
New Method for Improving Tracking Accuracy of Aero-Engine On-Board Model Based on Separability Index and Reverse Searching


Abstract
1. Introduction
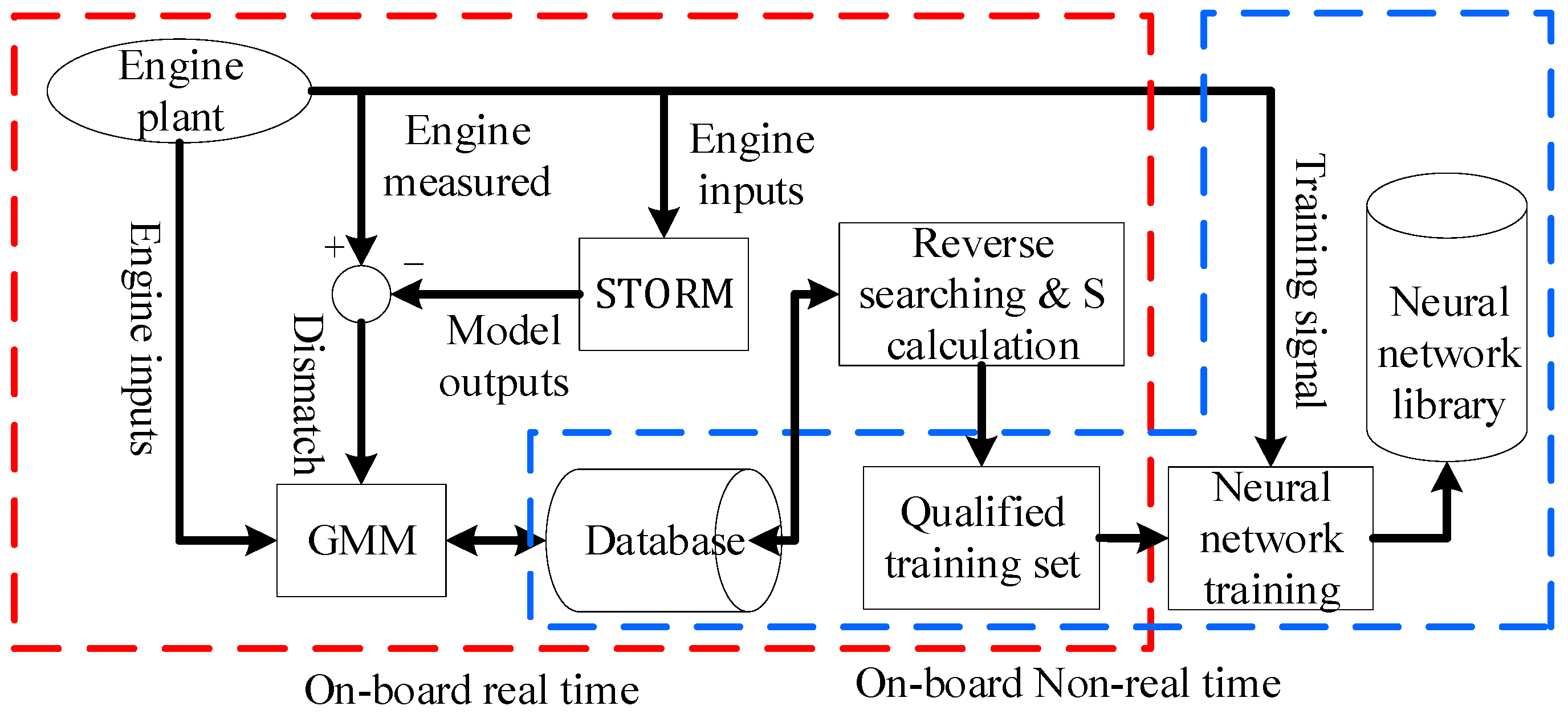
2. eSTORM and GMM
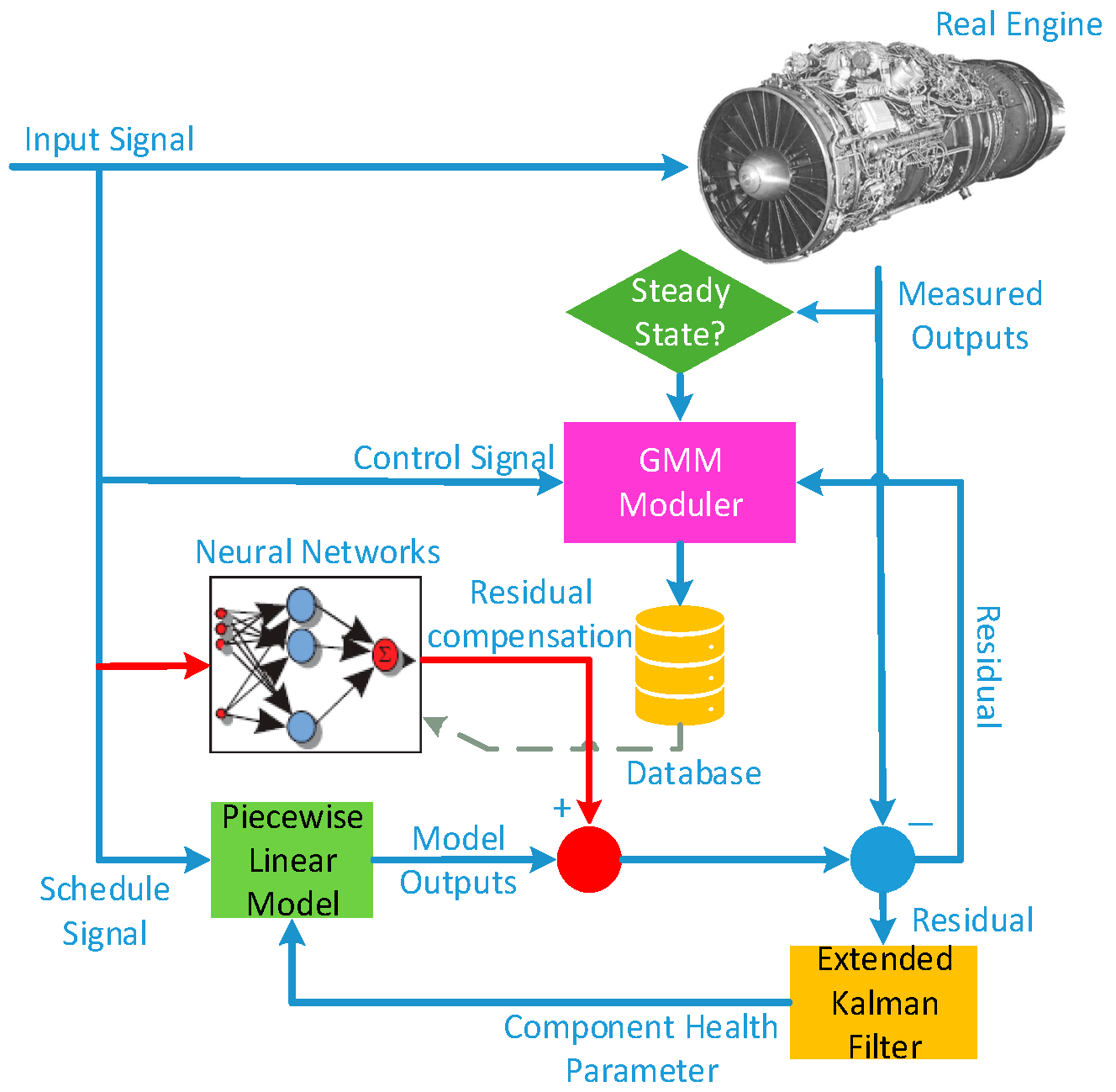
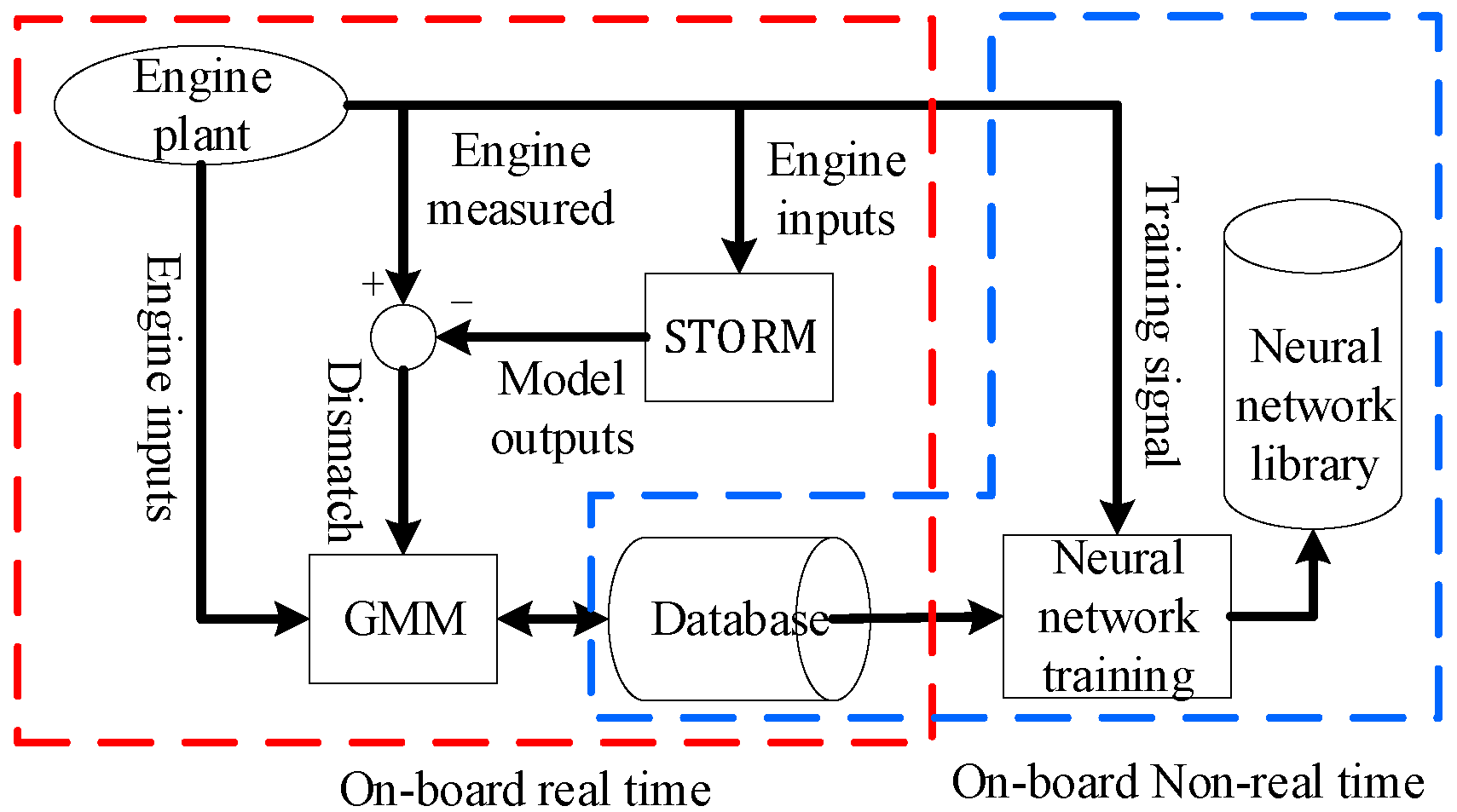
2.1. eSTORM Structure
2.2. GMM Module and Algorithm
2.3. Neural Networks and Training Algorithm
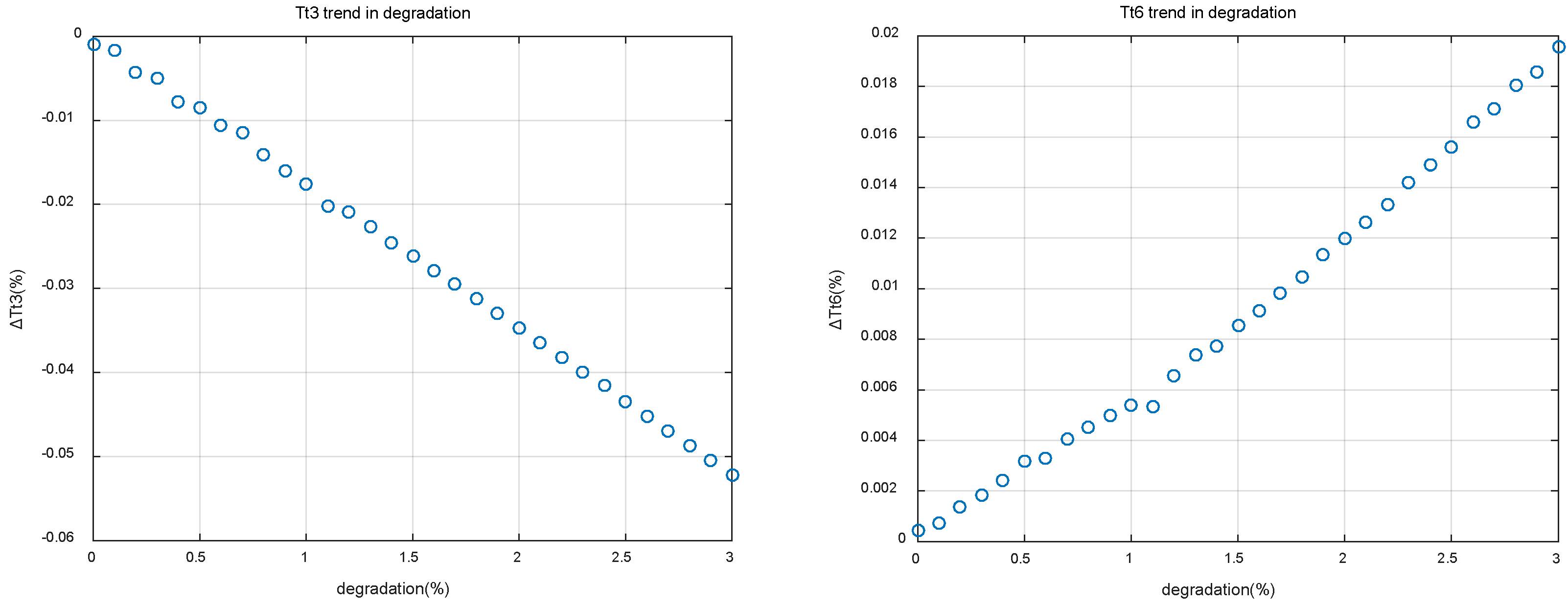
3. Problem
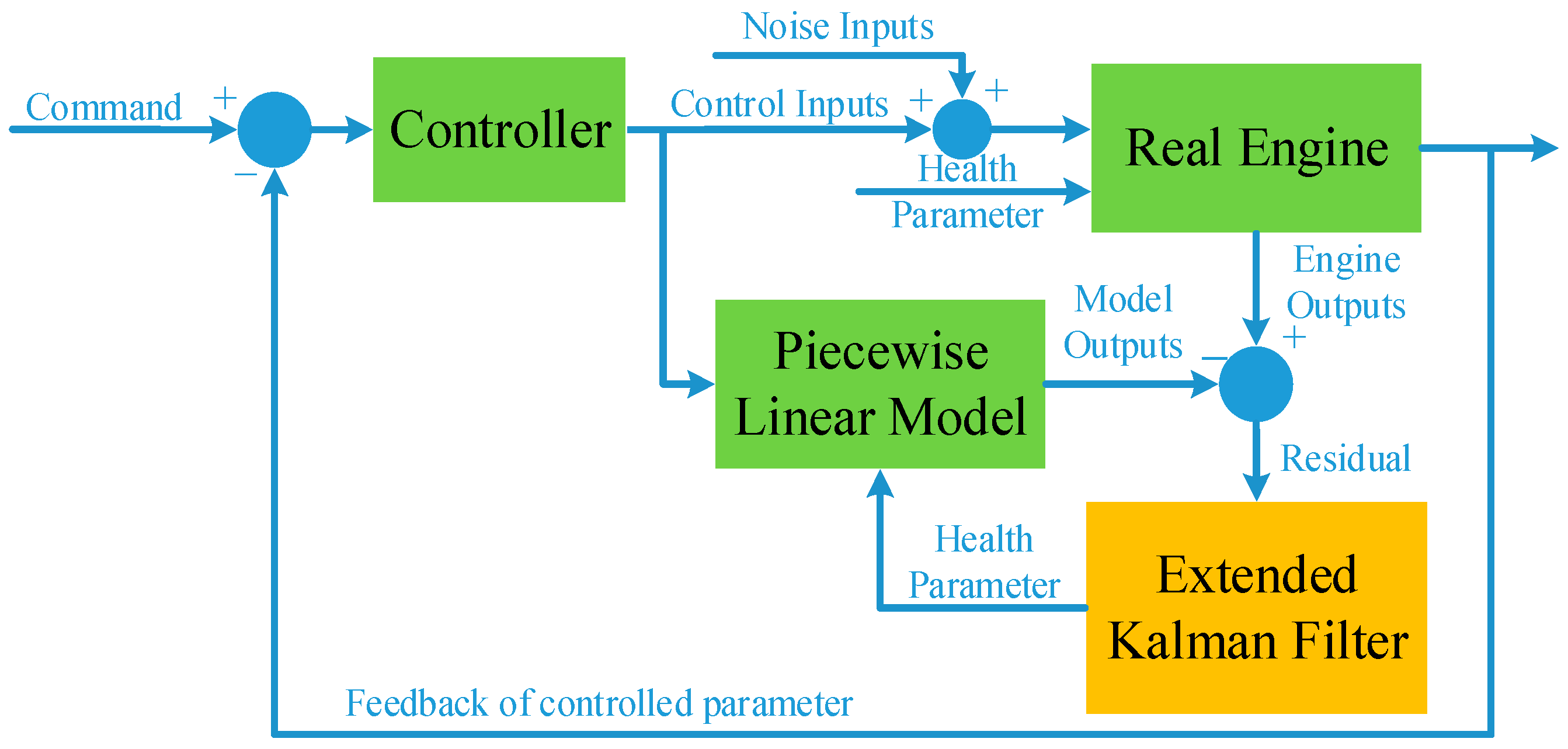
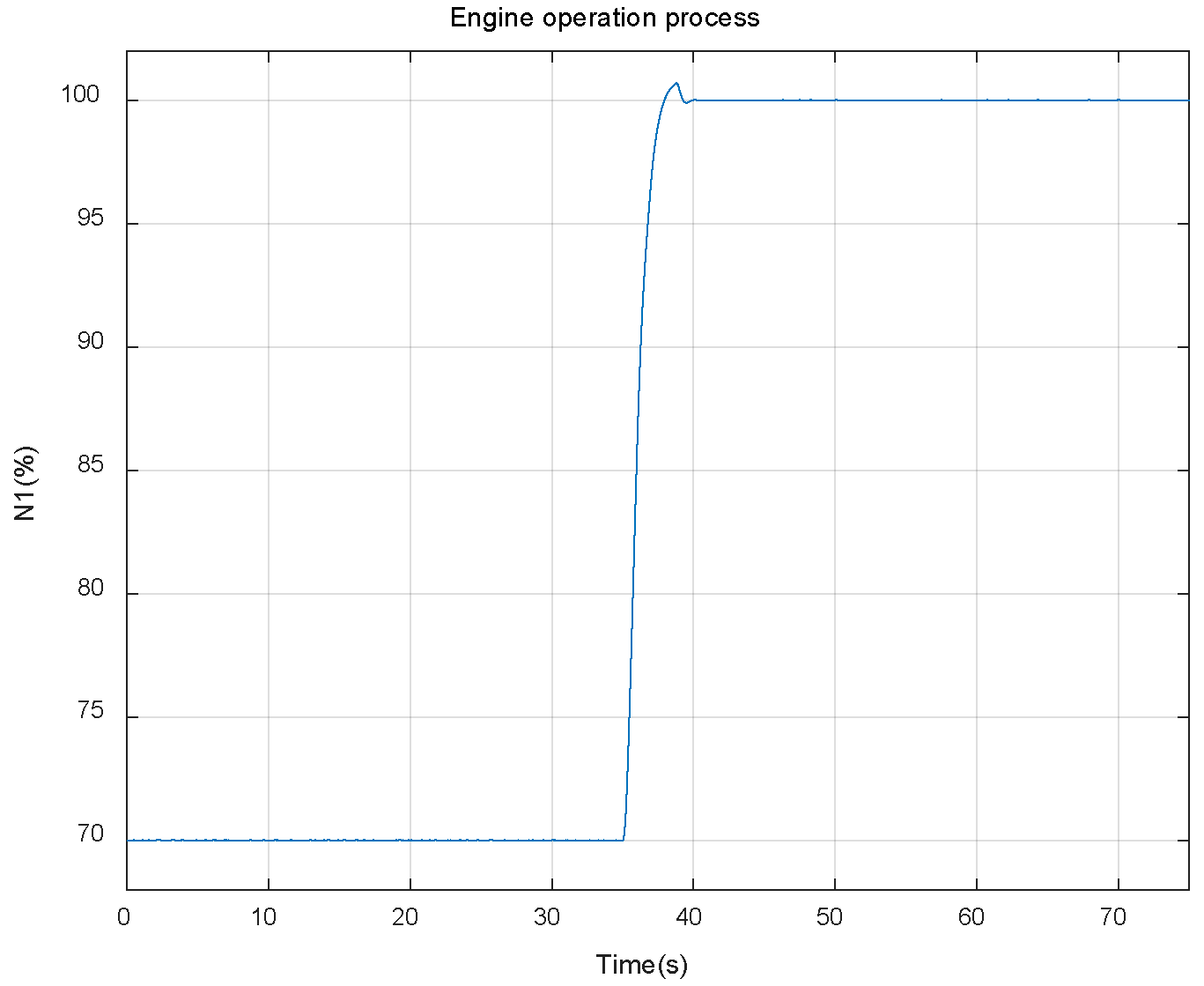
3.1. Illustration of Simulation Model
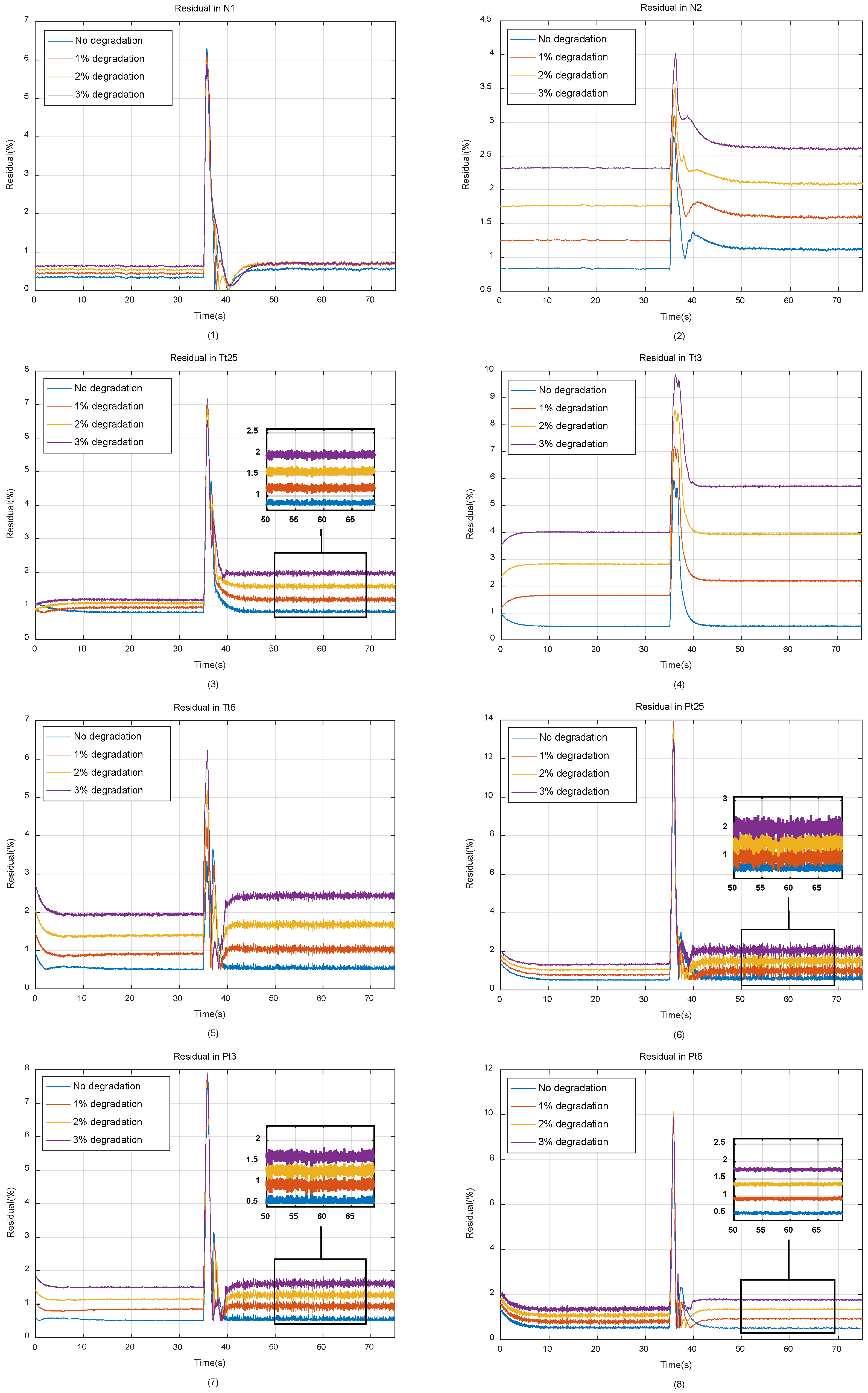
3.2. Simulation Settings and Results
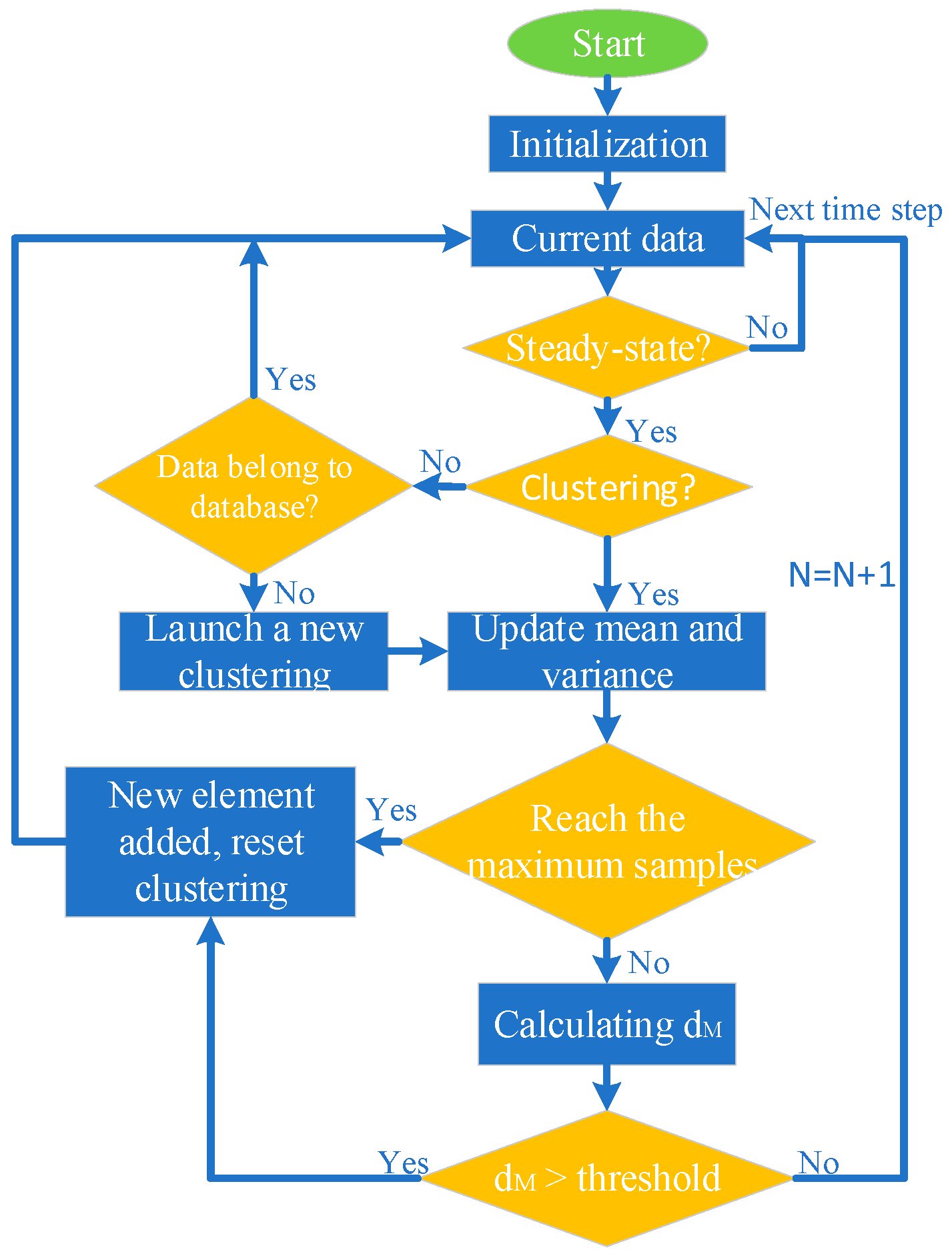
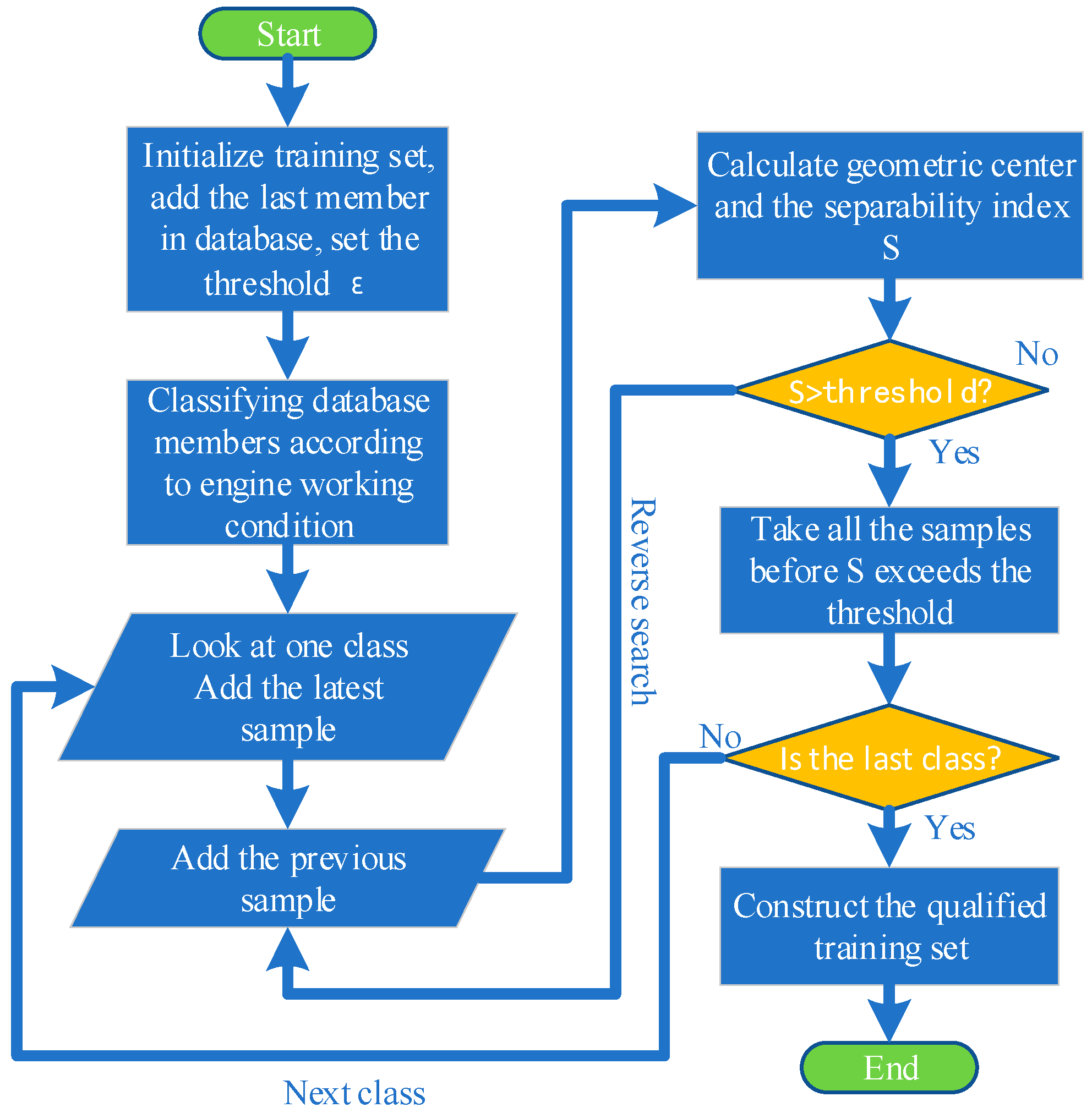
4. Separability Index and Algorithm
- (1)
- This method can completely eliminate the samples formed earlier in the database that can no longer represent the current state of the engine, improves the tracking accuracy of the neural network, and ensures that the training process always converges.
- (2)
- By comparing the definition of the separability index in Equation (9) with the cost function of the neural network in Equation (6), it can be found that they are very similar in mathematical form, so the threshold of the separability index can be set according to the cost function of the neural network.
- (3)
- The algorithm is relatively simple for implementation. As shown in Figure 9, the algorithm can run in the on-board environment in real time.
- (4)
- Finally, because the qualified training set is a subset of the database, which was generated by GMM module, the number of training samples is reduced, and the training speed of the neural network is improved.
5. Simulation and Comparison
6. Discussion of Separability Index in Engine Gas Path Monitoring
- (1)
- After the Gaussian clustering process of eSTORM, the original gas path parameters of the engine have formed a database containing all steady-state operating points, and the influence of noise in the system and measurement are mitigated. The data set constructed by using the separability index and reverse searching represents the current state of the engine. Therefore, the monitoring of the parameter trends does not require additional calculations.
- (2)
- Because the data samples are compressed in time dimension, there is no problem of low algorithm efficiency caused by too few abnormal samples in the sliding window method.
7. Conclusions
- (1)
- This method eliminates the influence of those early data elements in the database, which can no longer represent the current health state of the engine, and ensures the convergence of the training process of the neural networks.
- (2)
- Compared with the method of introducing sample memory factors, this method makes the on-board model maintain higher tracking accuracy during the whole service life of the engine.
- (3)
- The algorithm of reverse search and the construction of a qualified training set can run in real time, and the algorithm is simple for implementation. In addition, the training speed of the neural network is also improved due to fewer training samples.
- (4)
- Finally, the intermediate result obtained when calculating the data set separability index, namely the data set center, can be used for engine gas path monitoring. Compared with the traditional sliding window method, this method avoids the problem of low algorithm efficiency caused by fewer abnormal samples.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Alt | Altitude |
| ComEffDe | High pressure compressor efficiency degradation factor |
| ComWaDe | High pressure compressor mass flow degradation factor |
| dM | Mahalanobis distance |
| FanEffDe | Fan efficiency degradation factor |
| FanWaDe | Fan mass flow degradation factor |
| Ma | Mach number |
| HPC | High pressure compressor |
| HPT | High pressure turbine |
| HPTEffDe | High pressure turbine efficiency degradation factor |
| HPTWaDe | High pressure turbine mass flow degradation factor |
| LPT | Low pressure turbine |
| LPTEffDe | Low pressure turbine efficiency degradation factor |
| LPTWaDe | Low pressure turbine mass flow degradation factor |
| N1 | Low pressure rotor speed |
| N2 | High pressure rotor speed |
| Pt25 | Total pressure at the inlet of high pressure compressor |
| Pt3 | Total pressure at the inlet of combuster |
| Pt6 | Total pressure at the outlet of low pressure turbine |
| SFC | Specific Fuel Consumption |
| S | Separability index |
| Tt25 | Total temperature at the inlet of high pressure compressor |
| Tt3 | Total temperature at the inlet of combuster |
| Tt6 | Total temperature at the outlet of low pressure turbine |
| Center of data set | |
| wfm | Main fuel flow |
| λ | Sample memory factor |
References
- Mattingly, J.D.; Jaw, L.C. Aircraft Engine Controls: Design, System Analysis, and Health Monitoring; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2009; p. 361. [Google Scholar]
- Richter, H. Advanced Control of Turbofan Engines; Springer: New York, NY, USA, 2012; p. 266. [Google Scholar]
- Wei, Z.; Zhang, S.; Jafari, S.; Nikolaidis, T. Gas turbine aero-engines real time on-board modelling: A review, research challenges, and exploring the future. Prog. Aerosp. Sci. 2020, 121, 100693. [Google Scholar] [CrossRef]
- Luppold, R.H.; Roman, J.R.; Gallops, G.W.; Kerr, L.J. Estimating in-flight engine performance variations using Kalman filter concepts. In Proceedings of the 25th Joint Propulsion Conference, Monterey, CA, USA, 12–16 July 1989. [Google Scholar]
- Brotherton, T.; Volponi, A.; Luppold, R.; Simon, D.L. eSTORM: Enhanced self tuning on-board real-time engine model. In Proceedings of the 2003 IEEE Aerospace Conference Proceedings, Big Sky, MT, USA, 8–15 March 2003. [Google Scholar]
- Volponi, A.; Brotherton, T. A bootstrap data methodology for sequential hybrid engine model building. In Proceedings of the Aerospace Conference, Big Sky, MT, USA, 5–12 March 2005. [Google Scholar]
- Volponi, A.J. Use of hybrid engine modeling for on-board module performance tracking. In Proceedings of the ASME Turbo Expo 2005: Power for Land, Sea, and Air, Reno, NV, USA, 6–9 June 2005; pp. 992–1000. [Google Scholar]
- Volponi, A. Enhanced Self Tuning On-Board Real-Time Model (eSTORM) for Aircraft Engine Performance Health Tracking; National Aeronautics and Space Administration: Cleveland, OH, USA, 2008. [Google Scholar]
- Volponi, A.; Brotherton, T.; Luppold, R. Empirical Tuning of an On-Board Gas Turbine Engine Model for Real-Time Module Performance Estimation. J. Eng. Gas Turbines Power Trans. Asme 2008, 130, 96–105. [Google Scholar] [CrossRef]
- Feng, L.; Junning, Q.; Jinquan, H.; Xiaojie, Q. In-flight adaptive modeling using polynomial LPV approach for turbofan engine dynamic behavior. Aerosp. Sci. Technol. 2017, 64, 223–236. [Google Scholar]
- Li, Y.J.; Jia, S.L.; Zhang, H.B.; Zhang, T.H. Research on Modeling Method of On-Board Engine Model Based on Sparse Auto-Encoder. Tuijin Jishu/J. Propuls. Technol. 2017, 38, 1209–1217. [Google Scholar]
- Zheng, Q.; Zhang, H.; Li, Y.; Hu, Z. Aero-engine On-board Dynamic Adaptive MGD Neural Network Model within a Large Flight Envelope. IEEE Access 2018, 6, 1–7. [Google Scholar] [CrossRef]
- Zheng, Q.; Pang, S.; Zhang, H.; Hu, Z. A Study on Aero-Engine Direct Thrust Control with Nonlinear Model Predictive Control Based on Deep Neural Network. Int. J. Aeronaut. Space Sci. 2019, 20, 933–939. [Google Scholar] [CrossRef]
- Zheng, Q.; Fu, D.; Wang, Y.; Chen, H.; Zhang, H. A study on global optimization and deep neural network modeling method in performance-seeking control. Proc. Inst. Mech. Eng. 2020, 234, 46–59. [Google Scholar] [CrossRef]
- Zhao, S.F.; Li, B.W.; Song, H.Q.; Pang, S.; Zhu, F.X. Thrust Estimator Design Based on K-Means Clustering and Particle Swarm Optimization Kernel Extreme Learning Machine. J. Propuls. Technol. 2019, 40, 259–266. [Google Scholar]
- Xiang, D.; Zheng, Q.; Zhang, H.; Chen, C.; Fang, J. Aero-engine on-board adaptive steady-state model base on NN-PSM. J. Aerosp. Power 2022, 37, 409–423. [Google Scholar]
- Tayarani-Bathaie, S.S.; Vanini, Z.N.S.; Khorasani, K. Dynamic neural network-based fault diagnosis of gas turbine engines. Neurocomputing 2014, 125, 153–165. [Google Scholar] [CrossRef]
- Chao, M.A.; Kulkarni, C.S.; Goebel, K.; Fink, O. Fusing Physics-based and Deep Learning Models for Prognostics. Reliab. Eng. Syst. Saf. 2020, 217, 107961. [Google Scholar] [CrossRef]
- Vladov, S.; Banasik, A.; Sachenko, A. Intelligent Method of Identifying the Nonlinear Dynamic Model for Helicopter Turboshaft Engines. Sensors 2024, 24, 6488. [Google Scholar] [CrossRef] [PubMed]
- Shuai, M.; Yafeng, W.; Hua, Z.; Linfeng, G. Parameter modelling of fleet gas turbine engines using gated recurrent neural networks. J. Phys. Conf. Ser. 2023, 2472, 012012. [Google Scholar] [CrossRef]
- Maesschalck, R.D.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis distance. Chemometr Intell Lab 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Hao, S.; Yingqing, G.; Wanli, Z. Improved model for on-board real-time by constructing empirical model via GMM clustering method. J. Northwestern Polytech. Univ. 2020, 38, 507–514. [Google Scholar]
- Gilyard, G.B.; Orme, J.S. Subsonic flight test evaluation of a performance seeking control algorithm on an F-15 airplane. In Proceedings of the 28th Joint Propulsion Conference and Exhibit, Nashville, TN, USA, 6–8 July 1992. [Google Scholar]
- Lu, J.; Guo, Y.Q.; Zhang, S.G. Aeroengine on-board adaptive model based on improved hybrid Kalman filter. J. Aerosp. Power 2011, 26, 2593–2600. [Google Scholar]
- Lu, J.; Guo, Y.Q.; Chen, X.L. Establishment of aero-engine state variable model based on linear fitting method. J. Aerosp. Power 2011, 26, 1172–1177. [Google Scholar]
- Sallee, G.P. Performance Deterioration Based on Existing (Historical) Data; JT9D jet engine diagnostics program; Pratt and Whitney Aircraft Group: East Hartford, CT, USA, 1978. [Google Scholar]
- Xu, M.; Wang, K.; Li, M.; Geng, J.; Wu, Y.; Liu, J.; Song, Z. An adaptive on-board real-time model with residual online learning for gas turbine engines using adaptive memory online sequential extreme learning machine. Aerosp. Sci. Technol. 2023, 141, 108513. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Pal, N.R. Some New Indexes of Cluster Validity. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1998, 28, 301–315. [Google Scholar] [CrossRef]
- Angiulli, F.; Fassetti, F. Detecting distance-based outliers in streams of data. Conference on Information and knowledge management, Lisbon. In Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management, CIKM 2007, Lisbon, Portugal, 6–10 November 2007. [Google Scholar]
- Zhang, C.; Cui, L.; Shi, H.Y. Online Anomaly Detection for Aeroengine Gas Path Based on Piecewise Linear Representation and Support Vector Data Description. IEEE Sens. J. 2022, 22, 22808–22816. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nomenclature | Parameter | Value Range |
|---|---|---|
| FanEffDe | Fan efficiency degradation factor | 0~3% |
| FanWaDe | Fan mass flow degradation factor | 0~3% |
| ComEffDe | High pressure compressor efficiency degradation factor | 0~3% |
| ComWaDe | High pressure compressor mass flow degradation factor | 0~3% |
| HPTEffDe | High pressure turbine efficiency degradation factor | 0~3% |
| HPTWaDe | High pressure compressor mass flow degradation factor | 0~3% |
| LPTEffDe | Low pressure turbine efficiency degradation factor | 0~3% |
| LPTWaDe | Low pressure turbine mass flow degradation factor | 0~3% |
| Parameters | Degradation | Tracking Error (%) | ||
|---|---|---|---|---|
| STORM | eSTORM with | eSTORM with | ||
| N2 | 1% | 1.659 | 0.414 | 0.387 |
| 2% | 2.103 | 1.244 | 0.059 | |
| 3% | 2.622 | 1.844 | 0.316 | |
| Tt25 | 1% | 1.191 | 0.823 | 0.237 |
| 2% | 1.583 | 0.979 | 0.235 | |
| 3% | 1.975 | 1.027 | 0.237 | |
| Tt3 | 1% | 2.197 | 0.930 | 0.309 |
| 2% | 3.933 | 1.228 | 0.277 | |
| 3% | 5.510 | 1.344 | 0.195 | |
| Tt6 | 1% | 1.034 | 0.884 | 0.291 |
| 2% | 1.676 | 0.924 | 0.239 | |
| 3% | 2.432 | 0.986 | 0.272 | |
| Pt25 | 1% | 0.993 | 0.967 | 0.433 |
| 2% | 1.507 | 1.059 | 0.382 | |
| 3% | 2.042 | 0.978 | 0.232 | |
| Pt3 | 1% | 0.937 | 0.743 | 0.311 |
| 2% | 1.371 | 0.740 | 0.245 | |
| 3% | 1.616 | 0.737 | 0.252 | |
| Pt6 | 1% | 0.922 | 0.820 | 0.264 |
| 2% | 1.345 | 0.804 | 0.340 | |
| 3% | 1.768 | 0.883 | 0.242 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Guo, Y.; Ren, X. New Method for Improving Tracking Accuracy of Aero-Engine On-Board Model Based on Separability Index and Reverse Searching. Aerospace 2025, 12, 175. https://doi.org/10.3390/aerospace12030175
Li H, Guo Y, Ren X. New Method for Improving Tracking Accuracy of Aero-Engine On-Board Model Based on Separability Index and Reverse Searching. Aerospace. 2025; 12(3):175. https://doi.org/10.3390/aerospace12030175
Chicago/Turabian StyleLi, Hui, Yingqing Guo, and Xinyu Ren. 2025. "New Method for Improving Tracking Accuracy of Aero-Engine On-Board Model Based on Separability Index and Reverse Searching" Aerospace 12, no. 3: 175. https://doi.org/10.3390/aerospace12030175
APA StyleLi, H., Guo, Y., & Ren, X. (2025). New Method for Improving Tracking Accuracy of Aero-Engine On-Board Model Based on Separability Index and Reverse Searching. Aerospace, 12(3), 175. https://doi.org/10.3390/aerospace12030175