
Speech Recognition for Air Traffic Control Utilizing a Multi-Head State-Space Model and Transfer Learning


Abstract
1. Introduction
2. Methodology
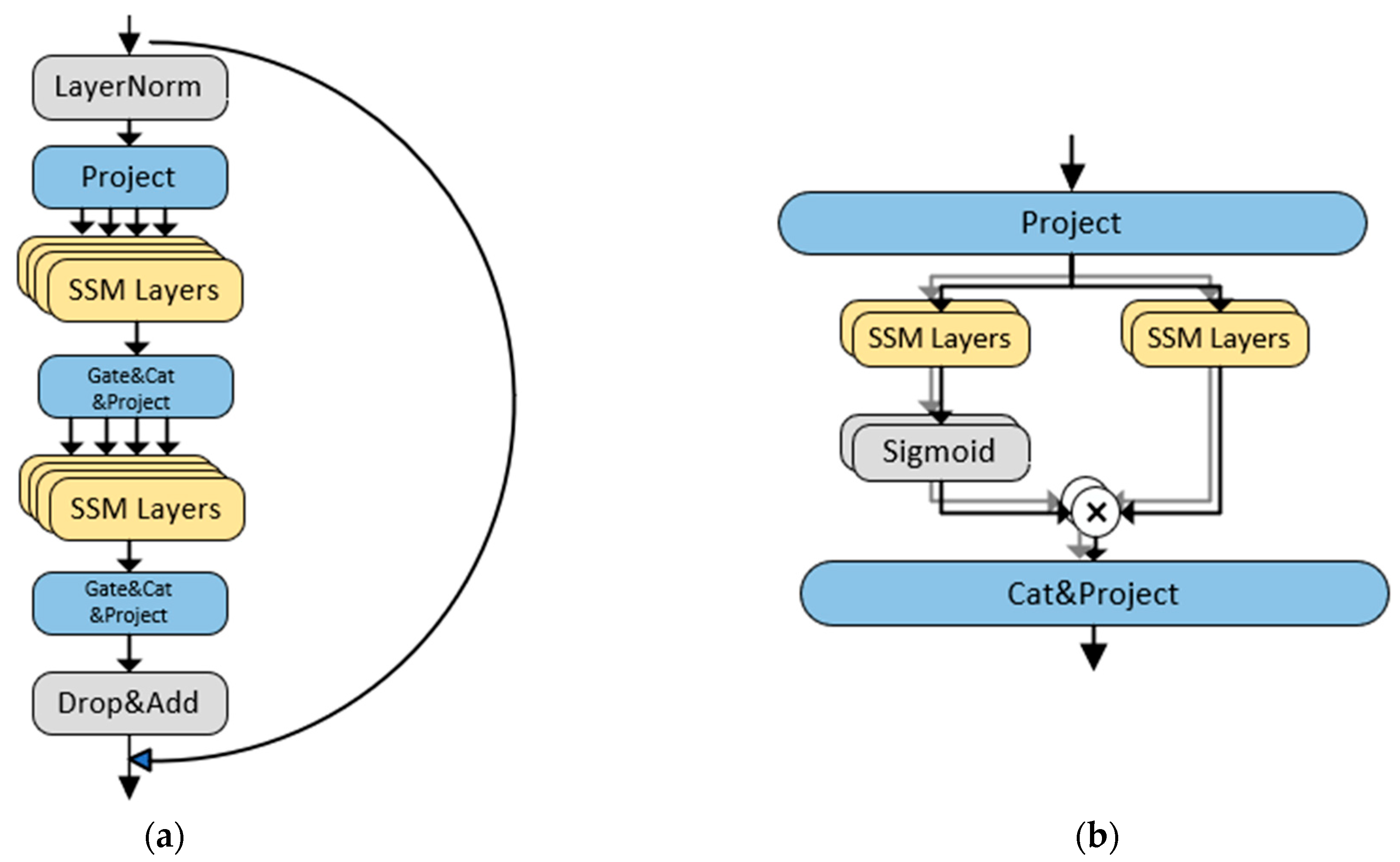
2.1. Mssm Module
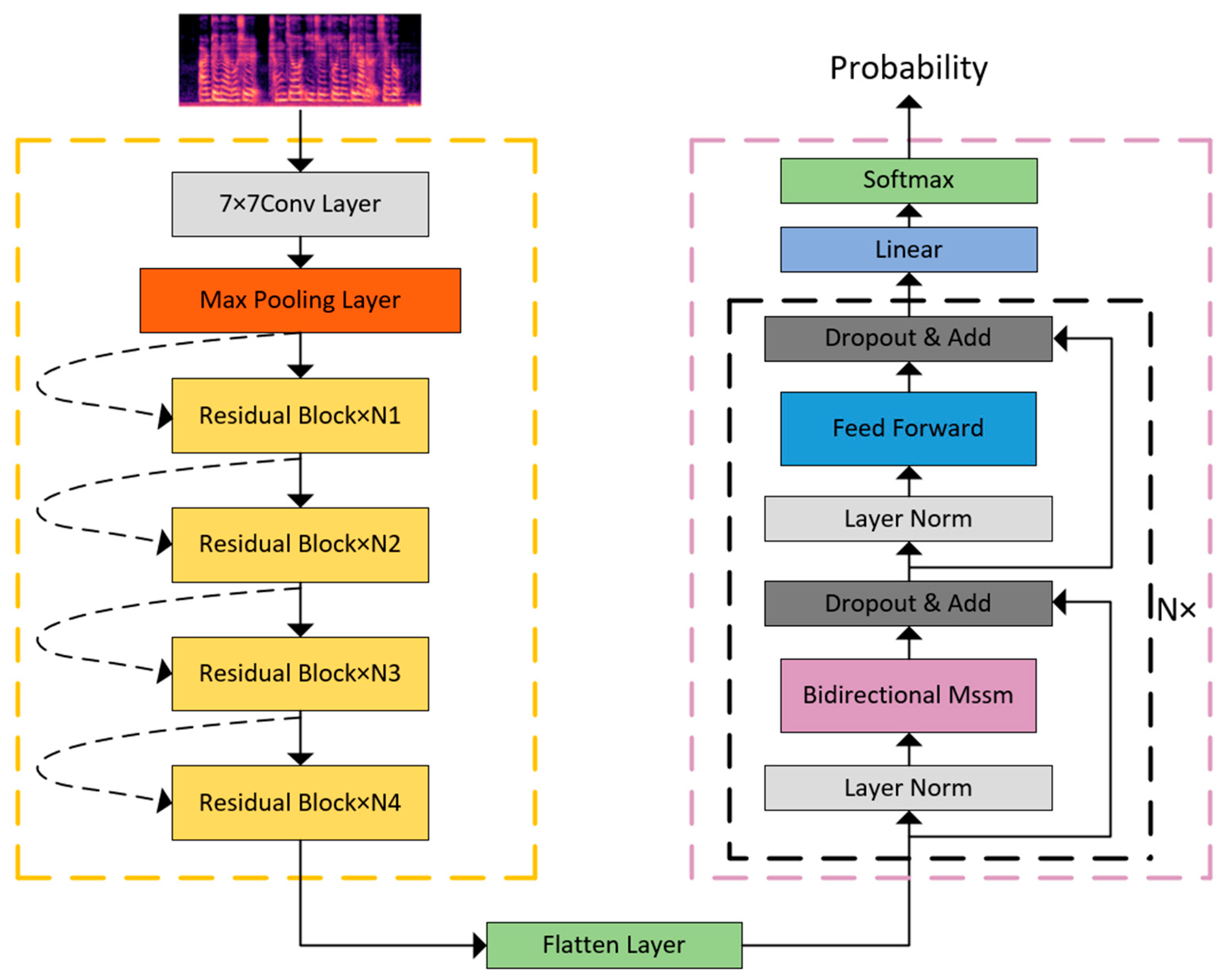
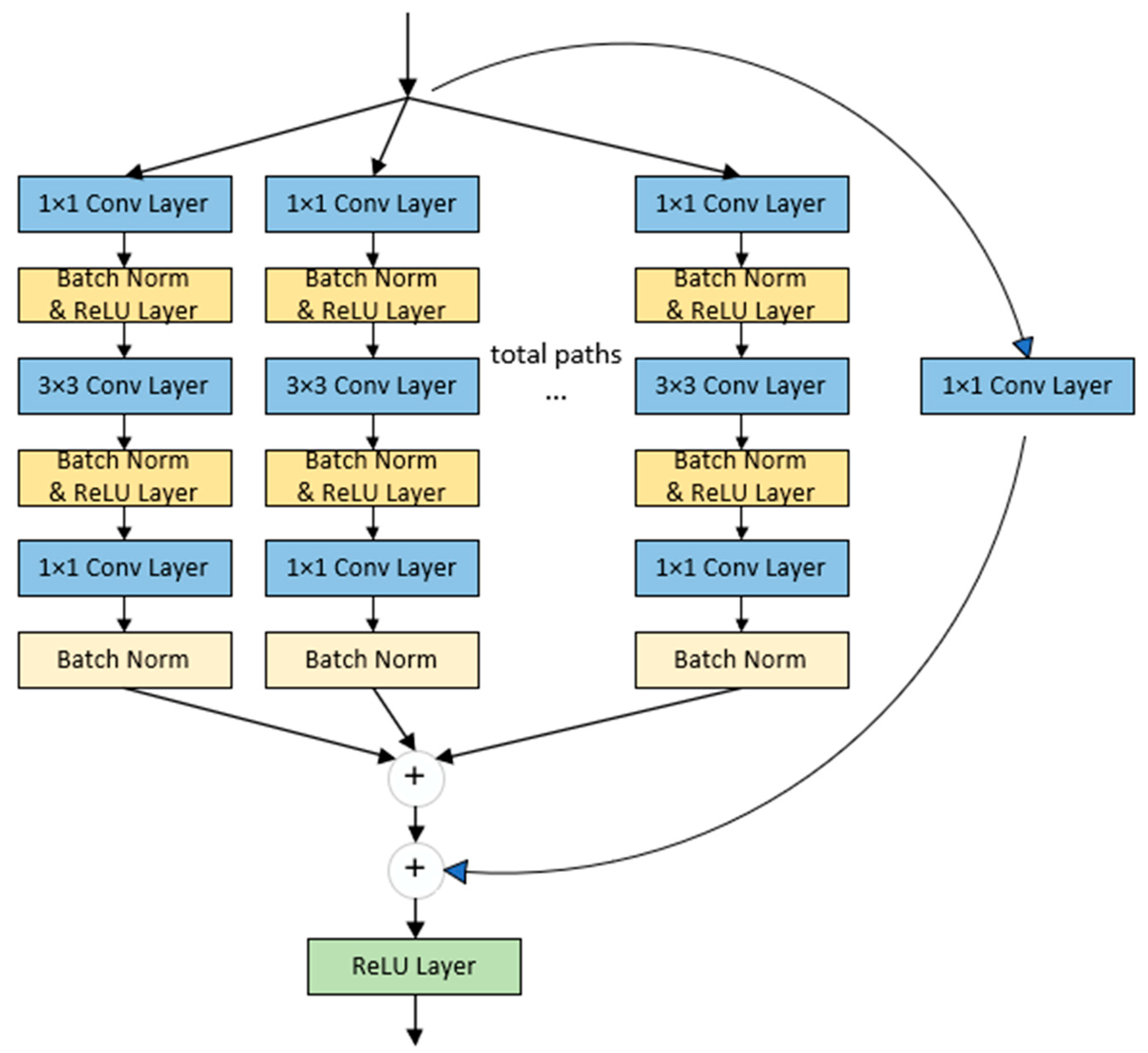
2.2. Overall Architecture of the Model
2.3. Training and Decoding
2.4. Transfer Learning
3. Experimental Evaluation
3.1. Experimental Data
3.2. Experimental Platform
3.3. Experimental Analysis
3.4. Model Parameters
4. Results and Discussion
4.1. Main Results
4.2. Ablation Studies
4.2.1. Pretraining Results for Different Backend Models on the Extended Aishell Corpus
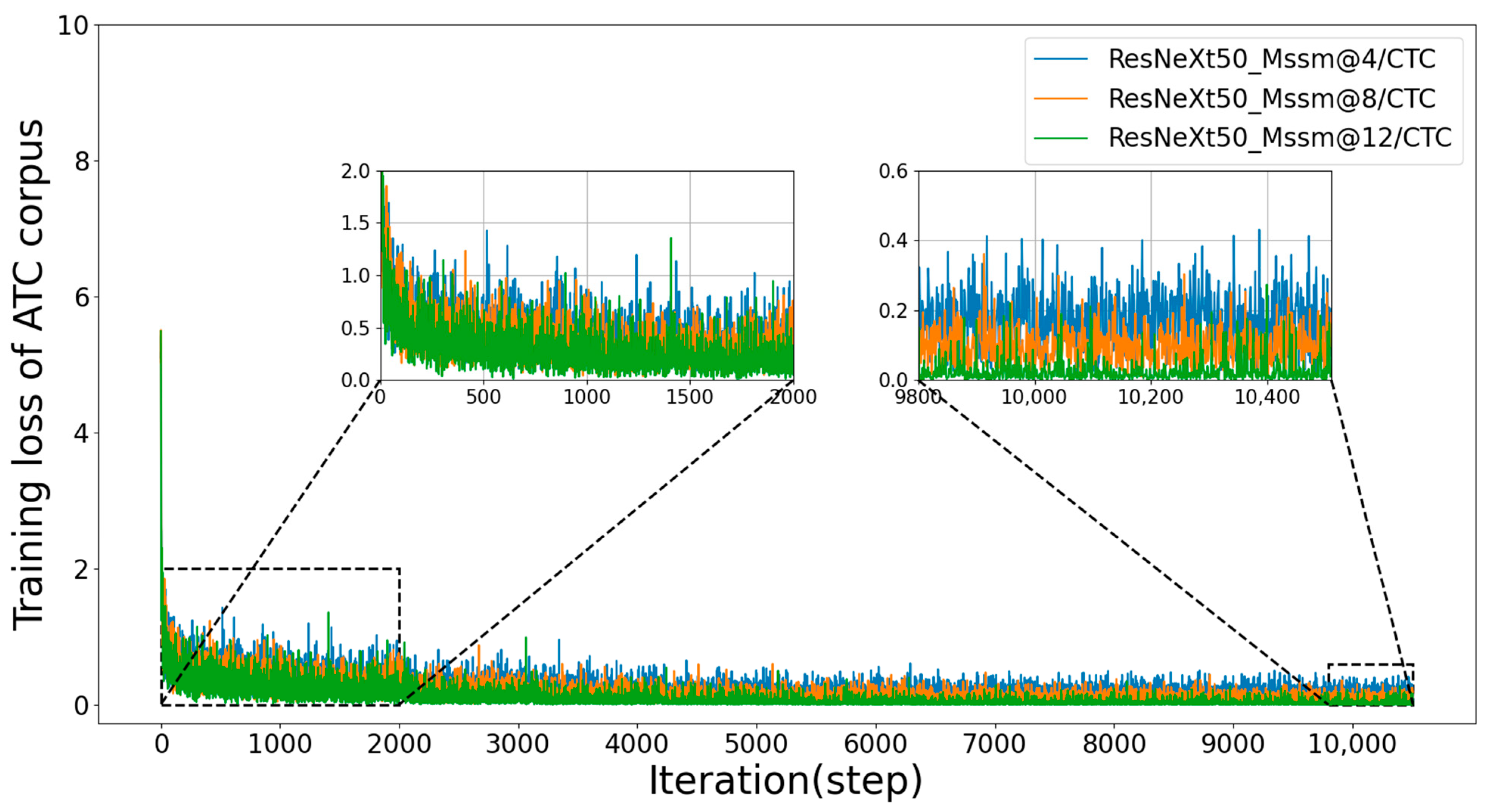
4.2.2. Experimental Results for Mssm Modules with Different Numbers of Layers in the ATC Corpus
4.2.3. Experiment Results with Different Convolutional Structures in the ATC Corpus
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Y. Spoken instruction understanding in air traffic control: Challenge, technique, and application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A unified framework for multilingual speech recognition in air traffic control systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3608–3620. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Deng, L.; Chen, Z.; Wu, X.; Zhang, J.; Yang, B. A real-time ATC safety monitoring framework using a deep learning approach. IEEE Trans. Neural Netw. Learn. Syst. 2019, 21, 4572–4581. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Zhang, Y.; Lu, X. A speech recognition acoustic model based on LSTM-CTC. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1052–1055. [Google Scholar]
- Shi, Y.; Hwang, M.Y.; Lei, X. End-to-end speech recognition using a high rank lstm-ctc based model. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7080–7084. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Peng, Y.; Dalmia, S.; Lane, I.; Watanabe, S. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding. In Proceedings of the International Conference on Machine Learning, London, UK, 2–5 July 2022; PMLR: London, UK, 2022; pp. 17627–17643. [Google Scholar]
- Kim, K.; Wu, F.; Peng, Y.; Pan, J.; Sridhar, P.; Han, K.J.; Watanabe, S. E-branchformer: Branchformer with enhanced merging for speech recognition. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 84–91. [Google Scholar]
- Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.; Ré, C. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Adv. Neural Inf. Process. Syst. 2021, 34, 572–585. [Google Scholar]
- Voelker, A.; Kajić, I.; Eliasmith, C. Legendre memory units: Continuous-time representation in recurrent neural networks. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Lei, T.; Zhang, Y.; Wang, S.I.; Dai, H.; Artzi, Y. Simple recurrent units for highly parallelizable recurrence. arXiv 2017, arXiv:1709.02755. [Google Scholar]
- Lei, T. When attention meets fast recurrence: Training language models with reduced compute. arXiv 2021, arXiv:2102.12459. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Durbin, J.; Koopman, S.J. Time Series Analysis by State Space Methods; OUP Oxford: Oxford, UK, 2012. [Google Scholar]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. Hippo: Recurrent memory with optimal polynomial projections. Adv. Neural Inf. Process. Syst. 2020, 33, 1474–1487. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Mehta, H.; Gupta, A.; Cutkosky, A.; Neyshabur, B. Long range language modeling via gated state spaces. arXiv 2022, arXiv:2206.13947. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Fathullah, Y.; Wu, C.; Shangguan, Y.; Jia, J.; Xiong, W.; Mahadeokar, J.; Liu, C.; Shi, Y.; Kalinli, O.; Seltzer, M.; et al. Multi-Head State Space Model for Speech Recognition. arXiv 2023, arXiv:2305.12498. [Google Scholar]
- Chilkuri, N.R.; Eliasmith, C. Parallelizing legendre memory unit training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: London, UK, 2021; pp. 1898–1907. [Google Scholar]
- Smith, J.T.H.; Warrington, A.; Linderman, S.W. Simplified state space layers for sequence modeling. arXiv 2022, arXiv:2208.04933. [Google Scholar]
- Gu, A.; Johnson, I.; Timalsina, A.; Rudra, A.; Ré, C. How to train your hippo: State space models with generalized orthogonal basis projections. arXiv 2022, arXiv:2206.12037. [Google Scholar]
- Goel, K.; Gu, A.; Donahue, C.; Ré, C. It’s raw! audio generation with state-space models. In Proceedings of the International Conference on Machine Learning, London, UK, 2–5 July 2022; PMLR: London, UK, 2022; pp. 7616–7633. [Google Scholar]
- Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; Kumar, S. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7829–7833. [Google Scholar]
- Yao, Z.; Wu, D.; Wang, X.; Zhang, B.; Yu, F.; Yang, C.; Peng, Z.; Chen, X.; Xie, L.; Lei, X. Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit. arXiv 2021, arXiv:2102.01547. [Google Scholar]
- Yao, Z.; Guo, L.; Yang, X.; Kang, W.; Kuang, F.; Yang, Y.; Jin, Z.; Lin, L.; Povey, D. Zipformer: A faster and better encoder for automatic speech recognition. arXiv 2023, arXiv:2310.11230. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | Language | Access | Size | Utterances | ||
|---|---|---|---|---|---|---|
| Train | Dev | Test | ||||
| expanded Aishell-1 | Chinese | Public | 329 h | 240,288 | 14,326 | 7176 |
| ATC speech (Mandarin) | Chinese | Simulation | 67 h | 28,785 | 1240 | 1371 |
| Structural Order | Output Size | Parameter Setup |
| Conv layer | ||
| Max pooling layer | ||
| Residual block × 3 | 3 | |
| Residual block × 4 | ||
| Residual block × 6 | 6 | |
| Residual block × 3 | 3 | |
| Permute | ||
| Flatten layer | ||
| Mssm module × X | , | |
| Linear layer |
| Model | Type | Params | CER (%) | |
|---|---|---|---|---|
| Dev | Test | |||
| Transformer [29] | Transducer | 64.5 M | 6.9 | 8.2 |
| Conformer in WeNet [30] | CTC/AED | 46.3 M | 5.8 | 7.1 |
| Branchformer [11] | CTC/AED | 45.4 M | 5.6 | 7.0 |
| Zipformer m [31] | Transducer | 73.4 M | 5.6 | 6.9 |
| ResNeXt50_Mssm@12 (ours) | CTC | 54.03 M | 5.5 | 6.7 |
| Model | CER (%) | RTF | Params | Training Time | |
|---|---|---|---|---|---|
| Dev | Test | ||||
| ResNeXt50_BiLSTM@4 | 13.0 | 14.4 | 0.24 | 46.9 M | 1.51 s/step |
| ResNeXt50_BiGRU@4 | 12.9 | 14.1 | 0.23 | 41.2 M | 1.36 s/step |
| ResNeXt50_MHSA_FFN@8 | 8.1 | 8.9 | 0.20 | 32.6 M | 1.33 s/step |
| ResNeXt50_Mssm@8(ours) | 7.2 | 8.3 | 0.21 | 38.5 M | 1. 35 s/step |
| Model | CER (%) | RTF | Params | Training Time | |
|---|---|---|---|---|---|
| Dev | Test | ||||
| ResNeXt50_Mssm@4 | 6.2 | 7.4 | 0.17 | 22.4 M | 1.02 s/step |
| ResNeXt50_Mssm@8 | 5.8 | 6.9 | 0.21 | 38.5 M | 1. 35 s/step |
| ResNeXt50_Mssm@12 | 5.5 | 6.7 | 0.24 | 54.03 M | 1.83 s/step |
| Model | CER (%) | RTF | Params | Training Time | |
|---|---|---|---|---|---|
| Dev | Test | ||||
| VGG16_Mssm@12 | 6.0 | 7.1 | 0.23 | 54.3 M | 2.11 s/step |
| VGG19_Mssm@12 | 5.8 | 7.0 | 0.25 | 62.4 M | 2.23 s/step |
| ResNet34_Mssm@12 | 5.7 | 7.0 | 0.23 | 53.5 M | 1.76 s/step |
| ResNet50_Mssm@12 | 5.7 | 6.8 | 0.24 | 61.6 M | 1.96 s/step |
| ResNeXt50_Mssm@12 | 5.5 | 6.7 | 0.24 | 54.03 M | 1.83 s/step |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Chang, H.; Kong, J. Speech Recognition for Air Traffic Control Utilizing a Multi-Head State-Space Model and Transfer Learning. Aerospace 2024, 11, 390. https://doi.org/10.3390/aerospace11050390
Liang H, Chang H, Kong J. Speech Recognition for Air Traffic Control Utilizing a Multi-Head State-Space Model and Transfer Learning. Aerospace. 2024; 11(5):390. https://doi.org/10.3390/aerospace11050390
Chicago/Turabian StyleLiang, Haijun, Hanwen Chang, and Jianguo Kong. 2024. "Speech Recognition for Air Traffic Control Utilizing a Multi-Head State-Space Model and Transfer Learning" Aerospace 11, no. 5: 390. https://doi.org/10.3390/aerospace11050390
APA StyleLiang, H., Chang, H., & Kong, J. (2024). Speech Recognition for Air Traffic Control Utilizing a Multi-Head State-Space Model and Transfer Learning. Aerospace, 11(5), 390. https://doi.org/10.3390/aerospace11050390