
Estimating the Competitive Storage Model with Stochastic Trends in Commodity Prices


Abstract
1. Introduction
2. Storage Model
2.1. State-Space Formulation with a Stochastic Trend
2.2. Stochastic Trends and Storage Decisions
3. Statistical Inference
3.1. Preliminaries and Prior Selection
3.2. Bayesian Inference Using Particle Markov Chain Monte Carlo
3.3. State Prediction for Diagnostics and Marginal Likelihood
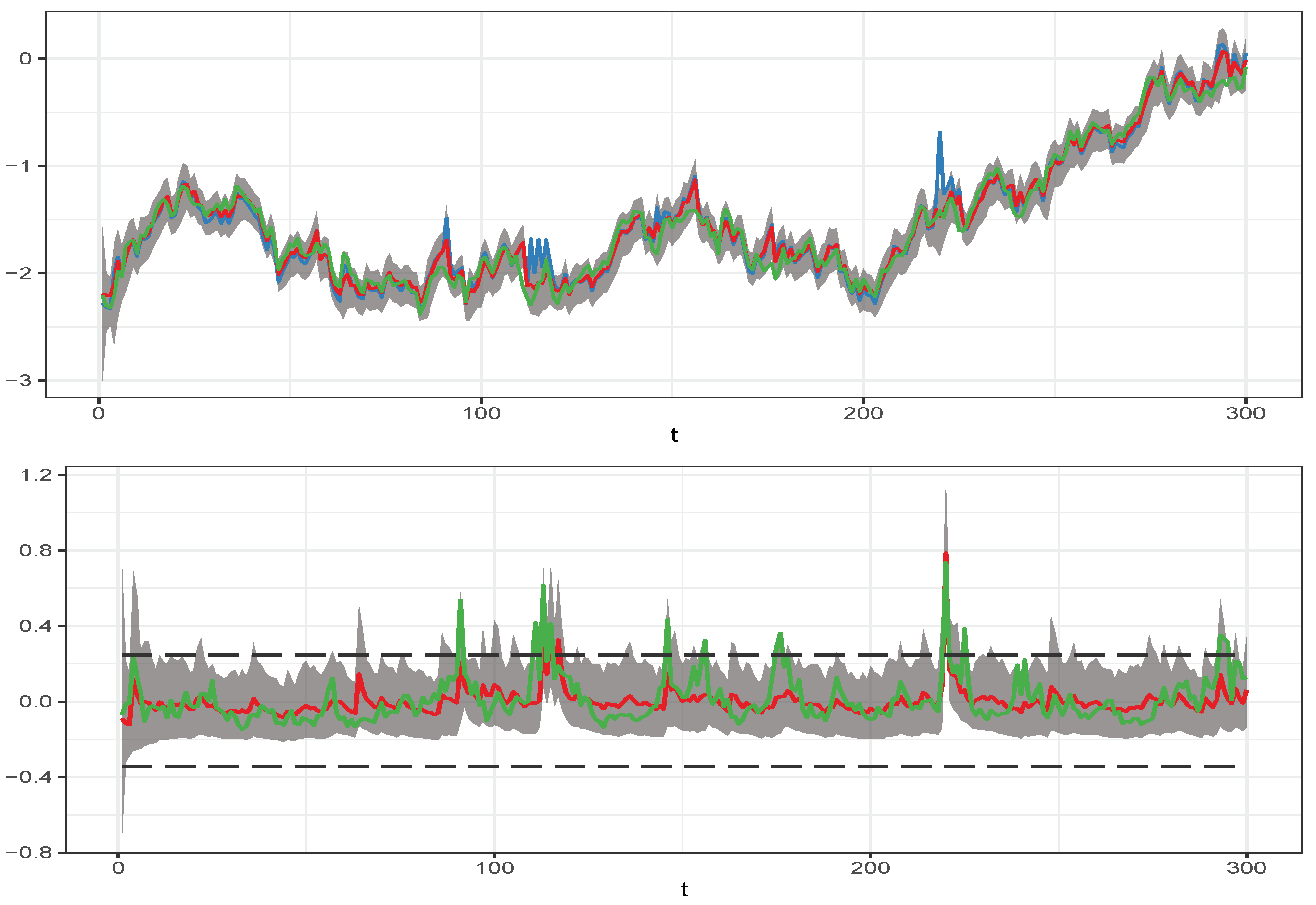
4. Ability to Isolate the Trend and Storage Model Component
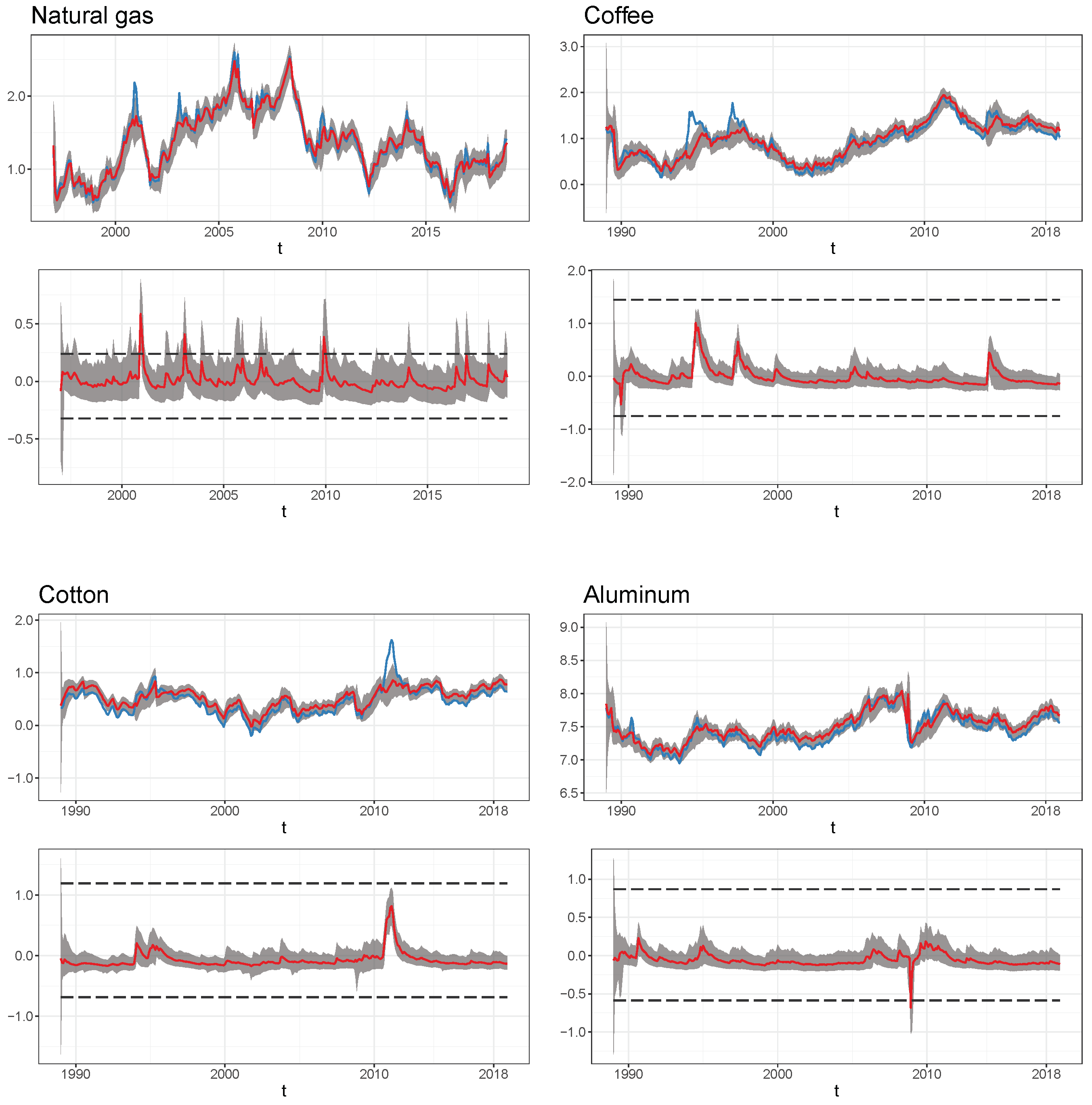
5. Empirical Application
5.1. Estimation Results for the Storage SSM with a Stochastic Trend
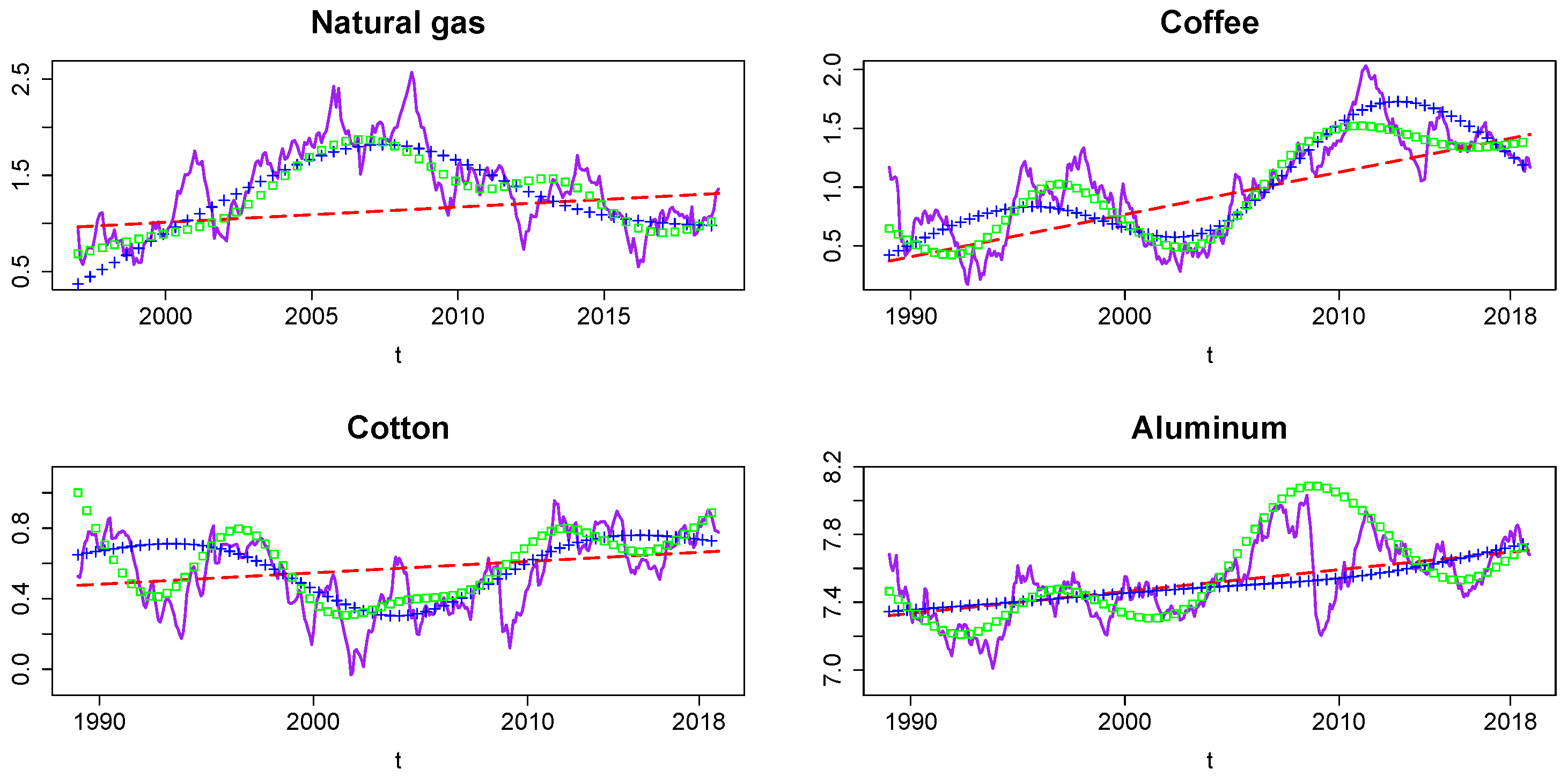
5.2. Model Comparisons
5.2.1. Alternative Models
5.2.2. Marginal Likelihood Model Comparisons and Diagnostics Checks
5.2.3. Estimates for Annual Storage Costs and Price Elasticity of Demand
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Numerical Solution of the Price Function
- Select an initial guess, e.g., , where is the linear function such that , . Set ;
- Update the left kink point according to:
- Update the right kink point according to:
- Update the grid to be on
- For each grid point j, find the update as the solution in s to:using a univariate nonlinear root-finding algorithm. Notice that the solution is constrained to be in and that , ;
- Until convergence, set and go back to Step 2.
Appendix B. Computational Details for Statistical Inference
Appendix B.1. Particle Filter
- For period (initialization): Sample for , and set the corresponding (normalized) IS weights to . For initialization, set ;
- For periods : Sample for , and set . Compute the IS weights as:and their normalized versions . Then use the IS weights to obtain the period-t likelihood contribution as , and compute the effective particle sample size defined by . If , resample from the particles with replacement according to their IS weights to obtain the resampled particles , and set their weights to . Otherwise, set .
Appendix B.2. Marginal Likelihood
Appendix B.3. Residuals for the Deterministic Trend Models
Appendix C. Additional Results

{kind=link}
{kind=link}
{kind=link}
| C | Natgas | Coffee | Cotton | Aluminum |
|---|---|---|---|---|
| 10 | 164.13 | 420.07 | 522.80 | 545.36 |
| 15 | 163.89 | 425.93 | 530.93 | 549.77 |
| 20 | 163.68 | 429.32 | 536.81 | 553.16 |
| 25 | 163.57 | 431.10 | 539.89 | 555.41 |
| Natgas | Coffee | Cotton | Aluminum | |||
|---|---|---|---|---|---|---|
| Linear | Post. mean | 0.0110 | 0.0041 | 0.0009 | 0.0046 | |
| Post. std. | 0.0051 | 0.0049 | 0.0007 | 0.0026 | ||
| RCS3 | Post. mean | 0.0073 | 0.0023 | 0.0009 | 0.0037 | |
| Post. std. | 0.0040 | 0.0014 | 0.0007 | 0.0021 | ||
| RCS7 | Post. mean | 0.0087 | 0.0055 | 0.0034 | 0.0015 | |
| Post. std. | 0.0080 | 0.0021 | 0.0007 | 0.0010 | ||
| b | Linear | Post. mean | 4.85 | 4.18 | 3.56 | 2.09 |
| Post. std. | 0.200 | 0.282 | 0.153 | 0.106 | ||
| RCS3 | Post. mean | 3.18 | 4.37 | 3.62 | 3.25 | |
| Post. std. | 0.164 | 0.190 | 0.154 | 0.172 | ||
| RCS7 | Post. mean | 5.99 | 4.04 | 3.64 | 2.11 | |
| Post. std. | 0.920 | 0.316 | 0.163 | 0.095 |
| 1 | The knots for the RCS3 specification are located at the 25%, 50%, and 75% quantiles of the time index and for the RCS7 at the 12.5%, 25%, 37.5%, 50%, 67.5%, 75%, and 87.5% quantiles. |
| 2 | The smoothed mean was computed using the particle smoothing algorithm, which adds to the BPF, as outlined in Appendix B.1, a backward sampling step (Doucet and Johansen 2009, Section 5). |
References
- Andrieu, Christophe, Arnaud Doucet, and Roman Holenstein. 2010. Particle markov chain monte carlo methods. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 72: 269–342. [Google Scholar] [CrossRef]
- Bobenrieth, Eugenio, Brian Wright, and Di Zeng. 2013. Stocks-to-use ratios and prices as indicators of vulnerability to spikes in global cereal markets. Agricultural Economics 44: 43–52. [Google Scholar] [CrossRef]
- Bos, Charles S., and Neil Shephard. 2006. Inference for adaptive time series models: Stochastic volatility and conditionally gaussian state space form. Econometric Reviews 25: 219–44. [Google Scholar] [CrossRef]
- Cafiero, Carlo, Eugenio Bobenrieth, and Juan Bobenrieth. 2011. Storage arbitrage and commodity price volatility. In Safeguarding Food Security in Volatile Global Markets. Rome: Food and Agriculture Organization of the United Nations (FAO), pp. 288–326. [Google Scholar]
- Cafiero, Carlo, Eugenio Bobenrieth, Juan Bobenrieth, and Brian D. Wright. 2011. The empirical relevance of the competitive storage model. Journal of Econometrics 162: 44–54. [Google Scholar] [CrossRef]
- Cafiero, Carlo, Eugenio Bobenrieth, Juan Bobenrieth, and Brian D. Wright. 2015. Maximum likelihood estimation of the standard commodity storage model: Evidence from sugar prices. American Journal of Agricultural Economics 97: 122–36. [Google Scholar] [CrossRef]
- Canova, Fabio. 2014. Bridging dsge models and the raw data. Journal of Monetary Economics 67: 1–15. [Google Scholar] [CrossRef]
- Cappé, Olivier, Simon J. Godsill, and Eric Moulines. 2007. An overview of existing methods and recent advances in sequential monte carlo. Proceedings of the IEEE 95: 899–924. [Google Scholar] [CrossRef]
- Chib, Siddhartha, and Ivan Jeliazkov. 2001. Marginal likelihood from the Metropolis-Hastings output. Journal of the American Statistical Association 96: 270–81. [Google Scholar] [CrossRef]
- Deaton, Angus, and Guy Laroque. 1992. On the behaviour of commodity prices. The Review of Economic Studies 59: 1–23. [Google Scholar] [CrossRef]
- Deaton, Angus, and Guy Laroque. 1995. Estimating a nonlinear rational expectations commodity price model with unobservable state variables. Journal of Applied Econometrics 10: S9–S40. [Google Scholar] [CrossRef]
- Deaton, Angus, and Guy Laroque. 1996. Competitive Storage and Commodity Price Dynamics. The Journal of Political Economy 104: 896–923. [Google Scholar] [CrossRef]
- DeJong, David N., and Chetan Dave. 2011. Structural Macroeconometrics, 2nd ed. Princeton: Princeton University Press. [Google Scholar]
- Doucet, Arnaud, and Adam M. Johansen. 2009. A tutorial on particle filtering and smoothing: Fifteen years later. In The Oxford Handbook of Nonlinear Filtering. Oxford: Oxford University Press, pp. 656–704. [Google Scholar]
- Duffy, Patricia A., Michael K. Wohlgenant, and James W. Richardson. 1990. The elasticity of export demand for us cotton. American Journal of Agricultural Economics 72: 468–74. [Google Scholar] [CrossRef]
- Durbin, James, and Siem Jan Koopman. 2012. Time Series Analysis by State Space Methods, 2nd ed. Number 38 in Oxford Statistical Science. Oxford: Oxford University Press. [Google Scholar]
- Flury, Thomas, and Neil Shephard. 2011. Bayesian inference based only on simulated likelihood: Particle filter analysis of dynamic economic models. Econometric Theory 27: 933–56. [Google Scholar] [CrossRef]
- Geyer, Charles J. 1992. Practical Markov chain Monte Carlo. Statistical Science 7: 473–83. [Google Scholar] [CrossRef]
- Gordon, Neil J., David J. Salmond, and Adrian F. M. Smith. 1993. Novel approach to nonlinear/non-gaussian bayesian state estimation. IEE Proceedings F-Radar and Signal Processing 140: 107–113. [Google Scholar] [CrossRef]
- Gouel, Christophe, and Nicolas Legrand. 2017. Estimating the competitive storage model with trending commodity prices. Journal of Applied Econometrics 32: 744–63. [Google Scholar] [CrossRef]
- Guerra, Ernesto A., Eugenio S. A. Bobenrieth, Juan R. A. Bobenrieth, and Carlo Cafiero. 2015. Empirical commodity storage model: The challenge of matching data and theory. European Review of Agricultural Economics 42: 607–23. [Google Scholar] [CrossRef]
- Gustafson, Robert L. 1958. Carryover Levels for Grains: A Method for Determining Amounts That Are Optimal under Specified Conditions; Number 1178; Washington: US Department of Agriculture.
- Haario, Heikki, Eero Saksman, and Johanna Tamminen. 2001. An adaptive Metropolis algorithm. Bernoulli 7: 223–42. [Google Scholar] [CrossRef]
- Kim, Sangjoon, Neil Shephard, and Siddhartha Chib. 1998. Stochastic volatility: Likelihood inference and comparison with arch models. The Review of Economic Studies 65: 361–93. [Google Scholar] [CrossRef]
- Kleppe, Tore Selland, and Atle Oglend. 2017. Estimating the competitive storage model: A simulated likelihood approach. Econometrics and Statistics 4: 39–56. [Google Scholar] [CrossRef][Green Version]
- Kleppe, Tore Selland, and Atle Oglend. 2019. Can limits-to-arbitrage from bounded storage improve commodity term-structure modeling? Journal of Futures Markets 39: 865–89. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2013. Large time-varying parameter vars. Journal of Econometrics 177: 185–98. [Google Scholar] [CrossRef]
- Legrand, Nicolas. 2019. The empirical merit of structural explanations of commodity price volatility: Review and perspectives. Journal of Economic Surveys 33: 639–64. [Google Scholar] [CrossRef]
- Liesenfeld, Roman, and Jean-François Richard. 2003. Univariate and multivariate stochastic volatility models: Estimation and diagnostics. Journal of Empirical Finance 10: 505–31. [Google Scholar] [CrossRef]
- Mehta, Aashish, and Jean-Paul Chavas. 2008. Responding to the coffee crisis: What can we learn from price dynamics? Journal of Development Economics 85: 282–311. [Google Scholar] [CrossRef]
- Miltersen, Kristian R., and Eduardo S. Schwartz. 1998. Pricing of options on commodity futures with stochastic term structures of convenience yields and interest rates. Journal of Financial and Quantitative Analysis 33: 33–59. [Google Scholar] [CrossRef]
- Oglend, Atle, and Tore Selland Kleppe. 2017. On the behavior of commodity prices when speculative storage is bounded. Journal of Economic Dynamics and Control 75: 52–69. [Google Scholar] [CrossRef]
- Richard, Jean-François, and Wei Zhang. 2007. Efficient high-dimensional importance sampling. Journal of Econometrics 127: 1385–411. [Google Scholar] [CrossRef]
- Routledge, Bryan R., Duane J. Seppi, and Chester S. Spatt. 2000. Equilibrium forward curves for commodities. The Journal of Finance 55: 1297–337. [Google Scholar] [CrossRef]
- Sala, Luca. 2015. Dsge models in the frequency domains. Journal of Applied Econometrics 30: 219–40. [Google Scholar] [CrossRef]
- Schwartz, Eduardo S. 1997. The stochastic behavior of commodity prices: Implications for valuation and hedging. The Journal of Finance 52: 923–73. [Google Scholar] [CrossRef]
- Shephard, Neil, and Michael K. Pitt. 1997. Likelihood analysis of non-Gaussian measurement time series. Biometrika 84: 653–67. [Google Scholar] [CrossRef]
- Tang, Ke. 2012. Time-varying long-run mean of commodity prices and the modeling of futures term structures. Quantitative Finance 12: 781–90. [Google Scholar] [CrossRef][Green Version]
- Wang, Dabin, and William G. Tomek. 2007. Commodity prices and unit root tests. American Journal of Agricultural Economics 89: 873–89. [Google Scholar] [CrossRef]



| Natgas | Coffee | Cotton | Aluminum | ||
|---|---|---|---|---|---|
| v | Post. mean | 0.0972 | 0.0574 | 0.0443 | 0.0422 |
| Post. std. | 0.0083 | 0.0034 | 0.0023 | 0.0022 | |
| ESS | 634 | 627 | 914 | 636 | |
| Post. mean | 0.0112 | 0.0025 | 0.0019 | 0.0014 | |
| Post. std. | 0.0048 | 0.0014 | 0.0010 | 0.0009 | |
| ESS | 580 | 544 | 708 | 770 | |
| b | Post. mean | 0.4196 | 1.4847 | 1.2969 | 1.0283 |
| Post. std. | 0.2594 | 0.4242 | 0.3080 | 0.3058 | |
| ESS | 515 | 741 | 1188 | 786 | |
| C | 10 | 25 | 25 | 25 |
| Natgas | Coffee | Cotton | Aluminum | |
|---|---|---|---|---|
| Storage SSM | 164.13 | 431.10 | 539.89 | 555.41 |
| [10] | [25] | [25] | [25] | |
| LGLL SSM | 146.76 | 404.09 | 510.28 | 540.88 |
| (17.37) | (27.01) | (29.61) | (14.53) | |
| Linear trend | 138.36 | 386.70 | 507.51 | 546.59 |
| [20] | [25] | [25] | [20] | |
| (25.77) | (44.40) | (32.38) | (8.82) | |
| RCS3 trend | 144.68 | 405.50 | 518.41 | 531.56 |
| [15] | [25] | [25] | [25] | |
| (19.45) | (25.60) | (21.48) | (23.85) | |
| RCS7 trend | 137.58 | 401.78 | 519.11 | 540.74 |
| [25] | [25] | [25] | [20] | |
| (26.55) | (29.32) | (20.78) | (14.67) |
| Skew (ξt) | Kurt (ξt) | JB (ξt) | ρ1 (ηt) | LB12 (ηt) | LB12 () | |
|---|---|---|---|---|---|---|
| Storage SSM | ||||||
| Natgas | 0.053 | 3.069 | 0.915 | 0.075 | 0.027 | 0.297 |
| Coffee | 0.452 | 4.050 | <0.001 | 0.224 | <0.001 | 0.452 |
| Cotton | −0.024 | 3.669 | 0.035 | 0.452 | <0.001 | <0.001 |
| Aluminum | −0.090 | 3.105 | 0.723 | 0.245 | <0.001 | <0.001 |
| LGLL SSM | ||||||
| Natgas | 0.033 | 4.298 | <0.001 | 0.084 | 0.055 | 0.452 |
| Coffee | 0.801 | 7.679 | <0.001 | 0.257 | <0.001 | <0.001 |
| Cotton | −0.230 | 6.325 | <0.001 | 0.502 | <0.001 | <0.001 |
| Aluminum | −0.381 | 4.652 | <0.001 | 0.268 | <0.001 | <0.001 |
| Linear trend | ||||||
| Natgas | 0.181 | 5.295 | <0.001 | 0.023 | 0.206 | 0.276 |
| Coffee | −0.680 | 5.736 | <0.001 | 0.246 | <0.001 | 0.095 |
| Cotton | −0.073 | 5.938 | <0.001 | 0.481 | <0.001 | <0.001 |
| Aluminum | 0.516 | 6.389 | <0.001 | 0.247 | <0.001 | <0.001 |
| RCS3 trend | ||||||
| Natgas | −0.109 | 4.022 | 0.003 | 0.014 | 0.002 | 0.031 |
| Coffee | −0.498 | 4.681 | <0.001 | 0.182 | <0.001 | 0.004 |
| Cotton | 0.143 | 4.832 | <0.001 | 0.449 | <0.001 | <0.001 |
| Aluminum | 0.391 | 5.246 | <0.001 | 0.261 | <0.001 | <0.001 |
| RCS7 trend | ||||||
| Natgas | −0.093 | 4.343 | <0.001 | −0.010 | <0.001 | 0.004 |
| Coffee | −0.666 | 5.939 | <0.001 | 0.195 | <0.001 | 0.002 |
| Cotton | 0.131 | 4.319 | <0.001 | 0.462 | <0.001 | <0.001 |
| Aluminum | −0.039 | 3.332 | 0.419 | 0.198 | <0.001 | <0.001 |
| Natgas | Coffee | Cotton | Aluminum | |||||
|---|---|---|---|---|---|---|---|---|
| Costs | Elast. | Costs | Elast. | Costs | Elast. | Costs | Elast. | |
| Storage SSM | 12.6 | −1.03 | 2.9 | −0.07 | 2.2 | −0.07 | 1.7 | −0.10 |
| linear trend | 12.5 | −0.02 | 4.8 | −0.02 | 1.1 | −0.02 | 5.4 | −0.05 |
| RCS3 trend | 8.4 | −0.04 | 2.7 | −0.02 | 1.1 | −0.02 | 4.4 | −0.02 |
| RCS7 trend | 10.0 | −0.01 | 6.4 | −0.02 | 4.0 | −0.02 | 1.8 | −0.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osmundsen, K.K.; Kleppe, T.S.; Liesenfeld, R.; Oglend, A. Estimating the Competitive Storage Model with Stochastic Trends in Commodity Prices. Econometrics 2021, 9, 40. https://doi.org/10.3390/econometrics9040040
Osmundsen KK, Kleppe TS, Liesenfeld R, Oglend A. Estimating the Competitive Storage Model with Stochastic Trends in Commodity Prices. Econometrics. 2021; 9(4):40. https://doi.org/10.3390/econometrics9040040
Chicago/Turabian StyleOsmundsen, Kjartan Kloster, Tore Selland Kleppe, Roman Liesenfeld, and Atle Oglend. 2021. "Estimating the Competitive Storage Model with Stochastic Trends in Commodity Prices" Econometrics 9, no. 4: 40. https://doi.org/10.3390/econometrics9040040
APA StyleOsmundsen, K. K., Kleppe, T. S., Liesenfeld, R., & Oglend, A. (2021). Estimating the Competitive Storage Model with Stochastic Trends in Commodity Prices. Econometrics, 9(4), 40. https://doi.org/10.3390/econometrics9040040