1. Introduction
With the continuous advancement of modern aerospace technology, high-speed maneuvering targets exhibit an increasingly enhanced capability to penetrate integrated air defense systems [
1,
2]. In this context, ensuring the effective interception of these targets, particularly when high-value targets are at risk [
3,
4], has emerged as a critical issue in contemporary air and space defense operations. In the interception of high-value aerial targets, traditional methods typically rely on single-agent engagement strategies [
5]. However, such approaches impose stringent requirements on interceptor performance, resulting in elevated costs and an excessive dependence on the individual agent’s maneuverability, guidance accuracy, and warhead effectiveness [
6]. These challenges lead to increased complexity in both design and manufacturing processes. To overcome these limitations, cooperative multi-agent interception has been proposed as a promising and cost-effective alternative [
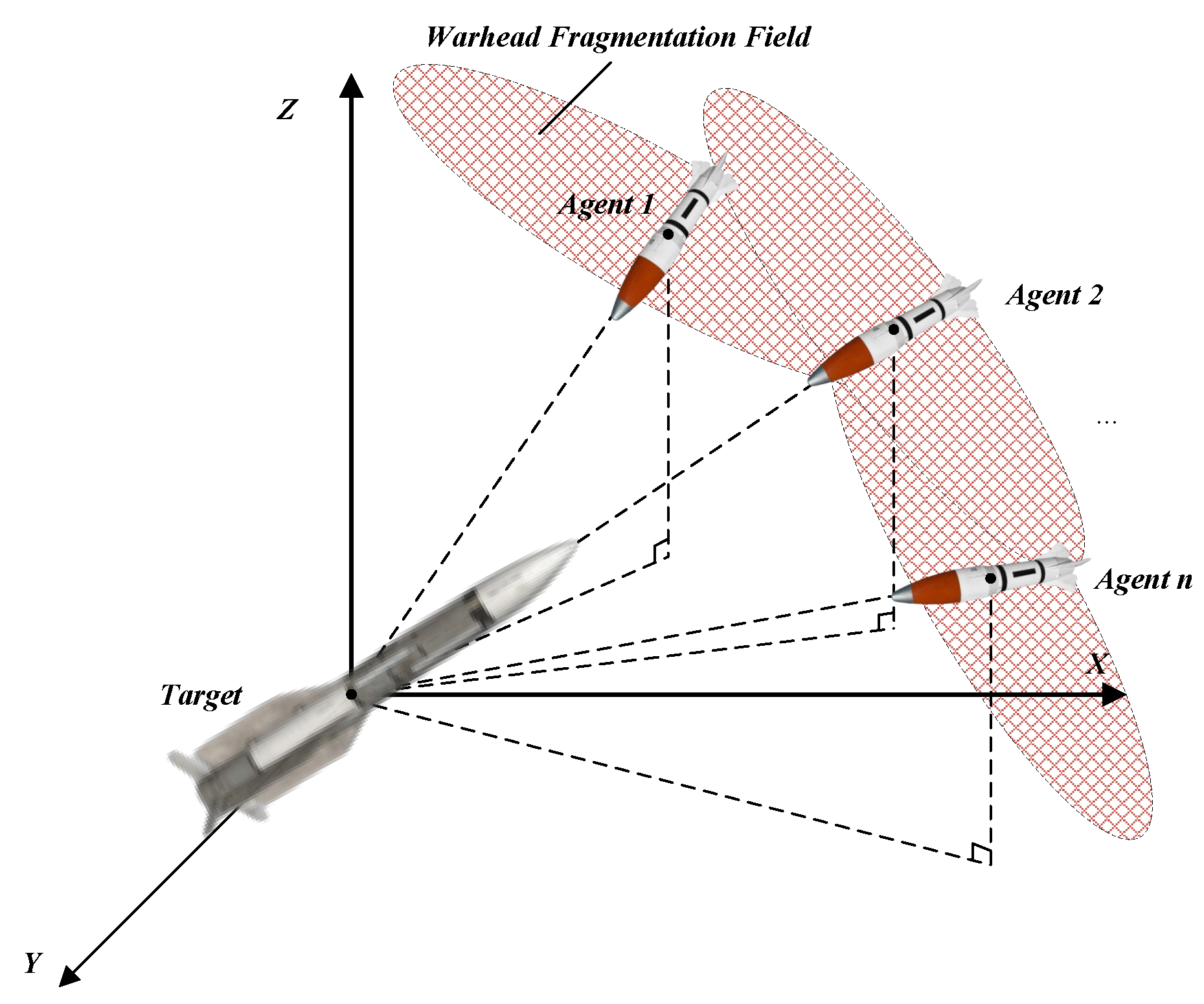
7]. By deploying multiple relatively low-cost interceptors, this strategy enables coordinated engagement of the target. Under the framework of a cooperative guidance law, the agents are driven to simultaneously approach the target from multiple directions. Subsequently, proximity fuzes initiate warhead detonation, forming a large-area fragmentation pattern that substantially enhances the probability and the overall interception effectiveness [
8,
9].
In recent years, cooperative multi-agent guidance technology has witnessed rapid development and has found broad applications in scenarios such as synchronized interception against high-value targets and coordinated interception of high-speed aerial threats [
5,
10]. Whether employed offensively as a “spear” or defensively as a “shield,” the core challenge in multi-agent cooperative operations lies in achieving consistency in the time-to-go among participating interceptors [
11,
12]. Generally, two methods are commonly adopted for time-to-go estimation. The first method computes the time-to-go based on the proportional navigation guidance (PNG) principle [
13], while the second estimates it as the ratio of the agent–target relative distance to their relative velocity. Although the PNG-based approach considers multiple factors, it suffers from high computational complexity and often relies on an empirical constant, typically fixing the navigation ratio to three. Such assumptions may lead to poor adaptability and reduced accuracy under varying engagement conditions. In contrast, the second approach offers a more intuitive and computationally efficient solution by directly utilizing kinematic information. This simplicity makes it particularly attractive for cooperative guidance scenarios. Building upon the estimation of time-to-go, various cooperative guidance laws have been developed to steer agent formations towards coordinated interception. Literature [
14] designs control inputs along both the tangential and normal directions of the agent trajectory. Although it achieves high control precision, it requires two independent control channels, which increases the computational and implementation burden on the agent’s onboard guidance and control system. The literature [
15,
16] generates acceleration commands along the line-of-sight (LOS) direction, directly regulating the agent–target relative velocity. By precisely shaping the closing speed, this approach facilitates fast and effective convergence of time-to-go among agents, making it particularly suitable for time-critical interception missions.
The design of cooperative guidance laws intrinsically relies on inter-agent communication networks, as each interceptor must continuously share its real-time motion states with the formation to compute appropriate control commands [
17]. Currently, two main types of communication topologies are commonly adopted in agent formations: global communication network and distributed communication network. In a global communication network, all agents are able to directly exchange information with every other agent in the formation. Although this structure ensures complete information sharing and facilitates straightforward consensus algorithms, its practical implementation faces significant engineering challenges. These include the difficulty of establishing reliable long-range communication links among spatially dispersed agents and the adverse effects of communication delays [
18]. Moreover, the failure of a single agent’s communication node could potentially compromise the entire cooperative interception system [
19]. Unlike the global network, the distributed network allows each agent to communicate only with its local neighbors, thereby achieving coordinated guidance through decentralized information exchange. This approach fully exploits the advantages of swarm intelligence and is inherently resilient to communication failures [
20,
21]. Even if a subset of agents loses connectivity, the overall interception capability is preserved. Furthermore, the distributed framework mitigates communication delays associated with distant nodes and significantly reduces bandwidth requirements and system complexity. Instead of relying on predefined interception times, the formation dynamically adjusts the guidance commands based on the consensus of shared coordination variables, achieving time-to-go synchronization in a flexible and robust manner. Given its ability to accommodate uncertainties, adapt to dynamic scenarios, and efficiently utilize networked information, the distributed communication network has emerged as a focal point of recent research on cooperative agent guidance systems.
Early research on cooperative guidance primarily focused on static targets. Proportional navigation (PN)-based cooperative guidance laws were developed against stationary targets by synchronizing the interception time according to a pre-assigned schedule [
22]. Subsequently, distributed cooperative guidance laws based on communication networks were proposed to improve system robustness. In particular, improved versions of the PN guidance law have been designed to mitigate the adverse effects of input delays and communication topology switching [
23].
To further enhance synchronization performance, cooperative guidance strategies based on finite-time convergence were introduced [
24], providing better control over the convergence time of the time-to-go. Building upon this, the literature [
25] proposed a fixed-time consensus-based cooperative guidance law, which guarantees convergence within a fixed-time bound independent of the system’s initial conditions. While these guidance strategies offer satisfactory performance against static targets, they are less effective when dealing with maneuvering targets. To address this limitation, recent studies have extended cooperative guidance methods to dynamic scenarios. For example, the literature [
26] analyzed the terminal capture region and introduced the concept of capture windows under heading angle constraints, allowing the computation of controllable margins for all feasible positions, thus improving interception performance against maneuvering targets.
It is worth noting that most existing cooperative guidance laws remain limited to two-dimensional (2D) scenarios [
27], which are inconsistent with the actual three-dimensional (3D) interception environments encountered in practice. In recent years, some researchers have started extending cooperative guidance laws to 3D engagement scenarios. References [
3,
10] proposed a cooperative guidance strategy capable of achieving arrival-time consensus within finite time; however, their work has not been generalized to full 3D applications. Extending the guidance law from 2D to 3D is a crucial step toward practical engineering implementation. The literature [
28] successfully applied cooperative guidance laws in 3D space by introducing a reference plane that decomposes the 3D dynamics into two orthogonal 2D components. Separate guidance laws were then designed for each component to achieve convergence of the agent formation’s motion states. Further, reference [
29] addressed the 3D cooperative interception problem by establishing an agent–target LOS coordinate frame on top of the conventional ground-fixed coordinate system, enabling the formulation of a complete 3D relative motion dynamic model suitable for a cooperative guidance design.
Building upon the aforementioned research, this paper proposes a multi-agent, multi-directional cooperative interception guidance law for maneuvering targets. First, a fixed-time observer is designed to estimate the target’s acceleration. Based on this estimation, control inputs are developed along the three axes of the agent–target LOS coordinate frame, enabling the synchronization of the time-to-go and the coordination of azimuth and elevation angles. This approach not only ensures simultaneous interception by all agents but also forms a fan-shaped interception formation, significantly improving interception effectiveness. The main contributions of this work are summarized as follows:
- 1.
In the literature [
25], a cooperative guidance law was proposed by combining time-to-go consensus control with finite-time convergence techniques. However, its convergence time depends on the initial state of the system. In contrast, the LOS-direction guidance law designed in this paper is based on a novel fixed-time control technique that guarantees convergence within a predefined time boundary, independent of the initial state, and is applicable to various communication topologies.
- 2.
The literature [
30] addressed the control of elevation and azimuth angles by integrating sliding mode control with fixed-time control to ensure angle convergence within a fixed time boundary. In this paper, an adaptive sliding mode control scheme is proposed, which integrates fixed-time and finite-time control techniques. Specifically, the controller adaptively switches control commands based on the value of the sliding mode variable. In the first stage, a high-order sliding mode controller ensures rapid convergence to a predefined sliding threshold. Once the threshold is reached, the second stage reduces the order and incorporates finite-time control to achieve stable convergence to zero. Since the initial state of the second stage is determined by the predefined sliding threshold, the finite-time technique can achieve the effect of fixed-time convergence.
- 3.
Regarding the estimation of time-to-go, the key to achieving accurate time-consensus cooperative interception lies in ensuring that the error between the estimated and actual time-to-go converges to zero before the agents reach the target. In this paper, the proposed guidance law ensures that this estimation error asymptotically converges to zero under the Lyapunov stability framework, thereby guaranteeing highly accurate time-consensus cooperative interception.
The remainder of this paper is organized as follows:
Section 2 describes the useful mathematical lemmas. The engagement geometry and problem formulation are presented in
Section 3. The distributed guidance law against the maneuvering target is described in
Section 4.
Section 5 analyzes the relationship between the estimated time-to-go and the actual time-to-go, providing a rigorous validation of the estimation accuracy. The designed guidance law is simulated and verified in
Section 6. Finally, the conclusions are presented in
Section 7.
4. Design of Fixed-Time Cooperative Guidance Law Against the Maneuvering Target
In this section, we propose a three-dimensional multi-agent cooperative guidance law based on fixed-time control technology. First, an acceleration control input along the LOS direction is designed to ensure that all agents in the formation reach the target simultaneously. Beyond using LOS-directional control to achieve consistency in arrival-time within the formation of the agent, additional control inputs for elevation and azimuth angles are designed. These inputs guide the agents into a multidirectional interception formation as they approach the target, expanding the fragmentation warhead’s dispersion area and enhancing interception efficiency against maneuvering targets.
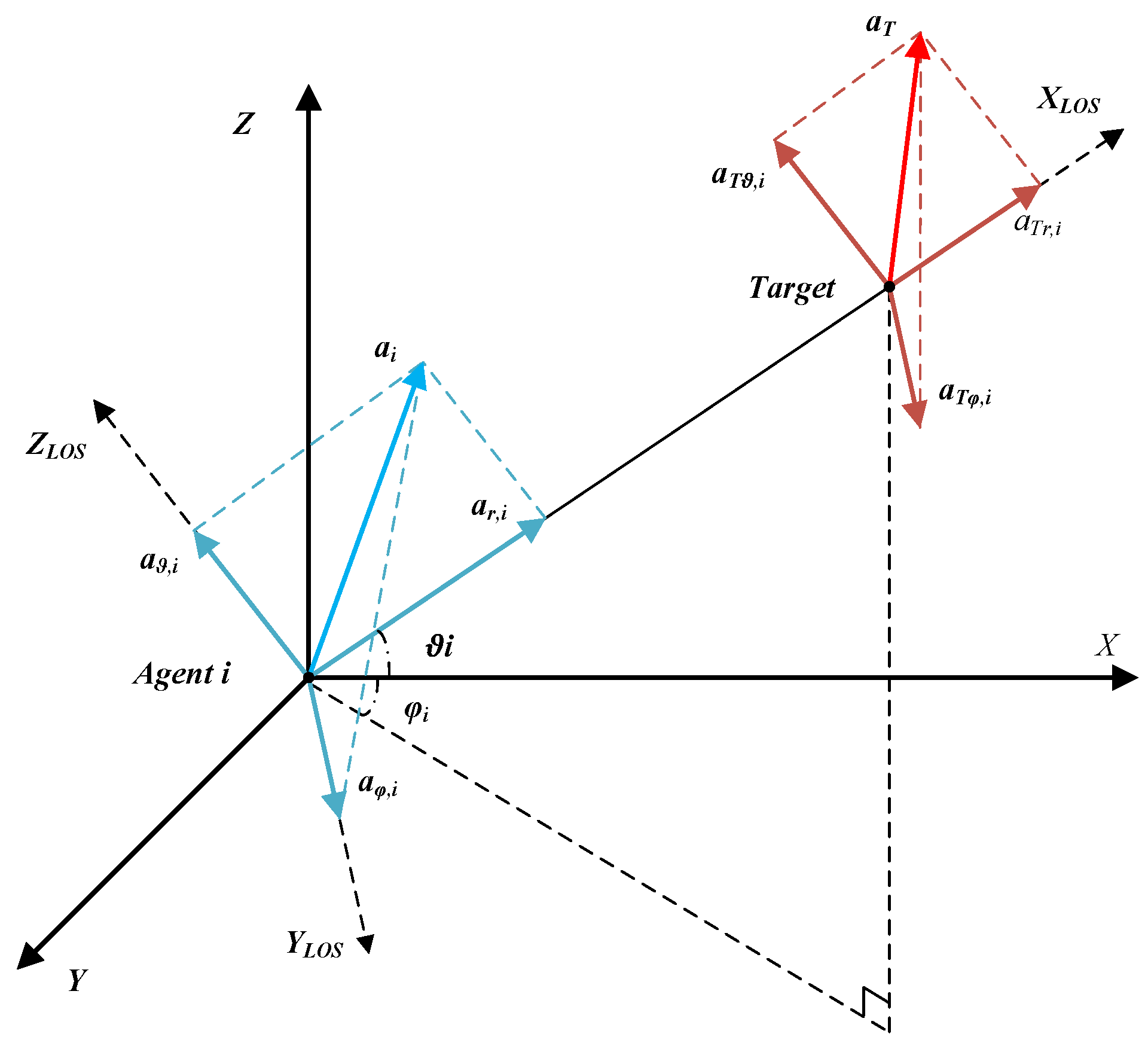
4.1. Guidance Law Design Based on the LOS Direction
This section designs the control input along the LOS direction, with the aim of driving all the agents in the formation to reach the target simultaneously and perform a synchronized interception mission. To drive the agents’ time-to-go to achieve consistent convergence, the estimated time-to-go deviations of each agent will be computed through the agent-to-agent communication network. Simply put, each agent compares its estimated time-to-go with that of its neighboring agents, using this as input to design the acceleration control along the LOS direction.
The time-to-go for the agent can be calculated using the following formula:
where
represents agent–target relative distance, and
is the agent–target relative velocity along the LOS direction,
.
It is important to note that since the agent–target relative velocity along the LOS direction is not constant, the calculated value here does not represent the actual time-to-go in a strict sense. Instead, it should be regarded as the estimated time-to-go. The relationship between the estimated and actual time-to-go will be discussed and analyzed in detail in the next section. Define the time-to-go deviation, which is used to compare the time-to-go of neighboring agents based on the agent-to-agent communication topology. When the time-to-go deviation converges to zero, it can be considered that the agent and its neighboring agents have achieved synchronization of the arrival time. The time-to-go deviation is calculated using the following formula:
In the equation,
represents the elements of the adjacency matrix,
. The agent acceleration input along the LOS direction is designed as follows:
where
,
,
,
.
represents the estimated acceleration of the target along the LOS direction of the
agent.
For the estimation of the target’s acceleration, we design the following fixed-time observer:
In the equation, is the observed value of , and is the observed value of the corresponding variable. , , , and are determined according to Lemma 3.
Theorem 1. Consider the agent system in Equation (11) with the communication graph . The cooperative guidance law in Equation (14) guarantees that the fixed-time consensus objective of is achieved, where the settling time is bounded bywhere . Proof. According to Equations (11)–(13), it follows that
The following Lyapunov function is chosen:
According to Equation (
17), we obtain
Note that
is always bounded in
due to the fixed-time convergence of Equation (
15). Moreover,
. The above equation can be further simplified as
Based on
and
, it can be further obtained that
. According to the properties of the Laplacian matrix, we can obtain
, where
. According Lemma 2, the equation satisfies
For the Laplacian matrix, there exists a column vector with all elements equal to 1 that satisfies
Then, there exists
, and further
B, so the following inequality holds:
Furthermore, we can obtain
Not only that, but also, based on
and
, we can conclude that
Combining with Equation (
22), we can obtain
Further, let
, and differentiate it.
When
, the stability time boundary can be further updated as Equation (
16). □
4.2. Design of Multi-Agent Interception Formation Control Method
Currently, the interception of aerial targets mainly relies on proximity fuzes and directional warheads. In practical interception scenarios, point-to-point interception is highly unlikely due to the existence of a certain miss distance. Therefore, under high closing speeds, as long as the warhead fragment dispersion zone forms an interception surface capable of capturing the target, successful interception can be achieved. The multi-directional interception formation proposed in this paper aims to create an interception net composed of multiple fragment dispersion zones formed by several agents surrounding the target. In the previous section, the cooperative guidance law for simultaneous multi-agent arrival on the target has been established. Next, to achieve the multi-directional cooperative interception formation of the agent swarm, acceleration inputs in the elevation and azimuth directions will be designed. The objective is to guide each agent within the swarm to arrange itself in the vicinity of the target according to the desired multi-directional interception formation through the designed control inputs.
4.2.1. Design of Elevation Angle Control Law
In the agent–target elevation angle control problem, an adaptive sliding mode control approach is designed to drive the deviation between each agent’s actual elevation angle and the predefined desired elevation angle to converge to zero within a fixed-time boundary. Define the deviation between the elevation angle and the desired elevation angle.
Here,
is a constant parameter representing the desired elevation angle of the
agent, which is predetermined and embedded into the agent’s onboard computing unit prior to launch. When
. This indicates that the elevation angle successfully converges to its desired value. Once both the elevation and azimuth angles complete their convergence within a fixed time, an efficient multi-directional interception formation of the agent swarm can be established. The specific design of the control input for the elevation angle is as follows:
where
,
,
.
is designed as an adaptive factor, which adjusts the parameter according to the magnitude of the sliding mode value, ensuring a balance between the convergence speed and stability of the elevation angle. When
, the design of
. Here,
is the predefined sliding mode threshold. The adaptive factor is designed to vary with the sliding mode value to adjust the power order in the control law. A higher-order parameter is used for rapid convergence when the sliding mode value is large, while a lower-order parameter is adopted to enhance stability when the sliding mode value is small. The specific design is
Note that the sliding mode is designed based on Equation (
30), as described in the following:
In the design of the control law, in order to alleviate the chattering phenomenon during the control process, the traditional function is replaced with the function as an improved alternative. This modification effectively reduces the chattering effect near the end of the control process. In addition, a piecewise control strategy is implemented based on a sliding mode threshold. When the sliding variable is small, a lower power term is used in the control output to reduce the control gain and limit the amplitude of control input variation.
Remark 1. In Equation (31), represents the acceleration component of the target in the LOS coordinate system as observed by the fixed-time observer. The design of the fixed-time observer is referenced in the previous section for the LOS direction and will not be repeated here. Theorem 2. Consider the following sliding surface. Under the designed control input Equation (31), the deviation of the elevation angle is guaranteed to converge to zero within the fixed-time boundary. Proof. The following Lyapunov function is chosen:
The derivative of the Lyapunov function is computed as follows:
The derivative of
in the expression is as follows:
By combining Equations (31), (36), and (37),
Based on
and
, it can be further obtained that
. In the following analysis, the predefined sliding mode threshold is used as a boundary to prove the fixed-time convergence in the first stage. When
,
. Equation (
38) can be further expressed as
According to Lemma 4, the first-stage convergence time of the elevation angle control is determined as follows:
When
,
, Equation (
38) can be further expressed as
According to Lemma 5, the second-stage convergence time of the elevation angle control is determined as follows:
From the perspective of the overall control process, the first stage involves the convergence from the initial sliding mode value to the predefined sliding mode threshold. The convergence time boundary for this stage is determined as the fixed time
through Lyapunov stability proof, where
actually constrains
. However, the actual convergence process in the first stage is represented by
. Therefore, in practice, the true convergence time of the first stage is much smaller than
. The convergence in the second stage is represented by
. By referencing Lemma 5, the stability of the convergence process is proved using finite-time convergence. Compared with fixed-time convergence, finite-time convergence has a lower design complexity and fewer system requirements; however, its convergence time is less predictable and depends on the initial state. It is worth noting that, although the second stage is designed for finite-time convergence, its initial state is the predefined sliding mode threshold
. Therefore, the time boundary
for the second-stage control is also fixed. Considering the entire convergence process of the elevation angle, the fixed convergence time can be expressed as
□
4.2.2. Design of Azimuth Angle Control Law
The previous section has completed the demonstration of the elevation angle control method. In this section, we will focus on the control input for the azimuth angle to complete the design of the multi-directional interception formation in three-dimensional space. Similar to the elevation angle, we define the azimuth angle deviation as
The sliding mode surface design refers to Equation (
33). It is expressed as
.
Based on the above definitions, the agent–target azimuth control law is designed as
where
,
,
,
.
is an adaptive factor referring to Equation (
32). The design of the fixed-time observer for
can refer to Equation (
15).
Theorem 3. Consider the following sliding surface. Under the designed control input, Equation (45), the deviation of the azimuth angle is guaranteed to converge to zero within the fixed-time boundary, as follows: Proof. The following Lyapunov function is chosen:
The derivative of the Lyapunov function is computed as follows:
where
In the following analysis, the predefined sliding mode threshold is used as a boundary to prove the fixed-time convergence in the first stage.
According to Lemma 4, the first-stage convergence time is determined as follows:
When
, we can obtain
According to Lemma 5, the second-stage convergence time
is
Considering the entire convergence process of the azimuth angle, the fixed convergence time can be expressed as
□
5. Guidance Law Performance Analysis
In the previous sections, we have completed the proof of the multi-agent cooperative guidance law designed for the consistency of time-to-go. The results show that the proposed guidance law is capable of achieving synchronous interception of the target within a fixed-time boundary. However, regarding the calculation of time-to-go, when the agent–target relative velocity
is not constant, the computed result is strictly only an estimated time-to-go. The relationship between the estimated time-to-go and the actual time-to-go can be derived from Equation (
11) as follows:
Substituting into Equation (
14),
According to the fixed-time observer in Equation (
15), within the fixed-time boundary,
,
. Equation (
56) can be further rewritten as
In this equation, the time-to-go deviation
can be driven to converge to zero within the fixed-time boundary defined in Equation (
16) under the control of Equation (
14). When
, it is evident that
.
In summary, it can be concluded that beyond the fixed-time boundary, the agent–target relative velocity can be regarded as constant. Therefore, the estimated time-to-go obtained from Equation (
12) can be considered equal to the actual time-to-go. This not only ensures the consistency of time-to-go among the agents but also guarantees the accuracy of their arrival at the target.
6. Example Scenario
In this section, the results of the simulation are reported to illustrate the effectiveness of the proposed guidance law. Consider a coordinated interception scenario involving a swarm of five agents engaging a maneuvering target. The objective is to achieve time-synchronized interception while maintaining a spatial fan-shaped formation using the control inputs designed in this study. The initial states of each agent are provided in
Table 1. The final selection of the control parameters is shown in
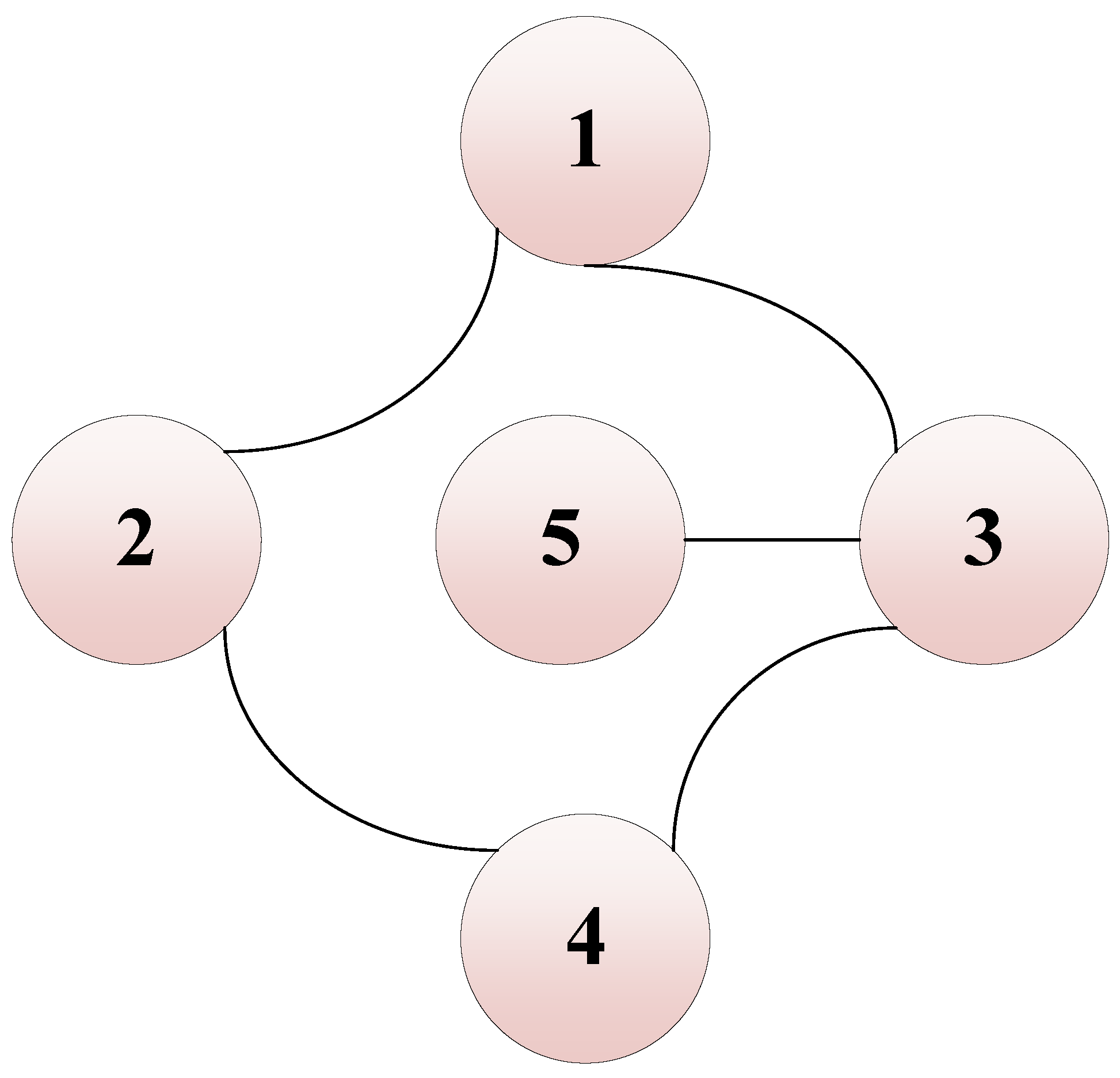
Table 2. We take agents in a network with an undirected graph, as shown in
Figure 3, which indicates that Node 1 can exchange information bidirectionally with Nodes 2 and 3. In the simulation, this is primarily reflected in the ability of adjacent nodes to share time-to-go information. Based on this, each agent can compute the time-to-go deviation relative to its neighbors, which in turn supports the adjustment of its control input. The interactions between Node 5 and Node 3, as well as between Node 4 and Nodes 2 and 3, follow a similar mechanism.
Figure 4a illustrates the flight trajectories of the agents and the target in three-dimensional space. As observed in conjunction with
Figure 4b, all five agents successfully reach the target position at
s, achieving coordinated interception.
Figure 4c shows the trajectory of the target in three-dimensional space, where the red dot indicates the starting position and the black cross indicates the final position.
Figure 4d presents the target’s acceleration along the
X,
Y, and
Z axes. The amplitude of the target’s maneuvering acceleration is approximately within the range of
.
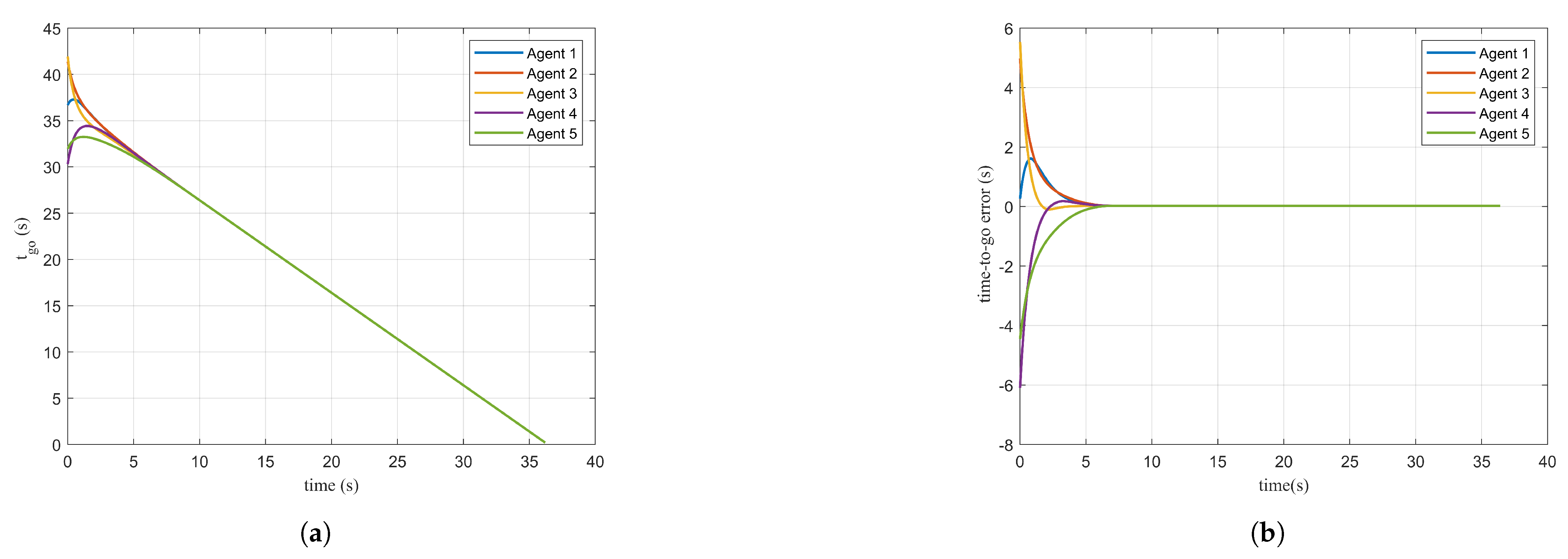
Figure 5a presents the time-to-go for each agent. As shown in
Figure 5b, at the beginning of the control process, due to differences in the motion states of each agent, a deviation exists between the computed estimated time-to-go and the actual time-to-go. The maximum deviation occurs for
at the initial moment. Driven by the control input designed for time consistency, the estimation error between the computed and actual time-to-go approaches zero at approximately
s. Furthermore, in
Figure 6a, it can be observed that the relative velocity of each agent with respect to the target stabilizes after
, indicating that the agents enter a uniform motion phase relative to the target. This observation is consistent with the theoretical analysis of the guidance law presented in
Section 5.
Figure 6a shows that the control inputs in the LOS direction remain within
. From an engineering application perspective, this control input range aligns well with practical constraints.
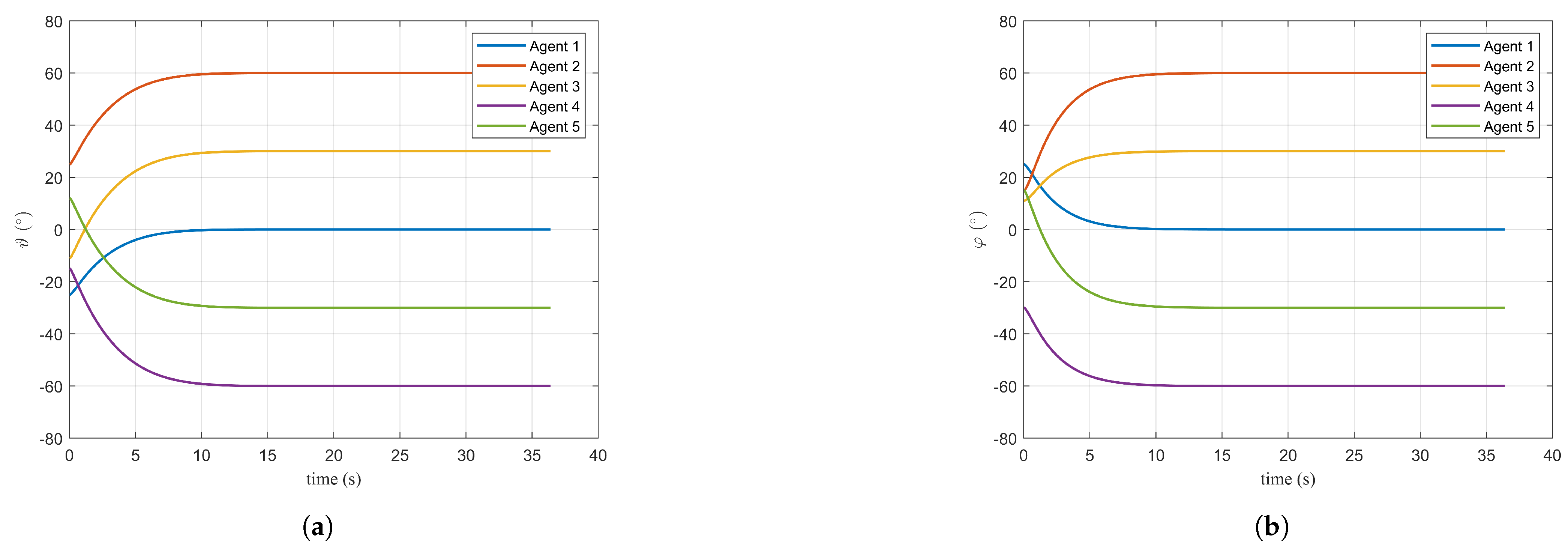
Figure 7a,b primarily demonstrate the effectiveness of the proposed control method for pitch and azimuth angles. When these angles are distributed according to the desired values, a fan-shaped interception formation is established in front of the target. This configuration increases the warhead fragment dispersion area, thereby enhancing interception effectiveness.
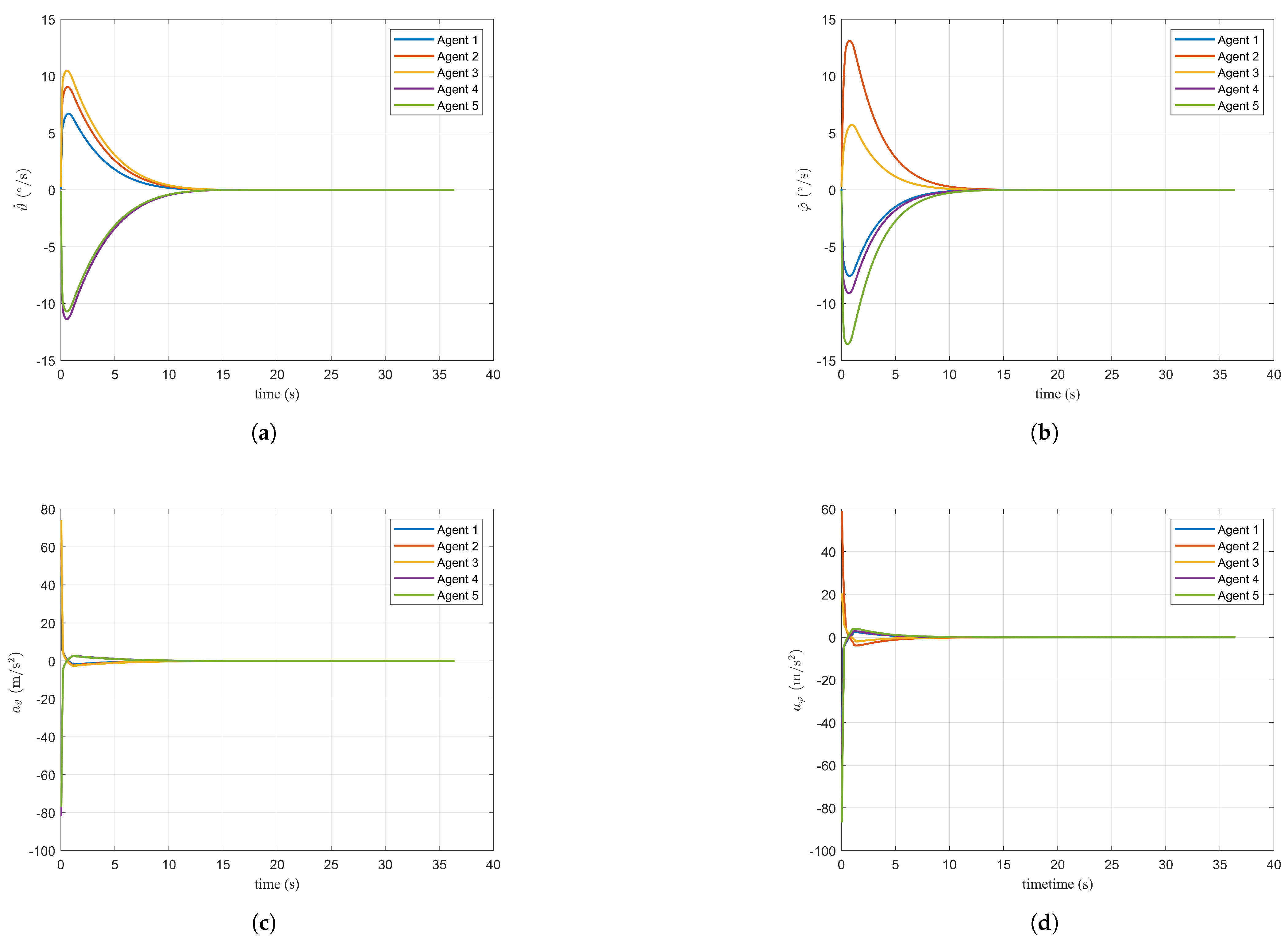
Figure 8a–d depict the control inputs for angular velocity and angular acceleration in both pitch and azimuth directions. As observed in the figures, the convergence times for these two angles are 12.8 s and 13.2 s, respectively. Similar to the LOS direction, the angular acceleration remains within a relatively small range of
,which meets practical engineering application requirements.
Figure 9a,b correspond to the sliding mode surfaces designed for pitch and azimuth angle control. As shown in
Table 2, the sliding mode threshold is set to
in the simulation. The local magnified view clearly shows a noticeable slope change at
, corresponding to the designed control input, which results in a change in the power term.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}