2.1. Dataset
We download the CAD model of the published spacecraft from open-source websites, such as NASA
https://www.nasa.gov/, accessed on 21 March 2022 and Free3d
https://free3d.com/, accessed on 21 March 2022. Lately, we print the CAD models utilizing the 3D printing technology to get the 3D printed models. As shown in
Figure 2,
Figure 2a illustrates the CAD model of AcrimSAT
https://nasa3d.arc.nasa.gov/detail/jpl-vtad-acrimsat, accessed on 21 March 2022 downloaded from NASA, and
Figure 2b presents the 3D printed model of this satellite. 28 CAD models and 5 3D printed models of different sizes shapes are eventually obtained (Considering the expensive cost of the 3D printing technology, we only print a trivial number of spacecraft CAD models).
Further, the simulated point clouds and the actual point clouds are obtained. There are three methods to gain 3D point clouds: generating 3D point clouds via AirSim, generating 3D point clouds via VisualSFM, generating 3D point clouds via 3D scanning of spacecraft models.
Generation of 3D point clouds via AriSimAirSim is an open-source and cross-platform simulation engine which can imitate the lidar data for multiple different channels. In experiments, lidars of 32 channels are configured on the simulation engine, and parameters are listed in the following
Table 1.
To obtain a rather completed 3D model, the flight trajectory of the simulation engine is designed in
Figure 3a. Besides, to obtain accurate scanning results, it is necessary to rebuild the collision model to the max for each component imported into the spacecraft. The final scanned 3D point cloud is shown in
Figure 3c.
Generation of 3D point clouds via VisualSFM: VisualSFM [
29] is a GUI application for 3D reconstruction using 2D images. VisualSFM is able to run very fast by exploiting multicore parallelism in feature detection, feature matching, and bundle adjustment. There are two methods to gain image sequences: Blender simulation, or using the camera on the Nvidia Jetson TX2
https://developer.nvidia.com/embedded/jetson-tx2, accessed on 15 March 2022.
Blender2.8.2
https://www.blender.org/, accessed on 15 March 2022 is used to gain the simulation image sequence of spacecraft. As shown in
Figure 4a, the CAD model of the Aqua satellite is imported into Blender, and a circle with a radius of 10 m at 10 m above the CAD model is drawn. Setting the camera’s light center aligned with the model, 600 simulation images with the size of 1024 × 1024 are obtained by shooting around along the circular trajectory. Lately, the simulated vision point clouds are obtained via VisualSFM, and the noise within them is manually removed to get the relatively clean point clouds as shown in
Figure 4b.
The acquisition of actual image sequences uses the camera on the Nvidia Jetson TX2 developer component
https://developer.nvidia.com/embedded/jetson-tx2, accessed on 15 March 2022, as shown in
Figure 5a. The image acquisition frequency is 30 FPS, The TX2’s camera is aligned to the 3D printed model, 600 actual images with the size of 1920 × 1080 are obtained by shooting around along the circular trajectory. The real vision point clouds are obtained using the VisualSFM method.
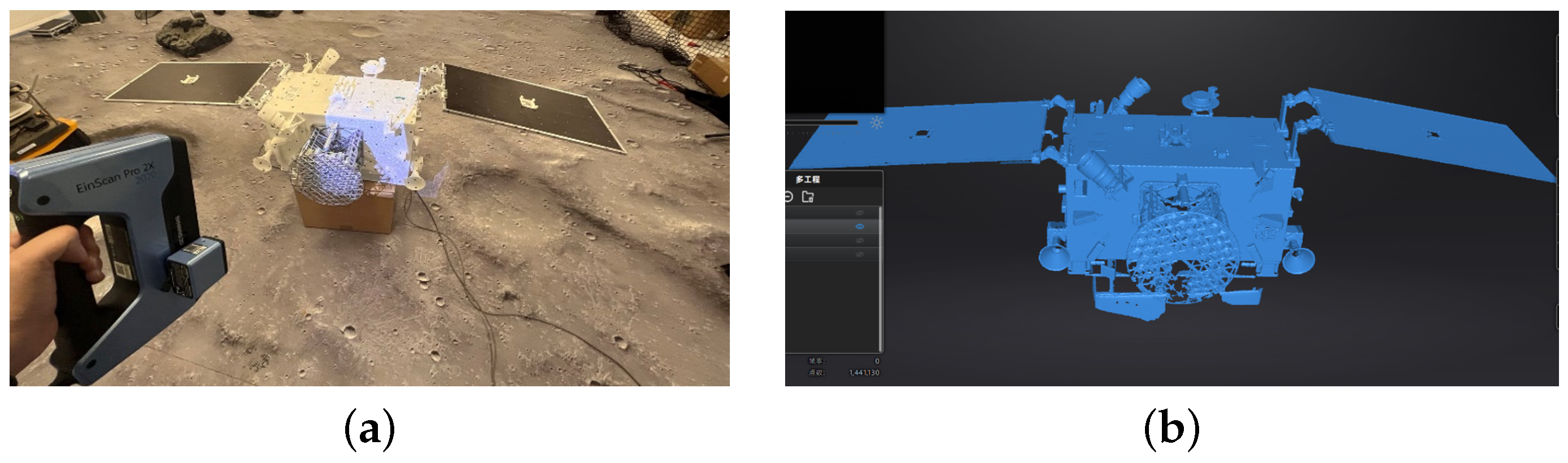
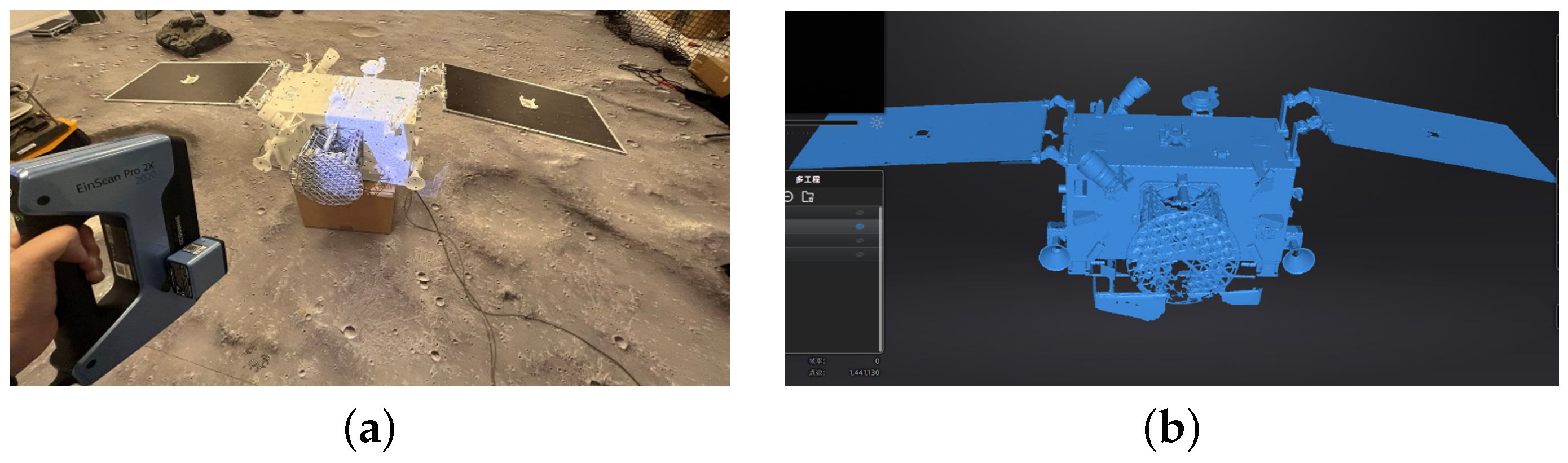
Generation of 3D point clouds via 3D scanner: The scanner selected in this experiment is EinScan Pro 2X Plus Handheld 3D scanner
https://www.einscan.com/handheld-3d-scanner/2x-plus/, accessed on 17 March 2022, as shown in
Figure 6a below.
Figure 6b shows the scene of the 3D scanner scans a 3D printing model of spacecraft. According to the different materials of spacecraft, the scanning mode includes handheld fine scanning and handheld fast scanning. The handheld fine scanning mode is used to scan high reflective objects by pasting control points on the target, while the handheld fast scanning mode which does not need to paste control points is feasible for scanning general materials.
As the initial CAD models have different sizes and shapes, varying from around 50 cm to 6 m, which makes it difficult for MLP-based models to deal with. Furthermore, different CAD models have different coordinate systems, for example, AcrimSAT satellite may use the left vertex of the panel as the origin of coordinates while LRO
https://nasa3d.arc.nasa.gov/detail/jpl-vtad-lro, accessed on 23 April 2022 may use the centroids. Thus, point cloud pre-processing methods including size normalization and centroid-based centralization is required.
The pre-processing methods of point clouds are based on Equations (
1) and (
2), after this pre-processing, the point clouds are transformed within the range of (0, 1) in
x,
y, and
z-axis. Where
is raw point clouds,
m is point numbers,
is the centralized and normalized point clouds data.
For a point cloud
containing
n points,
represents the
ith points in
P,
represents the
ith point in the point cloud after centralization.
represents the point cloud after normalization.
represents the minimum value of the three channels
in
. Similarly,
represents the maximum value of the three channels. Through the above two steps, the coordinate range of the spacecraft is normalized to (0, 1), and the coordinate origin is changed to the center of mass of the spacecraft.
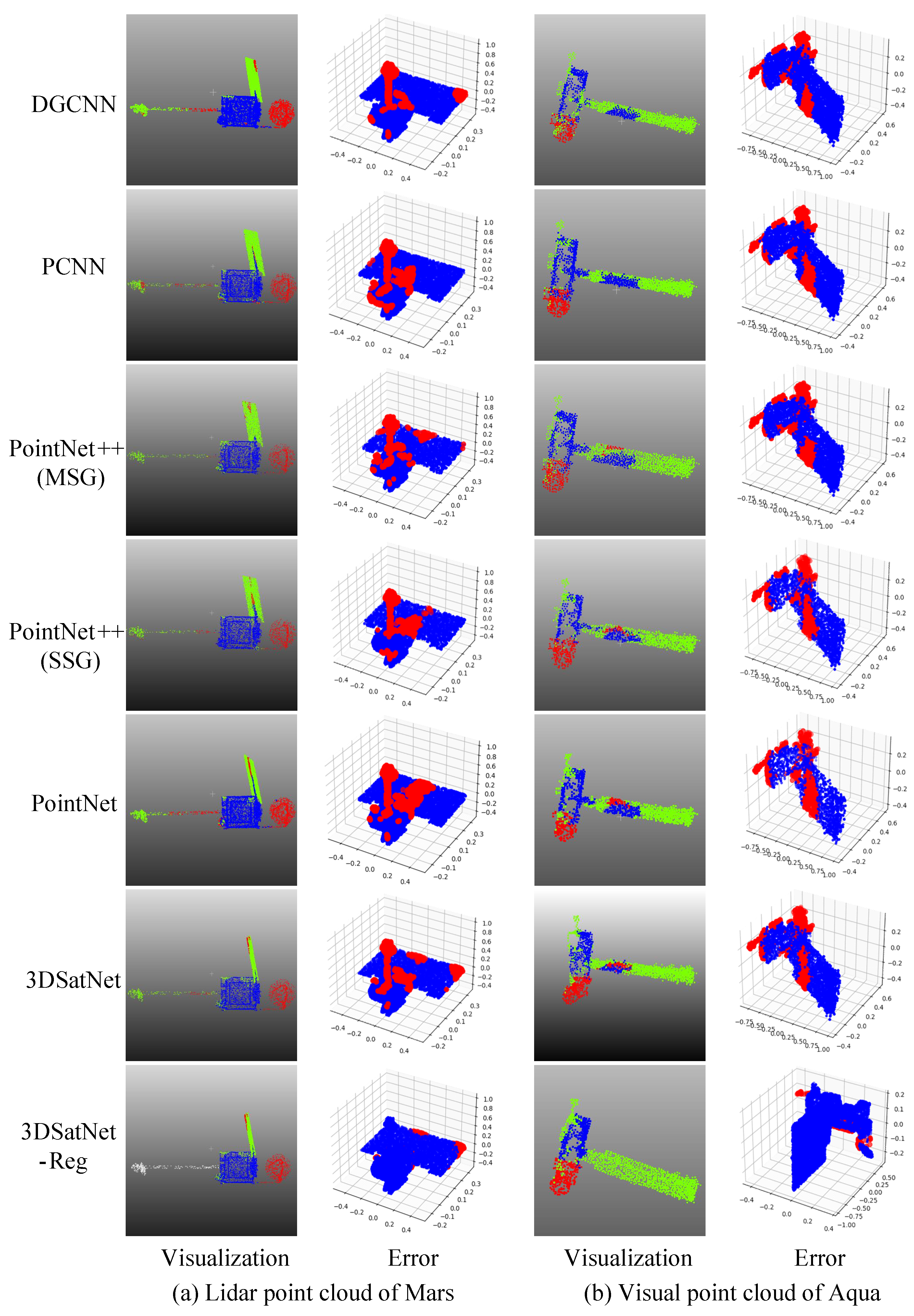
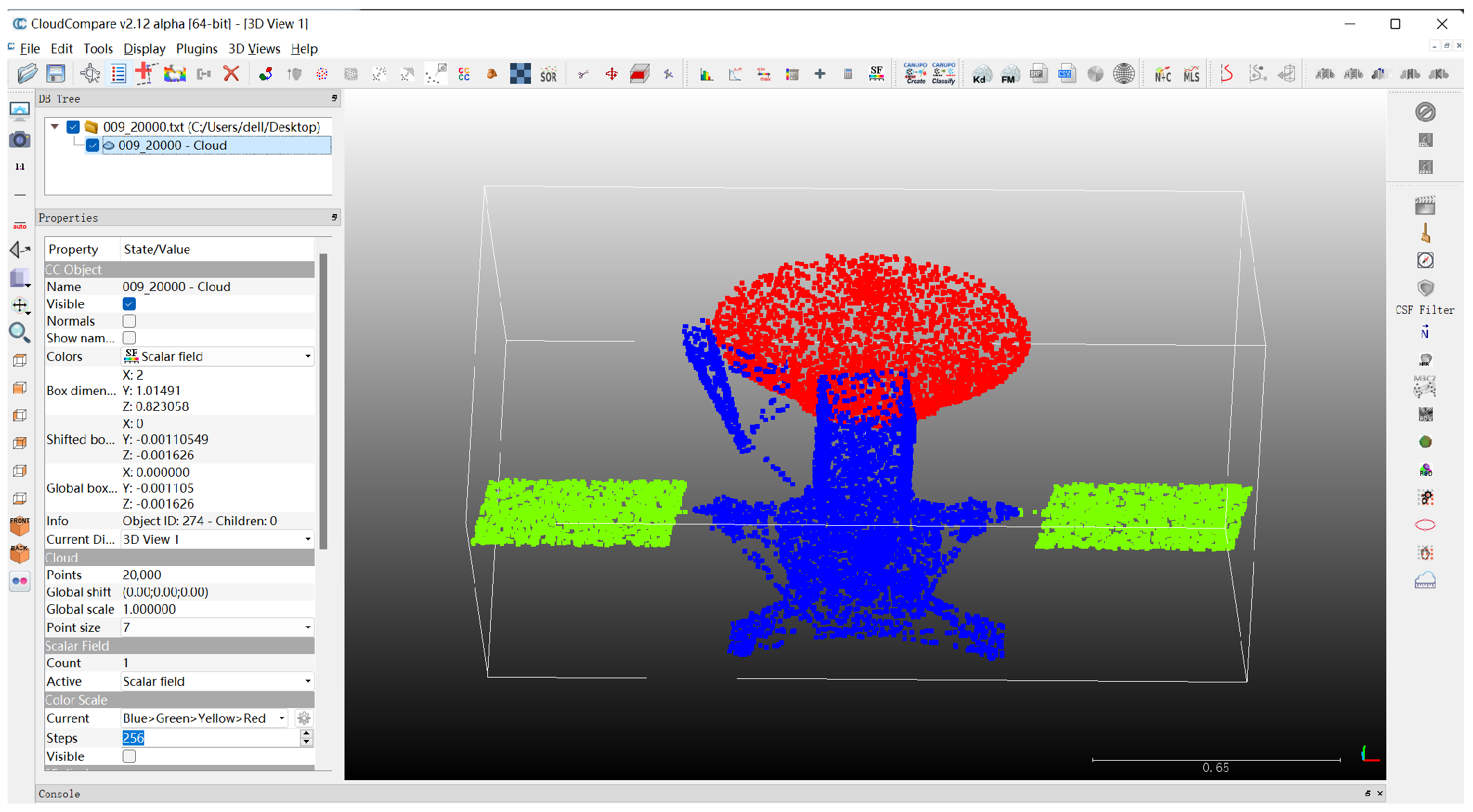
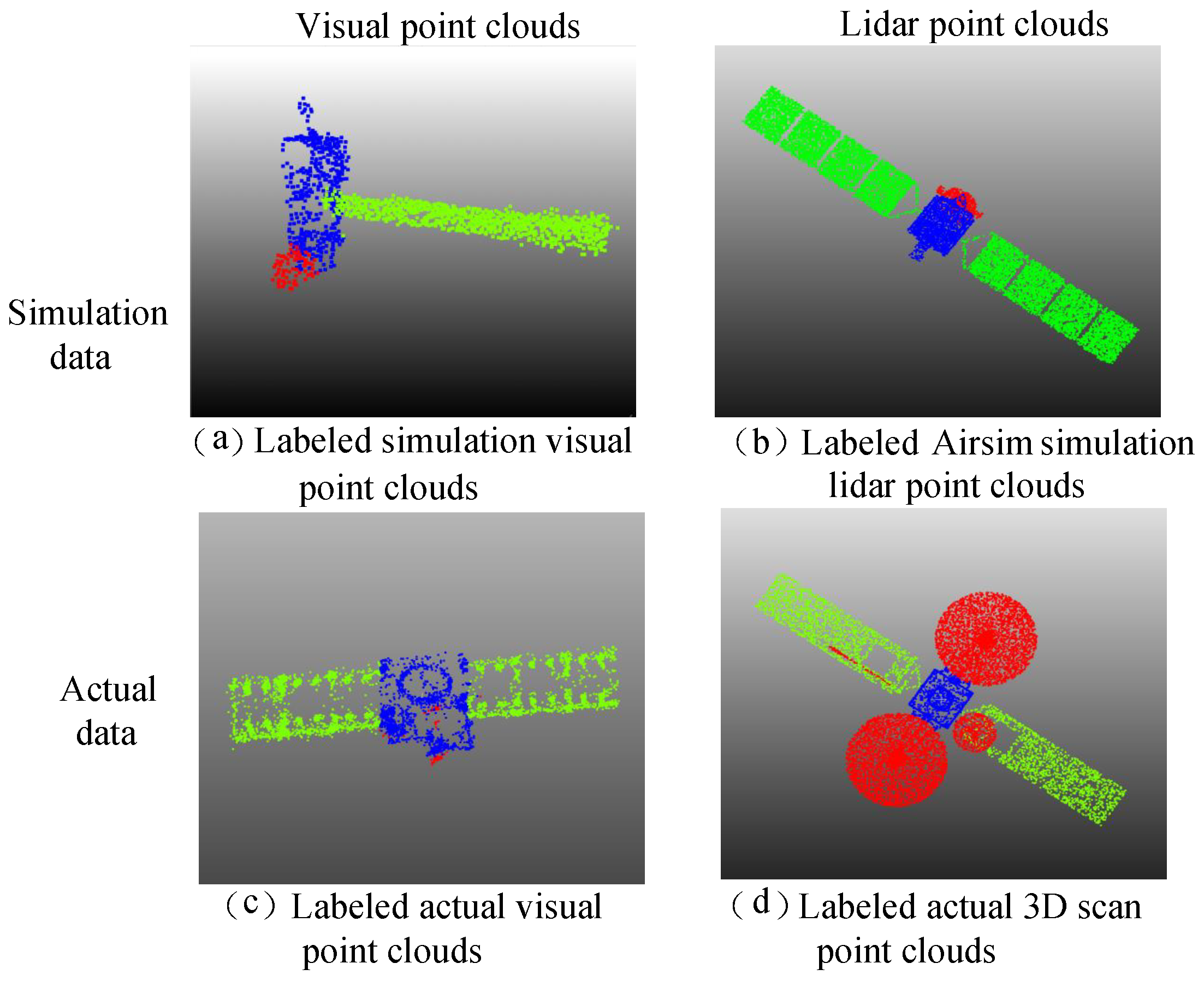
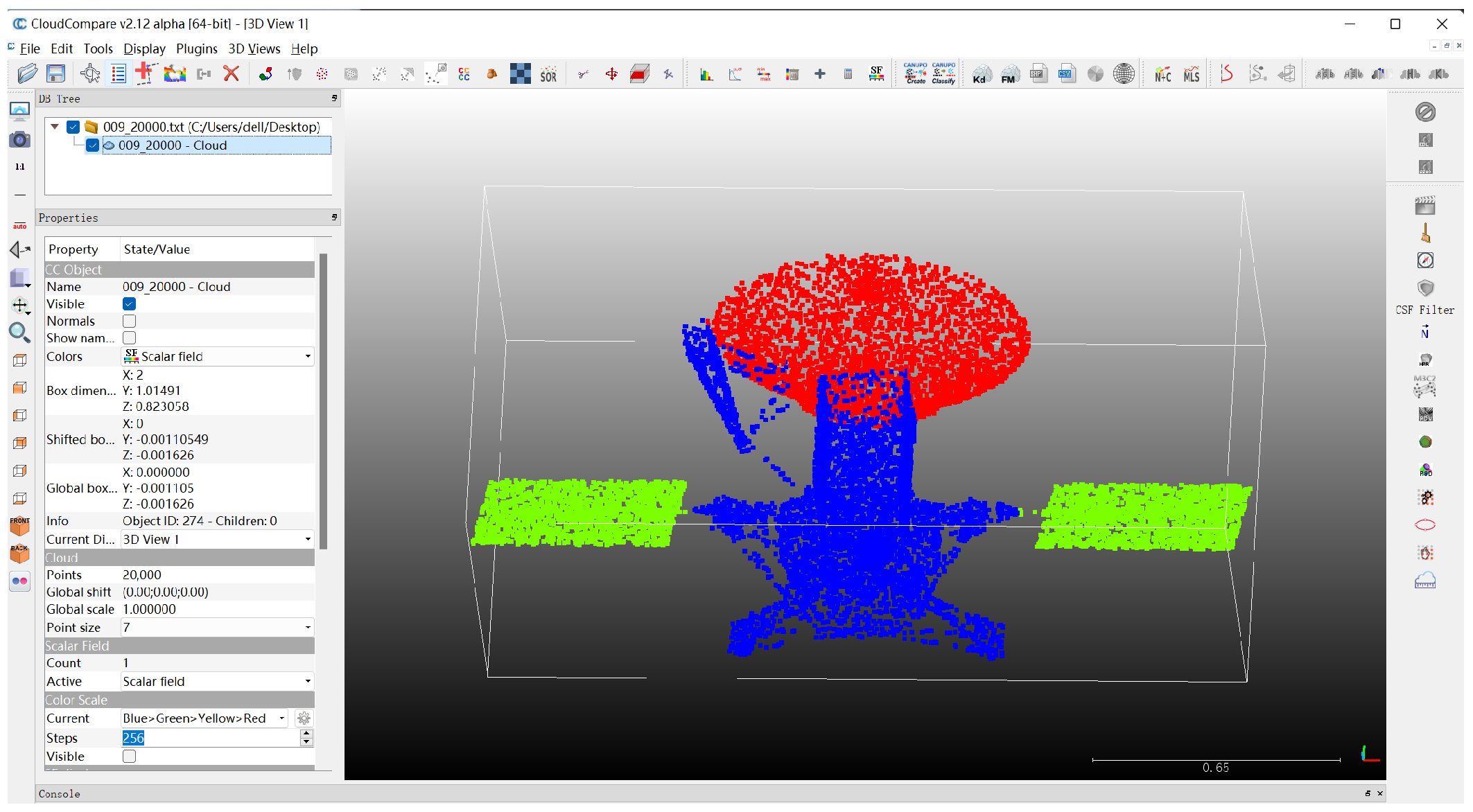
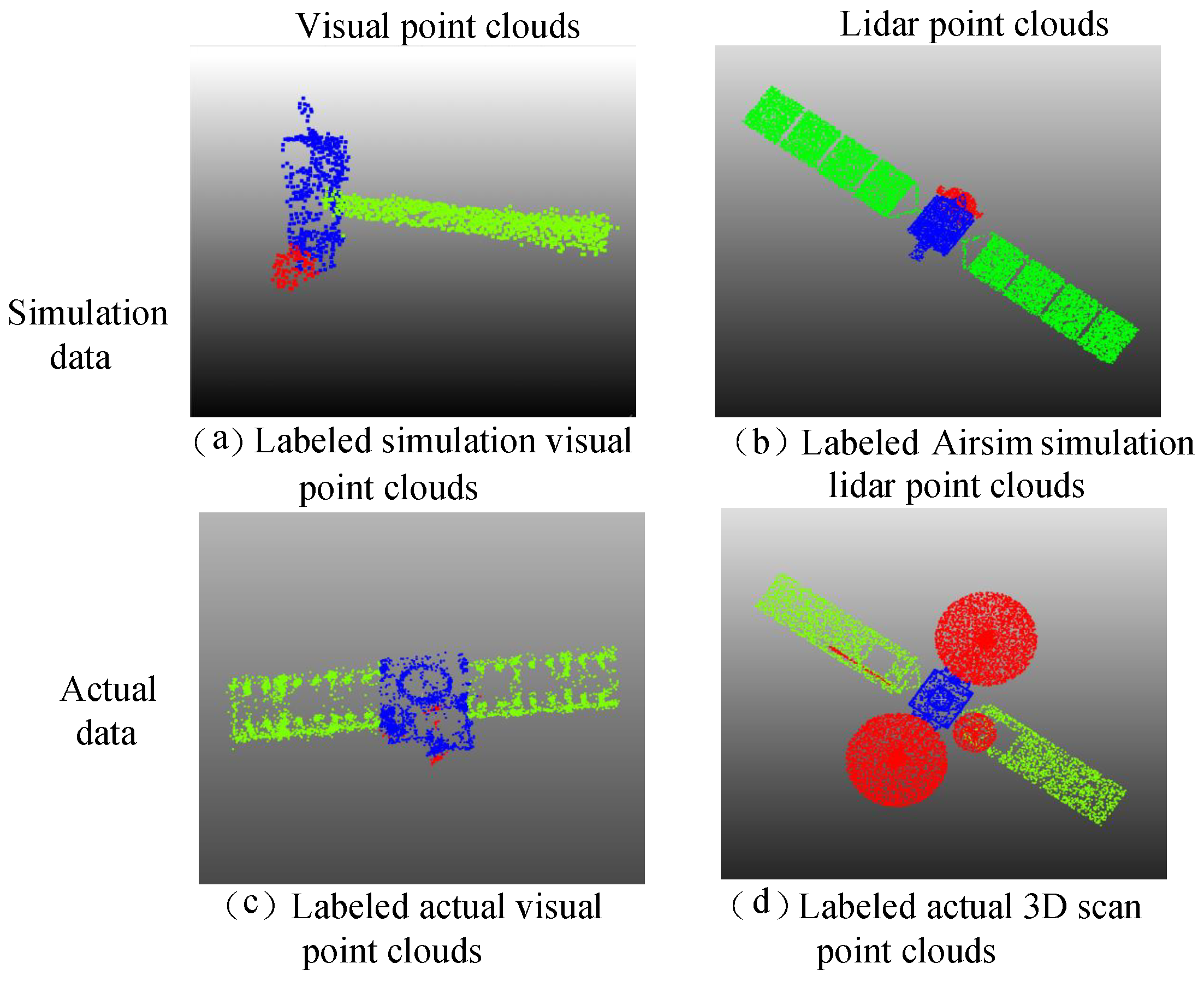
As shown in
Table 2, the 3D spacecraft component segmentation dataset divides spacecraft into three categories: body, panel, antenna. In this dataset, the points distribution between different components in a spacecraft can be largely varied, a solar panel occupies 8000–15,000 points, while an antenna only occupies 300–1500 points in point clouds with 20,000 points.
The results of some annotations are shown in
Figure 8.
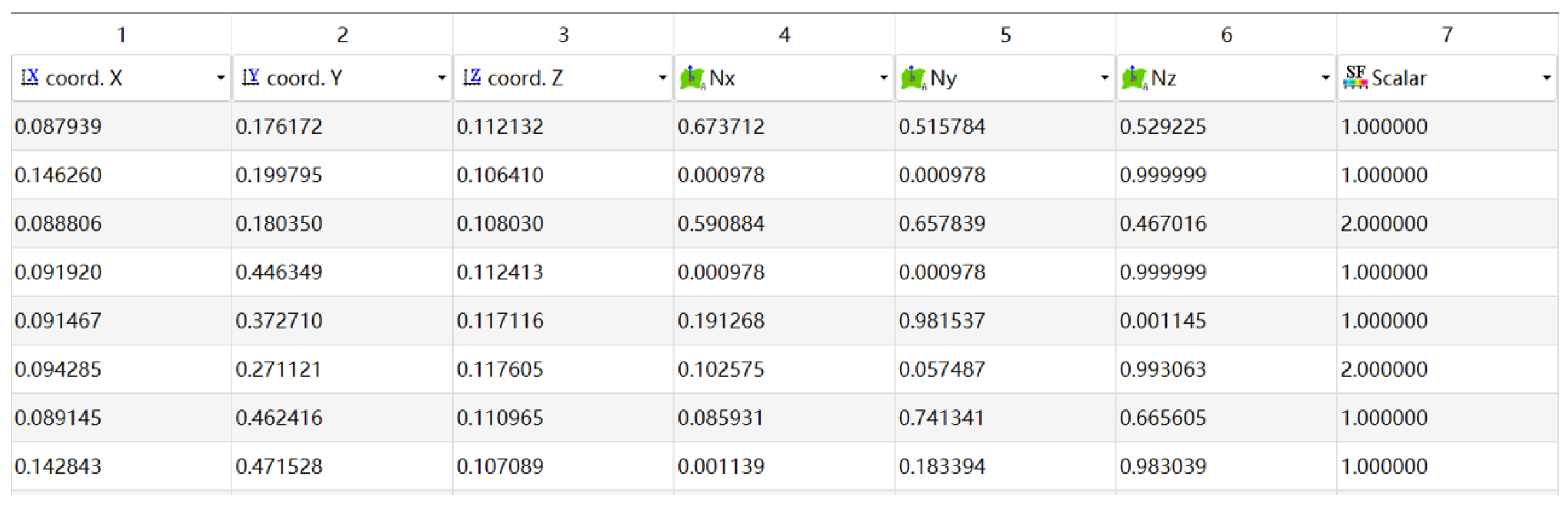
As shown in
Figure 9, the format of the annotated point clouds is described as follows: the first three columns are
coordinates, the following three columns are normal vectors, and the last column is semantic labels.
A total of 66 raw point clouds of four types are generated, as is shown in
Figure 3 each containing 20,000 points. Then, various methods are adopted to enhance the obtained point clouds, such as randomly adding noise points, translating and rotating point clouds, and adding different degrees of occlusion. After data enhancement, 792 point clouds are obtained.
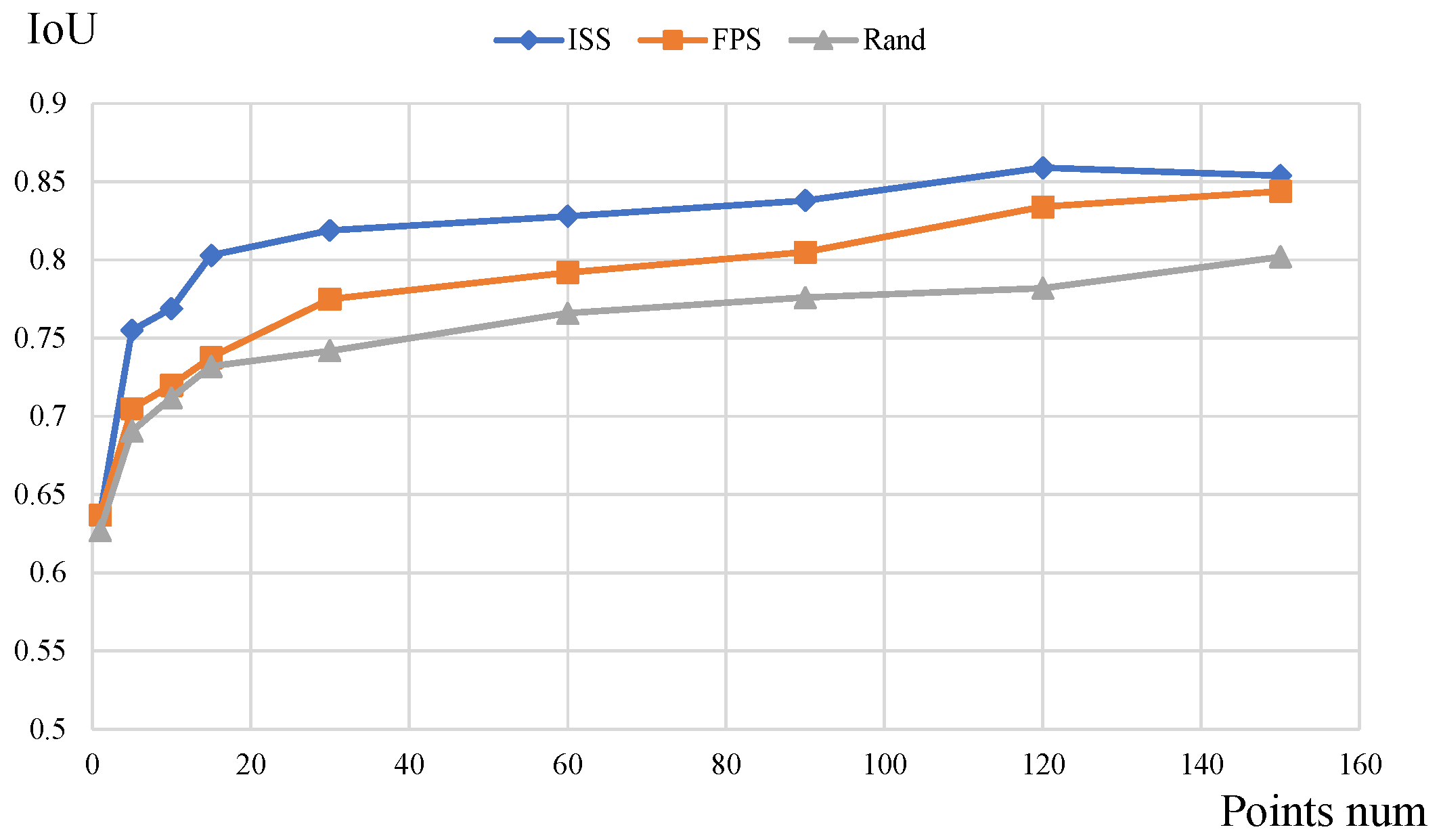
To facilitate the testing of various models, the final released dataset consists of two versions: one with 20,000 points per point cloud which provides a detailed representation of the three-dimensional structure of spacecraft, the other with around 2500 points per point clouds which share similar point numbers per shape as the ShapeNet dataset. To be specific, each point cloud with 20,000 points is downsampled to around 2500 points using ISS methods.
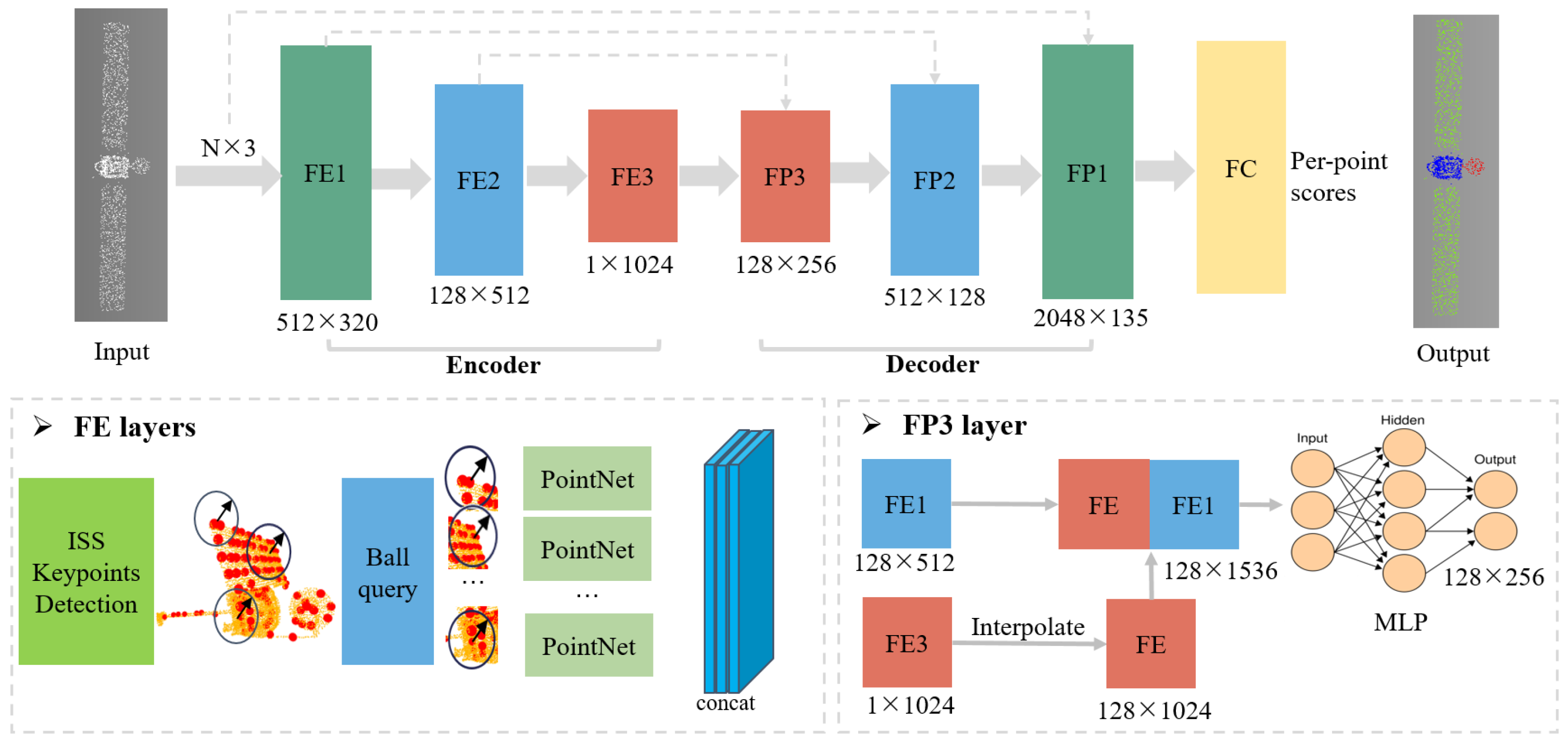
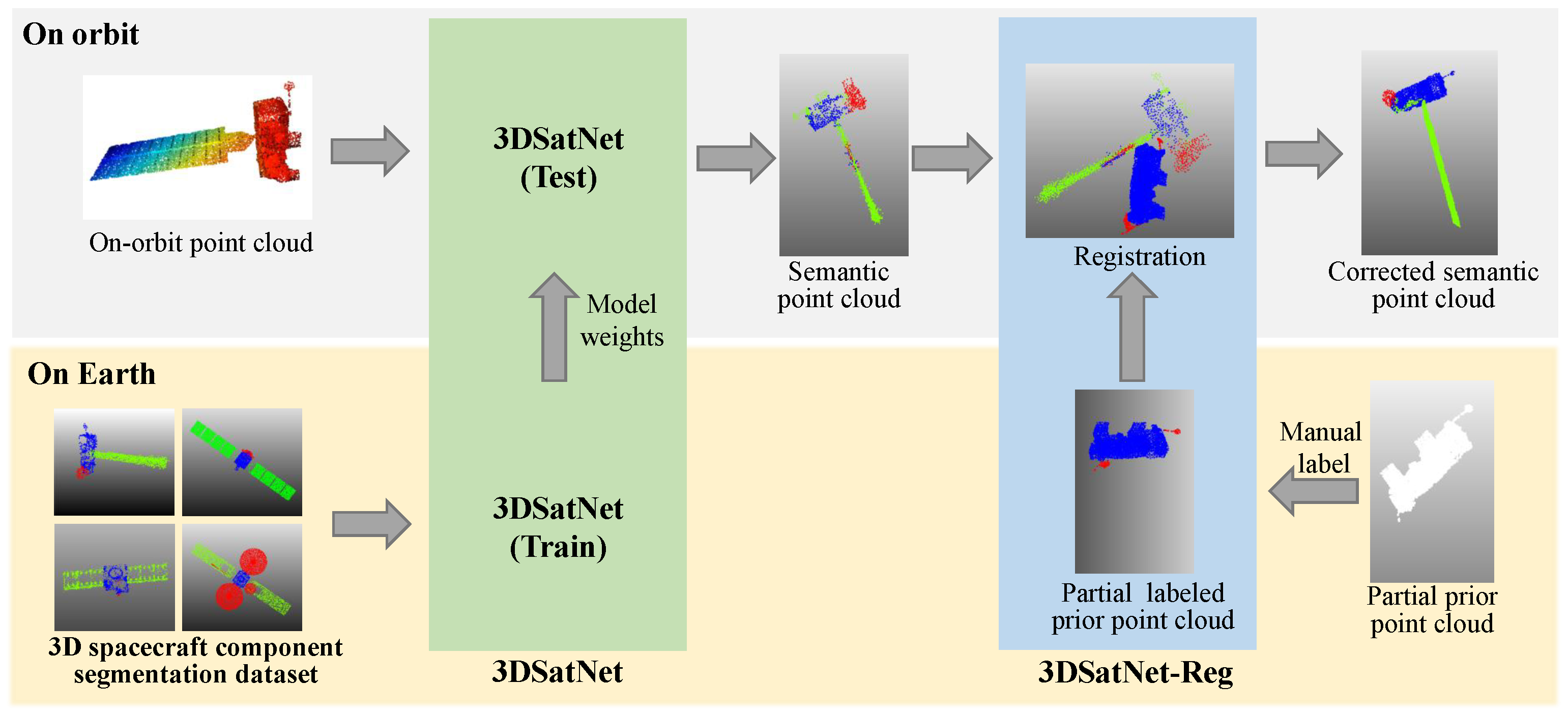
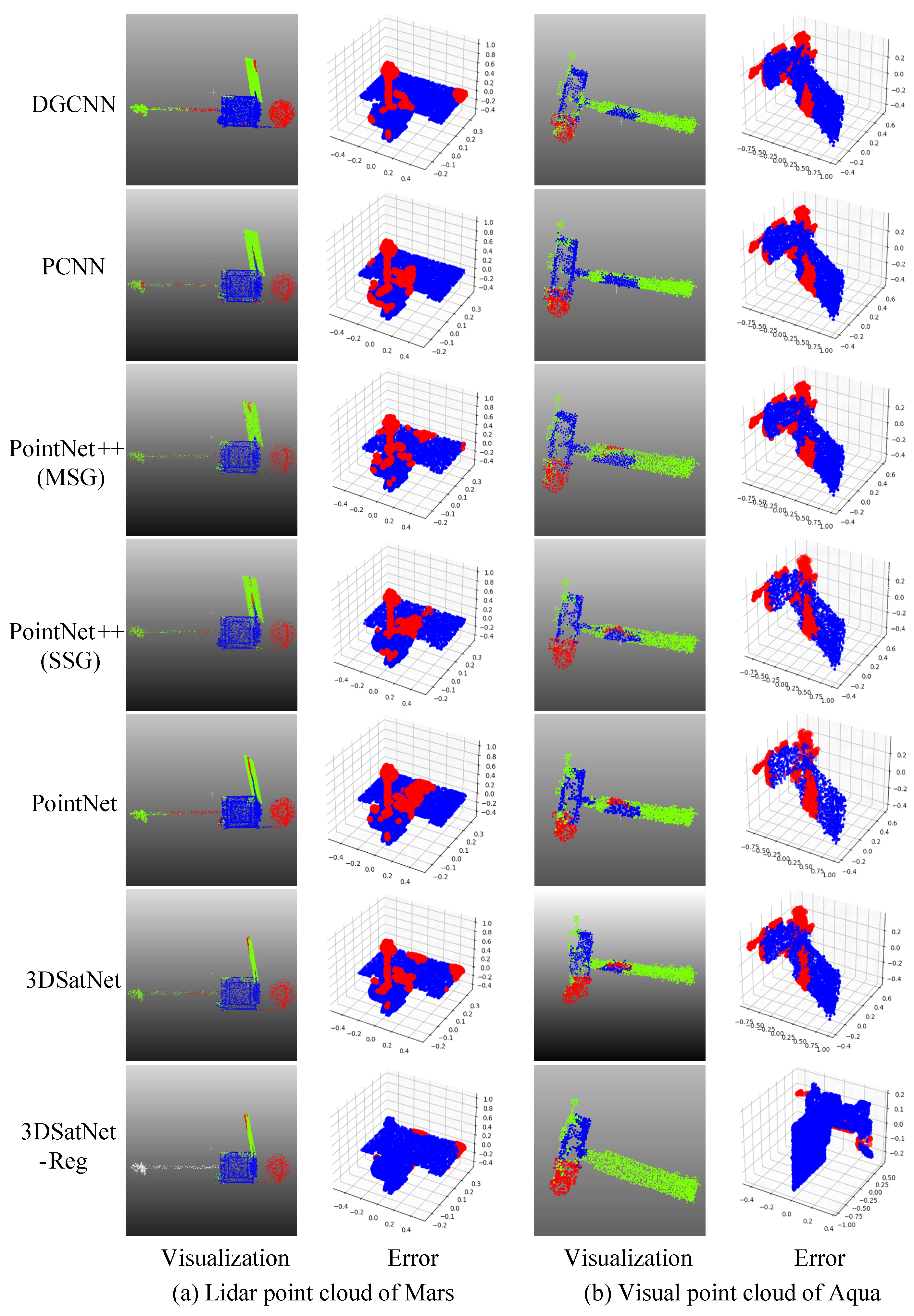
2.2. 3DSatNet
The proposed 3DSatNet is inspired by PointNet++ [
26]. The pipeline of the proposed 3DSatNet is demonstrated in
Figure 10. Firstly, A geometrical-aware feature extraction layer named the FE layer is proposed to extract geometric and transformation invariant features. When extracting features, the point cloud is continuously down-sampled. Then, the FP (Feature Propagation) layer is used for feature aggregation, which includes an up-sampling and skip connection parts. Moreover, a new loss function is proposed to increase the segmentation accuracy of the component with fewer points, such as antenna. The following sections will describe more details of the network.
2.2.1. The Proposed Geometrical-Aware FE Layers
The proposed FE layers contain three parts: ISS (Intrinsic Shape Signatures) point selection, ball query, and PointNet. We first partition the set of points into overlapping local regions by the ISS [
27], ball query, and then feed them into PointNet for further feature extractions.
ISS [
27] point selection method has better coverage of the structure point set given the same number of centroids. The ISS saliency measure is based on the Eigenvalue Decomposition (EVD) of the scatter matrix
.
means the neighborhood point of the point
p,
means the scatter matrix of the points belonging to the neighborhood of
p.
q represents the points in
.
N means the total number of
.
Given
, the eigenvalues
are computed, points whose ratio between two successive eigenvalues is below a threshold are retained:
where
and
.
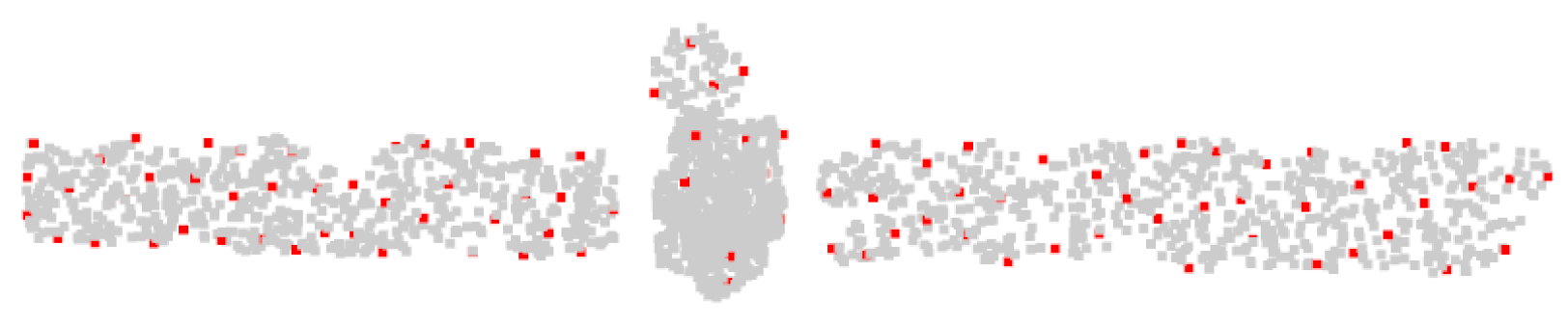
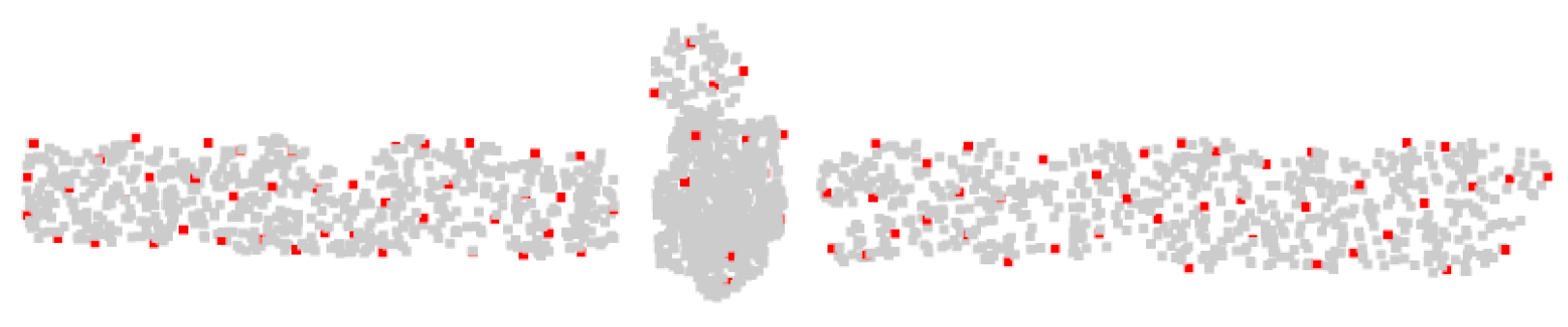
After the detection step, a point will be considered as an ISS keypoint if it has the maximum salience value in a given neighborhood, as is shown in
Figure 11.
After obtaining the ISS key points, we take them as the center of the sphere and draw a sphere with a certain radius (given that point clouds in the dataset have been normalized, the radius is taken as 0.2 in this paper). Then the points located in the sphere are indexed. Although the number of points varies across groups, the PointNet layer can convert them into feature vectors with fixed-length.
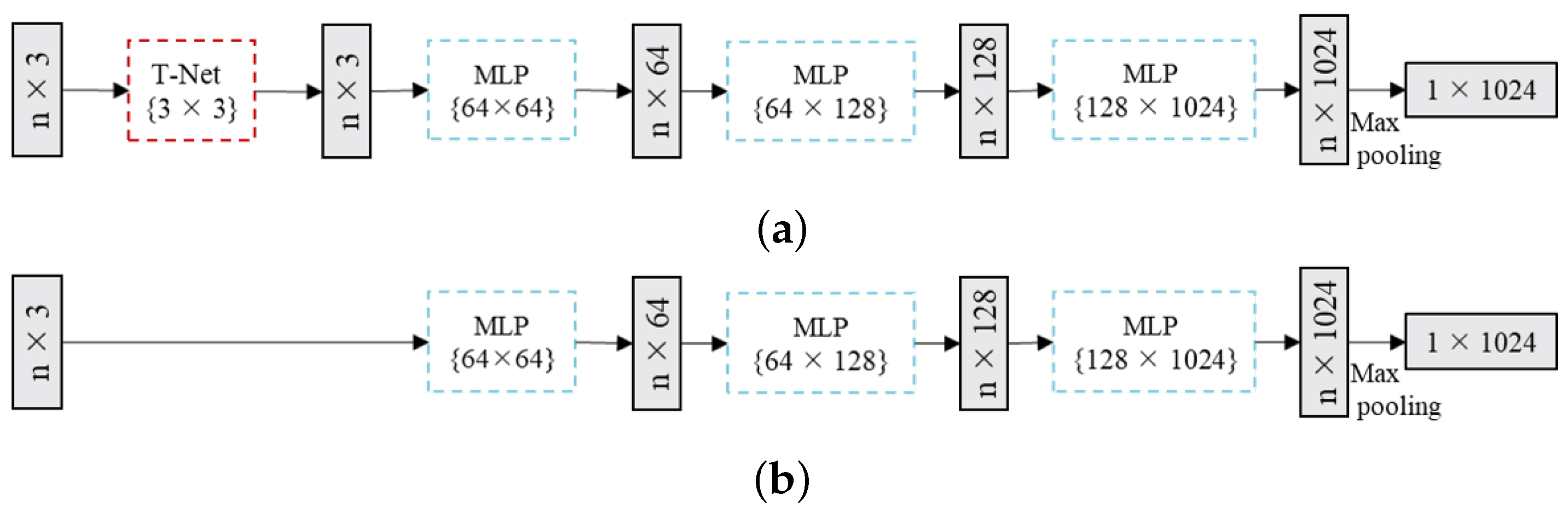
The PointNet network is used as the backbone to extract feature vectors of point clouds. In order to reduce the model size, this paper prunes the PointNet network structure. For the input point clouds, PointNet firstly uses a T-Net network to learn matrices to convert the input of different perspectives into the input of the same perspective, but this part doubles the size of the network. So we remove the T-Net Network and use MLP to extract transformation invariant features.
The following
Figure 12 shows the original structure of PointNet network and the PointNet network structure used in our FE layer.
We convert the MLP to matrix form, it can be found that the hidden feature vector is as follows:
are coordinates of one point
in the point cloud
P,
k represents the output chanel of MLP, in our network
.
The learnable parameters of the MLP can act as a many rotation martix. The output of the T-Net is a 3 × 3 rotation matrix. Considering that the point cloud is put into a 3 × 64 MLP, the 64 output channels is stroung enough to make the network’s rotation invariant approximately.
2.2.2. The FP Layers
FP layers share a similar structure as PointNet++’s decoder part, which adopts a hierarchical propagation strategy with distance-based interpolation and across-level skip links. Taking the FP3 layer as an example, for the 1 × 1024 feature output by FE3 layer, it was simply repeated 128 times to . Then the feature was combined with the features output by the FE2 layer to form a new feature, and then mapped to by MLP.
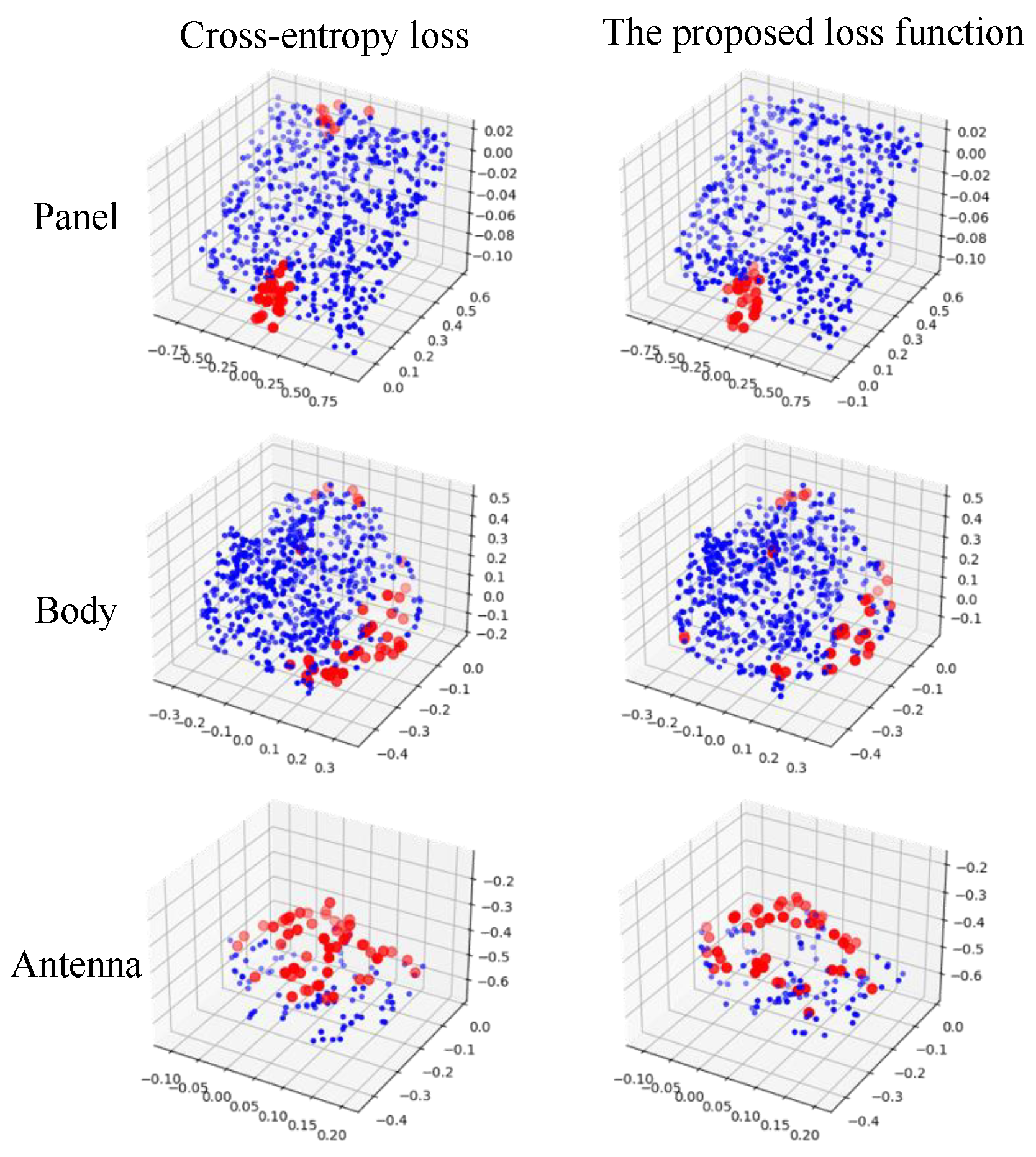
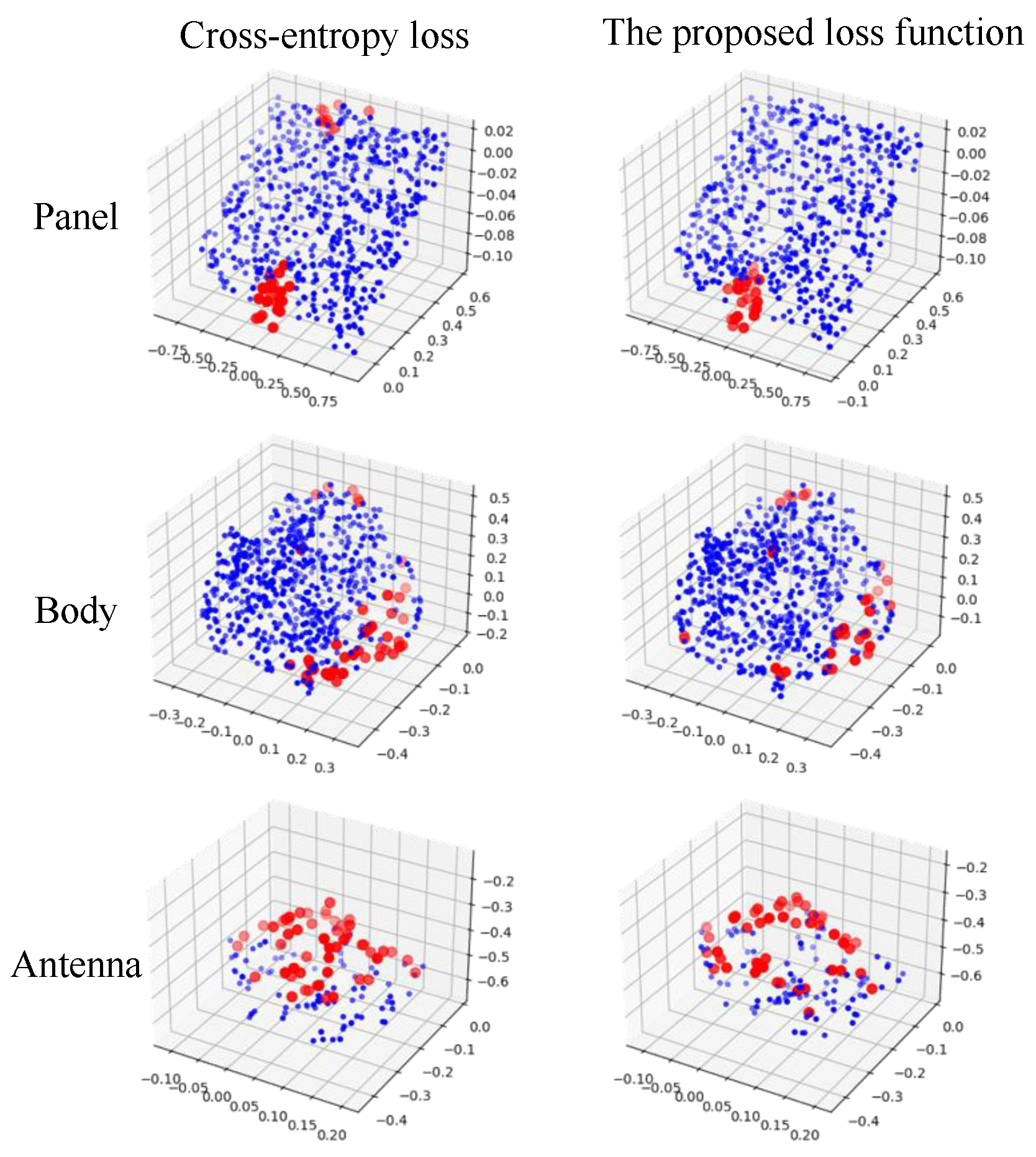
2.2.3. Loss Function
As stated in
Section 1 that data distribution between different components in a spacecraft can be largely varied. To improve the segmentation accuracy of components with few points(e.g., antenna), we proposed a new weighted cross-entropy loss.
is a weighted parameter indicating that the point belongs to a certain category,
represents the number of points belonging to the class
c,
is a one-hot vector. If the segmentation result is consistent with the prior label, the value of
is set as 1; otherwise, the value will be set as 0.
represents the probability that the predicted sample belongs to class
c.
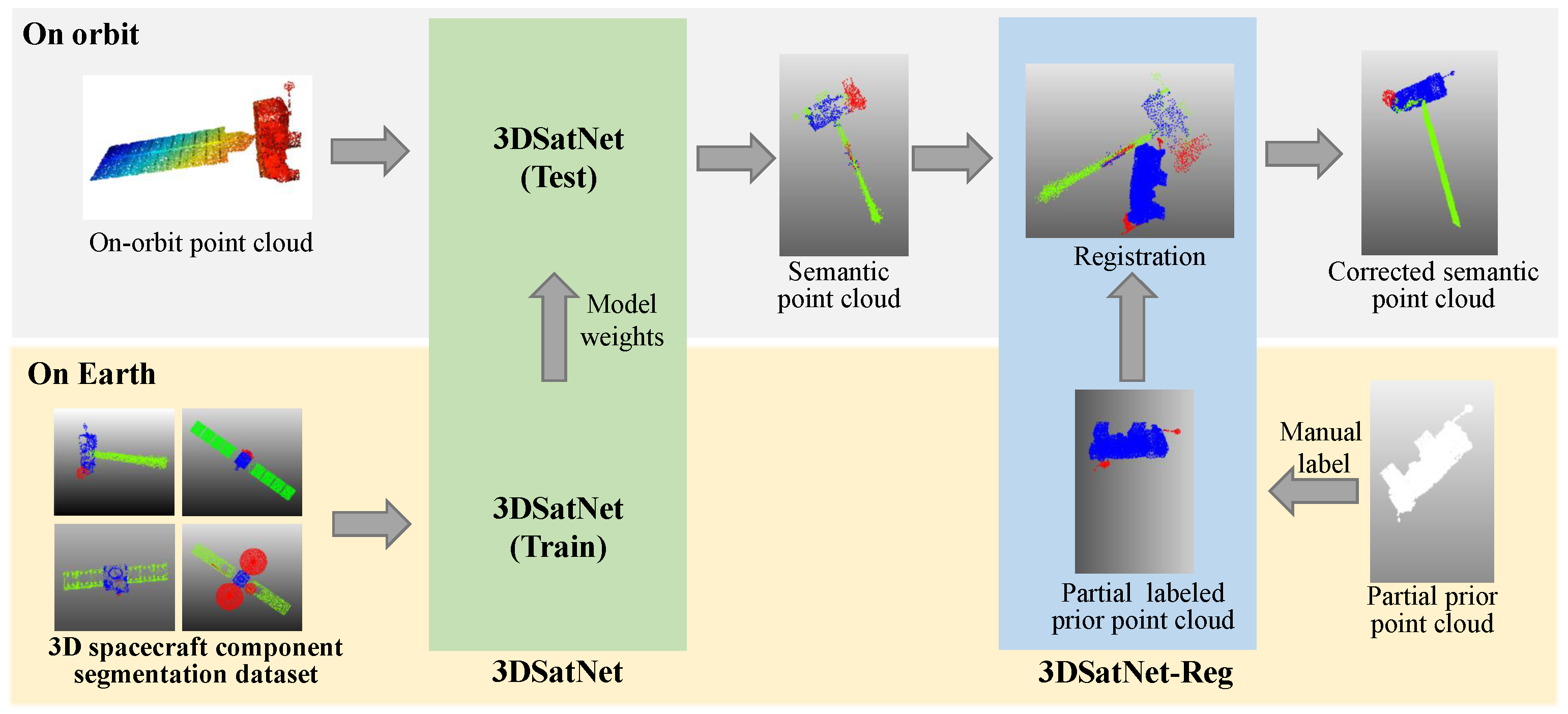
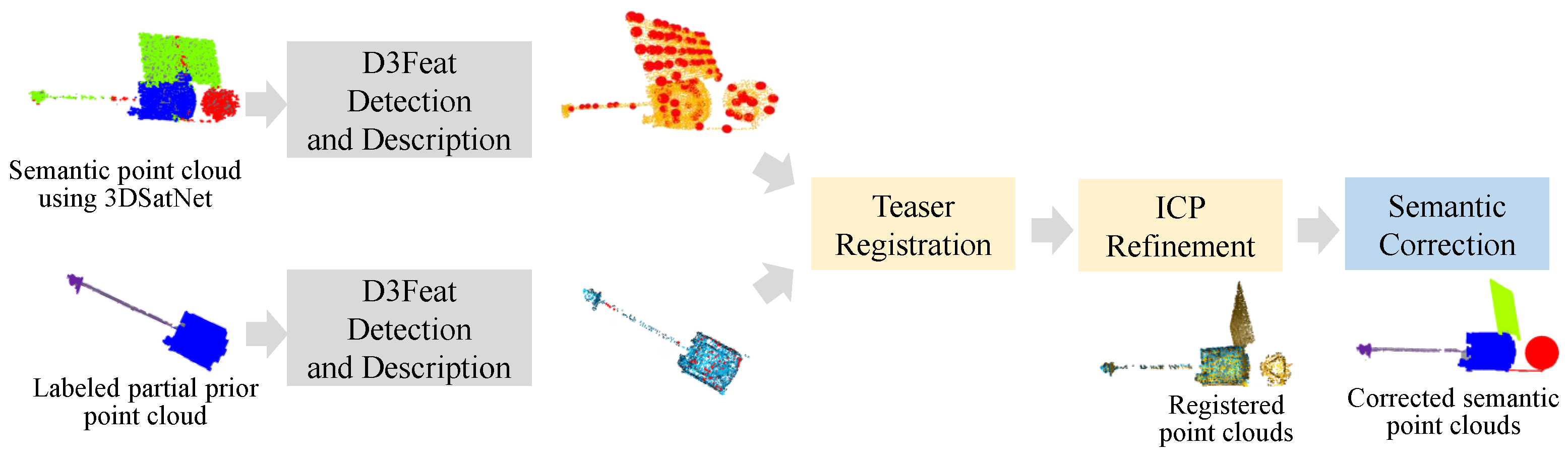
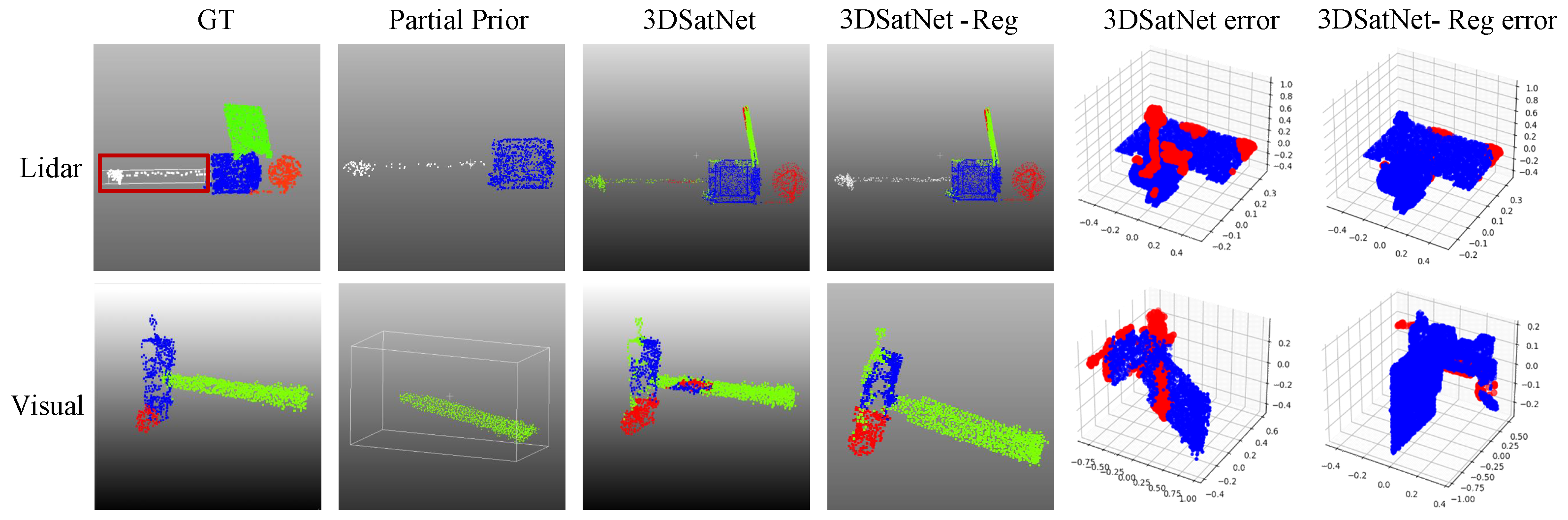
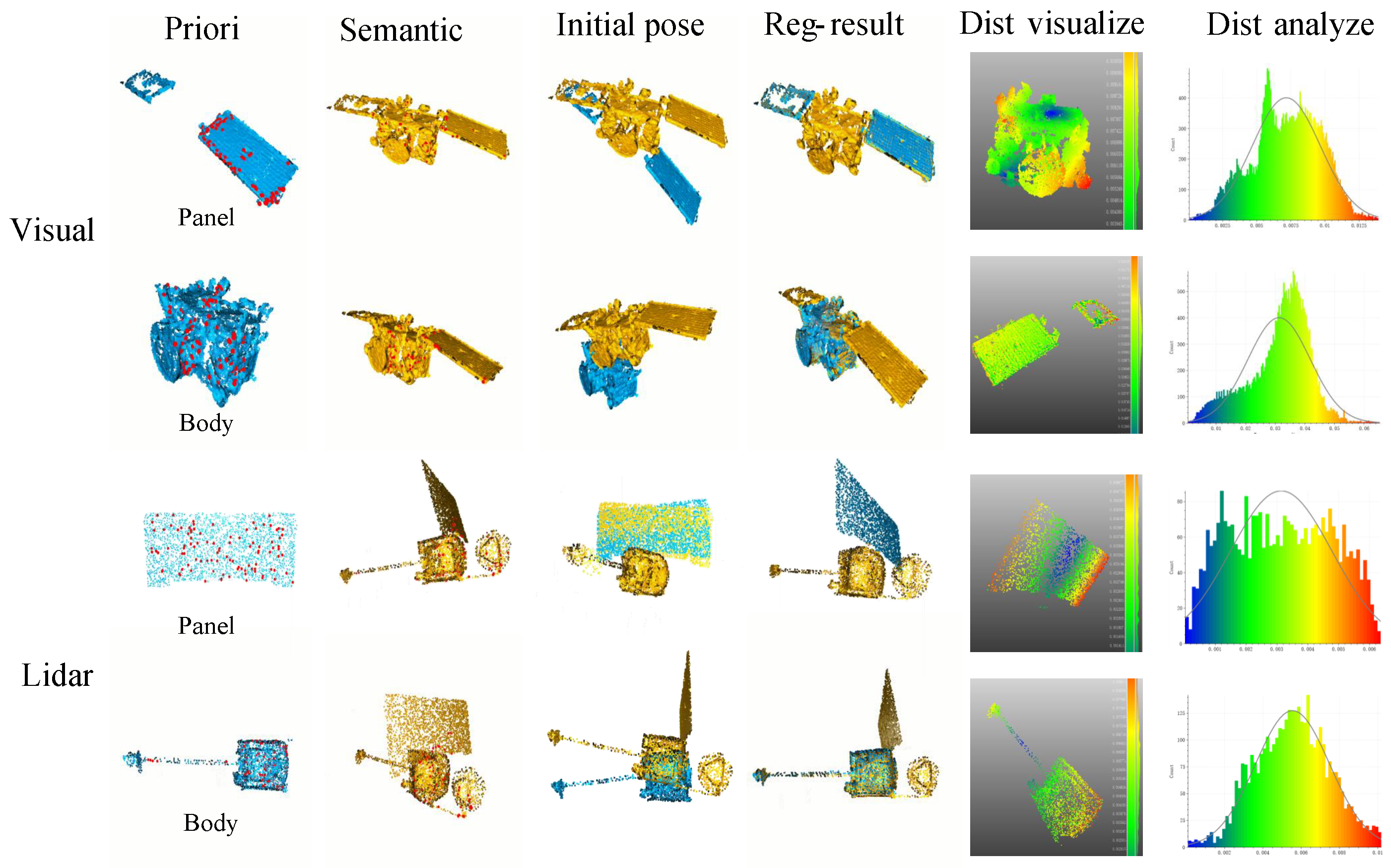
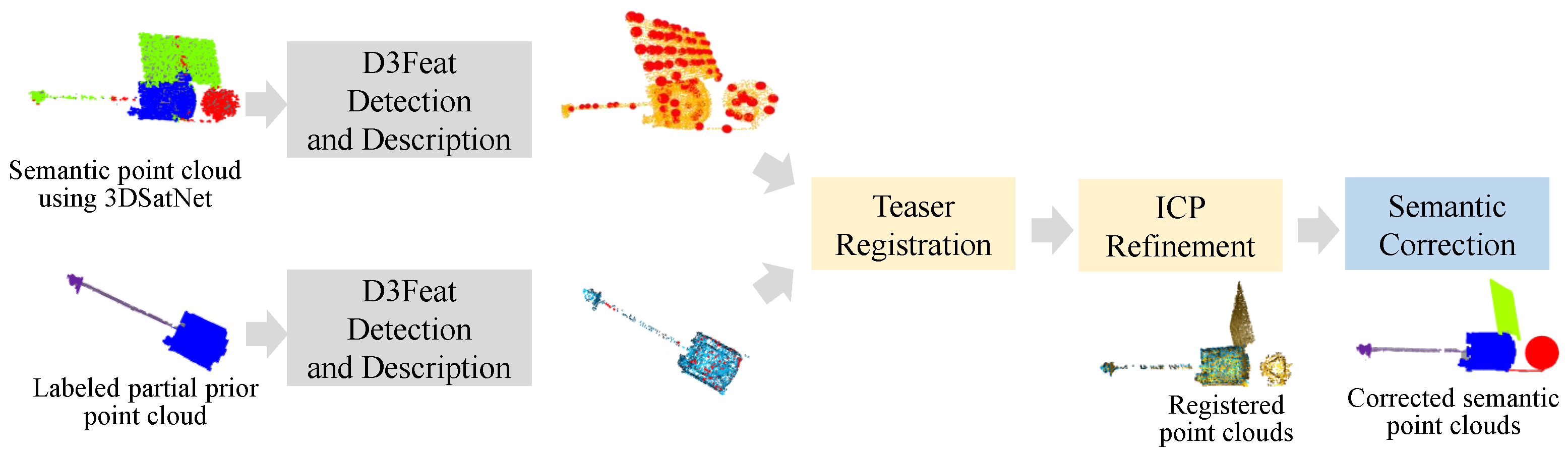
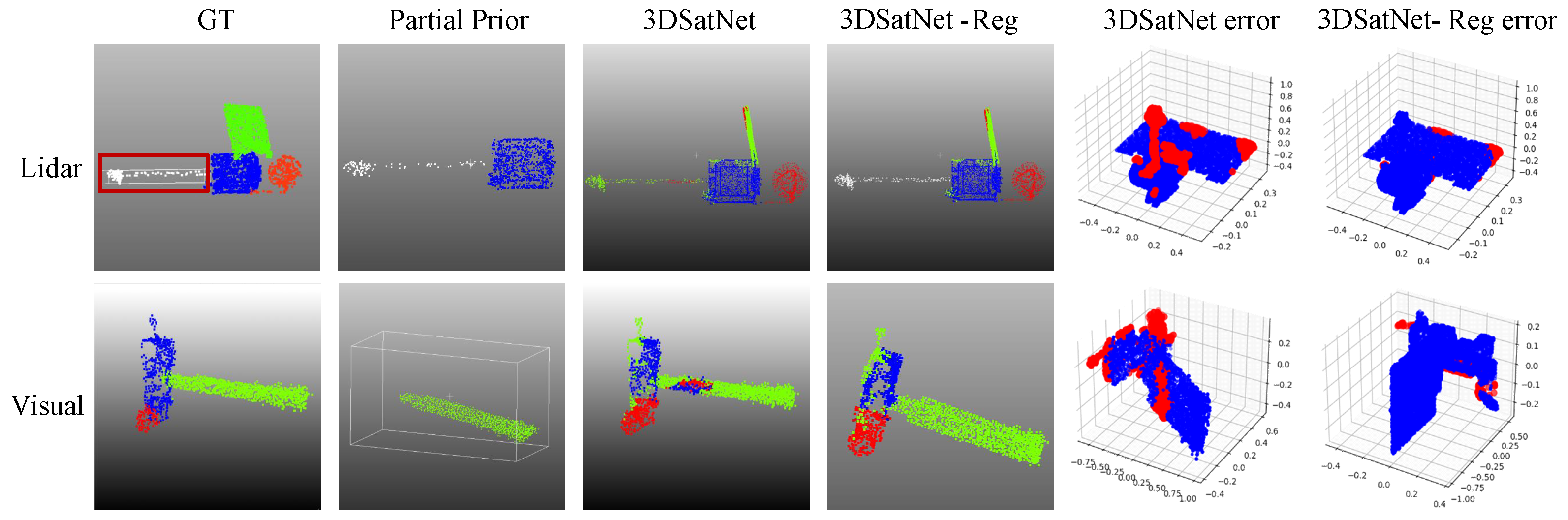
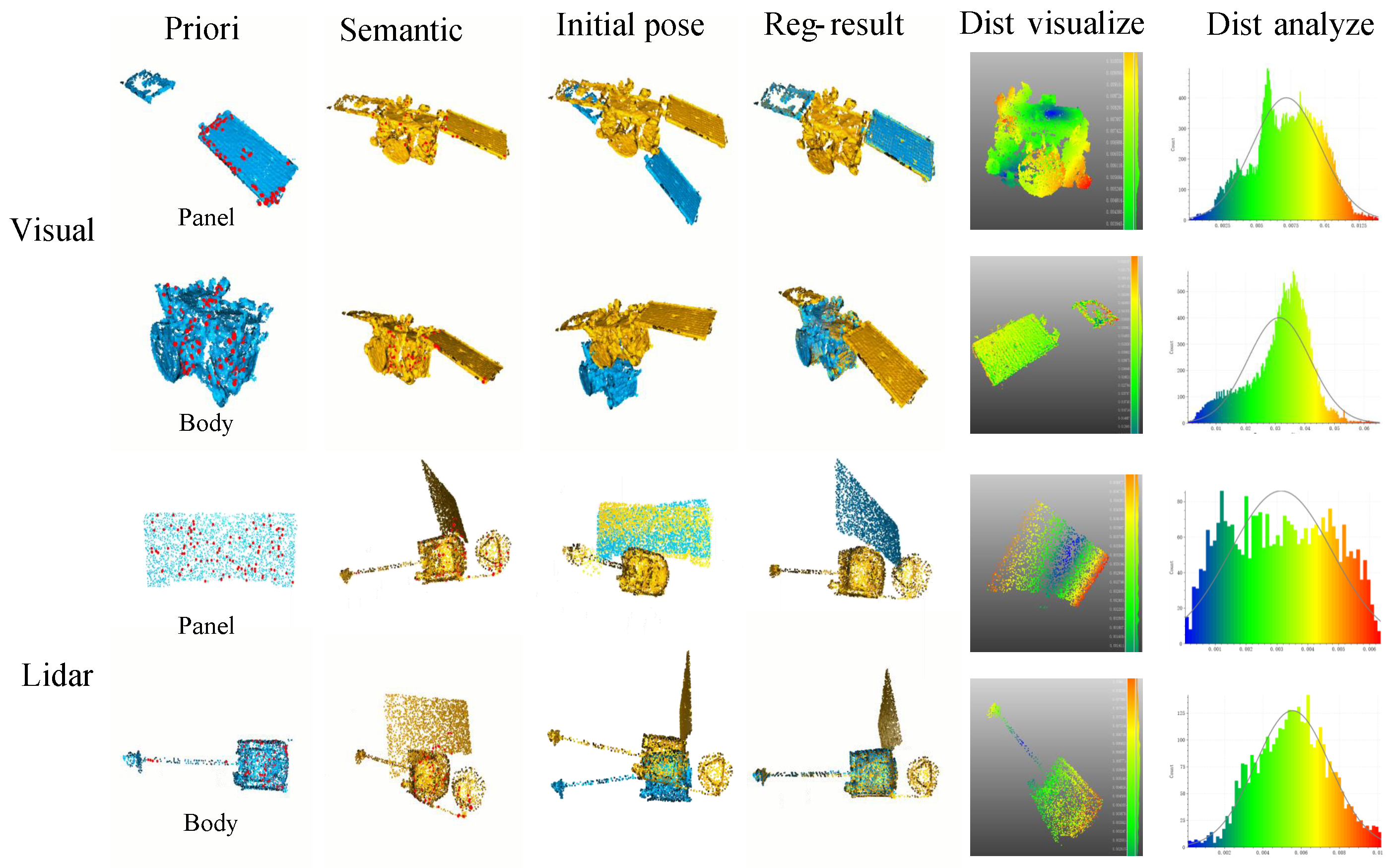
2.3. 3DSatNet-Reg
In OOS tasks, several pictures and several frames of lidar scanning results of the target spacecraft can be obtained, and then visual 3D reconstruction technology and lidar 3D reconstruction techniques are used to obtain partial prior point clouds. Aiming at the problems of spatial target component segmentation with prior point clouds, this section proposes a Teaser-based [
28] component semantic segmentation network 3DSatNet-Reg. The labels of the prior point clouds labeled on earth are assigned to the closest point of the raw semantic point cloud gained by 3DSatNet. The pipeline of the proposed 3DSatNet-Reg is shown in
Figure 13.
The point cloud registration problem aims to find the optimal rotation, translation and scale transformation matrices of the labeled prior point clouds
and the on-orbit semantic point cloud
. Considering the influence of the noise of the on-orbit semantic point cloud, the problem can be modeled as Equation (
7):
where
,
,
,
models the measurement noise, and
is a vector of zeros if the pair
is an inlier.
, where
is a given bound.
The critical technology to realize partial prior point clouds and overall semantic point cloud registration is to detect the corresponding point pairs on the two point clouds. Traditional feature extraction methods such as FPFH (Fast Point Feature Histogram) and VFH (Viewpoint Feature Histogram) can’t perform well, so we use D3Feat [
30] to realize local feature detection and description which can be used to find key points and point correspondences with noise.
ICP (Iterative Closest Point) [
31] is a commonly used registration algorithm when the initial pose between the two point clouds is not too large. Considering the large poses and scale difference between the prior point clouds and the semantic point cloud, a highly robust Teaser [
28] registration algorithm is added to achieve a rough registration and estimation scale of two point clouds before ICP. Then, ICP is used to optimize the registration results.
Teaser [
28] is a registration algorithm that can tolerate a large amount of noise. Teaser uses a TLS (Truncated Least Squares) cost that makes the estimation insensitive to a large fraction of spurious correspondences. It assumed the noise is unknown but bounded and proposed a general approach to decouple the estimation of scale, translation, and rotation.
The TRIMS (Translation and Rotation Invariant Measurements) [
28] is used to estimate the scale
.
Equation (
8) can be solved exactly and in polynomial time via adaptive voting. bounded noise
.
Given the scale estimate
produced by the scale estimation and TIMS (Translation Invariant Measurements). The rotation estimate
is defined as Equation (
9) which can be solved in polynomial time via a tight semi-definite relaxation. bounded noise
.
After obtaining the scale and rotation estimates
and
,
is estimated from
in Equation (
10) which can be solved exactly and in polynomial time via adaptive voting.
Finally, the ICP [
31] algorithm is used to complete fine registration. Estimate the combination of rotation and translation using a point to point distance metric minimization technique defined in Equation (
11) which will best align each source point to its match found in the previous step. Then transform the labeled prior point clouds using the obtained scale, translation, and rotation.
After registration, we calculate the closest point between the on-orbit semantic point cloud and the labeled prior point clouds and assign the label to the closest point.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}