Refunctionalization and Usage Frequency: An Exploratory Questionnaire Study


Abstract
:1. Introduction
2. Usage Frequency as a Determinant of Refunctionalization
| a. | Me | lo | ha | dicho | a | mí. |
| to.me | it | have.prs.3sg | say.ptcp | to | me | |
| “She said it to me (not you).” | ||||||
| b. | Me | lo | ha | dicho. | ||
| to.me | it | have.prs.3sg | say.ptcp | |||
| “She said it to me.” | ||||||
| c. | ?Lo | ha | dicho | a | mí. | |
| it | have.prs.3sg | say.ptcp | to | me | ||
| “She said it to me (not you).” | ||||||
3. Folk Etymology as Refunctionalization
a type of reanalysis. Due to their formal phonetic similarity, speakers relate two words to each other. This reanalysis always contradicts the real etymology of the reanalyzed word.
Folk etymology is a process in which a synchronically isolated and as such unmotivated word or word constituent is attributed to a word that is phonetically similar or (partially) identical […] in a way that is incorrect from an etymological and diachronic perspective. Consequently, the word or word constituent receives a new motivation and interpretation, and is de-isolated.
4. Questionnaire Study
4.1. Materials
4.2. Procedure
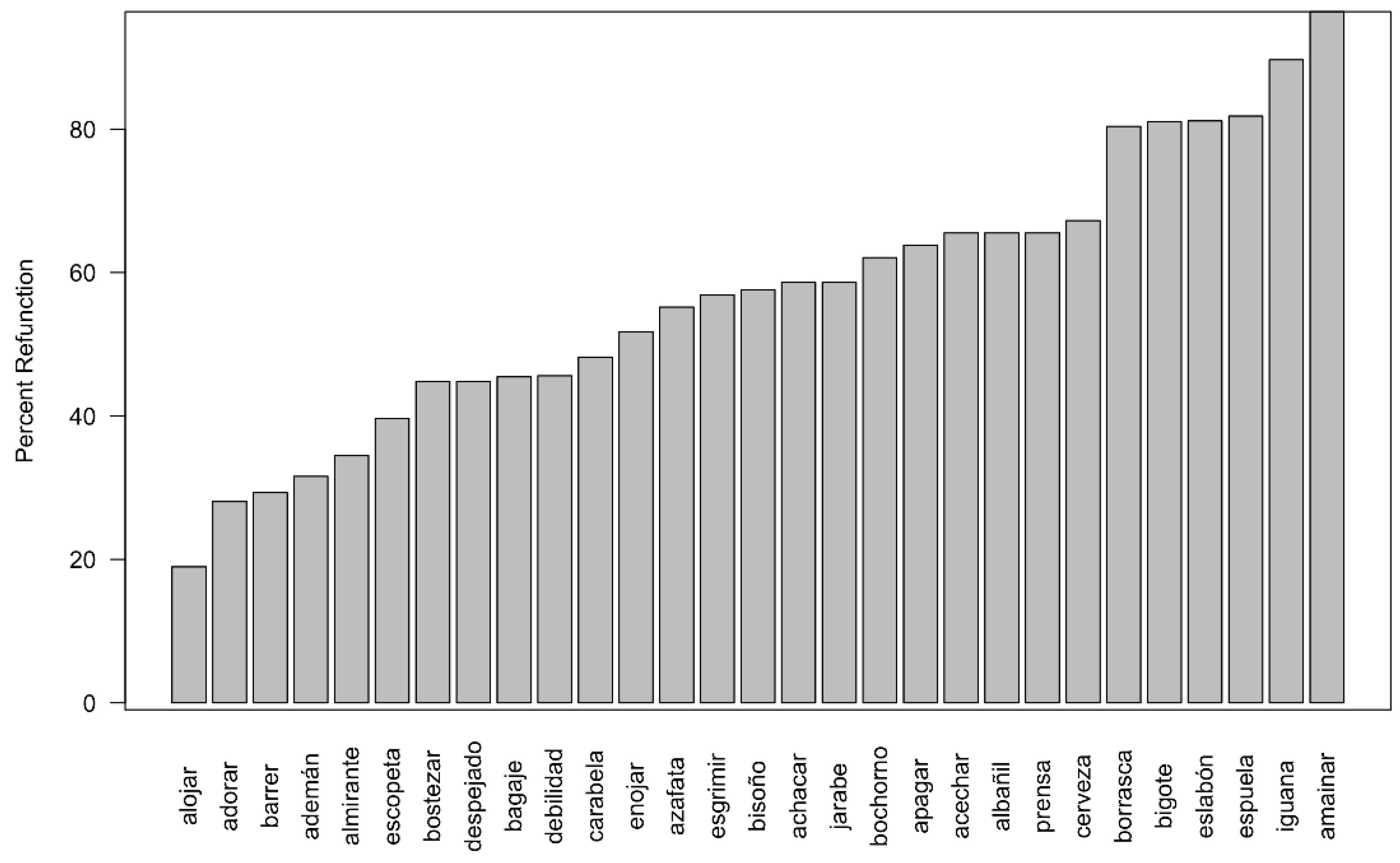
4.3. Results
4.3.1. Social Indicators
4.3.2. Length of Target Word and Proposed Etymon
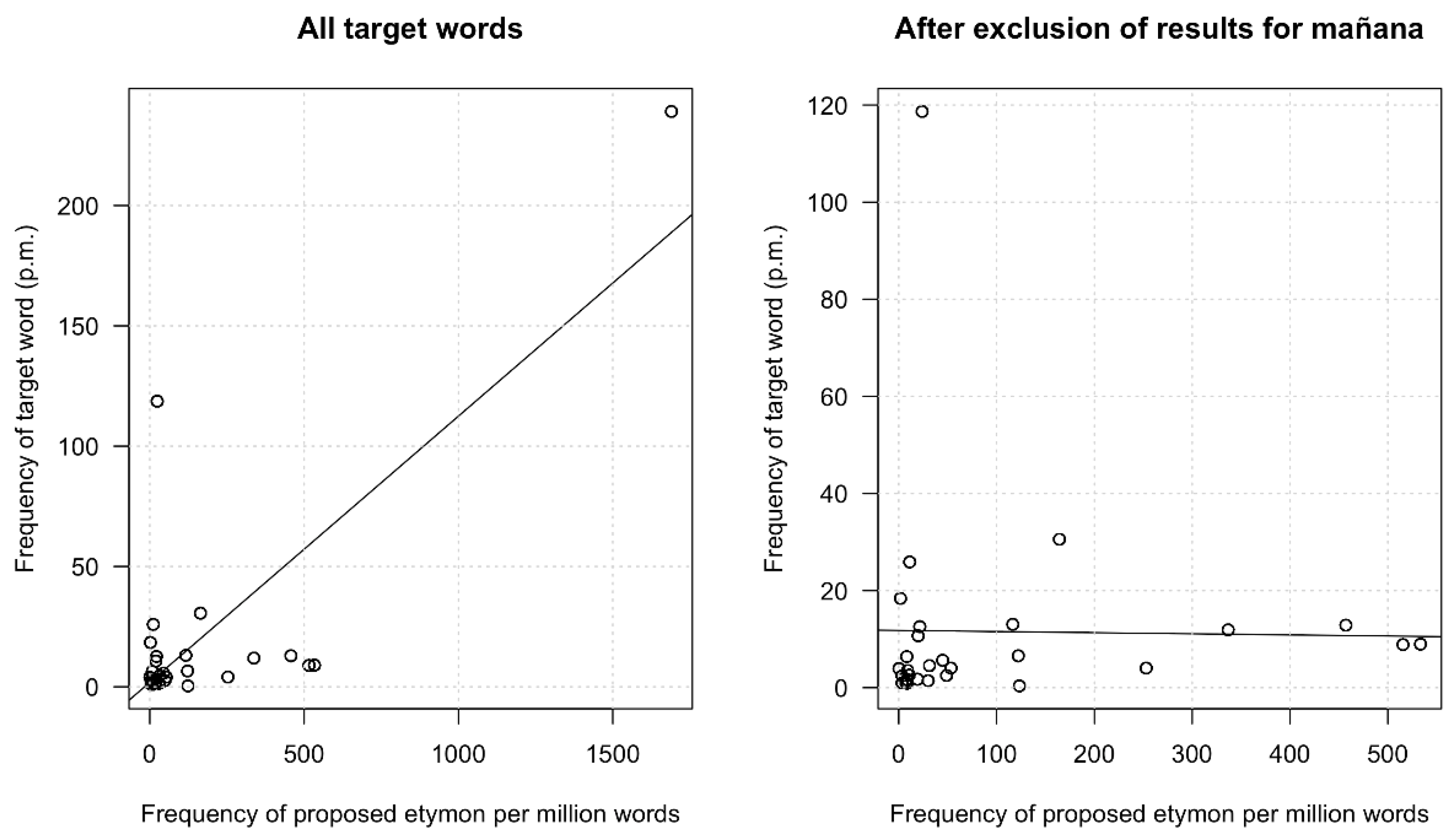
4.3.3. Usage Frequency of Target Word and Proposed Etymon
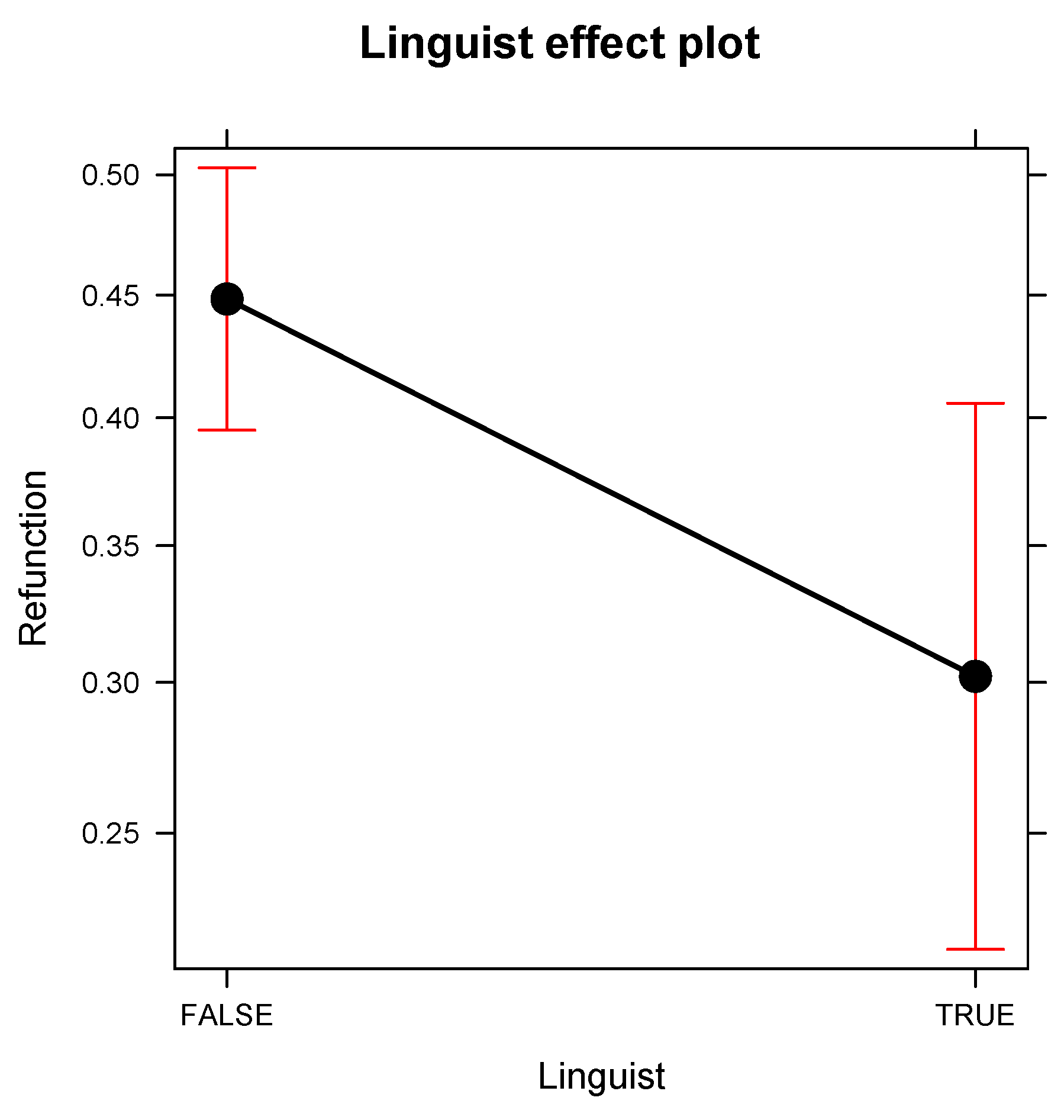
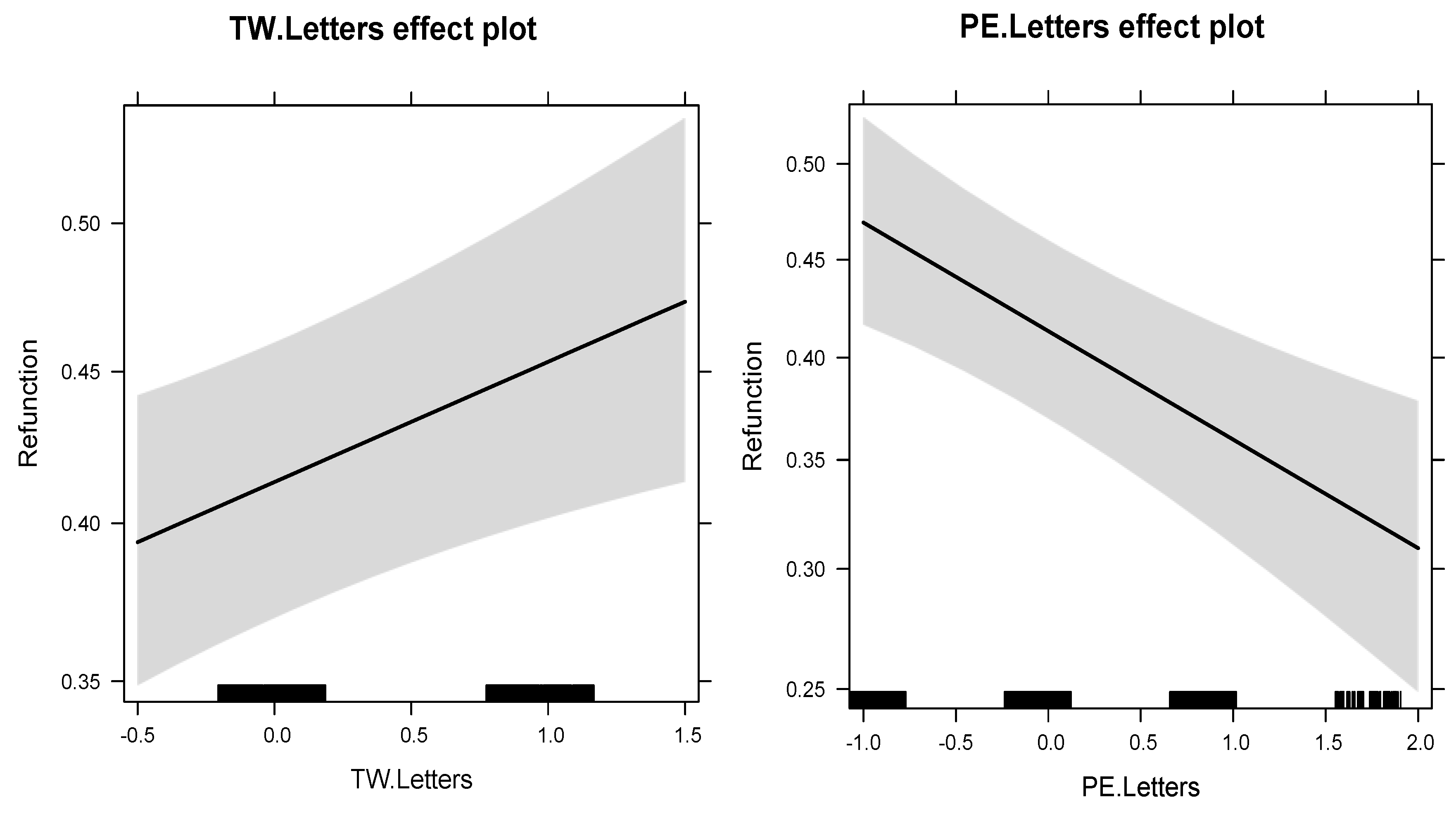
5. Discussion
6. Conclusions
Funding
Conflicts of Interest
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Word | Etymology (Dworkin 2012; Real Academia Española 2014) | Proposed Etymon |
|---|---|---|
| Acechar “to stalk” | lat. * assectare “attend to” (Dworkin 2012, p. 102) | echar “to throw” |
| achacar “to blame” | arab. tasakka “blame” (Dworkin 2012, p. 102) | atacar “to attack” |
| ademán “gesture” | arab. ad-daman “legal guarantee” (Dworkin 2012, p. 46) | Mano “hand” |
| adorar “to adore” | lat. ad-orare “towards-pray” (Dworkin 2012, p. 161) | oro “gold” |
| albañil “bricklayer” | arab. al-banna “the construer” (Dworkin 2012, p. 112) | Baño “bathroom” |
| almirante “admiral” | arab. amîr “commander” (Dworkin 2012, p. 90) | mirar “to look” |
| alojar “to lodge” | sp. lonja “portico, porch” (Dworkin 2012, p. 146) | lugar “place” |
| amainar “to weaken, flag” | goth. af-maginon “lower the sails” (Dworkin 2012, p. 72) | marginal “marginal” |
| apagar “to turn off” | lat. pacare “pacify, quiet” (Dworkin 2012, p. 55) | pagar “to pay” |
| azafata “stewardess” | arab. al-safát “basket” (Dworkin 2012, p. 109) | zarpar “to set sails” |
| bagaje “baggage” | fr. bagage “baggage” (Dworkin 2012, p. 127) | vagar “to wander” |
| barrer “to sweep” | lat. verrere “sweep” (Dworkin 2012, p. 46) | barro “mud” |
| bigote “mustache” | ger. Bei Gott “with god” or fr. bigot (Dworkin 2012, pp. 77–78) | gota “drop” |
| bisoño “greenhorn” | it. bisogno “need” (Dworkin 2012, pp. 151–52) | sueño “dream” |
| bochorno “extreme heat” | lat. vulturnus “south wind” (Dworkin 2012, p. 49) | horno “oven” |
| borrasca “storm (at sea)” | probably it. burrasca “storm“ (Dworkin 2012, p. 145) | rascar “to scratch” |
| bostezar “to yawn” | lat. oscitare “open the mouth wide” (Dworkin 2012, p. 52) | voz “voice” |
| carabela “type of ship” | ptg. caravela “type of ship” < greek κάραβος “light boat” (Real Academia Española 2014) | vela “to sail” |
| cerveza “beer” | celtic cervisia “beer” (Dworkin 2012, p. 28) | hervir “to boil” |
| debilidad “weakness” | fr. debilité “weakness” (Dworkin 2012, p. 132) < PIE *bel “power, strength” | bilis “bile” |
| despejado “cloudless” | ptg. despejar “pour” (Dworkin 2012, p. 188) | espejo “mirror” |
| enojar “anger” | o.provenz. enojar “anger” (Dworkin 2012, p. 125) | ojo “eye” |
| escopeta “shotgun” | it. schipetto “firearm” (Dworkin 2012, p. 152) | escupir “to spit” |
| esgrimir “to wield a weapon” | o.provenz. esgremir “wield a weapon” (Dworkin 2012, p. 125) | grima “chills” |
| eslabón “link (of a chain)” | goth. snôbô “link“ (Dworkin 2012, p. 72) | eslavo “slave” |
| espuela “spur” | goth. spaúra “spur” (Dworkin 2012, p. 71) | esposo “husband” |
| iguana “type of saurian” | taíno iguana “type of saurian” (Dworkin 2012, p. 200) | guante “glove” |
| jarabe “syrup” | arab. sharb “syrup” (Dworkin 2012, p. 84) | jarro “jug” |
| mañana “morning” | v.lat. *maneana “morning” (Dworkin 2012, p. 56) | año “year” |
| prensa “press” | cat. premer “press, squeeze” (Dworkin 2012, p. 194) | prender “to take" |
| Original Text | English Translation |
|---|---|
| 1. Introduction ¡Hola! Muchas gracias por cooperar en nuestro EtimoTest. Pretendemos examinar el conocimiento que tienen de la etimología—el origen de las palabras—los hablantes nativos del español. A menudo, las nuevas palabras se basan en otras palabras ya existentes en la lengua. Por ejemplo, el adjetivo barato deriva del verbo baratar (“trocar, comprar a bajo precio”). La palabra escarnimiento (“desengaño”) deriva del antiguo verbo escanir (“hacer burla de alguien”). A veces tenemos una intuición sobre la palabra que fue la base para una nueva palabra; otras veces, en cambio, no la tenemos. Para examinar tu nivel de conocimiento de la etimología de las palabras, te presentaremos 30 palabras españolas. Para cada de una de ellas, te ofrecemos una palabra base como solución. En algunos casos, esta palabra es la palabra base correcta; en otros casos, no. Te preguntaremos si es posible que la palabra derive de la palabra base, y te daremos tres opciones: SÍ, NO, y NO CONOZCO LA(S) PALABRA(S). Por favor, selecciona esta última opción solo si no conoces una de las palabras. En total, el EtimoTest dura alrededor de 10 minutos. Un aviso importante: por favor rellena el cuestionario sin utilizar recursos como diccionarios, google, etc. Así invalidarías los resultados de tu EtimoTest. Antes de empezar, tenemos que hacerte unas breves preguntas sobre tu persona. Te garantizamos que tus respuestas van a ser tratadas con la máxima discreción. | 1. Introduction Hi! Thank you very much for participating in our EtimoTest. We want to investigate the knowledge of etymology—the origin of words—of native speakers of Spanish. Frequently, new words are based on other words that already exist in a language. For instance, the adjective barato “cheap” derives from the verb baratar “to bargain, buy at a cheap price”. The words escarnimiento “punishment” derives from the old verb escanir “make fun of somebody”. Sometimes we have an intuition about which word served as a basis for the new word, sometimes we do not. In order to examine your level of knowledge of the etymology of words, we will present you with 30 Spanish words. For each one of these, we offer you an origin word as a solution. In some cases, this word is the correct origin word, in some cases it is not. We will ask you if it is possible that the word derives from the origin word, and we will give you three options: YES, NO, and I DO NOT KNOW THE WORD(S). Please select this last option only if you do not know one of the words. The EtimoTest will last around 10 min. One important point: please fill out the questionnaire without using dictionaries, Google, etc. In doing so, you would invalidate the results of your EtimoTest. Before we begin, we have to ask you a few questions about yourself. We guarantee you that your answers will be treated with maximal discretion. |
| 2. Background questions 2.1 ¿Cuál es tu sexo? Femenino Masculino 2.2 ¿Cuál es tu edad? Menos de 20 años Entre 20 y 30 años Más de 30 años 2.3 ¿Eres hablante nativo del español? Sí No 2.4 ¿Cuál es tu nivel de educación? Estudios Primarios Educación Secundaria Obligatoria Bachillerato Educación secundaria post obligatoria Estudios universitarios (Grado/Máster/Posgrado/Doctorado) 2.5 Sí estás realizando/has realizado estudios universitarios, ¿cuál era la asignatura/las asignaturas? __________________________________ | 2. Background questions 2.1 What is your sex? Feminine Masculine 2.2 What is your age? Less than 20 years Between 20 and 30 years More than 30 years 2.3 Are you a native speaker of Spanish? Yes No 2.4 What is your level of education? Estudios Primarios Educación Secundaria Obligatoria Bachillerato Educación secundaria post obligatoria Estudios universitarios (Grado/Máster/Posgrado/Doctorado) 2.5 If you are studying/have studied at a university, what was the study subject? __________________________________ |
| 3. Test ¿Es posible que la palabra [TARGET] derive de la palabra [PROPOSED ETYMON]? Sí No No conozco la(s) palabra(s) [30 questions in total, randomized order] | 3. Test Is it possible that the word [TARGET] derives from the word [PROPOSED ETYMON]? Yes No I do not know the word(s) [30 questions in total, randomized order] |
| 4. Confirmation text Esta ha sido la última pregunta. ¡Muchas gracias por tu participación en el EtimoTest! | 4. Confirmation text This has been the last question. Thank you very much for your participation in the EtimoTest! |
| Variable | Level | Betas | Odds | SE | ZVAL | p | |
|---|---|---|---|---|---|---|---|
| (Intercept) | 0.00 | 1.00 | 0.30 | 0.10 | 0.994 | ||
| AGE | <20 | Reference level | |||||
| 21–30 | −0.18 | 0.84 | 0.31 | −0.58 | 0.562 | ||
| >31 | −0.44 | 0.64 | 0.32 | −1.39 | 0.164 | ||
| Sex | Feminine | Reference level | |||||
| Masculine | 0.15 | 1.16 | 0.20 | 0.74 | 0.458 | ||
| Linguist | FALSE | Reference level | |||||
| TRUE | −0.63 | 0.53 | 0.27 | −2.33 | 0.020 | * | |
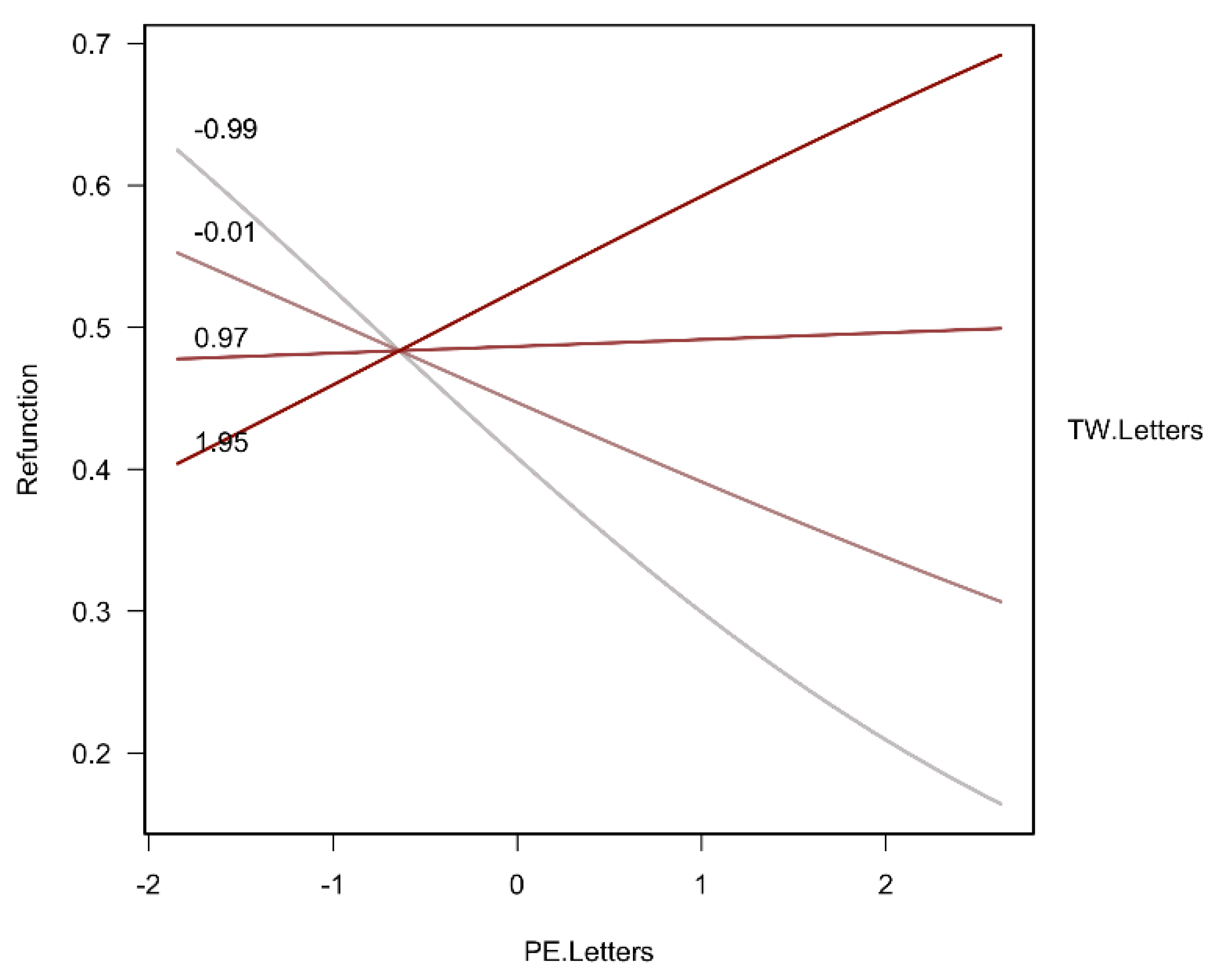
| TW.Letters | 0.16 | 1.18 | 0.06 | 2.86 | 0.004 | ** | |
| PE.Letters | −0.23 | 0.80 | 0.06 | 3.77 | 0.000 | *** | |
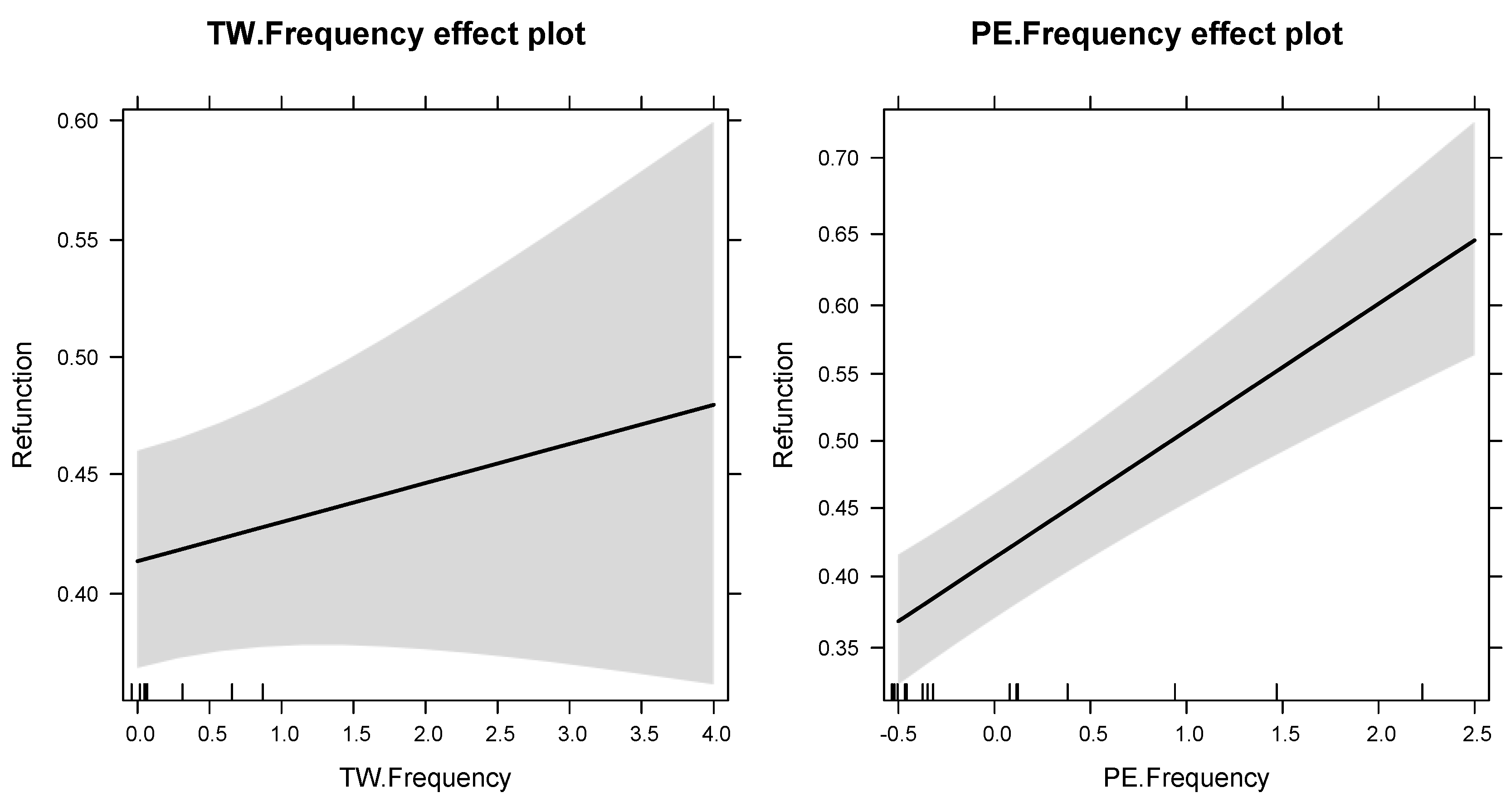
| TW.Frequency | 0.07 | 1.07 | 0.06 | 1.17 | 0.243 | ||
| PE.Frequency | 0.38 | 1.46 | 0.06 | 6.35 | 0.000 | *** | |
| TW.Letters: PE.Letters | 0.25 | 1.29 | 0.07 | 3.77 | 0.000 | *** | |
| Model evaluation | Number of observations = 1629 C index of concordance = 0.74 Somers’ dxy = 0.47 AIC = 2082.2 BIC = 2141.5 | ||||||
| p values: * = <0.05, ** = <0.01, *** = <0.001 | |||||||
References
- Baayen, Harald. 2008. Analyzing Linguistic Data. A Practical Introduction to Statistics Using R. Cambridge: Cambridge University Press. [Google Scholar]
- Blank, Andreas. 2001. Einführung in die lexikalische Semantik für Romanisten. Tübingen: Niemeyer. [Google Scholar]
- Bybee, Joan L. 2006. From usage to grammar: The mind’s response to repetition. Language 82: 711–33. [Google Scholar] [CrossRef]
- Bybee, Joan L. 2010. Language, Usage, and Cognition. Cambridge: Cambridge University Press. [Google Scholar]
- Davies, Mark. 2002. Corpus del Español (100 Million Words, 1200s–1900s). Available online: http://www.corpusdelespanol.org (accessed on 22 December 2015).
- De Smet, Hendrik. 2012. The course of actualization. Language 88: 601–33. [Google Scholar] [CrossRef]
- Dworkin, Steven N. 2012. A History of the Spanish Lexicon: A Linguistic Perspective. Oxford: Oxford University Press. [Google Scholar]
- Jarema, Gonia. 2005. Compound representation and processing: A cross-language perspective. In Representation and Processing of Compound Words. Edited by Gary Libben and Gonia Jarema. Oxford: Oxford University Press, pp. 45–70. [Google Scholar]
- Kluge, Friedrich. 2003. Etymologisches Wörterbuch der deutschen Sprache. Berlin: De Gruyter. [Google Scholar]
- Lass, Roger. 1990. How to do things with junk: Exaptation in language evolution. Journal of Linguistics 1: 79–102. [Google Scholar] [CrossRef]
- Libben, Gary, and Roberto G. De Almeida. 2002. Is there a morphological parser? In Morphology 2000. Edited by Sabrina Bendjaballah, Wolfgang U. Dressler, Oskar E. Pfeiffer and Maria D. Voeikova. Amsterdam and Philadelphia: John Benjamins, pp. 213–25. [Google Scholar]
- Mackenzie, Ian. 2006. Unaccusative Verbs in Romance Languages. Basingstoke: Palgrave Macmillan. [Google Scholar]
- Maiden, Martin. 2008. Lexical nonsense and morphological sense: On the real importance of ‘folk etymology’ and related phenomena for historical linguists. In Grammatical Change and Linguistic Theory: The Rosendal Papers. Edited by Thórhallur Eythórsson. Amsterdam and Philadelphia: John Benjamins, pp. 307–28. [Google Scholar]
- Narrog, Heiko. 2016. Exaptation in Japanese and beyond. In Exaptation and Language Change. Edited by Muriel Norde and Freek Van de Velde. Amsterdam and Philadelphia: John Benjamins, pp. 93–120. [Google Scholar]
- Norde, Muriel. 2009. Degrammaticalization. Oxford: Oxford University Press. [Google Scholar]
- Norde, Muriel, and Freek Van de Velde, eds. 2016. Exaptation. Taking stock of a controversial notion in linguistics. In Exaptation and Language Change. Amsterdam and Philadelphia: John Benjamins, pp. 1–35. [Google Scholar]
- Olschansky, Heike. 1996. Volksetymologie. Berlin: De Gruyter. [Google Scholar]
- Pinheiro, Jose, Douglas Bates, Saikat DebRoy, Deepayan Sarkar, and the R Development Core Team. 2018. nlme: Linear and Nonlinear Mixed Effects Models, R Package Version 3.1-137; Available online: https://CRAN.R-project.org/package=nlme (accessed on 23 October 2018).
- Poplack, Shana. 2001. Variability, frequency, and productivity in the irrealis domain of French. In Frequency and the Emergence of Linguistic Structure. Edited by Joan L. Bybee and Paul J. Hopper. Amsterdam and Philadelphia: John Benjamins, pp. 405–28. [Google Scholar]
- Poplack, Shana, Allison Lealess, and Nathalie Dion. 2013. The evolving grammar of the French subjunctive. Probus 25: 139–95. [Google Scholar]
- R Development Core Team. 2015. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, Available online: http://www.R-project.org (accessed on 26 December 2015).
- Real Academia Española. 2010. Nueva gramática de la lengua española. Manual. Madrid: Escasa Libros. [Google Scholar]
- Real Academia Española. 2014. Diccionario de la lengua española. Madrid: Real Academia Española. [Google Scholar]
- Rodríguez Molina, Javier. 2006. Ser + participio en español antiguo: Perífrasis resultativa, no tiempo compuesto. In Actas del VI Congreso Internacional de Historia de la Lengua Española. Edited by José J. Bustos Tovar and José L. Girón Alchonchel. Madrid: Arco Libros, vol. II, pp. 1059–72. [Google Scholar]
- Rosemeyer, Malte. 2014. Auxiliary Selection in Spanish. Gradience, Gradualness, and Conservation. Amsterdam and Philadelphia: John Benjamins. [Google Scholar]
- Smith, John C. 2006. How to do things without junk. The refunctionalization of a pronominal subsystem between Latin and Romance. In New Perspectives on Romance Linguistics: Vol. II: Phonetics, Phonology and Dialectology. Selected Papers from the 35th Linguistic Symposium on Romance Languages (LSRL), Austin, Texas, February 2005. Edited by J. Montreuil. Amsterdam and Philadelphia: John Benjamins, pp. 183–205. [Google Scholar]
- Willis, David. 2010. Degrammaticalization and obsolescent morphology: Evidence from Slavonic. In Grammaticalization: Current Views and Issues. Edited by Ekatherini Stathi, Elke Gehweiler and Ekkehard König. Amsterdam and Philadelphia: John Benjamins, pp. 151–78. [Google Scholar]
| 1 | |
| 2 | All participants were informed about the aims of the study and the anonymity of their responses, and they provided their consent. |
| 3 | It would, of course, have been possible to also include factual etymologies as a control group, or even give the participants the choice between the false and the factual etymology. For the sake of simplicity of interpretation of the results, I did not consider this option in this experiment. However, I do believe that it would be viable in follow-up studies. |
| 4 | See, for instance, Baayen (2008, p. 244), who claims that “a value above 0.8 indicates that model may have some real predictive capacity”. |
| 5 |
| Variable Name | Short Description | Levels |
|---|---|---|
| Age | Age of participant | <20, 20–30, >31 |
| Sex | Sex of participant | f, m |
| Linguist | Whether or not the participant has university education in linguistics | yes, no |
| TW.Letters | Length of target word in letters | (numeric, z-standardized) |
| PE.Letters | Length of proposed etymon in letters | (numeric, z-standardized) |
| TW.Frequency | Frequency of target word per million | (numeric, z-standardized) |
| PE.Frequency | Frequency of proposed etymon word per million | (numeric, z-standardized) |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosemeyer, M. Refunctionalization and Usage Frequency: An Exploratory Questionnaire Study. Languages 2018, 3, 39. https://doi.org/10.3390/languages3040039
Rosemeyer M. Refunctionalization and Usage Frequency: An Exploratory Questionnaire Study. Languages. 2018; 3(4):39. https://doi.org/10.3390/languages3040039
Chicago/Turabian StyleRosemeyer, Malte. 2018. "Refunctionalization and Usage Frequency: An Exploratory Questionnaire Study" Languages 3, no. 4: 39. https://doi.org/10.3390/languages3040039
APA StyleRosemeyer, M. (2018). Refunctionalization and Usage Frequency: An Exploratory Questionnaire Study. Languages, 3(4), 39. https://doi.org/10.3390/languages3040039