A Symbiotic Relationship Based Leader Approach for Privacy Protection in Location Based Services



Abstract
1. Introduction
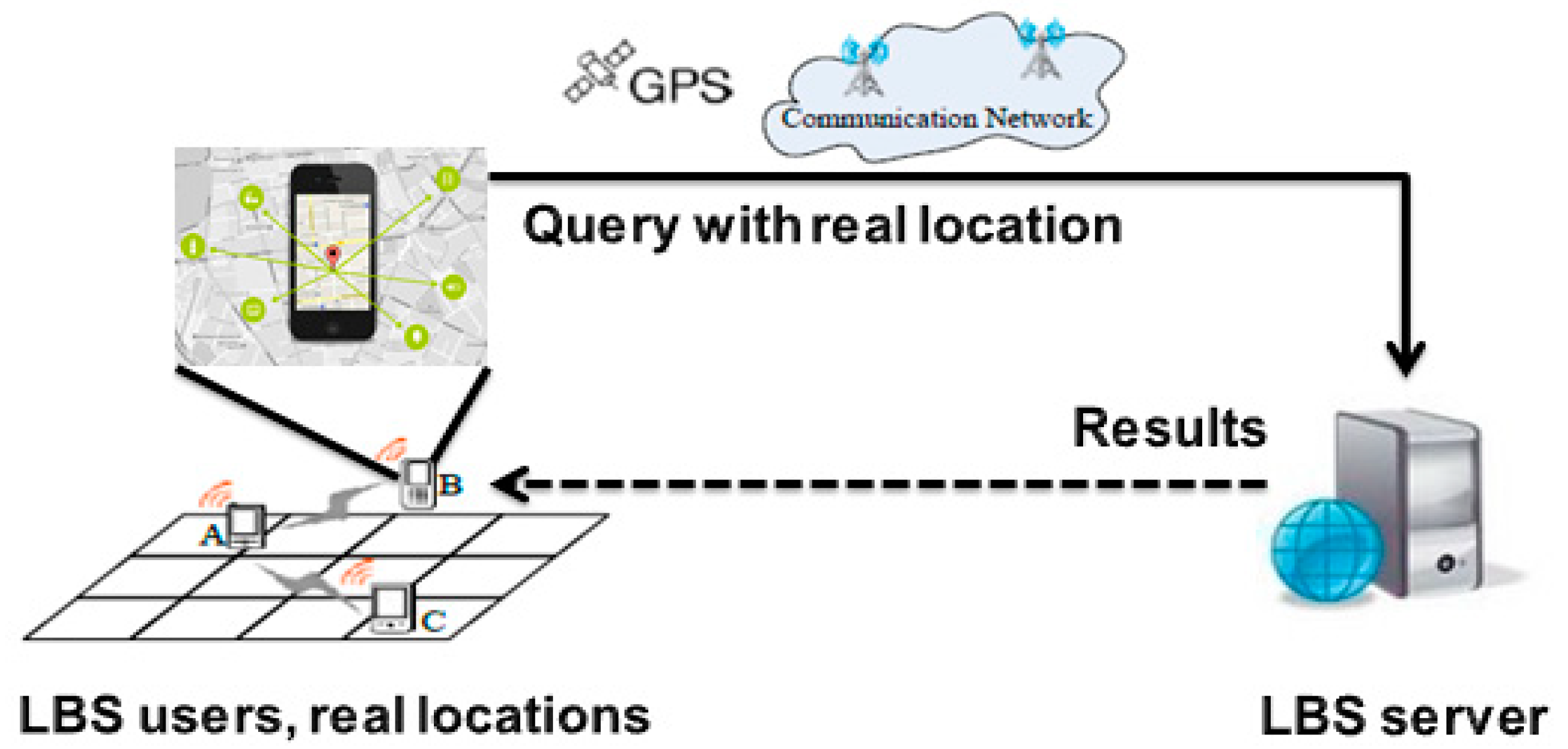
1.1. Statement of Problem
1.2. Motivation
1.3. Contribution
- The paper proposes a leader approach to completely prevent LBS users (members of a cluster) from connecting to the untrusted party (LBS server). A symbiotic relationship is used to form the trust base between the cluster members and their leader. Consequently, the leader is considered a strong TTP.
- The paper introduces a solution to the dummy generation problem, which is considered as an expensive and open problem for achieving comprehensive privacy protection (i.e., location and query privacy protection).
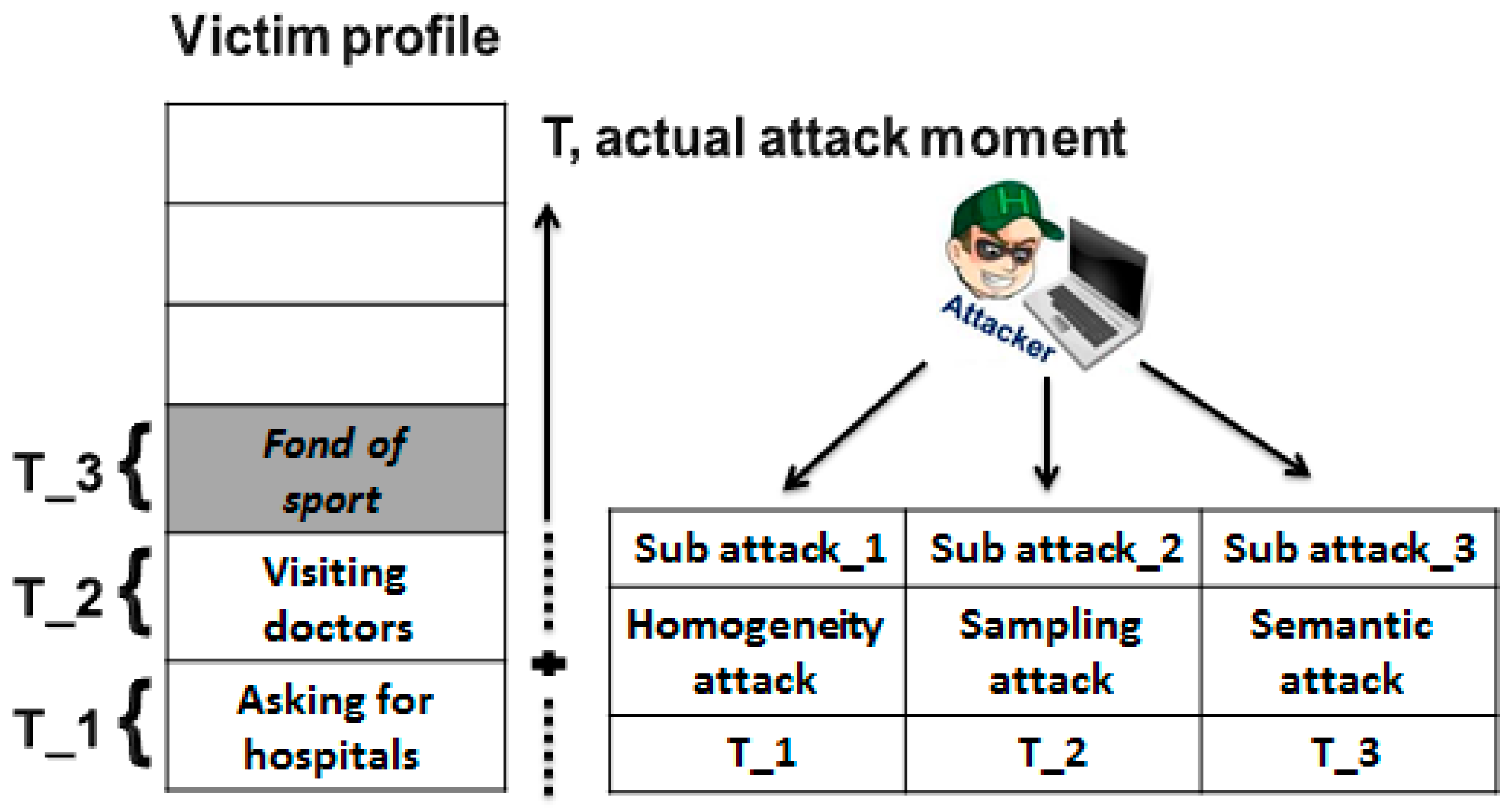
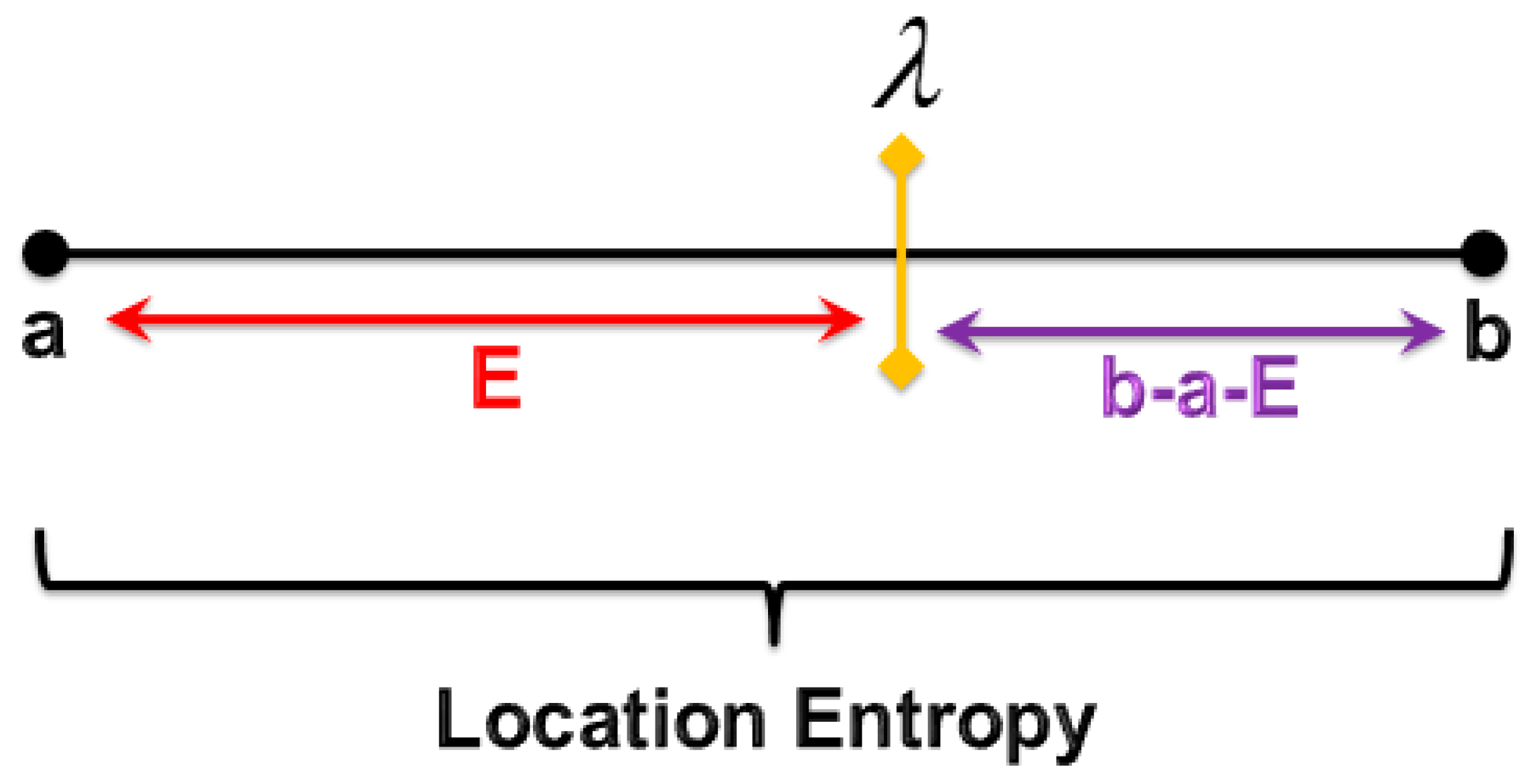
- Depending on location entropy, a novel privacy metric is provided. It is used to measure the closeness of the attacker to the moment of his/her attack launch.
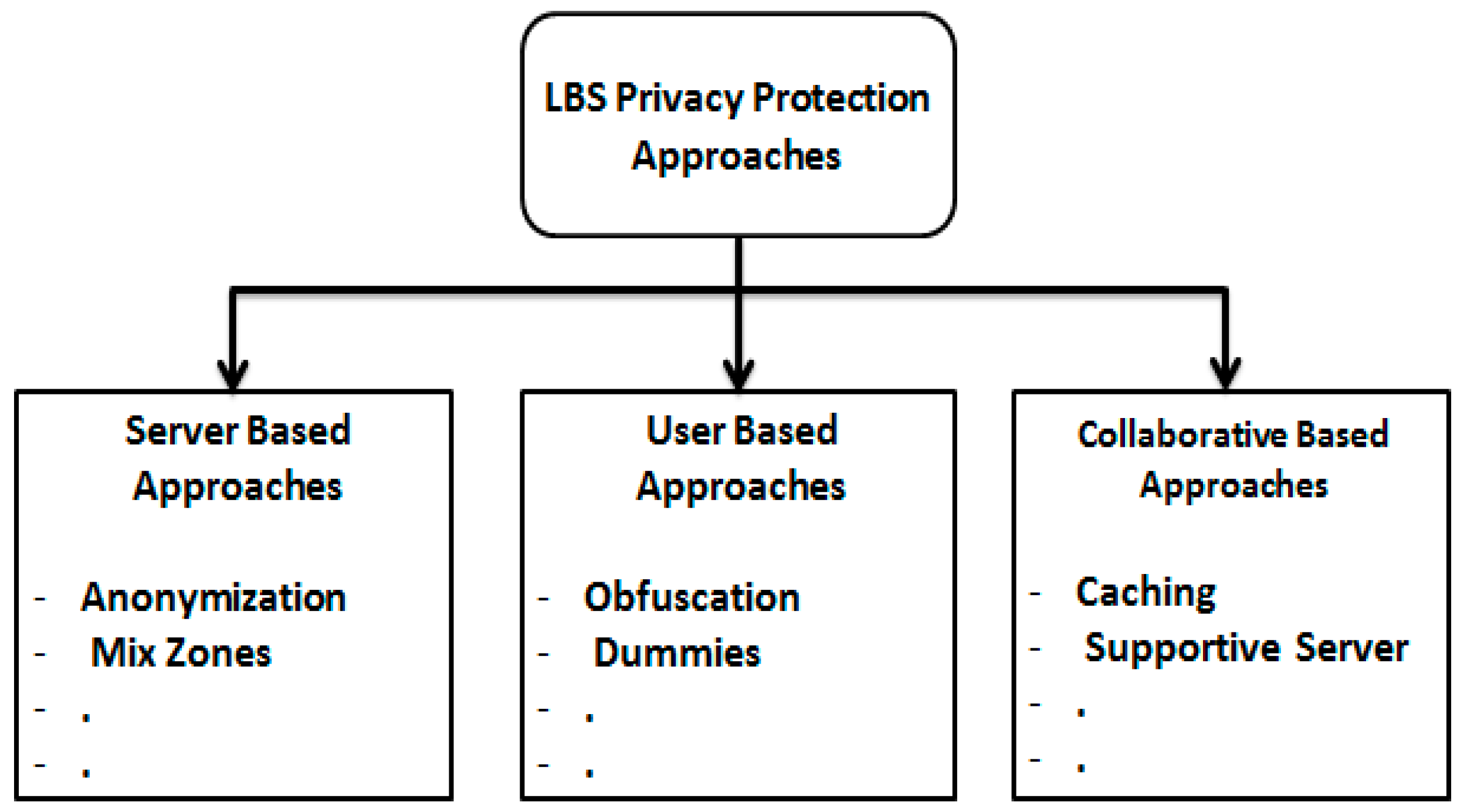
2. Related Work
2.1. First Group: Most of The Load on The Server Side
2.2. Second Group: Most of The Load on The User Side
2.3. Third Group: Load Balancing
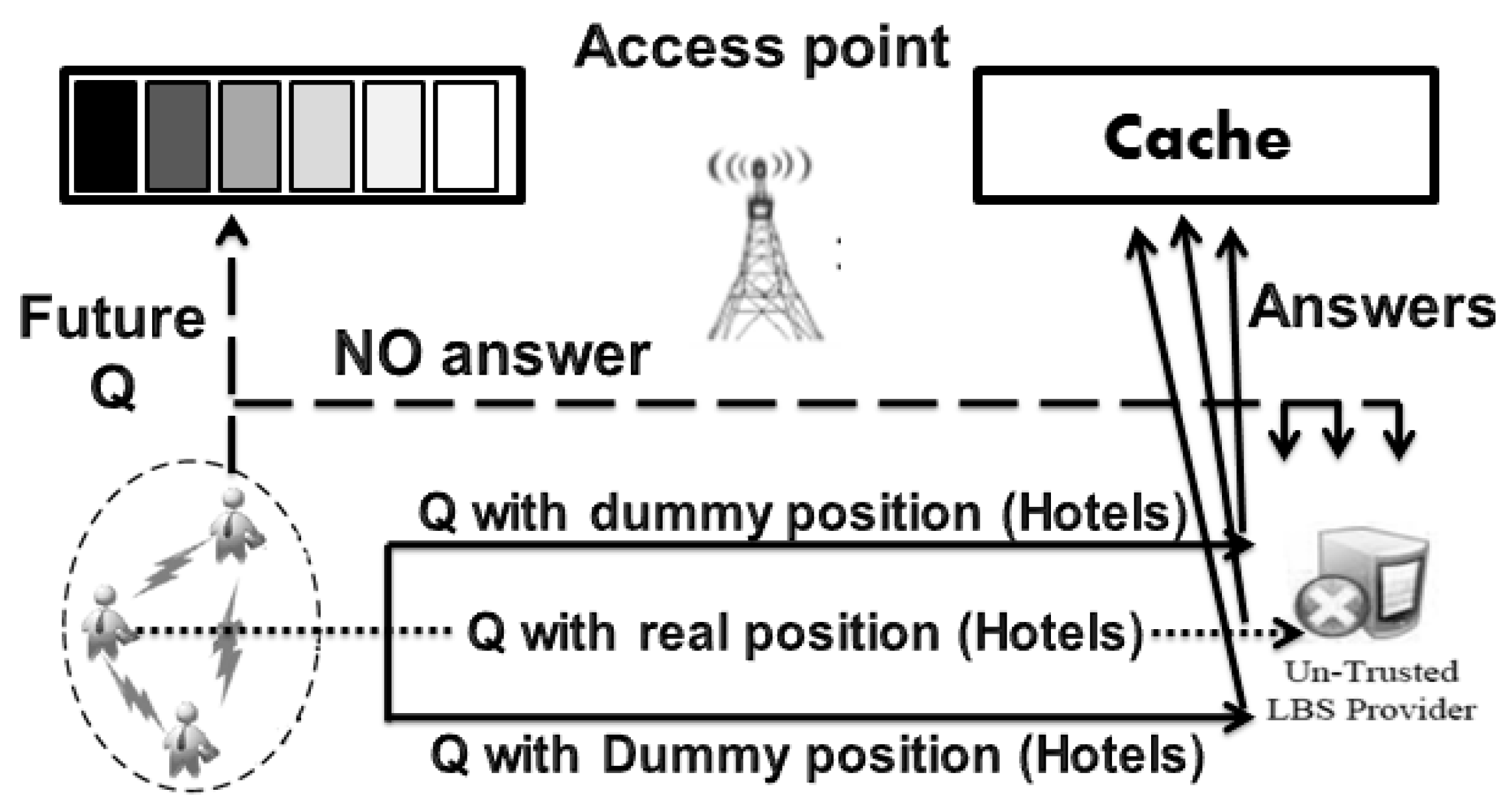
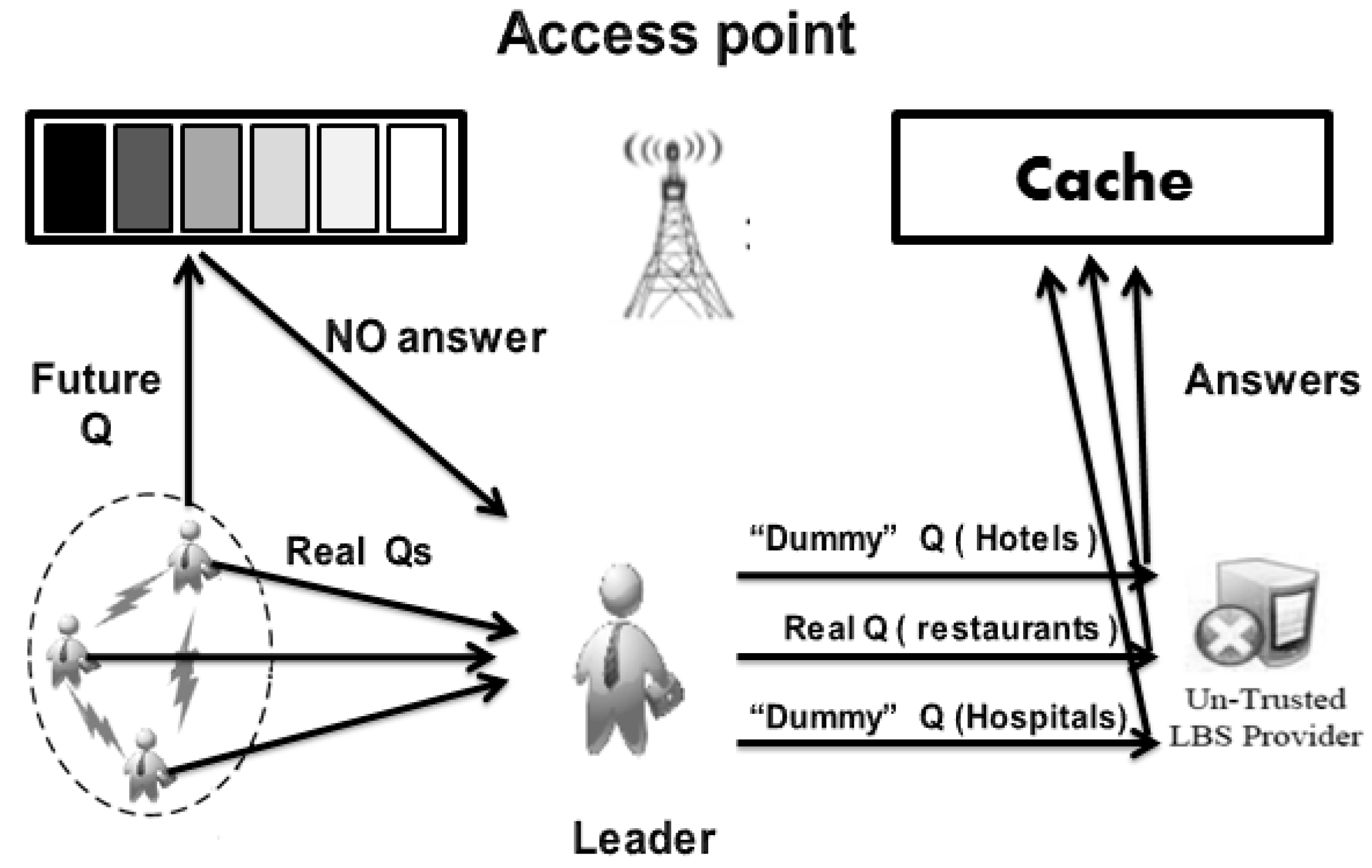
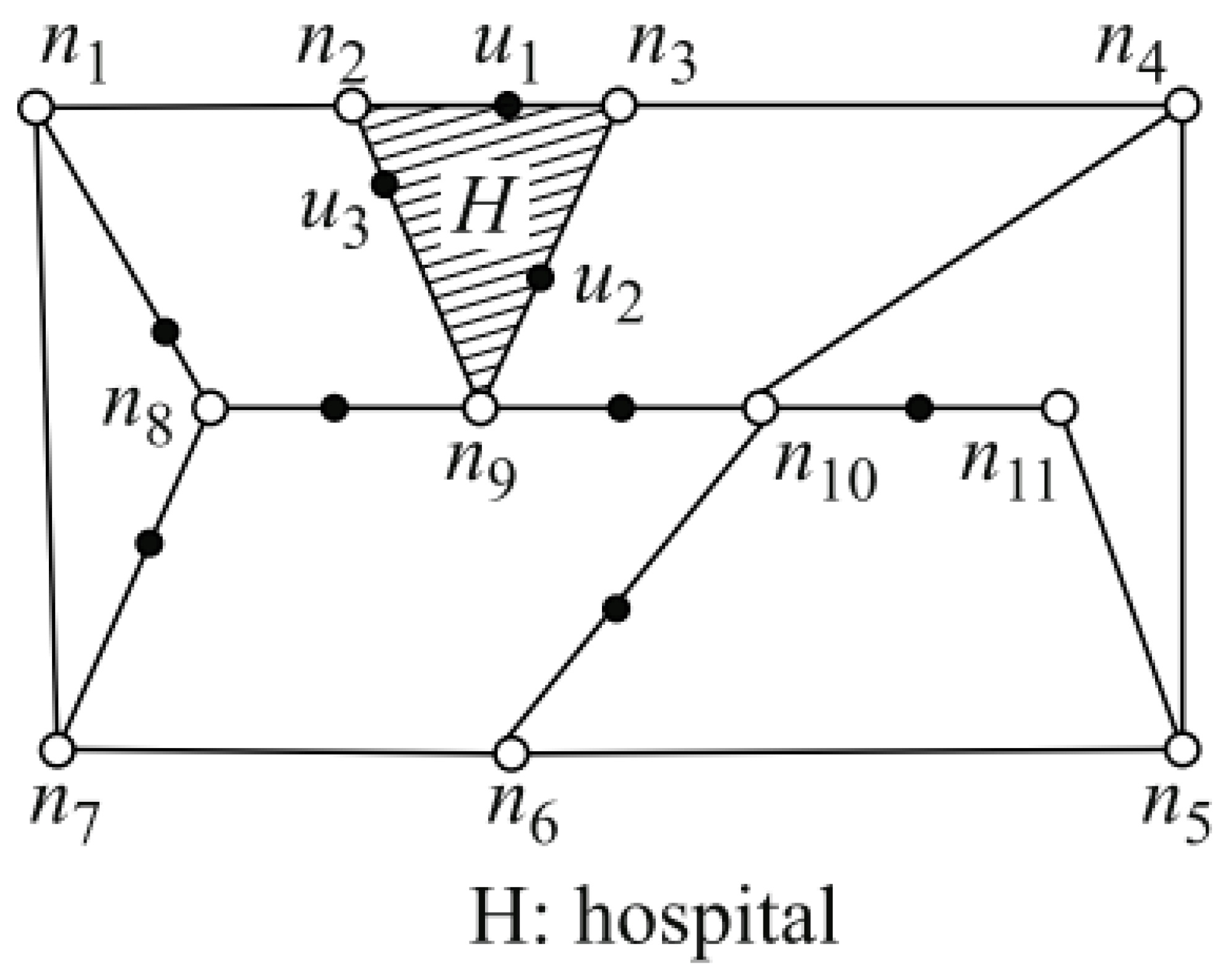
3. Proposed Privacy Protection Approach
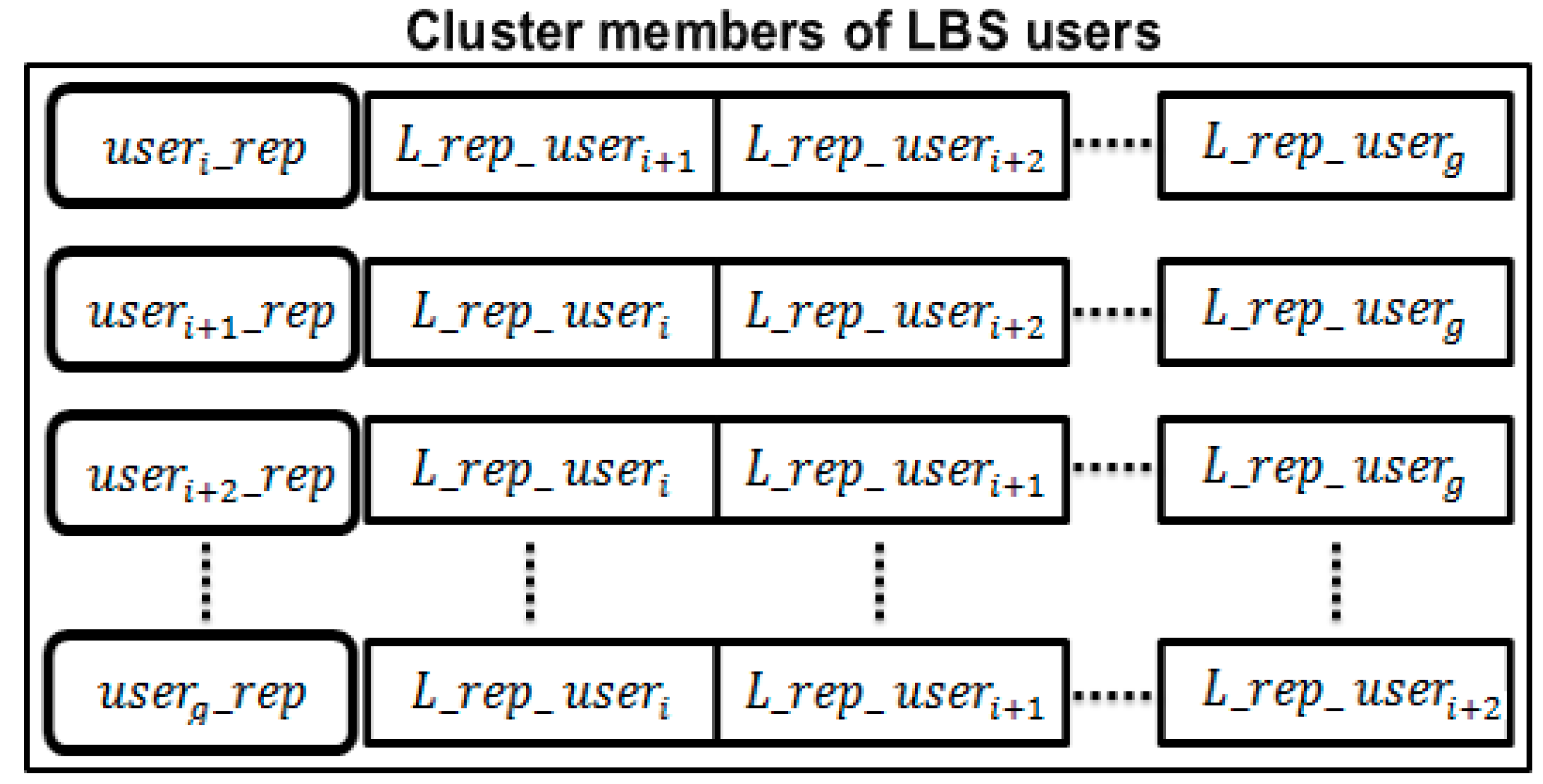
3.1. Proposed Approach (Leader)
3.2. Trusting in The Leader
| Algorithm 1: Leader Election Algorithm |
| Input: (number of cells or clusters), (number of LBS users in a cell or cluster), (number of connections to the LBS server in the past for user ), . |
| Output: (general reputation of the leader in cell ) |
 |
| Algorithm 2: Calculating the Local Reputation () |
| Function |
| Input: |
| Output: |
| 1: Answersreciever_u = Testi(TQS,u) |
| 2: Number of Matching |
| 3: (NWA) = Number (TQS) − NRA |
| 4: new = old |
| 5: = new |
| 6: return |
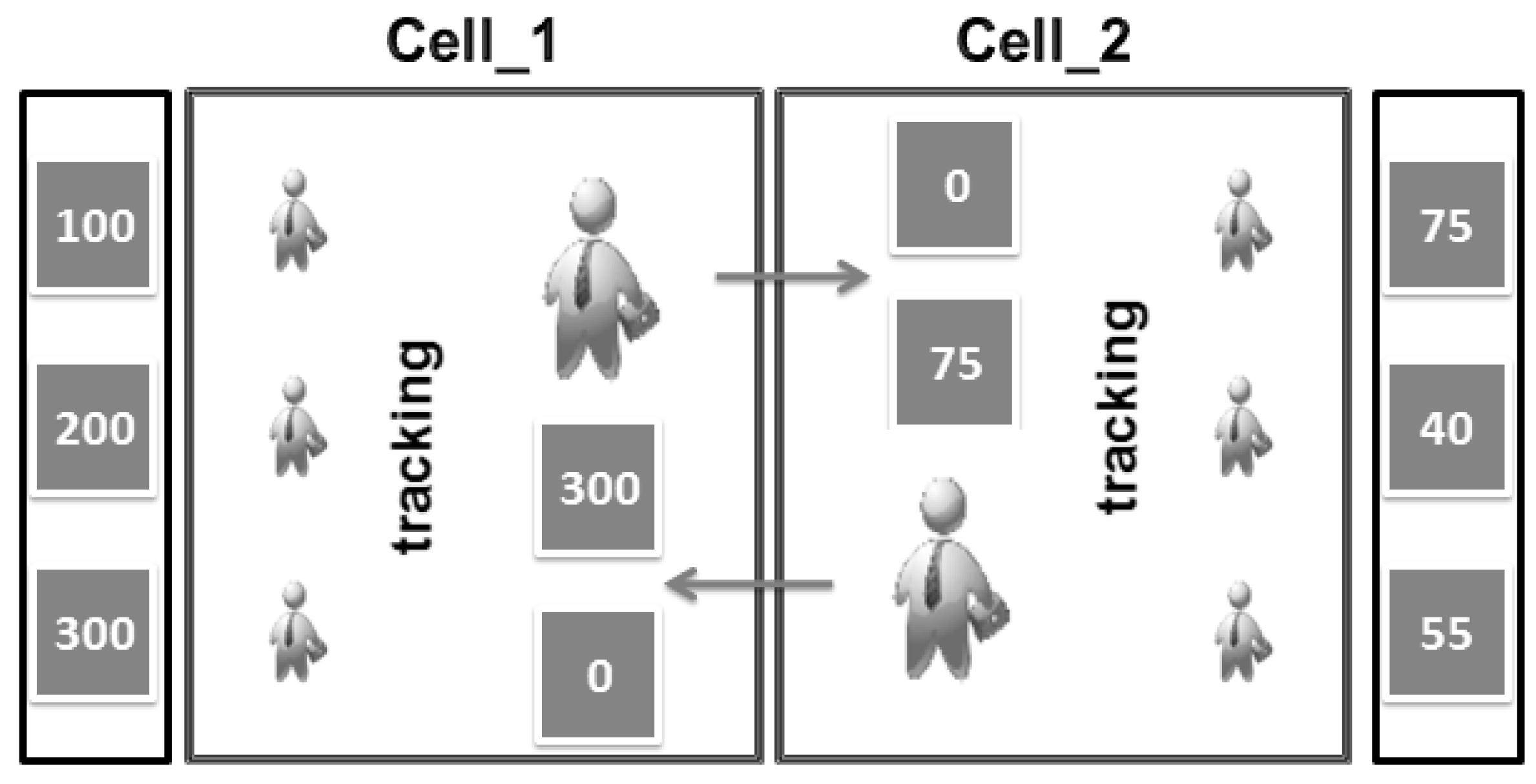
4. Used Privacy Metrics
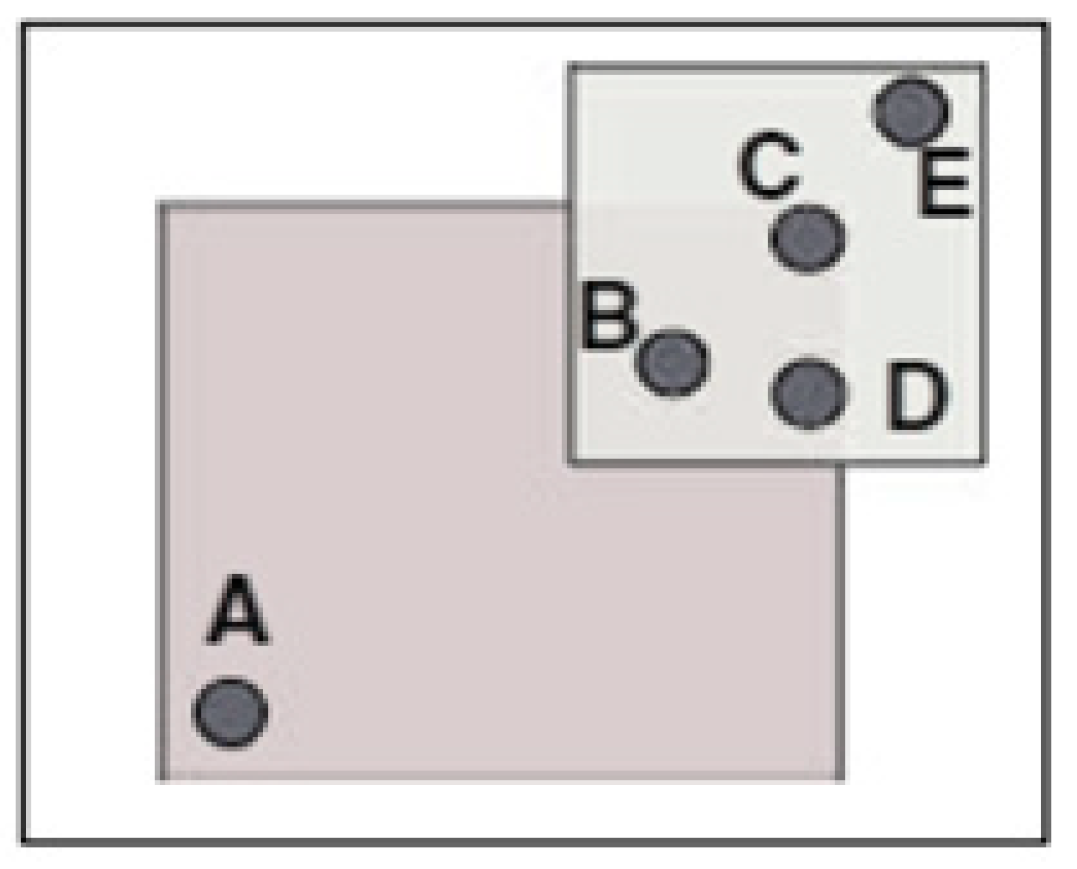
4.1. Inferences Attacks
4.2. Types of Used Privacy Metrics
4.2.1. Leader Privacy Metric
4.2.2. System Privacy Metric
5. Experimental Results and Evaluation
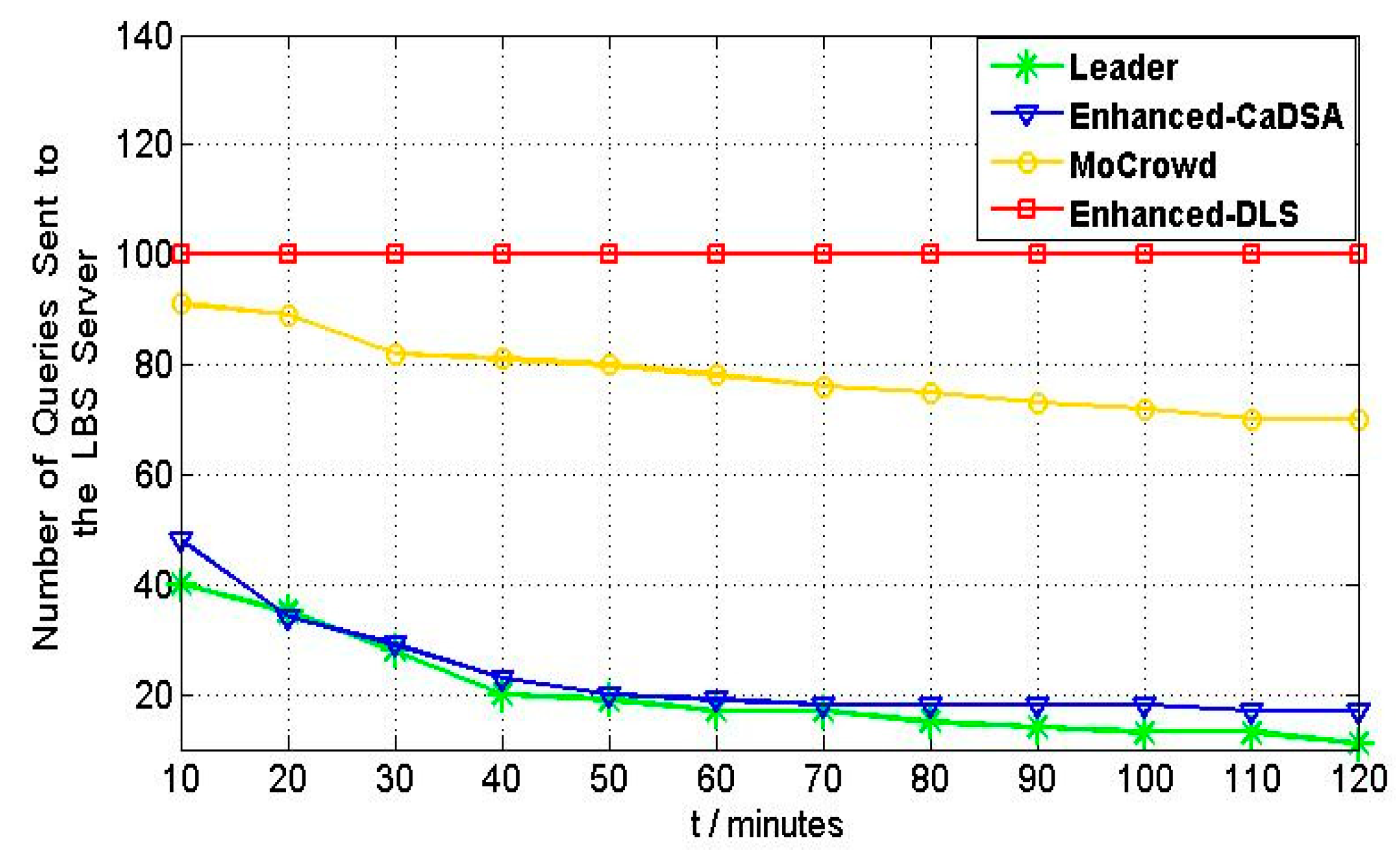
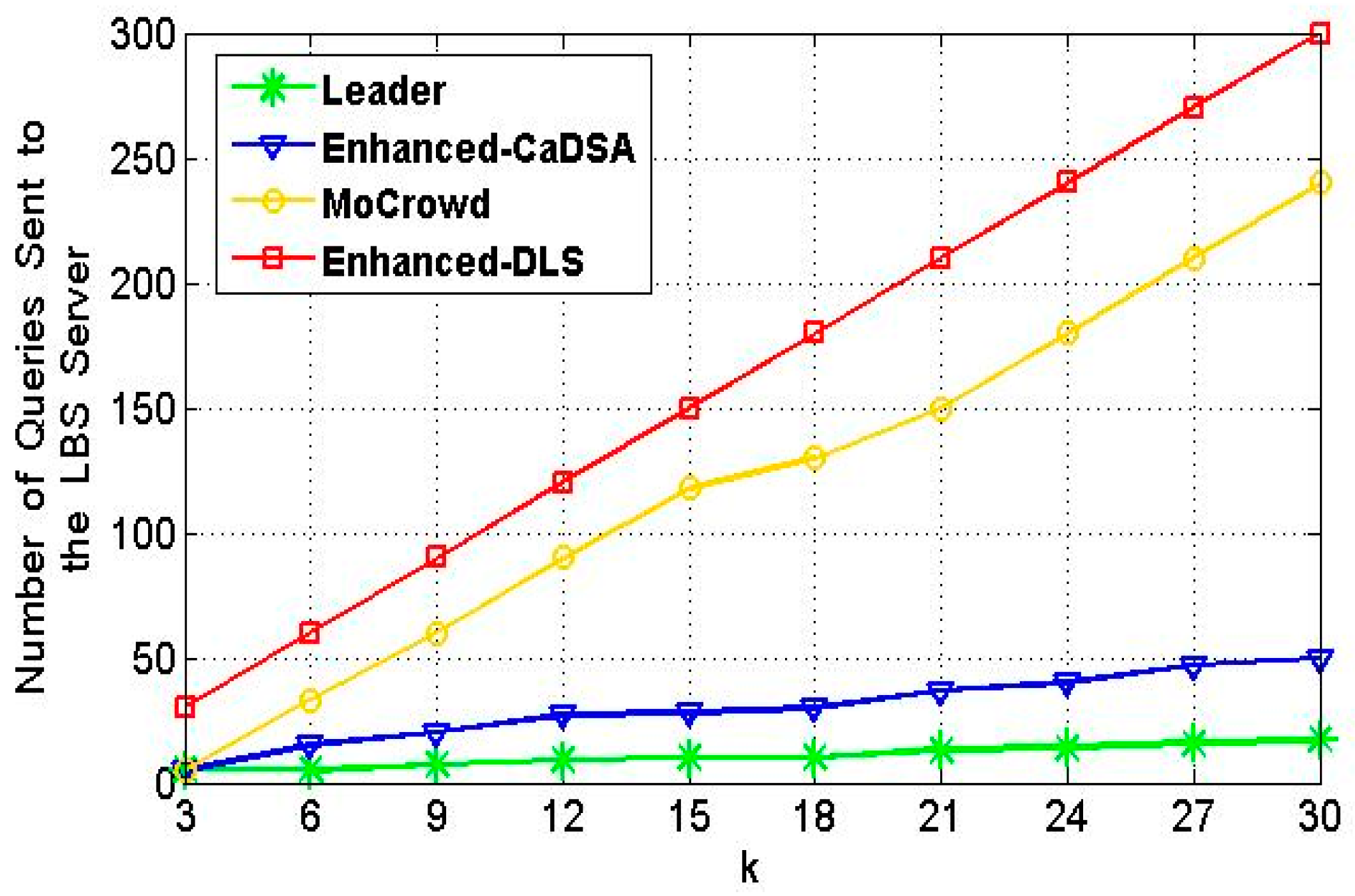
5.1. Communication Cost Results Evaluation
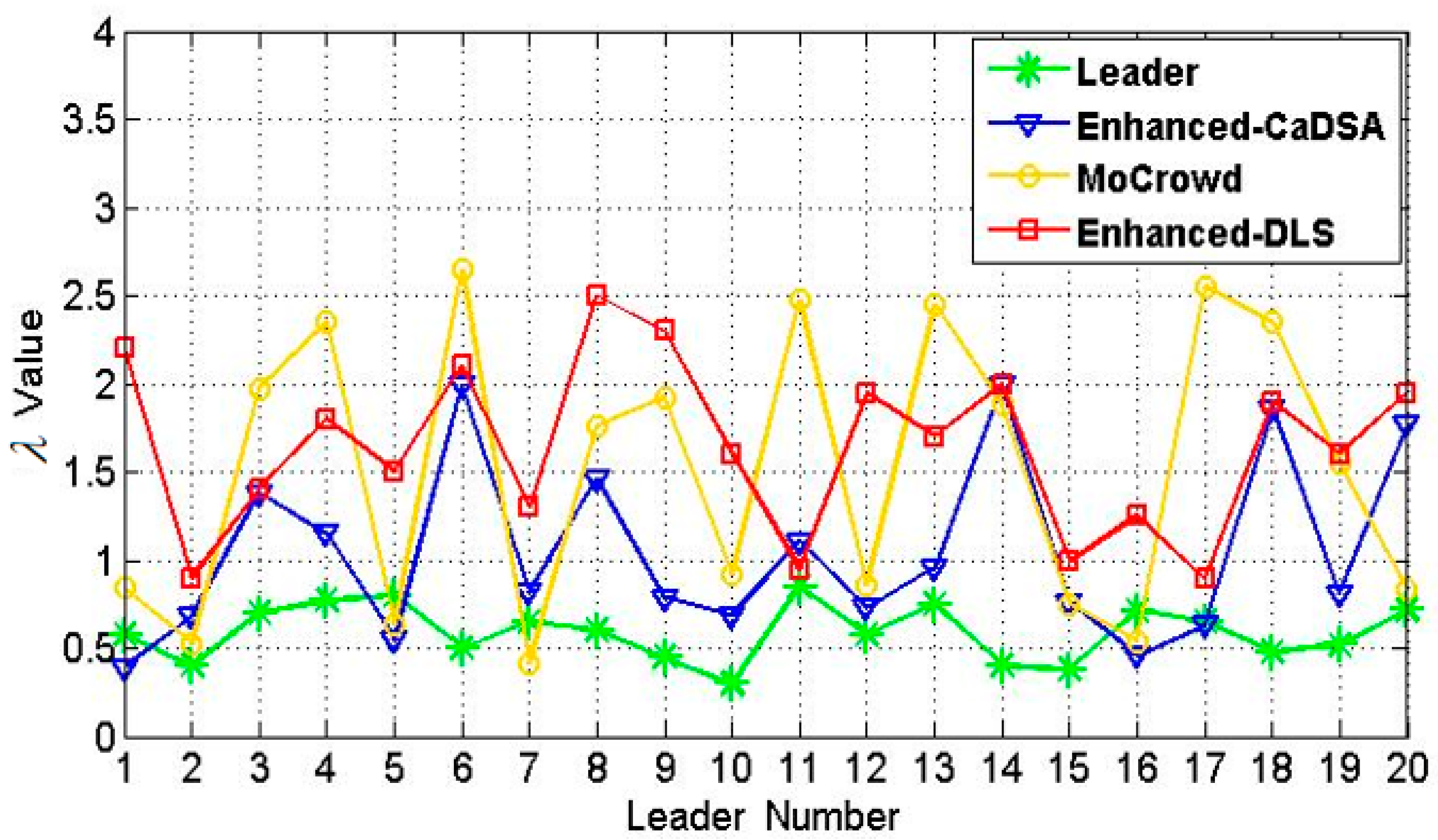
5.2. Resistance Against Inferences Attacks Results Evaluation
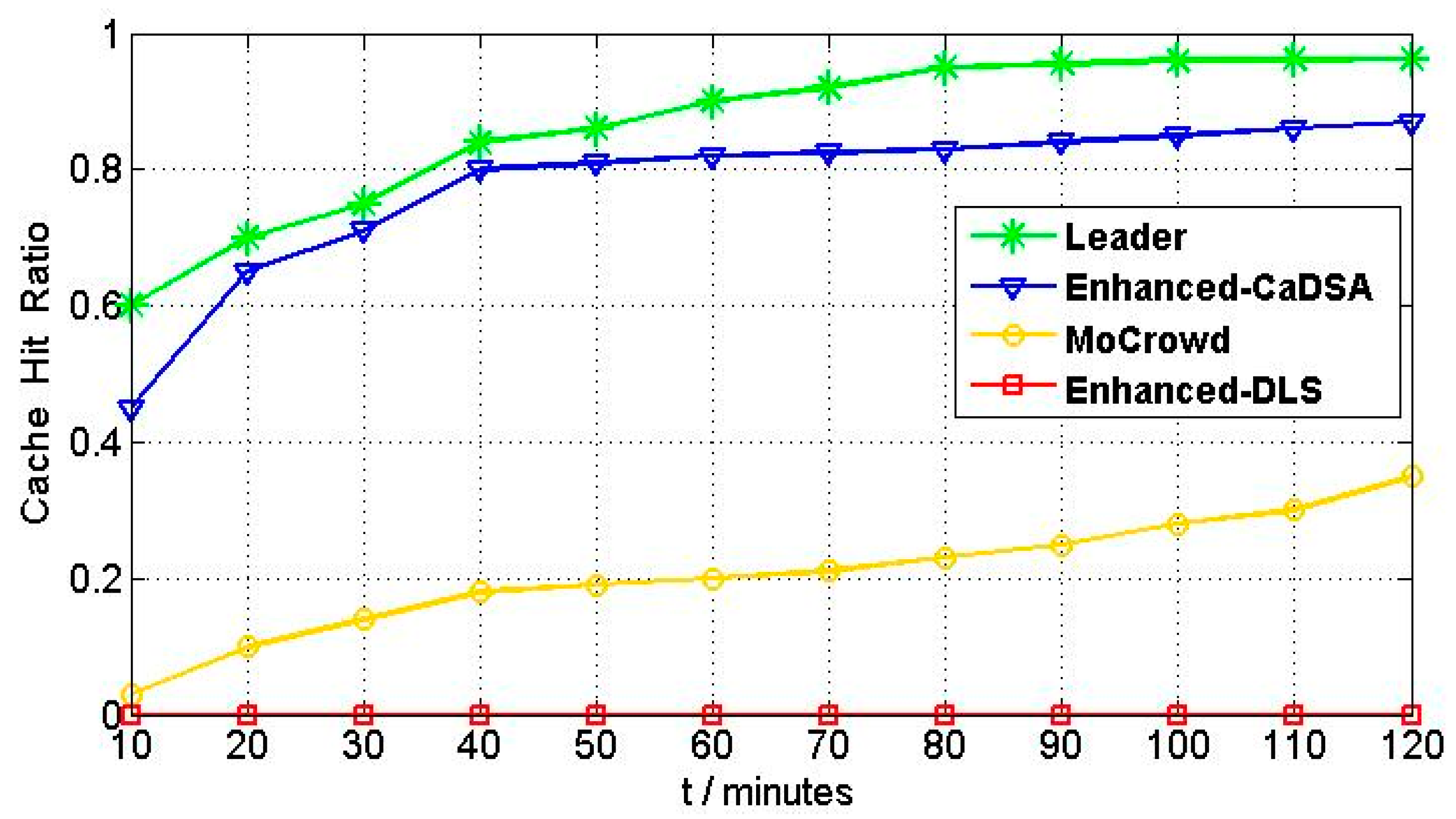
5.3. Cache Hit Ratio Results Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, L.; Thombre, S.; Jarvinen, K.; Simona, L.E.; Alén-Savikko, A.; Leppakoski, H.; Bhuiyan, M.Z.H.; Bu-Pasha, S.; Ferrara, G.N.; Honkala, S.; et al. Robustness, Security and Privacy in Location-Based Services for Future IoT: A Survey. IEEE Access 2017, 5, 8956–8977. [Google Scholar] [CrossRef]
- Elmisery, A.M.; Rho, S.; Botvich, D. A Fog Based Middleware for Automated Compliance With OECD Privacy Principles in Internet of Healthcare Things. IEEE Access 2016, 4, 8418–8441. [Google Scholar] [CrossRef]
- Zhou, J.; Cao, Z.; Dong, X.; Vasilakos, A.V. Security and privacy for cloud-based IoT: Challenges. IEEE Commun. Mag. 2017, 55, 26–33. [Google Scholar]
- Sun, G.; Chang, V.; Ramachandran, M.; Sun, Z.; Li, G.; Yu, H.; Liao, D. Efficient location privacy algorithm for Internet of Things (IoT) services and applications. J. Netw. Comput. Appl. 2017, 89, 3–13. [Google Scholar] [CrossRef]
- Ullah, I.; Shah, M.A. A novel model for preserving Location Privacy in Internet of Things. In Proceedings of the 2016 22nd International Conference on Automation and Computing (ICAC), Colchester, UK, 7–8 September 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Abdelmoty, A.; Alrayes, F. Towards understanding location privacy awareness on geo-social networks. ISPRS Int. J. Geo-Inf. 2017, 6, 109. [Google Scholar] [CrossRef]
- Pagallo, U.; Durante, M.; Monteleone, S. What Is New with the Internet of Things in Privacy and Data Protection? Four Legal Challenges on Sharing and Control in IoT. In Data Protection and Privacy: (In) Visibilities and Infrastructures; Springer International Publishing: Cham, Switzerland, 2017; pp. 59–78. [Google Scholar]
- Hasan, A.S.M.; Qu, Q.; Li, C.; Chen, L.; Jiang, Q. An effective privacy architecture to preserve user trajectories in reward-based LBS applications. ISPRS Int. J. Geo-Inf. 2018, 7, 53. [Google Scholar] [CrossRef]
- Alrawais, A.; Alhothaily, A.; Hu, C.; Cheng, X. Fog Computing for the Internet of Things: Security and Privacy Issues. IEEE Internet Comput. 2017, 21, 34–42. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Y.; Yang, J.; Miao, Y.; Li, W. Big Health Application System based on Health Internet of Things and Big Data. IEEE Access 2017, 5, 7885–7897. [Google Scholar] [CrossRef]
- Samarah, S.; Zamil, M.G.A.; AlEroud, A.F.; Rawashdeh, M.; Alhamid, M.F.; Alamri, A. An Efficient Activity Recognition Framework: Toward Privacy-Sensitive Health Data Sensing. IEEE Access 2017, 5, 3848–3859. [Google Scholar] [CrossRef]
- Dardari, D.; Closas, P.; Djuric, P.M. Indoor tracking: Theory, methods, and technologies. IEEE Trans. Veh. Technol. 2015, 64, 1263–1278. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, K.; Jiang, Y.; Li, X.-Y.; Liu, Y.; Yang, P.; Li, Z.; Yang, P. Montage: Combine frames with movement continuity for realtime multi-user tracking. IEEE Trans. Mob. Comput. 2017, 16, 1019–1031. [Google Scholar] [CrossRef]
- Shin, K.G.; Ju, X.; Chen, Z.; Hu, X. Privacy protection for users of location-based services. IEEE Wirel. Commun. 2012, 19, 30–39. [Google Scholar] [CrossRef]
- Wernke, M.; Skvortsov, P.; Dürr, F.; Rothermel, K. A classification of location privacy attacks and approaches. Pers. Ubiquitous Comput. 2014, 18, 163–175. [Google Scholar] [CrossRef]
- Feng, W.; Yan, Z.; Xie, H. Anonymous Authentication on Trust in Pervasive Social Networking Based on Group Signature. IEEE Access 2017, 5, 6236–6246. [Google Scholar] [CrossRef]
- Yu, R.; Bai, Z.; Yang, L.; Wang, P.; Move, O.A.; Liu, Y. A Location Cloaking Algorithm Based on Combinatorial Optimization for Location-Based Services in 5G Networks. IEEE Access 2016, 4, 6515–6527. [Google Scholar] [CrossRef]
- Gedik, B.; Liu, L. Protecting Location Privacy With Personalized k-Anonymity: Architecture and Algorithms. IEEE Trans. Mob. Comput. 2008, 7, 1–18. [Google Scholar] [CrossRef]
- Gruteser, M.; Grunwald, D. Anonymous Usage of Location-Based Services Through Spatial and Temporal Cloaking. In MobiSys ’03: Proceedings of the 1st International Conference on Mobile Systems, Applications and Services; ACM: New York, NY, USA, 2003. [Google Scholar]
- Mokbel, M.F.; Chow, C.-Y.; Aref, W.G. The New Casper: Query Processing for Location Services Without Compromising Privacy. In Proceedings of the VLDB ‘06, Seoul, Korea, 12–15 September 2006; ACM: New York, NY, USA, 2006; pp. 763–774. [Google Scholar]
- Beresford, A.; Stajano, F. Location Privacy in Pervasive Computing. IEEE Pervasive Comput. 2003, 2, 46–55. [Google Scholar] [CrossRef]
- Hoh, B.; Gruteser, M. Protecting location privacy through path confusion. In Proceedings of the First International Conference on Security and Privacy for Emerging Areas in Communications Networks (SECURECOMM’05), Athens, Greece, 5–9 September 2005; pp. 194–205. [Google Scholar]
- Meyerowitz, J.; Roy Choudhury, R. Hiding stars with fireworks: Location privacy through camouflage. In Proceedings of the 15th Annual International Conference on Mobile Computing and Networking, Beijing, China, 20–25 September 2009; pp. 345–356. [Google Scholar]
- Xu, T.; Cai, Y. Feeling-Based Location Privacy Protection for Location-Based Services. In Proceedings of the 2009 ACM Conference on Computer and Communications Security, CCS 2009, Chicago, IL, USA, 9–13 November 2019; ACM: New York, NY, USA, 2009; pp. 348–357. [Google Scholar]
- Pingley, A.; Yu, W.; Zhang, N.; Fu, X.; Zhao, W. Cap: A context-Aware Privacy Protection System for Location-Based Services. In Proceedings of the 2009 29th IEEE International Conference on Distributed Computing Systems, Montreal, QC, Canada, 22–26 June 2009; pp. 49–57. [Google Scholar]
- Hong, S.; Liu, C.; Ren, B.; Huang, Y.; Chen, J. Personal privacy protection framework based on hidden technology for smartphones. IEEE Access 2017, 5, 6515–6526. [Google Scholar] [CrossRef]
- Manweiler, J.; Scudellari, R.; Cox, L.P. Smile: Encounter-Based Trust for Mobile Social Services. In Proceedings of the CCS ’09, Chicago, IL, USA, 9–13 November 2009; ACM: New York, NY, USA, 2009; pp. 246–255. [Google Scholar]
- Hu, H.; Xu, J. Non-Exposure Location Anonymity. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 1120–1131. [Google Scholar]
- Chen, Z. Energy-Efficient Information Collection and Dissemination in Wireless Sensor Networks. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2009. [Google Scholar]
- Ardagna, C.; Cremonini, M.; Damiani, E.; De Capitani di Vimercati, S.; Samarati, P. Location privacy protection through obfuscation-based techniques. In Proceedings of the 21st Annual IFIP WG 11.3 Working Conference on Data and Applications Security, Redondo Beach, CA, USA, 8–11 July 2007; pp. 47–60. [Google Scholar]
- Gutscher, A. Coordinate transformation—A solution for the privacy problem of location based services? In Proceedings of the 20th International Conference on Parallel and Distributed Processing (IPDPS ’06), Rhodes Island, Greece, 25–29 April 2006; p. 354. [Google Scholar]
- Kido, H.; Yanagisawa, Y.; Satoh, T. An Anonymous Communication Technique Using Dummies for Location- based Services. In Proceedings of the ICPS ’05. Proceedings. International Conference on Pervasive Services 2005, Santorini, Greece, 11–14 July 2005. [Google Scholar]
- Pingley, A.; Zhang, N.; Fu, X.; Choi, H.-A.; Subramaniam, S.; Zhao, W. Protection of Query Privacy for Continuous Location Based Services. In Proceedings of the 2011 proceedings IEEE INFOCOM, Shanghai, China, 10–15 April 2011. [Google Scholar]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H. Achieving k-anonymity in privacy-aware location-based services. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Hara, T.; Suzuki, A.; Iwata, M.; Arase, Y.; Xie, X. Dummy-Based User Location Anonymization Under Real-World Constraints. IEEE Access 2016, 4, 673–687. [Google Scholar] [CrossRef]
- Sun, W.; Chen, C.; Zheng, B.; Chen, C.; Liu, P. An Air Index for Spatial Query Processing in Road Networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 382–395. [Google Scholar] [CrossRef]
- Dewri, R.; Thurimella, R. Exploiting service similarity for privacy in location-based search queries. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 374–383. [Google Scholar] [CrossRef]
- Shokri, R.; Theodorakopoulos, G.; Papadimitratos, P.; Kazemi, E.; Hubaux, J.-P. Hiding in the mobile crowd: Locationprivacy through collaboration. IEEE Trans. Dependable Secur. Comput. 2014, 11, 266–279. [Google Scholar]
- Zhu, X.; Chi, H.; Niu, B.; Zhang, W.; Li, Z.; Li, H. Mobicache: When k-anonymity meets cache. In Proceedings of the 2013 IEEE Global Communications Conference (GLOBECOM), Atlanta, GA, USA, 9–13 December 2013. [Google Scholar]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H.; Ben, N. Enhancing privacy through caching in location-based services. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015. [Google Scholar]
- Georgiadou, Y.; de By, R.A.; Ourania, K. Location Privacy in the Wake of the GDPR. ISPRS Int. J. Geo-Inf. 2019, 8, 157. [Google Scholar] [CrossRef]
- Pan, X.; Chen, W.; Wu, L.; Piao, C.; Hu, Z. Protecting personalized privacy against sensitivity homogeneity attacks over road networks in mobile services. Front. Comput. Sci. 2016, 10, 370–386. [Google Scholar] [CrossRef]
- Lin, C.; Wu, G.; Yu, C.W. Protecting location privacy and query privacy: A combined clustering approach. Concurr. Comput. Pract. Exp. 2015, 27, 3021–3043. [Google Scholar] [CrossRef]
- Saravanan, S.; Ramakrishnan, B.S. Preserving privacy in the context of location based services through location hider in mobile-tourism. Inf. Technol. Tour. 2016, 16, 229–248. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, Y.; Wang, G.; Chen, L.; Li, J. Semantic-Aware Location Privacy Preservation on Road Networks. In International Conference on Database Systems for Advanced Applications; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Lee, B.; Oh, J.; Yu, H.; Kim, J. Protecting location privacy using location semantics. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2011. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Number of Leaders Exceeded the Threshold | Percentage of Encroachment | |
|---|---|---|---|
| Approach | |||
| Leader | 2 | 0.1 | |
| Enhanced-CaDSA | 12 | 0.6 | |
| Mobile Crowd | 15 | 0.75 | |
| Enhanced-DLS | 20 | 1 | |
| Try NO | NO of Leaders | Percentage of Encroachment | |||||
|---|---|---|---|---|---|---|---|
| Leader | Enhanced-CaDSA | Mobile Crowd | Enhanced-DLS | ||||
| 1 | 40 | 130 | 0.75 | 0.13 | 0.53 | 0.67 | 1 |
| 2 | 60 | 140 | 0.7 | 0.15 | 0.55 | 0.83 | 1 |
| 3 | 80 | 150 | 0.65 | 0.22 | 0.42 | 0.71 | 1 |
| 4 | 100 | 160 | 0.6 | 0.17 | 0.45 | 0.59 | 1 |
| 5 | 120 | 170 | 0.55 | 0.14 | 0.4 | 0.57 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alrahhal, H.; Alrahhal, M.S.; Jamous, R.; Jambi, K. A Symbiotic Relationship Based Leader Approach for Privacy Protection in Location Based Services. ISPRS Int. J. Geo-Inf. 2020, 9, 408. https://doi.org/10.3390/ijgi9060408
Alrahhal H, Alrahhal MS, Jamous R, Jambi K. A Symbiotic Relationship Based Leader Approach for Privacy Protection in Location Based Services. ISPRS International Journal of Geo-Information. 2020; 9(6):408. https://doi.org/10.3390/ijgi9060408
Chicago/Turabian StyleAlrahhal, Hosam, Mohamad Shady Alrahhal, Razan Jamous, and Kamal Jambi. 2020. "A Symbiotic Relationship Based Leader Approach for Privacy Protection in Location Based Services" ISPRS International Journal of Geo-Information 9, no. 6: 408. https://doi.org/10.3390/ijgi9060408
APA StyleAlrahhal, H., Alrahhal, M. S., Jamous, R., & Jambi, K. (2020). A Symbiotic Relationship Based Leader Approach for Privacy Protection in Location Based Services. ISPRS International Journal of Geo-Information, 9(6), 408. https://doi.org/10.3390/ijgi9060408