
An Actor–Critic-Based Hyper-Heuristic Autonomous Task Planning Algorithm for Supporting Spacecraft Adaptive Space Scientific Exploration


Abstract
1. Introduction
- Relying on the philosophy of building autonomous capabilities onboard spacecraft and the “goal-driven” methodology, this study introduces a spacecraft task planning framework designed to meet the requirements of adaptive scientific exploration and conducts mathematical modeling of the planning issue.
- Based on a mathematical model, we designed an Actor–Critic-based Hyper-heuristic Autonomous Task Planning Algorithm (AC-HATP) to support spacecraft Adaptive Space Scientific Exploration.
- At the lower tier of hyper-heuristic algorithms, by considering three aspects, namely global search capabilities, quality of solution optimization, and speed of convergence, we selected and designed suitable heuristic algorithms, establishing an algorithmic library.
- At the higher tier of hyper-heuristic algorithms, we employed a reinforcement learning strategy based on the actor–critic model, in conjunction with the network architecture, to construct an advanced heuristic algorithm selection framework.
- Through designed experiments, our research validated that the algorithm meets the needs of adaptive scientific exploration. Compared with other algorithm types, it was demonstrated that our approach achieves faster convergence speeds and superior solution quality in addressing deep space exploration challenges.
2. Related Work
2.1. Traditional Methods of Autonomous Task Planning
2.2. Task Planning Based on Heuristic and Metaheuristic Algorithms
2.3. Task Planning Based on Reinforcement Learning
2.4. Summary of Related Work
3. Framework and Modeling for Spacecraft Onboard Autonomous Task Planning
3.1. Target-Driven and Task-Level Objective Commands
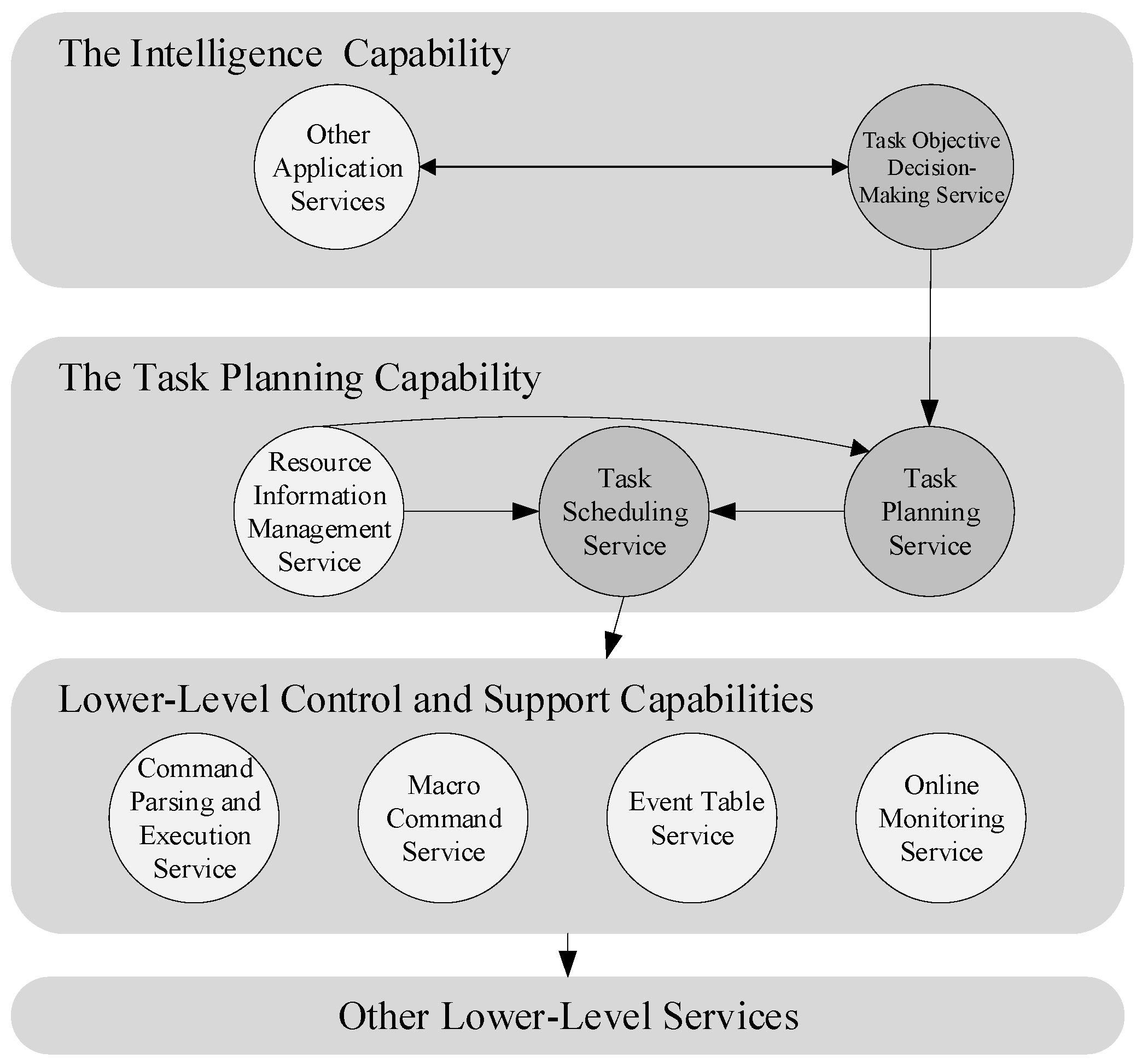
3.2. Spacecraft Autonomous and Task Planning Framework
3.3. Mathematical Description of Spacecraft Autonomous Mission Planning Problem
4. Methodology
4.1. Overview
4.2. Low-Level Heuristic Algorithm Selection and Design
- (1)
- Model mapping method
- (2)
- Low-level heuristic operator selection
| Algorithm 1: Particle Swarm Optimization (PSO) with Cost-Benefit Ratio |
| Initialize particle positions and velocities based on tasks while termination criteria not met do for each particle do Calculate fitness using the cost-benefit ratio if is better than then Update with end if if is better than then Update global best with end if Update and based on and end for end while return the global best solution |
| Algorithm 2: Grey Wolf Optimizer (WOA) with Cost-Benefit Ratio |
| Initialize wolf positions based on tasks Identify alpha, beta, and delta wolves based on while termination criteria not met do for each wolf do Update the position towards alpha, beta, and delta using , Calculate fitness using the cost-benefit ratio end for Update alpha, beta, and delta positions based on best values end while return the position of the alpha wolf |
| Algorithm 3: Sine Cosine Algorithm (SCA) with Cost-Benefit Ratio |
| Initialize solutions for all tasks Calculate fitness for all using Identify the best solution while not converged do for each solution do for each dimension do Calculate randomly if rand (); 0.5 then else end if end for Update improves the fitness end for Update if better solutions are found end while return |
| Algorithm 4: Differential Evolution Algorithm (DE) |
| Initialize population vectors for to Evaluate the fitness of each individual Identify the best individual while not converged do for each individual in the population do Select random individuals from the population, Generate the donor vector Initialize trial vector to be an empty vector for each dimension do if or then else end if end for Evaluate the fitness if then else end if end for Update if a better solution is found end while return |
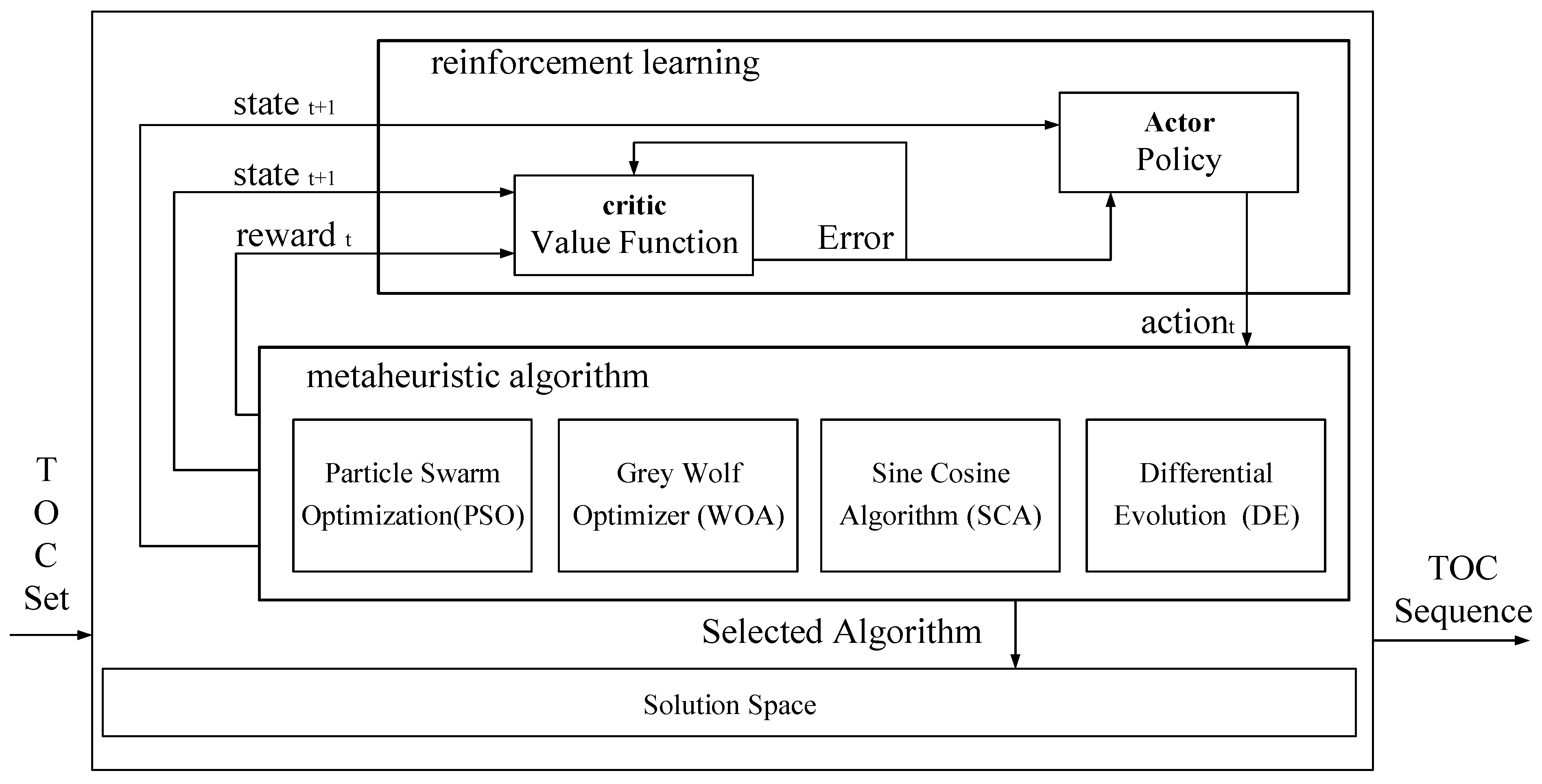
4.3. High-Level Algorithm Based on Actor–Critic Reinforcement Learning
- (1)
- Overview
- (2)
- State
- (3)
- Action selection
- (4)
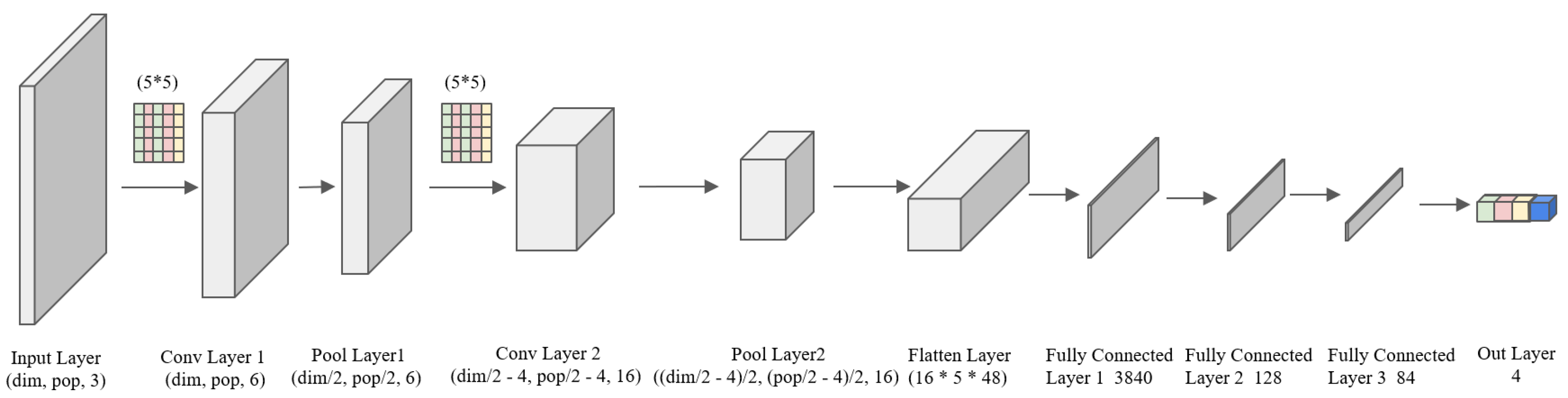
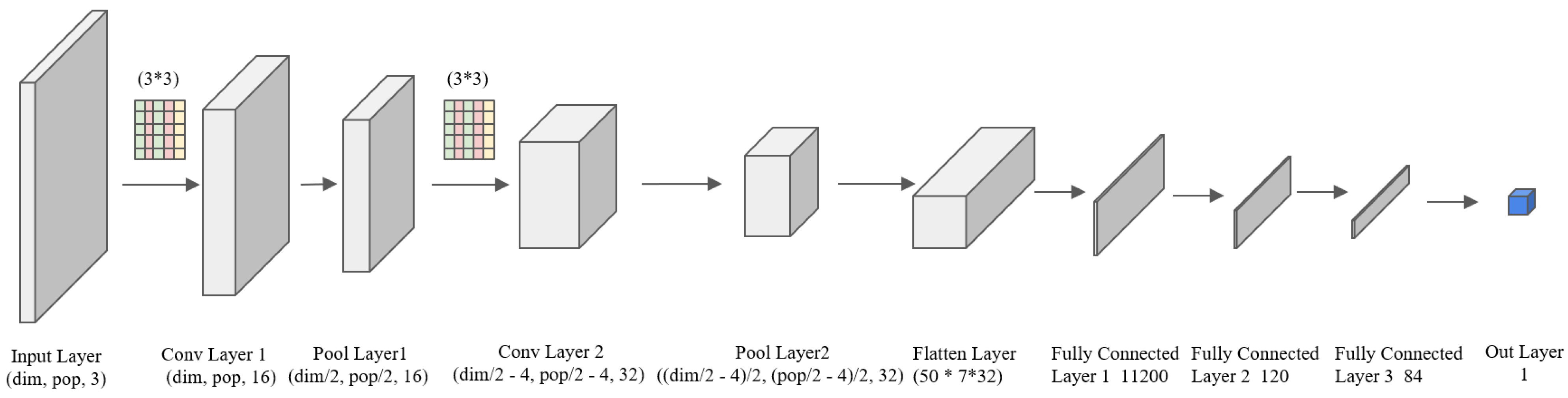
- Actor–Critic network structure design
| Algorithm 5: Actor-Critic Based Metaheuristic Algorithm |
| Initialize policy network parameters , value network parameters Initialize environment and state for each episode do Reset environment and observe initial state while not done do action according to the policy Execute action in the environment Observe reward and new state Compute advantage estimate Update policy Update value end while if end of evaluation period then Evaluate the policy end if end for |
- (5)
- Optimization Metrics
- (6)
- Reward
- (7)
- Training strategy
5. Experiment
5.1. Parameter and Environment Settings
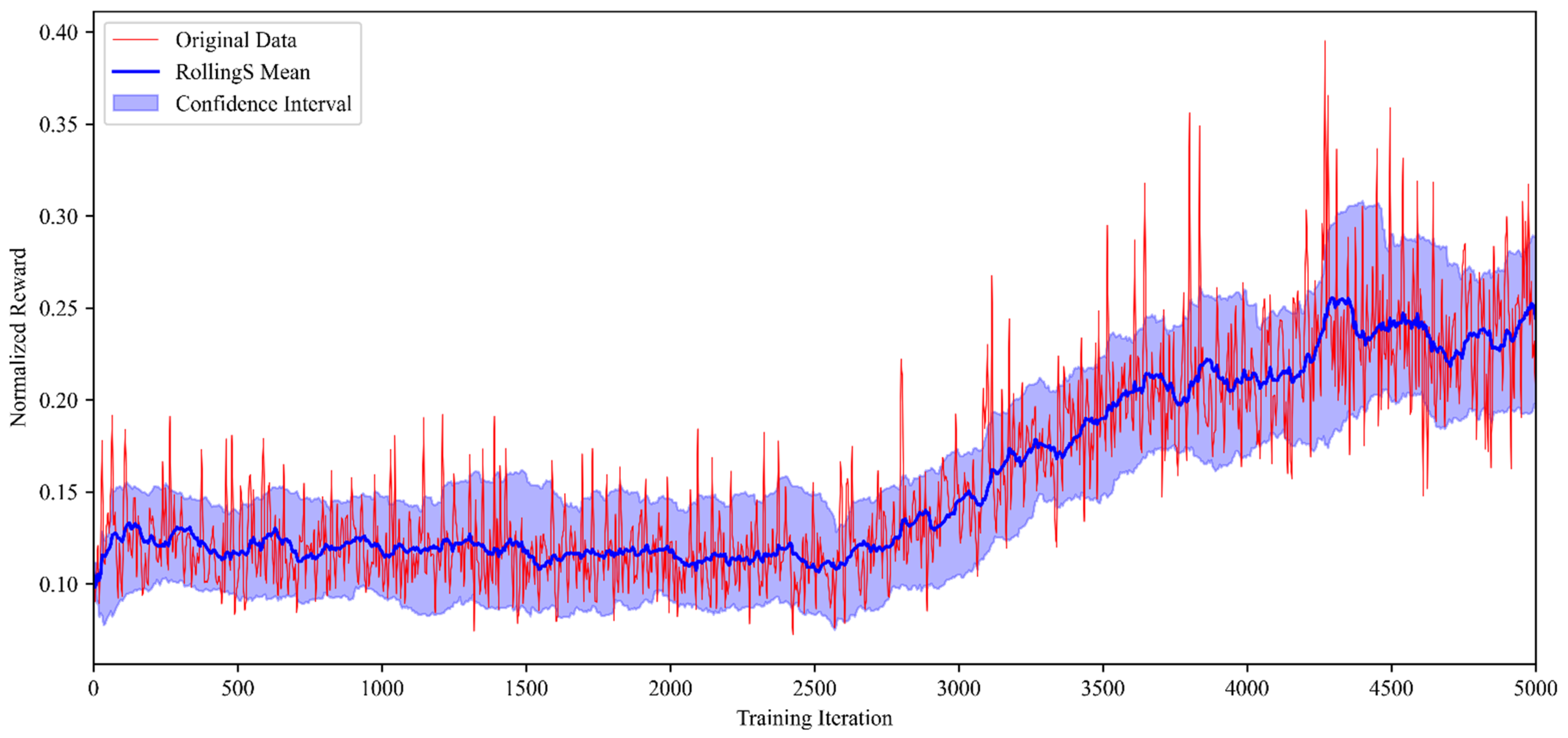
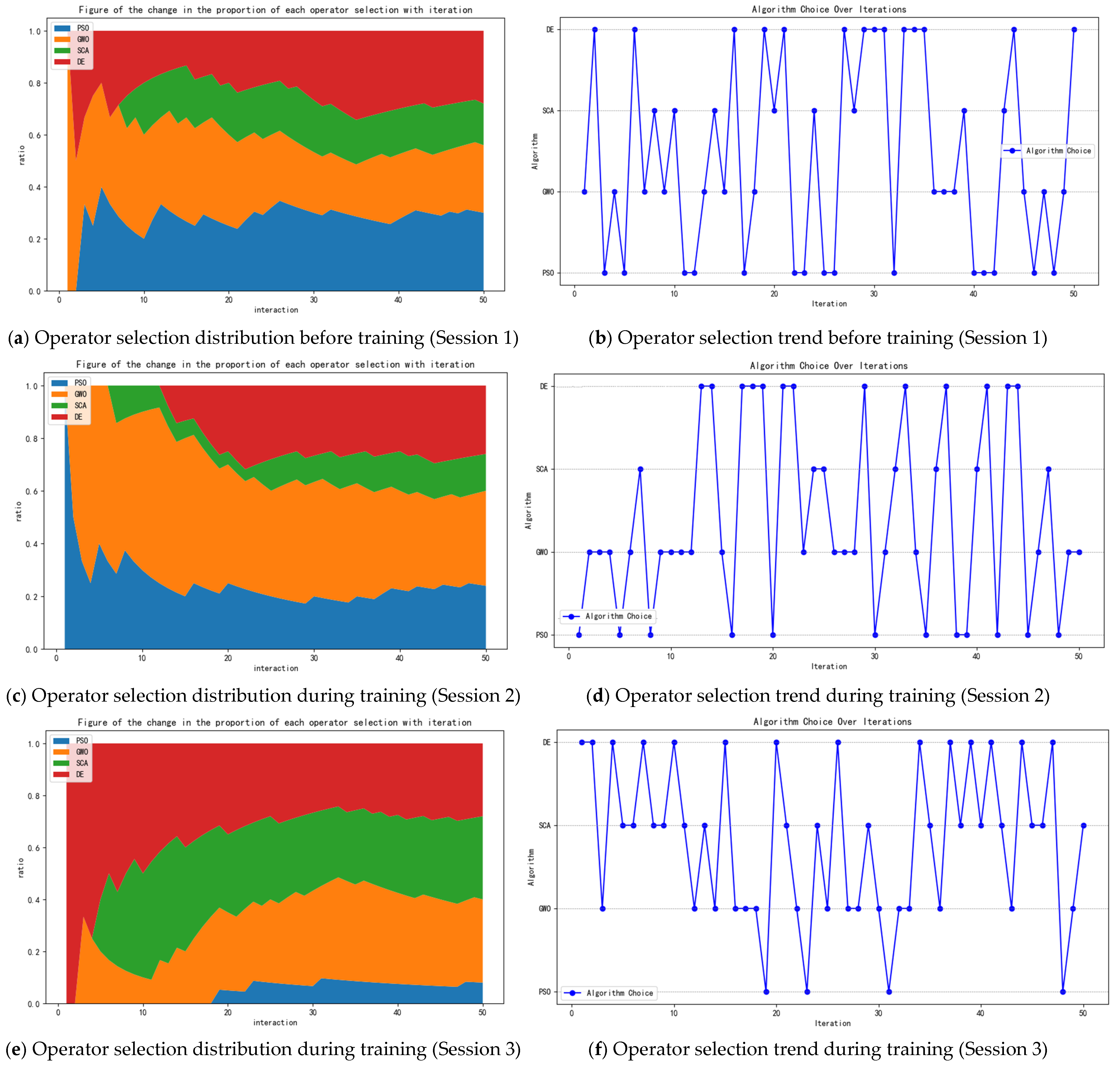
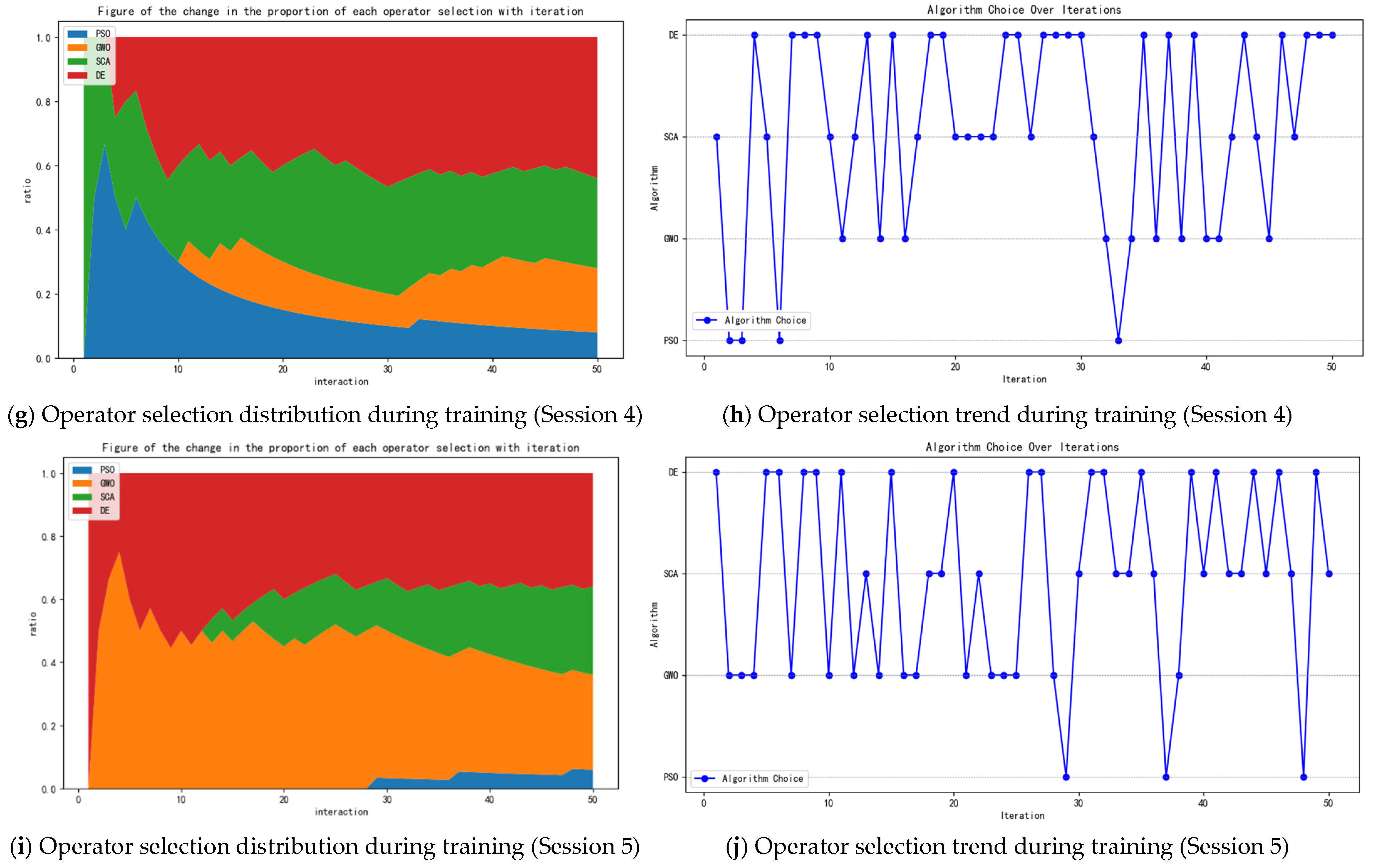
5.2. Model Training
5.3. Comparative Experiments with AC-HATP and Operators
5.4. Comparative Experiments with Other Algorithms
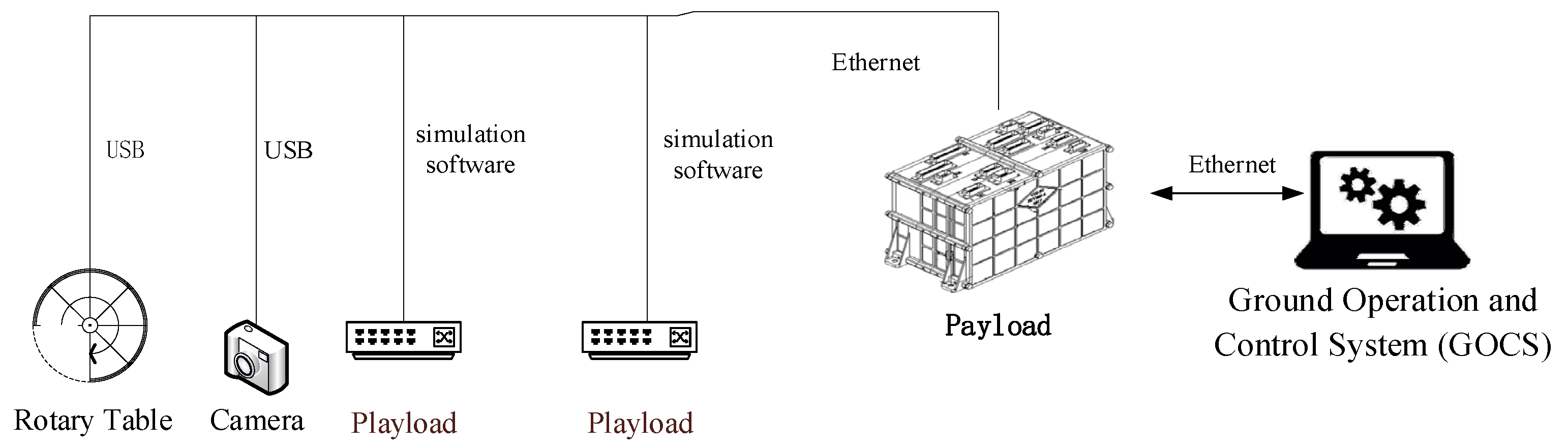
6. Applications
7. Conclusions and Future Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dvorak, D.D.; Ingham, M.D.; Morris, J.R.; Gersh, J.R. Goal-based operations: An overview. J. Aerosp. Comput. Inf. Commun. 2009, 6, 123–141. [Google Scholar] [CrossRef]
- Turky, A.; Sabar, N.R.; Dunstall, S.; Song, A. Hyper-heuristic local search for combinatorial optimization problems. Knowl.-Based Syst. 2020, 205, 106264. [Google Scholar] [CrossRef]
- Pillay, N.; Qu, R. Assessing hyper-heuristic performance. J. Oper. Res. Soc. 2021, 72, 2503–2516. [Google Scholar] [CrossRef]
- Asta, S.; Özcan, E.; Curtois, T. A tensor based hyper-heuristic for nurse rostering. Knowl.-Based Syst. 2016, 98, 185–199. [Google Scholar] [CrossRef]
- Pour, S.M.; Drake, J.H.; Burke, E.K. A choice function hyper-heuristic framework for the allocation of maintenance tasks inf Danish railways. Comput. Oper. Res. 2018, 93, 15–26. [Google Scholar] [CrossRef]
- Choong, S.S.; Wong, L.P.; Lim, C.P. An artificial bee colony algorithm with a modified choice function for the traveling salesman problem. Swarm Evol. Comput. 2019, 44, 622–635. [Google Scholar] [CrossRef]
- Lamghari, A.; Dimitrakopoulos, R. Hyper-heuristic approaches for strategic mine planning under uncertainty. Comput. Oper. Res. 2020, 115, 104590. [Google Scholar] [CrossRef]
- Singh, E.; Pillay, N. A study of ant-based pheromone spaces for generation constructive hyper-heuristics. Swarm Evol. Comput. 2022, 72, 101095. [Google Scholar] [CrossRef]
- Hu, R.J.; Zhang, Y.L. Fast path planning for long-range planetary roving based on a hierarchical framework and deep reinforcement learning. Aerospace 2022, 9, 101. [Google Scholar] [CrossRef]
- Kallestad, J.; Hasibi, R.; Hemmati, A.; Sörensen, K. A general deep reinforcement learning hyperheuristic framework for solving combinatorial optimization problems. Eur. J. Oper. Res. 2023, 309, 446–468. [Google Scholar] [CrossRef]
- Qin, W.; Zhuang, Z.L.; Huang, Z.Z.; Huang, H. A novel reinforcement learning-based hyper-heuristic for heterogeneous vehicle routing problem. Comput. Ind. Eng. 2021, 156, 107252. [Google Scholar] [CrossRef]
- Panzer, M.; Bender, B.; Gronau, N. A deep reinforcement learning based hyper-heuristic for modular production control. Int. J. Prod. Res. 2024, 62, 2747–2768. [Google Scholar] [CrossRef]
- Tu, C.; Bai, R.; Aickelin, U.; Zhang, Y.; Du, H. A deep reinforcement learning hyper-heuristic with feature fusion for online packing problems. Expert Syst. Appl. 2023, 230, 120568. [Google Scholar] [CrossRef]
- Chen, K.W.; Bei, A.N.; Wang, Y.J.; Zhang, H. Modeling of imaging satellite mission planning based on PDDL. Ordnance Ind. Autom. 2018, 27, 41–44. [Google Scholar]
- Chen, A.X.; Jiang, Y.F.; Cai, X.L. Research on the Formal Representation of Planning Problem. Comput. Sci. 2008, 35, 105–110. [Google Scholar]
- Green, C. Theorem proving by resolution as a basis for question-answering systems. Mach. Intell. 1969, 4, 183–205. [Google Scholar]
- McCarthy, J. Situations, Actions, and Causal Laws; Comtex Scientific: New York, NY, USA, 1963; pp. 410–417. [Google Scholar]
- Fikes, R.E.; Nilsson, N.J. STRIPS: A new approach to the application of theorem proving to problem solving. Artif. Intell. 1971, 2, 189–208. [Google Scholar] [CrossRef]
- Ghallab, M.; Howe, A.; Knoblock, C.; McDermott, D.; Ram, A.; Veloso, M.; Weld, D.; Wilkins, D. PDDL—The Planning Domain Definition Language—Version 1.2; Technical Report CVC TR-98-003/DCS TR-1165; Yale Center for Computational Vision and Control, Yale University: New Haven, CT, USA, 1998. [Google Scholar]
- Fox, M.; Long, D. PDDL2.1: An extension to PDDL for expressing temporal planning domains. J. Artif. Intell. Res. 2003, 20, 61–124. [Google Scholar] [CrossRef]
- Edelkamp, S.; Hoffmann, J. PDDL2.2: The Language for the Classical Part of the Fourth International Planning Competition; Technical Report 195; Institut für Informatik, Albert-Ludwigs-Universität Freiburg: Freiburg, Germany, 2004. [Google Scholar]
- Gerevini, A.; Long, D. Plan Constraints and Preferences in PDDL3: The Language of the Fifth International Planning Competition; University of Brescia Italy: Brescia, Italy, 2005. [Google Scholar]
- Batusov, V.; Soutchanski, M. A logical semantics for PDDL+. Proc. Int. Conf. Autom. Plan. Sched. 2019, 29, 40–48. [Google Scholar] [CrossRef]
- Zhu, L.Y.; Ye, Z.L.; Li, Y.Q.; Fu, Z.; Xu, Y. Modeling of Autonomous Flight Mission Intelligent Planning for Small Body Exploration. J. Deep. Space Explor. 2019, 6, 463–469. [Google Scholar]
- Zemler, E.; Azimi, S.; Chang, K.; Morris, R.A.; Frank, J. Integrating task planning with robust execution for autonomous robotic manipulation in space. In Proceedings of the ICAPS Workshop on Planning and Robotics, Nancy, France, 19–30 October 2020. [Google Scholar]
- Li, X.; Li, C.G.; Guo, X.Y.; Zhi, Q. A Modeling Method for Inter-Satellite Transmission Tasks Planning in Collaborative Network based on PDDL. In Proceedings of the 2019 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI) 2019, Changsha, China, 1–3 November 2019; pp. 1460–1467. [Google Scholar]
- Ma, M.H.; Zhu, J.H.; Fan, Z.L.; Luo, X. A Model of Earth Observing Satellite Application Task Describing. J. Natl. Univ. Def. Technol. 2011, 33, 89–94. [Google Scholar]
- Chen, J.Y.; Zhang, C.; Li, Y.B. Multi-star cooperative task planning based on hyper-heuristic algorithm. J. China Acad. Electron. Inf. Technol. 2018, 13, 254–259. [Google Scholar]
- Xue, Z.J.; Yang, Z.; Li, J.; Zhao, B. Autonomous Mission Planning of Satellite for Emergency. Command. Control Simul. 2015, 37, 24–30. [Google Scholar]
- Xu, W.M. Autonomous Mission Planning Method and System Design of Deep Space Explorer. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2006. [Google Scholar]
- Wang, X.H. Study on Autonomous Mission Planning Technology for Deep Space Explorer Under Dynamic Uncertain Environment. Master’s Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2017. [Google Scholar]
- Chien, S.; Rabideau, G.; Knight, R.; Sherwood, R.; Engelhardt, B.; Mutz, D.; Estlin, T.; Smith, B.; Fisher, F.; Barrett, T.; et al. Aspen-automated planning and scheduling for space mission operations. In Proceedings of the Space Ops, Cape Town, South Africa, 18–22 May 2000; p. 82. [Google Scholar]
- Fratini, S.; Cesta, A. The APSI framework: A platform for timeline synthesis. In Proceedings of the Workshop on Planning and Scheduling with Timelines, Sao Paulo, Brazil, 25–29 June 2012; pp. 8–15. [Google Scholar]
- Johnston, M.D. Spike: Ai scheduling for nasa’s hubble space telescope. In Proceedings of the Sixth Conference on Artificial Intelligence for Applications, Santa Barbara, CA, USA, 5–9 May 1990; IEEE Computer Society: Los Alamitos, CA, USA, 1990; pp. 184–185. [Google Scholar]
- Jiang, X.; Xu, R.; Zhu, S.Y. Research on Task Planning Problems for Deep Space Exploration Based on Constraint Satisfaction. J. Deep. Space Explor. 2018, 5, 262–268. [Google Scholar]
- Du, J.W. Modeling mission planning for imaging satellite based on colored Petri nets. Comput. Appl. Softw. 2012, 29, 324–328. [Google Scholar]
- Liang, J.; Zhu, Y.H.; Luo, Y.Z.; Zhang, J.-C.; Zhu, H. A precedence-rule-based heuristic for satellite onboard activity planning. Acta Astronaut. 2021, 178, 757–772. [Google Scholar] [CrossRef]
- Bucchioni, G.; De Benedetti, M.; D’Onofrio, F.; Innocenti, M. Fully safe rendezvous strategy in cis-lunar space: Passive and active collision avoidance. J. Astronaut. Sci. 2022, 69, 1319–1346. [Google Scholar] [CrossRef]
- Muscettola, N. HSTS: Integrating Planning and Scheduling; The Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 1993. [Google Scholar]
- Chang, Z.X.; Chen, Y.N.; Yang, W.Y.; Zhou, Z. Mission planning problem for optical video satellite imaging with variable image duration: A greedy algorithm based on heuristic knowledge. Adv. Space Res. 2020, 66, 2597–2609. [Google Scholar] [CrossRef]
- Zhao, Y.B.; Du, B.; Li, S. Agile satellite mission planning via task clustering and double-layer tabu algorithm. Comput. Model. Eng. Sci. 2020, 122, 235–257. [Google Scholar] [CrossRef]
- Jin, H.; Xu, R.; Cui, P.Y.; Zhu, S.; Jiang, H.; Zhou, F. Heuristic search via graphical structure in temporal interval-based planning for deep space exploration. Acta Astronaut. 2020, 166, 400–412. [Google Scholar] [CrossRef]
- Federici, L.; Zavoli, A.; Colasurdo, G. On the use of A* search for active debris removal mission planning. J. Space Saf. Eng. 2021, 8, 245–255. [Google Scholar] [CrossRef]
- Long, J.; Wu, S.; Han, X.; Wang, Y.; Liu, L. Autonomous task planning method for multi-satellite system based on a hybrid genetic algorithm. Aerospace 2023, 10, 70. [Google Scholar] [CrossRef]
- Xiao, P.; Ju, H.; Li, Q.; Xu, H. Task planning of space maintenance robot using modified clustering method. IEEE Access 2020, 8, 45618–45626. [Google Scholar] [CrossRef]
- Wang, F.R. Research on Autonomous Mission Planning Method of Microsatellite Based on Improved Genetic Algorithm. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2017. [Google Scholar]
- Zhao, P.; Chen, Z.M. An adapted genetic algorithm applied to satellite autonomous task scheduling. Chin. Space Sci. Technol. 2016, 36, 47–54. [Google Scholar]
- Feng, X.E.; Li, Y.Q.; Yang, C.; He, X.; Xu, Y.; Zhu, L. Structural design and autonomous mission planning method of deep space exploration spacecraft for autonomous operation. Control Theory Appl. 2019, 36, 2035–2041. [Google Scholar]
- Harris, A.; Valade, T.; Teil, T.; Schaub, H. Generation of spacecraft operations procedures using deep reinforcement learning. J. Spacecr. Rocket. 2022, 59, 611–626. [Google Scholar] [CrossRef]
- Huang, Y.; Mu, Z.; Wu, S.; Cui, B.; Duan, Y. Revising the observation satellite scheduling problem based on deep reinforcement learning. Remote Sens. 2021, 13, 2377. [Google Scholar] [CrossRef]
- Wei, L.N.; Chen, Y.N.; Chen, M.; Chen, Y. Deep reinforcement learning and parameter transfer based approach for the multi-objective agile earth observation satellite scheduling problem. Appl. Soft Comput. 2021, 110, 107607. [Google Scholar] [CrossRef]
- Zhao, X.X.; Wang, Z.K.; Zheng, G.T. Two-phase neural combinatorial optimization with reinforcement learning for agile satellite scheduling. J. Aerosp. Inf. Syst. 2020, 17, 346–357. [Google Scholar] [CrossRef]
- Eddy, D.; Kochenderfer, M. Markov decision processes for multi-objective satellite task planning. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–12. [Google Scholar]
- Truszkowski, W.; Hallock, H.; Rouff, C.; Karlin, J.; Rash, J.; Hinchey, M.; Sterritt, R. Autonomous and Autonomic Systems: With Applications to NASA Intelligent Spacecraft Operations and Exploration Systems; Springer Science & Business Media: London, UK, 2009. [Google Scholar]
- Maullo, M.J.; Calo, S.B. Policy management: An architecture and approach. In Proceedings of the 1993 IEEE 1st International Workshop on Systems Management, Los Angeles, CA, USA, 14–16 April 1993; pp. 13–26. [Google Scholar]
- Zhang, J.W.; Lyu, L.Q. A Spacecraft Onboard Autonomous Task Scheduling Method Based on Hierarchical Task Network-Timeline. Aerospace 2024, 11, 350. [Google Scholar] [CrossRef]
- Lyu, L.Q. Design and Application Study of Intelligent Flight Software Architecture on Spacecraft. Ph.D. Thesis, University of Chinese Academy of Sciences (National Space Science Center of Chinese Academy of Sciences), Beijing, China, 2019. [Google Scholar]
- Menger, K.; Dierker, E.; Sigmund, K.; Dawson, J.W. Ergebnisse eines Mathematischen Kolloquiums; Springer: Vienna, Austria, 1998. [Google Scholar]
- Gai, W.D.; Qu, C.Z.; Liu, J.; Zhang, J. An improved grey wolf algorithm for global optimization. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 2494–2498. [Google Scholar]
- Floudas, C.A.; Gounaris, C.E. An overview of advances in global optimization during 2003–2008. Lect. Glob. Optim. 2009, 55, 105–154. [Google Scholar]
- Lee, C.Y.; Zhuo, G.L. A hybrid whale optimization algorithm for global optimization. Mathematics 2021, 9, 1477. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- DaCosta, L.; Fialho, A.; Schoenauer, M.; Sebag, M. Adaptive operator selection with dynamic multi-armed bandits. In Proceedings of the 10th Annual Conference on Genetic and Evolutionary Computation, Atlanta, GA, USA, 12–16 July 2008; pp. 913–920. [Google Scholar]
- Fialho, Á.; Da Costa, L.; Schoenauer, M.; Sebag, M. Analyzing bandit-based adaptive operator selection mechanisms. Ann. Math. Artif. Intell. 2010, 60, 25–64. [Google Scholar] [CrossRef]
- Lu, G.Y.; Lyu, L.Q.; Zhang, J.W. Design of Data Injection Tool Based on CCSDS RASDS Information Object Modeling Method. Spacecr. Eng. 2023, 32, 90–96. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Features | Applications | Limitations |
|---|---|---|---|---|
| Traditional Methods |
|
|
|
|
| Heuristic Algorithms |
|
|
|
|
| Meta-Heuristic Algorithms |
|
|
|
|
| Reinforcement Learning |
|
|
|
|
| Name | Decision-Making | Planning | Scheduling |
|---|---|---|---|
| Input | Spacecraft’s current environment and status | Unordered set of task-level objective commands without timestamps | Task-level objective commands |
| Output | Task-level objective commands and their parameters | Timestamped sequence of task-level objective commands | Schedule-level commands Primitive-level commands |
| Problem Category | Decision problem | Optimization problem | Decomposition problem |
| Term | Definition |
|---|---|
| , otherwise 0 | |
| -th dimension (e.g., time, fuel consumption) of transitioning from task i to task j | |
| -th type of resource | |
| Minimum cost–benefit ratio threshold | |
| ; equals 1 if within the window, otherwise 0 | |
| The relative position of task i during task execution. | |
| The time required to transition from task i to task j | |
| The profit obtained after executing task i and then task j | |
| Task feasibility constraint parameter, representing the constraint condition for whether a task is executable |
| No. | Algorithm Name | Principle of the Algorithm | Feature of the Algorithm | Explanation of the Feature |
|---|---|---|---|---|
| 1 | PSO | Simulates the foraging behavior of bird flocks, moving through the search space via collaboration and information sharing to find the optimal solution. | Global Search Capability | Particles in the particle swarm optimization algorithm explore the space randomly, with stochastic parameters ensuring that different particles explore different areas. |
| 2 | WOA | Emulates the social hierarchy and group hunting behaviors of grey wolves to optimize, simulating the processes of tracking, encircling, and capturing prey in the search space to find the optimal solution. | Fast Convergence Rate | Utilizes the leader and follower mechanism along with the strategy of encircling prey to ensure fast convergence rate in the search space. |
| 3 | SCA | Adjusts the search path of solutions using sine and cosine rules. | Global Search Capability | Leverages the properties of mathematical sine and cosine functions to quickly adjust the direction and position of solutions, improve the global search capability. |
| 4 | DE | Simulates the evolutionary process of biological populations, finding optimal solutions through iterative mutation, crossover, and selection operations. | High Quality of Solution Optimization | Efficiently adapts to diverse optimization landscapes, consistently delivering high-quality solutions even in complex problem spaces. |
| Property | Value |
|---|---|
| Spatial Range | (0,0) to (100,100) |
| Spacecraft Position Range | (0,0) to (100,100) |
| Max TOC Capacity | 100 |
| Number of Generated TOCs | (0,100) |
| Object | Property | Value |
|---|---|---|
| RL strategy | Action Dimension | 4 |
| Actor Learning Rate | 2 × 10−4 | |
| Critic Learning Rate | 3 × 10−3 | |
| Hidden Dimension | 120 | |
| Discount Factor (γ) | 0.95 | |
| Entropy Beta | 0.05 | |
| Epsilon Start | 1.5 | |
| Epsilon End | 0.01 | |
| Epsilon Decay | 500 | |
| Num Episodes | 10,000 | |
| Optimizer | Adam | |
| Actor Scheduler Gamma | 0.9 | |
| Critic Scheduler Gamma | 0.9 | |
| SCA | scale | 200 |
| Growth Rate | 0.1 | |
| Competition Rate | 0.1–0.25 | |
| Iterations | 1000 | |
| PSO | scale | 200 |
| C1 | 2.0 | |
| C2 | 1.0 | |
| W | Typically between 0.5 and 1.0 | |
| Velocity | −0.2–0.2 | |
| Iterations | 1000 | |
| w | 0.9 | |
| DE | scale | 200 |
| Differential Weight | 0.5 | |
| Crossover Probability | 0.9 | |
| Iterations | 1000 | |
| GWO | scale | 200 |
| A | Linearly decreasing from 2 to 0 | | |
| C | Random values between 0 and 2 | |
| Iterations | 1000 |
| Instance ID | Number of Tasks in Instance | PSO | GWO | SCA | DE | AC-HATP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | ||
| Task Case1 | 10 | 195 | 193 | 4.73 | 200 | 193 | 7.34 | 195 | 193 | 4.29 | 193 | 193 | 0.68 | 193 | 193 | 0.72 |
| Task Case2 | 14 | 270 | 244 | 12.07 | 266 | 244 | 16.12 | 266 | 244 | 15.36 | 269 | 244 | 8.99 | 264 | 244 | 9.13 |
| Task Case3 | 18 | 321 | 292 | 23.91 | 321 | 292 | 23.19 | 350 | 304 | 28.4 | 299 | 292 | 1.98 | 298 | 292 | 3.25 |
| Task Case4 | 22 | 471 | 407 | 45.64 | 448 | 403 | 37.57 | 542 | 489 | 36.1 | 403 | 383 | 9.08 | 403 | 383 | 12.06 |
| Task Case5 | 26 | 563 | 421 | 70.76 | 494 | 410 | 52.89 | 662 | 558 | 53.08 | 416 | 387 | 15.1 | 410 | 387 | 20.06 |
| Task Case6 | 30 | 605 | 506 | 56.49 | 535 | 450 | 61.25 | 755 | 676 | 45.73 | 436 | 412 | 33.38 | 439 | 415 | 35.25 |
| Task Case7 | 34 | 731 | 564 | 134.9 | 586 | 440 | 90.93 | 1055 | 859 | 98.83 | 428 | 411 | 24.67 | 425 | 411 | 41.12 |
| Task Case8 | 38 | 900 | 679 | 141.33 | 715 | 592 | 89.13 | 1227 | 995 | 88.89 | 588 | 499 | 56.88 | 593 | 499 | 72.23 |
| Task Case9 | 42 | 1017 | 774 | 145.88 | 769 | 570 | 98.64 | 1277 | 1077 | 86.11 | 630 | 534 | 63.84 | 616 | 532 | 75.86 |
| Task Case10 | 46 | 1224 | 931 | 232.78 | 948 | 707 | 175.21 | 1582 | 1468 | 72.1 | 706 | 640 | 90.3 | 701 | 633 | 102.5 |
| Task Case11 | 50 | 1264 | 1038 | 144.3 | 887 | 597 | 144.49 | 1654 | 1481 | 99.79 | 689 | 591 | 69.22 | 655 | 584 | 80.36 |
| Task Case12 | 54 | 1654 | 1099 | 287.04 | 1235 | 785 | 340.97 | 1938 | 1765 | 87.5 | 879 | 709 | 123.98 | 863 | 702 | 159.56 |
| Task Case13 | 58 | 1815 | 1370 | 260.31 | 1143 | 891 | 133.38 | 2099 | 1931 | 91.08 | 959 | 768 | 136.3 | 933 | 745 | 122.5 |
| Task Case14 | 62 | 2207 | 1670 | 289.41 | 1431 | 982 | 347.48 | 2446 | 2267 | 95.82 | 1172 | 949 | 131.4 | 1103 | 932 | 153.2 |
| Task Case15 | 66 | 1930 | 1545 | 201.28 | 1191 | 745 | 367.68 | 2220 | 2045 | 72.18 | 1190 | 999 | 134.94 | 1186 | 993 | 155.36 |
| Task Case16 | 70 | 2320 | 1629 | 245.54 | 1505 | 1126 | 251.42 | 2549 | 2349 | 87.79 | 1424 | 1068 | 178.04 | 1385 | 1033 | 186.46 |
| Instance ID | Number of Tasks in Instance | PSO | GWO | SCA | DE | AC-HATP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | Max. | Std. | Avg. | Max. | Std. | Avg. | Max. | Std. | Avg. | Max. | Std. | Avg. | Max. | Std. | ||
| Task Case1 | 10 | 0.0001 | 0.0002 | 0.0001 | 0.0078 | 18.7091 | 0.2149 | 0.0056 | 15.6761 | 0.1553 | 0.0098 | 13.0767 | 0.2322 | 0.0104 | 17.1645 | 0.4554 |
| Task Case2 | 14 | 0.0003 | 0.0005 | 0.0001 | 0.0324 | 46.7765 | 0.8429 | 0.0169 | 46.1657 | 0.4844 | 0.0282 | 50.8921 | 0.6474 | 0.0366 | 48.3744 | 0.2364 |
| Task Case3 | 18 | 0.0001 | 0.0002 | 0.0001 | 0.0243 | 25.1133 | 0.567 | 0.0207 | 31.5107 | 0.546 | 0.0233 | 32.6495 | 0.4282 | 0.0225 | 36.6633 | 0.3665 |
| Task Case4 | 22 | 0.0008 | 0.001 | 0.0003 | 0.0363 | 62.1455 | 0.927 | 0.0178 | 26.4711 | 0.3928 | 0.0317 | 34.2578 | 0.6099 | 0.0324 | 45.5843 | 0.5364 |
| Task Case5 | 26 | 0.0007 | 0.0009 | 0.0002 | 0.0296 | 69.4211 | 0.8448 | 0.0255 | 49.6433 | 0.744 | 0.0481 | 72.3222 | 1.0356 | 0.0368 | 63.331 | 0.8223 |
| Task Case6 | 30 | 0.0002 | 0.0003 | 0.0001 | 0.0349 | 58.9927 | 0.8913 | 0.0158 | 30.0202 | 0.3971 | 0.043 | 47.6987 | 0.7876 | 0.0361 | 62.3372 | 0.5746 |
| Task Case7 | 34 | 0.0003 | 0.0004 | 0.0001 | 0.047 | 64.098 | 1.0587 | 0.0293 | 48.1168 | 0.8451 | 0.0599 | 113.4906 | 1.3527 | 0.0511 | 72.2661 | 0.3661 |
| Task Case8 | 38 | 0.0005 | 0.0007 | 0.0002 | 0.0343 | 37.8841 | 0.7375 | 0.0247 | 84.3945 | 0.8828 | 0.0435 | 69.839 | 0.8695 | 0.0395 | 56.1353 | 0.4366 |
| Task Case9 | 42 | 0.0007 | 0.0008 | 0.0003 | 0.0327 | 88.3789 | 1.0344 | 0.0294 | 58.6144 | 0.7744 | 0.045 | 54.0082 | 0.8037 | 0.0438 | 56.6332 | 0.8735 |
| Task Case10 | 46 | 0.0003 | 0.0005 | 0.0001 | 0.0445 | 86.4128 | 1.1192 | 0.0281 | 41.1967 | 0.691 | 0.0568 | 97.9028 | 1.3335 | 0.0633 | 75.4003 | 0.8614 |
| Task Case11 | 50 | 0.0001 | 0.0002 | 0.0001 | 0.0335 | 49.1717 | 0.8569 | 0.038 | 87.688 | 1.2255 | 0.0528 | 52.0891 | 0.96 | 0.0462 | 69.4387 | 0.6339 |
| Task Case12 | 54 | 0.0003 | 0.0005 | 0.0001 | 0.0285 | 44.1303 | 0.7858 | 0.0359 | 84.1254 | 1.1072 | 0.0433 | 80.951 | 1.0153 | 0.0458 | 76.6436 | 0.7268 |
| Task Case13 | 58 | 0.0005 | 0.0007 | 0.0002 | 0.0421 | 77.9441 | 1.1603 | 0.0333 | 74.6741 | 0.9905 | 0.0564 | 84.4854 | 1.3202 | 0.0495 | 86.6395 | 0.5244 |
| Task Case14 | 62 | 0.0006 | 0.0007 | 0.0003 | 0.034 | 78.1847 | 1.0699 | 0.0328 | 73.4801 | 0.9486 | 0.0463 | 74.291 | 1.0593 | 0.0497 | 72.3664 | 0.7353 |
| Task Case15 | 66 | 0.0002 | 0.0003 | 0.0001 | 0.0412 | 80.9367 | 1.1975 | 0.0288 | 55.8044 | 0.802 | 0.0372 | 46.2811 | 0.6629 | 0.0447 | 96.1353 | 0.9562 |
| Task Case16 | 70 | 0.0004 | 0.0005 | 0.0002 | 0.0345 | 65.941 | 0.8935 | 0.0395 | 104.4515 | 1.3269 | 0.0469 | 50.9532 | 0.9381 | 0.0489 | 72.1054 | 1.0254 |
| Instance ID | Number of Tasks in Instance | PSO-Avg. | GWO-Avg. | SCA-Avg. | DE-Avg. | AC-HATP-Avg. |
|---|---|---|---|---|---|---|
| Task Case1 | 10 | 0.0502 | 0.1141 | 0.302 | 0.0057 | 0.1336 |
| Task Case2 | 14 | 0.1834 | 0.3873 | 0.7741 | 0.0078 | 0.1845 |
| Task Case3 | 18 | 0.8787 | 0.5562 | 0.877 | 0.0152 | 0.2259 |
| Task Case4 | 22 | 0.898 | 0.6594 | 0.9249 | 0.0188 | 0.2746 |
| Task Case5 | 26 | 0.9926 | 0.773 | 0.9449 | 0.0232 | 0.3103 |
| Task Case6 | 30 | 1 | 0.8372 | 0.9586 | 0.0271 | 0.3065 |
| Task Case7 | 34 | 1 | 0.8662 | 0.9709 | 0.032 | 0.3564 |
| Task Case8 | 38 | 1 | 0.8814 | 0.9765 | 0.0262 | 0.3362 |
| Task Case9 | 42 | 1 | 0.9149 | 0.9812 | 0.0279 | 0.3523 |
| Task Case10 | 46 | 1 | 0.9407 | 0.9844 | 0.0303 | 0.3198 |
| Task Case11 | 50 | 1 | 0.9602 | 0.9881 | 0.0315 | 0.3664 |
| Task Case12 | 54 | 1 | 0.9577 | 0.99 | 0.0293 | 0.3342 |
| Task Case13 | 58 | 1 | 0.9631 | 0.991 | 0.0295 | 0.3462 |
| Task Case14 | 62 | 1 | 0.9681 | 0.9925 | 0.0289 | 0.3321 |
| Task Case15 | 66 | 1 | 0.982 | 0.9935 | 0.0262 | 0.3558 |
| Task Case16 | 70 | 1 | 0.9794 | 0.9946 | 0.0255 | 0.3226 |
| Instance ID | Number of Tasks in Instance | GA | SA | WDO | TSA | DMAB | SLMAB | AC-HATP | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | Avg. | Min. | Std. | ||
| Task Case1 | 10 | 227 | 204 | 9.03 | 196 | 193 | 3.57 | 222 | 203 | 9.7 | 214 | 204 | 1.12 | 193 | 193 | 0.85 | 193 | 193 | 0.80 | 193 | 193 | 0.72 |
| Task Case2 | 14 | 401 | 335 | 21.82 | 302 | 278 | 10.43 | 367 | 322 | 17.41 | 398 | 264 | 13.26 | 265 | 244 | 12.24 | 265 | 244 | 10.25 | 264 | 244 | 9.13 |
| Task Case3 | 18 | 546 | 480 | 27.68 | 431 | 392 | 17.62 | 519 | 441 | 36.53 | 578 | 523 | 10.54 | 301 | 292 | 7.76 | 300 | 294 | 4.53 | 298 | 292 | 3.25 |
| Task Case4 | 22 | 774 | 719 | 28.96 | 648 | 599 | 21.65 | 735 | 670 | 25.07 | 752 | 709 | 4.34 | 412 | 383 | 20.13 | 408 | 385 | 14.63 | 403 | 383 | 12.06 |
| Task Case5 | 26 | 974 | 862 | 39.83 | 809 | 741 | 28.39 | 954 | 869 | 42.27 | 993 | 803 | 13.25 | 416 | 392 | 21.66 | 421 | 394 | 19.68 | 410 | 387 | 20.06 |
| Task Case6 | 30 | 1014 | 882 | 43.6 | 893 | 857 | 27.29 | 997 | 933 | 38.66 | 1022 | 956 | 22.36 | 446 | 423 | 39.44 | 453 | 436 | 37.18 | 439 | 415 | 35.25 |
| Task Case7 | 34 | 1340 | 1246 | 43.32 | 1160 | 1070 | 38.45 | 1298 | 1172 | 51.56 | 1428 | 1201 | 32.11 | 437 | 411 | 39.24 | 440 | 411 | 45.56 | 425 | 411 | 41.12 |
| Task Case8 | 38 | 1527 | 1450 | 32.27 | 1373 | 1336 | 23.17 | 1532 | 1454 | 44.09 | 1639 | 1466 | 19.87 | 601 | 522 | 56.39 | 612 | 519 | 80.13 | 593 | 499 | 72.23 |
| Task Case9 | 42 | 1569 | 1503 | 39.74 | 1401 | 1305 | 41.66 | 1555 | 1457 | 36.82 | 1663 | 1585 | 29.63 | 629 | 546 | 82.25 | 627 | 559 | 87.75 | 616 | 532 | 75.86 |
| Task Case10 | 46 | 1895 | 1839 | 37.21 | 1727 | 1660 | 33.17 | 1903 | 1766 | 64.29 | 1934 | 1896 | 31.56 | 715 | 665 | 110.68 | 723 | 667 | 119.32 | 701 | 633 | 102.5 |
| Task Case11 | 50 | 1950 | 1849 | 53.02 | 1769 | 1665 | 40.1 | 1856 | 1709 | 53.64 | 2033 | 1994 | 42.22 | 671 | 601 | 81.13 | 667 | 596 | 75.52 | 655 | 584 | 80.36 |
| Task Case12 | 54 | 2252 | 2138 | 42.69 | 2044 | 1908 | 62.17 | 2170 | 2034 | 56.11 | 2278 | 2156 | 36.26 | 878 | 726 | 113.5 | 891 | 731 | 183.21 | 863 | 702 | 159.56 |
| Task Case13 | 58 | 2390 | 2256 | 65.73 | 2226 | 2154 | 32.52 | 2387 | 2212 | 66.65 | 2456 | 2334 | 56.47 | 961 | 778 | 92.2 | 955 | 751 | 135.33 | 933 | 745 | 122.5 |
| Task Case14 | 62 | 2822 | 2709 | 53.25 | 2615 | 2541 | 38.66 | 2744 | 2611 | 57.29 | 2874 | 2836 | 23.56 | 1128 | 940 | 155.76 | 1145 | 958 | 159.36 | 1103 | 932 | 153.2 |
| Task Case15 | 66 | 2480 | 2372 | 44.45 | 2321 | 2259 | 31.74 | 2397 | 2270 | 53.48 | 2503 | 2468 | 24.66 | 1203 | 993 | 160.23 | 1206 | 1001 | 140.11 | 1186 | 993 | 155.36 |
| Task Case16 | 70 | 2804 | 2644 | 56.97 | 2625 | 2438 | 60.24 | 2788 | 2565 | 81.5 | 2866 | 2786 | 56.33 | 1405 | 1047 | 194.37 | 1411 | 1065 | 196.73 | 1385 | 1033 | 186.46 |
| Instance ID | Number of Tasks in Instance | GA | SA | WDO | TSA | DMAB | SLMAB | AC-HATP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | Std. | Avg. | Std. | Avg. | Std. | Avg. | Std. | Avg. | Std. | Avg. | Std. | Avg. | Std. | ||
| Task Case1 | 10 | 0.012 | 0.5414 | 0.0066 | 0.1622 | 0.0025 | 0.1023 | 0.0072 | 0.1244 | 0.0093 | 0.5033 | 0.0091 | 0.4629 | 0.0104 | 0.4554 |
| Task Case2 | 14 | 0.0169 | 0.7764 | 0.0173 | 0.4239 | 0.0114 | 0.4114 | 0.0233 | 0.5662 | 0.0272 | 0.4331 | 0.0269 | 0.2591 | 0.0366 | 0.2364 |
| Task Case3 | 18 | 0.0222 | 1.0173 | 0.0177 | 0.4871 | 0.0076 | 0.3059 | 0.0156 | 0.2556 | 0.0183 | 0.4261 | 0.0203 | 0.4008 | 0.0225 | 0.3665 |
| Task Case4 | 22 | 0.0369 | 1.3935 | 0.0197 | 0.4648 | 0.0196 | 0.6746 | 0.0113 | 0.5311 | 0.0294 | 0.5649 | 0.0277 | 0.5147 | 0.0324 | 0.5364 |
| Task Case5 | 26 | 0.041 | 1.4387 | 0.027 | 0.7155 | 0.0132 | 0.4421 | 0.0152 | 0.3205 | 0.0311 | 0.7947 | 0.0305 | 0.9361 | 0.0368 | 0.8223 |
| Task Case6 | 30 | 0.0377 | 1.4142 | 0.0204 | 0.5453 | 0.0165 | 0.5929 | 0.0154 | 0.4331 | 0.0274 | 0.7014 | 0.0289 | 0.6505 | 0.0361 | 0.5746 |
| Task Case7 | 34 | 0.0323 | 1.5912 | 0.0385 | 0.9892 | 0.0204 | 0.871 | 0.0198 | 0.7923 | 0.0413 | 0.5065 | 0.0331 | 0.4962 | 0.0511 | 0.3661 |
| Task Case8 | 38 | 0.0525 | 2.3508 | 0.0362 | 1.2245 | 0.0104 | 0.4622 | 0.0122 | 0.3112 | 0.0377 | 0.5652 | 0.0425 | 0.5329 | 0.0395 | 0.4366 |
| Task Case9 | 42 | 0.0386 | 1.3996 | 0.0274 | 0.6701 | 0.0232 | 0.8322 | 0.021 | 0.2195 | 0.0384 | 0.9666 | 0.0328 | 0.9496 | 0.0438 | 0.8735 |
| Task Case10 | 46 | 0.0435 | 1.2414 | 0.0407 | 1.2635 | 0.0107 | 0.3935 | 0.0131 | 0.2693 | 0.0569 | 0.8553 | 0.0544 | 0.9143 | 0.0633 | 0.8614 |
| Task Case11 | 50 | 0.075 | 2.7175 | 0.0341 | 0.8146 | 0.0337 | 1.304 | 0.0249 | 0.6374 | 0.0423 | 0.6141 | 0.0456 | 0.6294 | 0.0462 | 0.6339 |
| Task Case12 | 54 | 0.0465 | 1.9702 | 0.042 | 1.1092 | 0.027 | 1.1501 | 0.0235 | 1.0548 | 0.0496 | 0.8056 | 0.0477 | 0.7998 | 0.0458 | 0.7268 |
| Task Case13 | 58 | 0.0628 | 2.5316 | 0.0383 | 0.9056 | 0.0257 | 1.1572 | 0.0264 | 1.1022 | 0.0535 | 0.6117 | 0.0483 | 0.6354 | 0.0495 | 0.5244 |
| Task Case14 | 62 | 0.0522 | 1.9523 | 0.0376 | 0.8541 | 0.0264 | 1.0832 | 0.0331 | 0.9321 | 0.0487 | 0.8961 | 0.0492 | 0.7965 | 0.0497 | 0.7353 |
| Task Case15 | 66 | 0.0335 | 1.0349 | 0.0456 | 1.2645 | 0.0282 | 0.881 | 0.0263 | 0.8596 | 0.0423 | 0.9564 | 0.0399 | 0.9322 | 0.0447 | 0.9562 |
| Task Case16 | 70 | 0.0567 | 1.7681 | 0.0485 | 1.2016 | 0.0165 | 0.6416 | 0.0311 | 0.9108 | 0.0475 | 0.4109 | 0.0414 | 0.3643 | 0.0489 | 1.0254 |
| Instance ID | Number of Tasks in Instance | PSO | GWO | SCA | DE | GA | SA | WDO | TSA | DMAB | SLMAB | AC-HATP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task Case1 | 10 | 0.964 | 1.028 | 1.027 | 1.043 | 1.038 | 1.027 | 0.964 | 1.003 | 1.047 | 1.049 | 1.055 |
| Task Case2 | 14 | 1.082 | 1.167 | 1.154 | 1.136 | 0.993 | 1.095 | 1.01 | 1.007 | 1.15 | 1.154 | 1.167 |
| Task Case3 | 18 | 1.27 | 1.316 | 1.286 | 1.32 | 1.071 | 1.171 | 1.042 | 1.013 | 1.319 | 1.329 | 1.328 |
| Task Case4 | 22 | 1.331 | 1.406 | 1.27 | 1.441 | 1.057 | 1.135 | 1.047 | 1 | 1.439 | 1.443 | 1.451 |
| Task Case5 | 26 | 1.522 | 1.654 | 1.399 | 1.79 | 1.059 | 1.2 | 1.024 | 0.951 | 1.788 | 1.779 | 1.8 |
| Task Case6 | 30 | 1.502 | 1.643 | 1.307 | 1.807 | 1.053 | 1.134 | 1.021 | 0.987 | 1.786 | 1.775 | 1.802 |
| Task Case7 | 34 | 2.025 | 2.384 | 1.457 | 2.825 | 1.098 | 1.307 | 1.125 | 0.985 | 2.798 | 2.787 | 2.836 |
| Task Case8 | 38 | 2.12 | 2.603 | 1.514 | 2.986 | 1.158 | 1.308 | 1.089 | 0.976 | 2.946 | 2.912 | 2.971 |
| Task Case9 | 42 | 1.916 | 2.521 | 1.484 | 2.93 | 1.131 | 1.298 | 1.117 | 1 | 2.935 | 2.94 | 2.977 |
| Task Case10 | 46 | 2.054 | 2.786 | 1.425 | 3.63 | 1.066 | 1.234 | 1.011 | 0.973 | 3.597 | 3.565 | 3.653 |
| Task Case11 | 50 | 2.19 | 3.318 | 1.467 | 4.126 | 1.132 | 1.292 | 1.186 | 0.987 | 4.21 | 4.229 | 4.285 |
| Task Case12 | 54 | 1.871 | 2.964 | 1.423 | 4.386 | 1.078 | 1.28 | 1.12 | 1.003 | 4.394 | 4.331 | 4.466 |
| Task Case13 | 58 | 1.906 | 3.991 | 1.437 | 4.89 | 1.117 | 1.261 | 1.071 | 0.998 | 4.88 | 4.912 | 5.033 |
| Task Case14 | 62 | 1.96 | 4.607 | 1.546 | 6.138 | 1.105 | 1.303 | 1.14 | 1.02 | 6.446 | 6.326 | 6.627 |
| Task Case15 | 66 | 1.772 | 3.988 | 1.344 | 3.988 | 1.059 | 1.234 | 1.125 | 1.018 | 3.934 | 3.921 | 4.008 |
| Task Case16 | 70 | 1.721 | 4.208 | 1.391 | 4.6 | 1.115 | 1.292 | 1.07 | 1.015 | 4.7 | 4.668 | 4.804 |
| Number of Maximums | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 13 | |
| Command Name | Command Meaning | ID | Number of Parameters | Parameter 1 | Value | Parameter 2 | Value |
|---|---|---|---|---|---|---|---|
| Rotary table load scheduling | Execute the rotary table command. | 0 × 65 | 2 | Azimuth | 0–180 | Pitch angle | 0–180 |
| Instance | Instance 1 | Instance 2 | Instance 3 | Instance 4 |
|---|---|---|---|---|
| Total Run Time(s) | 20.4743 | 20.0304 | 20.6862 | 19.8063 |
| Convergence Run Time | 4.8613 | 3.7557 | 4.1372 | 2.4757 |
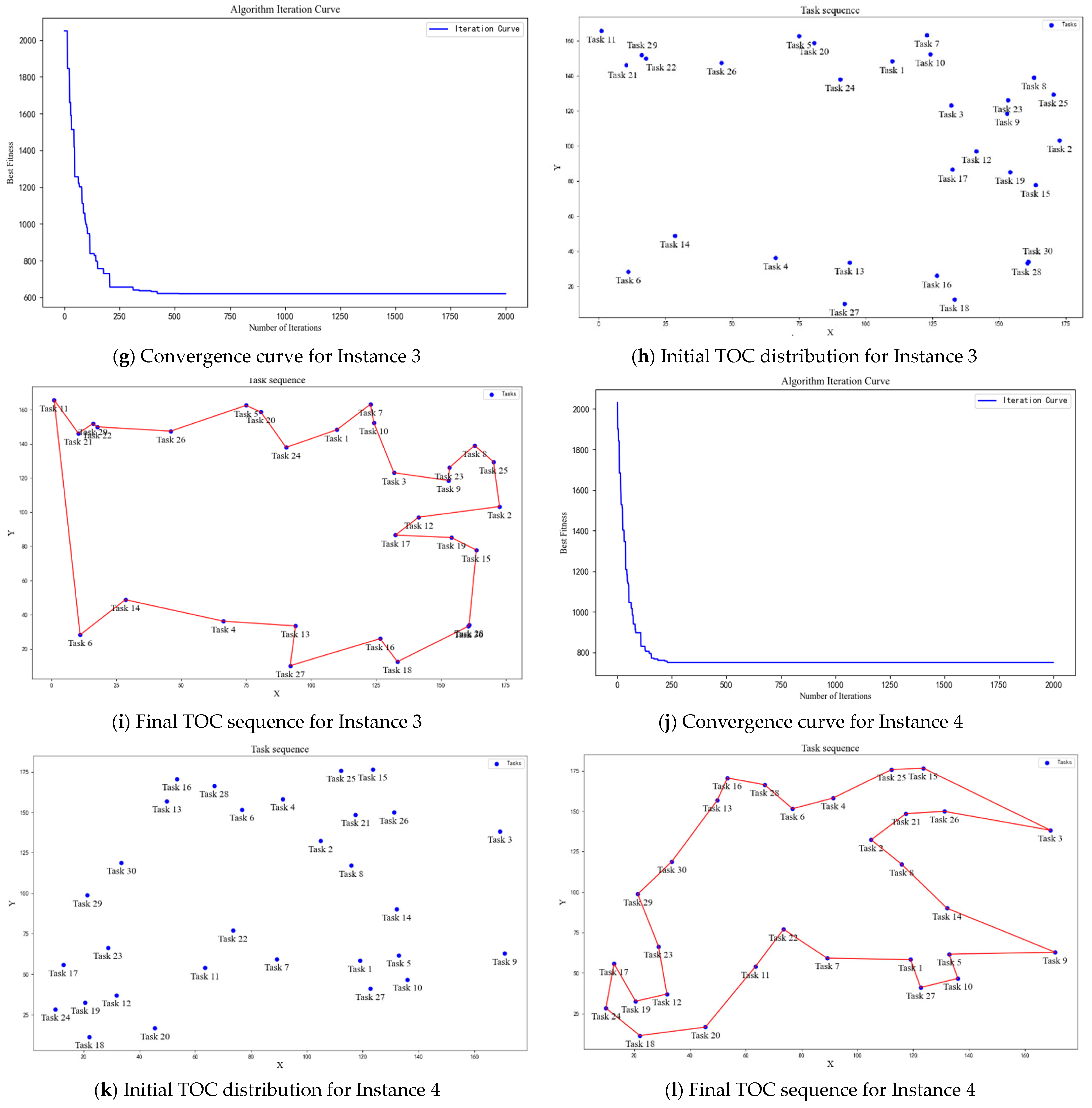
| Initial Fitness Value | 1963 | 2189 | 2023 | 2045 |
| Execution Result Fitness Value | 772 | 820 | 619 | 750 |
| Solution Diversity Index | 0.3177 | 0.3032 | 0.2993 | 0.3013 |
| Memory Usage (KB) | 9284 | 8963 | 9032 | 9114 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Lyu, L. An Actor–Critic-Based Hyper-Heuristic Autonomous Task Planning Algorithm for Supporting Spacecraft Adaptive Space Scientific Exploration. Aerospace 2025, 12, 379. https://doi.org/10.3390/aerospace12050379
Zhang J, Lyu L. An Actor–Critic-Based Hyper-Heuristic Autonomous Task Planning Algorithm for Supporting Spacecraft Adaptive Space Scientific Exploration. Aerospace. 2025; 12(5):379. https://doi.org/10.3390/aerospace12050379
Chicago/Turabian StyleZhang, Junwei, and Liangqing Lyu. 2025. "An Actor–Critic-Based Hyper-Heuristic Autonomous Task Planning Algorithm for Supporting Spacecraft Adaptive Space Scientific Exploration" Aerospace 12, no. 5: 379. https://doi.org/10.3390/aerospace12050379
APA StyleZhang, J., & Lyu, L. (2025). An Actor–Critic-Based Hyper-Heuristic Autonomous Task Planning Algorithm for Supporting Spacecraft Adaptive Space Scientific Exploration. Aerospace, 12(5), 379. https://doi.org/10.3390/aerospace12050379