Highly Predictive Genetic Markers Distinguish Drug-Type from Fiber-Type Cannabis sativa L

 , ,
, , 
 and
and
Abstract
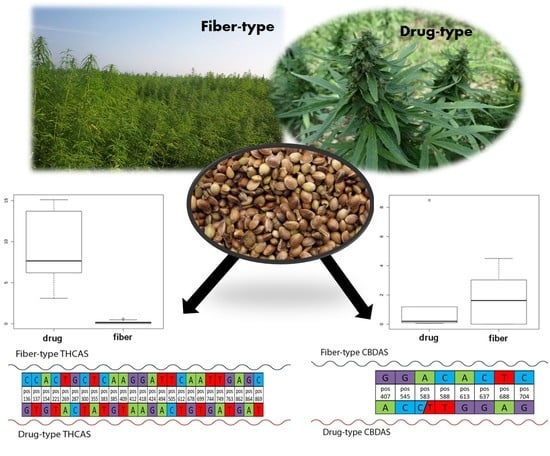
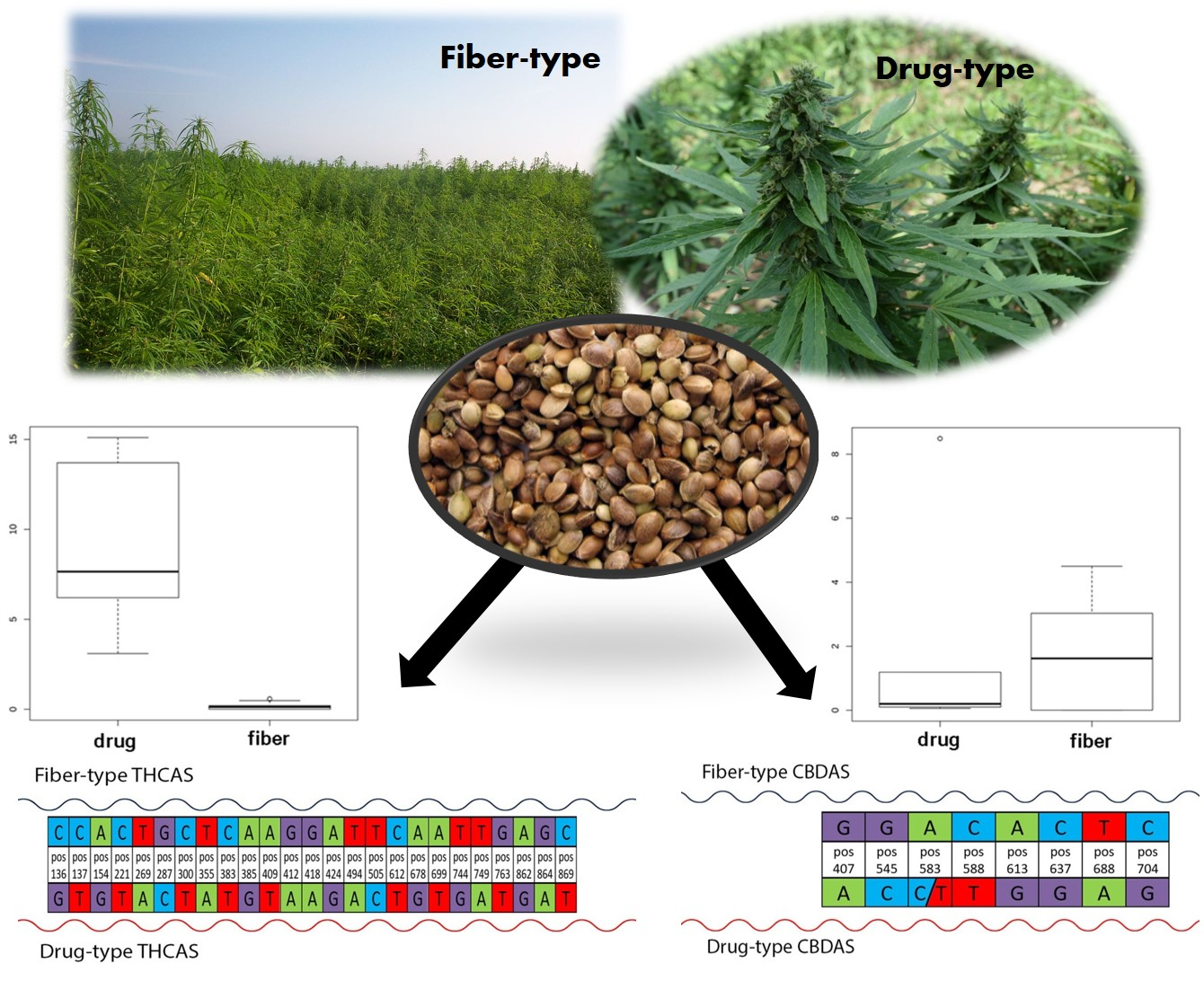
1. Introduction
2. Materials and Methods
2.1. Experimental Cultivations and Chemical Analyses: Fiber-Type Cannabis
2.2. Experimental Cultivations and Chemical Analyses: Drug-Type Cannabis
2.3. Isolation and Sequencing of DNA
2.4. Data Analysis
3. Results
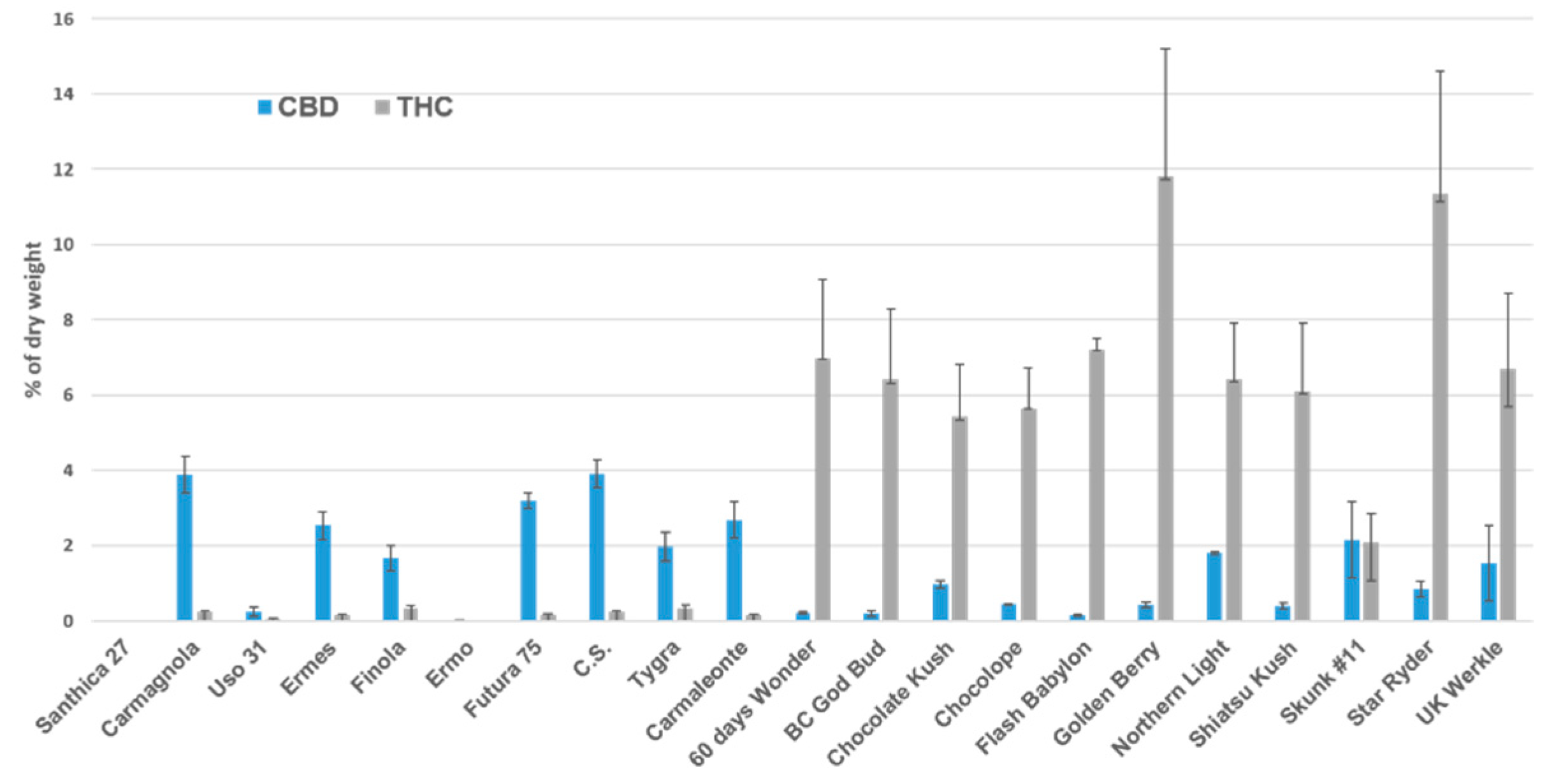
3.1. Chemical Analysis
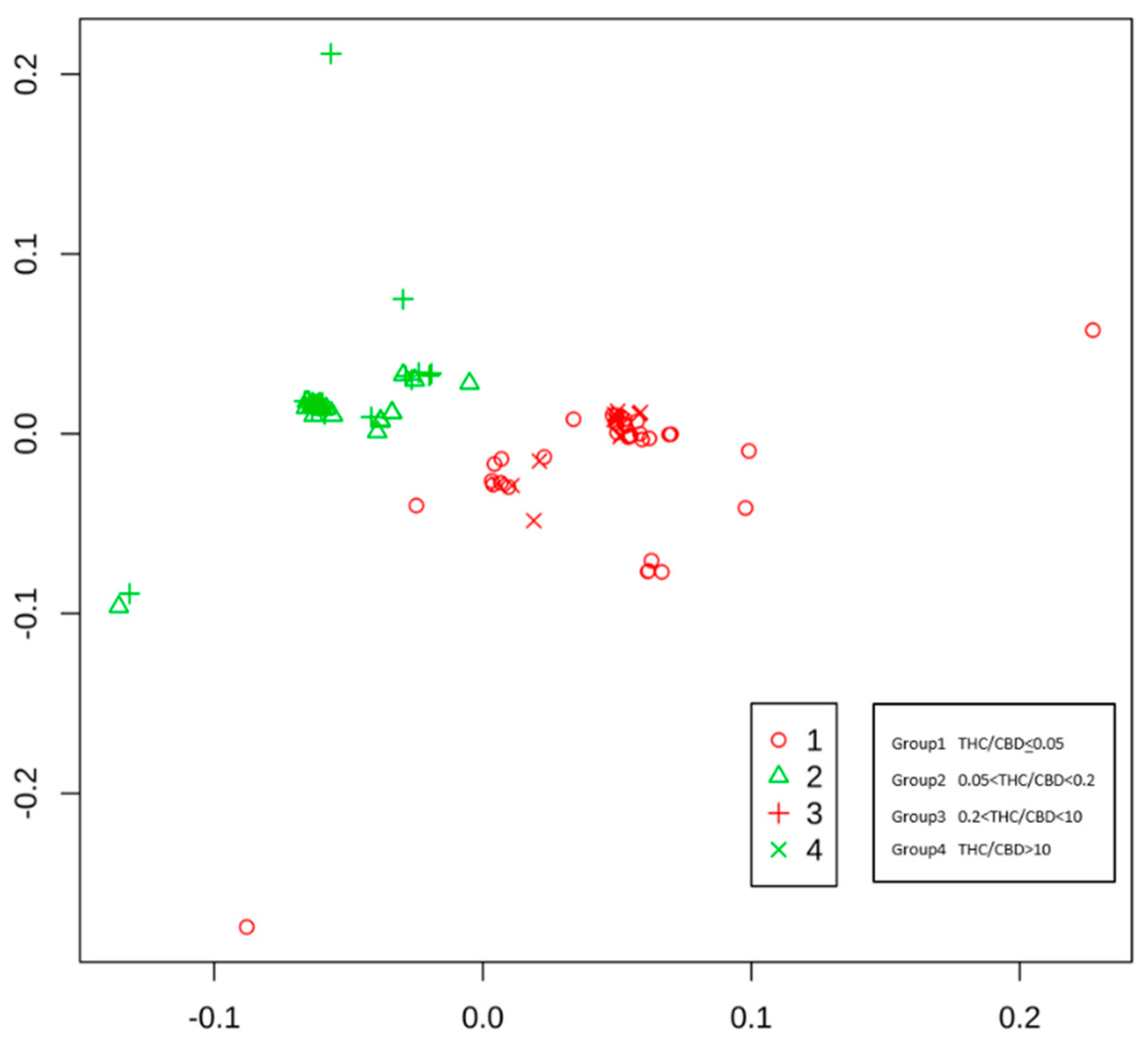
3.2. Multidimensional Scaling
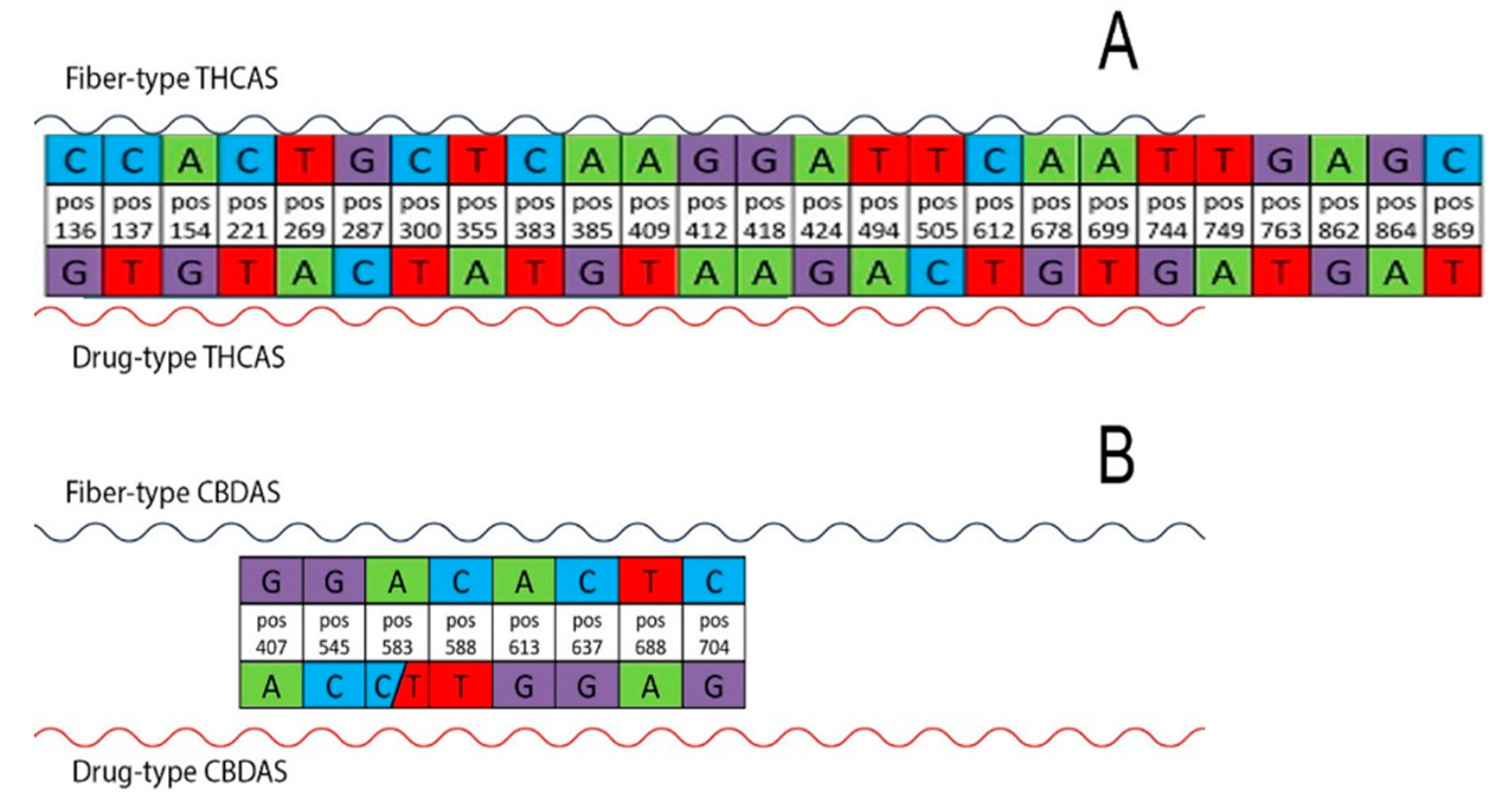
3.3. Discovery of Highly Predictive Markers
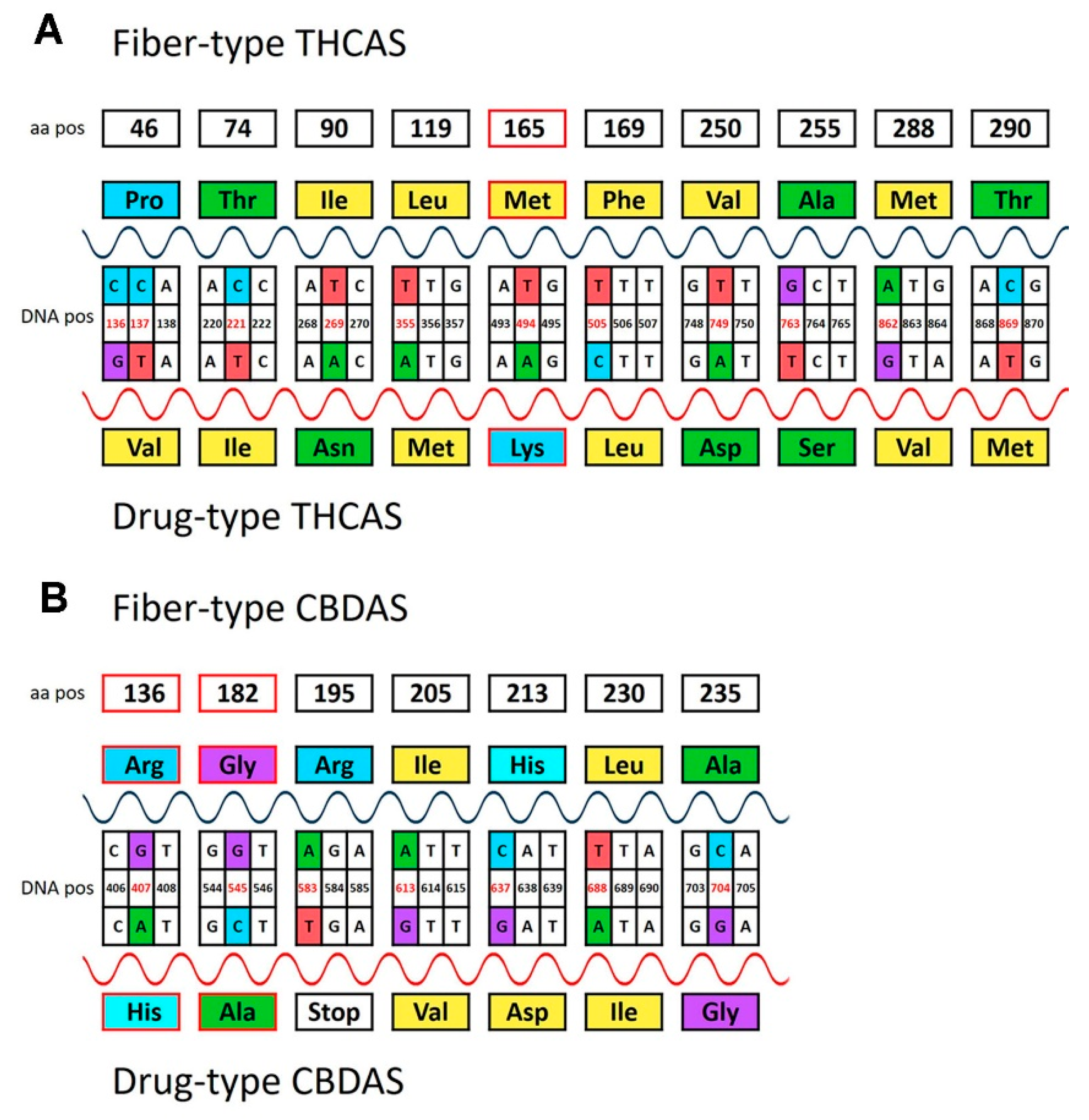
3.4. Predicted Protein Sequence of THCAS and CBDAS
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- ElSohly, M.A.; Slade, D. Chemical constituents of marijuana: The complex mixture of natural cannabinoids. Life Sci. 2005, 78, 539–548. [Google Scholar] [CrossRef] [PubMed]
- Hillig, K.W. Genetic evidence for speciation in Cannabis (Cannabaceae). Genet. Res. Crop. Evol. 2005, 52, 161–180. [Google Scholar] [CrossRef]
- Fellermeier, M.; Zenk, M.H. Prenylation of olivetolate by a hemp transferase yields cannabigerolic acid, the precursor of tetrahydrocannabinol. FEBS Lett. 1998, 427, 283–285. [Google Scholar] [CrossRef]
- Fellermeier, M.; Eisenreich, W.; Bacher, A.; Zenk, M.H. Biosynthesis of cannabinoids. Incorporation experiments with C13-labeled glucoses. Eur. J. Biochem. 2001, 268, 1596–1604. [Google Scholar] [CrossRef] [PubMed]
- Raharjo, T.J.; Widjaja, I.; Roytrakul, S.; Verpoorte, R. Comparative proteomics of Cannabis sativa plant tissues. J. Biomol. Tech. 2004, 15, 97–106. [Google Scholar] [PubMed]
- Taura, F.; Morimoto, S.; Shoyama, Y.; Mechoulam, R. First direct evidence for the mechanism of delta.1-tetrahydrocannabinolic acid biosynthesis. J. Am. Chem. Soc. 1995, 117, 9766–9767. [Google Scholar] [CrossRef]
- Taura, F.; Morimoto, S.; Shoyama, Y. Purification and characterization of cannabidiolic-acid synthase from Cannabis sativa L.: Biochemical analysis of a novel enzyme that catalyzes the oxidocyclization of cannabigerolic acid to cannabidiolic acid. J. Biol. Chem. 1996, 271, 17411–17416. [Google Scholar] [CrossRef] [PubMed]
- Thakur, G.A.; Duclos, R.I.; Makriyannis, A. Natural cannabinoids: Templates for drug discovery. Life Sci. 2005, 78, 454–466. [Google Scholar] [CrossRef] [PubMed]
- Dussy, F.E.; Hamberg, C.; Luginbühl, M.; Schwerzmann, T.; Briellmann, T.A. Isolation of b9-THCA-A from hemp and analytical aspects concerning the determination of n9-THC in cannabis products. Forensic Sci. Int. 2005, 149, 3–10. [Google Scholar] [CrossRef] [PubMed]
- Kojoma, M.; Seki, H.; Yoshida, S.; Muranaka, T. DNA polymorphisms in the tetrahydrocannabinolic acid (THCA) synthase gene in “drug-type” and “fiber-type” Cannabis sativa L. Forensic Sci. Int. 2006, 159, 132–140. [Google Scholar] [CrossRef] [PubMed]
- de Meijer, E.P.M.; Hammond, K.M.; Sutton, A. The inheritance of chemical phenotype in Cannabis sativa L. (IV): Cannabinoid-free plants. Euphytica 2009, 168, 98–112. [Google Scholar] [CrossRef]
- Pacifico, D.; Miselli, F.; Micheler, M.; Carboni, A.; Ranalli, P.; Mandolino, G. Genetics and marker-assisted selection of the chemotype in Cannabis sativa L. Mol. Breed. 2006, 17, 257–268. [Google Scholar] [CrossRef]
- Sirikantaramas, S.; Morimoto, S.; Shoyama, Y.; Ishikawa, Y.; Wada, Y.; Shoyama, Y.; Taura, F. The gene controlling marijuana psychoactivity: Molecular cloning and heterologous expression of 1-tetrahydrocannabinolic acid synthase from Cannabis sativa L. J. Biol. Chem. 2004, 279, 39767–39774. [Google Scholar] [CrossRef] [PubMed]
- Yoshikai, K.; Taura, T.; Morimoto, S.; Shoyama, Y. DNA Encoding Cannabidiolate Synthase. Patent in Japan JP 2000-78979A, 2001. DDBJ/EMBL/GenBank Database Accession Numbers E55107. [Google Scholar]
- Rotherham, D.; Harbison, S.A. Differentiation of drug and non-drug Cannabis using a single nucleotide polymorphism (SNP) assay. Forensic Sci. Int. 2010, 207, 193–197. [Google Scholar] [CrossRef] [PubMed]
- Staginnus, C.; Zörntlein, S.; de Meijer, E. A PCR marker linked to a THCA synthase polymorphism is a reliable tool to discriminate potentially THC-rich plants of Cannabis sativa L. J. Forensic Sci. 2014, 59, 919–926. [Google Scholar] [CrossRef] [PubMed]
- de Meijer, E.P.M.; Bagatta, M.; Carboni, A.; Crucitti, P.; Moliterni, V.M.C.; Ranalli, P.; Mandolino, G. The inheritance of chemical phenotype in Cannabis sativa L. Genetics 2003, 163, 335–346. [Google Scholar] [PubMed]
- van Bakel, H.; Stout, J.; Cote, A.; Tallon, C.; Sharpe, A.; Hughes, T.; Page, J.E. The draft genome and transcriptome of Cannabis Sativa. Genome Biol. 2001, 12, R102. [Google Scholar] [CrossRef] [PubMed]
- Weiblen, G.D.; Wenger, J.P.; Craft, K.J.; ElSohly, M.A.; Mehmedic, Z.; Treiber, E.L.; Marks, M.D. Gene duplication and divergence affecting drug content in Cannabis sativa. New Phytol. 2015, 208, 1241–1250. [Google Scholar] [CrossRef] [PubMed]
- Appendino, G.; Giana, A.; Gibbons, S.; Maffei, M.; Gnavi, G.; Grassi, G.; Sterner, O. A polar cannabinoid from Cannabis sativa var. Carma. Nat. Prod. Commun. 2008, 3, 1977–1980. [Google Scholar] [CrossRef]
- Calzolari, D.; Magagnini, G.; Lucini, L.; Grassi, G.; Appendino, G.B.; Amaducci, S. High added-value compounds from Cannabis threshing residues. Ind. Crop. Prod. 2017, 108, 558–563. [Google Scholar] [CrossRef]
- Gouy, M.; Guindon, S.; Gascuel, O. Seaview version 4: A multiplatform graphical user interface for sequence alignment and phylogenetic tree building. Mol. Biol. Evol. 2010, 27, 221–224. [Google Scholar] [CrossRef] [PubMed]
- Onofri, C.; de Meijer, E.P.M.; Mandolino, G. Sequence heterogeneity of cannabidiolic- and tetrahydrocannabinolic acid-synthase in Cannabis sativa L. and its relationship with chemical phenotype. Phytochemistry 2015, 116, 57–68. [Google Scholar] [CrossRef] [PubMed]
- Taura, F.; Sirikantaramas, S.; Shoyama, Y.; Yoshikai, K.; Shoyama, Y.; Morimoto, S. Cannabidiolic-acid synthase, the chemotype-determining enzyme in the fiber-type Cannabis Sativa. FEBS Lett. 2007, 581, 2929–2934. [Google Scholar] [CrossRef] [PubMed]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acid Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef] [PubMed]
- Tamura, K.; Stecher, G.; Peterson, D.; Filipski, A.; Kumar, S. MEGA6: Molecular evolutionary genetics analysis version 6.0. Mol. Biol. Evol. 2013, 30, 2725–2729. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.; Sims, G.E.; Murphy, S.; Miller, J.R.; Chan, A.P. Predicting the Functional Effect of Amino Acid Substitutions and Indels. PLoS ONE 2012, 7, e46688. [Google Scholar] [CrossRef] [PubMed]
- Firth, D. Bias reduction of maximum likelihood estimates. Biometrika 1993, 80, 27–38. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Stat. Methodol. 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Farcomeni, A. More powerful control of the false discovery rate under dependence. Stat. Methods Appl. 2006, 15, 43–73. [Google Scholar] [CrossRef]
- Farcomeni, A. Some results on the control of the false discovery rate under dependence. Scand. J. Stat. 2007, 34, 275–297. [Google Scholar] [CrossRef]
- Pepe, M.S. The Statistical Evaluation of Medical Tests for Classification and Prediction; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Cox, T.F.; Cox, M.A.A. Multidimensional Scaling; Chapman and Hall: London, UK, 2001. [Google Scholar]
- Cascini, F.; Aiello, C.; Di Tanna, G. Increasing delta-9-tetrahydrocannabinol (Δ-9-THC) content in herbal cannabis over time: Systematic review and meta-analysis. Curr. Drug Abus. Rev. 2012, 5, 32–40. [Google Scholar] [CrossRef]
- Cascini, F.; Boschi, I. Tetrahydrocannabinol Concentration and Genetic Characterization of Cannabis. In Handbook of Cannabis and Related Pathologies; Preedy, V.R., Ed.; Elsevier: London, UK, 2017. [Google Scholar]
- Mehmedic, Z.; Chandra, S.; Slade, D.; Denham, H.; Foster, S.; Patel, A.S.; Ross, S.A.; Khan, I.A.; ElSohly, M.A. Potency trends of n9-THC and other cannabinoids in confiscated cannabis preparations from 1993 to 2008. J. Forensic Sci. 2010, 55, 1209–1217. [Google Scholar] [CrossRef] [PubMed]
- Taura, F.; Tanaka, S.; Taguchi, C.; Fukamizu, T.; Tanaka, H.; Shoyama, Y.; Morimoto, S. Characterization of olivetol synthase, a polyketide synthase putatively involved in cannabinoid biosynthetic pathway. FEBS Lett. 2009, 583, 2061–2066. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NAME | No. of Plants | CBD | SD* | THC | SD* | THC/CBD | Group |
|---|---|---|---|---|---|---|---|
| Santhica 27 | 5 | 0.00 | - | 0.00 | - | 0.0 | Fiber |
| Carmagnola | 5 | 3.89 | 0.49 | 0.24 | 0.04 | 0.06 | Fiber |
| Uso 31 | 5 | 0.24 | 0.13 | 0.03 | 0.02 | 0.12 | Fiber |
| Ermes | 5 | 2.53 | 0.37 | 0.15 | 0.03 | 0.06 | Fiber |
| Finola | 5 | 1.66 | 0.34 | 0.31 | 0.1 | 0.18 | Fiber |
| Ermo | 5 | 0.01 | 0.01 | 0.00 | - | 0.0 | Fiber |
| Futura 75 | 5 | 3.18 | 0.21 | 0.18 | 0.02 | 0.05 | Fiber |
| C.S. | 5 | 3.91 | 0.36 | 0.24 | 0.02 | 0.08 | Fiber |
| Tygra | 5 | 1.97 | 0.38 | 0.31 | 0.12 | 0.18 | Fiber |
| Carmaleonte | 5 | 2.68 | 0.47 | 0.15 | 0.03 | 0.05 | Fiber |
| 60 Days Wonder | 3 | 0.22 | 0.19 | 6.97 | 3.64 | 32.17 | Drug |
| BC God Bud | 11 | 0.20 | 0.08 | 6.40 | 3.89 | 32.00 | Drug |
| Chocolate Kush | 4 | 0.96 | 0.77 | 5.42 | 2.75 | 5.67 | Drug |
| Chocolope | 3 | 0.44 | 0.02 | 5.65 | 1.06 | 12.84 | Drug |
| Flash Babylon | 2 | 0.14 | 0.18 | 7.20 | 0.30 | 51.43 | Drug |
| Golden Berry | 2 | 0.42 | 0.35 | 11.80 | 4.30 | 28.10 | Drug |
| Northern Light | 4 | 1.81 | 1.84 | 6.40 | 4.90 | 3.53 | Drug |
| Shiatsu Kush | 8 | 0.40 | 0.19 | 6.10 | 3.39 | 15.44 | Drug |
| Skunk #11 | 4 | 2.15 | 1.34 | 2.08 | 0.77 | 0.97 | Drug |
| Star Ryder | 4 | 0.84 | 1.04 | 11.33 | 3.28 | 13.53 | Drug |
| UK Werkle | 2 | 1.54 | 1.79 | 6.70 | 4.70 | 4.36 | Drug |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cascini, F.; Farcomeni, A.; Migliorini, D.; Baldassarri, L.; Boschi, I.; Martello, S.; Amaducci, S.; Lucini, L.; Bernardi, J. Highly Predictive Genetic Markers Distinguish Drug-Type from Fiber-Type Cannabis sativa L. Plants 2019, 8, 496. https://doi.org/10.3390/plants8110496
Cascini F, Farcomeni A, Migliorini D, Baldassarri L, Boschi I, Martello S, Amaducci S, Lucini L, Bernardi J. Highly Predictive Genetic Markers Distinguish Drug-Type from Fiber-Type Cannabis sativa L. Plants. 2019; 8(11):496. https://doi.org/10.3390/plants8110496
Chicago/Turabian StyleCascini, Fidelia, Alessio Farcomeni, Daniele Migliorini, Laura Baldassarri, Ilaria Boschi, Simona Martello, Stefano Amaducci, Luigi Lucini, and Jamila Bernardi. 2019. "Highly Predictive Genetic Markers Distinguish Drug-Type from Fiber-Type Cannabis sativa L" Plants 8, no. 11: 496. https://doi.org/10.3390/plants8110496
APA StyleCascini, F., Farcomeni, A., Migliorini, D., Baldassarri, L., Boschi, I., Martello, S., Amaducci, S., Lucini, L., & Bernardi, J. (2019). Highly Predictive Genetic Markers Distinguish Drug-Type from Fiber-Type Cannabis sativa L. Plants, 8(11), 496. https://doi.org/10.3390/plants8110496