
Aircraft Engine Gas-Path Monitoring and Diagnostics Framework Based on a Hybrid Fault Recognition Approach


Abstract
:1. Introduction
- We propose a diagnostic system based on a hybrid fault-recognition method that exploits the advantages of the low computational complexity of ELM and high recognition accuracy and noise-robustness of sparse representation classification method to improve the aircraft engine diagnostic decisions.
- Up to now, the majority of the published solutions using ProDiMES work with an anomaly detection algorithm followed by another fault identification algorithm, causing delays in the diagnostic decisions. The present methodology performs both stages as a common process by computing their corresponding performance metrics at the same time and with the same fault recognition algorithm.
- The paper contributes to the advancement of the state-of-the-art in the area of gas turbine engine health management since it provides a robust and fair comparison with all the available diagnostic algorithms published in the literature using ProDiMES from worldwide leading and established researchers, including the authors of the benchmarking platform. Additionally, the work stimulates the competition between diagnostic solutions and further development of the area of gas turbine diagnostics.
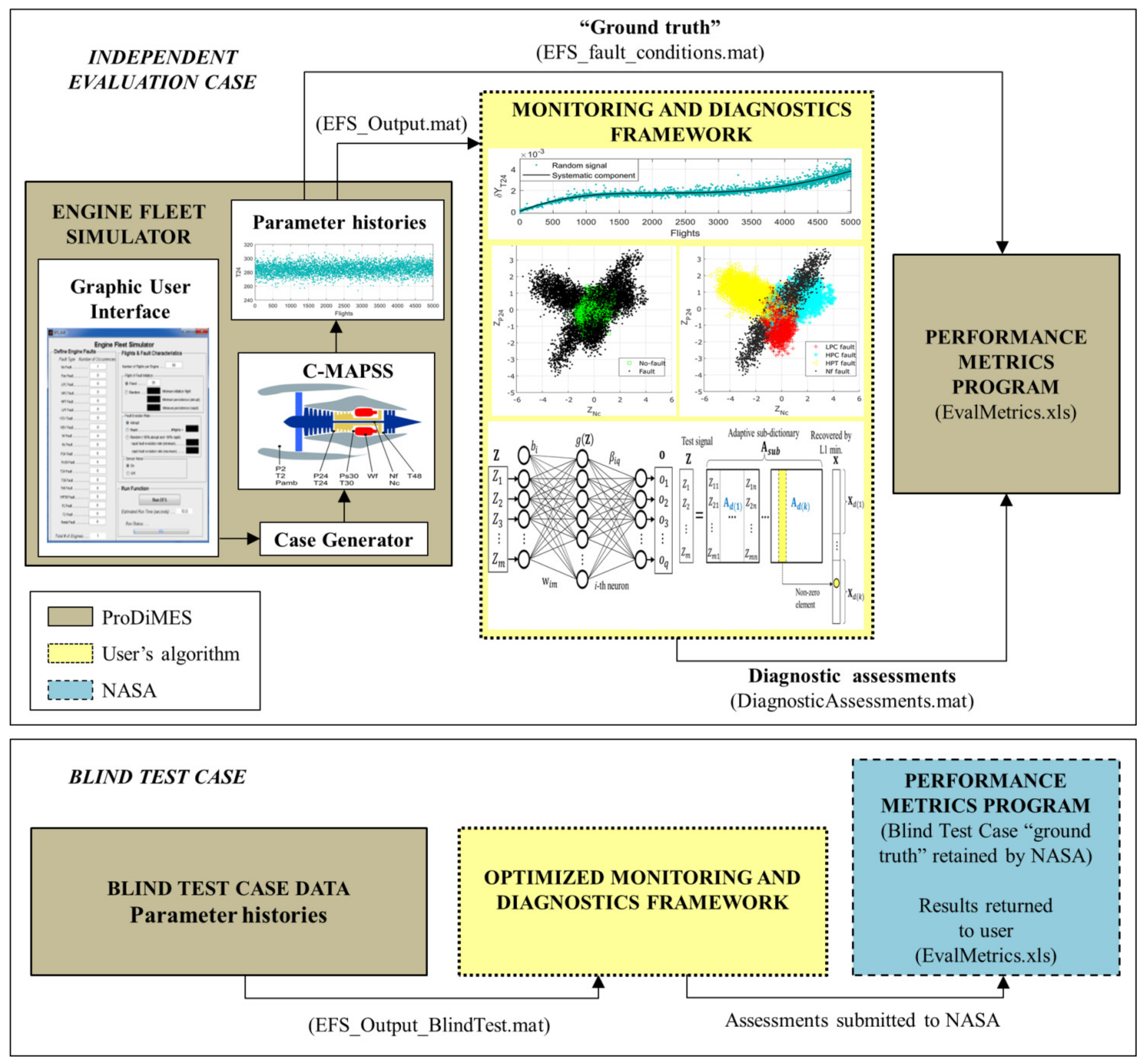
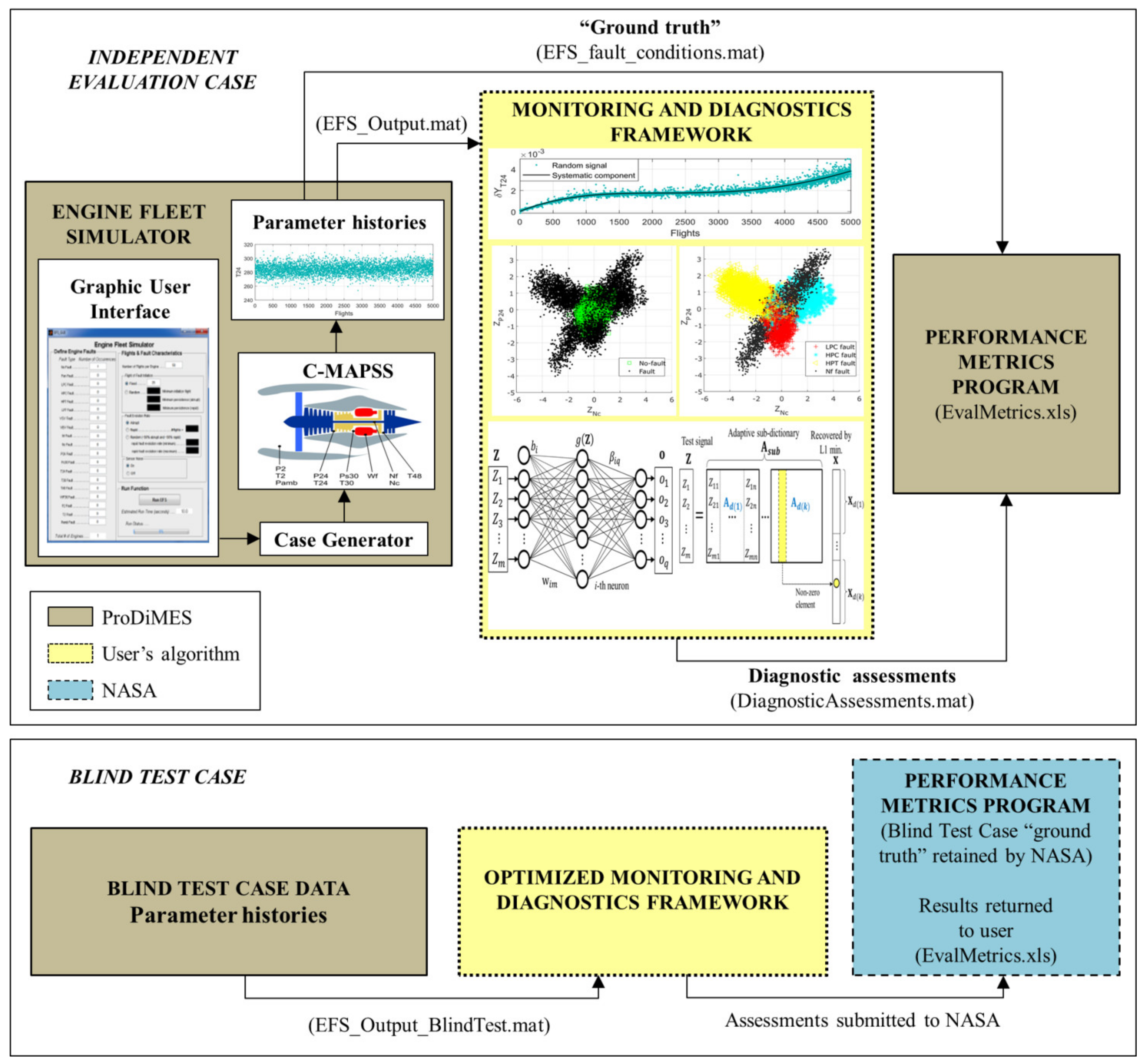
2. ProDiMES Benchmarking Process
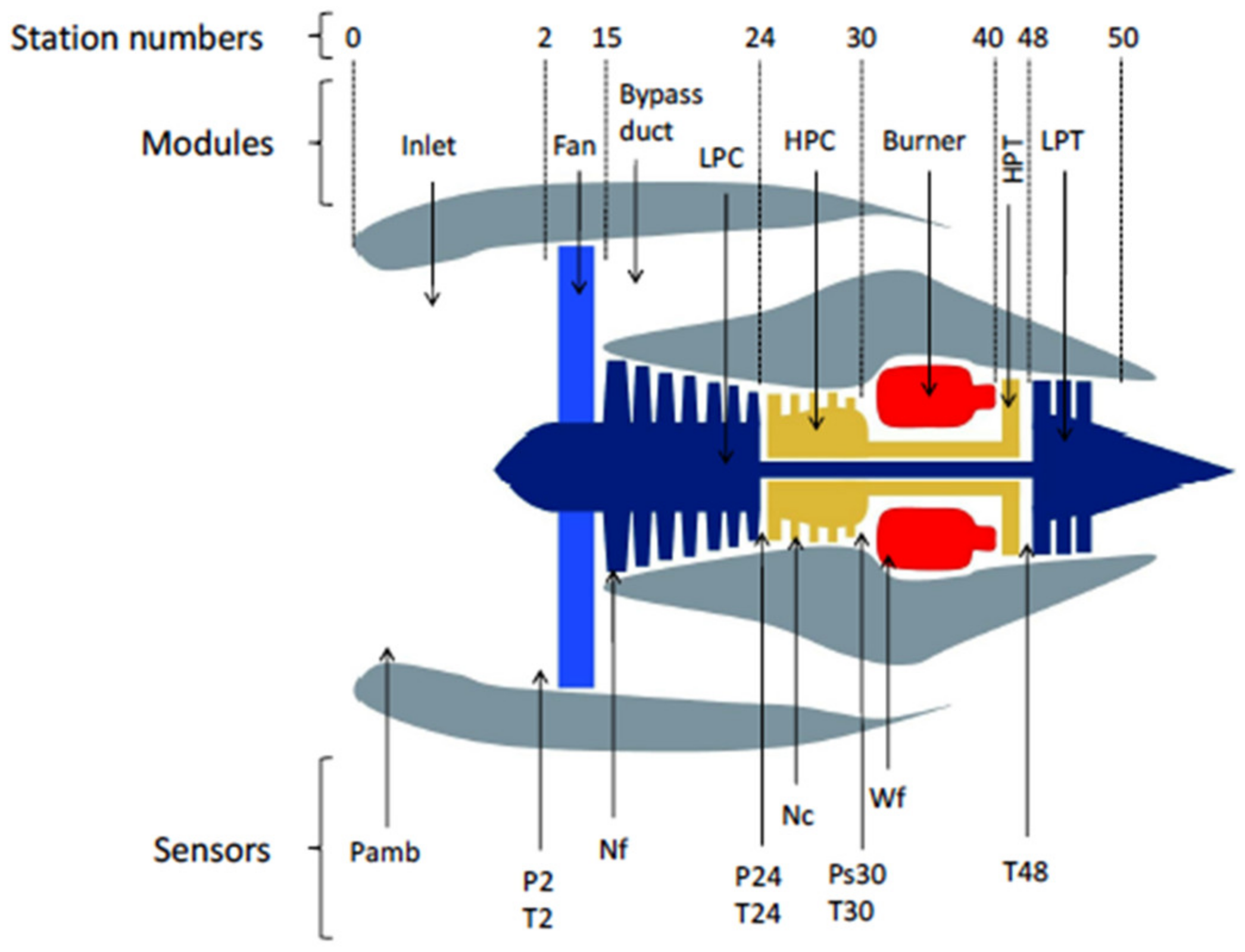
2.1. Engine Fleet Simulator
2.2. Performance Metrics
- Detection: true-positive rate (TPR), true-negative rate (TNR), false negative rate (FNR), and false positive rate (FPR).
- Classification: correct classification rate (CCR), misclassification rate (MCR), and kappa coefficient (it indicates the capability of the diagnostic framework to accurately classify a fault considering the expected number of correct classifications that occur by chance. If kappa = 1, then the diagnostic technique produces a perfect classification; if kappa < 0, then the classification is worse than expected).
- Latency metrics: detection latency as the average number of flights a fault persists before a true-positive detection and classification latency as the average number of flights a fault must persist prior to correct classification.
3. Proposed Monitoring and Diagnostics Framework
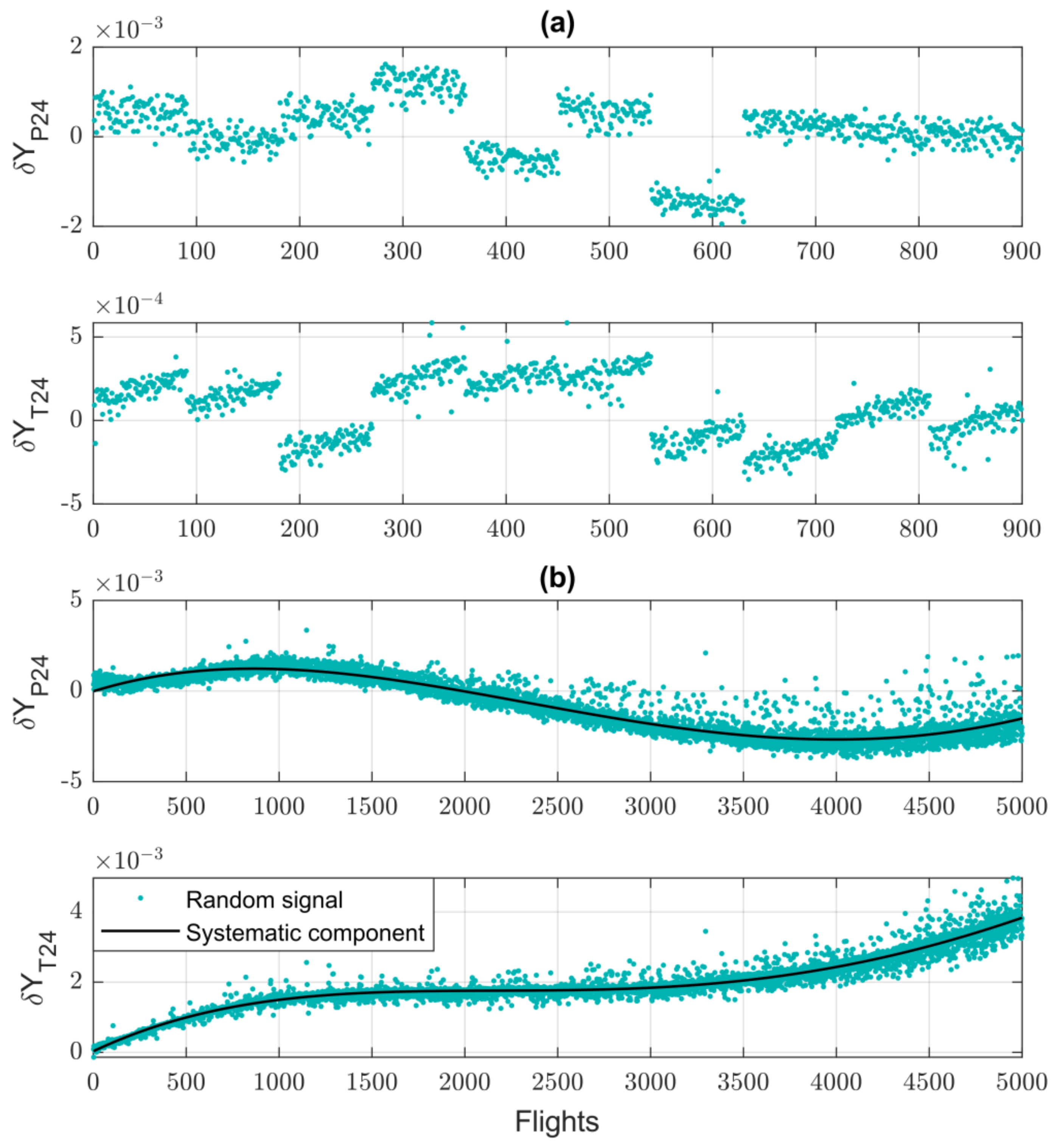
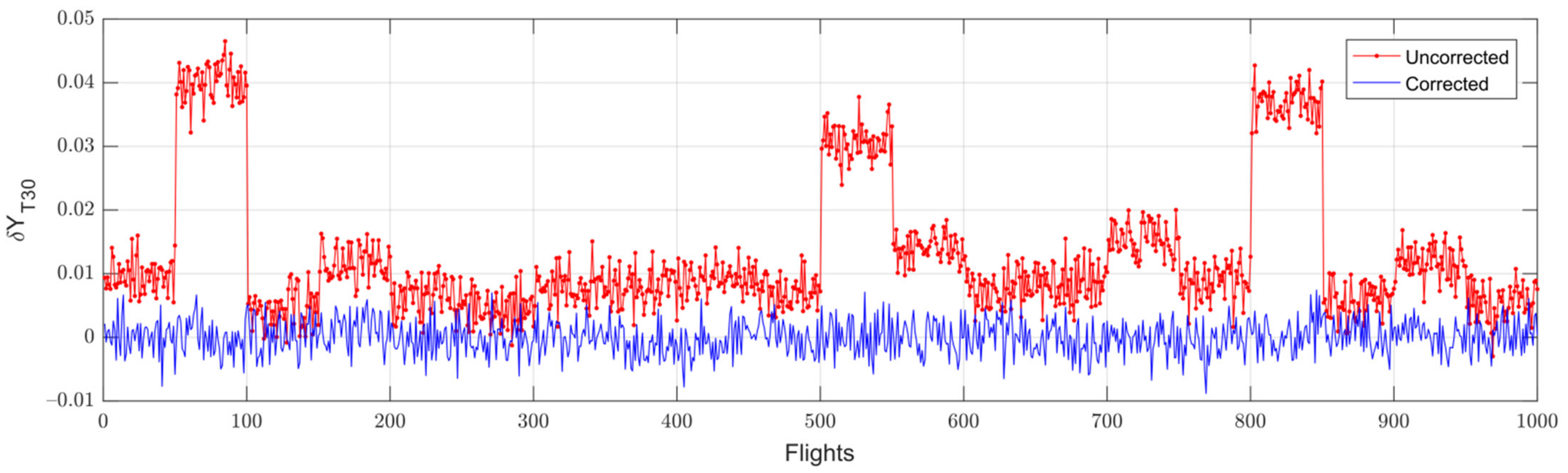
3.1. Averaged Baseline Model for Engine Fleet
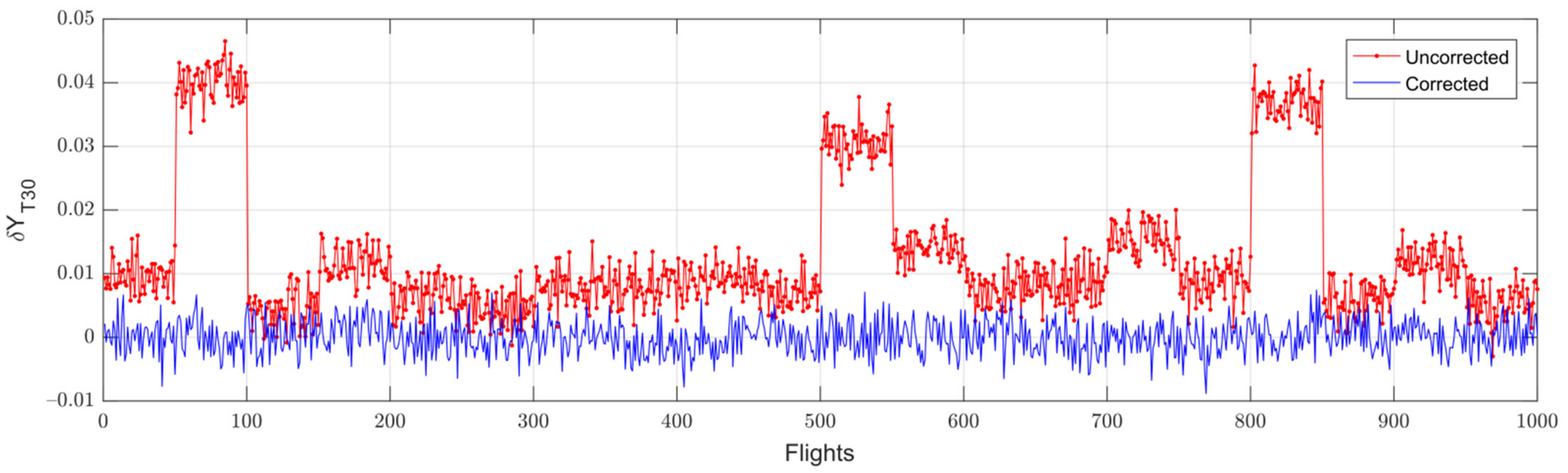
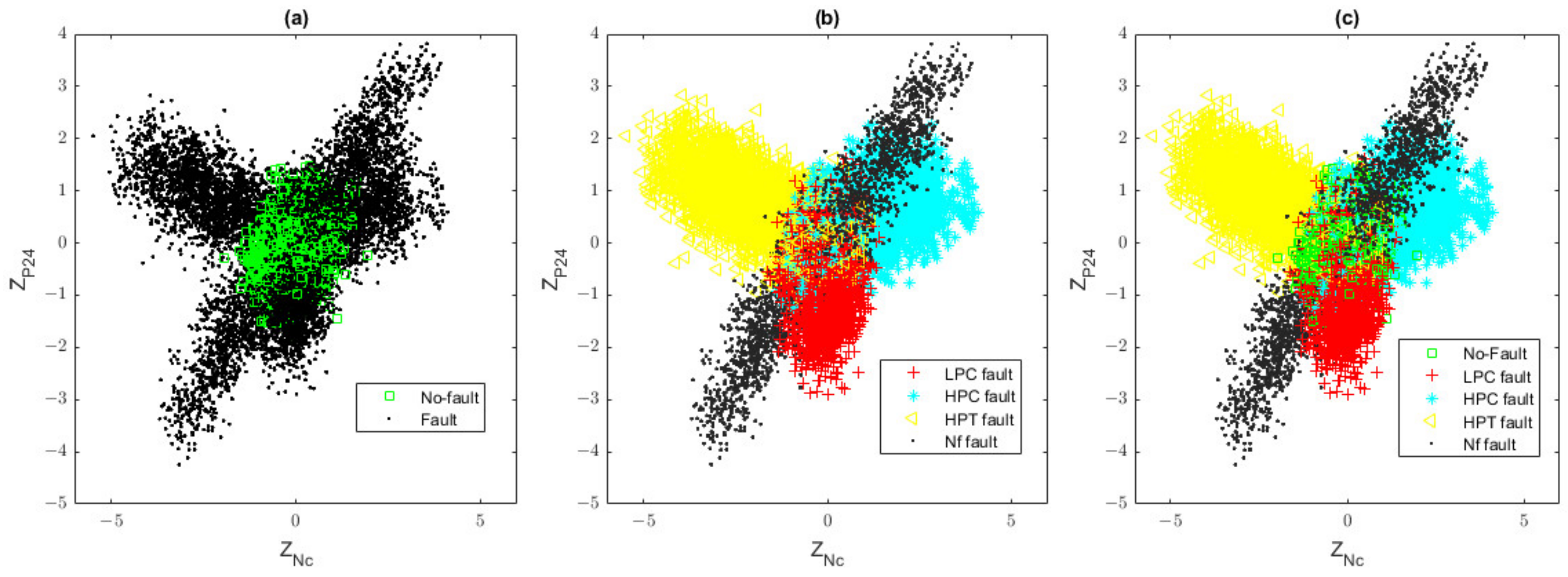
3.2. Baseline Model Correction and Class Formation
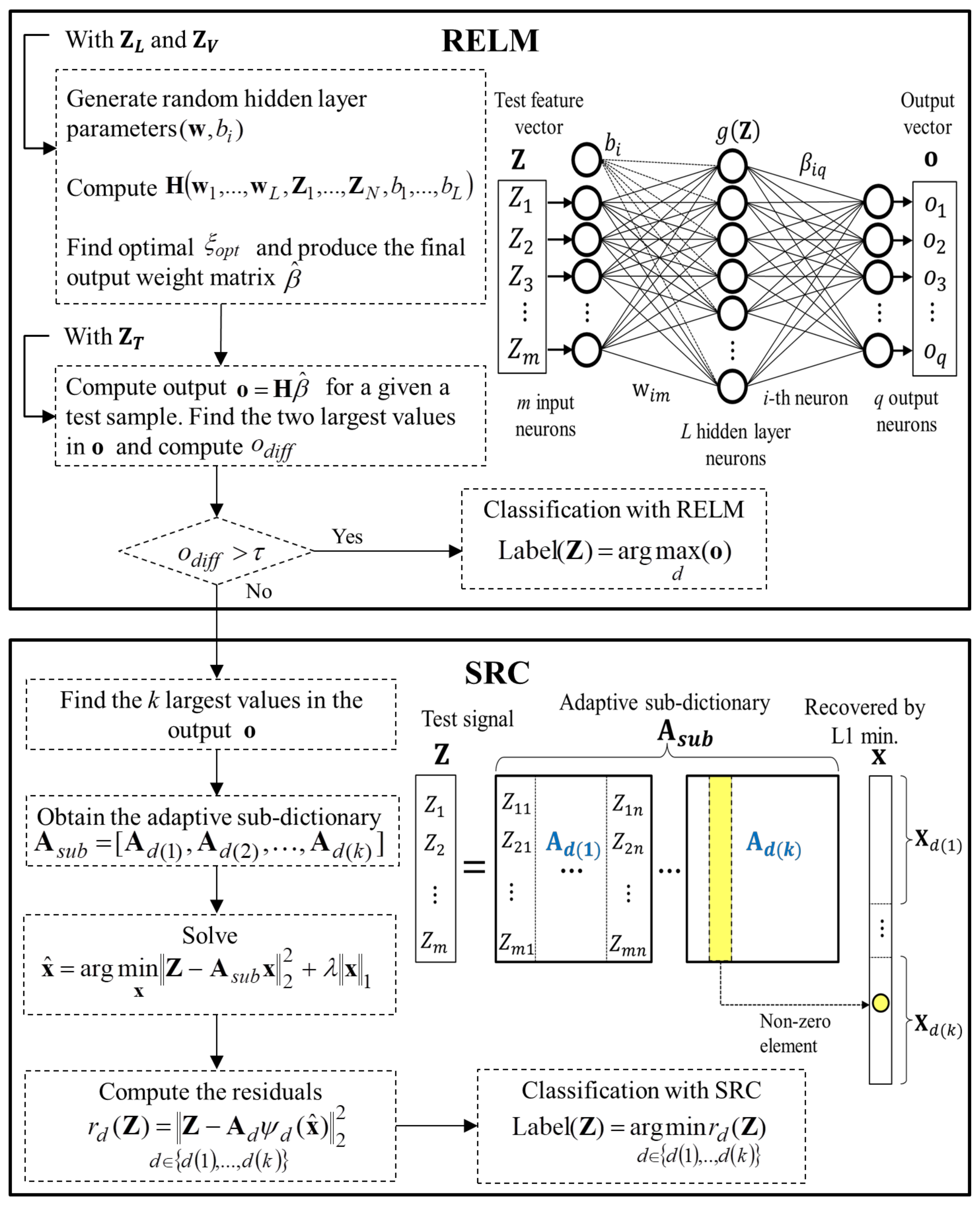
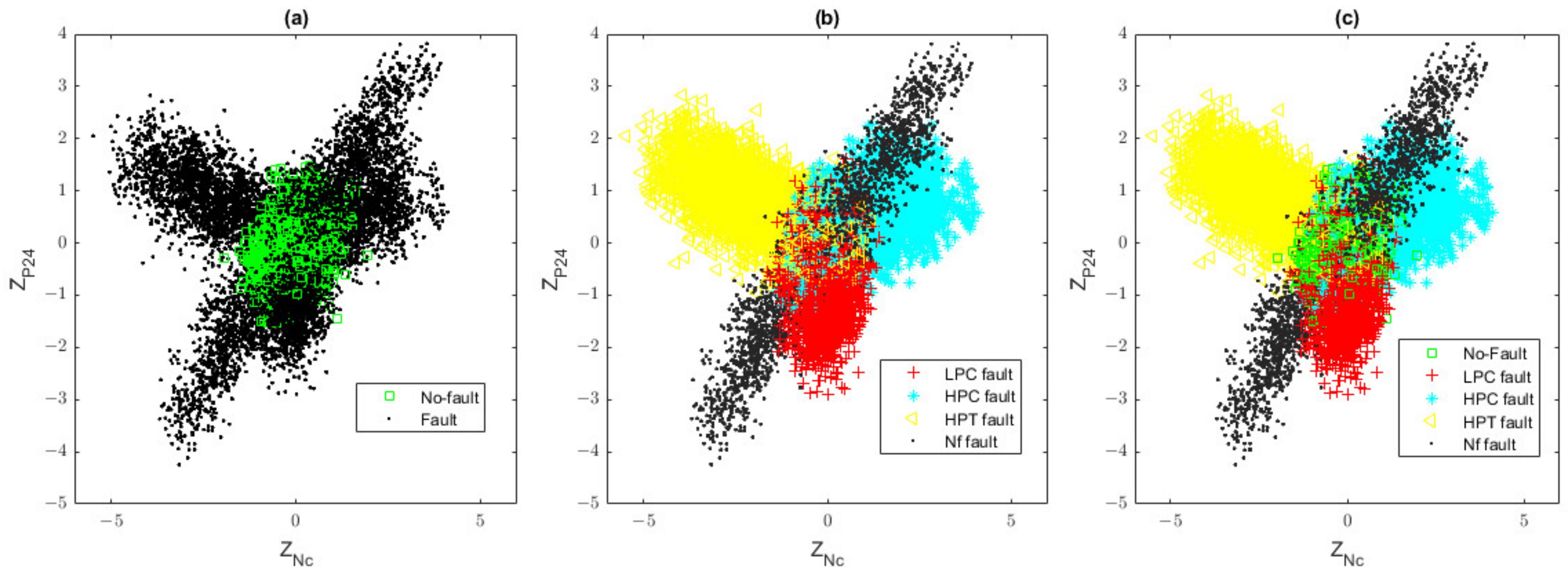
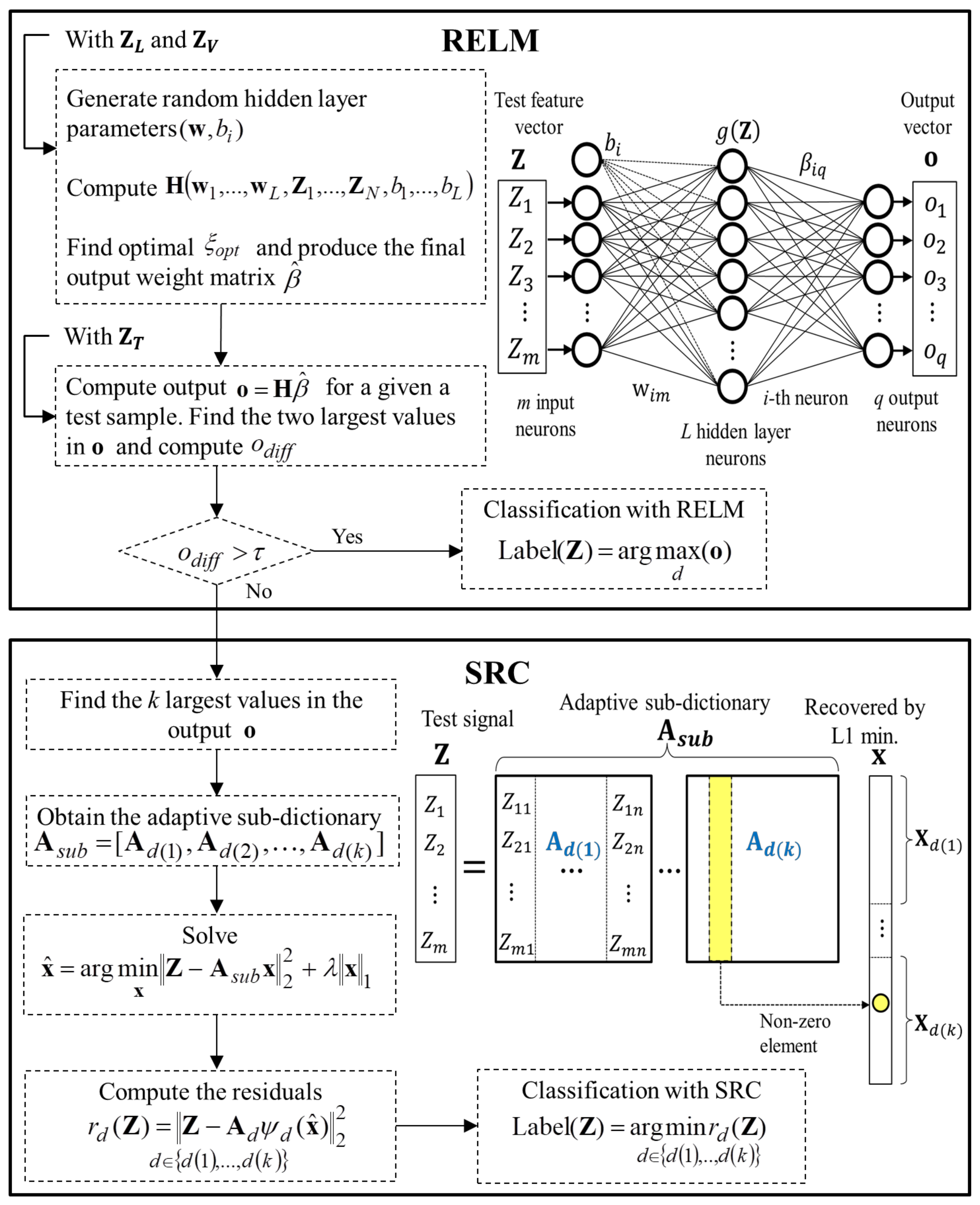
3.3. Hybrid Fault Classification Approach
3.4. Anomaly Detection and Fault Identification as a Common Process
4. Comparison of Diagnostic Frameworks
4.1. Stage 1: Comparison with Other Diagnostic Frameworks Using ProDiMES Cruise Dataset
4.2. Stage 2: Comparison with Other Diagnostic Frameworks Using Self-Generated Cruise Dataset
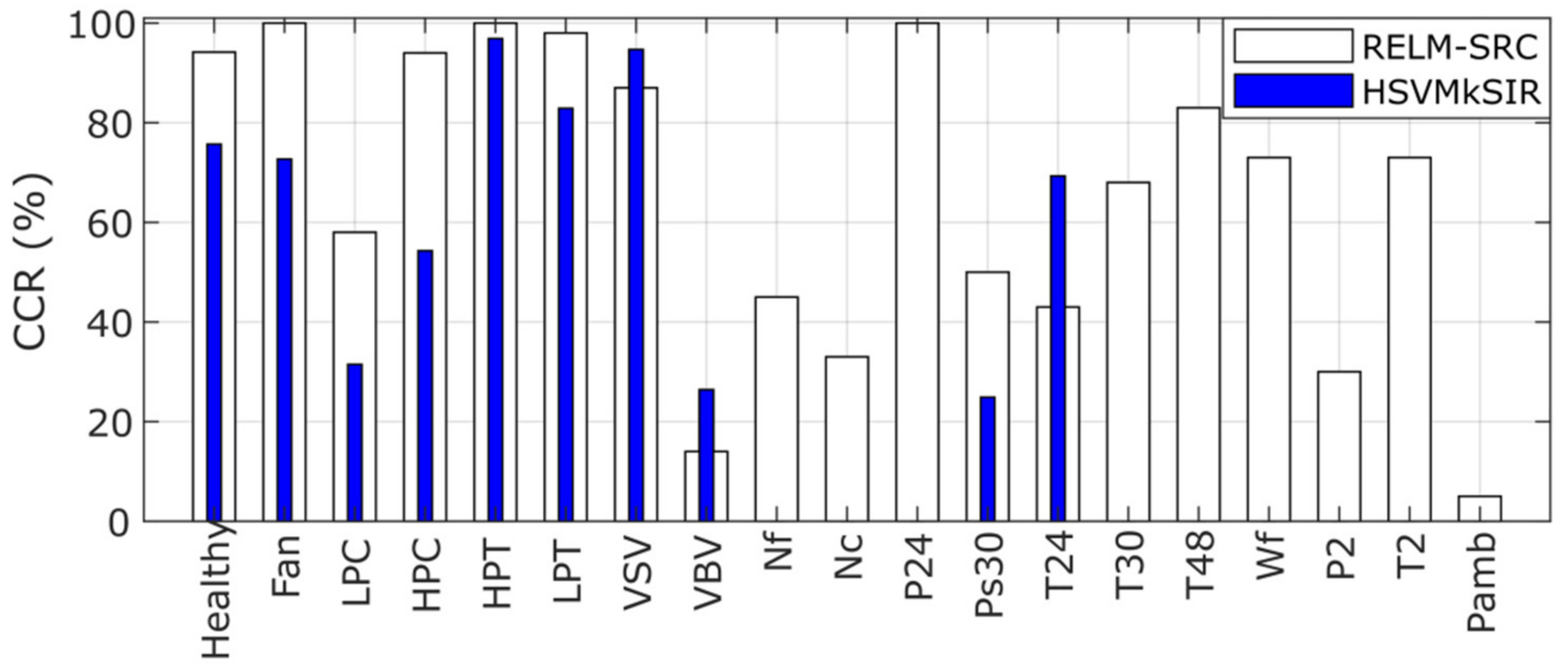
4.3. Stage 3: Comparison with Other Diagnostic Frameworks Using ProDiMES Dataset and Multipoint Analysis
4.4. Stage 4: Blind Test Case (Multi-Point Analysis)
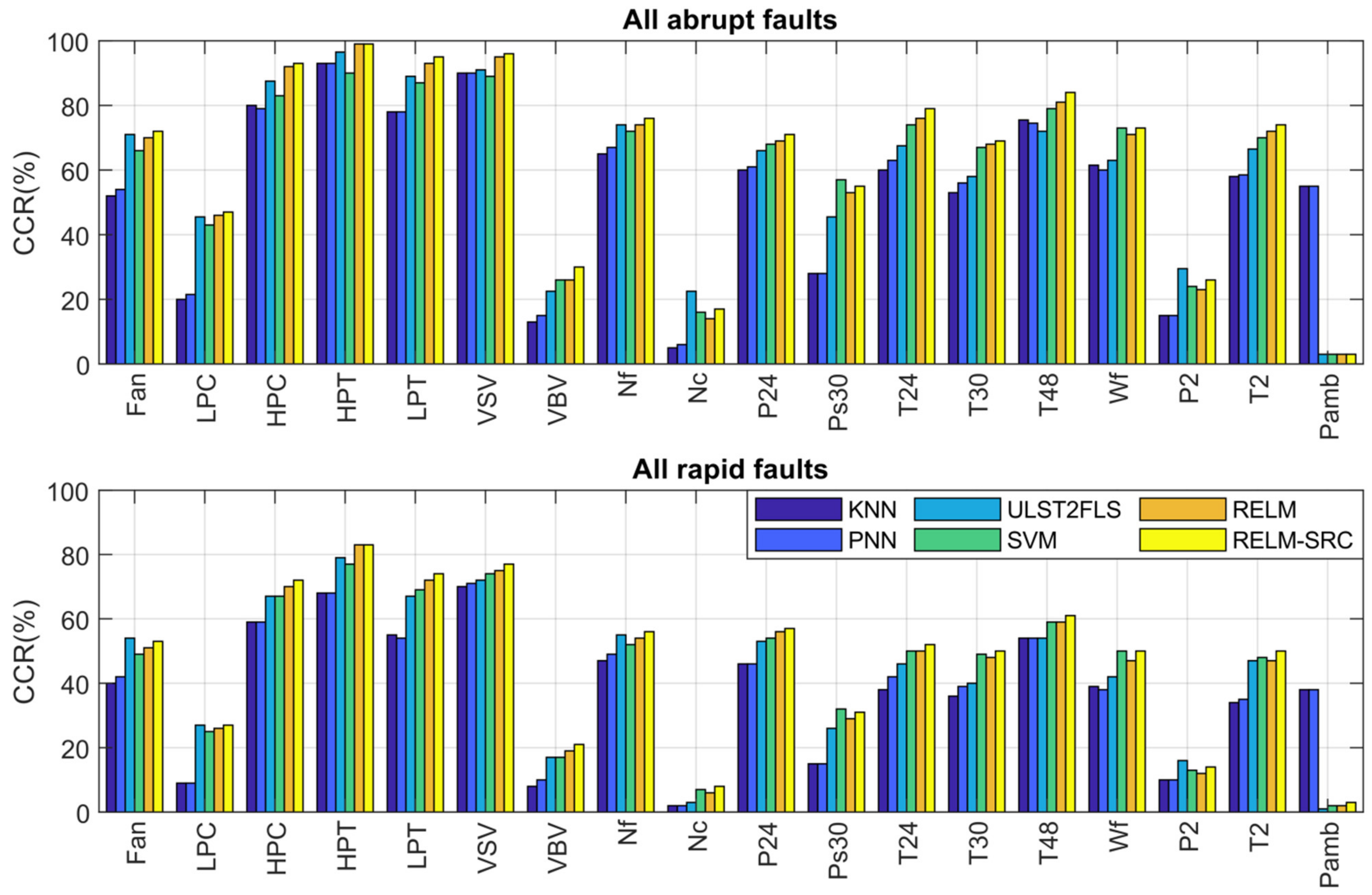
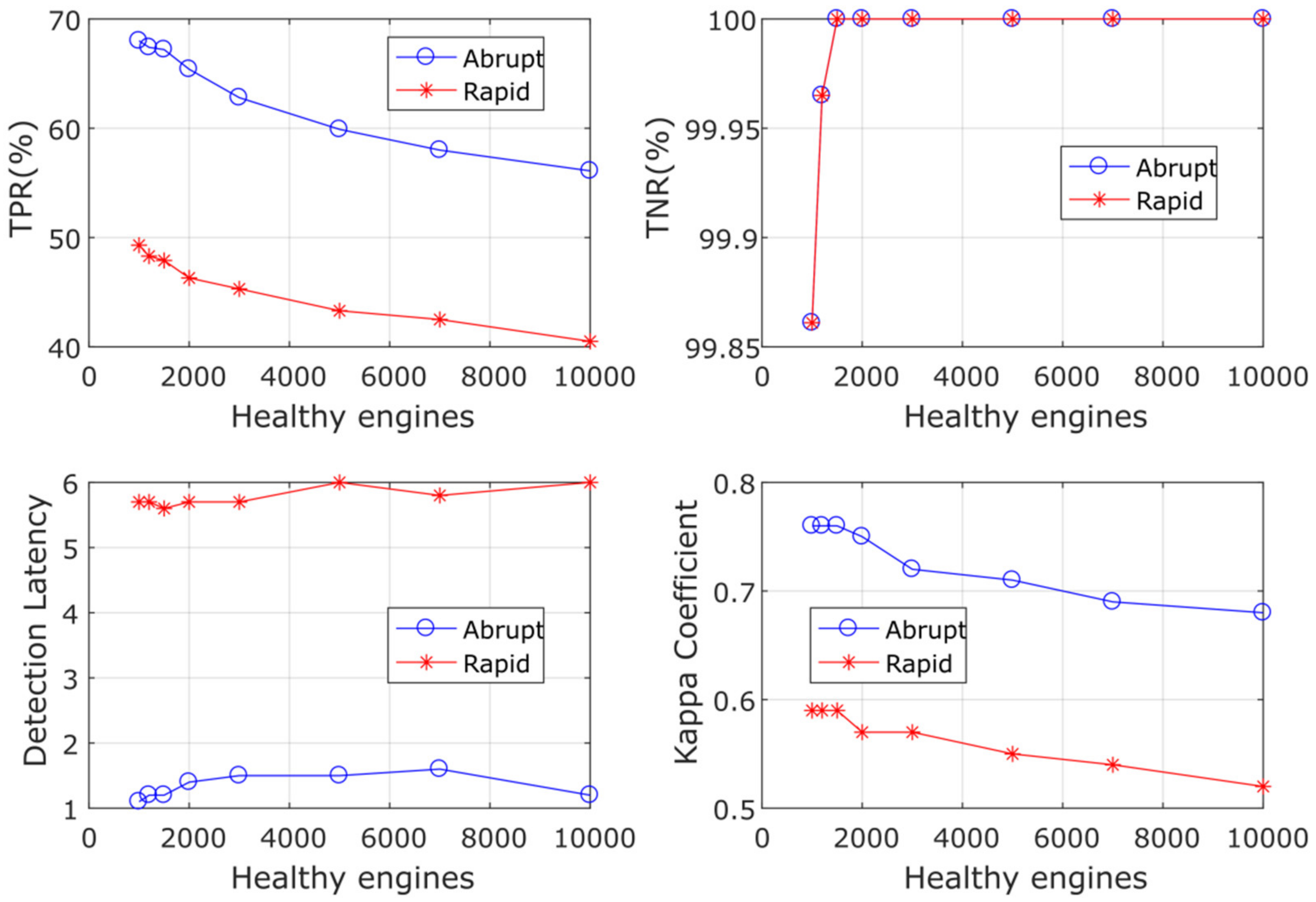
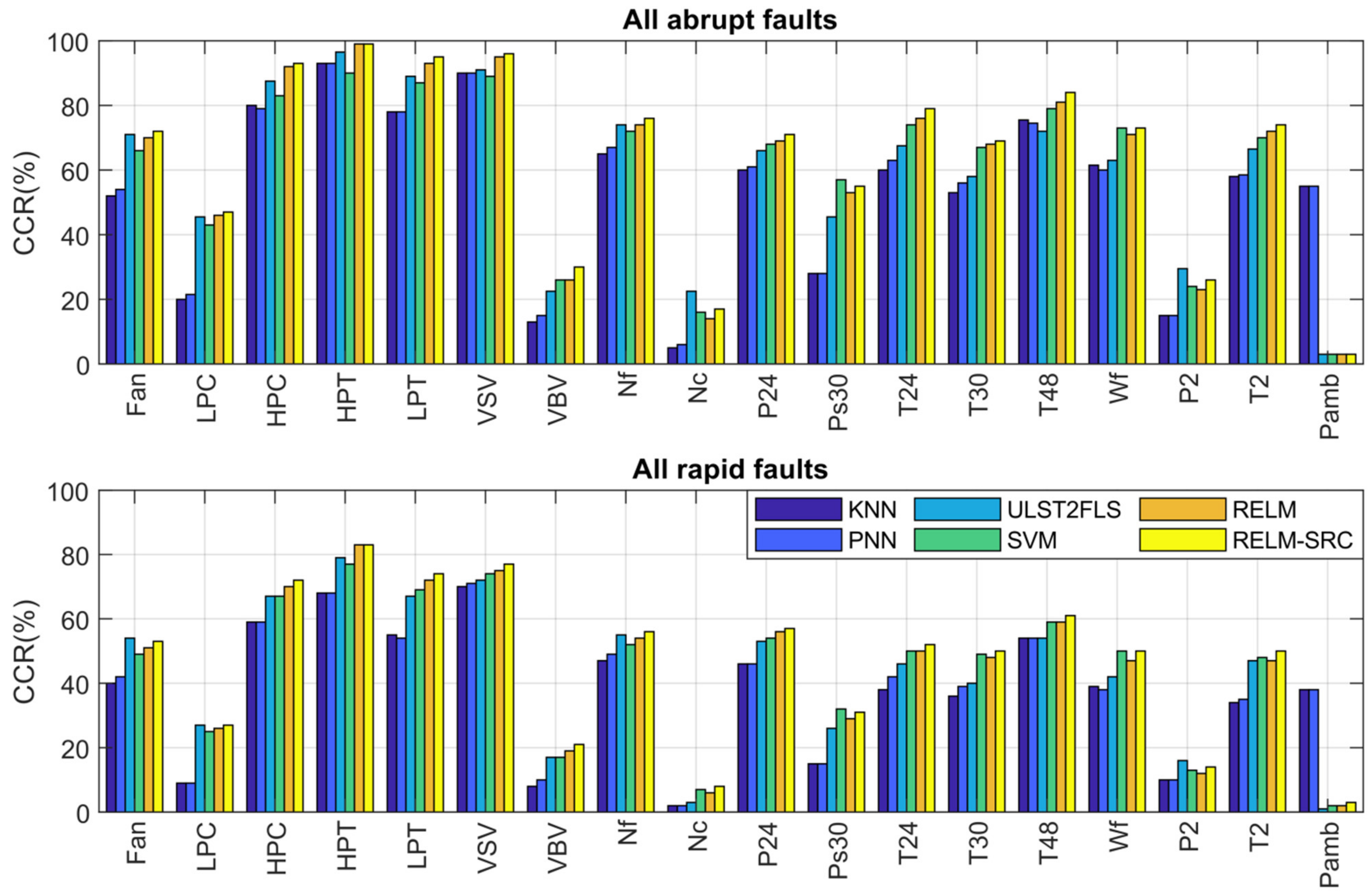
- As in the case of TPR, abrupt faults present higher CCR than rapid ones since the former are easier to detect.
- RELM-SRC wins in 12 rapid and 12 abrupt fault scenarios; the rest are draws and some wins with RELM, SVM, and ULST2-FLS.
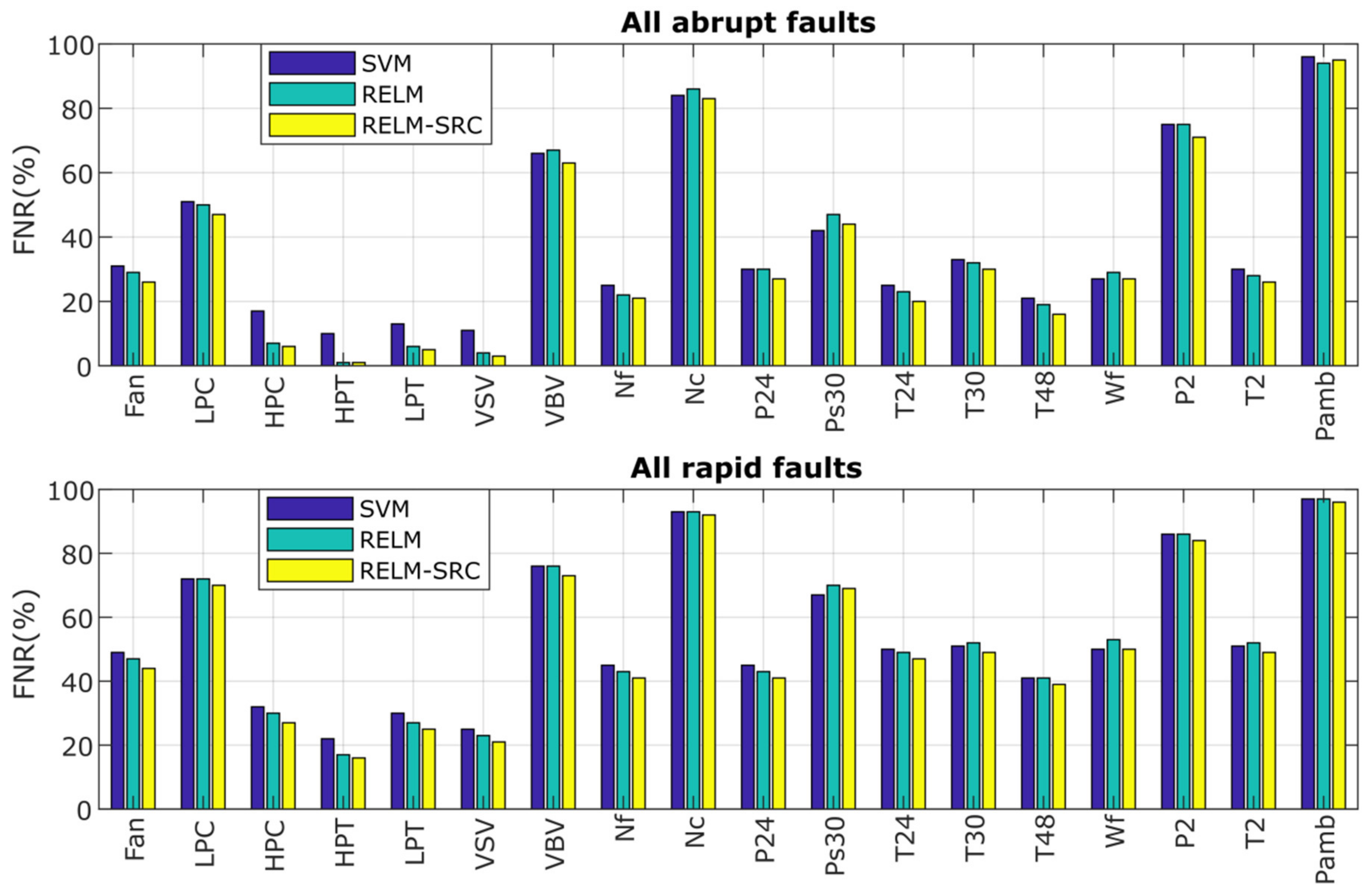
- The algorithms have problems identifying VBV actuator faults and three sensor faults related to Nc, P2, and Pamb, as also reported in papers [13,21]. Some present slightly better performance than others except for PNN and KNN, which effectively recognize the Pamb fault, but in general, the CCR values are low, especially for rapid faults. This identification problem occurs due to the nature of the faults and the possible combination of the following reasons:
- (a)
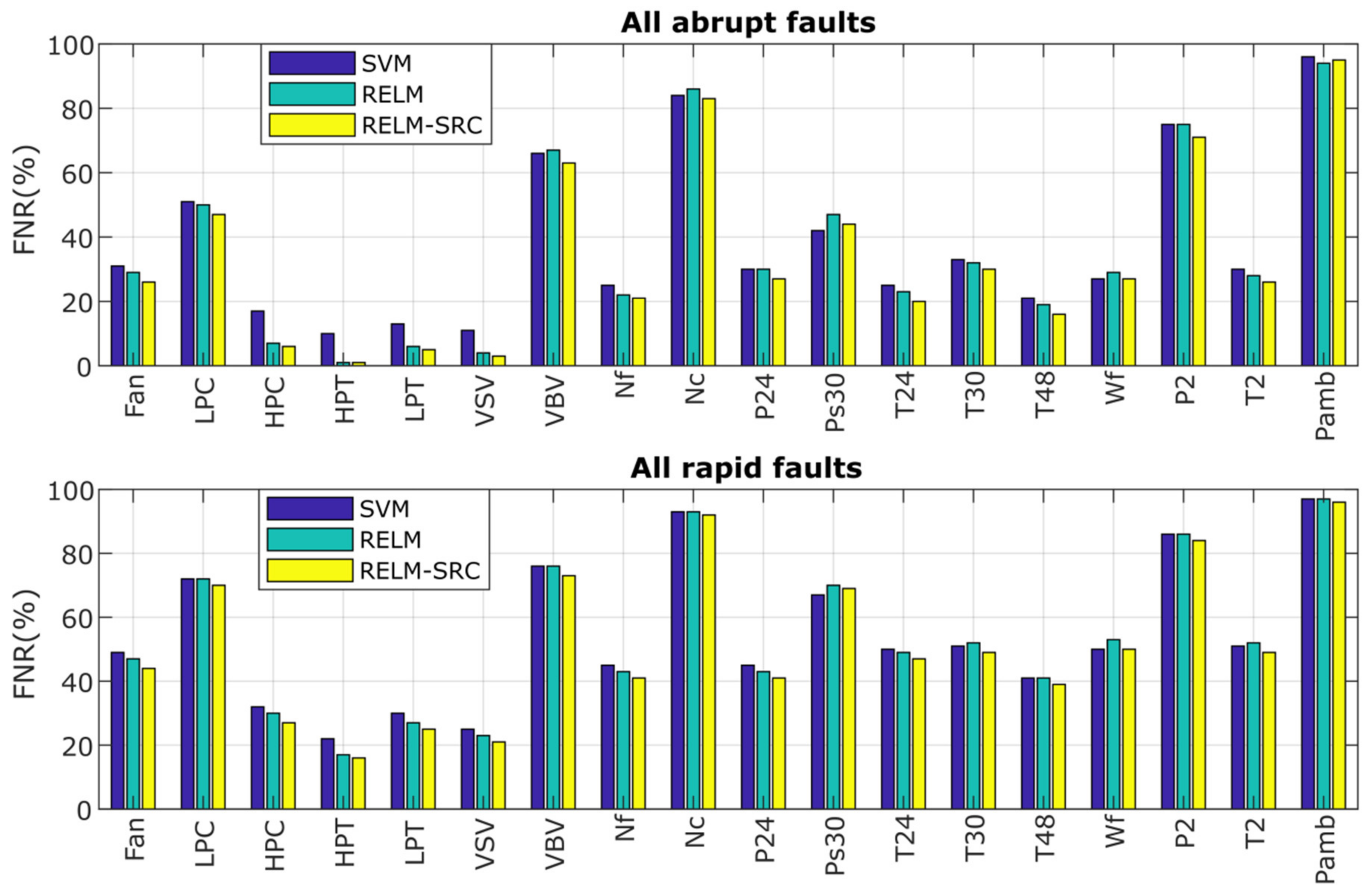
- The false-negative rate (FNR or omitted faults) and the false-positive rate (FPR or false alarms) are interconnected, i.e., when FNR reduces, FPR increases. This is precisely the case when the ProDiMES condition of false alarms (one false alarm per 1000 flights or FPR < 0.1%) is applied to the algorithm, increasing the probabilities of omitted faults. In other words, the column of FNR values in the confusion matrix contains a big number of incorrect diagnosis decisions due to the great influence of the no-fault class, demonstrating that the algorithm misclassifies the actual faults as healthy cases. Figure 9 displays the FNR for each rapid and abrupt fault class obtained by the three techniques. It is visible that Nc, P2, and especially Pamb have the highest FNR values (greater than 80%) since they are highly confused as the healthy class;
- (b)
- The low magnitudes assigned to these faults in ProDiMES affect the recognition task since the faults are contained in same the region of the healthy class, causing their misclassification as healthy cases; and
- (c)
- The problematic faults present low signal-to-noise ratios, and according to [13], the sensor noise levels averaged for an engine fleet and implemented in ProDiMES are much higher compared to other references that use the same type of turbofan engine, producing a significant challenge to correctly perform the diagnosis. Simon et al. [21] reported the use of additional logic to help improve the diagnosis in these fault scenarios, while in the case of [13], the improvement was associated with a fault detector based on calculated Mach value monitoring. The implementation of both types of approaches to increase the probabilities of these particular faults at expense of other classes is not the objective of the benchmarking analysis but to have a global performance (meeting the requirement of FPR < 0.1%). Thus, in general terms, it is neither an advantage for the algorithms in [13,21] nor a deficiency in our proposed methodology;
- (d)
- With other faults presenting FNR values of 50%, the total number of fault scenarios, the amount of testing samples, and the total level of fault classification accuracy is impacted negatively.
5. Discussion
5.1. About the Stages of Comparison
5.2. About the Factors in the Algorithm That Contributed to the High Performance
5.3. About Some Advantages and Disadvantages of the Compared Fault Identification Techniques
5.4. About Future Areas of Research
- -
- A more robust algorithm that reduces deviation errors through the adaptation of baseline models according to the current level of engine deterioration.
- -
- A more complete and integrated approach that considers all the stages of feature extraction, anomaly detection, fault identification, lifetime prediction, and fault-severity estimation.
- -
- The use of operating conditions along with monitored variables as inputs to the fault recognition technique to provide more information about the engine operation.
- -
- The need for a method addressing imbalanced fault classification.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Adaptive sub-dictionary for SRC | |
| b | Bias in RELM |
| CCR | Correct Classification Rate |
| C-MAPSS | Commercial Modular Aero-Propulsion System Simulation |
| DT | Decision Tree |
| EFS | Engine Fleet Simulator |
| EMA | Exponential Moving Average |
| FNR | False-negative rate |
| FPR | False-positive rate |
| GE | Generalized Estimator |
| GUI | Graphic user interface |
| GPA | Gas-Path Analysis |
| Hidden layer output matrix in RELM | |
| HSVMkSIR | Hierarchical SVM with kernel sliced inverse regression |
| Average correction coefficient | |
| KNN | K-Nearest Neighbors |
| L | Number of hidden neurons |
| Number of monitored variables | |
| MCR | Misclassification rate |
| MLP | Multi-Layer Perceptron |
| N | Total samples for network training |
| NB | Naïve Bayes |
| NSVMkSIR | Non-linear version of HSVMkSIR |
| Output vector in RELM | |
| Difference between the two largest values in the output | |
| PATKF | Performance Analysis Tool with Kalman Filter |
| PNN | Probabilistic Neural Network |
| Weighted mean probability for global diagnostic accuracy | |
| ProDiMES | Propulsion Diagnostic Method Evaluation Strategy |
| RELM | Regularized Extreme Learning Machines |
| Residual or reconstruction error in SRC | |
| SRC | Sparse Representation Classification |
| SVM | Support Vector Machines |
| Target matrix in RELM | |
| TCR | True Classification Rate |
| TNR | True-negative rate |
| TPR | True-positive rate |
| ULST2-FLS | Upper and lower singleton type-2 fuzzy logic system |
| Vector of operating conditions | |
| Hidden layer weight matrix in RELM | |
| WLS | Weighted Least Squares |
| WMFLS | Wang–Mendel Fuzzy Logic System |
| Non-zero scalar coefficients in SRC | |
| Vector of gas-path monitored variables | |
| Vector of individual baseline values | |
| Vector of normalized deviations (feature vector) | |
| , , | Learning, validation, and testing sets |
| Output weight matrix in RELM | |
| Vector of monitored variable deviations | |
| A trade-off between sparsity and signal reconstruction in SRC | |
| Threshold for reclassification | |
| Regularization parameter in RELM | |
| Subscripts and superscripts | |
| 0 | Baseline |
| * | Measured value |
| Monitored variable index | |
Appendix A

References
- Tahan, M.; Tsoutsanis, E.; Muhammad, M.; Abdul Karim, Z.A. Performance-based health monitoring, diagnostics and prognostics for condition-based maintenance of gas turbines: A review. Appl. Energy 2017, 198, 122–144. [Google Scholar] [CrossRef] [Green Version]
- Oster, C.V.; Strong, J.S.; Zorn, K. Why airplanes crash: Causes of accidents worldwide. In Proceedings of the 51st Annual Transportation Research Forum, Arlington, VA, USA, 11–13 March 2010. [Google Scholar]
- Kahn, M.; Nickelsburg, J. An Economic Analysis of U.S Airline Fuel Economy Dynamics from 1991 to 2015; National Bureau of Economic Research: Cambridge, MA, USA, 2016; pp. 1–34. [Google Scholar]
- Zhao, N.; Wen, X.; Li, S. A review on gas turbine anomaly detection for implementing health management. In Proceedings of the ASME Turbo Expo 2016, Seoul, Korea, 13–17 June 2016; p. V001T22A009. [Google Scholar]
- Zaccaria, V.; Rahman, M.; Aslanidou, I.; Kyprianidis, K. A Review of Information Fusion Methods for Gas Turbine Diagnostics. Sustainability 2019, 11, 6202. [Google Scholar] [CrossRef] [Green Version]
- Volponi, A.J. Gas Turbine Engine Health Management: Past, Present, and Future Trends. J. Eng. Gas Turbines Power 2014, 136, 5. [Google Scholar] [CrossRef]
- Fentaye, A.D.; Baheta, A.T.; Gilani, S.I.; Kyprianidis, K.G. A review on gas turbine gas-path diagnostics: State-of-the-art methods, challenges and opportunities. Aerospace 2019, 6, 83. [Google Scholar] [CrossRef] [Green Version]
- Jaw, L.C.; Lee, Y.-J. Engine diagnostics in the eyes of machine learning. In Proceedings of the ASME Turbo Expo 2014: Turbine Technical Conference and Exposition, Düsseldorf, Germany, 16–20 June 2014; p. 8. [Google Scholar]
- Li, Y.-G. Diagnostics of power setting sensor fault of gas turbine engines using genetic algorithm. Aeronaut. J. 2017, 121, 1109–1130. [Google Scholar] [CrossRef] [Green Version]
- Fentaye, A.D.; Gilani, S.I.; Aklilu, B.T.; Mojahid, A. Two-shaft stationary gas turbine engine gas path diagnostics using fuzzy logic. J. Mech. Sci. Technol. 2017, 31, 5593–5602. [Google Scholar]
- Hanachi, H.; Liu, J.; Mechefske, C. Multi-Mode Diagnosis of a Gas Turbine Engine Using an Adaptive Neuro-Fuzzy System. Chin. J. Aeronaut. 2018, 31, 1–9. [Google Scholar] [CrossRef]
- Pérez-Ruiz, J.L.; Loboda, I.; Miró-Zárate, L.A.; Toledo-Velázquez, M.; Polupan, G. Evaluation of gas turbine diagnostic techniques under variable fault conditions. Adv. Mech. Eng. 2017, 9, 16. [Google Scholar] [CrossRef]
- Koskoletos, A.O.; Aretakis, N.; Alexiou, A.; Romesis, C.; Mathioudakis, K. Evaluation of Aircraft Engine Gas Path Diagnostic Methods Through ProDiMES. J. Eng. Gas Turbines Power 2018, 140, 12. [Google Scholar] [CrossRef]
- Lu, F.; Jiang, J.; Huang, J.; Qiu, X. Dual reduced kernel extreme learning machine for aero-engine fault diagnosis. Aerosp. Sci. Technol. 2017, 71, 742–750. [Google Scholar] [CrossRef]
- Zhao, Y.P.; Huang, G.; Hu, Q.K.; Tan, J.F.; Wang, J.J.; Yang, Z. Soft extreme learning machine for fault detection of aircraft engine. Aerosp. Sci. Technol. 2019, 91, 70–81. [Google Scholar] [CrossRef]
- Amare, D.F.; Aklilu, T.B.; Gilani, S.I. Gas path fault diagnostics using a hybrid intelligent method for industrial gas turbine engines. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 578. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Liu, J.; Li, M.; Geng, J.; Wu, Y.; Song, Z. An improved hybrid modeling method based on extreme learning machine for gas turbine engine. Aerosp. Sci. Technol. 2020, 107, 106333. [Google Scholar] [CrossRef]
- Togni, S.; Nikolaidis, T.; Sampath, S. A combined technique of Kalman filter, artificial neural network and fuzzy logic for gas turbines and signal fault isolation. Chin. J. Aeronaut. 2020, 34, 124–135. [Google Scholar] [CrossRef]
- Simon, D.L.; Bird, J.; Davison, C.; Volponi, A.; Iverson, R.E. Benchmarking gas path diagnostic methods: A public approach. In Proceedings of the ASME Turbo Expo 2008, Berlin, Germany, 9–13 June 2008; pp. 325–336. [Google Scholar]
- Simon, D.L. Propulsion Diagnostic Method Evaluation Strategy (ProDiMES) User’s Guide; National Aeronautics and Space Administration: Cleveland, OH, USA, 2010.
- Simon, D.L.; Borguet, S.; Léonard, O.; Zhang, X. Aircraft engine gas path diagnostic methods: Public benchmarking results. J. Eng. Gas Turbines Power 2014, 136, 4. [Google Scholar] [CrossRef] [Green Version]
- Borguet, S.; Leonard, O.; Dewallef, P. Regression-Based Modeling of a Fleet of Gas Turbine Engines for Performance Trending. J. Eng. Gas Turbines Power 2016, 138, 2. [Google Scholar] [CrossRef]
- Loboda, I.; Pérez-Ruiz, J.L.; Yepifanov, S. A Benchmarking analysis of a data-driven gas turbine diagnostic approach. In Proceedings of the ASME Turbo Expo 2018, Oslo, Norway, 11–15 June 2018; p. V006T05A027. [Google Scholar]
- Calderano, P.H.S.; Ribeiro, M.G.C.; Amaral, R.P.F.; Vellasco, M.M.B.R.; Tanscheit, R.; de Aguiar, E.P. An enhanced aircraft engine gas path diagnostic method based on upper and lower singleton type-2 fuzzy logic system. J. Braz. Soc. Mech. Sci. Eng. 2019, 41, 70. [Google Scholar] [CrossRef]
- Teixeira, T.; Tanscheit, R.; Vellasco, M. Sistema de inferência fuzzy para diagnóstico de desempenho de turbinas a gás aeronáuticas. In Proceedings of the Fourth Brazilian Conference on Fuzzy Systems, Campinas, Brazil, 16–18 November 2016; pp. 242–253. [Google Scholar]
- Frederick, D.K.; DeCastro, J.A.; Litt, J.S. User’s Guide for the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS); National Aeronautics and Space Administration: Cleveland, OH, USA, 2007.
- Loboda, I. Gas turbine diagnostics. In Efficiency, Performance and Robustness of Gas Turbines; InTech: Rijeka, Croatia, 2012; pp. 191–212. [Google Scholar]
- Salvador, F.-A.; Felipe de Jesús, C.-A.; Igor, L.; Juan Luis, P.-R. Gas Turbine Diagnostic Algorithm Testing Using the Software ProDiMES. Ing. Investig. Tecnol. 2017, 18, 75–86. [Google Scholar]
- Van Heeswijk, M.; Miche, Y. Binary/ternary extreme learning machines. Neurocomputing 2015, 149, 187–197. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; van Gool, L. Adaptive and Weighted Collaborative Representations for image classification. Pattern Recognit. Lett. 2014, 43, 127–135. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Zhang, K.; Luo, M.; Yin, C.; Lai, X. Extreme learning machine and adaptive sparse representation for image classification. Neural Netw. 2016, 81, 91–102. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Fault Type | Fault Description | Fault Magnitude |
|---|---|---|---|
| 0 | None | No-fault | None |
| 1 | Component | Fan | 1 to 7% |
| 2 | LPC | 1 to 7% | |
| 3 | HPC | 1 to 7% | |
| 4 | HPT | 1 to 7% | |
| 5 | LPT | 1 to 7% | |
| 6 | Actuator | VSV | 1 to 7% |
| 7 | VBV | 1 to 19% | |
| 8 | Sensor | Nf | ±1 to 10 σ |
| 9 | Nc | ±1 to 10 σ | |
| 10 | P24 | ±1 to 10 σ | |
| 11 | Ps30 | ±1 to 10 σ | |
| 12 | T24 | ±1 to 10 σ | |
| 13 | T30 | ±1 to 10 σ | |
| 14 | T48 | ±1 to 10 σ | |
| 15 | Wf | ±1 to 10 σ | |
| 16 | P2 | ±1 to 10 σ | |
| 17 | T2 | ±1 to 10 σ | |
| 18 | Pamb | ±1 to 19 σ |
| ID | Symbol | Description | Units |
|---|---|---|---|
| 1 | Nf | Physical fan speed | rpm |
| 2 | P2 | Total pressure at fan inlet | psia |
| 3 | T2 | Total temperature at fan inlet | °R |
| 4 | Pamb | Ambient pressure | psia |
| ID | Symbol | Description | Units |
|---|---|---|---|
| 1 | Nc | Physical core speed | rpm |
| 2 | P24 | Total pressure at LPC outlet | psia |
| 3 | Ps30 | Static pressure at HPC outlet | psia |
| 4 | T24 | Total temperature at LPC outlet | °R |
| 5 | T30 | Total temperature at HPC outlet | °R |
| 6 | T48 | Total temperature at HPT outlet | °R |
| 7 | Wf | Fuel flow | pps |
| Comparison Conditions | Comparison Options | Comparison Stages | |||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| Operating points | Cruise | X | X | ||
| Multipoint | X | X | |||
| Diagnostic metrics | X | ||||
| ProDiMES metrics | X | X | X | X | |
| Testing Data | Generated by authors | X | |||
| ProDiMES dataset | X | X | X | ||
| Blind test dataset | X | ||||
| Description | Training Conf.1 | Training Conf.2 | Training Conf.3 (EMA) | Testing Set |
|---|---|---|---|---|
| Fault scenarios | 19 | 19 | 19 | 19 |
| Engines per fault scenario | 40 | 100 | 100 | 10 |
| Simulated flights per engine | 50 | 50 | 50 | 50 |
| Fault initiation and evolution rate | Random | Random | Random | Random |
| Minimum initiation flight | 11 | 11 | 11 | 11 |
| Rapid fault evol. rate (min, max) | 9 | 9 | 9 | 9 |
| Sensor measurement noise | On | On | On | On |
| Total number of engines | 760 | 1900 | 1900 | 190 |
| Total samples for diagnosis | 30400 | 76000 | 76000 | 7600 |
| Method | Training Configuration | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| MLP | 65.07% | 66.60% | 70.75% |
| PNN | 64.66% | - | - |
| SVM | 66.63% | 67.01% | 72.39% |
| RELM | 65.61% | 66.15% | 73.29% |
| RELM-SRC | 65.60% | 65.88% | 73.70% |
| Method | TPR | TNR | Latency | Kappa |
|---|---|---|---|---|
| SVM | 60.10% | 94.51% | 3.9 | 0.58 |
| RELM | 58.20% | 96.07% | 3.8 | 0.60 |
| RELM-SRC | 62.10% | 94.16% | 3.7 | 0.60 |
| Algorithm | TPR | TNR | Latency | CCR | Faults |
|---|---|---|---|---|---|
| NB | 31.58% | 80.33% | - | - | 10 |
| DT | 37.20% | 92.40% | - | 38.76% | |
| KNN | 45.30% | 96.10% | - | 44.95% | |
| LSVM | 23.87% | 85.55% | - | - | |
| NSVM | 70.50% | 72.80% | - | 53.50% | |
| HSVMkSIR | 77.06% | 75.70% | 0.70 | 62.93% | |
| NSVMkSIR | 58.30% | 96.00% | 1.35 | 57.83% | |
| SVM | 68.50% | 94.51% | 1.80 | 63.81% | 19 |
| RELM | 66.50% | 96.07% | 1.70 | 62.95% | |
| RELM-SRC | 71.00% | 94.16% | 1.60 | 65.69% |
| Algorithm | Type of Fault | TPR | TNR | Detection Latency |
|---|---|---|---|---|
| Anomaly detection algorithm | Abrupt | 45.50% | 99.90% | 1.7 |
| Rapid | 27.10% | 99.90% | 6.7 | |
| SVM | Abrupt | 68.50% | 94.51% | 1.8 |
| Rapid | 51.70% | 94.51% | 6.0 | |
| RELM | Abrupt | 66.50% | 96.07% | 1.7 |
| Rapid | 49.90% | 96.07% | 5.9 | |
| RELM-SRC | Abrupt | 71.00% | 94.16% | 1.6 |
| Rapid | 53.20% | 94.16% | 5.8 |
| Algorithm | Faults | TPR | TNR | Latency | Kappa |
|---|---|---|---|---|---|
| ProDiMES solution | Abrupt | 50.5% | 99.896% | 2.6 | 0.29 |
| Rapid | 37.4% | 99.896% | 7.0 | 0.21 | |
| ProDiMES user’s guide | Abrupt | 61.0% | 99.997% | 2.5 | 0.73 |
| Rapid | 41.9% | 99.997% | 6.8 | 0.56 | |
| MLP | Abrupt | 62.8% | 99.931% | 1.8 | 0.69 |
| Rapid | 46.6% | 99.931% | 6.0 | 0.50 | |
| SVM | Abrupt | 61.0% | 99.965% | 1.4 | 0.71 |
| Rapid | 46.2% | 99.965% | 5.6 | 0.57 | |
| RELM | Abrupt | 66.6% | 99.965% | 1.3 | 0.75 |
| Rapid | 46.9% | 99.965% | 5.8 | 0.57 | |
| RELM-SRC | Abrupt | 67.4% | 99.965% | 1.2 | 0.76 |
| Rapid | 48.3% | 99.965% | 5.7 | 0.59 |
| Algorithm | TPR | TNR | CCR | MCR | Latency | Kappa |
|---|---|---|---|---|---|---|
| WLS | 44.7% 9th | 99.908% 3rd | 43.4% 9th | 1.35% 4th | 4.86 8th | 0.588 10th |
| PNN * | 44.7% 9th | 99.908% 3rd | 43.7% 8th | 1.04% 3rd | 4.86 8th | 0.590 9th |
| PATKF | 50.9% 6th | 99.908% 3rd | 46.7% 4th | 4.15% 9th | 4.02 3rd | 0.627 5th |
| GE | 51.9% 5th | 99.906% 4th | 45.2% 6th | 6.78% 10th | 4.24 4th | 0.617 6th |
| PNN ** | 48.5% 7th | 99.908% 3rd | 45.2% 6th | 3.29% 7th | 4.70 7th | 0.595 8th |
| KNN | 48.5% 7th | 99.908% 3rd | 46.1% 5th | 2.37% 5th | 4.70 7th | 0.605 7th |
| PNN-Adapt | 48.5% 7th | 99.908% 3rd | 45.0% 7th | 3.51% 8th | 4.70 7th | 0.595 8th |
| ULST2-FLS | 52.2% 4th | 99.904% 5th | 49.4% 4th | 2.72% 6th | 4.45 6th | 0.647 4th |
| WMFLS | 45.7% 8th | 99.902% 6th | - | - | 4.30 5th | 0.517 11th |
| SVM | 52.5% 3rd | 99.904% 5th | 52.2% 3rd | 0.3% 2nd | 3.30 1st | 0.660 3rd |
| RELM | 53.6% 2nd | 99.958% 1st | 53.6% 2nd | 0 1st | 3.45 2nd | 0.670 2nd |
| RELM-SRC | 55.7% 1st | 99.916% 2nd | 55.4% 1st | 0.3% 2nd | 3.30 1st | 0.685 1st |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Ruiz, J.L.; Tang, Y.; Loboda, I. Aircraft Engine Gas-Path Monitoring and Diagnostics Framework Based on a Hybrid Fault Recognition Approach. Aerospace 2021, 8, 232. https://doi.org/10.3390/aerospace8080232
Pérez-Ruiz JL, Tang Y, Loboda I. Aircraft Engine Gas-Path Monitoring and Diagnostics Framework Based on a Hybrid Fault Recognition Approach. Aerospace. 2021; 8(8):232. https://doi.org/10.3390/aerospace8080232
Chicago/Turabian StylePérez-Ruiz, Juan Luis, Yu Tang, and Igor Loboda. 2021. "Aircraft Engine Gas-Path Monitoring and Diagnostics Framework Based on a Hybrid Fault Recognition Approach" Aerospace 8, no. 8: 232. https://doi.org/10.3390/aerospace8080232
APA StylePérez-Ruiz, J. L., Tang, Y., & Loboda, I. (2021). Aircraft Engine Gas-Path Monitoring and Diagnostics Framework Based on a Hybrid Fault Recognition Approach. Aerospace, 8(8), 232. https://doi.org/10.3390/aerospace8080232