
Machine Learning-Based Detection for Unauthorized Access to IoT Devices

 , , ,
, , ,  , , and
, , and
Abstract
:1. Introduction
- Study the effect of different sets of features on building ML models for detecting various IoT attacks and investigate the models’ performance using features selection techniques;
- Perform a comparative analysis of binary and multiclass experiments on the dataset to detect and classify IoT attacks;
- Achieve better benchmark results on the utilized IoT attacks dataset.
2. Related Works
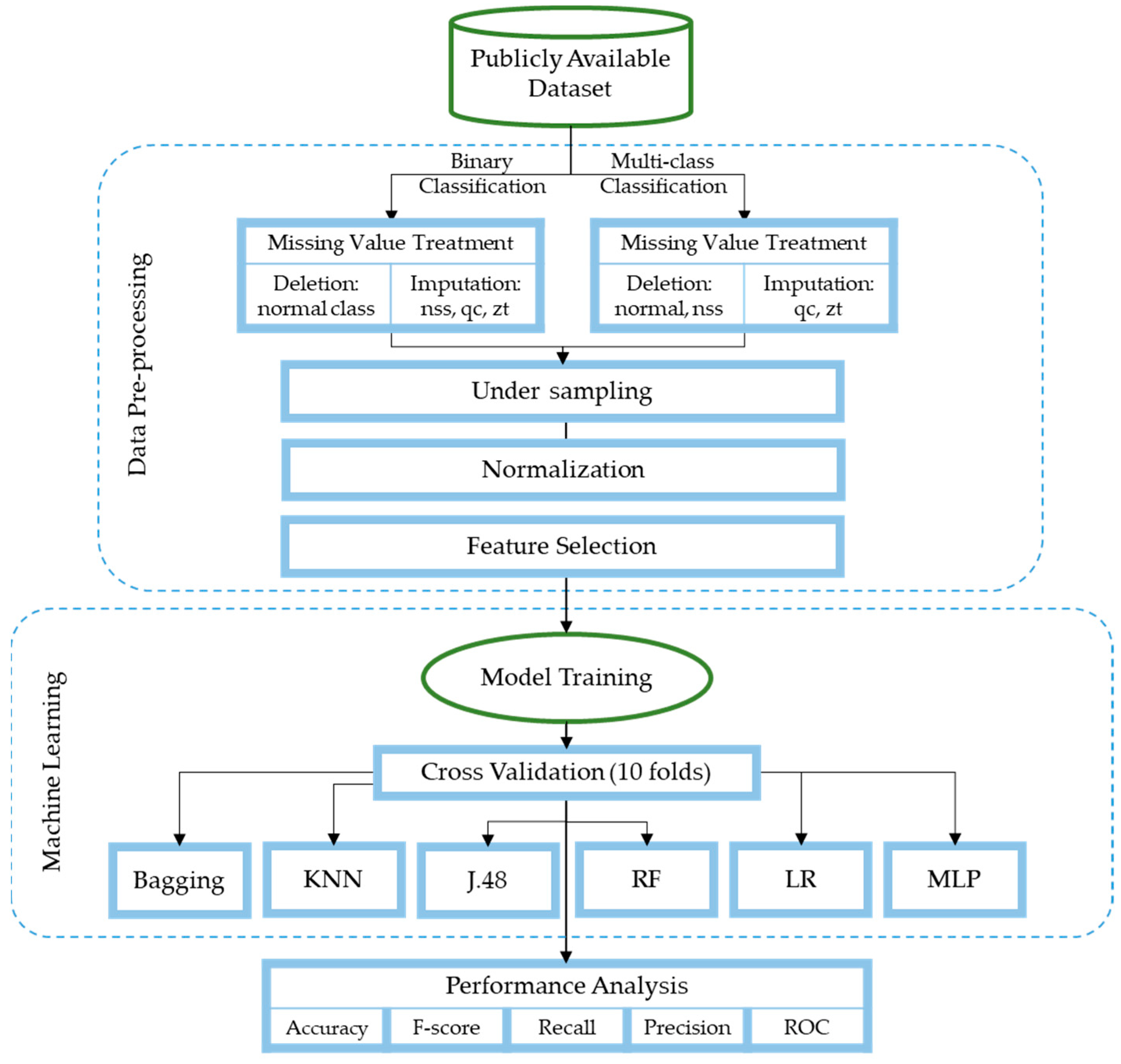
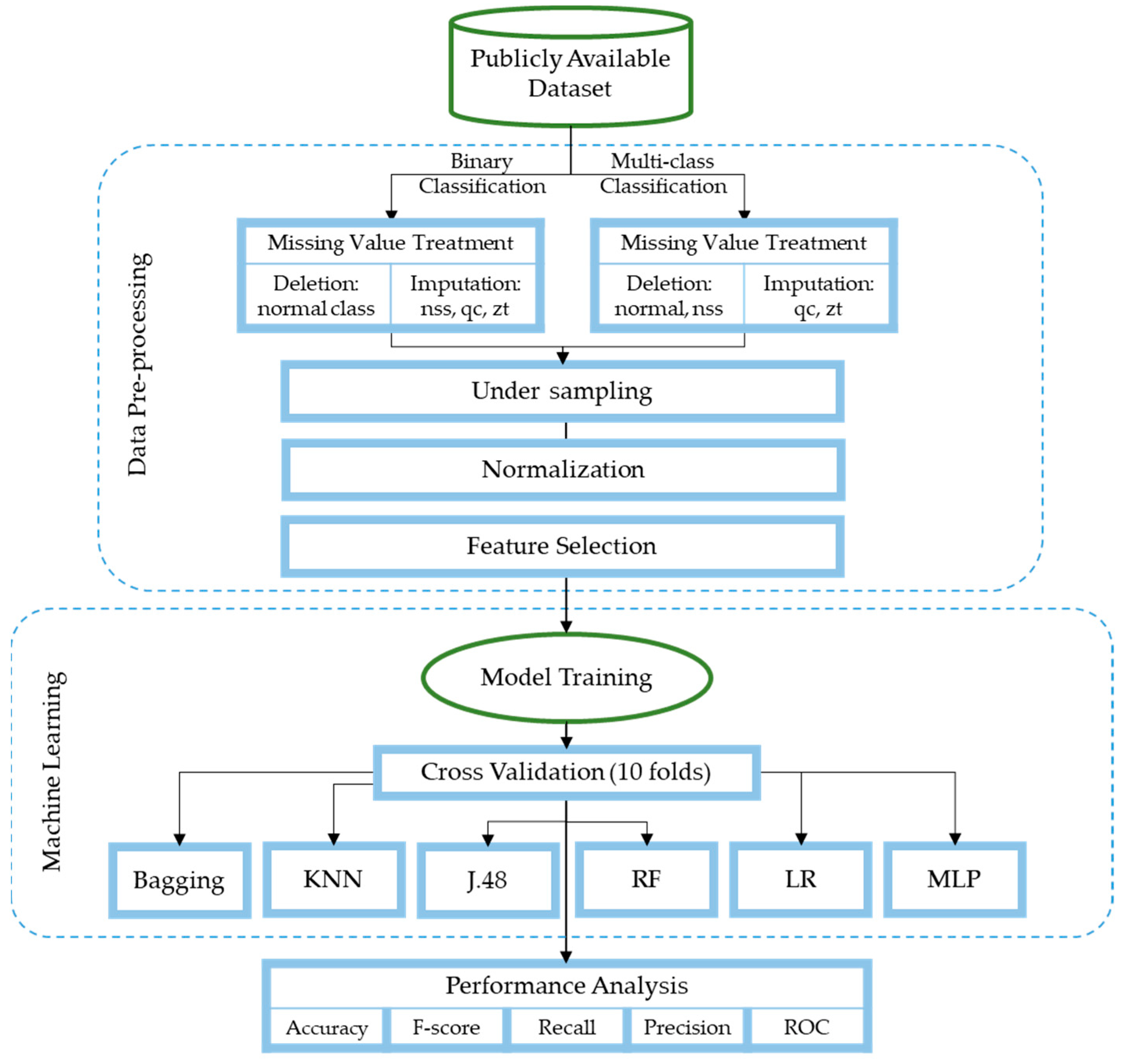
3. Methodology
3.1. Dataset Description
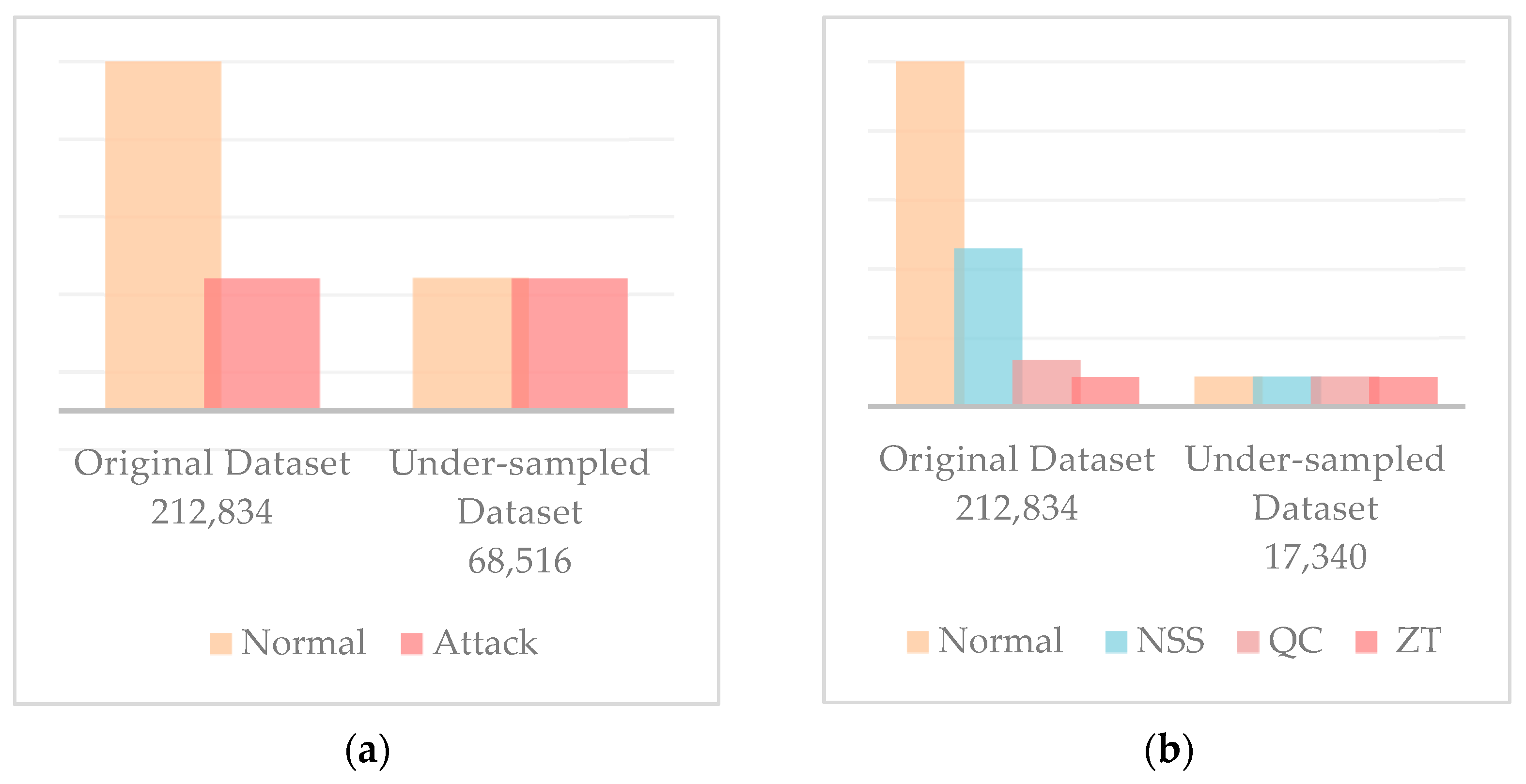
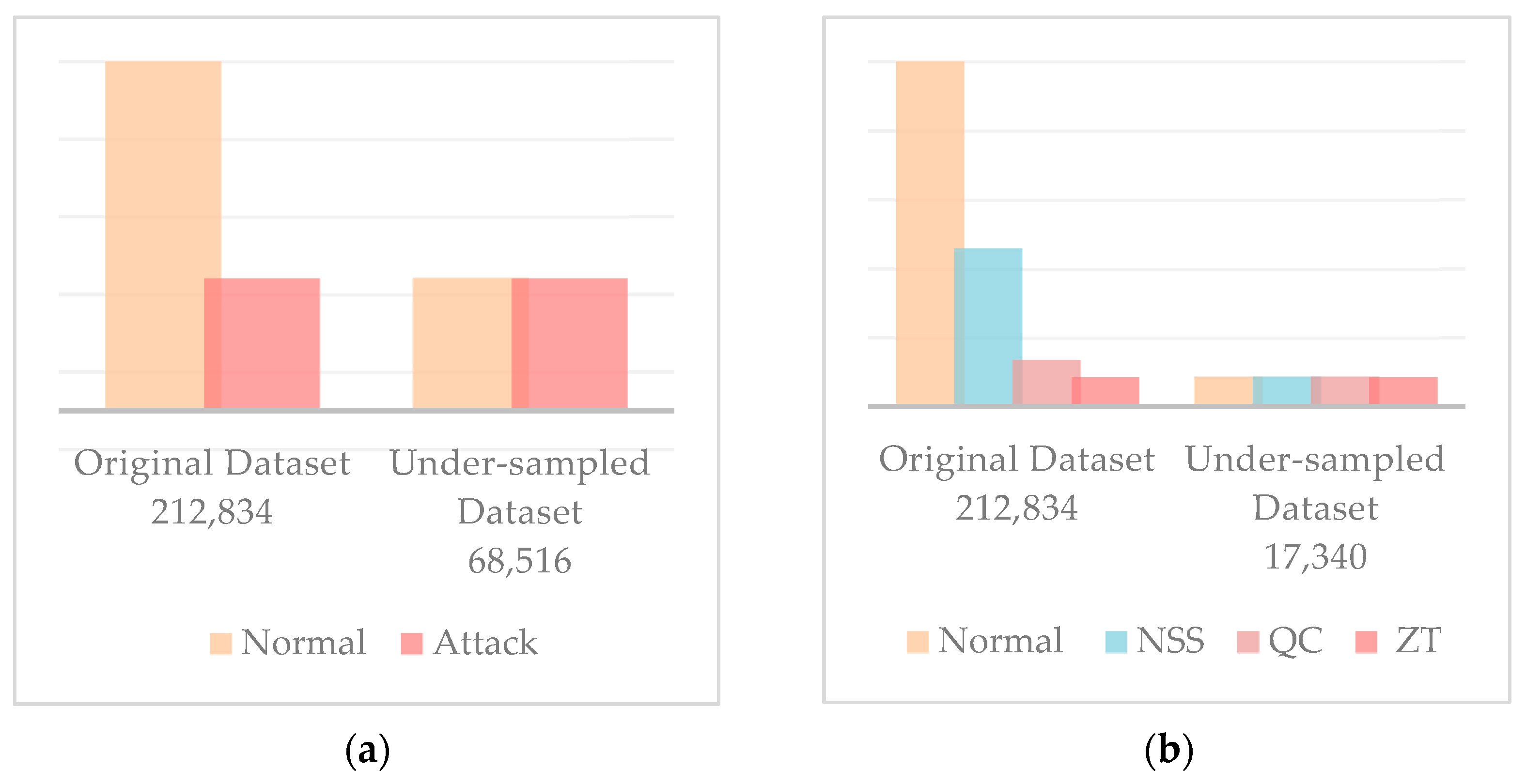
3.2. Preprocessing
3.3. Feature Selection
3.4. Evaluation Metrics
- True positive (TP): TP refers to attack classes that were correctly predicted;
- False positive (FP): FP signifies the normal classes that were incorrectly predicted as attack;
- True negative (TN): TN reflects the normal classes that were correctly predicted;
- False negative (FN): FN refers to attack classes that were incorrectly predicted as normal.
4. Results and Discussion
4.1. Experimental Setup
4.2. Parameter Settings
4.3. Experimental Results
4.3.1. Binary Class Results
4.3.2. Multiclass Results
4.4. Discussion
4.5. Comparison with Benchmark Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aljabri, M.; Zagrouba, R.; Shaahid, A.; Alnasser, F.; Saleh, A.; Alomari, D.M. Machine learning-based social media bot detection: A comprehensive literature review. Soc. Netw. Anal. Min. 2023, 13, 20. [Google Scholar] [CrossRef]
- Global IoT and Non-IoT Connections 2010–2025|Statista. Available online: https://www.statista.com/statistics/1101442/iot-number-of-connected-devices-worldwide/ (accessed on 21 February 2022).
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and other botnets. Computer Long. Beach. Calif. 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Aljabri, M.; Alhaidari, F.; Mohammad, R.M.A.; Mirza, U.S.; Alhamed, D.H.; Altamimi, H.S.; Chrouf, S.M.B. An Assessment of Lexical, Network, and Content-Based Features for Detecting Malicious URLs Using Machine Learning and Deep Learning Models. Comput. Intell. Neurosci. 2022, 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Aljabri, M.; Aldossary, M.; Al-Homeed, N.; Alhetelah, B.; Althubiany, M.; Alotaibi, O.; Alsaqer, S. Testing and Exploiting Tools to Improve OWASP Top Ten Security Vulnerabilities Detection. In Proceedings of the 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN), Al-Khobar, Saudi Arabia, 4–6 December 2022; pp. 797–803. [Google Scholar]
- Das, R.; Tuna, A.; Demirel, S.; Yurdakul, M.K. A Survey on the Internet of Things Solutions for the Elderly and Disabled: Applications, Prospects, and Challenges. Int. J. Comput. Netw. Appl. 2017, 4, 84–92. [Google Scholar] [CrossRef]
- Aljabri, M.; Alahmadi, A.A.; Mohammad, R.M.A.; Aboulnour, M.; Alomari, D.M.; Almotiri, S.H. Classification of Firewall Log Data Using Multiclass Machine Learning Models. Electron 2022, 11, 1851. [Google Scholar] [CrossRef]
- Aljabri, M.; Mirza, S. Phishing Attacks Detection using Machine Learning and Deep Learning Models. In Proceedings of the 2022 7th International Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 1–3 March 2022; pp. 175–180. [Google Scholar]
- MORE Alarming Cybersecurity Stats For 2021 ! Available online: https://www.forbes.com/sites/chuckbrooks/2021/10/24/more-alarming-cybersecurity-stats-for-2021-/?sh=4a9c31b24a36 (accessed on 21 February 2022).
- Aljabri, M.; Aljameel, S.S.; Mohammad, R.M.A.; Almotiri, S.H.; Mirza, S.; Anis, F.M.; Aboulnour, M.; Alomari, D.M.; Alhamed, D.H.; Altamimi, H.S. Intelligent Techniques for Detecting Network Attacks: Review and Research Directions. Sensors 2021, 21, 7070. [Google Scholar] [CrossRef] [PubMed]
- Aljabri, M.; Altamimi, H.S.; Albelali, S.A.; Al-Harbi, M.; Alhuraib, H.T.; Alotaibi, N.K.; Alahmadi, A.A.; Alhaidari, F.; Mohammad, R.M.A.; Salah, K. Detecting Malicious URLs Using Machine Learning Techniques: Review and Research Directions. IEEE Access 2022, 10, 121395–121417. [Google Scholar] [CrossRef]
- Alzahrani, R.A.; Aljabri, M. AI-Based Techniques for Ad Click Fraud Detection and Prevention: Review and Research Directions. J. Sens. Actuator Netw. 2023, 12, 4. [Google Scholar] [CrossRef]
- The UNSW-NB15 Dataset|UNSW Research. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 19 February 2022).
- Verma, A.; Ranga, V. Machine Learning Based Intrusion Detection Systems for IoT Applications. Wirel. Pers. Commun. 2020, 111, 2287–2310. [Google Scholar] [CrossRef]
- CIDDS—Coburg Intrusion Detection Data Sets: Hochschule Coburg. Available online: https://www.hs-coburg.de/forschung/forschungsprojekte-oeffentlich/informationstechnologie/cidds-coburg-intrusion-detection-data-sets.html (accessed on 19 February 2022).
- Datasets|Research|Canadian Institute for Cybersecurity|UNB. Available online: https://www.unb.ca/cic/datasets/index.html (accessed on 19 February 2022).
- Khatib, A.; Hamlich, M.; Hamad, D. Machine Learning based Intrusion Detection for Cyber-Security in IoT Networks. E3S Web Conf. 2021, 297, 01057. [Google Scholar] [CrossRef]
- Rashid, M.M.; Kamruzzaman, J.; Hassan, M.M.; Imam, T.; Gordon, S. Cyberattacks detection in iot-based smart city applications using machine learning techniques. Int. J. Environ. Res. Public Health 2020, 17, 9347. [Google Scholar] [CrossRef] [PubMed]
- Alrashdi, I.; Alqazzaz, A.; Aloufi, E.; Alharthi, R.; Zohdy, M.; Ming, H. AD-IoT: Anomaly detection of IoT cyberattacks in smart city using machine learning. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference, CCWC, Las Vegas, NV, USA, 7–9 January 2019; pp. 305–310. [Google Scholar]
- Gad, A.R.; Nashat, A.A.; Barkat, T.M. Intrusion Detection System Using Machine Learning for Vehicular Ad Hoc Networks Based on ToN-IoT Dataset. IEEE Access 2021, 9, 142206–142217. [Google Scholar] [CrossRef]
- The TON_IoT Datasets|UNSW Research. Available online: https://research.unsw.edu.au/projects/toniot-datasets (accessed on 19 February 2022).
- Verma, P.; Dumka, A.; Singh, R.; Ashok, A.; Gehlot, A.; Malik, P.K.; Gaba, G.S.; Hedabou, M. A Novel Intrusion Detection Approach Using Machine Learning Ensemble for IoT Environments. Appl. Sci. 2021, 11, 10268. [Google Scholar] [CrossRef]
- IDS 2018|Datasets|Research|Canadian Institute for Cybersecurity|UNB. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 21 February 2022).
- Arora, P.; Kaur, B.; Teixeira, M.A. Evaluation of Machine Learning Algorithms Used on Attacks Detection in Industrial Control Systems. J. Inst. Eng. India Ser. B 2021, 102, 605–616. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated Learning-based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2022, 9, 2545–2554. [Google Scholar] [CrossRef]
- Frazão, I.; Abreu, P.H.; Cruz, T.; Araújo, H.; Simões, P. Denial of Service Attacks: Detecting the Frailties of Machine Learning Algorithms in the Classification Process. Lect. Notes Comput. Sci. 2018, 11260, 230–235. [Google Scholar]
- Wheelus, C.; Zhu, X. IoT Network Security: Threats, Risks, and a Data-Driven Defense Framework. IoT 2020, 1, 259–285. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Ref. | Method | Dataset | Features | Results |
|---|---|---|---|---|
| [14] | AB, RF, GBM, XGB, CART, ERT, and MLP | CIDDS-001, UNSW-NB15, and NSL-KDD | - | Accuracy = 96.74% using CART |
| [17] | RF, DT, AdaBoost, LR, LDA, SVM, and Nystrom-SVM | UNSW-NB15, 2,540,044 samples | 49 features | Binary classification: Accuracy = 95% using Nystrom-SVM, RF, and DT. Multiclass classification: Accuracy = 93% using SVM. |
| [18] | LR, SVM, RF, DT, KNN, ANN, bagging, boosting, and stacking ensemble | UNSW-NB15, 175,341 samples, and CIC-IDS2017, 190,774 samples. | 25 features | Accuracy = 99.9% using stacking ensemble |
| [19] | RF | UNSW-NB15, 699,934 samples. | 12 features | Accuracy = 99.34% |
| [20] | LR, NB, DT, SVM, KNN, RF, AB, and XGB | ToN-IoT | 20 features | Binary classification: Accuracy = 99.1% Multiclass classification: Accuracy = 98.3%, both using XGB. |
| [22] | RF, and GBM | CSE-CIC-IDS2018-V2 | Accuracy = 98.27% | |
| [24] | RF, SVM, DT, ANN, KNN, and NB | SCADA attacks dataset | 7 features | Accuracy = 99.84% using RF |
| [25] | GRU | Modbus-based network dataset | - | Accuracy = 90.286 |
| # | Feature Name | Description |
| 1 | in_rep | Session repetition—packet count of packets that are of the most common packet size |
| 2 | out_rep | |
| 3 | in_prdcty | Session periodicity—measure of periodicity in a session, given by the variance of timestamp differences between packets |
| 4 | out_prdcty | |
| 5 | in_conv | Session convergence—self-similarity of the packets in the session, determined by examining the variance in the size of the packets |
| 6 | out_conv | |
| 7 | invel_pps | Packets per second—velocity of the traffic measured in packets per second |
| 8 | outvel_pps | |
| 9 | invel_bps | Bits per second—velocity of the traffic measured in bits per second |
| 10 | outvel_bps | |
| 11 | invel_bpp | Bytes per packet—velocity of the traffic measured in bytes per packet |
| 12 | outvel_bpp | |
| 13 | riotp | RIOT packets—ratio of inbound to outbound traffic measured in packets (inbound and outbound combined) |
| 14 | riotb | RIOT bytes—ratio of inbound to outbound traffic measured in bytes (inbound and outbound combined) |
| 15 | duration | Duration—the total elapsed time of the session (inbound and outbound combined) |
| 16 | orig_bytes | Byte count—session traffic size in bytes |
| 17 | resp_bytes | |
| 18 | orig_packets | Packet count—session traffic size in packets |
| 19 | resp_packets |
| Exterminate | Class | Number of Instances | |
|---|---|---|---|
| Before Treating the Missing Values | After Treating the Missing Values | ||
| Binary classification | Normal | 178,576 | 163,876 |
| Attack | 34,258 | 34,258 | |
| Multiclass classification | Normal | 178,576 | 163,876 |
| NSS | 23,022 | 5597 | |
| QC | 6901 | 6901 | |
| ZT | 4335 | 4335 | |
| Feature | Correlation | Information Gain |
|---|---|---|
| orig_packets | 0.6609 | 0.658 |
| riotp | 0.6391 | 0.82 |
| outvel_bpp | 0.6339 | 0.814 |
| orig_bytes | 0.6277 | 0.87 |
| resp_packets | 0.5999 | 0.623 |
| resp_bytes | 0.5275 | 0.831 |
| duration | 0.2827 | 0.649 |
| Model | Parameter | Optimal Value | |
|---|---|---|---|
| Binary Experiments | Multiclass Experiments | ||
| J48 | Binary split | False | False |
| Confidence factor | 0.25 | 0.2 | |
| LR | Maxlts | −1 | −1 |
| Ridge | 1.0 × 10−8 | 1.0 × 10−8 | |
| RF | Iterations | 100 | 50 |
| Batch Size | 100 | 100 | |
| Features | 0 | 0 | |
| KNN | K value | 3 | 1 |
| Distance | Euclidean | Euclidean | |
| Bagging | Classifier | REPTree | |
| Iterations | 50 | 50 | |
| Bag size percent | 100 | 100 | |
| MLP | Hidden layers | 3 | 3 |
| Activation function | ReLU | ReLU | |
| Optimizer | Adam | Adam | |
| Epochs | 60 | 60 | |
| Model | Precision | Recall | F1-Score | Accuracy | ROC |
|---|---|---|---|---|---|
| KNN | 0.932 | 0.924 | 0.924 | 92.4% | 0.924 |
| LR | 0.984 | 0.984 | 0.984 | 98.38% | 0.994 |
| J84 | 0.994 | 0.994 | 0.994 | 99.43% | 0.996 |
| RF | 0.996 | 0.996 | 0.996 | 99.59% | 0.999 |
| Bagging | 0.995 | 0.995 | 0.995 | 99.46% | 0.999 |
| MLP | 0.992 | 0.992 | 0.992 | 99.16% | 0.993 |
| Model | Precision | Recall | F1-Score | Accuracy | ROC |
|---|---|---|---|---|---|
| KNN | 0.993 | 0.993 | 0.993 | 99.28% | 0.997 |
| LR | 0.978 | 0.978 | 0.978 | 97.83% | 0.993 |
| J84 | 0.993 | 0.993 | 0.993 | 99.31% | 0.995 |
| RF | 0.995 | 0.995 | 0.995 | 99.59% | 0.999 |
| Bagging | 0.993 | 0.993 | 0.993 | 99.34% | 0.999 |
| MLP | 0.991 | 0.991 | 0.991 | 98.94% | 0.992 |
| Model | Precision | Recall | F1-Score | Accuracy | ROC |
| KNN | 0.875 | 0.795 | 0.799 | 79.48% | 0.864 |
| LR | 0.949 | 0.948 | 0.948 | 94.83% | 0.991 |
| J84 | 0.981 | 0.981 | 0.981 | 98.08% | 0.991 |
| RF | 0.989 | 0.989 | 0.989 | 98.87% | 0.999 |
| Bagging | 0.982 | 0.982 | 0.982 | 98.22% | 0.999 |
| MLP | 0.973 | 0.973 | 0.973 | 96.58% | 0.992 |
| Model | Precision | Recall | F1-Score | Accuracy | ROC |
|---|---|---|---|---|---|
| KNN | 0.979 | 0.979 | 0.979 | 97.88% | 0.990 |
| LR | 0.904 | 0.905 | 0.904 | 90.46% | 0.982 |
| J84 | 0.981 | 0.981 | 0.981 | 98.06% | 0.993 |
| RF | 0.987 | 0.987 | 0.987 | 98.67% | 0.999 |
| Bagging | 0.981 | 0.981 | 0.981 | 98.06% | 0.998 |
| MLP | 0.973 | 0.973 | 0.973 | 96.58% | 0.990 |
| Prediction | |||
|---|---|---|---|
| Normal | Attack | ||
| Actual | Normal | 34,299 | 29 |
| Attack | 237 | 34,021 | |
| Prediction | |||||
|---|---|---|---|---|---|
| Normal | ZT | NSS | QC | ||
| Actual | Normal | 4301 | 2 | 30 | 2 |
| ZT | 0 | 4333 | 2 | 0 | |
| NSS | 125 | 1 | 4208 | 1 | |
| QC | 16 | 0 | 16 | 4303 | |
| Study | Model | Precision | Recall | F1-Score | Accuracy | ROC |
|---|---|---|---|---|---|---|
| IoT Network Security: Threats, Risks, and a Data-Driven Defense Framework | RF | 0.905 | 0.894 | 0.891 | - | 0.976 |
| Proposed tudy (multiclass) | RF | 0.989 | 0.989 | 0.989 | 98.87% | 0.999 |
| Proposed study (binary-class) | RF | 0.996 | 0.996 | 0.996 | 99.59% | 0.999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aljabri, M.; Alahmadi, A.A.; Mohammad, R.M.A.; Alhaidari, F.; Aboulnour, M.; Alomari, D.M.; Mirza, S. Machine Learning-Based Detection for Unauthorized Access to IoT Devices. J. Sens. Actuator Netw. 2023, 12, 27. https://doi.org/10.3390/jsan12020027
Aljabri M, Alahmadi AA, Mohammad RMA, Alhaidari F, Aboulnour M, Alomari DM, Mirza S. Machine Learning-Based Detection for Unauthorized Access to IoT Devices. Journal of Sensor and Actuator Networks. 2023; 12(2):27. https://doi.org/10.3390/jsan12020027
Chicago/Turabian StyleAljabri, Malak, Amal A. Alahmadi, Rami Mustafa A. Mohammad, Fahd Alhaidari, Menna Aboulnour, Dorieh M. Alomari, and Samiha Mirza. 2023. "Machine Learning-Based Detection for Unauthorized Access to IoT Devices" Journal of Sensor and Actuator Networks 12, no. 2: 27. https://doi.org/10.3390/jsan12020027
APA StyleAljabri, M., Alahmadi, A. A., Mohammad, R. M. A., Alhaidari, F., Aboulnour, M., Alomari, D. M., & Mirza, S. (2023). Machine Learning-Based Detection for Unauthorized Access to IoT Devices. Journal of Sensor and Actuator Networks, 12(2), 27. https://doi.org/10.3390/jsan12020027