1. Introduction
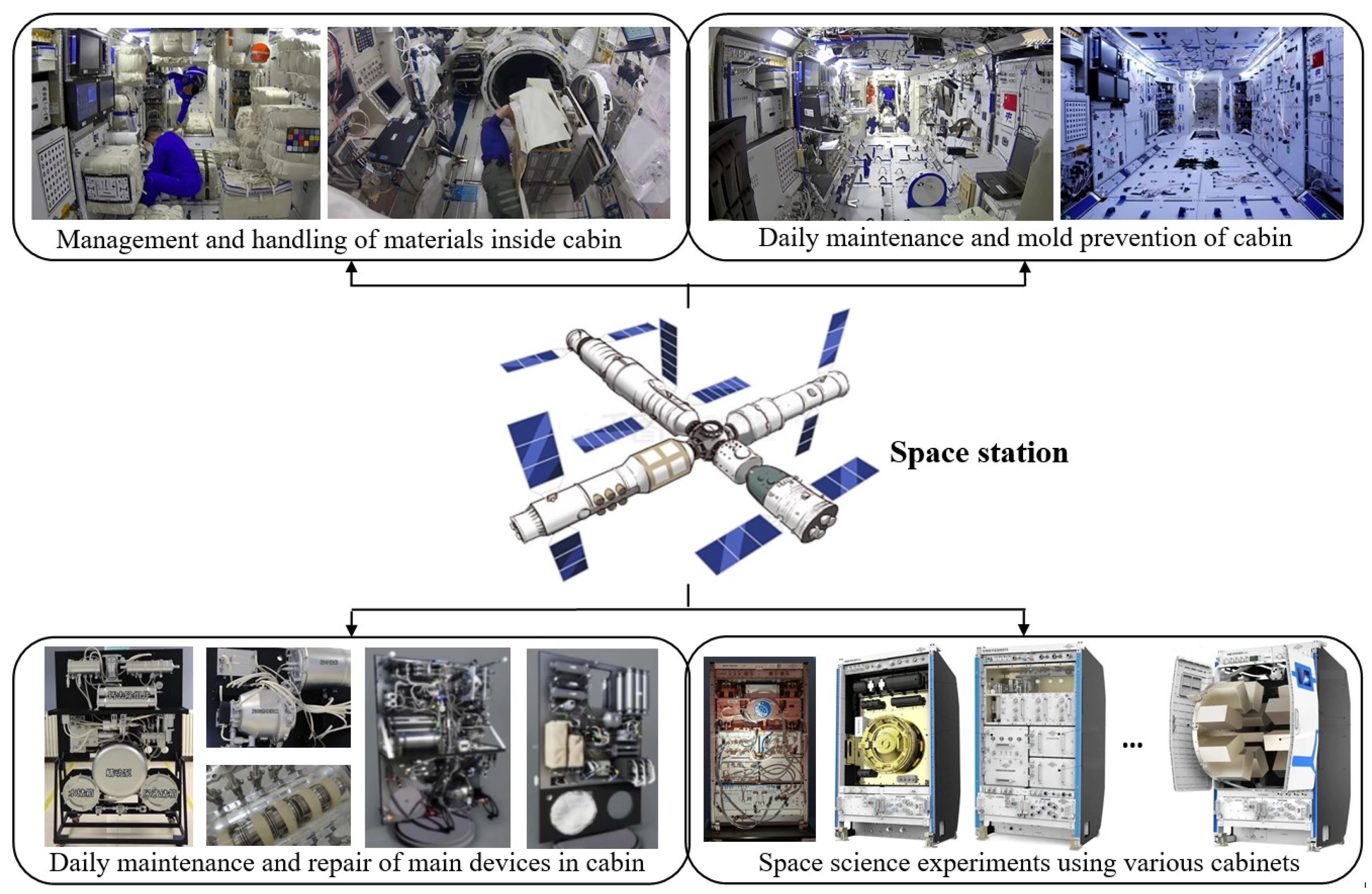
With the rapid development and deployment of China space station technologies, the daily workloads of astronauts in space stations in orbit [
1] are increasing day by day. Like the International Space Station (ISS), on the one hand, astronauts need to accomplish the normal maintenance tasks inside the space station, such as cabin cleaning tasks, living material handling tasks, or safety inspection tasks [
2], etc. On the other hand, the space station has also deployed a large number of scientific experimental cabinets [
3] for conducting various kinds of scientific research in materials science, biological science, physical science, etc.; therefore, maintaining and operating those experimental cabinets will also occupy a lot of time and energy in astronauts’ daily work (
Figure 1). Some practical applications have shown that engaging in monotonous and boring work for a long time can increase the mental fatigue of astronauts in space stations. Clearly, small operational errors and decision mistakes in orbit may lead to some significant flight safety accidents [
4]. Therefore, to reduce the daily workload of astronauts and improve the reliability of in-orbit tasks, it is necessary to develop a device using artificial intelligence technology [
5] to assist them in carrying out various scientific research and daily maintenance tasks [
6].
During the operations of the ISS, artificial intelligence technologies were applied to assist astronauts in space stations in their daily work and life schedules from a long time ago [
7]. Since 2019, space collaborative robots have been used to assist astronauts in their daily operations on the ISS. A small cubic flying robot called “Astrobee” [
8] is designed to assist astronauts in completing daily management tasks, participating in various scientific experiments, and conducting safety monitoring of astronauts’ daily behaviors. To further improve the human–machine-friendly performance of collaborative robots, much research work [
9,
10] has been carried out around the design of interactive operation processes, scene understanding, and human–computer interface display methods. For example, in [
11], scholars developed a kind of intelligent Polipo pressure sensing system for assessing injury inside the space suit. The sensitivity model was used for data analyses of sensing data. In [
12], a wide-ranging stable motion control method for robot astronauts in space stations using human dynamics was reported. A viscoelastic dynamic humanoid model of parking under a microgravity environment was established. In [
13], the virtual reality technique was also considered for improving the psychological and psychosocial health state of astronauts. The exergaming was proposed for application during the long-duration flight mission.
In the past, a large number of studies have been conducted regarding semantic segmentation [
14] to alleviate the workloads of people. Semantic segmentation aims to accurately classify each pixel of an image into its corresponding category, thereby achieving a refined understanding of image content. The core feature of semantic segmentation is pixel-level classification. Each pixel is assigned to a predefined semantic category, but different instances of the same category are not distinguished. It is widely applied in autonomous driving [
15] or medical image processing [
16]. Its common models include the U-Net [
17], DeepLab network [
18], SegNet [
19], etc. The encoder and decoder of U-Net are closely connected through skip connections, allowing the decoder to fully utilize the feature information of different levels of the encoder when restoring image resolution. The DeepLab series models introduce dilated convolution [
20], which expands the receptive field of the convolution kernel without increasing computational complexity. It can better capture contextual information from images and has advantages in segmenting large-scale objects and complex scenes [
21]. SegNet adopts an encoder–decoder structure, characterized in that the decoder part uses pooling indexes corresponding to the encoder for upsampling, reducing the number of model parameters and improving the running efficiency of the model. Clearly, although the above networks have shown good computational performance in their specific applications, it is still worth researching how to develop a real-time and high-accuracy scene understanding method for space station applications [
22].
Regarding the semantic segmentation technology, from the perspective of network training, it can be classified into fully supervised, semi-supervised, and unsupervised networks [
23]. The fully supervised network needs to label all training data before it can be trained. The semi-supervised network only needs a small amount of complete labeled data, supplemented by a large number of unlabeled data for network training. And the unsupervised network aims to achieve accurate image segmentation without relying on annotation data or only a small amount of annotation data. For example, the semi-supervised network includes the generative adversarial network (GAN)-based method [
24], the multi-network architecture-based method [
25], the multi-stage architecture-based method [
26], and the single-stage end-to-end architecture-based method [
27], etc., while the unsupervised networks include the adaptive adversarial learning-based method [
28], the adaptive image segmentation transfer-based method [
29], and the adaptive self-training-based method [
30], etc. In comparison, the fully supervised network can accurately learn the mapping relationship between input and output data, so its calculation accuracy is highest. In addition, the design of a semi-supervised or unsupervised network is more difficult than that of a fully supervised network. In this article, because the working scene in the space station is all known and the ambient light is also controllable, as a result, the fully supervised network is selected for semantic segmentation calculation.
The semantic segmentation technology can also be classified into the traditional or the real-time computational network according to its processing speed. In general, the real-time semantic segmentation network refers to a model with a computational frame rate of 30 frames per second on a specific device. The traditional non-real-time semantic segmentation methods [
31] rely on fine imaging details and rich spatial context information, which have the disadvantages of a large amount of calculation and a complex network structure. Differently, through the reasonable improvement of network structure, the real-time semantic segmentation network can retain more abundant spatial information with less computational cost and capture more effective multi-scale context so as to achieve the balance between the calculation speed and accuracy of the model. According to the network structure, the real-time semantic segmentation network can be roughly classified into the single-branch network [
32], the double-branch network [
33], the multi-branch network [
34], the U-shaped network [
35], and the neural structure search network [
36], etc. The main disadvantage of the real-time semantic segmentation method is its limited fine segmentation ability. Considering that the application requirements of device maintenance guidance in this paper have higher requirements for calculation effect but little demand on the real-time calculation, a non-real-time network design method is adopted to reduce the difficulty of network design.
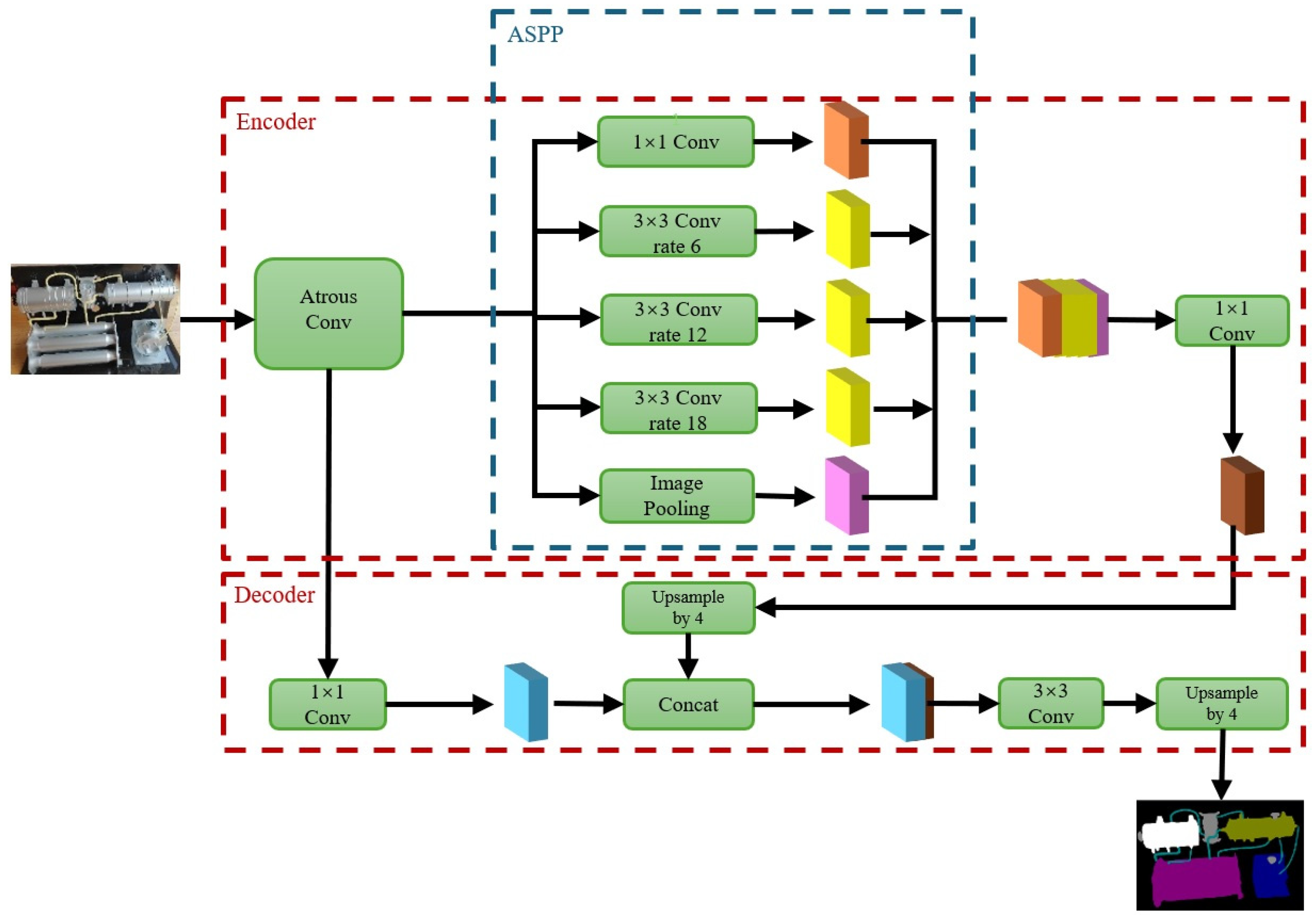
For the fully supervised non-real-time semantic segmentation networks, the common methods include the encoder–decoder model-based method, the dilated convolution model-based method, and the multi-task learning model-based method, etc. The encoder–decoder model-based method converts original data into low-dimensional representations, captures their key features, and then converts them back to the original data space. The common networks have RefineNet [
37], U-Net, SegNet, etc. The dilated convolution model expands the receptive field of the convolution kernel by introducing dilated convolution; its typical model is the DeepLab series networks. The multi-task learning model combines the network framework with complementary tasks, and its network structure can make the parameters shared in the training process and reduce the maintenance cost of different tasks. Its common methods include the multi-scale convolutional neural network (MSCNN) [
38], the prediction-and-distillation network (PAD-Net) [
39], etc. In comparison, the DeepLab network has a fine calculation effect and fast processing speed, which is more suitable for the application of this article. The DeepLab series network is derived from VGG16 [
40]. DeepLabV1 uses the full convolution network to replace the last full connection layer, removes the last two pooling layers, and expands the receptive field using dilated convolution. DeepLabV2 uses ResNet-101 [
41] as the basic network and puts forward the pyramid pool structure. DeepLabV3 further improves the atrous spatial pyramid pooling (ASPP) structure to solve the problem of low computational efficiency of dilated convolution. DeepLabV3+ upgrades ResNet-101 to Xception, which further reduces the number of network parameters.
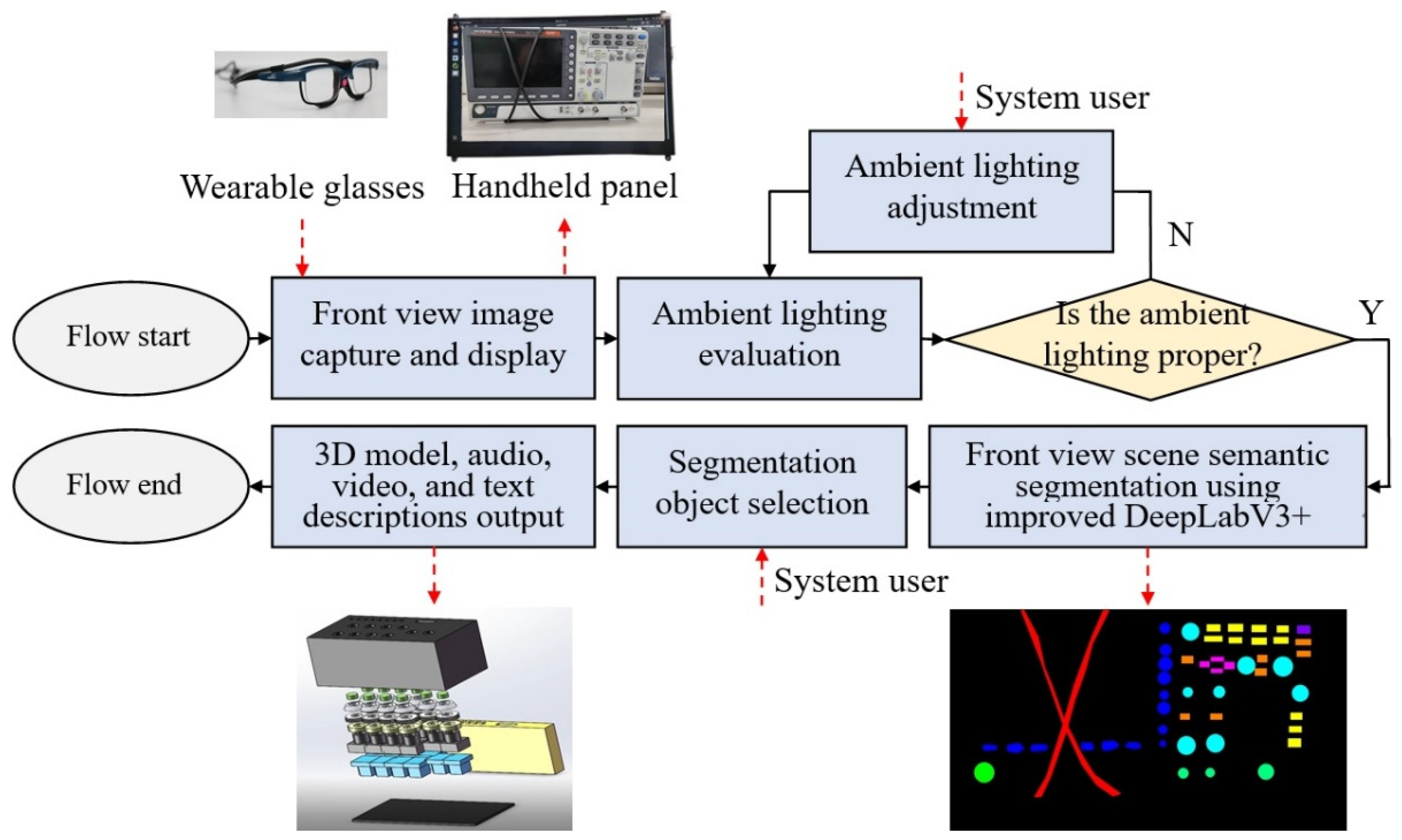
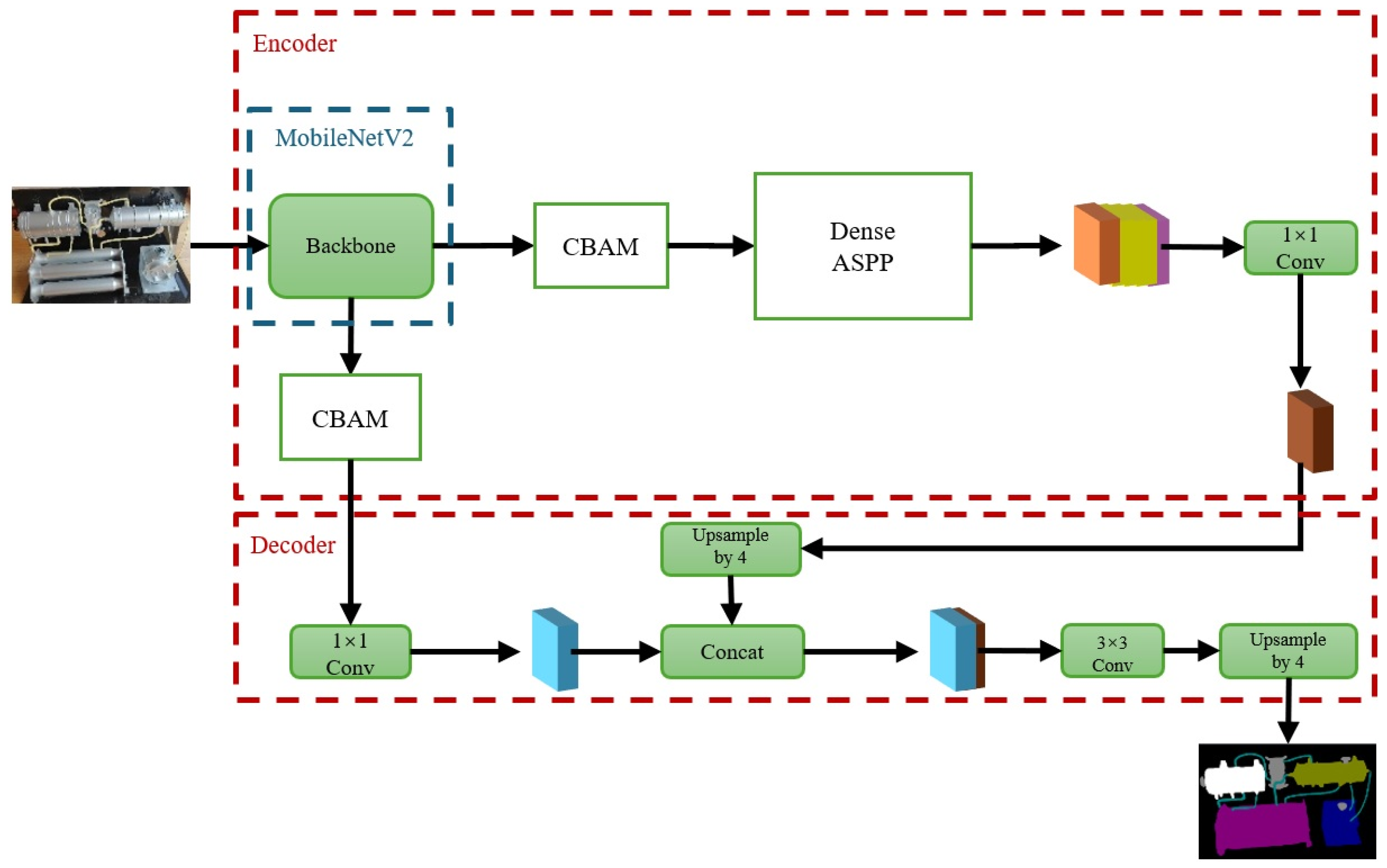
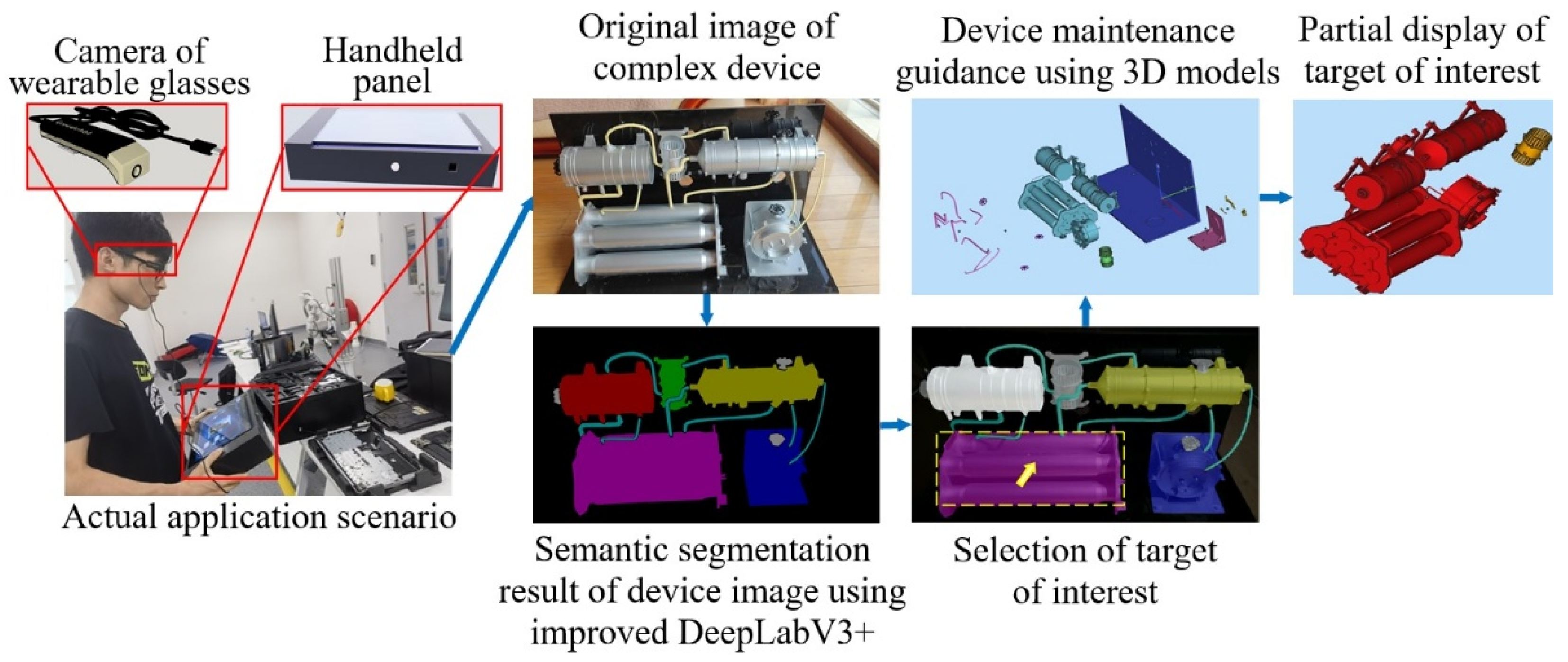
In this paper, an interactive maintenance technique of the space station complex devices using the scene semantic segmentation method is proposed. First, a glasses-style wearable device and a piece of handheld panel equipment are both designed and used to assist astronauts in space stations to collect and play the scene imaging information. In a microgravity environment, the handheld panel can be secured to an astronaut by a restraint strap. Second, the image quality evaluation parameters [
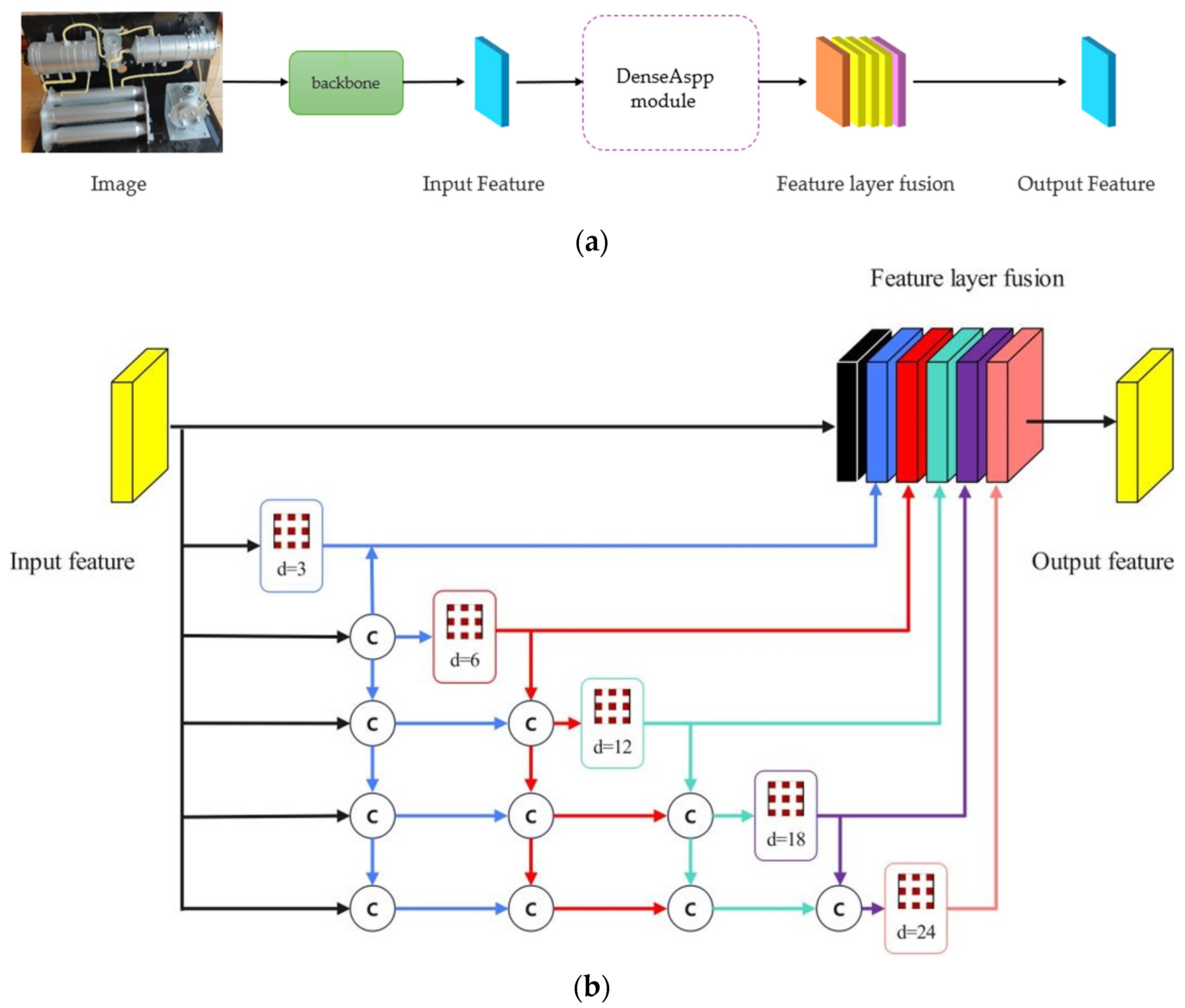
42] are used for evaluating environmental lighting. Since the working environment inside of a space station cabin is entirely an artificial system, it will be very easy to achieve environmental lighting control by astronauts. Third, a semantic segmentation network, i.e., an improved DeepLabV3+ network [
43], is proposed for scene understanding application. MobileNetV2 [
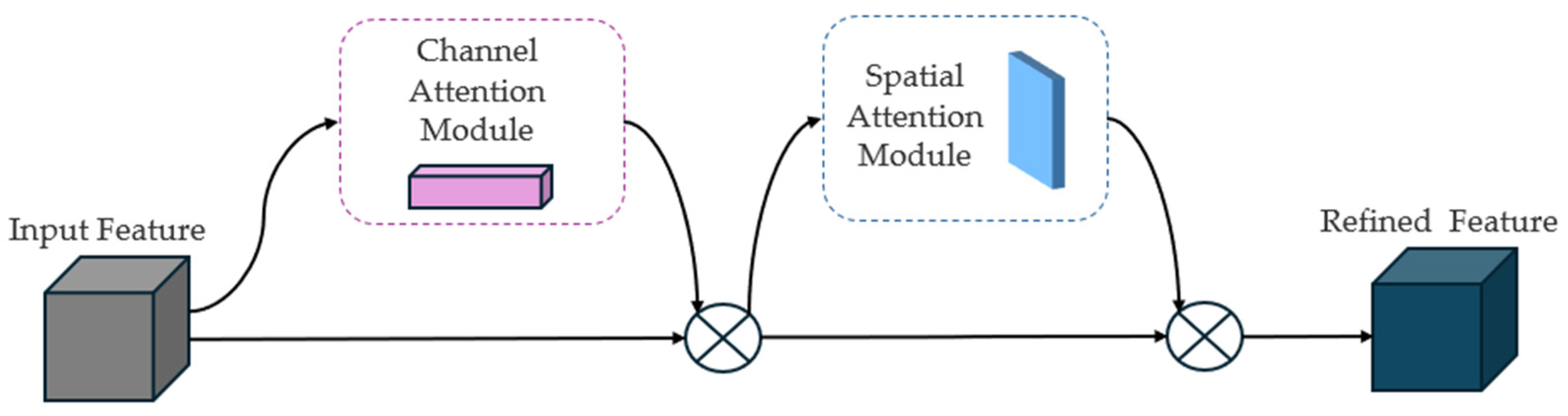
44] is employed as the backbone network, a convolutional block attention module (CBAM) [
45] is considered to participate in the feature computations, and a kind of ASPP module [
46] is also used. The main contributions of this paper include (1) a new interactive task assistance system proposed for astronauts working in orbit during space station missions, which effectively reduces the complexity of astronauts’ work and improves mission reliability [
47]. (2) An effective computational model for scene perception and understanding has been proposed in this paper, which has the advantages of lightweight deployment and high computational accuracy.
In the following sections, the key techniques of the proposed system and method will be presented in
Section 2, some evaluation experiments will be illustrated in
Section 3, further data analyses and discussions will be given in
Section 4, and a conclusion will be made in
Section 5.
4. Discussion
The importance of space station technology is self-evident as the forefront base for human exploration of space. However, space station in-orbit devices face many serious challenges. The enclosed and narrow space characteristics of the space station make its internal air circulation dependent on the ventilation system. Meanwhile, astronauts in space stations breathing, sweating, and even the water vapor generated by equipment operation will make the devices in the space station prone to surface contamination and mold problems, seriously threatening the performance and service life of the space station and thus affecting the safe and stable operation of space missions as well as the health and work efficiency of astronauts in space stations. To ensure the long-term reliable operation of the space station, astronauts working on the station need to regularly maintain the equipment. Due to the heavy workload of astronauts, wearable glasses and handheld panels can be designed based on semantic segmentation methods to identify the devices within the astronaut’s line of sight, allowing astronauts to directly interact with the device models and view their working principles. The performance parameters of our system can include the scene understanding semantic segmentation accuracy, the system response speed, the system mean time between failure (MTBF), etc. Clearly, the application of this kind of interactive artificial intelligence technology can significantly improve the safety of space flight missions, reduce the workload of astronauts, and avoid many potential risks.
Numerous experiments have shown that ambient light can affect the computational performance of the semantic segmentation network proposed in this paper. Therefore, in this paper, we further evaluate and analyze the computational performance of our improved DeepLabV3+ on images with different ambient light ratios. The experiments use images collected under different proportions of strong and ordinary lighting sources for network training and then randomly extract data from the image dataset (including images under various lighting conditions) for testing the training network. Currently, a total of 5 experiments are tested, with the number of strong lighting environment images and ordinary lighting environment images being 600 and 0 (experiment 1), 400 and 200 (experiment 2), 300 and 300 (experiment 3), 200 and 400 (experiment 4), and 0 and 600 (experiment 5), respectively. The number of test datasets is 60, including 30 images from strong lighting environments and 30 images from ordinary lighting conditions. The relevant network calculation results are shown in
Table 8 and
Figure 12. From the results in
Table 8, it can be seen that using data under ordinary lighting conditions for network training can achieve the best computational performance. Strong (i.e., overly bright) lighting environments may not achieve the best segmentation results; the possible reason for this result is that the device surfaces segmented in this paper are mostly metallic, which are prone to producing bright areas or reflectors and therefore affect the subsequent calculations. Clearly, the final lighting output control also needs to consider the subjective visual perception of astronauts in space stations and cannot be determined solely based on the imaging semantic segmentation results.
Generally speaking, the device maintenance missions of space stations in orbit have gone through three stages of development. In the first stage, in order to assist astronauts in space stations in completing various tasks in space stations, the paper operation manual is universally used to provide guidance to astronauts on relevant work details. Clearly, using paper-based operation manuals will lead to an increasing number of accumulated operation manuals and data generated during the long-term implementation of space station missions. In addition, paper manuals are not conducive to the storage and electronic processing of information, nor are they convenient for the efficient analysis of complex information. During the second stage, the use of a fixed electronic manual to assist astronauts in orbit operations emerged. Conventional electronic manuals only provide some principal system introductions, typical schematic diagrams, photo playback, and other functions, and cannot perform online interactive analysis of device status in actual scenarios, so their application effectiveness is also relatively limited. In the third stage, interactive scene understanding techniques using imaging analysis have emerged [
63]. Astronauts in space stations can perform online interactive operations anytime and anywhere based on the information they are actually capturing, which significantly enhances their work interest and reduces workload [
64]. As a result, the application of these techniques will significantly simplify astronauts’ in-orbit operations and improve mission reliability.
The system and method proposed in this paper have at least the following advantages. First, the network structure of our improved DeepLabV3+ method is lightweight, computationally efficient, and fast to implement, which can meet the real-time application of scene understanding in space stations. The actual experimental results show that the processing speed of our method is better than 1.0 s per frame. Second, the designed method has high reliability and can be used independently, making it suitable for practical applications in space stations. Based on the imaging lighting range inside the space station, we conduct a series of semantic segmentation calculations under different lighting environments, and the experimental results all show the effectiveness of the proposed method. Third, the designed method has strong scalability and can easily be combined with other deep learning methods for computation or replaced with other networks with more powerful computing capabilities. Of course, our methods also have certain shortcomings. For example, our method currently does not further process the segmentation of the same object under occlusion conditions. The semantic segmentation of small-sized targets remains a challenge in this field. In the future, we will further optimize the design methods of semantic segmentation networks, combining pre-training, transfer learning [
65] and reinforcement learning techniques [
66] to improve network computing performance. And the proposed system and method are expected to be applied in the maintenance of the life support system of the space station.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}