1. Introduction
The advent of sensor rich pervasive devices, including smartphones and wearables, promises a significant shift in the paradigm of human behavior studies. As a result, this has led to the introduction of new concepts, such as the Quantified Self, and has allowed us to re-focus existing concepts such as lifelogging and wearable computing. Lifelogging can be defined as, “
a form of pervasive computing, consisting of a unified digital record of the totality of an individual’s experiences, captured multi-modally through digital sensors and stored permanently as a personal multimedia archive” [
1]. In other words, lifelogging allow us to capture, from a variety of data sources, rich information about our environment and ourselves [
2] and has several use cases such as memory augmentation [
3]. Quantified Self is a more general term that has been used for a movement to collect daily information, via digital devices. Lifelogging could be interpreted as a subset of Quantified Self.
Both smartphones and wearable devices (e.g., smartwatches) can be used to collect information on human behavior. However, wearable devices such as fitness trackers and smartwatches have two major advantages over smartphones: (i) they are constantly connected to the skin and (ii) their location on the body is fixed [
4]. These features make them more capable than smartphones to collect physiological data, such as heart rate and physical activity.
Although wearable devices can be seen as an ideal platform to collect data, there have been few efforts that have explored this avenue of wrist mounted wearable data collection in comparison to smartphones. In contrast, several research efforts have benefited from collecting contextual information from users’ smartphones such as Eagle
et al. [
5], Aharony
et al. [
6], Kiukkonen
et al. [
7] and Wagner
et al. [
8]. One argument suggests, despite the success and market acceptability of wearables, these devices have a short lifespan, with some studies suggesting that many wearable users churn (abandon, or upgrade the device) after as little as six months [
9]. An older argument suggests that both wearables and smartphones are too focused on data collection (continuous context sensing) and that there is a lack of compelling and useful applications or even efficient data visualization for end users [
10]. Despite efforts in filtering the content to wearable displays and improving the usability of wearables [
11], recent critiques on the usability of wearables [
12], demonstrates that this argument could be still valid.
We believe the short lifespan of wearables [
13] originates from a lack of meaningful reflection outlets and appropriate data analysis methods that result in applications that have not been widely accepted by the end-user. For example, existing tools often provide limited visualization mechanisms, such as single variable visualization, but users are seeking correlations between their activities [
14]. Furthermore, there is a body of research that focuses on only analyzing single pieces of specific information, such as activity [
15] and location recognition through mobile devices [
16]. However, whilst they do provide promising results, these data analytical approaches are still not widely adopted in the end-user market.
In this article, we have provided our overview of the difficulties that researchers and developers may face while developing these systems. In doing so, we report on three lifelogging data collection studies that we have undertaken. Two of these studies utilized smartphones, where participants were required to install the lifelogging app
UbiqLog [
17] on their phones. These studies included fourteen different brands of phones, among 57 participants (three participants were repeated in both studies). The third study used a smartwatch, as an information collection tool to collect physical activity, location and self-reported mood.
During these studies, we have faced several common challenges, including user-centric and technical obstacles. As a result, this often forced a re-design of the data collection requirements on-the-fly or occasionally we have had to terminate the study (as was the case for the first study with smartphones). Therefore, we believe that by classifying and describing these challenges, it will be helpful for future research effort that involve personal information collection, such as the quantified self, lifelogging, and personal informatics.
Our studies were designed to collect a significant number of traces among users in an environment near to the real-world setting. In this context, we have (i) relied on
participants’ devices, which are diverse in terms of different software and hardware configurations; (ii) participants are able to
change the configuration of the data collection module and
disable/enable a sensor, which is similar to the real world and no mandatory configuration is required (the next section describes more about our data collection tools); and (iii) we recruited volunteers with the understanding there will be
no reward for their participation in the study. Therefore, volunteers who were generally interested in using such a system were recruited, with the goal to get closer to how users interact with these applications in the real world. One can argue that this approach would introduce some bias if those interested in the study are mainly not individuals with low IT skills. However, this is the same scenario when a user installs an application from the market. Moreover, our smartphone based study settings are much closer to the real-world settings than previous experiments, which hand over specific devices to users, or support the experiment with rewards [
5,
6,
7].). However, due to the lack of wide availability of smartwatches at the time of running our studies, the smartwatch study hands over a device to the users.
This paper contributes by discussing the main findings of our studies as follows: (i) to reduce churn, it is useful if the developer can
minimize the need for manual intervention, while continuously collecting information, even optional annotation. (ii) While mobile and wearable devices collect data, there is an element of
uncertainty and data loss that originates from manual sensor configuration changes (e.g., disabling WiFi to preserve battery) or sensor quality (e.g., geographical coordinates read from Cell ID). This should be considered while analyzing the collected data. (iii) There is a
lack of multivariate reflection methods to analyze the collected daily life information, e.g., visualizing incoming calls based on the location and time of the day. Privacy issues [
18] and battery limitations [
19,
20] are important but known issues, and thus we do not list them as our novel findings. Nevertheless, we have tackled them from another perspective, which is worth further explanation. In particular, we have summarized these challenges in a single report, which we think could benefit the community and further research in this area.
The remainder of this paper is organized as follows: the next section describes the related work in the field. This is then followed by a description of our study materials and methods. Afterwards, we explore the challenges that the area faces. This is followed by discussions of our findings, before concluding.
3. Materials and Methods
This section briefly describes the tools that have been utilized for our studies. Afterward, to give an overview about the data collection process, a summary for each study has also been included. In total, we have conducted three user studies. Two studies utilized the Android smartphones of the participants (mobileStd(s) 1 and 2) and the other study (watchStd) used a specific brand of smartwatch, with a customized version of the Android operating system, named i’m Droid. It is important to note that the objectives of mobileStd(s) are different than watchStd. In other words, there will be no unique generalizable hypothesis among our studies. In contrast, challenges and difficulties that we have encountered are common among these studies.
3.1. Study Instruments
For mobileStd(s) 1 and 2, we used
UbiqLog [
17].
UbiqLog [
36] is an open source smartphone based lifelogging tool. It provides an interface that enables users to access the list of available sensors and also allows them to enable/disable specific sensors or even change the sampling interval. It also provides visualizations to users about their past activities. In particular, it includes Application usage, Calls, SMS, Physical Activity, Location traces, and Bluetooth proximity visualizations.
To preserve the users’ privacy, participants in mobileStd 1 could manipulate or remove the data before uploading it to the server. They could export their data and annonymize/pseduonymize them through a tool called LiDSec [
37]. However, due to user feedback, mobileStd 2 performed the annonymization and pseudonymization process automatically, and thus there is no need for this type of intervention.
In terms of manual data entry, mobileStd 1 only requires manual data manipulation for the sake of privacy at the data at the end of the data collection phase. However, mobileStd 2 and watchStd both required manual data entry during the data collection phase. The manual interventions in mobileStd 2 are manual “mood” data entry and controlling the “sleep-monitoring” app,
SleepBot [
38]. SleepBot requires users to click a button while they go to sleep and click the wakeup button after waking up. mobileStd 2 uses Positive and Negative Affect Schedule (PANAS) [
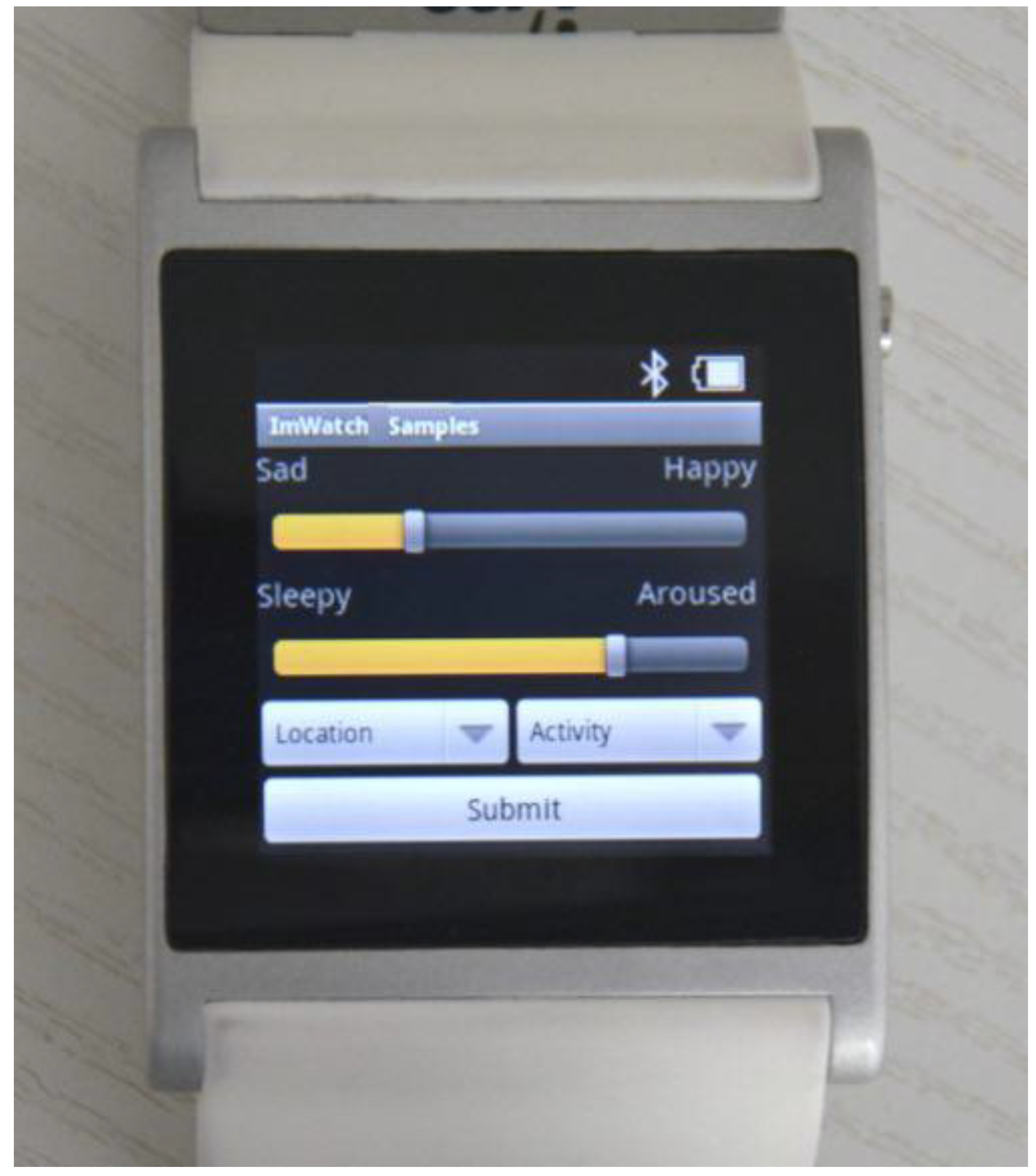
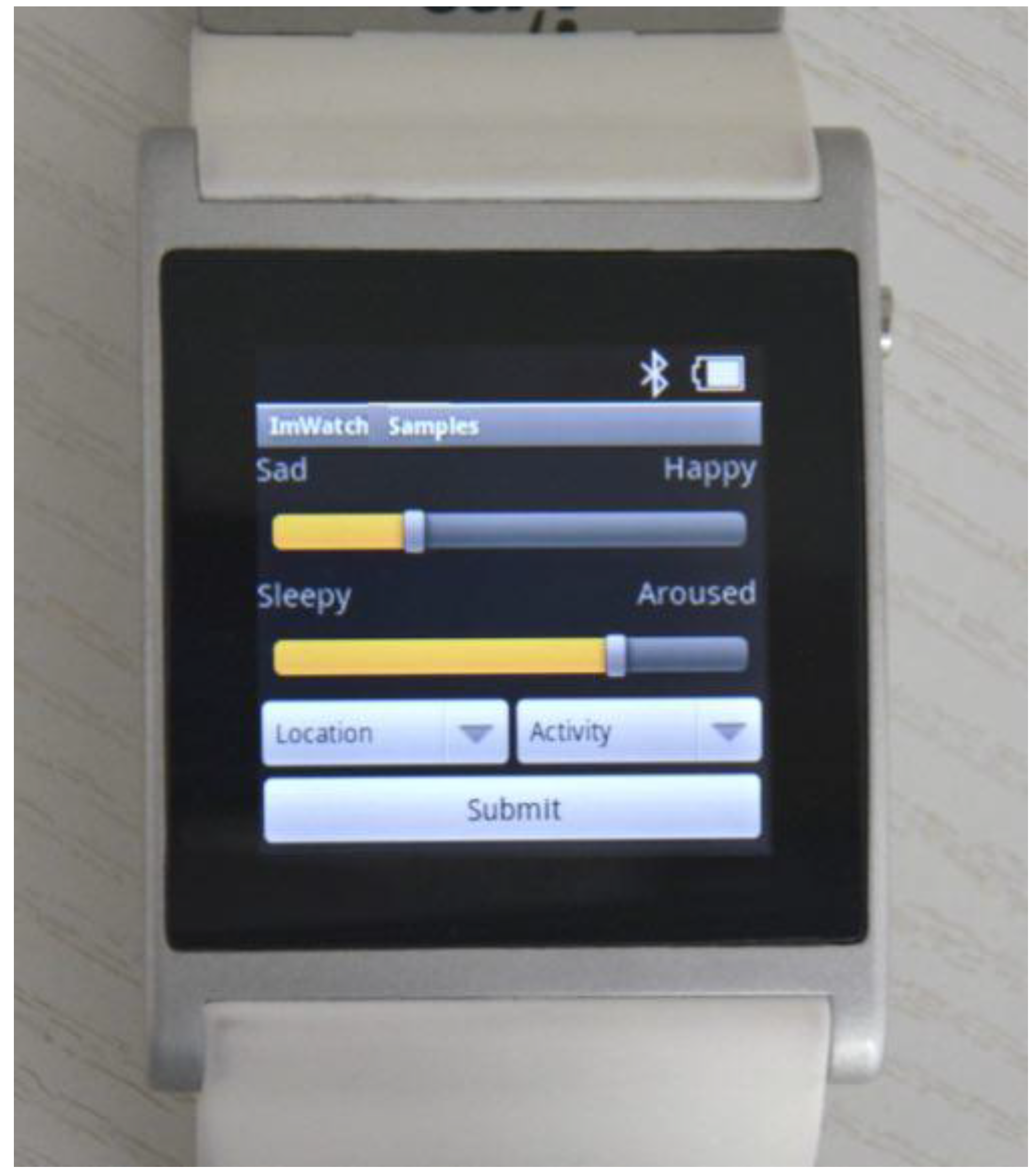
39] data collection protocol, which is used for describing emotion. Once a day, users were required to summarize their mood using the five terms from the given PANAS scale. Similarly, watchStd also asked users four times per day to explicitly enter their current mood, as well as location (home, work, leisure), and activity data. However, watchStd uses Circumplex affect model for manual mood data collection, due to the difficulties of PANAS scale terms, which will be explained later. In terms of data entry, for the watchStd study, a simple smartwatch data collection application has been implemented (see
Figure 1).
As a development platform, we used
i’m Watch smartwatch [
40], as this was the only brand available at the time of development (2013 and early 2014). This device uses a custom built Android version of
i’m Droid, and collects users’ moods and locations as explicit inputs within the users’ physical activities as implicit inputs. Physical activity terms are inspired by Google Play API services, and collected by using the accelerometer sensor, automatically. Mood annotation terms are adopted from the Circumplex affect model [
41], with two orthogonal dimensions: pleasure (from sad to happy), and activeness (from sleepy to aroused). If the user shakes the watch, then a pop-up will appear to let them enter both mood and location manually.
Table 1 summarizes the data collection elements, the duration spent on collecting data, and the number of participants in each study. The Manual Task/Data column shows tasks or data entries that users should do manually.
Before the commencement of all studies, participants have been briefed about the privacy implications that they may face as a result of participating. In all instances, we have sought their agreement by the administration and signing of ethics consent forms.
Figure 1.
Smartwatch manual data collection interface.
Figure 1.
Smartwatch manual data collection interface.
3.2. Study Setup for mobileStd(s) 1 and 2
Objective: With the exception of camera images, one limitation for lifelogging research is the lack of robust data analytical methods [
10]. Although a multi-sensor data collection applications has been deployed in the wild [
29], there is still no open and accessible dataset available. As a result, this makes such experiments not deployable in the real-world, because in the real-world different people use different devices. It has been this distinct lack of a real-world dataset that motivates us to conduct both mobile phone based studies. We believe that a large dataset could benefit several mobile-based human-centric applications, such as personal transportation quantification, daily habit mining, health monitoring,
etc. A preliminary requirement of these use cases is a set of data analytical methods. However, discussing such methods has not been the scope of this paper. We have described the need for such a dataset to volunteers and have also described Quantified Self systems (for the ones who are not familiar). We then requested that individuals who are interested in using lifelogging applications that collect/share their smartphone data to participate in our studies (with no reward).
As previously stated, mobileStd(s) 1 and 2 have utilized the UbiqLog application to collect data. In particular, these studies have created a large mobile phone lifelogging dataset with real-world settings. mobileStd 1 produced 6.1 million and mobileStd 2 produced about 9.8 million records of contextual information about the users. Each record represents a sample from the observation in the dataset, as opposed to just raw sensor data, such as raw accelerometer data. For instance, the following are two sample records:
{“Application”: {
“ProcessName”: “com.skype.raider”,
“start_time”: “15 October 2013 11:21:40 AM”, “end_time”: “15 October 2013 11:29:12 AM”,}}
{“SMS”: {“Address”: “9999999”, “Type”: “send”,
“Time”:“24 December 2013 11:23:01 PM”, “Body”: “anonymized”}}
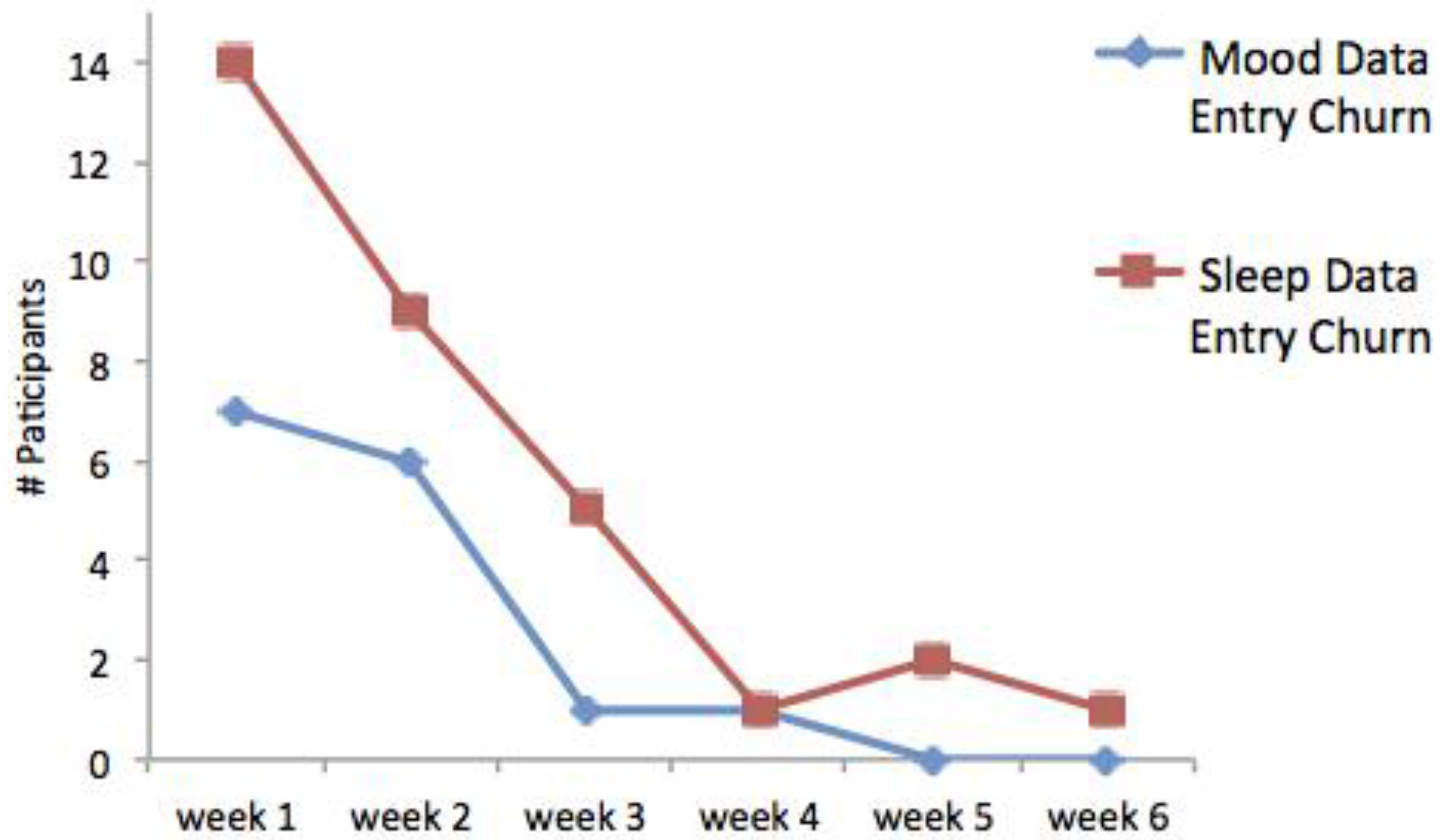
Participants: The mobileStd study has been conducted twice, firstly with 25 participants, age range 19–22, (mean = 21.1, SD = 1.4) consisting of 18 females and 7 males, and secondly with 35 participants, again age range 19–32, (mean = 22.5, SD = 5.6) consisting of 25 females and 10 males. All participants were university students and volunteered to participate in the study. To simulate real-world deployment, mobileStd relies only on users who own a smartphone. Moreover, there is no reward for participation and we asked only for participants that volunteered. One major obstacle that we faced was the fragility of having a no reward study, and thus 19 participants withdrew from the study. We started mobileStd 2 study with 54 participants and by the end had 35 left. Moreover, mobileStd 1 started with 32 participants and when we terminated the study only 25 participants remained.
During the volunteer enrollment process, we described to them about the privacy implications and asked them to sign an ethical consent form, to give us access to their data.
Procedure: As previously stated, in order to collect the data, participants were required to install
UbiqLog, on their phone. They were also required to report daily on their mood, via the PANAS scale [
39], and use a sleep tracking app,
SleepBot.
We repeated the study twice for two reasons: (i) Obtrusiveness of WiFi and Bluetooth sensors were turned on automatically by the application; and (ii) privacy issues that cause participants to leave the study and thus forced us to suspend the first study. Both reasons will be explained in more detail in the next section. This means that both mobileStd(s) 1 and 2 have unique motivations and objectives, but because of the aforementioned reasons, we have been forced to repeat the study.
After the second study, we conducted a short (10 to 15 min) semi-structured interview. During this time we asked the participants about their general experiences of using the app and how they might get a reflection of their data through visualizations. The interview text was then analyzed, through theme extraction [
42], which assisted us in identifying challenges that were associated with the data collection.
Collecting mood and sleep data, was more challenging task. Due to the nature and burden of manually entering data, participants lacked motivation to complete these tasks. As a result, not enough data were able to be collected. Hence we cannot provide any argument for these types of information.
3.3. Study Setup for watchStd
Objective: As it has been previously stated, the ubiquity of smartwatches makes them an ideal candidate for continuously collecting vital signs and contextual information. Our objective in this study was to understand the correlation, if any, between three variables: mood, physical activity, and location. As such, the following study reports about the challenges and capabilities of using smartwatches for lifelogging. Therefore we have created and used the simple smartwatch app that has been described previously. Findings of this study have been used to create a resource efficient smartwatch framework for contextual data collection [
20].
Participants: The watchStd study has been conducted on 14 participants, age range 20–44, mean = 33, and SD = 9.72. Eight participants were students (graduate students) and five were other professionals, such as business consultants, biologist and lecturers. Participant selection is based on a formative pilot study. This study enabled us to identify volunteers who would like to know more about the origins of their stress and the correlation of stress to other spatio-temporal factors. Moreover, participants believe quantifying their emotions, might improve their control over stressful situation.
Procedure: As previously stated, for this study we have implemented a simple smartwatch data collection application that has been described on the i’m Watch smartwatch. We lent each participant a smartwatch for a period of about 30 days. Although we have argued that restricting the experiment to a specific hardware brand limits the acceptability of the results in the real-world, at the time of running our study (2013 and early 2014) the only programmable watch available in the market of the target city was the i’m Watch. Therefore, unlike mobileStd, watchStd participants are not using their own device and the study is limited to using a specifically configured piece of hardware.
Similar to mobileStd 2, after the study we conducted a short (10 to 15 min) semi-structured interview to learn about the users’ experiences with using the watch and its data collection application. We then analyzed the interview text through theme extraction to identify challenges associated with smartwatch data collection.
5. Discussion and Findings
We have conducted three studies that collect daily life information through devices capable of such a requirement; two were based on smartphones and one was based on smartwatches. These studies have helped us to identify the challenges associated with continuous data collection from pervasive mobile devices.
It is important to note that battery and privacy issues have been stated in other research, and we have faced them too. Since there has been an extensive amount of research that focuses on these two topics, we do not repeat them here. Although we do acknowledge that they exist, they have been described as our challenges because we have faced them from another perspective. Furthermore, we have only listed findings that are not yet widely explored, and that we believe are novel. Based on our identified challenges, we recommend that the following topics are important to consider for further analysis.
5.1. Resolving Uncertainty and Data Loss
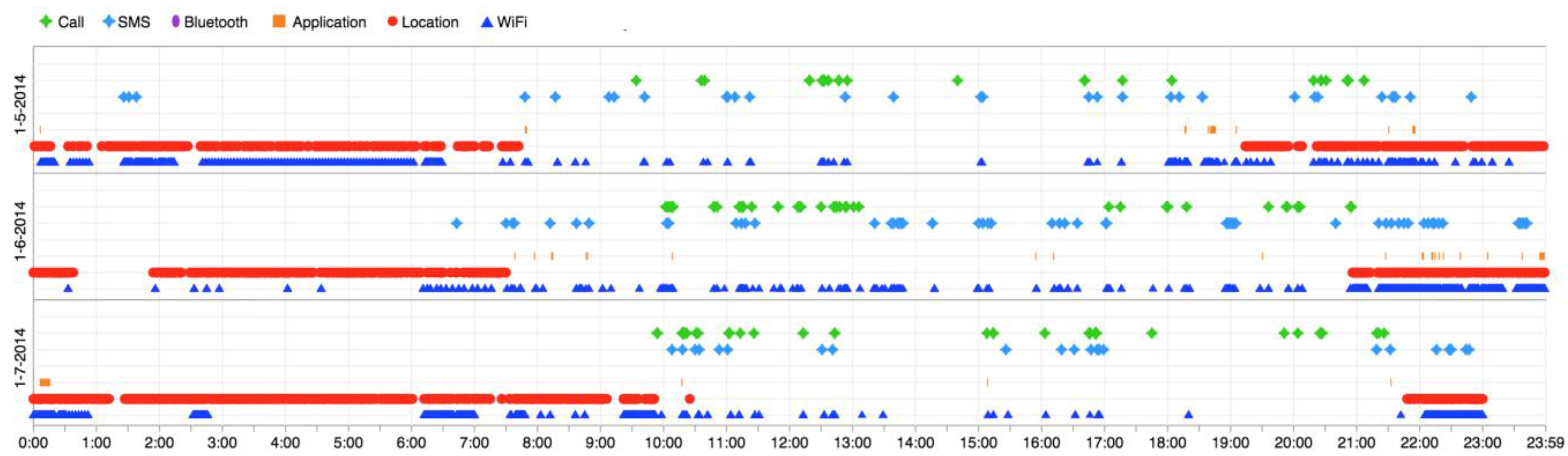
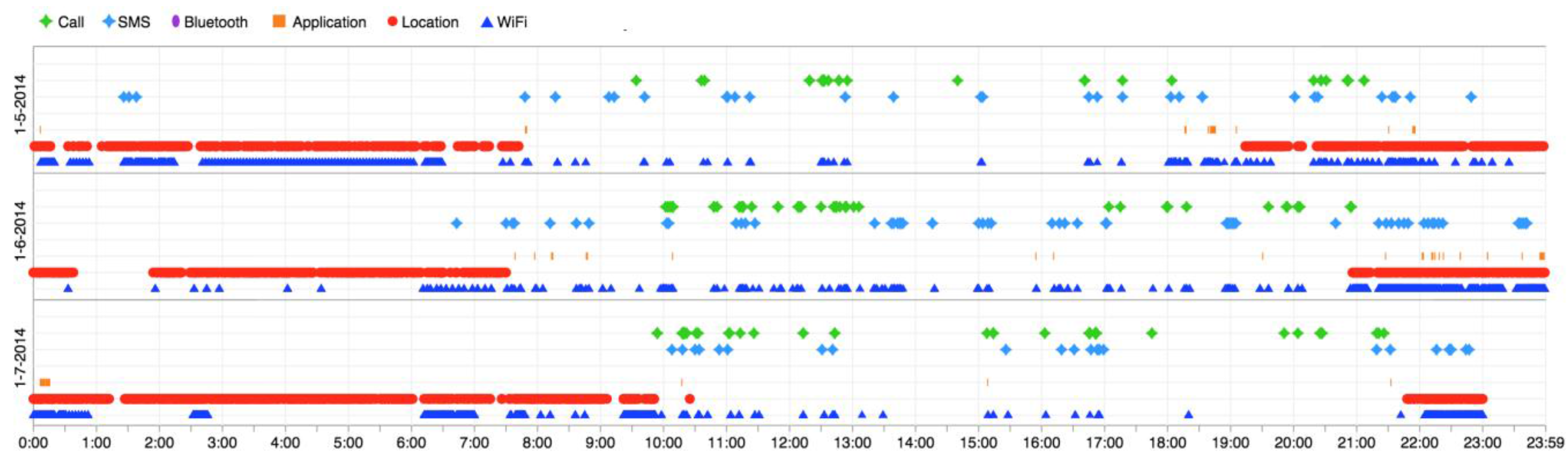
The three experimental studies that we have undertaken reveal that simply reading and storing the sensed information is not enough for collecting useful information about the user, unless it is not a specifically configured device with a guarantee about the quality of data. To have a realistic scenario, we need more rigorous data analysis methods to deal with the uncertainty of the data and to be able to estimate lost data. For instance,
Figure 4 shows the WiFi and Location coordinates detected by a user in three days. As it can be seen, there are daily repetitive data points from location and WiFi sensors in approximately between 8:00 p.m. to 8:00 a.m. This could be fed into a data mining mechanism to augment the quality of the data and resolve the uncertainty, via levering the history. However, delving deeper into analyzing the data is not in the scope of this paper.
We also suggest other reflection methods. For example, visualizations should consider reflection with uncertainty and sparsity. This is due to the fact that uncertainty affects the reflection (visualization) too. For instance, when Cell-ID location coordinates are being used instead of GPS they cannot easily be shown on a map, due to 800–1000 m precision. Uncertainty of location data have been considered by some continuous context sensing applications such as Moves [
48], but only for location data.
5.2. Minimizing Manual Intervention
Our studies show that users are not behaving according to our initial assumption when there is a requirement for manual intervention or they are able to manually change a sensor settings. For instance, the complexity of scientific mood data collection, such as PANAS, causes them to stop providing data. They also use a very small amount of words to describe their emotions. Furthermore, clicking a button for going to sleep and waking up is not widely accepted among users, unless there is a strong motivation behind it.
The same issue occurred in watchStd, with participants frequently forgetting to input their information. Manual input is also prone to errors and is subjective. There are still several Quantified Self efforts that rely on manual intervention [
49]. We can argue that this is an open topic for these applications and even this could be one of the reasons of significant churn [
9] from using wearable devices. The challenge of manual intervention has been recognized in some domain-specific user studies, such as food quantification [
50]. However, we believe it should be considered in all user-centric data collection approaches, irrespective of the motivation of the data collection process.
Recently, Nintendo announced a “touchless” sleep monitoring device [
51], which does not need manual user intervention while digitally tracking sleep. This illustrates the need to develop sensing devices with
silent and unobtrusive sensing capabilities. In other words, manual input and controlling should be kept to a minimum.
However, since it is not always possible to completely remove manual intervention, persuasive approaches for manual intervention, such as incentification and gamifications, have been used by quantified self applications. For instance, Foursquare (Swarm) supports socializing manual check-ins and awards users with badges.
5.3. Multivariate Reflection
One of the reasons for suspending mobileStd 1 was due to a high interest of using
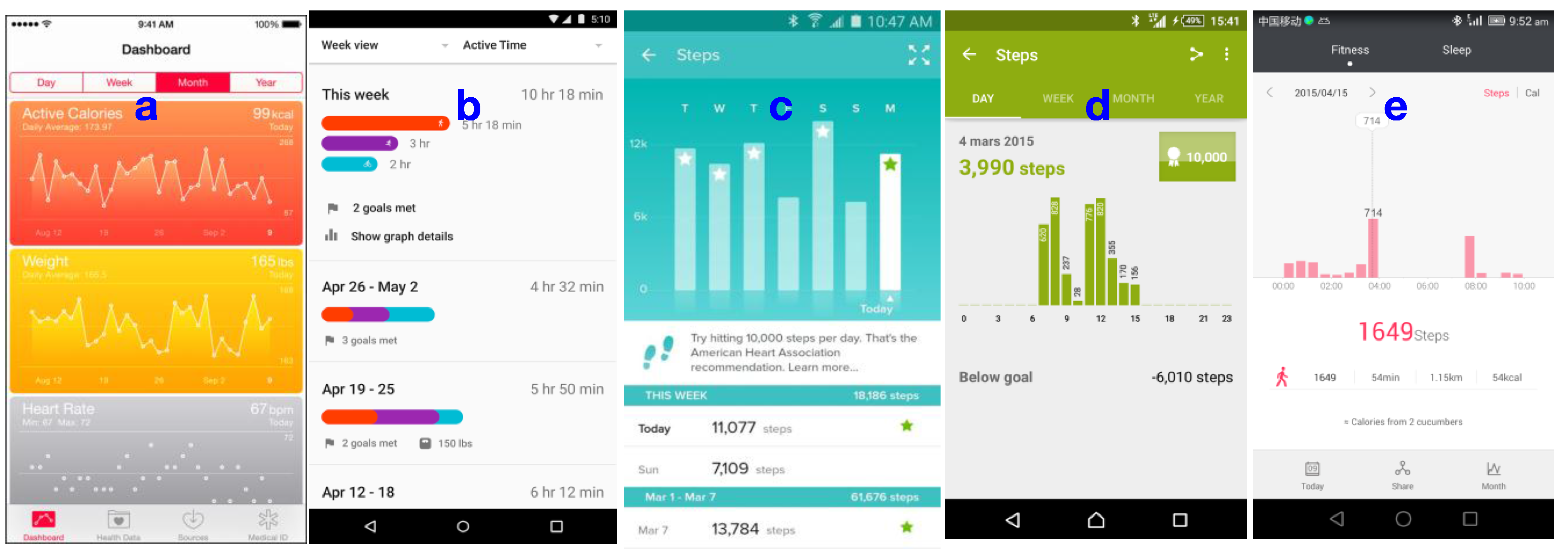
Ubiqlog visualizations and its impact on users’ behavior. The interview session included questions about further improvements of such a system. One of the most received feedbacks was a need for multivariate visualizations (or other reflection methods). During theme extraction, nine of 25 participants answered the further improvement questions with a visualization that could show what they have done in each location and time. The watchStd participants also expressed a desire to have a system that can automatically predict their mood. In other words, participants were looking for a reflection method that shows them correlations between their mood and social activity or locations. For instance, if visualization used as a reflection method, it should provide different data objects in the same screen, similar to
Figure 5a.
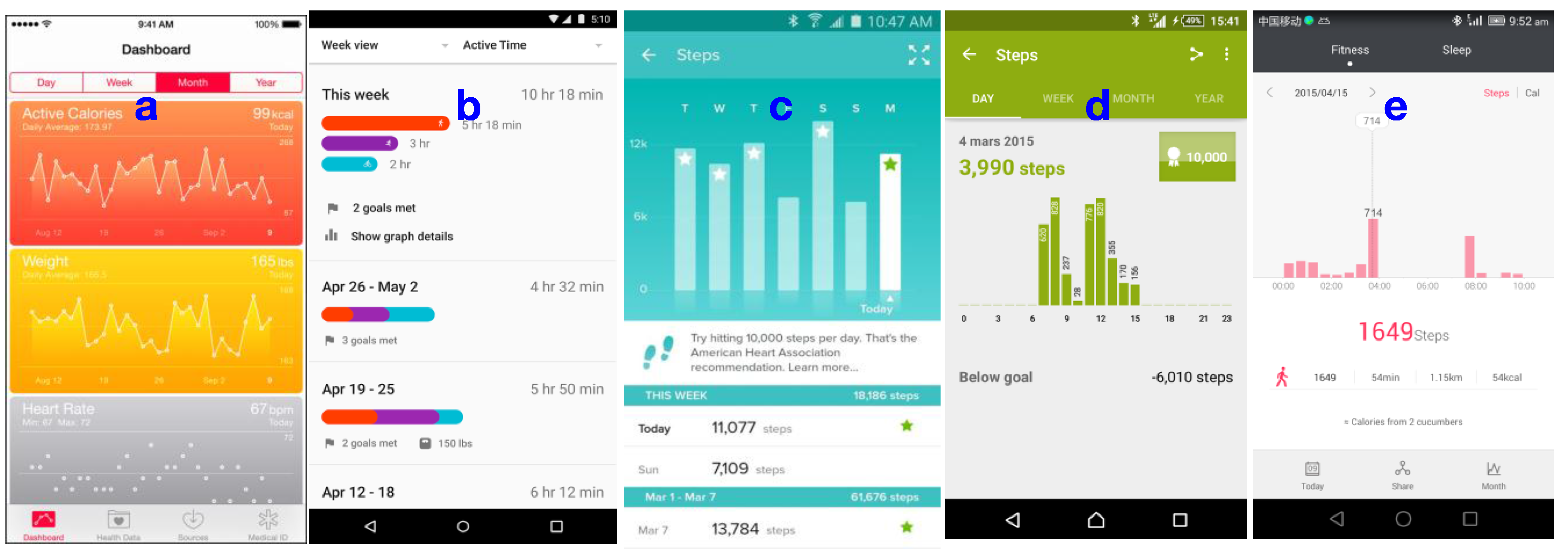
Figure 5 shows well-known activity tracking, Lifelogging and Quantified Self applications that are currently available in the market. Although all of the listed applications are capable of collecting more than one data object, except Apple Health, all of them provide a single variable visualization for historical data. For instance, Google API collects different forms of activities (running, walking, cycling, being inside vehicle, being still, heart rate), but visualizes only physical activities (partially multivariate) (
Figure 5b). Fitbit collects both physical activity and sleep, but visualizes them separately (
Figure 5c). Sony Lifelog collects physical activities, application usage, transport behavior, sleep, pictures taken, and communication, but its history-based visualization (retrospective view) only supports single variable visualizations (
Figure 5d). Nevertheless, Sony Lifelog time-line visualization supports multivariable visualization but only for one day. Huawei wear is similar to Fitbit, it collects both physical activities and sleep, but supports only single variable visualization (e).
Figure 5.
Five examples of Lifelogging and Quantified Self applications that are currently available in the market. (a) Apple Health; (b) Google Fit; (c) Fitbit; (d) Sony Lifelog; and (e) Huawei Wear. All of these applications are capable collecting data from multiple source of information, but only Apple Health provides multivariate visualization on its historical data. Google Fit also fuses different physical activities, but use separate visualizations for other data such as heart rate.
Figure 5.
Five examples of Lifelogging and Quantified Self applications that are currently available in the market. (a) Apple Health; (b) Google Fit; (c) Fitbit; (d) Sony Lifelog; and (e) Huawei Wear. All of these applications are capable collecting data from multiple source of information, but only Apple Health provides multivariate visualization on its historical data. Google Fit also fuses different physical activities, but use separate visualizations for other data such as heart rate.
Recently, the need to sense and analyze multiple information objects together has been identified. For instance, images in a Lifelogging scenario [
18] were recorded with location, timestamps and annotations such as emotions of faces pictured. Based on the user feedback of nine individuals, we have identified two appropriate links to connect different sources of information together,
i.e.,
time and
location. However, since location is not always available, time could be used to link several information objects together.
Figure 3 and
Figure 4 are visualizations examples that are based on linking information objects through time.
6. Conclusions
In conclusion, due to the advent of sensor-rich wearable devices and the proliferation of smartphones, data collection and analysis approaches are becoming more popular and thus the field of lifelogging and quantified self are growing rapidly. This paper discusses the main novel findings of our studies from two perspectives of user-centric and technical as follows: (i) the need to minimize as much as possible manual interventions, including optional annotations, while collecting continuous information. In this instance, if users required to continuously input data they will churn from using the system. (ii) While mobile and wearable devices collect data, there is a level of uncertainty and data loss that originates from manual changes or sensor quality. This should be considered while analyzing the collected data. (iii) There is a lack of multivariate reflection methods to analyze the collected daily life information, e.g., visualizing incoming calls based on the location and time of the day. In addition, we have also encountered battery limitations and privacy issues. However, since they are not novel findings we did not list them as novel findings.
There are several quantified self or lifelogging applications that have been released in the market and suspended after few months. We believe that the challenges that we have identified play an important role in the suspension of those apps. We recommend that developers and researchers: (i) Consider reflections that are not based on a single variable. Instead, information objects should be linked through timestamps and/or locations, and the system should recognize the correlation between information objects automatically. (ii) Remove manual user interactions where possible. (iii) Resolve the problem of uncertainty and data loss through the continued use of data analysis and data mining methods. Perhaps data analysis should be done on the device so it is not affected by privacy and network issues that occur from handing over this process to the cloud. As a future work, we plan to analyze on device data analysis, its drawbacks and advantages versus traditional cloud data analysis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}