
SpaceDrones 2.0—Hardware-in-the-Loop Simulation and Validation for Orbital and Deep Space Computer Vision and Machine Learning Tasking Using Free-Flying Drone Platforms


Abstract
:1. Introduction
2. Motivation
3. Research Questions
- Can synthetic data be used for reliable real-world object tracking?
- Can domain randomization and data augmentation be used to increase cross-domain computer vision performance?
- Can synthetically trained computer vision models be used for Hardware-in-the-loop testing, sensing, and localization for real-world applications?
4. State of the Art
4.1. Domain Randomization
4.2. Physical Simulation
4.3. Synthetic/Virtual Reality Space Simulation
5. Materials and Methods
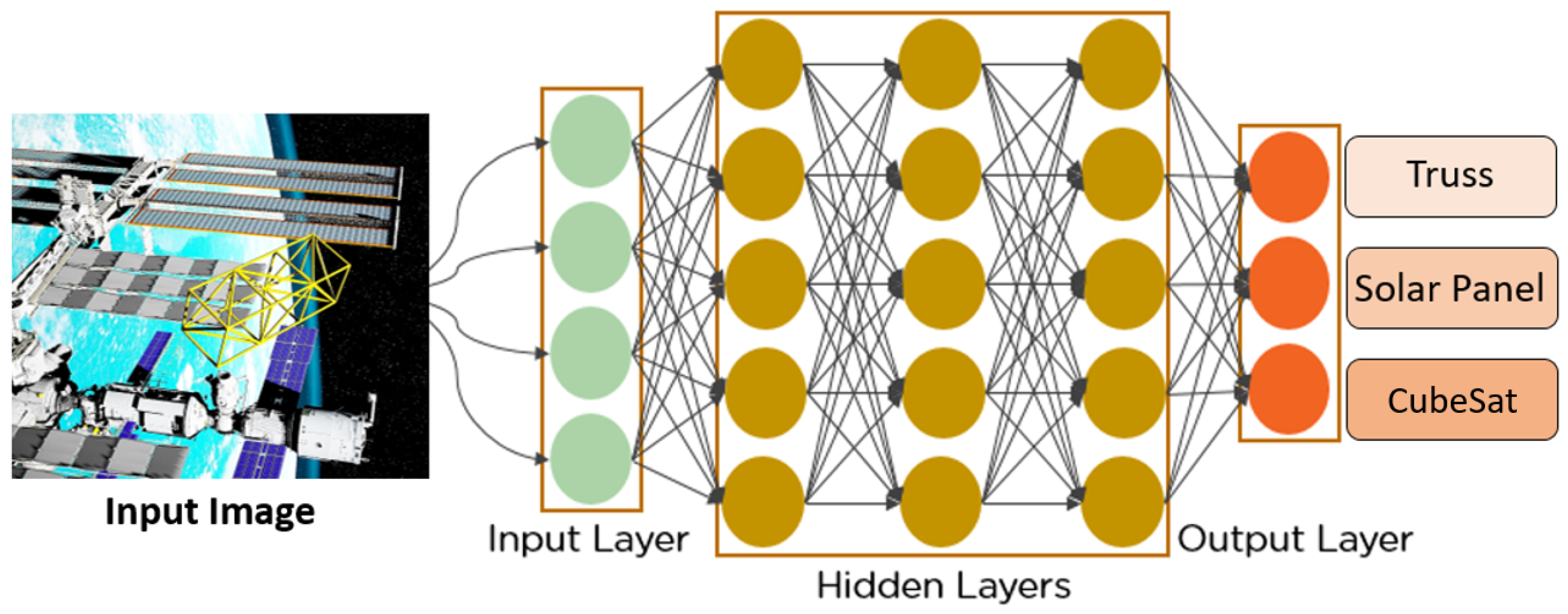
5.1. CNN Architecture Selection
5.2. Synthetic Reality Creation and Collection
5.3. Synthetic Domain Randomization
5.4. Porting CAD Models and Hardware into Synthetic Environments
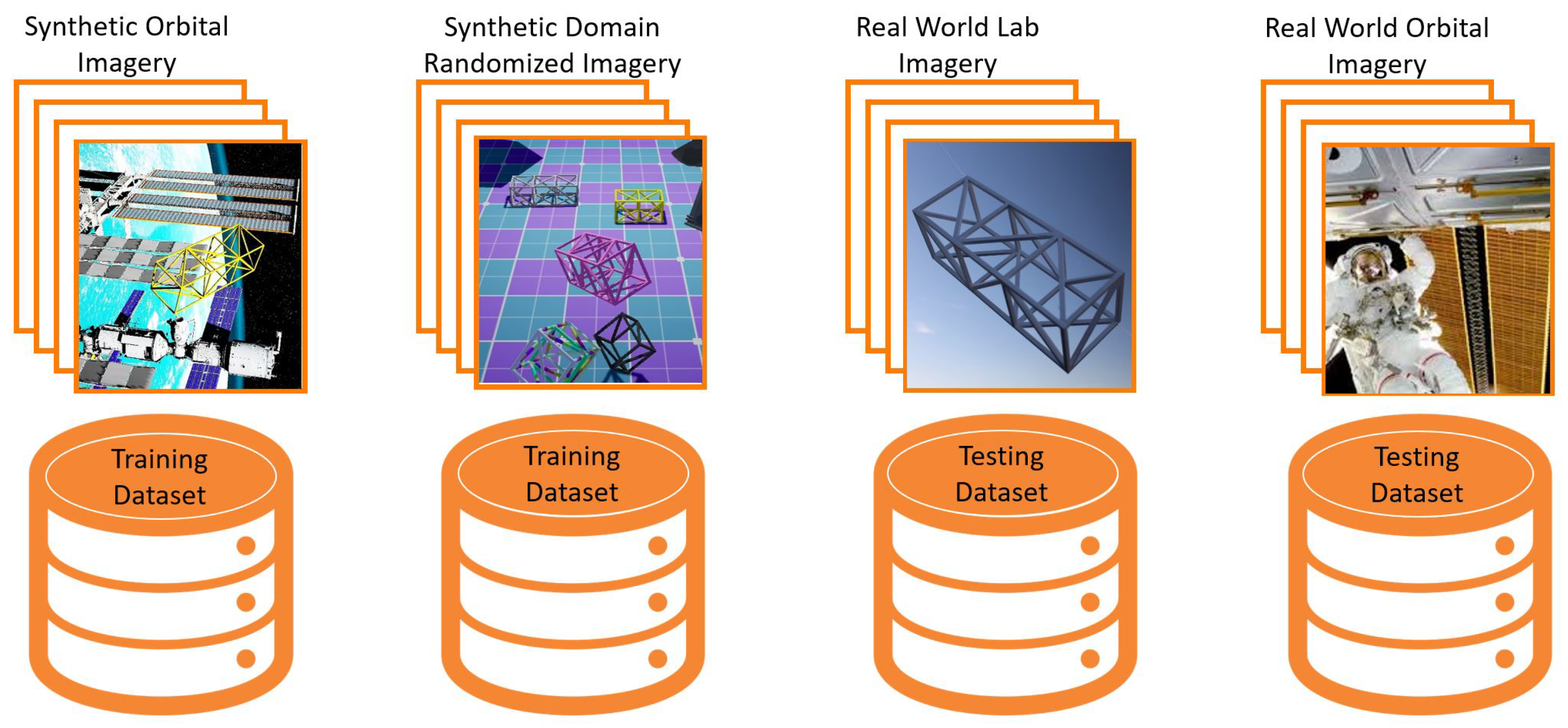
5.5. Division of Data Sets
5.6. Evaluation Metric
6. Flight Hardware
7. SpaceDrones 2.0 Architecture
7.1. Lighthouse Tracking
7.2. Target Localization
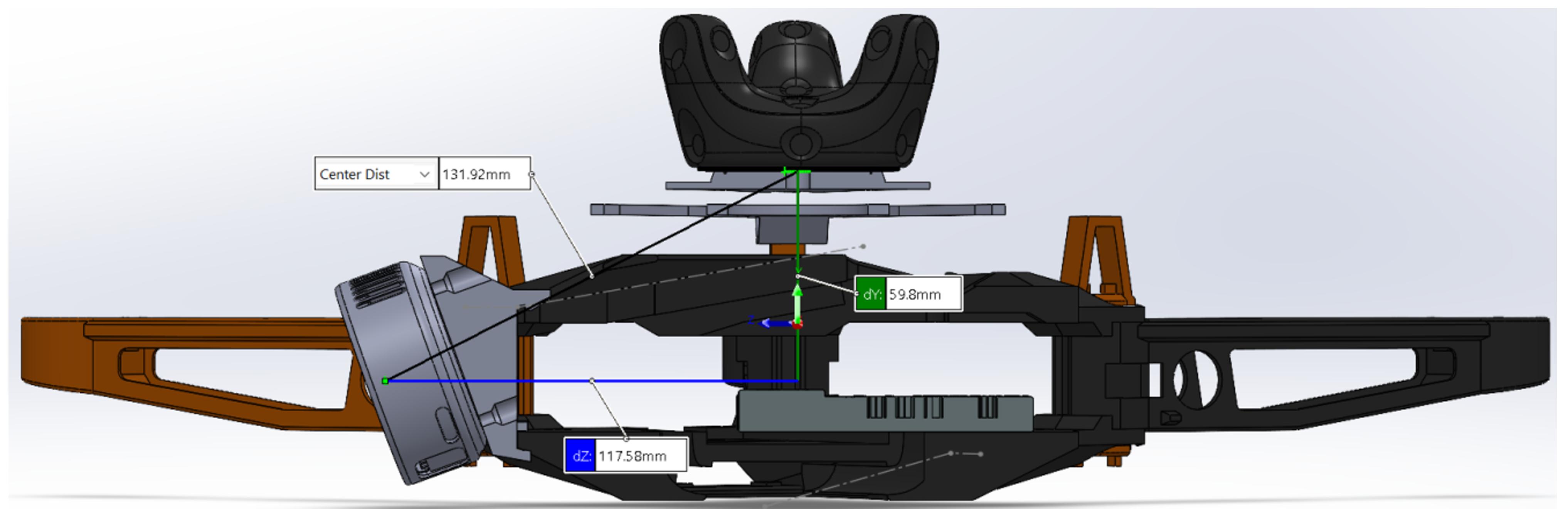
8. Drone Design
8.1. Drone Body
8.2. Drone Power Distribution
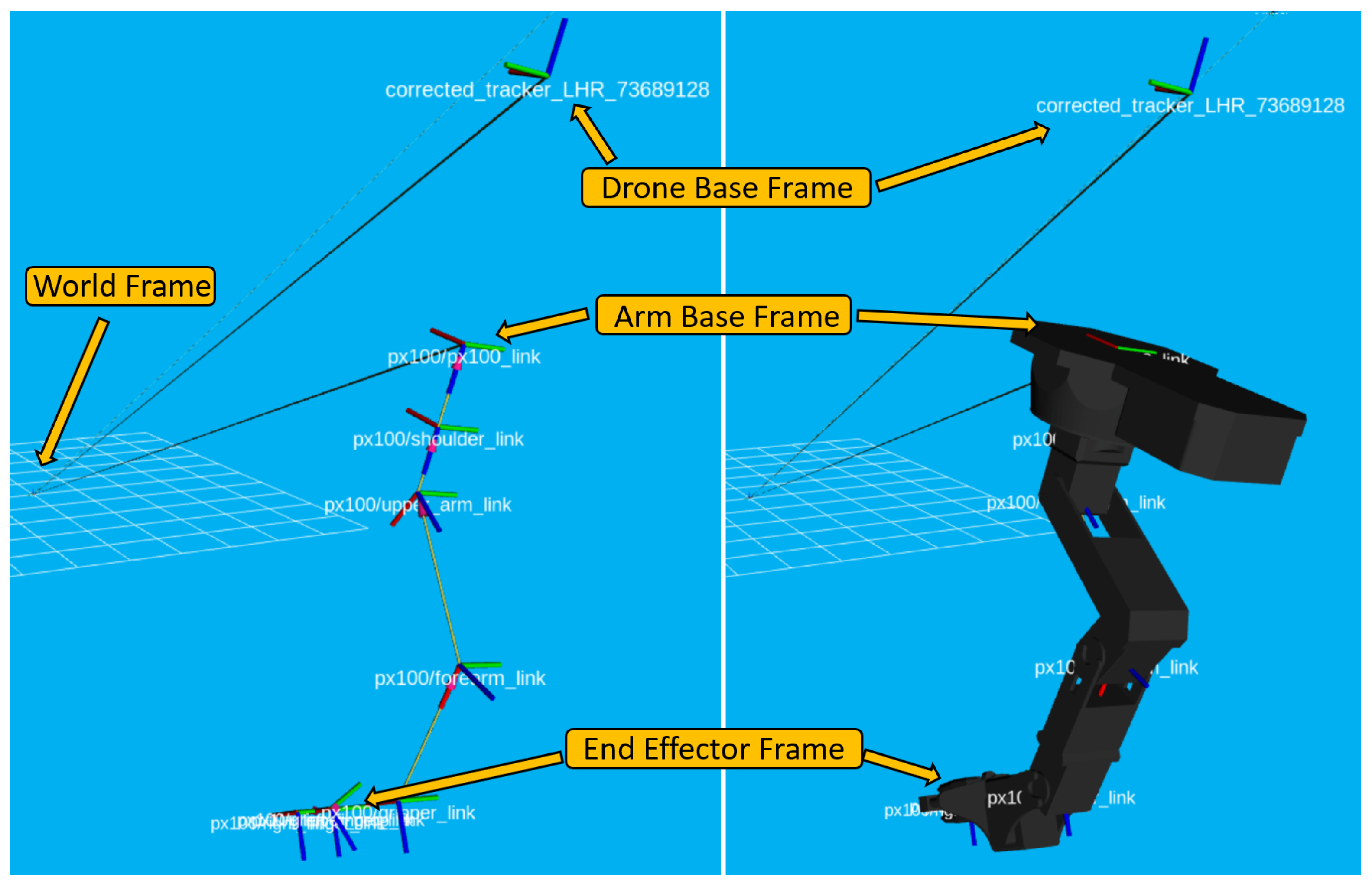
8.3. Drone Reference Frames
8.3.1. Drone Body Frames
8.3.2. Robotic Arm Frames
8.3.3. Robotic Arm Airborne Inverse Kinematics
8.3.4. Drone Limitations
8.4. Spaceborne Sensor Limitations
9. CUBE Theater Complex
10. Results
10.1. Synthetic Data vs. Real World Results
10.2. Real-World Data Base Tests
10.3. Synthetic Training vs. Real-World Results
10.4. Domain Randomization Results
10.5. Computer Vision Results Summery
10.6. Localization and Robotic Arm Capture Results
10.7. CUBE Computer Vision Results
| Algorithm 1 Sensor detection and Robotic Arm capture. |
| Require: Input for desired object |
| Conduct CNN object search |
| if CNN > 0.60 then |
| (x,y) object location = bounding box center |
| (z) object location = LiDAR point cloud of bounding box center |
| end if |
| if drone location ≠ Object location then |
| Maneuver drone to object of interest |
| end if |
| if drone location = Object location then |
| initiate robotic arm IK for object capture |
| if capture = True then |
| Stow captured object for transport |
| end if |
| end if |
| if capture = False then |
| Conduct CNN object search |
| re-initiate robotic arm IK for object capture |
| end if |
11. Discussion
12. Contributions
- The introduction of several thousand labeled synthetic and real-world orbital data sets available here [45];
- Ready made synthetic worlds and domain randomization tools for orbital/deep space environments available here [35];
- To our knowledge, it is the world’s first application of pre-processed domain randomized imagery for space-based machine learning tasks;
- Real-time hardware-in-the-loop optical testing environment for computer vision systems inside a projection space such as the Virginia Tech CUBE [39];
- Real-time machine learning, computer vision, and robotics integration of all the above-mentioned contributions on-board a flying drone testbed platform to further implement and test such capabilities.
13. Conclusions
14. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| JWST | James Webb Telescope |
| L2 | Lagrange Point 2 |
| LiDAR | Light Detection and Ranging |
| COTS | Commercial off-the-shelf |
| DOF | Degree of Freedom |
| HIL | Hardware-in-the-loop |
| IK | Inverse Kinematics |
| EVA | Extravehicular Activity |
| C2IAS | The Commonwealth Center for Innovation in Autonomous Systems |
References
- Hoyt, R.P. SpiderFab: An architecture for self-fabricating space systems. In Proceedings of the AIAA SPACE 2013 Conference and Exposition, San Diego, CA, USA, 10–12 September 2013; p. 5509. [Google Scholar]
- Jairala, J.C.; Durkin, R.; Marak, R.J.; Sipila, S.A.; Ney, Z.A.; Parazynski, S.E.; Thomason, A.H. EVA Development and Verification Testing at NASA’s Neutral Buoyancy Laboratory. In Proceedings of the 42nd International Conference on Environmental Systems (ICES), San Diego, CA, USA, 15–19 July 2012; No. JSC-CN-26179. [Google Scholar]
- Zero Gravity Research Facility—Glenn Research Center. NASA. Available online: https://www1.grc.nasa.gov/facilities/zero-g/ (accessed on 17 March 2020).
- Daryabeigi, K. Thermal Vacuum Facility for Testing Thermal Protection Systems; National Aeronautics and Space Administration, Langley Research Center: Hampton, VA, USA, 2002. [Google Scholar]
- Christensen, B.J.; Gargioni, G.; Doyle, D.; Schroeder, K.; Black, J. Space Simulation Overview: Leading Developments towards using Multi-Rotors to Simulate Space Vehicle Dynamics. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 1134. [Google Scholar]
- D’Amico, S.; Eddy, D.; Makhadmi, I. TRON—The Testbed for Rendezvous and Optical Navigation—Enters the Grid; Space Rendezvous Laboratory: Stanford, CA, USA, 2016. [Google Scholar]
- Oestreich, C.; Lim, T.W.; Broussard, R. On-Orbit Relative Pose Initialization via Convolutional Neural Networks. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar]
- Scharf, D.P.; Hadaegh, F.Y.; Keim, J.A.; Benowitz, E.G.; Lawson, P.R. Flight-like ground demonstration of precision formation flying spacecraft. Proc. SPIE 2007, 6693, 669307. [Google Scholar] [CrossRef]
- Trigo, G.F.; Maass, B.; Krüger, H.; Theil, S. Hybrid optical navigation by crater detection for lunar pin-point landing: Trajectories from helicopter flight tests. CEAS Space J. 2018, 10, 567–581. [Google Scholar] [CrossRef] [Green Version]
- Enright, J.; Hilstad, M.; Saenz-Otero, A.; Miller, D. The SPHERES guest scientist program: Collaborative science on the ISS. In Proceedings of the 2004 IEEE Aerospace Conference Proceedings (IEEE Cat. No. 04TH8720), Big Sky, MT, USA, 6–13 March 2004; Volume 1. [Google Scholar]
- Sharma, S.; Ventura, J.; D’Amico, S. Robust model-based monocular pose initialization for noncooperative spacecraft rendezvous. J. Spacecr. Rockets 2018, 55, 1414–1429. [Google Scholar] [CrossRef] [Green Version]
- Thomas, D.; Kelly, S.; Black, J. A monocular SLAM method for satellite proximity operations. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 4035–4040. [Google Scholar] [CrossRef]
- Mark, C.P.; Kamath, S. Review of active space debris removal methods. Space Policy 2019, 47, 194–206. [Google Scholar] [CrossRef]
- Peng, H.; Bai, X. Improving orbit prediction accuracy through supervised machine learning. Adv. Space Res. 2018, 61, 2628–2646. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Lu, R.; Zhang, L.; Peng, Y. Image Processing Algorithms For Deep-Space Autonomous Optical Navigation. J. Navig. 2013, 66, 605–623. [Google Scholar] [CrossRef] [Green Version]
- Petkovic, M.; Lucas, L.; Kocev, D.; Džeroski, S.; Boumghar, R.; Simidjievski, N. Quantifying the effects of gyroless flying of the mars express spacecraft with machine learning. In Proceedings of the 2019 IEEE International Conference on Space Mission Challenges for Information Technology (SMC-IT), Pasadena, CA, USA, 30 July–1 August 2019; pp. 9–16. [Google Scholar]
- Fang, H.; Shi, H.; Dong, Y.; Fan, H.; Ren, S. Spacecraft power system fault diagnosis based on DNN. In Proceedings of the 2017 Prognostics and System Health Management Conference (PHM-Harbin), Harbin, China, 9–12 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Rubinsztejn, A.; Sood, R.; Laipert, F.E. Neural network optimal control in astrodynamics: Application to the missed thrust problem. Acta Astronaut. 2020, 176, 192–203. [Google Scholar] [CrossRef]
- Shirobokov, M.; Trofimov, S.; Ovchinnikov, M. Survey of machine learning techniques in spacecraft control design. Acta Astronaut. 2021, 186, 87–97. [Google Scholar] [CrossRef]
- Izzo, D.; Märtens, M.; Pan, B. A survey on artificial intelligence trends in spacecraft guidance dynamics and control. Astrodynamics 2019, 3, 287–299. [Google Scholar] [CrossRef]
- Jocher, G. ultralytics/yolov5: v3.1—Bug Fixes and Performance Improvements. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 5 April 2022). [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:cs.CV/1504.08083. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:cs.CV/1605.06409. [Google Scholar]
- Boone, B.; Bruzzi, J.; Dellinger, W.; Kluga, B.; Strobehn, K. Optical simulator and testbed for spacecraft star tracker development. In Optical Modeling and Performance Predictions II. International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2005; Volume 5867, p. 586711. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lebreton, J.; Brochard, R.; Baudry, M.; Jonniaux, G.; Salah, A.H.; Kanani, K.; Goff, M.L.; Masson, A.; Ollagnier, N.; Panicucci, P.; et al. Image simulation for space applications with the SurRender software. arXiv 2021, arXiv:2106.11322. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:cs.CV/1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2018, arXiv:cs.CV/1708.02002. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region Proposal by Guided Anchoring. arXiv 2019, arXiv:cs.CV/1901.03278. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:stat.ML/1406.2661. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ye, C.; Evanusa, M.; He, H.; Mitrokhin, A.; Goldstein, T.; Yorke, J.A.; Fermüller, C.; Aloimonos, Y. Network Deconvolution. arXiv 2020, arXiv:cs.LG/1905.11926. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Peterson, M.; Du, M. SpaceDrones Unreal Engine Projects; Virginia Tech Library: Blacksburg, VA, USA, 2022. [Google Scholar] [CrossRef]
- Gargioni, G.; Peterson, M.; Persons, J.; Schroeder, K.; Black, J. A full distributed multipurpose autonomous flight system using 3D position tracking and ROS. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 1458–1466. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Du, M.; Gargioni, G.; Peterson, M.A.; Doyle, D.; Black, J. IR based local tracking system Assessment for planetary exploration missions. In Proceedings of the ASCEND 2020, Virtual Event, 16–18 November 2020. [Google Scholar] [CrossRef]
- Lyon, E.; Caulkins, T.; Blount, D.; Ico Bukvic, I.; Nichols, C.; Roan, M.; Upthegrove, T. Genesis of the cube: The design and deployment of an hdla-based performance and research facility. Comput. Music J. 2016, 40, 62–78. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Yue, X.; Zhang, Y.; Zhao, S.; Sangiovanni-Vincentelli, A.; Keutzer, K.; Gong, B. Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2100–2110. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:cs.CV/1405.0312. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; D’Amico, S. Pose Estimation for Non-Cooperative Rendezvous Using Neural Networks. arXiv 2019, arXiv:cs.CV/1906.09868. [Google Scholar]
- Peterson, M. SpaceDrones Labeled Training Images and Results; Virginia Tech Library: Blacksburg, VA, USA, 2022. [Google Scholar] [CrossRef]
- Deans, C.; Furgiuele, T.; Doyle, D.; Black, J. Simulating Omni-Directional Aerial Vehicle Operations for Modeling Satellite Dynamics. In Proceedings of the ASCEND 2020, Virtual Event, 16–18 November 2020; p. 4023. [Google Scholar] [CrossRef]
- Blandino, T.; Leonessa, A.; Doyle, D.; Black, J. Position Control of an Omni-Directional Aerial Vehicle for Simulating Free-Flyer In-Space Assembly Operations. In Proceedings of the ASCEND 2021, Las Vegas, NV, USA, 15–17 November 2021; p. 4100. [Google Scholar] [CrossRef]
- Yu, Y.; Elango, P.; Topcu, U.; Açıkmeşe, B. Proportional-Integral Projected Gradient Method for Conic Optimization. arXiv 2021, arXiv:2108.10260. [Google Scholar]
- Yu, Y.; Topcu, U. Proportional-Integral Projected Gradient Method for Infeasibility Detection in Conic Optimization. arXiv 2021, arXiv:2109.02756. [Google Scholar]











































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLO Neural Network Performance | ||
|---|---|---|
| Data Set (s) | mAP | mAP |
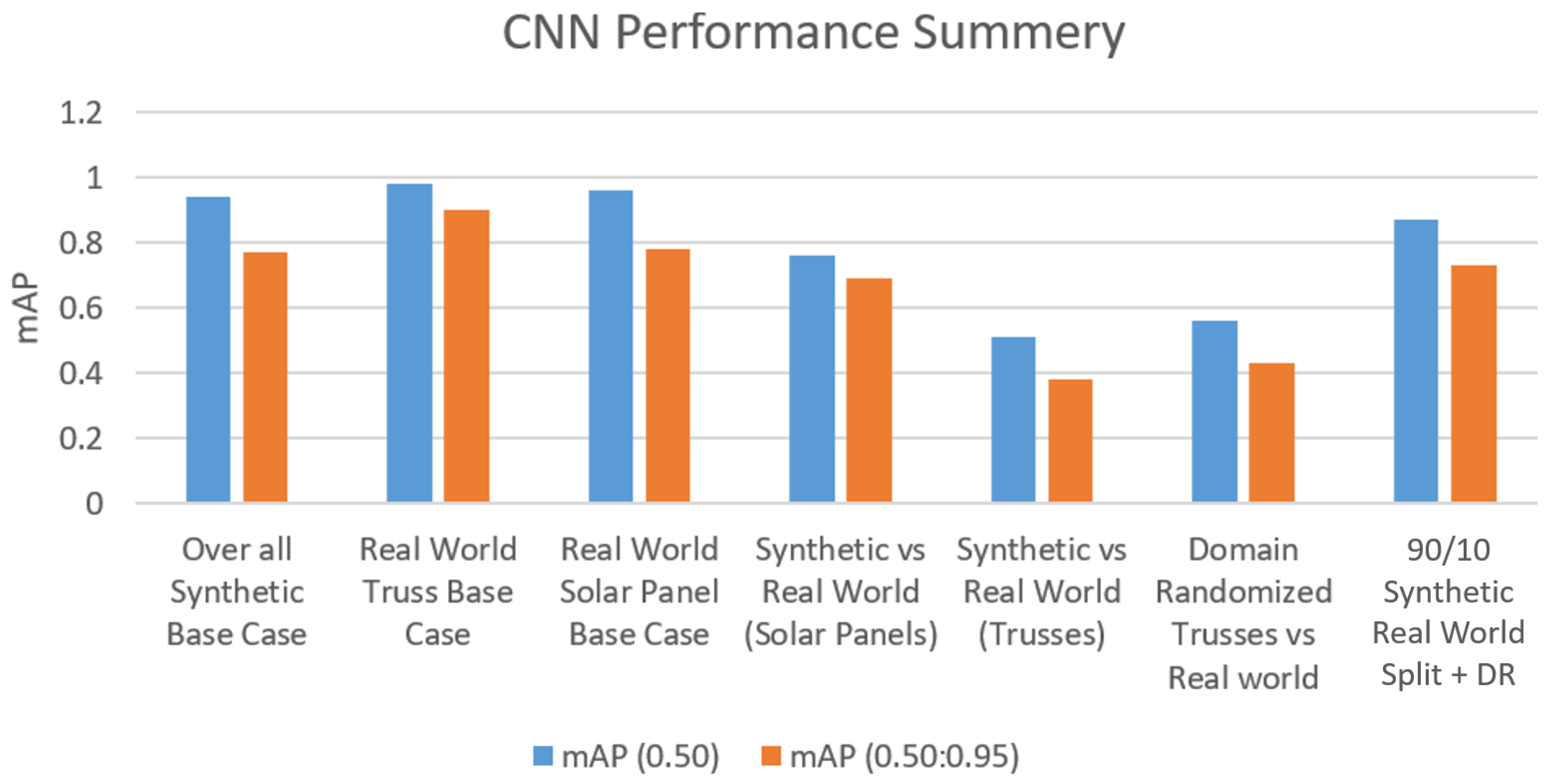
| Overall Synthetic Base Case | 94% | 77% |
| Real world Truss Base Case | 98% | 90% |
| Real world Solar Panel Base Case | 96% | 78% |
| Synthetic vs. Real World (Solar Panel) | 76% | 69% |
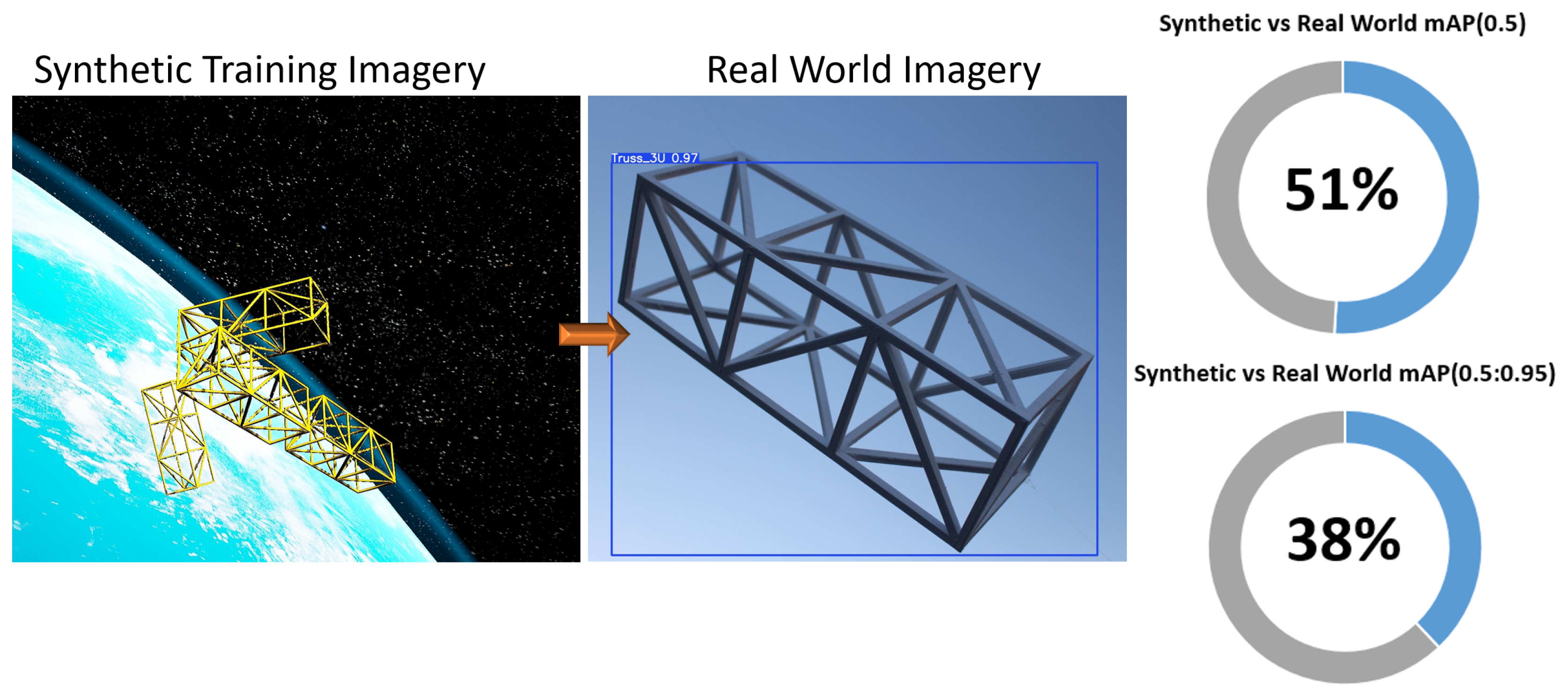
| Synthetic vs. Real World (Trusses) | 51% | 38% |
| DR vs. Real World (Trusses) | 56% | 43% |
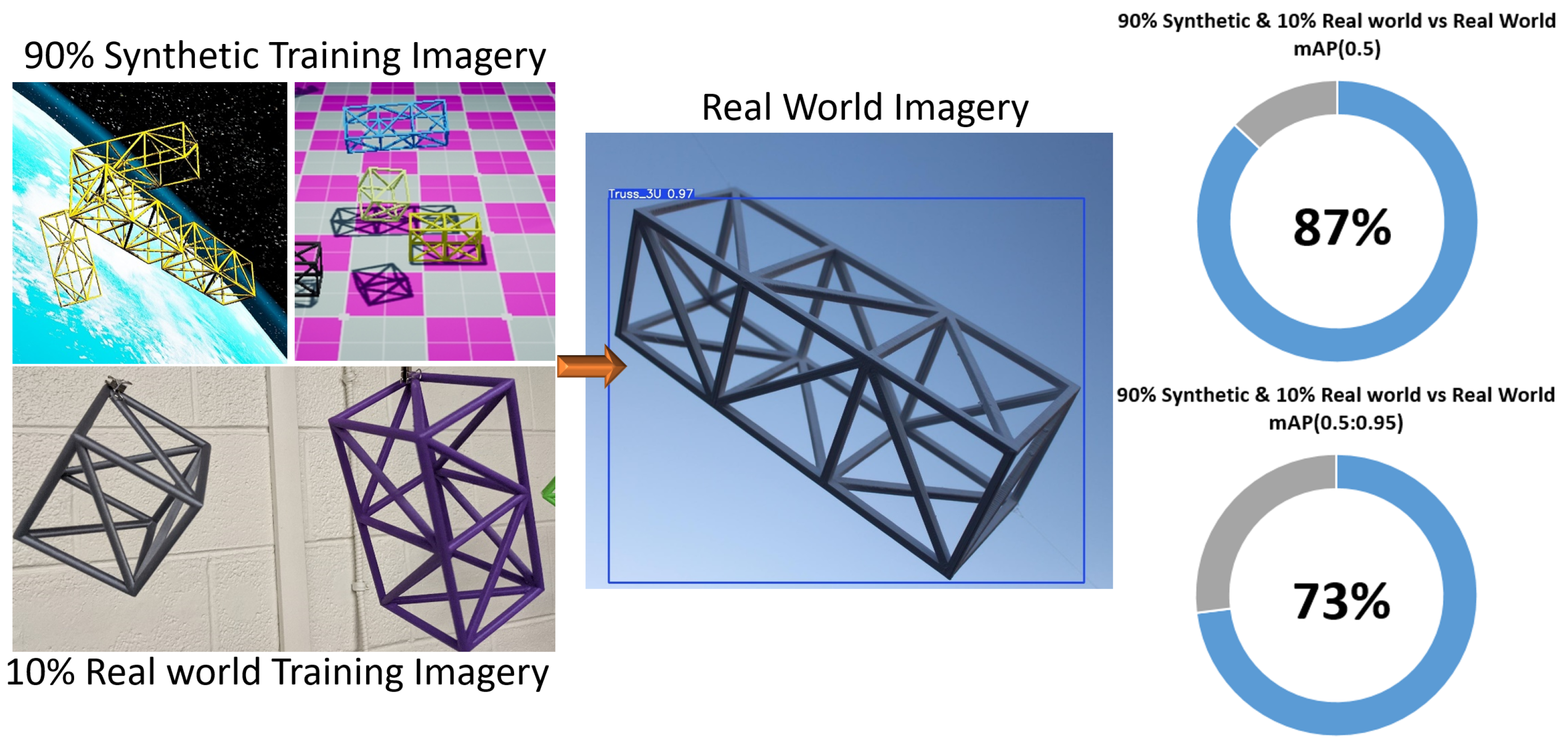
| 90/10 Synthetic Real World split + DR | 87% | 73% |
| YOLO Neural Network Performance | ||
|---|---|---|
| Data Set (s) | mAP | mAP |
| CUBE Computer Vision Results | 83% | 68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peterson, M.; Du, M.; Springle, B.; Black, J. SpaceDrones 2.0—Hardware-in-the-Loop Simulation and Validation for Orbital and Deep Space Computer Vision and Machine Learning Tasking Using Free-Flying Drone Platforms. Aerospace 2022, 9, 254. https://doi.org/10.3390/aerospace9050254
Peterson M, Du M, Springle B, Black J. SpaceDrones 2.0—Hardware-in-the-Loop Simulation and Validation for Orbital and Deep Space Computer Vision and Machine Learning Tasking Using Free-Flying Drone Platforms. Aerospace. 2022; 9(5):254. https://doi.org/10.3390/aerospace9050254
Chicago/Turabian StylePeterson, Marco, Minzhen Du, Bryant Springle, and Jonathan Black. 2022. "SpaceDrones 2.0—Hardware-in-the-Loop Simulation and Validation for Orbital and Deep Space Computer Vision and Machine Learning Tasking Using Free-Flying Drone Platforms" Aerospace 9, no. 5: 254. https://doi.org/10.3390/aerospace9050254
APA StylePeterson, M., Du, M., Springle, B., & Black, J. (2022). SpaceDrones 2.0—Hardware-in-the-Loop Simulation and Validation for Orbital and Deep Space Computer Vision and Machine Learning Tasking Using Free-Flying Drone Platforms. Aerospace, 9(5), 254. https://doi.org/10.3390/aerospace9050254