: 113–52. [Google Scholar]
- Dorta, Josefa. 2002–2019. Profondis. Available online: http://ampercan.webs.ull.es/ (accessed on 1 October 2018).
- Dorta, Josefa. 2008. La entonación de las interrogativas simples en voz femenina. Zonas urbanas de las islas canarias. In La variation diatopique de l’intonation dans le domain roumain et roman. Edited by Adrian Turculeţ. Rumanía: Presses de l’Université «Al. I. Cuza» de Iaşi, pp. 123–50. [Google Scholar]
- Dorta, Josefa, ed. 2013. Estudio comparativo preliminar de la entonación de Canarias, Cuba y Venezuela. Madrid-Santa Cruz de Tenerife: La Página ediciones S/L, Colección Universidad. [Google Scholar]
- Dorta, Josefa, ed. 2018. La entonación declarativa e interrogativa en cinco zonas fronterizas del español: Canarias, Cuba, Venezuela, Colombia y San Antonio de Texas. Studien zur Romanischen Sprachwissenschaft und Interkulturellen Kommunikation. Frankfurt: Peter Lang Edition. [Google Scholar]
- Dorta, Josefa, and Carolina Jorge. 2017. Influencia del corpus de habla en los patrones entonativos de Canarias. Círculo de Lingüística Aplicada a la Comunicación 72: 95–110. [Google Scholar] [CrossRef]
- Dorta, Josefa, and Elsa Mora. 2011. Patrones entonativos en La Palma (Islas Canarias) y Mérida (andes venezolanos). In La lengua, Lugar de encuentro. Actas del XVI Congreso Internacional de la Asociación de Lingüística y Filología de América Latina. Sección Análisis de estructuras lingüísticas. Edited by Ana María Cesteros, Isabel Molina and Florentino Paredes. Madrid: Servicio de Publicaciones, pp. 85–94. [Google Scholar]
- Dorta, Josefa, José Antonio Martín Gómez, and Carolina Jorge Trujillo. 2018a. La entonación canaria. In La entonación declarativa e interrogativa en cinco zonas fronterizas del español: Canarias, Cuba, Venezuela, Colombia y San Antonio de Texas. Edited by Josefa Dorta. Studien zur Romanischen Sprachwissenschaft und Interkulturellen Kommunikation. Frankfurt: Peter Lang Edition, pp. 85–107. [Google Scholar]
- Dorta, Josefa, José Antonio Martín Gómez, Mercedes Muñetón, and Moisés Betancort. 2018b. Estudio dialectométrico de las variedades del español. In La entonación declarativa e interrogativa en cinco zonas fronterizas del español: Canarias, Cuba, Venezuela, Colombia y San Antonio de Texas. Edited by Josefa Dorta. Studien zur Romanischen Sprachwissenschaft und Interkulturellen Kommunikation. Frankfurt: Peter Lang Edition, pp. 251–66. [Google Scholar]
- Elvira-García, Wendy, Simone Balocco, Ana María Fernández-Planas, Paolo Roseano, and Eugenio Martínez Celdrán. 2015. Presentació d’una aplicació informàtica per a l’anàlisi dialectomètrica de dades prosòdiques en el marc de l’Atles Multimèdia de la Prosòdia de l’Espai Romànic. Paper presented at Workshop sobre la prosòdia del català, Universitat de Barcelona, Barcelona, Spain, June 22. [Google Scholar]
- Elvira-García, Wendy, Simone Balocco, Paolo Roseano, and Ana María Fernández-Planas. 2016. Comparació de mesures de distància prosòdica entrevarietats dialectals. Paper presented at VIII Workshop sobre prosodia del catalá, UPF, Barcelona, Spain, July 4. [Google Scholar]
- Fernández-Planas, Ana María. 2016a. Aspectos de ProDis, una nueva herramienta para el análisis dialectométrico prosódico. Paper presented at Workshop Approaches to Sociolinguistics Aspect of Romanian and Spanish Intonation, Alexandru Ioan Cuza University of Iasi, Iasi, Romania, October 21. [Google Scholar]
- Fernández-Planas, Ana María. 2016b. Características generales de ProDis (herramienta para analizar distancias prosódicas). Paper presented at Servei de Rtactament de la Parla i el So (STPS), UAB, Birmingham, AL, USA, November 18. [Google Scholar]
- Fernández-Planas, Ana María, Paolo Roseano, Eugenio Martínez Celdrán, and Lourdes Romera Barrios. 2011. Aproximación al análisis dialectométrico de la entonación en algunos puntos del dominio lingüístico catalán. Estudios de Fonética Experimental 20: 141–78. [Google Scholar]
- Fernández-Planas, Ana María, Josefa Dorta, Paolo Roseano, Chaxiraxi Díaz, Wendy Elvira-García, José Antonio Martín Gómez, and Eugenio Martínez Celdrán. 2015. Distancia y proximidad prosódica entre algunas variedades del español: Un estudio dialectométrico a partir de datos acústicos. Revista de Lingüística teórica y Aplicada 53: 13–45. [Google Scholar] [CrossRef]
- Fernández-Planas, Ana María, Paolo Roseano, Wendy Elvira-García, and Simone Balocco. 2017. Génesis y aspectos fundamentales de ProDis. Paper presented at Congreso Subsidia: Herramientas y recursos para las ciencias del habla, Universidad de Málaga, Málaga, Spain, June 21–23. [Google Scholar]
- Fernández-Planas, Ana María, Wendy Elvira-García, Paolo Roseano, and Simone Balocco. 2019. Análisis dialectométrico con ProDis: Un paso más en los estudios prosódicos de AMPER. In Investigación geoprosódica. AMPER: análisis y retos. Edited by Josefa Dorta. Frankfurt: Iberoamericana Vervuert. [Google Scholar]
- Goebl, Hans. 1981. Eléments d’analyse dialectométrique (avec application à l’AIS). Revue de Linguistique Romane 45: 349–420. [Google Scholar]
- Goebl, Hans. 1987. Points chauds de l’analyse dialectométrique: pondération et visualisation. Revue de Linguistique Romane 51: 63–118. [Google Scholar]
- Goebl, Hans. 2002. Analyse dialectométrique des structures de profondeur de l’ALF. Revue de Linguistique Romane 66: 5–63. [Google Scholar]
- Goebl, Hans. 2003. Regards dialectométriques sur les données de l’Atlas linguistique de la France (ALF): Relations quantitatives et structures de profondeur. Estudis Romànics 25: 59–120. [Google Scholar]
- Jorge Trujillo, Carolina. 2015. Patrones entonativos de las declarativas e interrogativas de El Hierro y Fuerteventura. Ph.D. thesis, Universidad de La Laguna, San Cristóbal de La Laguna, Spain. [Google Scholar]
- Kruskal, Joseph. 1964. Multidimensional scaling by optimizing goodness of fit to a non-metric hypothesis. Psychometrika 29: 1–27. [Google Scholar] [CrossRef]
- Martínez Calvo, Adela, and Elisa Fernández Rei. 2015. Unha ferramenta informática para a análise dialectométrica da prosodia. Estudios de Fonética Experimental 24: 289–303. [Google Scholar]
- Polanco Roig, Lluís B. 1992. Llengua i dialecte: una aplicació dialectomètrica a la llengua catalana. In Miscel·lània Sanchis Guarner. Edited by Antoni Ferrando Francés. Abadia de Montserrat: Universitat de València, Departament de Filologia Catalana, vol. 3, pp. 5–28. [Google Scholar]
- Rilliard, Albert, and Jean Pierre Lai. 2008. Outils pour le calcul et la comparaison prosodique dans le cadre du projet AMPER-L’exemple des variétés occitane et sarde. In La variation diatopique de l’intonation dans le domaine roumain et roman. Edited by Adrian Turculeţ. Iaşi: Presses de l’Université «Al. I. Cuza» de Iaşi, pp. 217–29. [Google Scholar]
- Romano, Antonio. 1995. Développement d’un environnement de travail pour l’étude des structures sonores et intonatives de la parole. In Mémoire de DEA En Sciences Du Langage. Grenoble: ICP, Univ. Stendhal. [Google Scholar]
- Romano, Antonio, Michel Contini, Jean Pierre Lai, and Albert Rilliard. 2011. Distancias prosódicas entre variedades románicas en el marco del proyecto AMPER. Revista Internacional de Linguística Iberoamericana RILI IX: 17–26. [Google Scholar]
- Saramago, João. 2002. Diferenciação lexical interpontual nos territórios galego e português (Estudo dialectométrico aplicado a materiais galegos do ALGa). In Dialectoloxía e léxico. Edited by Rosario Álvarez, Francisco Dubert García and Xulio Sousa Fernández. Santiago de Compostela: Instituto da Lingua Galega/Consello da Cultura Galega, Sección de Lingua, pp. 41–68. [Google Scholar]
- Séguy, Jean. 1973. La dialectométrie dans l’Atlas lingüística de la Gascuña. Revue de Linguistique Romane 37: 1–24. [Google Scholar]
- Sousa, Xulio. 2006. Aproximación á análise dialectométrica da variedades xeolingüísticas galegas: un estudo comparativo. In Actas do I Encontro de Estudos Dialectológicos. Edited by Maria Clara Rolão Bernardo and Helena Mateus Montenegro. Ponta Delgada: Instituto Cultural de Ponta Delgada, pp. 345–62. [Google Scholar]
| 1 | In the code of each informant W stands for Spanish, C stands for the variety of the Canary Islands; the third digit identifies the place of origin and the last digit sex of the informants (women = 1; men = 2). |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Informants | ||||
|---|---|---|---|---|
| Code1 | Hometown and Survey Area | Age | Study Levels | |
| Women | Men | |||
| WCq1 | WCq2 | Valverde (El Hierro) | 25–55 years old | Without higher education |
| WCo1 | WCo2 | San Sebastián de La Gomera (La Gomera) | ||
| WCm1 | WCm2 | Santa Cruz de La Palma (La Palma) | ||
| WC91 | WC92 | San Cristóbal de La Laguna (Tenerife) | ||
| WCk1 | WCk2 | Las Palmas de Gran Canaria (Gran Canaria) | ||
| WCn1 | WCn2 | Puerto del Rosario (Fuerteventura) | ||
| WCp1 | WCp2 | Arrecife (Lanzarote) | ||
| Corpus | ||||
|---|---|---|---|---|
| S + V + O | S + V + O + EXP | |||
| D | I | D | I | |
| Women | 189 | 189 | 567 | 567 |
| Men | 189 | 189 | 567 | 567 |
| Total | 378 | 378 | 1134 | 1134 |
| 756 | 2268 | |||
| 3024 | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dorta, J.; González Rodríguez, M.J. Tonal Proximity Relationship in the Spanish of the Canary Islands in the Light of Dialectometry. Languages 2019, 4, 29. https://doi.org/10.3390/languages4020029
Dorta J, González Rodríguez MJ. Tonal Proximity Relationship in the Spanish of the Canary Islands in the Light of Dialectometry. Languages. 2019; 4(2):29. https://doi.org/10.3390/languages4020029
Chicago/Turabian StyleDorta, Josefa, and María José González Rodríguez. 2019. "Tonal Proximity Relationship in the Spanish of the Canary Islands in the Light of Dialectometry" Languages 4, no. 2: 29. https://doi.org/10.3390/languages4020029
APA StyleDorta, J., & González Rodríguez, M. J. (2019). Tonal Proximity Relationship in the Spanish of the Canary Islands in the Light of Dialectometry. Languages, 4(2), 29. https://doi.org/10.3390/languages4020029