
Investigating the Relationship Between Oral Reading Miscues and Comprehension in L2 Chinese


Abstract
1. Introduction
2. Literature Review
2.1. Theoretical Framework of Oral Reading Miscue Analysis
2.2. Unique Features of Chinese Reading
2.3. Oral Reading and Miscue Analysis in L2 Chinese
3. The Current Study
- What types of oral reading miscues do L2 Chinese learners produce when reading Chinese texts?
- What is the relationship between oral reading miscues and literal-level passage comprehension in L2 Chinese reading?
4. Materials and Methods
4.1. Participants
4.2. Instruments
4.2.1. Oral Reading Passages
4.2.2. Literal Comprehension Task
4.3. Data Collection
4.4. Data Coding and Scoring
5. Analysis and Results
5.1. RQ1: What Types of Oral Reading Miscues Do L2 Chinese Learners Produce When Reading Chinese Texts?
5.2. RQ2: What Is the Relationship Between Oral Reading Miscues and Literal-Level Passage Comprehension in L2 Chinese Reading?
6. Discussion
6.1. Miscue Types and Categories in L2 Chinese Reading
6.2. Relationships Between Oral Reading Miscues and Literal-Level Reading Comprehension
7. Pedagogical Implication
8. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| L2 | Second language |
| ORF | Oral reading fluency |
| MT | Mispronouncing tones |
| MC | Misreading characters |
| SU | Substitution |
| IN | Insertion |
| OM | Omission |
| SC | Self-correction |
| RWO | Reversal of word order |
| RT | Repetition |
| PL | Long pauses between words |
| IP | Inappropriate pauses within a word |
| IWS | Inappropriate word segmentation |
| RM | Radical-related or shape-similar misreading |
| MP | Misreading polyphones |
| TR | English translation |
| ORM | Orthographic miscues |
| SYM | Syntactic miscues |
| SEM | Semantic miscues |
| WPM | Word processing miscues |
Appendix A
Oral Reading Passages
| Passage 1 理想职业 | 有的人想当医生,有的人想当警察,你呢?你有自己的理想职业吗?如果没有,请你先问问自己几个问题。我的兴趣是什么?我喜欢做什么?我适合做什么? 一个人要是能根据自己的爱好去选择职业,他就会更爱自己的工作、更想去工作。比如,科学家爱迪生,他差不多每天都工作十几个小时,但是他一点儿也不觉得辛苦,反而觉得每天都非常快乐。 很多人总是很难了解自己的兴趣是什么、自己适合什么。我们可以在生活中发现自己、认识自己,了解自己能做什么、不能做什么。比如作家斯贝克一开始也没有想到自己会成为作家。开始的时候,因为他有一米九高,所以爱上了篮球,当了一名运动员。后来,因为打球打得不是很好,而且年龄也越来越大了,又改行当了画家。最后他终于发现原来自己有写文章的才能,于是成为了一个有名的作家。 发现自己的兴趣,根据兴趣选择自己的职业,你的生活才会更快乐,才更容易把工作做好。 |
| Passage 2 当代大学生与名牌消费 | 最近中国经济快速发展。中国作为世界上最大的市场,吸引了来自世界各地的商品。很多品牌成为中国人心中的“世界名牌”。大家追求生活品质的标准越来越高,人人都开始赶时髦、要面子、买名牌。 顾客喜欢名牌可能有几个原因。第一,虽然名牌商品的价格比较高,但是质量有保证。第二,在各个大城市的商场一般都有名牌的专卖店,所以退换商品都很方便。第三,用名牌不但能体现自己的生活方式,而且还会受到别人的尊重。 选择名牌商品有很多好处,但是非名牌不买就一定好吗?名牌商品价格很高,有的大学生为了买到名牌,用各种办法省钱,连正常生活水平都不能保证。有的人想显示身份却又没有那么多钱,于是开始买假名牌。名牌热也给学生们带来了不好的影响。有的大学生买东西上瘾,甚至忘记了学习。 大学生应该建立正确的购物观,在选择名牌商品以前应该先考虑自己的经济能力。 |
Appendix B
Task Instructions
- a.
- Oral Reading Task Instructions:
- b.
- Literal Comprehension Task Instructions:
References
- Almazroui, K. M. (2007). Learning together through retrospective miscue analysis: Salem’s case study. Reading Improvement, 44(3), 153–169. [Google Scholar]
- Basaraba, D., Yovanoff, P., Alonzo, J., & Tindal, G. (2013). Examining the structure of reading comprehension: Do literal, inferential, and evaluative comprehension truly exist? Reading and Writing, 26, 349–379. [Google Scholar] [CrossRef]
- Beatty, L., & Care, E. (2009). Learning from their miscues: Differences across reading ability and text difficulty. The Australian Journal of Language and Literacy, 32(3), 226–244. [Google Scholar] [CrossRef]
- Bernhardt, E. (2005). Progress and procrastination in second language reading. Annual Review of Applied Linguistics, 25, 133–150. [Google Scholar] [CrossRef]
- Bernhardt, E. (2010). Understanding advanced second-language reading. Routledge. [Google Scholar] [CrossRef]
- Blair, H., Filipek, J., Fu, H., Lin, X., & Sun, M. (2022). When learners read in two languages: Understanding Chinese-English bilingual readers through miscue analysis. Language and Literacy, 24(2), 245–266. [Google Scholar] [CrossRef]
- Ehrich, J. F., Zhang, L. J., Mu, J. C., & Ehrich, L. C. (2013). Are alphabetic language-derived models of L2 reading relevant to L1 logographic background readers? Language Awareness, 22(1), 39–55. [Google Scholar] [CrossRef]
- Everson, M. E. (1998). Word recognition among learners of Chinese as a foreign language: Investigating the relationship between naming and knowing. The Modern Language Journal, 82(2), 194–204. [Google Scholar] [CrossRef]
- Fuchs, L. S., Fuchs, D., Hosp, M. K., & Jenkins, J. R. (2001). Oral reading fluency as an indicator of reading competence: A theoretical, empirical, and historical analysis. Scientific Studies of Reading, 5(3), 239–256. [Google Scholar] [CrossRef]
- Geva, E., & Farnia, F. (2012). Developmental changes in the nature of language proficiency and reading fluency paint a more complex view of reading comprehension in ELL and EL1. Reading and Writing, 25, 1819–1845. [Google Scholar] [CrossRef]
- Gillet, J. W., Temple, C. A., Crawford, A. N., & Cooney, B. (1990). Understanding reading problems: Assessment and instruction. Scott Foresman/Little, Brown Higher Education. [Google Scholar]
- Goodman, K. S. (1969). Analysis of oral reading miscues: Applied psycholinguistics. Reading Research Quarterly, 5, 9–30. [Google Scholar] [CrossRef]
- Goodman, Y. M. (2014). Retrospective miscue analysis: Illuminating the voice of the reader. In Making sense of learners making sense of written language (pp. 205–221). Routledge. [Google Scholar]
- Goodman, Y. M. (2015). Miscue analysis: A transformative tool for researchers, teachers, and readers. Literacy Research: Theory, Method, and Practice, 64(1), 92–111. [Google Scholar] [CrossRef]
- Goodman, Y. M., & Goodman, K. S. (2014). To err is human: Learning about language processes by analyzing miscues. In Making sense of learners making sense of written language (pp. 115–134). Routledge. [Google Scholar]
- Huang, S. (2018). Effective strategy groups used by readers of Chinese as a foreign language. Reading in a Foreign Language, 30(1), 1–28. [Google Scholar]
- Jeon, E. H. (2012). Oral reading fluency in second language reading. Reading in a Foreign Language, 24(2), 186–208. [Google Scholar]
- Jiang, L. (2012). 体验汉语中级教程 (Intermediate course of experiencing Chinese). 高等教育出版社 (Higher Education Press). Available online: https://books.google.com/books?id=_ybjsgEACAAJ (accessed on 4 March 2021).
- Jiang, X. (2016). The role of oral reading fluency in ESL reading comprehension among learners of different first language backgrounds. Reading Matrix: An International Online Journal, 16(2), 227–242. [Google Scholar]
- Ke, S., & Chan, S.-D. (2017). Strategy use in L2 Chinese reading: The effect of L1 background and L2 proficiency. System, 66, 27–38. [Google Scholar] [CrossRef]
- Kintsch, W. (1988). The role of knowledge in discourse comprehension: A construction-integration model. Psychological Review, 95(2), 163. [Google Scholar] [CrossRef] [PubMed]
- Kintsch, W. (1998). Comprehension: A paradigm for cognition. Cambridge University Press. [Google Scholar]
- Kucer, S. B. (2009). Examining the relationship between text processing and text comprehension in fourth grade readers. Reading Psychology, 30(4), 340–358. [Google Scholar] [CrossRef]
- Latham Keh, M. (2017). Understanding and evaluating English learners’ oral reading with miscue analysis. Journal of Adolescent & Adult Literacy, 60(6), 643–653. [Google Scholar] [CrossRef]
- Lee-Thompson, L. C. (2008). An investigation of reading strategies applied by American learners of Chinese as a foreign language. Foreign Language Annals, 41(4), 702–721. [Google Scholar] [CrossRef]
- Luo, Y. C., Chen, X., Deacon, S. H., Zhang, J., & Yin, L. (2013). The role of visual processing in learning to read Chinese characters. Scientific Studies of Reading, 17(1), 22–40. [Google Scholar] [CrossRef]
- McKenna, M. C., & Picard, M. C. (2006). Revisiting the role of miscue analysis in effective teaching. The Reading Teacher, 60(4), 378–380. [Google Scholar] [CrossRef]
- McNeil, L. (2012). Extending the compensatory model of second language reading. System, 40(1), 64–76. [Google Scholar] [CrossRef]
- Moore, R. A., & Brantingham, K. L. (2003). Nathan: A case study in reader response and retrospective miscue analysis. The Reading Teacher, 56(5), 466–474. [Google Scholar]
- Orton, J. (2013). Developing Chinese oral skills: A research base for practice. Research in Chinese as a Second Language, 9, 9–32. [Google Scholar]
- Perfetti, C., & Harris, L. N. (2013). Universal reading processes are modulated by language and writing system. Language Learning and Development, 9(4), 296–316. [Google Scholar] [CrossRef]
- Perfetti, C., & Stafura, J. (2014). Word knowledge in a theory of reading comprehension. Scientific Studies of Reading, 18(1), 22–37. [Google Scholar] [CrossRef]
- Shen, H. H. (2005). An investigation of Chinese-character learning strategies among non-native speakers of Chinese. System, 33(1), 49–68. [Google Scholar] [CrossRef]
- Shen, H. H. (2013). Chinese L2 literacy development: Cognitive characteristics, learning strategies, and pedagogical interventions. Language and Linguistics Compass, 7(7), 371–387. [Google Scholar] [CrossRef]
- Shen, H. H. (2019). An investigation on instructional-level reading among Chinese L2 learners. Journal of Second Language Teaching and Research, 7, 184–211. [Google Scholar]
- Shen, H. H., & Bear, D. R. (2000). Development of orthographic skills in Chinese children. Reading and Writing, 13, 197–236. [Google Scholar] [CrossRef]
- Shen, H. H., & Jiang, X. (2013). Character reading fluency, word segmentation accuracy, and reading comprehension in L2 Chinese. Reading in a Foreign Language, 25(1), 1–25. [Google Scholar]
- Shen, H. H., & Ke, C. (2007). Radical awareness and word acquisition among nonnative learners of Chinese. The Modern Language Journal, 91(1), 97–111. [Google Scholar] [CrossRef]
- Shen, H. H., Zhou, Y., & Gao, G. (2020). Oral reading miscues and reading comprehension by Chinese L2 learners. Reading in a Foreign Language, 32(2), 143–168. [Google Scholar]
- Shu, H., Chen, X., Anderson, R. C., Wu, N., & Xuan, Y. (2003). Properties of school Chinese: Implications for learning to read. Child Development, 74(1), 27–47. [Google Scholar] [CrossRef] [PubMed]
- Sproat, R., & Gutkin, A. (2021). The taxonomy of writing systems: How to measure how logographic a system is. Computational Linguistics, 47(3), 477–528. [Google Scholar] [CrossRef]
- Theurer, J. L. (2002). The power of retrospective miscue analysis: One preservice teacher’s journey as she reconsiders the reading process. Reading Matrix: An International Online Journal, 2(1), 1–23. [Google Scholar]
- Wang, Y. (2020). Adult English learners and the bilingual reading process: Retrospective miscue analysis. Bilingual Research Journal, 43(4), 433–449. [Google Scholar] [CrossRef]
- Wilde, S. (2000). Miscue analysis made easy: Building on student strengths. ERIC. [Google Scholar]
- Wurr, A. J., Theurer, J. L., & Kim, K. J. (2008). Retrospective miscue analysis with proficient adult ESL readers. Journal of Adolescent & Adult Literacy, 52(4), 324–333. [Google Scholar] [CrossRef]
- Yang, S. (2021a). Diagnosing reading problems for low-level Chinese as second language learners. System, 97, 102433. [Google Scholar] [CrossRef]
- Yang, S. (2021b). Investigating word segmentation of Chinese second language learners. Reading and Writing, 34(5), 1273–1293. [Google Scholar] [CrossRef]
- Zhang, H. (2018). Current trends in research of Chinese sound acquisition. In The Routledge handbook of Chinese second language acquisition (pp. 217–233). Routledge. [Google Scholar]
- Zhang, L. (2019). Tone features of Chinese and teaching methods for second language learners. International Journal of Chinese Language Education, 5, 45–66. [Google Scholar]
- Zhang, T., & Ke, C. (2018). Research on L2 Chinese character acquisition. In The Routledge handbook of Chinese second language acquisition (pp. 103–133). Routledge. [Google Scholar]

{kind=link}
{kind=link}
| Score for Each Chinese Sentence * | Criteria | Example (Chinese: 最后他终于发现原来自己有写文章的才能,于是成为了一个有名的作家。) |
|---|---|---|
| 5 | The English translation totally matches the original text in Chinese, with no omissions. (Accuracy: 100%) | “In the end, he finally discovered his talent for writing, thus he finally became a famous writer.” |
| 4 | The English translation generally matches the original text in Chinese, or has minor omissions. (Accuracy: 80~100%) | “Lastly, he found his ability to write articles, so he became a famous_____.” Minor omission: “作家” not translated. |
| 3 | The English translation somewhat matches the original text in Chinese, or has several omissions. (Accuracy: 60~80%) | “Finally, he wrote, and became a writer.” Several details omitted: “终于发现” and “才能”. |
| 2 | The English translation significantly changes the meaning of the original text, or has many omissions. (Accuracy: 30~60%) | “Finally, he developed himself through reading, become a well-known person.” Significant changes: “发现” (discover) changed to “developed”, “写文章的才能” (talent for writing) replaced with “reading”, “作家” (writer) replaced with “person”. |
| 1 | The English translation is almost entirely different from the original text in Chinese. (Accuracy: 0~30%) | “At last, he found a job in a famous company because of his talent in writing Chinese characters.” Almost entirely different meaning: “成为作家” (become a writer) changed to “found a job”, “有名的” (famous) misapplied to “company” instead of the person, “写文章” (writing articles) confused with “写汉字” (writing Chinese characters). |
| 0 | The participant did not translate the sentence. (Accuracy: 0%) | Left blank or Chinese text copied without translation. |
| Miscue Type | Description | Example | |
|---|---|---|---|
| Correct Oral Reading | Incorrect Oral Reading | ||
| Mispronouncing tones (MT) | Incorrect tone used for a syllable | 问问自己wènwèn ask yourself | 问问自己wénwén |
| Misreading characters (MC) | Incorrect pronunciation of the initial part, final part, or both | 选择职业xuǎn choose a career | 选择职业suǎn |
| Substitution (SU) | Replacing a target character, word, or phrase | (a) 自己的理想职业 your own dream job (b) 有几个原因 There are several reasons | (a) Grammatically acceptable: 自己的理想工作 (b) Grammatically unacceptable: 有几个原来 |
| Insertion (IN) | Adding an extra character, word, or phrase | (a) 一个有名的作家 a famous author (b) 来自世界各地的商品 products from all over the globe | (a) Grammatically acceptable: 一个(很)有名的作家 (b) Grammatically unacceptable: 来自(己)世界各地的商品 |
| Omission (OM) | Skipping a character, word, or phrase | (a) 忘记了学习 forget their studies (b) 年龄也越来越大了 He was getting older | (a) Grammatically acceptable: 忘(OM)了学习 (b) Grammatically unacceptable: 年(OM)也越来越大了 |
| Self-correction (SC) | Immediate correction after a mistake | 十几个小时 over ten hours | read 小时 as 时候, then make a correction. |
| Reversal of word order (RWO) | Changing the sequence of characters or words | 我适合做什么? What am I well-suited to doing | 我合适做什么? |
| Repetition (RT) | Repeating a character, word, or phrase | 根据自己的爱好 in accordance with your interests | 根据根据自己的爱好 |
| Long pause between words (PL) | Pausing for >3 s between words | 不但能体现自己的生活方式 not only allows you to show your lifestyle | 不但能(PL)体现自己的生活方式 |
| Inappropriate pause within word (IP) | Pausing between characters in a word | 快速发展 develop rapidly | 快(IP)速发展 |
| Inappropriate word segmentation (IWS) | Incorrect grouping of characters | 用/各种/办法/省钱 use all kinds of methods to save money | 用各/种办/法省钱 |
| Radical-related or shape-similar misreading (RM) | Reading based on character components | (a) 终于发现 finally realized (b) 考虑自己的经济能力 consider their economic situation (c) 最大的市场 the largest market | (a) Read the phonetic or semantic radical: 冬于发现 (b) Use another character that shares the same radical as the target character: 考虎自己的经济能力 (c) Read a similarly shaped character: 最大的市物 |
| Misreading polyphones (MP) | Incorrect reading of characters with multiple pronunciations | 又改行(háng)当了画家 changed careers and became a painter | 又改行(xíng)当了画家 |
| English translation (TR) | Using English instead of Chinese pronunciation | 价格很高 The price is very high | price很高 |
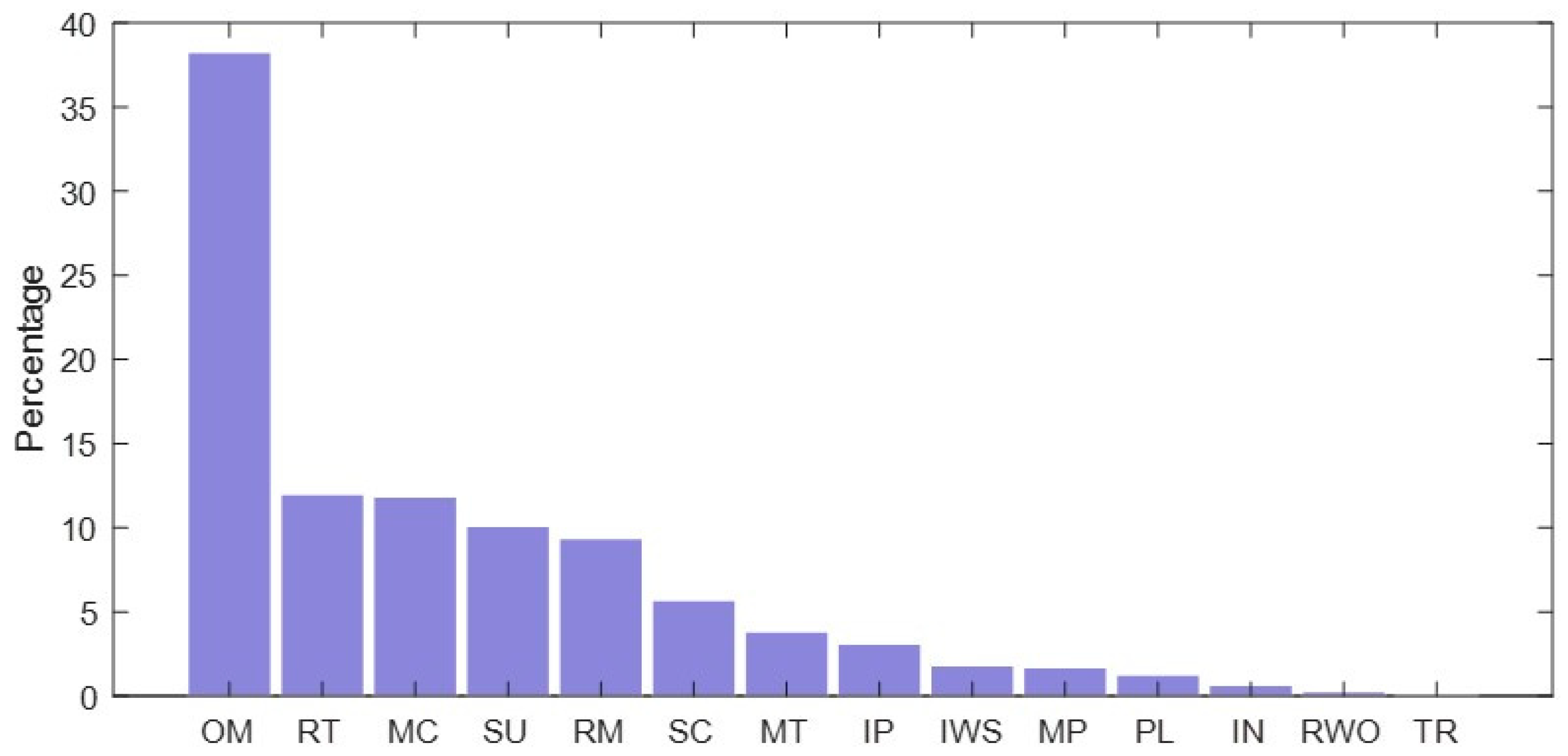
| Miscue Type | Occurrences | Percentage |
|---|---|---|
| MT | 209 | 3.84% |
| MC | 638 | 11.84% |
| SU | 545 | 10.11% |
| IN | 35 | 0.65% |
| OM | 2063 | 38.27% |
| SC | 307 | 5.70% |
| RWO | 15 | 0.28% |
| RT | 646 | 11.99% |
| PL | 69 | 1.28% |
| IP | 167 | 3.10% |
| IWS | 98 | 1.82% |
| RM | 505 | 9.37% |
| MP | 92 | 1.71% |
| TR | 3 | 0.06% |
| Total | 5392 | 100% |
| Category | Included Miscue Types |
|---|---|
| ORM | MT, MC, RM |
| SYM | Partial SU, IN, OM |
| SEM | Remaining partial SU, IN, OM |
| WPM | RT, PL, IP, IWS, MP |
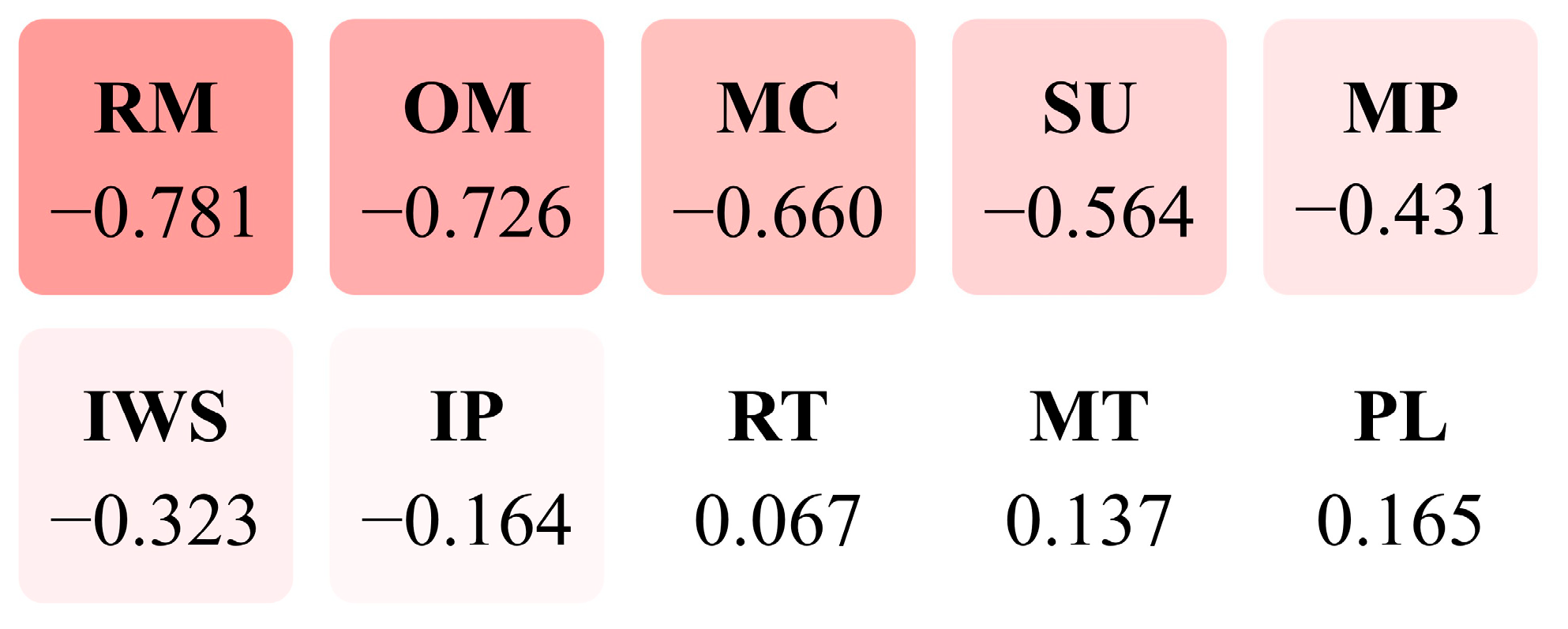
| Miscue Type | Correlation Coefficient (r) |
|---|---|
| MT | 0.137 |
| MC | −0.660 ** |
| SU | −0.564 ** |
| OM | −0.726 ** |
| RT | 0.067 |
| PL | 0.165 |
| IP | −0.164 |
| IWS | −0.323 ** |
| RM | −0.781 ** |
| MP | −0.431 ** |
| ORM | SYM | SEM | WPM | |
|---|---|---|---|---|
| Literal comprehension | −0.735 ** | −0.755 ** | −0.505 ** | −0.089 |
| Category | ORM | SYM | SEM | WPM |
|---|---|---|---|---|
| ORM | -- | 0.366 ** | 0.281 * | 0.073 |
| SYM | -- | 0.565 ** | 0.014 | |
| SEM | -- | 0.019 | ||
| WPM | -- |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S. Investigating the Relationship Between Oral Reading Miscues and Comprehension in L2 Chinese. Languages 2025, 10, 115. https://doi.org/10.3390/languages10050115
Wang S. Investigating the Relationship Between Oral Reading Miscues and Comprehension in L2 Chinese. Languages. 2025; 10(5):115. https://doi.org/10.3390/languages10050115
Chicago/Turabian StyleWang, Sicheng. 2025. "Investigating the Relationship Between Oral Reading Miscues and Comprehension in L2 Chinese" Languages 10, no. 5: 115. https://doi.org/10.3390/languages10050115
APA StyleWang, S. (2025). Investigating the Relationship Between Oral Reading Miscues and Comprehension in L2 Chinese. Languages, 10(5), 115. https://doi.org/10.3390/languages10050115