To conduct a thorough evaluation of the efficacy the effectiveness of the new model, this paper chooses a diverse range of commonly utilized multi-label classification models as baseline models for comparative analysis. These baseline models encompass both machine learning-based models and conventional deep learning-based multi-label classification models to verify the advantages of the proposed model from different perspectives. The selected baseline models comprise BR (Binary Relevance), CC (Classifier Chains), LP (Label Powerset), RF (Random Forest), LSTM (Long Short Term Memory), and BERT (Bidirectional Encoder Representation from Transformers).
3.1. Comparison of Results
In order to systematically compare and analyze the performance of various models in multi-label classification tasks, this paper employs a five-fold cross-validation approach to ensure the reliability and stability of the evaluation results. Specifically,
Table 4 summarizes the core principles, hyperparameter configurations, and training procedures for each benchmark model, while
Table 6 presents the average performance of evaluation metrics for each model on the test set.
Table 7 shows that deep learning approaches based on pre-trained Transformer models (such as RoBERTa and BERT) have significant advantages in multi-label classification tasks. Specifically, when these models are combined with Graph Convolutional Networks to model the intricate relationships between labels, the model’s performance is further improved. In comparison, although traditional machine learning methods perform satisfactorily on certain metrics, their overall classification performance and generalization capabilities are inferior to those of deep learning methods. The RoBERTa + GCN model, by integrating text features with label relationships, fully capitalizes on the strengths of both, not only taking the lead in accuracy and F1 score but also excelling in handling multi-label dependencies. This attests to the effectiveness and practical value of the model in the automatic classification task of flight instructor comments.
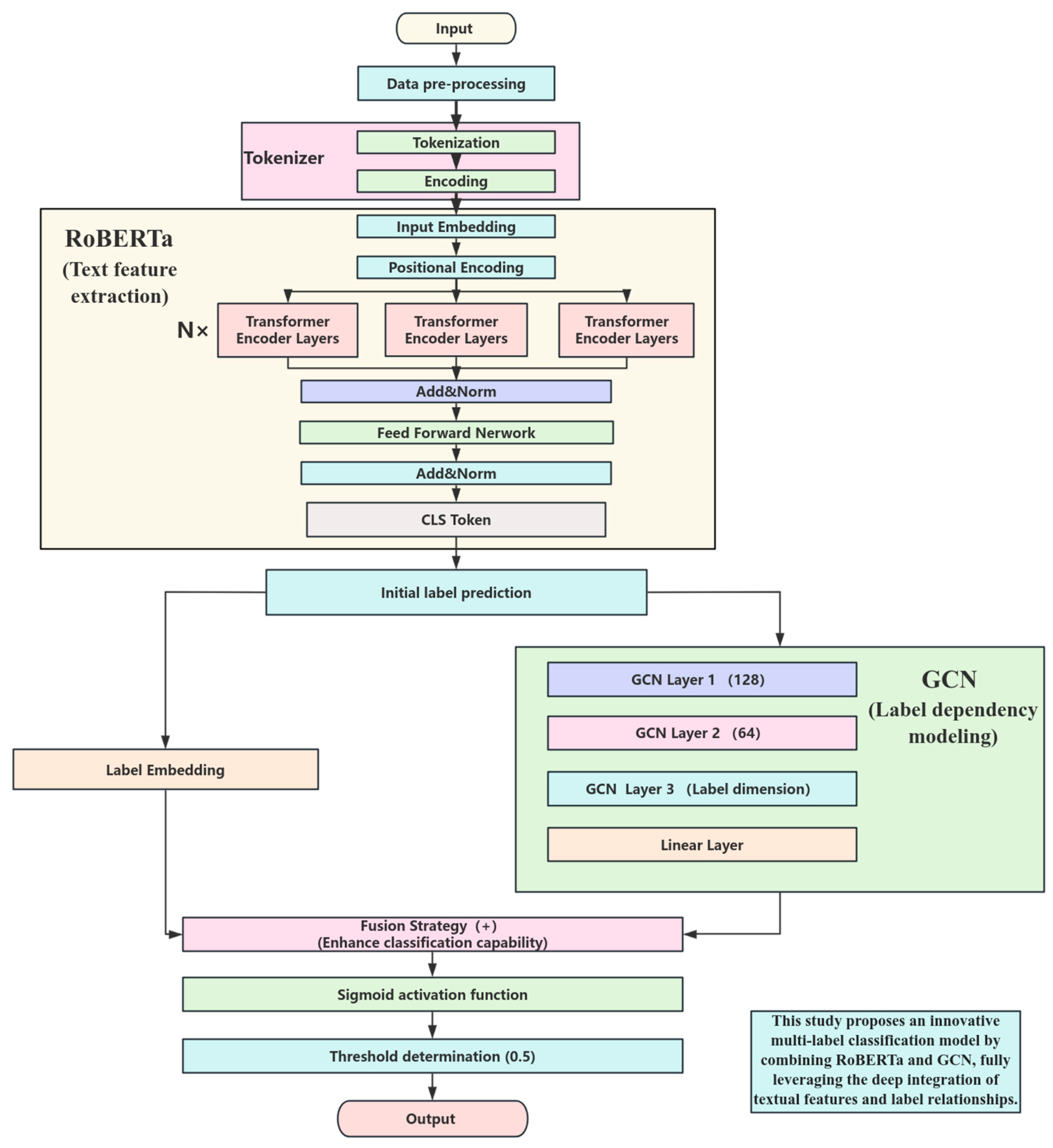
In terms of selecting text processing models, the training times per epoch of RoBERTa and BERT were compared as a reference. The performance in training time between the two is similar (RoBERTa: 11.25 s, 11.09 s, 11.3 s, 11.25 s, and 11.31 s; BERT: 11.25 s, 11.32 s, 11.23 s, 11.28 s, and 11.32 s). The choice to choose RoBERTa over BERT is primarily based on the following reasons. From the experimental results, the RoBERTa model outperforms BERT across all evaluation metrics, particularly demonstrating higher performance in accuracy and F1 score. RoBERTa employs more optimized strategies and larger datasets during its pre-training process, which endows it with better generalization capabilities and robustness when handling natural language tasks. In automatically classifying flight instructor comments, this advantage translates into higher classification performance and more stable model behavior. Considering the comprehensive requirements for accuracy and efficiency in practical applications, selecting RoBERTa as the text processing model is a more suitable choice.
Based on the experimental results outlined above, the RoBERTa + GCN model exhibits superiority over all other baseline models across every evaluation metric. It particularly stands out in terms of average accuracy (0.8702), average precision (0.9854), average recall (0.9623), and average F1 score (0.9737). These findings highlight the model’s high effectiveness and robustness in handling the multi-label classification task of flight instructor comments.
Based on the comparative analysis of the experimental data, both the RoBERTa and RoBERTa + GCN models show substantial enhancements in performance, particularly in metrics such as accuracy, precision, recall, and F1 score.
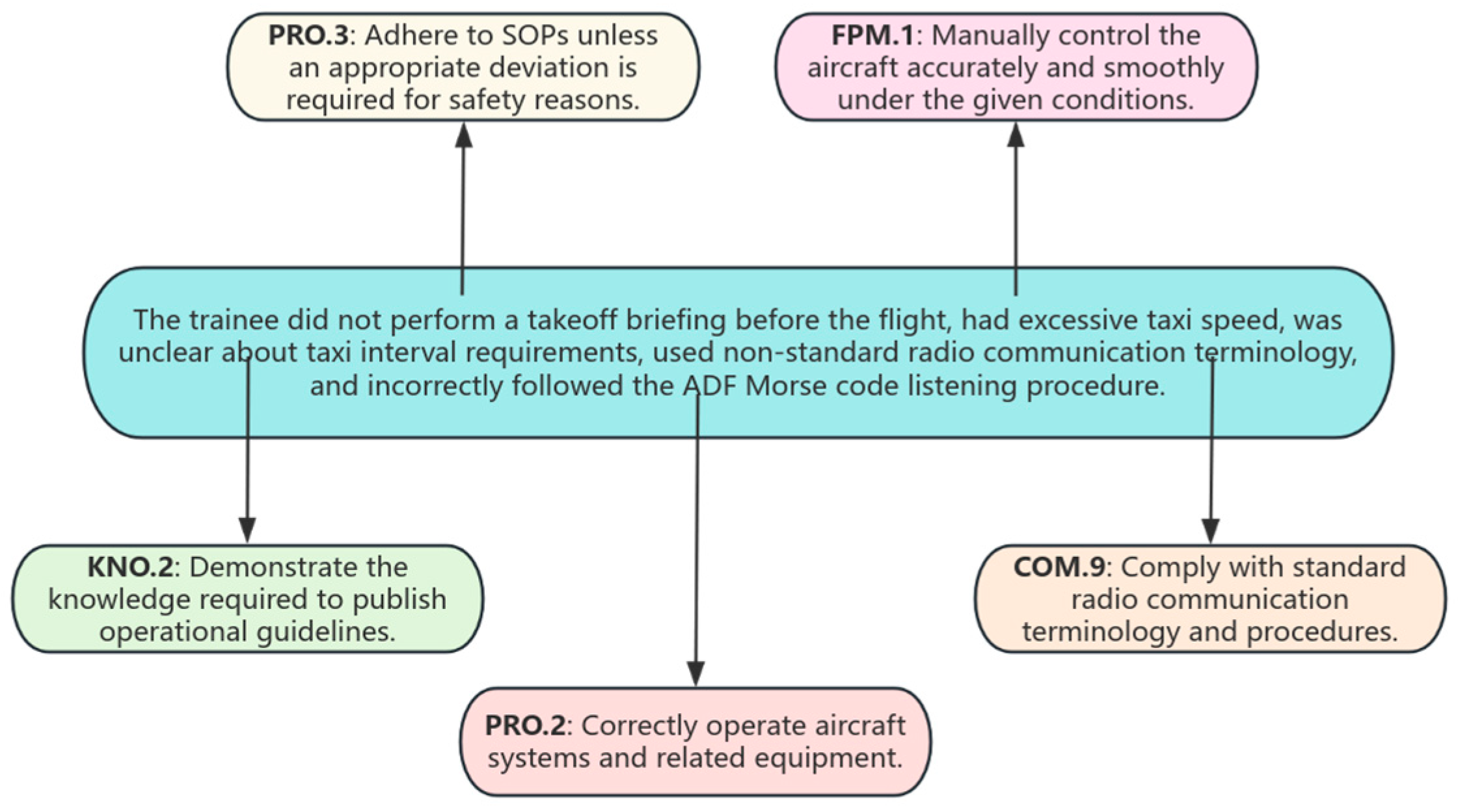
(1) Enhanced Text Feature Extraction Capability, RoBERTa, as a pre-trained Transformer model, boasts robust contextual understanding and semantic representation capabilities. During the experiments, RoBERTa attained an accuracy of 0.8108, a precision of 0.98, a recall of 0.9418, and an F1 score of 0.9605. In contrast, other models such as BERT (accuracy: 0.7931, precision: 0.9759, recall: 0.9397, F1 score: 0.9574) and LSTM (accuracy: 0.6782, precision: 0.9281, recall: 0.9038, F1 score: 0.9157) exhibited relatively weaker performance on these metrics. By undergoing pre-training on large-scale corpora, RoBERTa can generate high-quality text embeddings. These embeddings can capture subtle differences and complex semantics within the comments. For example, it can precisely understand the distinct dimensional behaviors expressed in comments like “high taxiing speed” versus “unclear taxiing interval requirements”, thus improving its performance in classification tasks.
(2) Optimization of Label Relationship Modeling. After incorporating the GCN module, the RoBERTa + GCN model efficiently captures higher-order dependency information among labels by constructing an optimized label graph. The GCN module strengthens the model’s ability to model relationships between labels, which is evident in the performance metrics. The RoBERTa + GCN model achieved an accuracy of 0.8702, a precision of 0.9854, a recall of 0.9623, and an F1 score of 0.9737, all significantly higher than the performance of RoBERTa when used in isolation. Particularly in scenarios where there are co-occurrence and dependency relationships between labels (such as the association between operational capabilities and decision-making abilities in flight instructor comments), the GCN can effectively capture these hidden relationships. This, in turn, further enhances the classification accuracy and the overall performance of the model.
(3) Effectiveness of the Fusion Strategy. The fusion strategy put forward in this paper, which entails element-wise addition of the initial label logits produced by RoBERTa and the label logits generated by GCN, exhibits significant advantages in the RoBERTa + GCN model. This fusion strategy is succinct and efficient, not only elevating prediction accuracy but also enhancing the model’s stability and generalization capabilities. In the experiments, the RoBERTa + GCN model surpassed other models across all metrics. There were particularly notable enhancements in the F1 score (0.9737) and recall (0.9623). This suggests that by combining text feature extraction and label relationship modeling, the model can capitalize on the strengths of both, achieving a more comprehensive classification capability.
3.2. Analysis of Model Performance
To better demonstrate the specific performance of the model on each label, we calculated the precision, recall, F1 score, and support data for each label, and randomly selected 10 labels to present the results, as shown in
Table 8.
Based on the experimental results, we analyzed the performance of the RoBERTa + GCN model across various label dimensions, particularly focusing on the impact of data volume on model performance. The data presented in the tables indicate that labels with larger data volumes (such as COM.1, COM.9, and FPM.2) generally exhibit better performance, whereas labels with smaller data volumes (such as FPM.1 and FPM.3) show a certain degree of performance degradation.
For labels with abundant data, the model can fully learn the features and patterns associated with those labels, resulting in outstanding performance. For instance, both COM.1 and COM.9 achieve perfect scores of 1.00 in precision, recall, and F1 score, demonstrating exceptional classification capabilities. Similarly, FPM.2 attains a precision of 0.99, a recall of 1.00, and an F1 score of 1.00, reflecting high accuracy and comprehensiveness.
However, labels with limited data suffer from performance deficiencies. For example, FPM.1 has a precision and recall of 0.75 each, with an F1 score of 0.75. Although the model can recognize this label, the small sample size prevents the model from fully learning the label’s characteristics during training, leading to inferior classification performance compared to labels with larger data volumes. FPM.3 achieves a precision of 1.00 but a recall of only 0.57, resulting in an F1 score of 0.73, which reveals the model’s inadequacy in handling this label.
In summary, the volume of data directly influences the model’s performance across different labels. A larger data volume improves classification precision and recall, particularly in helping the model effectively learn the complex relationships between labels. Conversely, labels with limited data result in poorer recognition performance, especially evident in the gaps in recall and F1 score.
3.3. Ablation Experiments
Through ablation experiments, specific model components can be selectively eliminated to assess the influence of these alterations on model performance, identifying which modules are crucial to overall effectiveness. This study carries out ablation experiments from three perspectives.
- (1)
Transformer Baseline Model: Employing only a pre-trained Transformer encoder (RoBERTa) for multi-label classification, excluding the GCN module.
- (2)
Transformer with Fusion Strategy: Adding a fully connected layer after the output of the Transformer encoder (RoBERTa) for label prediction, without integrating the GCN module.
- (3)
Full Transformer + GCN Model: Integrating both the Transformer encoder (RoBERTa) and the GCN module for multi-label classification.
The experimental results are presented in
Table 9.
Analyzing
Table 9, it becomes apparent that as the model complexity increases, there is a general uptrend in performance metrics. Specifically, when employing only the Transformer encoder (RoBERTa) for classification, the F1 score is 0.8108. This indicates that the model’s performance is somewhat deficient when dealing with imbalanced labels or certain low-frequency labels. By introducing a straightforward fusion strategy on top of the Transformer encoder (RoBERTa), which further refines label prediction through an additional linear layer, the average accuracy improves to 0.8553, the average precision slightly increases to 0.9855, the average recall improves to 0.9556, and the average F1 score reaches 0.9703. This implies that the simple fusion strategy effectively enhances the model’s ability to capture relationships between labels to some extent. The Transformer + GCN model, building upon the previous model, further incorporates a Graph GCN module to model the complex relationships between labels. This enables further improvement in classification performance through information interaction between labels. The average accuracy further improves to 0.8702, the average precision remains at 0.9854, the average recall ascends to 0.9623, and the average F1 score reaches 0.9737.
The ablation experiment results clearly show that the gradual incorporation of model components (from RoBERTa to RoBERTa + FC, and then to RoBERTa + GCN) significantly boosts the model’s performance. This reveals the following key points:
- (1)
The fusion strategy proves to be highly effective. By adding a simple fully connected layer (FC) on top of RoBERTa, it enhances the model’s performance. The average F1 value of RoBERTa + FC reaches 0.9703, representing a substantial improvement compared to the 0.9605 of RoBERTa alone. RoBERTa + FC achieves an average precision of 0.8553, an average recall of 0.9556, and an average precision of 0.9855. This shows that the simple fully connected layer (FC) efficiently combines the features extracted by the Transformer through linear transformation and addition operations, which enhances the model’s ability to understand and predict the relationship between labels. The proposed fusion strategy avoids the computational overhead caused by complex fusion while maintaining the performance improvement of the model. This undeniably verifies its effectiveness.
To further validate the fusion strategy, an Ablation Study was conducted to compare the performance of RoBERTa + FC and RoBERTa + GCN. The results show that while both strategies provide improvements over the baseline model, RoBERTa + GCN outperforms RoBERTa + FC, particularly in terms of capturing high-order label dependencies. This comparison emphasizes the advantages of incorporating the GCN module, further highlighting the effectiveness of the fusion strategy.
- (2)
After introducing the GCN module, the average precision of the RoBERTa + GCN model is further improved to 0.8702, and the average recall rate is improved to 0.9623. Compared with RoBERTa and RoBERTa + FC, the GCN module exhibits distinct advantages in improving the model performance. Through the multi-layer graph convolution operation, GCN effectively captures the high-order dependencies among labels and enhances the classification ability of the model in comprehending the complex relationships in multi-label tasks. By modeling the complex relationships between labels, the GCN module improves the adaptability of the model to the diversity of label combinations. Consequently, this leads to an improvement in the classification performance.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}