Using Sensors to Study Home Activities †



Abstract
:1. Introduction
2. Related Work
3. Experiment Setting
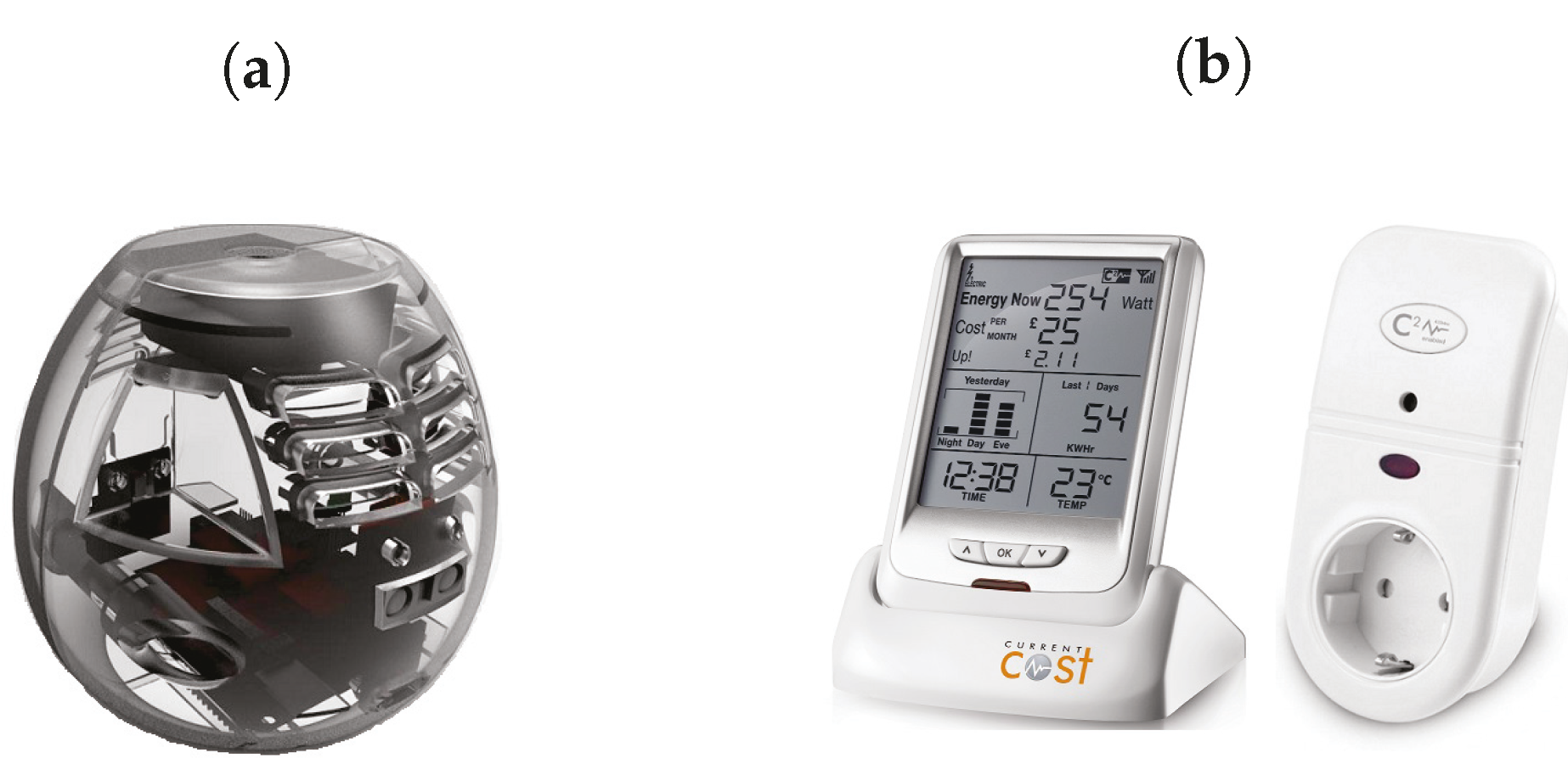
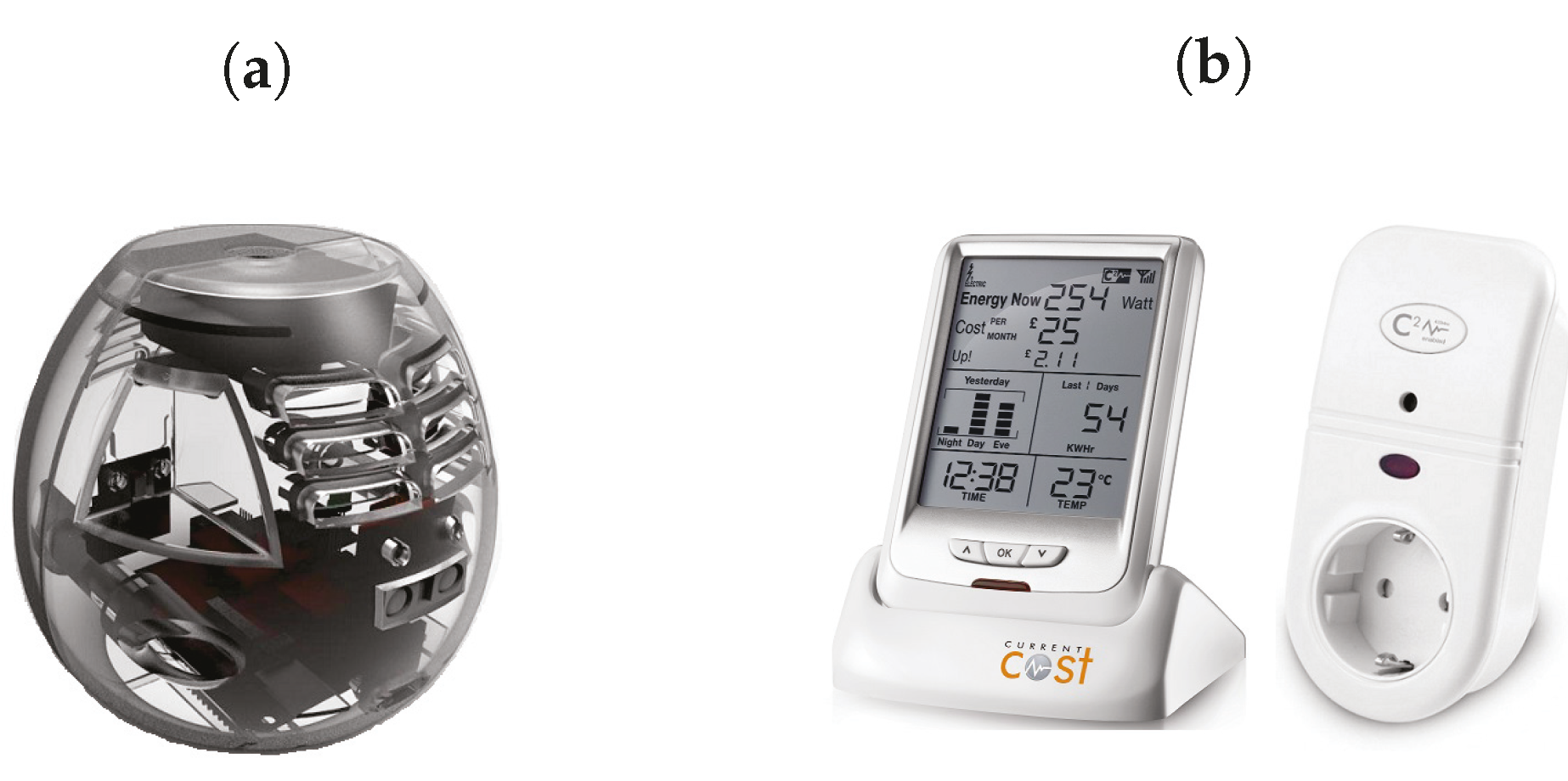
3.1. Sensor Modules
3.2. Demonstration and Installation
3.3. Trial Households
4. Data Sets
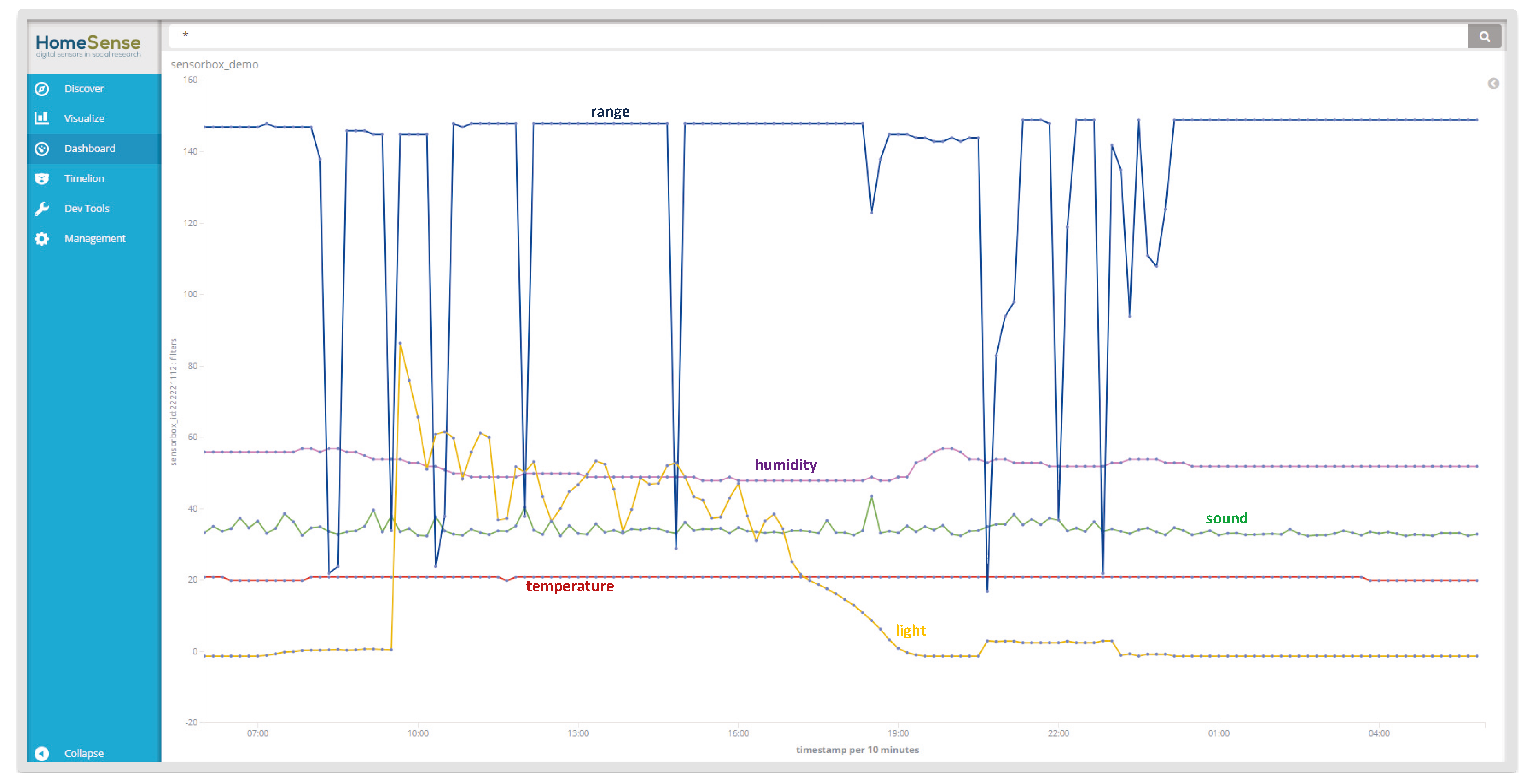
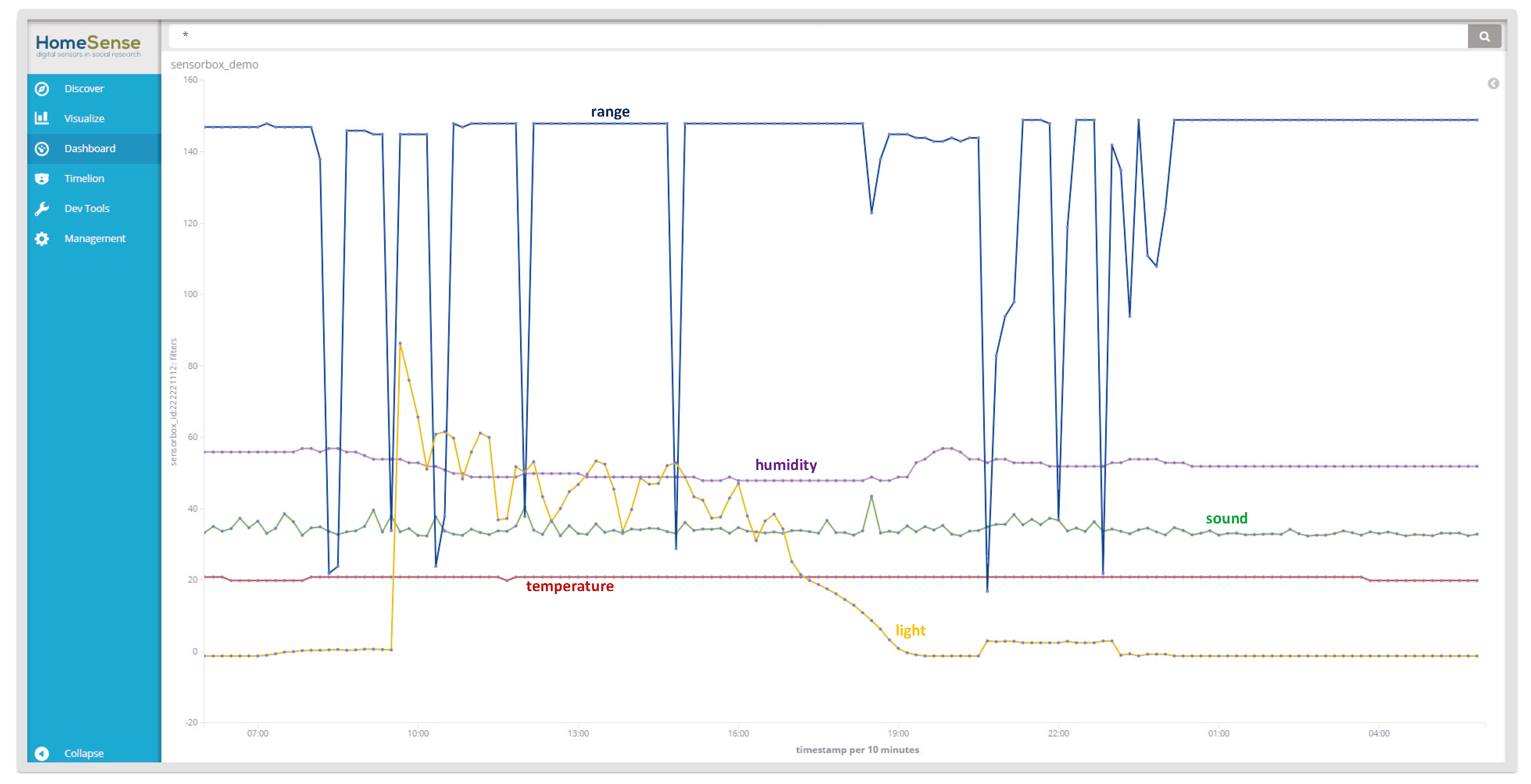
4.1. Sensor-Generated Data
“Humidity”: 50, “Sound”: 45, “Range”: 100, “Light”: 583}
4.2. Time Use Diary
4.3. Data Reliability
5. Recognising Activities
5.1. Feature Extraction
5.1.1. Re-Sampling
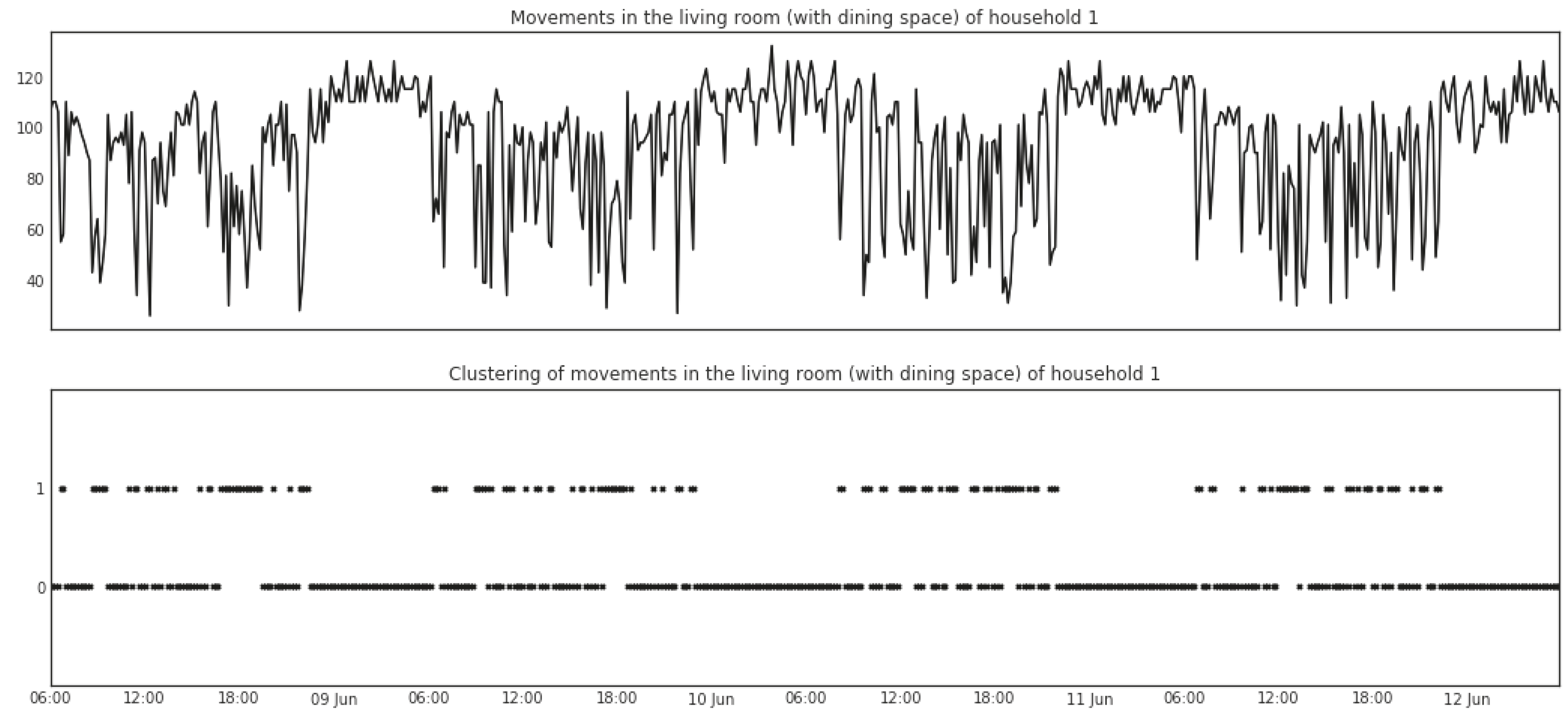
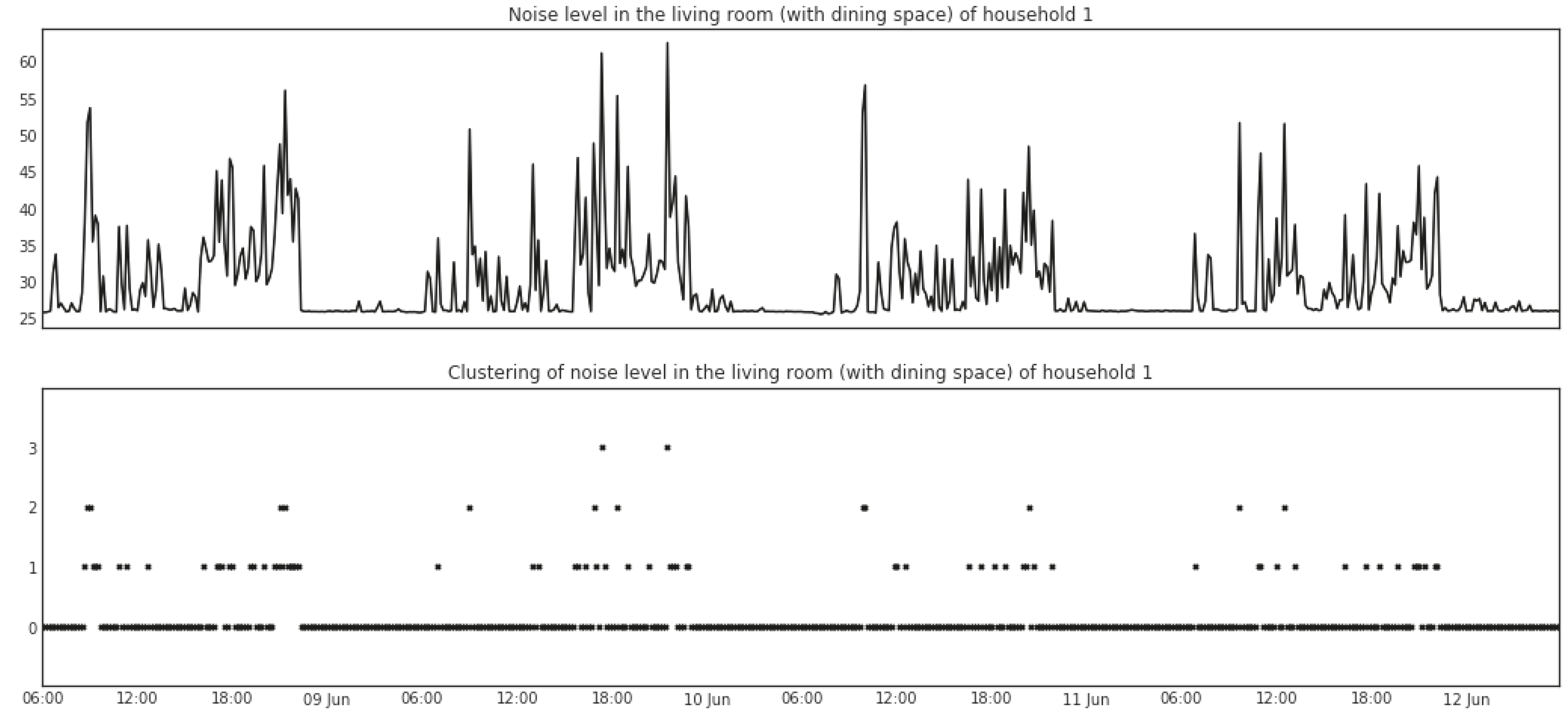
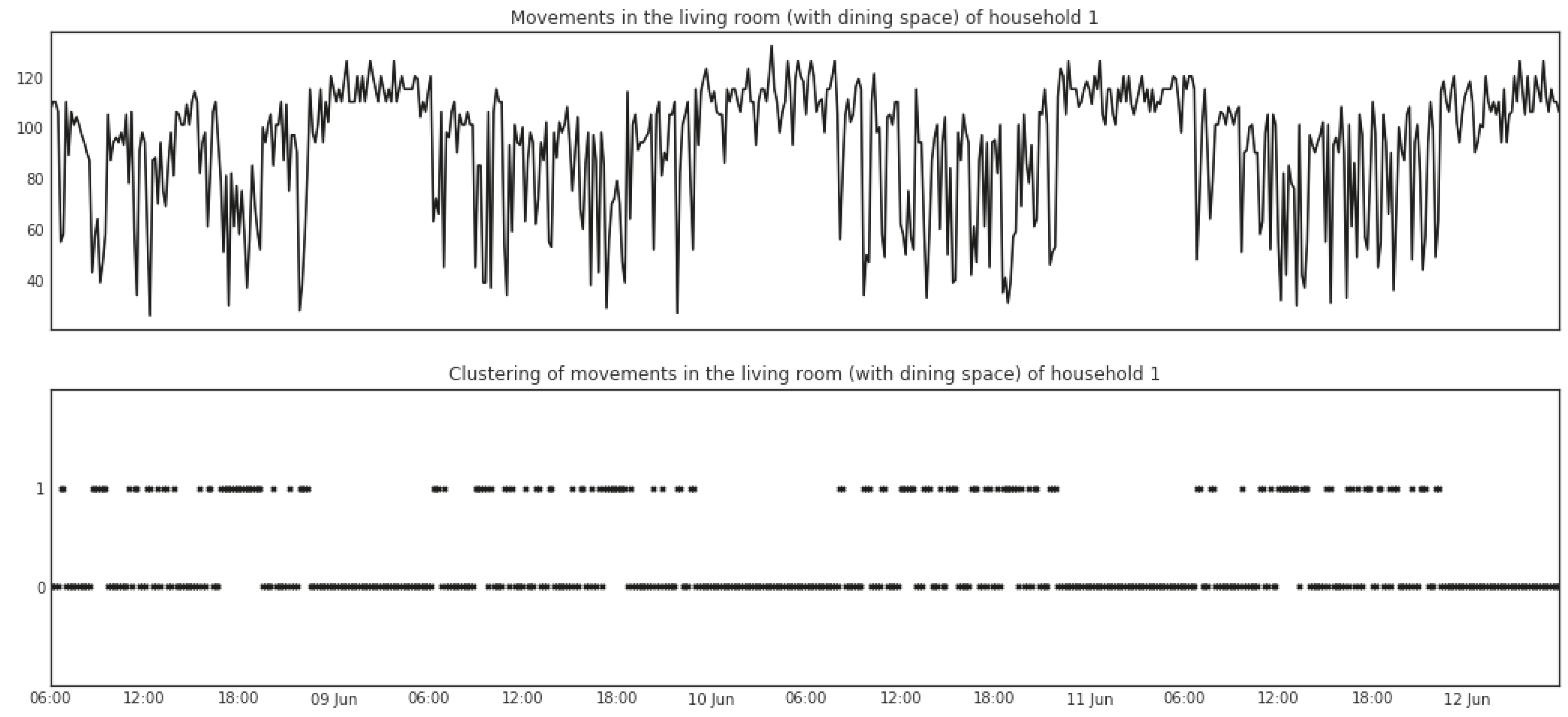
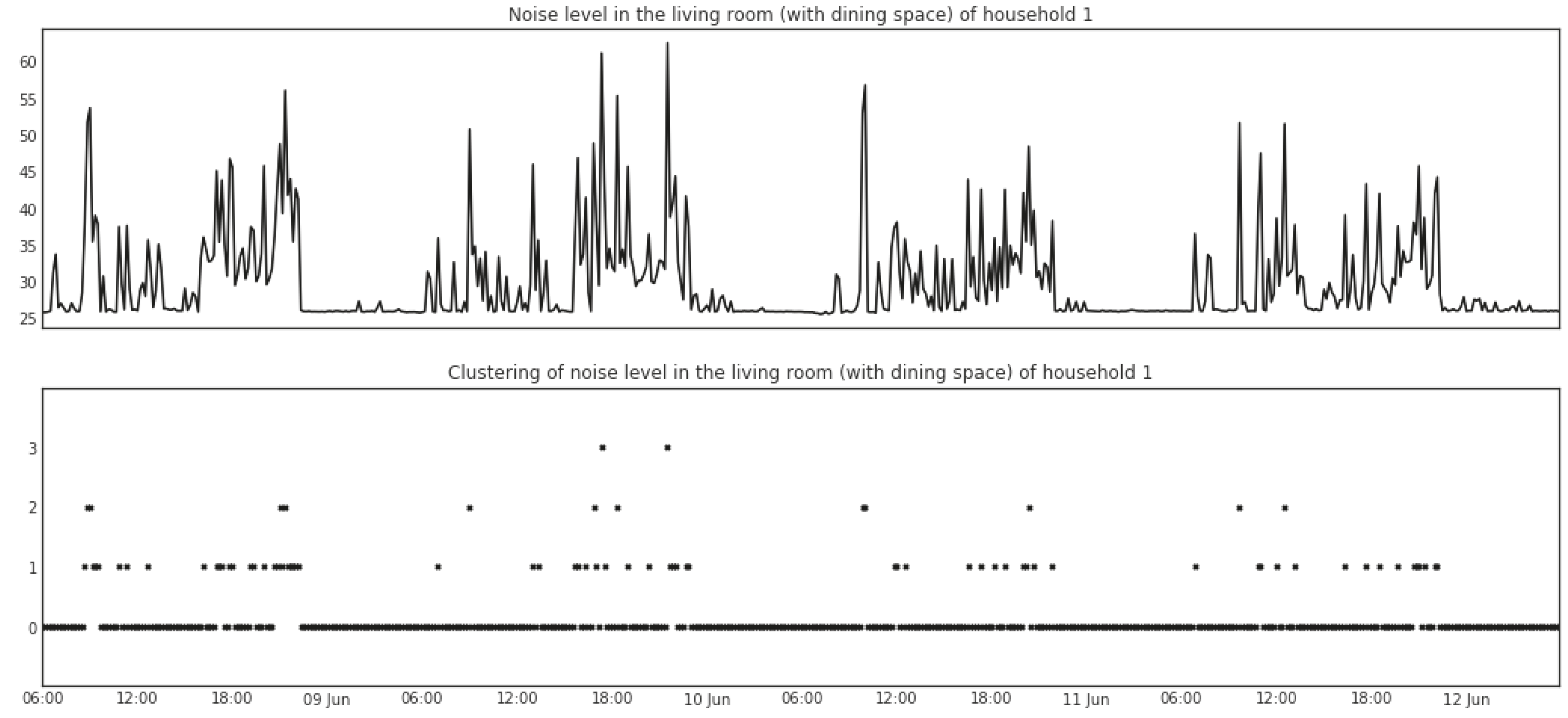
5.1.2. Mean Shift
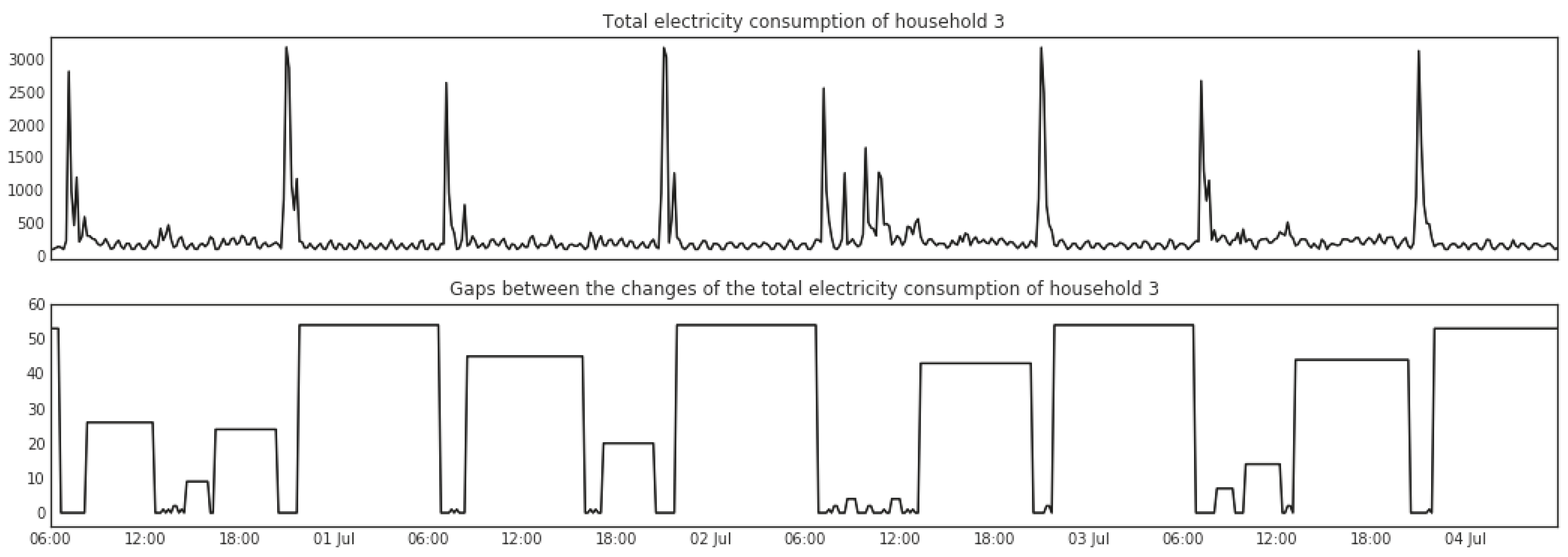
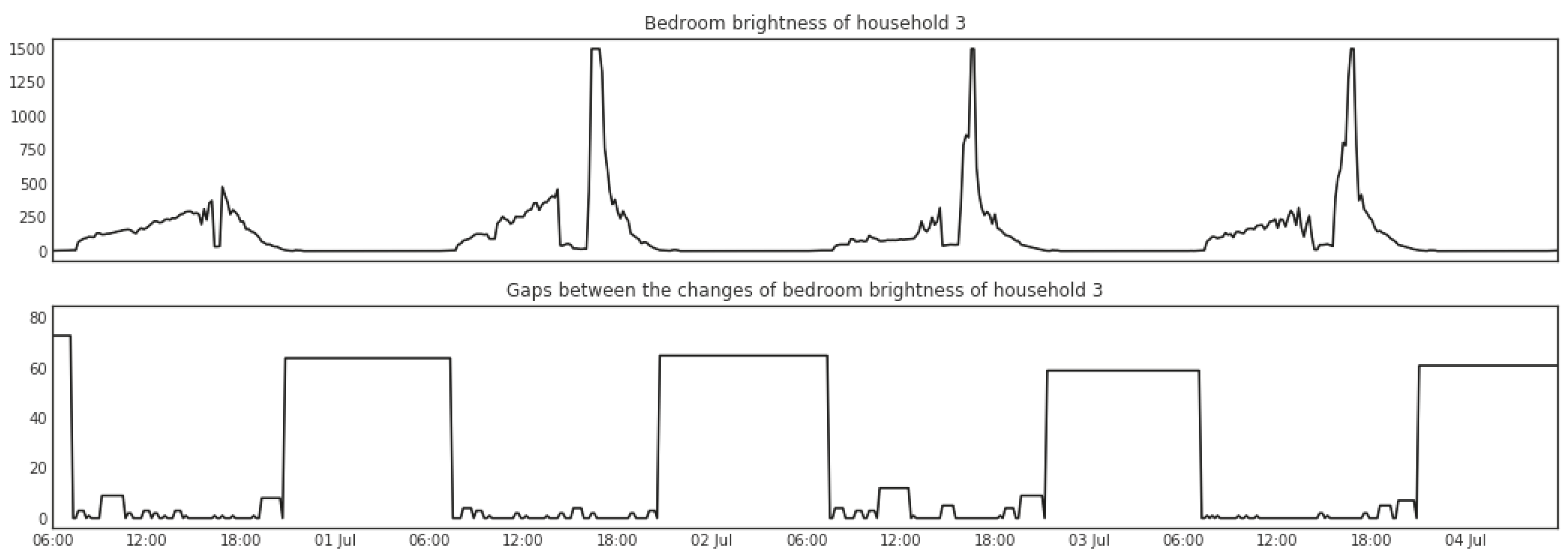
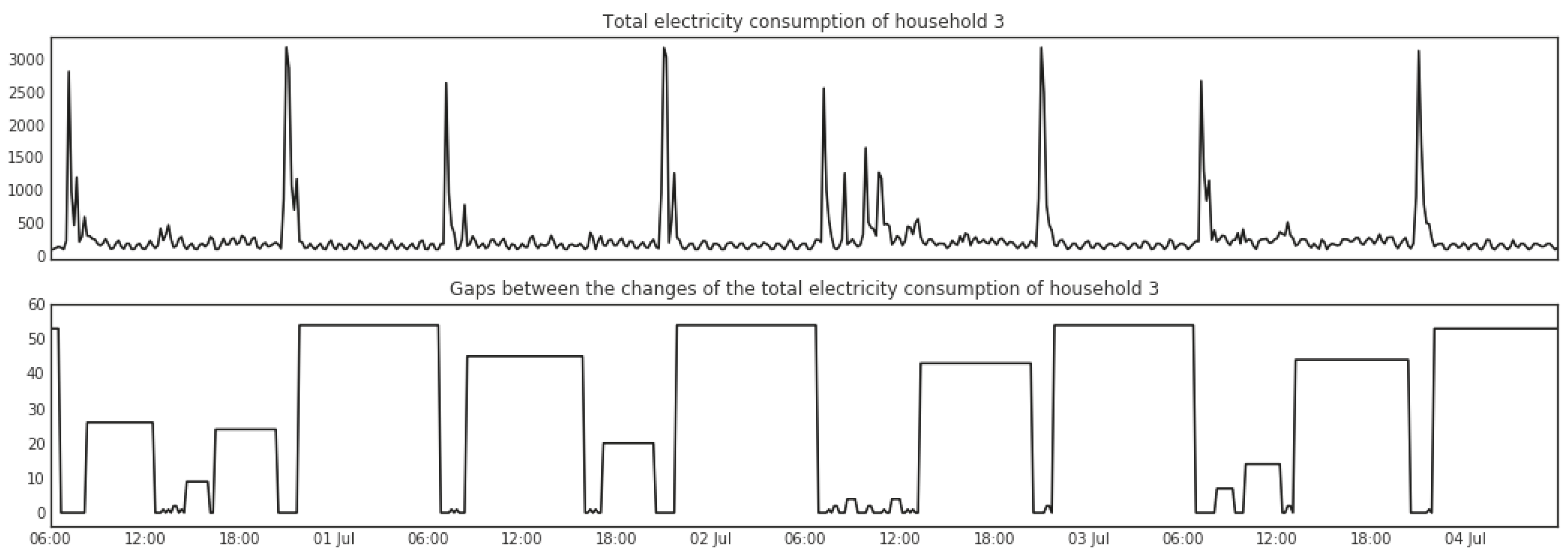
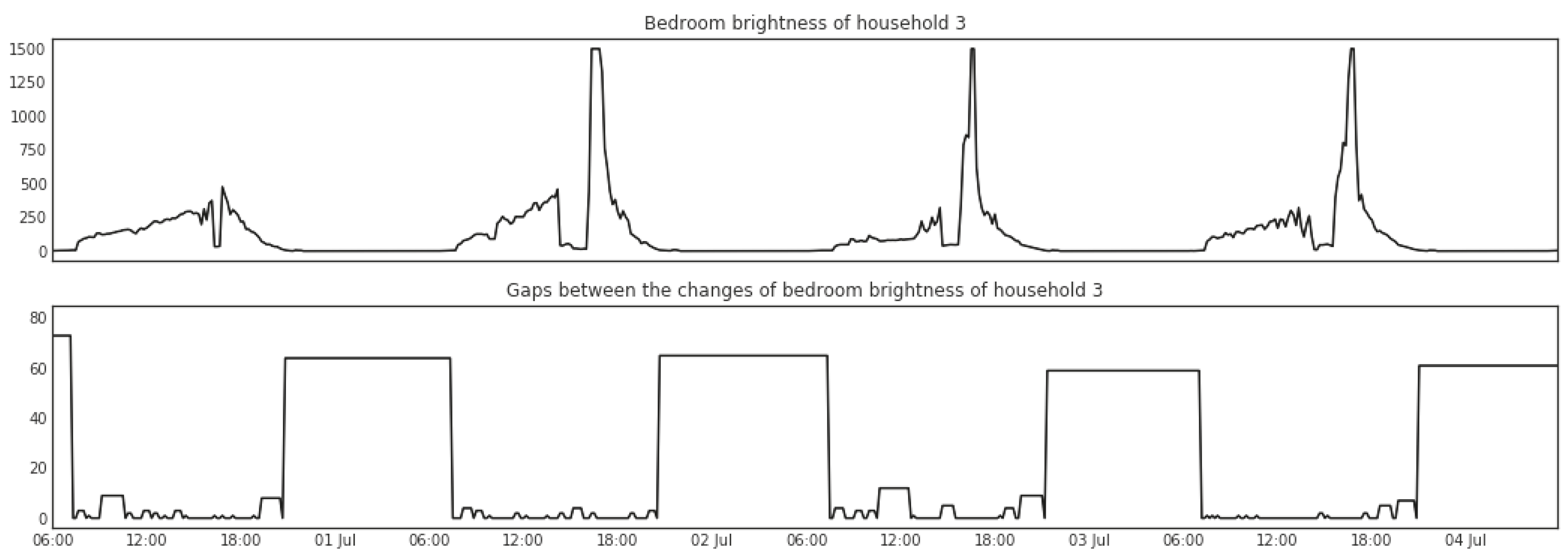
5.1.3. Change Points Detection
5.1.4. Change Point Gaps
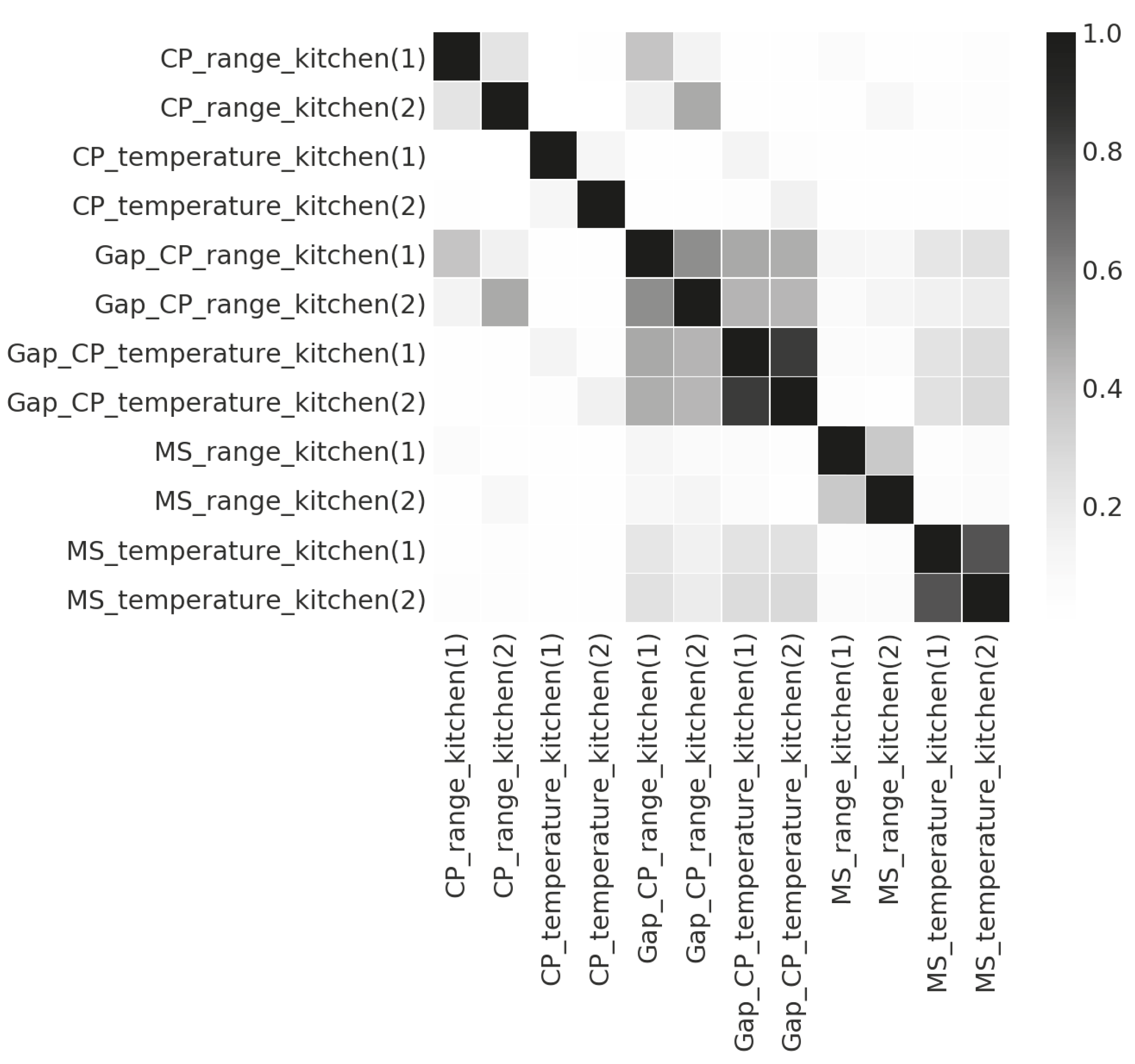
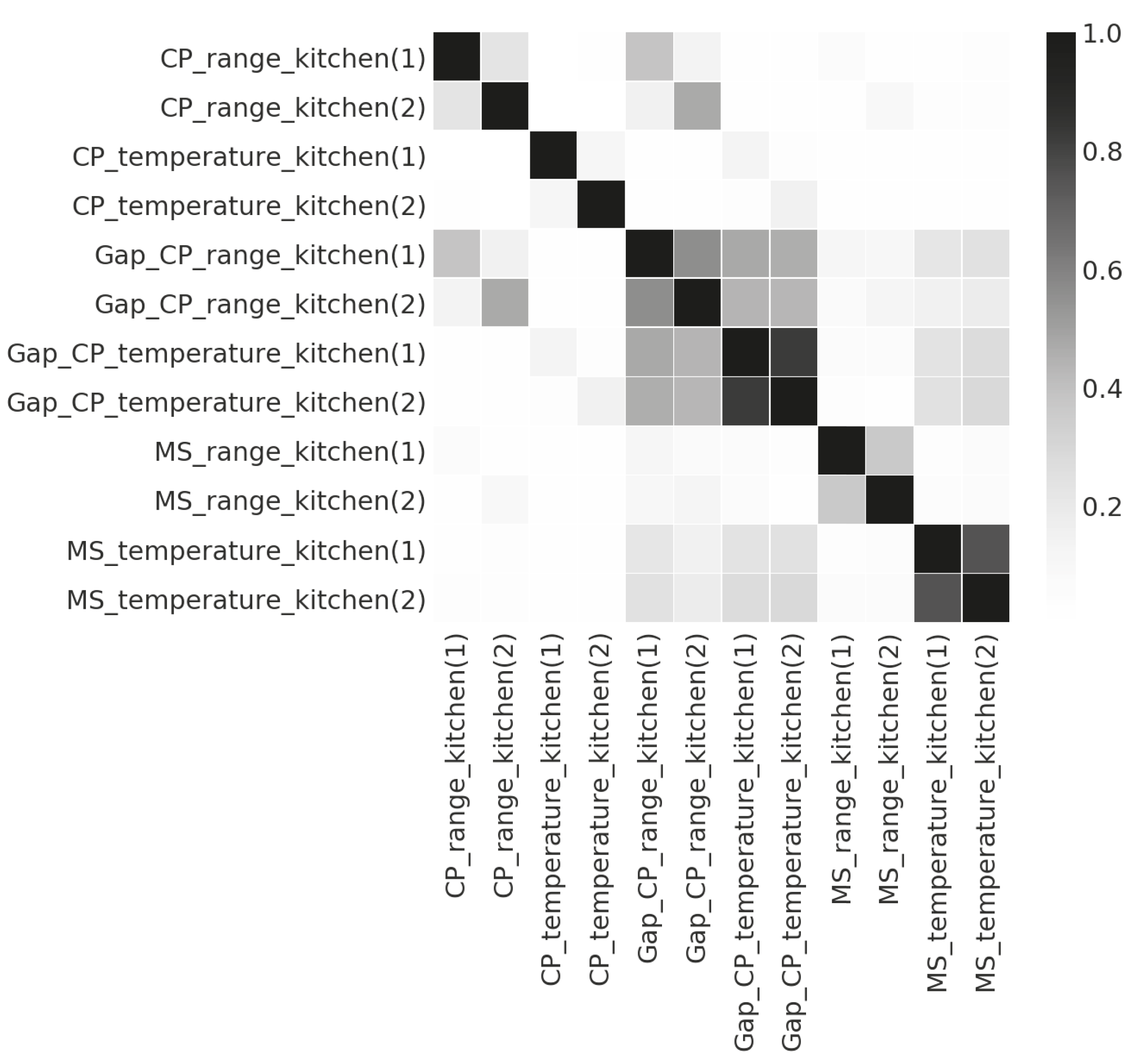
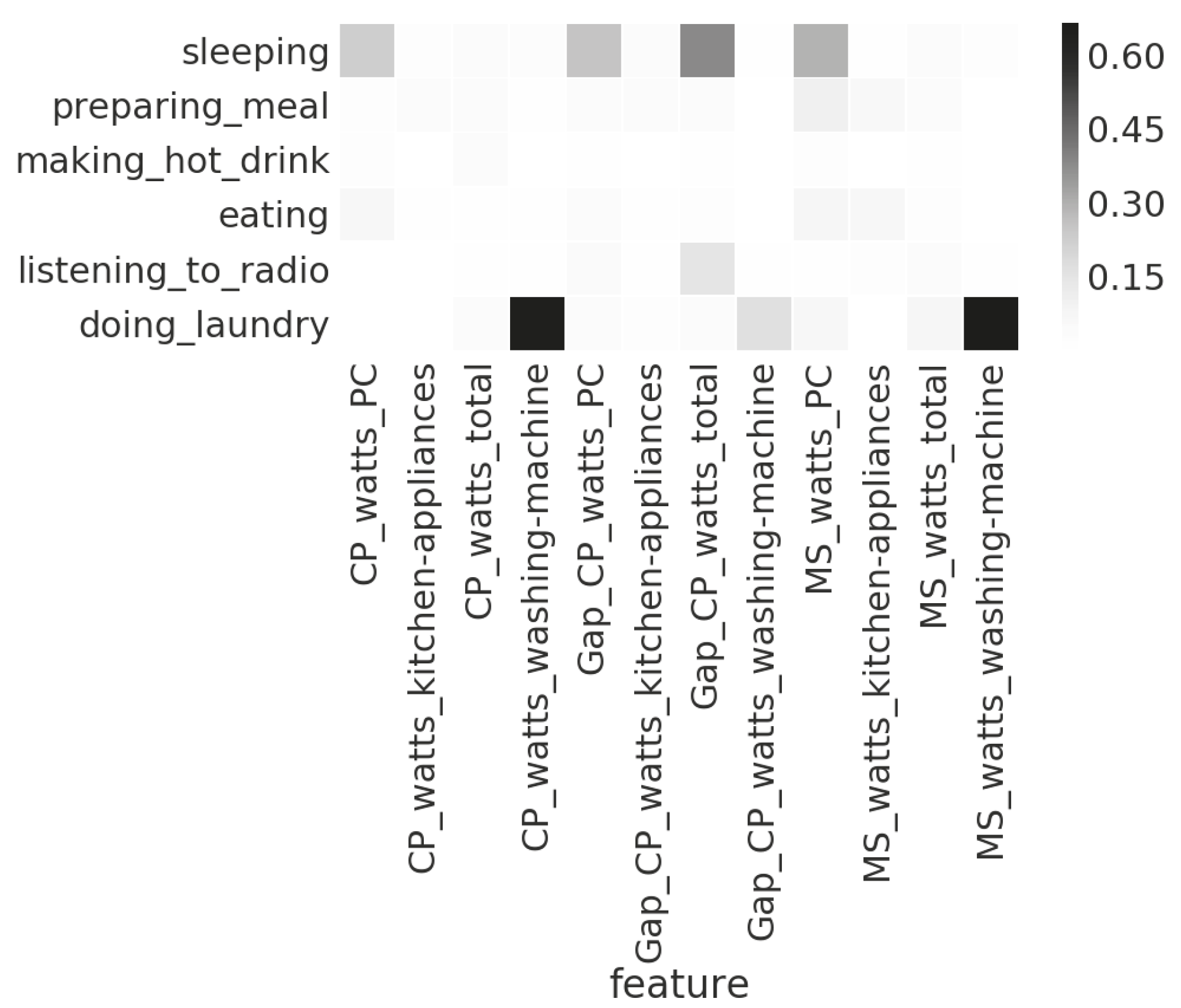
5.2. Feature Selection
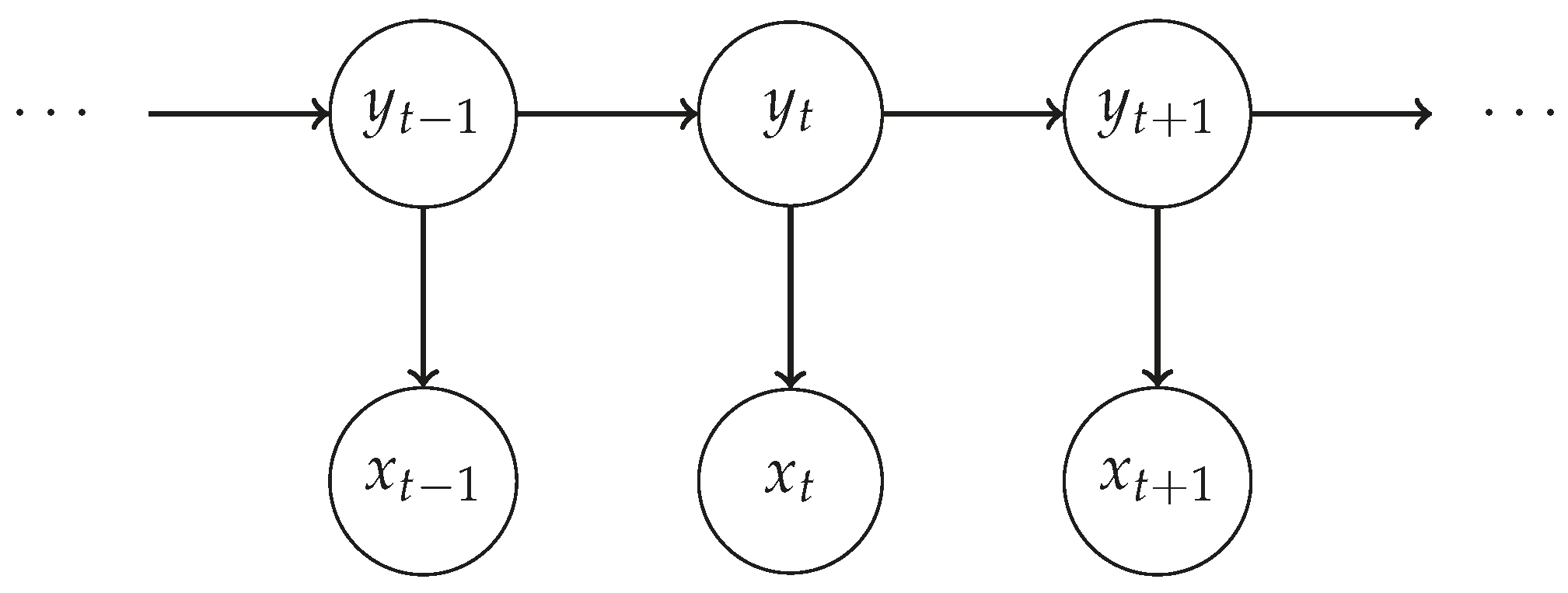
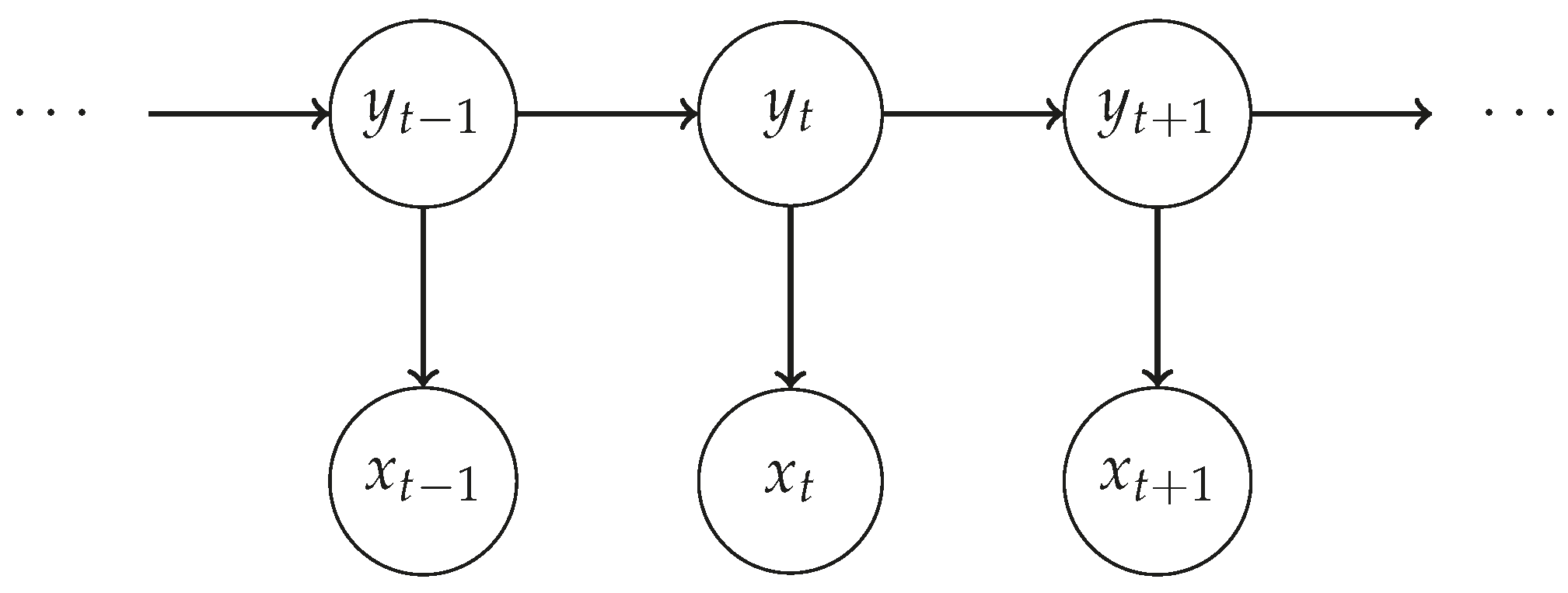
5.3. Recognition Method
6. Agreement Evaluation
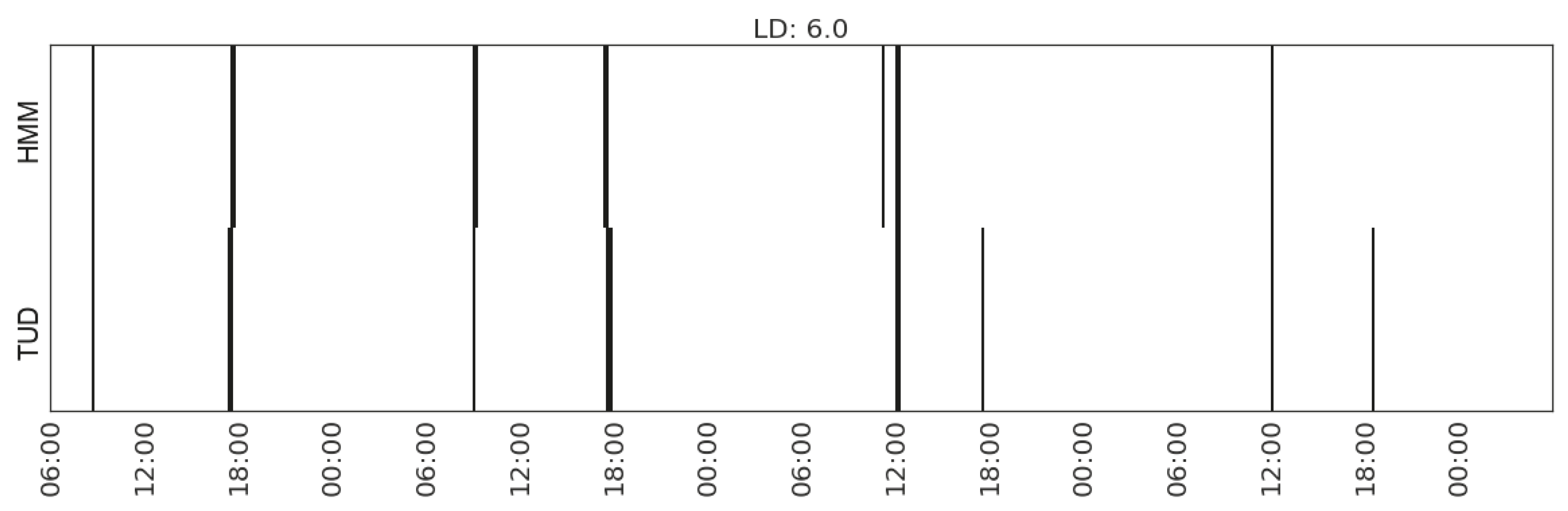
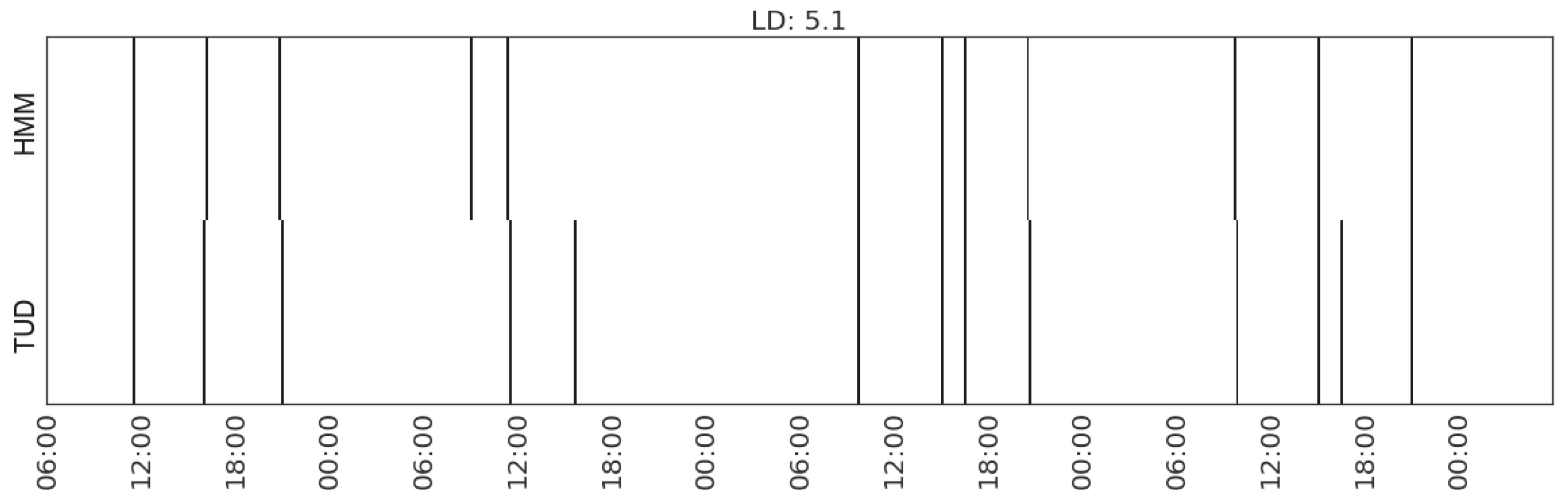
6.1. Evaluation Metric
6.2. Results and Analysis
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ruppanner, L. Contemporary Family Issues; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Atkinson, R.; Jacobs, K. House, Home and Society; Palgrave: London, UK, 2016. [Google Scholar]
- Gattshall, M.L.; Shoup, J.A.; Marshall, J.A.; Crane, L.A.; Estabrooks, P.A. Validation of a survey instrument to assess home environments for physical activity and healthy eating in overweight children. Int. J. Behav. Nutr. Phys. Act. 2008, 5, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Williams, S.J.; Coveney, C.; Meadows, R. ‘M-apping’ sleep? Trends and transformations in the digital age. Sociol. Health Illn. 2015, 37, 1039–1054. [Google Scholar] [CrossRef] [PubMed]
- López, D.; Sánchez-Criado, T. Analysing Hands-on-Tech Care Work in Telecare Installations. Frictional Encounters with Gerontechnological Designs. In Aging and the Digital Life Course; Prendergast, D., Garattini, C., Eds.; Berghahn: New York, NY, USA, 2015; Chapter 9. [Google Scholar]
- Mort, M.; Roberts, C.; Callen, B. Ageing with telecare: care or coercion in austerity? Sociol. Health Illn. 2013, 35, 799–812. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, O.; Gershuny, J. Change in Spousal Human Capital and Housework: A Longitudinal Analysis. Eur. Sociol. Rev. 2016, 32, 864–880. [Google Scholar] [CrossRef]
- Pierce, J.; Schiano, D.J.; Paulos, E. Home, Habits, and Energy: Examining Domestic Interactions and Energy Consumption. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems CHI ’10, Atlanta, GA, USA, 10–15 April 2010; pp. 1985–1994. [Google Scholar]
- Shannon-Baker, P. Making Paradigms Meaningful in Mixed Methods Research. J. Mixed Methods Res. 2016, 10, 319–334. [Google Scholar] [CrossRef]
- Ganong, L.; Coleman, M. Qualitative research on family relationships. J. Soc. Person. Relatsh. 2014, 31, 451–459. [Google Scholar] [CrossRef]
- British Social Attitudes Survey (33rd ed.). Available online: http://www.bsa.natcen.ac.uk/latest-report/british-social-attitudes-33/introduction.aspx (accessed on 30 March 2017).
- Office for National Statistic (UK). Available online: https://www.ons.gov.uk/ (accessed on 30 March 2017).
- Chenu, A.; Lesnard, L. Time Use Surveys: A Review of their Aims, Methods, and Results. Eur. J. Sociol. 2006, 47, 335–359. [Google Scholar] [CrossRef]
- Gershuny, J.; Harms, T.A. Housework Now Takes Much Less Time: 85 Years of US Rural Women’s Time Use. Soc. Forces 2016, 95, 503–524. [Google Scholar] [CrossRef]
- European Communities. Harmonised European Time Use Surveys: 2008 Guidelines; Eurostat Methodologies and Working Papers; Population and social conditions; European Communities: Luxembourg, 2009. [Google Scholar]
- Kelly, P.; Thomas, E.; Doherty, A.; Harms, T.; Burke, O.; Gershuny, J.; Foster, C. Developing a Method to Test the Validity of 24 Hour Time Use Diaries Using Wearable Cameras: A Feasibility Pilot. PLOS ONE 2015, 10, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Benmansour, A.; Bouchachia, A.; Feham, M. Multioccupant Activity Recognition in Pervasive Smart Home Environments. ACM Comput. Surv. 2015, 48, 34:1–34:36. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A Survey of Online Activity Recognition Using Mobile Phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Amft, O.; Tröster, G. Recognition of dietary activity events using on-body sensors. Artif. Intell. Med. 2008, 42, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, Z.; Li, B.; Lee, S.; Sherratt, R.S. An enhanced fall detection system for elderly person monitoring using consumer home networks. IEEE Trans. Consum. Electron. 2014, 60, 23–29. [Google Scholar] [CrossRef]
- Lin, Z.H.; Fu, L.C. Multi-user Preference Model and Service Provision in a Smart Home Environment. In Proceedings of the 2007 IEEE International Conference on Automation Science and Engineering, Scottsdale, AZ, USA, 22–25 September 2007; pp. 759–764. [Google Scholar]
- van Kasteren, T.L.M.; Englebienne, G.; Kröse, B.J.A. Human Activity Recognition from Wireless Sensor Network Data: Benchmark and Software. In Activity Recognition in Pervasive Intelligent Environments; Chen, L., Nugent, C.D., Biswas, J., Hoey, J., Eds.; Atlantics Press: Amsterdam, The Netherland, 2011; pp. 165–186. [Google Scholar]
- Hsu, K.C.; Chiang, Y.T.; Lin, G.Y.; Lu, C.H.; Hsu, J.Y.J.; Fu, L.C. Strategies for Inference Mechanism of Conditional Random Fields for Multiple-Resident Activity Recognition in a Smart Home. In Trends in Applied Intelligent Systems, Proceedings of the 23rd International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, Cordoba, Spain, 1–4 June 2010; García-Pedrajas, N., Herrera, F., Fyfe, C., Benítez, J.M., Ali, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 417–426. [Google Scholar]
- Fan, X.; Zhang, H.; Leung, C.; Miao, C. Comparative study of machine learning algorithms for activity recognition with data sequence in home-like environment. In Proceedings of the 2016 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Baden-Baden, Germany, 19–21 September 2016; pp. 168–173. [Google Scholar]
- Cook, D.J.; Crandall, A.; Singla, G.; Thomas, B. Detection of Social Interaction in Smart Spaces. Cybern. Syst. 2010, 41, 90–104. [Google Scholar] [CrossRef] [PubMed]
- Silverman, D. Interpreting Qualitative Data: Methods for Analyzing Talk, Text and Interaction, 3rd ed.; SAGE Publications: Thousand Oaks, CA, USA, 2006. [Google Scholar]
- Wang, L.; Gu, T.; Tao, X.; Chen, H.; Lu, J. Recognizing multi-user activities using wearable sensors in a smart home. Pervasive Mob. Comput. 2011, 7, 287–298. [Google Scholar] [CrossRef]
- Cheng, Y. Mean Shift, Mode Seeking, and Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Picard, D. Testing and estimating change-points in time series. Adv. Appl. Probab. 1985, 17, 841–867. [Google Scholar] [CrossRef]
- Hall, M.A.; Smith, L.A. Feature Selection for Machine Learning: Comparing a Correlation-Based Filter Approach to the Wrapper. In Proceedings of the Twelfth International Florida Artificial Intelligence Research Society Conference, San Francisco, CA, USA, 1–5 May 1999; AAAI Press: Palo Alto, CA, USA, 1999; pp. 235–239. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Cybern. Control Theory 1966, 10, 707–710. [Google Scholar]
- Jiang, J.; Pozza, R.; Gunnarsdóttir, K.; Gilbert, N.; Moessner, K. Recognising Activities at Home: Digital and Human Sensors. In Proceedings of the International Conference on Future Networks and Distributed Systems ICFNDS ’17, Cambridge, UK, 19–20 July 2017; ACM: New York, NY, USA, 2017; pp. 17:1–17:11. [Google Scholar]
- Cook, D.J.; Youngblood, M.; Heierman, E.O.; Gopalratnam, K.; Rao, S.; Litvin, A.; Khawaja, F. MavHome: An agent-based smart home. In Proceedings of the First IEEE International Conference on Pervasive Computing and Communications, Fort Worth, TX, USA, 23–26 March 2003; pp. 521–524. [Google Scholar]
- Cook, D.J.; Schmitter-edgecombe, M.; Crandall, A.; Sanders, C.; Thomas, B. Collecting and Disseminating Smart Home Sensor Data in the CASAS Project. In Proceedings of the CHI Workshop on Developing Shared Home Behavior Datasets to Advance HCI and Ubiquitous Computing Research, Boston, MA, USA, 4–9 April 2009. [Google Scholar]
- Singla, G.; Cook, D.J.; Schmitter-Edgecombe, M. Recognizing independent and joint activities among multiple residents in smart environments. J. Ambient Intell. Humaniz. Comput. 2010, 1, 57–63. [Google Scholar] [CrossRef] [PubMed]
- Chiang, Y.T.; Hsu, K.C.; Lu, C.H.; Fu, L.C.; Hsu, J.Y.J. Interaction models for multiple-resident activity recognition in a smart home. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3753–3758. [Google Scholar]
- Fatima, I.; Fahim, M.; Lee, Y.K.; Lee, S. A Unified Framework for Activity Recognition-Based Behavior Analysis and Action Prediction in Smart Homes. Sensors 2013, 13, 2682–2699. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; He, L.; Si, H.; Liu, P.; Xie, X. Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans. 2014, 53, 1629–1638. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, N.C.; Cook, D.J. Activity Recognition on Streaming Sensor Data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [PubMed]
- Dawadi, P.N.; Cook, D.J.; Schmitter-Edgecombe, M. Modeling Patterns of Activities Using Activity Curves. Pervasive Mob. Comput. 2016, 28, 51–68. [Google Scholar] [CrossRef] [PubMed]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Prossegger, M.; Bouchachia, A. Multi-resident Activity Recognition Using Incremental Decision Trees. In Proceedings of the Third International Conference ICAIS 2014 Adaptive and Intelligent Systems, Bournemouth, UK, 8–10 September 2014; Bouchachia, A., Ed.; Springer: Cham, Switzerland, 2014; pp. 182–191. [Google Scholar]
- Kröse, B.; Kasteren, T.V.; Gibson, C.; Dool, T.V.D. Care: Context awareness in residences for elderly. In Proceedings of the Conference of the International Society for Gerontechnology, Pisa, Italy, 21–25 June 2008. [Google Scholar]
- van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate Activity Recognition in a Home Setting. In Proceedings of the 10th International Conference on Ubiquitous Computing UbiComp ’08, Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
- Nez, F.J.O.; Englebienne, G.; de Toledo, P.; van Kasteren, T.; Sanchis, A.; Kröse, B. In-Home Activity Recognition: Bayesian Inference for Hidden Markov Models. IEEE Pervasive Comput. 2014, 13, 67–75. [Google Scholar]
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human Activity Recognition Using Recurrent Neural Networks. In Machine Learning and Knowledge Extraction: First IFIP TC 5, WG 8.4, 8.9, 12.9, Proceedings of the International Cross-Domain Conference, CD-MAKE 2017, Reggio, Italy, 29 August–1 September 2017; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer: Berlin, Germany, 2017; pp. 267–274. [Google Scholar]
- Laput, G.; Zhang, Y.; Harrison, C. Synthetic Sensors: Towards General-Purpose Sensing. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; ACM: New York, NY, USA, 2017; pp. 3986–3999. [Google Scholar]
- Seeeduino Arch-Pro. Available online: https://developer.mbed.org/platforms/Seeeduino-Arch-Pro (accessed on 30 March 2017).
- SparkFun Humidity and Temperature Sensor Breakout—HTU21D. Available online: https://www.sparkfun.com/products/retired/12064 (accessed on 30 March 2017).
- SparkFun RGB and Gesture Sensor—APDS-9960. Available online: https://www.sparkfun.com/products/12787 (accessed on 30 March 2017).
- Pololu Carrier with Sharp GP2Y0A60SZLF Analog Distance Sensor. Available online: https://www.pololu.com/product/2474 (accessed on 30 March 2017).
- SparkFun MEMS Microphone Breakout—INMP401 (ADMP401). Available online: https://www.sparkfun.com/products/9868 (accessed on 30 March 2017).
- Current Cost—Individual Appliance Monitor (IAM). Available online: http://www.currentcost.com/product-iams.html (accessed on 30 March 2017).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal Detection of Changepoints with a Linear Computational Cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]
- Killick, R.; Eckley, I.A. Changepoint: An R package for changepoint analysis. J. Stat. Softw. 2014, 58, 1–19. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Ghiselli, E.E. Theory of Psychological Measurement; McGraw-Hill: New York, NY, USA, 1964. [Google Scholar]
- Press, W.H.; Flannery, B.P.; Teukolski, S.A.; Vetterling, W.T. Numerical Recipes in C; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Quinlan, J.R. Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. arXiv 2016, arXiv:1601.07996. [Google Scholar] [CrossRef]
- Zucchini, W.; MacDonald, I.L. Hidden Markov Models for Time Series: An Introduction Using R; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Hmmlearn. Available online: http://hmmlearn.readthedocs.io/ (accessed on 30 March 2017).
- Weighted-Levenshtein. Available online: http://weighted-levenshtein.readthedocs.io/ (accessed on 30 March 2017).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Modules | Measurement | |
|---|---|---|
| Sensor Box | Temperature sensor | °C |
| Humidity sensor | % | |
| Light Sensor | ||
| Ranging sensor | cm | |
| Microphone | dB SPL | |
| Energy monitor | watts | |
| Household | Rooms | Sensor Boxes (Location Installed) | Electricity Monitors (Appliances Attached) |
|---|---|---|---|
| 1 | Master bedroom | Next to bed | |
| Guest bedroom | Next to bed | Teasmade | |
| Kitchen | Entrance; Food preparation area | Washing machine; Microwave; Kettle | |
| Living room with dining space | Entrance; Sitting area | TV | |
| Living room | Sitting area | ||
| Hallway | On the wall | ||
| 2 | Bedroom | Next to bed | |
| Kitchen | Cooking area | Washing machine; Kettle, Toaster, Bread maker | |
| Living room with dining space | Dining area; Sitting area | TV; Ironing/Vacuum | |
| Living room | Sitting area | Laptop | |
| Study | Book shelf | ||
| Hallway | On the wall | ||
| 3 | Bedroom | Next to bed | |
| Kitchen | Food preparation area; Cooking area | Washing machine; Kettle, Toaster | |
| Dining room combined with study | Sitting area; Next to desktop computer | Desktop computer | |
| Living room | Sitting area | ||
| First utility room | Near entrance | ||
| Second utility room | Near entrance | ||
| Hallway | On the wall | Vacuum cleaner |
| Household | Sensor Boxes | Energy Monitors | Total |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 |
| Time | Primary Activity | Secondary Activity | Location | Devices |
|---|---|---|---|---|
| 08:00–08:10 | Preparing meal | Listening to radio | Kitchen | Kettle, Radio |
| 08:10–08:20 | Eating | Watching TV | Living room | TV |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 18:00–18:10 | Preparing meal | ─── | Kitchen | Oven |
| 18:10–18:20 | Preparing meal | ─── | Kitchen | Oven |
| Activity | Household 1 | Household 2 | Household 3 | |||
|---|---|---|---|---|---|---|
| Number of Occurrences | Percentage of Time | Number of Occurrences | Percentage of Time | Number of Occurrences | Percentage of Time | |
| Sleeping | 5 | 36.94% | 5 | 31.08% | 5 | 40.28% |
| Preparing meal | 8 | 2.08% | 10 | 2.78% | 7 | 3.47% |
| Making hot drink | 13 | 2.26% | 11 | 1.91% | 2 | 0.52% |
| Eating | 10 | 4.17% | 8 | 3.65% | 8 | 3.30% |
| Watching TV | 13 | 16.15% | 2 | 1.39% | / | / |
| Listening to radio | / | / | 15 | 10.42% | 6 | 17.88% |
| Doing Laundry | 1 | 0.17% | 6 | 1.04% | 2 | 2.43% |
| Sensor Reading | Temperature | Humidity | Light | Range | Sound |
|---|---|---|---|---|---|
| Household 1 (kitchen) | 0.94 | 0.75 | 0.90 | 0.56 | 0.88 |
| Household 1 (living/dining room) | 0.93 | 0.89 | 0.95 | 0.21 | 0.86 |
| Household 2 (living/dining room) | 0.49 | 0.62 | 0.85 | 0.33 | 0.57 |
| Household 3 (kitchen) | 0.90 | 0.92 | 0.97 | 0.29 | 0.80 |
| Household 3 (dining room/study) | 0.83 | 0.90 | 0.71 | 0.20 | 0.57 |
| Household | Activities | Feature Sets | LD |
|---|---|---|---|
| 1 | Sleeping | (MS_light_living/dining-room, Gap_CP_light_bedroom) | 11.9 |
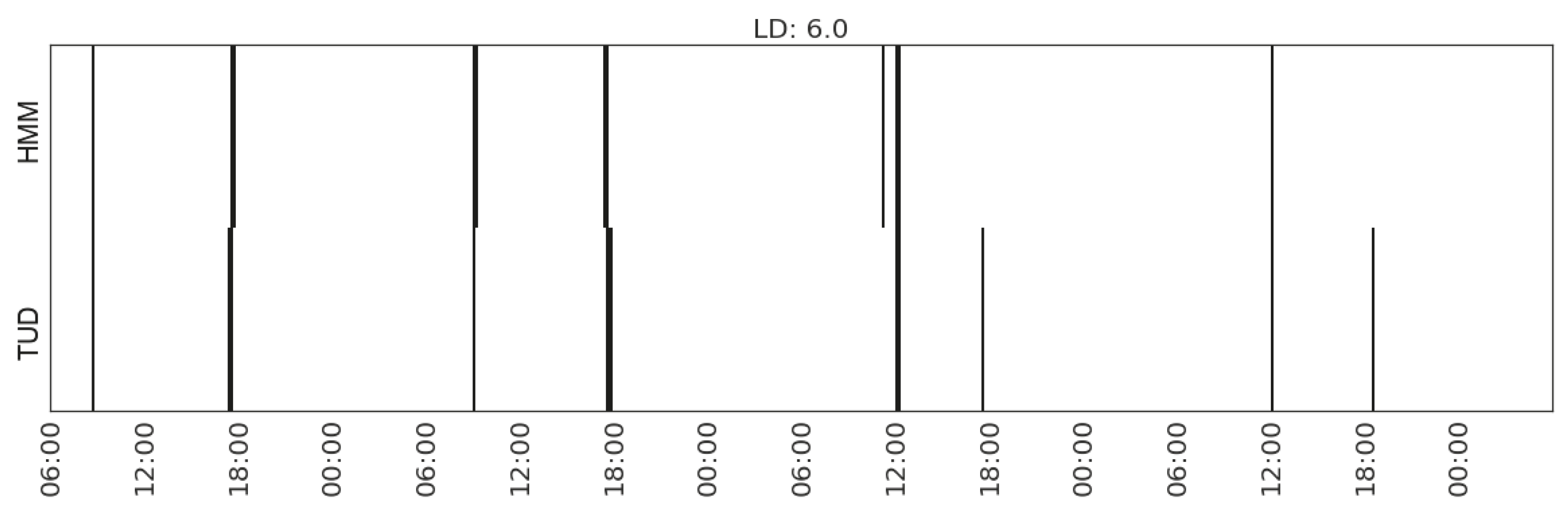
| Preparing meal | (MS_watts_total, MS_watts_microwave) | 6.0 | |
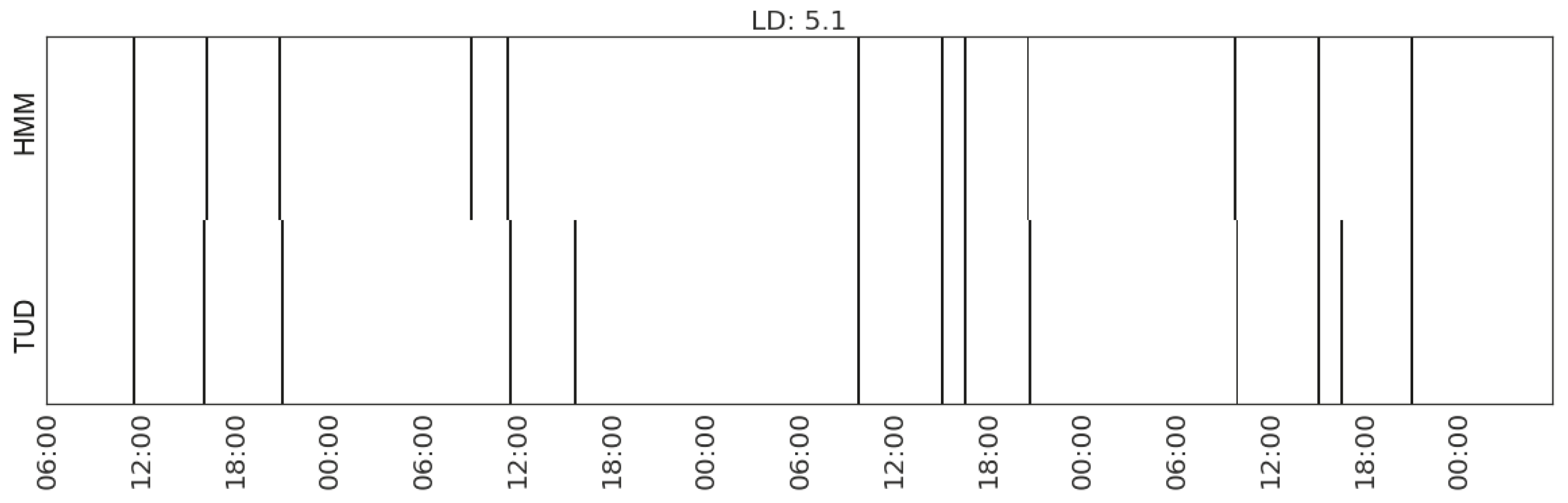
| Making hot drink | (MS_watts_kitchen-appliances) | 5.1 | |
| Eating | (MS_watts_total) | 17.0 | |
| Watching TV | (MS_watts_TV) | 16.6 | |
| Doing laundry | (MS_watts_washing-machine) | 0.7 | |
| 2 | Sleeping | (CP_light_kitchen(1), CP_light_bedroom, MS_temperature_living/dining-room(2)) | 16.7 |
| Preparing meal | (MS_watts_kitchen-appliances) | 11.2 | |
| Making hot drink | (MS_sound_kitchen(1)) | 11.6 | |
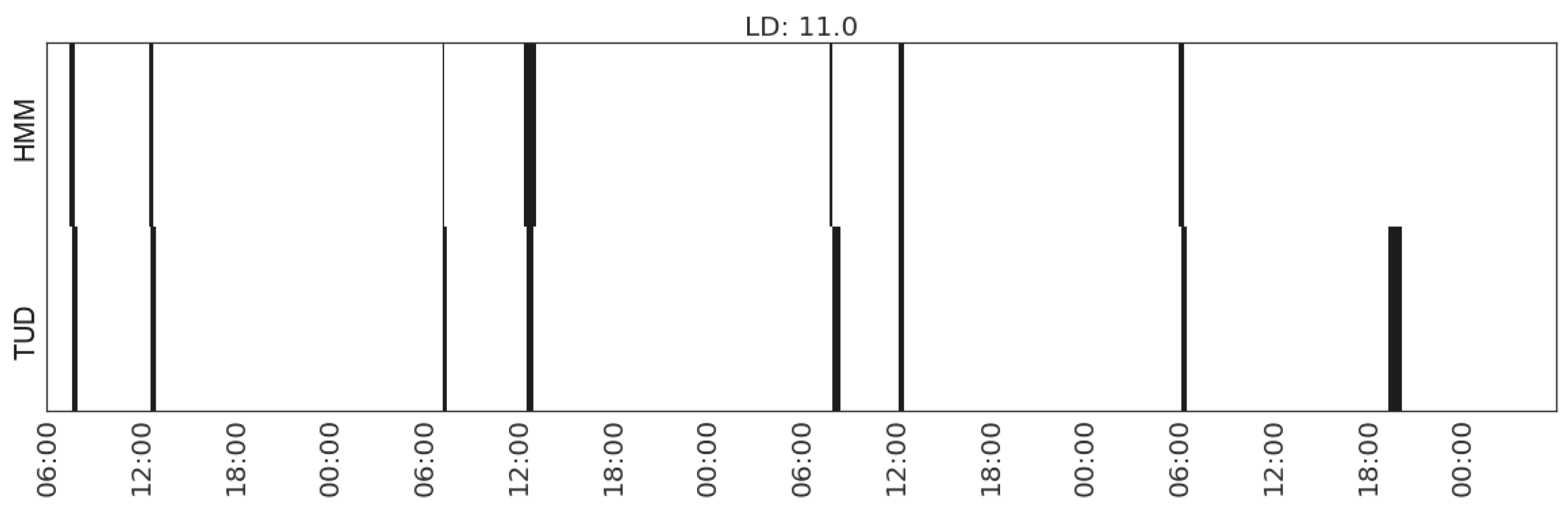
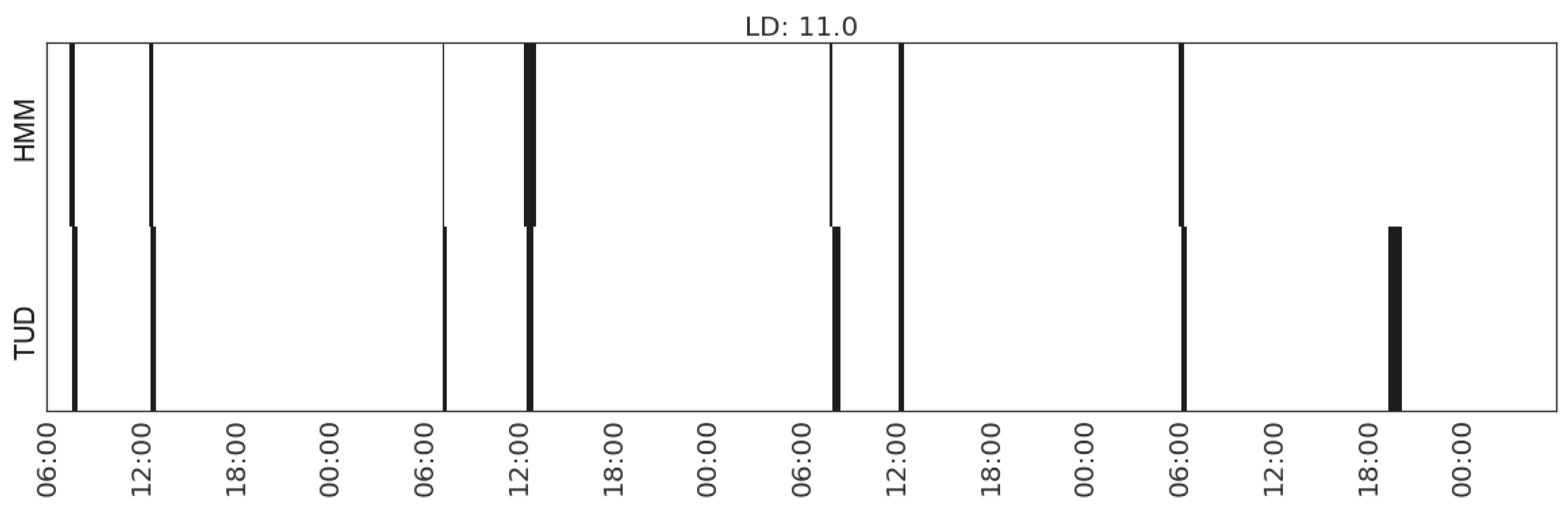
| Eating | (MS_watts_kitchen-appliances, MS_range_living/dining-room(2)) | 11.0 | |
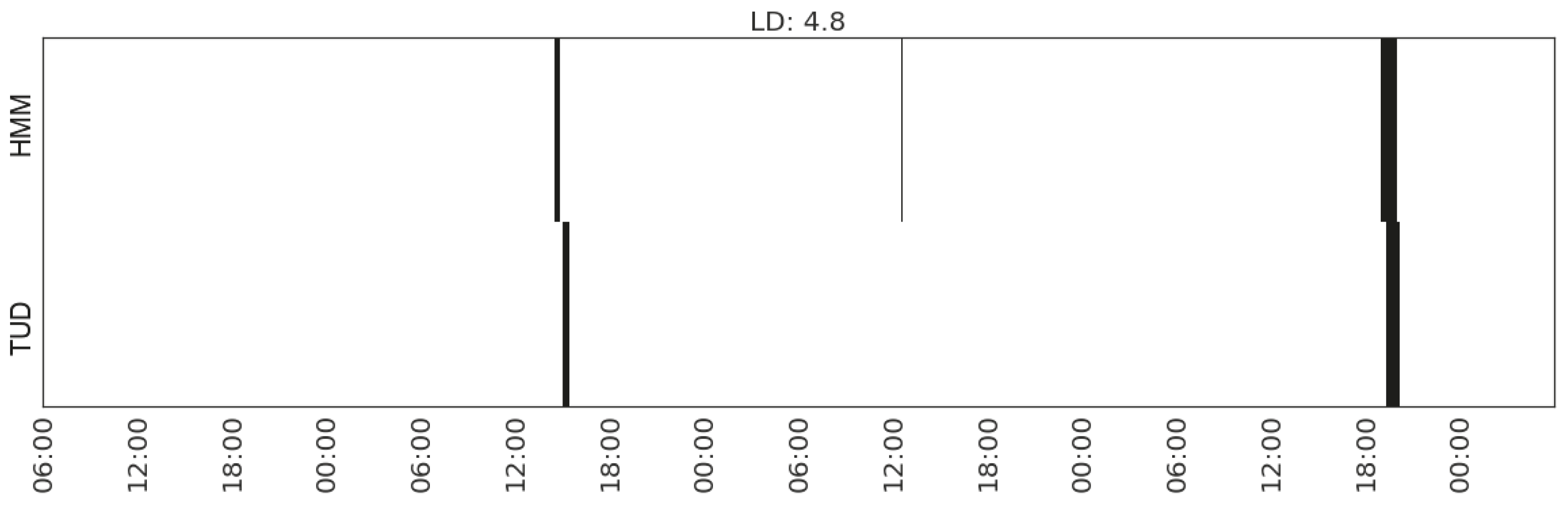
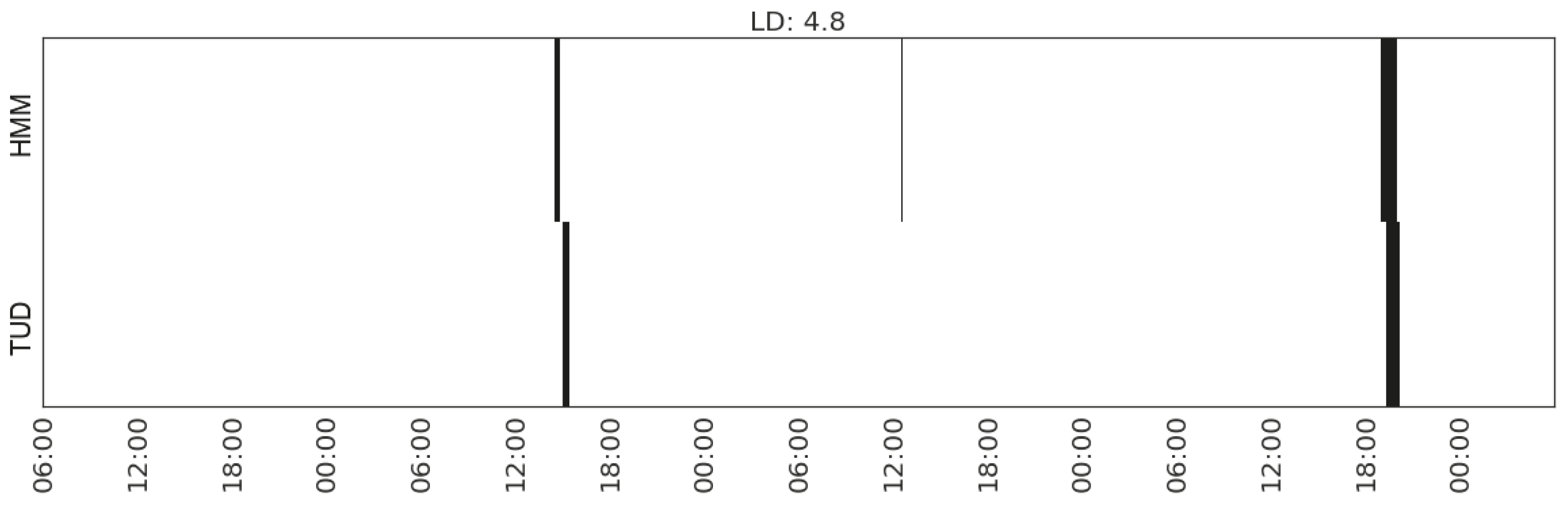
| Watching TV | (MS_watts_TV) | 4.8 | |
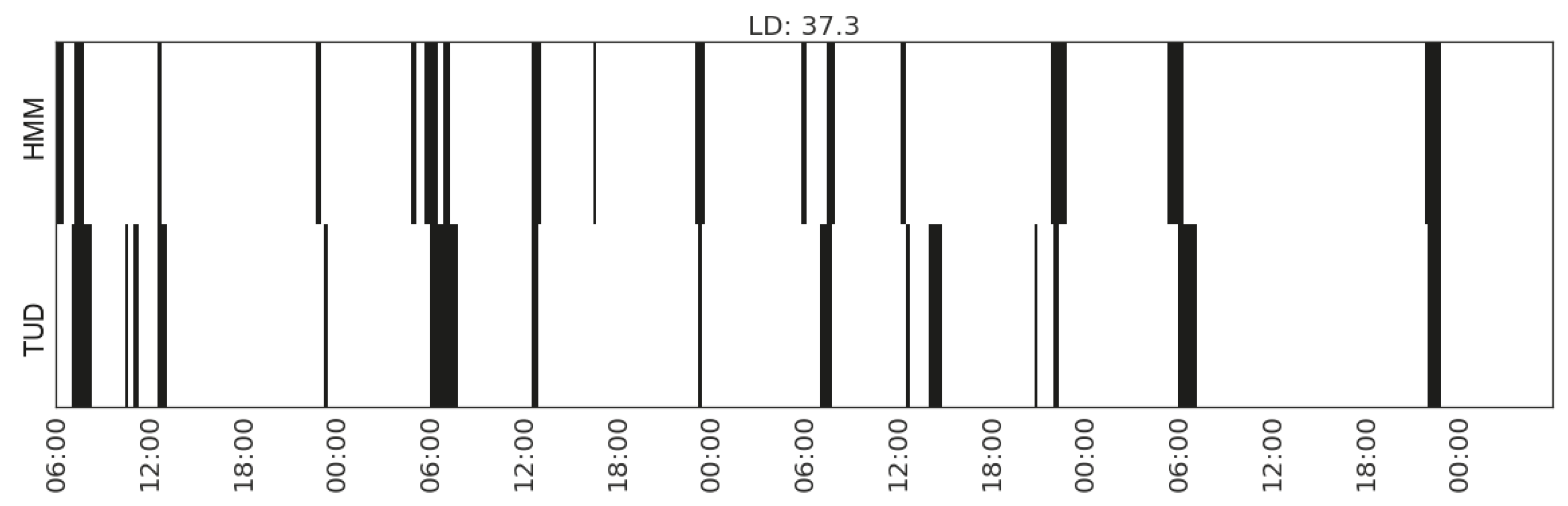
| Listening to radio | (CP_range_hallway, MS_watts_kitchen-appliances, MS_range_bedroom) | 37.3 | |
| Doing laundry | (CP_watts_total, CP_watts_kitchen-appliances, CP_watts_washing-machine) | 12.1 | |
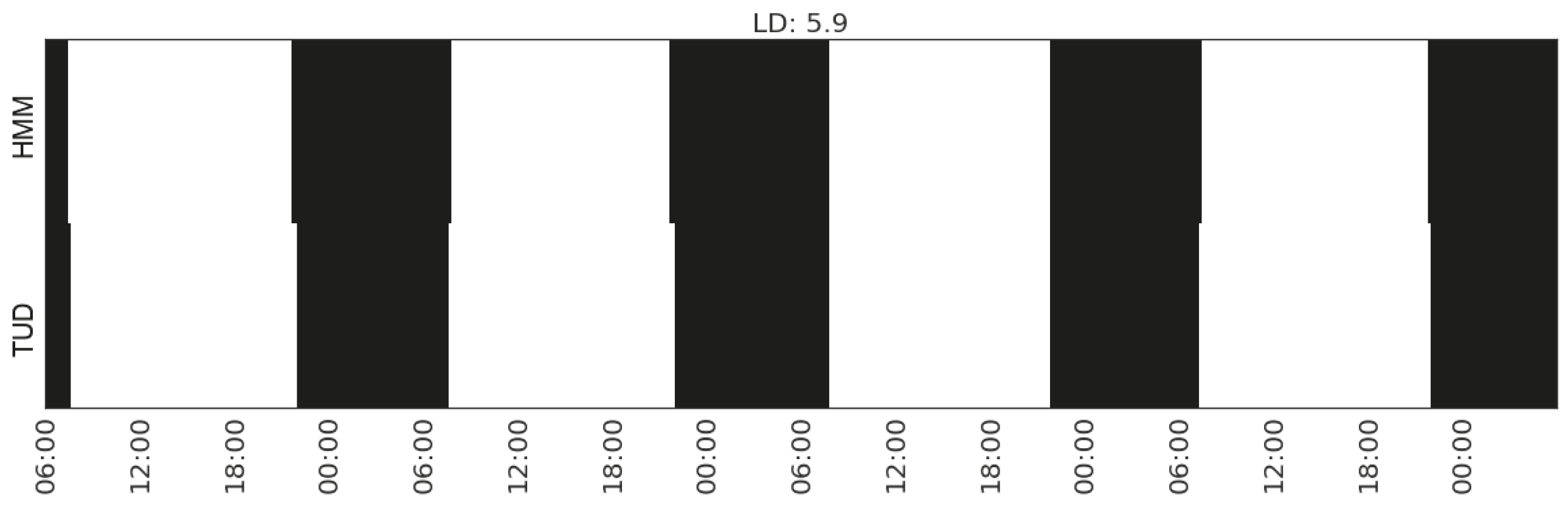
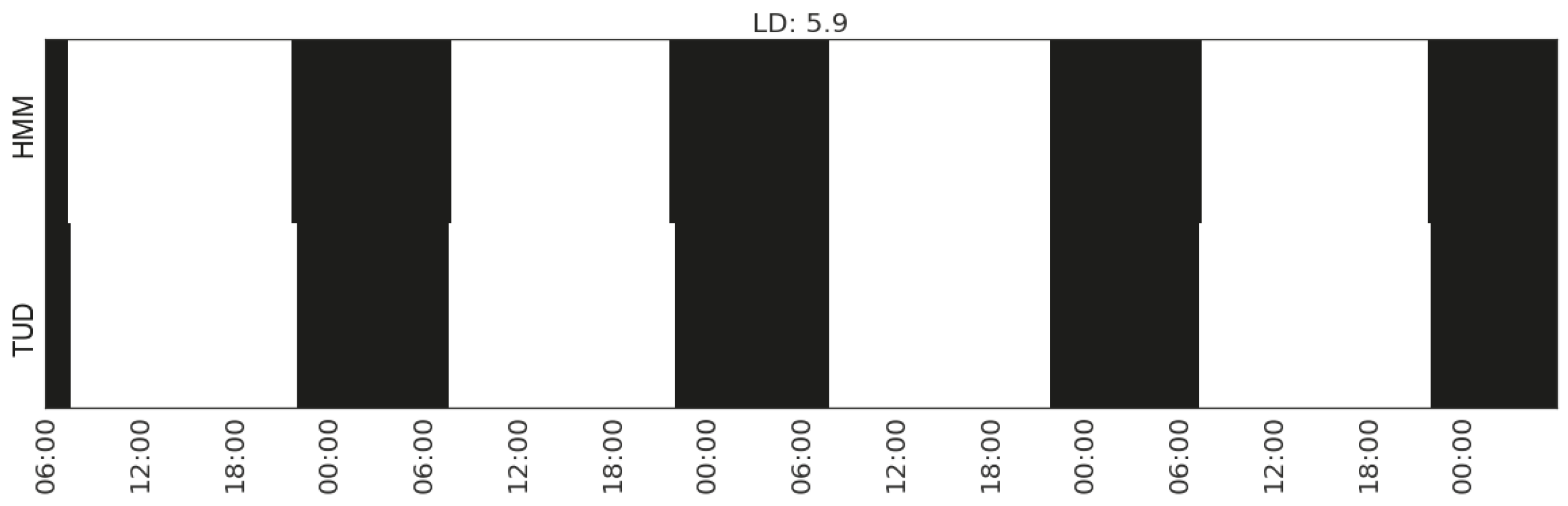
| 3 | Sleeping | (Gap_CP_range_living-room) | 5.9 |
| Preparing meal | (MS_range_kitchen(2), MS_watts_PC) | 26.1 | |
| Making hot drink | (CP_humidity_second-utility, CP_temperature_kitchen(2), CP_humidity_bedroom) | 1.7 | |
| Eating | (MS_range_kitchen(2), CP_temperature_dining-room/study(1)) | 16.0 | |
| Listening to radio | (MS_sound_living-room) | 37.2 | |
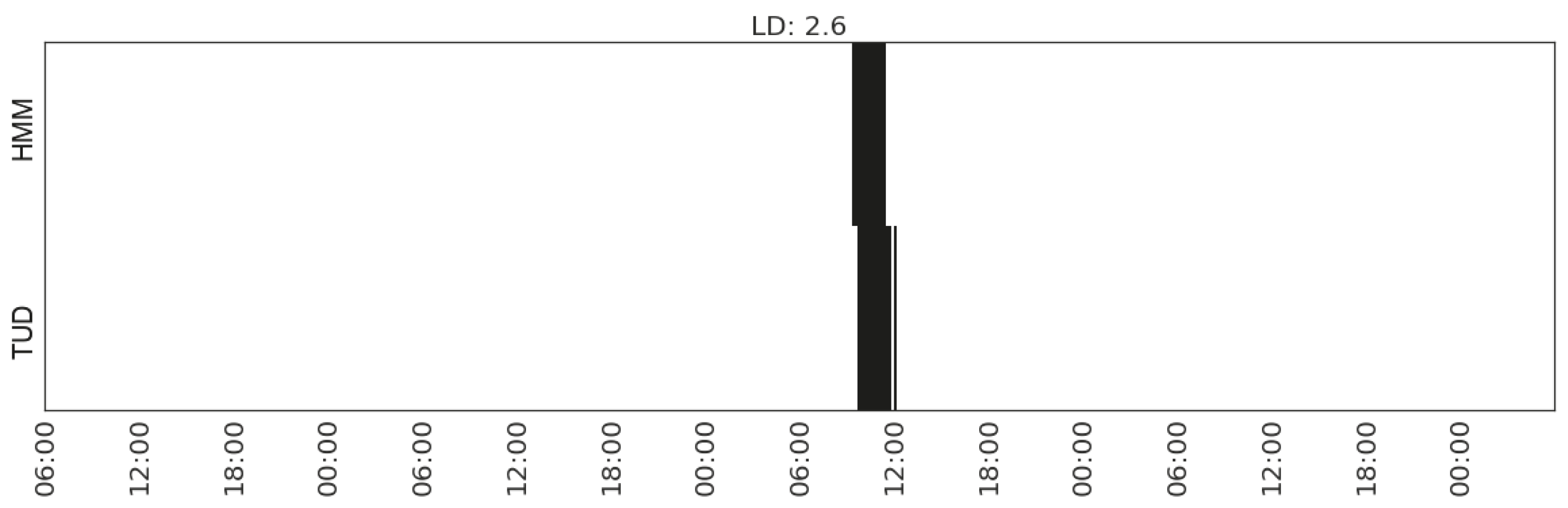
| Doing laundry | (MS_watts_washing-machine, CP_watts_washing-machine) | 2.6 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Pozza, R.; Gunnarsdóttir, K.; Gilbert, N.; Moessner, K. Using Sensors to Study Home Activities. J. Sens. Actuator Netw. 2017, 6, 32. https://doi.org/10.3390/jsan6040032
Jiang J, Pozza R, Gunnarsdóttir K, Gilbert N, Moessner K. Using Sensors to Study Home Activities. Journal of Sensor and Actuator Networks. 2017; 6(4):32. https://doi.org/10.3390/jsan6040032
Chicago/Turabian StyleJiang, Jie, Riccardo Pozza, Kristrún Gunnarsdóttir, Nigel Gilbert, and Klaus Moessner. 2017. "Using Sensors to Study Home Activities" Journal of Sensor and Actuator Networks 6, no. 4: 32. https://doi.org/10.3390/jsan6040032
APA StyleJiang, J., Pozza, R., Gunnarsdóttir, K., Gilbert, N., & Moessner, K. (2017). Using Sensors to Study Home Activities. Journal of Sensor and Actuator Networks, 6(4), 32. https://doi.org/10.3390/jsan6040032