1. Introduction
Geographic location estimation of wireless sensor nodes, also know as sensor localization, is an important requirement in wireless sensor networks (WSNs). The locations from where sensor observations are obtained are required in most WSN applications. In addition, many networking protocols, such as geographic routing, sensor collaboration, and tracking, require the knowledge of sensor locations. However, sensor localization, similar to all other processes executed in WSNs, must be designed under the constraints of cost and size of the sensor node hardware. Moreover, wireless sensor nodes may be located in environmental conditions that preclude the reception of wireless signals from satellites due to blockages by trees or other physical structures and beyond the reach of cellular base stations. Consequently, existing solutions to geographic location estimation, such as the use of the Global Positioning System (GPS) or cellular location services, are prohibitive in WSNs. As a result, the development of low-cost sensor localization schemes that work within the hardware constraints of WSNs to meet the application requirements has been a subject of extensive research.
Practical approaches for location estimation utilize triangulation using a sufficient number of distance and angle estimates from a set of known reference points. The main challenge for applying triangulation in WSNs is obtaining low-cost solutions for acquiring distance and/or angle estimates. Conventional techniques for accurately estimating a distance from a reference point involve measuring the time-of-arrival (TOA) or the time-difference-of-arrival (TDOA) of wireless signals transmitted from the reference location. These methods require high-precision local clocks and sophisticated processing techniques that are not viable to use in WSNs. Estimation of the angle-of-arrivals (AOA) also requires additional hardware. A popular approach for distance estimation in WSNs is the use of the received RF signal strength from a reference transmitter. Estimation of the RF signal strength indicator (RSSI) does not require any additional hardware at the sensor nodes since the sensor nodes are already equipped with an RF transceiver. It only requires prior knowledge of the estimated path loss factor in the corresponding environment, which can be estimated offline. However, distance estimation from RSSI measurements suffer from errors due to inaccurate path loss factor estimates and shadowing effects. Nevertheless, the benefits of achieving a low-cost solution have motivated extensive research to be focused on the development of techniques to mitigate the effect of errors in RSSI-based localization schemes.
The conventional way to reduce ranging errors is multilateration, which involves obtaining the minimum mean-square error (MMSE) location using a sufficiently large number of reference points, i.e., more than the minimum number of range estimates that are required for localization when the estimates are error-free (which is three for localization over a planar surface and four for localization in a three-dimensional space). However, the MMSE location estimate is still adversely affected by outliers, i.e., those range estimates that have unusually high errors, which is common in environments characterized by physical obstructions causing shadowing. The current research is based on the fact that the elimination of outliers while performing multilateration can significantly reduce the localization error despite the reduction in the number of reference points, when the shadowing attenuation is sufficiently high.
We assume that a reasonably large number of reference or beacon signals are available to perform localization, of which an unknown number are affected by shadowing, leading to relatively higher ranging errors. It is assumed that the locations of the beacon nodes (BN) are known, but those of the obstructions are unknown. With these, we propose and investigate three different RSSI-based localization schemes that utilize outlier detection to eliminate potentially shadowed beacon signals to reduce errors:
All three schemes are aimed at the detection of outliers under the premise that the candidate multilateration results obtained from subsets of beacons that have line-of-sight (i.e., are unobstructed) will have lower errors, and hence, they will be clustered near the actual location of the unknown node. On the other hand, the location estimates from subsets involving one or more obstructed beacons will have relatively higher errors, and consequently, will result in locations that are comparatively widely dispersed. Hence, schemes that apply spatial correlation or clustering would lead to the elimination of candidate results that are affected by obstructed signals.
We illustrate, using simulations as well as experimental tests, that all three approaches improve the accuracy of sensor node localization in comparison to that using multilateration applied to distance estimates from all beacon nodes. We also present performance comparison with the range-only simultaneous localization and mapping scheme (RO-SLAM), a popular method applied in robotics [
4]. In addition to localization accuracy, we present the computation requirements of the three proposed schemes. We organize the rest of our paper as follows. In
Section 2, we present prior research related to this work. A detailed description of the assumed network model and channel characteristics as well as the motivation behind the proposed approach are presented in
Section 3. The proposed outlier-based localization schemes are described in
Section 4. Performance evaluations obtained from simulations and experiments are presented in
Section 5 and conclusions are presented in
Section 6.
2. Related Research
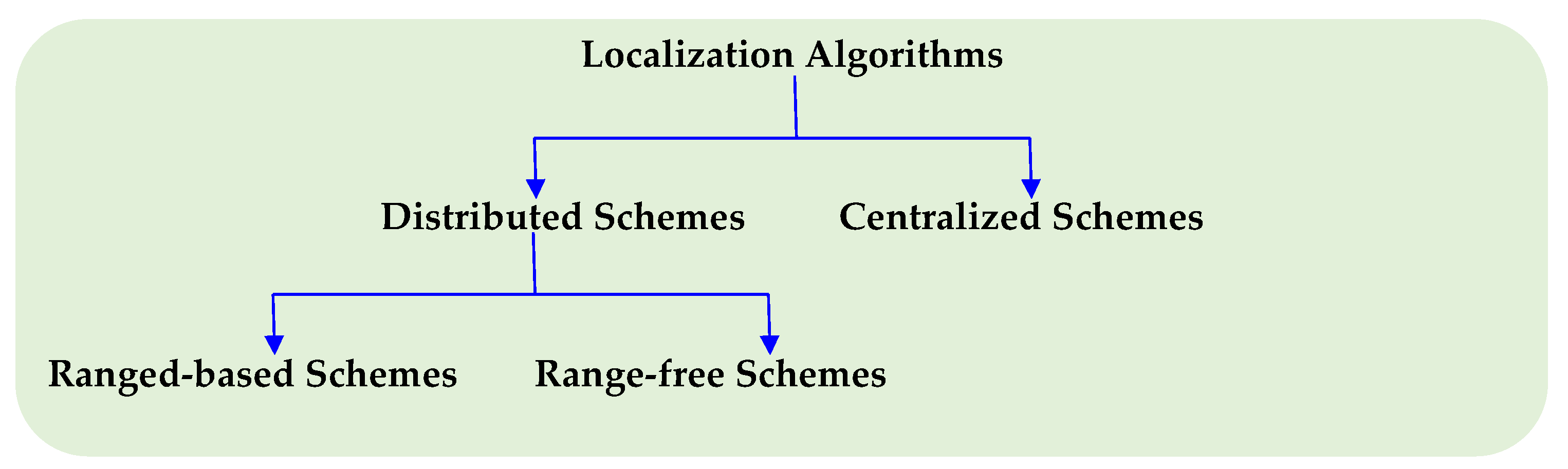
An extensive amount of research has been reported on sensor localization schemes that address a wide range of requirements and constraints such as accuracy, technology, communication constraints, computational constraints, node dynamics, hardware restrictions/availability, and many others. These approaches may be broadly classified as illustrated in
Figure 1.
Centralized localization schemes perform all computations at a central station to overcome the computational constraints of sensor nodes. However, this increases the communication cost in lieu of local computation. The schemes presented in refs. [
5,
6,
7,
8] are a few examples of centralized localization schemes. In ref. [
7], the authors present MDS-MAP, which starts with a relative map that is eventually used to reduce the sum of squares of the difference between the estimated positions in the MDS-MAP and the true positions of the BNs. The MDS-MAP approach, though effective especially in networks with a small number of BNs, has a major drawback in that it requires global information of the sensor network. In ref. [
8], the authors propose a three-stage scheme that involves RF mapping of the network which is stored in memory tables, creation of a ranging model using recording of ordered BN-pairs, and finally estimating the location of the sensor node by solving the optimization problem. This scheme is practical and self-organizing, but suffers from a high energy-consumption due to its reliance on a large amount of packet generation and the transmission of significant amount of data to a central device. The authors in ref. [
5] propose a scheme to localize sensor nodes that suffer from the flip ambiguity problem. However, the scheme does not perform well in networks with low node density. In ref. [
6], the authors combine the multidimensional scaling (MDS) and proximity distance mapping (PDM) localization techniques in a phased approach to achieve good localization results and lower computation cost.
Distributed localization schemes, on the other hand, perform all localization computations at the sensor nodes. This results in lower energy consumption since, unlike in the centralized schemes, only inter-node communication occurs. Distributed localization schemes can be classified into range-based [
9,
10,
11,
12,
13,
14] and range-free [
15,
16,
17,
18,
19,
20] localization schemes. In range-based localization schemes, estimates of the distances or angles between BNs and a sensor node are used in trilateration or triangulation to estimate the location of a sensor node. The distance estimates are calculated using RSSI, time-of-arrival (TOA) or time-difference-of-arrival (TDOA) of beacons sent from BNs and the sensor node. Angle estimates can be obtained using highly directional antennas, phased array antennas, or the usage of complex electromagnetic waveforms, all of which are relatively complex. Both range- and angle-based localization schemes produce more accurate localization results but require additional hardware for range or angle estimation. The authors in ref. [
11] developed an RSSI-based experimental testbed at a wheat field, where they collected and analyzed measurement data. They found that the best fitted parametric exponential decay model (OFPEDM) achieves a better accuracy in distance estimation as well as adaptability to variations in the environment when compared to the typical path loss models. Xu et al. [
10], implemented an RSSI-based radio frequency identification indoor positioning system to estimate the 3D location of a tag using multiple trilateration calculations. Some range-based localization schemes such as the convex optimization [
21], systems of complex equations [
22], and the Kalman filters [
23] combine range estimates from multiple beacons in estimating the location of a sensor node. A major drawback of these schemes is that they require a substantial cost in computation and communications.
Unlike range-based schemes, range-free localization schemes do not use range measurements to estimate the location of a sensor node. Range-free schemes are often used in applications that do not require accurate estimates of the location of a sensor node. A select few range-free schemes can be seen in the refs. [
16,
17,
18,
19,
20].
A significant amount of research work has also been reported on reducing the errors in RSSI-based sensor localization, which is the focus of this research. While the localization error in multilateration generally decreases with increasing number of reference points (BNs) when all range estimates have the same error distribution, the error increases when one or more of the distance estimates are affected by obstructions due to additional shadowing losses. If the distance estimates that have comparatively higher errors (outliers) can be identified and removed, the sensor location estimate will be more accurate. Prior research on methods to detect, eliminate, or suppress such outliers include [
24,
25,
26]. The authors in ref. [
25] used the graph embeddability with rigidity theory to detect and filter outliers in the range estimates. However, they assume that measurements are generally accurate, which is not possible in RSSI-based ranging due to long-term fading effects in terrestrial environments. To the best of our knowledge, this scheme has not been implemented in an outdoor environment. The authors in ref. [
24] developed a majority rule-based sensor fusion system and particle filter method to eliminate or suppress outlier measurements adversely affected by noise. They assumed that different sensor types are not influenced by the same noise type at the same time, hence they employed different sensor types in their technique to detect and remove biased measurement distributions that they deem as outliers. In ref. [
26], the authors use the proximity of sensor nodes within a network, using a term they call closeness centrality (CC) to show how important a node is in relation to other nodes within the network. They then use the CC to remove sensor nodes with noisy measurements from being used in the localization of unknown nodes. This scheme involves training data and there is no statement from the authors whether the clusters formed using their scheme reduces the effect of obstructed signals on sensor localization.
Another very effective localization approach is the estimation of the position of a sensor node using a map of landmarks and embedded sensor to take measurements of the said landmarks. Accurate positions of a beacon node or robot in an environment can also be used to obtain the map of the landmarks. The former is termed localization and the latter is termed mapping. A combination of these two whereby the positions of a robot and building of the map of landmarks is simultaneously obtained in a process called simultaneous localization and mapping (SLAM). This is a very important concept used in robotics, as can be seen in the works shown in refs. [
4,
27,
28,
29,
30]. When the inbuilt robot sensor described above can take only range measurements, a special case of range-only SLAM emerges [
31,
32,
33,
34]. Numerous variants of SLAM exist using mechanisms, such as the Kalman filter (KF), extended Kalman filter (EKF), particle filter (PF), and sparse extended information filter (SEIF).
Our proposed localization schemes differ from the other schemes described in this section, in that they rely on the fact that some beacon signals in a sensor network are not obstructed by obstacles. Our localization schemes improve on the typically used multilateration method by minimizing the effects of the obstructed beacon signals on estimating the location of an unknown node. Another difference between our schemes and the others schemes is that ours do not only use the majority rule technique but also use simple clustering mechanisms of spatially correlated RSSI measurements in determining the final location estimate of an unknown node.
3. Preliminaries
In this section, we describe the details of our assumed network model, the RF channel characteristics, and explain the motivation for the sensor localization approach proposed in this research. The objective of this work is to develop a practical and low-cost solution for obtaining the locations of sensor nodes in large-scale WSN deployments, where the manual recording of locations of sensors nodes is difficult. We require that each sensor node is able to perform self-localization with minimum additional consumption of the energy resources at the sensor nodes. It is assumed that the sensor nodes are static, and hence it is sufficient to execute the localization scheme executed only once at the time of deployment or at any time when network reconfiguration is made. We assume a 2D space for localization, however the results can be easily extended to 3D.
3.1. System Model
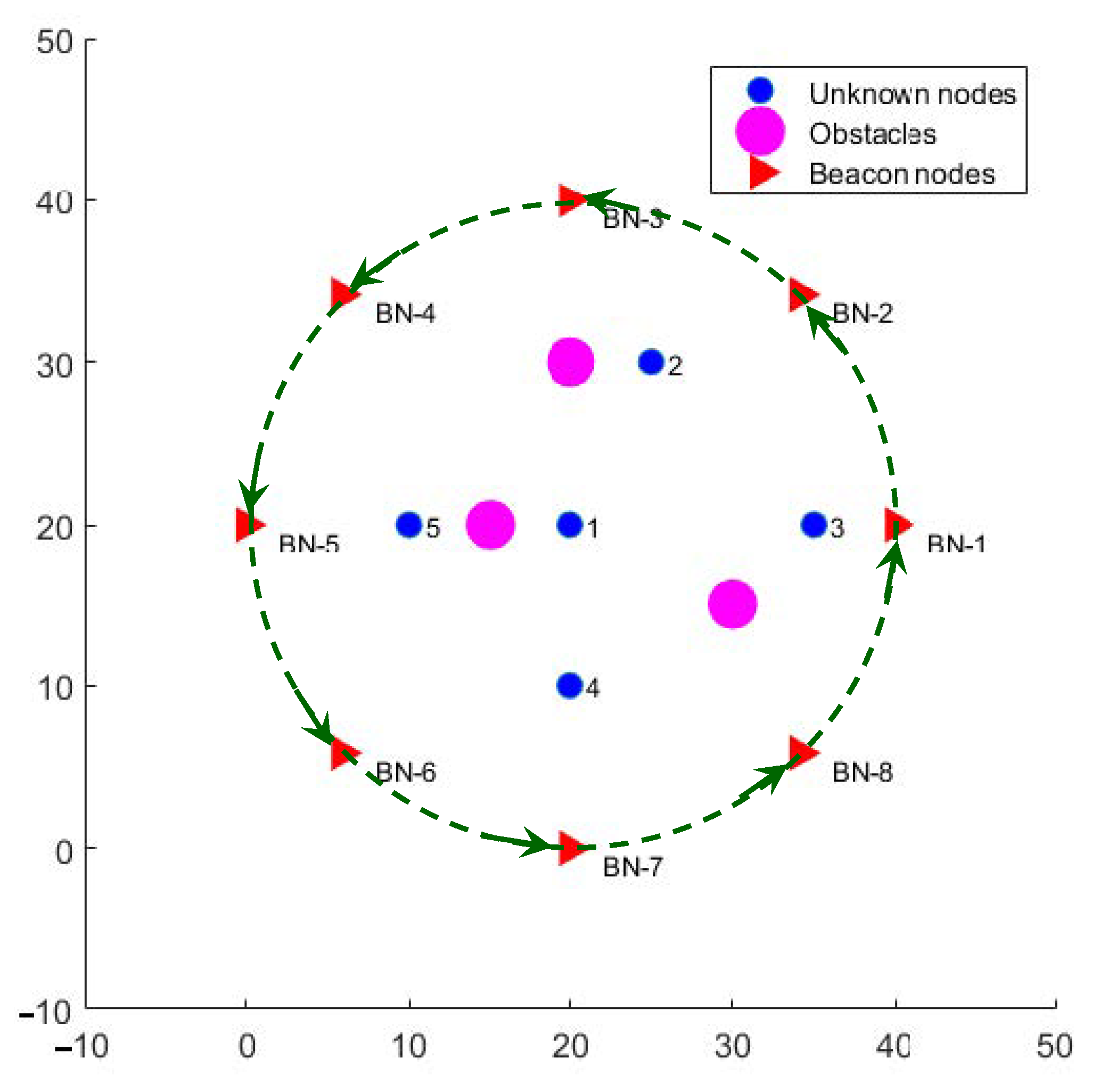
The assumed system model is illustrated in
Figure 2, where we make the following assumptions. A set of wireless sensor nodes is randomly deployed and will be referred to as unknown nodes (UN), since their exact locations within the network area are not known. A set of
B number of beacon nodes (BNs) with known locations are available, which transmit RF beacon signals to enable the unknown nodes to estimate their locations. It is assumed that
, which is the minimum number of reference distances needed for triangulation over a 2D place. Since the beacons are needed only when localization is to be performed, a lower cost solution to avoid deploying a large number of BNs is to use a mobile robotic platform equipped with GPS to generate beacon signals from various reference locations around the WSN deployment region. Each reference location will be considered equivalent to a BN for the purpose of localization. When a sensor node receives a transmitted beacon signal, it estimates its distance from the beacon node using the RSSI of the beacon signal, the reference transmission power level of the beacon signals, and the path loss model of the RF signal in the network location. It is assumed that the average path-loss factor is known in advance from offline channel measurements. However, the estimated distances are characterized by errors that are caused by random and unpredictable effects of channel noise, interference, and fading of the RF signal. In addition, it is assumed that the network region contains physical natural or man-made objects such as trees, pillars, and metallic objects that serve as obstacles in the path of beacon signals. These obstacles, depicted by the pink circles in
Figure 2, cause additional attenuation to some of the beacon signals due to shadowing. The locations of obstacles as well as their effect on beacon signals (additional attenuation) are not known. We assume that the number of BNs is sufficiently larger than the number of obstructions, which can be achieved by reducing the intervals between beacon transmission points of robotic beacon generator.
3.2. RF Channel Model
In order to effectively model the radio propagation channel to capture the effects of path loss, long-term fading, as well as the shadowing effect of obstacles, we assume that the received signal strength (RSSI) of the beacon signals can be modeled using one of two models. The unobstructed or line-of-sight (LoS) signals are modeled by the lognormal shadowing model, and the obstructed or non-line-of-sight (NLoS) signals are modeled as a lognormal shadowing channel with additional attenuation loss. Hence, for our performance analysis, we model the RSSI as follows:
Here, is the received power at reference distance , n is the path loss exponent (typically between 2 and 4) and is a zero-mean Gaussian random variable with standard deviation , which represents long-term fading, and is the additional attenuation due to obstructions to beacon signals.
3.3. Motivation for the Proposed Approach
Distance estimation from RSSI basically relies on application of the assumed path loss model for known values of the transmitted power level and the estimated path-loss factor. This implies that with prior knowledge of
n,
, and
, the estimated distance
d for a measured value of the received signal strength
is obtained using the path loss expression, as follows:
Parameters such as n and can be determined offline using a small set of RSSI measurements and used as input to the localization scheme. Due to differences between the offline average measurements and the true values specific to the environment at any given instance, such RSSI-based distance estimates will always have random errors.
The localization error from multilateration generally reduces with increasing number of reference distances as long as they are not from collinear beacon sources and do not have shadowing effects. The errors in estimated distances from reference locations using RSSI of the beacon signals are reasonably small for LoS signals. However, the additional attenuation caused by shadowing results in the distance estimates of NLOS signals to have disproportionately large errors. Consequently, the localization error increases when one or more beacons are affected by shadowing. If these outliers can be removed, the localization error is reduced significantly despite the reduction in the number of distance estimates, which is the motivation of this research.
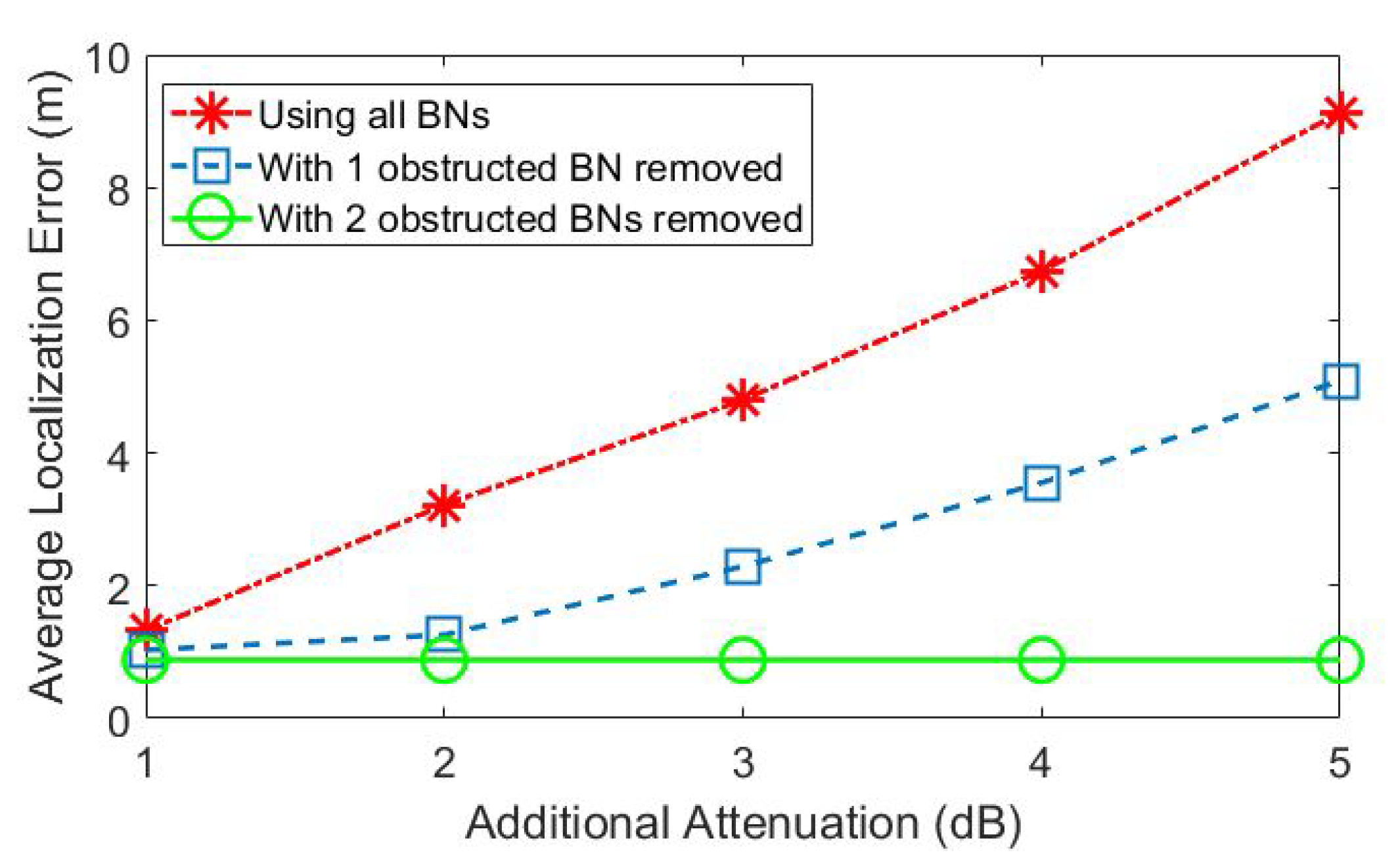
We illustrate this benefit using a numerical example obtained from computer simulations. Consider the localization problem of node 1 in the network scenario depicted in
Figure 2, which is in line-of-sight from all beacons except BNs 3 and 5. Hence, the distance estimates from BN-3 and BN-5 have relatively higher errors due to the additional attenuation caused by shadowing. The localization errors as obtained from multilateration using all 8 beacons increase significantly with increasing shadowing attenuation levels, as depicted in
Figure 3 (plotted in red). On the other hand, if the multilateration is performed by first removing either one or both of BN-3 and BN-5, the results have much lower errors, as illustrated by the blue and green plots. However, distinguishing between LoS and NLoS beacon signals is not trivial.
We address the problem of designing RSSI-based self-localization schemes that try to exclude the beacon signals that increase the error than that computed with all beacon signals received. Assuming that LoS beacons have smaller errors and agree best with the true location, the idea is to detect beacon signals that are “outliers” in the sense that they do not agree with the true location. The main challenge is to detect outliers without prior knowledge of the true locations of sensor nodes.
4. Proposed Sensor Localization Schemes
We now present the proposed RSSI-based localization schemes that apply the above principle for detection and removal of outlier distance estimates during localization. Let
represent the set of beacon nodes available. The proposed outlier detection schemes start by forming an exhaustive set of subsets
of
, each comprising
M non-co-linear BNs, i.e.,
,
, where no three of more of
, fall on the same line. Hence, with
, each subset
of BNs can be used by any UN to obtain its estimated location using multilateration. For any unknown node
k, if
be the estimated distance between
to node
k, then we represent the multilateration operation on
,
, as follows
where
represents a candidate estimated location of node
k from subset
. Note that there can be up to
distinct subsets
, and consequently, the same number of candidate estimated locations. The smallest value of
M is 3 for 2D localization.
The proposed localization schemes are based on the fact that if all BNs in
are in LoS of node
k, then the corresponding distance estimates will have small errors, and consequently, the candidate location estimate
will be close to the true location of node
k. On the other hand, if one or more of the BNs in
are not in the line of sight of node
k, the corresponding distance estimate(s) will have large errors, leading to the candidate location estimate
to be far from the true location of node
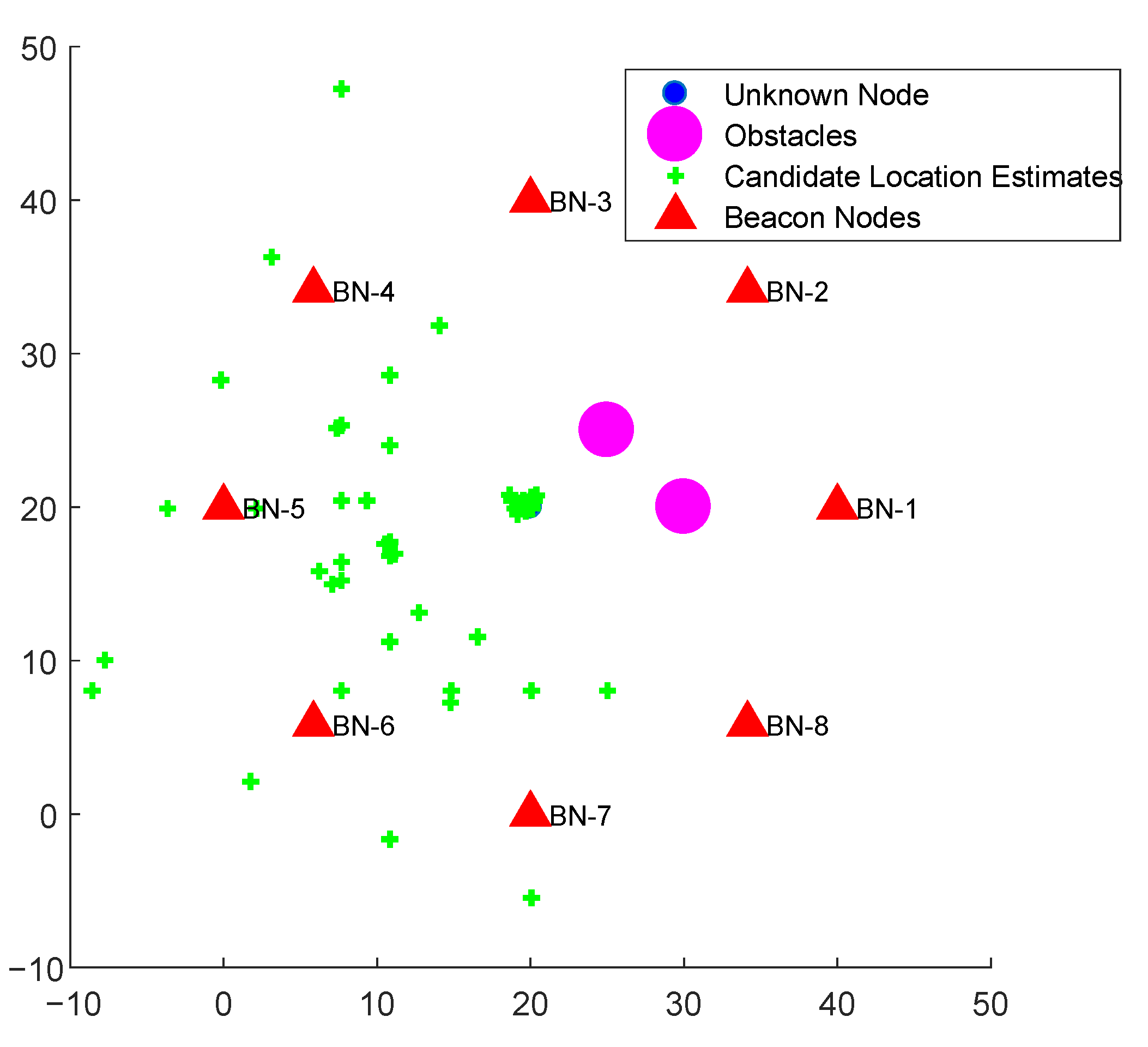
k. An illustration of the candidate location estimates of an unknown node with a system with
and
is depicted in
Figure 4. The figure depicts the effect of two obstacles that cause a large number of candidate location estimates to be geographically dispersed, but a significant number of location estimates to lie close to the true location of node
k. We propose schemes that systematically exploit the above observation and combine the spatially correlated candidate location estimates and subsequently filter out the outliers.
4.1. Majority Rule Scheme
The proposed majority rule approach leads to a location estimate that is agreed upon by a majority of the beacons, while disregarding those that do not agree with the majority. This approach differs from that of multilateration which considers all beacons as equally important and uses the minimum mean square error location calculated from all the beacon signals to estimate the location of an unknown node. For the proposed approach to work, two conditions should be met:
The number of erroneous or NLOS beacons is not too large so that the majority or consensus is evident.
A mechanism should exist to determine the location estimate agreement with other beacon signals within a given margin of error, since all beacon signals have some error due to fading.
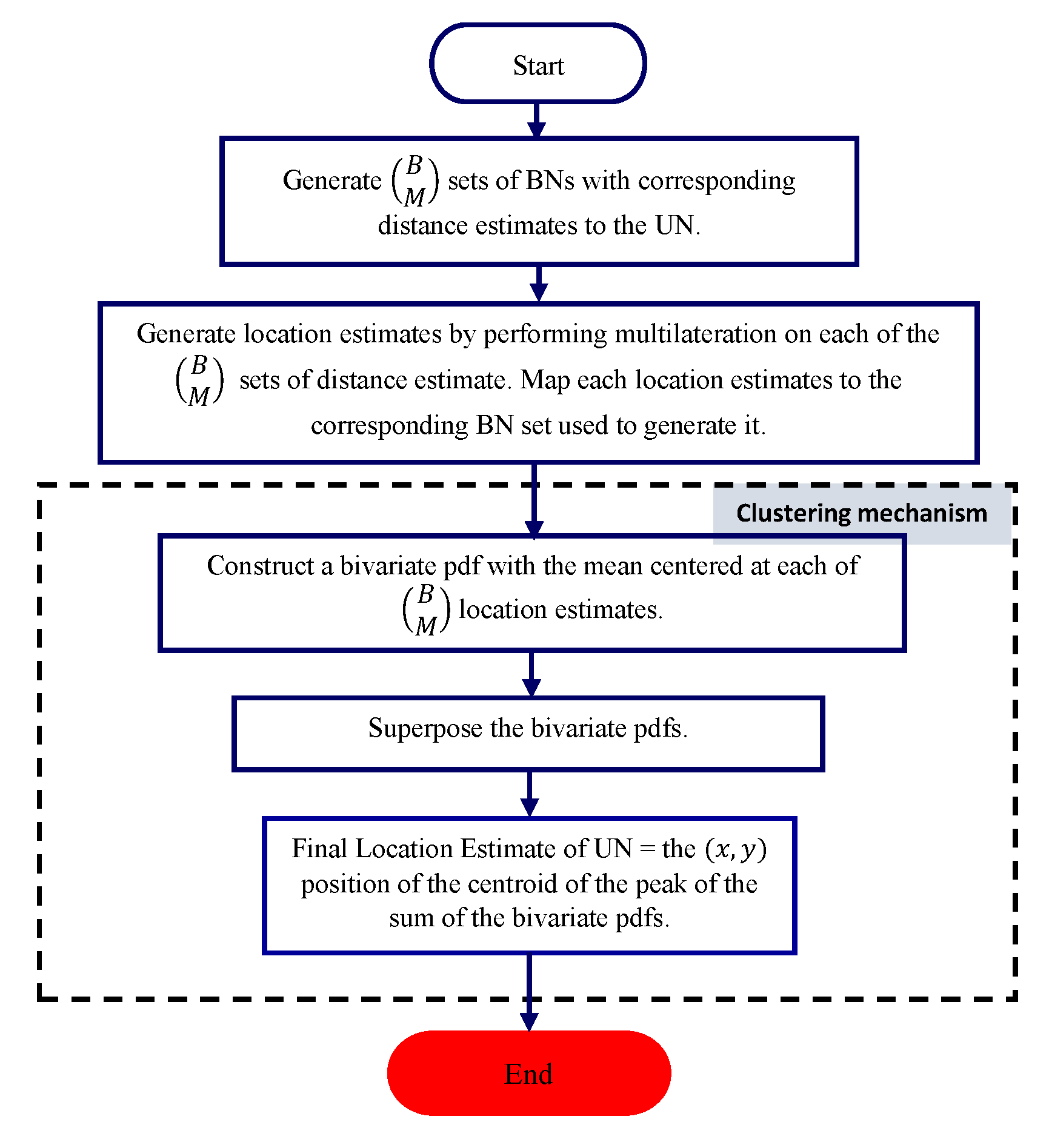
The flowchart of the proposed scheme is illustrated in
Figure 5. The scheme represents each candidate location estimate by an assumed two-dimensional probability density function (pdf) of the node location. The summation of the pdf’s from all candidate locations leads to the final location estimate. Overlapping of multiple pdfs indicate an “agreement” from spatial correlation. This spatial correlation concept is illustrated in
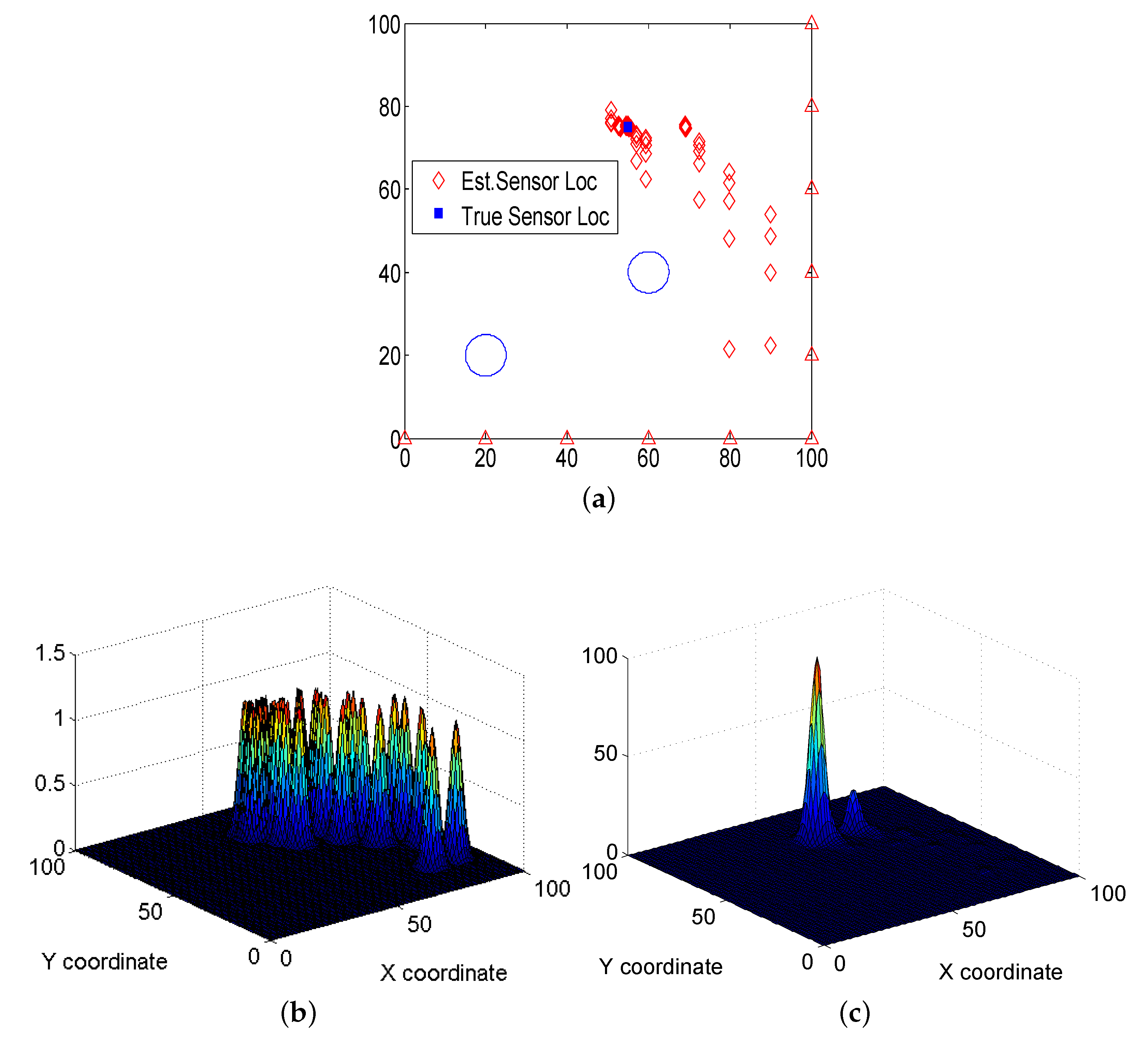
Figure 6 with an example. Here, we consider a localization problem over a 100 m × 100 m network area with
and
. This results in a total of
candidate location estimates of a node for which the true location is (55,75). These 165 candidate location estimates are depicted by red diamond marks in
Figure 6a. Assuming a bivariate Gaussian pdf for each candidate location, we represent the corresponding pdfs in
Figure 6b. By summing all the pdfs, the corresponding location with the highest location probability of node
k is obtained, as depicted in
Figure 6c. Note that the peak value of the sum represents that location of maximum agreement of reference distance estimates from multiple subsets
. By keeping
B small, we generate more data points that help in distinguishing between those that are affected by outliers and those that agree to the true location.
Several design considerations may be applied to the above scheme towards implementation of the majority rule scheme in low-cost wireless sensor nodes, as described below. Some of these have also been discussed in our earlier work [
1,
2].
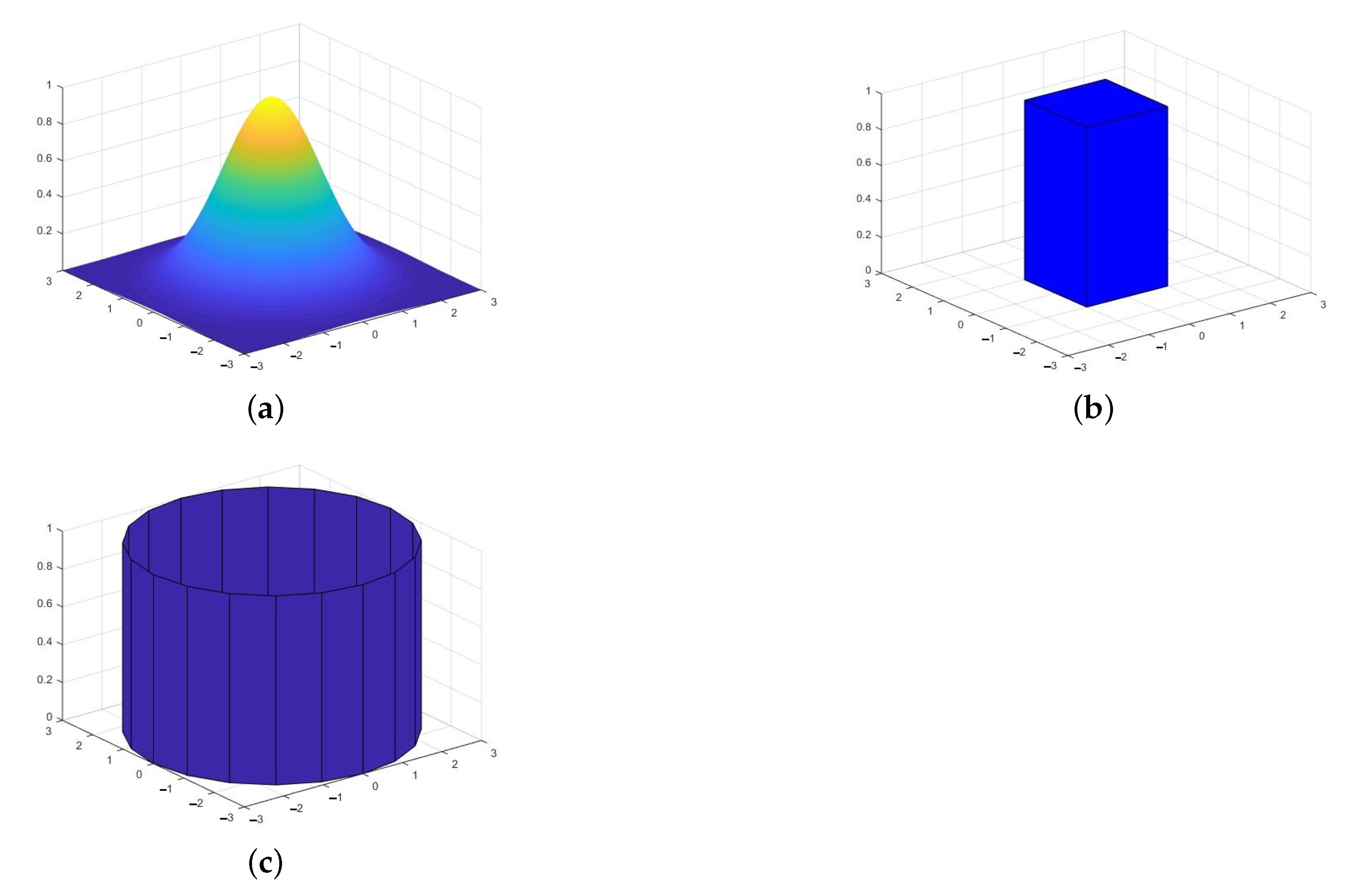
Shape of the superposition pdf: While a Gaussian pdf represents the most appropriate choice due to its effectiveness in capturing a number of unrelated causes of errors in the candidate location estimates, the calculation of the summation of multiple Gaussian pdfs involves significant computation costs that may be prohibitive for low cost wireless sensor nodes. To reduce this computation complexity, we explored simpler shapes for the approximation of the pdfs, such as cuboid and cylindrical pdfs, as depicted in
Figure 7b,c respectively. When such flat-topped pdf’s are used, the region of agreement of multiple candidate locations would have a flat-top as well. For such cases, the final location estimate of the unknown node can be obtained as the centroid of the region of highest agreement, which is illustrated in
Figure 8. Based on performance results comparing the effectiveness of various shapes of pdfs, which are excluded due to space considerations, the cuboid shape was assumed in this paper.
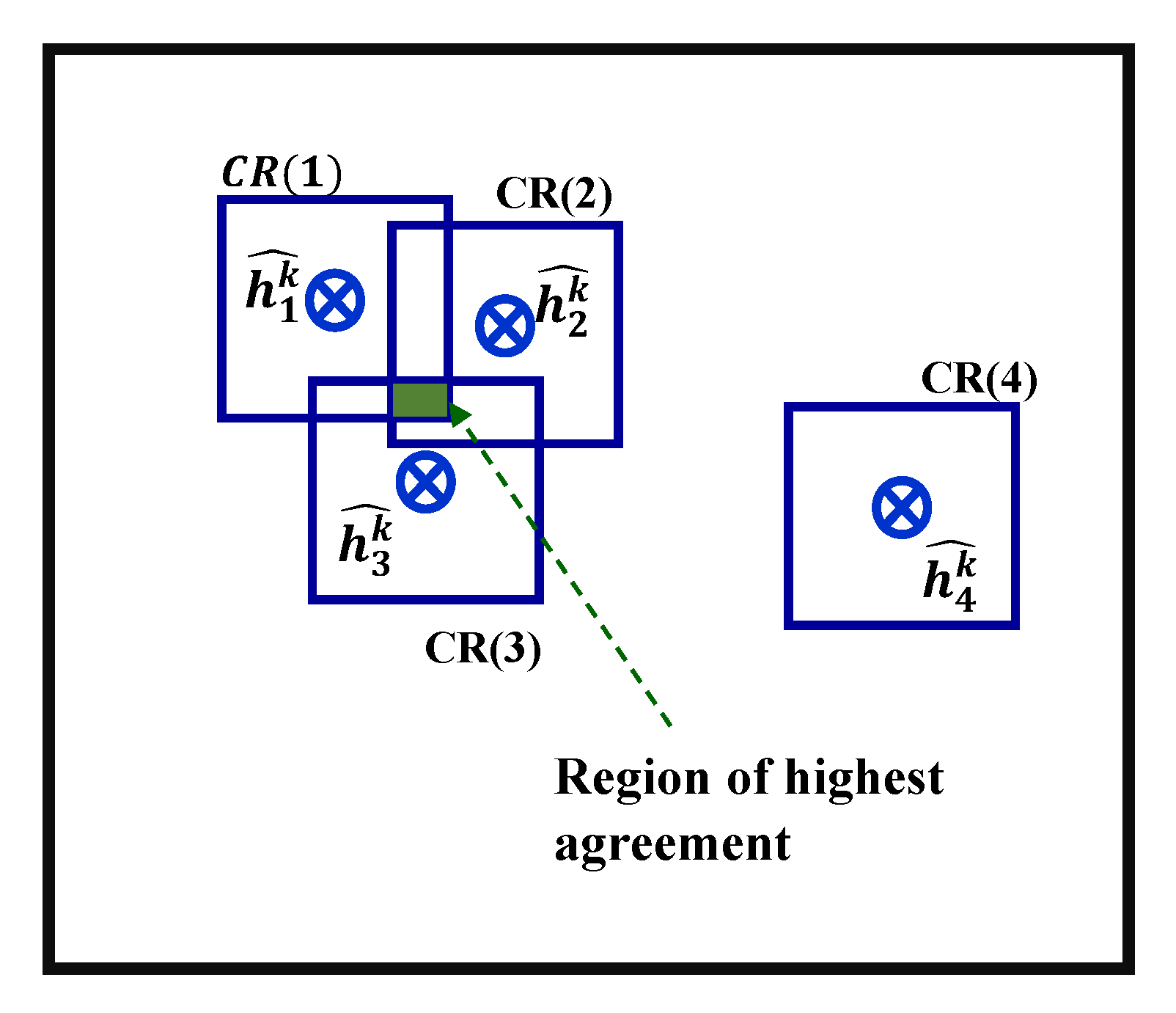
Footprint size of the selected superposition pdf: The size of the footprint of the assumed pdf represents the margin of error in the candidate location estimate. However, it also represents the area within which agreements between adjacent candidate location estimates are computed at the time of summation. We term this footprint area as the “correlation region” (CR). Using a small CR size has an adverse effect on the majority rule principle, as the individual pdfs will have insufficient total overlap, resulting in ineffective localization of the UN. Conversely, using very large CR sizes introduces erroneous location estimates, resulting in an erroneous final location of the UN. A tradeoff has to be made between having the sufficient total overlap of majority of the location estimates in one hand and reducing the number of erroneous location estimates introduced on the other.
4.2. Centroid-Based Outlier Detection Scheme
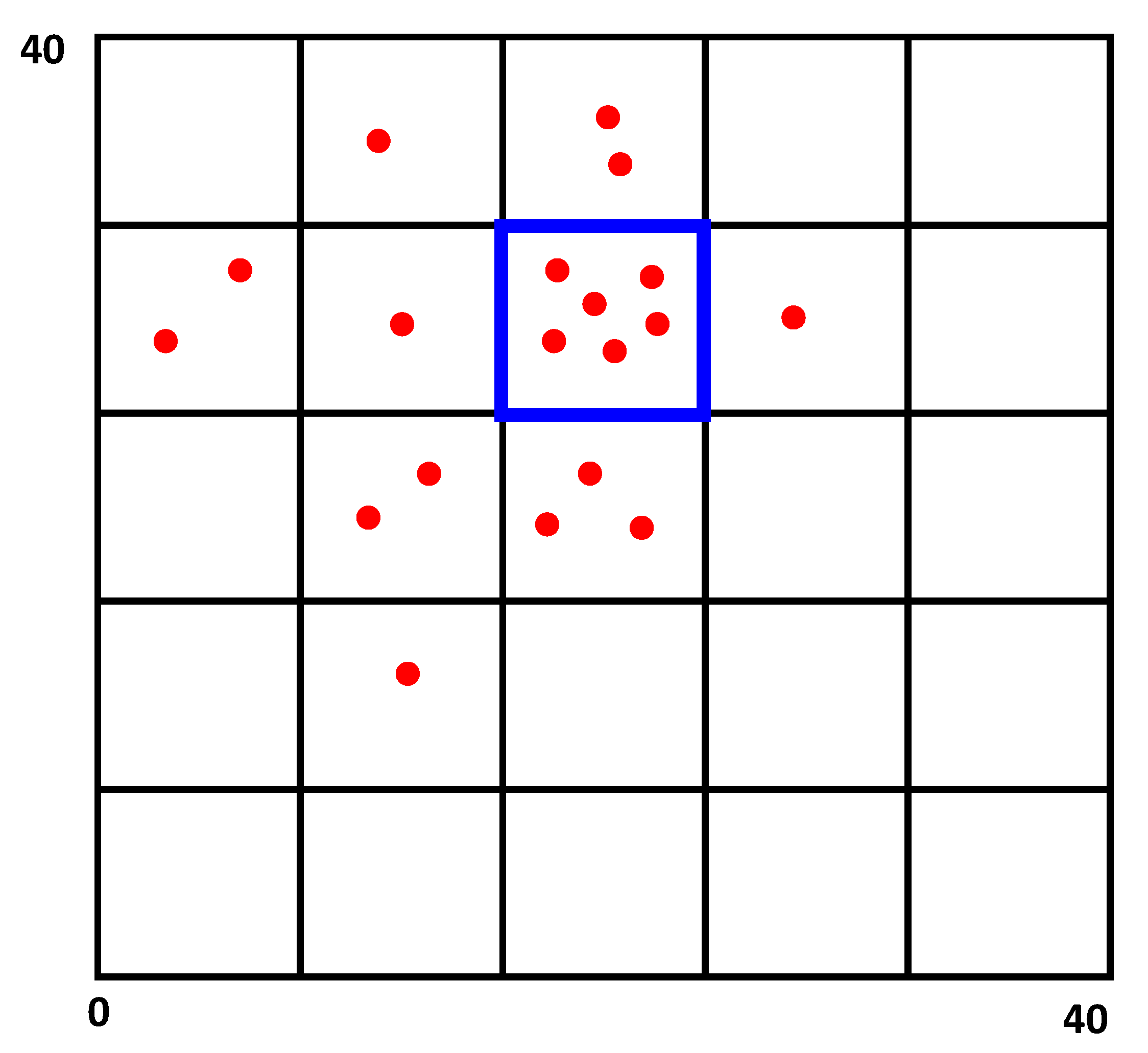
We next describe the proposed centroid-based outlier detection scheme, termed as OD_CTRD, which applies a simple clustering mechanism on the candidate location estimates to detect the location of highest agreement. The objective is to use clustering as a tool for filtering out outliers from the data points, i.e., candidate location estimates, in order to effectively estimate the location of an UN. For simplicity, we first use a heuristic for clustering, which is described using
Figure 9. The figure illustrates that the
network region is broken into a grid of smaller partitions, which are
blocks in the example. The clustering mechanism maps the data points
to the corresponding partitions and determines the partition that has the highest number of data points, indicating the location of a cluster.
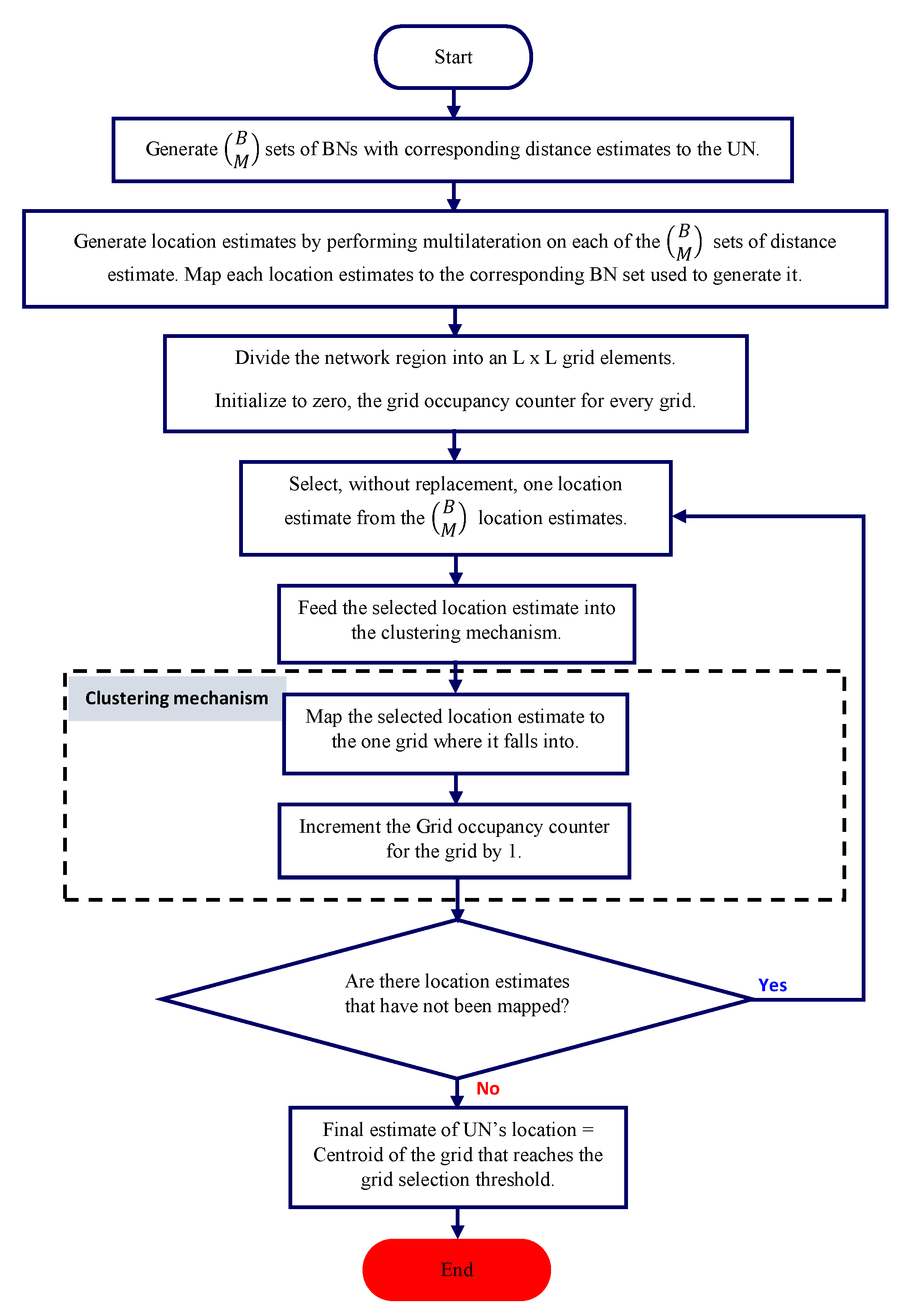
The proposed OD_CTRD localization scheme applies the clustering approach presented above, as described in the flowchart depicted in
Figure 10. The clustering algorithm outputs the grid ID of the partition that has maximum occupancy and the centroid of the selected partition is considered as the final location estimate of the UN. However, there may be cases where multiple partitions contain the same number of maximum location estimates. For such cases, further processing is needed to determine the location of highest density. One such method is to compute the degree of spread of the constituent candidate location estimates in each of the competing partitions, and choose the partition with the tightest spread. We will not explore these special cases further in this paper.
The primary design consideration for the OD_CTRD method is the selection of the appropriate size of the network partitions. Typically, the size of the partitions should be chosen to meet the expected cluster size. Smaller partitions would lead to large number of grid elements, which will increase the computational cost of implementing the scheme. On the other hand, larger partitions would lead to a small number of grid elements, which will result in the degraded accuracy of the scheme. A tradeoff has to be made between reducing the computation cost of the scheme in one hand and improving the localization accuracy. Preliminary work on this scheme was presented in ref. [
3].
To improve the effectiveness of the clustering of arbitrary data sets, we also explore a more conventional clustering algorithm, which is described next.
4.3. Mean Shift Clustering-Based Outlier Detection Scheme
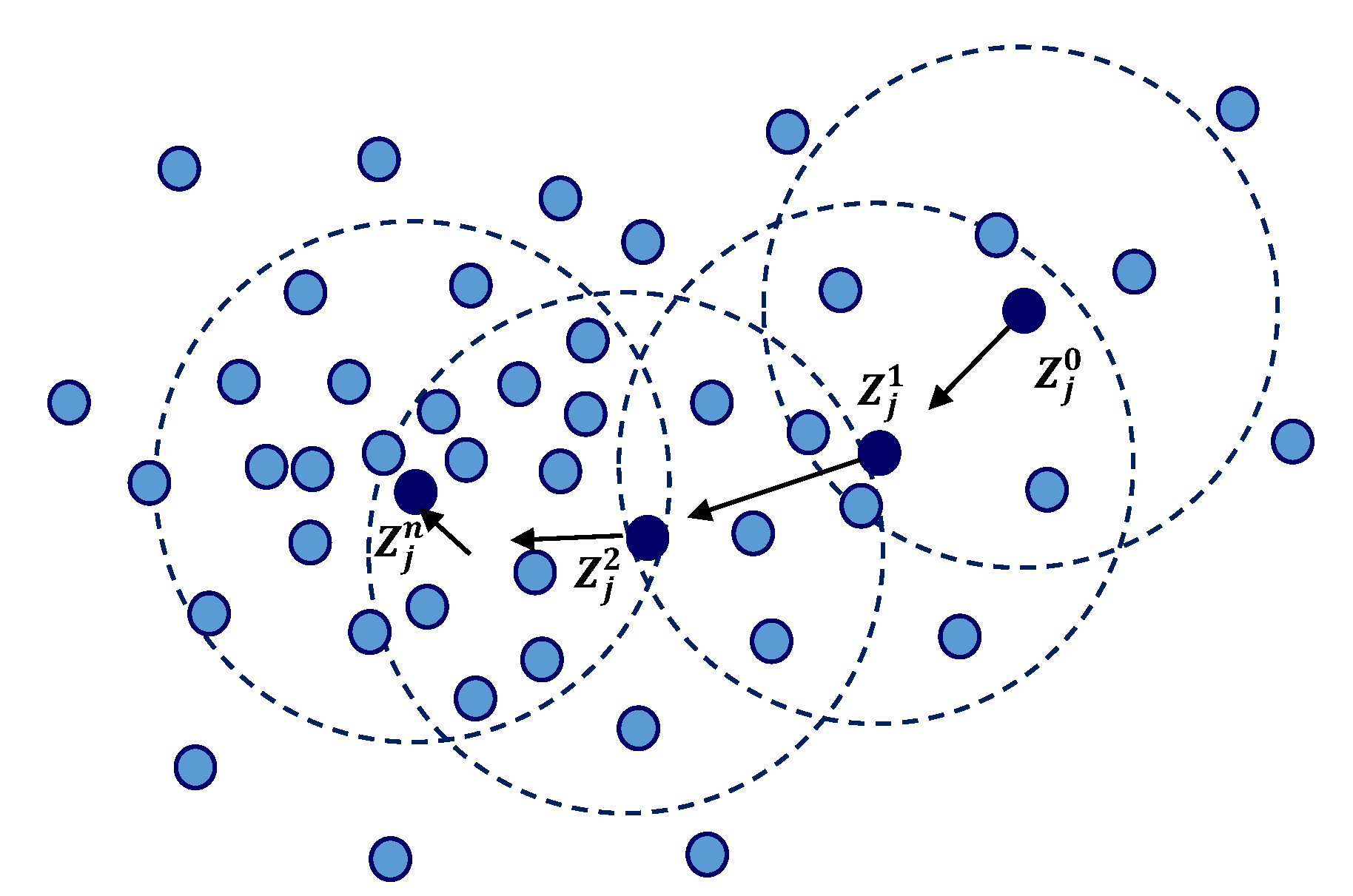
Mean shift clustering (MSC), proposed by Fukunaga & Hostetler in 1975, is an algorithm that is based on a non-parametric sliding-window mechanism used to find dense regions of data points and used to find the center points of each of these regions [
35]. The MSC uses a sliding window that is incrementally centered at the centroid of the data points within the window. The algorithm converges when the center of the window eventually coincides with the centroid of the data points in the window. A post-processing procedure is initiated to filter out candidate windows in order to remove duplicates.
Figure 11 illustrates the mean shift process, where the first step is to represent the data set as data points. The MSC process begins at any chosen data point
, then stationary points of the density function are found. In
Figure 11, the superscripts represent the mean shift process iteration, the shaded dots represent the input data points and the black dots represent the successive centers of the windows, and finally, the dotted circles represent the density estimation windows.
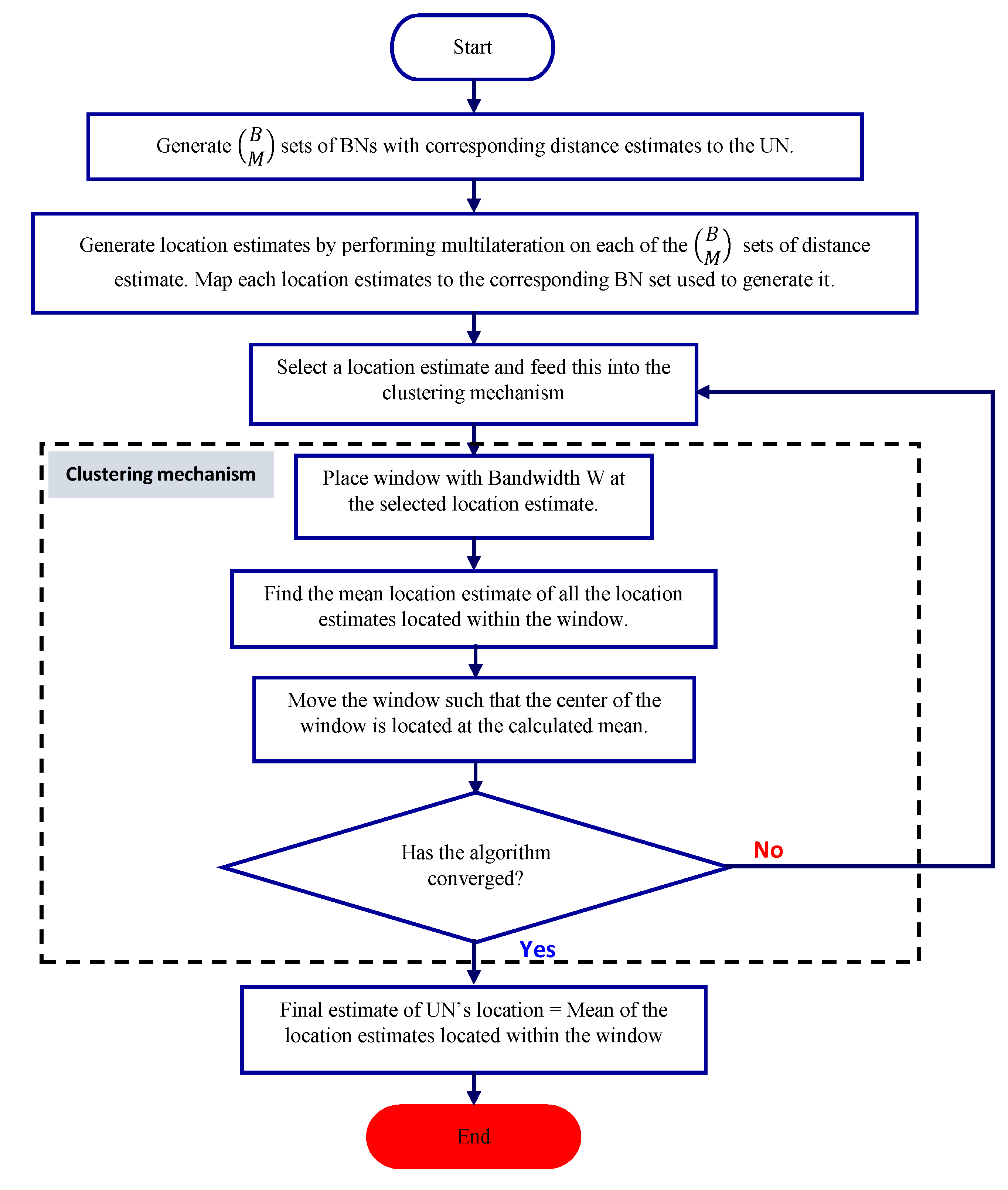
The flowchart of the proposed MSC-based localization scheme (OD_MSC) is depicted in
Figure 12. The MSC algorithm requires only one parameter, which is the window size or bandwidth. It is known to be robust to outliers, independent of the type of model used. One disadvantage of the MSC algorithm is its dependence on the bandwidth (window size). It also has the likelihood of being computationally expensive, which is
. This can be overcome by using special steps, such as reducing the number of data points search without adversely affecting the output of the scheme. Due to its many benefits, the MSC algorithm is widely applied in computer vision research. For the localization problem, with the candidate location estimates being spatially correlated, the MSC mechanism systematically moves through the candidate location estimates moving from regions of low density (low agreement by individual location estimates) to regions of higher density (higher agreement). In this work, we evaluated several window sizes 1, 3, 5, 7 and 9 and chose window size of 5 because it gave the best localization accuracy given the execution time.
5. Performance Evaluations
We now present performance evaluations of the proposed localization schemes: majority rule (MajRULE), centroid-based outlier detection (OD_CTRD), and mean shift clustering-based outlier detection (OD_MSC). Numerical performance evaluations of the errors performances of various schemes were obtained using computer simulations as well as from experimental tests, as discussed below. For comparison, we also evaluated the performance of multilateration-based localization, where all BNs are considered, together and ROSLAM localization schemes under similar situations, wherever applicable.
Simulation Results
We first present the average localization error (in meters) and the effect of the number of BNs on the localization accuracy of various schemes discussed above, using computer simulations. Simulations were performed using MATLAB R2017a and a common system model to evaluate the five localization schemes. The assumed network model was as described in
Section 4 and the simulation parameters are listed in
Table 1. We modeled the three obstacles located within the network region. A lognormal fading factor parameter
= 1 dB was used for both LoS and NLoS signals. For the non-line of sight beacon signals, we introduced an additional attenuation
using varying values ranging from 1 dB to 5 dB. The obstacles were assumed to be in the same locations for all simulations and random outcomes of the fading variable was simulated and the corresponding results averaged from 10 independent runs for each case.
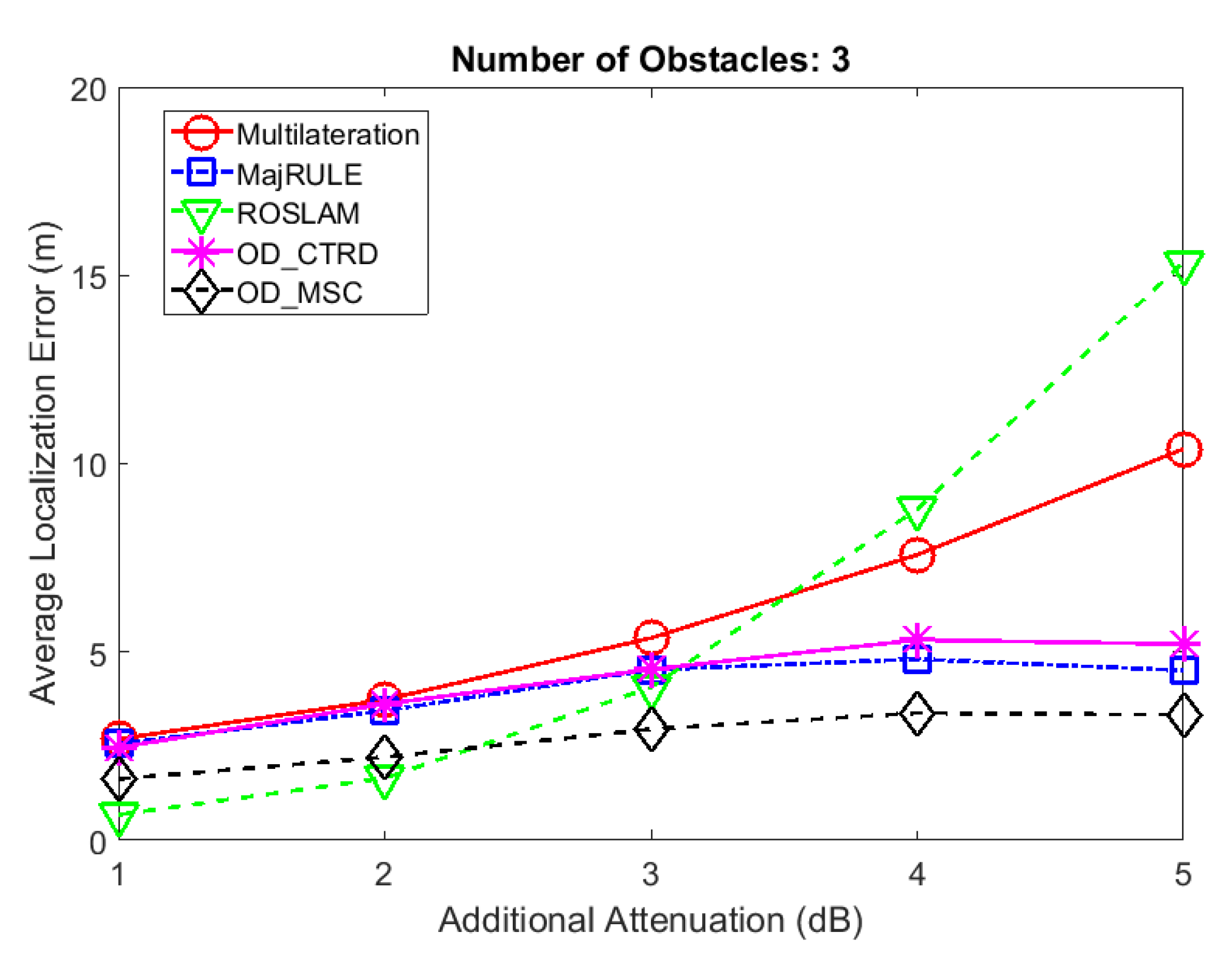
Figure 13 shows a comparison of the average localization errors for an UN located at coordinates (20,20) using the five localization schemes with increasing values of
. The results show that the MajRULE, OD_CTRD and OD_MSC methods perform better than multilateration, as well as ROSLAM when additional attenuation factor exceeds 3 dB. This indicates that when the effect of the outlier becomes more significant, all three proposed schemes that are based on outlier detection generate lower localization errors, on average. This proves the benefits of using systematic mechanisms to reduce the effects of shadowing in RSSI based localization calculations. However, ROSLAM outperforms all of the localization schemes considered for lower values of
, where the proposed schemes are not effective in detecting the outlier range estimates.
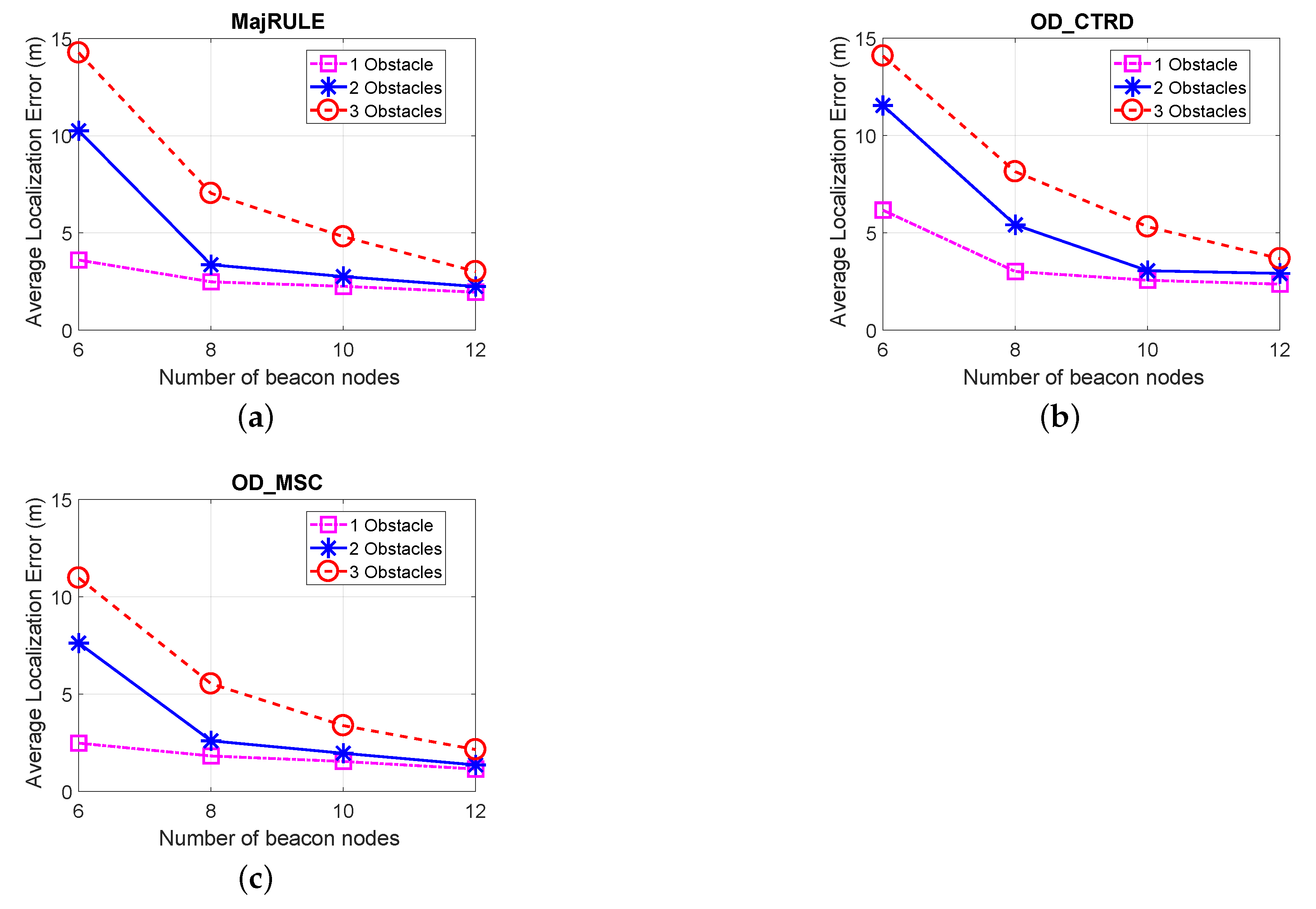
In
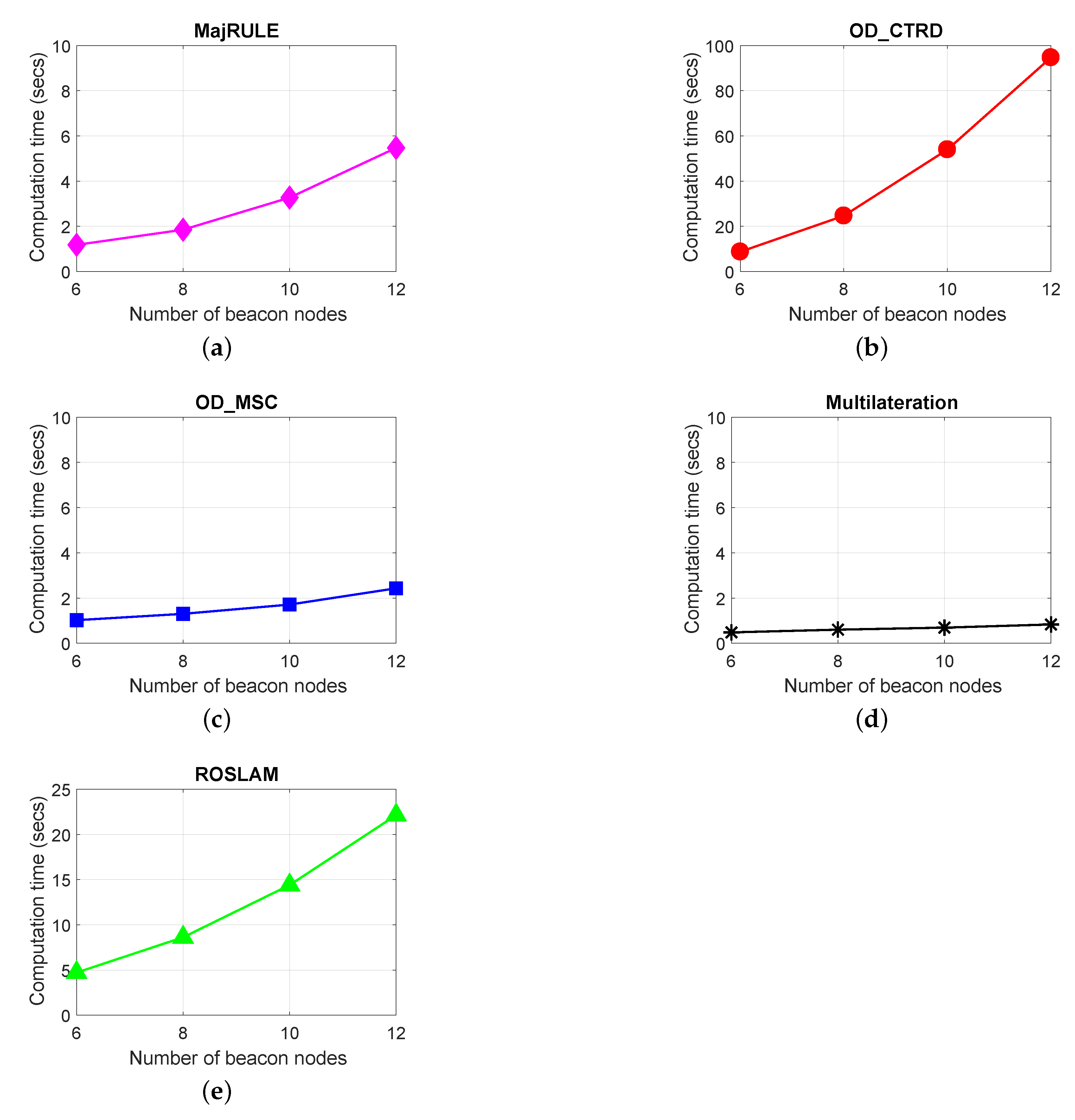
Figure 14, we show the effect the number of BNs used in the localization errors of the localization schemes: MajRULE, OD_CTRD and the OD_MSC. As expected, the localization error for all schemes reduces with increasing number of BNs used. This is due to the fact that with an increase in the number of unique BNs or beacon positions, the number of candidate location estimates to be used for estimating the location of the UN increases, resulting in an improved localization efficiency of the schemes. However, improvement in localization accuracy due to increase in the number of BNs used introduces a cost in computation time. We have evaluated, as shown in
Figure 15, the effect of an increase in BNs on the computation time of the localization schemes. For the evaluation of the computation time, we used the execution time of the algorithms on an Intel(R) Core(TM) i5-7200U @ 2.70GHz laptop system with 8 GB of RAM, x64-based processor and 64-bit operating system. The channel propagation model used is the same as we used in the previous sections for additional attenuation (NLOS noise); we used 5dB. The plots in
Figure 15 show that the multilateration method has the best computation time, followed by the OD_MSC, the MajRule, ROSLAM and finally the OD_CTRD. The reduction in localization error using the OD_MSC and MajRUle localization schemes far outweighs the slight increase in their computation time. The reason for the very high increase in computation time for the OD_CTRD is attributed to the fact that the OD_CTRD localization process includes additional processes such as: breaking the network region into grids of 1 × 1 square area, mapping of location estimates to grids etc. An increase in the number of BNs used will result in an increase in the number of location estimates to be mapped, hence the computation time increases. The much higher increase in computation time using the OD_CTRD may also not be a problem in situations where the localization computation is not done on a resource-constrained device such as a wireless sensor node.
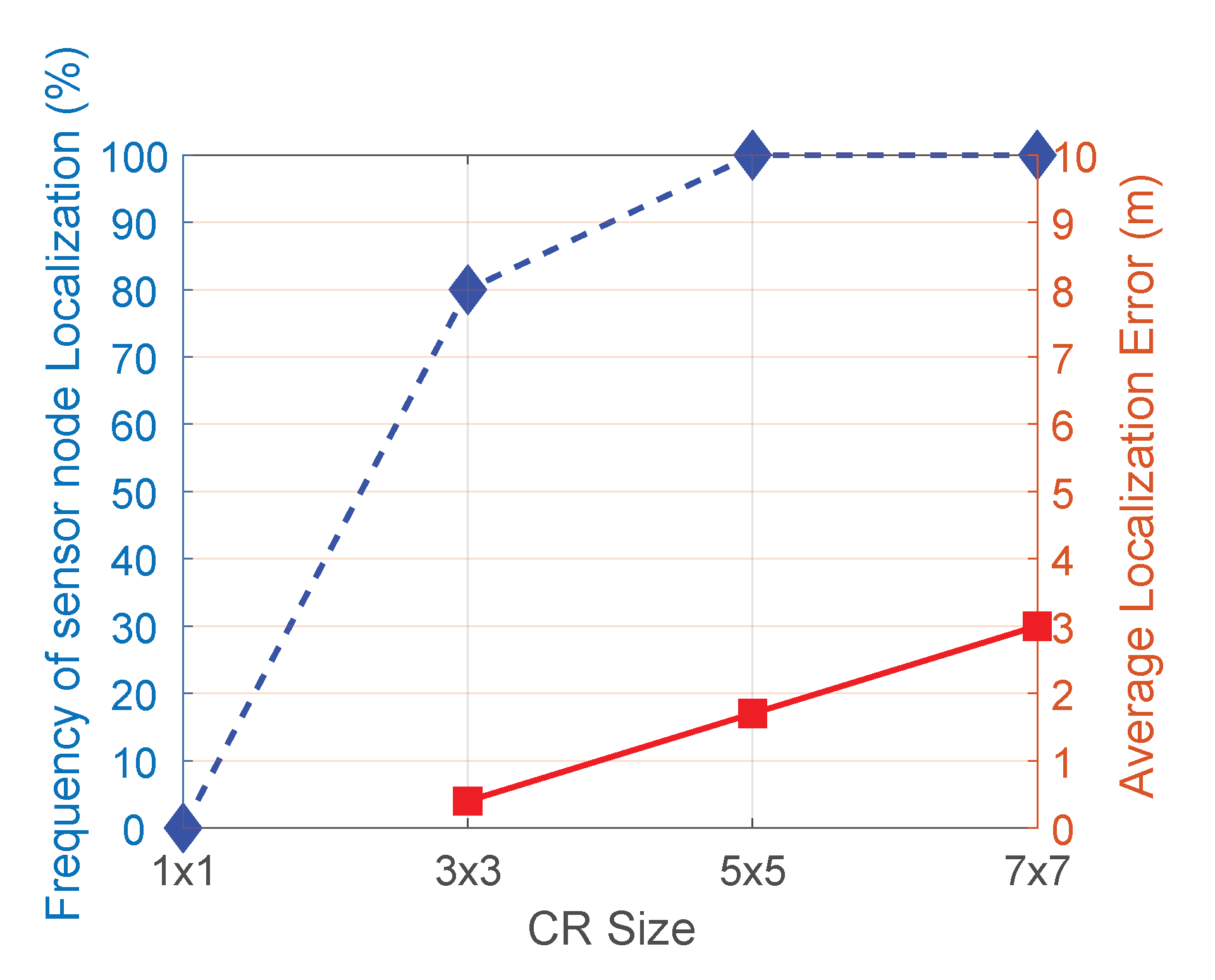
As explained in
Section 4.1, the CR size is an important parameter for the proposed MajRULE localization scheme, since it affects the error performance as well as localization efficiency. To evaluate the effect of the CR size on these outcomes, we simulated the localization performance of 100 randomly distributed UNs in the network using the MajRULE scheme with different CR sizes. In
Figure 16, we show the percentage of nodes localized and the corresponding average localization errors for different CR sizes used in the simulations experiment. The results indicate that using a very small CR size adversely affects the majority rule voting mechanism, as the individual pdfs will have minimal overlap and may not effectively localize the UN. Using a very large CR size, on the other hand, will increase the probability of the CRs overlapping, but increases the error margin for the candidate location estimates.
Figure 16 also shows that CR size of
localizes the UN 80% of the time (as against 100% for
or larger CR sizes), however,
has the least localization error. So, we use
as the CR size for all our simulations and experimental tests.
Experimental Results
The proposed schemes were also evaluated experimentally using commercially available off-the-shelf MICAz wireless sensor nodes (developed by Crossbow Technologies and later marketed by MEMSIC. Currently, this product is out of production).
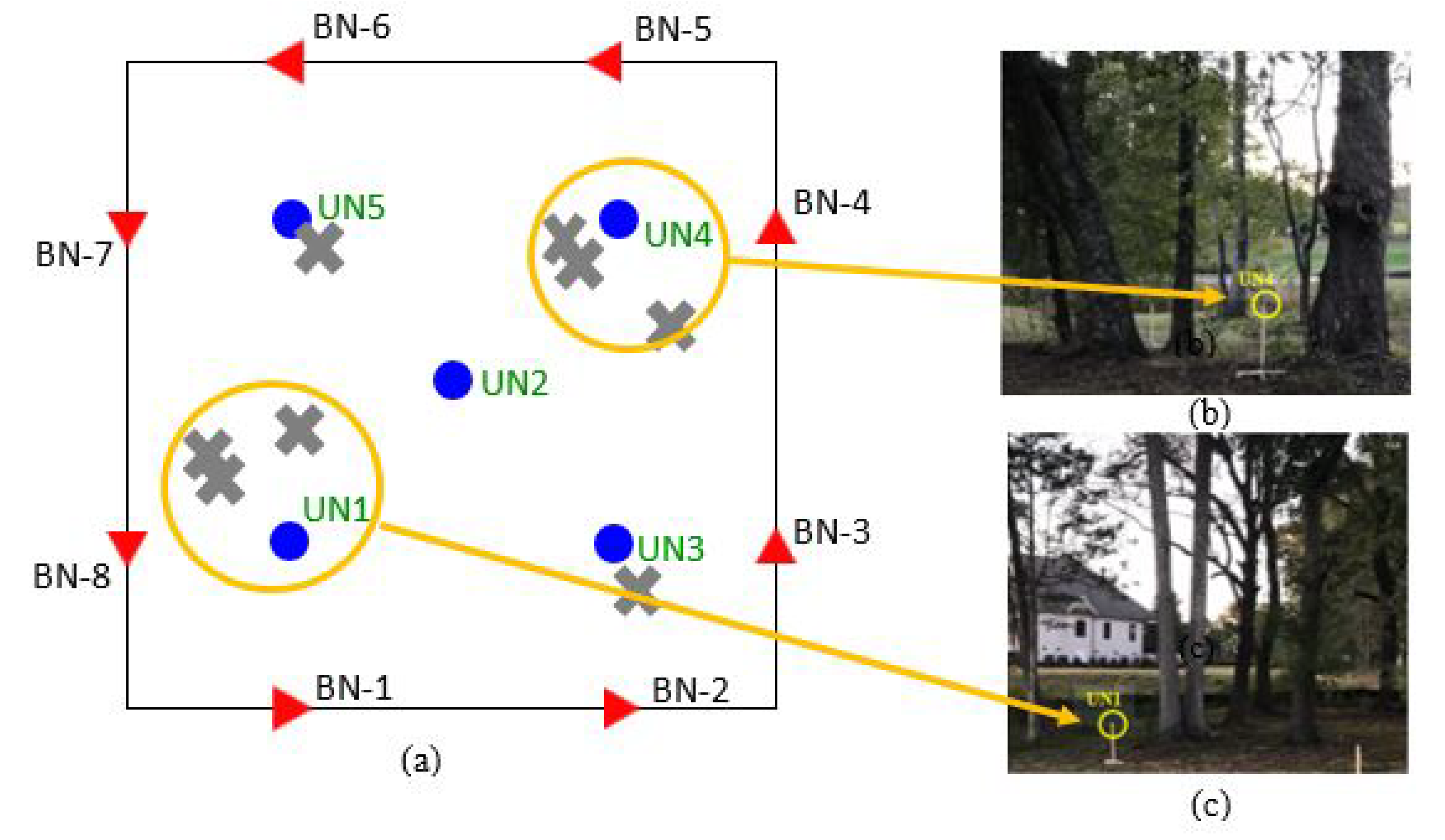
Table 2 includes the list of hardware components used in the experimental tests. The experiments were conducted in a 20 m × 20 m wooded region, as illustrated in
Figure 17. Five unknown nodes were placed at specific locations of the deployment site, as indicated in the figure. For these experiments, a set of 8 BNs was used, which were implemented by placing a MICAz mote transmitting beacon signals at the indicated beacon locations around the perimeter of the deployment region. The path loss factor was experimentally determined to be
.
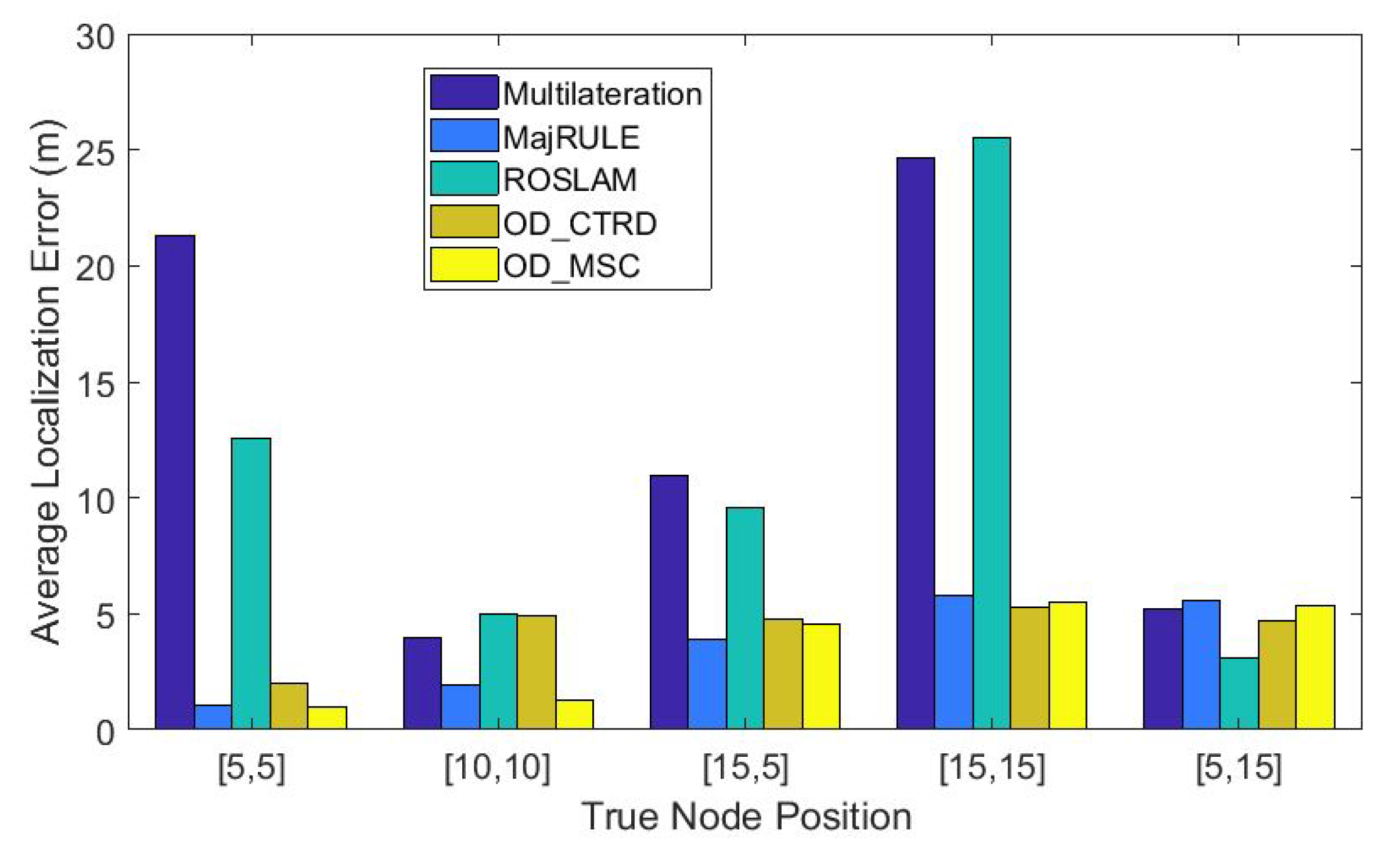
In
Figure 18, we plot the localization errors for all five UN locations for all the five localization schemes discussed in this paper: multilateration using all BN signals, ROSLAM, MajRULE, OD_CTRD, and OD_MSC. The x-axis indicates the locations of UN1, UN2, UN3, UN4, and UN5, respectively. Results indicate that the proposed outlier-based localization schemes have lower localization errors for all UNs in comparison to multilateration using all BNs and ROSLAM. The proposed majority rule localization scheme provides the lowest error, on average. An interesting observation is that both multilateration and ROSLAM schemes produce very high localization errors for UN1 and UN4, and relatively high errors for UN3 as well. To gain further insights into these results, we list the average RSSI values received from all BNs at the five UNs in
Table 3 and the corresponding errors on the estimated distances from the UNs to these BNs in
Table 4.
Table 4 shows very high errors in the estimated distances between the UNs listed below and the BN positions (marked in red):
UN1 to BN position 4 (11.39 m) and UN1 to BN position 6 (29.24 m).
UN3 to BN position 2 (13.66 m) and UN1 to BN position 5 (13.14 m).
UN4 to BN position 1 (19.41 m), UN4 to BN position 3 (20.57 m) and UN4 to BN position 8 (15.49 m).
UN5 to BN position 3 (13.57 m).
For UNs 1 and 4, multilateration performed poorly because they performed location estimation using multiple reference distance estimates that have very high errors. The reason for the high errors is because the clusters of trees around UN1 and UN4, shown in
Figure 17b,c respectively, caused additional attenuation to the received beacon signals. The localization error result for UN3 was comparatively lower, because though two of the reference distance estimates had high errors, they were not as high as those experienced by UN1 and UN4. UN5 had a lower reference distance error resulting in a smaller localization error using multilateration. These clearly show the fundamental problems encountered with multilateration which uses distance estimates from all received beacon signals, obstructed and unobstructed, which was the motivation behind our research.
ROSLAM did not perform as well when compared to our proposed localization schemes, even though ROSLAM uses a weighting mechanism called the Kalman gain to weight received measurement data to determine whether to give the measured data more significance in the localization process. The reason for the poor performance of ROSLAM in our experimental testbed can be attributed to the relatively small number of reference distances available in our testbed, which affects the error performance of ROSLAM.
The experimental evaluation proves that the localization schemes that use outlier detection are effective in minimizing the adverse effects of erroneous location estimates caused by shadowing, hence produce better location estimates for UNs.
6. Conclusions
We address the development of practical and effective methods for improving the accuracy in estimating the location of wireless sensor nodes using RSSI-based distance estimates that are impacted by obstacles located within a sensor network environment. Three different RSSI based localization schemes were proposed, all of which apply the primary approach of deriving a large number of candidate location estimates or data points from different subsets of reference points, and deriving the estimated location from maximum agreement. It was demonstrated that this approach is effective in removing the effect of outliers, i.e., reference distances that have disproportionately high errors. The performance of the proposed schemes was compared with the conventional multilateration scheme that does not eliminate outliers as well as the range-only SLAM scheme, which is a popular method for localization and mapping in robotics.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}