Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives




Abstract
1. Introduction
2. Background and Research Objective
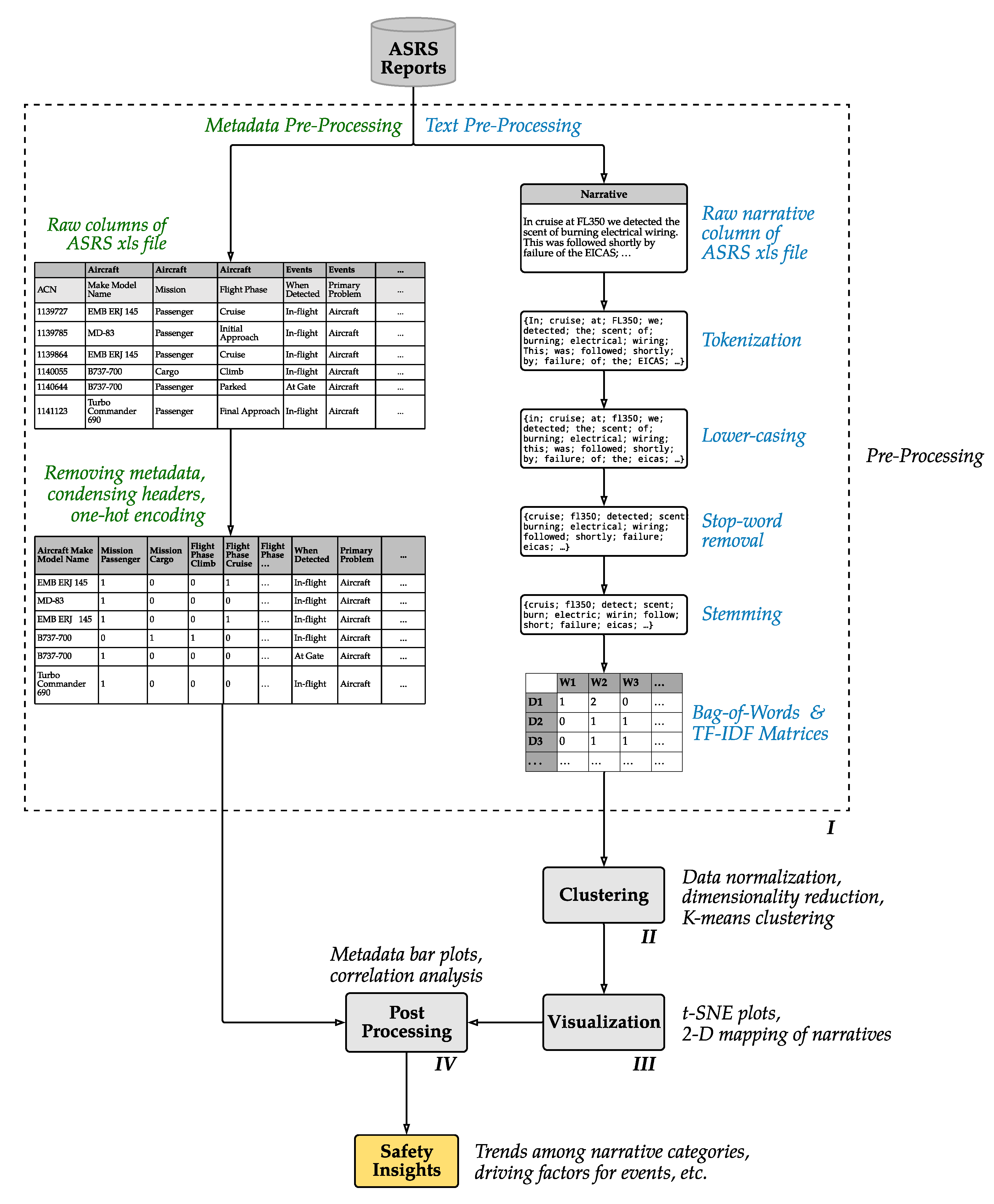
3. Method
3.1. Asrs Data Framework
3.2. Pre-Processing
3.3. Clustering
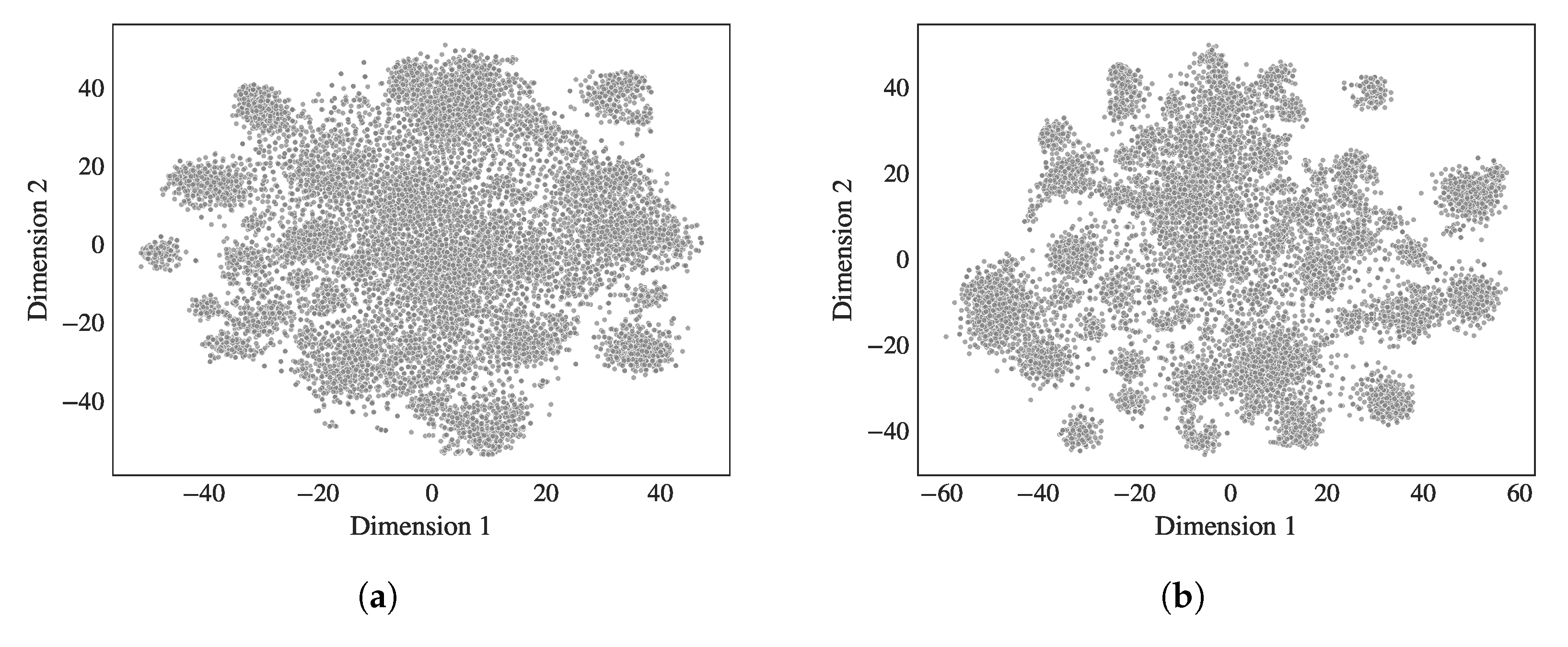
3.4. T-Sne and Visualization
3.5. Post-Processing
4. Results
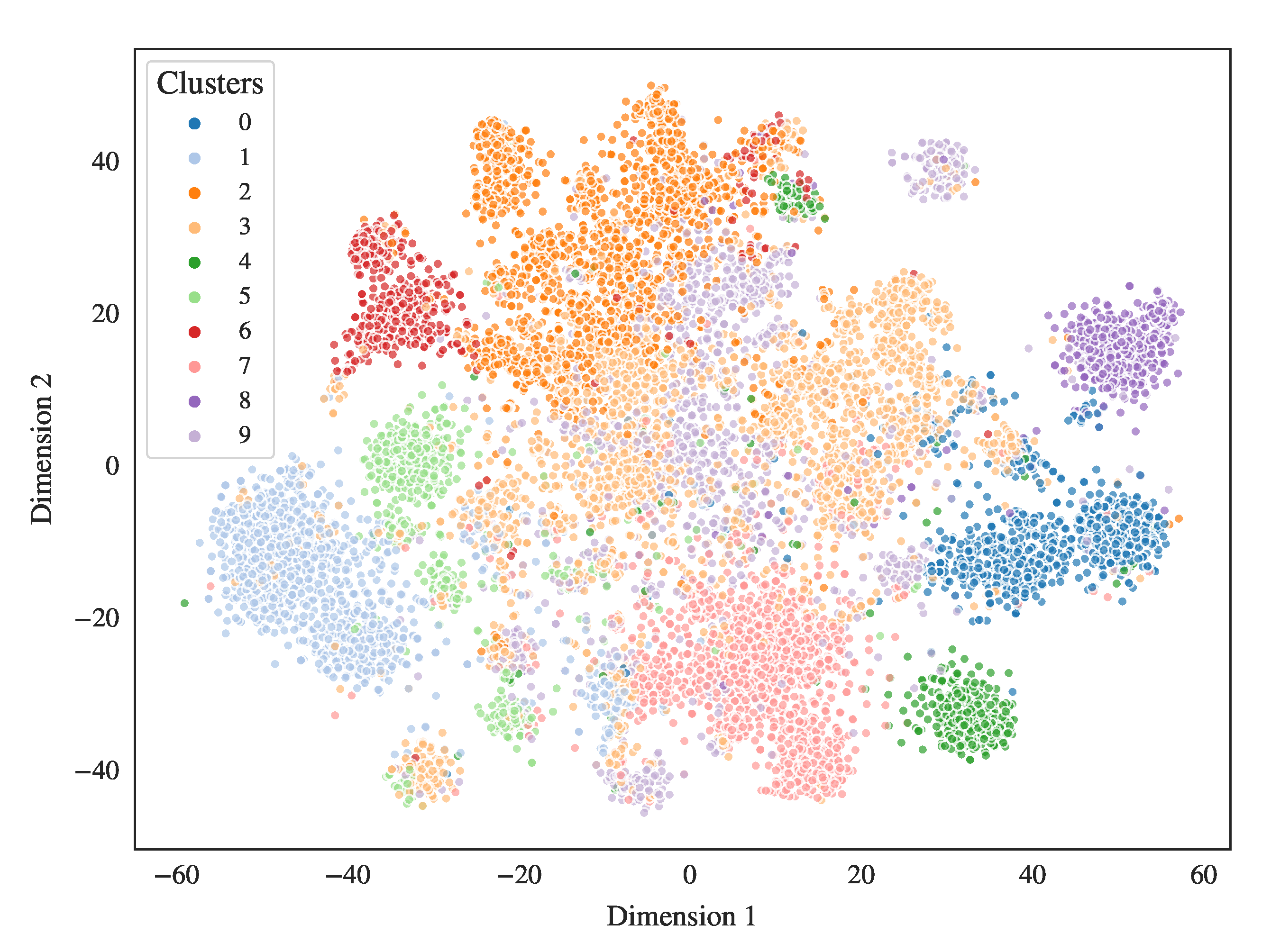
4.1. Overall Clustering Behavior
4.2. Individual Cluster Post-Processing
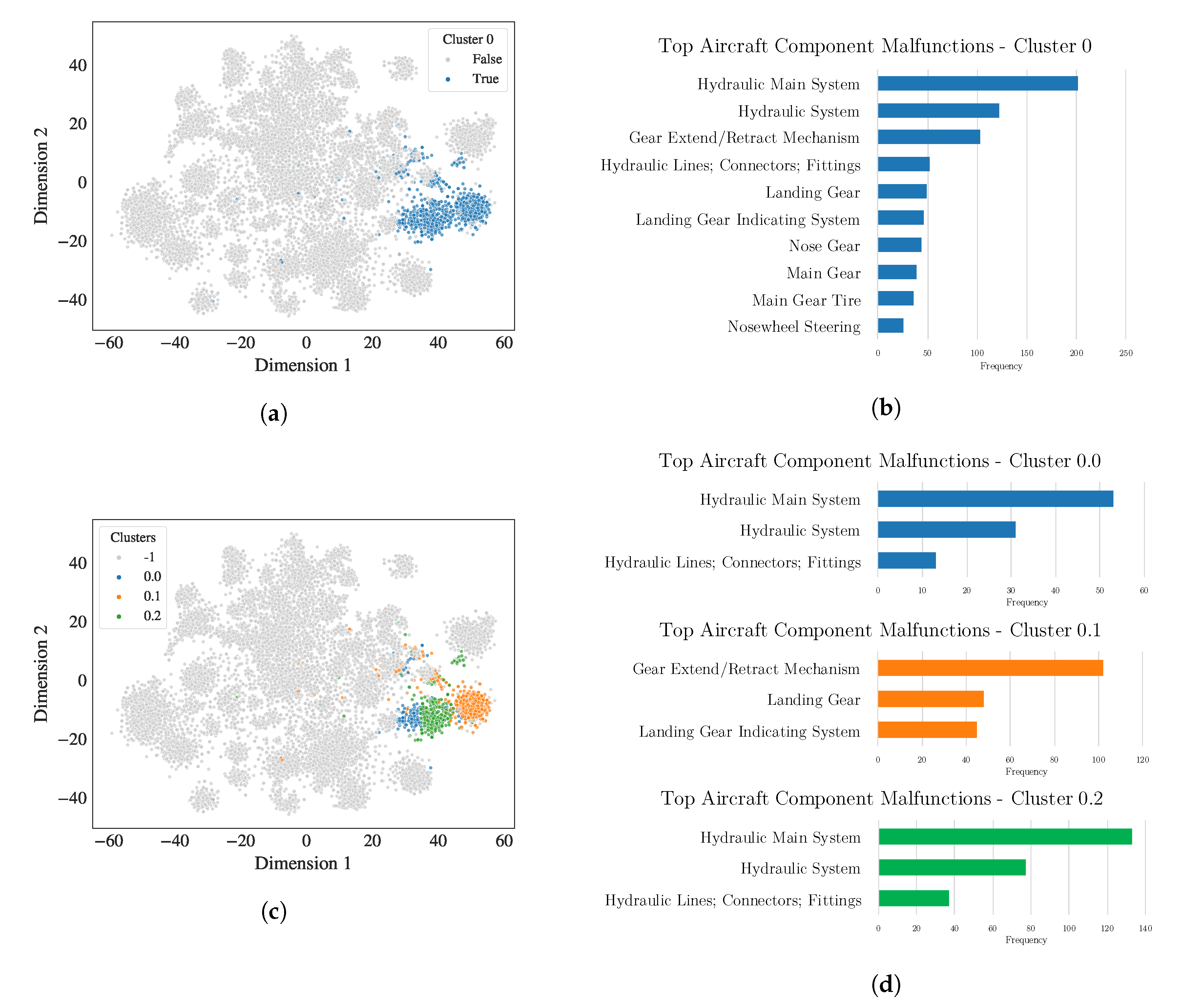
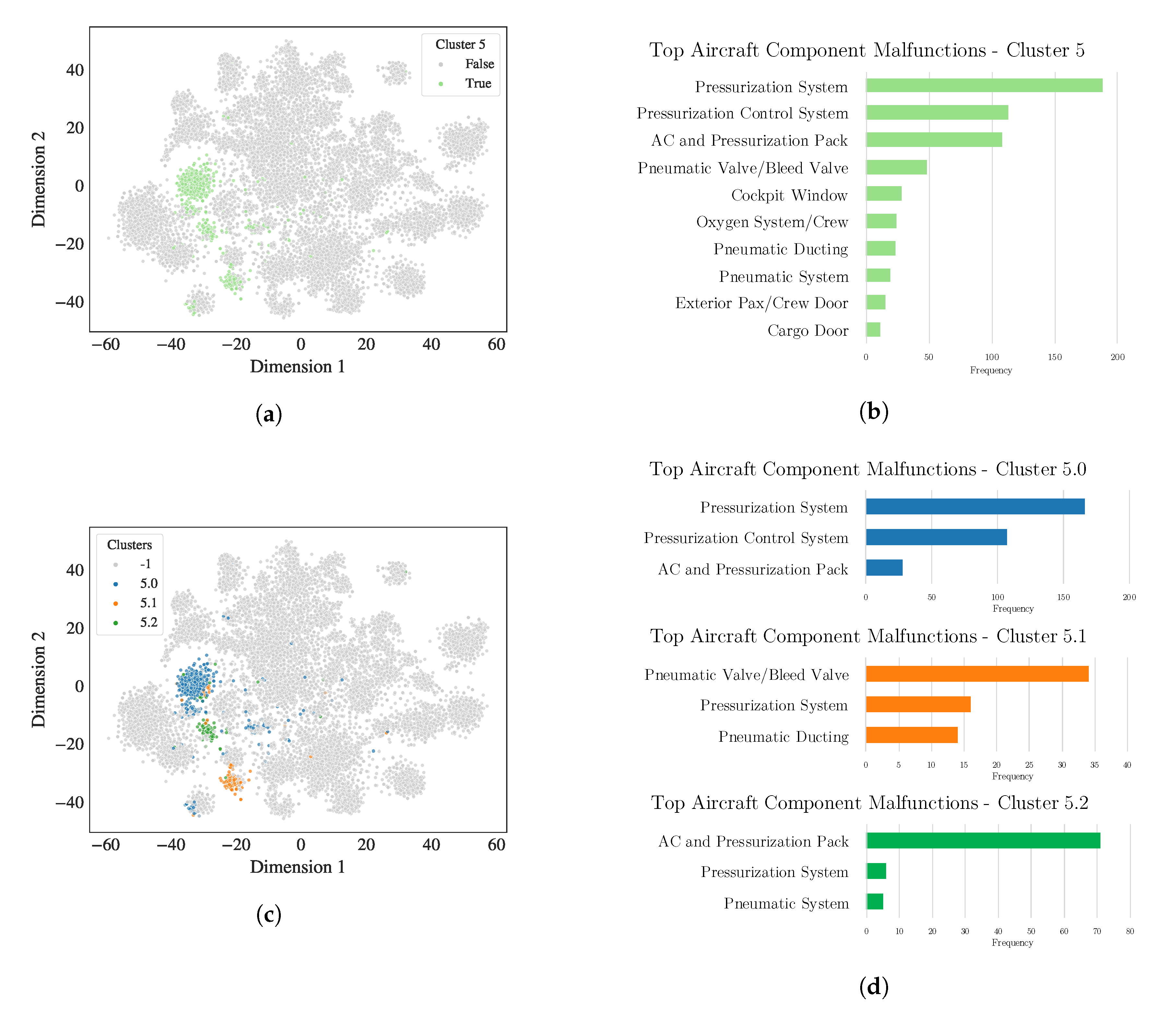
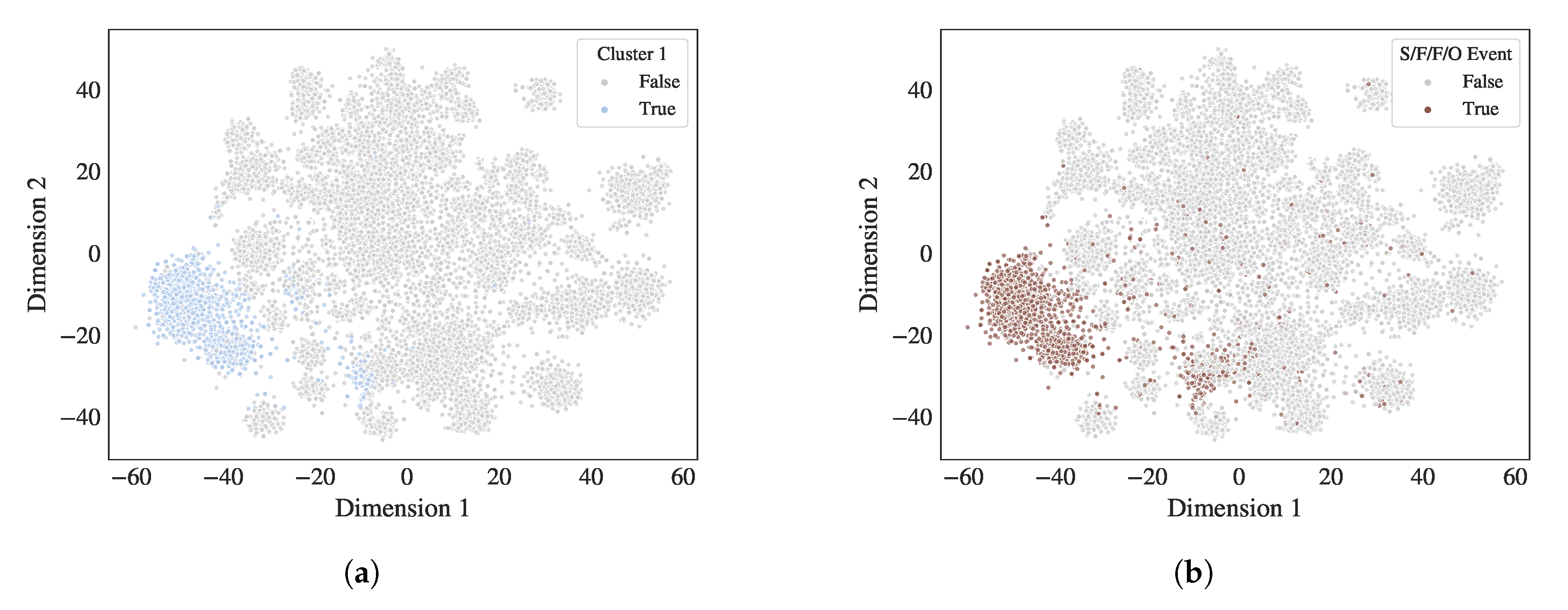
4.2.1. Precise Clusters and Sub-Clusters with High Metadata Correlation
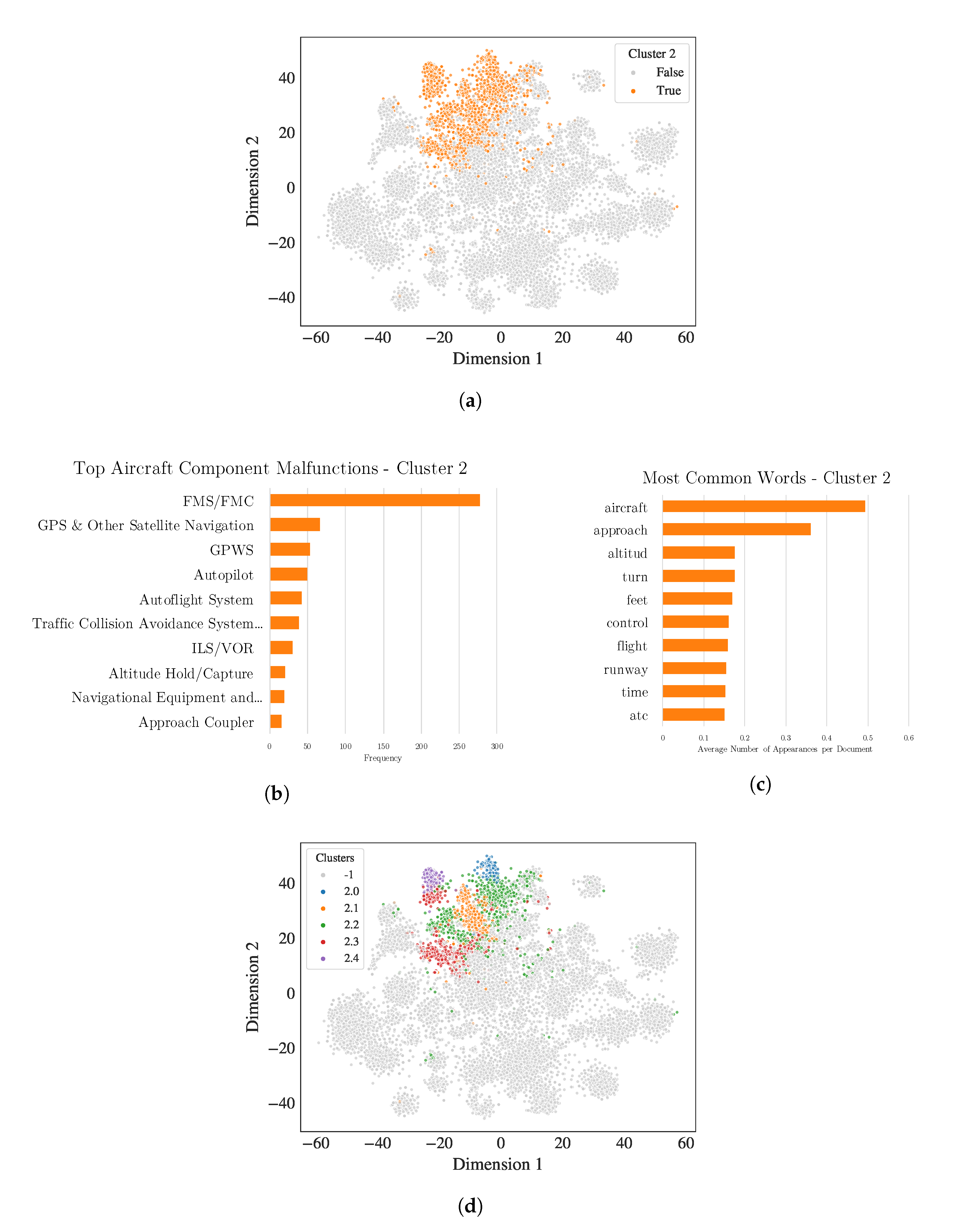
4.2.2. Imprecise Clusters with Precise Sub-Clusters and High Metadata Correlation
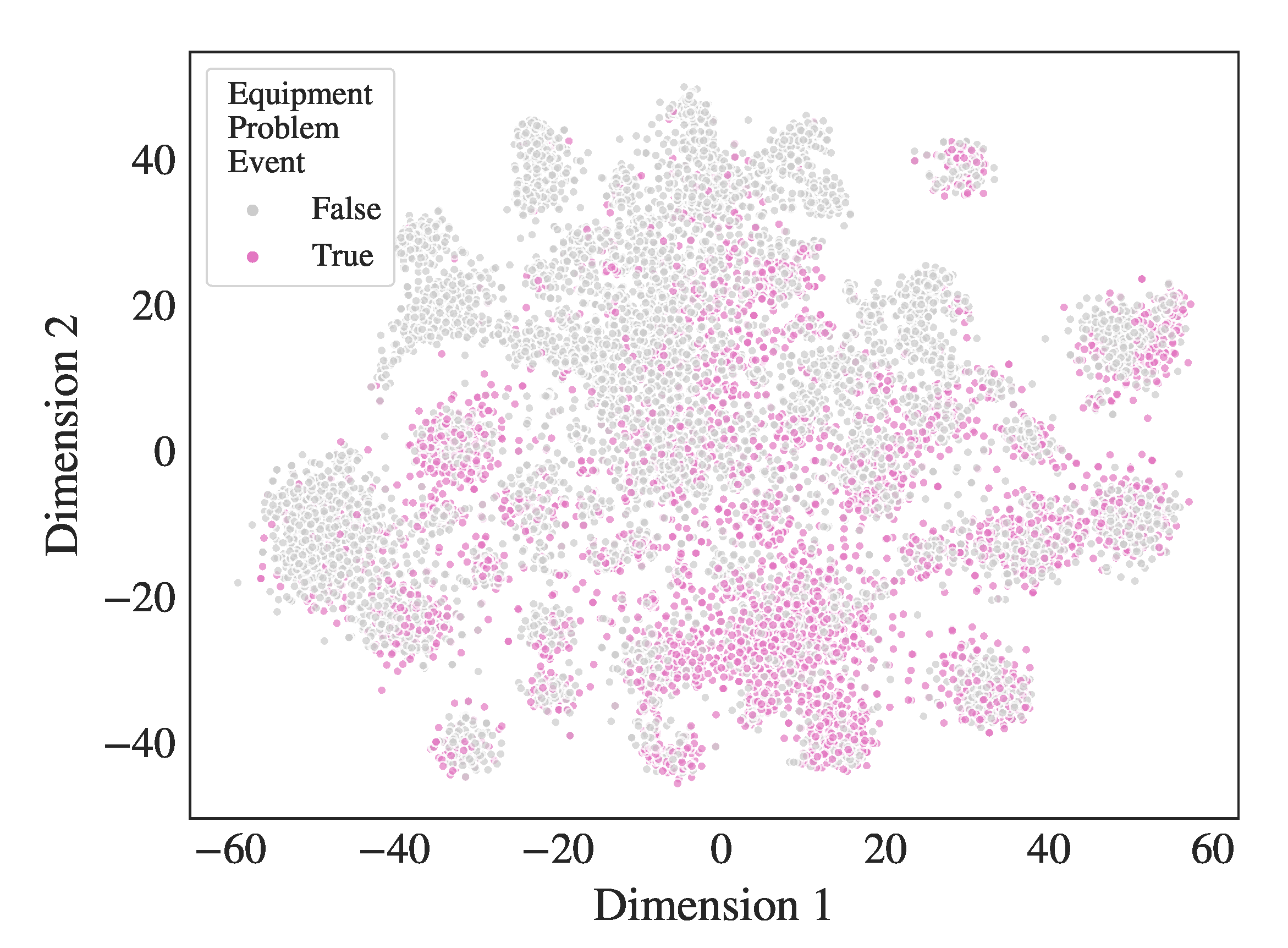
4.2.3. Imprecise Clusters and Sub-Clusters with Low Metadata Correlation
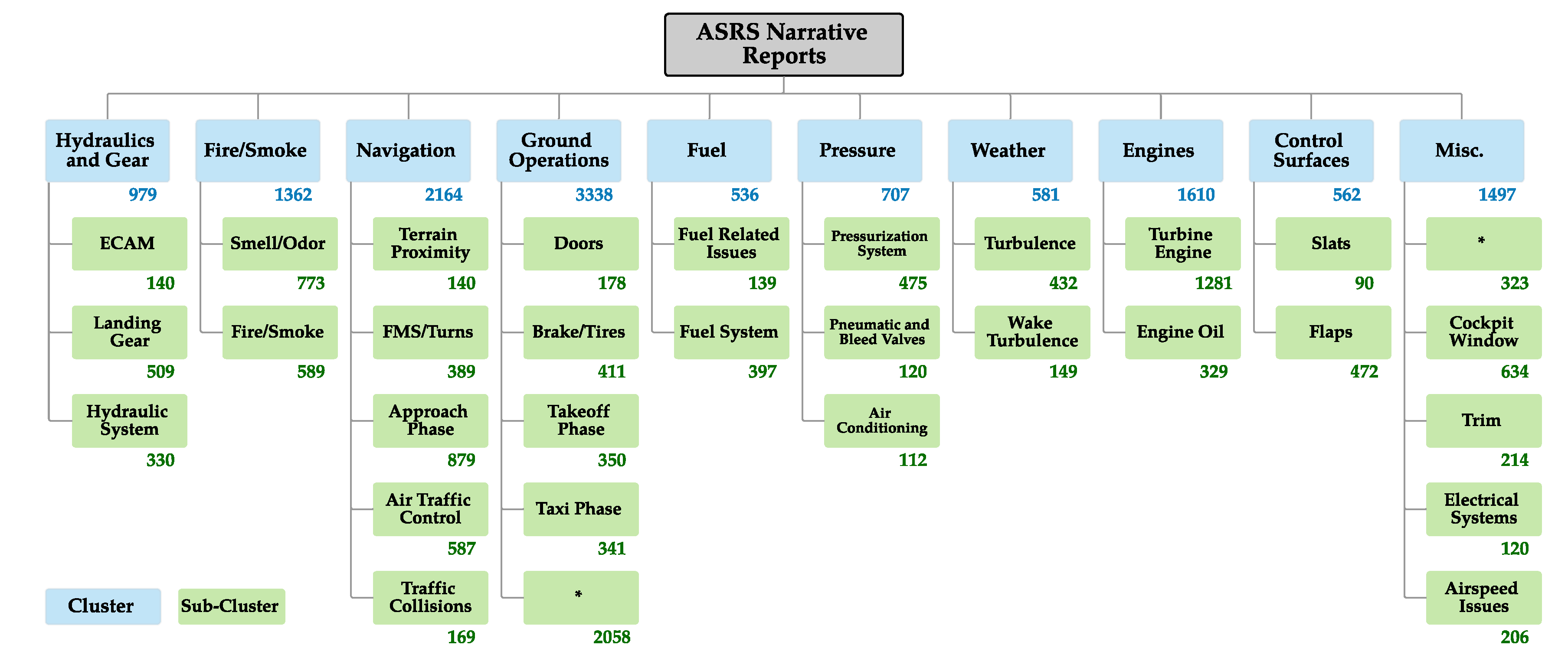
4.3. Sub-Cluster Hierarchical Structure
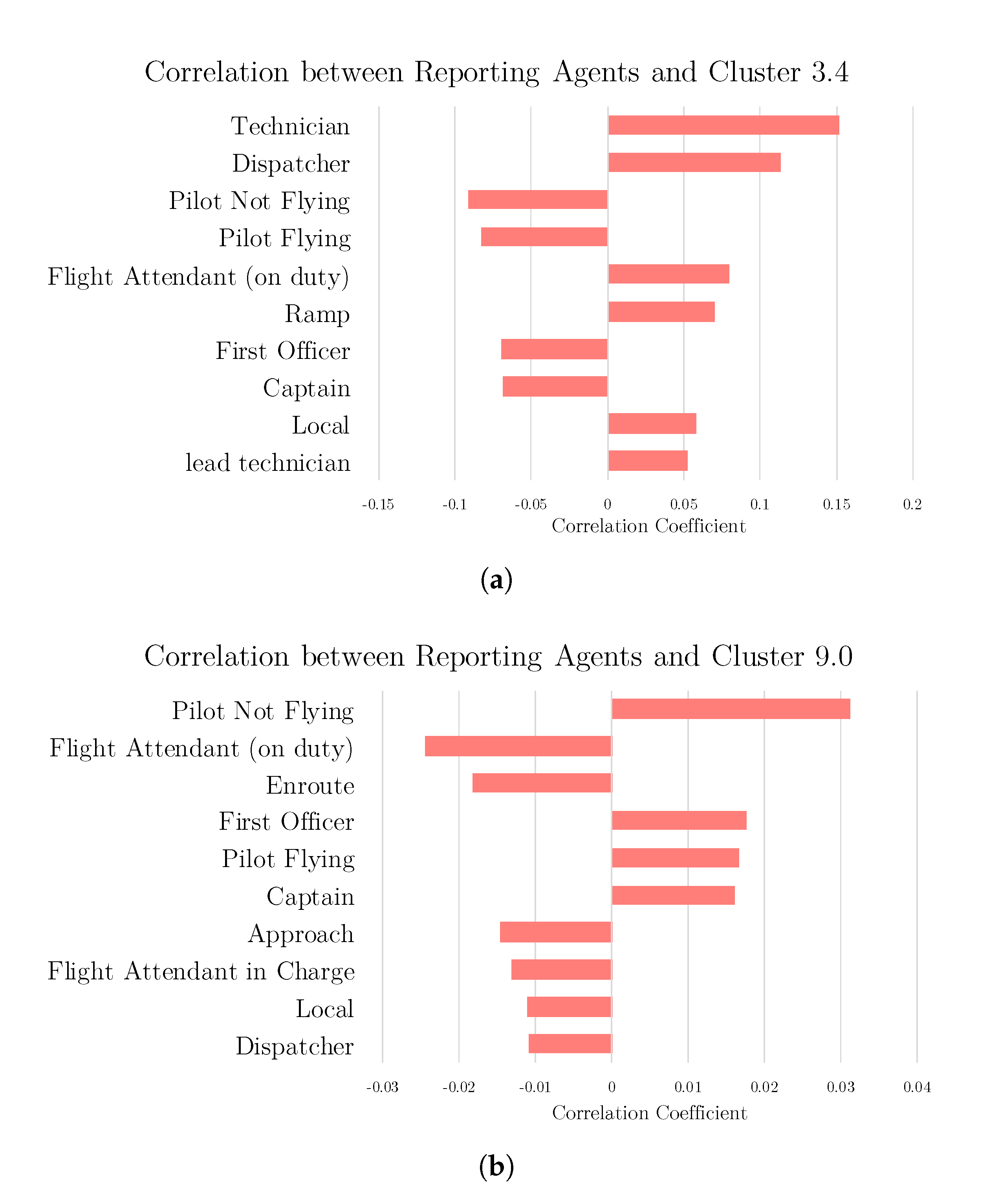
4.4. Cluster-Anomaly Correlation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACARS | Aircraft Communication Addressing Reporting Systems |
| ADREP | Accident/Incident Data Reporting |
| ASRS | Aviation Safety Reporting System |
| ATC | Air Traffic Control |
| BoW | Bag-of-Words |
| CH | Calisnki-Harabasz |
| CVR | Cockpit Voice Recorder |
| DBSCAN | Density-based spatial clustering of applications with noise |
| ECAM | Electronic Centralised Aircraft Monitor |
| FAA | Federal Aviation Administration |
| FDR | Flight Data Recorder |
| FOQA | Flight Operations Quality Assurance |
| ICAO | International Civil Aviation Organization |
| PCA | Principal Component Analysis |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| TF-IDF | Term-Frequency-Inverse-Document-Frequency |
References
- Statistical Summary of Commercial Jet Airplane Accidents-Boeing Commercial Airplanes. 2018. Available online: http://www.boeing.com/resources/boeingdotcom/company/about_bca/pdf/statsum.pdf (accessed on 1 August 2020).
- Federal Aviaition Administration Aerospace Forecasts Fiscal Years 2019–2039. 2019. Available online: https://www.faa.gov/data_research/aviation/aerospace_forecasts/media/FY2019-39_FAA_Aerospace_Forecast.pdf (accessed on 1 August 2020).
- Puranik, T.G.; Mavris, D.N. Identification of Instantaneous Anomalies in General Aviation Operations using Energy Metrics. J. Aerosp. Inf. Syst. 2019, 17, 1–15. [Google Scholar] [CrossRef]
- Memarzadeh, M.; Matthews, B.; Avrekh, I. Unsupervised Anomaly Detection in Flight Data Using Convolutional Variational Auto-Encoder. Aerospace 2020, 7, 115. [Google Scholar] [CrossRef]
- Deshmukh, R.; Hwang, I. Incremental-Learning-Based Unsupervised Anomaly Detection Algorithm for Terminal Airspace Operations. J. Aerosp. Inf. Syst. 2019, 16, 362–384. [Google Scholar] [CrossRef]
- Janakiraman, V.M.; Matthews, B.; Oza, N. Discovery of precursors to adverse events using time series data. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 639–647. [Google Scholar] [CrossRef]
- Ackley, J.; Puranik, T.G.; Mavris, D.N. A Supervised Learning Approach for Safety Event Precursor Identification in Commercial Aviation. In Proceedings of the AIAA Aviation Forum, Reno, Mexico, 15–19 June 2020. [Google Scholar] [CrossRef]
- Lee, H.; Madar, S.; Sairam, S.; Puranik, T.G.; Payan, A.P.; Kirby, M.; Pinon, O.J.; Mavris, D.N. Critical Parameter Identification for Safety Events in Commercial Aviation Using Machine Learning. Aerospace 2020, 7, 73. [Google Scholar] [CrossRef]
- Mangortey, E.; Monteiro, D.; Ackley, J.; Gao, Z.; Puranik, T.; Kirby, M.; Pinon, O.; Mavris, D. Application of Machine Learning Techniques to Parameter Selection for Flight Risk Identification. In Proceedings of the AIAA SciTech Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar] [CrossRef]
- Federal Aviation Administration Advisory Circular, 120-82-Flight Operational Quality Assurance. 2004. Available online: https://www.faa.gov/regulations_policies/advisory_circulars/index.cfm/go/document.information/documentID/23227 (accessed on 1 August 2020).
- Maheshwari, A.; Davendralingam, N.; DeLaurentis, D. A Comparative Study of Machine Learning Techniques for Aviation Applications. In Proceedings of the AIAA Aviation Forum, Atlanta, GA, USA, 25–29 June 2018. [Google Scholar] [CrossRef]
- Christopher, A.A.; Vivekanandam, V.S.; Anderson, A.A.; Markkandeyan, S.; Sivakumar, V. Large-scale data analysis on aviation accident database using different data mining techniques. Aeronaut. J. 2016, 120, 1849–1866. [Google Scholar] [CrossRef]
- Omar Alkhamisi, A.; Mehmood, R. An Ensemble Machine and Deep Learning Model for Risk Prediction in Aviation Systems. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020; pp. 54–59. [Google Scholar]
- Zhang, X.; Mahadevan, S. Ensemble machine learning models for aviation incident risk prediction. Decis. Support Syst. 2019, 116, 48–63. [Google Scholar] [CrossRef]
- Korvesis, P.; Besseau, S.; Vazirgiannis, M. Predictive Maintenance in Aviation: Failure Prediction from Post-Flight Reports. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1414–1422. [Google Scholar]
- Gui, G.; Liu, F.; Sun, J.; Yang, J.; Zhou, Z.; Zhao, D. Flight Delay Prediction Based on Aviation Big Data and Machine Learning. IEEE Trans. Veh. Technol. 2020, 69, 140–150. [Google Scholar] [CrossRef]
- Gürbüz, F.; Özbakir, L.; Yapici, H. Classification rule discovery for the aviation incidents resulted in fatality. Knowl. Based Syst. 2009, 22, 622–632. [Google Scholar] [CrossRef]
- Srinivasan, P.; Nagarajan, V.; Mahadevan, S. Mining and Classifying Aviation Accident Reports. In Proceedings of the AIAA Aviation 2019 Forum, Dallas, TX, USA, 17–21 June 2019. [Google Scholar] [CrossRef]
- Chowdhary, K.R. Natural Language Processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar] [CrossRef]
- Pimm, C.; Raynal, C.; Tulechki, N.; Hermann, E.; Caudy, G.; Tanguy, L. Natural Language Processing (NLP) tools for the analysis of incident and accident reports. In Proceedings of the International Conference on Human-Computer Interaction in Aerospace (HCI-Aero), Brussels, Belgium, 12–14 September 2012. [Google Scholar]
- Tanguy, L.; Tulechki, N.; Urieli, A.; Hermann, E.; Raynal, C. Natural language processing for aviation safety reports: From classification to interactive analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar] [CrossRef]
- Subramanian, S.V.; Rao, A.H. Deep-learning Based Time Series Forecasting of Go-around Incidents in the National Airspace System. In Proceedings of the 2018 AIAA Modeling and Simulation Technologies Conference, Kissimmee, FL, USA, 8–12 January 2018; p. AIAA 2018-0424. [Google Scholar] [CrossRef]
- Kuhn, K. Using structural topic modeling to identify latent topics and trends in aviation incident reports. Transp. Res. Part Emerg. Technol. 2018, 87, 105–122. [Google Scholar] [CrossRef]
- Ghaoui, L.; Pham, V.; Li, G.; Duong, V.; Srivastava, A.; Bhaduri, K. Understanding Large Text Corpora via Sparse Machine Learning. Stat. Anal. Data Min. 2013, 6. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Srivastava, A. Enabling the discovery of recurring anomalies in aerospace problem reports using high-dimensional clustering techniques. In Proceedings of the 2006 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2006; p. 17. [Google Scholar] [CrossRef]
- Robinson, S. Visual representation of safety narratives. Saf. Sci. 2016, 88, 123–128. [Google Scholar] [CrossRef]
- Kauffmann, J.; Esders, M.; Montavon, G.; Samek, W.; Müller, K. From Clustering to Cluster Explanations via Neural Networks. arXiv 2019, arXiv:1906.07633. [Google Scholar]
- Potdar, K.; Pardawala, T.; Pai, C. A Comparative Study of Categorical Variable Encoding Techniques for Neural Network Classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Rajaraman, A.; Ullman, J.D. Data Mining. In Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011; pp. 1–17. [Google Scholar] [CrossRef]
- Qaiser, S.; Ali, R. Text Mining: Use of TF-IDF to Examine the Relevance of Words to Documents. Int. J. Comput. Appl. 2018, 181. [Google Scholar] [CrossRef]
- Madhulatha, T.S. An Overview on Clustering Methods. IOSR J. Eng. 2012, 2. [Google Scholar] [CrossRef]
- Patro, S.G.K.; Sahu, K.K. Normalization: A Preprocessing Stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Determining the Number of Clusters/Segments in Hierarchical Clustering/Segmentation Algorithms. In Proceedings of the International Conference on Tools for Artificial Intelligence (ICTAI), Boca Raton, FL, USA, 15–17 November 2004; pp. 576–584. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; Kdd: Washington, DC, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Zhao, Y.; Karypis, G. Evaluation of Hierarchical Clustering Algorithms for Document Datasets. Int. Conf. Inf. Knowl. Manag. Proc. 2002. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Gisbrecht, A.; Schulz, A.; Hammer, B. Parametric nonlinear dimensionality reduction using kernel t-SNE. Neurocomputing 2015, 147, 71–82. [Google Scholar] [CrossRef]
- Linderman, G.C.; Steinerberger, S. Clustering with t-SNE, Provably. SIAM J. Math. Data Sci. 2019, 1, 313–332. [Google Scholar] [CrossRef]
- Thinsungnoen, T.; Kaoungku, N.; Durongdumronchai, P.; Kerdprasop, K.; Kerdprasop, N. The Clustering Validity with Silhouette and Sum of Squared Errors. In Proceedings of the International Conference on Industrial Application Engineering, Kitakyushu, Japan, 28–31 March 2015; pp. 44–51. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of Internal Clustering Validation Measures. In Proceedings of the IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 911–916. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Environment | Aircraft 1 | Person 1 | Events | Report 1 | ... |
|---|---|---|---|---|---|---|
| Date | Weather | Make Model Name | Function | Anomaly | Narrative | ... |
| January 2019 | Rain | B737 | Captain; Pilot Flying | Aircraft Equipment Problem Critical | During taxi out, ATC alerted us... | ... |
| January 2019 | Large Transport | Captain; Pilot Flying | Deviation: Procedural Published Material/Policy | The purpose of this report... | ... | |
| January 2019 | Rain | B737 | Ground | ATC Issue; Ground Conflict | I was working GC (ground control)... | ... |
| January 2019 | Windshear | B757 | Captain; Pilot Flying | Aircraft Equipment Problem Less Severe | I was the Captain on flight XXX... | ... |
| January 2019 | EMB ERJ 145 | First Officer; Pilot Not Flying | Aircraft Equipment Problem Critical | After landing at ZZZ on Runway... | ... | |
| ... | ... | ... | ... | ... | ... | ... |
| Non-Encoded Data | One-Hot Encoded Data | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Aircraft | Flight Phase | B737 | B757 | A320 | A330 | Takeoff | Cruise | Landing | |
| B737 | Takeoff | 1 | 0 | 0 | 0 | 1 | 0 | 0 | |
| B757 | Cruise | 0 | 1 | 0 | 0 | 0 | 1 | 0 | |
| B737 | Landing | ⟹ | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| A320 | Cruise | 0 | 0 | 0 | 1 | 0 | 1 | 0 | |
| B757 | Landing | 0 | 1 | 0 | 0 | 0 | 0 | 1 | |
| A330 | Landing | 0 | 0 | 0 | 1 | 0 | 0 | 1 | |
| B737 | Takeoff | 1 | 0 | 0 | 0 | 1 | 0 | 0 | |
| Bag-of-Words Matrix | TF-IDF Matrix | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Aircraft | Land | Weather | Runway | Fire | Aircraft | Land | Weather | Runway | Fire | ||
| D1 | 6 | 5 | 4 | 0 | 0 | D1 | 0.223 | 0.186 | 0.611 | 0 | 0 |
| D2 | 15 | 12 | 0 | 9 | 0 | D2 | 0.223 | 0.179 | 0 | 0.306 | 0 |
| D3 | 9 | 8 | 0 | 10 | 7 | D3 | 0.201 | 0.179 | 0 | 0.511 | 1.13 |
| D4 | 2 | 0 | 3 | 0 | 0 | D4 | 0.149 | 0 | 0.916 | 0 | 0 |
| D5 | 0 | 4 | 0 | 7 | 0 | D5 | 0 | 0.127 | 0 | 0.511 | 0 |
| Cluster | Correlation Coefficient |
|---|---|
| 0 | 0.0982 |
| 1 | −0.0855 |
| 2 | −0.2671 |
| 3 | −0.0991 |
| 4 | 0.0151 |
| 5 | 0.1518 |
| 6 | −0.1609 |
| 7 | 0.2848 |
| 8 | 0.0554 |
| 9 | 0.1066 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rose, R.L.; Puranik, T.G.; Mavris, D.N. Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace 2020, 7, 143. https://doi.org/10.3390/aerospace7100143
Rose RL, Puranik TG, Mavris DN. Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace. 2020; 7(10):143. https://doi.org/10.3390/aerospace7100143
Chicago/Turabian StyleRose, Rodrigo L., Tejas G. Puranik, and Dimitri N. Mavris. 2020. "Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives" Aerospace 7, no. 10: 143. https://doi.org/10.3390/aerospace7100143
APA StyleRose, R. L., Puranik, T. G., & Mavris, D. N. (2020). Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace, 7(10), 143. https://doi.org/10.3390/aerospace7100143