1. Introduction
A hypersonic vehicle (HV) refers to a vehicle that flies through the atmosphere between 20 km and 100 km at a speed above Mach 5, which possesses the characteristics of special flight airspace and high flight speed [
1]. In recent years, with the continuous development of anti-hypersonic technology, it has become necessary for the HV to solve the pursuit–evasion (PE) problem [
2,
3,
4] between itself and the interceptor.
The PE problem of HV is capable of describing a scenario where the interceptor called pursuer aims at capturing the HV called evader, while the evader struggles to avoid getting caught [
2].
In the past, hypersonic aircraft mainly used traditional solutions, including unilateral trajectory planning [
5,
6,
7,
8,
9,
10,
11] and bilateral game maneuvering [
12,
13,
14,
15,
16,
17,
18,
19], to deal with the PE problem.
Unilateral trajectory planning is achieved by pre-planning a trajectory and optimizing it to bypass the interceptor using optimal control [
5,
6,
7,
8] or other algorithms [
9,
10,
11]. In the trajectory optimization strategy mentioned above, the literature [
5] considers the optimization of hypersonic glide vehicle (HGV) evasion trajectory as a nonconvex optimal control problem and solves the second-order cone programming (SOCP) problem by state-of-the-art interior-point methods. In the study [
9], the improved pigeon-inspired optimization algorithm (PIO) is proposed to adjust the anticipated control parameters and to achieve the ideal trajectory for hypersonic vehicles.
Contrary to the unilateral design, game maneuvering considering the capabilities of both offensive and defensive sides generates maneuvering instructions by differential games [
12,
13,
14], game theory [
15,
16,
17], or other methods [
18,
19] to evade interceptors and implement target strikes. Among them, the most representative ones are the reference [
13,
15]. According to the article [
13], PE problems for the spacecraft in an uncompleted environment can be solved by switching methods based on differential game theory. Another study [
15] used game theory and the speed advantage of hypersonic aircraft for capability gaming to design a broad evasion strategy for the cruise phase of the air-breathing hypersonic vehicle (AHV). The references [
18,
19] all utilize an adaptive dynamic program (ADP), which is a unique solution method belonging to the differential game to solve the hypersonic PE game and keep track of the control system. The above methods each have their own advantages; the requirements, however, of the detection of current excessive situation information of both the pursuer and the evader as well as of computing power of missile-borne computers, make the traditional solutions unsuitable for practical engineering applications.
Nowadays, with the increasing artificial intelligence technology, the development direction of the solutions of the HV’s PE problem is shifting from traditional maneuver solutions to intelligent game maneuver strategies [
20]. That is, obtaining interceptor motion information through external data links or self-detectors, and generating corresponding game maneuvers by intelligent algorithms at the intersection critical point based on the guidance method characteristics. The intelligent game maneuver adopts a closed-loop maneuver scheme of “interceptor movement-situational awareness-maneuver strategy generation-maneuver control implementation” that realizes timely maneuvering to increase miss distance and increase evasion probability. The key to intelligent game maneuver lies in the selection of intelligent algorithms
Among the intelligent algorithms associated with hypersonic aircraft, deep learning (DL)and reinforcement learning (RL) are the first to bear the brunt [
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. Due to its strong nonlinear fitting ability, the deep neural network (DNN) in DL has been widely used in the PE problems of hypersonic aircraft [
21,
22,
23]. Among these, the most prevalent study [
21] resolves the tension between the accuracy and speed of the IPP by building an IPP neural network model after using the ballistic model to create training data. And the algorithms of reinforcement learning, especially deep reinforcement learning (DRL), provide a new approach to the design of HVs’ evasion strategies [
24,
25,
26,
27,
28,
29,
30,
31,
32]. As an unsupervised heuristic algorithm without an accurate model, RL and DRL can generate actions based on the interaction with the environment, that is, conduct intelligent maneuvering games based on both attack and defense sides. It was suggested in references [
24,
25] to create a new guidance law based on proximal policy optimization (PPO) and meta-learning for an exo-atmospheric interception because interceptors using IR seekers can only gather angle information. The study [
26], based on DRL, created a maneuver evasion guidance method considering both guidance accuracy and evasion capabilities with a focus on the terminal evasion scenario. Another study [
27] transformed the problem into a Markov decision process (MDP) and proposed the anti-interception guidance law utilizing a DRL algorithm consisting of an actor–critic framework to solve it. The research [
28] improved the reinforcement learning algorithm to a certain extent to achieve the interception of the maneuvering target. In the study [
29], the RL was used to solve the optimal attitude-tracking problem for hypersonic vehicles in the reentry phase. Another study [
30] based on the RL algorithm and deep neural network (DNN), generated the HV’s three-dimensional (3D) trajectory in the glide phase. One paper [
31] designs the HV’s autonomous optimal trajectory planning method based on the deep deterministic policy gradient (DDPG) algorithm, where the trajectory terminal position errors with satisfying hard constraints are minimized by the design of the reward function. It is worth noting that the reference [
32] carefully designed offensive and defensive adversarial scenario, namely the standard head-on scenario, where the speed advantage of HV was offset, and directly applied the twin delayed deep deterministic (TD3) gradient strategy to solve the hypersonic PE problem under the standard head-on scenario but ignoring the shortcomings of the algorithm itself, such as the weak generalization and slow training speed.
In addition to reference [
32], references [
5] and [
33] also believe that the PE game problem of HV should be considered and solved in head-on situations, and reference [
5] distinguishes the head-on situations from other situations in detail through illustrations. Among various offensive and defensive confrontation situations, the head-on situation is the toughest challenge for the HV to deal with, because the interceptor can intercept HV in the head-on situation easily and successfully. On the one hand, under the head-on situation, the speed difference between HV and interceptor is greatly eliminated, which is significantly beneficial for the low-speed interceptor. On the other hand, the interceptor’s seeker can stably track the target from the front until successful interception is achieved. In other words, considering existing interception technologies, the pursuer is most likely to adopt the head-on impact strategy [
28,
34] to achieve a successful intercept.
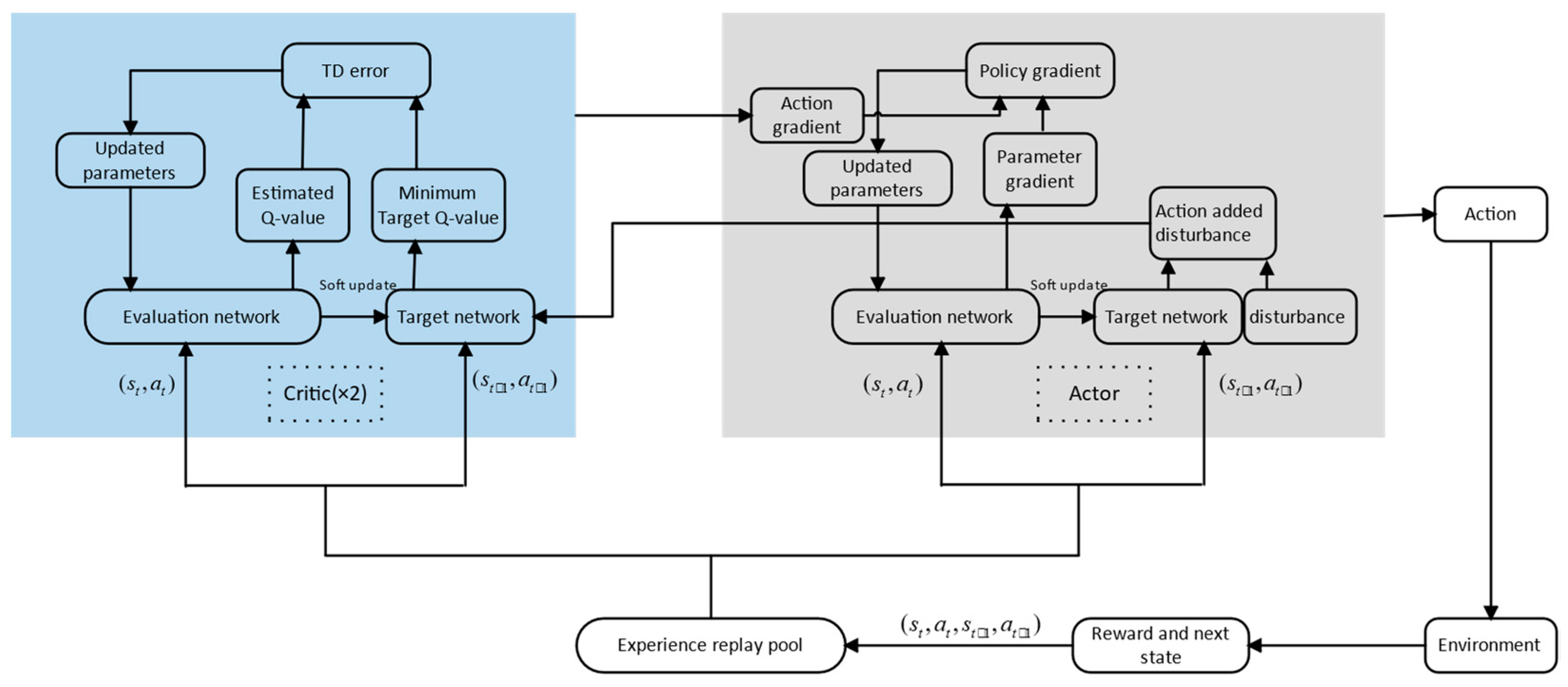
Motivated by the above research status and research difficulties, an intelligent maneuver strategy combining TD3 and DNN algorithms is studied to solve the hypersonic PE game problem. The attack and defense confrontation scenarios expand from the standard head-on situation in reference [
32] to approximate head-on situations. The twin delayed deep deterministic (TD3) gradient strategy algorithm is used to explore potential maneuver instructions, the DNN is used to fit to broaden application scenarios, and an intelligent maneuver strategy is generated with the initial situation of both the pursuit and evasion sides as the input and the maneuver game overload of the HV as the output. In order to increase the training convergence, the study proposes the experience pool classification strategy to improve the TD3 algorithm. The study designs a set of reward functions to achieve adaptive adjustment of evasion miss distance and energy consumption under different initial situations. The numerical simulation results show the effectiveness of the proposed method.
Compared with the existing literature, the benefits of the proposed method are as follows: The proposed intelligent maneuver is based on DRL, which is generated through continuous interaction between the pursuer and evader, two parties in the game of confrontation and is more suitable than the unilateral penetration trajectory optimization [
5] under the highly dynamic adversarial situation. And the intelligent method proposed does not occupy awful onboard computer resources and does not require intercepting information from the pursuer at all times in the PE procedure compared with the differential game method [
12]. In addition, compared with the DDPG algorithm used in the study [
27], the TD3 algorithm owns better performance by improving the shortcoming of overestimation of DDPG. And the proposed method further improves the TD3 algorithm in the training stage. In addition to the above algorithm improvement, the biggest difference from reference [
32] is that the TD3 algorithm in the proposed method does not directly output overload instructions but serves as the data generator; using DNN instead of the actor network to merge and output overload instructions. The computational complexity has been further reduced and the generalization has been improved.
Accordingly, the main novelties of this study are as follows:
The study constructs the adversarial model of both pursuer and evader under the most difficult head-on scenarios and proposes the maneuver strategy based on improved TD3 and DNN to achieve intelligent game maneuvers under the above model.
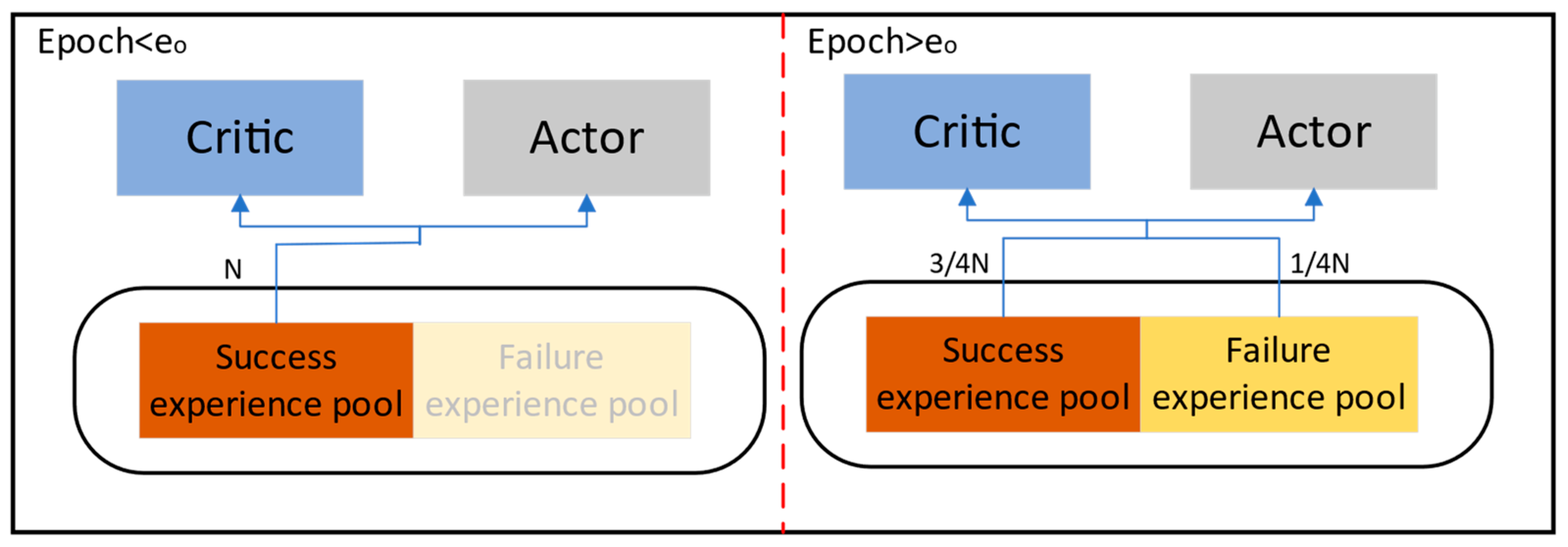
In order to improve the rate and stability of convergence of the TD3 algorithm, the study proposes the experience pool classification strategy, which classifies and stores samples in different experience pools and adaptively adjusts the number of samples taken in training.
The study designs a set of reward functions considering both successful evasion and energy consumption and introduces NN to improve the generalization of the algorithm. The intelligent maneuver strategy can achieve successful evasion and maneuver overload adaptively adjustment under different scenarios.
The research arrangement is as follows:
Section 2 provides a model for the PE problem of the HV and the interceptor under the head-on situation. In
Section 3, the intelligent maneuver strategy based on the “offline training + online application” framework is designed. In
Section 4, simulations are conducted to validate the algorithms and methods derived from the intelligent maneuver strategy. The conclusion is drawn in
Section 5.
4. Discussion
To solve the PE game successfully, using the intelligent maneuver strategy requires the following operations: firstly, training the DRL agent under the feature point, then making the Monte Carlo simulation biasing initial parameters, and finally training the DNN to obtain the intelligent maneuver model. The simulation software selected is MATLAB 2021a in the study, and the hardware information is Intel (R) Core (TM) i5-10300H CPU @ 2.50 GHz, RTX 2060 14 GB, DDR4 16 GB, 512 GB SSG. Considering the need for the application of deep reinforcement learning and deep neural networks, it is recommended to use software and hardware not lower than the above specifications.
Table 1 shows the parameters used in the entire simulation process.
Figure 6 shows the training curve of the reinforcement learning agent.
Figure 7 shows the simulation verification of the trained agent under the selected feature point.
Figure 8 shows Monte Carlo simulation and
Figure 9 shows neural network training.
Figure 10 shows the simulation verification of the obtained intelligent maneuvering strategy under several typical situations.
The initial relative positions and pertinent angles determine the strict head-on scenario between HV and interceptor. Among these, the HV’s initial position is set to (0, 0), and the pursuer’s initial position is set to (10,000, 0). Set the pursuer’s initial line-of-sight angle to 0 between the HV. The HV’s initial ballistic deflection angle is set to 0, and the pursuer’s initial ballistic deflection angle is set to −π.
In real engineering practice, due to the limitations of its own characteristics, HV usually has more speed and less overload during PE games compared to the interceptor. Therefore, we set the speed of the pursuer to 3 Ma and the speed of the HV to 6 Ma. At the same time, the overload capacity of HV is set to 3, and the overload capacity of the pursuer is set to 6. Accordingly, we need to take advantage of the HV’s high speed and seize the opportunity and time of maneuvering to achieve successful evasion within limited overload. And the lowest boundary value of miss distance is set to 5 m.
Set the maximum number of training rounds to 600. To ensure the effectiveness of training, some initial parameters will be randomly skewed during each training process.
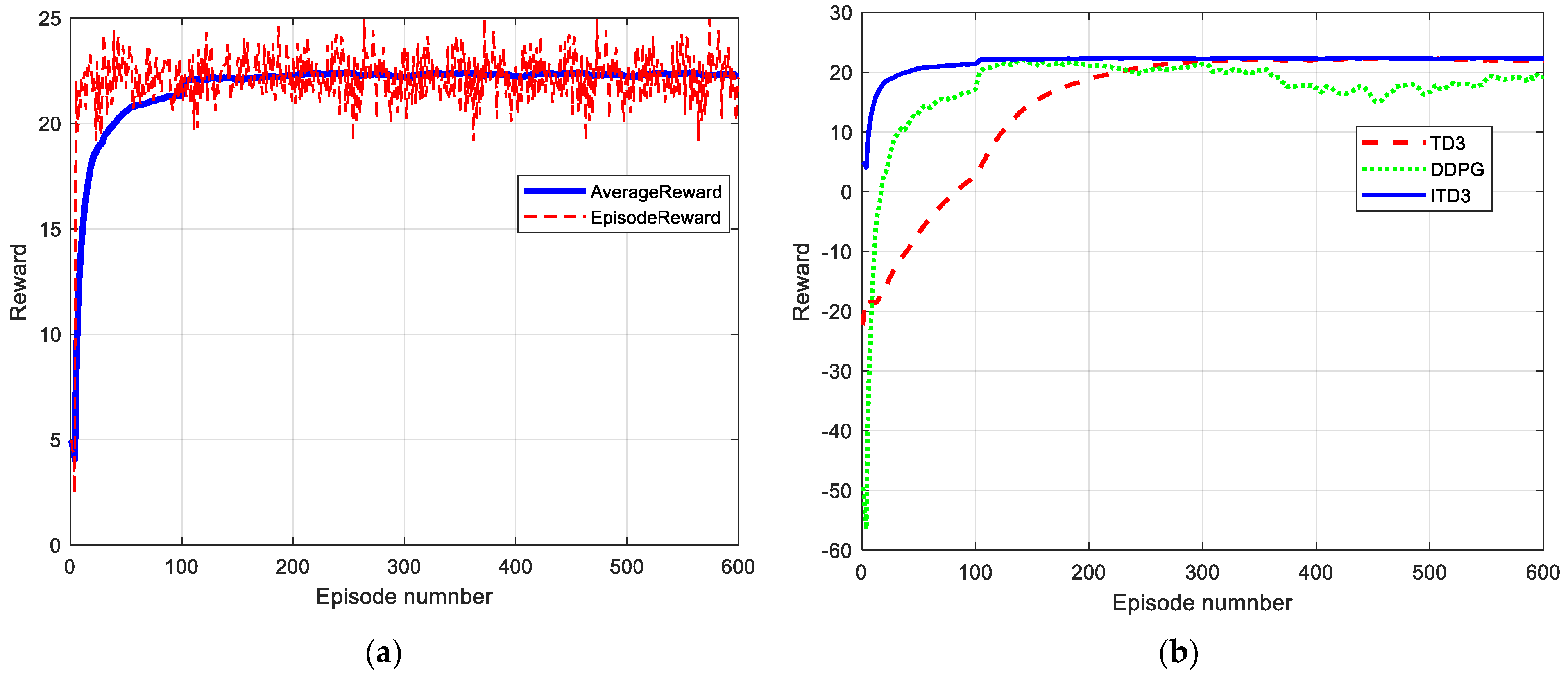
Figure 6a shows that as the number of training updates grows, the average reward and episode reward gradually rise. The agent continuously engages with the environment during the iterative training process to modify its approach to maximize reward values. As training rounds increase, the agent gradually finds the optimal maneuvering strategy. It can be seen that after nearly 100 rounds of training, the reward value curve converges to the highest point, which means that the agent ultimately gets the best solution to the HV’s PE game problem through continuous interaction with the environment. This indicates that the entire training process of the DRL algorithm designed in this study is stable and successful with good convergence.
Figure 6b shows that in contrast to the still fluctuating training process of the DDPG algorithm after 300 rounds, the TD3 and ITD3 algorithms, which have better performances, gradually approach a stable optimal solution through training and interaction. In the comparison between TD3 and ITD3 algorithms, due to the classified experience pool strategy, the convergence speed of ITD3 is better than the basic TD3′s speed that basic TD3 algorithm requires 300 rounds to converge to the stable state. In addition, the small batch sampling during the training process is adaptively adjusted according to the training rounds, which ensures that the ITD3 algorithm not only has good training speed, but also has good convergence stability, and the two curves nearly coincide after 300 rounds in
Figure 6b. Through comparison, it is verified that the experience pool classification strategy proposed in the study can effectively improve the speed of algorithm training and ensure training convergence.
After completing the agent training, we selected a strict head-on scenario for aircraft pursuit and evasion confrontation and conducted agent scenario testing. The simulation results are shown in
Figure 7:
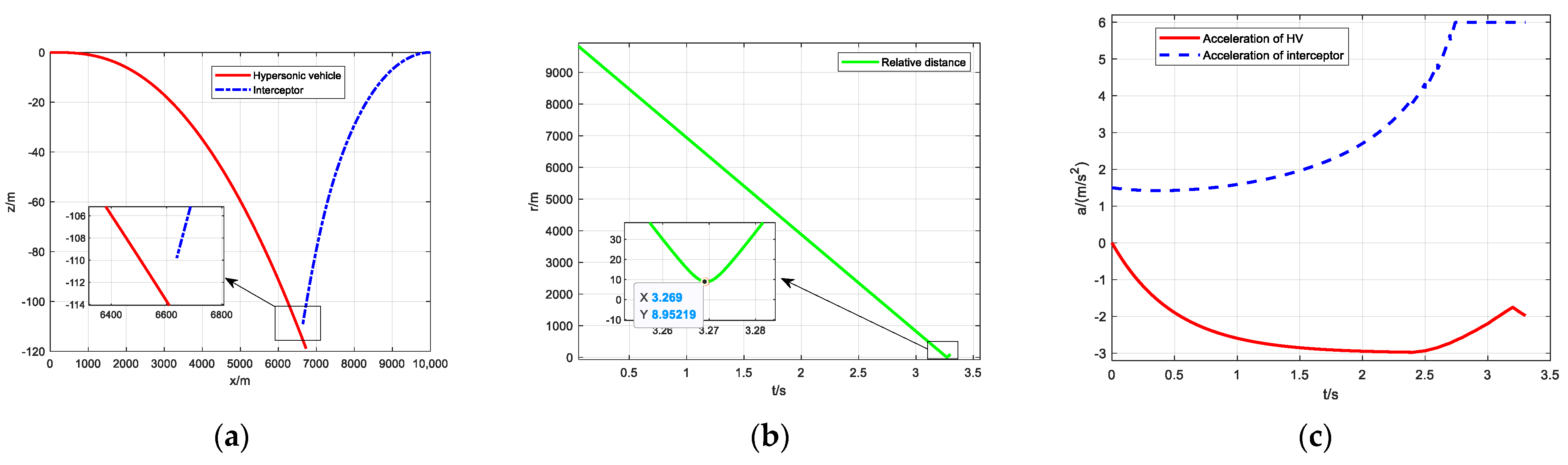
Figure 7.
Simulation results of DRL verifying: (a) two–dimensional planar trajectory map; (b) relative distance curve; (c) overload change curve.
Figure 7.
Simulation results of DRL verifying: (a) two–dimensional planar trajectory map; (b) relative distance curve; (c) overload change curve.
Figure 7a shows the motion trajectories of the attacking and defending sides in a horizontal two-dimensional plane, and
Figure 7b shows the variation of their relative distance over time. Combining the two figures, it can be seen that both the attack and defense sides are initially in the strict head-on scenario. The interceptor is guided by the APN guidance law, and the HV uses an intelligent maneuver strategy obtained through reinforcement learning training to start game maneuvering. The minimum relative distance during the entire evasion process is 8.95219, which met the minimum miss distance requirement for evasion. It is judged that the HV successfully evaded in this scenario.
Figure 7c shows the overload changes between HV and interceptor. It can be seen that the interceptor, based on its guidance law, exerts the advantage of large maneuvers within the overload capacity range to intercept as much as possible, while HV also successfully achieves maneuver avoidance based on intelligent games within the overload capacity range. This indicates that the selected state space, action space, and designed reward and termination functions are all reasonable. In addition, HV’s overload does not always maintain full overload but decreases after 2.5 s, indicating that the intelligent agent is pursuing greater miss distance while also minimizing energy consumption, proving that the initial goal can be achieved through the designed reward function.
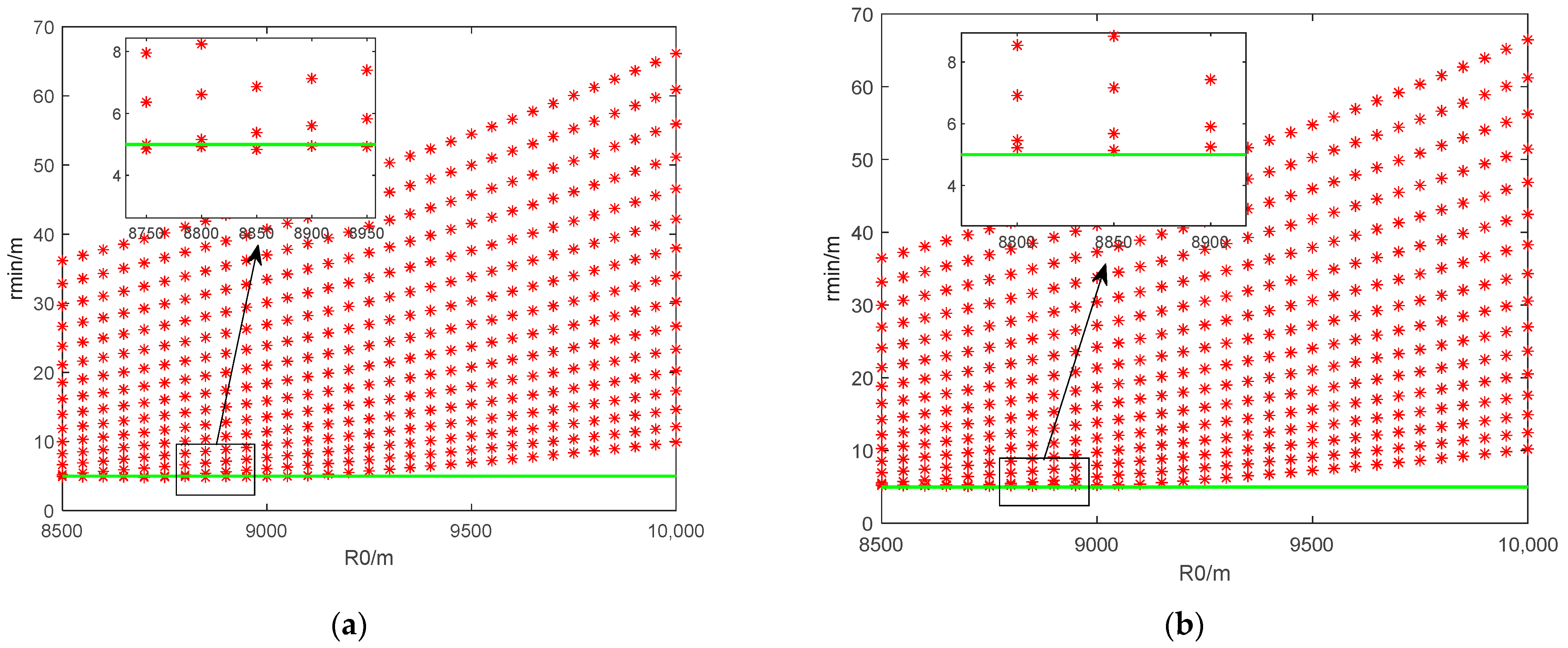
The agent trained through DRL can already achieve maneuvering evasion in the strict head-on scenario. However, to apply the strategy in more scenarios, we pull off the initial parameters under the premise of the approximate head-on scenarios, and select different initial parameters within the range of the initial line-of-sight angle [0°, 1.8°] and initial relative distance [8500, 10,000] for Monte Carlo simulations to collect the dataset full of successful samples. The available simulation results obtained are as follows:
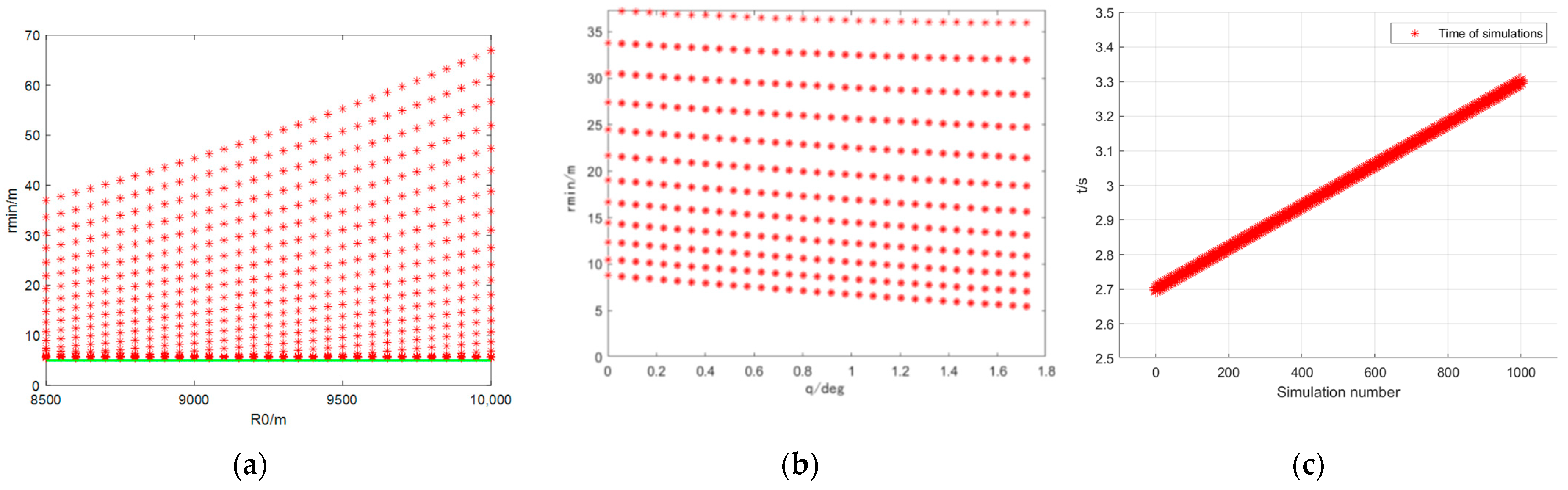
Figure 8.
Monte Carlo simulation biasing initial parameters: (a) miss distances at different initial distances; (b) miss distances at different initial line-of-sight angles; (c) time spent at different initial parameters.
Figure 8.
Monte Carlo simulation biasing initial parameters: (a) miss distances at different initial distances; (b) miss distances at different initial line-of-sight angles; (c) time spent at different initial parameters.
By the way, from
Figure 8c, it can be found that the reinforcement learning agent generates maneuver commands while interacting with the environment taking time between 2.7 s and 3.3 s. If applied to the airborne computer, the ability to generate evasion commands in real time is questionable. That also indicates that we need the intelligent evasion strategy can generate evasion commands only from the initial situation.
After the Monte Carlo simulation, input the selected maneuver data into DNNs for training to generate the intelligent evasion model. The training outcomes of the neural network are as follows:
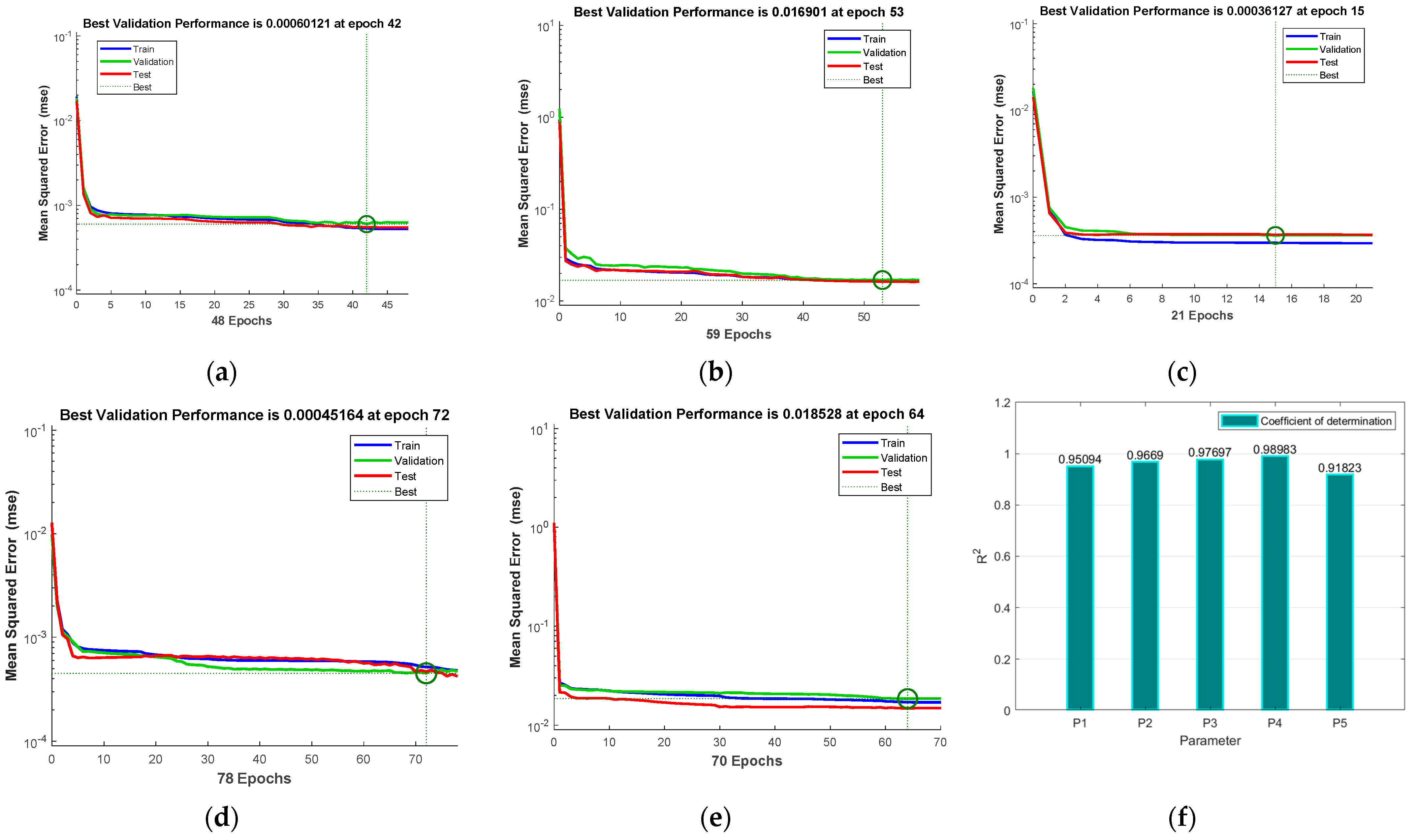
Figure 9.
Performance indicators of neural networks: (a–e) DNNs’ MSE values in different datasets; (f) DNNs’ determination coefficient values.
Figure 9.
Performance indicators of neural networks: (a–e) DNNs’ MSE values in different datasets; (f) DNNs’ determination coefficient values.
As the standard for evaluating network performance, the smaller the mean square error (MSE) value and the closer the determination coefficient (R
2) to 1, the better the accuracy of the sample data described by the prediction model.
Figure 9a–e show that the MSE values of the training set, validation set, and test set ultimately converge to minimum values close to 0.
Figure 9f shows the determination coefficient of the model, and the r-squared values of the five coefficients fitted by the model are all greater than 0.9. These two evaluation criteria demonstrate that the model has a good fitting performance.
To verify the generalization of intelligent evasion strategies, three extreme scenarios were selected for verification: strict head-on scenario, maximum initial line-of-sight angle situation, and minimum initial relative distance situation.
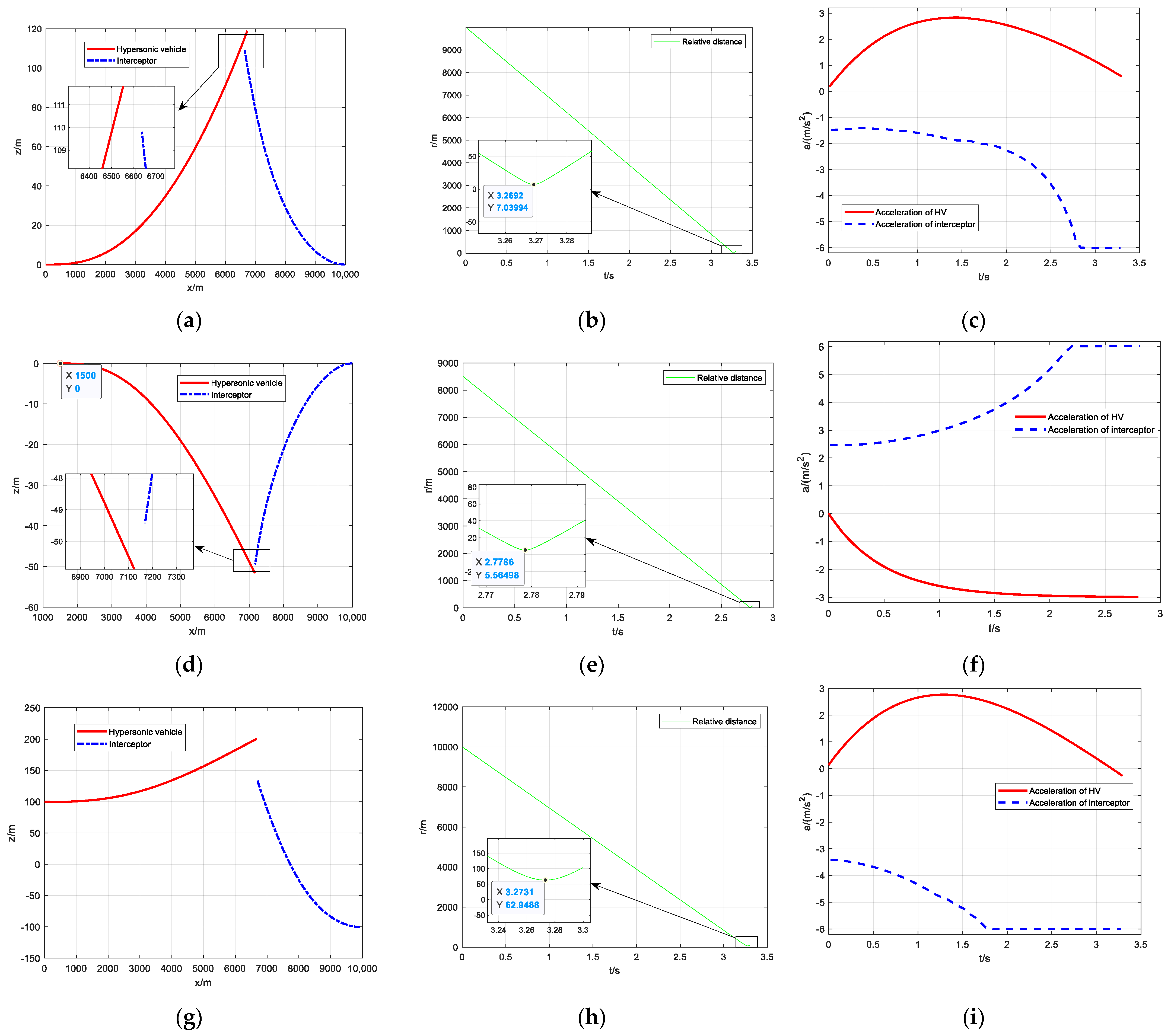
Figure 10.
Simulation results of intelligent maneuver strategy under three typical situations: (a,d,g) two−dimensional planar trajectory map; (b,e,h) relative distance curve; (c,f,i) overload change curve.
Figure 10.
Simulation results of intelligent maneuver strategy under three typical situations: (a,d,g) two−dimensional planar trajectory map; (b,e,h) relative distance curve; (c,f,i) overload change curve.
Figure 10a–c show the application of intelligent maneuver strategy for HV to achieve evasion under the strict head-on scenario. Compared with the previous reinforcement learning maneuvers, both of them can successfully evade, but as the price for improving reliability and generalization, the minimum relative distance under the intelligent maneuver strategy has been reduced by 1 m, which is caused by the relevant deviation in the parameter fitting process. In
Figure 10c, the overload curve of HV still takes into account both successful evasion and energy consumption. Therefore, the study believes that the performance of the intelligent evasion strategy is acceptable.
Figure 10d–f shows the evasion strategy at the minimum relative distance, which is also the most difficult initial situation considering the initial position of HV (1500, 0). From
Figure 10e, although HV has successfully evaded, the minimum relative distance is only 5.56498, which is just enough to meet the minimum miss distance. To successfully evade, HV directly chooses to fully inflate the overload, as shown in
Figure 10f.
Figure 10g–i shows the evasion strategy at the maximum initial line-of-sight angle under the approximate head-on situations we have determined. Due to deviating from the strict head-on scenario, HV can use speed advantage to achieve relatively easy evasion. From
Figure 10i, HV can significantly reduce overload and energy consumption.
Through the analysis of three typical characteristic scenarios, the study believes that the proposed intelligent maneuver strategy can generate maneuver overload with the effect of solving the PE game of HV in the head-on situation.
To further verify the improvement in terms of generalization, the combined dispersion and Monte Carlo simulation are conducted, respectively, on the proposed method based on ITD3 and DNN and the TD3 method under approximate head-on situations, with specific parameter ranges as above. And the simulation results are shown in the following
Figure 11.
As the initial situation changes, using the TD3 algorithm solely to evade under certain harsh initial situations may result in evasion failure, where the minimum relative distance is less than 5, as shown in
Figure 11a. Correspondingly, the proposed method by combining ITD3 and DNN algorithms utilizes successful sample fitting to replace failed cases, which can achieve successful evasion against interceptors in different initial situations under all difficult approximate head-on situations shown in
Figure 11b, greatly improving the generalization of maneuvering strategies. Through comparison, it is verified that the proposed method can handle more difficult situations, and the application scenarios of the intelligent maneuver strategy are further expanded.
In addition, the average time consumption would not exceed 1 ms after testing, and the DNN used during “online application” only occupies approximately 10 kB of storage space. The above analysis indicates that the intelligent maneuver strategy proposed in this study has less computational burden and can be executed on modern-borne computers.
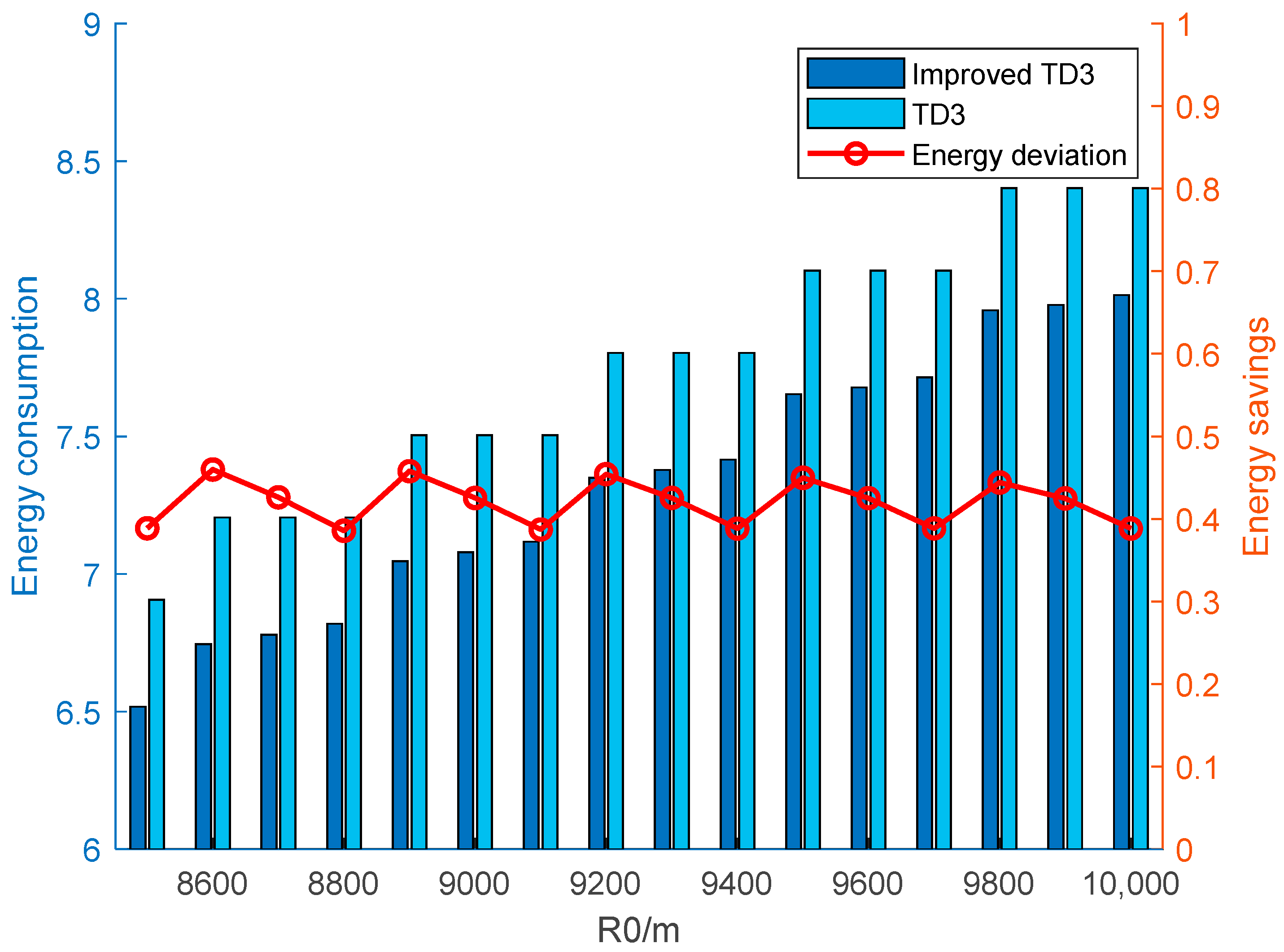
Finally, numerical simulations are conducted on the energy consumption issue. In the study, the accumulation of overload over time is utilized to represent the energy consumed, namely
. The energy consumptions of the proposed ITD3 method and the TD3 method in the maneuver evasion process are calculated for different initial relative distances. From
Figure 12, as the relative distance increases, the energy consumption of both methods increases, which is due to the longer maneuvering time. Regardless of the initial state, the energy consumption of the proposed ITD3 method is lower than that of the TD3 method, and the energy consumption difference between the two methods fluctuates between 0.4 and 0.5 g. That proves that the proposed method’s energy-saving design is effective, and the intelligent maneuvering strategy can effectively balance energy consumption and evasion miss distance, and adaptively adjust according to the initial states.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}