
The Neglected Group: Cognitive Discourse Markers as Signposts of Prosodic Unit Boundaries



Abstract
1. Introduction
2. Theoretical Background
2.1. Prosodic Units
Prosodic Unit Boundaries
2.2. Discourse Markers and Prosody
2.2.1. Cognitive Discourse Markers in Previous Research
2.2.2. Interface of Cognitive Markers and Prosodic Boundaries
3. Methodology
3.1. Materials: Corpus ROG
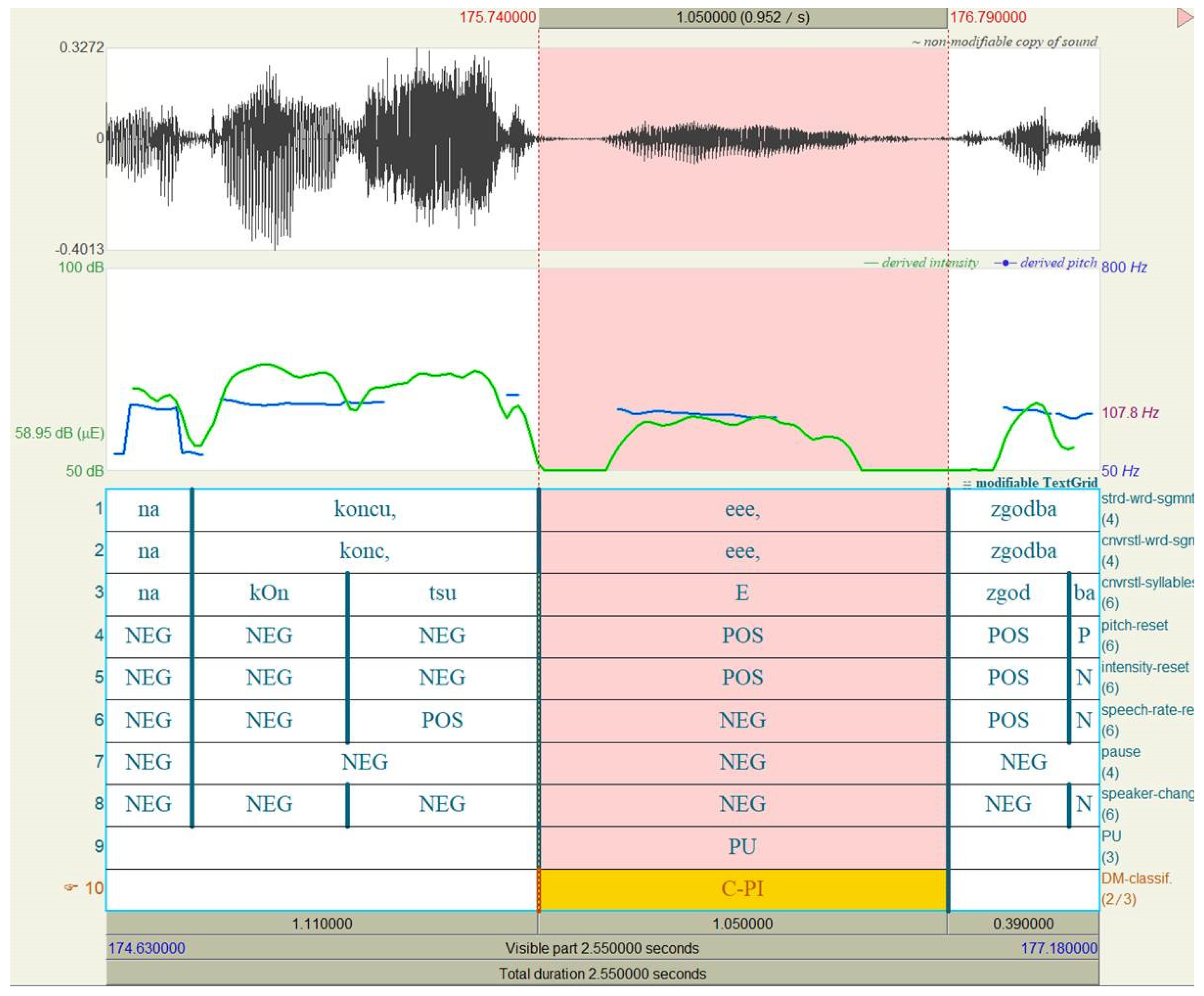
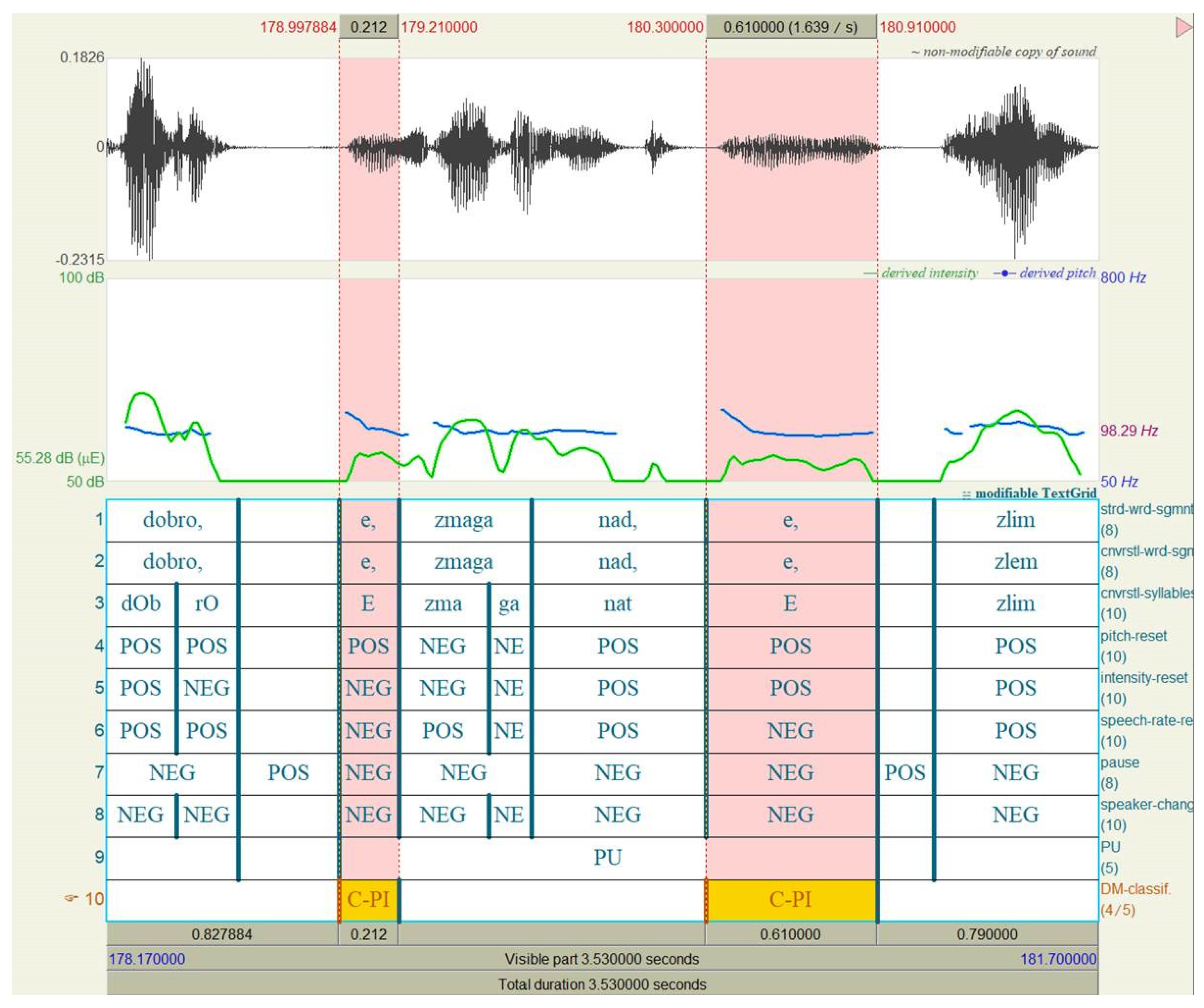
3.2. Prosodic Unit Annotation
3.3. Discourse Marker Annotation
4. Results
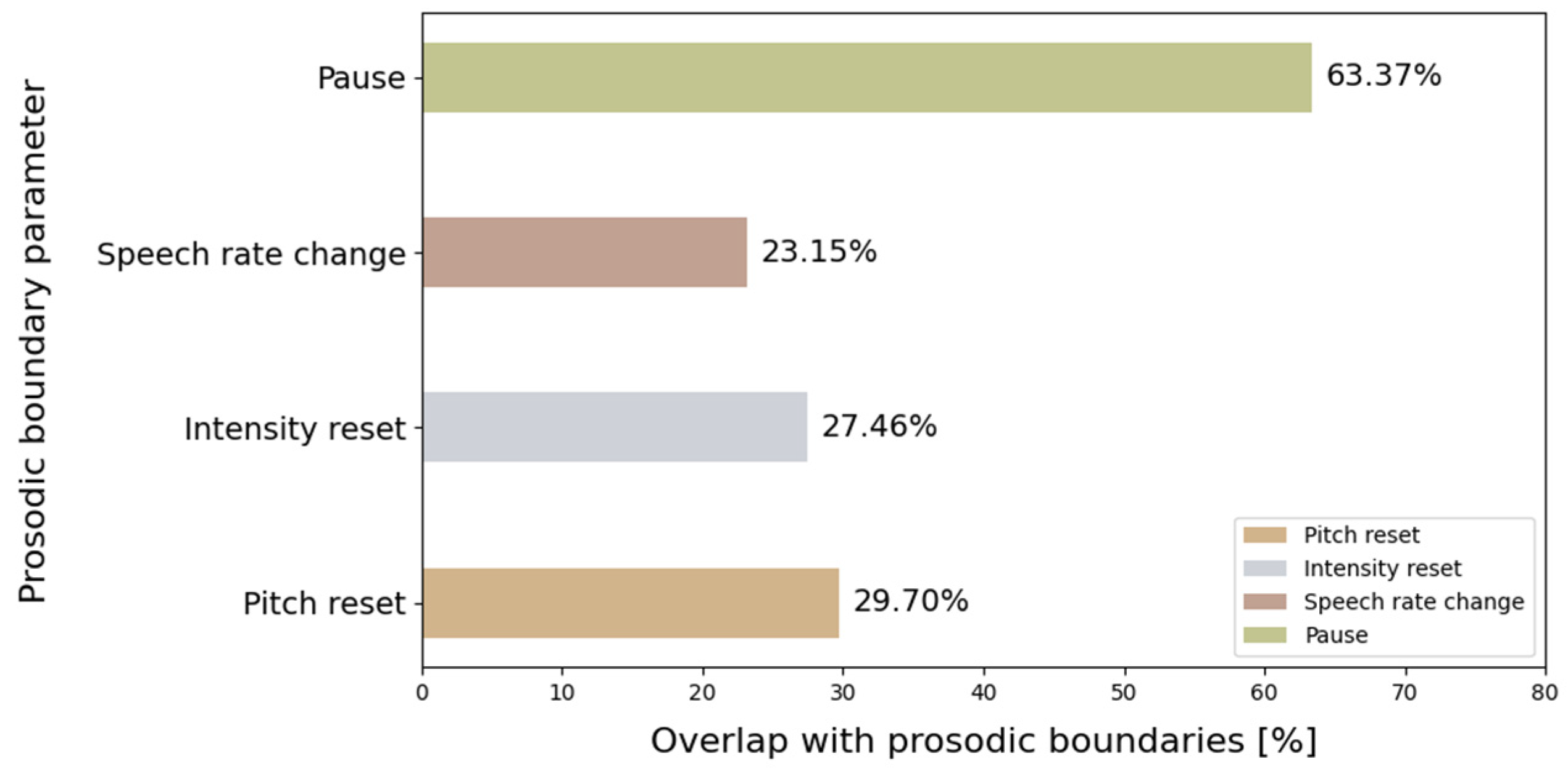
4.1. Automatic Segmentation Parameters
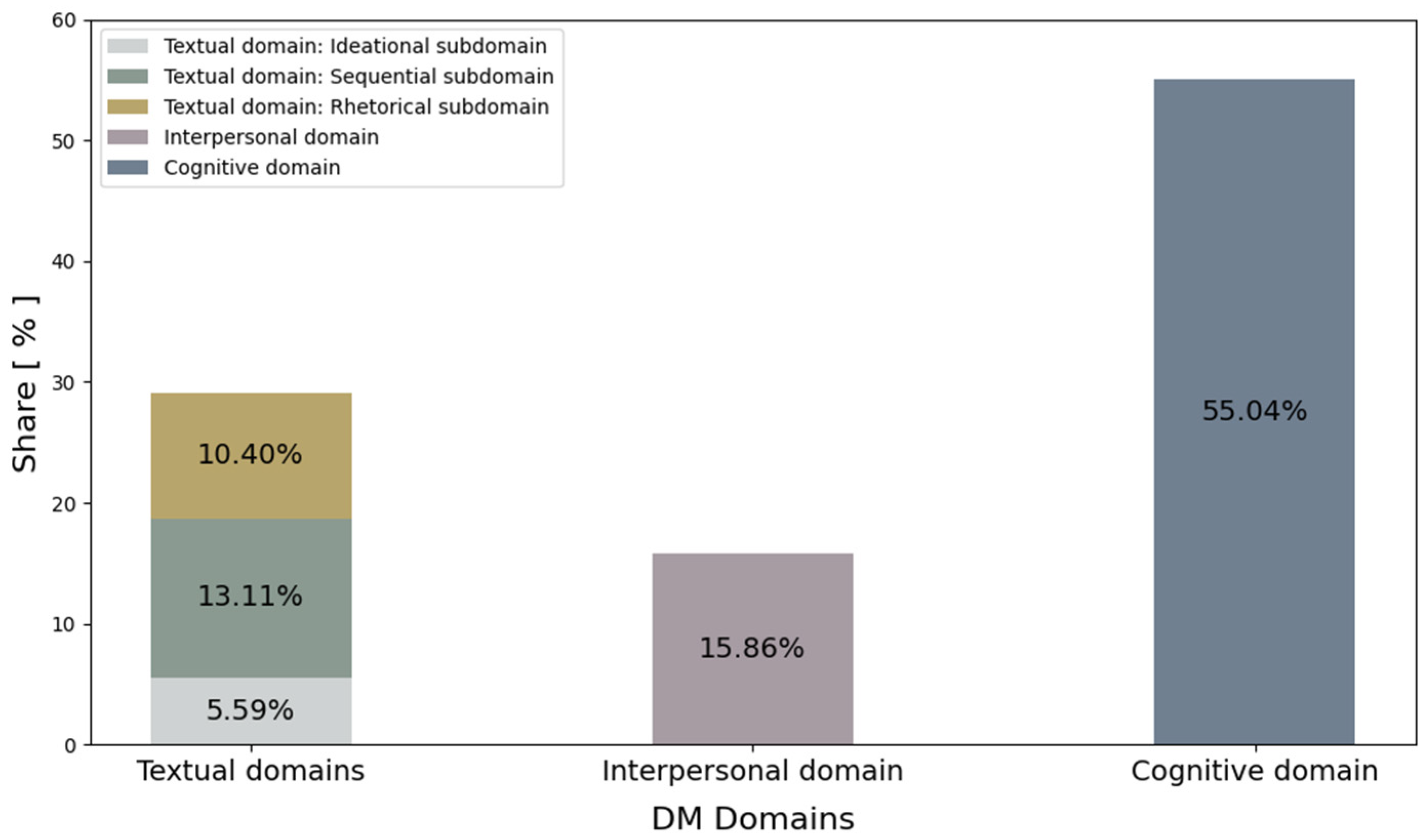
4.2. Cognitive Discourse Markers
4.2.1. Hesitation
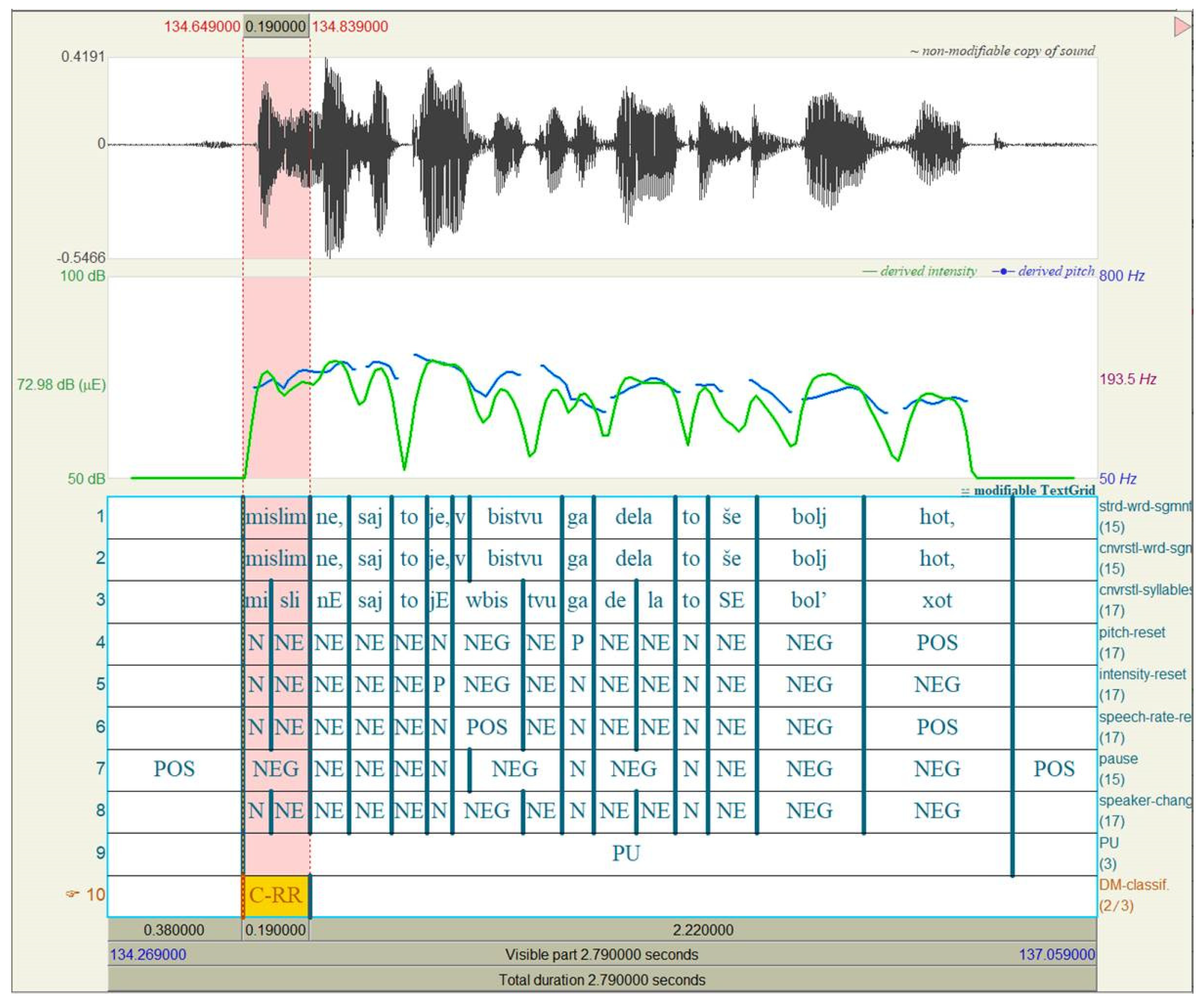
4.2.2. Restructuring
4.2.3. Realising New Information
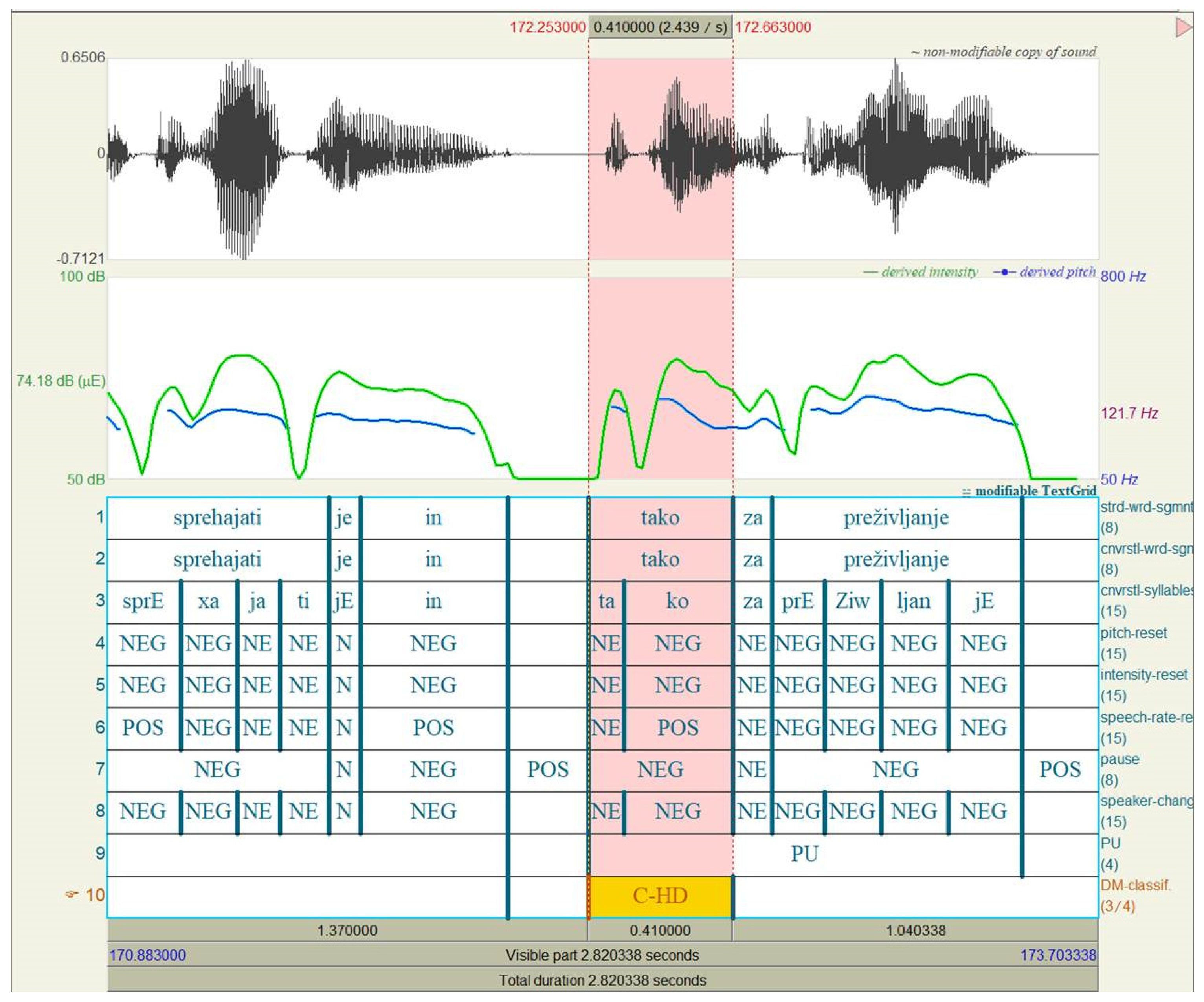
4.2.4. Hedging
4.2.5. Emphasis
4.2.6. Information Processing
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DM(s) | Discourse marker(s) |
| C-DM(s) | Cognitive discourse marker(s) |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Function Label | Description (based on Crible (2016), Crible and Degand (2019), and Maschler (2009)) |
|---|---|---|
| AD | Addition | Adds discourse-new information, often extending the discourse. |
| AG | Agreeing and Confirming | Signals speaker agreement or confirmation, either with self or the interlocutor. |
| CA | Cause | Introduces a causal explanation or reason for the prior segment. |
| CG | Closing | Closes a discourse unit or interactional segment. |
| CL | Conclusion | Summarises or draws a conclusion from the preceding discourse. |
| CM | Comment | Provides a metalinguistic or reflective comment. |
| CQ | Consequence | Introduces a logical or epistemic result of the prior discourse content. |
| CT | Contrast | Marks contrast between two ideas or discourse segments. |
| DG | Disagreement | Expresses dissent or a differing opinion. |
| EL | Elliptical | Marks an elliptical construction, typically resuming or reframing discourse. |
| EM | Emphasis | Highlights or intensifies a particular point in the discourse. |
| EN | Enumeration | Lists or orders items or ideas in sequence. |
| HD | Hedging | Marks speaker uncertainty, approximation, or lack of full commitment to the proposition. |
| HS | Hesitation | Signals planning difficulties, pauses, or speaker hesitation. |
| MC | Maintaining Contact | Manages interactional contact with the interlocutor (e.g., phatic or floor-holding functions). |
| MO | Monitoring | Indicates speaker control over the discourse, including self-monitoring. |
| MT | Motivation | Provides a subjective or rhetorical justification for what follows. |
| OG | Opening | Opens a new discourse segment, topic, or interaction. |
| OP | Opposition | Presents an opposing viewpoint or contradicts previous discourse. |
| PI | Processing Information | Indicates ongoing cognitive processing or effort to plan/formulate upcoming discourse. |
| QT | Quoting | Introduces (pseudo-)reported speech or quotations. |
| RI | Realising New Information | Signals sudden awareness, recognition, or cognitive insight. |
| RR | Restructuring | Indicates reformulation, self-repair, or reorganisation of a previous utterance. |
| SC | Specification | Provides more detailed or specific information (e.g., examples, elaboration). |
| TE | Temporal | Marks chronological order or progression in discourse. |
| TS | Topic Shift | Indicates a change in topic, usually initiating a new discourse segment. |
| TU | Topic Resuming | Returns to a previously suspended topic or ongoing discourse thread. |
| UC | Encouraging to Continue | Encourages the interlocutor to proceed or keep speaking. |
References
- Aijmer, K. (2002). English discourse particles. John Benjamins Publishing. [Google Scholar]
- Aijmer, K. (2013). Understanding pragmatic markers: A variational pragmatic approach. Edinburgh University Press. [Google Scholar]
- Altenberg, B. (1987). Prosodic patterns in spoken English. Studies in the correlation between prosody and grammar for text-to-speech conversion. Lund University Press. [Google Scholar]
- Arnold, J. E., Tanenhaus, M. K., Altmann, R. J., & Fagnano, M. (2004). The old and thee, uh, new: Disfluency and reference resolution. Psychological Science, 15(9), 578–582. [Google Scholar] [CrossRef] [PubMed]
- Barnwell, B. (2013). Perception of prosodic boundaries by untrained listeners. In Units of talk–Units of action (pp. 125–166). John Benjamins Publishing Company. [Google Scholar]
- Barth-Weingarten, D. (2013). From “intonation units” to cesuring—An alternative approach to the prosodic-phonetic structuring of talk-in-interaction. In B. Szczepek Reed, & R. Geoffrey (Eds.), Units of talk–Units of action (Series “studies in language and social interaction”, pp. 91–124). Benjamins. [Google Scholar]
- Bazzanella, C. (2006). Discourse markers in Italian: “Compositional” meaning. In K. Fischer (Ed.), Approaches to discourse particles (pp. 449–464). Elsevier. [Google Scholar]
- Beňuš, Š. (2021). Investigating spoken English: A practical guide to phonetics and phonology using Praat. Palgrave Macmillan. [Google Scholar]
- Biron, T., Baum, D., Freche, D., Matalon, N., Ehrmann, N., Weinreb, E., Biron, D., & Moses, E. (2021). Automatic detection of prosodic boundaries in spontaneous speech. PLoS ONE, 16, e0250969. [Google Scholar] [CrossRef]
- Boersma, P., & Weenink, D. (2019). Praat: Doing phonetics by computer. Computer program (Version 6.4.27). Available online: https://www.fon.hum.uva.nl/praat/ (accessed on 14 April 2025).
- Brennan, S. E., & Williams, M. (1995). The feeling of another’s knowing: Prosody and filled pauses as cues to listeners about the metacognitive states of speakers. Journal of Memory and Language, 34(3), 383–398. [Google Scholar] [CrossRef]
- Cabedo, A. (2014). On the delimitation of discursive units in colloquial Spanish: Val. Es. Co. application model. Discourse segmentation in Romance languages (pp. 157–183). John Benjamins. [Google Scholar]
- Carter, R., & McCarthy, M. (2006). Cambridge grammar of English: A comprehensive guide; spoken and written English grammar and usage. Cambridge University Press. [Google Scholar]
- Chafe, W. (1994). Discourse, consciousness, and time: The flow and displacement of conscious experience in speaking and writing. University of Chicago Press. [Google Scholar]
- Collet, C. (2019). Graham ranger: Discourse markers: An enunciative approach (314p). Palgrave Macmillan. [Google Scholar]
- Crible, L. (2016). Towards an operational category of discourse markers: A definition and its model. In A. Sanso, & C. Fedriani (Eds.), Discourse markers, pragmatics markers and modal particles: New perspectives. John Benjamins. [Google Scholar]
- Crible, L., & Degand, L. (2019). Domains and functions: A two-dimensional account of discourse markers. Discours. Available online: https://journals.openedition.org/discours/9997 (accessed on 14 April 2025).
- Cuenca, M.-J. (2013). The fuzzy boundaries between discourse marking and modal marking. In L. Degand, B. Cornillie, & P. Pietrandrea (Eds.), Discourse markers and modal particles: Categorization and description (pp. 191–216). John Benjamins. [Google Scholar]
- Degand, L., & Simon, A. C. (2009). On identifying basic discourse units in speech: Theoretical and empirical issues. Discours. Revue de Linguistique, Psycholinguistique et Informatique. A Journal of Linguistics, Psycholinguistics and Computational Linguistics, (4). [Google Scholar] [CrossRef]
- Degand, L., Simon, A. C., Tanguy, N., & Van Damme, T. (2014). Initiating a discourse unit in spoken French. Discourse Segmentation Romance Languages, 250, 243–273. [Google Scholar]
- Du Bois, J. W. (1991). Transcription design principles for spoken discourse research. Pragmatics, 1(1), 71–106. [Google Scholar] [CrossRef]
- Du Bois, J. W., Schuetze-Coburn, S., Cumming, S., & Paolino, D. (1993). Discourse transcription. University of California. (Original work published 1992). [Google Scholar]
- Elordieta, G., & Romera, M. (2002, April 11–13). Prosody and meaning in interaction: The case of the Spanish discourse functional unit entonces “then”. Speech Prosody 2002 (pp. 263–266), Aix-en-Provence, France. [Google Scholar]
- Erman, B. (1987). Pragmatic expressions in English. Almqvist & Wiksell. [Google Scholar]
- Farrús, M., Lai, C., & Moore, J. (2016, May 31–June 3). Paragraph-based prosodic cues for speech synthesis applications. Speech Prosody (pp. 1143–1147), Boston, MA, USA. [Google Scholar]
- Fischer, K. (2014). Discourse Markers. In K. P. Schneider, & A. Barron (Eds.), Pragmatics of discourse (pp. 271–294). Berlin De Gruyter Mouton. [Google Scholar]
- Fox Tree, J. E. (2001). Listeners’ uses of um and uh in speech comprehension. Memory & Cognition, 29(2), 320–326. [Google Scholar] [CrossRef]
- Fraser, B. (1990). An account of discourse markers. International Review of Pragmatics, 1(2009), 293–320. [Google Scholar] [CrossRef]
- Hieke, A. E. (1981). A content-processing view of hesitation phenomena. Language and Speech, 24(2), 147–160. [Google Scholar] [CrossRef]
- Inbar, M., Genzer, S., Perry, A., Grossman, E., & Landau, A. N. (2023). Intonation units in spontaneous speech evoke a neural response. Journal of Neuroscience, 43(48), 8189–8200. [Google Scholar] [CrossRef]
- Izre’el, S. (2020). The basic unit of spoken language and the interfaces between prosody, discourse and syntax: A view from spontaneous spoken Hebrew. In In search of basic units of spoken language (pp. 77–106). John Benjamins Publishing Company. [Google Scholar]
- Izre’el, S., Mello, H., Panunzi, A., & Raso, T. (2020). In search of basic units of spoken language. A corpus-driven approach. John Benjamins Publishing Company. [Google Scholar]
- Izre’el, S., & Mettouchi, A. (2015). Representation of speech in CorpAfroAs: Transcriptional Strategies and Prosodic Units. In A. Mettouchi, M. Vanhove, & D. Caubet (Eds.), Corpus-based studies of lesser-described languages: The CorpAfroAs corpus of spoken AfroAsiatic languages (Studies in corpus linguistics, 68, pp. 13–41). Benjamins. [Google Scholar] [CrossRef]
- Kibrik, A. A., Korotaev, N. A., & Podlesskaya, V. I. (2020). The Moscow approach to local discourse structure: An application to English. In In search of basic units of spoken language (pp. 367–382). John Benjamins Publishing Company. [Google Scholar]
- Majhenič, S., Rojc, M., & Mlakar, I. (2022). Neprototipni diskurzni označevalec zdaj. Slavia Centralis, 15(2), 27–44. Available online: https://journals.um.si/index.php/slaviacentralis/article/view/2446 (accessed on 14 April 2025).
- Maschler, Y. (2009). Metalanguage in Interaction. Hebrew discourse markers. John Benjamins Publishing Company. [Google Scholar]
- Matzen, L. E. (2004). Discourse markers and prosody: A case study of so. LACUS Forum XXX: Language, Thought and Reality, (30), 75–94. [Google Scholar]
- McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., & Sonderegger, M. (2017). Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. Interspeech, 2017, 498–502. [Google Scholar]
- Mertens, P., & Simon, A. C. (2013, September 11–13). Towards automatic detection of prosodic boundaries in spoken French. In Prosody-discourse interface conference 2013 (IDP-2013), Leuven, Belgium (pp. 81–87). FranItalCo. [Google Scholar]
- Mithun, M. (2020). Basic units of speech segmentation. In In search of basic units of spoken language (pp. 349–358). John Benjamins Publishing Company. [Google Scholar]
- Morel, M. A., & Vladimirska, J. (2014). Intonation and gesture in the segmentation of speech units: The discursive marker vraiment: Integration, focalisation, formulation. In Discourse segmentation in Romance languages (pp. 185–218). John Benjamins Publishing Company. [Google Scholar]
- O’Grady, G. N. (2017). “I think” in televised political debate. International Review of Pragmatics, 9(2), 269–303. [Google Scholar] [CrossRef]
- Ots, N., & Taremaa, P. (2023). Chunking an unfamiliar language: Results from a perception study of German listeners. In F. Schubö, S. Zerbian, S. Hanne, & I. Wartenburger (Eds.), Prosodic boundary phenomena (pp. 87–117). Language Science Press. [Google Scholar]
- Raso, T., Barbosa, P. A., Cavalcante, F. A., & Mittmann, M. M. (2020). Segmentation and analysis of the two English excerpts: The Brazilian team proposal. In In search of basic units of spoken language (pp. 309–326). John Benjamins Publishing Company. [Google Scholar]
- Redeker, G. (2000). Coherence and structure in text and discourse. In H. Bunt, & W. Black (Eds.), Abduction, belief and context in dialogue: Studies in computational pragmatics (pp. 233–264). John Benjamins Publishing. [Google Scholar]
- Redeker, G. (2006). Discourse markers as attentional cues at discourse transitions. In K. Fischer (Ed.), Approaches to discourse particles (pp. 339–358). Elsevier. [Google Scholar]
- Rehbein, I. (2015, June 5). Filled pauses in user-generated content are words with extra-propositional meaning. In Second workshop on extra-propositional aspects of meaning in computational semantics (ExProM 2015), Denver, Colorado (pp. 12–21). Association for Computational Linguistics. [Google Scholar]
- Romero-Trillo, J. (2018). Prosodic modeling and position analysis of pragmatic markers in English conversation. Corpus Linguistics and Linguistic Theory, 14(1), 169–195. [Google Scholar] [CrossRef]
- Schiffrin, D. (1987). Discourse markers. Cambridge University Press. [Google Scholar]
- Selting, M. (1996). On the interplay of syntax and prosody in the constitution of turn-constructional units and turns in conversation. Pragmatics, 6(3), 371–388. [Google Scholar] [CrossRef]
- Selting, M., Auer, P., Barth-Weingarten, D., Bergmann, J. R., Bergmann, P., Birkner, K., Couper-Kuhlen, E., Deppermann, A., Gilles, P., Günthner, S., Hartung, M., Kern, F., Mertzlufft, C., Meyer, C., Morek, M., Oberzaucher, F., Peters, J., Quasthoff, U., Schütte, W., … Uhmann, S. (2009). Gesprächsanalytisches transkriptionssystem 2 (GAT 2). Online-Zeitschrift zur verbalen Interaktion, 10, 353–402. [Google Scholar]
- Steen, G. (2005). Basic discourse acts: Towards a psychological theory of discourse segmentation. In F. Ruiz de Mendoza Ibanez, & M. Sandra Pena Cervel (Eds.), Cognitive linguistics: Internal dynamics and interdisciplinary interaction (pp. 283–312). Mouton de Gruyter. [Google Scholar]
- Swerts, M. (1998). Filled pauses as markers of discourse structure. Journal of Pragmatics, 30(4), 485–496. [Google Scholar] [CrossRef]
- Tonetti Tübben, I., & Landert, D. (2022). Uh and Um as pragmatic markers in dialogues: A Contrastive perspective on the functions of planners in fiction and conversation. Contrastive Pragmatics, 4(2), 350–381. [Google Scholar] [CrossRef]
- Tottie, G. (2019). From pause to word: Uh, um and er in written American English. English Language and Linguistics, 23(1), 105–130. [Google Scholar] [CrossRef]
- Verdonik, D., Ljubešić, N., Rupnik, P., Dobrovoljc, K., & Čibej, J. (2024, September 19–20). Izbor in urejanje gradiv za učni korpus govorjene slovenščine ROG. In S. Arhar Holdt, & T. Erjavec (Eds.), Language technologies and digital humanities: Proceedings of the conference, Ljubljana, Slovenia (1st ed., pp. 469–484). Institute of Contemporary History. ISBN 978-961-7104-40-0. [Google Scholar] [CrossRef]
- Wellmann, C., Holzgrefe-Lang, J., Truckenbrodt, H., Wartenburger, I., & Höhle, B. (2023). Developmental changes in prosodic boundary cue perception in German-learning infants. In F. Schubö, S. Zerbian, S. Hanne, & I. Wartenburger (Eds.), Prosodic boundary phenomena (pp. 119–156). Language Science Press. [Google Scholar]
- Womack, K., McCoy, W., Alm, C. O., Calvelli, C., Pelz, J. B., Shi, P., & Haake, A. (2012, July 13). Disfluencies as extra-propositional indicators of cognitive processing. Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics (pp. 1–9), Jeju, Republic of Korea. [Google Scholar]
- Yang, L. (2006). Integrating prosodic and contextual cues in the interpretation of discourse markers. In K. Fischer (Ed.), Approaches to discourse particles (pp. 265–298). Elsevier. [Google Scholar]
- Yang, X., Shen, X., Li, W., & Yang, Y. (2014). How Listeners Weight Acoustic Cues to Intonational Phrase Boundaries. PLoS ONE, 9(7), e102166. [Google Scholar] [CrossRef] [PubMed]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majhenič, S.; Beras, M.; Križaj, J. The Neglected Group: Cognitive Discourse Markers as Signposts of Prosodic Unit Boundaries. Languages 2025, 10, 159. https://doi.org/10.3390/languages10070159
Majhenič S, Beras M, Križaj J. The Neglected Group: Cognitive Discourse Markers as Signposts of Prosodic Unit Boundaries. Languages. 2025; 10(7):159. https://doi.org/10.3390/languages10070159
Chicago/Turabian StyleMajhenič, Simona, Mitja Beras, and Janez Križaj. 2025. "The Neglected Group: Cognitive Discourse Markers as Signposts of Prosodic Unit Boundaries" Languages 10, no. 7: 159. https://doi.org/10.3390/languages10070159
APA StyleMajhenič, S., Beras, M., & Križaj, J. (2025). The Neglected Group: Cognitive Discourse Markers as Signposts of Prosodic Unit Boundaries. Languages, 10(7), 159. https://doi.org/10.3390/languages10070159