1. Introduction
Mandarins are rich in various vitamins and nutrients and particularly have high vitamin C content; each 100 g of mandarin pulp contains 53.2 mg of vitamin C. Their nutritional value and unique flavor make them one of the most consumed fruit categories worldwide [
1]. China is the largest mandarin producer globally, accounting for 28.3% of the world’s total production and 30% of the total cultivated area. Despite its large-scale operations, the mandarin harvesting sector faces challenges such as seasonal labor shortages, increasing labor costs, and low harvesting efficiency [
2]. To address these issues, the industry is accelerating the mechanization and intelligent transformation of harvesting operations [
3]. Against this backdrop, precise fruit detection technology has become a core technical barrier in the development of intelligent harvesting equipment [
4].
Traditional fruit detection relies on manually extracting fruit features such as texture and color, which are easily affected by subjective judgment and environmental interference [
5]. The emergence and development of deep learning have ushered fruit detection into a new phase. By using an end-to-end image processing approach, deep learning can directly output detection results and continuously optimize model performance as the data scale increases. Due to its outstanding performance, deep learning has become the primary method for addressing fruit detection challenges [
6].
In this context, many high-performance detection networks have been proposed and applied to fruit detection. These networks offer excellent scalability and can meet the demands of most fruit detection tasks. For example, ref. [
7] proposed the YOLOv4 Drone model, which introduces lightweight feature enhancement and multi-scale fusion strategies based on the YOLOv4 architecture, making fruit detection via drones feasible. UAV-based YOLO detection frameworks have also been extended to other complex scenarios, such as wind turbine crack inspection under motion blur conditions, further validating the adaptability and robustness of YOLO in real-world visual tasks beyond static conditions [
8]. However, due to limitations in handling small or occluded targets, this model inevitably suffers from a decline in detection accuracy. Ref. [
9] proposed the YOLO-P model, which combines inverted shuffle blocks and Convolutional Block Attention Module (CBAM) attention mechanisms to improve the accuracy and speed of plum detection in complex backgrounds Although the inverted shuffle blocks optimize computational efficiency through channel reorganization, their feature reuse mechanism has limitations in adapting to multi-scale occlusions. Ref. [
10] introduced the MSOAR-YOLOv10 model, which integrates multi-scale feature fusion and mixed loss strategies to improve apple detection in complex orchard environments. However, it was found, in practical deployment, that its multi-branch design increases memory access frequency, affecting the stability of real-time detection.
As can be seen from the above, most studies have yet to provide effective solutions to the challenges of severe occlusion and weak feature representation for small objects in complex orchard environments. The first challenge is occlusion. In complex orchard scenes, the dense distribution of fruit targets and tree backgrounds results in composite occlusions caused by leaf cover, fruit overlap, and background interference, which significantly hinder detection accuracy. The primary challenges in complex orchard environments are occlusion and small-object detection, both of which are closely associated with the issue of edge degradation. In densely distributed orchard scenes, occlusions caused by leaf cover, fruit overlap, and background interference often result in blurred or distorted object contours, making it difficult to distinguish object boundaries [
11]. Existing methods, such as those employing CBAM or multi-scale fusion strategies, aim to enhance feature saliency but are typically insensitive to fine-grained edge details, especially in overlapping regions. This leads to a loss of structural cues that are critical to accurate localization. On the other hand, small objects inherently possess weak and fragmented edge features. When further occluded, these features are easily overwhelmed by noise or background clutter. However, current detection networks lack explicit mechanisms to perceive such degraded boundaries, resulting in reduced robustness and detection accuracy under real-world orchard conditions.
To solve these problems, this study proposes the ELD-YOLO model, an improved version of the YOLO11 model for mandarin detection in complex orchard environments. The main contributions of this study are as follows:
A dataset of 2388 images was established, covering mandarin orchards under various weather and lighting conditions, in different occlusion scenarios, and against diverse backgrounds.
A multi-scale edge feature enhancement module, Edge-guided Multi-scale Dual-domain Enhancement (EMD), was proposed and embedded into the C3K2 layer. An edge feature fusion structure (EAFF) was designed to construct complementary high-frequency features, enabling the comprehensive extraction of edge features.
A lightweight task-interactive detection head (LIDH) was designed, combining group convolution with an IoU-based task interaction mechanism. This reduces parameters while decreasing the false-positive and false-negative rates for occluded and small targets, achieving lightweight and efficient detection.
The dynamic point sampling module (Dysample) was introduced to replace the original upsampling structure. This enhances the model’s ability to handle densely distributed fruit, preserves features of occluded and small mandarins, and reduces the parameter count.
4. Materials and Methods
4.1. Dataset Construction
4.1.1. Data Acquisition
Building a suitable dataset is a prerequisite for evaluating model performance. In this study, we conducted a field investigation in late October in Dongpo District, Meishan City, Sichuan Province—one of China’s renowned orchard regions [
32]. During the mandarin fruit-bearing season, we captured 2388 images of mandarin orchards by using a Canon R-10 and a Huawei Mate 60, with image resolutions of 6000 × 4000 and 3072 × 4096, respectively. These images contained a total of 19,494 mandarin fruits.
To replicate realistic and challenging orchard environments, images were captured under various weather conditions, including sunny and overcast days, covering three different time periods: morning, noon, and afternoon. To enhance visual diversity, various camera angles and distances were employed to capture mandarin fruits exhibiting differences in color, size, background complexity, maturity level, degree of overlap, and extent of leaf occlusion. The dataset includes three widely cultivated mandarin varieties in Meishan, i.e., Ehime mandarin (Aiwen Gan), Bapa mandarin (Baba Gan), and Wogan, each of which has unique morphological characteristics. All images were acquired during the fruit enlargement and ripening stages, which are critical to object detection due to increased fruit density, high occlusion rates, and strong visual similarity between fruits and surrounding foliage during these phenological phases.
Figure 7 illustrates a set of mandarin images captured in a typical complex environment. The collected 2388 images were randomly and independently divided into training, validation, and test sets in a ratio of 7:2:1.
Table 6 presents the dataset split details and the number of annotated objects.
4.1.2. Dataset Preprocessing
In this study, we used the LabelImg [
33] annotation tool to construct the object detection dataset, naming the fruit label “mandarin” and strictly following the YOLO format for data storage. The annotation task was assigned to six individuals: four annotators independently performed the labeling, while two additional annotators jointly reviewed the annotations to ensure quality and consistency. Discrepancies were discussed and resolved to maintain a high standard of annotation accuracy. The annotation process adhered to the following standards:
The bounding box must tightly fit the visible contour of the fruit.
Occluded fruits should be annotated by restoring their maximum possible contour.
Fruits with over 90% occlusion or bounding boxes shorter than 5 pixels must not be annotated.
Considering that the YOLO framework inherently integrates various data augmentation techniques—including basic spatial transformations, color adjustments, and composite strategies such as mosaic and mixup—we did not apply additional local augmentations to the dataset. This approach prevents model overfitting while preserving the authenticity of the dataset distribution. By leveraging the built-in augmentation mechanisms of YOLO, we avoided redundant enhancements that could introduce data bias.
4.2. ELD-YOLO
Orchard detection requires the comprehensive consideration of both model accuracy and computational efficiency. The YOLO series has long been known for its excellent detection speed and end-to-end training process. YOLO11 inherits the advantages of the YOLO series while further improving detection accuracy and robustness through network architecture optimization. Through experiments on the collected mandarin dataset, YOLO11 demonstrates strong adaptability compared with other models, particularly in complex background environments, where it can effectively handle both regression and classification tasks. Moreover, YOLO11 also offers computational efficiency advantages, allowing it to be effectively deployed on resource-constrained devices, thereby meeting real-time detection requirements. Considering the model’s accuracy and parameters, YOLO11 was ultimately chosen as the base model for this study.
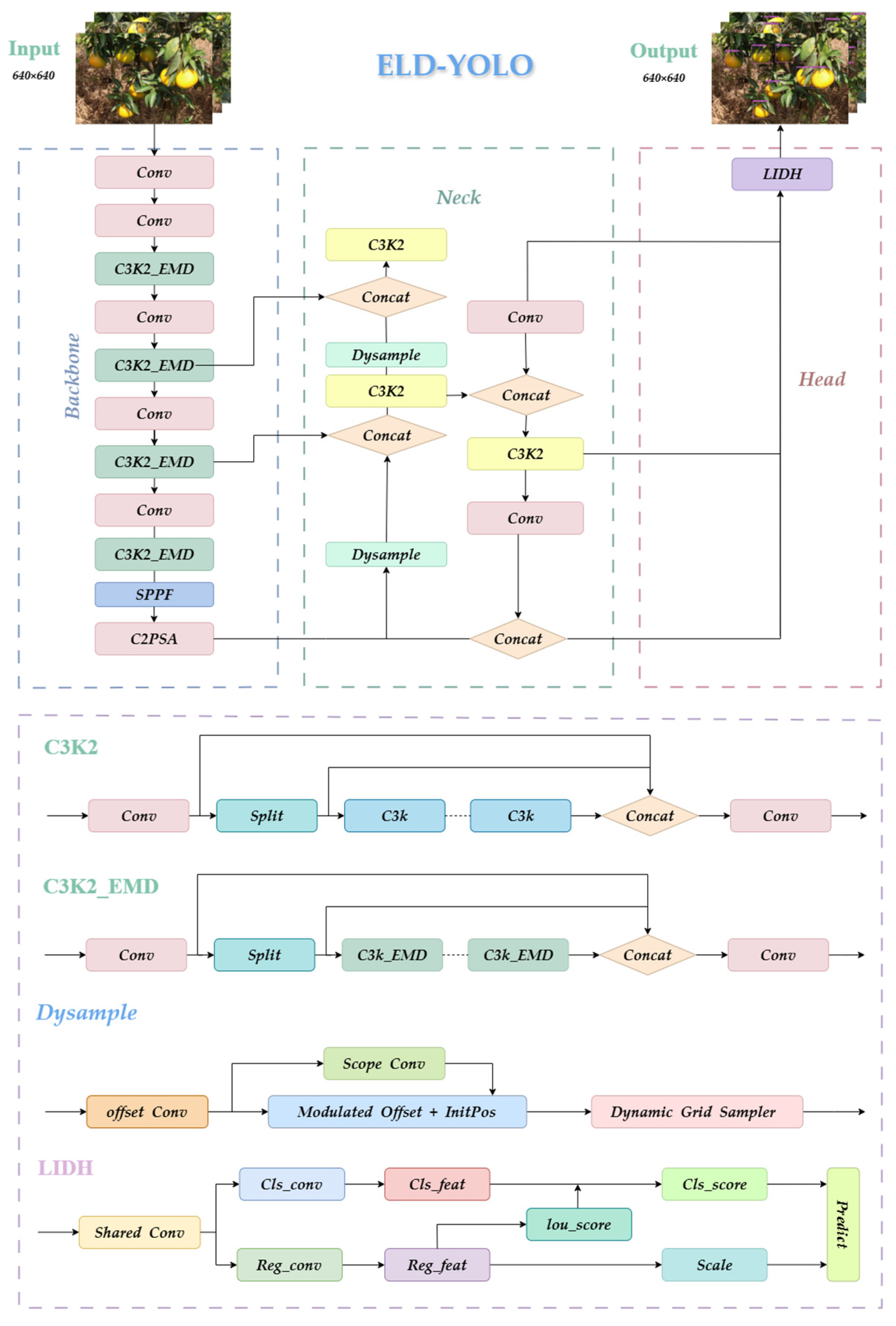
However, when dealing with mandarin detection tasks in complex orchard environments, YOLO11 still has certain limitations. For instance, mandarin fruits are often densely clustered on trees, overlapping with each other, leaves, and branches. In such cases, YOLO11 may make mistakes during detection, especially when objects are very close or completely overlapping. Additionally, due to the large number of mandarin fruits on fruit trees and the limited shooting distance, the dataset contains many small mandarin targets, which YOLO11 may struggle to detect effectively, resulting in missed detections. To address these issues, the study proposes ELD-YOLO, whose model structure is shown in
Figure 8.
ELD-YOLO consists of three parts: the backbone, the neck, and the head. In the backbone, ELD-YOLO introduces the EMD module to enhance the edge features in the image and embeds them into the C3K2 module, which optimizes the model’s ability to detect occluded and small objects. In the head, ELD-YOLO replaces the original detection head with LIDH, which reduces the number of parameters through group convolution and introduces a task interaction module to enhance feature expression for occluded and small objects, achieving efficient and accurate orchard mandarin detection. Additionally, ELD-YOLO replaces the upsampling module in the neck network with Dysample to improve the model’s ability to detect dense objects.
4.2.1. C3K2-EMD
In fruit detection in occlusion scenarios, edge features play a decisive role in the accuracy of target localization; due to occlusion, the semantic integrity of the target is compromised, and the generation of detection boxes heavily relies on contour features. Edge semantics offer better guidance for task regression than internal semantics, which are prone to interference. Based on this understanding, this study proposes an Edge-guided Multi-scale Dual-domain Enhancement (EMD) module. This module consists of multi-scale edge feature enhancement and a dual-domain feature selection mechanism, as shown in
Figure 9.
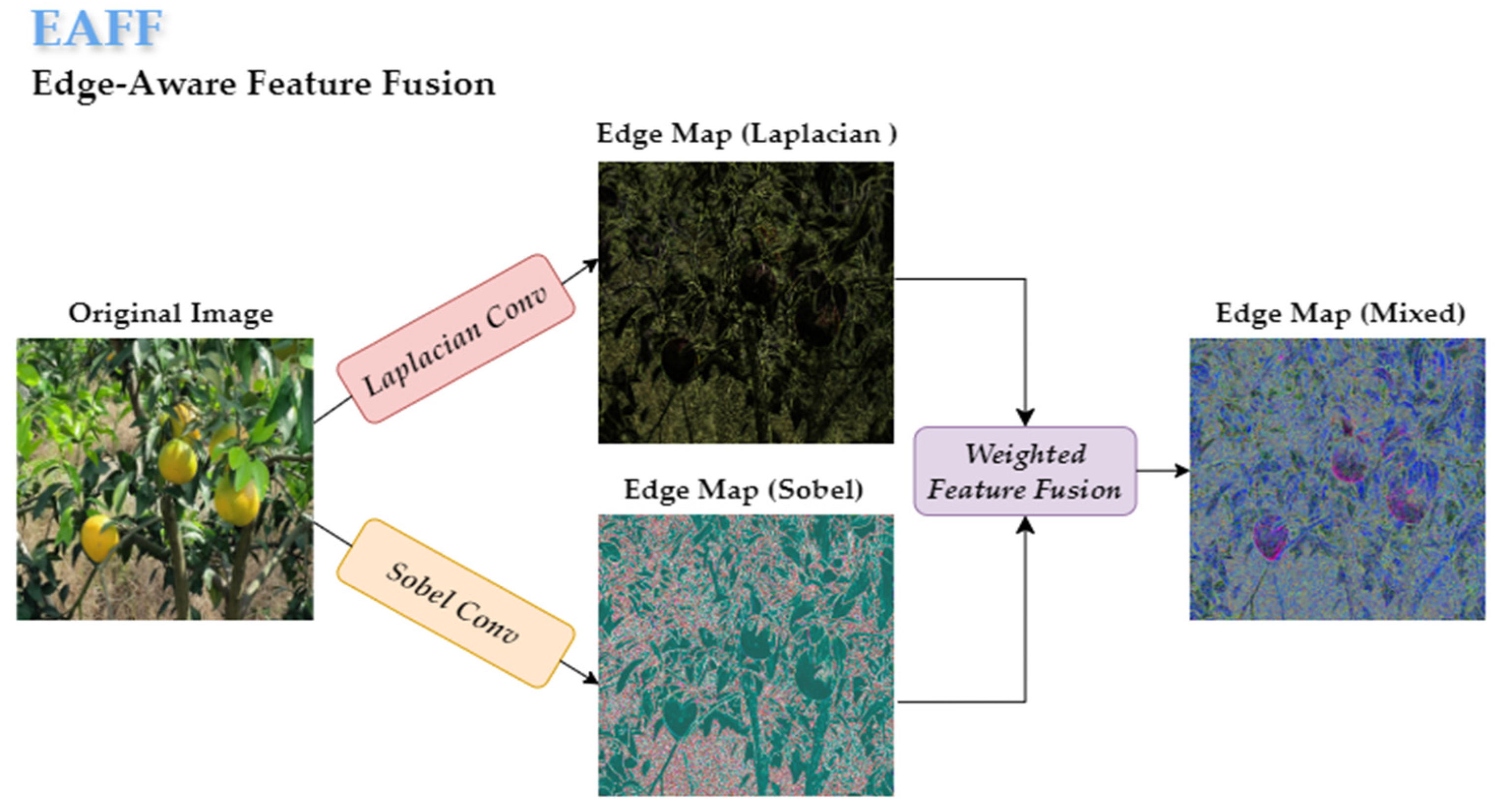
The multi-scale edge feature enhancement module strengthens edge features through a dual-path heterogeneous processing approach. The auxiliary path uses deformable convolution [
34] for geometrically adaptive feature extraction, retaining the target’s original spatial information. The main path generates a multi-scale feature pyramid through adaptive average pooling, which is then compressed by convolution and input into the edge enhancement unit (EAFF). Within the EAFF, the Sobel operator (first-order gradient filtering) and the Laplacian operator (second-order derivative filtering) are used in parallel to extract direction-independent fine details and direction-sensitive gradient edges. These are fused with a weighted combination to construct complementary high-frequency features, as shown in
Figure 10. The features processed by the main path are concatenated again with the auxiliary path features via a residual connection. This residual fusion not only preserves the edge structure but also facilitates effective cross-scale information integration, enabling the network to capture both fine-grained local cues and high-level semantics. The EMD module first enhances the edge details at the feature level and then merges cross-scale information at the path level, ultimately generating a multi-scale feature output
F that combines semantic integrity and edge sharpening.
For the final output feature
F after feature concatenation, this study introduces a dual-domain selection mechanism [
35]. This mechanism combines depthwise separable convolutions with a dynamic spatial gate (DSM SpatialGate) to enhance the edge contour features of the fruit, effectively suppressing background interference from branches and leaves while highlighting mandarin edge information. The enhanced spatial feature is computed as
where DWConv
1 and DWConv
2 are depthwise convolutions with different dilation rates and
denotes the sigmoid activation applied to the spatial attention weights derived from pooled features. In parallel, a local feature calibration module based on mean difference, called DSM LocalAttention, is introduced. This module adaptively reweights channels to enhance the detailed response of small and occluded targets, such as texture features of partially hidden fruits in leaf gaps. The attention mechanism is formulated as
where
is the input feature map,
is the mean of
over spatial dimensions, and a, b ∈ R
C×1×1 are learnable channel-wise parameters.
Finally, dynamic parameters are used to balance the intensity of spatial enhancement and local refinement, enabling the adaptive optimization of features based on occlusion levels and target scale differences. This effectively addresses core challenges in orchard scenarios such as blurred edges and the attenuation of small features by providing more discriminative representations for the detection head.
By cascading multiple C3K2-EMD layers, the proposed method constructs a cross-scale edge feature pyramid, reinforcing the representation ability of micro-edge features (shallow layers) and semantic edges (deep layers) at different depths of the backbone network. This enables the comprehensive multi-scale extraction of edge features.
To assess the individual contributions of the sub-components within the proposed C3K2-EMD module, we conducted a series of component-wise ablation experiments. As shown in
Table 7, we systematically removed key components such as the EAFF unit and the dual-domain selection mechanism. In particular, we also performed ablation on the Sobel and Laplacian operations within the EAFF module to assess their individual contributions. The results indicate that each component plays a positive role in enhancing detection performance, thereby validating the effectiveness of the overall module design.
4.2.2. LIDH
In complex orchard environments, occluded and small objects are often affected by their small size, which impacts their classification score (cls_score), leading to misdetection. Additionally, the complexity of orchard environments places certain demands on model lightweighting. To reduce missed detections and achieve a lightweight design for the detection head, the study innovatively proposes the lightweight task interaction detection head (LIDH). The LIDH reduces the number of parameters by constructing a lightweight feature-sharing structure through group convolutions and designs a task interaction module. This module enhances the classification score of small-sized targets by using the IoU scores obtained from the regression task, thus reducing missed detections.
The structure of the LIDH is shown in
Figure 11. The LIDH consists of two core components: a lightweight shared convolution structure [
36] and a feature–task interaction structure. The lightweight shared convolution module uses a staged processing flow: First, it applies 1 × 1 group convolutions to adjust the channel dimensions and align features across multiple scale feature layers (P3, P4, and P5). Then, the processed feature tensors are cross-scale-concatenated and fused. Finally, a 3 × 3 group convolution is used to extract deep features and share them across the fused features. This hierarchical feature processing mechanism using group convolutions effectively extracts and shares low-level features, providing the foundation for subsequent collaborative optimization between tasks.
The feature–task interaction structure of the LIDH first decouples the detection tasks to enable differentiated feature extraction and then enhances the detection of occluded and small targets through an IoU-based cross-task optimization mechanism. Since small targets occupy limited spatial regions, even slight localization deviations can cause a significant drop in the IoU, leading to training instability [
37]. Inspired by this observation, we explore how the IoU can be leveraged to guide classification for small and occluded targets. Although these targets often yield low IoU values, their actual positional errors may be negligible.
To address this, we propose an IoU-aware cross-task optimization mechanism that uses localization cues from the regression branches to refine classification confidence, thereby reducing the likelihood of misclassifying true targets as background. The workflow is as follows: The classification branch first generates initial classification confidence scores (cls_feat) through convolution followed by sigmoid activation. In parallel, the regression branch utilizes deformable convolutions to enhance localization features and then applies a 1 × 1 convolution to produce the predicted IoU score. Finally, the classification confidence is dynamically adjusted by combining cls_feat and the predicted IoU through a weighting strategy, as defined by the following formula:
where
is the enhancement weight and
is the sigmoid function, while 1 is an indicator function that returns 1 if the IoU score is less than 0.5 and 0 otherwise. This design compensates for the classification confidence of small and occluded targets with low IoU scores, reducing the missed detection rate, while avoiding excessive enhancement of high-IoU-score targets, thus preventing false detections. It effectively prevents missed detections caused by the decay of classification confidence (cls_feat) for small-scale and occluded targets in complex orchard detection scenarios. Experimental results show that the LIDH not only reduces the number of model parameters but also effectively improves detection accuracy and recall, validating the effectiveness of the interaction mechanism between classification and regression tasks.
To validate the effectiveness of the proposed LIDH module, we conducted a comprehensive comparison with representative detection heads, including YOLO11, DyHead, and SEAMHead. As presented in
Table 8, the LIDH’s precision is 88.9%, and the recall is 83.4%, slightly below DyHead’s 89.2% precision and 83,6% recall. However, the LIDH achieves the smallest model size at 2.18 million parameters and the fastest speed of 226.08 FPS. These results show that LIDH balances accuracy and efficiency well for real-time orchard detection.
4.2.3. Dysample
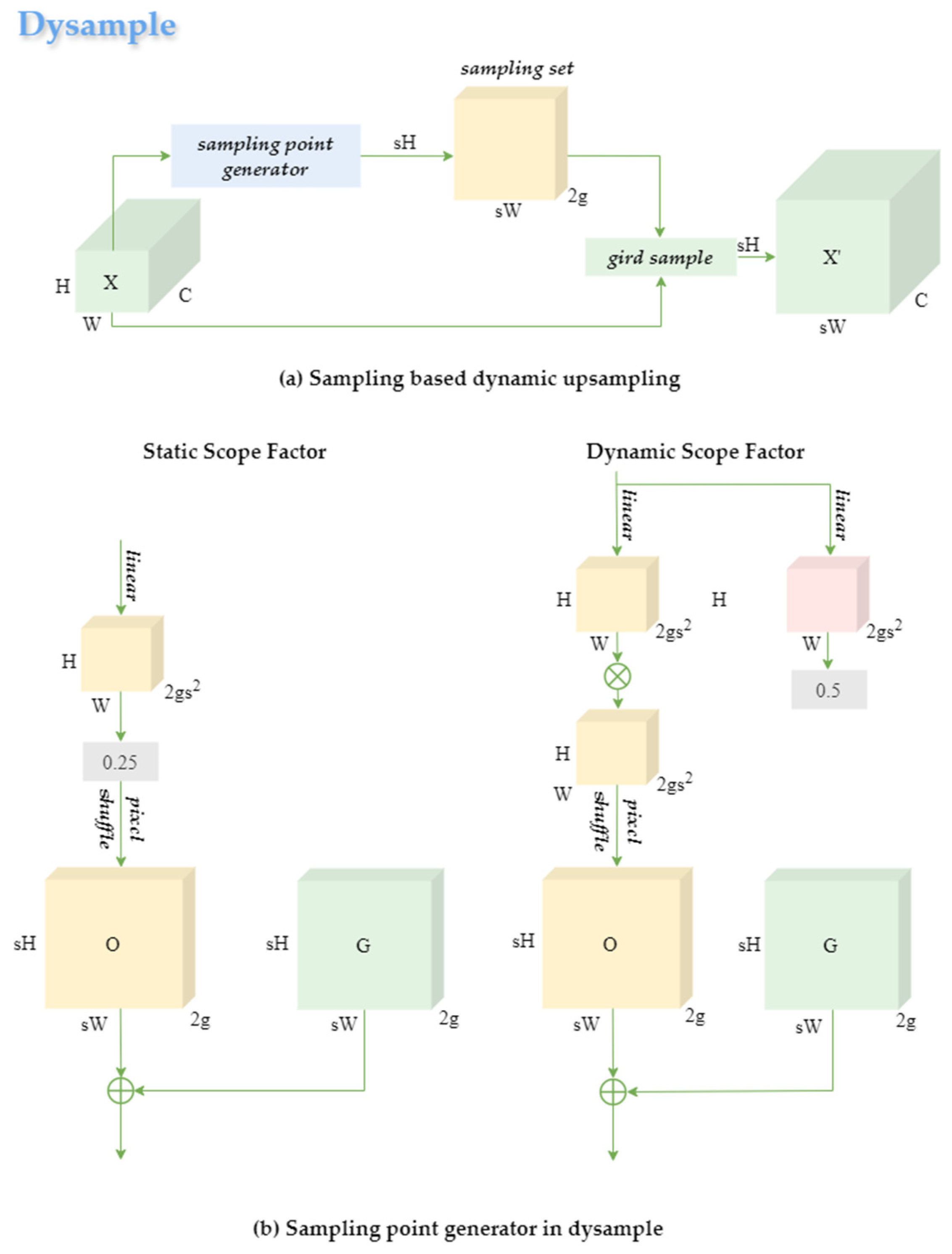
In complex orchard scenes, dense canopy growth and mutual occlusion among fruits lead to a significant reduction in visual features for small or partially hidden oranges. Traditional upsampling methods often degrade these features further due to interpolation artifacts. To mitigate this issue, our approach integrates Dysample [
38], a dynamic point sampling module, into the upsampling stage of the neck network, replacing conventional upsampling operations, as shown in
Figure 12.
Dysample performs upsampling by directly resampling feature points rather than relying on dynamic convolution or bilinear interpolation. This strategy enhances the resolution and fidelity of fine details while reducing computational cost. Specifically, given an input feature map x, a sampling set S is generated via a sampling point generator. The output
is then obtained by applying PyTorch’s grid_sample function:
Here, G denotes the original regular sampling grid, and O is the offset generated by a combination of static and dynamic range factors. The static offset component
is defined as
The dynamic offset component
, modulated through sigmoid-like control, is formulated as
The final sampling offset O aggregates these contributions. This design enables adaptive sampling grid adjustment guided by both low-level structure and high-level semantics, effectively capturing edge details and enhancing small-object regions.
As illustrated in
Figure 8, Dysample enhances the resolution of feature maps in the neck, making small and occluded fruits more distinguishable. The module’s “Pixel Shuffle + Linear” (PL) offset strategy notably reduces parameter count compared with the traditional “Linear + Pixel Shuffle” (LP) method, without sacrificing accuracy.
To assess the impact of different upsampling strategies on detection performance and efficiency, we replaced the Dysample module with three widely used alternatives: the original upsampling module used in the baseline, Transposed Convolution, and CARAFE.
Table 9 summarizes the comparison on the mandarin fruit dataset. It can be observed that integrating the Dysample module leads to notable improvements in recall, precision, and FPS. Although its mAP@50 is slightly lower than that of CARAFE, Dysample demonstrates clear advantages in terms of model size and real-time detection performance. These results highlight the effectiveness of the dynamic point sampling strategy and confirm the superiority of Dysample as an upsampling method in complex orchard scenarios.
4.3. Evaluation Metrics
To comprehensively evaluate the detection model’s capability to recognize mandarin fruits in real orchard operational scenarios, this study establishes a multi-dimensional analysis approach, adopting precision (P), recall (R), F1 score, and mean average precision (mAP) as core quantitative metrics. While these metrics are widely used in object detection, their behavior can vary significantly under certain conditions, such as class imbalance, occlusion, and small-object detection, and it is important to consider these factors when interpreting the results.
Precision (P) is defined as the ratio of correctly predicted positive samples to all predicted positive samples. This metric effectively reflects the model’s likelihood of falsely identifying background interference as mandarin. Higher precision indicates a lower false-positive rate and better overall performance. However, it does not account for missed detections, which are particularly problematic in crowded, occluded environments where fruits overlap. The specific calculation is shown in Equation (9), where TP denotes the number of correctly identified mandarin instances and FP represents the number of background elements incorrectly classified as mandarin.
Recall (R) measures the proportion of actual mandarin targets that are correctly detected, quantifying the model’s risk of missed detections in complex orchard and forestry environments. In cases of severe occlusion or small-object detection, recall may be underestimated because the model may detect large and visible fruits while failing to identify occluded or small ones. This highlights the need to balance recall with other metrics to avoid false assurances of completeness. The formula is shown in Equation (10), where TP is the number of correctly identified mandarin instances and FN refers to mandarin targets missed due to factors such as occlusion by foliage or long-distance shooting.
The F1 score, shown in Equation (11), represents the harmonic mean of precision and recall, offering a comprehensive evaluation of a model’s performance by balancing both metrics.
Average precision (AP) is a key metric for evaluating the performance of a model on a single class. It captures the overall detection ability by balancing precision and recall across different confidence thresholds. mAP generalizes this to multi-class scenarios, calculated as the arithmetic mean of AP values for all mandarin varieties, thus reflecting the model’s generalization capability. In mandarin detection tasks, the mean AP at an IoU threshold of 0.5 (mAP@50) serves as a basic performance benchmark, while the mean AP under progressively increasing IoU thresholds from 0.5 to 0.95 (mAP@50:95) provides a systematic evaluation of the model’s sensitivity to mandarin shape variations and localization accuracy. The relevant calculation formulas are defined as follows:
In Equation (12), the variable represents precision, referring to the precision value corresponding to different recall thresholds on the precision–recall curve. The integral operation, calculated as the area under the curve, globally quantifies the detection performance. In Equation (13), N denotes the total number of mandarin subspecies categories, and represents the average precision for the i-th mandarin category. This evaluation metric system effectively reveals the model’s practical detection capability under typical orchard challenges such as uneven lighting and occlusion interference.
4.4. Training Environment and Experimental Setup
To ensure the fairness and reproducibility of model training and evaluation, all experiments in this study were conducted under a unified experimental environment and fixed hyperparameter configurations, thereby avoiding interference in results caused by environmental differences or parameter fluctuations. The experimental environment and hyperparameter settings in this study are shown in
Table 10.
Before finalizing the hyperparameter values, we conducted preliminary experiments to identify configurations that led to stable convergence and good performance. The final choices, including 200 training epochs, a batch size of 32, a learning rate of 0.01, and momentum of 0.9, were found to yield the best results in terms of convergence speed and model generalization. The loss curves consistently converged within the training schedule, confirming the adequacy of these settings for effective model training.
6. Conclusions
This paper proposes ELD-YOLO, an edge-aware lightweight object detection framework designed to address the complex challenges of citrus fruit detection in orchard environments. By incorporating a multi-scale edge enhancement module (EMD), a lightweight task-interactive detection head (LIDH), and a dynamic point upsampling strategy (Dysample), the model significantly improves detection accuracy in scenarios involving occlusion and small objects while maintaining a compact architecture with only 2.2M parameters. Experimental results based on a custom-built orchard dataset show that ELD-YOLO outperforms existing mainstream models in terms of precision (89.7%), recall (83.7%), and mAP metrics.
Despite its strong quantitative performance, the model still has certain limitations. The current evaluation is restricted to specific mandarin varieties and environmental conditions, and its generalization ability across other citrus types, such as Tangelo and Kumquat, as well as under highly heterogeneous conditions like varying illumination, weather, and soil backgrounds, remains untested. Future work will focus on building a more diverse dataset covering multiple citrus species and phenological stages and validating the model under a broader range of environmental conditions. In terms of practical deployment, we also plan to explore implementing ELD-YOLO on embedded platforms such as agricultural robots or UAVs to evaluate its performance and energy efficiency tradeoffs in real-world operations.
In conclusion, ELD-YOLO provides an effective solution for high-precision and lightweight citrus detection in complex orchard environments. This work lays a solid foundation for developing scalable and adaptive fruit detection models in the context of smart agriculture.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}