Landslide Image Captioning Method Based on Semantic Gate and Bi-Temporal LSTM

 ,
,
Abstract
1. Introduction
- (1)
- Accumulated error: In the training process, the image captioning is generated depending on the ground truth (GT) word by word. However, in the prediction process, the wordt can only rely on the previous generated wordt−1, if the wordt−1 is incorrect, it may result in an incorrect chain in the image captioning that will cause an accumulated error.
- (2)
- The different parts of the image captioning often relies more on either the image features or the context information, but most of the current LSTM based on attention cannot make a dynamic and adaptive choice between the image and the context information [26].
- (3)
- The locations of the attentions are not sufficiently accurate, namely, the attentions do not always accurately locate the actual positions of the landslides and the hazard-affected bodies, in spite of this, there is no correction mechanism in the existing methods.
- (1)
- We introduced a novel double-temporal LSTM that use three losses of language, prediction and attention to train the network parameters so as to reduce the accumulated error in the process of prediction.
- (2)
- We proposed a semantic gate that enables the network to choose to rely on the image or the context dynamically and adaptively.
- (3)
- We construct a new attention correction mechanism for improving the location accuracy in the remote sensing images.
2. Relate Work
2.1. Landslide Analysis Based on Traditional Methods
2.2. Landslide Analysis Based on Neural Networks
3. Background of the Method Used
3.1. Semantic Segmentation
3.2. Image Captioning
3.3. The Fusion of Semantic Segmentation and Image Captioning
4. Methodology
4.1. Methodological Flow Chart
4.2. Network Architecture
4.3. U-Net and Geographic Objects
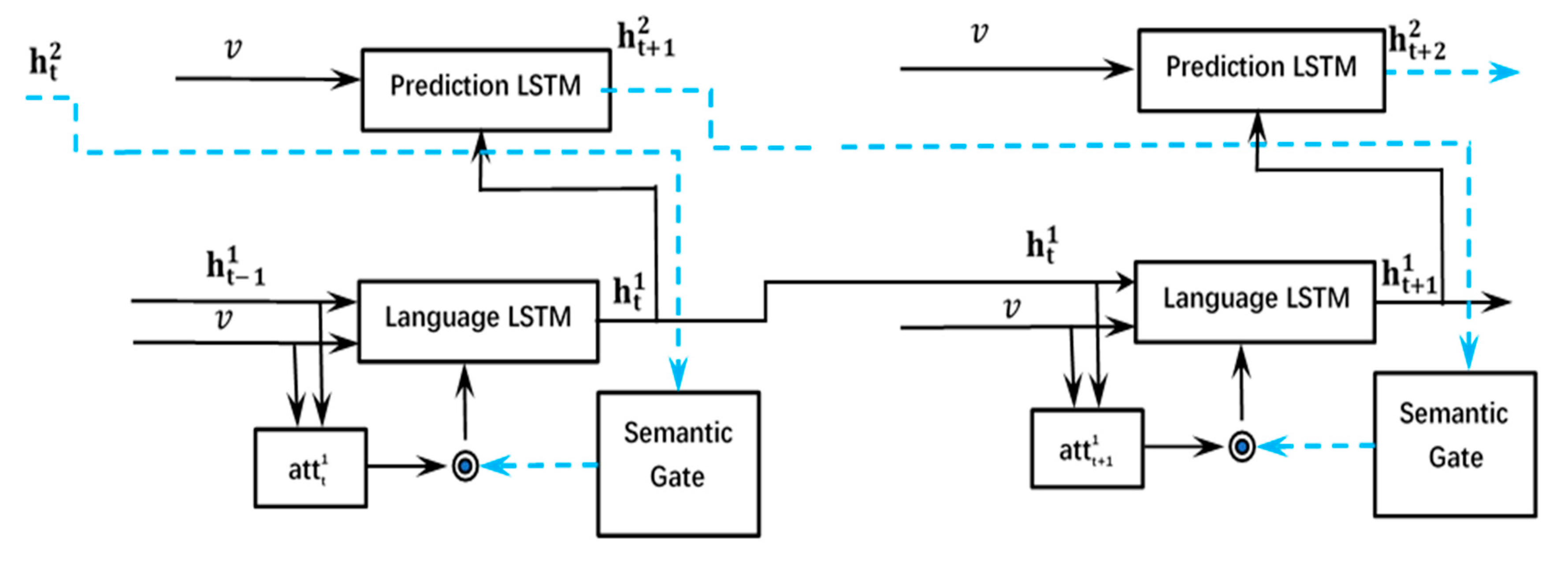
4.4. Bi-Temporal LSTM
4.5. Semantic Gate
- (1)
- We adopt the masks of landslides and other geographic objects that correspond to the word at time t as the GT of the attention when the generated word is a noun;
- (2)
- The GT of the attention is 0 when the generated word is not a noun, it means that the word does not describe the remote sensing object in the image at this time.
- (1)
- If from the prediction LSTM is the embedding vector of the noun, then ≥ 0, = 1, so the semantic gate is opened completely. This will maximize the effect of the remote sensing image on the generation of the word at the time.
- (2)
- If from the prediction LSTM is the embedding vector of the function words (e.g., relationships), then < 0, < 1, the semantic gate will inhibit the image information, which cause the LSTM more rely on the context information.
4.6. Comprehensive Loss Function
4.7. Prediction
- (1)
- Relationship transformation from part to the whole object: we added a channel to each pixel of the predicted sample of 224 × 224 as a flag, which will store the information of whether the pixel is adjacent to landslides. Going through all predicted samples (patches), we use an image caption sentence (for example, the image caption of sample a: “small landslide next to building and agriculture and greenland”) to find the objects (buildings) adjacent to the landslide, then use the focus weight matrix (e.g., Figure 8d,g) generated by SG-BiTLSTM to locate the corresponding object mask (e.g., Figure 9m). The additional channel value of the pixels of the part of the objects (o in l) was set to non-zero, so that the spatial relationship in the caption sentence can be projected onto the pixels of the part of the object.
- (2)
- Identify the hazard-affected bodies: we used the stitching program to merge the predicted sample patches to the whole image, then go through each whole object (O) to judge whether there is a non-zero flag. If it exists, the whole object O in m is the hazard-affected body.
- (3)
- Each pixel in the merged image corresponds to the same location point of the original image, and its spatial coordinates can be restored. In this way, the identified hazard-affected body can provide important information such as location, boundary and class label for emergency response.
5. Experiments and Analysis
5.1. Introduction of the Research Area and Samples
- The mean values of each band of images a–c and e are higher than that of image d, which means the radiation intensities of images a–c and e are higher than that of image d.
- The mean square deviations of each band of images a–c are higher than that of images d and e, which indicates that the information hierarchy of images a–c are better than that of images d and e.
- The homogeneities of images a–c are lower than that of images d and e, which means the former images have richer texture contrast than the latter images and can show clear boundaries between different geographic objects.
- The information entropies of each band of images a–c are higher than that of images d and e, indicating that the information contents of images a–c are richer than that of images d and e.
5.2. Introduction of the Training Modes
5.3. Semantic Accuracy Analysis
5.4. Model Stability Analysis
6. Discussion
6.1. Location Accuracy Analysis
6.2. Location Analysis of “Multiple to Multiple” and ”1 to 1” Samples
6.3. Semantic Gate Analysis
6.4. Summary
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Piralilou, S.T.; Shahabi, H.; Jarihani, B.; Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Aryal, J. Landslide Detection Using Multi-Scale Image Segmentation and Different Machine Learning Models in the Higher Himalayas. Remote Sens. 2019, 11, 2575. [Google Scholar] [CrossRef]
- Rawabdeh, A.; He, F.; Moussa, A.; Sheimy, N.E.; Habib, A. Using an Unmanned Aerial Vehicle-Based Digital Imaging System to Derive a 3D Point Cloud for Landslide Scarp Recognition. Remote Sens. 2016, 8, 95. [Google Scholar] [CrossRef]
- Scaioni, M.; Longoni, L.; Melillo, V.; Papini, M. Remote Sensing for Landslide Investigations: An Overview of Recent Achievements and Perspectives. Remote Sens. 2014, 6, 9600–9652. [Google Scholar] [CrossRef]
- Sun, R.; Gao, G.; Gong, Z.; Wu, J. A Review of Risk Analysis Methods for Natural Disasters. Nat. Hazards 2020, 100, 571–593. [Google Scholar] [CrossRef]
- Chen, L.; Huang, Y.; Bai, R.; Chen, A. Regional Disaster Risk Evaluation of China Based on the Universal Risk Model. Nat. Hazards 2017, 89, 647–660. [Google Scholar] [CrossRef]
- Gao, J.; Sang, Y. Identification and Estimation of Landslide-Debris Flow Disaster Risk in Primary and Middle School Campuses in a Mountainous Areas of Southwest China. Int. J. Disast. Res. 2017, 25, 60–71. [Google Scholar] [CrossRef]
- Zhang, W.; He, H.; Huang, H.; Cui, Y. HJ-1 Satellite’s Stable Operation 3 Anniversaries and Disaster Reduction Application. In Proceedings of the 2012 2nd International Conference on Remote Sensing, Environment and Transportation Engineering, Nanjing, China, 1–3 June 2012; pp. 1–4. [Google Scholar]
- Liu, S.; Wang, D.; Liang, S. Geo-hazards Risk Assessment in Loess Area: A Case Study of Rouyuan Township in Huachi County, Gansu Province, China. J. Eng. Geol. 2018, 26, 142–148. [Google Scholar]
- Qi, W.; Su, G. High-resolution Remote Sensing-based Method for Determining the Changes of Loss Risk from Earthquake-induced Geohazard-chain. In Proceedings of the 2013 the International Conference on Remote Sensing, Environment and Transportation Engineering, Nanjing, China, 26–28 July 2013. [Google Scholar]
- Yang, H.; Yu, B.; Luo, J. Semantic Segmentation of High Spatial Resolution Images with Deep Neural Networks. GIScience Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Bian, J.; Zhang, Z.; Chen, J.; Chen, H.; Cui, C.; Li, X.; Chen, S.; Fu, Q. Simplified Evaluation of Cotton Water Stress Uing High Resolution Unmanned Aerial Vehicle Thermal Image. Remote Sens. 2019, 11, 267. [Google Scholar] [CrossRef]
- Castilla, G.; Hay, G.J. Object-Based Image Analysis; Springer: Berlin, Germany, 2008; pp. 91–110. [Google Scholar]
- Cui, W.; Gao, L.; Wang, L.; Li, D. Study on Geographic Ontology Based on Object-Oriented Remote Sensing Analysis. In Proceedings of the International Conference on Earth Observation Data Processing and Analysis, Wuhan, China, 28–30 December 2008. [Google Scholar]
- Cui, W.; Li, R.; Yao, Z.; Chen, J.; Tang, S.; Li, Q. Study on Optimal Segmentation Scale Based on Fractal Dimension of Remote Sensing Images. J. Wuhan Univ. Technol. 2011, 12, 83–86. [Google Scholar]
- Cui, W.; Zheng, Z.; Zhou, Q.; Huang, J.; Yuan, Y. Application of a parallel spectral–spatial convolution neural network in object oriented remote sensing land use classification. Remote Sens. Lett. 2018, 9, 334–342. [Google Scholar] [CrossRef]
- Hay, G.J.; Marceau, D.J.; Dubé, P.; Bouchard, A. A Multiscale Framework for Landscape Analysis: Object-Specific Analysis and Upscaling. Landsc. Ecol. 2001, 16, 471–490. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.; St-Onge, B. A GEOBIA Framework to Estimate Forest Parameters from Lidar Transects, Quickbird Imagery and Machine Learning: A Case Study in Quebec, Canada. Int. J. Appl. Earth Obs. 2012, 15, 28–37. [Google Scholar] [CrossRef]
- Duynhoven, A.V.; Dragicevic, S. Analyzing the Effects of Temporal Resolution and Classification Confidence for Modeling Land Cover Change with Long Short-Term Memory Networks. Remote Sens. 2019, 11, 2784. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, X.; Zhang, X.; Wu, D.; Du, X. Long Time Series Land Cover Classification in China from 1982 to 2015 Based on Bi-LSTM Deep Learning. Remote Sens. 2019, 11, 1639. [Google Scholar] [CrossRef]
- He, T.; Xie, C.; Liu, Q.; Guan, S.; Liu, G. Evaluation and Comparison of Random Forest and A-LSTM Networks for Large-scale Winter Wheat Identification. Remote Sens. 2019, 11, 1665. [Google Scholar] [CrossRef]
- Teimouri, N.; Dyrmann, M.; Jorgansen, R.N. A Novel Spatio-Temporal FCN-LSTM Network for Recognizing Various Crop Types Using Multi-Temporal Radar Images. Remote Sens. 2019, 11, 990. [Google Scholar] [CrossRef]
- Qi, W.; Zhang, X.; Wang, N.; Zhang, M.; Cen, Y. A Spectral-Spatial Cascaded 3D Convolutional Neural Network with a Convolutional Long Short-Term Memory Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 2363. [Google Scholar] [CrossRef]
- Ma, C.; Li, S.; Wang, A.; Yang, J.; Chen, G. Altimeter Observation-Based Eddy Nowcasting Using an Improved Conv-LSTM Network. Remote Sens. 2019, 11, 783. [Google Scholar] [CrossRef]
- Chang, Y.; Luo, B. Bidirectional Convolutional LSTM Neural Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 2333. [Google Scholar] [CrossRef]
- Gallego, A.J.; Gil, P.; Pertusa, A.; Fisher, R.B. Semantic Segmentation of SLAR Imagery with Convolutional LSTM Selectional AutoEncoders. Remote Sens. 2019, 11, 1402. [Google Scholar] [CrossRef]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Sahana, M.; Chen, C.; Zhu, Z.; Wang, W.; Pham, B.T. Evaluating GIS-Based Multiple Statistical Models and Data Mining for Earthquake and Rainfall-Induced Landslide Susceptibility Using the Lidar DEM. Remote Sens. 2019, 11, 6. [Google Scholar] [CrossRef]
- Roy, J.; Saha, S.; Arabameri, A.; Blaschke, T.; Bui, D.T. A Novel Ensemble Approach for Landslide Susceptibility Mapping (LSM) in Darjeeling and Kalimpong Districts, West Bengal, India. Remote Sens. 2019, 11, 2866. [Google Scholar] [CrossRef]
- Shen, C.; Feng, Z.; Xie, C.; Fang, H.; Zhao, B.; Ou, W.; Zhu, Y.; Wang, K.; Li, H.; Bai, H.; et al. Refinement of Landslide Susceptibility Map Using Persistent Scattered Interferometry in Areas of Intense Mining Activities in the Karst Region of Southwest China. Remote Sens. 2019, 11, 2821. [Google Scholar] [CrossRef]
- Park, J.; Lee, C.W.; Lee, S.; Lee, M.J. Landslide Susceptibility Mapping and Comparison Using Decision Tree Models: A Case Study of Jumunjin Area, Korea. Remote Sens. 2018, 10, 1545. [Google Scholar] [CrossRef]
- Kadavi, P.R.; Lee, C.W.; Lee, S. Application of Ensemble-Based Machine Learning Models to Landslide Susceptibility Mapping. Remote Sens. 2018, 10, 1252. [Google Scholar] [CrossRef]
- Shao, X.; Ma, S.; Xu, C. Planet Image-Based Inventorying and Machine Learning-Based Susceptibility Mapping for the Landslides Triggered by the 2018 Mw6.6 Tomakomai, Japan Earthquake. Remote Sens. 2019, 11, 978. [Google Scholar] [CrossRef]
- Prakash, N.; Manconi, A.; Loew, S. Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Traditional Machine Learning Models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Meena, S.R.; Blaschke, T.; Aryal, J. UAV-Based Slope Failure Detection Using Deep-Learning Convolutional Neural Networks. Remote Sens. 2019, 11, 2046. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sens. 2018, 10, 1350. [Google Scholar] [CrossRef]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building Extraction in Very High-Resolution Imagery by Dense-Attention Networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef]
- Sun, G.; Huang, H.; Zhang, A.; Li, F.; Zhao, H.; Fu, H. Fusion of Multiscale Convolutional Neural Networks for Building Extraction in Very High-Resolution Images. Remote Sens. 2019, 11, 227. [Google Scholar] [CrossRef]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building Extraction from Multi-Source Remote Sensing Images via Deep Deconvolution Neural Networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar]
- Crommelinck, S.; Koeva, M.; Yang, M.; Vosselman, G. Application of Deep Learning for Delineation of Visible Cadastral Boundaries from Remote Sensing Imagery. Remote Sens. 2019, 11, 2505. [Google Scholar] [CrossRef]
- Zhang, T.; Tang, H. A Comprehensive Evaluation of Approaches for Built-up Area Extraction from Landsat Oli Images Using Massive Samples. Remote Sens. 2019, 11, 2. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, K.; Shen, Z.; Deng, J.; Gan, M.; Liu, X.; Lu, D.; Wang, K. Mapping Impervious Surfaces in Town–Rural Transition Belts Using China’s GF-2 Imagery and Object-Based Deep CNNs. Remote Sens. 2019, 11, 280. [Google Scholar] [CrossRef]
- Li, W.; Dong, R.; Fu, H.; Yu, L. Large-Scale Oil Palm Tree Detection From High-Resolution Satellite Images Using Two-Stage Convolutional Neural Networks. Remote Sens. 2019, 11, 11. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, D.; Gu, C.; Jin, N.; Zhao, H.; Chen, G.; Liang, H.; Liang, D. Using Neural Network to Identify the Severity of Wheat Fusarium Head Blight in the Field Environment. Remote Sens. 2019, 11, 2375. [Google Scholar] [CrossRef]
- Ethan, L.; Tyr, W.; Nicholas, K.; Chad, D.; Wu, H.; Hod, L.; Rebecca, J.; Michael, A. Quantitative Phenotyping of Northern Leaf Blight in UAV Images Using Deep Learning. Remote Sens. 2019, 11, 2209. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning. Remote Sens. 2019, 11, 83. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Convolutional Recurrent Neural Networks for Hyperspectral Data Classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef]
- Ndikumana, E.; Minh, D.H.T.; Baghdadi, N.; Courault, D.; Hossard, L. Deep Recurrent Neural Network for Agricultural Classification Using Multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G. Spectral-Spatial Classification of Hyperspectral Imagery Based on Recurrent Neural Networks. Remote Sens. Lett. 2018, 9, 1118–1127. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef]
- Ma, A.; Filippi, A.M.; Wang, Z.; Yin, Z. Hyperspectral Image Classification Using Similarity Measurements-Based Deep Recurrent Neural Networks. Remote Sens. 2019, 11, 194. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A Neural Image Caption Generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Karpathy, A.; Li, F.-F. Deep Visual-Semantic Alignments for Generating Image Descriptions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep Semantic Understanding of High-Resolution Remote Sensing Image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Shi, Z.; Zou, Z. Can a Machine Generate Humanlike Language Descriptions for a Remote Sensing Image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Wang, B.; Lu, X.; Zheng, X.; Liu, W. Semantic Descriptions of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 99, 1274–1278. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description Generation for Remote Sensing Images Using Attribute Attention Mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Hu, R.; Rohrbach, M.; Darrell, T. Segmentation from Natural Language Expressions. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Liu, C.; Lin, Z.; Shen, X.; Yang, J.; Lu, X.; Yuille, A. Recurrent Multimodal Interaction for Referring Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017. [Google Scholar]
- Chen, D.; Jia, S.; Lo, Y.; Chen, H.; Liu, T. See-Through-Text Grouping for Referring Image Segmentation. In Proceedings of the IEEE International Conference on Computational Photograph (ICCP), Tokyo, Japan, 15–17 May 2019. [Google Scholar]
- Luo, H.; Lin, G.; Liu, Z.; Liu, F.; Tang, Z.; Yao, Y. SegEQA Video Segmentation Based Visual Attention for Embodied Question Answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9967–9976. [Google Scholar]
- Peter, A.; He, X.; Chris, B.; Damien, T.; Mark, J.; Stephen, G.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual Semantic Reasoning for Image-Text Matching. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4654–4662. [Google Scholar]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-Scale Semantic Segmentation and Spatial Relationship Recognition of Remote Sensing Images Based on an Attention Model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic object-based image analysis (GEOBIA): Emerging trends and future opportunities. GIScience Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Blaschke, T.; Strobl, J. What’s Wrong with Pixels? Some Recent Developments Interfacing Remote Sensing and GIS. Z. Geoinformationssysteme 2001, 14, 12–17. [Google Scholar]
- Chen, M.; Zhou, W.; Yuan, T. GF-1 Image Quality Evaluation and Applications Potential for the Mining Area Land Use Classification. J. Geomat. Sci. Technol. 2015, 32, 494–499. [Google Scholar]
- Wu, H.; Clark, K.; Shi, W.; Fang, L.; Lin, A.; Zhou, J. Examining the Sensitivity of Spatial Scale in Cellular Automata Markov Chain Simulation of Land Use Change. Int. J. Geogr. Inf. Sci. 2019, 33, 1040–1061. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Band | E | σ | HOM | ENT |
|---|---|---|---|---|---|
| a | blue | 167.87029 | 46.297745 | 0.173274 | 8.8535319 |
| green | 164.76142 | 49.489792 | 0.1731411 | 8.9109432 | |
| red | 162.51355 | 49.703531 | 0.1715312 | 8.944059 | |
| b | blue | 162.97342 | 45.227041 | 0.1628429 | 8.9063794 |
| green | 159.33938 | 46.88811 | 0.1595825 | 8.9758587 | |
| red | 156.85538 | 47.43977 | 0.1580909 | 9.0122284 | |
| c | blue | 150.46089 | 41.27689 | 0.1812003 | 8.5812162 |
| green | 152.91233 | 43.758507 | 0.1837054 | 8.5986627 | |
| red | 151.17894 | 47.761041 | 0.1818619 | 8.6860094 | |
| d | blue | 127.06086 | 26.547448 | 0.2000544 | 7.9150757 |
| green | 130.71656 | 29.037766 | 0.2014483 | 7.9912087 | |
| red | 127.6713 | 32.800937 | 0.1994446 | 8.1189005 | |
| e | blue | 152.50067 | 25.744151 | 0.3164164 | 7.4239366 |
| green | 151.80391 | 23.895315 | 0.3185966 | 7.3490482 | |
| red | 150.09841 | 23.143344 | 0.3167386 | 7.329055 |
| Models | Bleu_1 | Bleu_2 | Bleu_3 | Bleu_4 | METEOR | ROUGE_L | CIDEr |
|---|---|---|---|---|---|---|---|
| Baseline | 0.8022 | 0.7290 | 0.6750 | 0.6300 | 0.4298 | 0.8093 | 4.9896 |
| Attention Correction Model | 0.8395 | 0.7977 | 0.7562 | 0.7114 | 0.4541 | 0.8491 | 6.0763 |
| Attention Correction with Semantic Gate Model I (batch) | 0.8494 | 0.7940 | 0.7643 | 0.7280 | 0.4744 | 0.8491 | 6.0863 |
| Attention Correction with Semantic Gate Model I (single) | 0.8555 | 0.8093 | 0.7646 | 0.7183 | 0.4799 | 0.8530 | 6.1889 |
| Attention Correction with Semantic Gate Model II | 0.8581 | 0.8149 | 0.774 | 0.7329 | 0.4813 | 0.8532 | 6.1999 |
| SG-BiTLSTM | 0.8611 | 0.8200 | 0.7801 | 0.7383 | 0.4872 | 0.8609 | 6.2810 |
| No. | bleu1 | bleu2 | bleu3 | bleu4 |
|---|---|---|---|---|
| 1 | 0.8596 | 0.8202 | 0.7809 | 0.739 |
| 2 | 0.8589 | 0.8182 | 0.7769 | 0.7332 |
| 3 | 0.8584 | 0.8152 | 0.7714 | 0.7252 |
| 4 | 0.8578 | 0.8126 | 0.7682 | 0.7217 |
| 5 | 0.8573 | 0.815 | 0.7732 | 0.7292 |
| 6 | 0.8567 | 0.8141 | 0.7716 | 0.7261 |
| 7 | 0.8599 | 0.8196 | 0.7796 | 0.7375 |
| 8 | 0.8571 | 0.8133 | 0.77 | 0.7247 |
| 9(Ours) | 0.8611 | 0.82 | 0.7801 | 0.7383 |
| 10 | 0.8589 | 0.8182 | 0.7769 | 0.7332 |
| Models | Total Generated Nouns | Total Correct Nouns | Total Matched Objects | Matching Accuracy % |
|---|---|---|---|---|
| Baseline | 2815 | 2616 | 1161 | 44.38% |
| Attention Correction with Semantic Gate Model I (batch) | 3034 | 2691 | 2147 | 79.78% |
| Attention Correction with Semantic Gate Model I (single) | 2967 | 2667 | 2235 | 83.80% |
| Attention Correction with Semantic Gate Model II | 2939 | 2619 | 2246 | 85.76% |
| SG-BiTLSTM | 2992 | 2701 | 2355 | 87.19% |
| Models | Total Generated Nouns | Correct Generated Nouns | Matching Number of Nouns | Matching Rate % |
|---|---|---|---|---|
| Attention Correction with Semantic Gate Model I (batch) | 3034 | 2691 | 2147 | 79.78% |
| Attention Correction with Semantic Gate Model I (single) | 2967 | 2667 | 2235 | 83.80% |
| Models | Total Generated Nouns | Correct Generated Nouns | Matching Number of Nouns | Matching Rate % |
|---|---|---|---|---|
| Attention Correction with Semantic Gate Model II (Sigmoid activation function) | 2939 | 2619 | 2246 | 85.76% |
| SG-BiTLSTM (a Customized activation) | 2992 | 2701 | 2355 | 87.19% |
| Models | Total Correct Nouns | “Multiple to Multiple” Nouns | “1 to 1” Nouns | |||||
|---|---|---|---|---|---|---|---|---|
| Correct Number | Percentage | Matching Number | Percentage | Correct Number | Matching Number | Percentage | ||
| Baseline | 2616 | 842 | 32.19% | 417 | 49.52% | 1774 | 744 | 41.94% |
| Attention Correction with Semantic Gate Model I (batch) | 2691 | 874 | 32.49% | 583 | 66.70% | 1817 | 1564 | 86.08% |
| Attention Correction with Semantic Gate Model I (single) | 2667 | 846 | 31.72% | 614 | 72.58% | 1821 | 1621 | 89.02% |
| Attention Correction with Semantic Gate Model II | 2619 | 858 | 32.76% | 659 | 76.81% | 1761 | 1587 | 90.12% |
| SG-BiTLSTM | 2701 | 858 | 31.77% | 668 | 77.86% | 1843 | 1687 | 91.54% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, W.; He, X.; Yao, M.; Wang, Z.; Li, J.; Hao, Y.; Wu, W.; Zhao, H.; Chen, X.; Cui, W. Landslide Image Captioning Method Based on Semantic Gate and Bi-Temporal LSTM. ISPRS Int. J. Geo-Inf. 2020, 9, 194. https://doi.org/10.3390/ijgi9040194
Cui W, He X, Yao M, Wang Z, Li J, Hao Y, Wu W, Zhao H, Chen X, Cui W. Landslide Image Captioning Method Based on Semantic Gate and Bi-Temporal LSTM. ISPRS International Journal of Geo-Information. 2020; 9(4):194. https://doi.org/10.3390/ijgi9040194
Chicago/Turabian StyleCui, Wenqi, Xin He, Meng Yao, Ziwei Wang, Jie Li, Yuanjie Hao, Weijie Wu, Huiling Zhao, Xianfeng Chen, and Wei Cui. 2020. "Landslide Image Captioning Method Based on Semantic Gate and Bi-Temporal LSTM" ISPRS International Journal of Geo-Information 9, no. 4: 194. https://doi.org/10.3390/ijgi9040194
APA StyleCui, W., He, X., Yao, M., Wang, Z., Li, J., Hao, Y., Wu, W., Zhao, H., Chen, X., & Cui, W. (2020). Landslide Image Captioning Method Based on Semantic Gate and Bi-Temporal LSTM. ISPRS International Journal of Geo-Information, 9(4), 194. https://doi.org/10.3390/ijgi9040194