Machine Learning Generalisation across Different 3D Architectural Heritage



Abstract
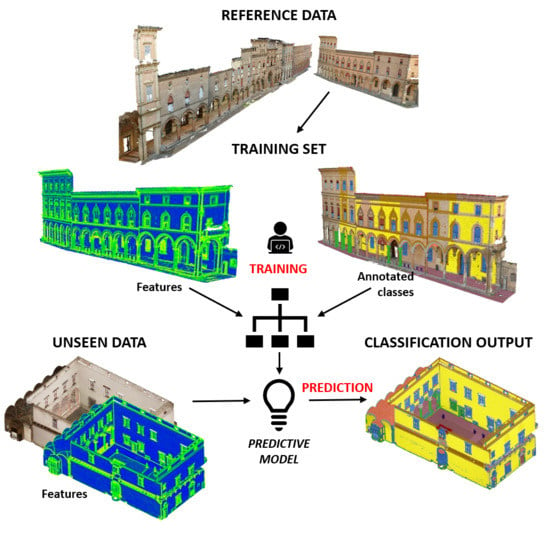
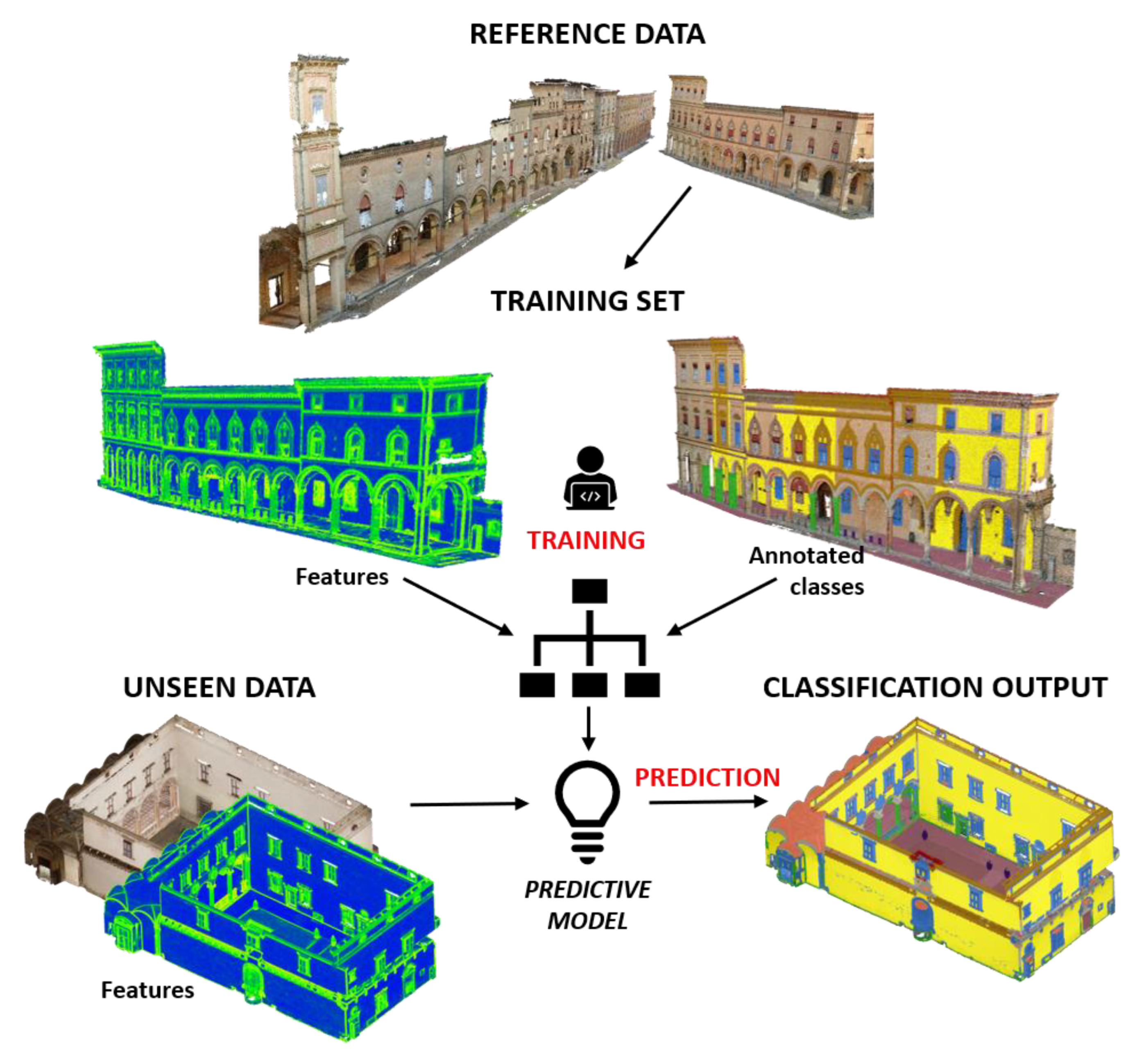
1. Introduction
1.1. State of the Art
1.2. Aim and Contribution of the Paper
- Identifying a set of transversal architectural classes and a few (geometric and radiometric) features that can behave similarly among different datasets;
- Generalising a pre-trained random forest (RF) classifier over unseen 3D scenarios, featuring similar characteristics;
- Classifying 3D point clouds featuring different characteristics, in terms of acquisition technique, geometric resolution and size.
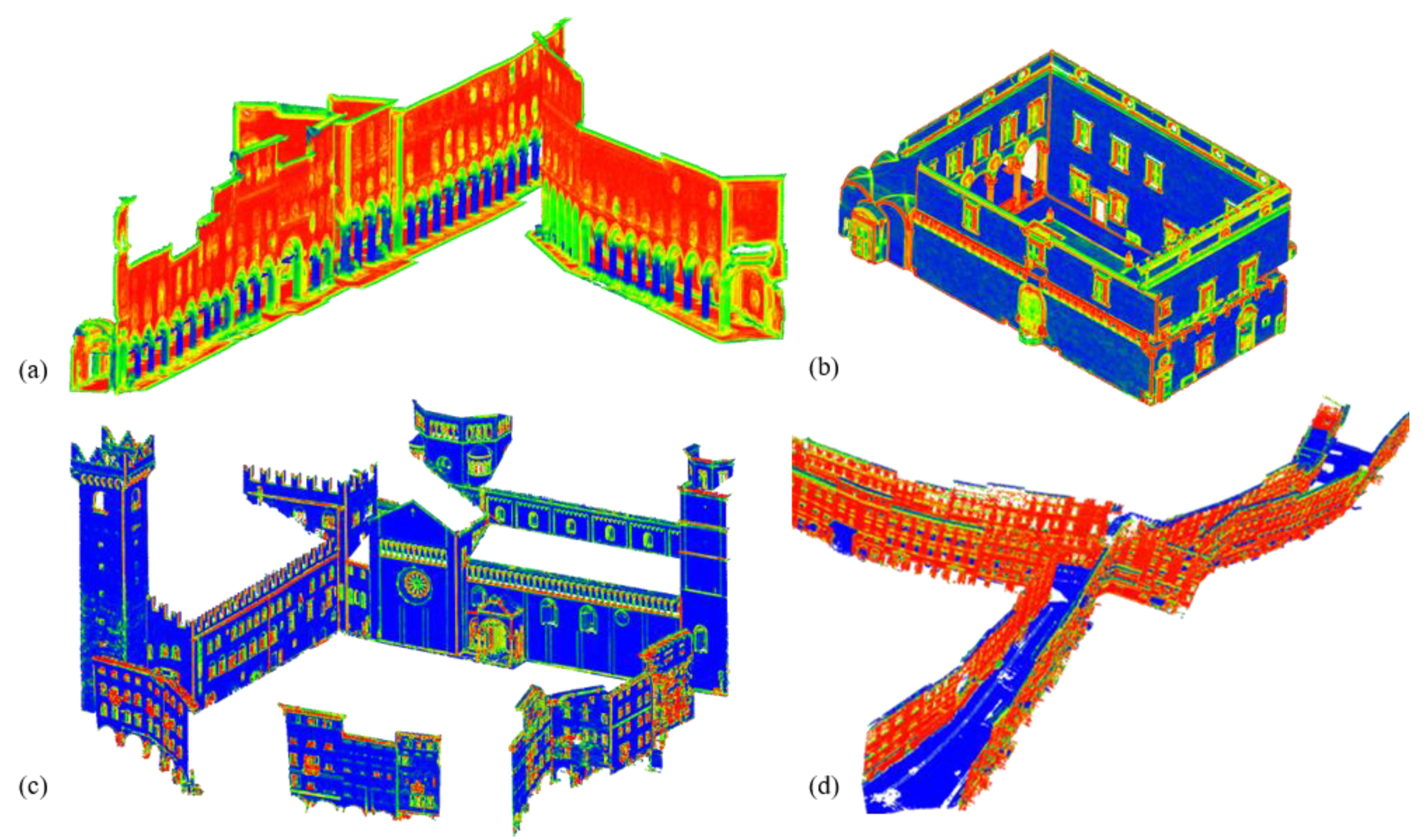
1.3. Datasets
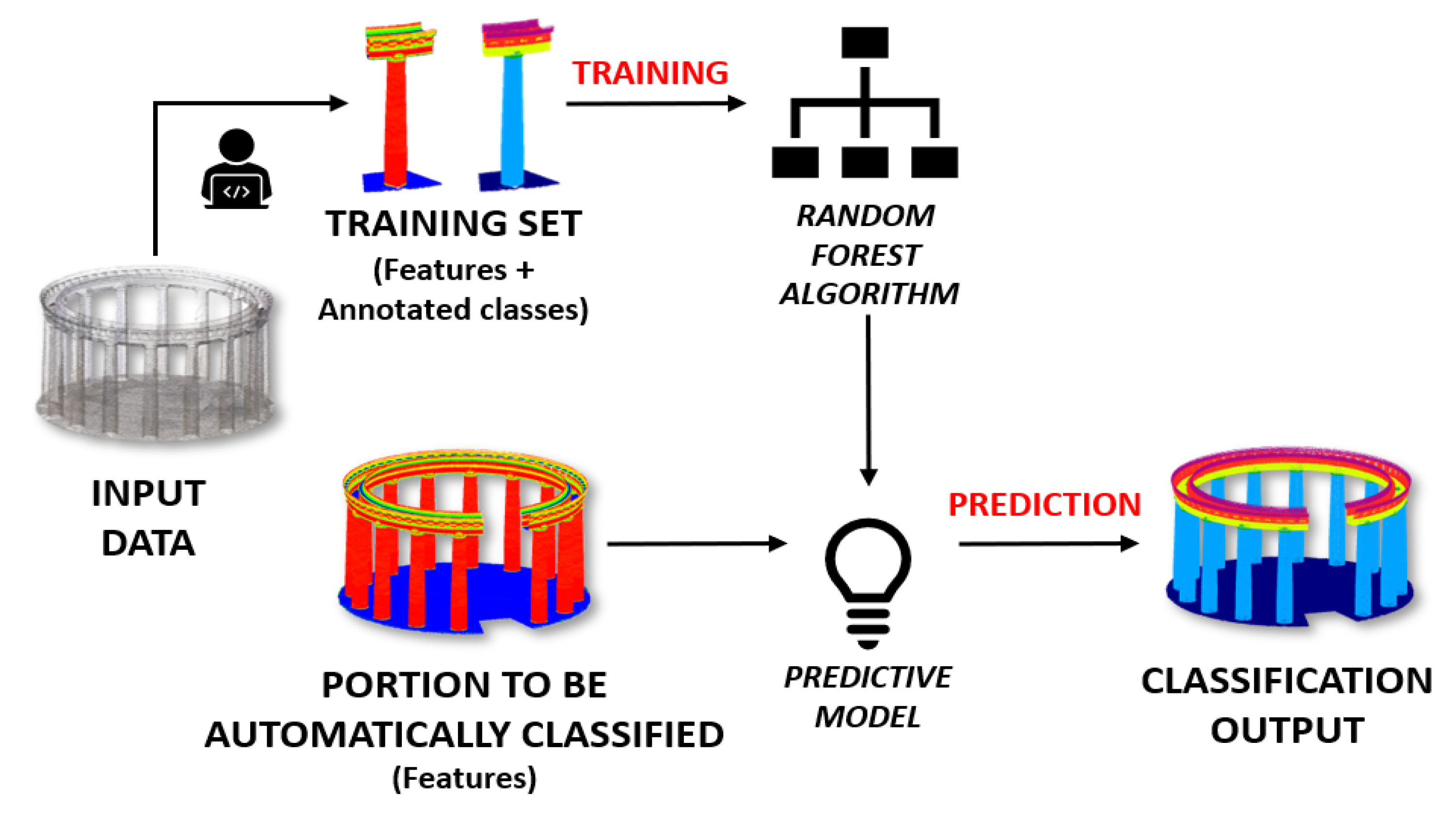
2. Methodology
- We wanted to extend the method presented in our previous study [38], and verify its applicability to larger and different scenarios;
- There is a lack of annotated architectural training data necessary for training a neural network.
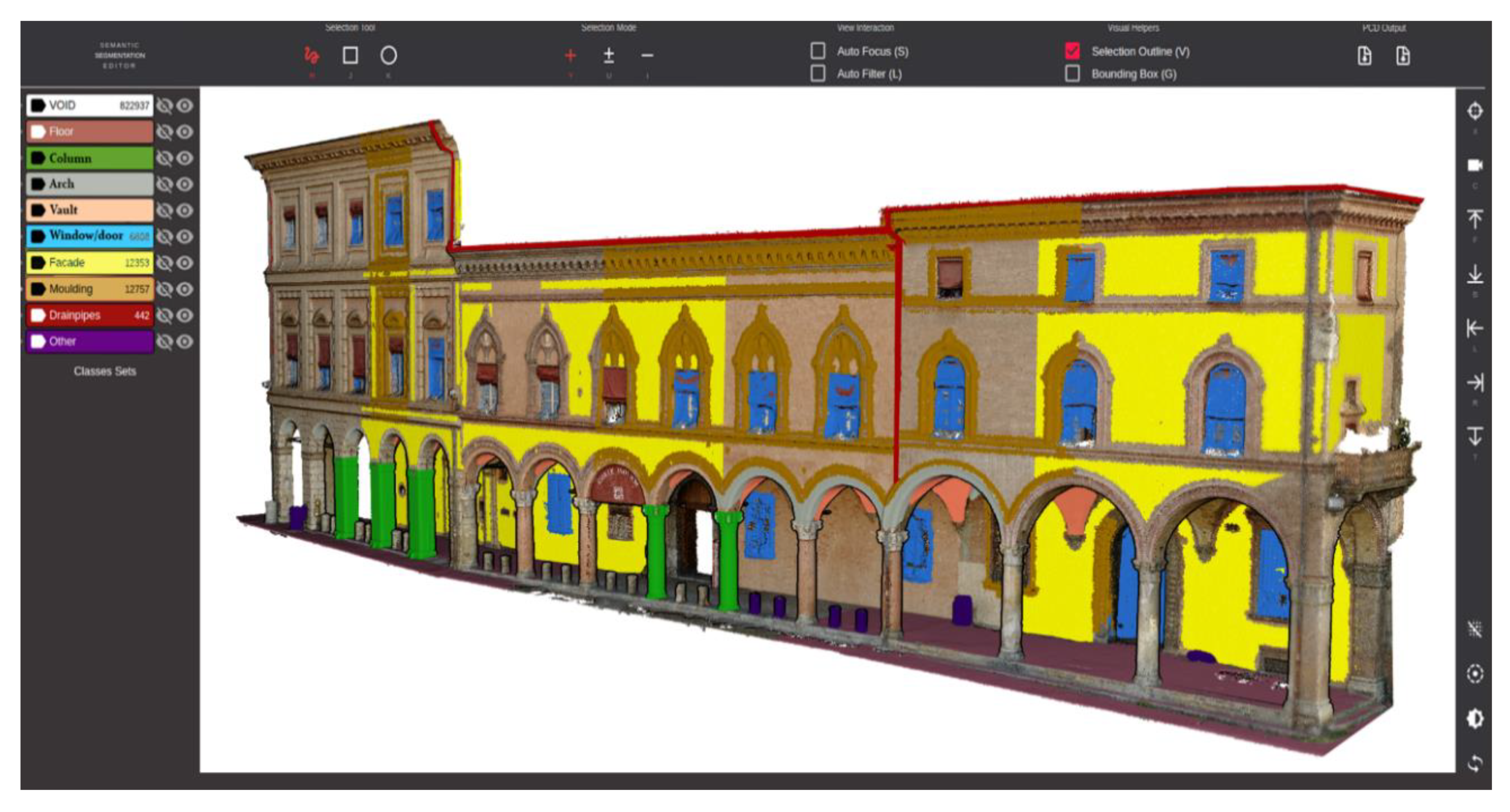
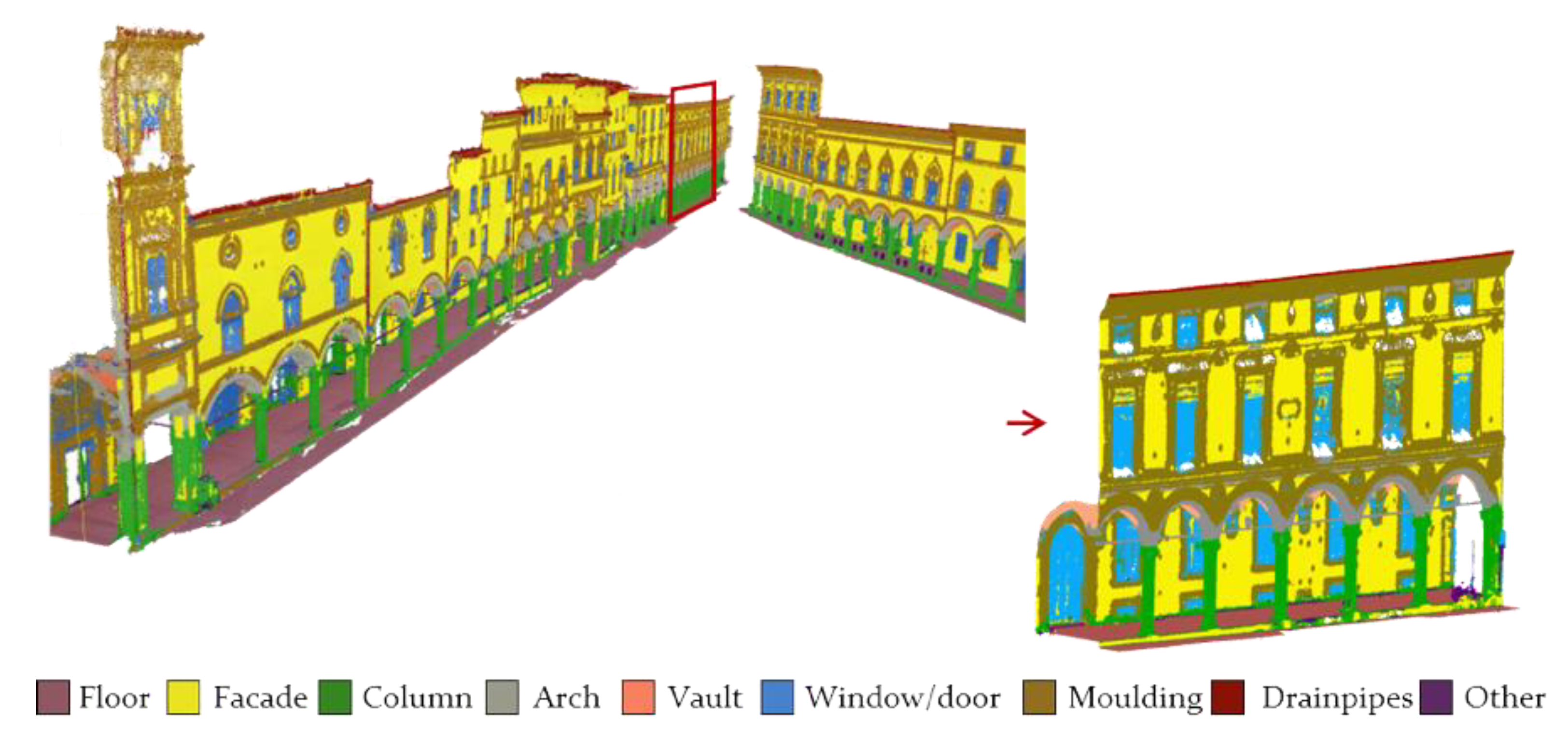
2.1. Class Selection
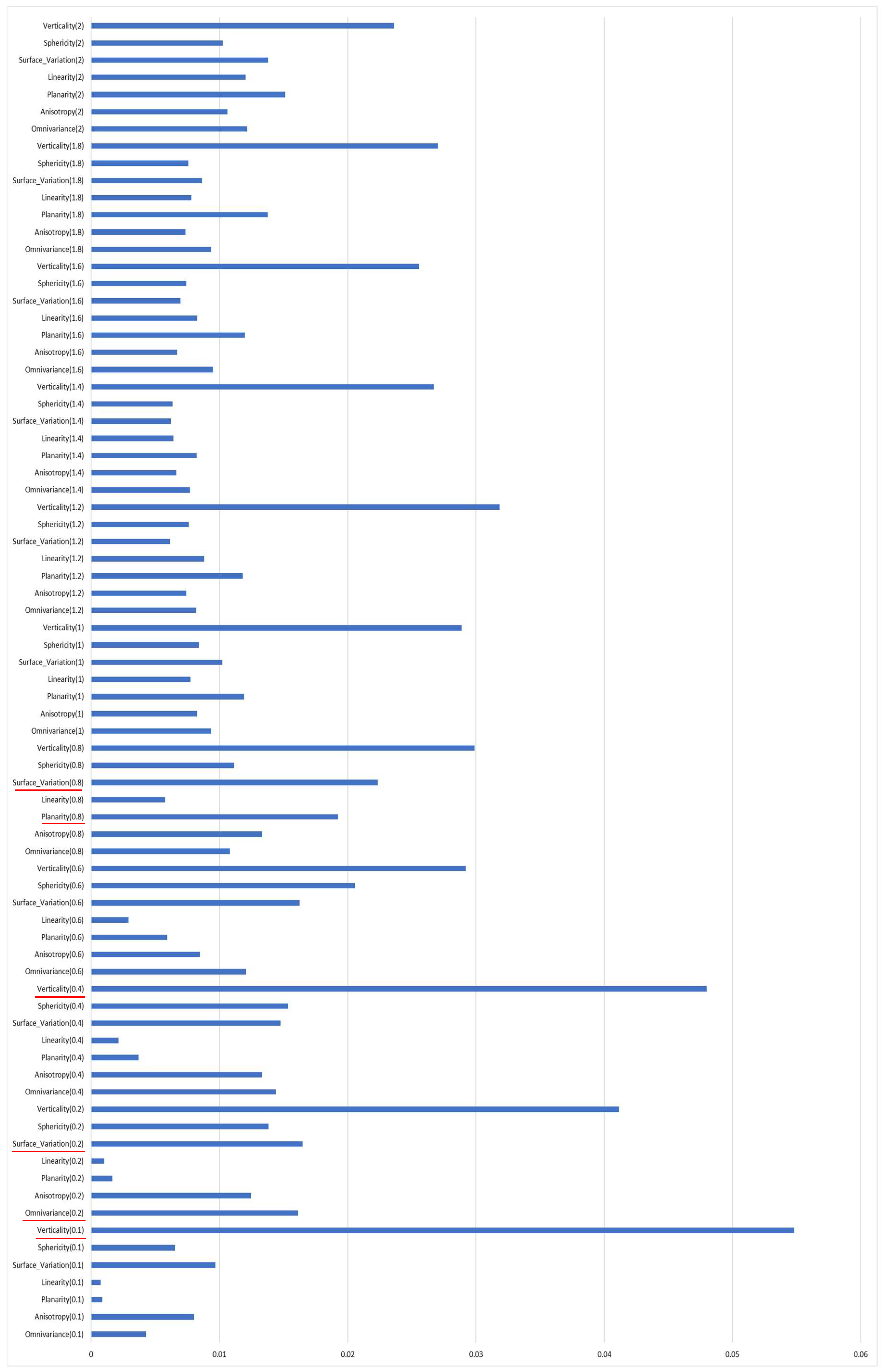
2.2. Feature Selection
2.2.1. Radiometric Features
2.2.2. Geometric Features–Covariance Features
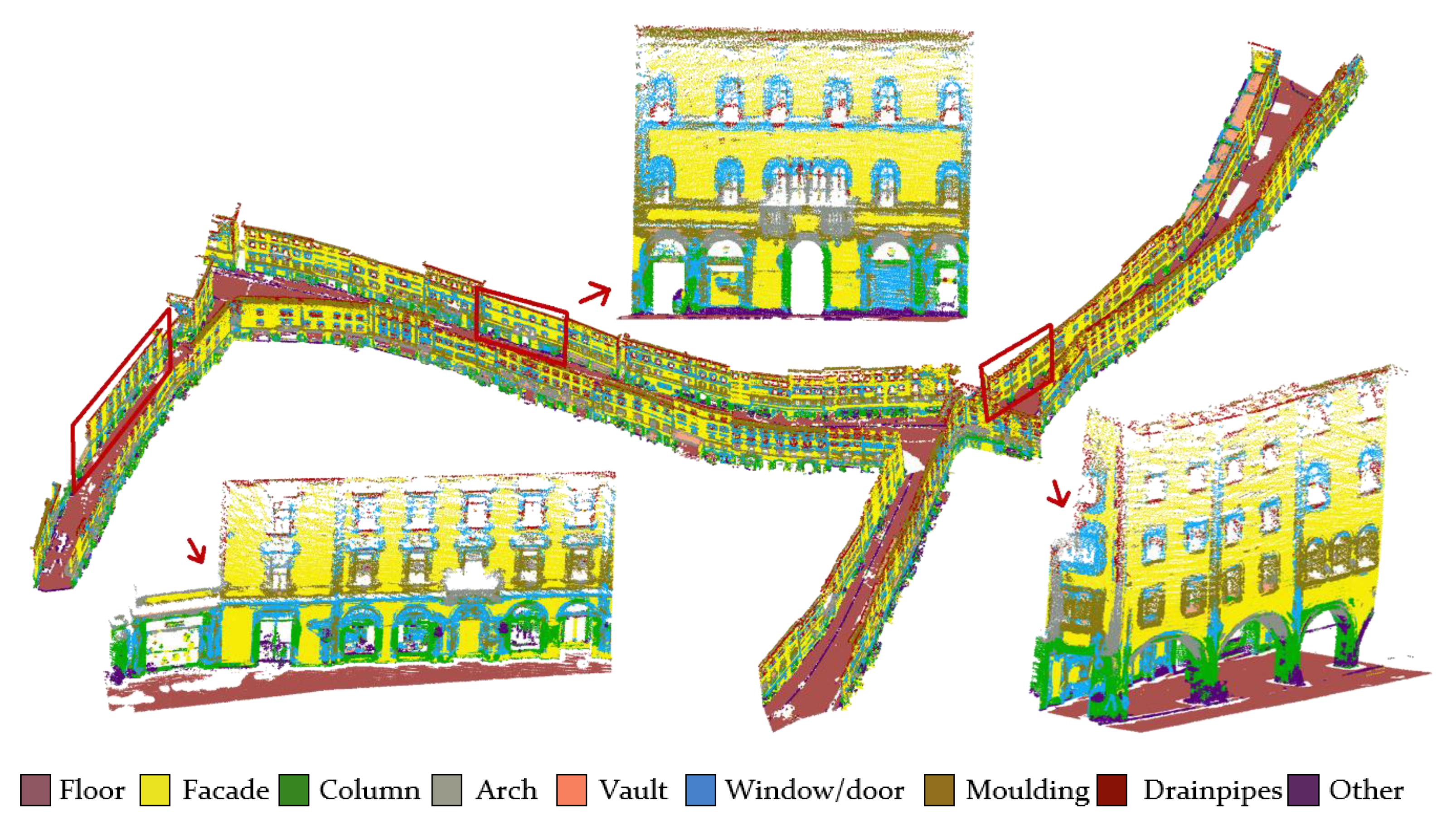
3. Experiments and Results
3.1. Evaluation Method
- Changing city and acquisition technique: a modified version (model 2) of the pre-trained model 1 is tested on the TL dataset F (Table 7, Figure 12). Since the handheld scanning dataset was not provided with RGB values, a re-training round was necessary including exclusively height and geometry-based features.
3.2. Results
4. Conclusions
- It is possible to classify a large dataset starting from a reduced number of annotated samples, saving time in both collecting and preparing data for training the algorithm; this is the first time that this has been demonstrated within the complex heritage field;
- The generalisation works even when training and test sets have different densities and the distribution of the points in the cloud is not uniform (Experiment 4, Figure 12);
- The quality of the results allows us to have a general idea of the distribution of the architectural classes and could support restoration works by providing approximate surface areas or volumes;
- The output can facilitate the scan-to-BIM problems, semantically separating elements in point clouds for the modelling procedure in a BIM environment;
- Automated classification methods can be used to accelerate the time-consuming process of the annotation of a significant number of datasets, in order to benchmark 3D heritages;
- The used RF model is easy to implement, and it does not require high computational efforts nor long learning or processing time.
Author Contributions
Funding
Conflicts of Interest
References
- Gruen, A. Reality-based generation of virtual environments for digital earth. Int. J. Digit. Earth 2008, 1, 88–106. [Google Scholar] [CrossRef]
- Remondino, F. Heritage Recording and 3D Modeling with Photogrammetry and 3D Scanning. Remote Sens. 2011, 3, 1104–1138. [Google Scholar] [CrossRef]
- Barsanti, S.G.; Remondino, F.; Fenández-Palacios, B.J.; Visintini, D. Critical Factors and Guidelines for 3D Surveying and Modelling in Cultural Heritage. Int. J. Herit. Digit. Era 2014, 3, 141–158. [Google Scholar] [CrossRef]
- Son, H.; Kim, C. Semantic as-built 3D modeling of structural elements of buildings based on local concavity and convexity. Adv. Eng. Inform. 2017, 34, 114–124. [Google Scholar] [CrossRef]
- Lu, Q.; Lee, S. Image-based technologies for constructing as-is building information models for existing buildings. J. Comput. Civ. Eng. 2017, 31, 04017005. [Google Scholar] [CrossRef]
- Rebolj, D.; Pučko, Z.; Babič, N.; Bizjak, M.; Mongus, D. Point cloud quality requirements for Scan-vs-BIM based automated construction progress monitoring. Autom. Constr. 2017, 84, 323–334. [Google Scholar] [CrossRef]
- Bassier, M.; Yousefzadeh, M. Comparison of 2D and 3D wall reconstruction algorithms from point cloud data for as-built BIM. J. Inf. Technol. Constr. 2020, 25, 173–192. [Google Scholar] [CrossRef]
- Apollonio, F.I.; Basilissi, V.; Callieri, M.; Dellepiane, M.; Gaiani, M.; Ponchio, F.; Rizzo, F.; Rubino, A.R.; Scopigno, R.; Sobra’, G. A 3D-centered information system for the documentation of a complex restoration intervention. J. Cult. Herit. 2018, 29, 89–99. [Google Scholar] [CrossRef]
- Valero, E.; Bosché, F.; Forster, A. Automatic segmentation of 3D point clouds of rubble masonry walls, and its application to building surveying, repair and maintenance. Autom. Constr. 2018, 96, 29–39. [Google Scholar] [CrossRef]
- Sánchez-Aparicio, L.; Del Pozo, S.; Ramos, L.; Arce, A.; Fernandes, F. Heritage site preservation with combined radiometric and geometric analysis of TLS data. Autom. Constr. 2018, 24–39. [Google Scholar] [CrossRef]
- Roussel, R.; Bagnéris, M.; De Luca, L. A digital diagnosis for the «Autumn» statue (Marseille, France): Photogrammetry, digital cartography and construction of a thesaurus. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 1039–1046. [Google Scholar] [CrossRef]
- Bosché, F. Automated recognition of 3D CAD model objects in laser scans and calculation of as-built dimensions for dimensional compliance control in construction. Adv. Eng. informatics 2010, 24, 107–118. [Google Scholar] [CrossRef]
- Ordóñez, C.; Martínez, J.; Arias, P.; Armesto, J. Measuring building façades with a low-cost close-range photogrammetry system. Autom. Constr. 2010, 19, 742–749. [Google Scholar] [CrossRef]
- Mizoguchi, T.; Koda, Y.; Iwaki, I.; Wakabayashi, H.; Kobayashi, Y.S.K.; Hara, Y.; Lee, H. Quantitative scaling evaluation of concrete structures based on terrestrial laser scanning. Autom. Constr. 2013, 35, 263–274. [Google Scholar] [CrossRef]
- Kashani, A.; Graettinger, A. Cluster-based roof covering damage detection in ground-based lidar data. Autom. Constr. 2015, 58, 19–27. [Google Scholar] [CrossRef]
- Barazzetti, L.; Banfi, F.; Brumana, R.; Gusmeroli, G.; Previtali, M.; Schiantarelli, G. Cloud-to-BIM-to-FEM: Structural simulation with accurate historic BIM from laser scans. Simul. Model. Pract. Theory 2015, 57, 71–87. [Google Scholar] [CrossRef]
- Banfi, F. BIM orientation: Grades of generation and information for different type of analysis and management process. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII–2/W5, 57–64. [Google Scholar] [CrossRef]
- Bitelli, G.; Castellazzi, G.; D’Altri, A.; De Miranda, S.; Lambertini, A.; Selvaggi, I. Automated voxel model from point clouds for structural analysis of cultural heritage ISPRS-Int. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 191–197. [Google Scholar] [CrossRef]
- Grilli, E.; Menna, F.; Remondino, F. A review of point cloud segmentation and classification algorithms. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W3, 339–344. [Google Scholar] [CrossRef]
- Vosselman, G. Point cloud segmentation for urban scene classification. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-7/W2, 257–262. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Mallet, C. Feature relevance assessment for the semantic interpretation of 3D point cloud data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, II-5/W2, 313–318. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 24 January 2019. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of Deep Learning and its applications: A new paradigm to Machine Learning. Arch. Comput. Methods Eng. 2019, 26, 1–22. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. arXiv 2019, arXiv:1910.13796. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012v1. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Savarese, S. Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Munoz, D.; Bagnell, J.A.; Vandapel, N.; Hebert, M. Contextual classification with functional max-margin markov networks. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009; pp. 975–982. [Google Scholar]
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.-E. Paris-rue-Madame database: A 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification methods. In Proceedings of the 3rd International Conference on Pattern Recognition, Applications and Methods ICPRAM, Angers, Loire Valley, France, 6–8 March 2014. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B.; R&d, D.A.; et al. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Grilli, E.; Remondino, F. Classification of 3D Digital Heritage. Remote Sens. 2019, 11, 847. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Grussenmeyer, P. Virtual Disassembling of Historical Edifices: Experiments and Assessments of an Automatic Approach for Classifying Multi-Scalar Point Clouds into Architectural Elements. Sensors 2020, 20, 2161. [Google Scholar] [CrossRef]
- Pierdicca, R.; Paolanti, M.; Matrone, F.; Martini, M.; Morbidoni, C.; Malinverni, E.S.; Frontoni, E.; Lingua, A.M. Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage. Remote Sens. 2020, 12, 1005. [Google Scholar] [CrossRef]
- Grilli, E.; Farella, E.M.; Torresani, A.; Remondino, F. Geometric features analysis for the classification of cultural heritage point clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 541–548. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Sarkar, D.; Bali, R.; Ghosh, T. Hands-On Transfer Learning with Python: Implement Advanced Deep Learning and Neural Network Models Using TensorFlow and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Remondino, F.; Gaiani, M.; Apollonio, F.; Ballabeni, A.; Ballabeni, M.; Morabito, D. 3D documentation of 40 km of historical porticoes—The challenge. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 711–718. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Bassier, M.; Genechten, B.V.; Vergauwen, M. Classification of sensor independent point cloud data of building objects using random forests. J. Build. Eng. 2019, 21, 468–477. [Google Scholar] [CrossRef]
- Kogut, T.; Weistock, M. Classifying airborne bathymetry data using the Random Forest algorithm. Remote Sens. Lett. 2019, 10, 874–882. [Google Scholar] [CrossRef]
- Poux, F.; Billen, R. Geo-Information Voxel-based 3D Point Cloud Semantic Segmentation: Unsupervised Geometric and Relationship Featuring vs Deep Learning Methods. ISPRS Int. J. Geo-Inf. 2019, 8, 213. [Google Scholar] [CrossRef]
- Grilli, E.; Ozdemir, E.; Remondino, F. Application of machine and deep learning strategies for the classification of heritage point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-4/W18, 447–454. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Malinverni, E.S.; Pierdicca, R.; Paolanti, M.; Martini, M.; Morbidoni, C.; Matrone, F.; Lingua, A. Deep learning for semantic segmentation of 3D point cloud. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 735–742. [Google Scholar] [CrossRef]
- Semantic Segmentation Editor. Available online: https://github.com/GerasymenkoS/semantic-segmentation-editor (accessed on 27 April 2020).
- Jurio, A.; Pagola, M.; Galar, M.; Lopez-Molina, C.; Paternain, D. A comparison study of different color spaces in clustering based image segmentation. In International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 532–541. [Google Scholar]
- Chehata, N.; Guo, L.; Mallet, C. Airborne lidar feature selection for urban classification using random forests. Laser Scanning IAPRS 2009, XXXVIII, 207–212. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Mallet, C.; Weinmann, M. Geometric features and their relevance for 3D point cloud classification. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1/W1, 157–164. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast Semantic Segmentation of 3D Point Clouds with Strongly Varying Density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2016, III–3, 177–184. [Google Scholar] [CrossRef]
- Blomley, R.; Weinmann, M.; Leitloff, J.; Jutzi, B. Shape distribution features for point cloud analysis-a geometric histogram approach on multiple scales. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 9–16. [Google Scholar] [CrossRef]
- Weinmann, M.; Schmidt, A.; Mallet, C.; Hinz, S.; Rottensteiner, F.; Jutzi, B. Contextual classification of point cloud data by exploiting individual 3D neigbourhoods. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W4, 271–278. [Google Scholar] [CrossRef]
- Thomas, H.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Le Gall, Y. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 390–398. [Google Scholar]
- Mauro, M.; Riemenschneider, H.; Signoroni, A.; Leonardi, R.; van Gool, L. A unified framework for content-aware view selection and planning through view importance. In Proceedings of the British Machine Vision Conference BMVC 2014, Nottingham, UK, 1–5 September 2014; pp. 1–11. [Google Scholar]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.S.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A benchmark for large-scale heritage point cloud semantic segmentation. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2, 4558–4567. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DATASET | ACQUISITION | POINTS (M) | AV. D. (cm) | L (m) | ||
|---|---|---|---|---|---|---|
| A | Bologna– S. Stefano |  | Photogrammetry | 14 | 0.8 | 230 |
| B | Bologna– S. Maggiore |  | Photogrammetry | 22 | 0.8 | 330 |
| C | Bologna–Castiglione |  | Photogrammetry | 14 | 0.8 | 235 |
| D | Trento–Lodge |  | Photogrammetry | 6 | 1.0 | 100 |
| E | Trento–Square |  | Photogrammetry | 11 | 1.3 | 330 |
| F | Trento–Streets |  | Handheld scanning | 13 | From 0.2 to 15.0 | 810 |
| FEATURE | FORMULA | NEIGHBOURHOOD SIZE (m) |
|---|---|---|
| Planarity | Equation (1) | 0.8 |
| Omnivariance | Equation (2) | 0.2 |
| Surface variation | Equation (3) | 0.2, 0.8 |
| Verticality | Equation (4) | 0.1, 0.4 |
| CLASS | Floor | Facade | Column | Arch | Vault | Window | Moulding | Drainpipe | Other | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| floor | 546304 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2619 | 1.00 | 1.00 | 1.00 |
| facade | 0 | 361751 | 4763 | 1175 | 0 | 185 | 0 | 0 | 2 | 0.98 | 0.99 | 0.99 |
| column | 0 | 218 | 59772 | 326 | 0 | 0 | 0 | 0 | 632 | 0.98 | 0.92 | 0.95 |
| arch | 0 | 507 | 94 | 57632 | 3972 | 20 | 5363 | 0 | 0 | 0.85 | 0.92 | 0.89 |
| vault | 0 | 0 | 0 | 3201 | 629809 | 1221 | 243 | 0 | 0 | 0.99 | 0.99 | 0.99 |
| window | 0 | 3030 | 0 | 2 | 24 | 78565 | 10531 | 852 | 0 | 0.84 | 0.88 | 0.86 |
| moulding | 0 | 200 | 143 | 227 | 1107 | 8668 | 304610 | 512 | 0 | 0.97 | 0.95 | 0.96 |
| drainpipe | 0 | 2 | 7 | 23 | 2 | 617 | 23 | 5641 | 0 | 0.89 | 0.81 | 0.85 |
| other | 111 | 137 | 230 | 0 | 0 | 0 | 0 | 0 | 18071 | 0.97 | 0.85 | 0.91 |
| ARITHMETIC AVERAGE | 0.94 | 0.92 | 0.93 | |||||||||
| WEIGHTED AVERAGE | 0.98 | 0.98 | 0.98 | |||||||||
| CLASS | Floor | Facade | Column | Arch | Vault | Window | Moulding | Drainpipe | Other | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| floor | 890967 | 207 | 20 | 0 | 0 | 4 | 0 | 0 | 3850 | 1.00 | 0.94 | 0.97 |
| facade | 3704 | 1084815 | 2530 | 16981 | 701 | 36776 | 17439 | 2 | 24741 | 0.91 | 0.91 | 0.91 |
| column | 20888 | 39614 | 200758 | 2672 | 0 | 961 | 1483 | 7 | 4664 | 0.74 | 0.85 | 0.79 |
| arch | 0 | 6855 | 21979 | 217040 | 6484 | 4477 | 16238 | 73 | 0 | 0.79 | 0.78 | 0.79 |
| vault | 76 | 0 | 0 | 27526 | 862579 | 833 | 1174 | 17 | 1 | 0.97 | 0.98 | 0.97 |
| window | 892 | 7801 | 163 | 657 | 4214 | 185498 | 51981 | 3231 | 677 | 0.73 | 0.66 | 0.69 |
| moulding | 4736 | 48394 | 13 | 14625 | 9687 | 44061 | 660871 | 815 | 74 | 0.84 | 0.88 | 0.86 |
| drainpipe | 0 | 9 | 17 | 26 | 0 | 8149 | 2478 | 25715 | 0 | 0.71 | 0.86 | 0.78 |
| other | 26107 | 5801 | 10828 | 0 | 5 | 519 | 385 | 0 | 34275 | 0.44 | 0.50 | 0.47 |
| ARITHMETIC AVERAGE | 0.79 | 0.82 | 0.80 | |||||||||
| WEIGHTED AVERAGE | 0.89 | 0.89 | 0.89 | |||||||||
| CLASS | Floor | Facade | Column | Arch | Vault | Window | Moulding | Drainpipe | Other | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| floor | 100514 | 613 | 787 | 0 | 0 | 0 | 184 | 0 | 3388 | 0.95 | 0.99 | 0.97 |
| facade | 0 | 204720 | 1305 | 341 | 0 | 4587 | 25349 | 0 | 71 | 0.87 | 0.94 | 0.90 |
| column | 39 | 3614 | 47864 | 1748 | 0 | 638 | 1073 | 0 | 877 | 0.86 | 0.84 | 0.85 |
| arch | 0 | 81 | 2923 | 20101 | 1665 | 242 | 992 | 0 | 0 | 0.77 | 0.79 | 0.78 |
| vault | 0 | 0 | 22 | 396 | 44387 | 450 | 533 | 0 | 0 | 0.97 | 0.95 | 0.96 |
| window | 19 | 5154 | 164 | 389 | 516 | 20424 | 13188 | 27 | 72 | 0.51 | 0.49 | 0.50 |
| moulding | 8 | 3203 | 1534 | 2376 | 328 | 15273 | 74301 | 1319 | 634 | 0.75 | 0.64 | 0.69 |
| drainpipe | 0 | 0 | 0 | 0 | 0 | 0 | 685 | 3047 | 11 | 0.81 | 0.69 | 0.75 |
| other | 832 | 143 | 2344 | 0 | 0 | 16 | 17 | 0 | 21208 | 0.86 | 0.81 | 0.83 |
| ARITHMETIC AVERAGE | 0.82 | 0.79 | 0.80 | |||||||||
| WEIGHTED AVERAGE | 0.84 | 0.85 | 0.85 | |||||||||
| CLASS | Floor | Facade | Column | Arch | Vault | Window | Moulding | Drainpipe | Other | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| floor | 8328 | 46 | 311 | 0 | 0 | 0 | 0 | 0 | 2253 | 0.76 | 0.97 | 0.85 |
| facade | 0 | 338699 | 3667 | 11911 | 1519 | 19313 | 6277 | 806 | 599 | 0.88 | 0.98 | 0.93 |
| column | 0 | 2286 | 40760 | 80 | 0 | 395 | 0 | 0 | 5831 | 0.83 | 0.56 | 0.66 |
| arch | 0 | 933 | 3494 | 63599 | 137 | 90 | 49 | 192 | 2966 | 0.89 | 0.70 | 0.78 |
| vault | 0 | 0 | 0 | 0 | 10924 | 0 | 6377 | 0 | 0 | 0.63 | 0.45 | 0.53 |
| window | 0 | 373 | 9432 | 8012 | 4913 | 118873 | 20431 | 1784 | 0 | 0.73 | 0.61 | 0.66 |
| moulding | 0 | 438 | 18 | 6716 | 6576 | 51118 | 160958 | 38202 | 291 | 0.61 | 0.82 | 0.70 |
| drainpipe | 0 | 1194 | 0 | 260 | 0 | 1279 | 3196 | 34627 | 0 | 0.85 | 0.46 | 0.60 |
| other | 251 | 2991 | 15559 | 0 | 15 | 3399 | 3 | 0 | 27772 | 0.56 | 0.70 | 0.62 |
| ARITHMETIC AVERAGE | 0.75 | 0.69 | 0.70 | |||||||||
| WEIGHTED AVERAGE | 0.77 | 0.80 | 0.78 | |||||||||
| CLASS | Floor | Facade | Column | Arch | Vault | Window | Moulding | Drainpipe | Other | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| floor | 2010296 | 0 | 78 | 0 | 0 | 38 | 16 | 0 | 1664 | 1.00 | 1.00 | 1.00 |
| facade | 1226 | 409440 | 7228 | 162 | 0 | 10308 | 6406 | 0 | 286 | 0.94 | 0.87 | 0.90 |
| column | 1574 | 2610 | 95728 | 5846 | 44 | 328 | 3068 | 0 | 4688 | 0.84 | 0.86 | 0.85 |
| arch | 0 | 682 | 3496 | 40202 | 792 | 778 | 4752 | 0 | 0 | 0.79 | 0.77 | 0.78 |
| vault | 0 | 0 | 0 | 3330 | 88774 | 1032 | 656 | 0 | 0 | 0.95 | 0.97 | 0.96 |
| window | 0 | 9174 | 1276 | 484 | 900 | 40848 | 30546 | 0 | 32 | 0.49 | 0.51 | 0.50 |
| moulding | 368 | 50698 | 2146 | 1984 | 1066 | 26376 | 148602 | 1370 | 34 | 0.64 | 0.75 | 0.69 |
| drainpipe | 0 | 0 | 0 | 0 | 0 | 54 | 2638 | 6094 | 0 | 0.69 | 0.81 | 0.75 |
| other | 6776 | 142 | 1754 | 0 | 0 | 144 | 1268 | 22 | 42416 | 0.81 | 0.86 | 0.83 |
| ARITHMETIC AVERAGE | 0.79 | 0.82 | 0.81 | |||||||||
| WEIGHTED AVERAGE | 0.94 | 0.93 | 0.93 | |||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grilli, E.; Remondino, F. Machine Learning Generalisation across Different 3D Architectural Heritage. ISPRS Int. J. Geo-Inf. 2020, 9, 379. https://doi.org/10.3390/ijgi9060379
Grilli E, Remondino F. Machine Learning Generalisation across Different 3D Architectural Heritage. ISPRS International Journal of Geo-Information. 2020; 9(6):379. https://doi.org/10.3390/ijgi9060379
Chicago/Turabian StyleGrilli, Eleonora, and Fabio Remondino. 2020. "Machine Learning Generalisation across Different 3D Architectural Heritage" ISPRS International Journal of Geo-Information 9, no. 6: 379. https://doi.org/10.3390/ijgi9060379
APA StyleGrilli, E., & Remondino, F. (2020). Machine Learning Generalisation across Different 3D Architectural Heritage. ISPRS International Journal of Geo-Information, 9(6), 379. https://doi.org/10.3390/ijgi9060379