
A Conflict Resolution Strategy at a Taxiway Intersection by Combining a Monte Carlo Tree Search with Prior Knowledge

Abstract
:1. Introduction
2. Problem Formulation
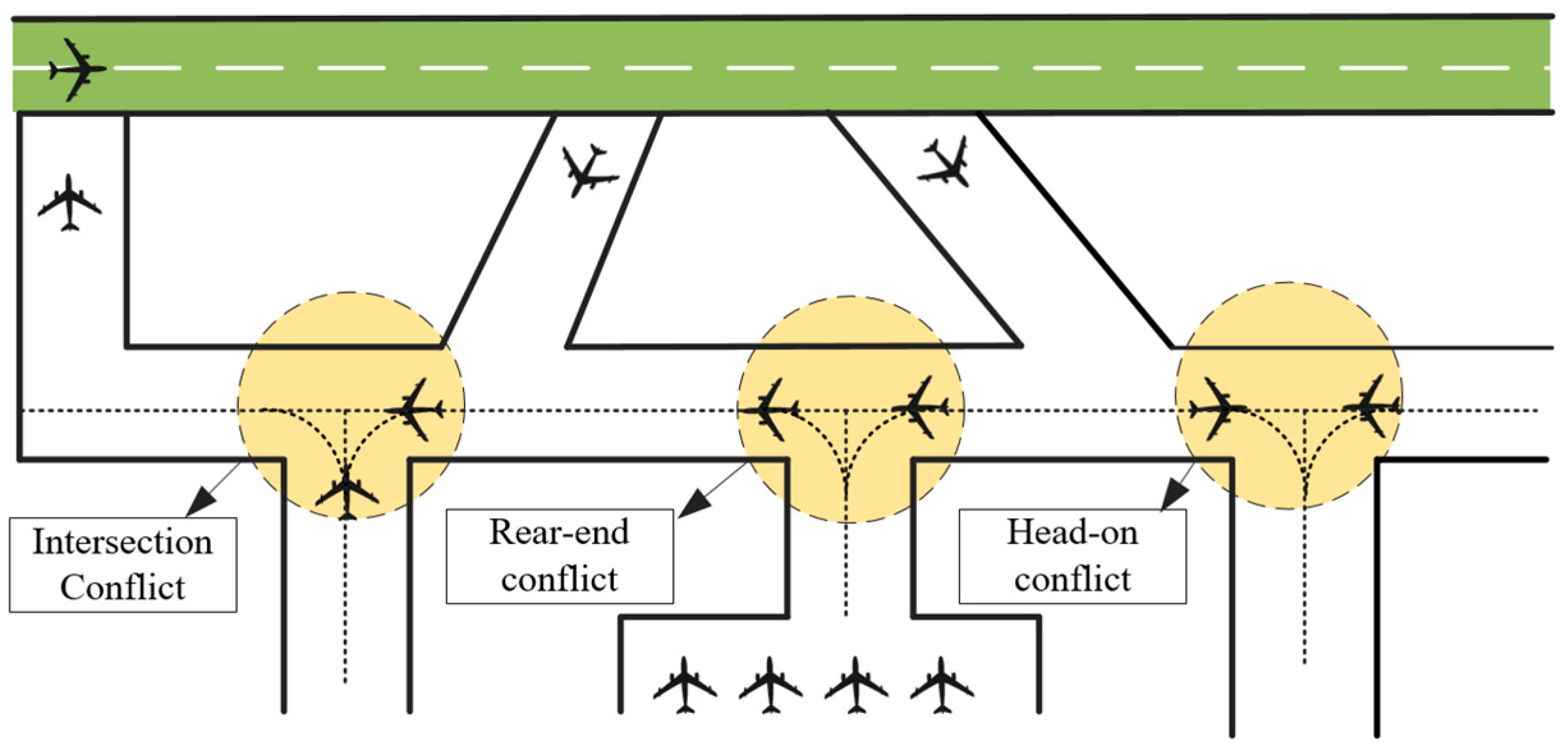
2.1. Problem Statement
2.2. MDP Formulation
- (1)
- The impact of weather and trajectory deviation is negligible, and the next position of the aircraft only depends on the current state and the commands received from the ATCOs.
- (2)
- The flight deck is equipped with a speed display and suggestion device; the time used for voice communication between the controller and the pilot as well as the response time of the aircraft operation are not considered.
- (3)
- The prioritization of the aircraft was not considered in the taxiing process.
- is a set of states that are possible in an environment (state space);
- is a set of actions available to perform in a state;
- is the probability that the action performed in the current state will lead to the next state ;
- is a reward for reaching the next state with action .
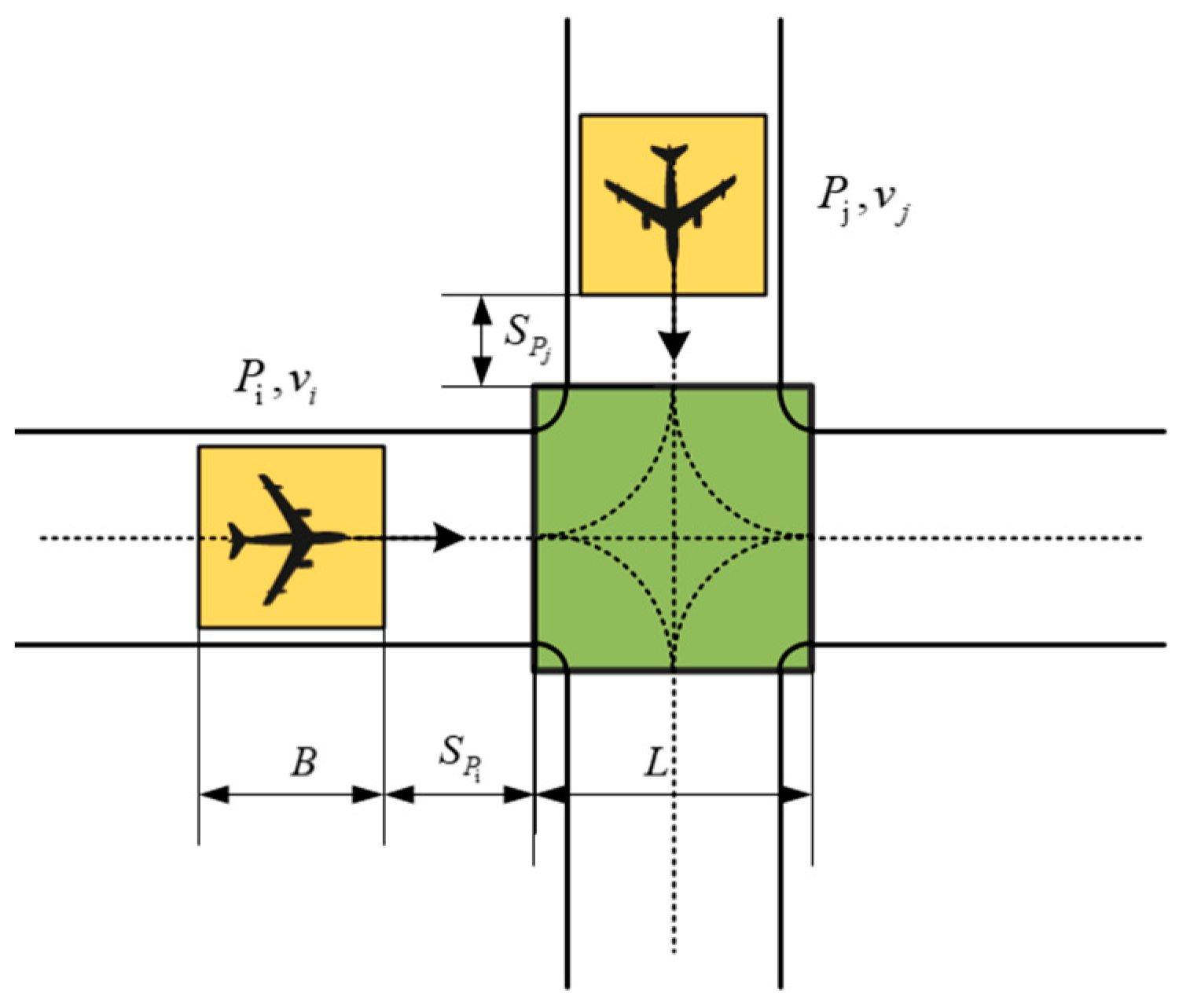
2.2.1. State Space
2.2.2. Action Space
2.2.3. State Transition
2.2.4. Reward Function
- When two aircrafts cannot maintain the non-conflict requirement, a conflict will ensue and the state will terminate instantaneously;
- When both aircrafts cross the intersection safely, it is regarded as the success state and it will terminate this process.
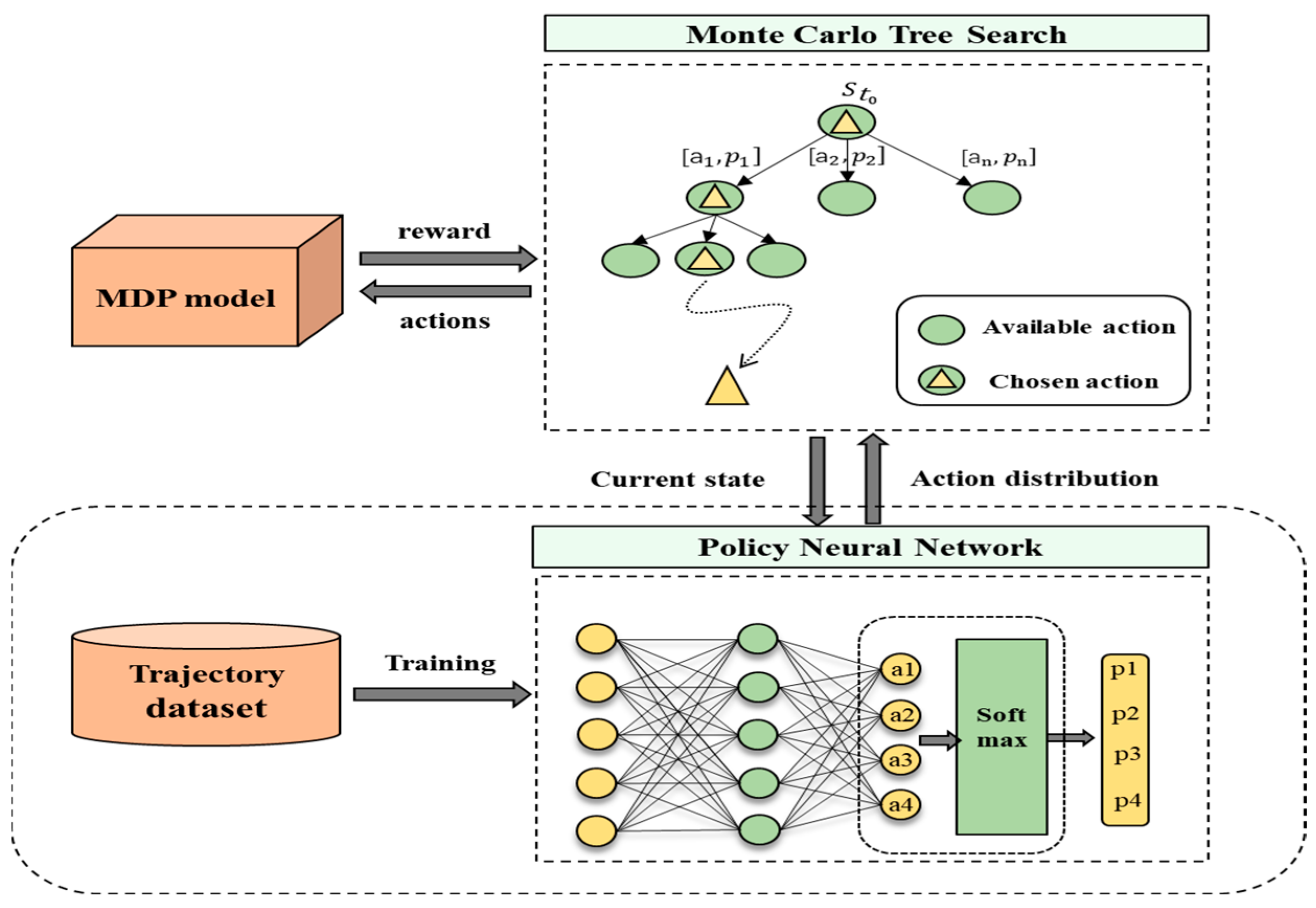
3. Methodology
- The MDP model updates the state and provides feedback to MCTS;
- MCTS is the main search component of the agent, used as an online MDP solver to generate optimal decisions;
- The policy neural network will be pre-trained based on the historical taxiing trajectory and takes the “current state” explored using the MCTS as inputs and gives out “action distribution” as outputs to guide MCTS.
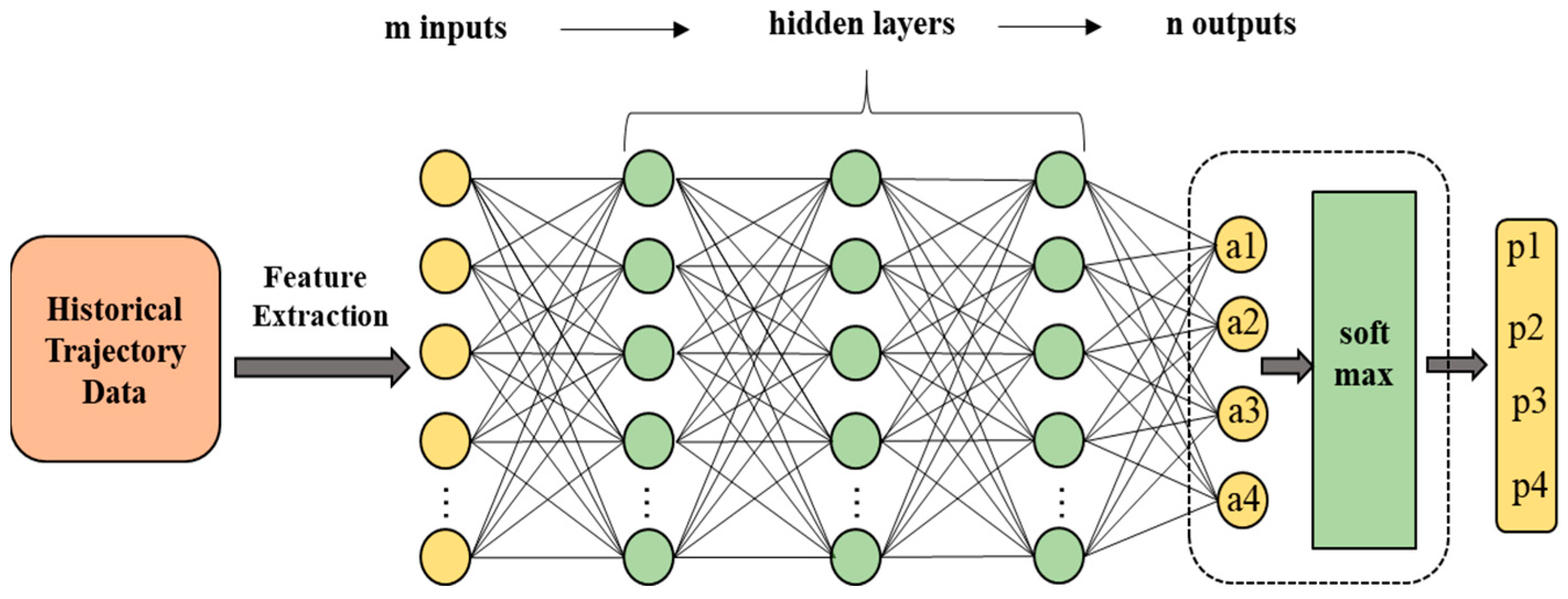
3.1. Policy Neural Network
- The taxiing trajectory data of each flight are preprocessed to eliminate singular points, match the taxiway map of the airport and obtain the actual path of every flight during taxiing.
- Identify flights that encounter stop-and-go situations during the taxiing process, and confirm the intersection position where the flight is located when waiting, as well as the start time of the waiting.
- Find out other flights passing through the same intersection, compare their time difference and determine the collision aircraft set.
- Extract the feature information of the conflict scene when the aircraft began to wait, including the aircraft’s own flight number, model, speed, position and heading, as well as the center position of the intersection. Additionally, categorize the waiting time of the conflict aircraft into four intervals: 5 s, 10 s, 15 s and 20 s.
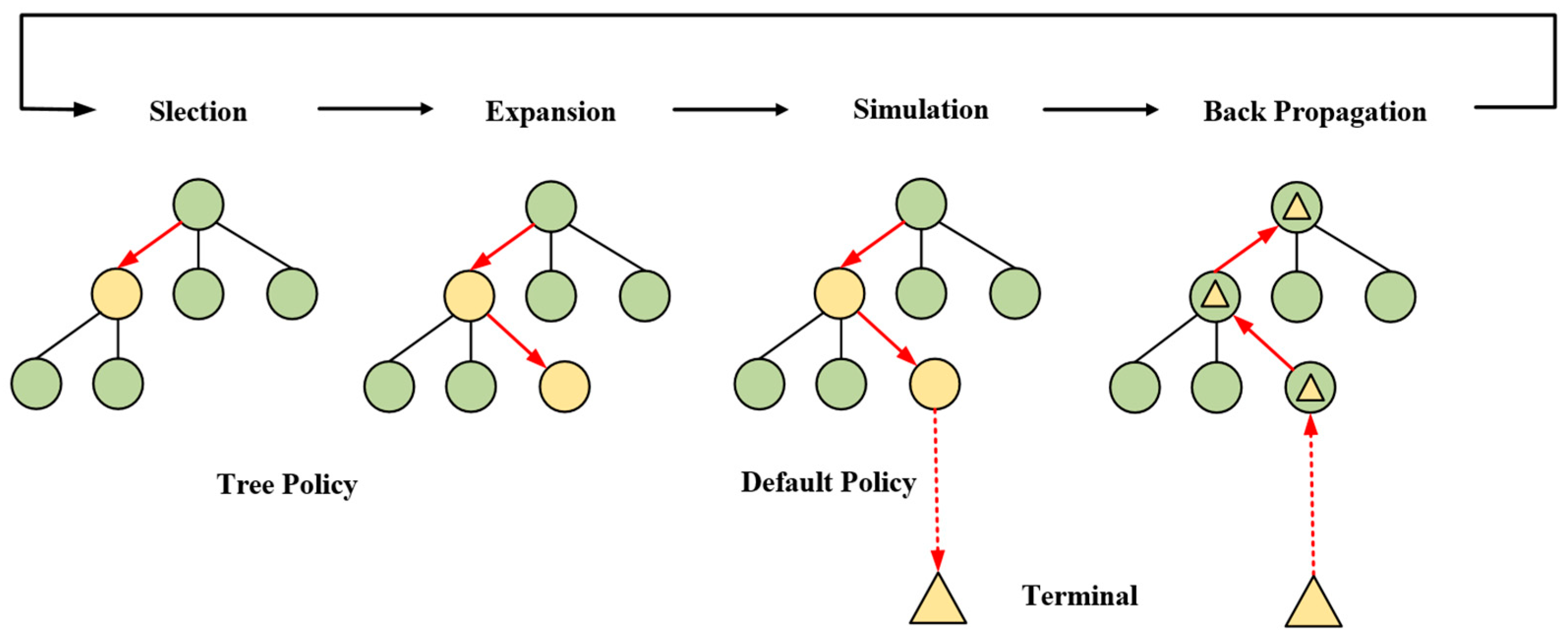
3.2. MCTS Combined with PNN
- (1)
- Selection: Starting from the root node, traverse down the child nodes already stored in the tree, and choose the most promising node to explore using the predefined tree policy. At this stage, the tree policy should ensure an appropriate balance between exploitation (selecting nodes with high rewards) and exploration (selecting nodes that have not been chosen before). Classic Upper Confidence Bounds applied to Trees (UCTs) are introduced to specifically handle the exploitation–exploration problem. Each node has an associated UCT value, and during selection, it always chooses the child node with the highest value [31]. We integrate PNN into MCTS and modify the UCT formula. The improved UCT formula is as follows:
- (2)
- Expand: It occurs when the current selected node is a non-terminal state and has not been visited before. In this case, at least one new child node can be added to the current tree under its parent node (the previous state). The specific expanding operation relies on PNN and the action set. During each expansion step, the state of the leaf node is processed through the PNN to derive a probability distribution of all possible child nodes. This distribution is subsequently used to determine the UCT value of the node during the action selection phase. Since the PNN only provides the action evaluation for waiting time, the expansion of nodes is divided into two situations. When the aircraft’s speed drops to 0, signaling its transition into a holding state, the PNN processes the current node to ascertain the waiting time action and its corresponding probability (P ≤ 1). Simultaneously, the probability of speed actions is uniformly set to 1 (P = 1), discouraging an aircraft from coming to a halt in the conflict area. Conversely, the node will not be put into PNN for evaluation and the child nodes are only created with a set of speed actions.
- (3)
- Simulation: After adding the new nodes to the tree, a node is randomly selected following a default policy for simulation, which generates a new state. The simulation continues in the new state using the random policy until reaching a terminal state with a final reward. In the context of this paper, the aircraft taxiing process is simulated using the aircraft kinematics model, the terminal state of MDP formulation is used to determine if the simulation process has ended and the final reward value is calculated based on the reward function.
- (4)
- Backpropagation: When simulating the whole process to a terminal state, the evaluation value will be retroactively propagated to all nodes along the path. This process involves updating the visit count and action value of each node. Specifically, the visit count of each node increases by 1, and the average reward value of the node is computed based on the final reward during the simulation and the number of visits accumulated. These updated parameters are then utilized to calculate and update the UCT value of each node.
4. Experiment
4.1. Experimental Setup
4.2. Experiment Results
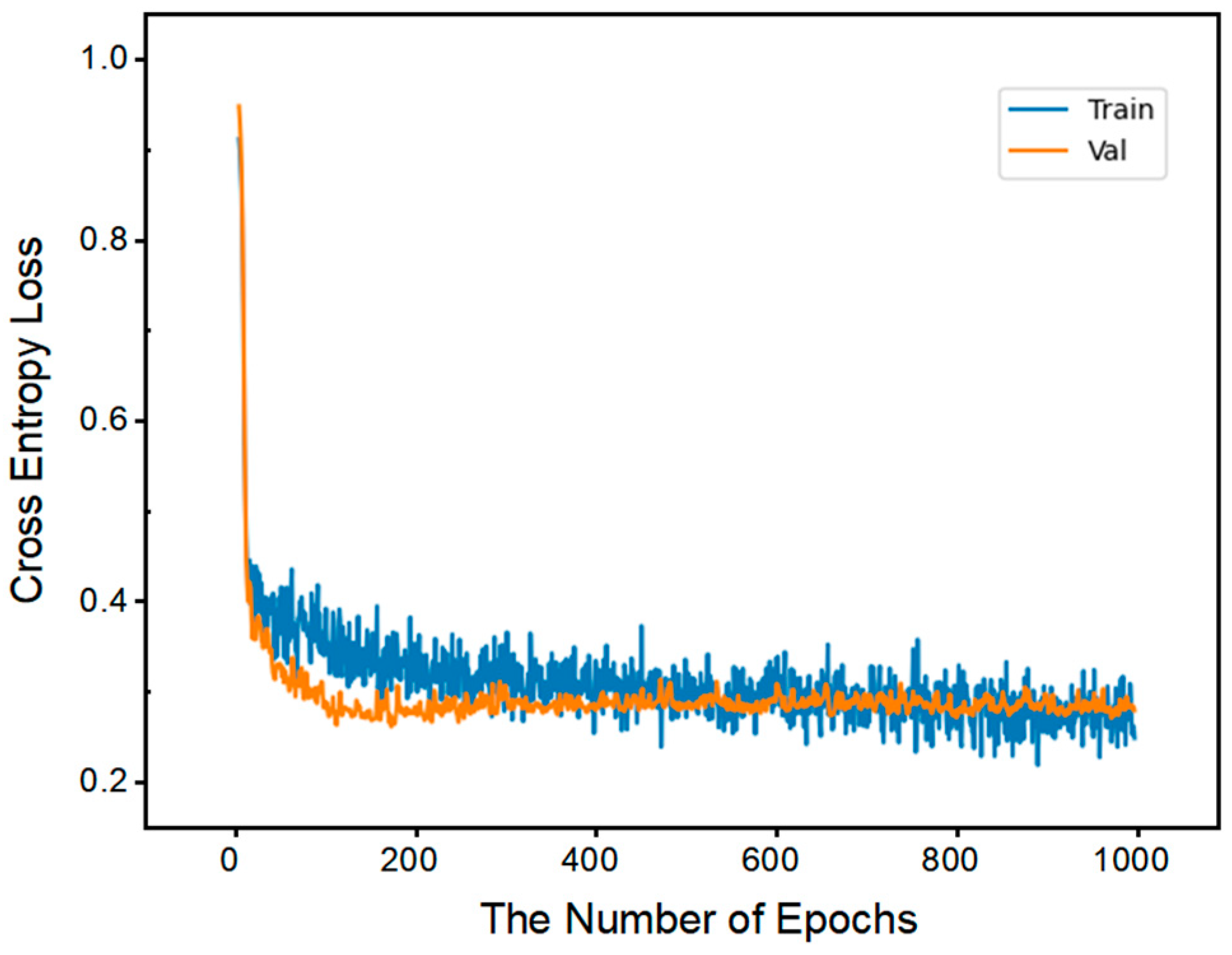
4.2.1. Training Results of PNN
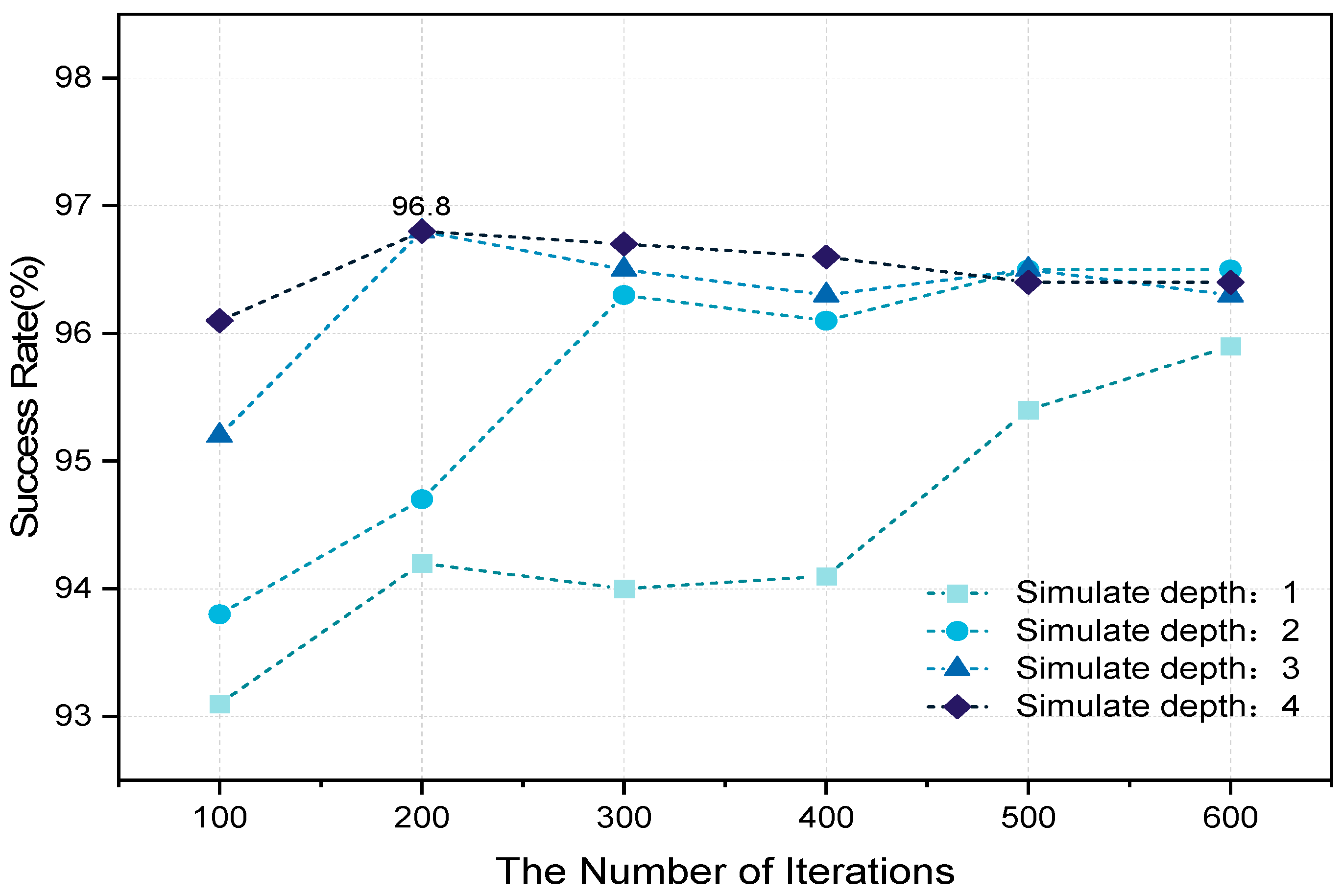
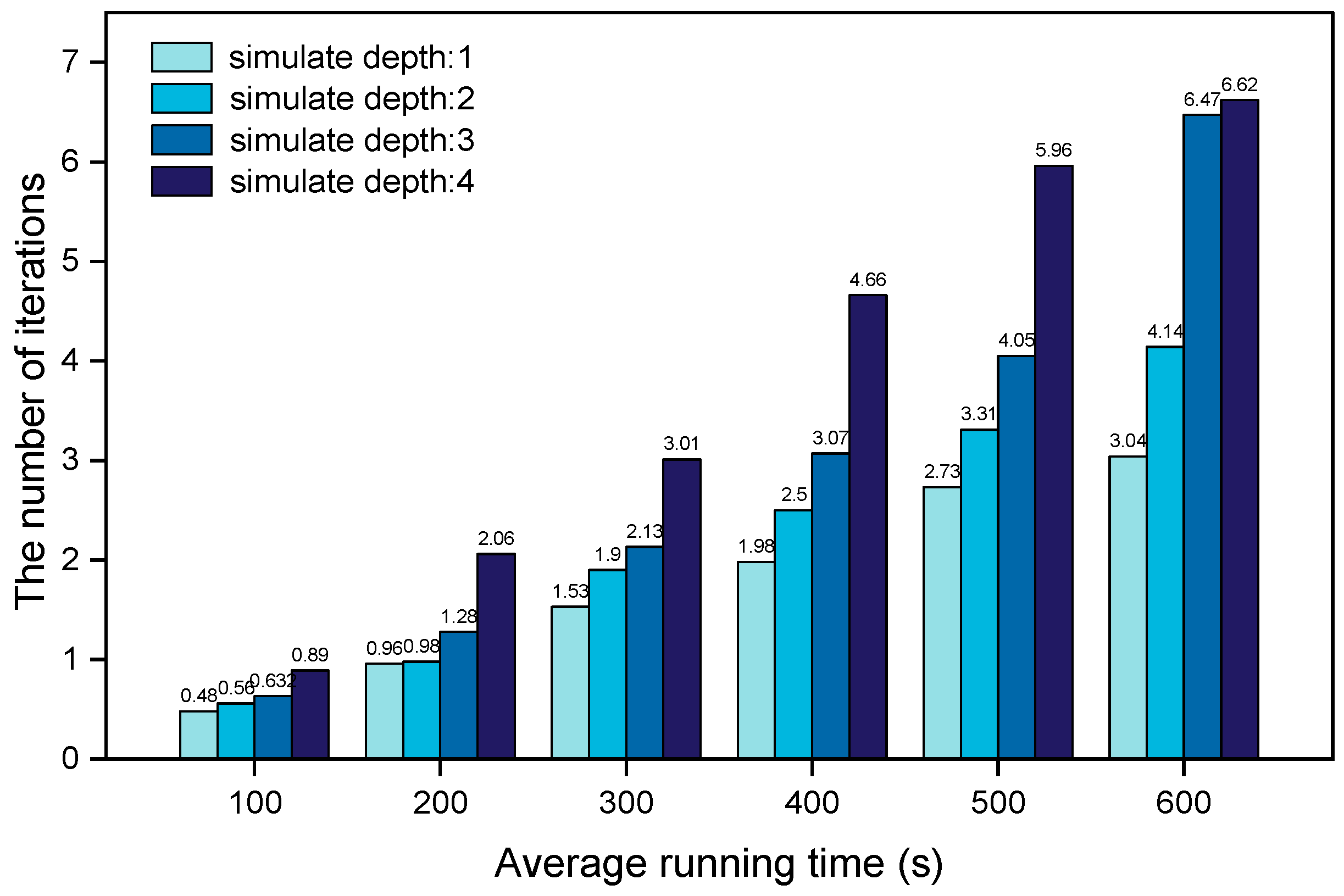
4.2.2. Performance of MCTS Combined with PNN
- (1)
- Parameter Settings
- (2)
- Evaluation metrics
- (3)
- Result analysis
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- IATA 2020 Air Passenger Numbers to Recover in 2024. Available online: https://www.iata.org/en/pressroom/2022-releases/2022-03-01-01/ (accessed on 30 September 2022).
- Vaddi, V.; Cheng, V.; Kwan, J.; Wiraatmadja, S.; Lozito, S.; Jung, Y. Air-ground integrated concept for surface conflict detection and resolution. In Proceedings of the 12th AIAA Aviation Technology, Integration, and Operations (ATIO) Conference and 14th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Indianapolis, Indiana, 17–19 September 2012; p. 5645. [Google Scholar]
- Yazgan, E.; Erdi, S.E.R.T.; ŞİMŞEK, D. Overview of studies on the cognitive workload of the air traffic controller. Int. J. Aviat. Sci. Technol. 2021, 2, 28–36. [Google Scholar] [CrossRef]
- IBCA-2019-03; Research and Practice Report on Smart Airport Development. Department of Airports, Civil Aviation Administration of China: Beijing, China, 2019.
- National Airspace System (NAS) Subsystem Level Specification for Airport Surface Detection Equipment—Model X (ASDE-X), FAA-E-2942, Version 1.1; Department of Transportation, Federal Aviation Administration: Washington, DC, USA, 2001.
- Scardina, J. Overview of the FAA ADS-B Link Decision, Office of System Architecture and Investment Analysis; Federal Aviation Administration: Washington, DC, USA, 2002. [Google Scholar]
- ICAO. Advanced Surface Movement Guidance and Control Systems (A-SMGCS) Manual; International Civil Aviation Organization: Montreal, QC, Canada, 2004. [Google Scholar]
- Vaddi, V.; Sweriduk, G.; Cheng, V.; Kwan, J.; Lin, V.; Nguyen, J. Concept and Requirements for Airport Surface Conflict Detection and Resolution. In Proceedings of the 11th AIAA Aviation Technology, Integration, and Operations (ATIO) Conference, including the AIAA Balloon Systems Conference and 19th AIAA Lighter-Than, Virginia Beach, VA, USA, 20–22 September 2011; p. 7050. [Google Scholar]
- Evertse, C.; Visser, H.G. Real-time airport surface movement planning: Minimizing aircraft emissions. Transp. Res. Part C Emerg. Technol. 2017, 79, 224–241. [Google Scholar] [CrossRef]
- Clare, G.; Richards, A.G. Optimization of Taxiway Routing and Runway Scheduling. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1000–1013. [Google Scholar] [CrossRef]
- Beke, L.; Uribe, L.; Lara, A.; Coello CA, C.; Weiszer, M.; Burke, E.K.; Chen, J. Routing and Scheduling in Multigraphs with Time Constraints-A Memetic Approach for Airport Ground Movement. IEEE Trans. Evol. Comput. 2023, 1. [Google Scholar] [CrossRef]
- Weiszer, M.; Burke, E.K.; Chen, J. Multi-objective routing and scheduling for airport ground movement. Transp. Res. Part C Emerg. Technol. 2020, 119, 102734. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, J.; Liang, M.; Delahaye, D. Data-driven trajectory-based analysis and optimization of airport surface movement. Transp. Res. Part C Emerg. Technol. 2022, 145, 103902. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, W. Taxiing Speed Intelligent Management of Aircraft Based on DQN for A-SMGCS. J. Phys. Conf. Ser. 2019, 1345, 042015. [Google Scholar] [CrossRef]
- Tien, S.L.; Tang, H.; Kirk, D.; Vargo, E. Deep Reinforcement Learning Applied to Airport Surface Movement Planning. In Proceedings of the 2019 IEEE/AIAA 38th Digital Avionics Systems Conference (DASC), San Diego, CA, USA, 8–12 September 2019; pp. 1–8. [Google Scholar]
- Ali, H.; Pham, D.T.; Alam, S. A Deep Reinforcement Learning Approach for Airport Departure Metering Under Spatial–Temporal Airside Interactions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23933–23950. [Google Scholar] [CrossRef]
- Zhao, N.; Li, N.; Sun, Y.; Zhang, L. Research on Aircraft Surface Taxi Path Planning and Conflict Detection and Resolution. J. Adv. Transp. 2021, 2021, 9951206. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, Z.; Hu, Z. A Priority-Based Conflict Resolution Strategy for Airport Surface Traffic Considering Suboptimal Alternative Paths. IEEE Access 2020, 9, 606–617. [Google Scholar] [CrossRef]
- Zhou, H.; Jiang, X. Research on Taxiway Path Optimization based on Conflict Detection. PLoS ONE 2015, 10, e0134522. [Google Scholar]
- Bode, S.; Feuerle, T.; Hecker, P. Local conflict resolution for automated taxi operations. In Proceedings of the 1st International Conference on Application and Theory of Automation in Command and Control Systems, Barcelona, Spain, 26–27 May 2011; pp. 60–67. [Google Scholar]
- Smeltink, J.W.; Soomer, M. An Optimisation Model for Airport Taxi Scheduling. Inf. J. Comput. Oper. Res. 2004, 11, 1. [Google Scholar]
- Luo, X.; Tang, Y.; Wu, H.; He, D. Real-time adjustment strategy for conflict-free taxiing route of A-SMGCS aircraft on airport surface. In Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015; pp. 929–934. [Google Scholar]
- Zhu, X.P.; Lu, N. Airport Taxiway Head-on Conflict Prediction and Avoidance in ASMGCS. Appl. Mech. Mater. 2014, 574, 621–627. [Google Scholar] [CrossRef]
- Bastas, A.; Vouros, G. Data-driven prediction of Air Traffic Controllers reactions to resolving conflicts. Inf. Sci. 2022, 613, 763–785. [Google Scholar] [CrossRef]
- Duggal, V.; Tran, T.N.; Alam, S. Modelling Aircraft Priority Assignment by Air Traffic Controllers During Taxiing Conflicts Using Machine Learning. In Proceedings of the 2022 Winter Simulation Conference (WSC), Singapore, 11–14 December 2022; pp. 394–405. [Google Scholar]
- Pham, D.T.; Tran, T.N.; Alam, S.; Duong, V.N. A Generative Adversarial Imitation Learning Approach for Realistic Aircraft Taxi-Speed Modeling. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2509–2522. [Google Scholar] [CrossRef]
- Lizotte, D.J.; Laber, E.B. Multi-objective Markov decision processes for data-driven decision support. J. Mach. Learn. Res. 2016, 17, 7378–7405. [Google Scholar]
- Browne, C.B.; Powley, E.; Whitehouse, D. A survey of Monte Carlo tree search methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Świechowski, M.; Godlewski, K.; Sawicki, B.; Mańdziuk, J. Monte Carlo Tree Search: A review of recent modifications and applications. Artif. Intell. Rev. 2022, 56, 2497–2562. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484. [Google Scholar] [CrossRef]
- Kocsis, L.; Szepesvári, C. Bandit based Monte Carlo planning. Machine Learning: ECML 2006. In Proceedings of the 17th European Conference on Machine Learning, Berlin, Germany, 18–22 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 282–293. [Google Scholar]
- 737/600/700/800/900 Flight Crew Training Manual. Available online: https://pdf4pro.com/view/737-600-700-800-900-flight-crew-training-manual-6f7587.html (accessed on 1 April 1999).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Parameters | Parameters’ Value |
|---|---|
| Number of layers in the network | 5 |
| Number of nodes in each layer | (9, 9, 9, 9, 4) |
| Activation function | Relu |
| Loss function | Cross Entropy |
| Number of training epochs | 1000 |
| Network optimizer | Adam |
| Batch size | 32 |
| Learning rate | 1 × 10−³ |
| Algorithm Parameters | Parameters’ Value |
|---|---|
| Number of iterations | (100, 200, 300, 400, 500, 600) |
| Number of search depths | (1, 2, 3, 4) |
| ATD% | D = 1 | D = 2 | D = 3 | D = 5 |
|---|---|---|---|---|
| N = 100 | 45.62% | 43.91% | 42.5% | 36.24% |
| N = 200 | 47.83% | 45.84% | 42.77% | 36.36% |
| N = 300 | 46.02% | 42.82% | 39.7% | 33.21% |
| N = 400 | 43.9% | 41.43% | 37.19% | 31.48% |
| N = 500 | 42.12% | 39.08% | 35.35% | 29.17% |
| N = 600 | 41.85% | 39.11% | 35.23% | 29.98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sui, D.; Chen, H.; Zhou, T. A Conflict Resolution Strategy at a Taxiway Intersection by Combining a Monte Carlo Tree Search with Prior Knowledge. Aerospace 2023, 10, 914. https://doi.org/10.3390/aerospace10110914
Sui D, Chen H, Zhou T. A Conflict Resolution Strategy at a Taxiway Intersection by Combining a Monte Carlo Tree Search with Prior Knowledge. Aerospace. 2023; 10(11):914. https://doi.org/10.3390/aerospace10110914
Chicago/Turabian StyleSui, Dong, Hanping Chen, and Tingting Zhou. 2023. "A Conflict Resolution Strategy at a Taxiway Intersection by Combining a Monte Carlo Tree Search with Prior Knowledge" Aerospace 10, no. 11: 914. https://doi.org/10.3390/aerospace10110914
APA StyleSui, D., Chen, H., & Zhou, T. (2023). A Conflict Resolution Strategy at a Taxiway Intersection by Combining a Monte Carlo Tree Search with Prior Knowledge. Aerospace, 10(11), 914. https://doi.org/10.3390/aerospace10110914