
Blended Phonetic Training with HVPT Features for EFL Children: Effects on L2 Perception and Listening Comprehension



Abstract
1. Introduction
- To what extent does the blended phonetic training program with HVPT features enhance EFL children’s L2 speech perception and listening comprehension?
- Does this intervention have differential effects on learners with varying levels of listening proficiency in terms of listening comprehension? If so, to what extent?
1.1. L2 Speech Model and L2 Perception
1.2. High Variability Phonetic Training in L2 Acquisition
1.3. From Perception to Comprehension: Effects of HVPT on L2 Listening
1.4. Phonological Challenges for Korean English Learners
1.5. Phonetic Training Design Considerations for Young Learners
2. Methods
2.1. Participants
2.2. Instruments
2.3. Experiment Materials
2.4. Procedures
3. Results
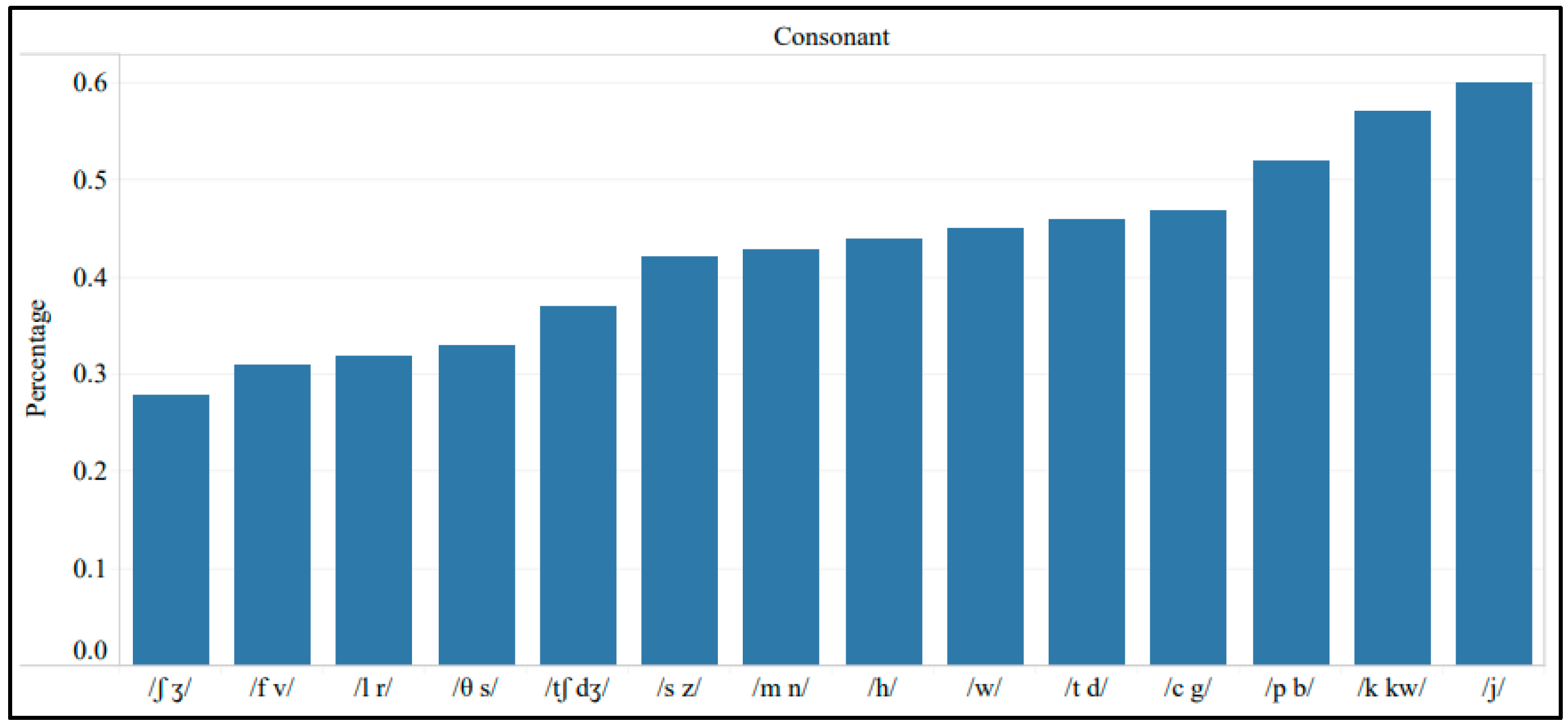
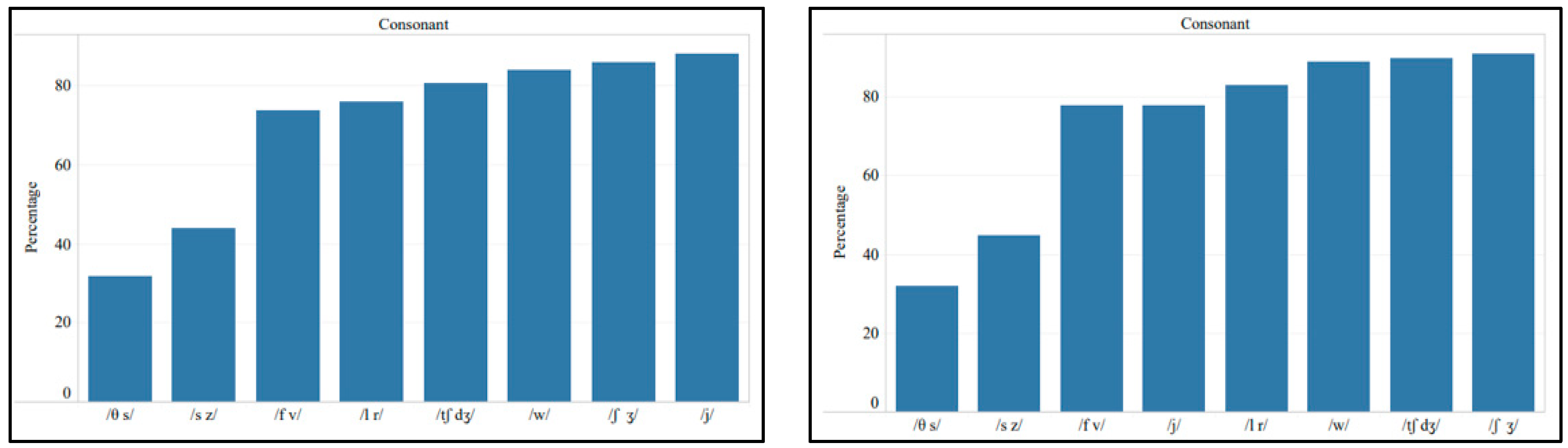
3.1. Effects on L2 Perception
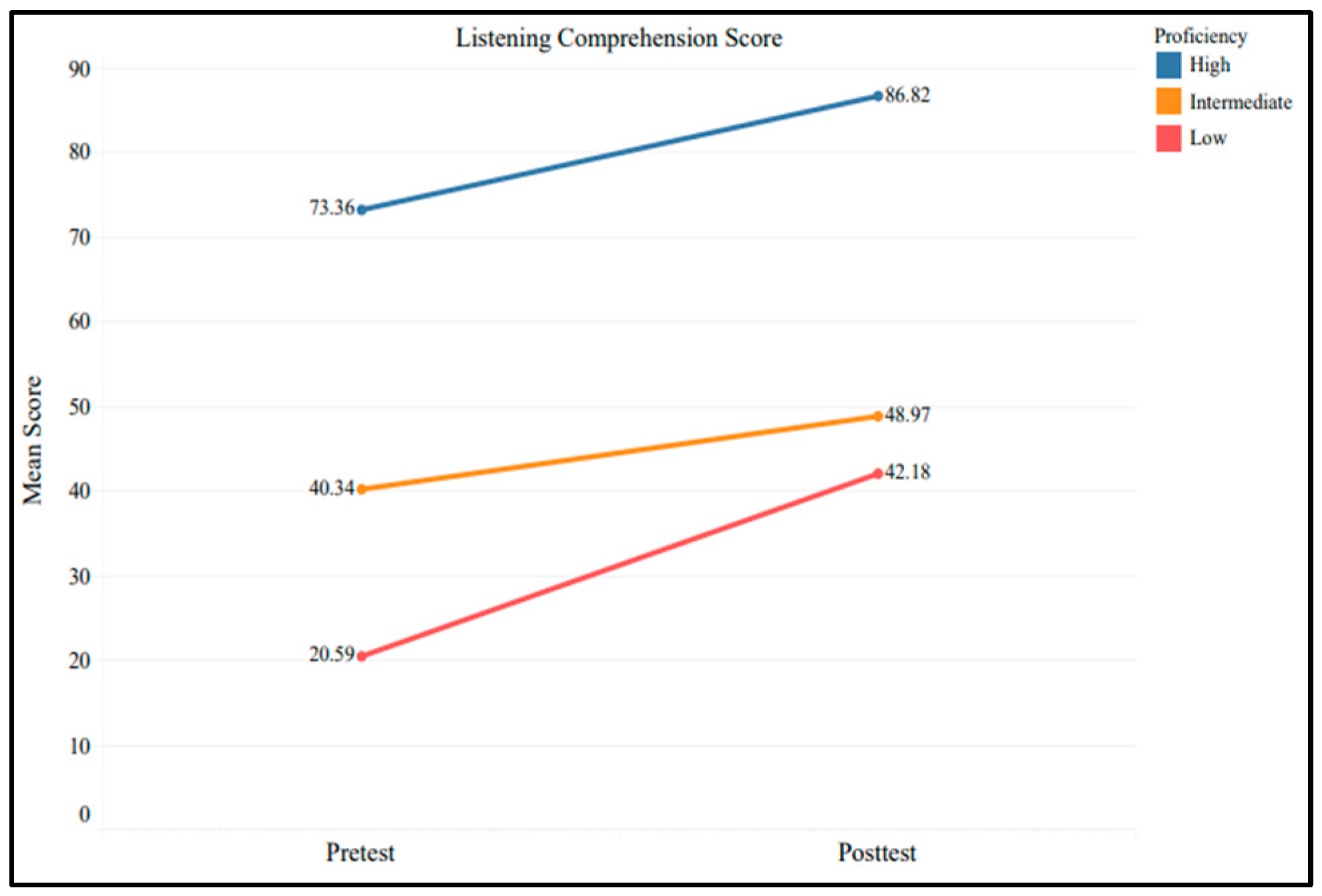
3.2. Effects on Listening Comprehension
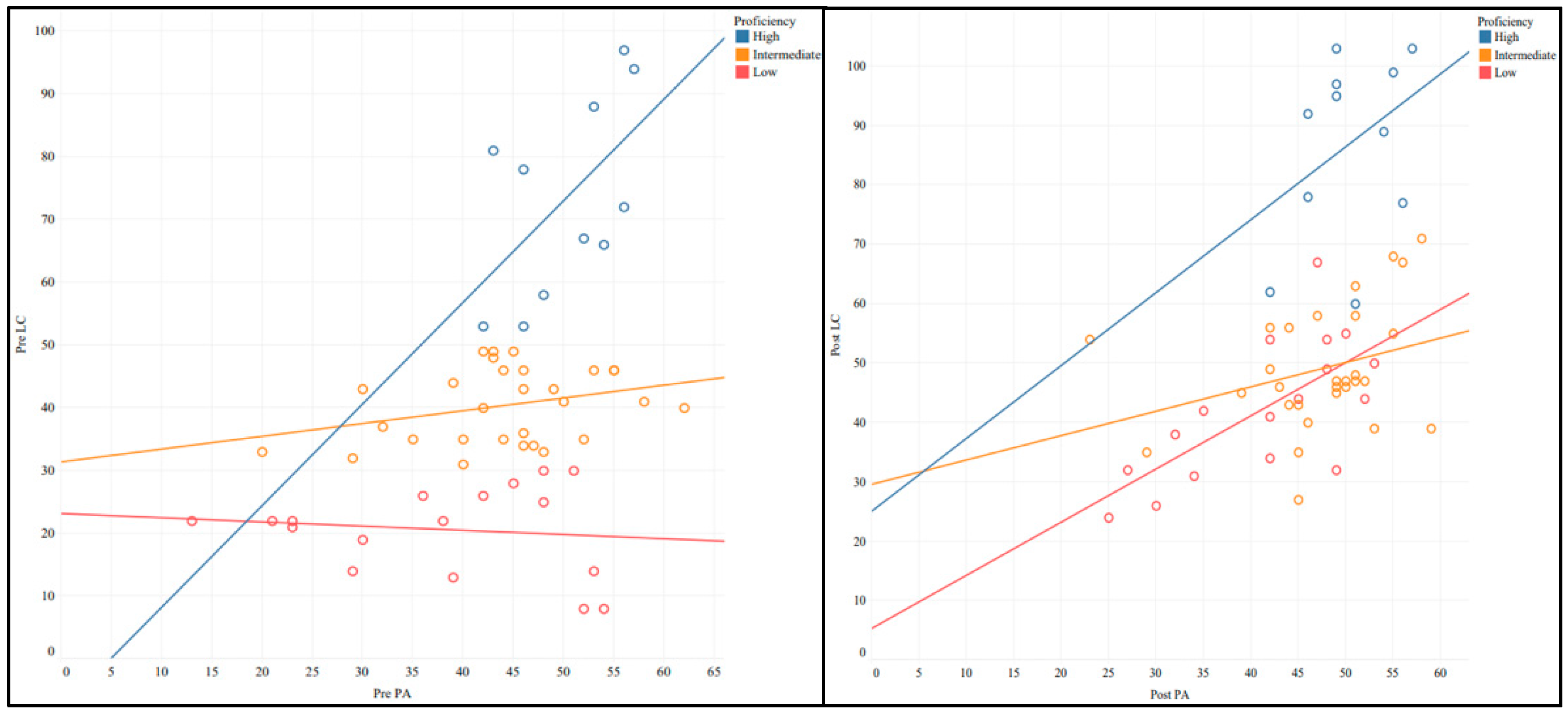
3.3. Comparison of the Effects by Proficiency Groups
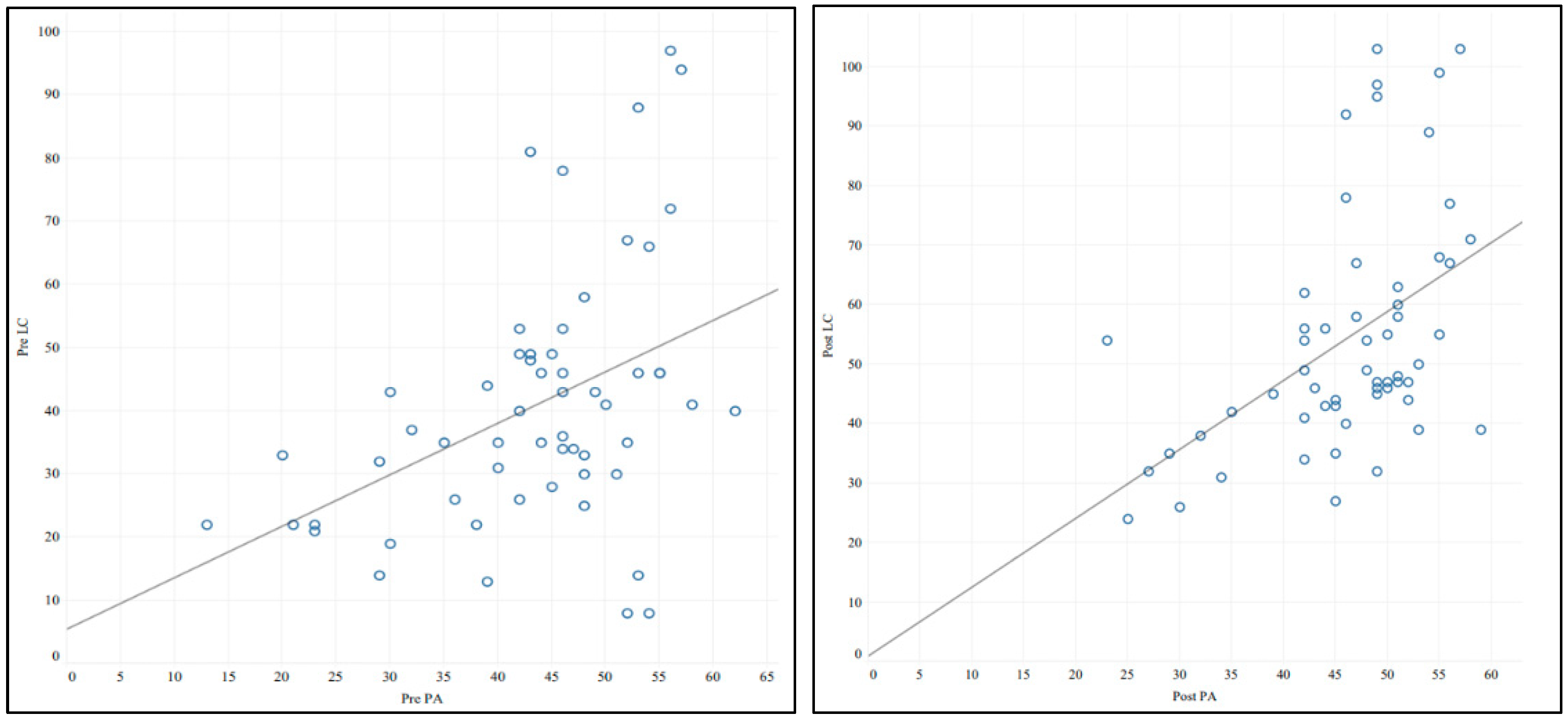
3.4. Relationship Between L2 Perception and Listening Comprehension
3.5. Post-Survey and Interview Results
4. Discussion
4.1. Effects on L2 Perception and Listening Comprehension
4.2. Effects Across Proficiency Groups
4.3. The Role of L2 Perception in Enhancing Listening Comprehension
4.4. Reflections from Student Survey and Interviews
5. Conclusions and Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Question Types for Listening Comprehension Test
| Type | Question # | Score |
| 1. Listen to the words and choose an odd one. | 2 | 4 |
| 2. Listen to the sentence and choose a picture that matches. | 3 | 6 |
| 3. Listen to conversations and answer questions (picture option). | 4 | 8 |
| 4. Listen to conversations, questions and answer the questions (picture option). | 5 | 20 |
| 5. Listen to conversations and choose a picture. | 2 | 6 |
| 6. Listen to conversations and answer questions (text option). | 5 | 12 |
| 7. Choose the appropriate response to complete the conversation. | 6 | 20 |
| 8. Understand the description of the visual material. | 2 | 6 |
| 9. Describe the picture. | 1 | 4 |
| 10. Understand the natural flow of conversation. | 3 | 9 |
| 11. Read relatively long conversations and answer questions (two questions for one conversation). | 2 | 8 |
| Total | 33 | 103 |
| Note. question types are the same for the listening pretest and posttest. | ||
Appendix B. L2 Perception Test Scripts Used in the Main Study
| Teacher A: 1. /f, v/ (1) fan—van—fan (2) vile—file—file (3) proof—prove—proof (4) fest—vest—vest 2. /s, θ/ (5) sing—thing—thing (6) theme—theme—seem (7) mouth—mouth—mouse (8) worth—worse—worth 3. /s, z/ (9) seal—zeal—zeal (10) scion– zion—scion (11) sip—zip—zip (12) bees—beez—bees 4. /ʃ, ʒ/ (13) assure—azure—assure (14) pleasure—pressure—pressure (15) rish—rish—ridge (16) shop—jop—shop 5. /tʃ, dʒ/ (17) batch—batch—badge (18) jeep—cheap—jeep (19) jump—chump—chump (20) jam—cham—jam (21) jeer—cheer—jeer (22) ridge—rich—ridge 6. /y/ (23) year—ear—year (24) east—yeast—east (25) yes—yes—es (26) be-ond—beyond—beyond 7. /w/ (27) ooze—woos—ooze (28) wink—wink—ink (29) wood—ood—ood (30) wet—et—wet (31) wool—ool—ool 8. /l, r/ (32) Raw—law—raw (33) lead—read—lead (34) rink—link—link (35) wait—ate—wait Teacher B: 1. /f, v/ (1) van—fan—fan (2) vile—vile—file (3) prove—prove—proof (4) vest—fest—vest 2. /s, θ/ (5) thing—sing—thing (6) theme—seem—seem (7) mouse—mouth—mouse (8) worse—worse—worth 3. /s, z/ (9) zeal—seal—zeal (10) scion—zion—zion (11) sip—zip—zip (12) bees—beez—bees 4. /ʃ, ʒ/ (13) azure—assure—assure (14) pleasure—pressure– pleasure (15) ridge—rish—ridge (16) shop—shop– jop 5. /tʃ, dʒ/ (17) badge—batch—badge (18) cheap—cheap—jeep (19) jump—jump—chump (20) jam—jam—cham (21) cheer—jeer—jeer (22) ridge—rich—rich 6. /y/ (23) year—ear—ear (24) east—yeast—yeast (25) es—yes—yes (26) beyond—beyond—be-ond 7. /w/ (27) ooze—ooze—woos (28) wink—ink—ink (29) ood—ood—wood (30) et—wet—wet (31) wool—wool—ool 8. /l, r/ (32) Raw—Raw—law (33) Lead—lead—read (34) Rink—link—rink (35) lay—ray—ray Book Source: Vaughan-Rees, M. (2002). |
Appendix C. L2 Perception Test Scripts Used in the Pilot Study
| Teacher A: 1. /p, b/: pay—bay—bay/boast—post—boast 2. /t, d/: trip—trip—drip/down—town—down 3. /c, g/: came—game—came/clue—clue—glue 4. /f, v/: few—view—view/fast—fast—vast 5. /s, z/: sing—sing—zing/zoo—sue—sue 6. /ʃ, ʒ/: pressure—pressure—pleasure/assure—azure—azure 7. /θ, s/: thigh—sigh—sigh/thin—sin—thin 8. /tʃ, dʒ/: chunk—junk—chunk/chin—gin—gin 9. /m, n/: mail—nail—nail/mine—nine—nine 10. /h/: how—ow—how/hi—I—I 11. /l, r/: rip—lip—rip/race—lace—lace 12. /w/: wood—ood—wood/wolf—wolf—olf 13. /j/: jet—yet—jet/jam—yam—yam 14. /kw, k/: queen—keen—queen/quick—kick—kick Teacher B: 1. /p, b/: pay—bay—pay/post—boast—boast 2. /t, d/: trip—drip—trip/down—down—town 3. /c, g/: came—came—game/glue—clue—clue 4. /f, v/: few—view—few/fast—vast—fast 5. /s, z/: sing—zing—sing/zoo—zoo—sue 6. /ʃ, ʒ/: pleasure—pressure—pressure/azure—assure—assure 7. /θ, s/: thigh—sigh—thigh/sin—thin—thin 8. /tʃ, dʒ/: chunk—chunk—junk/gin—chin—chin 9. /m, n/: nail—mail—mail/mine—mine—nine 10. /h/: ow—how—ow/I—hi—hi 11. /l, r/: lip—rip—rip/lace—race—race 12. /w/: ood—wood—ood/olf—wolf—olf 13. /j/: jet—jet—yet/yam—yam—jam 14. /kw, k/: queen—queen—keen/kick—quick—kick |
Appendix D. Listening Comprehension Pretest Scores for Assigning Proficiency Levels
| Listening Comprehension Pretest Score | |||
| Subject | Score | z-Score | Level |
| Student 1 | 8 | −1.64 | Low |
| Student 2 | 8 | −1.64 | Low |
| Student 3 | 13 | −1.39 | Low |
| Student 4 | 14 | −1.34 | Low |
| Student 5 | 14 | −1.34 | Low |
| Student 6 | 19 | −1.09 | Low |
| Student 7 | 21 | −0.99 | Low |
| Student 8 | 22 | −0.95 | Low |
| Student 9 | 22 | −0.95 | Low |
| Student 10 | 22 | −0.95 | Low |
| Student 11 | 22 | −0.95 | Low |
| Student 12 | 25 | −0.80 | Low |
| Student 13 | 26 | −0.75 | Low |
| Student 14 | 26 | −0.75 | Low |
| Student 15 | 28 | −0.65 | Low |
| Student 16 | 30 | −0.55 | Low |
| Student 17 | 30 | −0.55 | Low |
| Student 18 | 31 | −0.50 | Mid |
| Student 19 | 32 | −0.45 | Mid |
| Student 20 | 33 | −0.40 | Mid |
| Student 21 | 33 | −0.40 | Mid |
| Student 22 | 34 | −0.35 | Mid |
| Student 23 | 34 | −0.35 | Mid |
| Student 24 | 35 | −0.30 | Mid |
| Student 25 | 35 | −0.30 | Mid |
| Student 26 | 35 | −0.30 | Mid |
| Student 27 | 35 | −0.30 | Mid |
| Student 28 | 36 | −0.25 | Mid |
| Student 29 | 37 | −0.20 | Mid |
| Student 30 | 40 | −0.05 | Mid |
| Student 31 | 40 | −0.05 | Mid |
| Student 32 | 41 | 0.00 | Mid |
| Student 33 | 41 | 0.00 | Mid |
| Student 34 | 43 | 0.10 | Mid |
| Student 35 | 43 | 0.10 | Mid |
| Student 36 | 43 | 0.10 | Mid |
| Student 37 | 44 | 0.15 | Mid |
| Student 38 | 46 | 0.25 | Mid |
| Student 39 | 46 | 0.25 | Mid |
| Student 40 | 46 | 0.25 | Mid |
| Student 41 | 46 | 0.25 | Mid |
| Student 42 | 46 | 0.25 | Mid |
| Student 43 | 46 | 0.25 | Mid |
| Student 44 | 48 | 0.35 | Mid |
| Student 45 | 49 | 0.40 | Mid |
| Student 46 | 49 | 0.40 | Mid |
| Student 47 | 49 | 0.40 | Mid |
| Student 48 | 53 | 0.60 | High |
| Student 49 | 53 | 0.60 | High |
| Student 50 | 58 | 0.85 | High |
| Student 51 | 66 | 1.25 | High |
| Student 52 | 67 | 1.30 | High |
| Student 53 | 72 | 1.55 | High |
| Student 54 | 78 | 1.85 | High |
| Student 55 | 81 | 2.00 | High |
| Student 56 | 88 | 2.35 | High |
| Student 57 | 94 | 2.65 | High |
| Student 58 | 97 | 2.80 | High |
References
- Aliaga-García, C., & Mora, J. C. (2009). Assessing the effects of phonetic training on L2 sound perception and production. In M. A. Watkins, A. S. Rauber, & B. O. Baptista (Eds.), Recent research in second language phonetics/phonology: Perception and production (pp. 2–31). Cambridge Scholars Publishing. [Google Scholar]
- Barrios, E., Flotts, A., Manzi, S., & Fuente, S. (2016). Contrasts involving new features with acoustically salient cues are easier to acquire than contrasts involving feature redeployment. Frontiers in Language Sciences, 10, 1295265. [Google Scholar]
- Bartholomew, A. (2024). Juna accent coach [Mobile app]. App Store. Available online: https://apps.apple.com/us/app/juna-accent-coach/id957254390 (accessed on 1 December 2020).
- Best, C. T. (1995). A direct realist perspective on cross-language speech perception. In W. Strange (Ed.), Speech perception and linguistic experience: Theoretical and methodological issues in cross-language speech research (pp. 167–200). York Press. [Google Scholar]
- Best, C. T., & Tyler, M. D. (2007). Nonnative and second-language speech perception. In O.-S. Bohn, & M. J. Munro (Eds.), Language experience in second language speech learning: In honor of James Emil Flege (pp. 13–34). John Benjamins. [Google Scholar]
- Brekelmans, G., Evans, B. G., & Wonnacott, E. (2024). Training child learners on nonnative vowel contrasts with phonetic training: The role of task and variability. Language Learning, Advance online publication, 1–36. [Google Scholar] [CrossRef]
- Carlet, A. (2017). L2 perception and production of English vowels by Catalan speakers: The effects of attention and training task in a cross-training study [Unpublished doctoral dissertation]. Universitat Autònoma de Barcelona.
- Carlet, A. (2019, August 5–9). Different high variability procedures for training L2 vowels and consonants. Proceedings of the ICPhS, Melbourne, Australia. [Google Scholar]
- Carlet, A., & Cebrian, J. (2022). The roles of task, segment type, and attention in L2 perceptual training. Applied Psycholinguistics, 43(2), 271–299. [Google Scholar] [CrossRef]
- Catford, J. C. (1987). Phonetics and the teaching of pronunciation: A systemic description of English phonology. In J. Morley (Ed.), Current perspectives on pronunciation: Practices anchored in theory (pp. 87–100). TESOL. [Google Scholar]
- Chen, Y., & Pederson, E. (2017). The efficacy of phonetic training on the perception and production of English word stress by Mandarin EFL learners. TESOL Quarterly, 51(1), 111–132. [Google Scholar]
- Choe, S., Lee, K., & So, Y. (2020). The effects of phonemic awareness instructions on L2 listening comprehension: A meta-analysis. The Journal of AsiaTEFL, 17(4), 1294–1309. [Google Scholar] [CrossRef]
- Choi, I. (1988). The necessity of teaching English fast speech phenomena for better aural comprehension skill in the Korean context [Unpublished doctoral dissertation]. University of Illinois at Urbana-Champaign.
- Chung, H., & Ahn, H. (2000). Phonemic awareness: Is this a prerequisite or a consequence of learning to listen in L2? Korean Journal of Applied Linguistics, 16(2), 65–81. [Google Scholar]
- Dao, P., Nguyen, M., & Nguyen, N. (2021). Effect of pronunciation instruction on L2 learners’ listening comprehension. Journal of Second Language Pronunciation, 7(1), 10–37. [Google Scholar] [CrossRef]
- Darcy, I., Daidone, D., & Kojima, C. (2013). Asymmetric development in L2 perceptual acquisition: Evidence from a longitudinal study. Language Learning, 63(3), 602–633. [Google Scholar]
- Escudero, P. (2005). Linguistic perception and second language acquisition: Explaining the attainment of optimal phonological categorization [Unpublished doctoral dissertation]. Utrecht University.
- Fagan, M. H., Neill, S., & Wooldridge, B. R. (2008). Exploring the intention to use computers: An empirical investigation of the role of intrinsic motivation, extrinsic motivation, and perceived ease of use. Journal of Computer Information Systems, 48(3), 31–37. [Google Scholar]
- Felker, E., Janse, E., Ernestus, M., & Broersma, M. (2023). How explicit instruction improves phonological awareness and perception of L2 sound contrasts in younger and older adults. Linguistic Approaches to Bilingualism, 13(3), 372–408. [Google Scholar] [CrossRef]
- Field, J. (2003). Promoting perception: Lexical segmentation in L2 listening. ELT Journal, 57(4), 325–334. [Google Scholar] [CrossRef]
- Flege, J. E. (1987). The production of “new” and “similar” phones in a foreign language: Evidence for the effect of equivalence classification. Journal of Phonetics, 15(1), 47–65. [Google Scholar] [CrossRef]
- Flege, J. E. (1995). Second language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 233–277). York Press. [Google Scholar]
- Flege, J. E., & Bohn, O. S. (2020). The revised speech learning model (SLM-r). In M. J. Munro, & O.-S. Bohn (Eds.), The second language speech learning: Theoretical and empirical progress (pp. 3–31). John Benjamins. [Google Scholar]
- Giannakopoulou, G., Uther, M., & Ylinen, S. (2017). Increased exposure to high variability phonetic training enhances non-native phoneme learning in children. Journal of Phonetics, 62, 44–62. [Google Scholar] [CrossRef]
- Hazan, V., Sennema, A., Iba, M., & Faulkner, A. (2005). Effect of audiovisual perceptual training on the perception and production of consonants by Japanese learners of English. Speech Communication, 47(3), 360–378. [Google Scholar] [CrossRef]
- Hirata, Y. (2004). Training native English speakers to perceive Japanese length contrasts in word versus sentence contexts. Journal of the Acoustical Society of America, 116(4), 2384–2395. [Google Scholar] [CrossRef]
- Hulstijn, J. H. (2001). Intentional and incidental second language vocabulary learning: A reappraisal of elaboration, rehearsal and automaticity. In P. Robinson (Ed.), Cognition and second language instruction (pp. 258–286). Cambridge University Press. [Google Scholar]
- Iverson, P., & Evans, B. G. (2009). Learning English vowels with different first-language vowel systems: Perception of formant targets, formant movement, and duration. Journal of the Acoustical Society of America, 126(1), 866–877. [Google Scholar] [CrossRef]
- Jacewicz, E., & Fox, R. A. (2012). Cross-dialectal differences in prosodic patterns in American English. Journal of Phonetics, 41(3–4), 145–161. [Google Scholar]
- Jeon, S. (2005). Introduction to English phonetics. Eulyoo Publishing. [Google Scholar]
- Kang, O., & Moran, M. (2015). Functional loads of pronunciation features in nonnative speakers’ oral assessment. TESOL Quarterly, 48(1), 176–193. [Google Scholar] [CrossRef]
- Ke, F., & Wang, W. (2021). Aural decoding and its relation to second language listening comprehension. System, 96, 102405. [Google Scholar] [CrossRef]
- Kissling, E. M. (2018). Pronunciation instruction can improve L2 learners’ bottom-up processing for listening. The Modern Language Journal, 102(4), 653–675. [Google Scholar] [CrossRef]
- Kuhl, P. K., Conboy, B. T., Padden, D., Nelson, T., & Pruitt, J. (2005). Early speech perception and later language development: Implications for the “critical period”. Language Learning and Development, 1(3–4), 237–264. [Google Scholar] [CrossRef] [PubMed]
- Lacabex, E., Gallardo-del-Puerto, F., & García Lecumberri, M. L. (2014). Computer-assisted pronunciation training with young learners: Implementation and effectiveness. ReCALL, 26(2), 168–186. [Google Scholar]
- Ladefoged, P., & Johnson, K. (2014). A course in phonetics (7th ed.). Nelson Education. [Google Scholar]
- Lambacher, S. G., Martens, W. L., Kakehi, K., Marasinghe, C. A., & Molholt, G. (2005). The effects of identification training on the identification and production of American English vowels by native speakers of Japanese. Applied Psycholinguistics, 26(2), 227–247. [Google Scholar] [CrossRef]
- Latifi, M., Tavakoli, M., & Dabaghi, A. (2014). The effect of metacognitive instruction on improving listening comprehension ability of intermediate EFL learners. International Journal of Research Studies in Language Learning, 3(6), 67–78. [Google Scholar] [CrossRef]
- Lee, H. (2023). Hangul-lo baeuneun yeongeo baram [Learning English pronunciation through Hangul]. Hangeul Jaemin Type Association. [Google Scholar]
- Lee, H., & Hwang, H. (2016). Gradient of learnability in teaching English pronunciation to Korean learners. The Journal of the Acoustical Society of America, 139(4), 1859–1872. [Google Scholar] [CrossRef]
- Li, M., Cheng, L., & Kirby, J. R. (2012). Phonological awareness and listening comprehension among Chinese English-immersion students. International Education, 41(2), 4. [Google Scholar]
- Logan, J. S., Lively, S. E., & Pisoni, D. B. (1991). Training Japanese listeners to identify English /r/ and /l/: A first report. The Journal of the Acoustical Society of America, 89(2), 874–886. [Google Scholar] [CrossRef]
- Lund, R. J. (1991). A comparison of second language listening and reading comprehension. The Modern Language Journal, 75(2), 196–204. [Google Scholar] [CrossRef]
- Mahdi, H. S., & Mohsen, M. A. (2023). A meta-analysis of high variability phonetic training in second language pronunciation learning. Journal of Language and Linguistic Studies, 19(1), 365–385. [Google Scholar]
- Melnik, E., & Peperkamp, S. (2020). The lasting effects of high variability phonetic training on word recognition. Second Language Research, 36(3), 443–461. [Google Scholar]
- Mora, J. C., & Mora-Plaza, I. (2023). From research in the lab to pedagogical practices in the EFL classroom: The case of task-based pronunciation teaching. Education Sciences, 13(10), 1042. [Google Scholar] [CrossRef]
- Mora, J. C., Ortega, M., Mora-Plaza, I., & Aliaga-García, C. (2022). Training the pronunciation of L2 vowels under different conditions: The use of non-lexical materials and masking noise. Phonetica, 79(1), 1–43. [Google Scholar] [CrossRef]
- Nam, H., Goldstein, L., & Saltzman, E. (2009). Self-organization and gestural timing in syllable structure. Laboratory Phonology, 10, 387–424. [Google Scholar]
- Nishi, K., & Kewley-Port, D. (2007). Training Japanese listeners to perceive American English vowels: Influence of training sets. The Journal of the Acoustical Society of America, 122(2), 1954–1966. [Google Scholar] [CrossRef]
- Perfetti, C. A., Liu, Y., & Tan, L. H. (2005). The lexical constituency model: Some implications of research on Chinese for general theories of reading. Psychological Review, 112(1), 43–59. [Google Scholar] [CrossRef]
- Saito, K., & Plonsky, L. (2019). Effects of second language pronunciation teaching revisited: A proposed measurement framework and meta-analysis. Language Learning, 69(3), 652–708. [Google Scholar] [CrossRef]
- Sakai, M., & Moorman, C. (2018). Can perception training improve the production of second language phonemes? A meta-analytic review of 25 years of perception training research. Applied Psycholinguistics, 39(1), 187–224. [Google Scholar] [CrossRef]
- Serrano, R. (2022). Spacing effects in second language learning: Research insights and pedagogical implications. Language Teaching Research, 26(1), 27–49. [Google Scholar]
- Simonchyk, A., & Darcy, I. (2017). Lexical encoding of L2 sounds: Evidence from a mispronunciation detection task. Studies in Second Language Acquisition, 39(3), 403–437. [Google Scholar]
- Strange, W. (2011). Automatic selective perception (ASP) of first and second language speech: A working model. Journal of Phonetics, 39(4), 456–471. [Google Scholar] [CrossRef]
- The University of Iowa. (2014). Sounds of speech. Available online: https://soundsofspeech.uiowa.edu/main.english (accessed on 1 December 2020).
- Thomson, R. I. (2018). High variability [pronunciation] training (HVPT) A proven technique about which every language teacher and learner ought to know. Journal of Second Language Pronunciation, 4(2), 208–231. [Google Scholar] [CrossRef]
- Thomson, R. I. (2024). English accent coach. Available online: https://www.englishaccentcoach.com (accessed on 1 December 2020).
- Thomson, R. I., & Derwing, T. M. (2015). The effectiveness of L2 pronunciation instruction: A narrative review. Applied Linguistics, 37(4), 559–582. [Google Scholar] [CrossRef]
- Thomson, R. I., & Derwing, T. M. (2016). Is phonemic training using nonsense or real words more effective? In J. M. Levis, H. Le, I. Lucic, E. Simpson, & S. Vo (Eds.), Proceedings of the 7th pronunciation in second language learning and teaching conference (pp. 88–97). Iowa State University. [Google Scholar]
- Toyama, M., & Hori, K. (2025). Technology-enhanced multimodal approaches in classroom L2 pronunciation training. Frontiers in Education, 10, 1552470. [Google Scholar] [CrossRef]
- Uchihara, T., Karas, M., & Thomson, R. I. (2024). Does perceptual high variability phonetic training improve L2 speech production? A meta-analysis of perception-production connection. Applied Psycholinguistics, 45(4), 591–623. [Google Scholar] [CrossRef]
- Unsworth, S. (2005). Child L2, adult L2, child L1: Differences and similarities [Unpublished doctoral dissertation]. Utrecht University.
- Vandergrift, L., & Goh, C. C. M. (2012). Teaching and learning second language listening: Metacognition in action. Routledge. [Google Scholar]
- Van Ooijen, B. (1996). Vowel mutability and lexical selection in English: Evidence from a word reconstruction task. Memory & Cognition, 24, 573–583. [Google Scholar]
- Vaughan-Rees, M. (2002). Test your pronunciation. Pearson Education. [Google Scholar]
- Zhang, H., Inoue, Y., Saito, D., Minematsu, N., & Yamauchi, Y. (2019, August 5–9). Computer-aided high variability phonetic training to improve robustness of learners’ listening comprehension. Proceedings of the 19th International Congress of Phonetic Sciences (ICPhS) (pp. 924–928), Melbourne, Australia. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pair # | IPA Symbol | Pair # | IPA Symbol |
|---|---|---|---|
| 1 | /p, b/ | 8 | /t, d/ |
| 2 | /c, g/ | 9 | /f, v/ |
| 3 | /s, z/ | 10 | /ʃ, ʒ/ |
| 4 | /θ, s/ | 11 | /l, r/ |
| 5 | /m, n/ | 12 | /h/ |
| 6 | /tʃ, dʒ/ | 13 | /w/ |
| 7 | /j/ | 14 | /k, kw/ |
| Pair # | IPA Symbol |
|---|---|
| 1 | /l, r/ |
| 2 | /θ, s/ |
| 3 | /s, z/ |
| 4 | /f, v/ |
| 5 | /tʃ, dʒ/ |
| 6 | /ʃ, ʒ/ |
| 7 | /w/ |
| 8 | /j/ |
| Day | Activity |
|---|---|
| Day 1 | Pretest 1 (PA test), questionnaire |
| Day 2 | Pretest 2 (LC test) |
| Day 3 | Introduction of the course |
| Day 4–5 | Lesson of /l/, /r/ |
| Day 6 | * Review (classroom) |
| Day 7–9 | Lesson of /θ/, /s/, /z/ |
| Day 10 | * Review (classroom) |
| Day 11–12 | Lesson of /f/, /v/ |
| Day 13 | * Review (classroom) |
| Day 14–17 | Lesson of /tʃ/, /dʒ/, /ʃ/, /ʒ/ |
| Day 18 | * Review (classroom) |
| Day 19–20 | Lesson of /w/, /j/ |
| Day 21 | * Review (classroom) |
| Day 22 | Posttest 1 (PA test) |
| Day 23 | Posttest 2 (LC test), survey and interview |
| Test | min | max | M | SD | SE | Mean Diff | t | df | p | 95% CI | d |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pretest | 13 | 62 | 43.49 | 10.58 | 1.40 | ||||||
| Posttest | 23 | 59 | 46.10 | 8.30 | 1.10 | 2.61 | 2.8 | 56 | 0.01 ** | [0.74, 4.48] | 0.26 |
| Test | min | max | M | SD | SE | Mean Diff | t | df | p | 95% CI | d |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pretest | 8 | 97 | 40.82 | 20.18 | 2.67 | <0.001 *** | |||||
| Posttest | 24 | 103 | 54.24 | 20.05 | 2.66 | 13.42 | 8.18 | 56 | [10.13, 16.71] | 0.67 |
| Group | Source | N | min | max | M | SD | SE |
|---|---|---|---|---|---|---|---|
| High | LC Pretest | 11 | 53 | 97 | 73.36 | 15.62 | 4.71 |
| LC Posttest | 11 | 53 | 103 | 86.82 | 15.44 | 4.66 | |
| Gain score | 4 | 36 | 13.46 | ||||
| Intermediate | LC Pretest | 29 | 31 | 49 | 40.34 | 5.89 | 1.09 |
| LC Posttest | 29 | 27 | 71 | 48.97 | 10.33 | 1.20 | |
| Gain score | −8 | 30 | 8.63 | ||||
| Low | LC Pretest | 17 | 8 | 30 | 20.59 | 6.99 | 1.70 |
| LC Posttest | 17 | 24 | 67 | 42.18 | 11.68 | 2.83 | |
| Gain score | 17 | 4 | 59 | 21.59 | |||
| Total | 57 | 40.91 | 20.01 |
| Paired Differences | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| M | SD | SE | 95% CI | t | df | Sig. | d | ||
| Lower | Upper | ||||||||
| High | 13.45 | 9.83 | 2.96 | 6.85 | 20.06 | 4.84 | 10 | <0.001 *** | 0.87 |
| Intermediate | 8.62 | 9.39 | 1.77 | 5.05 | 12.19 | 4.94 | 28 | <0.001 *** | 1.74 |
| Low | 21.59 | 14.48 | 3.62 | 14.14 | 29.03 | 6.15 | 16 | <0.001 *** | 2.26 |
| Group | Source | LC Pretest | LC Posttest | |
|---|---|---|---|---|
| All | L2 perception pretest | Pearson Correlation | 0.427 *** | |
| Sig. | 0.000 | |||
| L2 perception posttest | Pearson Correlation | 0.479 *** | ||
| Sig. | 0.000 |
| Group | Source | LC Pretest | LC Posttest | |
|---|---|---|---|---|
| High (n = 11) | PA Pretest | Pearson correlation | 0.566 | |
| Sig. | 0.069 | |||
| PA Posttest | Pearson correlation | 0.377 | ||
| Sig. | 0.253 | |||
| Intermediate (n = 29) | PA Pretest | Pearson correlation | 0.314 | |
| Sig. | 0.097 | |||
| PA Posttest | Pearson correlation | 0.308 | ||
| Sig. | 0.104 | |||
| Low (n = 17) | PA Pretest | Pearson correlation | −0.122 | |
| Sig. | 0.64 | |||
| PA Posttest | Pearson correlation | 0.691 ** | ||
| Sig. | 0.002 |
| Questions | High (%) | Intermediate (%) | Low (%) | Total (%) | |
|---|---|---|---|---|---|
| 1 | Have you ever taken English sound perception lessons before? (Yes) | 5 (83.3) | 4 (20) | 3 (37.5) | 12 (35.3) |
| 2 | Was the lesson method effective? (Yes) | 5 (83.3) | 11 (55) | 4 (57.1) | 20 (58.8) |
| 3 | Can you distinguish phoneme pairs now? (Yes) | 6 (100) | 13 (65) | 3 (42.9) | 22 (64.7) |
| 4 | Do you think the lesson helped you improve your English listening skills? (Yes) | 6 (100) | 15 (75) | 6 (85.7) | 27 (79.4) |
| 5 | Do you think the lesson improved your confidence in English? (Yes) | 6 (100) | 11 (55) | 3 (37.5) | 20 (58.8) |
| 6 | Do you think you can utilize this English perception abilities? (Yes) | 4 (66.7) | 13 (65) | 5 (71.4) | 22 (64.7) |
| How Sincerely Have You Been Working on the Lessons? | 1 (%) | 2 (%) | 3 (%) | 4 (%) | 5 (%) | M |
|---|---|---|---|---|---|---|
| High (n = 6) | 0 | 0 | 2 (33.3) | 1 (16.7) | 3 (50) | 4.17 |
| Intermediate (n = 20) | 0 | 3 (15) | 10 (50) | 5 (25) | 2 (10) | 3.3 |
| Low (n = 8) | 0 | 2 (25) | 5 (62.5) | 0 | 1 (12.5) | 3 |
| Total | 0 | 5 | 17 | 6 | 6 | 3.38 |
| Questions | /θ/ | /ʒ/ | /l/ | /r/ | /f/ | /tʃ/ | /j/ | /z/ | /s/ | /ʃ/ | /w/ | /v/ | /y/ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Which English Sound Was the Most Unfamiliar and Difficult? | |||||||||||||
| High (n = 6) | 3 | 3 | 2 | 3 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 |
| Intermediate (n = 20) | 9 | 5 | 3 | 3 | 4 | 3 | 2 | 2 | 2 | 3 | 1 | 0 | 0 |
| Low (n = 8) | 4 | 1 | 3 | 1 | 1 | 2 | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
| Total | 16 | 9 | 8 | 7 | 6 | 6 | 5 | 5 | 4 | 4 | 2 | 1 | 1 |
| Group | Student | What I Have Learned | What I Want to Learn More | How I Felt about PA Lessons | How I Practiced Listening Before |
|---|---|---|---|---|---|
| High | S1 | -I could understand confusing pronunciations. | -I still can’t make a perfect distinction on /r/, so I want to practice more. | -It was fun and good. | -Dictations, Fill-in-the-Blanks |
| High | S2 | -I learned anew how to do things like mouth shape and tongue shape by pronunciation. | -Sometimes I’m confused about whether the pronunciation I’m practicing is correct. | -It was a little difficult at first, but it was fun as I gradually understood. | -Fill-in-the-Blanks |
| Intermediate | S3 | -I learned that there are many ways to pronounce English pronunciation. | -I want to study more phonemes. | -It was new to me so I became more focused than other classes. -By studying English sounds, I could speak English more accurately. | -Listen to the audio and memorize the pronunciation. |
| Intermediate | S4 | -I knew that the tongue was important when pronouncing English. | -I want to expand this lesson in a paragraph, as I can’t read an English paragraph well. | -When I listened to English, I was proud to know what was wrong because I kept listening. -When phonemes were difficult, like s, z, and th, it was good to see a video of native speakers repeating them. | -Listen to sentences and words on a laptop and take a test. |
| Low | S5 | -I found out that there are various sounds in English. | -I want to practice listening drills more. | -I didn’t know that English pronunciation was important, but while learning the lessons, I realized that pronunciation was crucial. | -Listening several times. |
| Low | S6 | -I learned the vibration of the vocal cord. | -I felt I had to study English more in the future. | -I have fun learning. It was amazing because it was my first time studying HVPT. | -Dictations. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Ahn, H. Blended Phonetic Training with HVPT Features for EFL Children: Effects on L2 Perception and Listening Comprehension. Languages 2025, 10, 122. https://doi.org/10.3390/languages10060122
Lee K, Ahn H. Blended Phonetic Training with HVPT Features for EFL Children: Effects on L2 Perception and Listening Comprehension. Languages. 2025; 10(6):122. https://doi.org/10.3390/languages10060122
Chicago/Turabian StyleLee, KyungA, and Hyunkee Ahn. 2025. "Blended Phonetic Training with HVPT Features for EFL Children: Effects on L2 Perception and Listening Comprehension" Languages 10, no. 6: 122. https://doi.org/10.3390/languages10060122
APA StyleLee, K., & Ahn, H. (2025). Blended Phonetic Training with HVPT Features for EFL Children: Effects on L2 Perception and Listening Comprehension. Languages, 10(6), 122. https://doi.org/10.3390/languages10060122