Digital Data Literacy in an Economic World: Geo-Spatial Data Literacy Aspects


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. SPATIONOMY—Spatial Exploration of Economic Data
3. Examples of Geo-Spatial Data
4. Data Literacy with Special Focus on Geo-Spatial Data
4.1. Level of Generalization
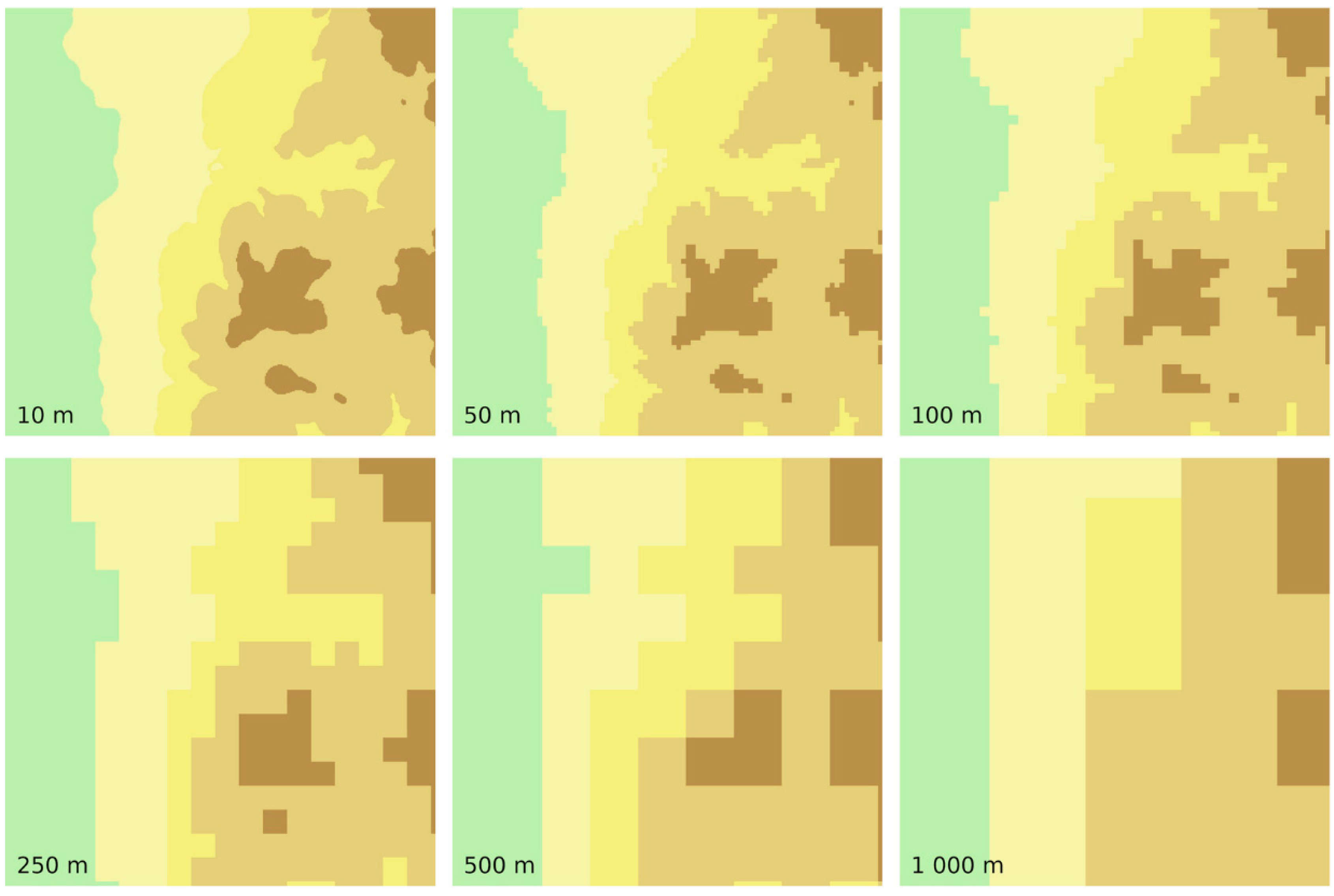
4.2. Raster Cell Size
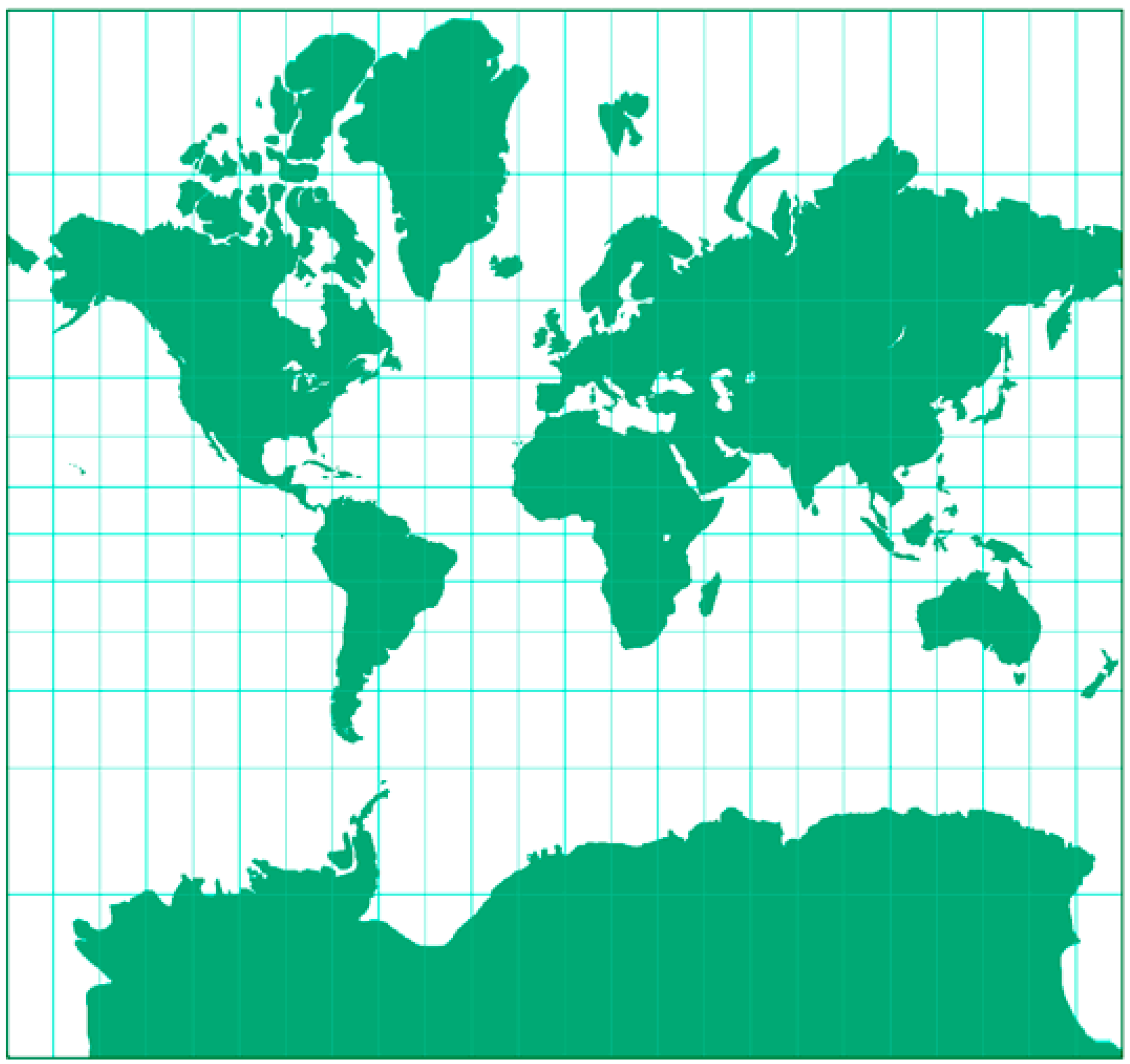
4.3. Map Projection
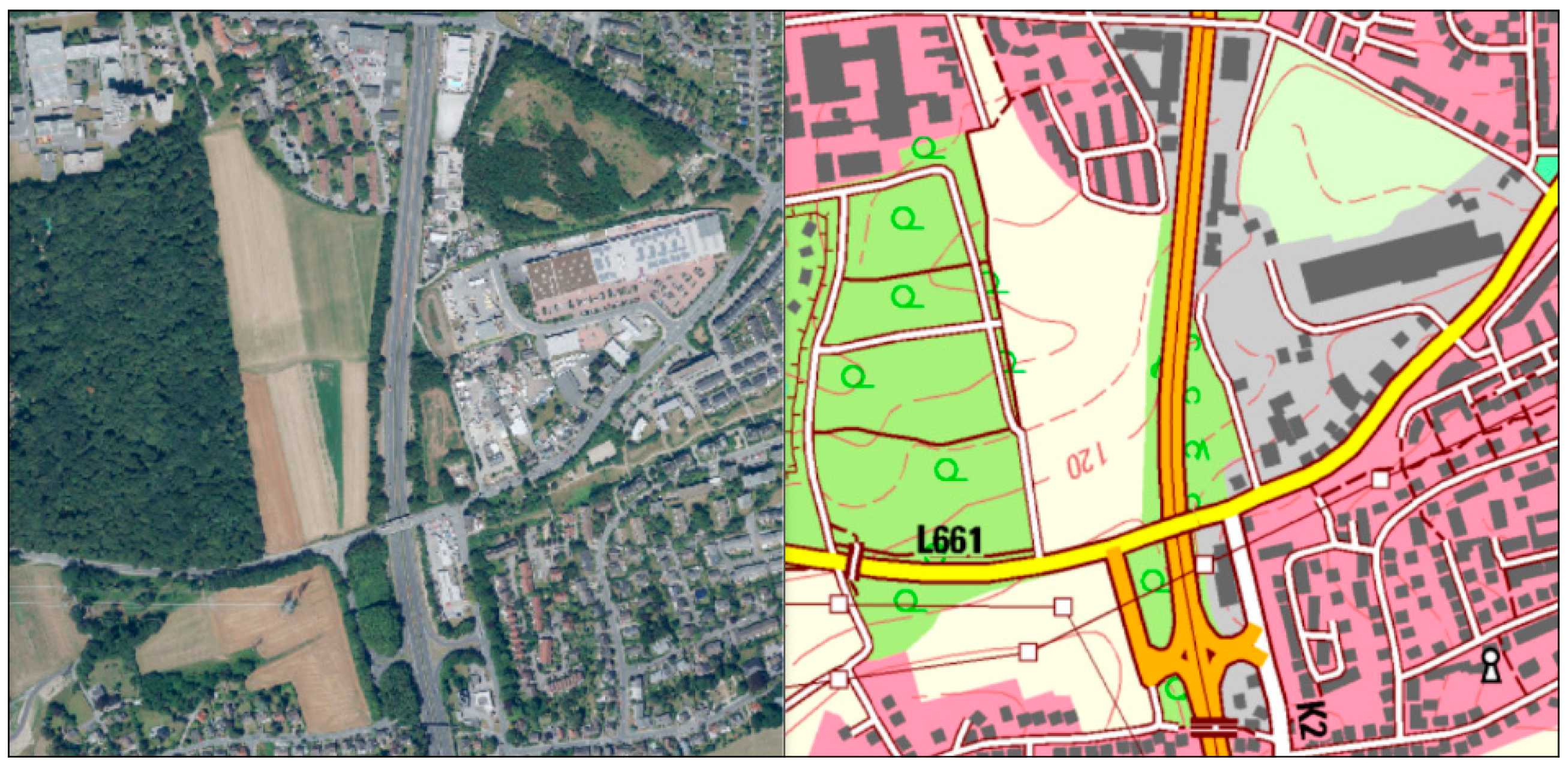
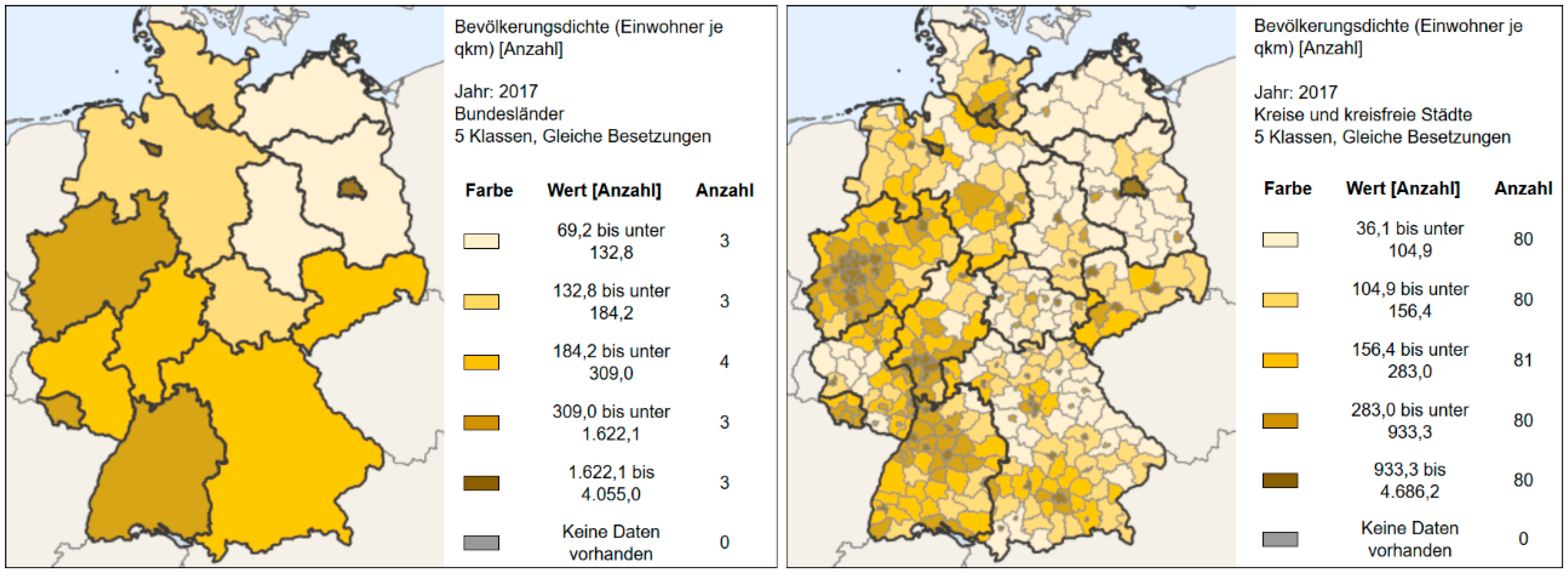
4.4. Scale or Level of Detail
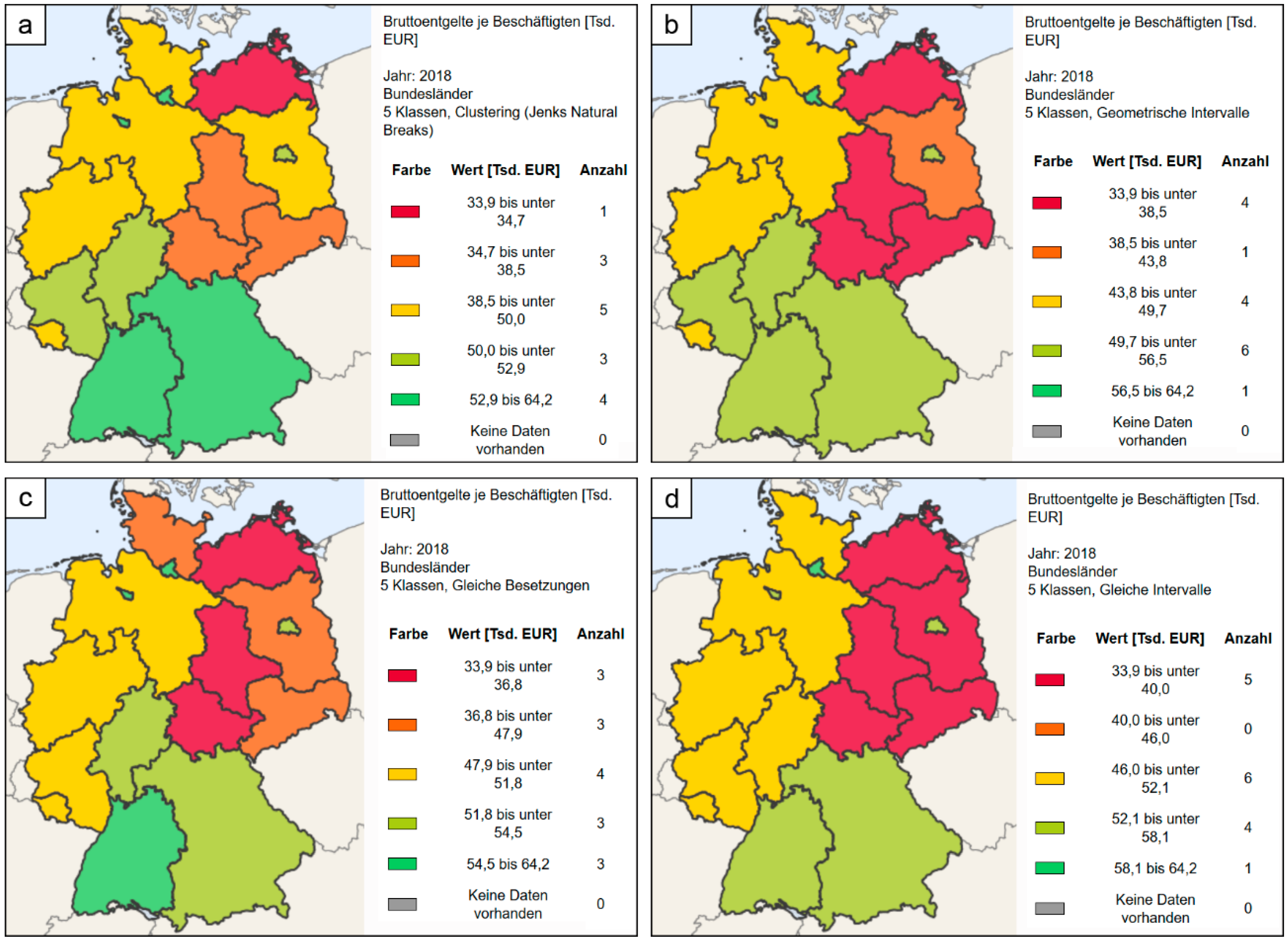
4.5. Classification Method of Thematic Maps
4.6. Map Design
4.7. Point Data Capture and Interpolation Issues
4.8. Semantic Reliability of Thematic Maps
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Donner, J.; Tellez, C.A. Mobile banking and economic development: Linking adoption, impact, and use. Asian J. Commun. 2008, 18, 318–332. [Google Scholar] [CrossRef]
- Westlund, O. Mobile news: A review and model of journalism in an age of mobile media. Digit. Journal. 2013, 1, 6–26. [Google Scholar] [CrossRef]
- Gürder, F.; Yılmaz, Y. Geographic Information Systems In Strategic Decision Making In Logistics Companies. Int. J. Bus. Soc. Res. 2012, 2, 76–86. [Google Scholar] [CrossRef]
- Pászto, V.; Zimmermannová, J. Relation of economic and environmental indicators to the European Union Emission Trading System: A spatial analysis. GeoScape 2019, 13, 1–15. [Google Scholar] [CrossRef]
- Hájek, M.; Zimmermannová, J.; Helman, K.; Rozenský, L. Analysis of carbon tax efficiency in energy industries of selected EU countries. Energy Policy 2019, 134. [Google Scholar] [CrossRef]
- Moos, N. Application—Site Analysis Furniture Store. In SPATIONOMY— Spatial Exploration of Economic Data and Methods of Interdiscyplinary Analytics; Pászto, V., Jürgens, C., Tominc, P., Burian, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 257–269. [Google Scholar] [CrossRef]
- Burian, J.; Macků, K.; Zimmermannová, J.; Kočvarová, B. Spatio-temporal changes and dependencies of land prices: A case study of the city of Olomouc. Sustainability 2018, 10, 4831. [Google Scholar] [CrossRef]
- Pászto, P.; Brychtová, A.; Tuček, P.; Marek, L.; Burian, J. Using a fuzzy inference system to delimit rural and urban municipalities in the Czech Republic in 2010. J. Maps 2015, 11, 231–239. [Google Scholar] [CrossRef]
- Henits, L.; Jürgens, C.; Mucsi, L. Seasonal multitemporal land-cover classification and change detection analysis of Bochum, Germany, using multitemporal Landsat TM data. Int. J. Remote Sens. 2016, 37, 3439–3454. [Google Scholar] [CrossRef]
- Mensik, M. Business and Finance. In SPATIONOMY—Spatial Exploration of Economic Data and Methods of Interdiscyplinary Analytics; Pászto, V., Jürgens, C., Tominc, P., Burian, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 149–171. [Google Scholar] [CrossRef]
- Landesbetrieb Wald und Holz. Available online: https://www.wald-und-holz.nrw.de/wald-in-nrw/wald-und-klima/kyrill-und-seine-folgen-in-nrw (accessed on 14 May 2020).
- Elwood, S. Volunteered geographic information: Key questions, concepts and methods to guide emerging research and practice. GeoJournal 2008, 72, 133–135. [Google Scholar] [CrossRef]
- Haklay, M. Citizen Science and Volunteered Geographic Information: Overview and Typology of Participation. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice; Sui, D., Elwood, S., Goodchild, M., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 105–122. [Google Scholar] [CrossRef]
- Paszto, V.; Darena, F.; Marek, L.; Fuskova, D. Spatial Analyses of Twitter Data—Case Studies. Geoinformatics 2014, 1, 785–792. [Google Scholar] [CrossRef]
- Pászto, V.; Redecker, A.; Macků, K.; Jürgens, C.; Moos, N. Data Sources. In SPATIONOMY—Spatial Exploration of Economic Data and Methods of Interdiscyplinary Analytics; Pászto, V., Jürgens, C., Tominc, P., Burian, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 3–38. [Google Scholar] [CrossRef]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Science and Systems, 4th ed.; Wiley: New York, NY, USA, 2015. [Google Scholar]
- GEOportal.NRW. Available online: www.geoportal.nrw (accessed on 28 April 2020).
- Nordrhein-Westfalen. Available online: De-be.topographic-map.com/maps/7j2l/Nordrhein-Westfalen/ (accessed on 28 April 2020).
- Jürgens, C. Earth Observation Data. In SPATIONOMY—Spatial Exploration of Economic Data and Methods of Interdiscyplinary Analytics; Pászto, V., Jürgens, C., Tominc, P., Burian, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 30–38. [Google Scholar] [CrossRef]
- Albertz, J. Einführung in die Fernerkundung: Grundlagen der Interpretation von Luft- und Satellitenbildern, 5th ed.; Wissenschaftliche Buchgesellschaft: Darmstadt, Germany, 2016. [Google Scholar]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation, 7th ed.; Wiley: New York, NY, USA, 2015. [Google Scholar]
- ESA Copernicus open access hub. Available online: Scihub.copernicus.eu (accessed on 20 April 2020).
- Kullenberg, C.; Kasperowski, D. What Is Citizen Science? A Scientometric Meta-Analysis. PLoS ONE 2016, 11, e0147152. [Google Scholar] [CrossRef] [PubMed]
- Monmonier, M. How to Lie with Maps. Am. Stat. 1996, 51. [Google Scholar] [CrossRef]
- Redecker, A.; Burian, J.; Moos, N.; Macku, K. Spatial Analysis in Geomatics. In SPATIONOMY—Spatial Exploration of Economic Data and Methods of Interdiscyplinary Analytics; Pászto, V., Jürgens, C., Tominc, P., Burian, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 65–92. [Google Scholar] [CrossRef]
- Kartenprojektionen vergleichen. Available online: Kartenprojektionen.de/single-view/mercator-84 (accessed on 22 April 2020).
- Kartenprojektionen vergleichen. Available online: kartenprojektionen.de/single-view/equalearth (accessed on 22 April 2020).
- Regionalatlas Deutschland. Available online: https://www-genesis.destatis.de/gis/genView?GenMLURL=https://www-genesis.destatis.de/regatlas/AI002-1.xml&CONTEXT=REGATLAS01 (accessed on 20 April 2020).
- Campbell, J.E.; Shin, M. Essentials of Geographic Information Systems; Saylor Academy: Washington, DC, USA, 2011; Available online: https://digitalcommons.liberty.edu/textbooks/2 (accessed on 28 April 2020).










© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juergens, C. Digital Data Literacy in an Economic World: Geo-Spatial Data Literacy Aspects. ISPRS Int. J. Geo-Inf. 2020, 9, 373. https://doi.org/10.3390/ijgi9060373
Juergens C. Digital Data Literacy in an Economic World: Geo-Spatial Data Literacy Aspects. ISPRS International Journal of Geo-Information. 2020; 9(6):373. https://doi.org/10.3390/ijgi9060373
Chicago/Turabian StyleJuergens, Carsten. 2020. "Digital Data Literacy in an Economic World: Geo-Spatial Data Literacy Aspects" ISPRS International Journal of Geo-Information 9, no. 6: 373. https://doi.org/10.3390/ijgi9060373
APA StyleJuergens, C. (2020). Digital Data Literacy in an Economic World: Geo-Spatial Data Literacy Aspects. ISPRS International Journal of Geo-Information, 9(6), 373. https://doi.org/10.3390/ijgi9060373