
Load-Identification Method for Flexible Multiple Corrugated Skin Using Spectra Features of FBGs


Abstract
1. Introduction
2. Background
2.1. Uniform Strain Sensing of the FBG
2.2. Nonuniform Strain Sensing of the FBG
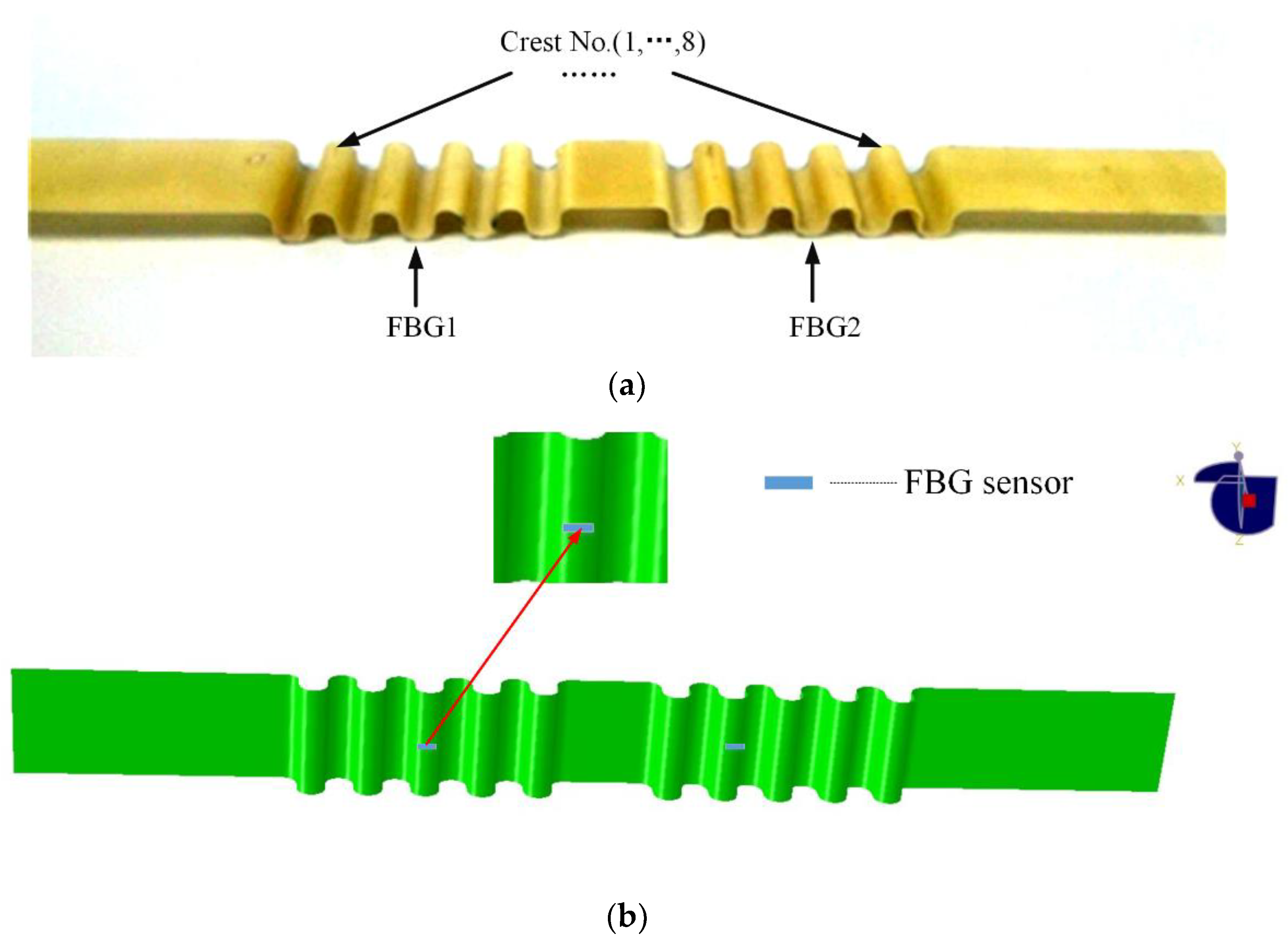
3. Experimental Setup
3.1. Specimen Analysis
3.2. Feature Extraction
- The central wavelength of the main peak shifted.
- Side-lobes were generated in the reflection spectrum.
- The bandwidth of the main peak broadened.
- The symmetry of the reflection spectrum changed.
- The magnitude of the main peak;
- The value of the main peak shift, , where is the absolute value of the main peak shift;
- The secondary peak magnitude;
- The wavelength difference between the secondary peak and the main peak. The form is the same as for parameter 2;
- The tertiary peak magnitude;
- The wavelength differences between the tertiary peak and the main peak. The form is the same as for parameter 2;
- The full width at half-maximum (FWHM), , where and are the left and right half-maximum widths, respectively;
- The index of local asymmetry (ILA), . This reflects the symmetry of the main peak of the reflection spectrum.
4. Algorithm Design
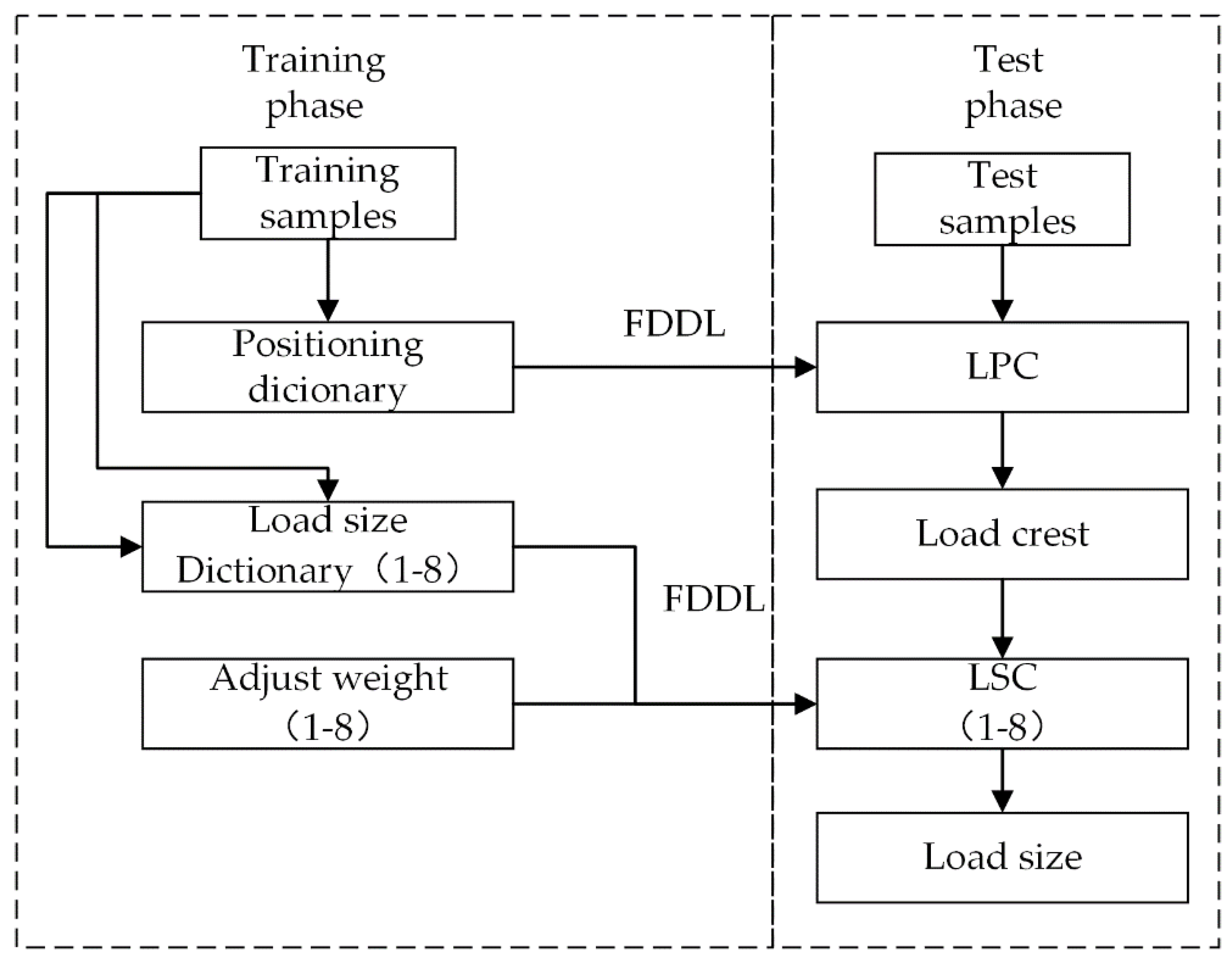
4.1. Algorithm Flow
4.2. Composition of Load-Size Dictionaries
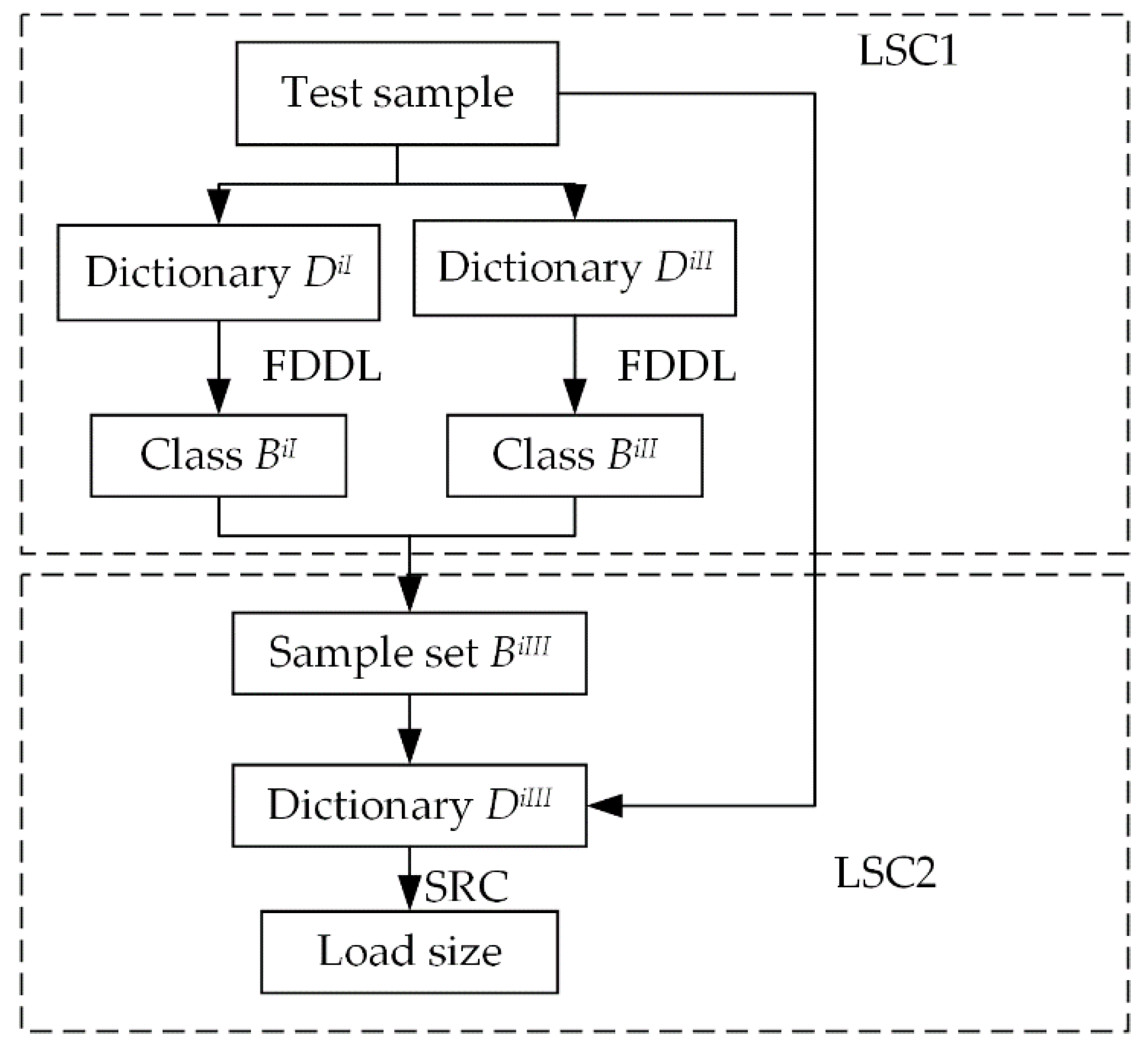
4.3. Two-Resolution LSCs
4.4. SRC Algorithm
4.5. Optimized FDDL Algorithm
4.5.1. FDDL Classifiers
4.5.2. GC Optimization
5. Experiments and Results
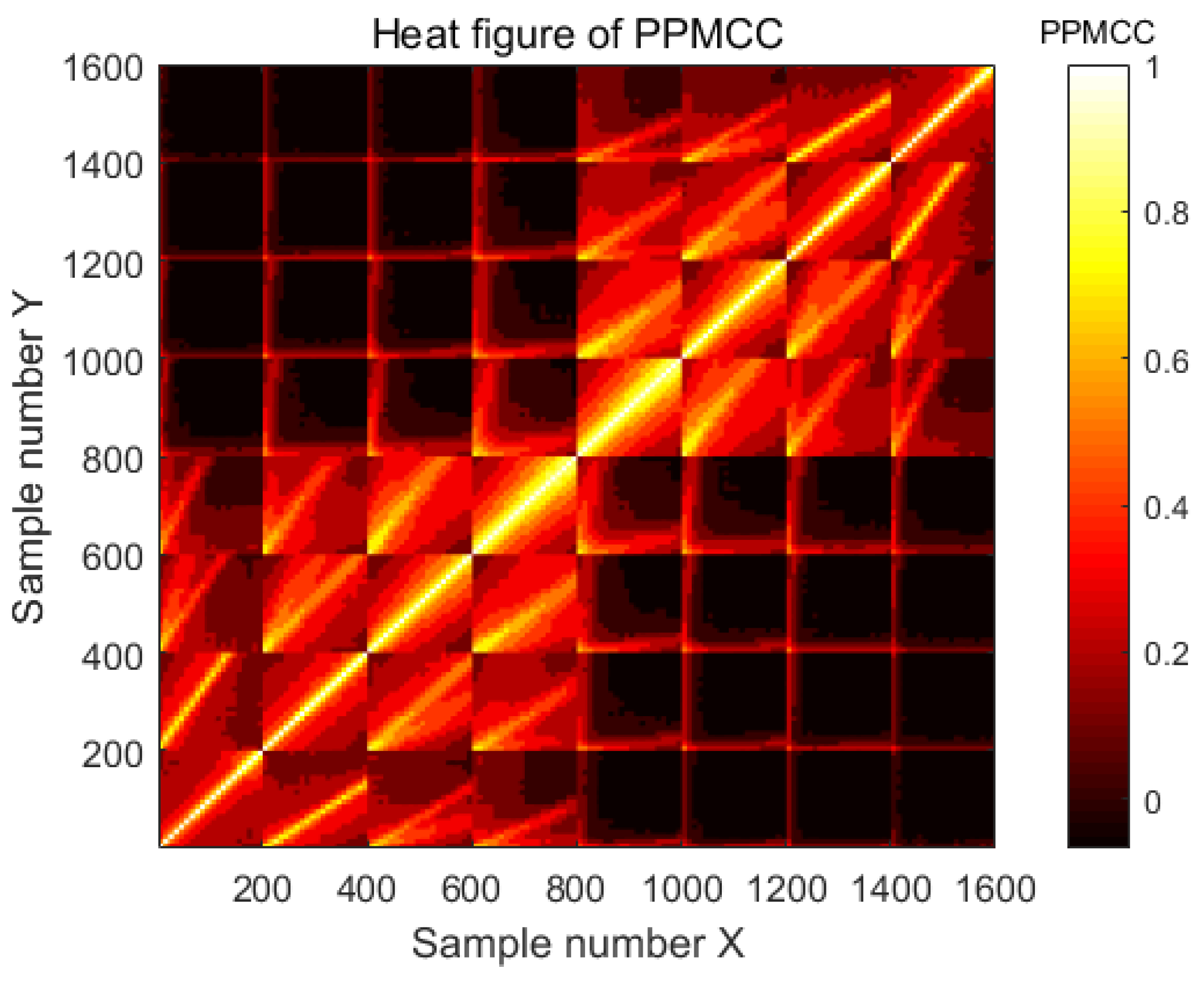
5.1. Parameter Selection
5.2. Control-Group (CG) Settings
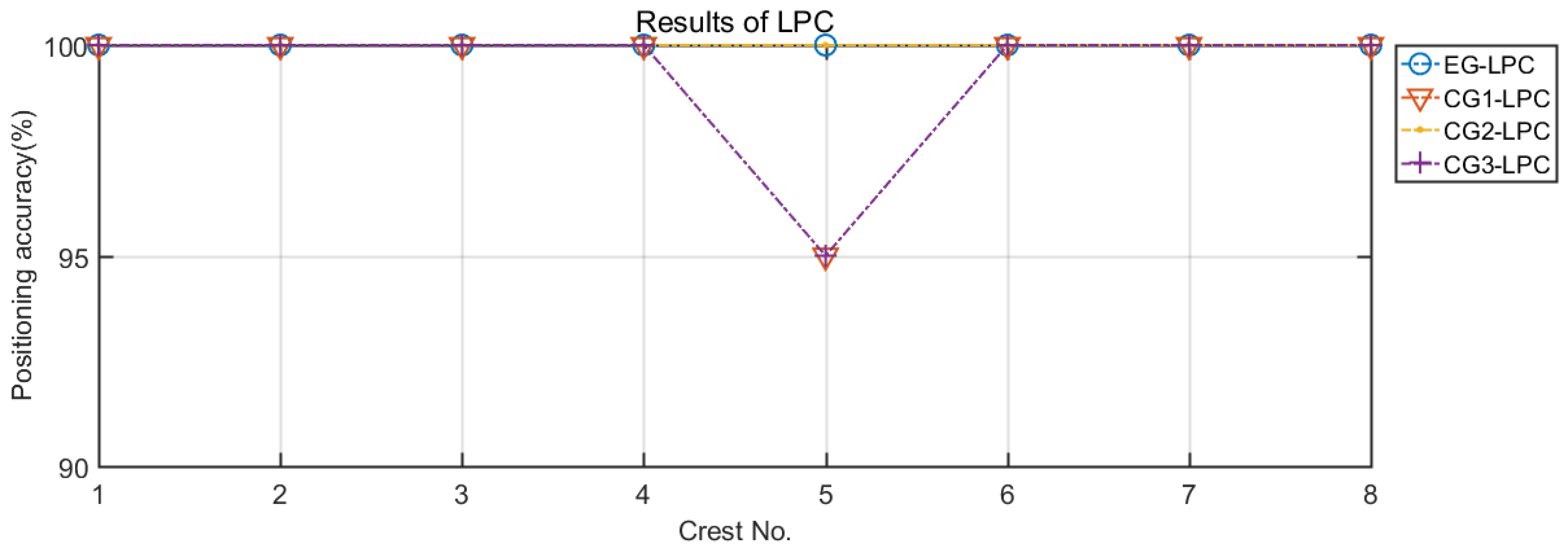
5.2.1. CG Settings of the LPCs
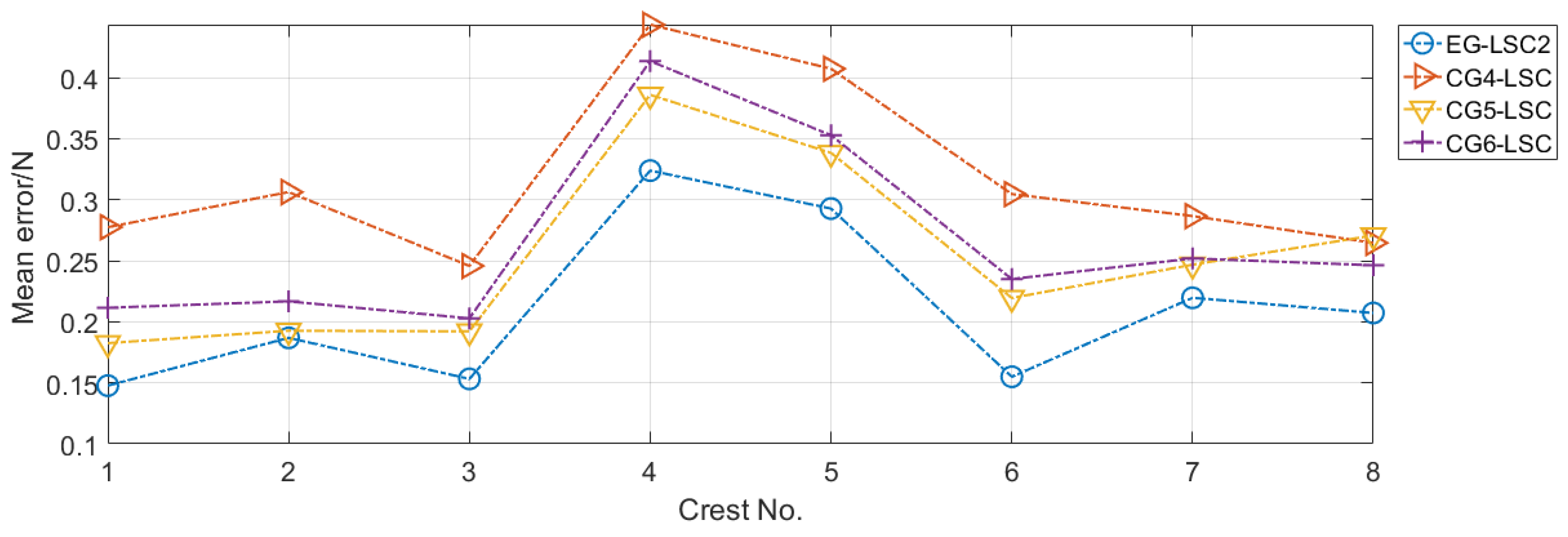
5.2.2. CG Settings of the LSCs
- CG1-LSC, with D-KSVD selected as the DL algorithm and the LSC1 classifier; LSC2 is not executed, and the other parts are the same as in EG-LSC1.
- CG2-LSC, with LC-KSVD selected as the DL algorithm and the LSC1 classifier; LSC2 is not executed, and the other parts are the same as in EG-LSC1.
- CG3-LSC, with the FDDL with adjustable weights selected as the DL algorithm. LSC2 is not executed, and the other parts are the same as in EG-LSC.
- CG4-LSC, with SVM selected as LSC1 and LSC2; the other parts are the same as in EG-LSC.
- CG5-LSC, with training samples grouped into continuous blocks in LSC1; other parts are the same as in EG-LSC. FDDL and SRC with adjustable weights are used in LSC1 and LSC2.
- CG6-LSC, with no adjustable weights used in LSC1 and LSC2; other parts are the same as in EG-LSC.
5.3. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Golzar, M.; Ghabezi, P. Corrugated composite skins. Mech. Compos. Mater. 2014, 50, 137–148. [Google Scholar] [CrossRef]
- Thill, C.; Downsborough, J.D.; Lai, S.J.; Bond, I.P.; Jones, D.P. Aerodynamic study of corrugated skins for morphing wing applications. Aeronaut. J. 2010, 114, 237–244. [Google Scholar] [CrossRef]
- Thill, C.; Ethche, J.A.; Bond, I.P.; Potter, K.D.; Weaver, P.M. Composite corrugated structures for morphing wing skin applications. Smart Mater. Struct. 2010, 19, 124009. [Google Scholar] [CrossRef]
- Mayes, J.S.; Andrew, C.H. Composite laminate failure analysis using multicontinuum theory. Compos. Sci. Technol. 2004, 64, 379–394. [Google Scholar] [CrossRef]
- Maimi, P.; Mayugo, J.A.; Camanho, P.P. A three-dimensional damage model for transversely isotropic composite laminates. J. Compos. Mater. 2008, 42, 2717–2745. [Google Scholar] [CrossRef]
- Qiao, P.; Lestari, W.; Shah, M.; Wang, J. Dynamics-based damage detection of composite laminated beams using contact and noncontact measurement systems. J. Compos. Mater. 2007, 41, 1217–1252. [Google Scholar] [CrossRef]
- Brown, S. Mechanically relevant consequences of the composite laminate-like design of the abdominal wall muscles and connective tissues. Med. Eng. Phys. 2012, 34, 521–523. [Google Scholar] [CrossRef]
- Xin, C.; Gu, Y.; Li, M.; Li, Y.; Zhang, Z. Online monitoring and analysis of resin pressure inside composite laminate during zero-bleeding autoclave process. Polym. Compos. 2011, 32, 314–323. [Google Scholar] [CrossRef]
- Navaratne, R.; Dayyani, I.; Woods, B.; Friswell, M. Development and testing of a corrugated skin for a camber morphing aerofoil. In Proceedings of the 23rd AIAA/AHS Adaptive Structures Conference, Kissimmee, FL, USA, 5–9 January 2015. [Google Scholar] [CrossRef]
- Grenestedt, J.; Jack, R. Wrinkling of corrugated skin sandwich panels. Compos. Part A Appl. Sci. Manuf. 2007, 38, 576–589. [Google Scholar] [CrossRef]
- Ghabezi, P.; Golzar, M. Mechanical analysis of trapezoidal corrugated composite skins. Appl. Compos. Mater. 2013, 20, 341–353. [Google Scholar] [CrossRef]
- Yokozeki, T.; Aya, S.; Yoshiyasu, H. Development of variable camber morphing airfoil using corrugated structure. J. Aircr. 2014, 51, 1023–1029. [Google Scholar] [CrossRef]
- Previtali, F.; Molinari, G.; Arrieta, A.; Guillaume, M.; Ermanni, P. Design and experimental characterisation of a morphing wing with enhanced corrugated skin. J. Intell. Mater. Syst. Struct. 2016, 27, 278–292. [Google Scholar] [CrossRef]
- Brachman, R.; Elshimi, T.; Mak, A.; Moore, I. Testing and analysis of a deep-corrugated large-span box culvert prior to burial. J. Bridge Eng. 2012, 17, 81–88. [Google Scholar] [CrossRef]
- Manko, Z.; Beben, D. Dynamic testing of a corrugated steel arch bridge. Can. J. Civ. Eng. 2008, 35, 246–257. [Google Scholar] [CrossRef]
- Beben, D. Field Performance of Corrugated Steel Plate Road Culvert under Normal Live-Load Conditions. J. Perform. Constr. Facil. 2013, 27, 807–817. [Google Scholar] [CrossRef]
- Kinet, D.; Mégret, P.; Goossen, K.; Qiu, L.; Heider, D.; Caucheteur, C. Fiber Bragg grating sensors toward structural health monitoring in composite materials: Challenges and solutions. Sensors 2014, 14, 7394. [Google Scholar] [CrossRef]
- Wei, P.; Liu, J.; Dai, Z.; Li, M. Monitoring the shape of satellite wing frame using FBG sensors in high electronic noise, vacuum, and-196 C environment. IEEE Trans. Ind. Electron. 2016, 64, 691–700. [Google Scholar] [CrossRef]
- Ramzyzan, R.; Kuntjoro, W.; Rahman, M. Using embedded fiber Bragg grating (FBG) sensors in smart aircraft structure materials. Procedia Eng. 2012, 41, 600–606. [Google Scholar] [CrossRef]
- Rajabzadeh, A.; Heusdens, R.; Hendriks, R.; Groves, R. Calculation of the mean strain of smooth non-uniform strain fields using conventional FBG sensors. J. Lightwave Technol. 2018, 36, 3716–3725. [Google Scholar] [CrossRef]
- Ling, H.; Lau, K.; Cheng, L.; Chow, K. Embedded fibre Bragg grating sensors for non-uniform strain sensing in composite structures. Meas. Sci. Technol. 2005, 16, 2415. [Google Scholar] [CrossRef]
- Song, C.; Shang, E.; Huang, X.; Zhang, J. Monitoring the cohesive damage of the adhesive layer in CFRP double-lapped bonding joint based on non-uniform strain profile reconstruction using dynamic particle swarm optimization algorithm. Measurement 2018, 123, 235–245. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, B.; Lu, J. Progressive damage monitoring of corrugated composite skins by the FBG spectral characteristics. Spectrosc. Spectr. Anal. 2014, 34, 757–761. [Google Scholar] [CrossRef]
- Julien, M.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2007, 17, 53–69. [Google Scholar] [CrossRef]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Chang, P.; Liu, J.; Yan, Z.; Wang, T.; Li, F. Kernel sparse representation-based classifier. IEEE Trans. Signal Process. 2011, 60, 1684–1695. [Google Scholar] [CrossRef]
- Ron, R.; Bruckstein, A.; Elad, M. Dictionaries for sparse representation modeling. Proc. IEEE 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Kreutz-Delgado, K.; Murray, J.; Rao, B.; Engan, K.; Lee, T.; Sejnowski, T. Dictionary learning algorithms for sparse representation. Neural Comput. 2003, 15, 349–396. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Xu, Y.; Yang, J.; Li, X.L.; Zhang, D. A survey of sparse representation: Algorithms and applications. IEEE Access 2015, 3, 490–530. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Fisher discrimination dictionary learning for sparse representation. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Sparse representation based fisher discrimination dictionary learning for image classification. Int. J. Comput. Vis. 2014, 109, 209–232. [Google Scholar] [CrossRef]
- Hill, K.; Meltz, G. Fiber Bragg grating technology fundamentals and overview. J. Lightwave Technol. 1997, 15, 1263–1276. [Google Scholar] [CrossRef]
- Yamada, M.; Kyohei, S. Analysis of almost-periodic distributed feedback slab waveguides via a fundamental matrix approach. Appl. Opt. 1987, 26, 3474–3478. [Google Scholar] [CrossRef] [PubMed]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the 2010 IEEE Computer society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 5 August 2010. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhe, L.; Davis, L. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2664. [Google Scholar] [CrossRef] [PubMed]
- Noble, W. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (mm) | (mm) | (mm) | (mm) | |
|---|---|---|---|---|
| 350 | 25 | 7.5 | 1.2 | 6 |
| (GPa) | (GPa) | (g/mm3) | (%) | (%) | |
|---|---|---|---|---|---|
| 37.08 | 5.56 | 1.78 × 10−6 | 48 | 52 | 0.26 |
| Crest No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Adjustable weight (Fisher discrimination dictionary learning, FDDL) | 0.40 | 0.20 | 0.45 | 0.70 | 0.85 | 0.30 | 0.15 | 0.35 |
| Adjustable weight (sparse representation classifier, SRC) | 1.00 | 0.75 | 0.80 | 0.85 | 0.90 | 0.80 | 0.85 | 0.75 |
| Group | EG-LSC | CG1-LSC | CG2-LSC | CG3-LSC | CG6-LSC |
|---|---|---|---|---|---|
| Mean error (N) | 0.1844 | 0.3625 | 0.3313 | 0.2844 | 0.2063 |
| Group | EG-LSC | CG4-LSC | CG5-LSC | CG6-LSC |
|---|---|---|---|---|
| Mean error (N) | 0.2106 | 0.3169 | 0.2531 | 0.2663 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Lu, J.; Liang, D. Load-Identification Method for Flexible Multiple Corrugated Skin Using Spectra Features of FBGs. Aerospace 2021, 8, 134. https://doi.org/10.3390/aerospace8050134
Zheng Z, Lu J, Liang D. Load-Identification Method for Flexible Multiple Corrugated Skin Using Spectra Features of FBGs. Aerospace. 2021; 8(5):134. https://doi.org/10.3390/aerospace8050134
Chicago/Turabian StyleZheng, Zhaoyu, Jiyun Lu, and Dakai Liang. 2021. "Load-Identification Method for Flexible Multiple Corrugated Skin Using Spectra Features of FBGs" Aerospace 8, no. 5: 134. https://doi.org/10.3390/aerospace8050134
APA StyleZheng, Z., Lu, J., & Liang, D. (2021). Load-Identification Method for Flexible Multiple Corrugated Skin Using Spectra Features of FBGs. Aerospace, 8(5), 134. https://doi.org/10.3390/aerospace8050134