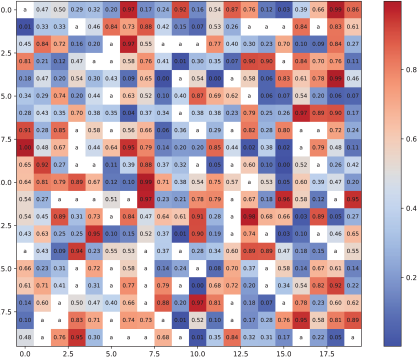
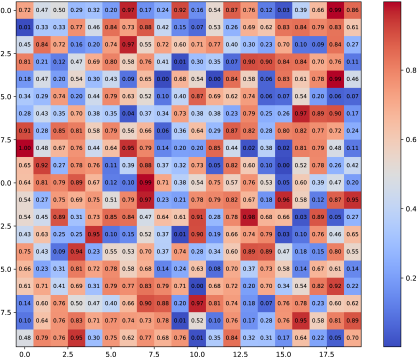
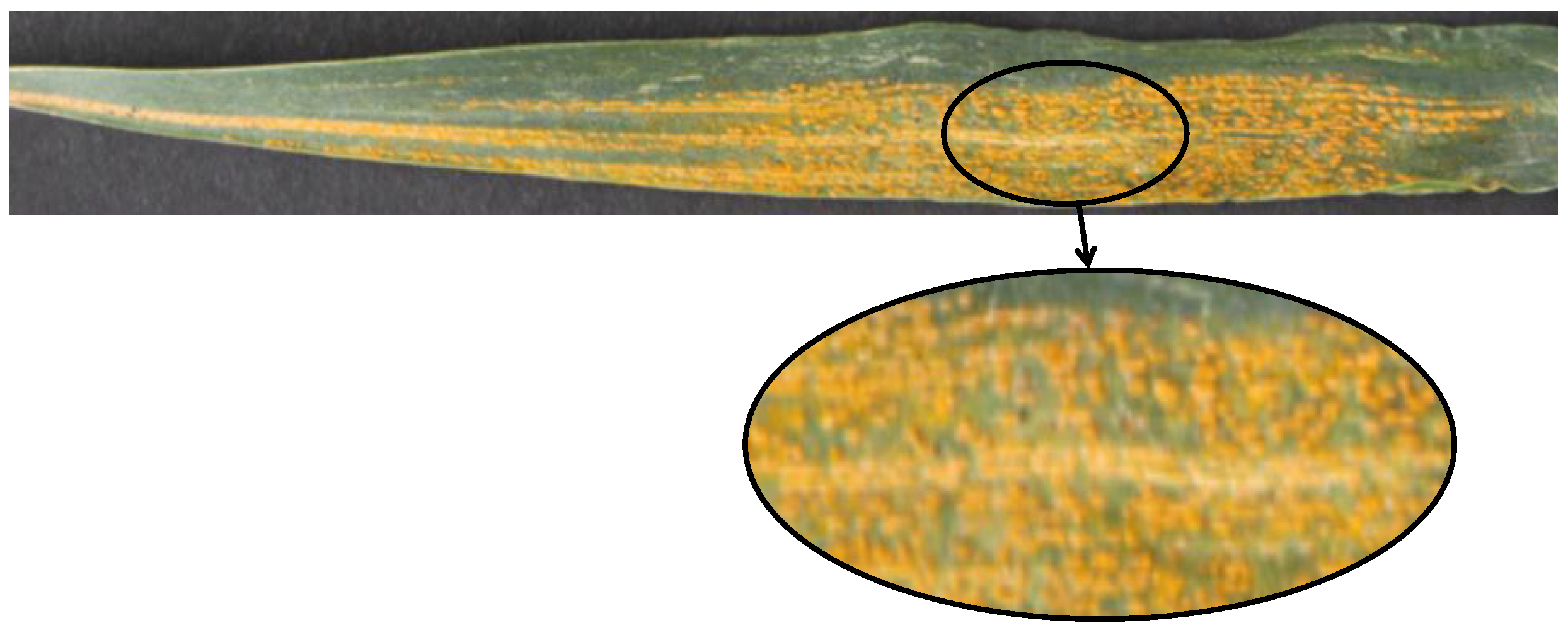
This section provides an overall introduction to the data and the methods used in this study.
2.2. The Assessment of Wheat Rust Severity in Planting Areas Based on Wheat Pathologists’ Scoring and the CRP
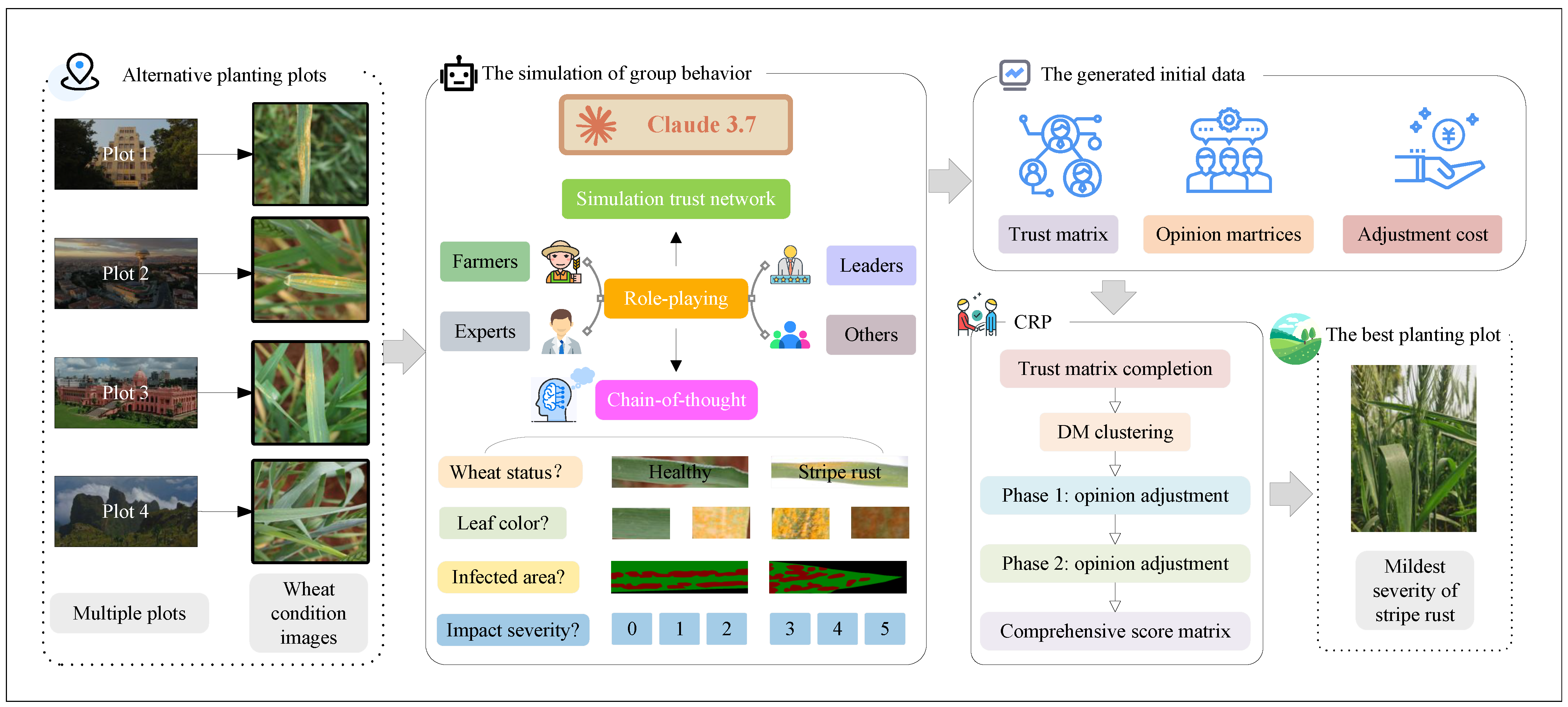
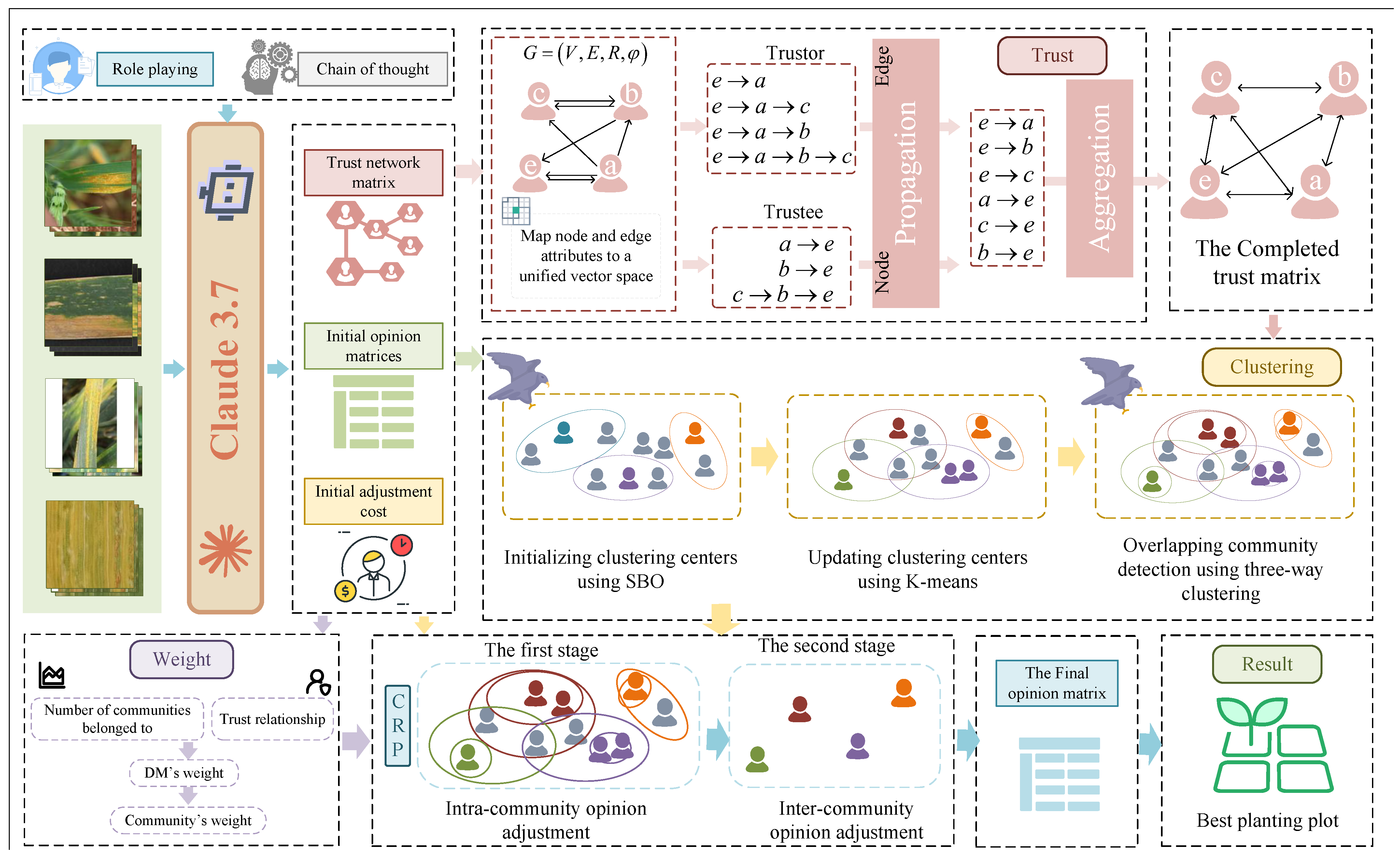
This study proposes a consensus model designed to optimize wheat pathologists’ opinion adjustment within a social network framework, with a focus on the assessment of the severity of wheat stripe rust, a significant crop disease affecting wheat production. The model incorporates overlapping wheat pathologist communities and considers mutual trust and fairness in the opinion adjustment process, thereby enhancing both the reliability and objectivity of group decision-making.
Wheat pathologist evaluations on the severity of wheat stripe rust were collected from four representative wheat-growing regions. These opinions were refined through a structured consensus mechanism, leading to an integrated severity ranking across regions. The overall evaluation framework, which leverages the collective insights of wheat pathologists, is illustrated in
Figure 11.
2.2.1. The Learnable and Composable Trust Propagation Based on GNNs
In wheat stripe rust assessment, the reliability of wheat pathologists’ opinions is a decisive factor. Trust relationships among them play a key role in influencing how their views are weighed during the consensus-reaching process. These relationships are often asymmetric and incomplete, making it essential to develop a robust method to complete the trust matrix. To address this, we propose a GNN-based framework that captures trust propagation and composability in a learnable manner. This framework maps node and edge attributes into a unified latent space, models trust propagation across trust chains (considering asymmetry), and aggregates trust information with attention mechanisms to complete the trust matrix and improve consensus reliability.
In this fully trusted network, denoted as , nodes and edges have heterogeneous attributes, which may differ in dimensionality or reside in different vector spaces. To address this, attributes are transformed into a unified dimensional space before being fed into the GNN.
Remark 1 (Node and edge attribute projection). A linear transformation is applied to all nodes to project their attributes into a unified space:where is the attribute vector of v, is its transformed representation, and is the learnable matrix. For edge types, the transformation for the i-th edge iswhere is the attribute vector of the i-th edge type, and is the corresponding learnable matrix. In cases of missing attributes, these are initialized as random vectors, which are treated as learnable parameters in the network. Trust relationships among pathologists are dynamically updated and propagated through existing trust chains in the social network. Within the GNN, trust chains are used for message passing with a propagation depth limited by a predefined threshold K to prevent degradation due to excessively long chains.
Remark 2 (Forward trust propagation). For a receiver node v, suppose there exists a trust chain of length k, denoted as . The trust value information from u to v needs to be updated based on the edges along this trust chain and the information from the initial node of the chain. The attributes of nodes and edges are processed in a manner similar to the RotatE method, where they are embedded in the complex plane.where is the embedding of the initial node u, represents the edge embedding of the i-th edge, and ∘ denotes the Hadamard (element-wise) product. Remark 3 (Reverse trust propagation). Let , where denotes the complex plane and . The Hadamard product of the edge embeddings can be viewed as a composite relation specific to the trust chain p. The embedding represents the information received by the node v along the chain p.
Trust is inherently asymmetric. Specifically, the node v also acts as a delegator in the trust graph. Therefore, comprehensive node embedding should incorporate both roles of being a trustee and a delegator. For the same trust chain p with the node v as the head (i.e., ), TGNN computesThe conjugate vector represents the inverse relation of (i.e., trust and trusted). This ensures that captures the information received by node v in its role as a trustor within the trust chain p. Multiple trust chains may exist between any two wheat pathologists. These chains can contribute unequally to the overall trust value due to diverse interaction patterns. To model this, a chain-type-level attention mechanism is applied that aggregates trust information across chains while differentiating their significance. The model further captures the trustee and delegator roles separately before combining them.
Remark 4 (Trust aggregation). Let v be a node and the set of trust chains of type j. The aggregated embedding for type j is computed aswhere is a mapping function for chain type j, is a learnable transformation matrix, and is the embedding propagated along the trust chain . To evaluate the importance of each chain type, the following attention score is computed:where , B, and q are shared learnable parameters. These scores are normalized via the softmax function:The final node embedding from the trustee perspective is calculated aswhere denotes the embedding matrix for chain type j. To account for the delegator perspective, an analogous aggregation is performed:Here, represents embeddings from the delegator role, and denotes the corresponding attention weights. 2.2.2. Weight Determination and CRP Under the Influence of Trust Relationships
This section analyzes trust dynamics within the wheat pathologist community, focusing on how overlapping community memberships and trust levels affect the weighting of their opinions in assessing wheat stripe rust severity.
Wheat pathologists often belong to specialized communities such as pest control, cultivation, or pathology. Trust within these communities significantly influences the impact of their opinions in decision-making.
For instance, a pathologist trusted for their expertise in disease management holds greater influence in rust control decisions. Those involved in multiple communities contribute broader insights, integrating knowledge across fields, which enhances consensus quality.
Trust relationships in overlapping communities further adjust opinion weights, reflecting trust levels in each community to better influence the final consensus.
Modeling these trust interactions ensures opinions are properly weighted, leading to more reliable consensus and targeted crop protection strategies.
Understanding the interplay of trust and community membership is crucial for optimizing consensus accuracy and delivering a comprehensive assessment of wheat stripe rust severity.
This section introduces a method for determining wheat pathologist weights in wheat research, focusing on the influence of trust relationships and involvement in overlapping pathologist communities. The trust received from peers and multi-community participation are key factors influencing their relative weights in discussions and decisions on pest control, planting technology, and variety improvement.
Remark 5 (Individual weight of wheat pathologists). The computation of individual wheat pathologist weights incorporates two key factors: (1) the cumulative trust received from other wheat pathologists and (2) the degree of overlapping community participation. These are formulated as follows.
Trust-based influence:This reflects the trust received by wheat pathologist i from all other wheat pathologists. Overlap-based adjustment:where represents the number of communities to which wheat pathologist i belongs, and γ is a tunable sensitivity parameter. Combined intermediate weight: Final normalized wheat pathologist weight: Community-level weight:After obtaining the weights of individual wheat pathologists, the overall weight of a community is computed by summing the weights of all wheat pathologists within that community.
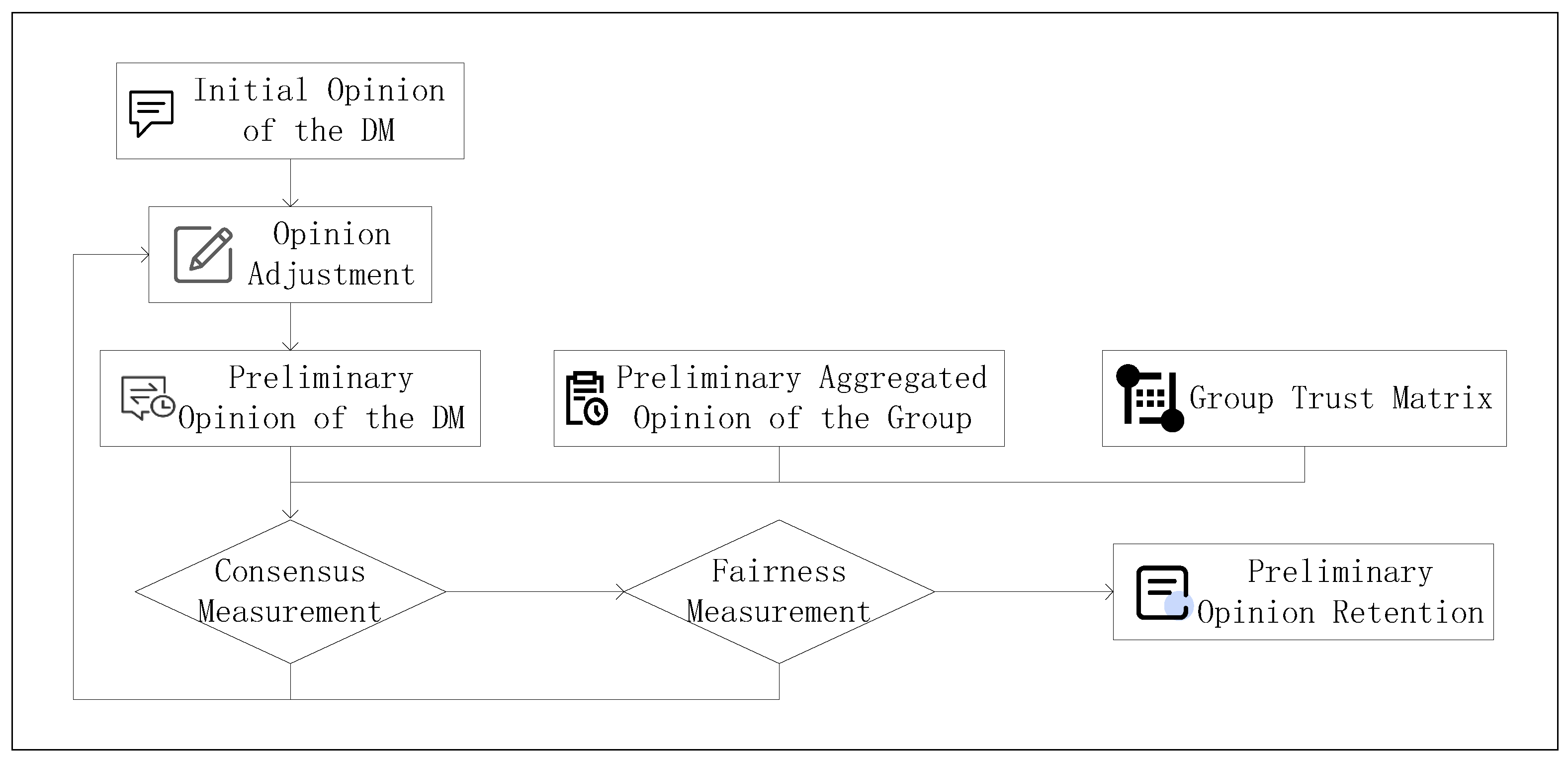
Before determining the optimal wheat planting location, it is necessary to evaluate whether sufficient consensus has been achieved among regional wheat pathologists. Traditional soft consensus methods assess agreement based on opinion differences. However, wheat pathologists’ trust relationships also reflect the degree to which a pathologist accepts collective judgment. To this end, a modified consensus evaluation framework is proposed, which incorporates both opinion divergence and mutual trust to provide a more comprehensive consensus measurement.
The traditional soft consensus level only considers the distance between a pathologist’s revised opinion and the collective opinion. If the deviation is within an acceptable threshold (less than twice the collective opinion), a normalized consensus score is assigned; otherwise, the pathologist is considered completely inconsistent with the group. The collective opinion is calculated as a weighted average of all pathologists’ inputs.
However, this does not account for how much a pathologist trusts the group. A highly trusted pathologist, or one who has high trust in others, should influence and be influenced more in consensus building. Therefore, a trust-based modification is added. The individual trust level is calculated from the average trust a pathologist receives from others, while the overall trust level is the average trust across the group. The final individual consensus level is then adjusted by considering both opinion deviation and trust deviation. The group consensus level is the average of all individual consensus scores.
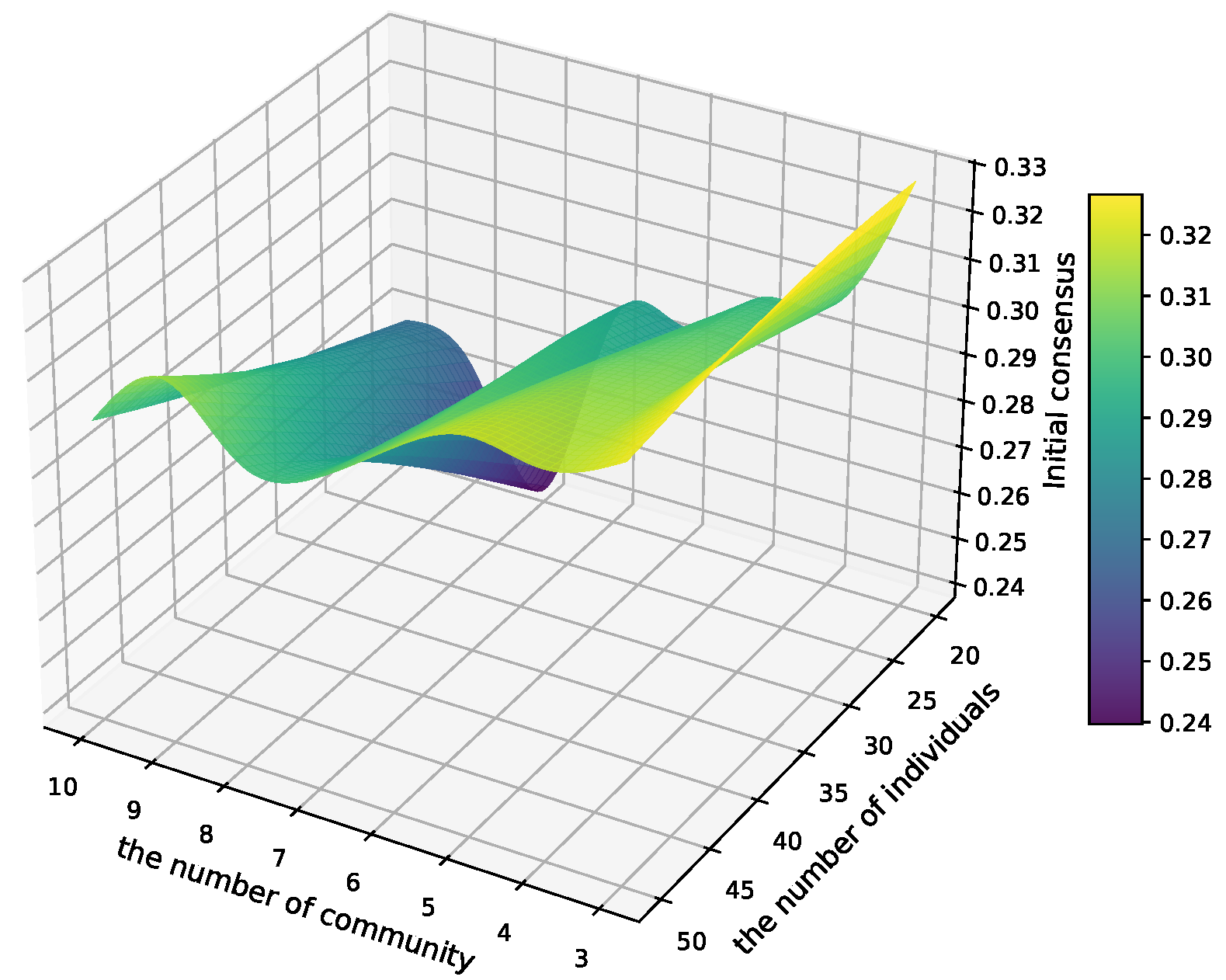
Remark 6 (Group consensus level). The collective opinion is given by the weighted sum: The individual trust level of wheat pathologist i is calculated as The overall group trust level T is The trust-enhanced consensus level is defined as The overall group consensus level is calculated by 2.2.3. Overlapping Community Detection Based on SBO K-Means and Three-Way Clustering
In wheat stripe rust assessment, wheat pathologists’ opinions may vary due to subjective biases and other influencing factors. To improve accuracy, incorporating multiple wheat pathologists’ opinions is essential. However, as the number of wheat pathologists increases, the decision-making process becomes more complex. To address this, clustering techniques can be employed to group wheat pathologists based on their opinions and trust levels, thus improving the efficiency of group consensus.
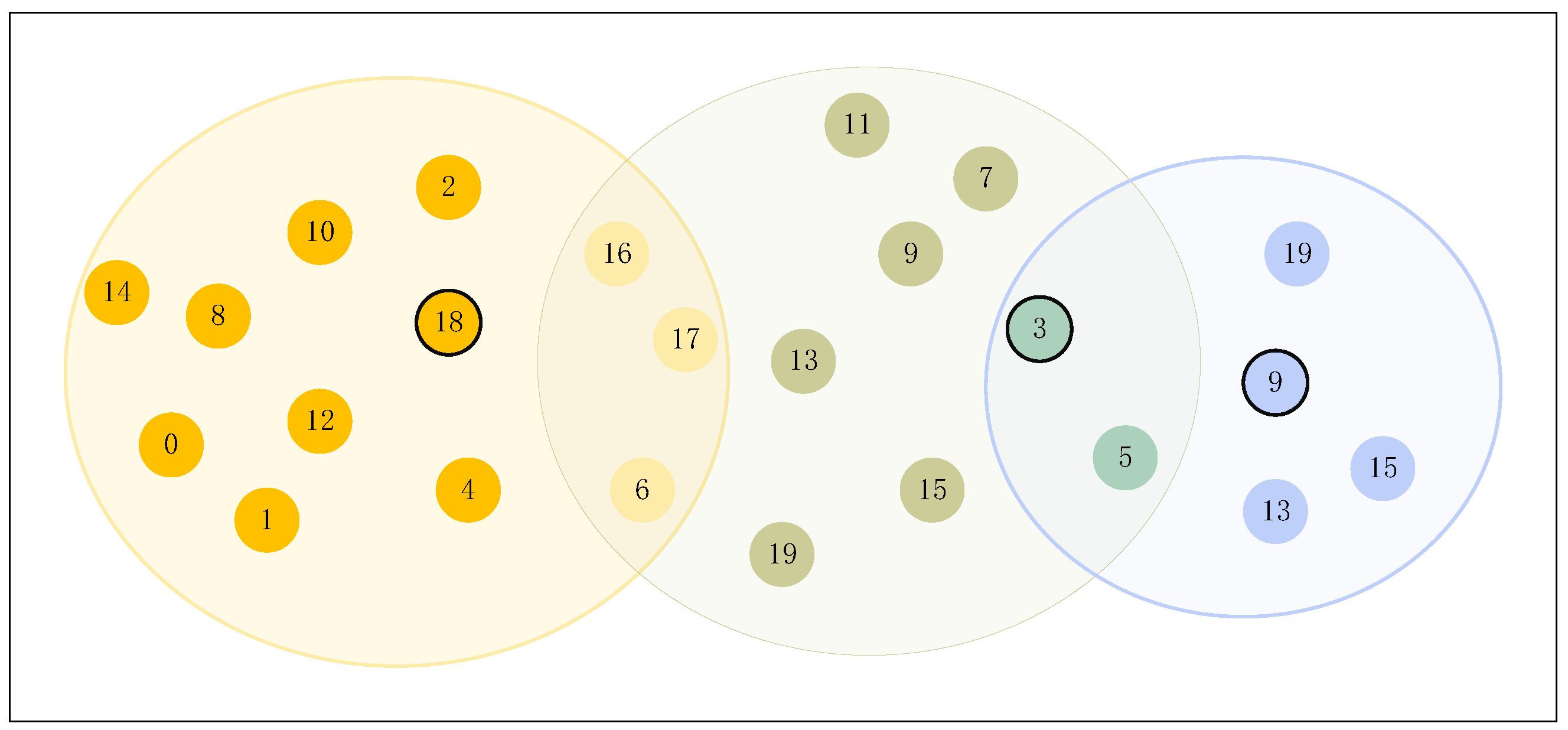
A common challenge in this process is the presence of overlapping communities, where a wheat pathologist belongs to multiple groups. This overlap is beneficial, as it reflects shared perspectives between groups and facilitates the adjustment of opinions across them. Such communities help reduce the cost of reconciling differing opinions, leading to a more accurate assessment of wheat stripe rust severity.
Traditional clustering methods, such as K-means and metaheuristic algorithms, often struggle with overlapping communities. However, by combining K-means with the SBO algorithm, cluster centers can be effectively identified, and a three-way clustering approach can be applied to partition wheat pathologists into core, boundary, and exclusion regions. This approach allows for the detection of overlapping communities, which is crucial for improving consensus in LSGDM, particularly in the context of wheat infection assessment.
The SBO algorithm is inspired by the hunting behavior of the secretary bird, a distinctive African raptor. It operates in three primary stages: initialization, hunting strategy, and escape strategy.
Remark 7 (Initialization phase). Random initialization updates the position of each secretary bird in the search space:where and are the upper and lower bounds and is a random number. Remark 8 (Hunting phase). The hunting strategy includes three intervals:
Remark 9 (Escape phase). The escape strategy involves camouflage or sudden running: To handle uncertainty in clustering, three-way clustering is used. Unlike traditional methods that assign each data point to a single cluster, three-way clustering categorizes elements into three regions: core, boundary, and exclusion. This method enhances robustness in uncertain environments.
Remark 10 (Three-way clustering). Let be the dataset. The result of three-way clustering isSubject to - (1)
,
- (2)
,
- (3)
, for .
If , it degenerates into two-way clustering.
The K-means algorithm is widely used to partition data into k clusters by minimizing the sum of squared distances within clusters. The basic steps include
Remark 11 (K-means clustering).
- 1.
Randomly initialize k cluster centers.
- 2.
Assign each data point to the nearest cluster using Euclidean distance: - 3.
Recalculate centers and iterate until convergence.
To overcome the local optima limitation of K-means, the SBO algorithm is used to optimize initial cluster centers. With k communities, set and , generating an matrix with random integers representing community assignments.
Remark 12 (Initial clustering).This matrix serves as the initialization for K-means and three-way clustering, enabling the identification of overlapping communities among wheat pathologists. In standard K-means, Euclidean distance is commonly used. However, for high-dimensional opinion data with many criteria, we use an improved Manhattan distance to simplify and stabilize the computation. Let and represent the opinions of two wheat pathologists. The distance between them is calculated as
Remark 13 (Clustering center identification).Let M be the number of wheat pathologists in a sub-community. Compute the distance matrix: Then, using the trust matrix , calculate the comprehensive distance from each wheat pathologist i to others as The wheat pathologist with the smallest is chosen as the cluster center. Iterate the process until centers stabilize.
To identify overlapping areas between core and boundary regions, upper and lower bounds (, ) are initialized using the principles in Remark 10. These bounds are adaptively refined based on the consensus level of the group.
The SBO’s hunting and escape strategies (see Remarks 8 and 9) are then employed to iteratively adjust these bounds. Parameters are updated as in the natural prey capture process of the secretary bird, and any improvements in partition quality are preserved.
Finally, based on the optimized bounds, the community partitioning is finalized, accurately reflecting overlapping community structures and enhancing the overall consensus process.
2.2.4. Fairness-Conscious Optimization for Robust Group Decision-Making
In the context of wheat stripe rust assessment, wheat pathologists are often required to adjust their opinions when confronted with new information or differing viewpoints. Given that the severity of wheat stripe rust is influenced by a variety of environmental and biological factors, reaching group consensus is often complex and uncertain. In such situations, fairness perception and adjustment costs become critical factors guiding the decision-making process.
Fairness is particularly important in wheat pathologists’ assessments of wheat stripe rust, as wheat pathologists are more likely to accept and cooperate with opinion adjustments when they perceive the process as fair. In this context, fairness can be reflected in ensuring that each wheat pathologist’s opinion is appropriately weighted, preventing any single individual’s view from dominating unfairly and maintaining transparency and equity across different regions. For example, if a wheat pathologist feels that their experience in diagnosing wheat diseases is undervalued in the decision-making process, they may be reluctant to cooperate or accept the final consensus. This could compromise the accuracy of the rust severity assessment and hinder the effectiveness of subsequent disease control measures.
At the same time, each opinion adjustment comes with certain costs, which vary depending on the specific situation. These costs may arise from the need for additional resources to collect field data or the time required for wheat pathologists to reassess their opinions in light of new information. For instance, in assessing wheat stripe rust, a wheat pathologist may encounter difficulties due to the lack of detailed data on disease progression or infection density. If certain planting regions lack real-time imagery of infected wheat, the wheat pathologist may be forced to rely on less accurate data or invest additional time and resources to obtain more reliable information. This uncertainty introduces potential adjustment costs that can delay or complicate consensus formation.
In light of these challenges, it is essential to incorporate fairness considerations and control adjustment costs effectively during the evaluation of wheat stripe rust severity. Specifically, a robust adjustment mechanism should be established to account for the costs of acquiring new information, addressing disagreements among wheat pathologists, and ensuring the fair representation of each wheat pathologist’s viewpoint. This not only minimizes the psychological and resource burden on individuals but also enables the final consensus to more accurately reflect the collective expertise of the group. As a result, the evaluation of rust spread and severity becomes more precise and reliable, providing a solid basis for disease control strategies and resource allocation.
Therefore, in such contexts, an optimized adjustment strategy that integrates fairness and cost control is essential for achieving efficient and rational decision-making. By reducing informational and psychological barriers and fostering collaboration among wheat pathologists, a more accurate, comprehensive, and actionable consensus on wheat stripe rust can be achieved.
Remark 14 (Fairness). The Procedural Fairness and Social Preference Model emphasizes fairness in income distribution. It is characterized by a small number of parameters, a simple structure, and strong predictive capabilities. Within this model, individuals evaluate fairness by comparing their own outcomes with those of others. When a wheat pathologist’s income is lower than that of others, feelings of envy may arise; conversely, when their income is higher, emotions such as pride or sympathy may be experienced. The model’s computational equation is presented as follows:In the above equation, denotes the utility of individual i, and represents the income of individual i. The envy aversion coefficient , and the sympathy/pride preference coefficient . Typically, these two parameters satisfy the condition . When the two parameters take different values, they reflect different behavioral states of the wheat pathologist.
When , the fairness utility of the wheat pathologist consists of compensation, the negative utility caused by envy preferences, and the positive utility generated by the pride coefficient.
When , the fairness utility consists of compensation, the negative utility caused by envy preferences, and the negative utility resulting from the sympathy coefficient.
The uncertainty of the unit adjustment cost for wheat pathologist is determined using an uncertain set U, represented as
Remark 15 (Adjustment cost). The uncertain set U is given by The fairness utility for wheat pathologist is The final fairness utility is Remark 16 (The robust group). Box Uncertainty Set: The corresponding optimization equation considering fairness effects is Elliptical uncertainty set:The corresponding optimization equation considering fairness effects is Polyhedral uncertainty set:The corresponding optimization equation considering fairness effects is Detecting overlapping communities during community partitioning is crucial for wheat pathologists. By utilizing the wheat pathologists in the overlapping regions, the overall gap between the opinions of different communities can be effectively reduced, thereby decreasing the need for opinion adjustments between communities.
In this paper, the weight of overlapping individuals is increased to make the group opinion lean toward the overlapping individuals, which in turn influences the adjustment direction of other opinions, ultimately guiding the opinions of other individuals toward the overlapping individuals.
The opinion adjustment process in this paper is divided into two stages. In the first stage, opinion adjustments are made within each community, and the consolidated opinion within each group is provided as the initial opinion for the second stage.
In the second stage, the consolidated opinions of different communities are adjusted, and the final adjusted opinion is provided.
The specific methods for optimization and adjustment at each stage are shown in
Figure 12.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}