A Survey on Big Data for Trajectory Analytics


Abstract
1. Introduction
2. Basic Concepts
- and represent the geographical coordinates;
- represents the instant of time of the object location; and
- < < … .
- 1.
- traj_id is the trajectory identifier;
- 2.
- ep_id is the episode identifier;
- 3.
- type is the episode type, that is, the criterion of the segmentation process (e.g., means of transport type, activity type, stopped, moving);
- 4.
- subseq is a maximal subsequence of spatio-temporal points < > from the raw trajectory that satisfies the episode criterion type (e.g., means of transport) and 1 ≤ i ≤ j ≤ n, where n is the number of trajectory points.
- In an explicit way, that is, using sensors such as GPS that transmit the geographic coordinates with almost standardized temporal and spatial distance rate to the receiver;
- Implicitly, when the trajectory is inferred through information obtained from devices that do not guarantee the temporal and spatial standardization, i.e., the time granularity is relatively large and the distribution of recorded time points is relatively random [11], as of vigilance camera sensors, magnetic cards, RFID (Radio-frequency identification), and GSM (Global System for Mobile Communications). Another way to get trajectory data implicitly is through VGI (Volunteered Geographic Information) [21,22], which comprises geographic information provided by citizens using geosocial media tools.
2.1. Semantic Trajectory
- 1.
- trajectoryID is the identifier of the trajectory;
- 2.
- objectID is the identifier of the mobile object;
- 3.
- trajectoryAnnotations is the set of annotations associated with the trajectory as a whole, for example: duration, size, objective;
- 4.
- track is the list of spatio-temporal positions of the moving object. The list is sorted temporarily;
- 5.
- ti are, usually, instants of time. All ti are disjoint;
- 6.
- p specifies a spatial element. Generally represented by a point (x, y) for 2D coordinates and (x, y, z) for 3D coordinates;
- 7.
- posAnnotations is an annotations set associated with the p position;
- 8.
- semanticGaps is the list of semantic gaps in the trajectory delimited by a period of time, and , where ≤ ;
- 9.
- interpretations is the interpretations set referring to a set of episodes of the trajectory, e.g., activity episodes, stop/move episodes, etc.;
- 10.
- interpretationID is the interpretation identifier;
- 11.
- episodes is the episodes list related to a particular interpretation.
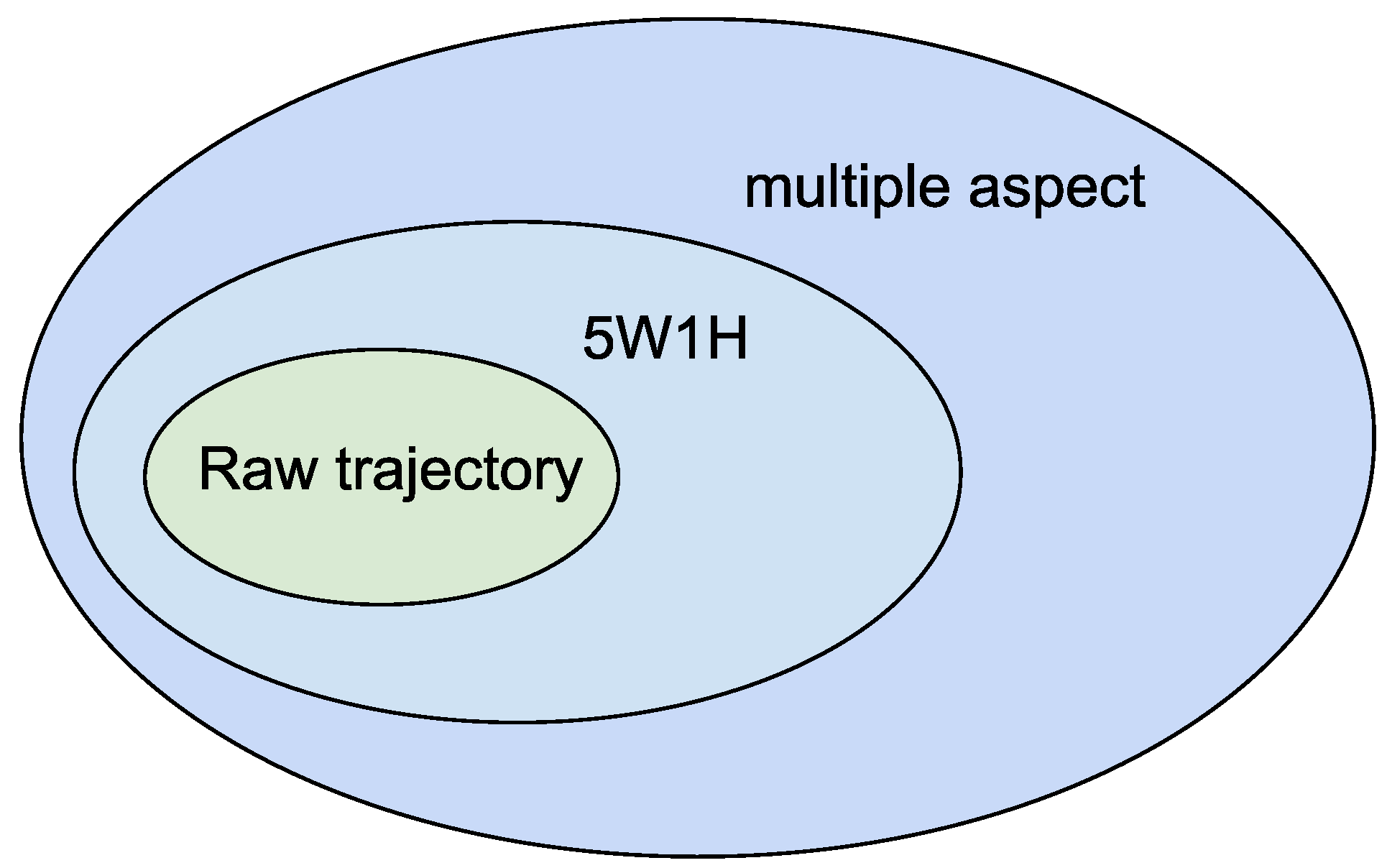
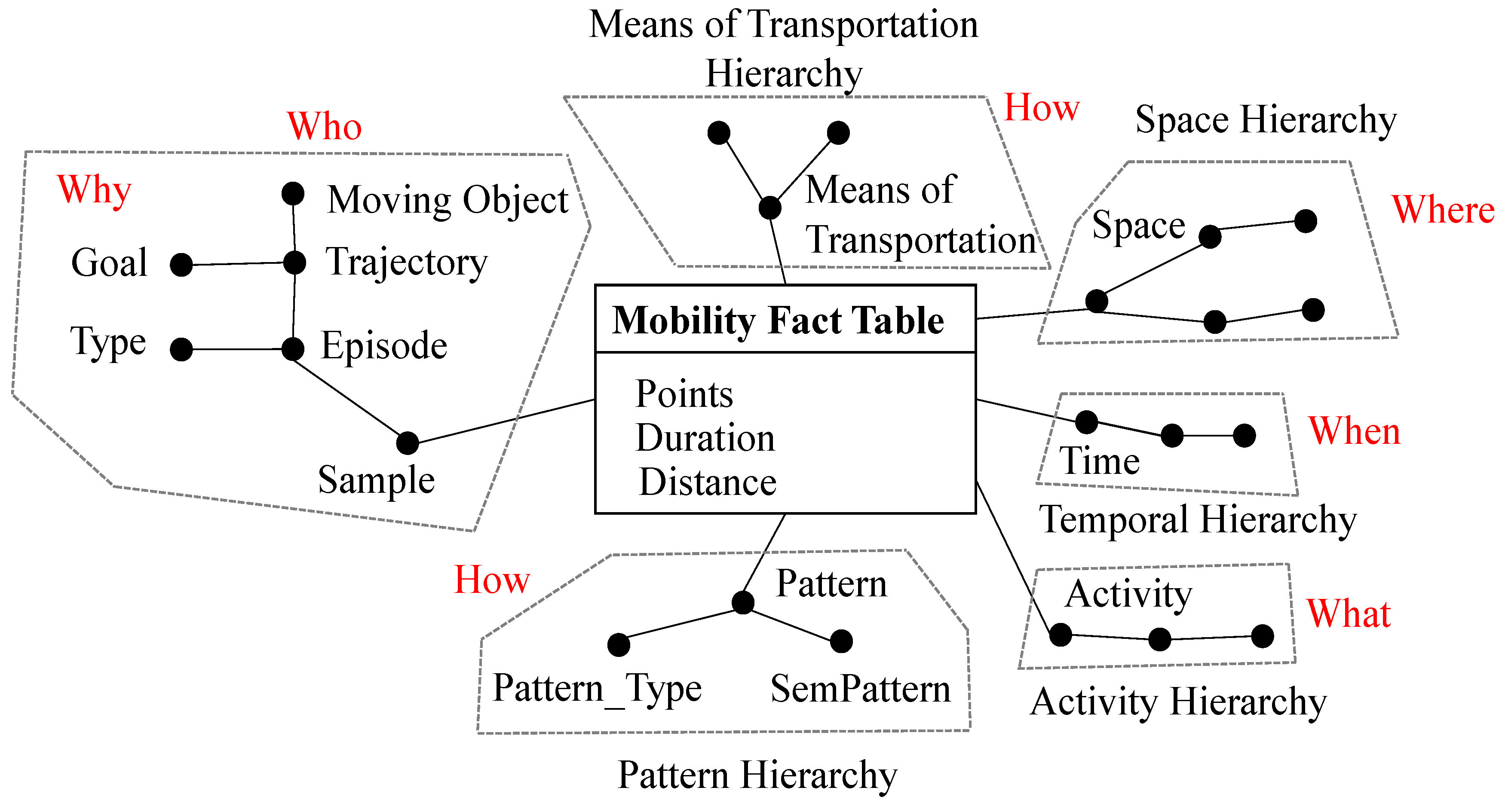
- Who: moving object identification;
- Where: the place where the trajectory point is located;
- When: the time related to the trajectory points;
- What: what the mobile object is, or was, doing;
- Why: represents the trip motivation;
- How: represents how the object moves, such as the transport means.
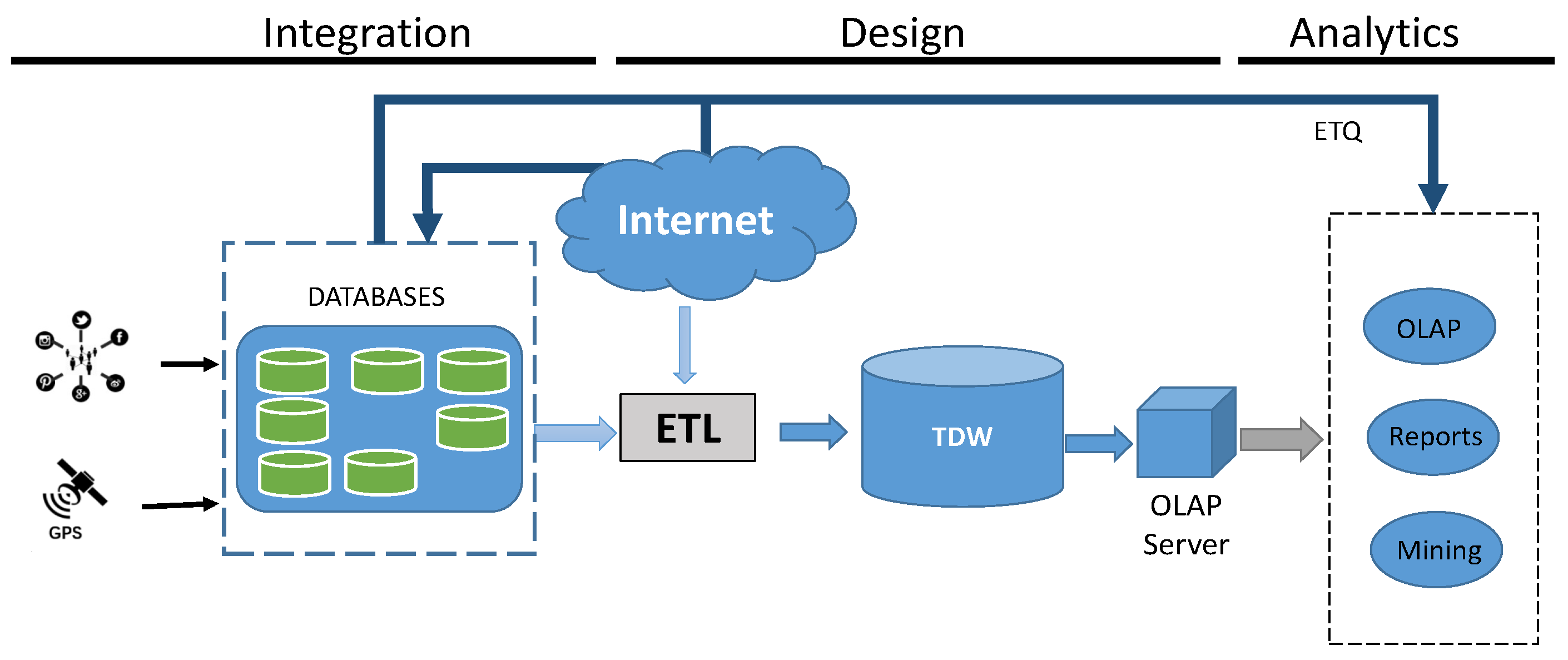
- Integration: comprises gathering and integrating raw trajectory data, such as geographic coordinates and time, and its consequent storage in a database. This step comprises data source and back-end layers of a data warehouse architecture, as described by Vaisman and Zimányi [2]. Along this process, the collected data can be enriched with other data gained from external sources of interest to the application, such as Geonames (https://www.geonames.org/), OpenStreetMaps, and Twitter. To enrich semantically the raw data collected, further information can be obtained. The semantic enrichment process can occur both in the integration and design steps;
- Design: this step corresponds to the stage where trajectory data can be summarized in a Data Warehouse through the ETL process;
- Analytics: this is the architecture exploratory step that queries the Data Warehouse, and other data sources if necessary, to generate reports and other decision-making information. If necessary, the analytics tool can directly query the data source through a process called ETQ (Extract, Transform, Query) [35]. The ETQ process delays data transformations to the last minute and serves to the user on demand [35]; more detail about ETQ is described in the section on Analytics.
3. Trajectory Data Integration
3.1. Trajectory Data Gathering and Storage
- offline compression: this category reduces the size of the trajectory after the trajectory has been fully generated. The classical algorithm is Douglas–Peucker (DP), which is based on heuristics that recursively divide the sequence of positions and stores only the representative position of each sub-sequence. Nowadays, there are already modifications and improvements in the DP like the Top-Down Time-Ratio (TD-TR) [53];
- online compression: the compression of the trajectory occurs following the movement of the object along the trajectory. Ideal for real-time environments, such as traffic monitoring. The main algorithms are Sliding Window, Open Window [53], and STTrace [54]. Sliding Window and Open Window are similar algorithms differing in the choice of point location of the sliding window. The algorithm causes a sliding window to grow along with the trajectory points. In contrast, the error of adjustment line segments (line going from the first and last point of the window) and the original trajectory are not greater than the specified error limit. The STTrace algorithm uses the coordinates, speed, and orientation of the current trajectory point to calculate a safe area where the next position can be located; if the next point falls in this region, it can be ignored.
3.2. Semantic Trajectories
4. Trajectory Data Warehouse Design
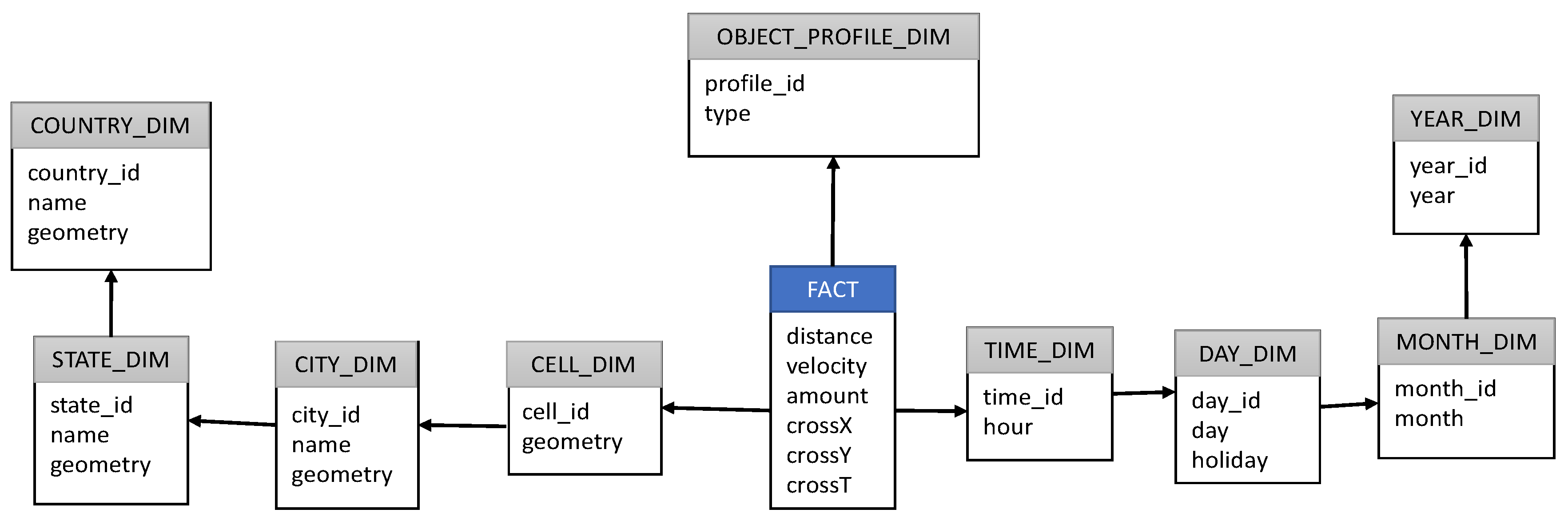
4.1. Trajectory Data Warehouse
- Stopping and moving;
- Period of time corresponding to the instant of the spatio-temporal position. Example: morning, noon, afternoon, evening; and
- Category of the city region corresponding to the location of the spatio-temporal position. Example: residence, tourism, commercial, recreation.
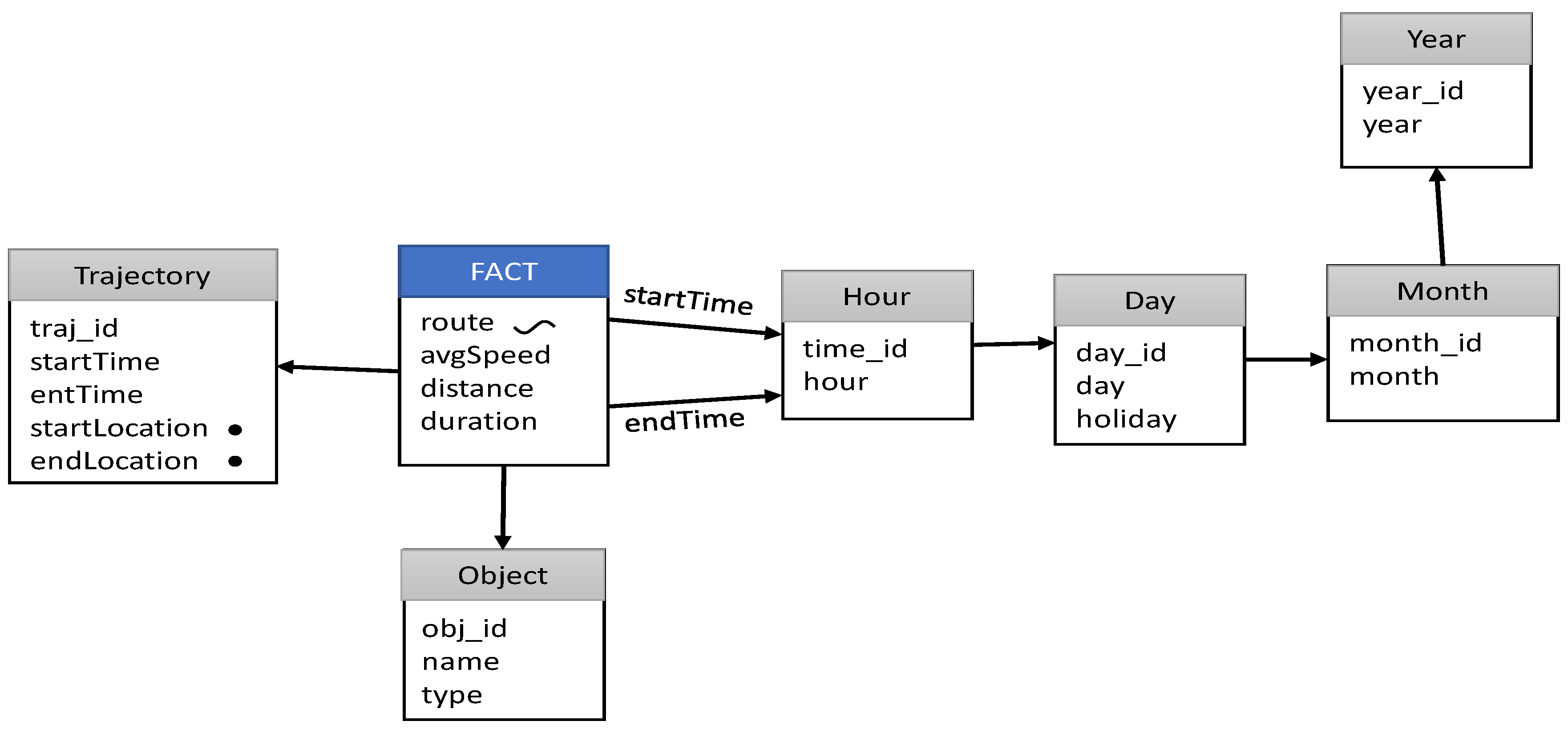
4.2. Semantic Trajectory Data Warehouse
5. Trajectory Data Analytics
- Descriptive: able to answer questions like, “what happened?”. These systems can only describe, summarize, or present the raw data that have been collected. Data are decoded, interpreted in a context, and then presented in the form of graphs, reports, statistics, among others;
- Diagnostic: try to understand why something is happening;
- Discovery: try to answer the question about what happened that was not yet known. For this, inference of non-trivial information, reasoning or detection techniques are applied to the raw data;
- Predictive: try to answer the question “What is likely to happen?”. To do this, they use past data and knowledge to predict future results and provide methods to assess the quality of these predictions;
- Prescriptive: try to analyze the question of what needs to be done about what happened or is likely to happen.
6. Open Challenges in Big Data for Trajectory Analytics
7. Final Considerations
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AIS | Automatic Identification System |
| BI | Business Intelligence |
| DBMS | Database Management Systems |
| DP | Douglas–Peucker |
| DSSP | Dataspace Support Platform |
| DW | Data Warehouse |
| ETL | Extraction, Transformation, and Loading |
| ETQ | Extract, Transform, Query |
| ExpSOLAP | Exploratory SOLAP |
| GPS | Global Positioning System |
| GRASP-SemTS | GRASP for Semi-supervised Trajectory Segmentation |
| GRASP-UTS | Greedy Randomized Adaptive Search Procedure for Unsupervised Trajectory |
| Segmentation | |
| GSM | Global System for Mobile Communications |
| HDFS | Hadoop Distributed File System |
| ISO | International Organization for Standardization |
| LOD | Linked Open Data |
| MDX | Multi-dimensional Data Expressions |
| MOD | Moving ObjectDatabase |
| NoSQL | Not Only SQL |
| OLAP | Online Analytical Processing |
| ORDBMS | Object-Relational DBMS |
| RDD | ResilientDistributed Dataset |
| RDF | Resource Description Framework |
| RFID | Radio-Frequency Identification |
| SDBMS | Spatial Database Management Systems |
| SOLAP | Spatial OLAP |
| SPARQL | SPARQL Protocol and RDF Query Language |
| SQL | Stands for Structured Query Language |
| STrDW | Semantic Trajectory Data Warehouse |
| TD-TR | Top-Down Time-Ratio |
| TDW | Trajectory DataWarehouses |
| VGI | Volunteered Geographic Information |
References
- Zheng, Y. Trajectory Data Mining: An Overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Vaisman, A.; Zimányi, E. Conceptual Data Warehouse Design. In Data Warehouse Systems; Springer: Berlin, Germany, 2014; pp. 89–119. [Google Scholar]
- Bogorny, V.; Renso, C.; de Aquino, A.R.; de Lucca Siqueira, F.; Alvares, L.O. Constant—A Conceptual Data Model for Semantic Trajectories of Moving Objects. Trans. GIS 2014, 18, 66–88. [Google Scholar] [CrossRef]
- Kolovson, C.P.; Neimat, M.A.; Potamianos, S. Interoperability of Spatial and Attribute Data Managers: A Case Study; Springer: Berlin, Germany, 1993; Volume 692, pp. 239–263. [Google Scholar]
- Xu, J.; Güting, R.H. A Generic Data Model for Moving Objects. GeoInformatica 2013, 17, 125–172. [Google Scholar] [CrossRef]
- Jin, X.; Wah, B.W.; Cheng, X.; Wang, Y. Significance and Challenges of Big Data Research. Big Data Res. 2015, 2, 59–64. [Google Scholar] [CrossRef]
- Ge, M.; Bangui, H.; Buhnova, B. Big Data for Internet of Things: A Survey. Future Gener. Comput. Syst. 2018, 87, 601–614. [Google Scholar] [CrossRef]
- Shekhar, S.; Gunturi, V.; Evans, M.R.; Yang, K. Spatial Big-Data Challenges Intersecting Mobility and Cloud Computing. In Proceedings of the Eleventh ACM International Workshop on Data Engineering for Wireless and Mobile Access, Scottsdale, AZ, USA, 20 May 2012; pp. 1–6. [Google Scholar]
- Bédard, Y.; Rivest, S.; Proulx, M.J. Spatial Online Analytical Processing (SOLAP): Concepts, Architectures, and Solutions from a Geomatics Engineering Perspective. In Data Warehouses and OLAP: Concepts, Architectures and Solutions; IGI Global: Pittsburgh, PA, USA, 2007; pp. 298–319. [Google Scholar]
- Parent, C.; Spaccapietra, S.; Renso, C.; Andrienko, G.; Andrienko, N.; Bogorny, V.; Damiani, M.L.; Gkoulalas-Divanis, A.; Macedo, J.; Pelekis, N.; et al. Semantic Trajectories Modeling and Analysis. ACM Comput. Surv. 2013, 45, 42. [Google Scholar] [CrossRef]
- Kong, X.; Li, M.; Ma, K.; Tian, K.; Wang, M.; Ning, Z.; Xia, F. Big Trajectory Data: A Survey of Applications and Services. IEEE Access 2018, 6, 58295–58306. [Google Scholar] [CrossRef]
- Bian, J.; Tian, D.; Tang, Y.; Tao, D. A Survey on Trajectory Clustering Analysis. arXiv 2018, arXiv:1802.06971. [Google Scholar]
- Feng, Z.; Zhu, Y. A Survey on Trajectory Data Mining: Techniques and Applications. IEEE Access 2016, 4, 2056–2067. [Google Scholar] [CrossRef]
- Alsahfi, T.; Almotairi, M.; Elmasri, R. A Survey on Trajectory Data Warehouse. Spat. Inf. Res. 2019, 28, 1–14. [Google Scholar] [CrossRef]
- Fileto, R.; Raffaetà, A.; Roncato, A.; Sacenti, J.A.; May, C.; Klein, D. A Semantic Model for Movement Data Warehouses. In Proceedings of the 17th International Workshop on Data Warehousing and OLAP, Shanghai, China, November 2014; pp. 47–56. [Google Scholar]
- Nardini, F.M.; Orlando, S.; Perego, R.; Raffaetà, A.; Renso, C.; Silvestri, C. Analysing Trajectories of Mobile Users: From Data Warehouses to Recommender Systems. In A Comprehensive Guide Through the Italian Database Research Over the Last 25 Years; Springer: Berlin, Germany, 2018; pp. 407–421. [Google Scholar]
- Andrienko, N.V.; Andrienko, G.L. Visual Analytics of Movement: A Rich Palette of Techniques to Enable Understanding 2013. Available online: https://www.cambridge.org/core/books/mobility-data/visual-analytics-of-movement-a-rich-palette-of-techniques-to-enable-understanding/D8CF79BD836291437ED501B4965498B8 (accessed on 31 January 2020).
- Etemad, M.; Júnior, A.S.; Hoseyni, A.; Rose, J.; Matwin, S. A Trajectory Segmentation Algorithm Based on Interpolation-based Change Detection Strategies. EDBT/ICDT Workshops. 2019. Available online: http://ceur-ws.org/Vol-2322/BMDA_4.pdf (accessed on 31 January 2020).
- Soares Júnior, A.; Moreno, B.N.; Times, V.C.; Matwin, S.; Cabral, L.d.A.F. GRASP-UTS: An Algorithm for Unsupervised Trajectory Segmentation. Int. J. Geogr. Inf. Sci. 2015, 29, 46–68. [Google Scholar] [CrossRef]
- Junior, A.S.; Times, V.C.; Renso, C.; Matwin, S.; Cabral, L.A. A Semi-Supervised Approach for the Semantic Segmentation of Trajectories. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 28 June 2018; pp. 145–154. [Google Scholar]
- Goodchild, M.F. Citizens as Sensors: The World of Volunteered Geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Granell, C.; Schade, S.; Hobona, G. Linked Data: Connecting Spatial Data Infrastructures and Volunteered Geographic Information. In Geospatial Web Services: Advances in Information Interoperability; IGI Global: Pittsburgh, PA, USA, 2011; pp. 189–226. [Google Scholar]
- Renso, C.; Spaccapietra, S.; Zimányi, E. Mobility Data; Cambridge University Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Zheng, Y.; Xie, X. Learning Location Correlation from GPS Trajectories. In Proceedings of the 2010 Eleventh International Conference on Mobile Data Management, Kansas City, MO, USA, 21 June 2010. [Google Scholar]
- Krumm, J.; Horvitz, E. Predestination: Inferring Destinations from Partial Trajectories; Springer: Berlin, Germany, 2006; pp. 243–260. [Google Scholar]
- Yan, Z.; Chakraborty, D.; Parent, C.; Spaccapietra, S.; Aberer, K. SeMiTri: A Framework for Semantic Annotation of Heterogeneous Trajectories. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21 March 2011; pp. 259–270. [Google Scholar]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macedo, J.A.; Porto, F.; Vangenot, C. A conceptual View on Trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef]
- Spaccapietra, S.; Parent, C. Adding Meaning to Your Steps; Springer: Berlin, Germany, 2011; pp. 13–31. [Google Scholar]
- Laube, P. The Low Hanging Fruit is Gone: Achievements and Challenges of Computational Movement Analysis. SIGSPATIAL Spec. 2015, 7, 3–10. [Google Scholar] [CrossRef]
- Nabo, R.G.; Fileto, R.; Nanni, M.; Renso, C. Annotating Trajectories by Fusing them with Social Media Users Posts. In Proceedings of the XV Brazilian Symposium on Geoinformatics (GeoInfo), Campos do Jordão, Brazil, 29 November 2014; pp. 25–36. [Google Scholar]
- Wagner, R.; de Macedo, J.A.F.; Raffaetà, A.; Renso, C.; Roncato, A.; Trasarti, R. Mob-Warehouse: A Semantic Approach for Mobility Analysis with a Trajectory Data Warehouse; Springer: Berlin, Germany, 2013; pp. 127–136. [Google Scholar]
- Fileto, R.; May, C.; Renso, C.; Pelekis, N.; Klein, D.; Theodoridis, Y. The Baquara2 Knowledge-Based Framework for Semantic Enrichment and Analysis of Movement Data. Data Knowl. Eng. 2015, 98, 104–122. [Google Scholar] [CrossRef]
- Mello, R.d.S.; Bogorny, V.; Alvares, L.O.; Santana, L.H.Z.; Ferrero, C.A.; Frozza, A.A.; Schreiner, G.A.; Renso, C. MASTER: A Multiple Aspect View on Trajectories. Trans. GIS 2019, 23, 805–822. [Google Scholar] [CrossRef]
- Malinowski, E.; Zimanyi, E. Advanced Data Warehouse Design—From Conventional to Spatial and Temporal Applications; Data-Centric Systems and Applications; Springer: Berlin, Germany, 2008. [Google Scholar] [CrossRef]
- Abelló, A.; Romero, O.; Pedersen, T.B.; Berlanga, R.; Nebot, V.; Aramburu, M.J.; Simitsis, A. Using semantic web technologies for exploratory OLAP: A survey. IEEE Trans. Knowl. Data Eng. 2014, 27, 571–588. [Google Scholar] [CrossRef]
- Braz, F.J.; Orlando, S. Trajectory Data Warehouses: Proposal of Design and Application to Exploit Data. GeoInfo 2007, 9, 61–72. [Google Scholar]
- Orlando, S.; Orsini, R.; Raffaetà, A.; Roncato, A.; Silvestri, C. Trajectory Data Warehouses: Design and Implementation Issues. J. Comput. Sci. Eng. 2007, 1, 211–232. [Google Scholar] [CrossRef]
- Marketos, G.; Frentzos, E.; Ntoutsi, I.; Pelekis, N.; Raffaetà, A.; Theodoridis, Y. Building Real-World Trajectory Warehouses. In Proceedings of the Seventh ACM International Workshop on Data Engineering for Wireless and Mobile Access, Vancouver, BC, Canada, 13 June 2008; pp. 8–15. [Google Scholar]
- Leonardi, L.; Marketos, G.; Frentzos, E.; Giatrakos, N.; Orlando, S.; Pelekis, N.; Raffaetà, A.; Roncato, A.; Silvestri, C.; Theodoridis, Y. T-warehouse: Visual Olap Analysis on Trajectory Data. In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA; 2010; pp. 1141–1144. [Google Scholar]
- Leonardi, L.; Orlando, S.; Raffaetà, A.; Roncato, A.; Silvestri, C.; Andrienko, G.; Andrienko, N. A General Framework for Trajectory Data Warehousing and Visual OLAP. GeoInformatica 2014, 18, 273–312. [Google Scholar] [CrossRef]
- Silva, M.C.T.; Times, V.C.; de Macêdo, J.A.; Renso, C. SWOT: A Conceptual Data Warehouse Model for Semantic Trajectories. In Proceedings of the ACM Eighteenth International Workshop on Data Warehousing and OLAP, Melbourne, VIC, Australia, 19 October 2015; pp. 11–14. [Google Scholar]
- Bao, J.; Li, R.; Yi, X.; Zheng, Y. Managing Massive Trajectories on the Cloud. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, October 2016; p. 41. [Google Scholar]
- Galić, Z. Spatio-Temporal Data Streams and Big Data Paradigm. In Spatio-Temporal Data Streams; Springer: Barlin, Germany, 2016; pp. 47–69. [Google Scholar]
- Manaa, M.; Akaichi, J. Ontology-Based Trajectory Data Warehouse Conceptual Model; Springer: Berlin, Germany, 2016; pp. 329–342. [Google Scholar]
- Soares Júnior, A.; Renso, C.; Matwin, S. ANALYTiC: An Active Learning System for Trajectory Classification. IEEE Comput. Graph. Appl. 2017, 37, 28–39. [Google Scholar] [CrossRef]
- Zhang, Z.; Jin, C.; Mao, J.; Yang, X.; Zhou, A. Trajspark: A Scalable and Efficient in-memory Management System for Big Trajectory Data; Springer: Berlin, Germany, 2017; pp. 11–26. [Google Scholar]
- Alarabi, L.; Mokbel, M.F.; Musleh, M. St-hadoop: A Mapreduce Framework for Spatio-Temporal Data. GeoInformatica 2018, 22, 785–813. [Google Scholar] [CrossRef]
- Dividino, R.; Soares, A.; Matwin, S.; Isenor, A.W.; Webb, S.; Brousseau, M. Semantic Integration of Real-Time Heterogeneous Data Streams for Ocean-Related Decision Making. Big Data Artif. Intell. Mil. Decis. Mak. STO 2018. [Google Scholar] [CrossRef]
- Nikitopoulos, P.; Vlachou, A.; Doulkeridis, C.; Vouros, G.A. DiStRDF: Distributed Spatio-temporal RDF Queries on Spark. In Proceedings of the EDBT/ICDT Workshops, Vienna, Austria, 26 March 2018; pp. 125–132. [Google Scholar]
- Soares, A.; Rose, J.; Etemad, M.; Renso, C.; Matwin, S. VISTA: A Visual Analytics Platform for Semantic Annotation of Trajectories. In Proceedings of the 22nd International Conference on Extending Database Technology (EDBT), Lisbon, Portugal, 26 March 2019; pp. 570–573. [Google Scholar]
- Georgiou, H.; Karagiorgou, S.; Kontoulis, Y.; Pelekis, N.; Petrou, P.; Scarlatti, D.; Theodoridis, Y. Moving Objects Analytics: Survey on Future Location & Trajectory Prediction Methods. arXiv 2018, arXiv:1807.04639. [Google Scholar]
- Zheng, Y.; Zhou, X. Computing with Spatial Trajectories; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Meratnia, N.; Rolf, A. Spatiotemporal Compression Techniques for Moving Point Objects; Springer: Berlin, Germany, 2004; pp. 765–782. [Google Scholar]
- Potamias, M.; Patroumpas, K.; Sellis, T. Sampling trajectory streams with spatiotemporal criteria. In Proceedings of the 18th International Conference on Scientific and Statistical Database Management (SSDBM’06), Vienna, Austria, 3–5 July 2006; pp. 275–284. [Google Scholar]
- Lee, J.G.; Kang, M. Geospatial Big Data: Challenges and Opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Burrough, P.A.; McDonnell, R.; McDonnell, R.A.; Lloyd, C.D. Principles of Geographical Information Systems; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Smith, T.R.; Menon, S.; Star, J.L.; Estes, J.E. Requirements and Principles for the Implementation and Construction of Large-Scale Geographic Information Systems. Int. J. Geogr. Inf. Syst. 1987, 1, 13–31. [Google Scholar] [CrossRef]
- Galić, Z.; Mešković, E.; Osmanović, D. Distributed Processing of Big Mobility Data as Spatio-Temporal Data Streams. Geoinformatica 2017, 21, 263–291. [Google Scholar] [CrossRef]
- Franklin, M.; Halevy, A.; Maier, D. From Databases to Dataspaces: A New Abstraction for Information Management. ACM Sigmod Rec. 2005, 34, 27–33. [Google Scholar] [CrossRef]
- Franklin, M.; Halevy, A.; Maier, D. A First, Tutorial on Dataspaces. Proc. VLDB Endow. 2008, 1, 1516–1517. [Google Scholar] [CrossRef]
- Halevy, A.; Franklin, M.; Maier, D. Principles of Dataspace Systems. In Proceedings of the Twenty-fifth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Chicago, IL, USA, 27 June 2006; pp. 1–9. [Google Scholar]
- International Organization for Standardization. ISO 19108 Geographic Information—Temporal Schema; ISO/TC 211, I; International Organization for Standardization: Geneva, Switzerland, 2002. [Google Scholar]
- International Organization for Standardization. ISO 19107 Geographic Information—Spatial Schema; ISO/TC 211, I; International Organization for Standardization: Geneva, Switzerland, 2003. [Google Scholar]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache flink: Stream and Batch Processing in a Single Engine. Bull. IEEE Comput. Soc. Tech. Comm. Data Eng. 2015, 36, 28–38. [Google Scholar]
- Marz, N.; Warren, J. Big Data: Principles and Best Practices of Scalable Real-Time Data Systems; Manning Publications Co.: New York, NY, USA, 2015; p. 328. [Google Scholar]
- Lenka, R.K.; Barik, R.K.; Gupta, N.; Ali, S.M.; Rath, A.; Dubey, H. Comparative Analysis of SpatialHadoop and GeoSpark for Geospatial Big Data Analytics. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Greater Noida, India, 14–17 December 2016; pp. 484–488. [Google Scholar]
- Marcu, O.C.; Costan, A.; Antoniu, G.; Pérez-Hernández, M.S. Spark Versus Flink: Understanding Performance in Big Data Analytics Frameworks. In Proceedings of the 2016 IEEE International Conference on Cluster Computing (CLUSTER), Beijing, China, 24–28 September 2012; pp. 433–442. [Google Scholar]
- Pelekis, N.; Theodoridis, Y.; Vosinakis, S.; Panayiotopoulos, T. Hermes—A Framework for Location-Based Data Management; Springer: Berlin, Germany, 2006; pp. 1130–1134. [Google Scholar]
- Santana, L.H.Z.; dos Santos Mello, R. Workload-Aware RDF Partitioning and SPARQL Query Caching for Massive RDF Graphs Stored in NoSQL Databases. SBBD 2017, 32, 184–195. [Google Scholar]
- Sorce, S.; Malizia, A.; Jiang, P.; Atherton, M.; Harrison, D. A Novel Visual Interface to Foster Innovation in Mechanical Engineering and Protect from Patent Infringement. J. Phys. 2018, 1004, 012024. [Google Scholar] [CrossRef]
- Newson, P.; Krumm, J. Hidden Markov Map Matching through Noise and Sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, November 2009; pp. 336–343. [Google Scholar]
- Giannotti, F.; Pedreschi, D. Mobility, Data Mining and Privacy: Geographic Knowledge Discovery; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Giannotti, F.; Nanni, M.; Pedreschi, D.; Renso, C. GeoPKDD Geographic Privacy-aware Knowledge Discovery 2009. Available online: https://pdfs.semanticscholar.org/f6c8/d0b66289c78b62e7877cbf60f1f09f1ba72e.pdf (accessed on 31 January 2020).
- Luján-Mora, S.; Trujillo, J. A Comprehensive Method for Data Warehouse Design. In Proceedings of the 5th International Workshop on Design and Management of Data Warehouses, DMDW’03, Berlin, Germany, 8 September 2003. [Google Scholar]
- Sheth, A.P.; Larson, J.A. Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases. ACM Comput. Surv. (CSUR) 1990, 22, 183–236. [Google Scholar] [CrossRef]
- Rigaux, P.; Scholl, M.; Voisard, A. Spatial Databases: With Application to GIS; Elsevier: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Ponniah, P. Data Warehousing Fundamentals for IT Professionals; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Gómez, L.; Kuijpers, B.; Moelans, B.; Vaisman, A. A State-of-the-art in Spatio-Temporal Data Warehousing, OLAP and Mining. In Data Mining: Concepts, Methodologies, Tools, and Applications; IGI Global: Pittsburgh, PA, USA, 2013; pp. 2021–2056. [Google Scholar]
- Brakatsoulas, S.; Pfoser, D.; Salas, R.; Wenk, C. On Map-Matching Vehicle Tracking Data. In Proceedings of the 31st International Conference on Very Large Data Bases, VLDB Endowment, Trondheim Norway, August 2005; pp. 853–864. [Google Scholar]
- Ibragimov, D.; Hose, K.; Pedersen, T.B.; Zimányi, E. Towards Exploratory OLAP over Linked Open Data—A Case Study. In Enabling Real-Time Business Intelligence; Springer: Berlin, Germany, 2014; pp. 114–132. [Google Scholar]
- Etcheverry, L.; Vaisman, A.A. QB4OLAP: A New Vocabulary for OLAP Cubes on the Semantic Web. In Proceedings of the Third International Conference on Consuming Linked Data, Boston, MA, USA, 12 November 2012; Volume 905, pp. 27–38. [Google Scholar]
- Siow, E.; Tiropanis, T.; Hall, W. Analytics for the Internet of Things: A survey. ACM Comput. Surv. 2018, 51, 74. [Google Scholar] [CrossRef]
- Leite, D.F.B.; de Souza Baptista, C.; de Oliveira, M.G.; Acioli Filho, J.A.M.; da Silva, T.E. ExpOLAP: Towards Exploratory OLAP. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 2 December 2016; pp. 1–8. [Google Scholar]
- Rivest, S.; Bédard, Y.; Proulx, M.J.; Nadeau, M. SOLAP: A New Type of User Interface to Support Spatio-Temporal Multi-dimensional Data Exploration and Analysis. In Proceedings of the ISPRS Joint Workshop on Spatial, Temporal and Multi-Dimensional Data Modelling and Analysis, Quebec, QC, Canada, October 2003; pp. 2–3. [Google Scholar]
- Leite, D.F.B.; Baptista, C.D.S.; Amorim, B.D.S.P. An exploratory SOLAP tool for linked open data. Int. J. Bus. Inf. Syst. 2019, 31, 391–413. [Google Scholar] [CrossRef]
- Furtado, A.S.; Pilla, L.L.; Bogorny, V. A Branch and Bound Strategy for Fast Trajectory Similarity Measuring. Data Knowl. Eng. 2018, 115, 16–31. [Google Scholar] [CrossRef]
- Keskin, S.; Yazici, A. Modelling and Designing Spatial and Temporal Big Data for Analytics; Springer: Berlin, Germany, 2018; pp. 104–112. [Google Scholar]
- Kong, X.; Song, X.; Xia, F.; Guo, H.; Wang, J.; Tolba, A. LoTAD: Long-Term Traffic Anomaly Detection Based on Crowdsourced Bus Trajectory Data. World Wide Web 2018, 21, 825–847. [Google Scholar] [CrossRef]
- Andrienko, N.; Andrienko, G.; Fuchs, G.; Jankowski, P. Visual Analytics Methodology for Scalable and Privacy-Respectful Discovery of Place Semantics from Episodic Mobility Data; Springer: Berlin, Germany, 2015; pp. 254–258. [Google Scholar]
- Kong, L.; He, L.; Liu, X.Y.; Gu, Y.; Wu, M.Y.; Liu, X. Privacy-Preserving Compressive Sensing for Crowdsensing Based Trajectory Recovery. In Proceedings of the 2015 IEEE 35th International Conference on Distributed Computing Systems, Columbus, OH, USA, 29 June 2015; pp. 31–40. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Title of Work | Category of Evaluation | Key Findings |
|---|---|---|---|---|
| Braz [36] | 2007 | Trajectory Data Warehouses: Proposal of Design and Application to Exploit Data | D | A | An application to store and compute the pre-aggregation values and to present final results about the trajectories |
| Orlando et al. [37] | 2007 | Trajectory Data Warehouses: Design and Implementation Issues | D | Challenges issues in design of a Trajectory Data Warehouse |
| Marketos et al. [38] | 2008 | Building Real-World Trajectory Warehouses | I | D | A | The steps for building a TDW |
| Leonardi et al. [39] | 2010 | T-warehouse: Visual OLAP Analysis on Trajectory Data | I | D | A | Visual OLAP analytics |
| Yan et al. [26] | 2011 | SeMiTri: A Framework for Semantic Annotation of Heterogeneous Trajectories | I | D | A | Semantic trajectory annotation |
| Wagner et al. [31] | 2013 | Mob-Warehouse: A Semantic Approach for Mobility Analysis with a Trajectory Data Warehouse | D | A Trajectory Data Warehouse model to answer the classical Why, Who, When, Where, What, How questions |
| Bogorny et al. [3] | 2014 | CONSTAnT—A Conceptual Data Model for Semantic Trajectories of Moving Objects | I | A semantic trajectory conceptual data model |
| Fileto et al. [15] | 2014 | A Semantic Model for Movement Data Warehouses | D | Multi-dimensional model for movement segments, movement patterns, their categories and hierarchies |
| Leonardi et al. [40] | 2014 | A General Framework for Trajectory Data Warehousing and Visual OLAP | D | A | A formal framework for modelling a trajectory data warehouse |
| Fileto et al. [32] | 2015 | The Baquara2 Knowledge-Based Framework for Semantic Enrichment and Analysis of Movement Data | D | A framework to semantically enrich and analyze movement data |
| Silva et al. [41] | 2015 | SWOT: A Conceptual Data Warehouse Model for Semantic Trajectories | D | A conceptual TDW model for answering semantic enriched mobility queries |
| Bao et al. [42] | 2016 | Managing Massive Trajectories on the Cloud | I | Trajectory data management |
| Galić [43] | 2016 | Spatio-Temporal Data Streams and Big Data Paradigm | I | Real-Time parallel processing |
| Manaa & Akaichi [44] | 2016 | Ontology-Based Trajectory Data Warehouse Conceptual Model | D | A trajectory data warehouse conceptual model based on ontology |
| Soares et al. [45] | 2017 | ANALYTiC: An Active Learning System for Trajectory Classification | I | Semantic enrichment of movement data |
| Zhang et al. [46] | 2017 | Trajspark: A Scalable and Efficient in-memory Management System for Big Trajectory Data | I | Big trajectory data support |
| Alarabi et al. [47] | 2018 | St-hadoop: A Mapreduce Framework for spatio-temporal data | I | MapReduce-Based systems |
| Dividino et al. [48] | 2018 | Semantic Integration of Real-Time Heterogeneous Data Streams for Ocean-Related Decision Making | I | Data streaming integration for real-time maritime situation |
| Nikitopoulos et al. [49] | 2018 | DiStRDF: Distributed Spatio-temporal RDF Queries on Spark | I | Processing SPARQL spatio-temporal queries in parallel Spark framework |
| Alsah et al. [14] | 2019 | A Survey on Trajectory Data Warehouse | I | D | A | A framework that aims to provide the requirements for building a TDW |
| Soares et al. [50] | 2019 | VISTA: A Visual Analytics Platform for Semantic Annotation of Trajectories | I | Trajectory annotation |
| Mello et al. [33] | 2019 | MASTER: A Multiple Aspect View on Trajectories | I | Conceptual and logical data model for multiple aspect trajectory |
| Reference | Year of Publication | Geometric Representation | Management Platforms or Storage | |
|---|---|---|---|---|
| Vector | Graphs | |||
| Leonardi et al. [39] | 2010 | ✔ | Hermes | |
| Yan et al. [26] | 2011 | ✔ | PostgreSQL+postgis | |
| Bao et al. [42] | 2016 | ✔ | ✔ | Azure and Redi |
| Galić [43] | 2016 | ✔ | Flink | |
| Soares et al. [45] | 2017 | ✔ | Solr | |
| Zhang et al. [46] | 2017 | ✔ | Spark | |
| Alarabi et al. [47] | 2018 | ✔ | Hadoop+HDFS | |
| Dividino et al. [48] | 2018 | ✔ | Apache Jena | |
| Nikitopoulos et al. [49] | 2018 | ✔ | Spark+Redis | |
| Soares et al. [50] | 2019 | ✔ | MongoDB | |
| Mello et al. [33] | 2019 | ✔ | Rendezvous | |
| Reference | Semantic Data | 5W1H | Semantic Annotation | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Who | What | When | Where | Why | How | Point | Seg | Traj | ||
| Yan et al. [26] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||
| Bao et al. [42] | ||||||||||
| Galić [43] | ||||||||||
| Soares et al. [45] | ✔ | ✔ | ✔ | |||||||
| Zhang et al. [46] | ||||||||||
| Alarabi et al. [47] | ||||||||||
| Dividino et al. [48] | ||||||||||
| Nikitopoulos et al. [49] | ||||||||||
| Soares et al. [50] | ✔ | ✔ | ✔ | |||||||
| Bogorny et al. [3] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Mello et al. [33] | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Reference | Year | Design Type | |
|---|---|---|---|
| Cell | Segment | ||
| Orlando et al. [37] | 2007 | ✔ | |
| Marketos et al. [38] | 2008 | ✔ | |
| Leonardi et al. [39] | 2010 | ✔ | |
| Wagner et al. [31] | 2013 | ✔ | |
| Leonardi et al. [40] | 2014 | ✔ | ✔ |
| Fileto et al. [15] | 2014 | ✔ | |
| Fileto et al. [32] | 2015 | ✔ | |
| Silva et al. [41] | 2015 | ✔ | |
| Manaa and Akaichi [44] | 2016 | ✔ | |
| Braz [36] | 2007 | ✔ | |
| Alsah et al. [14] | 2019 | ✔ | |
| Reference | Type | 5W1H | |||||
|---|---|---|---|---|---|---|---|
| Who | What | When | Where | Why | How | ||
| Fileto et al. [32] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Silva et al. [41] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Wagner et al. [31] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Manaa & Akaichi [44] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ||
| Leonardi et al. [40] | Conceptual model and implementation | ✔ | ✔ | ✔ | ✔ | ||
| Fileto et al. [15] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Alsah et al. [14] | Conceptual model | ✔ | ✔ | ✔ | ✔ | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ribeiro de Almeida, D.; de Souza Baptista, C.; Gomes de Andrade, F.; Soares, A. A Survey on Big Data for Trajectory Analytics. ISPRS Int. J. Geo-Inf. 2020, 9, 88. https://doi.org/10.3390/ijgi9020088
Ribeiro de Almeida D, de Souza Baptista C, Gomes de Andrade F, Soares A. A Survey on Big Data for Trajectory Analytics. ISPRS International Journal of Geo-Information. 2020; 9(2):88. https://doi.org/10.3390/ijgi9020088
Chicago/Turabian StyleRibeiro de Almeida, Damião, Cláudio de Souza Baptista, Fabio Gomes de Andrade, and Amilcar Soares. 2020. "A Survey on Big Data for Trajectory Analytics" ISPRS International Journal of Geo-Information 9, no. 2: 88. https://doi.org/10.3390/ijgi9020088
APA StyleRibeiro de Almeida, D., de Souza Baptista, C., Gomes de Andrade, F., & Soares, A. (2020). A Survey on Big Data for Trajectory Analytics. ISPRS International Journal of Geo-Information, 9(2), 88. https://doi.org/10.3390/ijgi9020088