Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach


Abstract
1. Introduction
2. Materials and Methods
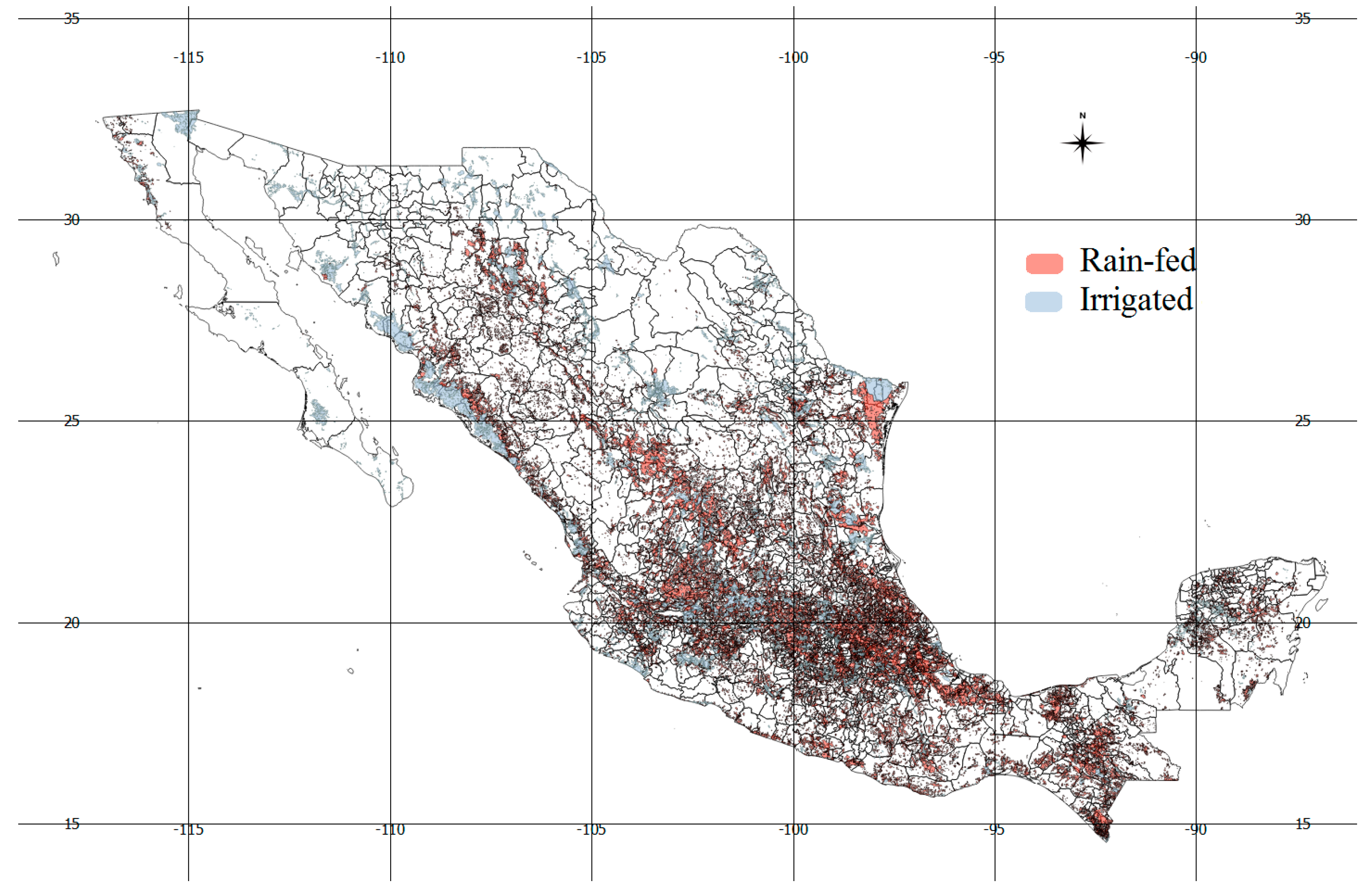
2.1. Study Area
2.2. Materials
2.2.1. In Situ Data
2.2.2. Remote Sensing Data
2.2.3. Meteorological Data
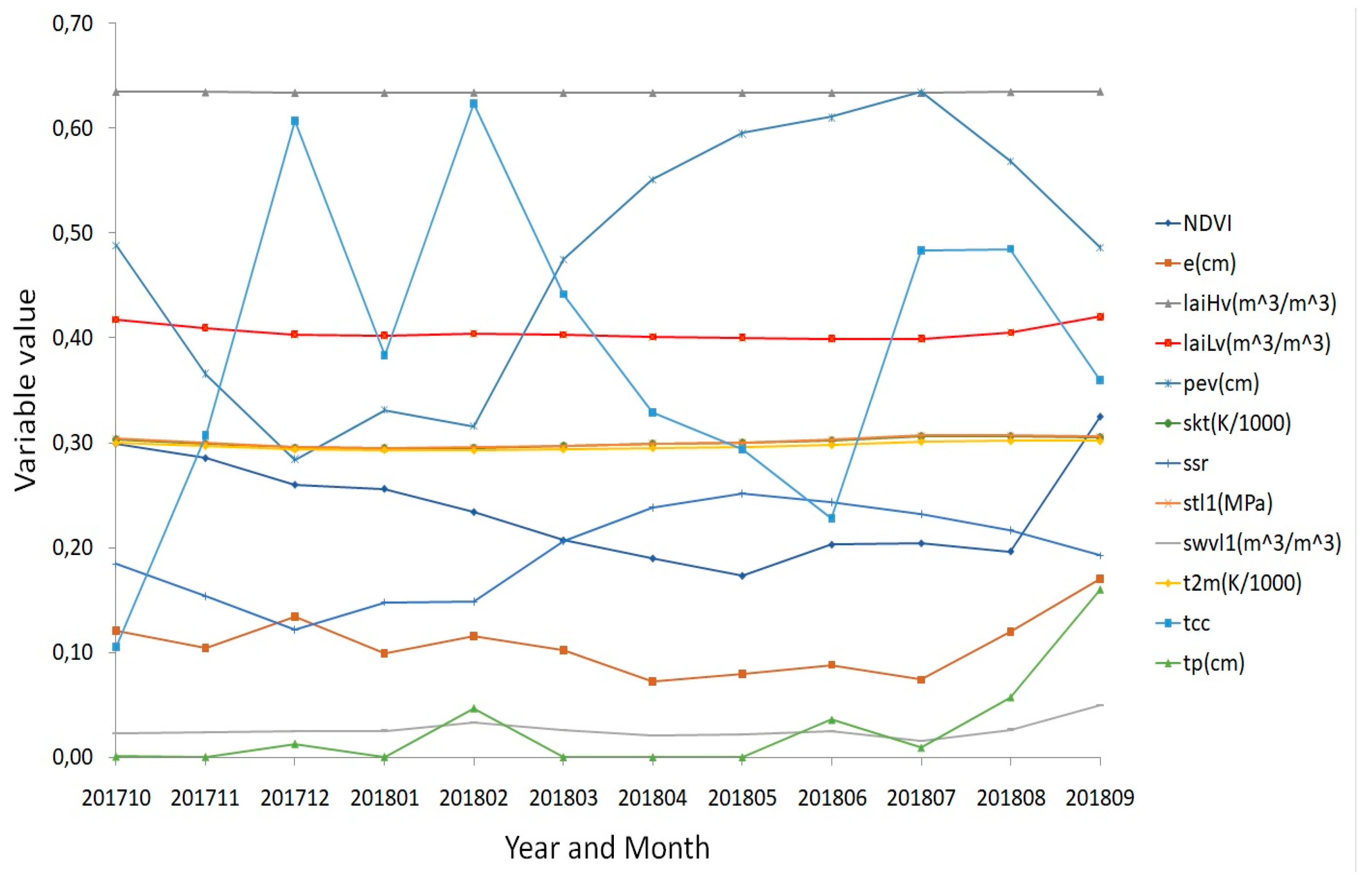
2.3. Methods
2.3.1. Data Preparation
2.3.2. Machine Learning Modeling
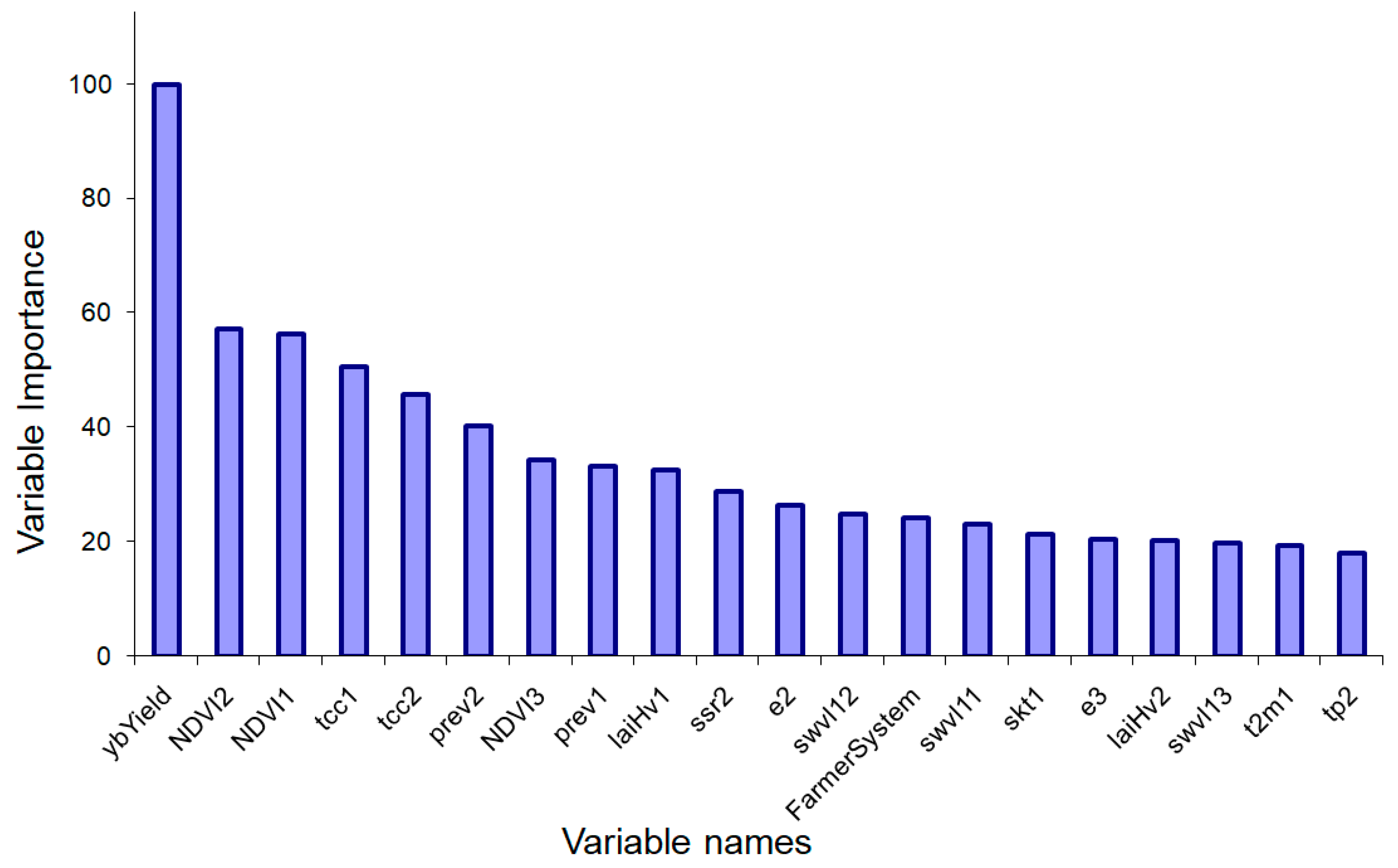
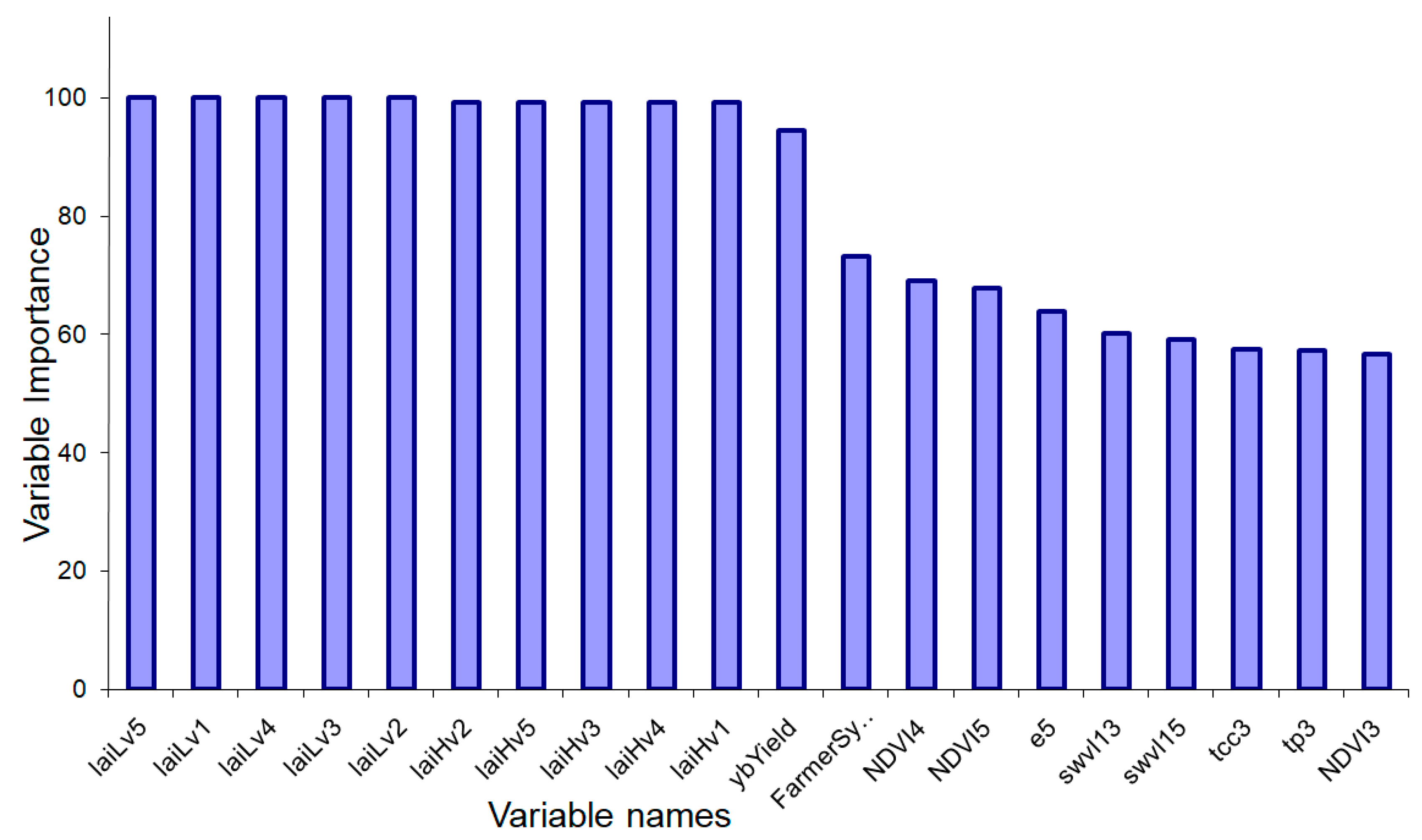
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Spooner, D.M.; Gavrilenko, T.; Jansky, S.H.; Ovchinnikova, A.; Krylova, E.; Knapp, S.; Simon, R. Ecogeography of ploidy variation in cultivated potato (Solanum sect. Petota). Am. J. Bot. 2010, 97, 2049–2060. [Google Scholar] [CrossRef] [PubMed]
- FAO. International Year of the Potato 2008: New Light on a Hidden Treasure. Available online: http://www.fao.org/potato-2008/en/events/book.html (accessed on 5 September 2019).
- Li, P.H. Potato Physiology; Academic Press: Cambridge, MA, USA, 1985; pp. 1–602. [Google Scholar]
- Zhao, J.; Zhang, Y.; Qian, Y.; Pan, Z.; Zhu, Y.; Zhang, Y.; Guo, J.; Xu, L. Coincidence of variation in potato yield and climate in northern China. Sci. Total Environ. 2016, 573, 965–973. [Google Scholar] [CrossRef] [PubMed]
- Devaux, A.; Kromann, P.; Ortiz, O. Potatoes for Sustainable Global Food Security. Potato Res. 2014, 57, 185–199. [Google Scholar] [CrossRef]
- Haverkorta, A.J.; Struik, P.C. Yield levels of potato crops: Recent achievements and future prospects. Field Crop. Res. 2015, 182, 76–85. [Google Scholar] [CrossRef]
- FAO. Statistical Databases FAOSTAT. Available online: http://www.fao.org/faostat/en/#data (accessed on 5 September 2019).
- El Sol de Mexico. Available online: https://www.elsoldemexico.com.mx/analisis/importancia-de-la-produccion-de-papa-en-mexico-3433659.html (accessed on 19 September 2019).
- Timlin, D.; Rahman, L.; Baker, S.M.; Reddy, J.; Fleisher, D.; Quebedeaux, B. Whole plant photosynthesis, development, and carbon partitioning in potato as a function of temperature. Agron. J. 2006, 98, 1195–1203. [Google Scholar] [CrossRef]
- Monteith, J.L. Solar Radiation and Productivity in Tropical Ecosystems. J. Appl. Ecol. 1972, 9, 747–766. [Google Scholar] [CrossRef]
- Monteith, J.L.; William, M.G.; Norman, C.; Pirie, W.; Douglas, G.; Bell, H. Climate and the efficiency of crop production in Britain Phil. Trans. R. Soc. Lond. B 1977, 281. [Google Scholar] [CrossRef]
- Kumar, M.; Monteith, J.L. Remote sensing of crop growth. In Plants and the Daylight Spectrum; Smith, H., Ed.; Academic Press: Cambridge, MA, USA, 1982; pp. 131–144. [Google Scholar]
- Lobell, D.B.; Asner, G.P.; Ortiz-Monasterio, J.I.; Benning, T.L. Remote sensing of regional crop production in the Yaqui Valley, Mexico: Estimates and uncertainties. Agric. Ecosyst. Environ. 2003, 94, 205–220. [Google Scholar] [CrossRef]
- Sessa, R.; Dolman, H. Terrestrial Essential Climate Variables for Climate Change Assessment, Mitigation and Adaptation (GTOS 52). Available online: http://www.fao.org/3/i0197e/i0197e.pdf (accessed on 13 January 2020).
- Asner, G.P.; Wessman, C.A.; Archer, S. Scale dependence of absorption of photosynthetically active radiation in terrestrial ecosystems. Ecol. Appl. 1998, 8, 1003–1021. [Google Scholar] [CrossRef]
- Steinmetz, S.; Guerif, M.; Delecolle, R.; Baret, F. Spectral estimates of the absorbed photosynthetically active radiation and light-use efficiency of a winter wheat crop subjected to nitrogen and water deficiencies. Int. J. Remote Sens. 1991, 11, 1797–1808. [Google Scholar] [CrossRef]
- Serrano, L.; Filella, I.; Peñuelas, J. Remote Sensing of Biomass and Yield of Winter Wheat under Different Nitrogen Supplies. Crop Sci. 2000, 40, 723–731. [Google Scholar] [CrossRef]
- Asrar, G.; Marcel, F.; Kanemasu, E.; Hatfield, J. Estimating Absorbed Photosynthetic Radiation and Leaf Area Index from Spectral Reflectance in Wheat. Agron. J. 1984, 76, 300–306. [Google Scholar] [CrossRef]
- Gallo, K.P.; Daughtry, C.S.T.; Wiegand, C.L. Errors in Measuring Absorbed Radiation and Computing Crop Radiation Use. Effic. Agron. J. 1993, 85, 1222–1228. [Google Scholar] [CrossRef]
- Benedetti, R.; Rossini, P. On the use of NDVI profiles as a tool for agricultural statistics: The case study of wheat yield estimate and forecast in Emilia Romagna. Remote Sens. Environ. 1993, 45, 311–326. [Google Scholar] [CrossRef]
- Hamar, D.; Ferencz, C.; Lichtenberger, J.; Tarcsai, G.; Ferencz-Árkos, I. Yield estimation for corn and wheat in the Hungarian Great Plain using Landsat MSS data. Int. J. Remote Sens. 1996, 17, 1689–1699. [Google Scholar] [CrossRef]
- Moriondo, M.; Maselli, F.; Bindi, M. A simple model of regional wheat yield based on NDVI data. Eur. J. Agron. 2007, 26, 266–274. [Google Scholar] [CrossRef]
- Chang, X.; Katchova, A.L. Predicting soybean yield with NDVI using a flexible fourier transform model. J. Agric. Appl. Econ. 2019, 51, 402–416. [Google Scholar]
- Quarmby, N.A.; Milnes, M.; Hindle, T.L.; Silleos, N. The use of multi-temporal NDVI measurements from AVHRR data for crop yield estimation and prediction. Int. J. Remote Sens. 1993, 14, 199–210. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Kottek, M. World Map of the Köppen-Geiger climate classification updated. Meteorol. Z. 2006, 15, 259–263. [Google Scholar] [CrossRef]
- INEGI. Available online: https://www.inegi.org.mx/temas/usosuelo/default.html#Herramientas (accessed on 5 June 2019).
- Hijmans, R.J. Diva-Gis. Vsn. 5.0. A Geographic Information System for the Analysis of Species Distribution Data. Available online: http://www.diva-gis.org/ (accessed on 13 January 2020).
- Sellers, P.J. Canopy reflectance, photosynthesis, and transpiration. Int. J. Remote Sens. 1985, 6, 1335–1372. [Google Scholar] [CrossRef]
- Ranson, K.J.; Collatz, G.J.; Diner, D.J.; Kahle, A.B.; Salomonson, V.V. Special issue on EOS AM-1 platform, instruments, and scientific data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1039–1350. [Google Scholar]
- Didan, K.; MOD13Q1 MODIS/Terra Vegetation Indices 16-Day L3 Global 250m SIN Grid V006 [Data set]. NASA EOSDIS Land Processes DAAC. Available online: https://doi.org/10.5067/MODIS/MOD13Q1.006 (accessed on 6 September 2019).
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classificaation in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. A comparison of MODIS 250 m EVI and NDVI data for crop mapping: A case study for southwest Kansas. Int. J. Remote Sens. 2010, 31, 805–830. [Google Scholar] [CrossRef]
- Copernicus Climate Change Service. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-pressure-levels?tab=overview (accessed on 13 January 2020).
- ENVI. ENVI Programmer’s Guide; Research System, Inc.: Norwalk, CT, USA, 1998; 930p. [Google Scholar]
- IDL. IDL User’s Guide; Research Systems, Inc.: Norwalk, CT, USA, 1997; 1200p. [Google Scholar]
- The R Development core team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Scholkopf, B.; Sung, K.K.; Burges, C.J.; Girosi, F.; Niyogi, P.; Poggio, T.; Vapnik, V. Comparing support vector machines with Gaussian kernels to radial basis function classifiers. IEEE Trans. Signal Proc. 1997, 45, 2758–2765. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W. Generalized linear models. J. R. Stat. Soc. Ser. A (Gen.) 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Doraiswamy, P.C.; Doraiswamy, P.C.; Moulin, S.; Cook, P.W.; Stern, A. Crop Yield Assessment from Remote Sensing. Photogrammetric. Eng. Remote Sens. 2003, 6, 665–674. [Google Scholar]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Berkeley/Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Grassini, P.; Lenny, G.J.; van Bussel, J.W.; Joost, W.; Lieven, C.; Haishun, Y.; Hendrik, B.; Groot, H.; Ittersum, M.; Cassman, K.G. How good is good enough? Data requirements for reliable crop yield simulations and yield-gap analysis. Field Crop. Res. 2015, 177, 49–63. [Google Scholar] [CrossRef]
- Teillet, P.M.; Staenz, K.; William, D.J. Effects of spectral, spatial, and radiometric characteristics on remote sensing vegetation indices of forested regions. Remote Sens. Environ. 1997, 61, 139–149. [Google Scholar] [CrossRef]
- Yang, W.; Yang, L.; Merchant, J.W. An assessment of AVHRR/NDVI-ecoclimatological relations in Nebraska, USA. Int. J. Remote Sens. 1997, 18, 2161–2180. [Google Scholar] [CrossRef]
- Maselli, F. Enrichment of land-cover polygons with eco-climatic information derived from MODIS NDVI imagery. J. Biogeogr. 2009, 36, 639–650. [Google Scholar] [CrossRef]
- Li, B.; Tao, S.; Dawson, R.W. Relations between AVHRR NDVI and ecoclimatic parameters in China. Int. J. Remote Sens. 2002, 23, 989–999. [Google Scholar] [CrossRef]
- Jayawardhana, W.G.N.N.; Chathurange, V.M.I. Extraction of Agricultural Phenological Parameters of Sri Lanka Using MODIS, NDVI Time Series Data. Proced. Food Sci. 2016, 6, 235–241. [Google Scholar] [CrossRef]
- Conagua. Available online: https://smn.conagua.gob.mx/es/climatologia/temperaturas-y-lluvias/resumenes-mensuales-de-temperaturas-y-lluvias (accessed on 29 September 2019).
- Newton, I.H.; Islam, T.; Saiful, I. Yield Prediction Model for Potato Using Landsat Time Series Images Driven Vegetation Indices. Remote Sens. Earth Syst. Sci. 2018, 1, 29–38. [Google Scholar] [CrossRef]
- Bala, S.K.; Islam, A.S. Correlation between potato yield and MODIS-derived vegetation indices. Int. J. Remote Sens. 2009, 30, 2491–2507. [Google Scholar] [CrossRef]
- Velde, M.; Nisini, L. Performance of the MARS-crop yield forecasting system for the European Union: Assessing accuracy, in-season, and year-to-year improvements from 1993 to 2015. Agric. Syst. 2009, 168, 203–212. [Google Scholar] [CrossRef]
- Mo, X.; Liu, S.; Lin, Z.; Guo, R. Regional crop yield, water consumption and water use efficiency and their responses to climate change in the North China Plain. Agric. Ecosyst. Environ. 2009, 134, 67–78. [Google Scholar] [CrossRef]
- Iizumi, T.; Shin, Y.; Kim, W.; Moosup, K.; Jaewon, C. Global crop yield forecasting using seasonal climate information from a multi-model ensemble. Clim. Serv. 2018, 11, 13–23. [Google Scholar] [CrossRef]
- Kasampalis, D.A.; Alexandridis, T.K.; Deva, C.; Challinor, A.; Moshou, D.; Zalidis, G. Contribution of Remote Sensing on Crop Models: A Review. J. Imaging 2018, 4, 52. [Google Scholar] [CrossRef]
- Meroni, M.; Rembold, F.; Verstraete, M.M.; Gommes, R.; Schucknecht, A.; Beye, G. Investigating the relationship between the inter-annual variability of satellite-derived vegetation phenology and a proxy of biomass production in the Sahel. Remote Sens. 2014, 6, 5868–5884. [Google Scholar] [CrossRef]
- MacDonald, R.B.; Hall, F.G. Global Crop Forecasting. Science 1980, 208, 670–679. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, C.F. Uses of satellite data for famine early warning in sub-Saharan Africa. Int. J. Remote Sens. 1991, 12, 1405–1421. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Short Name | Units |
|---|---|---|
| Evaporation | e | m of water equivalent |
| Leaf area index, high vegetation | lai_hv | m2/m2 |
| Leaf area index, low vegetation | lai_lv | m2/m2 |
| Potential evaporation | pev | m |
| Skin temperature | skt | K |
| Surface net solar radiation | ssr | J/m2 |
| Surface pressure | stl1 | Pa |
| Volumetric soil water layer 1 | swvl1 | m3/m3 |
| 2-meter temperature | t2m | K |
| Total cloud cover | tcc | Times one |
| Total precipitation | tp | m |
Cycle | Scenario | rf | svmR | svmL | svmP | glm | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | ||||
| Autumn–winter | 1 | 0.750 | 18.0 | 0.732 | 22.1 | 0.699 | 20.6 | 0.691 | 22.3 | 0.700 | 19.7 | ||
| 2 | 0.763 | 19.0 | 0.752 | 22.4 | 0.701 | 21.6 | 0.720 | 23.4 | 0.668 | 23.6 | |||
| 3 | 0.764 | 19.0 | 0.750 | 22.9 | 0.691 | 23.0 | 0.717 | 23.3 | 0.641 | 26.2 | |||
| 4 | 0.763 | 18.9 | 0.723 | 22.4 | 0.688 | 23.2 | 0.716 | 24.2 | 0.652 | 27.8 | |||
| 5 | 0.760 | 19.1 | 0.714 | 22.4 | 0.670 | 21.4 | 0.701 | 24.3 | 0.674 | 23.5 | |||
| 6 | 0.760 | 19.7 | 0.704 | 22.5 | 0.659 | 26.2 | 0.694 | 24.5 | 0.248 | 31.2 | |||
| Spring–summer | 1 | 0.809 | 17.6 | 0.848 | 15.3 | 0.876 | 14.4 | 0.837 | 15.7 | 0.841 | 16.6 | ||
| 2 | 0.824 | 16.7 | 0.848 | 15.6 | 0.873 | 14.9 | 0.816 | 17.4 | 0.855 | 16.2 | |||
| 3 | 0.826 | 17.0 | 0.855 | 14.8 | 0.867 | 15.3 | 0.870 | 14.3 | 0.855 | 16.5 | |||
| 4 | 0.845 | 16.3 | 0.850 | 14.8 | 0.865 | 15.1 | 0.868 | 14.4 | 0.846 | 16.1 | |||
| 5 | 0.843 | 16.3 | 0.842 | 15.6 | 0.847 | 16.5 | 0.854 | 15.4 | 0.814 | 17.6 | |||
| 6 | 0.835 | 16.6 | 0.791 | 18.0 | 0.838 | 16.2 | 0.842 | 15.9 | 0.790 | 17.9 | |||
Cycle | Scenario | rf | svmR | svmL | svmP | glm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | |||||
| Mean values | Autumn–winter | 1 | 0.764 | 19.0 | 0.733 | 22.1 | 0.689 | 22.3 | 0.717 | 23.2 | 0.612 | 24.9 | ||
| 2 | 0.755 | 19.1 | 0.729 | 22.5 | 0.687 | 22.3 | 0.713 | 23.4 | 0.596 | 25.6 | ||||
| 3 | 0.757 | 18.9 | 0.729 | 22.2 | 0.692 | 22.2 | 0.711 | 23.2 | 0.584 | 25.1 | ||||
| 4 | 0.751 | 19.4 | 0.726 | 22.8 | 0.682 | 22.6 | 0.706 | 23.6 | 0.594 | 25.2 | ||||
| 5 | 0.762 | 19.3 | 0.731 | 22.6 | 0.688 | 22.7 | 0.712 | 23.6 | 0.589 | 25.7 | ||||
| 6 | 0.760 | 19.0 | 0.727 | 22.3 | 0.690 | 22.5 | 0.707 | 23.4 | 0.598 | 24.9 | ||||
| Spring–summer | 1 | 0.839 | 16.3 | 0.833 | 16.0 | 0.863 | 15.3 | 0.857 | 15.1 | 0.830 | 16.9 | |||
| 2 | 0.839 | 16.3 | 0.837 | 15.9 | 0.857 | 15.7 | 0.859 | 15.1 | 0.830 | 17.0 | ||||
| 3 | 0.832 | 16.6 | 0.831 | 16.1 | 0.856 | 15.8 | 0.853 | 15.3 | 0.829 | 17.1 | ||||
| 4 | 0.837 | 16.5 | 0.835 | 16.0 | 0.860 | 15.4 | 0.854 | 15.2 | 0.833 | 16.8 | ||||
| 5 | 0.839 | 16.0 | 0.834 | 15.8 | 0.859 | 15.4 | 0.858 | 14.9 | 0.834 | 16.6 | ||||
| 6 | 0.839 | 16.4 | 0.836 | 16.0 | 0.860 | 15.7 | 0.862 | 15.0 | 0.828 | 17.2 | ||||
| Standard deviation | Autumn–winter | 1 | 0.025 | 1.5 | 0.026 | 1.5 | 0.040 | 2.9 | 0.035 | 1.6 | 0.144 | 4.4 | ||
| 2 | 0.031 | 1.4 | 0.031 | 1.2 | 0.035 | 2.4 | 0.035 | 1.5 | 0.154 | 3.9 | ||||
| 3 | 0.026 | 1.6 | 0.026 | 1.4 | 0.038 | 2.7 | 0.025 | 1.3 | 0.185 | 5.1 | ||||
| 4 | 0.019 | 1.1 | 0.030 | 1.4 | 0.025 | 2.2 | 0.034 | 1.4 | 0.163 | 3.8 | ||||
| 5 | 0.037 | 1.7 | 0.032 | 1.5 | 0.032 | 2.3 | 0.027 | 1.6 | 0.176 | 5.1 | ||||
| 6 | 0.029 | 1.2 | 0.022 | 0.8 | 0.034 | 2.8 | 0.018 | 1.0 | 0.161 | 4.1 | ||||
| Spring–summer | 1 | 0.012 | 0.7 | 0.023 | 1.1 | 0.015 | 0.8 | 0.016 | 0.9 | 0.032 | 1.2 | |||
| 2 | 0.015 | 0.8 | 0.021 | 1.1 | 0.018 | 1.0 | 0.015 | 0.8 | 0.029 | 1.2 | ||||
| 3 | 0.017 | 0.8 | 0.020 | 1.0 | 0.017 | 1.0 | 0.016 | 0.8 | 0.028 | 1.0 | ||||
| 4 | 0.014 | 0.7 | 0.022 | 1.1 | 0.017 | 0.9 | 0.018 | 0.9 | 0.027 | 0.9 | ||||
| 5 | 0.015 | 0.6 | 0.021 | 1.0 | 0.017 | 0.9 | 0.014 | 0.7 | 0.030 | 1.2 | ||||
| 6 | 0.017 | 0.8 | 0.021 | 1.2 | 0.017 | 1.0 | 0.016 | 0.9 | 0.032 | 1.2 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salvador, P.; Gómez, D.; Sanz, J.; Casanova, J.L. Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach. ISPRS Int. J. Geo-Inf. 2020, 9, 343. https://doi.org/10.3390/ijgi9060343
Salvador P, Gómez D, Sanz J, Casanova JL. Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach. ISPRS International Journal of Geo-Information. 2020; 9(6):343. https://doi.org/10.3390/ijgi9060343
Chicago/Turabian StyleSalvador, Pablo, Diego Gómez, Julia Sanz, and José Luis Casanova. 2020. "Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach" ISPRS International Journal of Geo-Information 9, no. 6: 343. https://doi.org/10.3390/ijgi9060343
APA StyleSalvador, P., Gómez, D., Sanz, J., & Casanova, J. L. (2020). Estimation of Potato Yield Using Satellite Data at a Municipal Level: A Machine Learning Approach. ISPRS International Journal of Geo-Information, 9(6), 343. https://doi.org/10.3390/ijgi9060343