_Zhu.png)
A Stackelberg Game Approach to Model Reference Adaptive Control for Spacecraft Pursuit–Evasion


Abstract
1. Introduction
- 1.
- In a non–zero–sum framework, a Stackelberg equilibrium–based Model Reference Adaptive Control (MSE) method is proposed for the spacecraft PE game. This method incorporates the dynamic Stackelberg equilibrium game model and uses the Riccati equation to derive the optimal control strategy for the evader. Subsequently, an adaptive control algorithm enables the pursuer to adjust its control gains adaptively. This approach is novel, as it specifically addresses the challenges of perturbations and non–zero–sum game dynamics within the PE context, which has not been thoroughly explored in prior literature.
- 2.
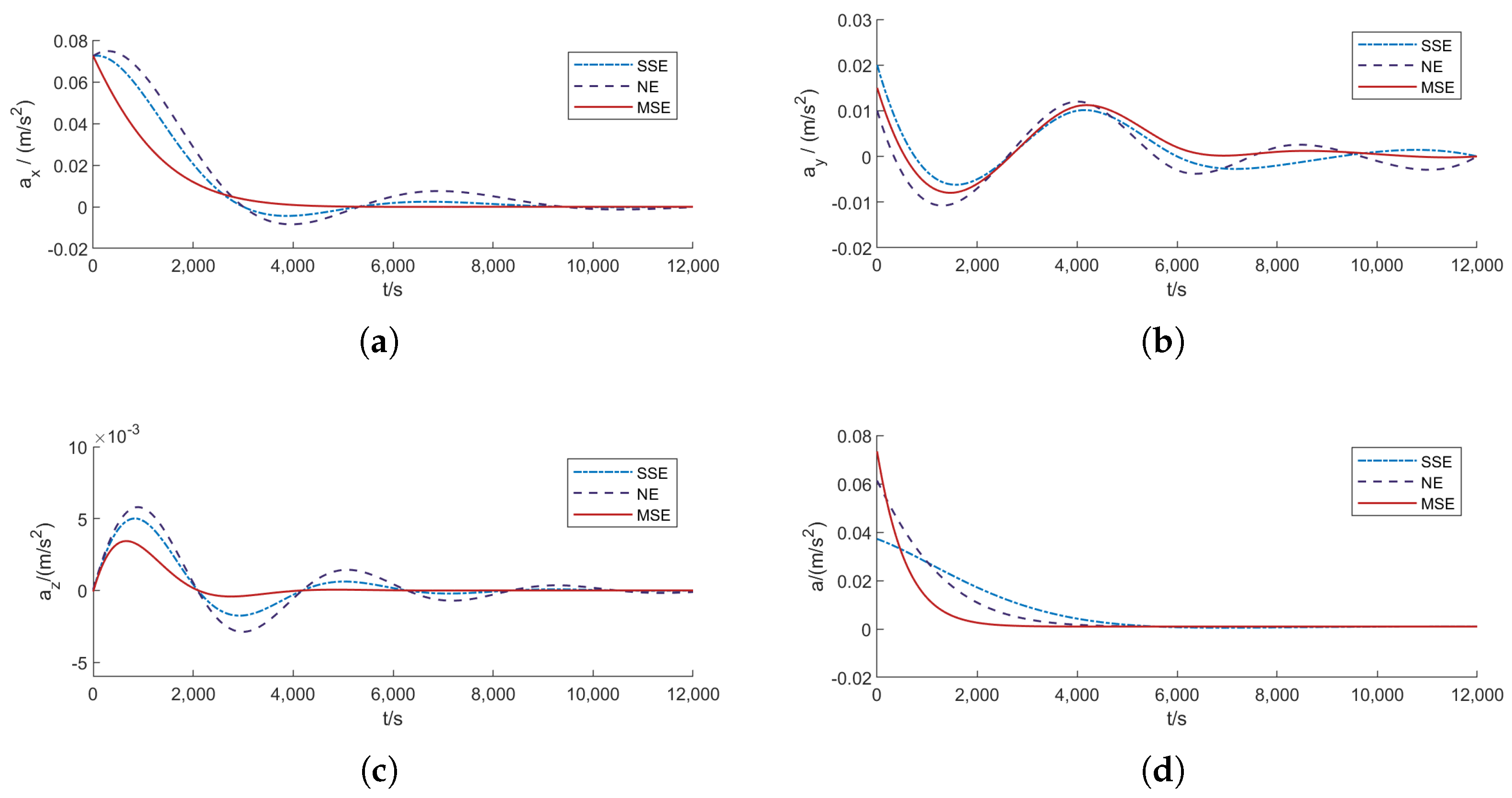
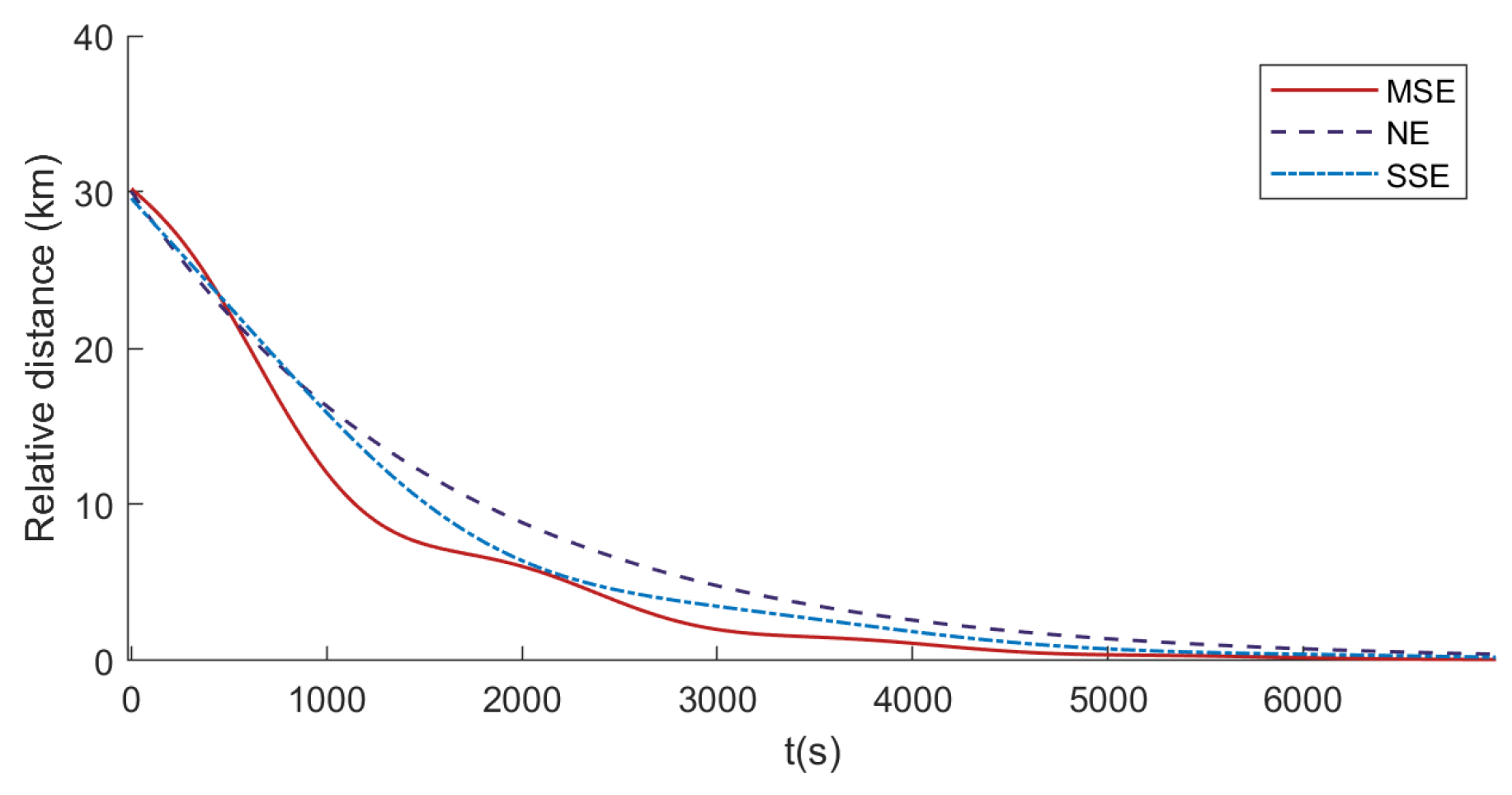
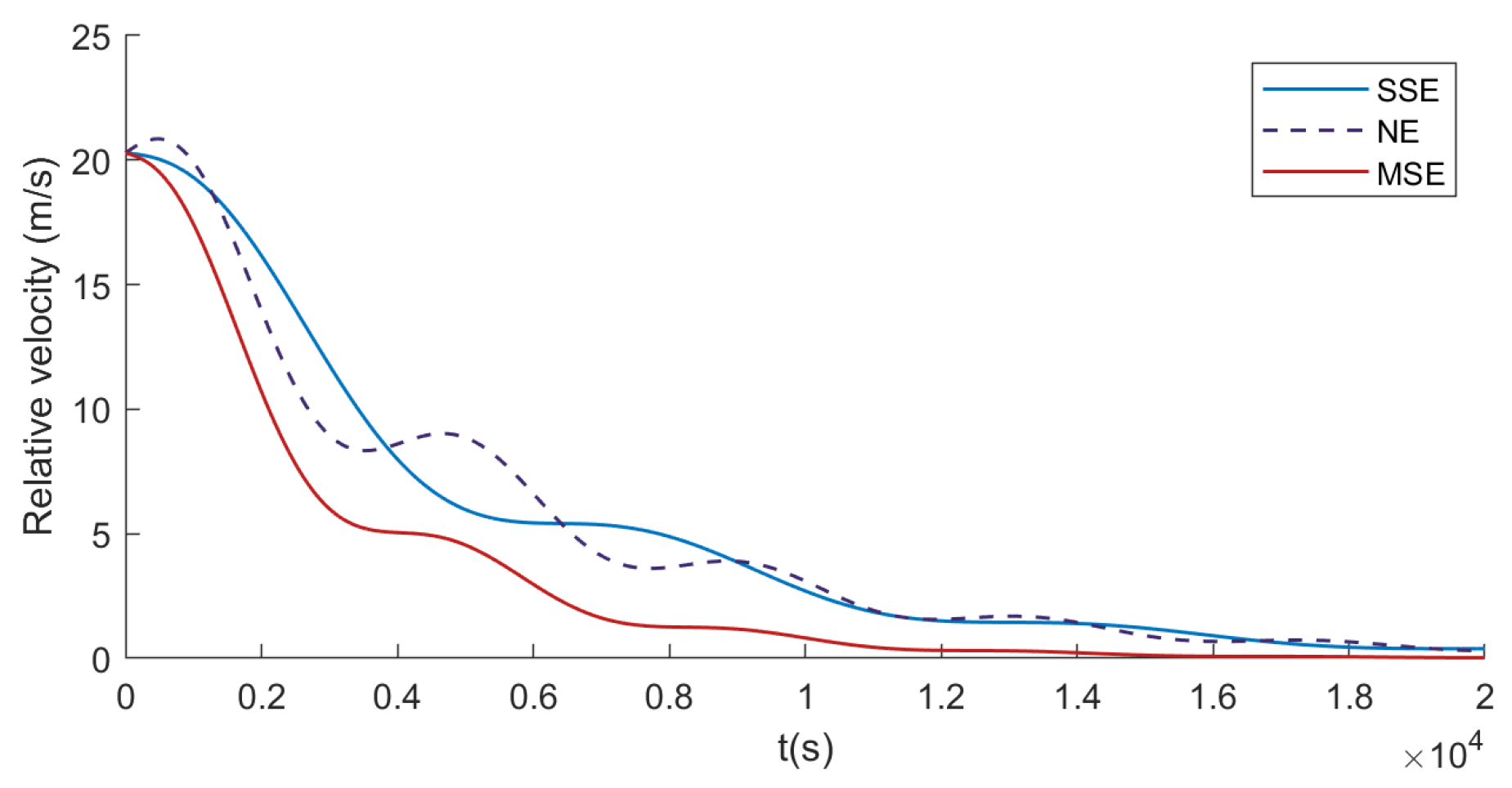
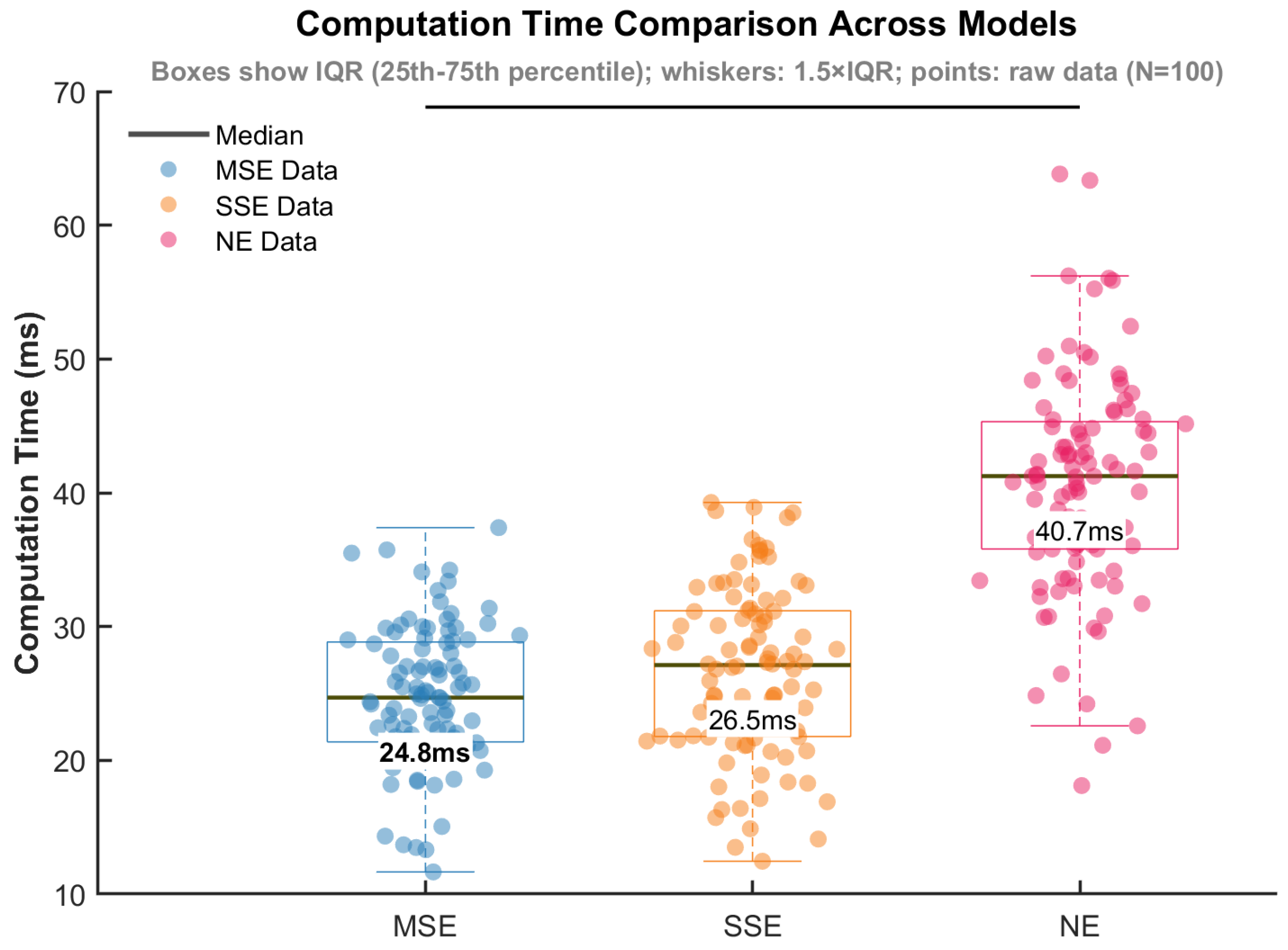
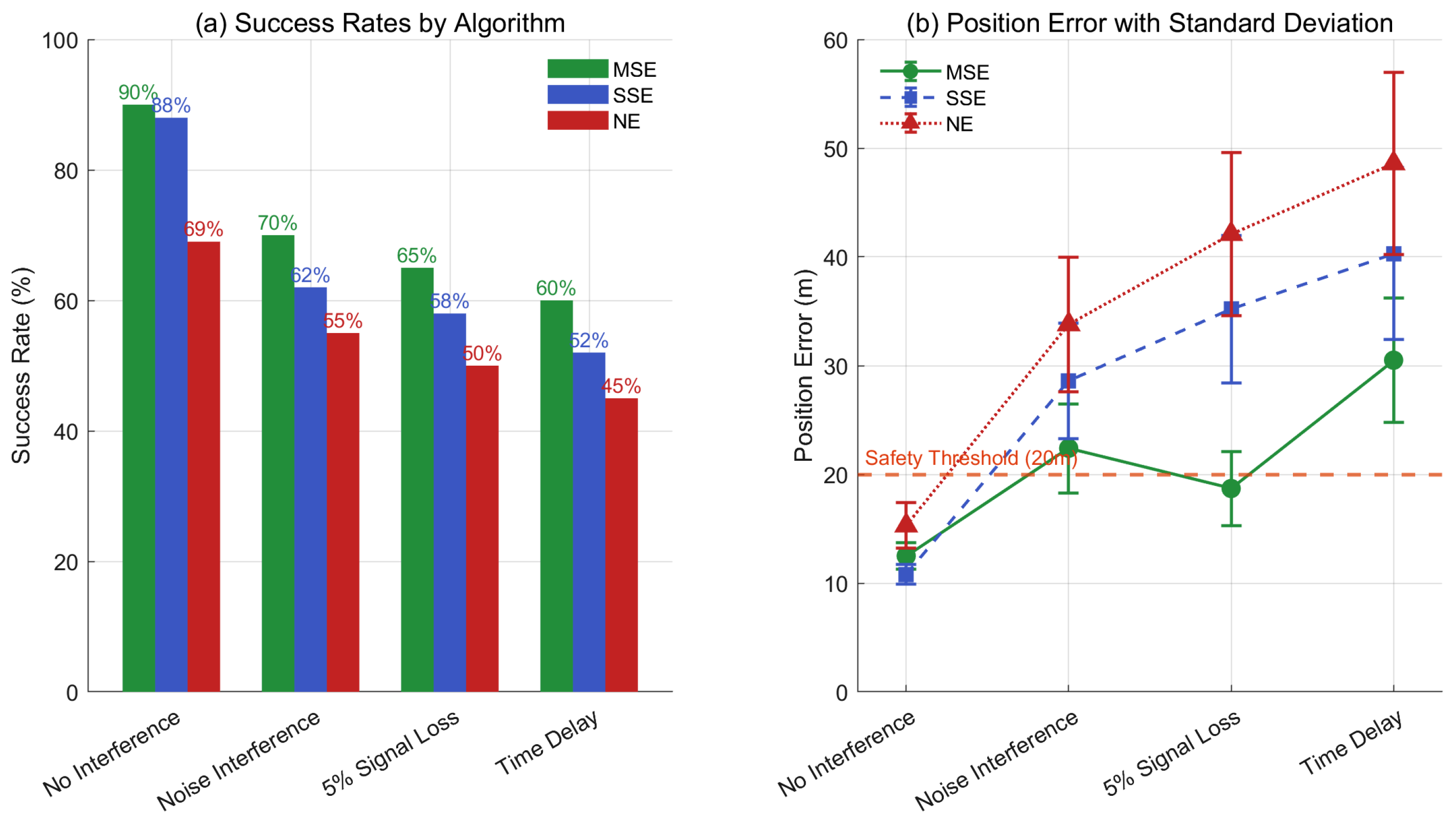
- The existence and uniqueness of the solution to the Stackelberg game model are rigorously proven. Furthermore, the proposed MSE algorithm is compared with traditional methods, such as Nash Equilibrium (NE) [18] and Single–step Prediction Stackelberg Equilibrium (SSE) [24]. Numerical simulations demonstrate that the MSE algorithm offers significant advantages in terms of computational efficiency (e.g., an average generation time of 24.79 ms, which is 7.36% less than SSE and 39.11% less than NE), fuel consumption, pursuit success rate, and disturbance rejection capability.
- 3.
- While Stackelberg games have been applied to spacecraft PE problems, this work lies in unifying Riccati–based Stackelberg solutions with model reference adaptive control, addressing perturbations and incomplete information—a gap in prior work.
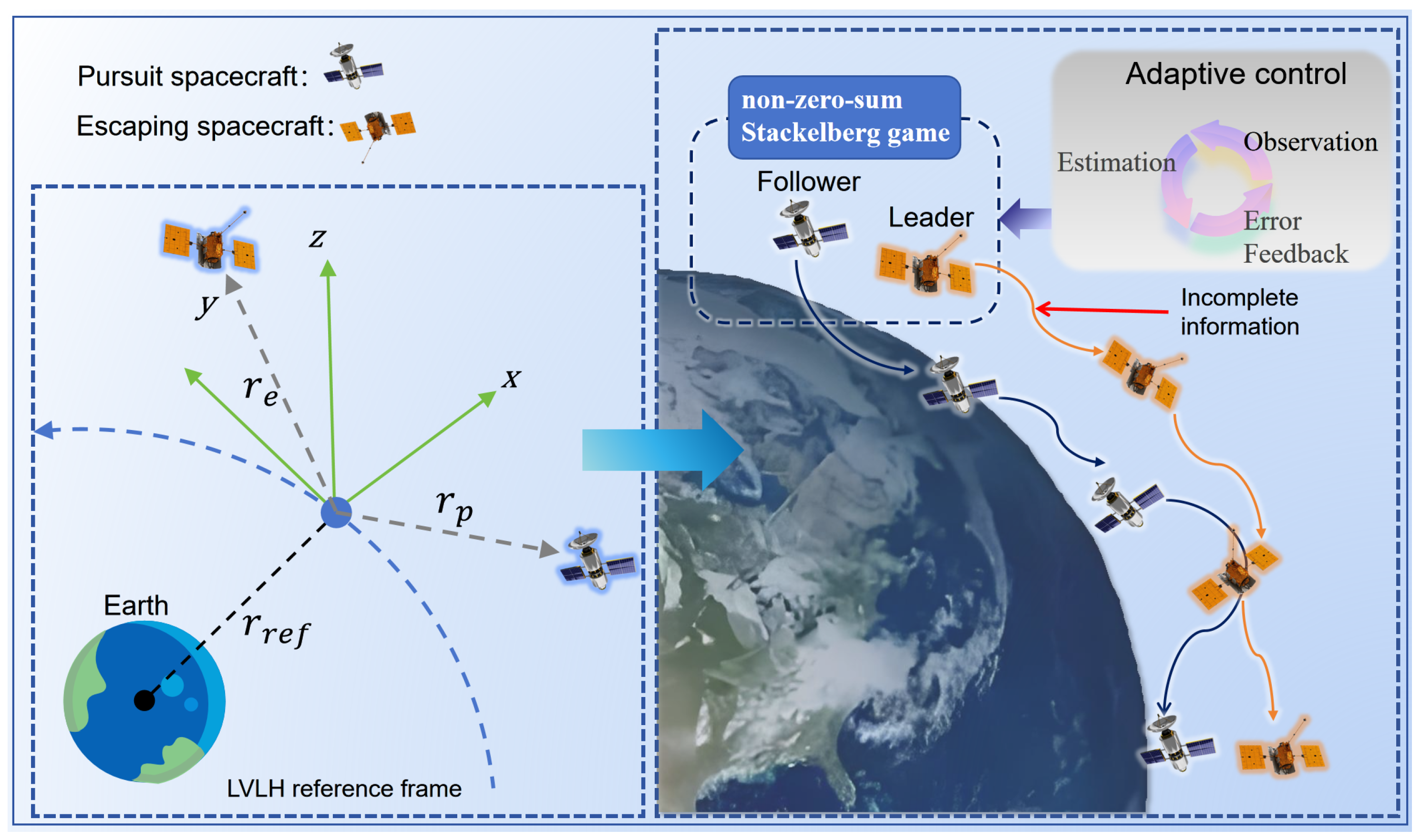
2. Problem Formulation
2.1. System Model
2.2. Dynamic Stackelberg Pursuit–Evasion Game
3. Stackelberg Equilibrium–Based Model Reference Adaptive Control Algorithm
3.1. Resolution of Stackelberg Game
3.2. Existence and Uniqueness of Stackelberg Equilibria
- 1.
- The strategy sets for the leader and follower are non–empty compact convex sets.
- 2.
- For a given leader’s strategy, a unique optimal solution for the follower exists.
- 3.
- For a given follower’s strategy, a unique optimal solution for the leader exists.
- 1.
- (Non–empty compact convex set): The strategy spaces are subsets of Euclidean space and are non–empty. The cost functions (3) and (4) are quadratic, and thus continuous, with respect to the control actions. As and are strictly convex and tend to infinity as the norms of the control actions approach infinity, this ensures the existence of a minimum and that the set of optimal strategies is compact and convex.
- 2.
- (Unique follower solution): For any given leader’s strategy , the follower’s (pursuer’s) cost function in (4) is strictly convex in . Strict convexity is guaranteed because its quadratic weighting matrix, , is positive definite. This holds because is chosen as positive definite, and , as a solution to the Riccati equation, is also positive definite, making positive semi–definite. A strictly convex function has a unique minimum.
- 3.
- (Unique leader solution): Similarly, when the follower’s strategy is given, the leader’s (evader’s) cost function in (3) is strictly convex in , as is designed to be positive definite. This guarantees a unique optimal solution for the leader.
3.3. Stackelberg Equilibrium–Based Model Reference Adaptive Control Algorithm
- 1.
- The system dynamics (2) are Lipschitz continuous with respect to state and parameter variations, i.e., there exists such that:
- 2.
- The reference signal
- 3.
- The disturbance is –bounded with known upper bound:
- 4.
- There exist constants and such that the regressor vector
- 5.
- The initial parameter estimation errors satisfy:
- 6.
- The matrix is uniformly positive definite, i.e., there exists such that:
- 7.
- The adaptive gain matrices are symmetric positive definite, with eigenvalues bounded by:and the higher–order term (h.o.t.) coefficient satisfies:where are design constants.
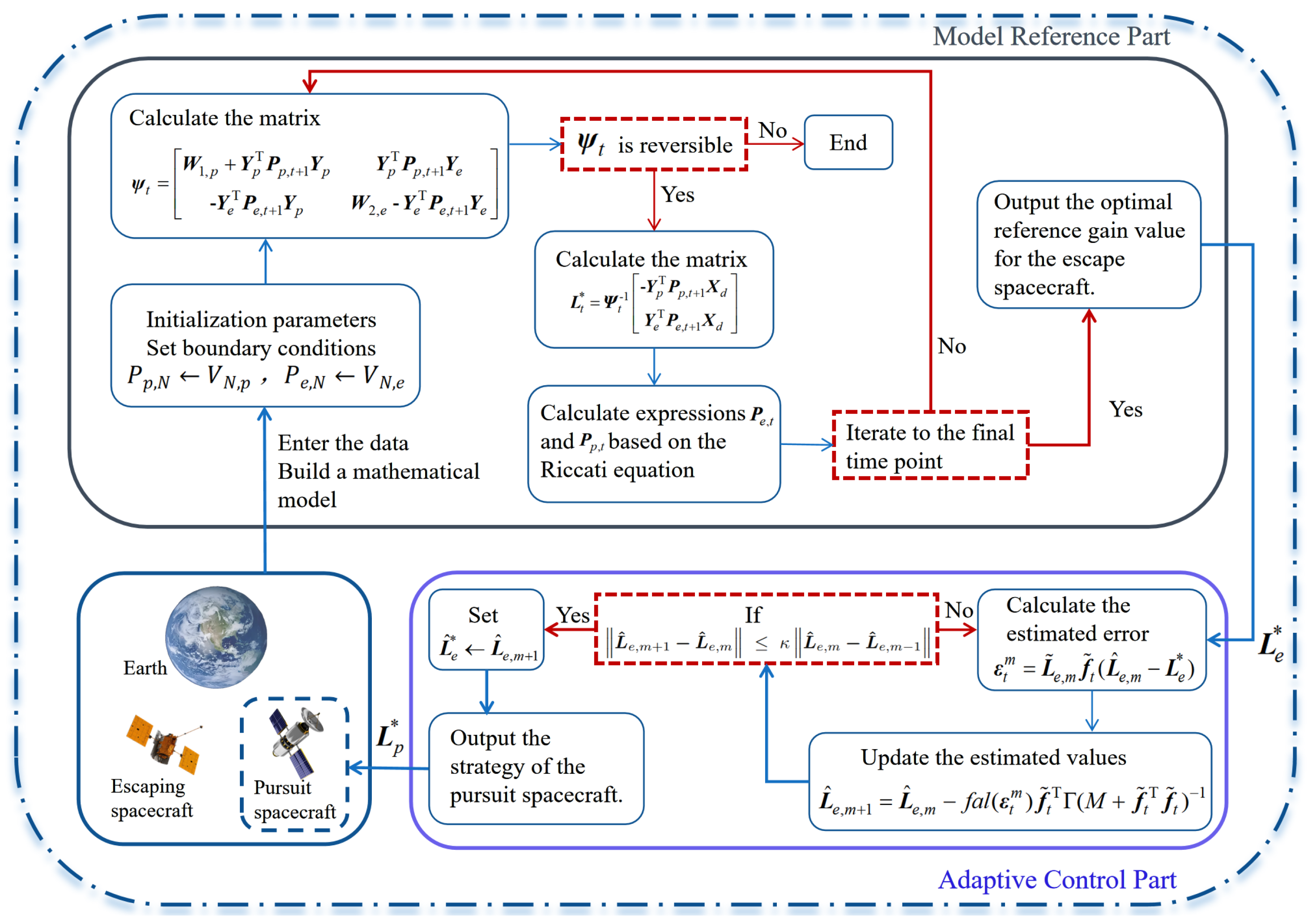
| Algorithm 1 Stackelberg Equilibrium–Based Model Reference Adaptive Control |
| Require: System matrices as defined in (2)–(4); estimation threshold Ensure: Optimal control strategies (pursuer) and (evader) |
- Lines 3–9 (Offline Reference Calculation): The algorithm first calculates the optimal control gains for a finite horizon N. It iterates backward in time, computing the coupling matrix and solving for the optimal gains at each step using the Riccati updates from (7) and (8). This produces the optimal evader gain , which will serve as the reference.
- Lines 10–18 (Online Pursuer Adaptation): This loop represents the online adaptive process. The pursuer evaluates the estimation error (line 11) and refines its estimate of the evader’s gain, , using the robust update law from (37) (line 12).
- Lines 13–16 (Convergence Check): The adaptation continues until the change in the estimated gain becomes small, determined by the threshold . At this point, the algorithm has converged to a good estimate of the evader’s current strategy.
- Line 19 (Final Pursuer Strategy): With the best available estimate of the evader’s strategy, the pursuer calculates its own optimal control gain using Equation (13). This gain is then used to control the pursuer spacecraft.
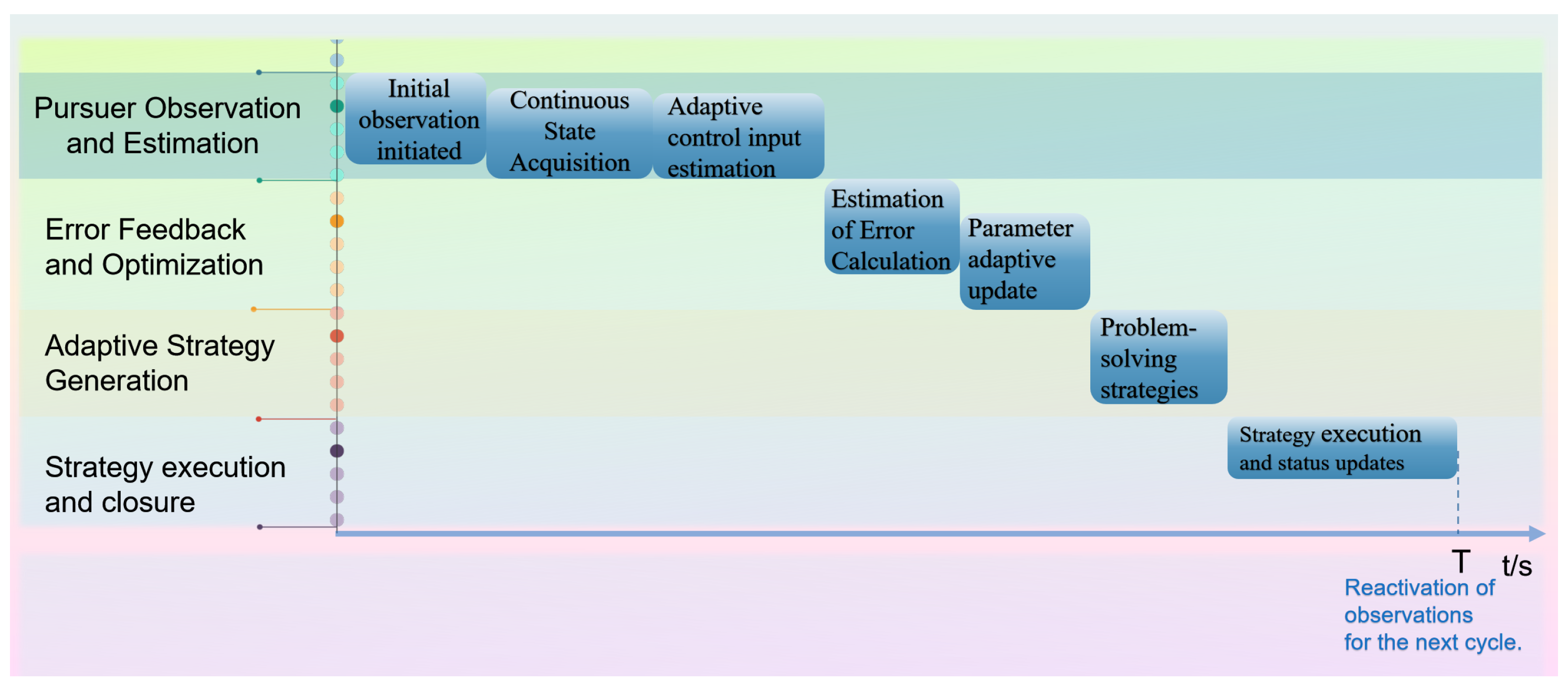
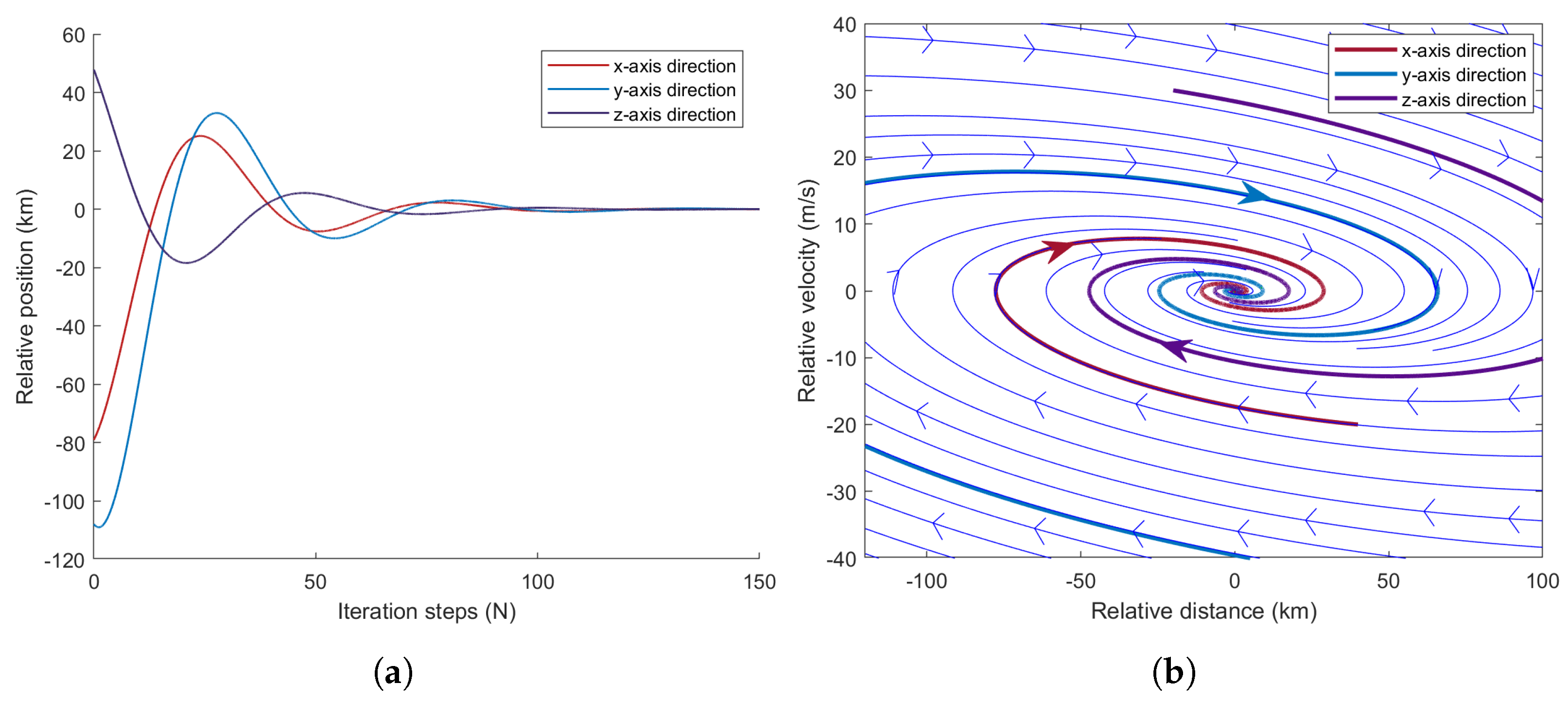
4. Simulation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Parameters and Equations
References
- Wong, K.K.L.; Chipusu, K. In-space cybernetical intelligence perspective on informatics, manufacturing and integrated control for the space exploration industry. J. Ind. Inf. Integr. 2024, 42, 100724. [Google Scholar] [CrossRef]
- Ye, M.; Chen, C.L.P.; Zhang, T. Hierarchical Dynamic Graph Convolutional Network with Interpretability for EEG-Based Emotion Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 42, 1–12. [Google Scholar] [CrossRef]
- Li, Q.; Yan, J.; Zhu, J.; Huang, T.; Zang, J. State of the Art and Development Trends of Top-Level Demonstration Technology for Aviation Weapon Equipment. Acta Aeronaut. Astronaut. Sin. 2016, 37, 1–15. [Google Scholar] [CrossRef]
- Zhao, L.-R.; Dang, Z.-H.; Zhang, Y.-L. Orbital Game: Concepts, Principles and Methods. J. Command. Control 2021, 7, 215. [Google Scholar]
- Vela, C.; Opromolla, R.; Fasano, G. A low-thrust finite state machine based controller for N-satellites formations in distributed synthetic aperture radar applications. Acta Astronaut. 2023, 202, 686–704. [Google Scholar] [CrossRef]
- Yao, J.; Xu, B.; Li, X.; Yang, S. A clustering scheduling strategy for space debris tracking. Aerosp. Sci. Technol. 2025, 157, 109805. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, X.; Ye, X.; Li, B. Dual generative adversarial networks for merging ocean transparency from satellite observations. GISci. Remote Sens. 2024, 61, 1. [Google Scholar] [CrossRef]
- Gu, Y.; Sun, X.; Fan, W. A fast star-ground coverage analysis method based on elevation angle visual element model. CEAS Aeronaut. J. 2025, 46, 330372. [Google Scholar] [CrossRef]
- Kreps, D. Game theory and economic modelling. J. Econ. Educ. 1990, 23, 2. [Google Scholar] [CrossRef]
- Başar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory, 2nd ed.; 7. Stackelberg Equilibria of Infinite Dynamic Games; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1998; Volume 23, pp. 365–422. [Google Scholar] [CrossRef]
- Abu-Khalaf, M.; Lewis, F.L.; Huang, J. Policy Iterations on the Hamilton–Jacobi–Isaacs Equation for State Feedback Control with Input Saturation. IEEE Trans. Autom. Control 2006, 51, 1989–1995. [Google Scholar] [CrossRef]
- Li, H.; Liu, D.; Wang, D. Integral Reinforcement Learning for Linear Continuous-Time Zero-Sum Games with Completely Unknown Dynamics. IEEE Trans. Autom. Sci. Eng. 2014, 11, 706–714. [Google Scholar] [CrossRef]
- Wei, Q.; Liu, D.; Lin, Q.; Song, R. Adaptive Dynamic Programming for Discrete-Time Zero-Sum Games. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 957–969. [Google Scholar] [CrossRef] [PubMed]
- Zhong, X.; He, H.; Wang, D.; Ni, Z. Model-Free Adaptive Control for Unknown Nonlinear Zero-Sum Differential Game. IEEE Trans. Cybern. 2018, 48, 1633–1646. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Yang, S.; Piao, H.; Bai, C.; Ge, J. A survey of air combat artificial intelligence. Acta Aeronaut. Astronaut. Sin. 2021, 42, 25799. [Google Scholar] [CrossRef]
- Xiong, T.; Zhang, R.; Liu, J.; Huang, T.; Liu, Y.; Yu, F.R. A blockchain-based and privacy-preserved authentication scheme for inter-constellation collaboration in Space-Ground Integrated Networks. Comput. Netw. 2022, 206, 108793. [Google Scholar] [CrossRef]
- Hellmann, J.K.; Stiver, K.A.; Marsh-Rollo, S.; Alonzo, S.H. Defense against outside competition is linked to cooperation in male–male partnerships. Behav. Ecol. 2019, 31, 432–439. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, P.; Yuan, J. Nonzero-Sum Pursuit-Evasion Game Control for Spacecraft Systems: A Q-Learning Method. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3971–3981. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Liu, H.; Zhang, K. Impulsive thrust strategy for orbital pursuit-evasion games based on impulse-like constraint. Chin. J. Aeronaut. 2025, 38, 103180. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, Y. Two-Step Stackelberg Approach for the Two Weak Pursuers and One Strong Evader Closed-Loop Game. IEEE Trans. Autom. Control 2024, 69, 1309–1315. [Google Scholar] [CrossRef]
- Eltoukhy, A.E.; Wang, Z.; Chan, F.T.; Fu, X. Data analytics in managing aircraft routing and maintenance staffing with price competition by a Stackelberg-Nash game model. Transp. Res. Part E Logist. Transp. Rev. 2019, 122, 143–168. [Google Scholar] [CrossRef]
- Han, C.; Huo, L.; Tong, X.; Wang, H.; Liu, X. Spatial Anti-Jamming Scheme for Internet of Satellites Based on the Deep Reinforcement Learning and Stackelberg Game. IEEE Trans. Veh. Technol. 2020, 69, 5331–5342. [Google Scholar] [CrossRef]
- Hu, X.; Liu, S.; Xu, J.; Xiao, B.; Guo, C. Integral reinforcement learning based dynamic stackelberg pursuit-evasion game for unmanned surface vehicles. Alexandria Eng. J. 2024, 108, 428–435. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Jiang, J.; Zhang, Y. A model predictive Stackelberg solution to orbital pursuit-evasion game. Chin. J. Aeronaut. 2025, 38, 103198. [Google Scholar] [CrossRef]
- Lancaster, P.; Rodman, L. Algebraic Riccati Equations. Birkhäuser 2005, 108, 289–318. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Liu [24] | Proposed Method | Advancement |
|---|---|---|---|
| J2 Handling |
|
|
|
| Control Strategy |
|
|
|
| Stability | Local convergence | Global UUB (Theorem 1) |
|
| Computation | 26.5 ms/step | 24.8 ms/step |
|
| Relative State | Pursuit | Evader |
|---|---|---|
| x (km) | 10 | 0 |
| y (km) | 0 | 0 |
| z (km) | 0 | 0 |
| (m/s) | 1.7 | 0 |
| (m/s) | 4.3 | 0 |
| (m/s) | 0 | 0 |
| Interference Factors | Description |
|---|---|
| Position measurement noise | |
| The probability of signal loss | |
| Signal delay time |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, G.; Chu, M.; Zhang, H.; Lin, S. A Stackelberg Game Approach to Model Reference Adaptive Control for Spacecraft Pursuit–Evasion. Aerospace 2025, 12, 613. https://doi.org/10.3390/aerospace12070613
Gan G, Chu M, Zhang H, Lin S. A Stackelberg Game Approach to Model Reference Adaptive Control for Spacecraft Pursuit–Evasion. Aerospace. 2025; 12(7):613. https://doi.org/10.3390/aerospace12070613
Chicago/Turabian StyleGan, Gena, Ming Chu, Huayu Zhang, and Shaoqi Lin. 2025. "A Stackelberg Game Approach to Model Reference Adaptive Control for Spacecraft Pursuit–Evasion" Aerospace 12, no. 7: 613. https://doi.org/10.3390/aerospace12070613
APA StyleGan, G., Chu, M., Zhang, H., & Lin, S. (2025). A Stackelberg Game Approach to Model Reference Adaptive Control for Spacecraft Pursuit–Evasion. Aerospace, 12(7), 613. https://doi.org/10.3390/aerospace12070613