1. Introduction
With the growing urgency of on-orbit servicing for space devices, the space robot has become a focal point of research for major aerospace powers worldwide. The space-based manipulator, as one of the pivotal technologies in the aerospace field, plays a crucial role in on-orbit services such as the assembly, maintenance, and refueling of spacecraft [
1,
2,
3]. The assembly, construction, maintenance, and application of the International Space Station have demonstrated that utilizing a space robot can assist or substitute astronauts in executing on-orbit operations under harsh conditions. Such tasks include maintaining and repairing malfunctioning spacecraft or satellites, replenishing fuel for space vehicles, and retrieving discarded launch objects [
4,
5]. This approach enhances efficiency, safety, and reduces the overall cost and risk associated with space exploration. In the microgravity environment of space, the base spacecraft exhibits non-fixed characteristics, leading to strong coupling between the manipulator and the base spacecraft. That is, the motion of the manipulator will, in turn, affect the motion state of the base spacecraft, causing pose disturbances to the base, which in turn impacts the accuracy and stability of the control, posing challenges to the design of the control system [
6,
7,
8]. Therefore, the control of the space manipulator has attracted significant attention [
9,
10,
11].
Given the importance of the space manipulator, precise control of them has been a focal research area for scholars [
12,
13]. In the control process of space manipulators, due to the limitations imposed by the operating time window, dynamic response, and workspace, the operational tasks must be completed within a fixed-time while ensuring that the end-effector meets physical constraints [
14,
15]. A fixed-time control strategy, addressing the aforementioned challenges and difficulties, has been proposed and implemented. Compared to traditional asymptotic convergence, fixed-time control offers faster convergence rates and enhanced robustness, ensuring that the system stabilizes within a fixed-time. In [
16], for flexible air-breathing hypersonic vehicles operating under actuator saturation conditions, a robust fixed-time control technique featuring adaptive anti-saturation capabilities has been developed. To ensure the tracking error of the autonomous robotic manipulator converges within a fixed time, Ref. [
17] introduces a unique globally integral terminal sliding mode surface. In [
18], a nonlinear fixed-time H∞ controller was devised utilizing the backstepping method. Ref. [
19] introduced a dual-arm humanoid space manipulator that employs a fixed-time state-dependent Riccati equation controller for regulating free flight.
Although fixed-time control algorithms have been successively developed and applied due to their advantages, the convergence time of trajectory tracking errors in fixed-time control is significantly dependent on the initial conditions of the system. This implies that the convergence time of the system state cannot be guaranteed when the initial condition values are not in the ideal state. In practical operating conditions, the initial states of the system are often complex and variable, which leads to the limitations of fixed-time control algorithms. Based on the research of fixed-time control, the fixed-time theory has been further proposed. Compared to traditional fixed-time control methods, fixed-time control overcomes the limitation of initial parameter values, does not rely on the initial state of the system, and provides a faster transition process and higher steady-state accuracy. In [
20], an adaptive non-singular sliding-mode control system with a fixed-time under saturated actuator conditions is presented. Fixed-time sliding mode control was developed in [
21] based on fixed-time sliding surfaces and fixed-time arrival strategies. In [
22], the task-space tracking control problem of a free-floating space robot is tackled using a fixed-time control strategy, which is based on an extended state observer. In [
23], fixed-time controllers and fixed-time perturbation observers are proposed simultaneously for fault-tolerant attitude tracking control of spacecraft, incorporating event-triggered mechanisms to enable autonomous spacecraft rendezvous and docking missions. In [
24], an adaptive fixed-time controller, featuring seamless transitions between fractional and quadratic form feedback, is developed.
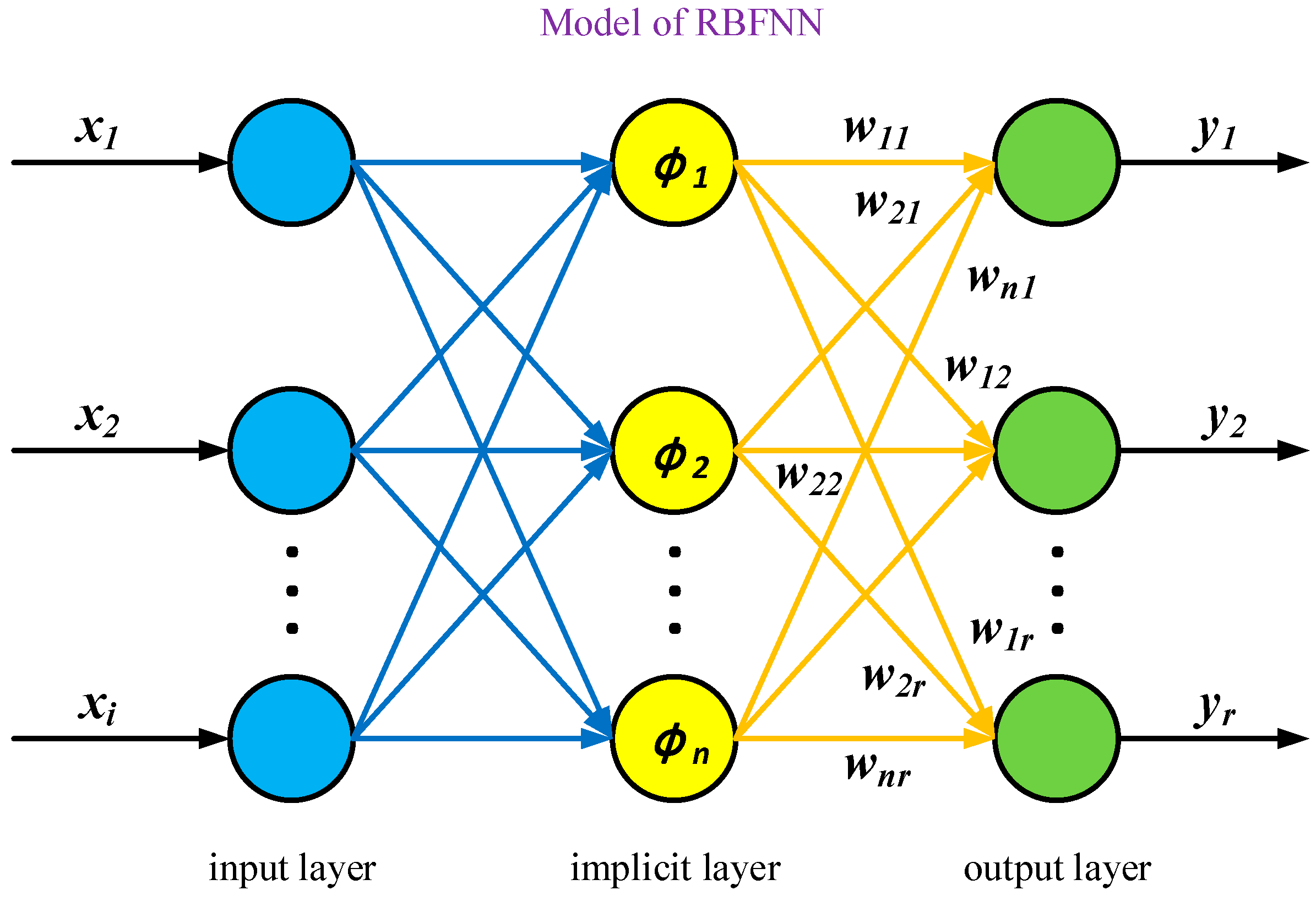
In the research of fixed-time convergence, linear systems predominantly garner attention. However, the space robot, as a prototypical nonlinear system, confronts the challenge of unavailable or inaccurate actual parameter values, complicating precise control and diminishing tracking performance. In addition, due to the interference of harsh environmental factors in space, uncertainty may exist in the model of the space robot. To address the issue of dynamic model uncertainty in nonlinear systems, neural networks have garnered significant attention from numerous scholars. Among them, the radial basis function neural network (RBFNN) stands out due to its straightforward structure, high fitting efficiency, exceptional nonlinear approximation capabilities, and advanced global approximation capabilities. It excellently compensates for unknown elements within dynamical models, making it one of the most commonly used methods for addressing nonlinear control model uncertainties. Ref. [
25] investigated an end-to-end neural network controller for optimal control of a quadcopter. Ref. [
26] proposed an adaptive neural network force tracking impedance control scheme based on a nonlinear observer. In Ref. [
27], an adaptive law is proposed to estimate the local upper bounds of the subsystems of a non-complete mobile robot, based on the developed robust adaptive neural network tracking controller. In [
28], for a flexible-joint free-floating space robot vibration suppression control orientated on error models, a reliable control technique based on an adaptive neural network is suggested. Ref. [
29] use an acceleration feedback-based RBFNN control technique to stifle self-excited vibration and ensure position precision. A general motion planning framework based on deep reinforcement learning and artificial neural networks is proposed in [
30] for a robot with arbitrary geometry. Ref. [
31] investigates the neural network-based control problem for robotic systems with error constraints. Ref. [
32] developed a nonsingular fixed-time adaptive neural control scheme via backstepping technique for a free-flying flexible-joint space robot when capturing a space target with unknown mass. Given the unique advantages of neural networks in approximating nonlinearities quickly and with high fitting efficiency, this paper eliminates the nonlinear effects of the space robot by designing a radial basis function neural network. Furthermore, compared to the traditional radial basis function neural network, the proposed update rate enhances the learning rate and iteration efficiency of the neural network.
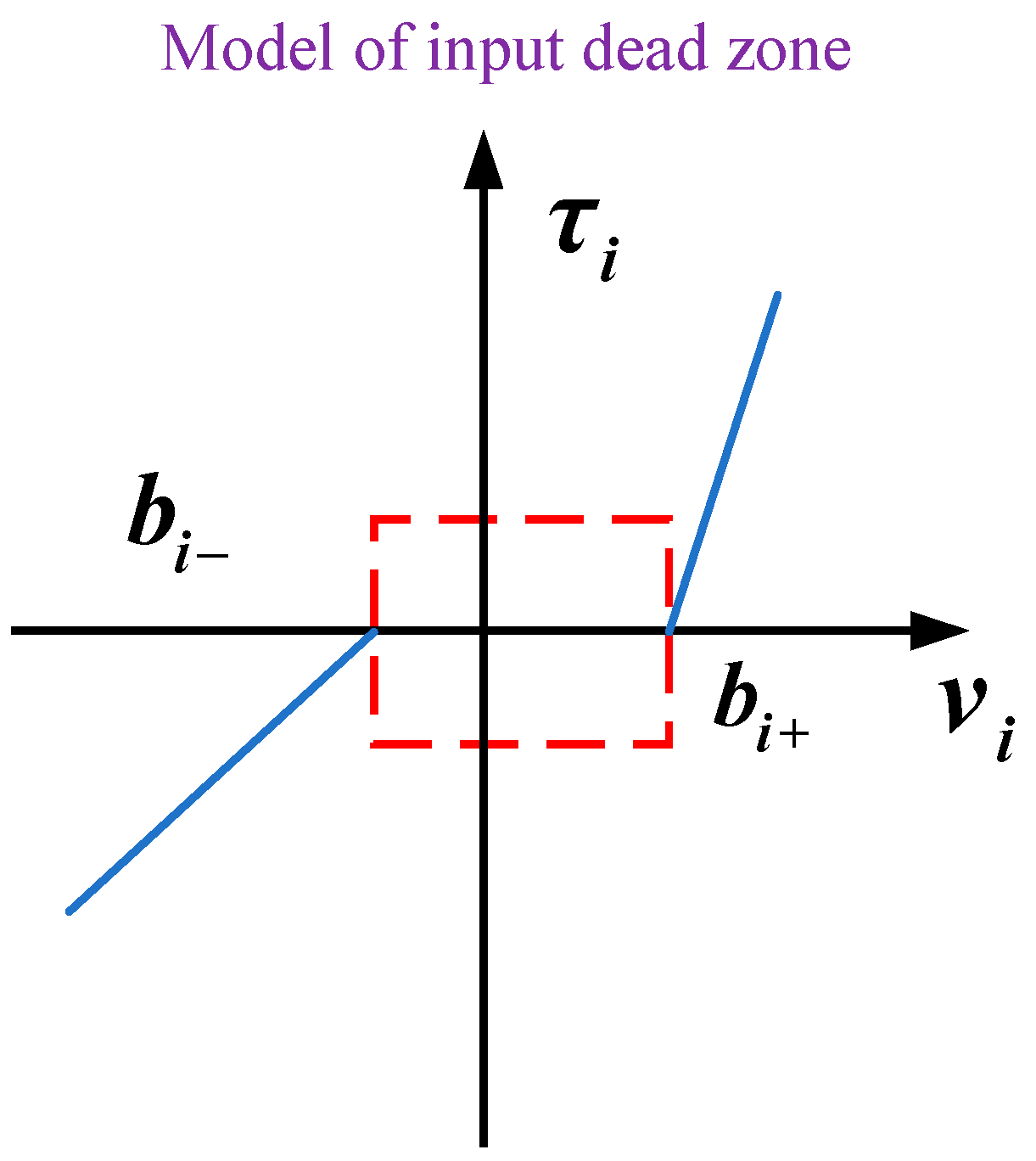
In space robots, joint dead zone characteristics are very common due to friction between the joints and the lack of sensitivity of sensors and actuators to subtle signals. The meaning of dead zone characteristics is that, until the input torque of the joint reaches the boundary value of the dead zone, the system’s output torque remains zero. In the control process of the space robot, the dead zone is a significant factor affecting the precision and stability of the control system and cannot be overlooked. Dead zone phenomena are commonly observed in the control systems of space robot actuators, where most of these phenomena are unpredictable and sporadically changing, exerting a profound impact on control precision, potentially causing system control failure and ultimately leading to the inability of the space robot to complete its space mission. Ref. [
33] address the matter through the design of a compensator aimed at mitigating the impacts of uncertain non-linear systems characterized by dead zone input nonlinearities and unspecified dead zone parameters. Ref. [
34] introduce converting the dead zone model into a nonlinear model that can be approximated by a fuzzy logic system to mitigate the impacts of the dead zone. In [
35], the backstepping method and the obstacle Lyapunov function are used to examine an uncertain manipulator with complete state restrictions and input dead zone. In the presence of external disturbances and parameter uncertainties, Ref. [
36] discusses the effects of a non-smooth dead zone during spacecraft attitude tracking operations. Inspired by the appeal work, the effect of the input dead zone on the space manipulator model must be fully considered during the system control process. Inspired by the aforementioned work, the impact of joint torque input dead zone on the space robot model must be fully considered during the system control process. Inadequate handling of a joint torque input dead zone may not only increase tracking errors but also cause limit oscillations in the system, leading to performance degradation or instability, thereby preventing the completion of pre-assigned tasks [
37,
38].
Based on the preceding discussion, the topics of fixed-time control, neural network compensation for uncertainties, and input dead zone remain pivotal in the field of space robot control, with substantial openness for further research. In [
39,
40,
41], although these situations were considered simultaneously, they were not space robots, and their methods do not account for the microgravity environment, kinematic redundancy, and contact uncertainty inherent to space robots. This paper proposes a fixed-time control strategy based on neural networks for space robotic systems with an input dead zone. By integrating fixed-time convergence into the design of model-based and neural network control methods, a new neural network update rate is proposed, which enhances the learning rate of the neural network and ensures the convergence of the neural network weights within a fixed time. Considering joint input dead zone issues affecting the precision and stability of space robots, a new adaptive law is designed by integrating system error feedback and neural networks into the controller to compensate. By using the Lyapunov stability theory, the stability of the closed-loop system is proved, with trajectory tracking errors and the neural network weights converging to a small region near zero. This control strategy not only compensates for the system’s uncertain terms, ensuring convergence within fixed time, but also eliminates the destabilizing effects of the joint input dead zone. A comparison with traditional PD and SMC controllers reveals that the proposed control algorithm demonstrates superior trajectory tracking performance, validating the effectiveness of the control algorithm.
The main contributions of this paper are as follows:
- (1)
For a space robot with an input dead zone, a fixed-time control algorithm based on neural networks was proposed on the basis of model-based control algorithms. This algorithm ensures the rapid tracking of desired trajectories by the manipulator and converges the error to a small neighborhood of zero within a fixed time.
- (2)
The proposed neural network update rate ensures the convergence of the neural network weights within a fixed time, handles uncertain system inertia parameters, and simultaneously enhances the learning rate of the neural network.
- (3)
A novel adaptive law was designed to compensate for an input dead zone based on feedback from the system’s error signal, thereby enhancing both the accuracy and stability of the system.
3. Controller Design
For the free-floating base space manipulator system, define
as the expected trajectory of the system, the tracking error being
serves as a virtual control law designed for the subsequent sections, and additionally, a time-varying switching function is to be designed as follows:
where
is a normal constant,
is the order of the system,
is the base of the natural logarithm function, and
is a custom time.
Let
with
being the
ith element of
, introducing the barrier function:
where
and
are positive functions that depend on the time of the bounded variable
, with
denoting the lower bound and
denoting the upper bound.
Remark 1. If , will establish the rate of convergence of the shift function (11), when is sufficiently small, as tends to 1, will converge rapidly to . If , can be obtained through Equation (11), then . Thus, if and only if or . If we can prove that is bounded, then can be guaranteed. This also implies that, by employing the barrier function (11), the originally constrained system is transformed into an unconstrained one. It should further be noted that when is applied, the system transitions to a conventional control type, with constraints imposed at the onset of operation.
Expanding the derivative for a yields
The elements of the above equation are
3.1. Model-Based Fixed-Time Control
Substituting (8) into the above Equation (12), we obtain
Bringing (9) into the above equation yields,
is the virtual control law designed in (17), which can be obtained as
Constructing the Lyapunov function candidate
Then, calculating the time derivative of
,
, therefore
Design the virtual control rate
as
where
,
are positive definite matrices.
Remark 2. According to the configuration, there are no singular points in the virtual control rate (17), and for the term , it is necessary to apply a smooth approximation to this function. A normal constant can be chosen to satisfy condition , with adjustments made to the value of to accommodate the system feedback, thereby achieving optimal results—adjusted to adapt to the system feedback to obtain the best result.
Substituting (17) into (16) yields the desired outcome
According to (9) and the kinetic (1), it can be obtained that
The transformed form, which is
Therefore, based on the appeal derivation, the Lyapunov function is then constructed as
Putting (20) into (21) and solving for the derivative, the time derivative of (22) can be obtained as
According to the literature [
44],
is a matrix with skew symmetry and its definition shows that
holds for
. Based on this property, the aforementioned equation can be rewritten as
where
, within the fixed-time convergence framework, we can propose control rates.
where
,
are positive definite matrices.
Taking the controller (24) into (23), we get
Let
,
, combining Lemma 1 and Lemma 2. yields
Theorem 1. With regard to the space manipulator (1), the proposed controller (24) enables fixed-time convergence of the closed-loop system, where the settling time function satisfies condition
Proof. From (26), we can assign , , , , put these values into (7) in Lemma 4, and (27) is proved. □
3.2. Fixed-Time Control Based on Neural Networks
Uncertainty in the model arises from nonlinearities and dead zone effects in the space manipulator, precluding the direct application of the previously mentioned control strategies. Consequently, a neural network is introduced. Neural networks serve as effective tools for addressing model uncertainties, with approximations as shown below:
where
shows the approximate error that satisfies
with
and
which is unknown,
represents the input of the neural network,
denoting the weights of the defined neural network, and
representing the combination of Gaussian basis functions.
Define
as an estimate of
,
. The control rate can be expressed as follows when using the neural network approximation:
The design update rate is
:
is a constant gain matrix, the role of the constant gain matrix lies in weighting the gradients of the neural network, facilitating adjustments that accelerate convergence during the weight update process. In certain cases, the gain matrix mitigates issues such as the explosion or disappearance of gradients.
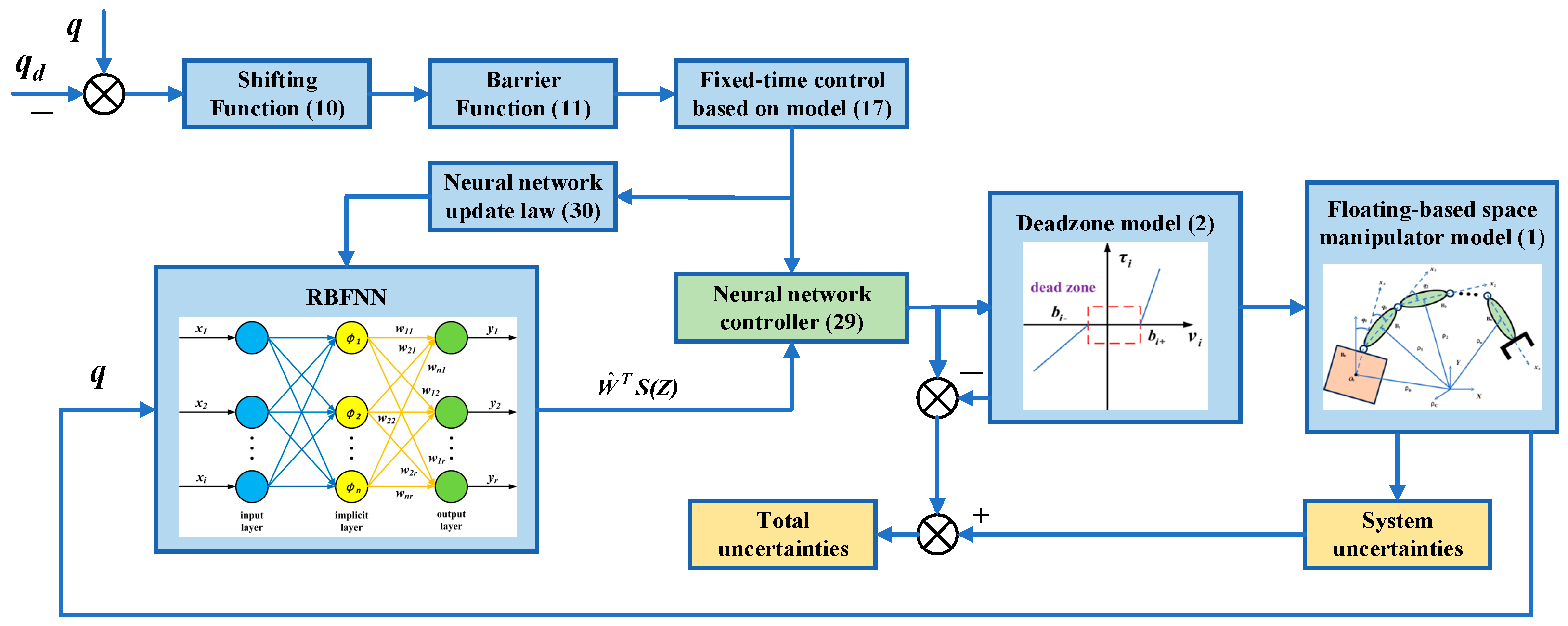
is a positive robustness term; positive robust factors help neural networks control parameter updates during training by providing additional constraints or stability mechanisms. This not only improves the robustness of the model in the face of uncertainty and noise but also helps accelerate convergence and avoid training instability. The diagram of the NNFT controller is shown in
Figure 4.
Then, the Lyapunov function is designed as
Considering (22) and (29), the time derivatives of (31) are
where,
, the update rate (30) is brought into (32) to obtain
It is worth noting that .
Therefore, given the equation that will be shown later, first determine a few of its elements:
can be broken down into
According to Lemma 3, it can be obtained that
where
,
, can be obviously seen in
. Therefore, (34) can be rewritten as
From the derivation of the equation above it is known that
Let ,
, (35) above becomes , where .
Based on Lemma 4 and the design above, the following theorem can be provided.
Theorem 2. For the space manipulator described by (1), the closed-loop system achieves fixed-time convergence under the control (29) with the updating law (30), and the settling time function is satisfied
Prove
when
, . Hence it can be concluded that is bounded and . Considering in (31), it follows that , , and converge in a specified amount of time to the compact set. Next, two instances are examined to demonstrate convergence of the errors in fixed-time , , and . They are defined as Case 1. For , when , , and therefore always satisfy . By the definition of , it follows that , , and converge in fixed time and ultimately to the compact collection , , and , respectively.
Case 2. For , there is . By (31), we have , it follows from Lemma 4 that converges to the set at a fixed-time, and the following inequality applies to the set time function ,. Due to , it follows that , , . This shows that converge in time to the compact set , which is assured to converge. Similarly, and will converge to in a fixed-time press, completing the proof.
Remark 3. As a result of Theorem 2, the virtual control rate (17) is bounded due to the boundedness of
, , and . Since the neural network is bounded, the actual controller given in (29) is also bounded.
Remark 4. The setting of fixed time is independent of initial conditions. According to (36), it is obvious that the setup time can be defined by using the control gains and without the initial state change. According to Theorem 2, the control gains and also affect the sizes of , and
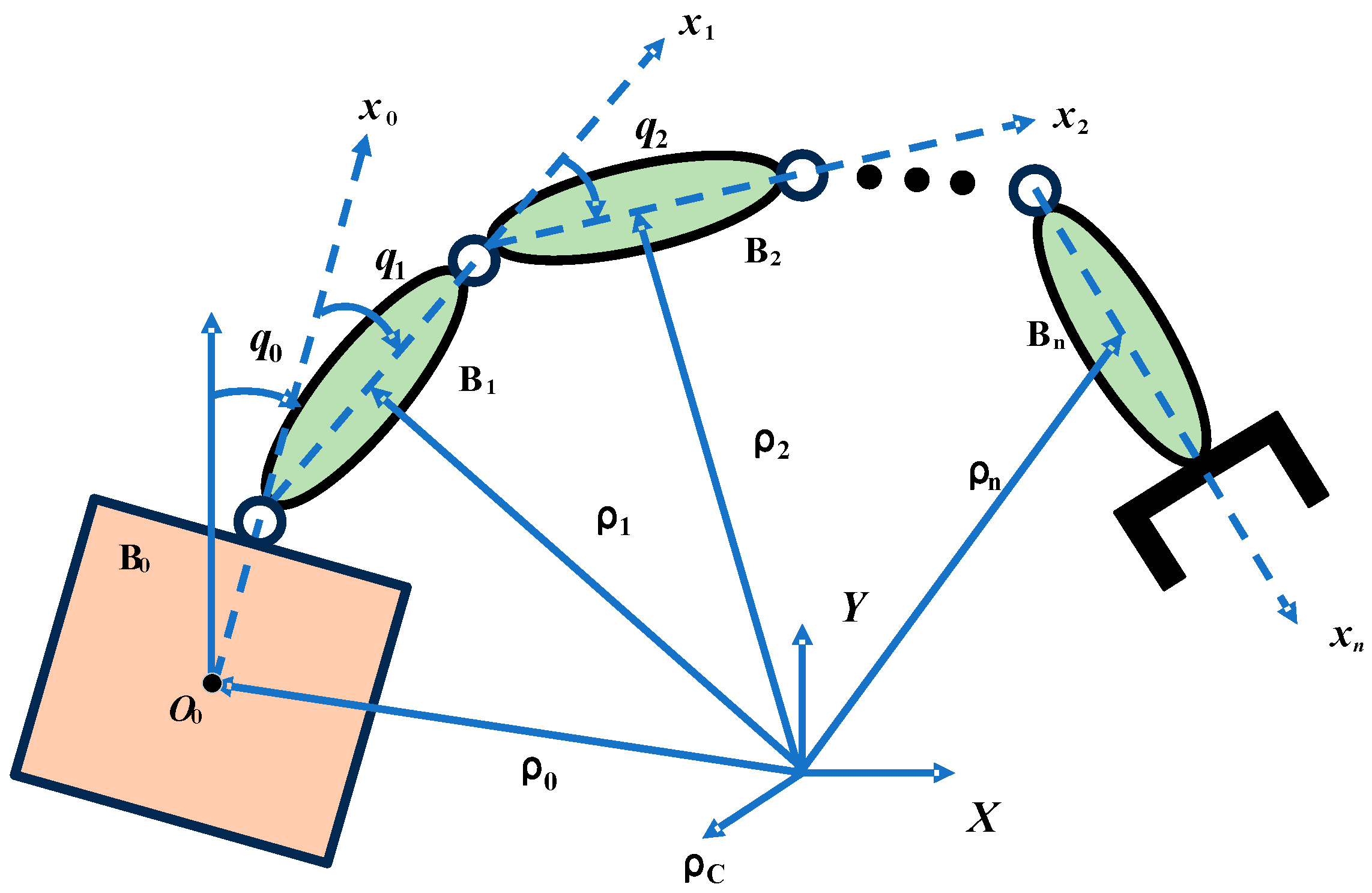
4. Numerical Simulations
To verify the effectiveness of the designed control algorithm, a system simulation is conducted using the space manipulator model depicted in
Figure 1. The following system inertia parameters are taken:
The proposed simulation parameters are given as follows:
The virtual control rate and the control gain of the controller are:
The parameters of the RBFNN are taken as follows: the number of base functions , the parameter of the center position of the basis function is taken according to the input range of the neural network, and its width is set to 5.
The initial state of the system is as follows: , , and ; the second initial value is the following: , , and ; the third initial value is the following: , , and . The desired trajectory of the configuration is the following: , , and . The simulation time is taken as 30 s.
4.1. Example 1
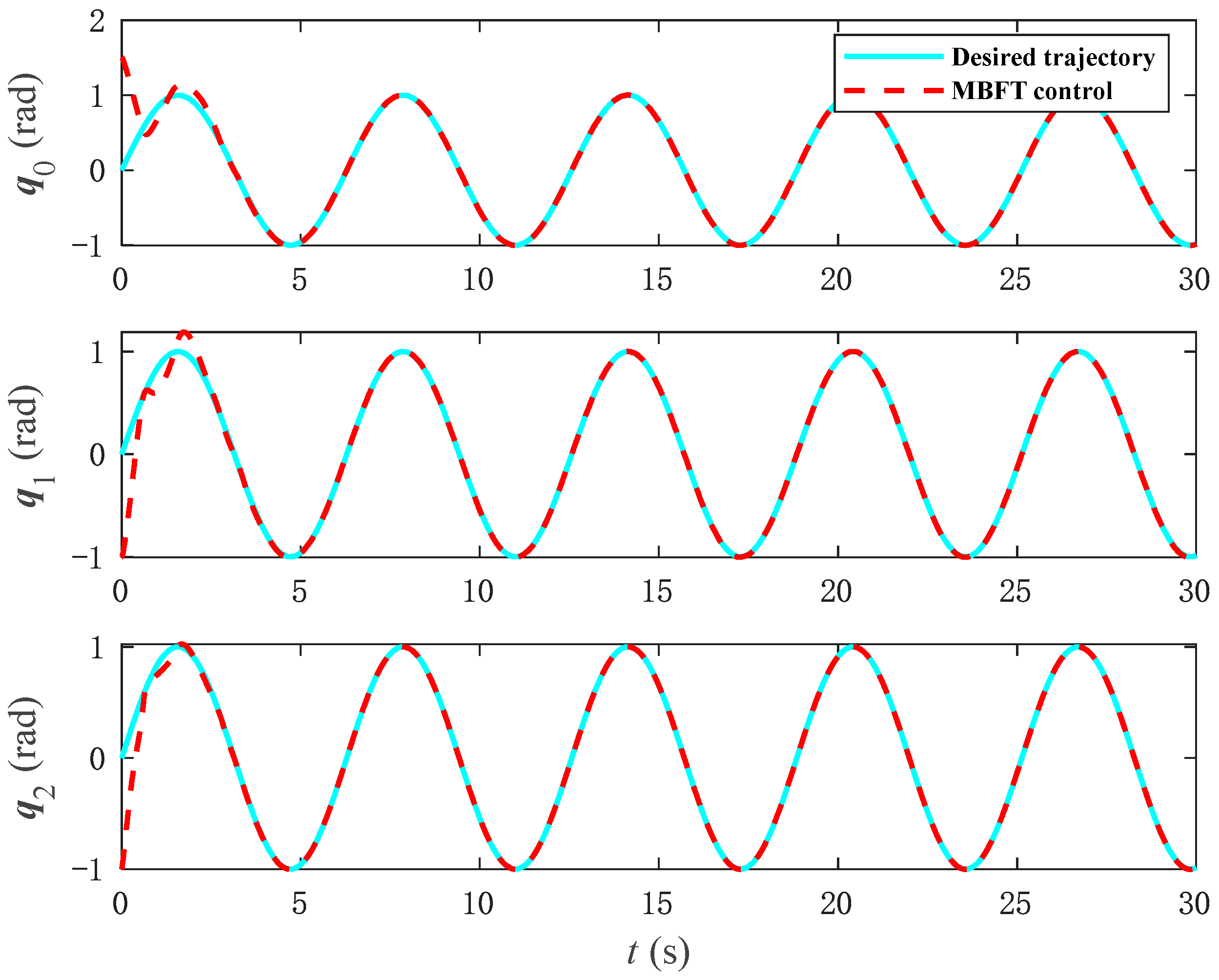
The simulation results of tracking performance based on model control are shown in
Figure 5 and
Figure 6. As illustrated in
Figure 5, the model-based control method achieves rapid convergence within a fixed time period and demonstrates excellent tracking performance.
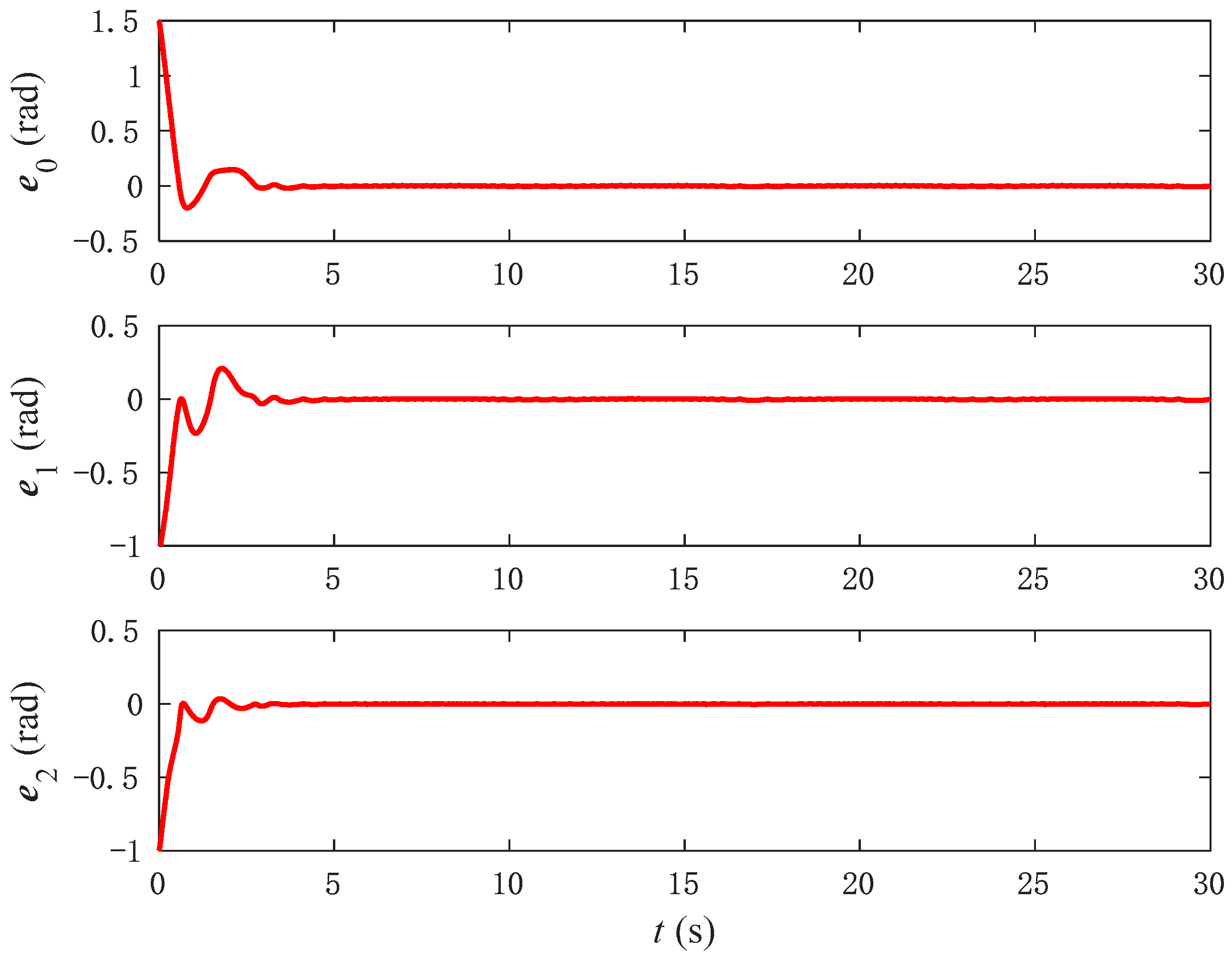
Figure 6 illustrates the error conditions corresponding to the three joint angles. Based on the simulation results, it can be observed that, although the tracking errors of the three joint angles are small and eventually converge to a subset near zero, noticeable fluctuations still occur, particularly with significant error variation within the 0–3 s interval. From
Figure 5 and
Figure 6, it can be inferred that system uncertainty significantly impacts model-based control methods.
Between the existence of an input dead zone and the uncertainties inherent in the system, the MBFT control method exhibits limitations in accuracy. Consequently, NNFT is incorporated to enhance the control approach. The MBFT is also a type of adaptive sliding mode control.
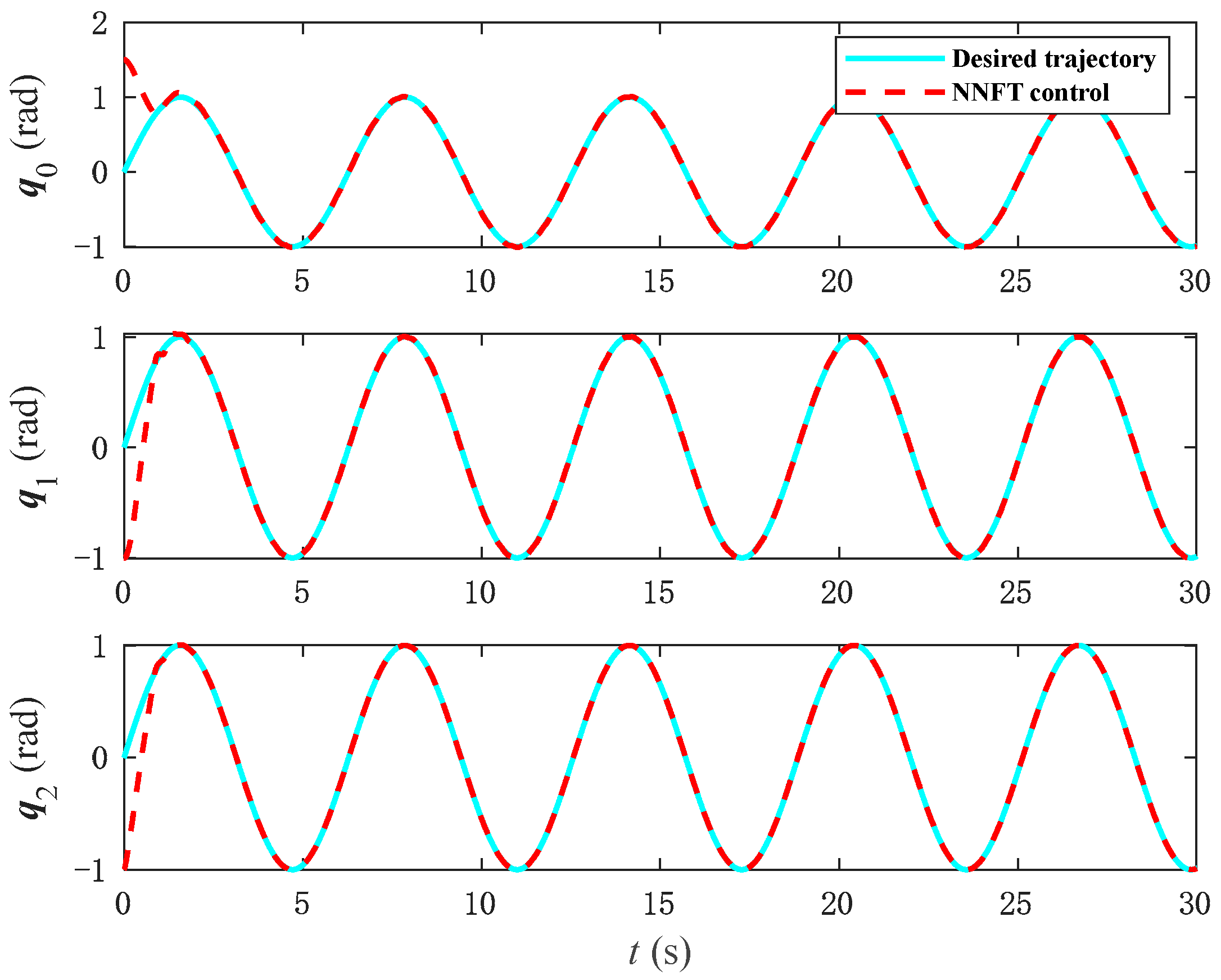
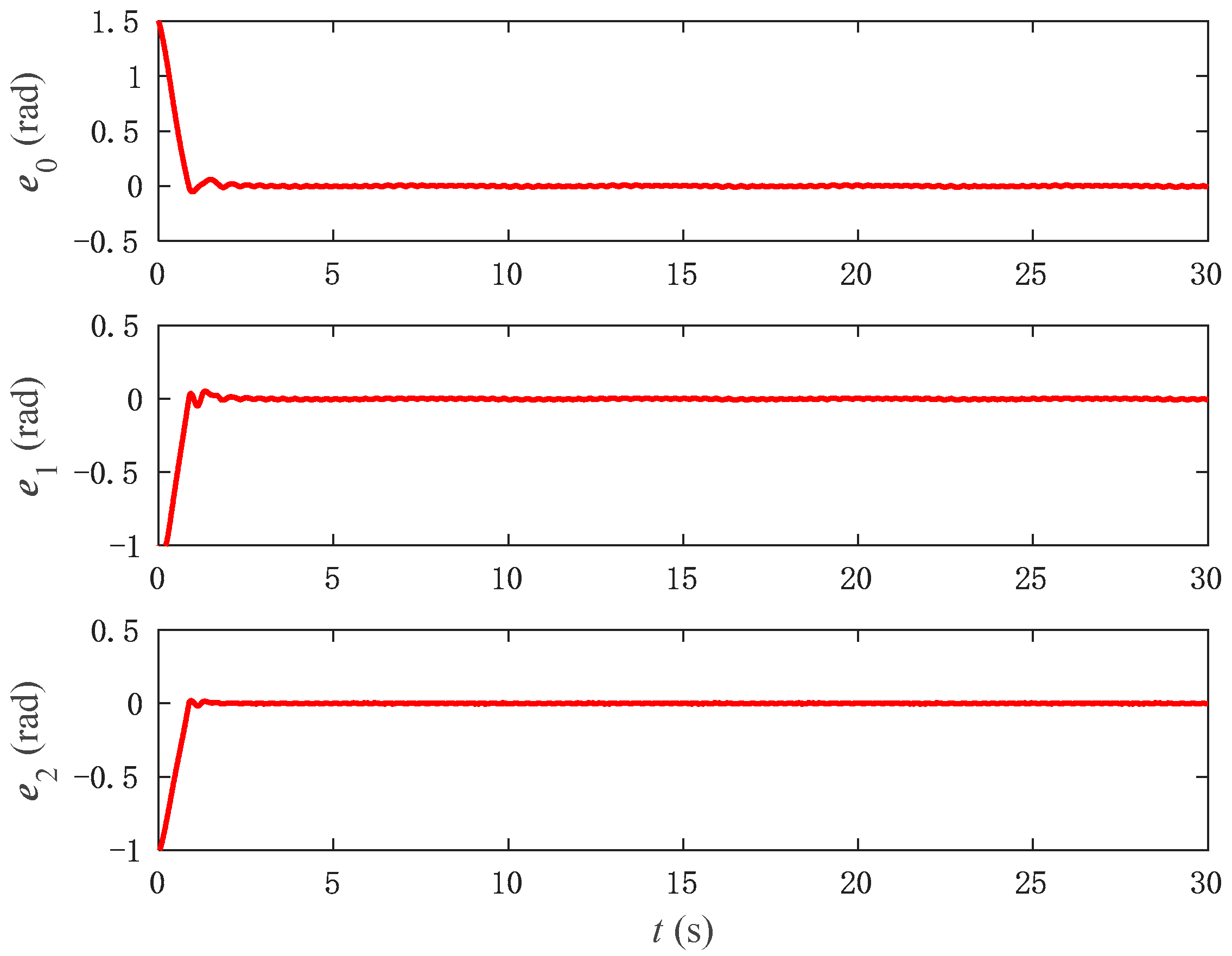
Figure 7,
Figure 8 and
Figure 9 depict the simulation outcomes of tracking performance under NNFT control. Specifically,
Figure 7 reveals that under neural network control, each joint angle of the space manipulator successfully attains the intended outcomes, as evidenced by
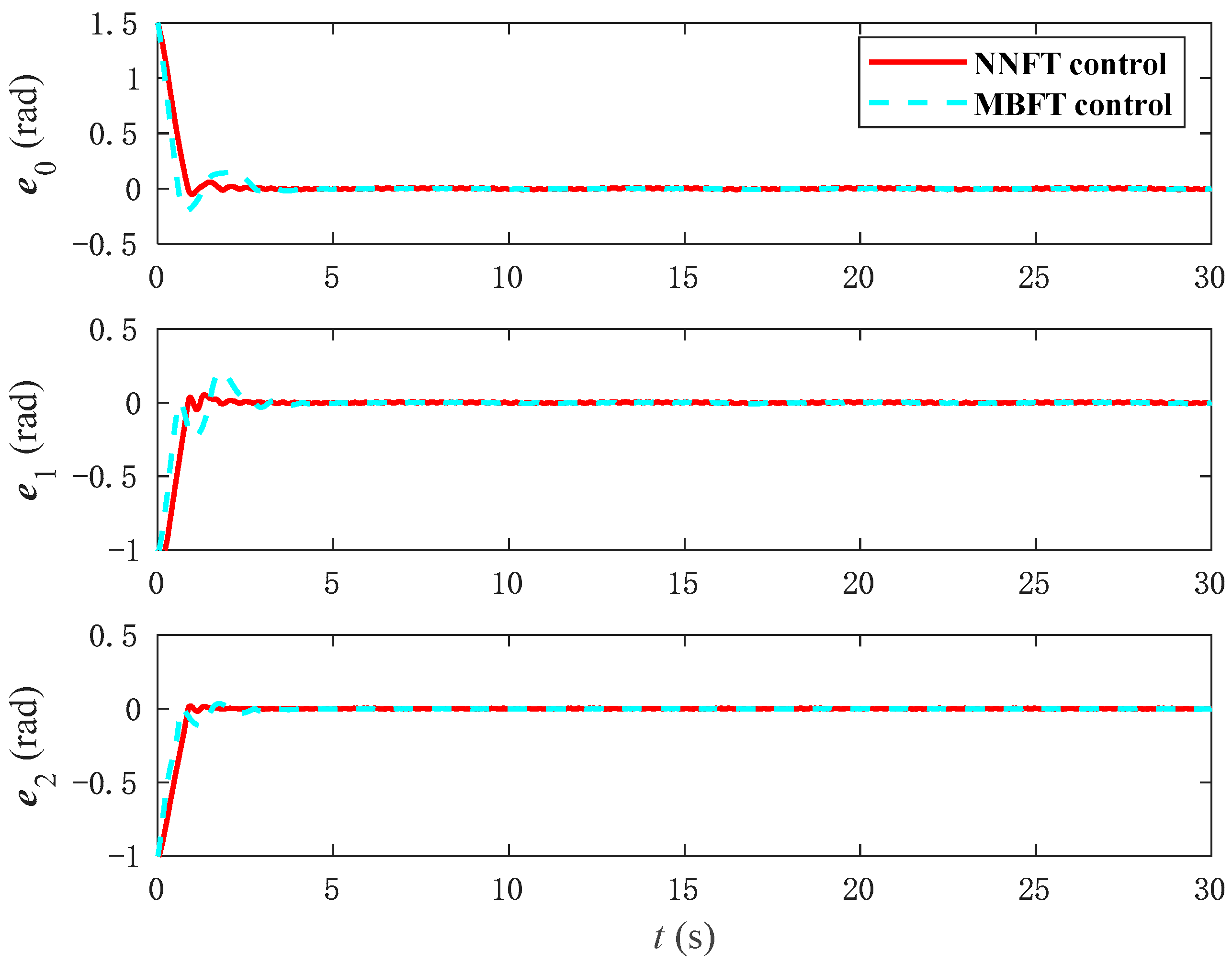
Figure 8. It is evident that the tracking error of NNFT control is smaller than that of the previous model-based control, with a faster convergence speed that rapidly converges to zero and exhibits minimal fluctuations. For a clearer visual comparison,
Figure 9 provides a comparison of the control errors between NNFT and MBFT. This underscores the superior performance of the NNFT control method compared to adaptive sliding mode control, where the neural network effectively compensates for the input dead zone and system uncertainties, resulting in stable tracking and improved accuracy.
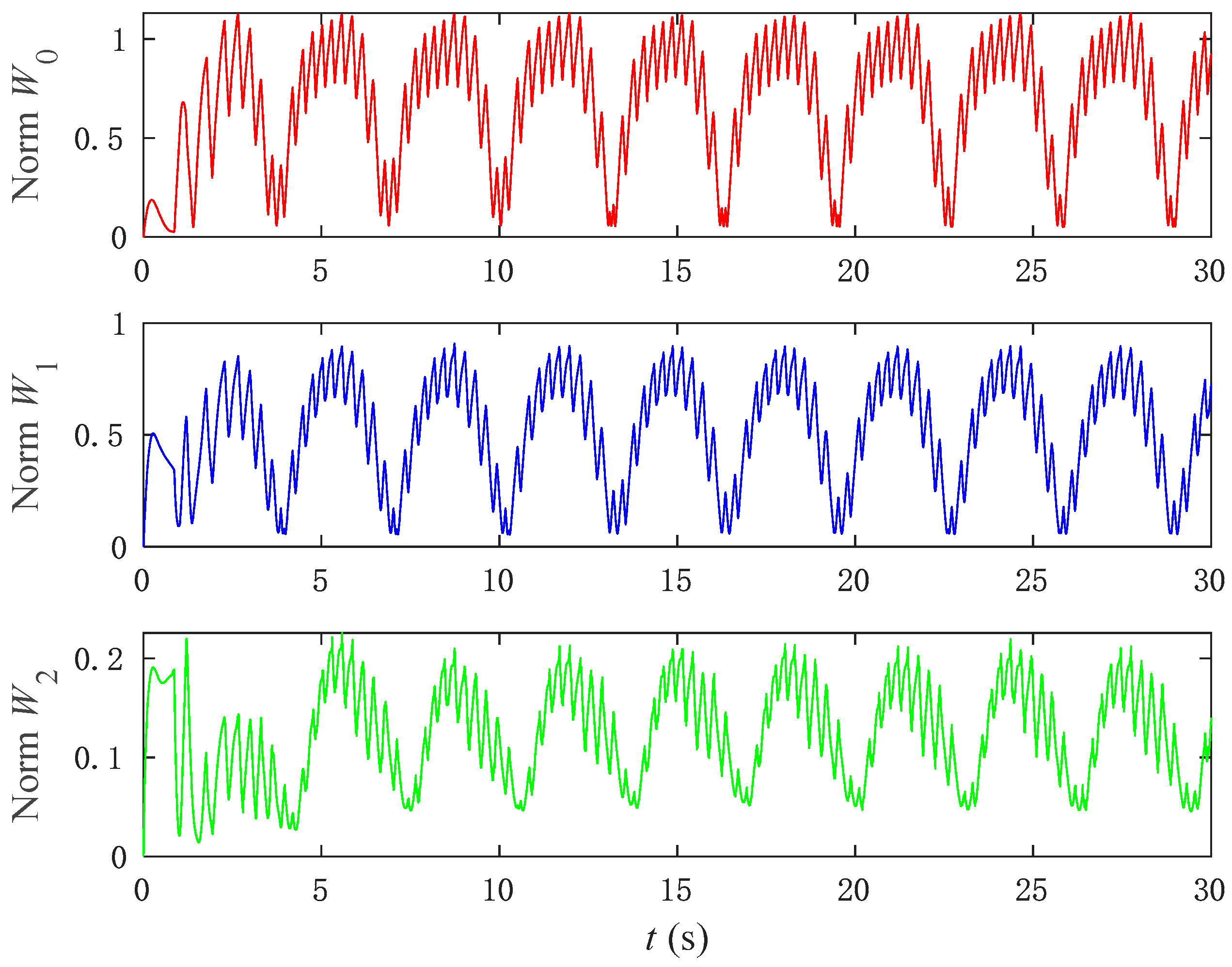
To further illustrate the effectiveness of the neural network, the updating of the weights of the neural network is analyzed.
Figure 10 shows the process of updating the weights of the neural network. As can be observed, the neural network’s weights converge over time within a bound, demonstrating the ability of the neural network to compensate for the input dead zone and approximate the unknown dynamics of the system.
4.2. Example 2
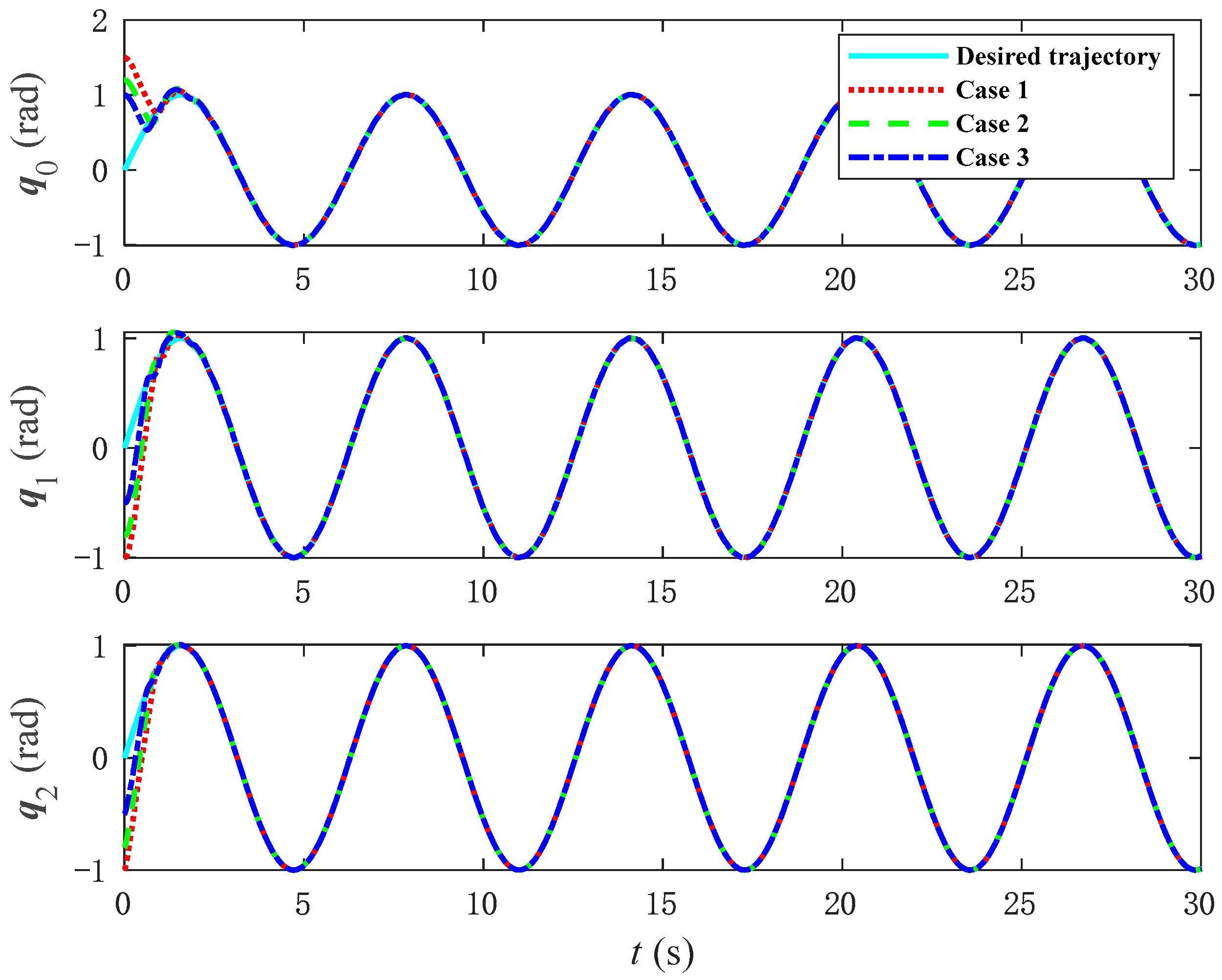
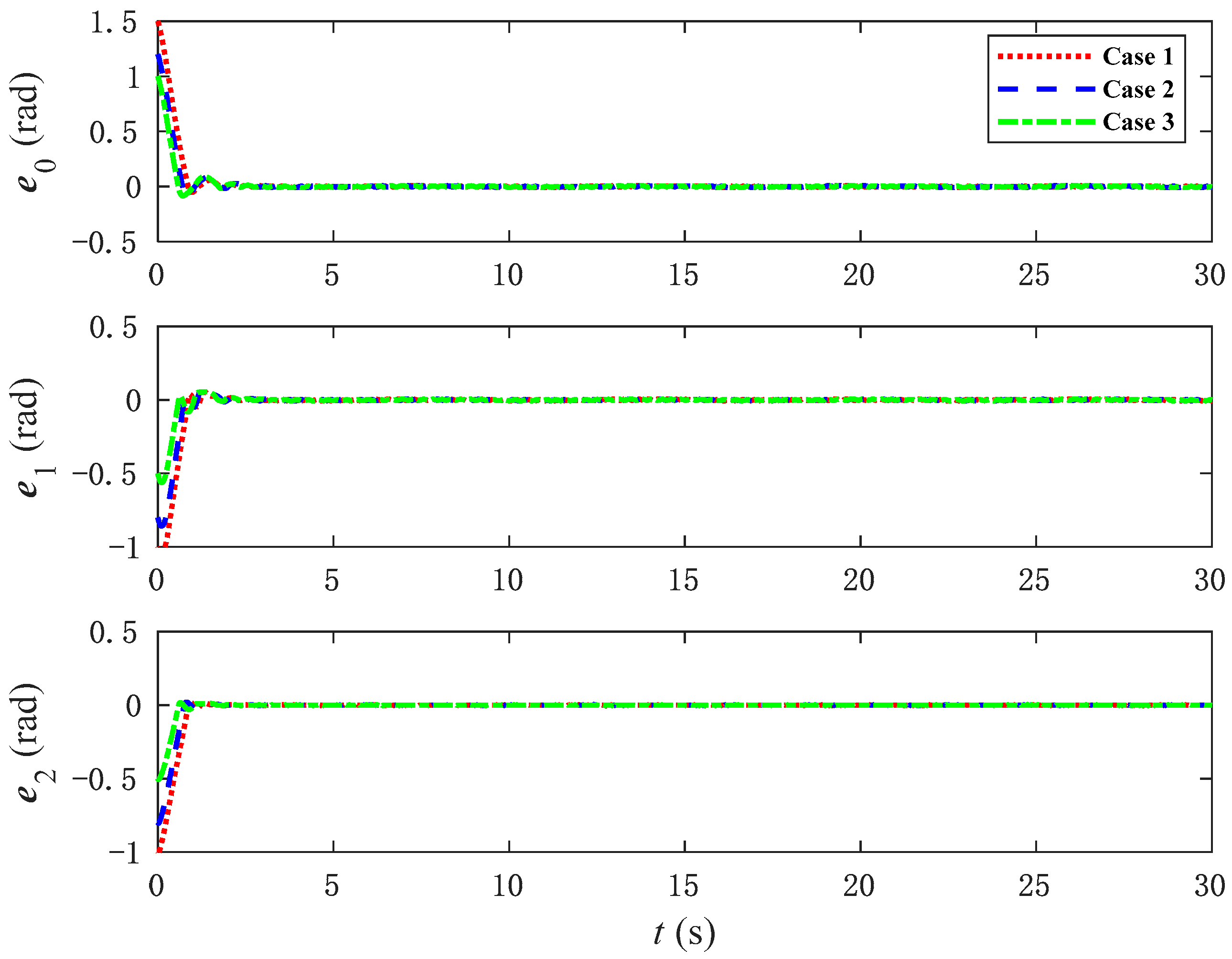
To verify the tracking performance of the NNFT control method, the initial values of the joint angles of the space manipulator are adjusted, and the tracking trajectories of the joint angles under different initial values are observed through simulation.
Figure 11 shows the tracking trajectories of Case 1 (
,
,
), Case 2 (
,
,
), and Case 3 (
,
,
) of the joint angles, respectively, and
Figure 12 shows the corresponding tracking errors. It can be observed that, even with changes in the initial joint angle values, the proposed NNFT control method can still quickly track the trajectory with good control performance and fast convergence speed, while maintaining a small error. It compensates for both the joint dead zone and system uncertainties. Regardless of variations in the initial joint angles, as long as they are within a reasonable range and do not reach the maximum singular value of the joint angle, the proposed control method based on neural networks remains fully effective.
4.3. Example 3
It is well known that traditional PD control offers high stability and is easy to implement, while sliding mode control has advantages such as higher precision, stronger robustness, better adaptability, and faster response speed. Therefore, the NNFT control method proposed in this paper is compared with these methods to verify the advantages of the proposed control approach.
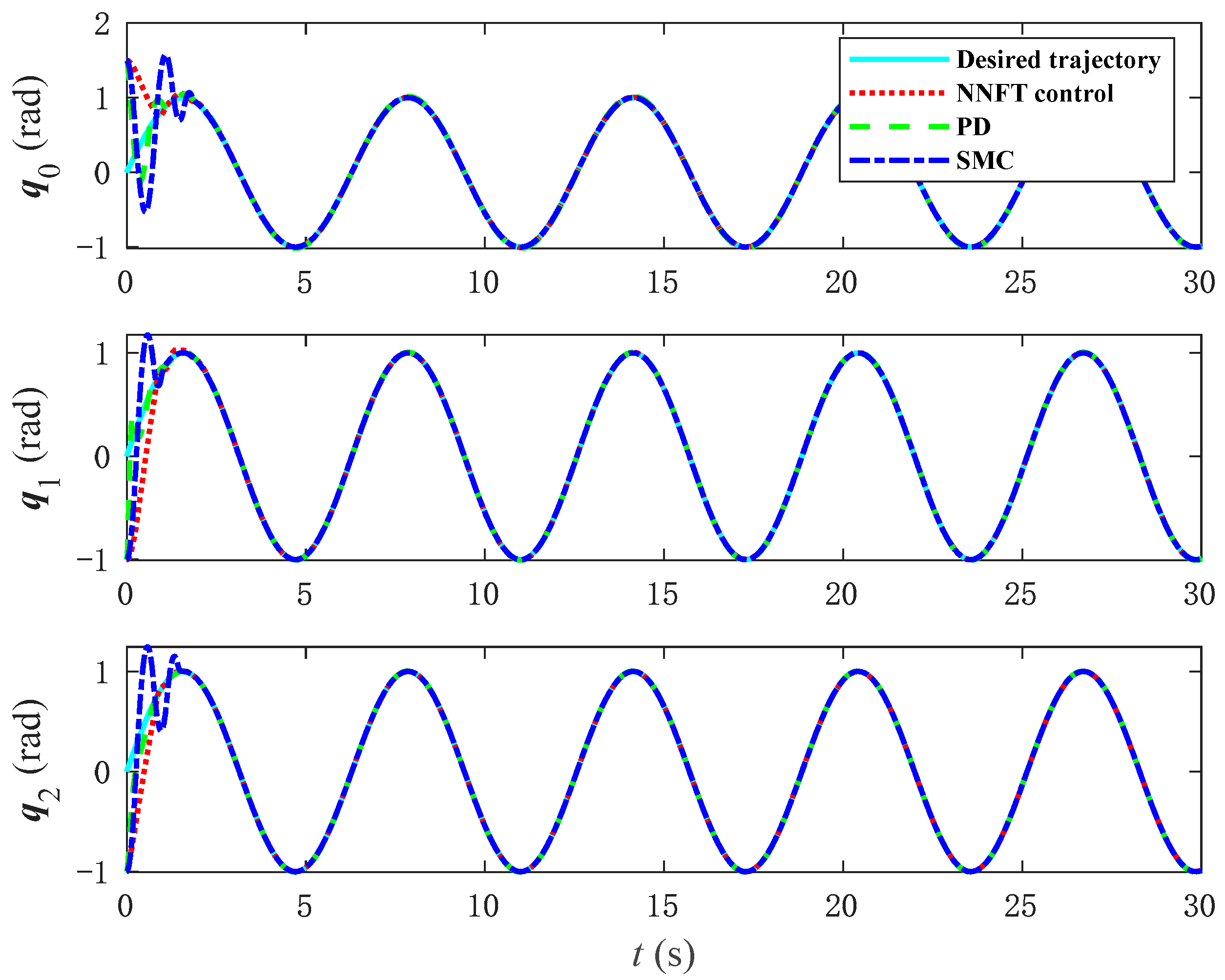
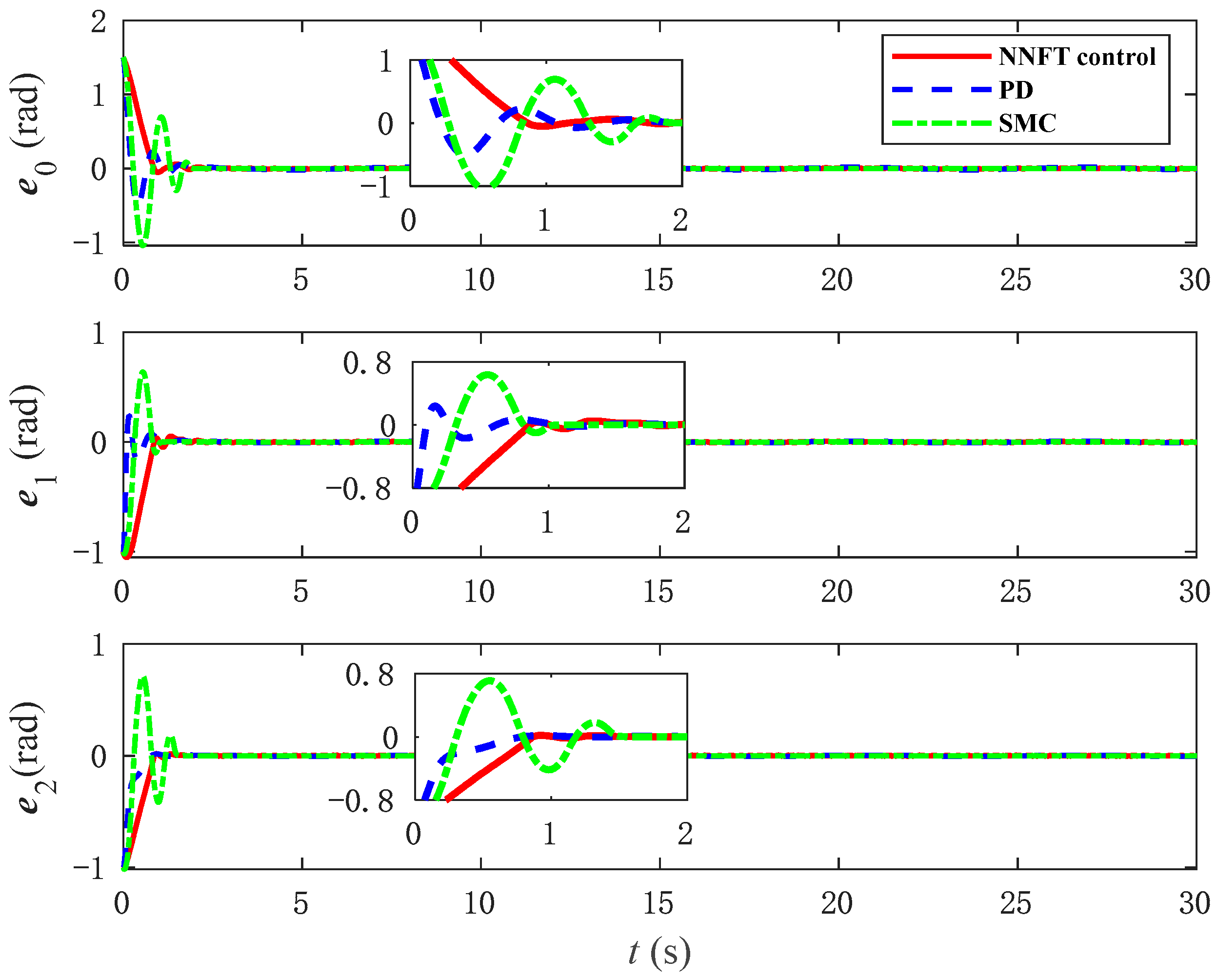
Figure 13 presents a comparative plot of joint angle trajectory tracking under three control methods, while
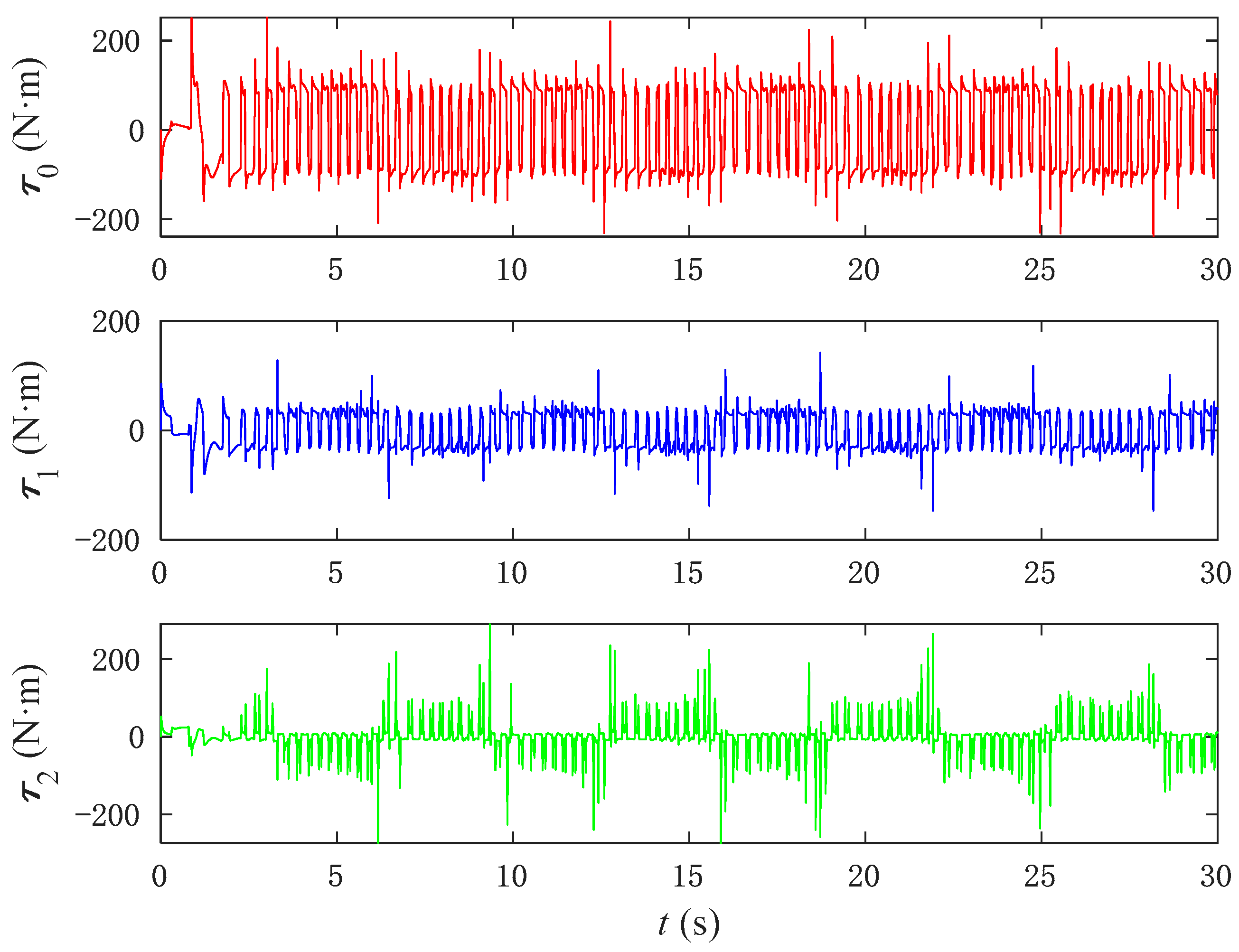
Figure 14 displays the corresponding tracking error graphs. As evidenced by the two diagrams, the NNFT control method proposed in this paper enables a smoother approach to zero in terms of posture. In addition, as indicated in
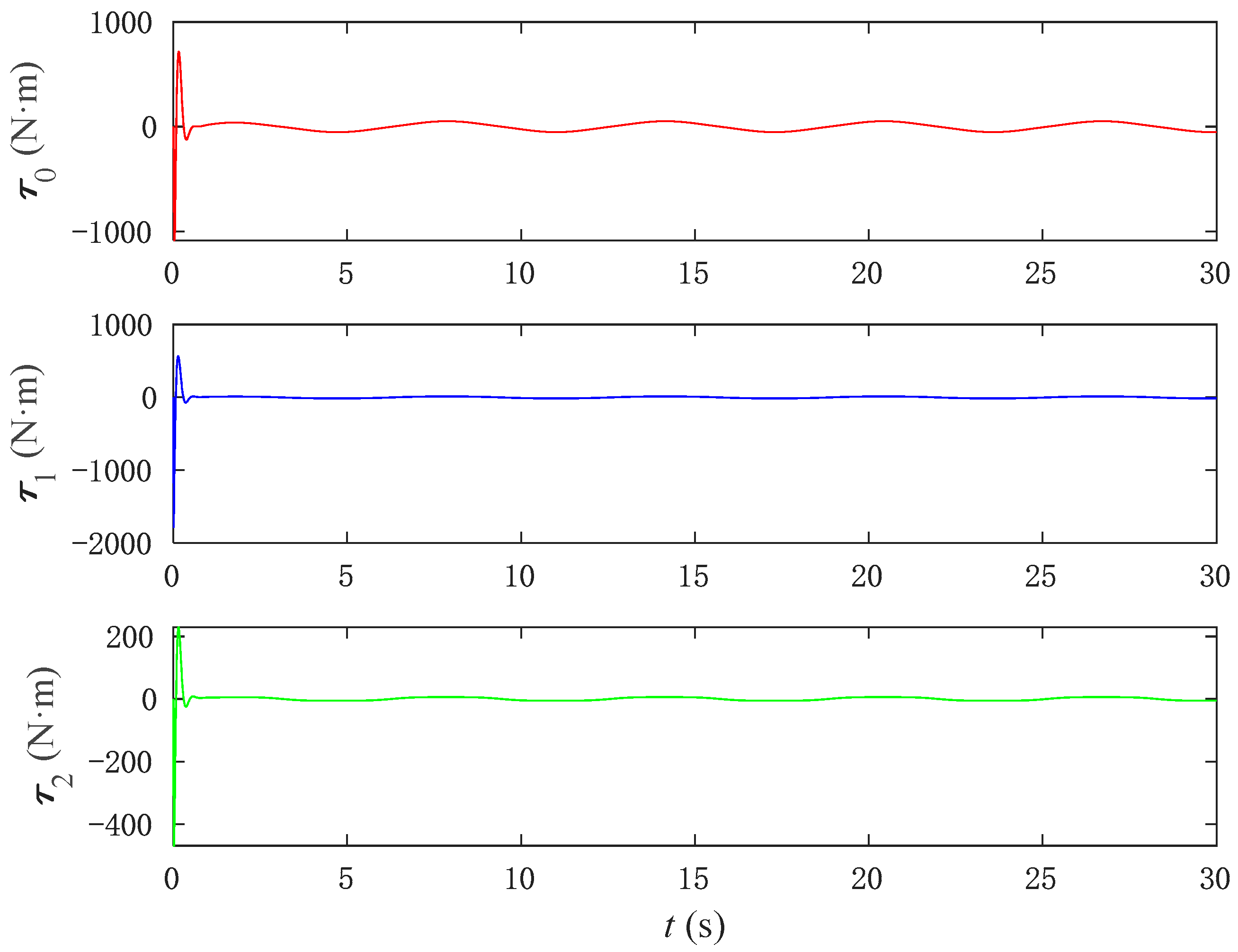
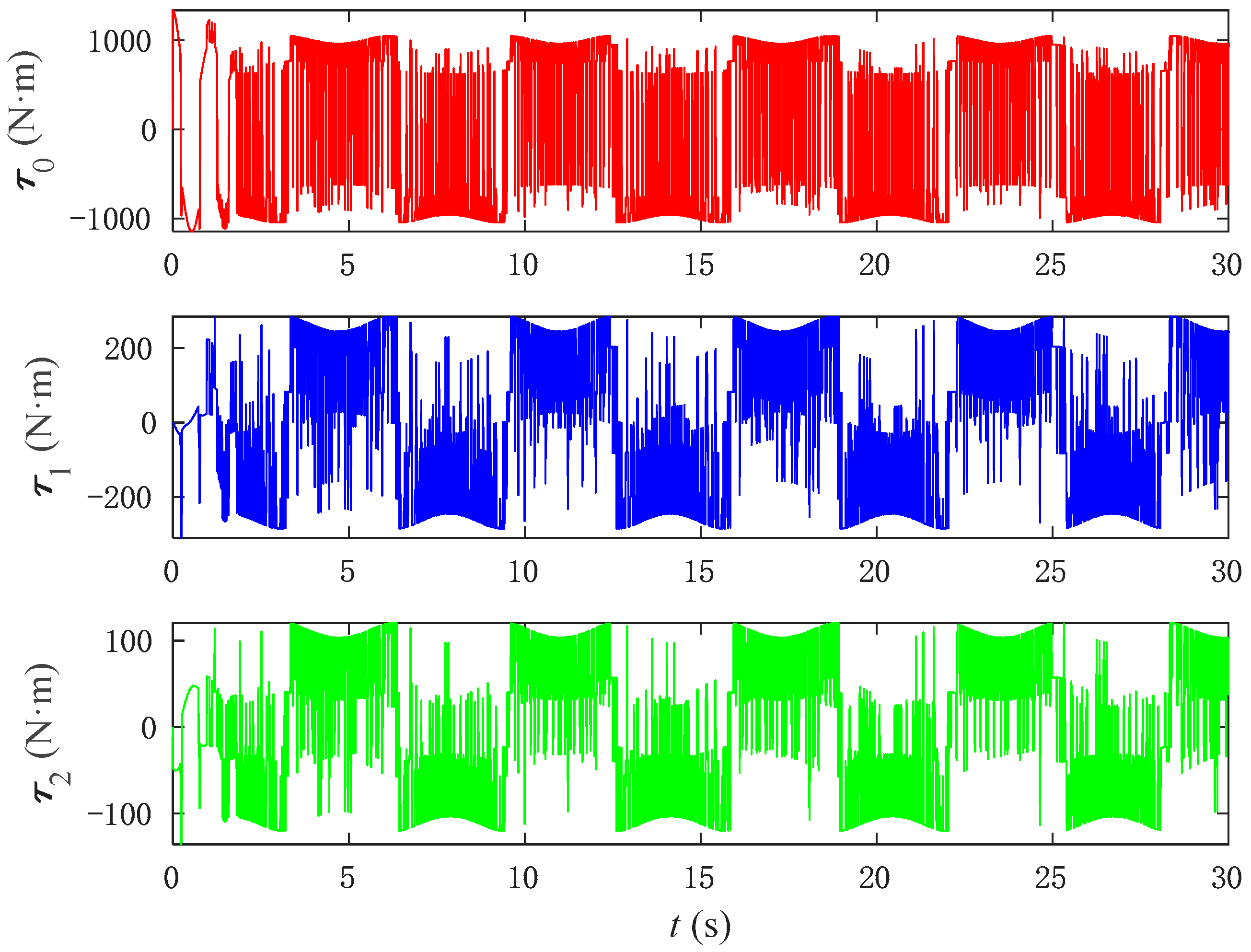
Figure 15, although the input torque of the PD control is relatively stable, it is excessively large, and such a large torque cannot be output in practical operating conditions. In
Figure 16, the input torque applied by the SMC to control the base joint angles is not only excessively large but also unstable across the joint angles. Compared to the NNFT control method shown in
Figure 17, the output torque generated is smaller, remaining within an appropriate range, and exhibits stable performance.
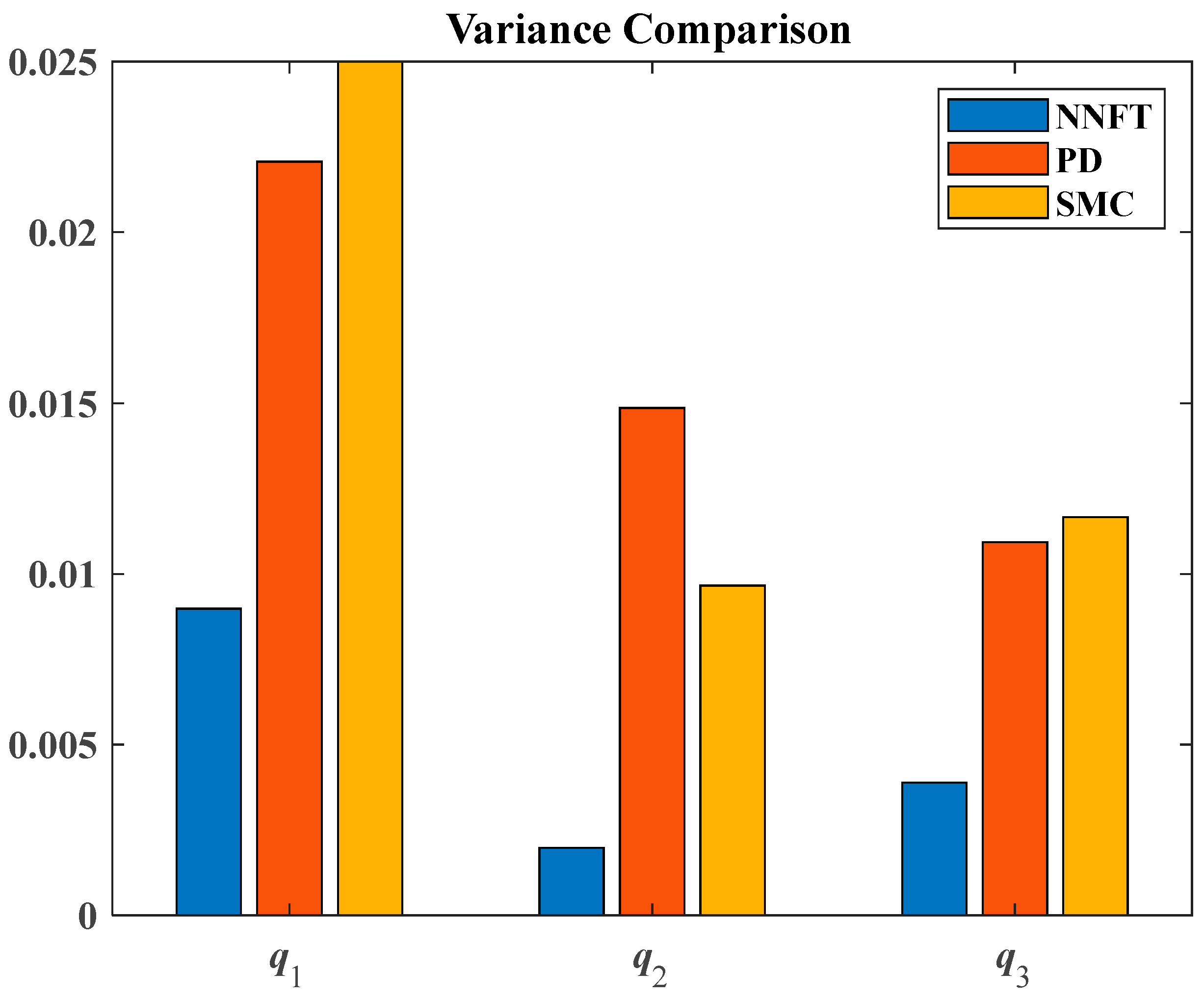
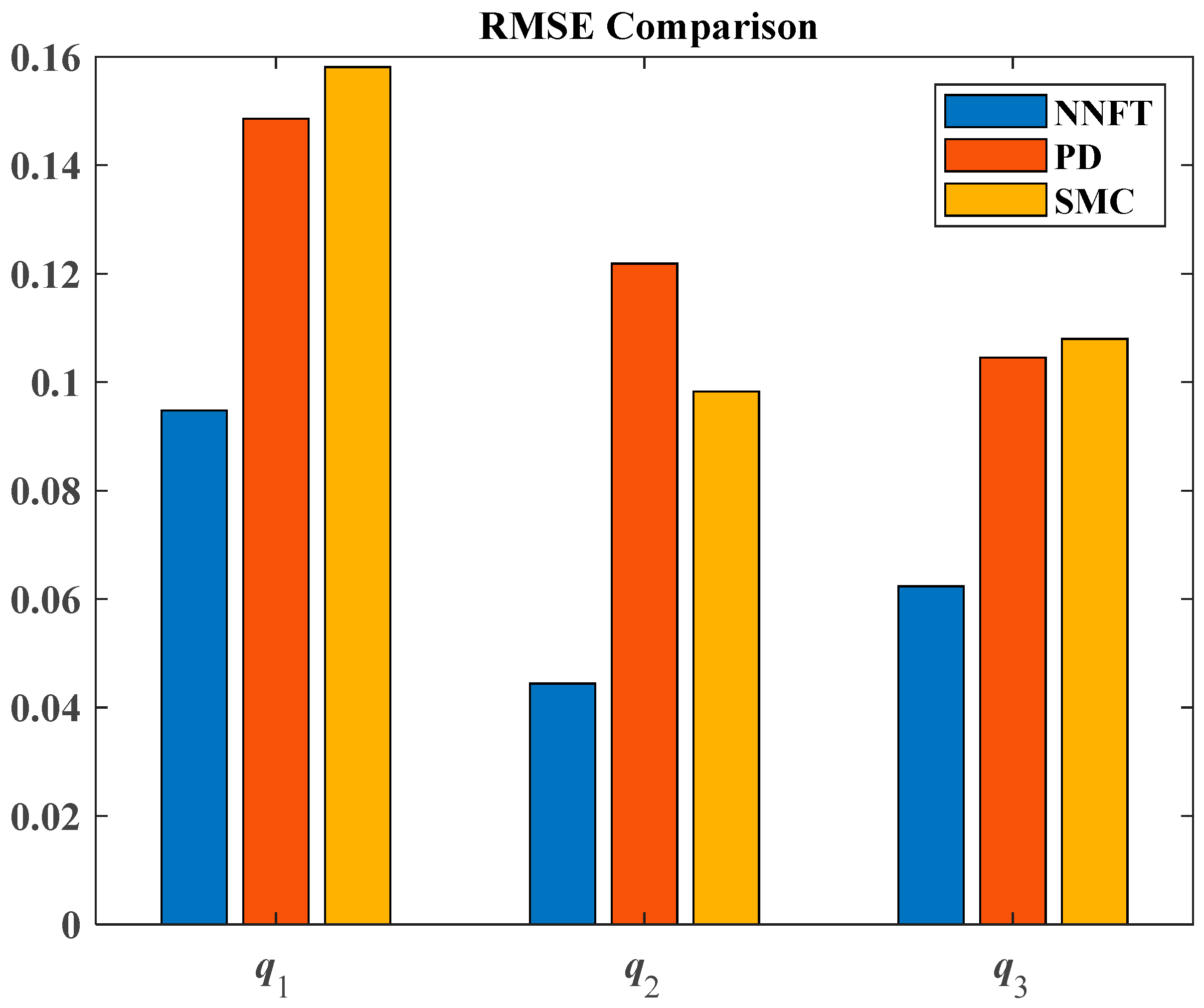
Figure 18 and
Figure 19 show the variances and root mean square errors of the three control methods, respectively. The bar charts indicate that the proposed control method has smaller error values, and has advantages. Based on the comparative analysis, the advantages of the fixed-time control method based on neural networks proposed in this paper are evident, demonstrating practical significance.
4.4. Example 4
In order to highlight the superiority of the neural network and its update rate proposed in this paper, we compared it with the neural network proposed in Reference [
46]. In Reference [
46], the passivity-based neural network (PNN) control used is mainly used to compensate for disturbance terms in the slow variable subsystem of a flexible space manipulator. We apply its network structure and update rate to the system in this paper.
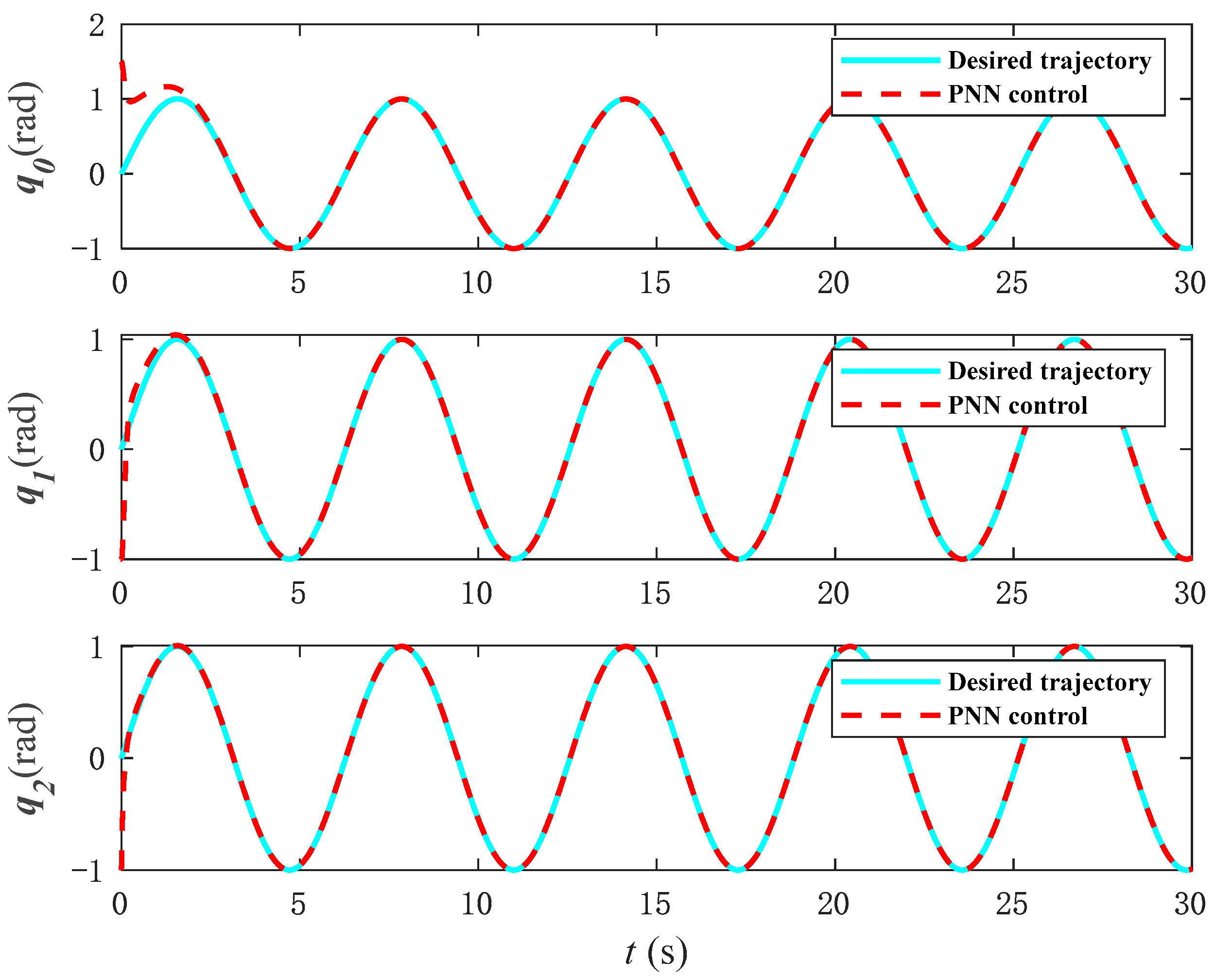
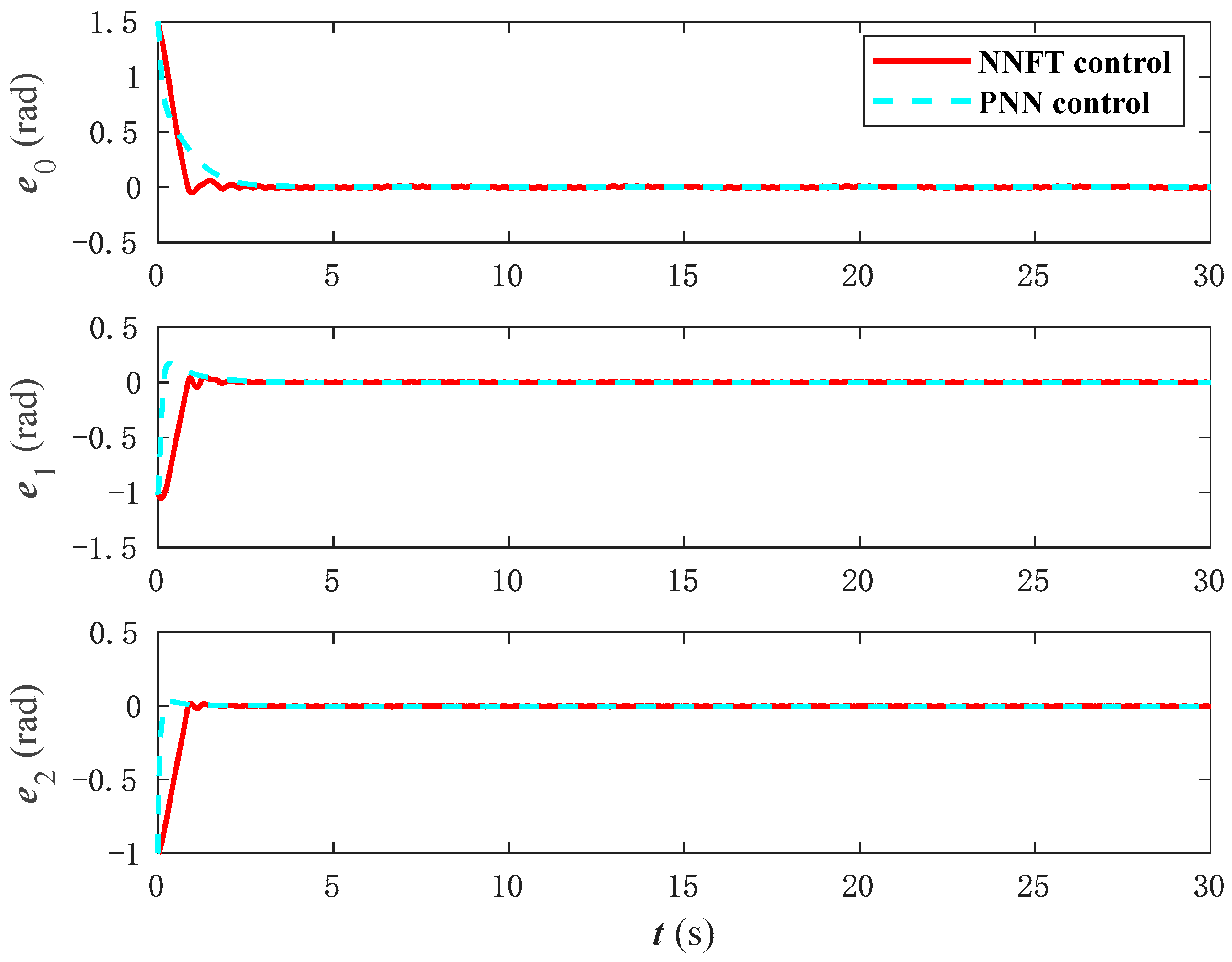
Figure 20 shows the control performance of PNN control, and
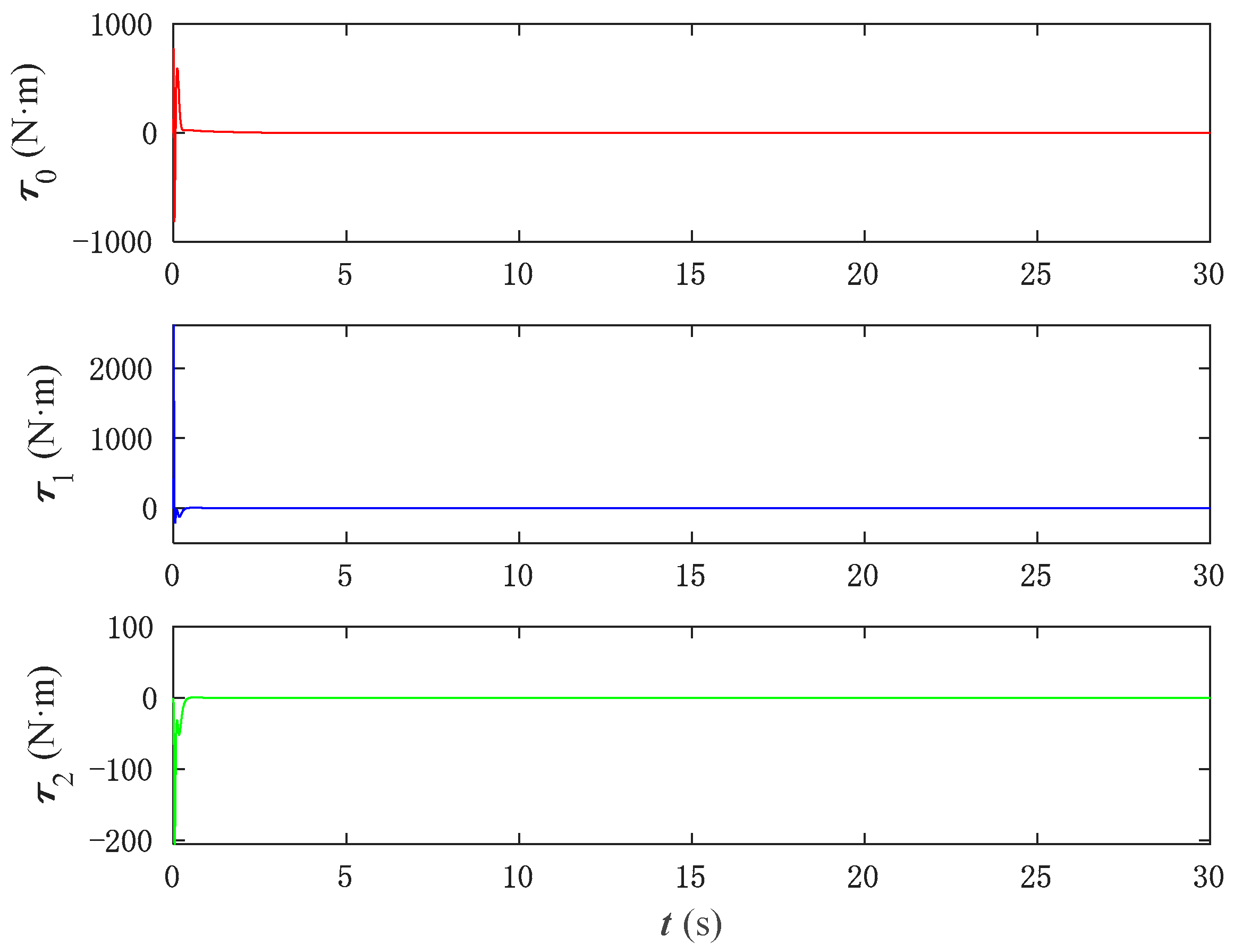
Figure 21 shows the error comparison between two control methods. It can be seen that the neural network control method proposed in this paper can converge and maintain stability in a faster time. However, from the torque input in
Figure 22, it can be seen that the PNN control will exceed the limit of the actuator when the torque is too large in the initial stage of system control, which is not advisable. Therefore, the neural network and its update rate of the control algorithm proposed in this paper have better control performance.

_Zhu.png)



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}