

SE-CBAM-YOLOv7: An Improved Lightweight Attention Mechanism-Based YOLOv7 for Real-Time Detection of Small Aircraft Targets in Microsatellite Remote Sensing Imaging


Abstract
1. Introduction
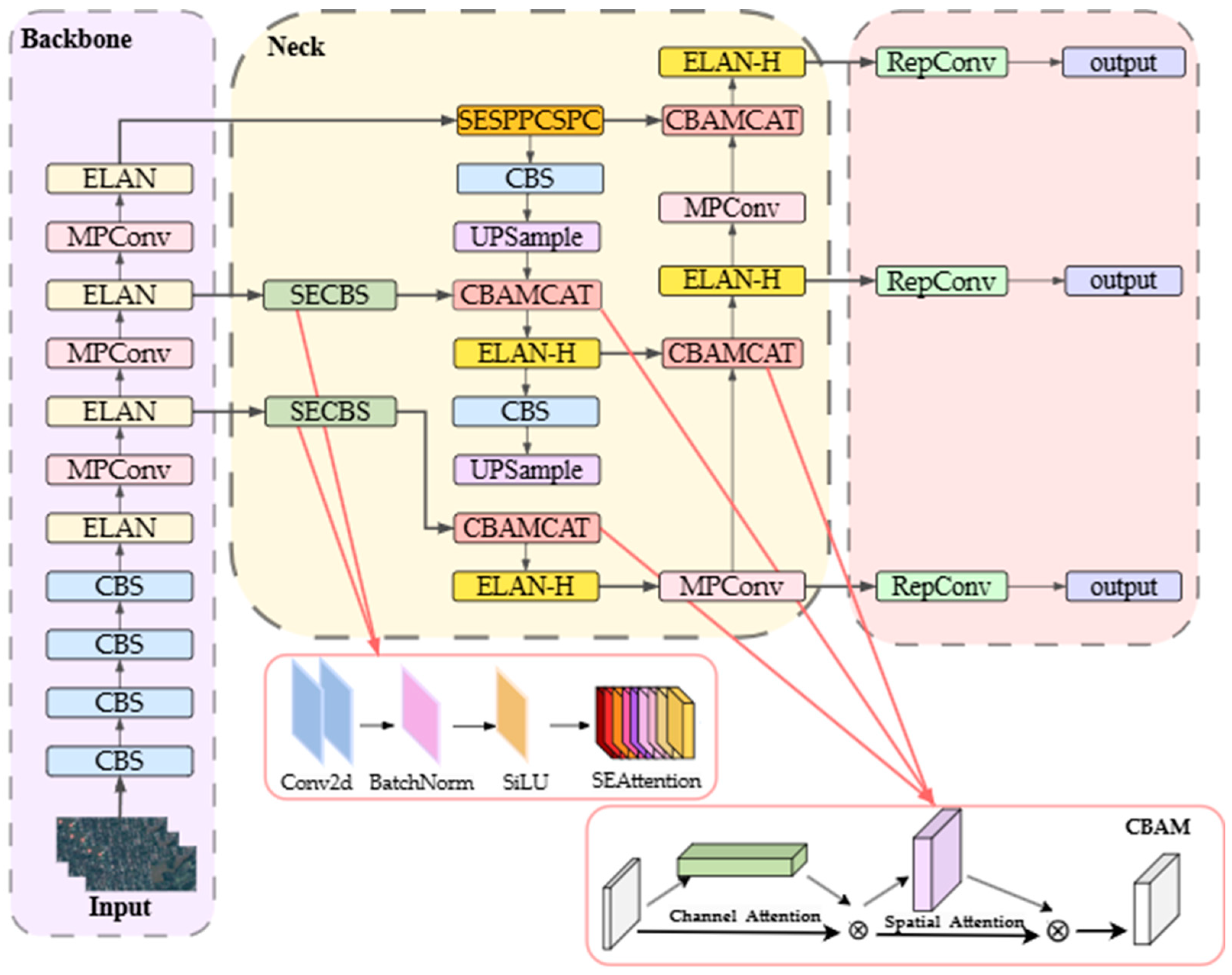
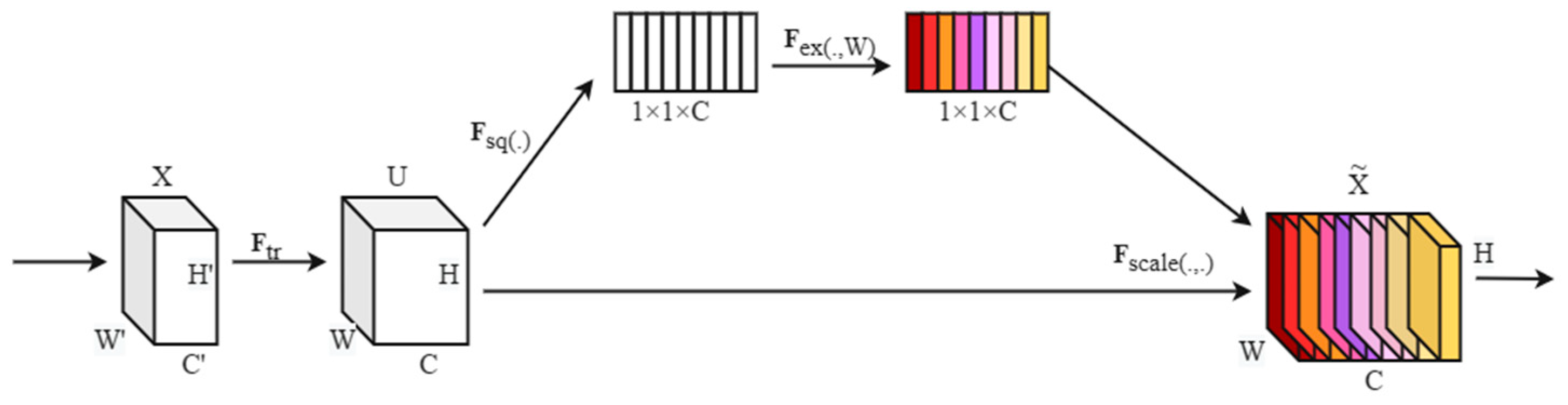
- Replacing the standard convolution (Conv) process with a new lightweight convolution (SEConv) to reduce the network’s computational parameters and speed up the detection process for small aircraft targets;
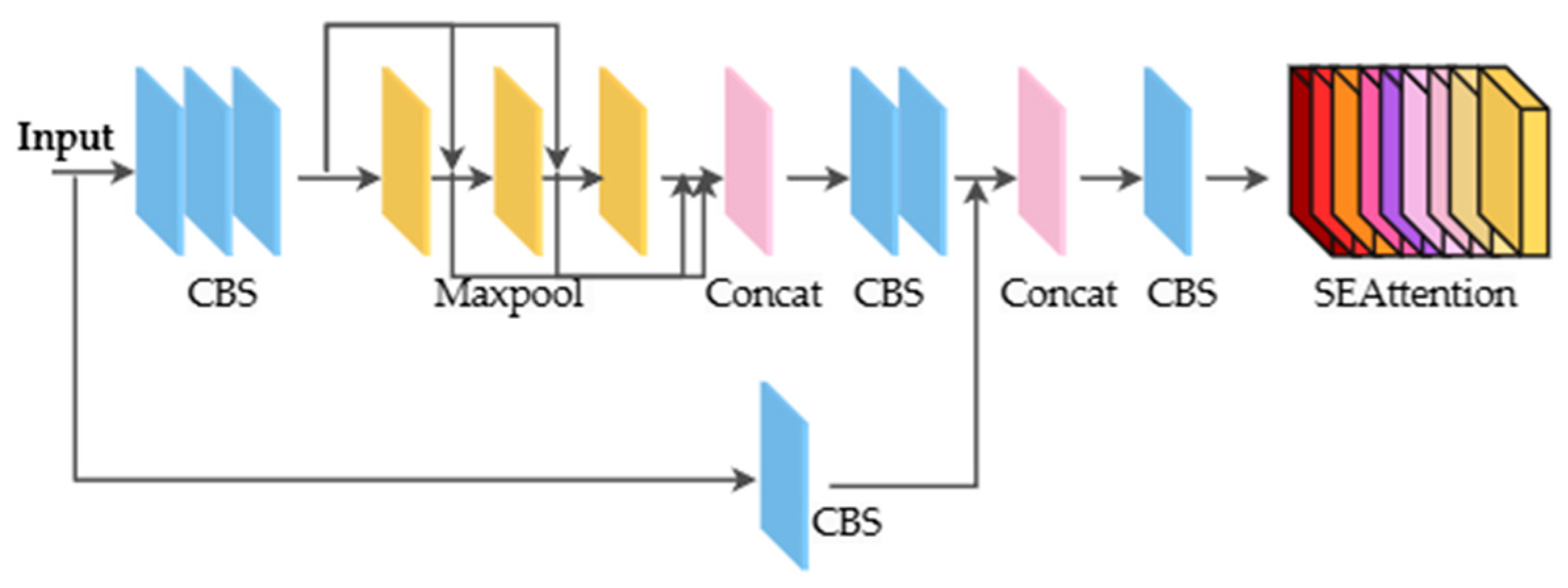
- Designing the SESPPCSPC module that integrates the channel attention mechanism network SENet. This achieves multi-scale spatial pyramid pooling on the input feature maps, enhances the model’s receptive field and feature expression capabilities, and improves the network’s feature extraction capability;
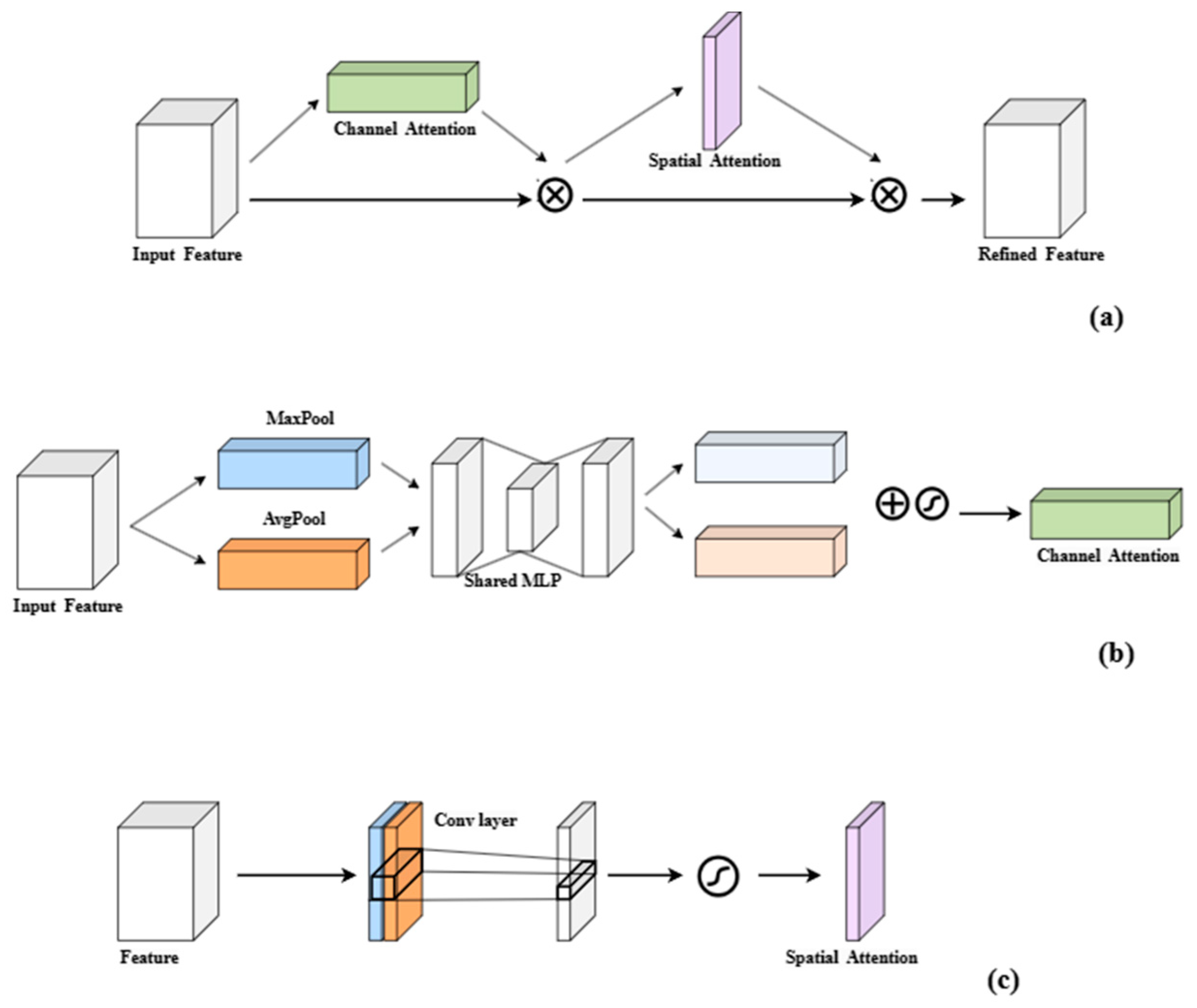
- Introducing CBAMCAT, a new feature fusion layer that sequentially infers attention maps along two independent dimensions (channel and spatial). The attention maps are multiplied with the input feature maps for adaptive optimization, improving the model’s feature fusion capability.
2. Related Work
3. Method
3.1. SEConv
3.2. SESPPCSPC
3.3. CBAMCAT
4. Experiments
4.1. Experimental Data
4.2. Space-Based Intelligent Processing Platform
4.3. Ground Link Experiment Syetem
4.4. Evaluation Metrics
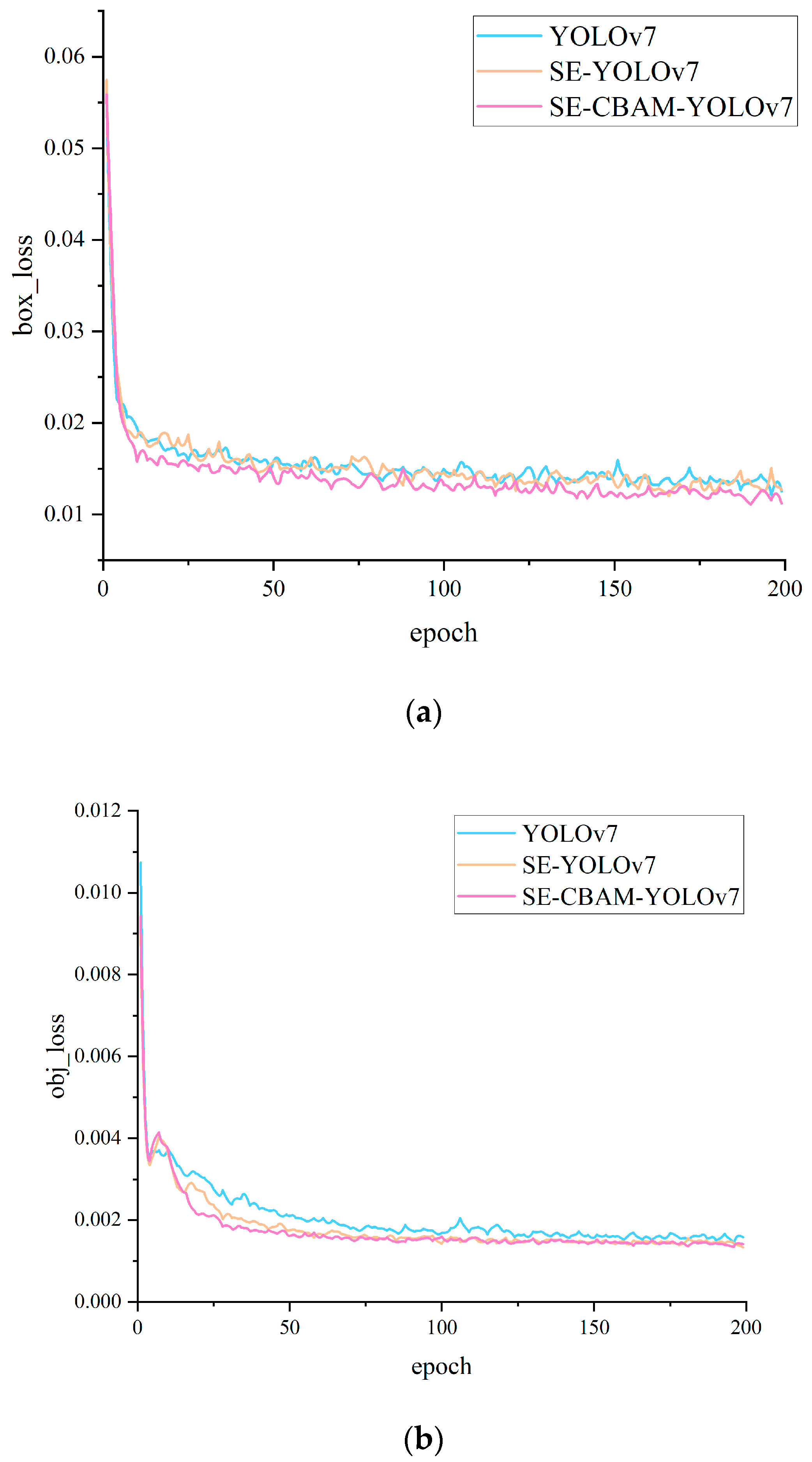
4.5. Experimental Results and Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, C.; Cui, J.; Wang, D.; Li, G.; Lu, H.; Tian, Z.; Zhao, C.; Li, M.; Zhang, L. Prediction of aquatic vegetation growth under ecological recharge based on machine learning and remote sensing. J. Clean. Prod. 2024, 452, 142054. [Google Scholar] [CrossRef]
- Yang, F.; Men, X.; Liu, Y.; Mao, H.; Wang, Y.; Wang, L.; Zhou, X.; Niu, C.; Xie, X. Estimation of Landslide and Mudslide Susceptibility with Multi-Modal Remote Sensing Data and Semantics: The Case of Yunnan Mountain Area. Land 2023, 12, 1949. [Google Scholar] [CrossRef]
- Braun, A.; Warth, G.; Bachofer, F.; Schultz, M.; Hochschild, V. Mapping Urban Structure Types Based on Remote Sensing Data—A Universal and Adaptable Framework for Spatial Analyses of Cities. Land 2023, 12, 1885. [Google Scholar] [CrossRef]
- Reyes, J.A.; Cowardin, H.M.; Velez-Reyes, M. Analysis of Spacecraft Materials Discrimination Using Color Indices for Remote Sensing for Space Situational Awareness. J. Astronaut. Sci. 2023, 70, 33. [Google Scholar] [CrossRef]
- Bai, L.; Ding, X.; Chang, L. Remote Sensing Target Detection Algorithm based on CBAM-YOLOv5. Front. Comput. Intell. Syst. 2023, 5, 12–15. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Computer Science. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.W. Adapting Mask-RCNN for Automatic Nucleus Segmentation. arXiv 2018, arXiv:1805.00500. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhang, Z.Y.; Liu, Y.P.; Liu, T.C.; Lin, Z.; Wang, S. DAGN: A real-time UAV remote sensing image vehicle detection framework. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1884–1888. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, Y.; Du, Q. YOLO-Class: Detection and Classification of Aircraft Targets in Satellite Remote Sensing Images Based on YOLO-Extract. IEEE Access 2024, 11, 109179–109188. [Google Scholar] [CrossRef]
- Sun, X.M.; Zhang, Y.J.; Wang, H.; Du, Y.X. Research on ship detection of optical remote sensing image based on Yolo V5. J. Phys. Conf. Ser. 2022, 2215, 012027. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Y.; Fan, J.Y.; Hu, Y.; Guo, J.; Zhu, Y. TBi-YOLOv5: A surface defect detection model for crane wire with Bottleneck Transformer and small target detection layer. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2024, 238, 2425–2438. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, C.; Bi, F.; Zhang, W.; Chen, L. An Intensity-Space Domain CFAR Method for Ship Detection in HR SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 529–533. [Google Scholar] [CrossRef]
- Ai, J.; Luo, Q.; Yang, X.; Yin, Z.; Xu, H. Outliers-Robust CFAR Detector of Gaussian Clutter Based on the Truncated-Maximum-Likelihood- Estimator in SAR Imagery. IEEE Trans. Intell. Transp. Syst. 2020, 21, 2039–2049. [Google Scholar] [CrossRef]
- Karvonen, J.; Gegiuc, A.; Niskanen, T.; Montonen, A.; Buus-Hinkler, J.; Rinne, E. Iceberg Detection in Dual-Polarized C-Band SAR Imagery by Segmentation and Nonparametric CFAR (SnP-CFAR). IEEE Trans. Geosci. Remote Sens. 2021, 60, 4300812. [Google Scholar] [CrossRef]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef]
- Ao, W.; Xu, F.; Li, Y.; Wang, H. Detection and Discrimination of Ship Targets in Complex Background from Spaceborne ALOS-2 SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 536–550. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite-Borne Intelligent Computing Platform | ||
|---|---|---|
| Basic parameter | volumetric | 208 ∗ 125 ∗ 55 mm ± 5 mm |
| weights | 1.5 kg ± 0.2 | |
| electricity supply | 28 ± 3 V | |
| ECU Modules Central Control Unit | microchip | ZYNQ 7100 |
| main frequency | 766 MHz (dual core) | |
| random access memory (RAM) | 512 MB × 2, DDR3, 1066 MHz | |
| storage | 32 GB eMMC × 2 | |
| SCC Module Central Computing Unit | microchip | Jetson AGXi Xavier |
| main frequency | CPU: 2.0 GHz (8 core) GPU: 1.2 GHz | |
| random access memory (RAM) | 32 GB, LPDDR4x, 136.5 GB/s | |
| storage | 1 TB SSD | |
| arithmetic power | 30 TOPS | |
| Satellite Data Simulator | ||
|---|---|---|
| Basic parameter | volumetric | 208 ∗ 125 ∗ 55 mm ± 5 mm |
| weights | 1.5 kg ± 0.2 | |
| electricity supply | 28 ± 3 V | |
| OBC On-board computing unit | microchip | ZYNQ 7100 |
| Storage module | storage | 1TB SSD |
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) | F1 (%) |
|---|---|---|---|---|
| YOLOv7 | 90.7 | 85.2 | 84.9 | 87.86 |
| SE- YOLOv7 | 84.5 | 85.7 | 83.4 | 85.10 |
| SE-CBAM-YOLOv7 | 91.2 | 85.7 | 86.6 | 88.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Z.; Liao, Y.; Du, S.; Li, H.; Li, Z. SE-CBAM-YOLOv7: An Improved Lightweight Attention Mechanism-Based YOLOv7 for Real-Time Detection of Small Aircraft Targets in Microsatellite Remote Sensing Imaging. Aerospace 2024, 11, 605. https://doi.org/10.3390/aerospace11080605
Kang Z, Liao Y, Du S, Li H, Li Z. SE-CBAM-YOLOv7: An Improved Lightweight Attention Mechanism-Based YOLOv7 for Real-Time Detection of Small Aircraft Targets in Microsatellite Remote Sensing Imaging. Aerospace. 2024; 11(8):605. https://doi.org/10.3390/aerospace11080605
Chicago/Turabian StyleKang, Zhenping, Yurong Liao, Shuhan Du, Haonan Li, and Zhaoming Li. 2024. "SE-CBAM-YOLOv7: An Improved Lightweight Attention Mechanism-Based YOLOv7 for Real-Time Detection of Small Aircraft Targets in Microsatellite Remote Sensing Imaging" Aerospace 11, no. 8: 605. https://doi.org/10.3390/aerospace11080605
APA StyleKang, Z., Liao, Y., Du, S., Li, H., & Li, Z. (2024). SE-CBAM-YOLOv7: An Improved Lightweight Attention Mechanism-Based YOLOv7 for Real-Time Detection of Small Aircraft Targets in Microsatellite Remote Sensing Imaging. Aerospace, 11(8), 605. https://doi.org/10.3390/aerospace11080605