


Dual-Vehicle Heterogeneous Collaborative Scheme with Image-Aided Inertial Navigation


Abstract
1. Introduction
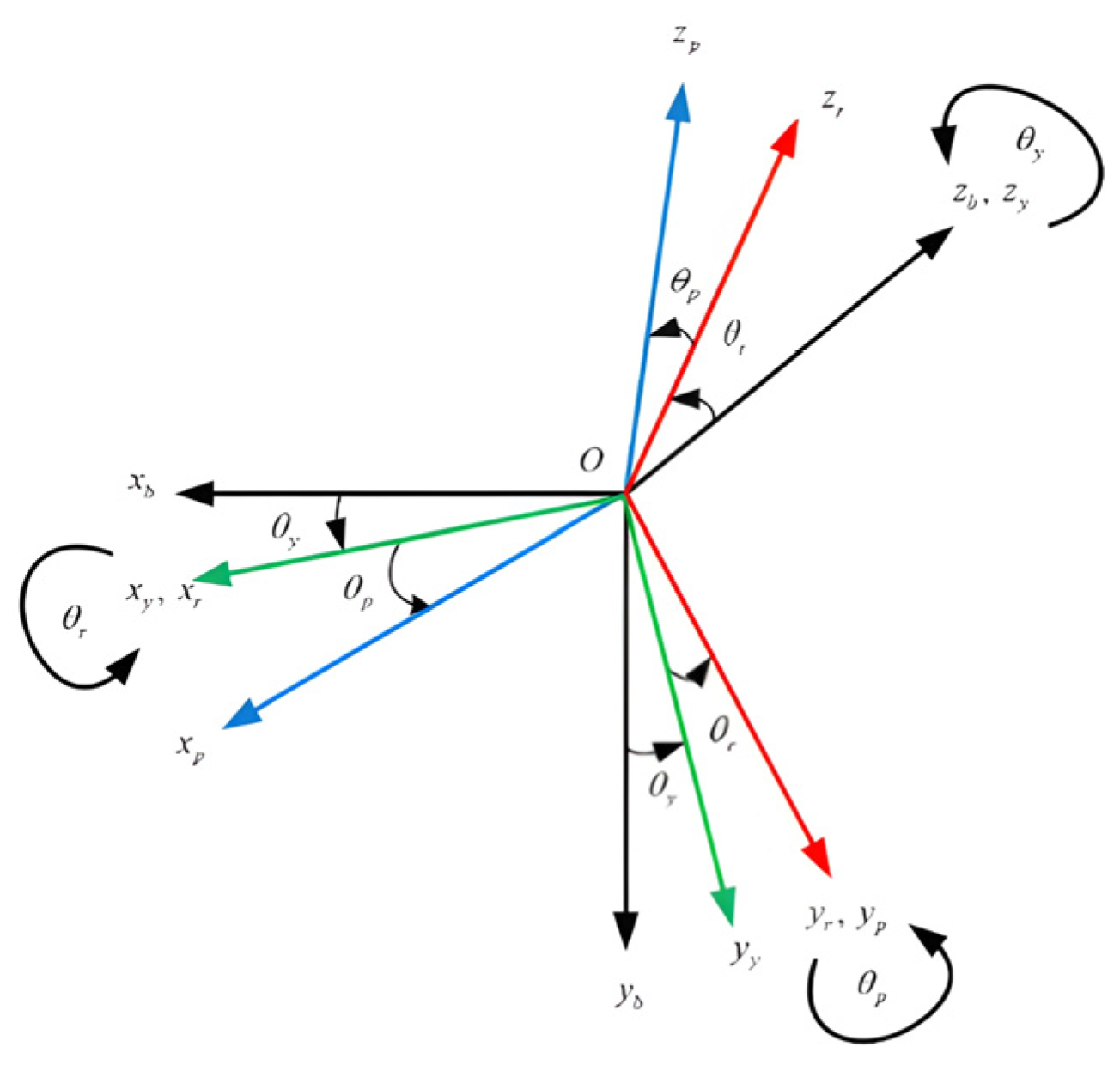
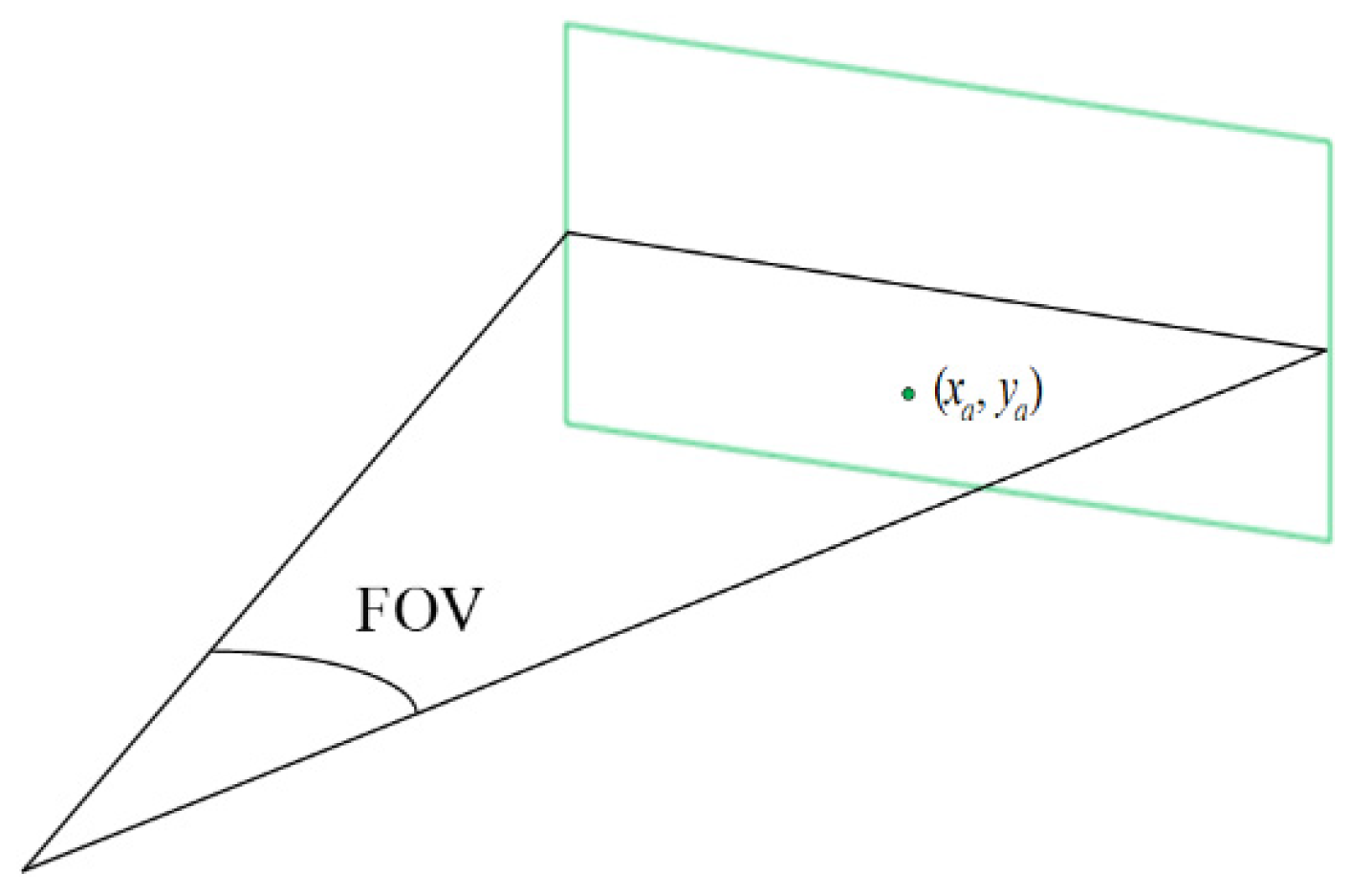
2. Locating Image Position
2.1. Object Recognition
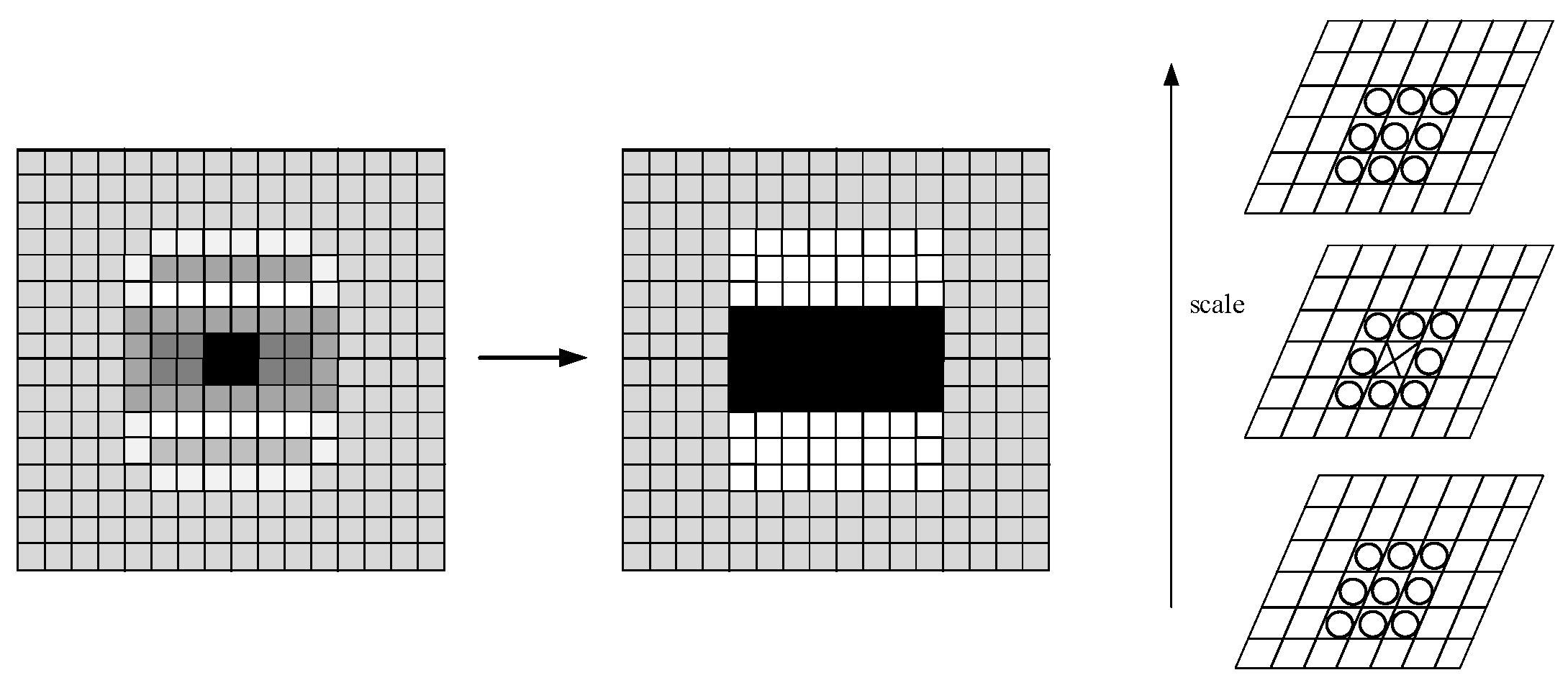
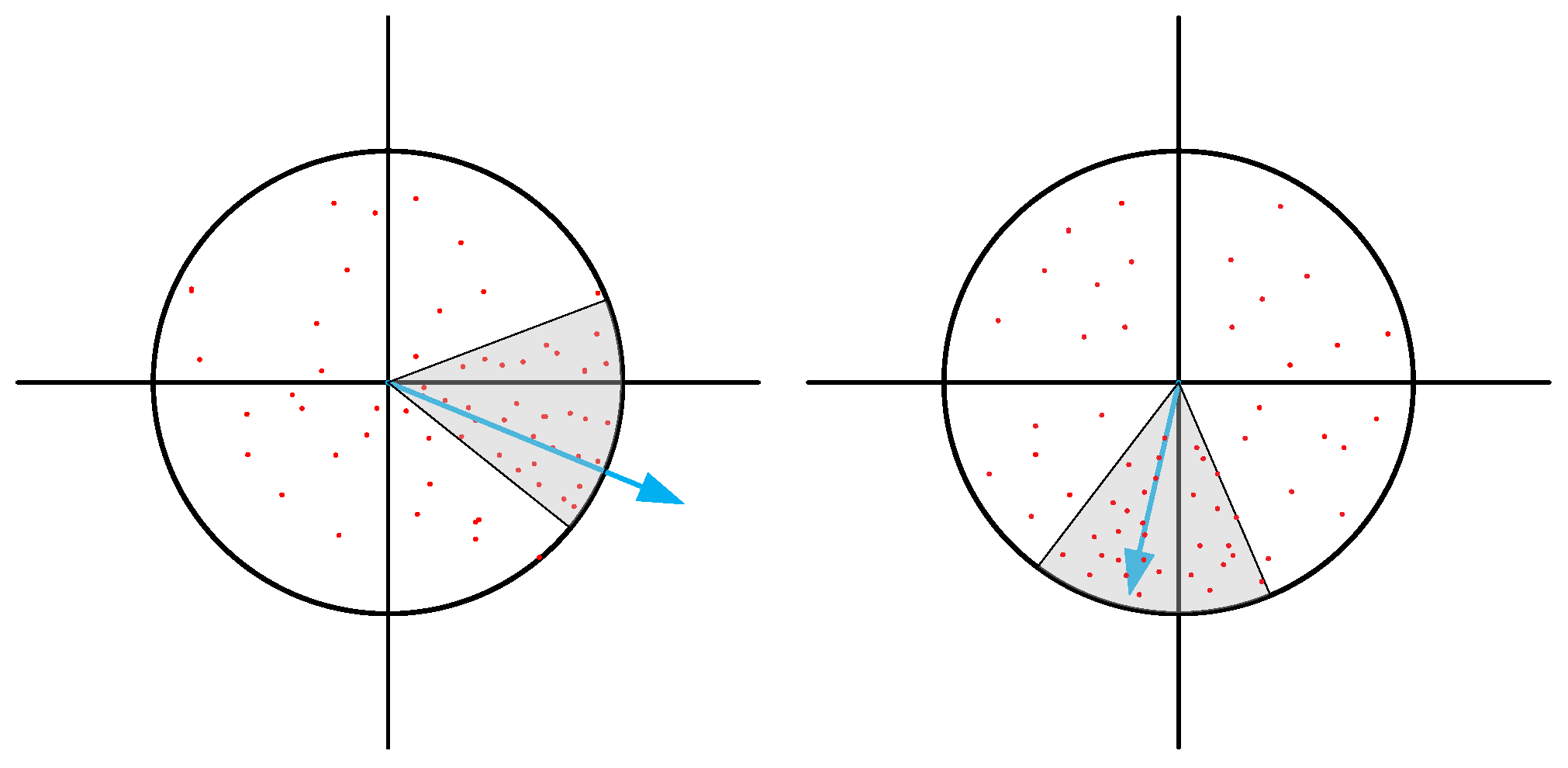
2.2. Feature Recognition
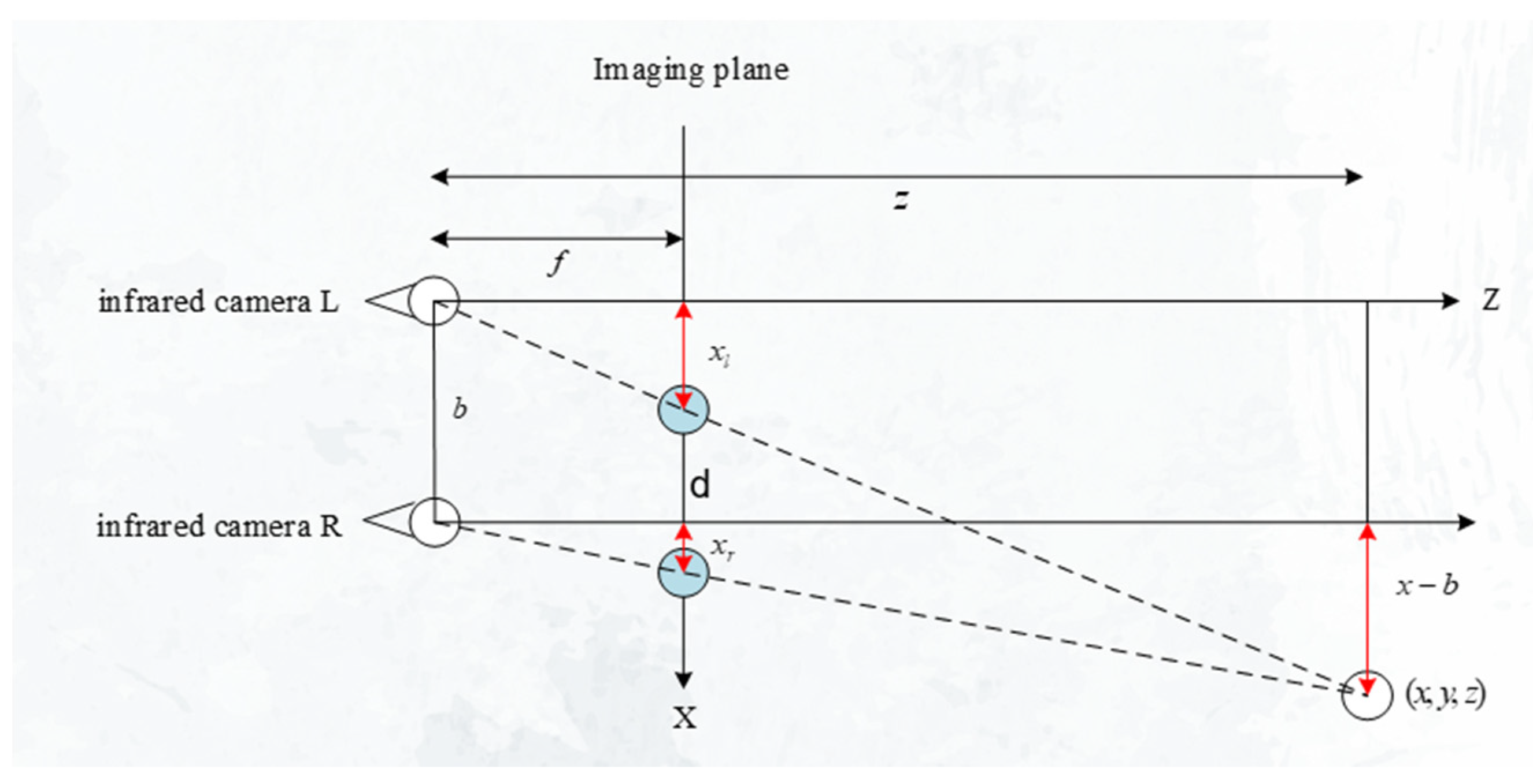
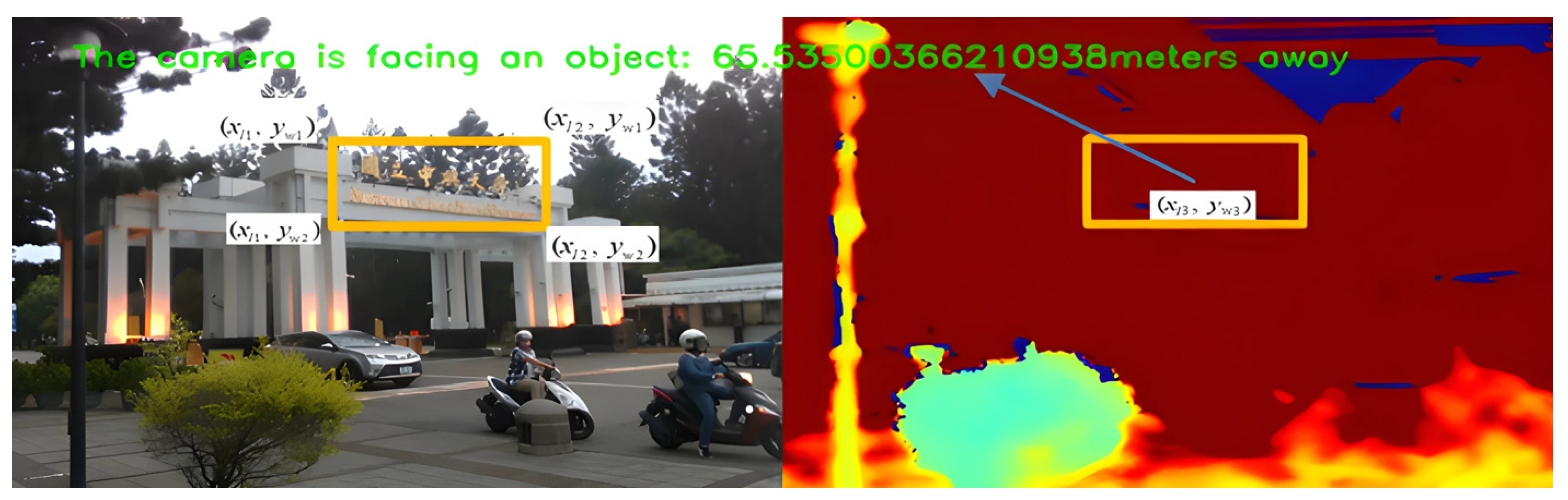
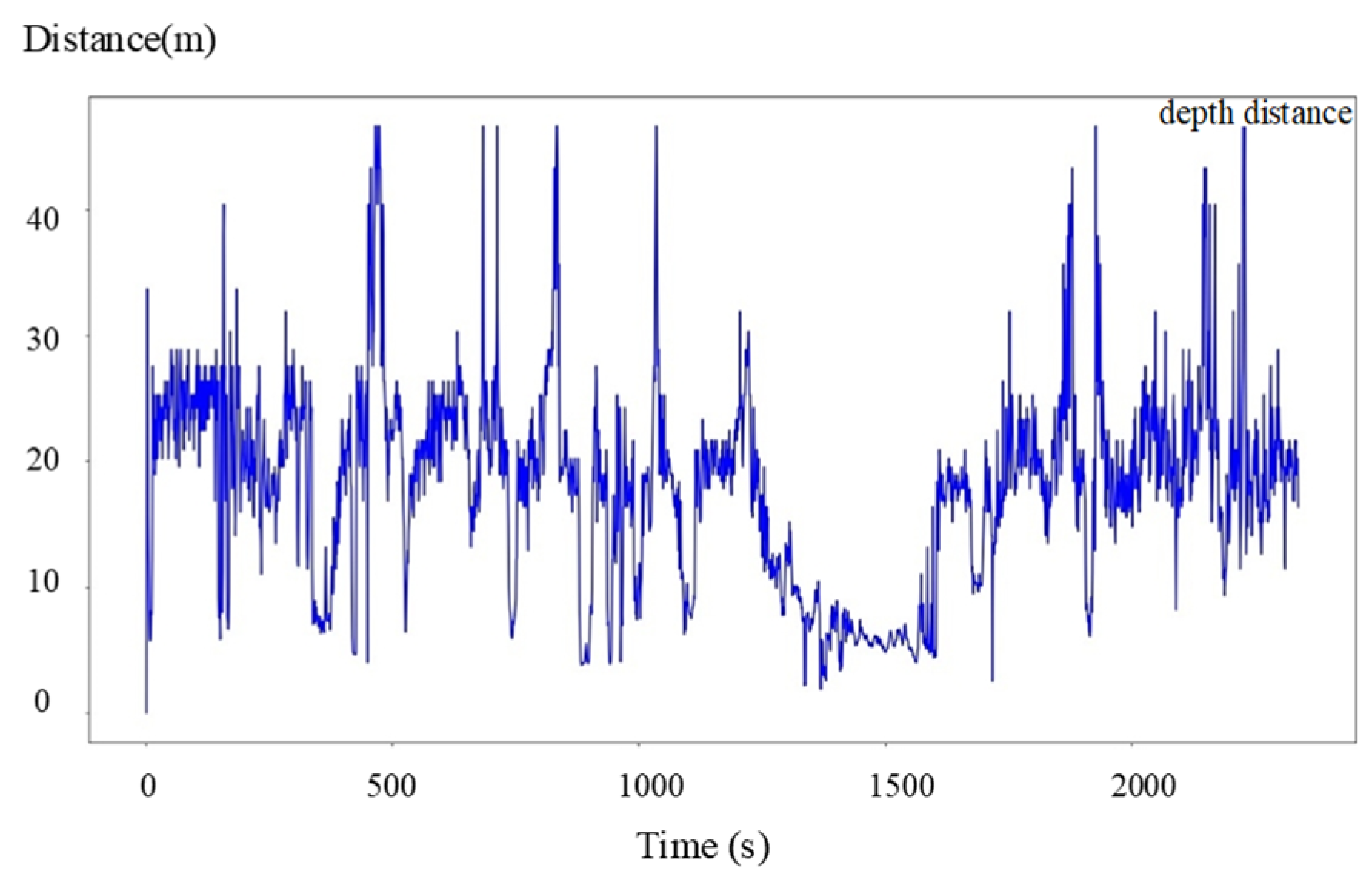
2.3. Depth Calculation
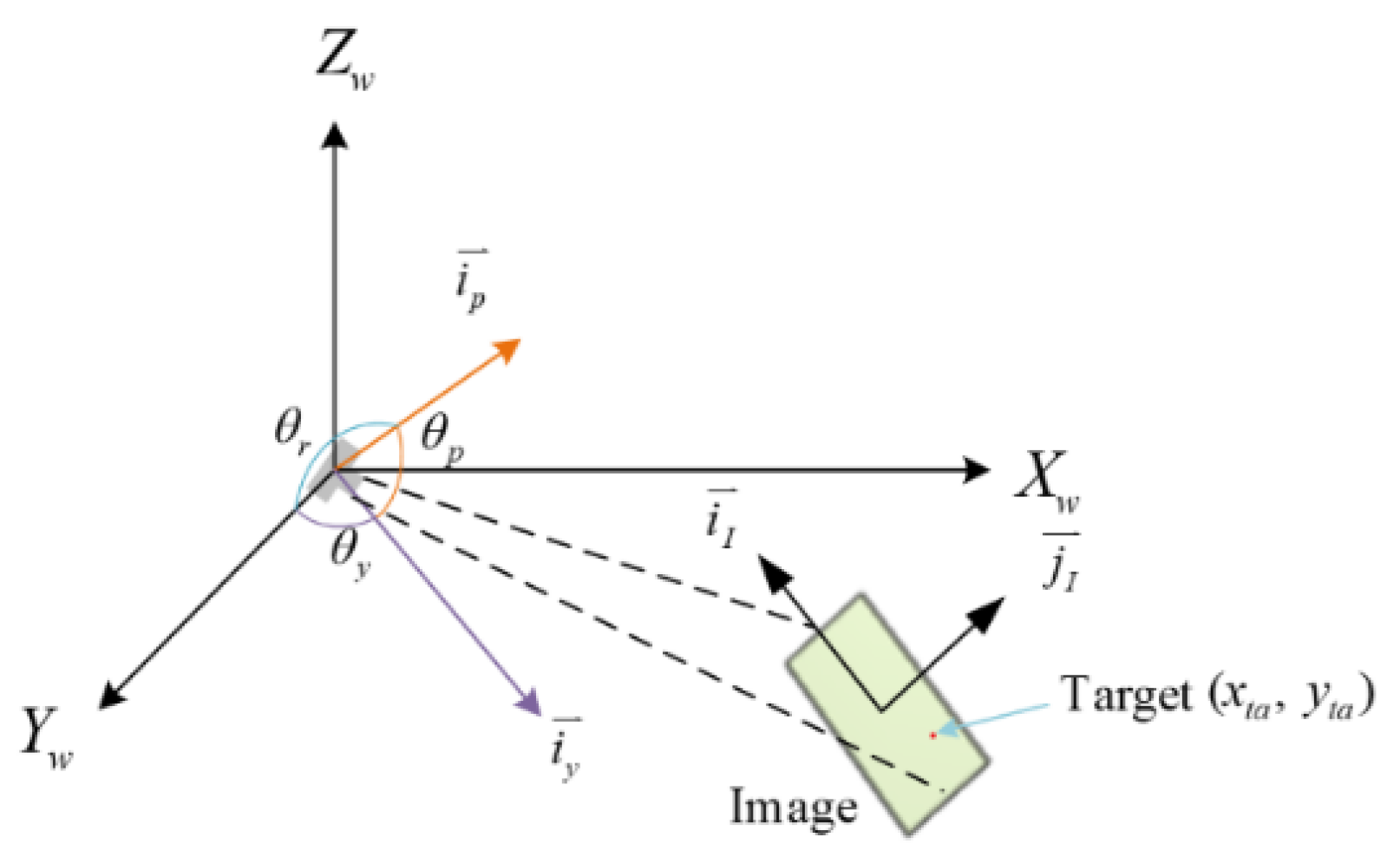
2.4. Information Fusion
3. Design of Heterogeneous Cooperation System
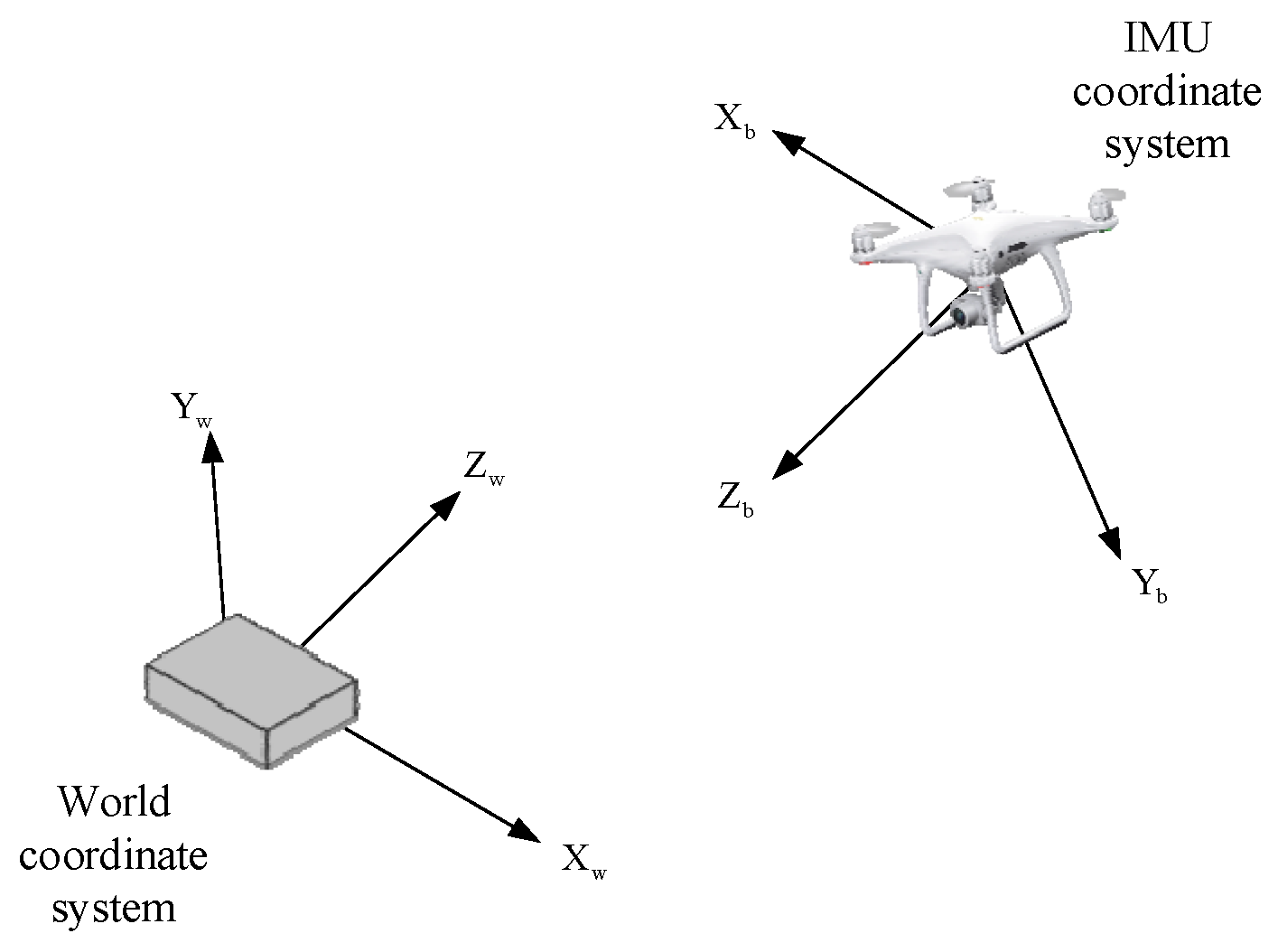
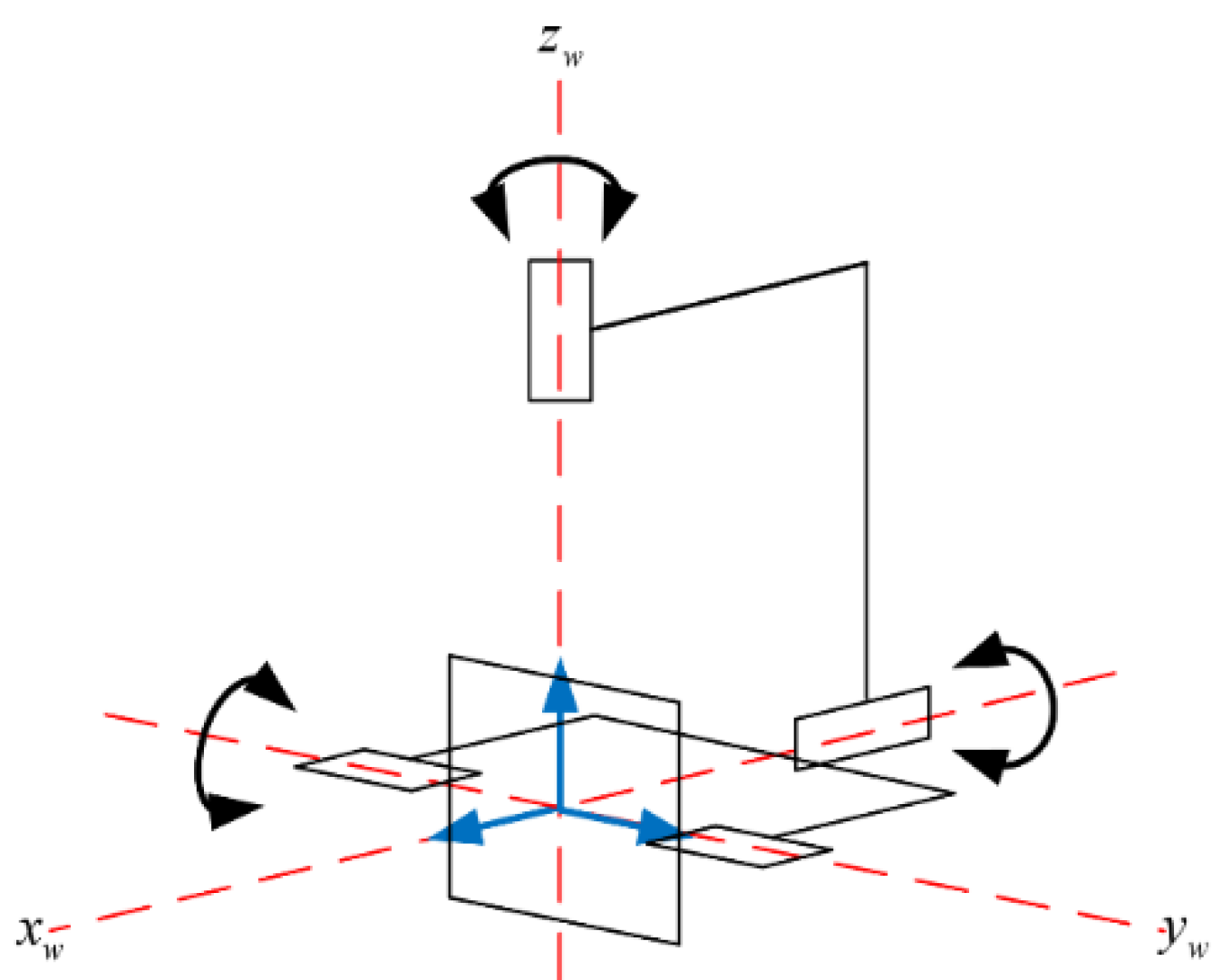
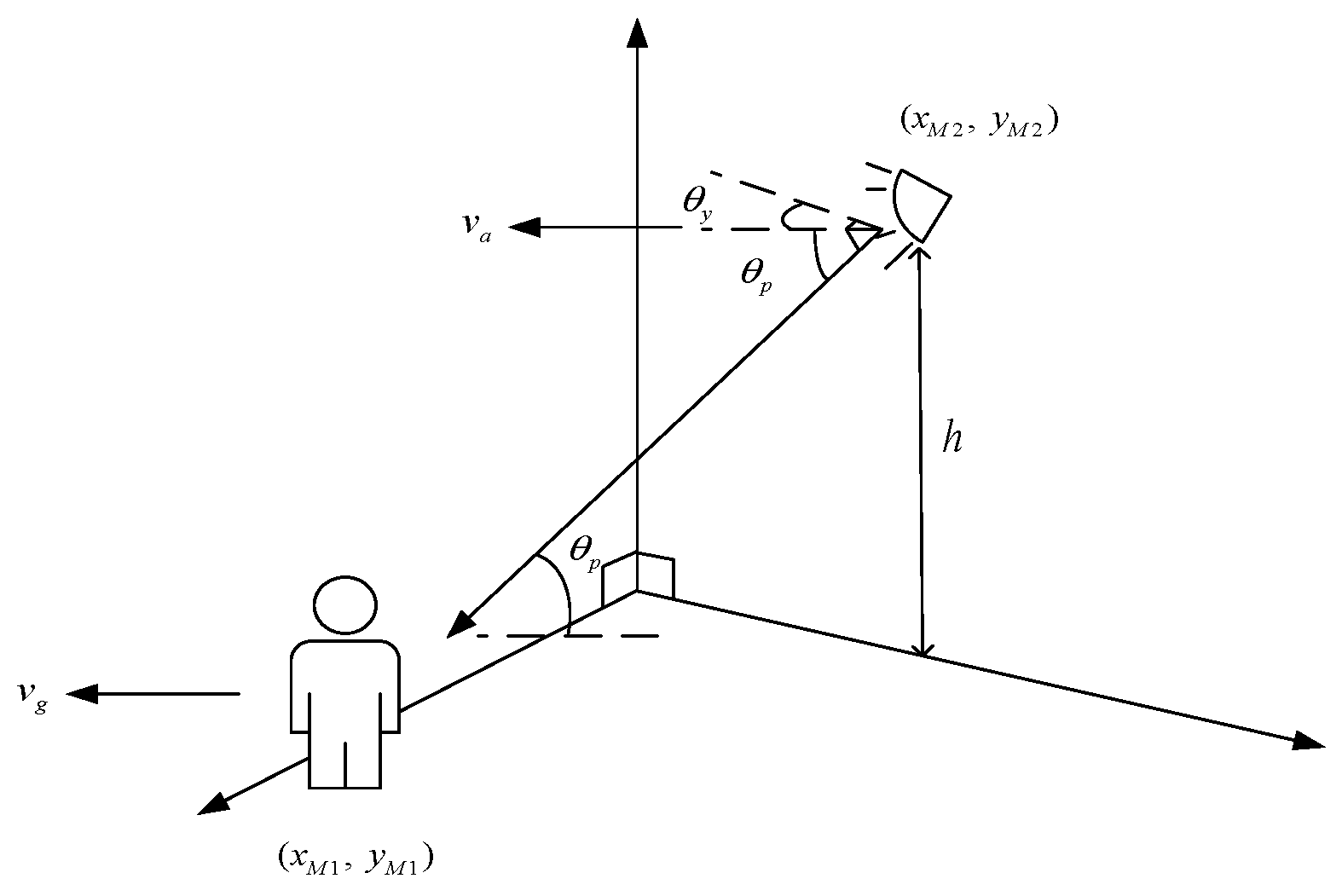
3.1. Scene Recognition in Aerial View
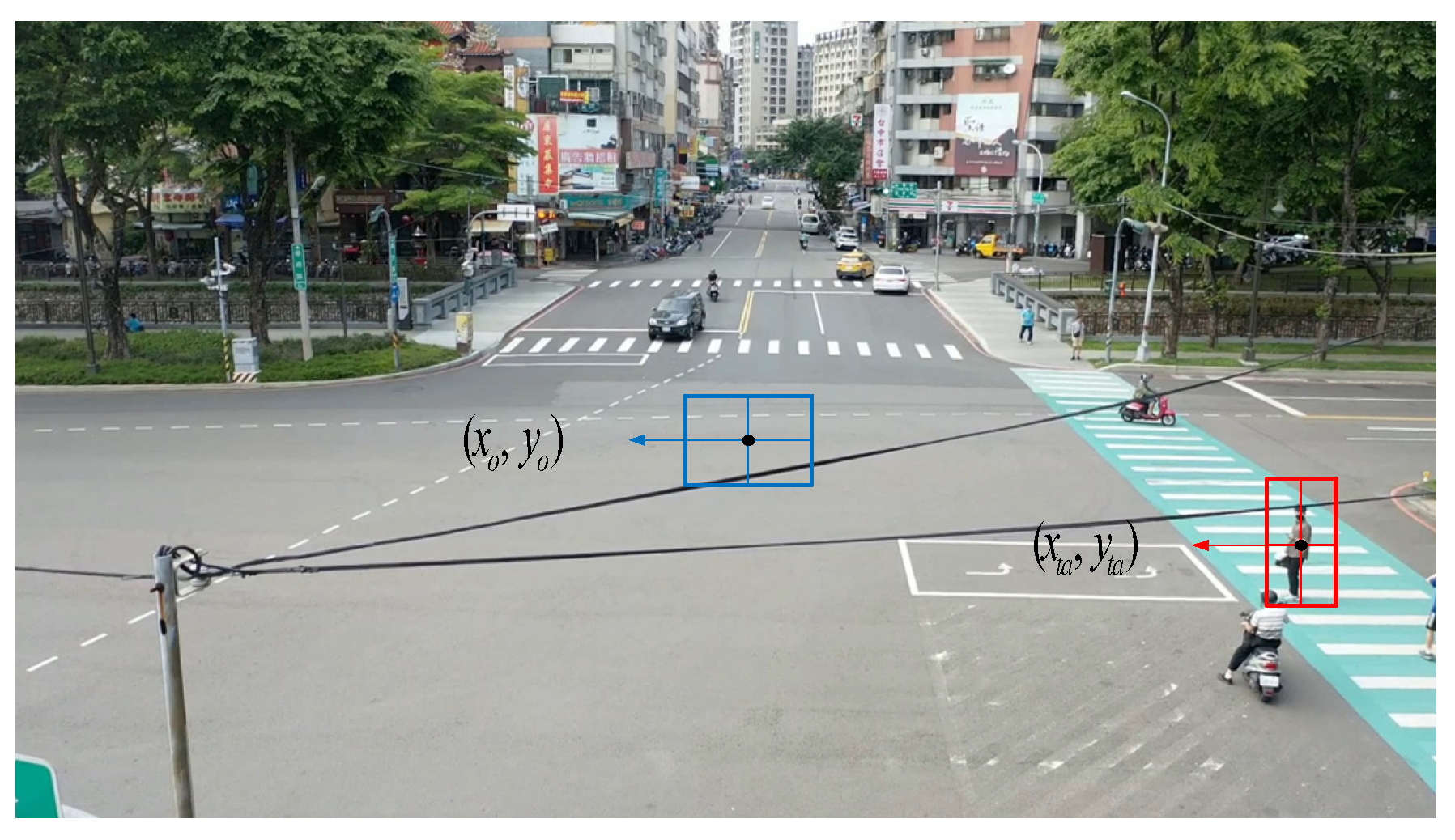
3.2. Heterogeneous Location Calculation and Camera Tracker
3.3. Position Conversion
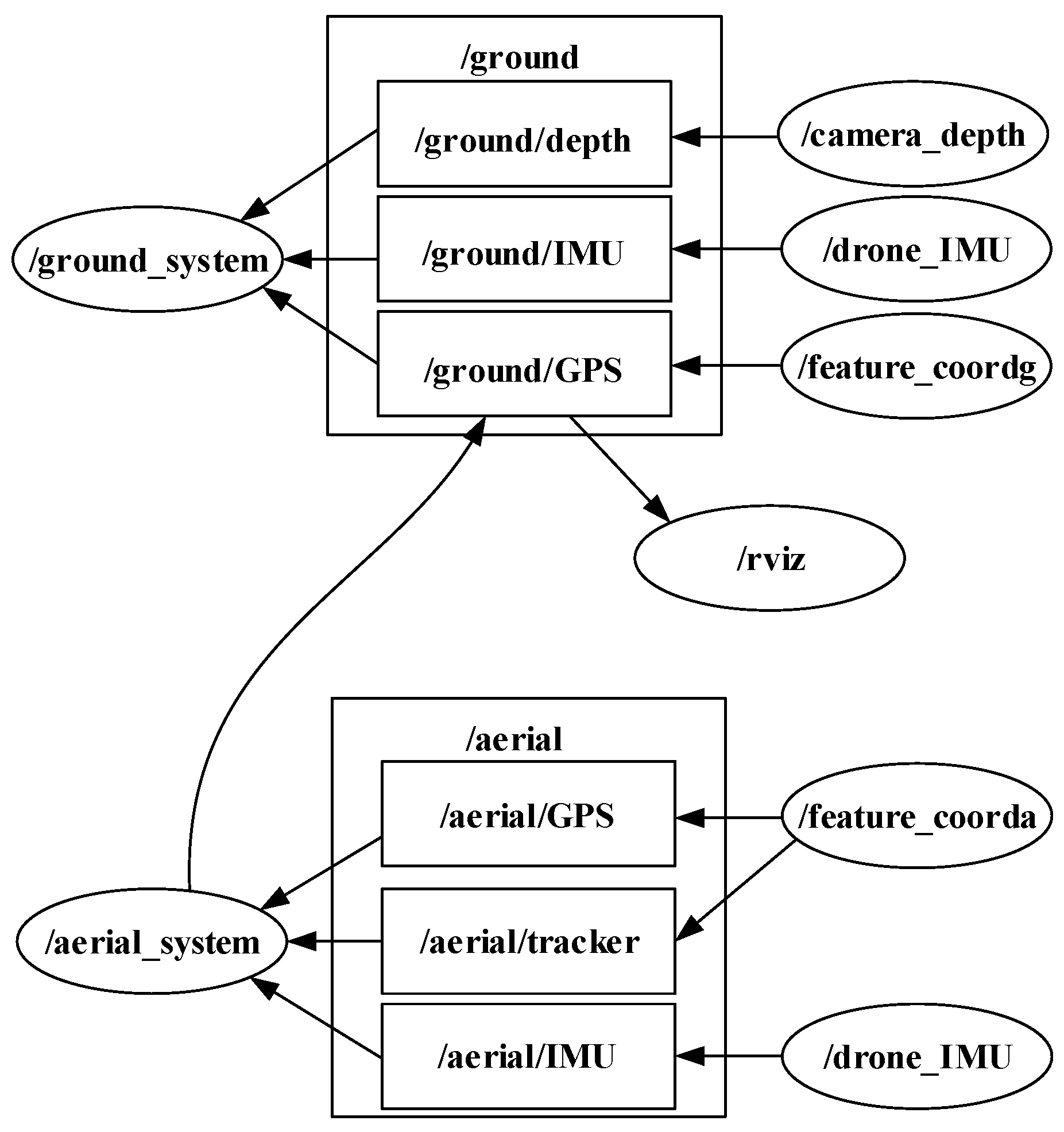
3.4. ROS Data Transfer
3.5. Complete System Architecture
4. Experiment
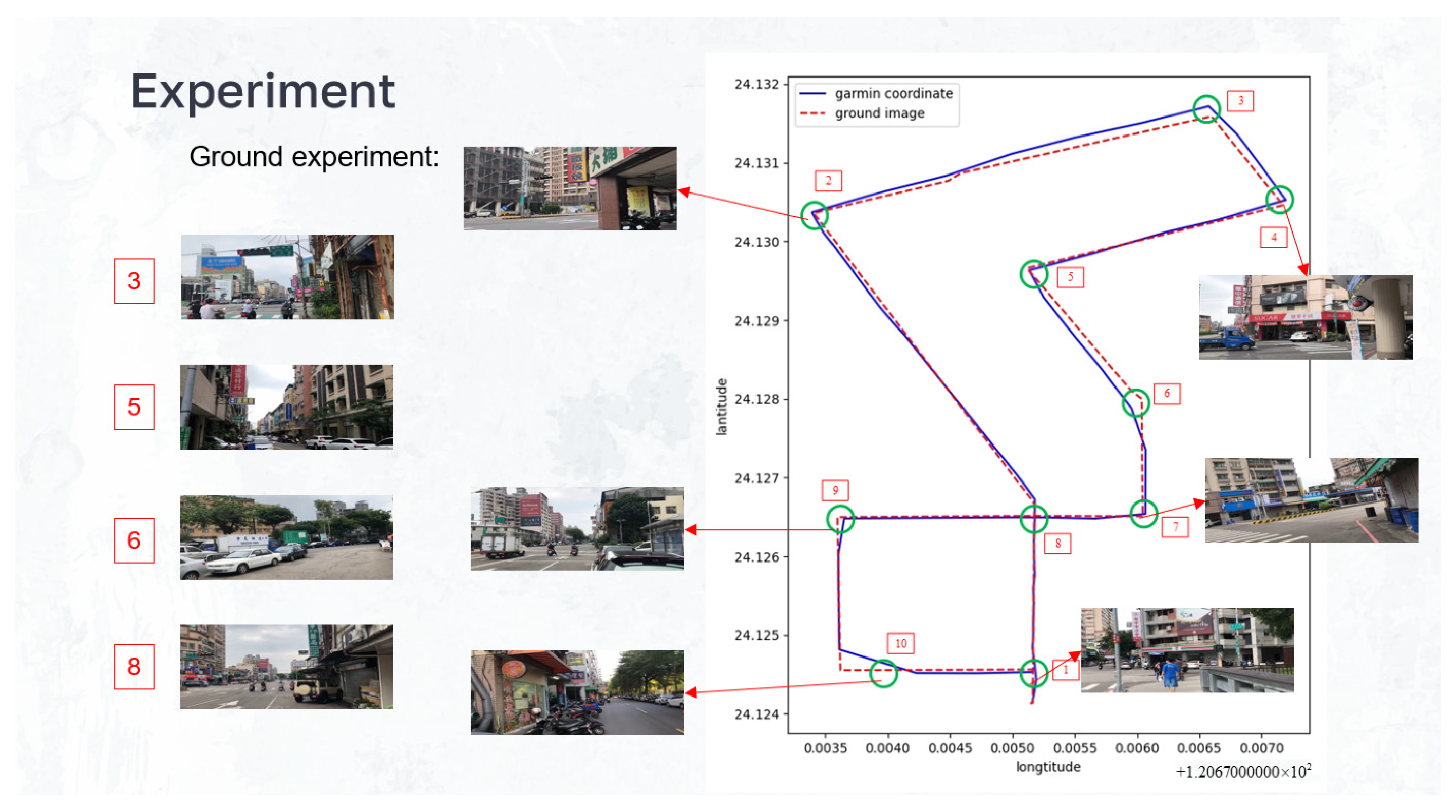
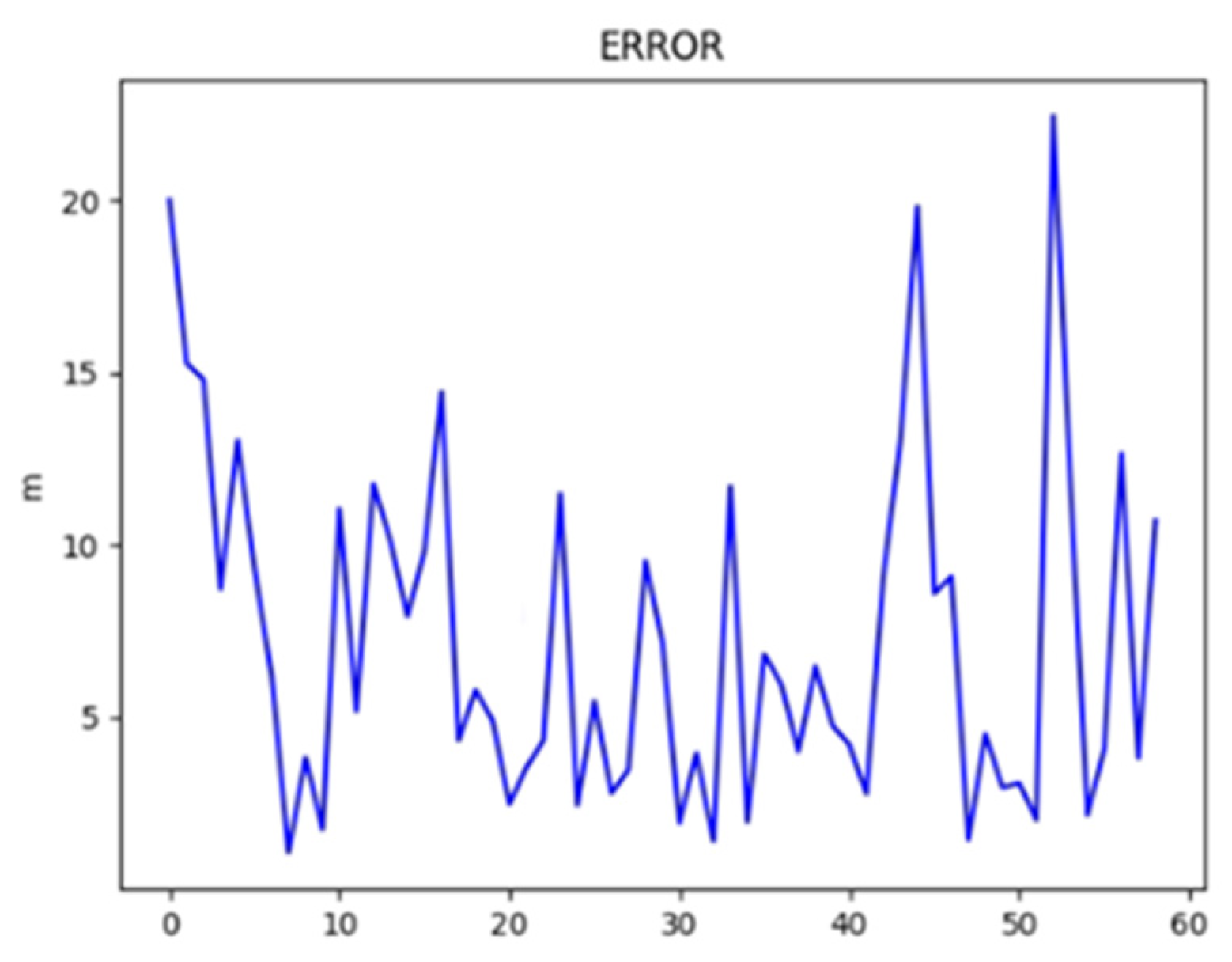
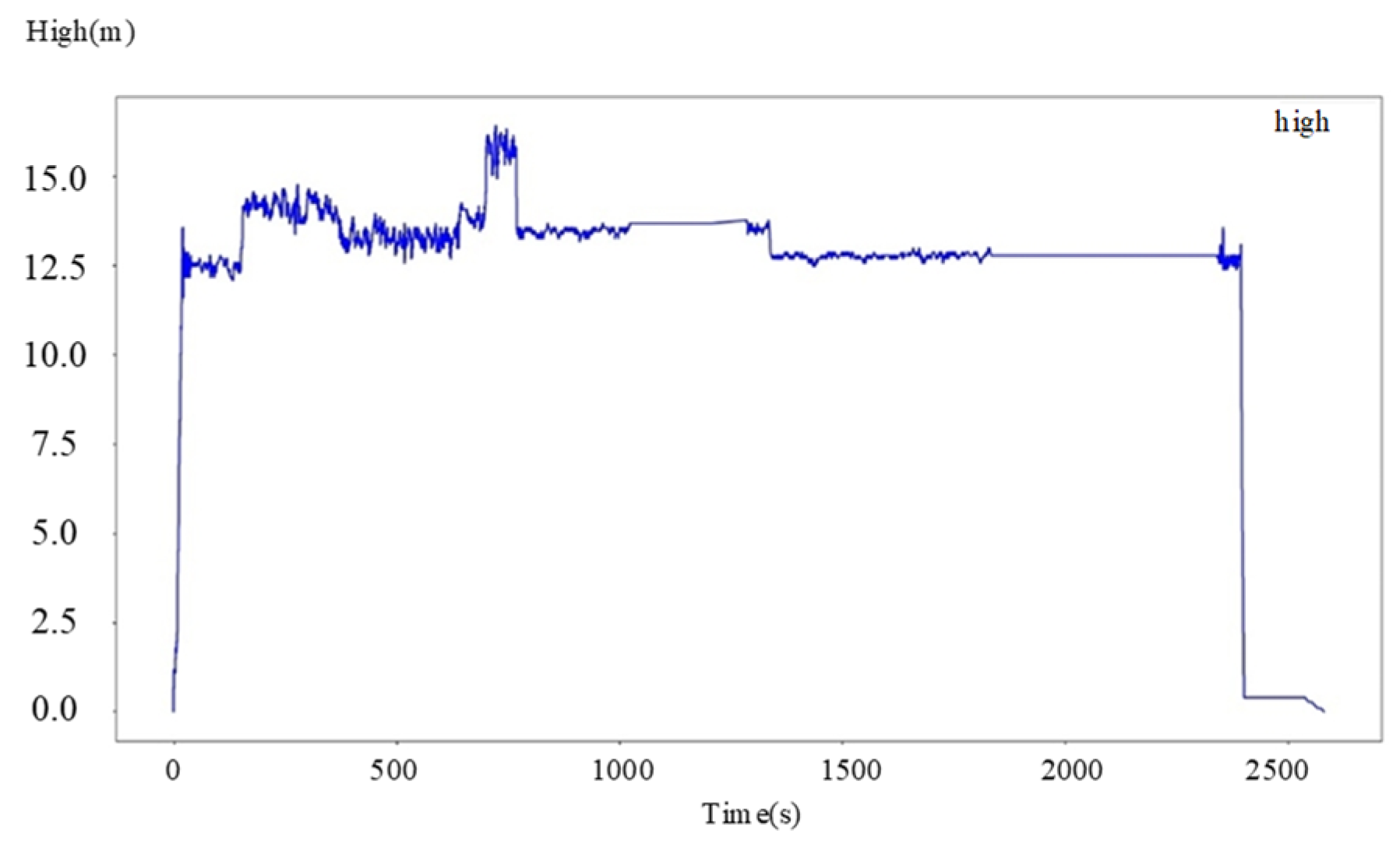
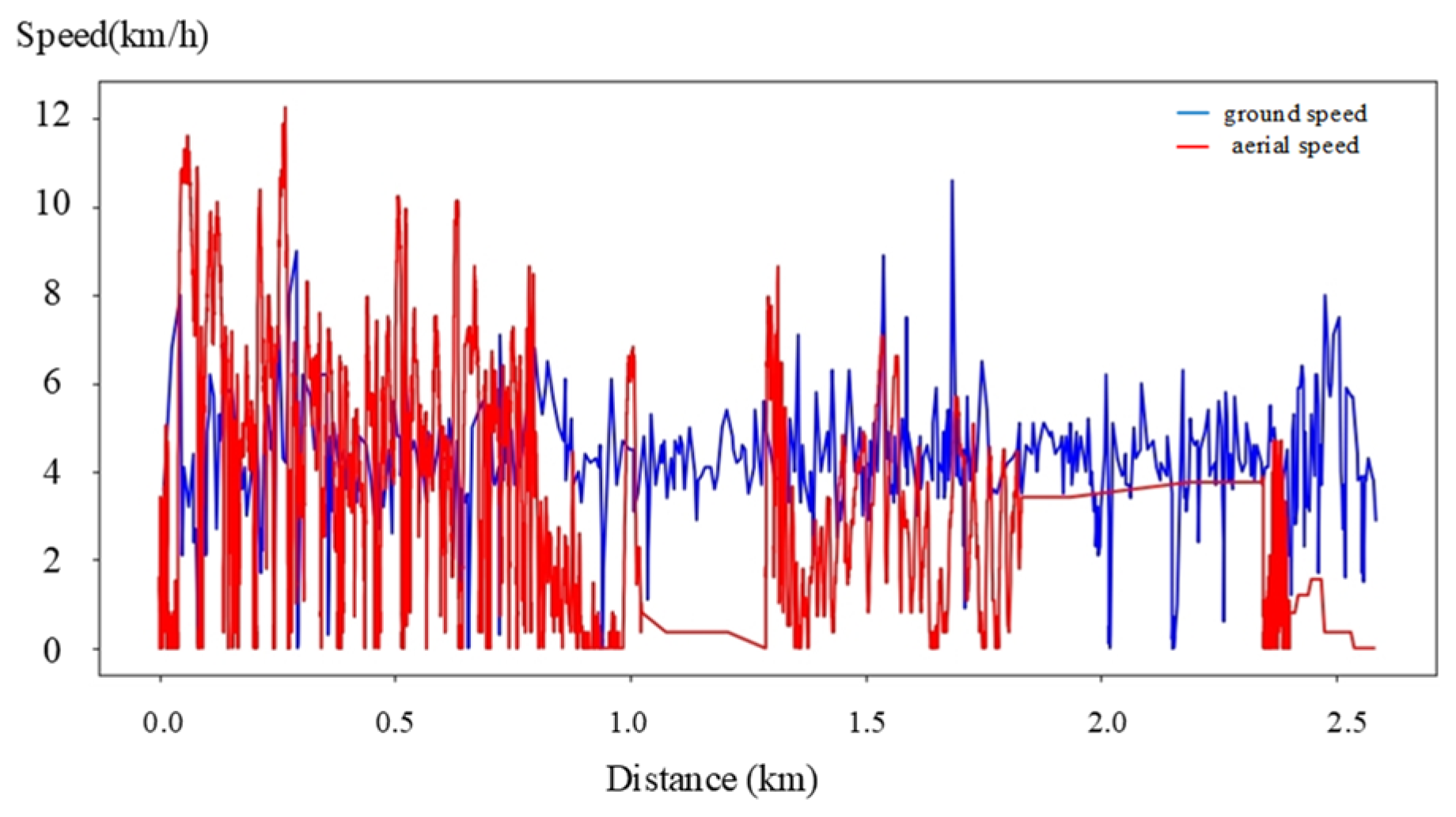
4.1. Ground Experiment
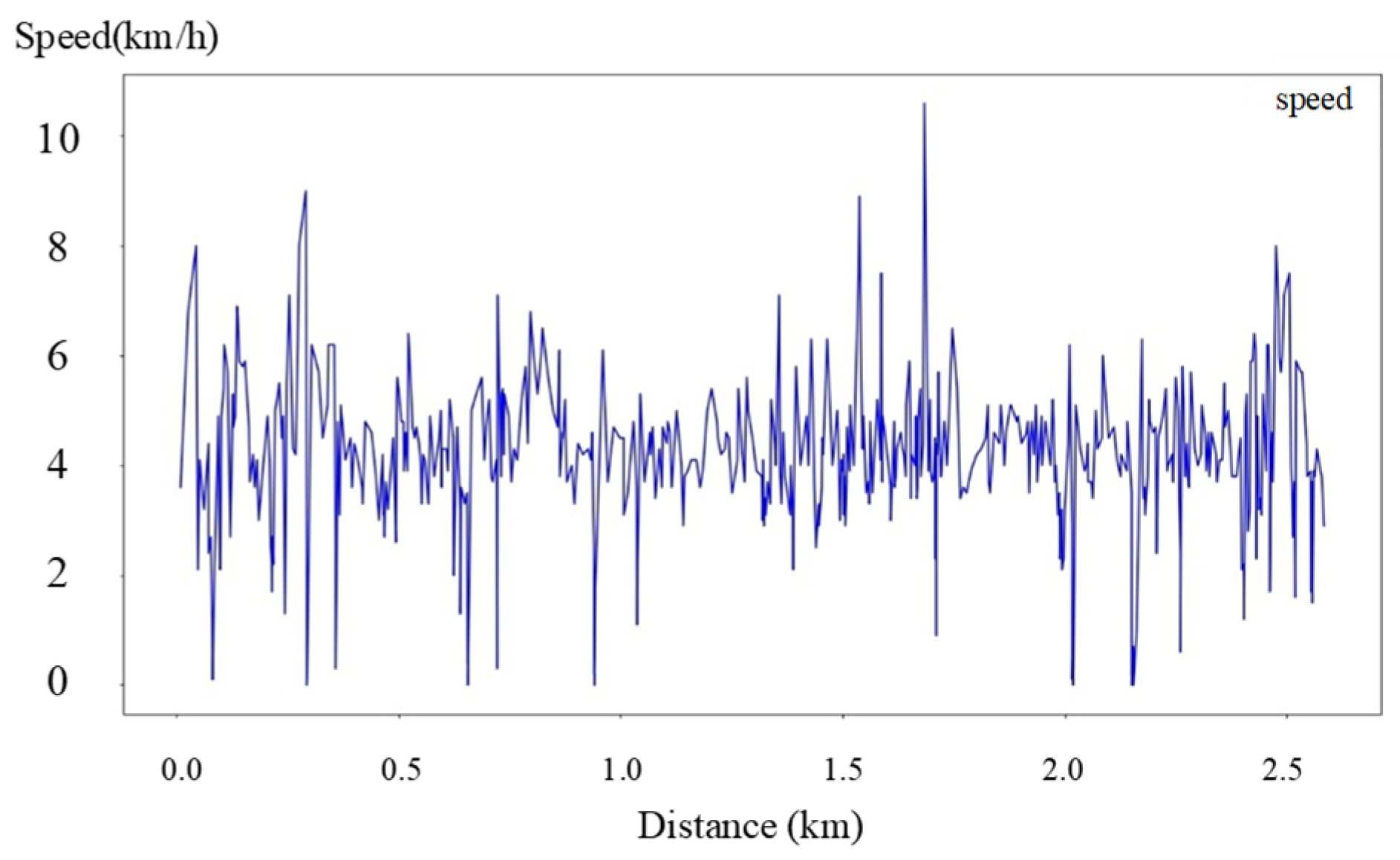
4.2. Aerial Experiments
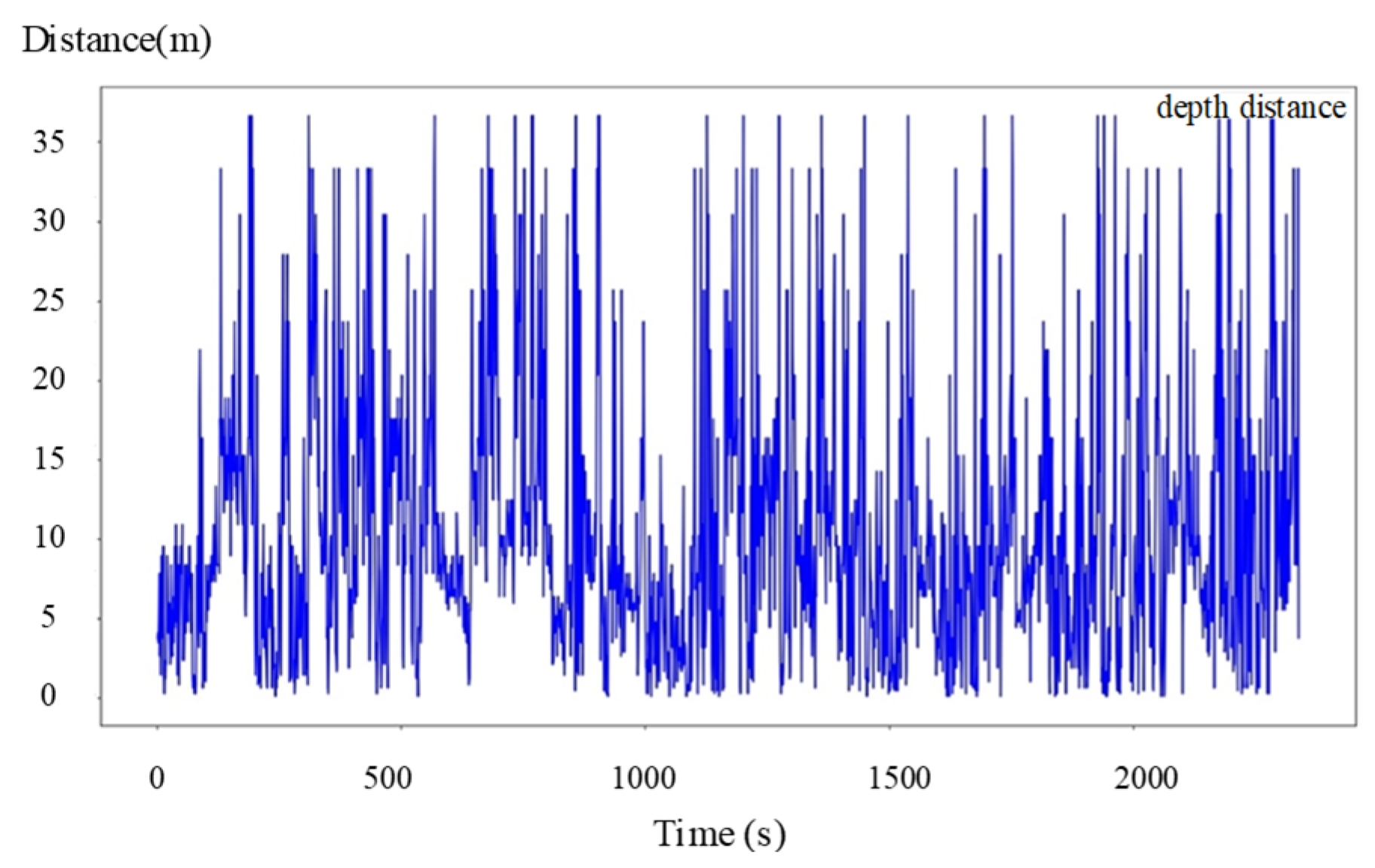
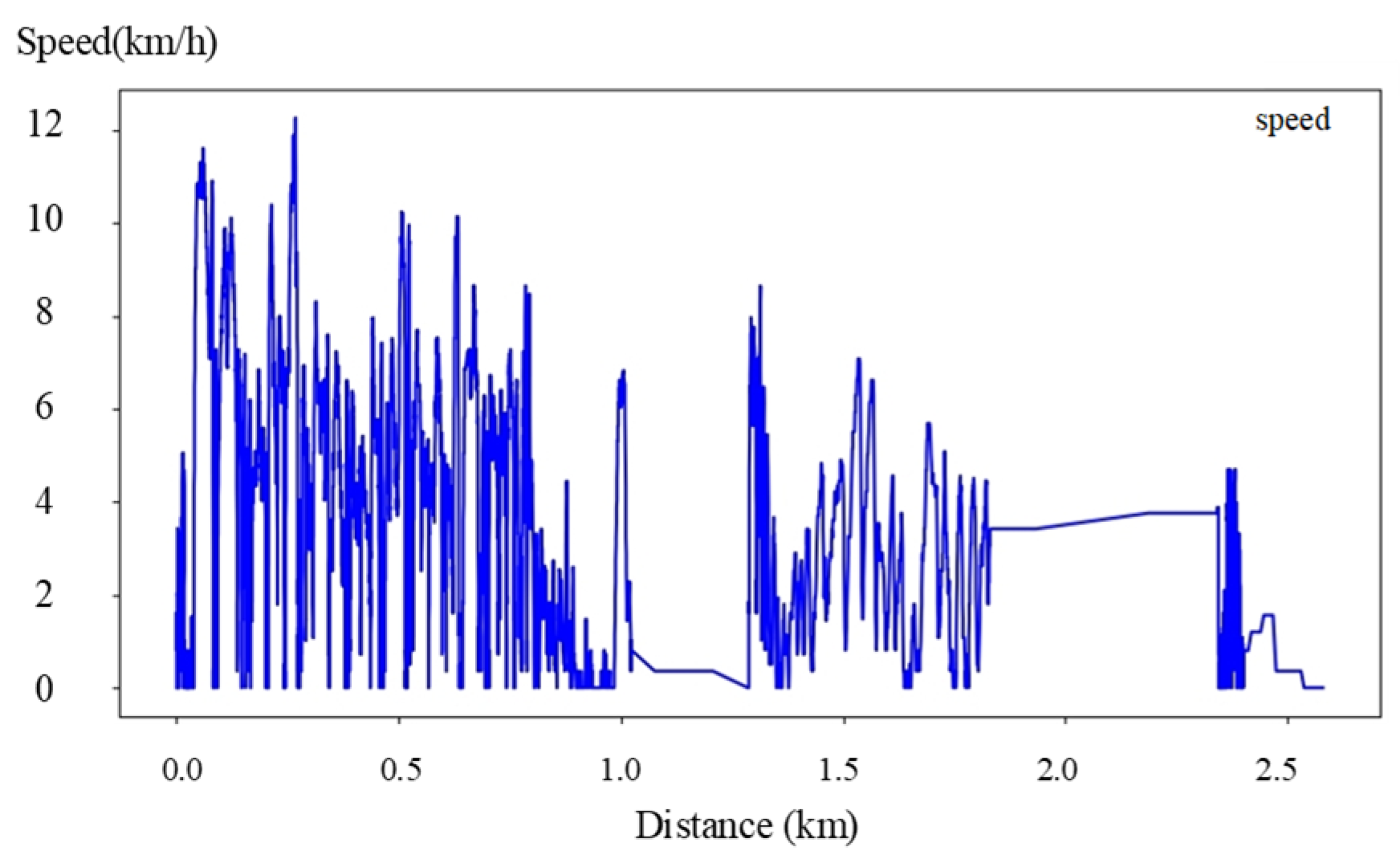
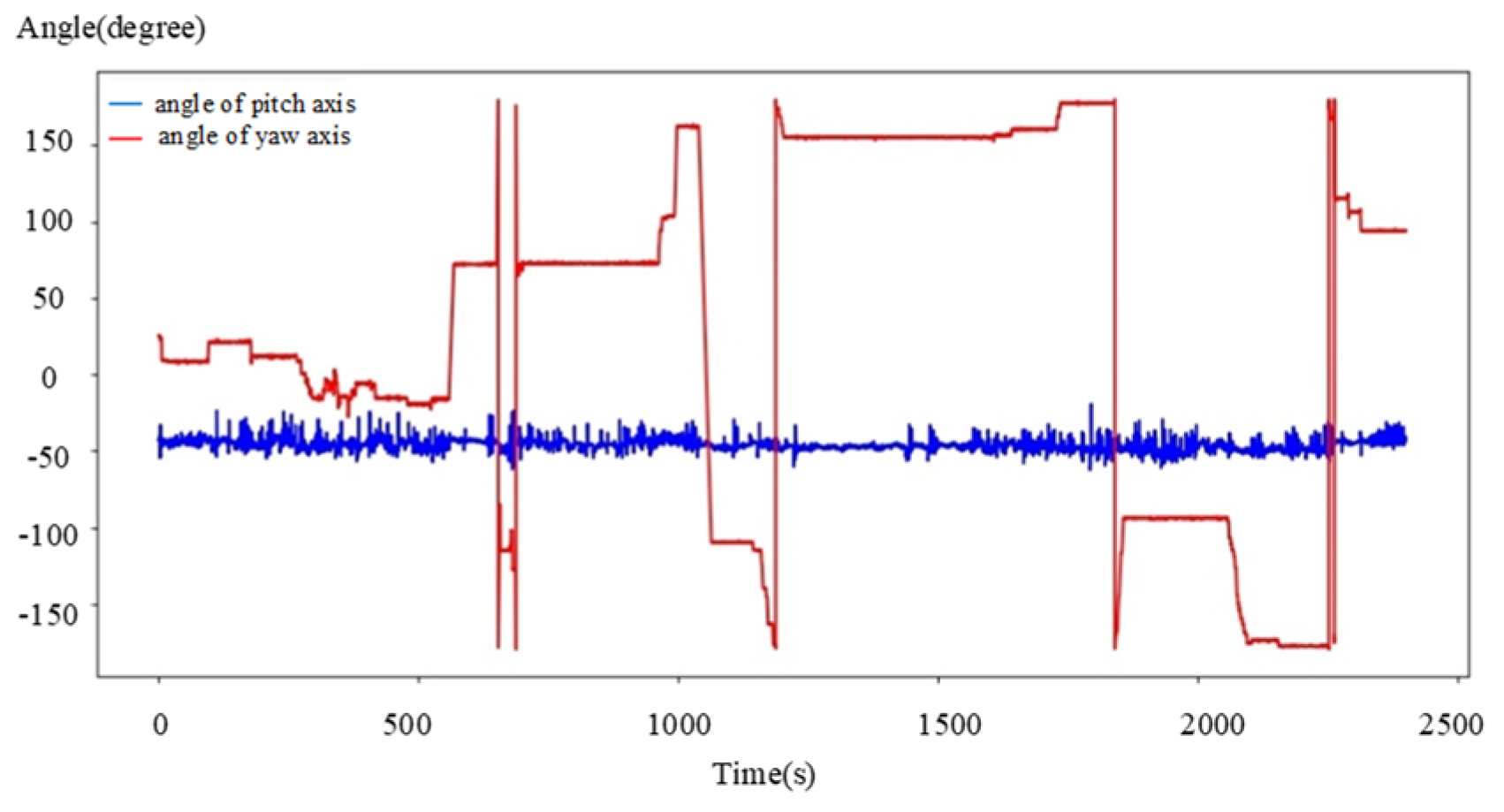
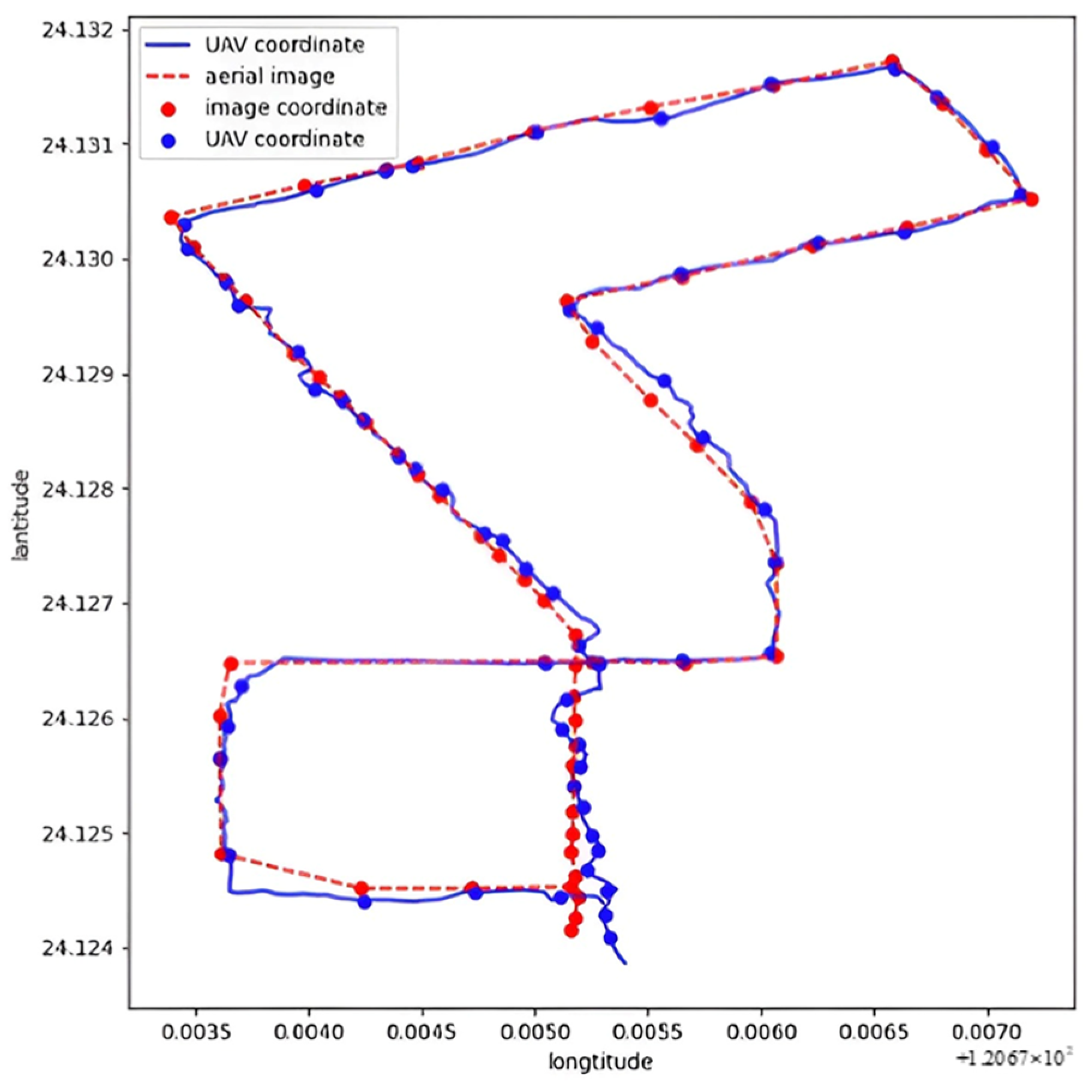
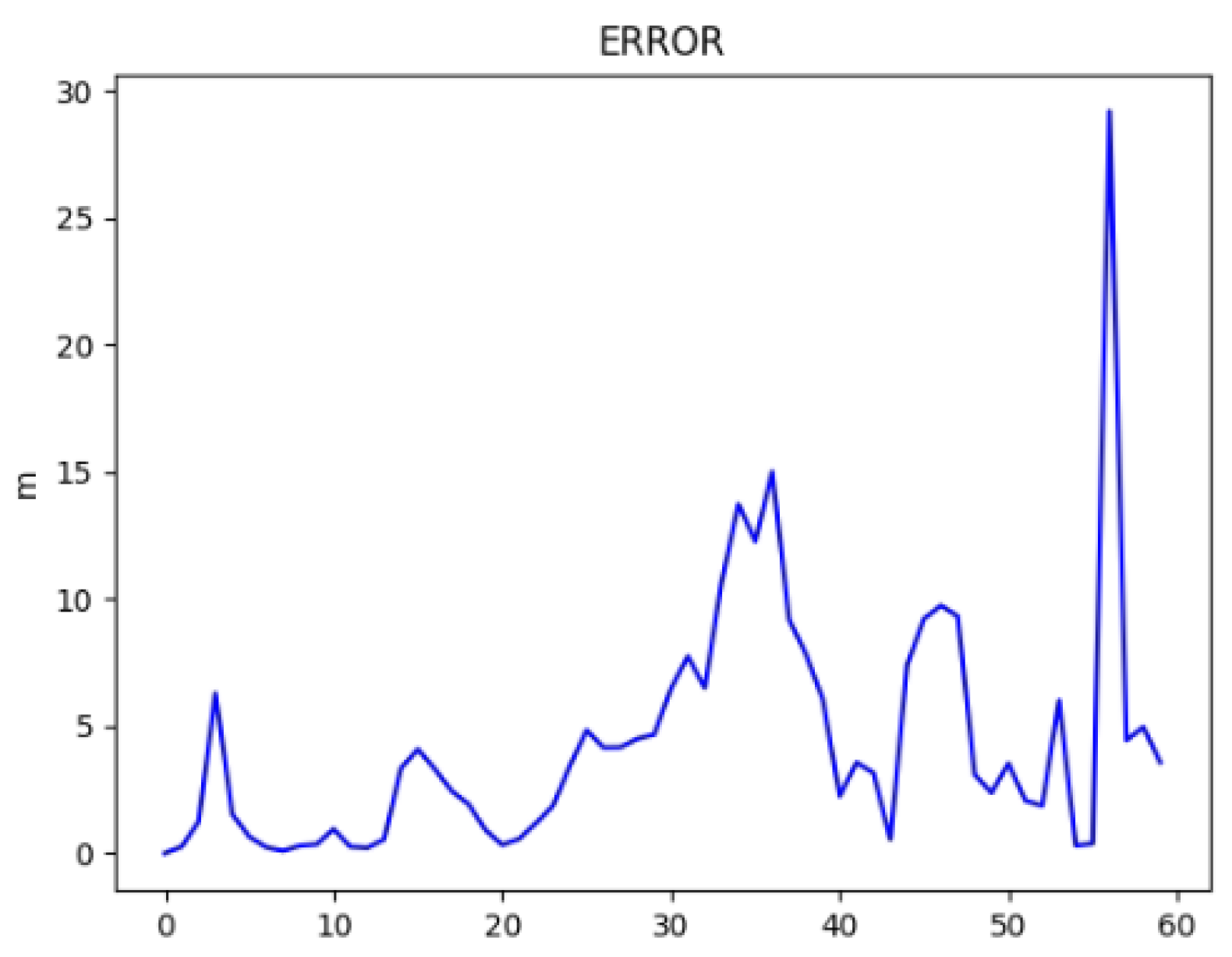
4.3. Heterogeneous Cooperation Experiments
- Speed Variations: fluctuations in UAV speed introduce delays in scene matching, leading to errors.
- Perspective Limitations: the UAV’s overhead view may result in mismatches in high-density or occluded areas.
- Camera Sensitivity: pitch and yaw angle sensitivity directly impact the accuracy of positioning results.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radicioni, F.; Stoppini, A.; Tosi, G.; Marconi, L. Multi-constellation Network RTK for Automatic Guidance in Precision Agriculture. In Proceedings of the IEEE Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Perugia, Italy, 3–5 November 2022; pp. 260–265. [Google Scholar]
- Feng, K.; Li, W.; Ge, S.; Pan, F. Packages delivery based on marker detection for UAVs. In Proceedings of the Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 2094–2099. [Google Scholar]
- Tippannavar, S.S.; Puneeth, K.M.; Yashwanth, S.D.; Madhu Sudanadhu, M.P.; Chandrashekar Murthy, B.N.; Prasad Vinay, M.S. SR2—Search and Rescue Robot for saving dangered civilians at Hazardous areas. In Proceedings of the International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 22–24 December 2022; pp. 21–26. [Google Scholar]
- Liu, K.; Lim, H.; Frazzoli, B.E.; Ji, H.; Lee, V.C.S. Improving Positioning Accuracy Using GPS Pseudorange Measurements for Cooperative Vehicular Localization. IEEE Trans. Veh. Technol. 2014, 63, 2544–2556. [Google Scholar] [CrossRef]
- Deepika, M.G.; Arun, A. Analysis of INS Parameters and Error Reduction by Integrating GPS and INS Signals. In Proceedings of the International Conference on Design Innovations for 3Cs Compute Communicate Control (ICDI3C), Bangalore, India, 25–28 April 2018; pp. 18–23. [Google Scholar]
- Cui, Y.-S. Performance Analysis of Deeply Integrated BDS/INS. In Proceedings of the Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1916–1921. [Google Scholar]
- Wu, Y.; Zhang, H.; Li, G.; Chen, P.; Hui, J.; Ning, P. Performance Analysis of Deeply Integrated GPS/BDS/INS. In Proceedings of the Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 81–85. [Google Scholar]
- Chen, Z.; Qi, Y.; Zhong, S.; Feng, D.; Chen, Q.; Chen, H. SCL-SLAM: A Scan Context-enabled LiDAR SLAM Using Factor Graph-Based Optimization. In Proceedings of the IEEE International Conference on Unmanned Systems (ICUS), Guangzhou, China, 28–30 October 2022; pp. 1264–1269. [Google Scholar]
- Tian, H.; Xia, L.; Mok, E. A Novel Method for Metropolitan-scale Wi-Fi Localization Based on Public Telephone Booths. In Proceedings of the IEEE/ION Position, Location and Navigation Symposium, Indian Wells, CA, USA, 3–6 May 2010; pp. 357–364. [Google Scholar]
- Zamir, A.R.; Shah, M. Accurate Image Localization Based on Google Maps Street View. In Computer Vision—ECCV 2010. Lecture Notes in Computer Science; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Li, X.; He, H.; Huang, C.; Shi, Y. PCB Image Registration Based on Improved SURF Algorithm. In Proceedings of the International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 76–79. [Google Scholar]
- Fanqing, M.; Fucheng, Y. A tracking Algorithm Based on ORB. In Proceedings of the International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shenyang, China, 20–22 December 2013; pp. 1187–1190. [Google Scholar]
- Borman, R.I.; Harjolo, A. Improved ORB Algorithm Through Feature Point Optimization and Gaussian Pyramid. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 268–275. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- Perišić, A.; Perišić, I.; Perišić, B. Simulation-Based Engineering of Heterogeneous Collaborative Systems—A novel Conceptual Framework. Sustainability 2023, 15, 8804. [Google Scholar] [CrossRef]
- Deng, H.; Huang, J.; Liu, Q.; Zhao, T.; Zhou, C.; Gao, J. A Distributed Collaborative Allocation Method of Reconnaissance and Strike Tasks for Heterogeneous UAVs. Drones 2023, 7, 138. [Google Scholar] [CrossRef]
- Kwon, Y.H.; Jeon, J.W. Comparison of FPGA Implemented Sobel Edge Detector and Canny Edge Detector. In Proceedings of the IEEE International Conference on Consumer Electronics, Seoul, Republic of Korea, 26–28 April 2020; pp. 1–2. [Google Scholar]
- Sudars, K.; Namatēvs, I.; Judvaitis, J.; Balašs, R.; Ņikuļins, A.; Peter, A.; Strautiņa, S.; Kaufmane, E.; Kalniņa, I. YOLOv5 Deep Neural Network for Quince and Raspberry Detection on RGB Images. In Proceedings of the Workshop on Microwave Theory and Techniques in Wireless Communications (MTTW), Riga, Latvia, 5–7 October 2022; pp. 19–22. [Google Scholar]
- Yu, X.; Kuan, T.W.; Zhang, Y.; Yan, T. YOLO v5 for SDSB Distant Tiny Object Detection. In Proceedings of the International Conference on Orange Technology (ICOT), Shanghai, China, 15–16 September 2022; pp. 1–4. [Google Scholar]
- Lestari, D.P.; Kosasih, R.; Handhika, T.; Murni; Sari, I.; Fahrurozi, A. Fire Hotspots Detection System on CCTV Videos Using You Only Look Once (YOLO) Method and Tiny YOLO Model for High Buildings Evacuation. In Proceedings of the International Conference of Computer and Informatics Engineering (ICCIE), Banyuwangi, Indonesia, 10–11 September 2019; pp. 87–92. [Google Scholar]
- Yijing, W.; Yi, Y.; Xue-Fen, W.; Jian, C.; Xinyun, L. Fig Fruit Recognition Method Based on YOLO v4 Deep Learning. In Proceedings of the International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Mai, Thailand, 19–22 May 2021; pp. 303–306. [Google Scholar]
- Fu, B.; Huang, L. Polygon Matching Using Centroid Distance Sequence in Polar Grid. In Proceedings of the IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 27–29 July 2016; pp. 733–736. [Google Scholar]
- Wu, Y.; Ying, S.; Zheng, L. Size-to-depth: A new perspective for single image depth estimation. arXiv 2018, arXiv:1801.04461. [Google Scholar]
- Liu, Y.; Sun, Z.; Wang, X.; Fan, Z.; Wang, X.; Zhang, L.; Fu, H.; Deng, F. VSG: Visual Servo Based Geolocalization for Long-Range Target in Outdoor Environment. IEEE Trans. Intell. Veh. 2024, 9, 4504–4517. [Google Scholar] [CrossRef]
- Woodall, W.; Liebhardt, M.; Stonier, D.; Binney, J. ROS Topics: Capabilities [ROS Topics]. IEEE Robot. Autom. Mag. 2014, 21, 14–15. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Feature Points | Matching Accuracy (%) | Computational Time (s) | |
|---|---|---|---|
| SIFT | 8765 | 84.32 | 10.15 |
| SURF | 8892 | 82.27 | 4.35 |
| ORB | 10,354 | 74.38 | 3.23 |
| Harris | 6743 | 70.52 | 8.67 |
| Number of Feature Points | Matching Accuracy (%) | Computational Time (s) | |
|---|---|---|---|
| SIFT | 8543 | 83.56 | 9.84 |
| SURF | 8623 | 82.25 | 4.30 |
| ORB | 9411 | 81.37 | 3.51 |
| Harris | 8953 | 76.55 | 8.54 |
| Number of Feature Points | Matching Accuracy (%) | Computational Time (s) | |
|---|---|---|---|
| SIFT | 4173 | 95.61 | 1.57 |
| SURF | 3985 | 86.32 | 1.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.-M.; Lin, C.-L.; Lu, C.-Y.; Wu, P.-C.; Chen, Y.-Y. Dual-Vehicle Heterogeneous Collaborative Scheme with Image-Aided Inertial Navigation. Aerospace 2025, 12, 39. https://doi.org/10.3390/aerospace12010039
Wang Z-M, Lin C-L, Lu C-Y, Wu P-C, Chen Y-Y. Dual-Vehicle Heterogeneous Collaborative Scheme with Image-Aided Inertial Navigation. Aerospace. 2025; 12(1):39. https://doi.org/10.3390/aerospace12010039
Chicago/Turabian StyleWang, Zi-Ming, Chun-Liang Lin, Chian-Yu Lu, Po-Chun Wu, and Yang-Yi Chen. 2025. "Dual-Vehicle Heterogeneous Collaborative Scheme with Image-Aided Inertial Navigation" Aerospace 12, no. 1: 39. https://doi.org/10.3390/aerospace12010039
APA StyleWang, Z.-M., Lin, C.-L., Lu, C.-Y., Wu, P.-C., & Chen, Y.-Y. (2025). Dual-Vehicle Heterogeneous Collaborative Scheme with Image-Aided Inertial Navigation. Aerospace, 12(1), 39. https://doi.org/10.3390/aerospace12010039