Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows


Abstract
1. Introduction
2. Big Spatial Data and AI
- (1)
- Difficulty in calibrating training datasets: This problem often occurs in remote sensing data. The spatial resolution determines the size of each pixel and how much land it covers. For instance, if AI models use remote sensing data as inputs and ground-collected data as outputs, the accuracy can be critically affected if images are slightly shifted, resulting in ground sample points matching the wrong pixels. Appropriate project transformation and resampling algorithms are required to ensure the location match between input and output is right. Otherwise, the model will be very hard to converge and the trained models are useless.
- (2)
- Difficulty in synchronizing observation time: Most spatial information is also time-sensitive. The observation time is important to associate observed events with triggering causes and later potential consequences. Dealing with spatial data must keep in mind the data’s exact observation time, approximate observation period, and time zones (if the dataset is regional). In many studies, high temporal resolution granules are processed into more coarse resolution products, for example, daily, weekly, biweekly, monthly, or annual products [32]. The time processing could use maximum, minimum, average, standard deviation, and even some customized algorithms.
- (3)
- Difficulty in reducing the bias in training datasets: Most spatial datasets are naturally biased. For instance, in the North Dakota agriculture, the growing acres of canola are much smaller than soybean, creating bias in datasets that contain more soybean samples than canola. Bias creates problems for AI training, as AI will get much better accuracy on unbiased datasets. Extra processes need be done to reduce the bias in the training dataset such as batch normalization or restraining the representation sample numbers of each category in the training datasets [53]. However, one should be aware that bias is not the only reason for poor fitting performances and reducing bias might cause the trained model to underfit in the major classes and overfit in the minor classes. Scientists are still looking for solutions to balance between major and minor class samples.
- (4)
- Difficulty in treating data gaps: Data gaps caused by mechanical issues, weather, cloud, and human reasons are very common in long-term observatory datasets. A typical example of mechanics failure is the gap on the Landsat 7 imagery caused by the Scan Line Correction failure since 2003. Clouds are the major reason blocking satellites from observing the land surface. Misconduct by device operators can also cause gaps in the datasets. Data gaps may lead to missing information of key phenomenon and make AI models unable to capture the patterns. There are several proposed solutions to fill the gaps, but require human invention and take a long time, which is not very efficient for big data.
- (5)
- Difficulty in dealing with spatiotemporal data fuzziness: Fuzzy data, which are datasets using qualitative descriptions instead of quantitative measures, are everywhere [54]. Social media text [55], for example, will give a fuzzy location like “San Francisco” and fuzzy time like “yesterday” about some observed event. Spatiotemporal analysis normally requires a precise location (longitude/latitude) and time (accurate to hours/minutes/seconds) [56]. Feeding fuzzy information into AI models might make the models even more inaccurate. How to deal with fuzzy spatiotemporal data is also an important issue faced by AI today [57].
3. Workflow Management Software
3.1. Atomic Process
3.2. Function Chain
3.3. Error Control
3.4. Provenance
3.5. Big Data Processing Workflow
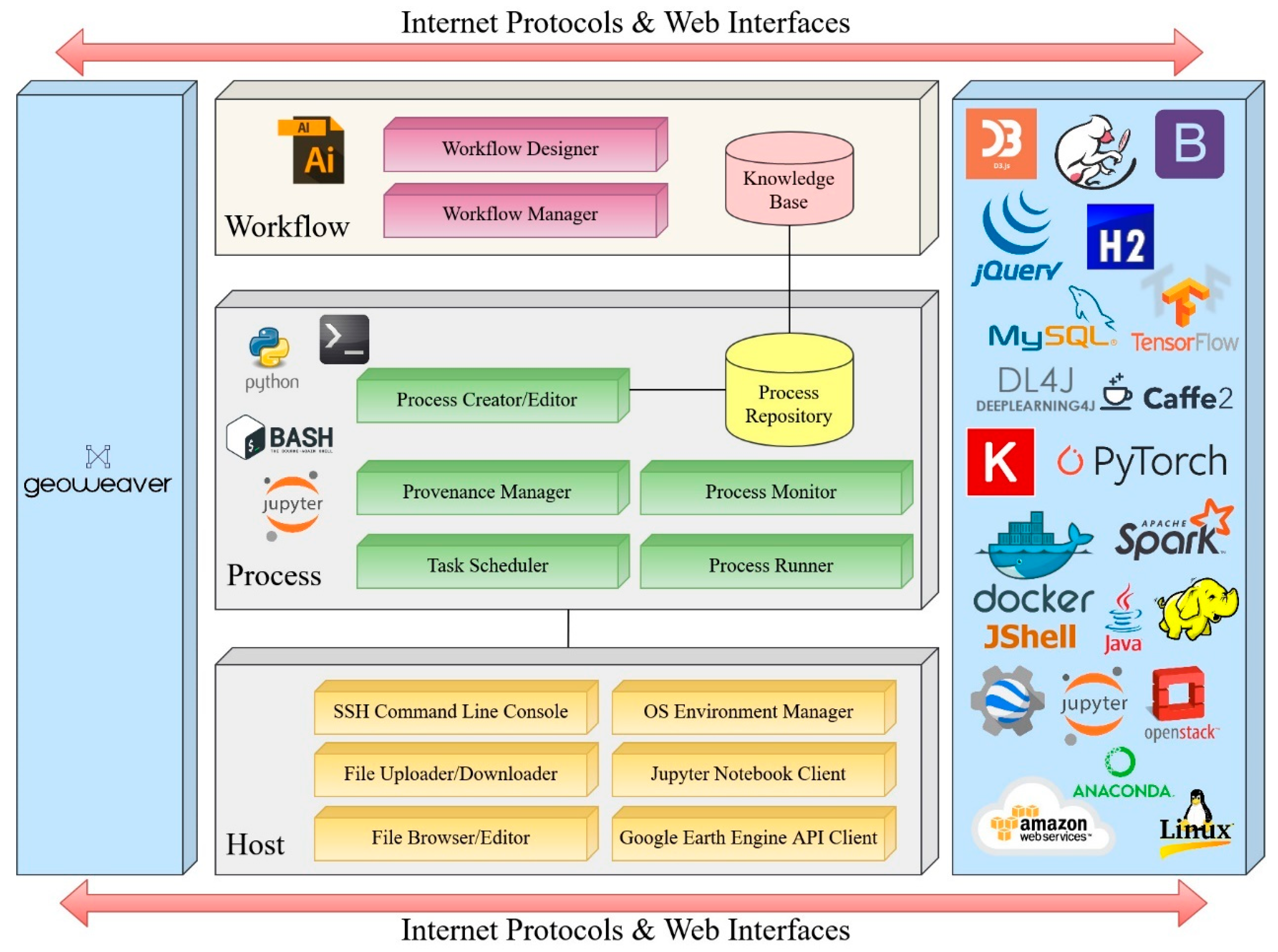
4. Framework
4.1. Host
4.2. Process
4.3. Workflow
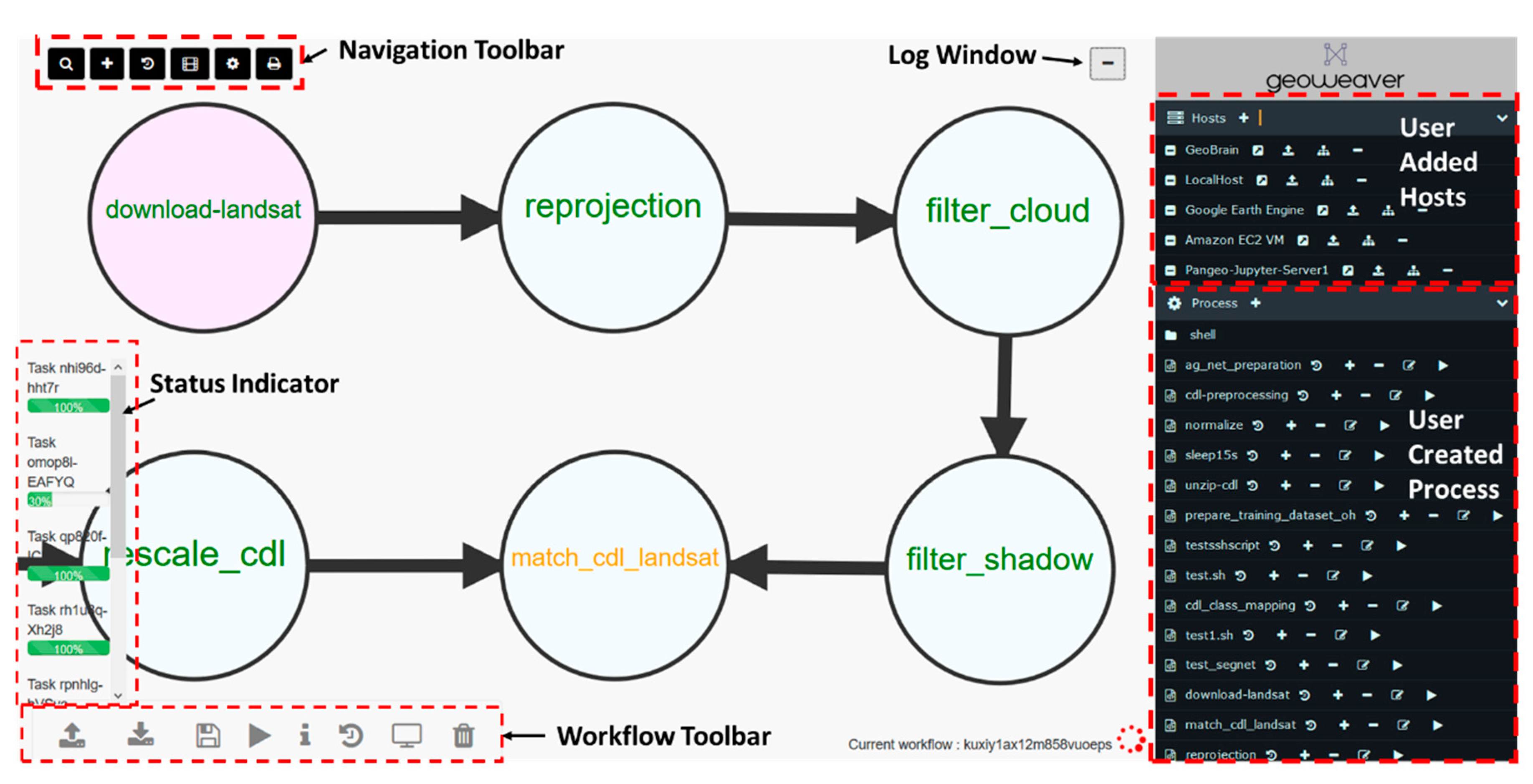
5. A Prototype: Geoweaver
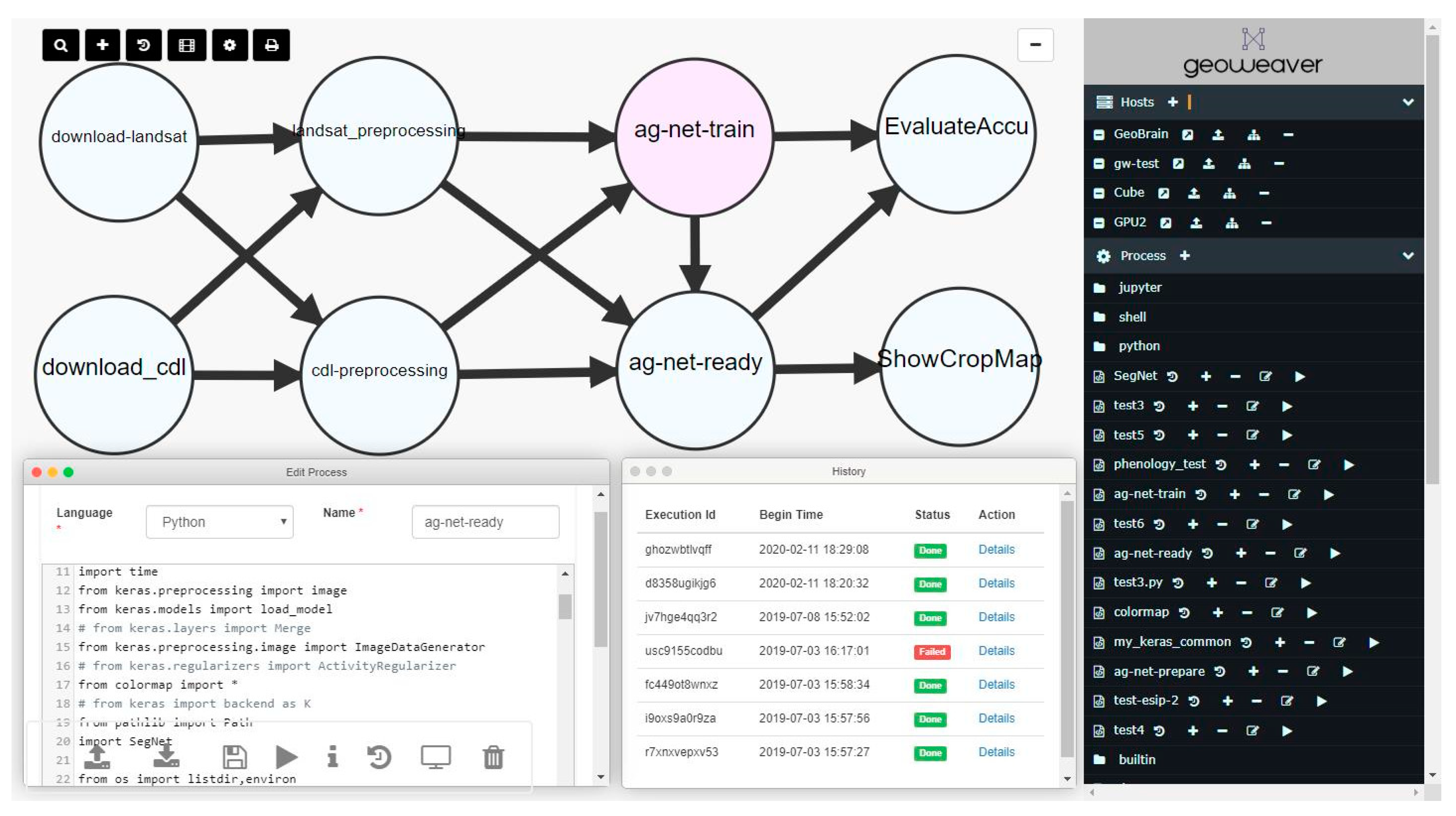
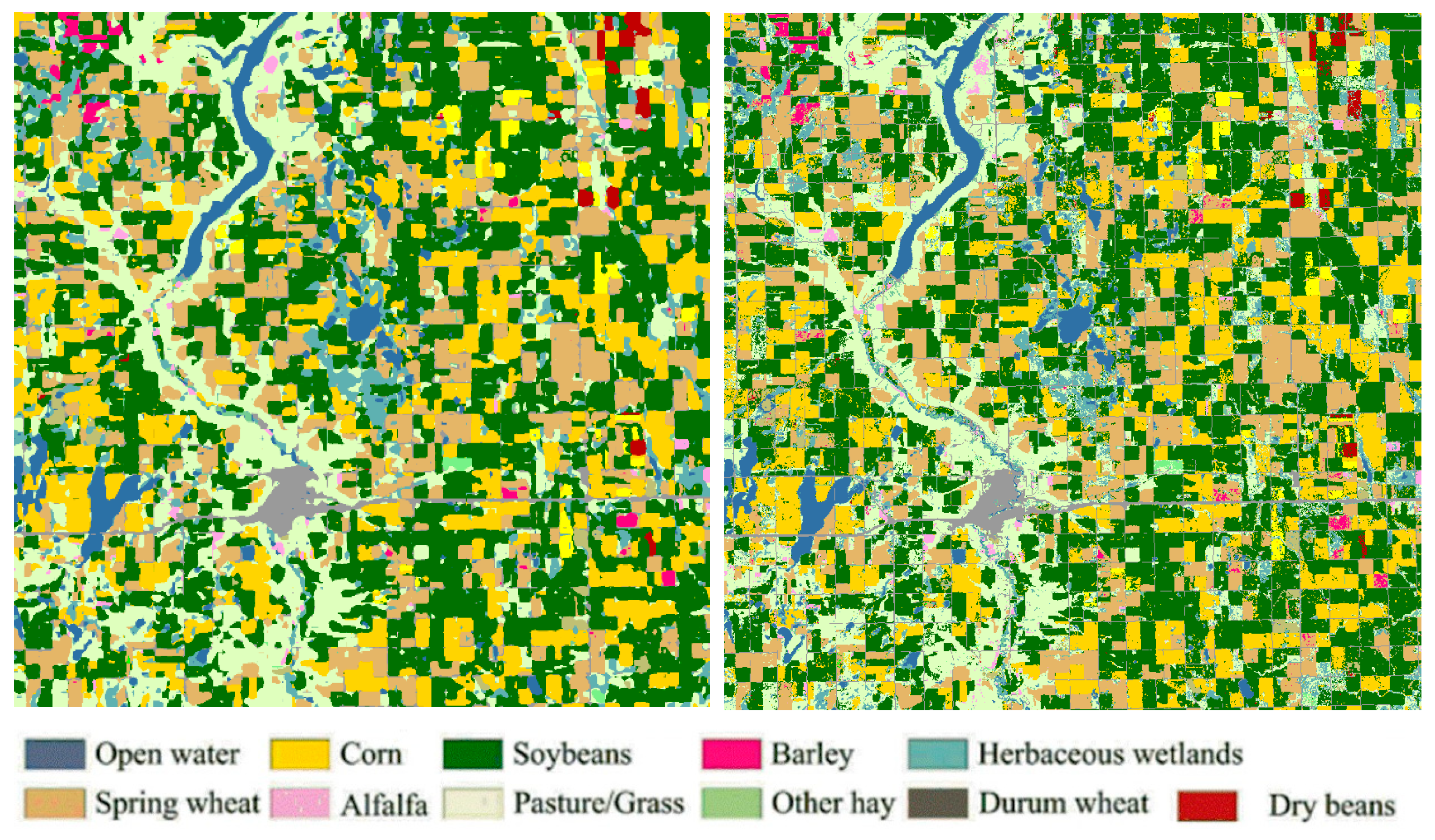
6. Use Case: AI-Based Agriculture Mapping
7. Discussion
- (1)
- Hybrid Workflow: Geoweaver can help AI practitioners to take advantage of both public resources and private resources and combine them together into one workflow. The training dataset preparation needs a lot of legacy datasets and the programs transforming them into AI-ready format. However, the AI model training facilities are mostly in the public domain, such as Amazon EC2 GPU instances. It is hard to connect the legacy data processing with the AI model training using other WfMS. Geoweaver uses the host module and dynamic computing binding to allow scientists to combine the processes executed on private servers and the public platforms into one workflow and enable the hybrid workflow management in one place.
- (2)
- Full Access of Remote Files: As mentioned above, most files associated with AI workflow are stored on remote servers/virtual machines. Users always appreciate the tools that allow them to have full and convenient control over the actual files, including creating new files, browsing file folder structure, downloading files, and editing files in place. Geoweaver is not only a workflow system, but also a file management system of multiple remote servers.
- (3)
- Hidden Data Flow: Business workflows such as BPEL usually separate the content of workflow into two divisions: control flow and data flow. The former defines the sequence of involved processes, and the latter defines the data transfer among input and output variables. It takes a lot of attention to maintain the data flow once the data are big and the file count is dynamic. Geoweaver can create a familiar environment for people to create the workflows without concern about the data flow. Each process is independent and data flow is taken care of by the process content logic.
- (4)
- Code-Machine Separation: Another feature of Geoweaver is that it separates the code from the execution machine. There are couples of benefits by doing this. The code will be managed in one place and version control for better code integrity would be much easier. Geoweaver will dynamically write code into a file on the remote servers and execute the code. Once the process is over, Geoweaver will remove the code from the remote servers. Regarding the fact that the GPU servers are usually shared by multiple users, the mechanism will better protect the code privacy from other users on the same machine.
- (5)
- Process-Oriented Provenance: Distinct from data-centric provenance architecture, Geoweaver uses process as major objects to record provenance. The recorded information is also different. In Geoweaver, the inputs are the executed code content, and the outputs are the execution log. Rather than storing partially completed data products, process-oriented provenance can save disk space and enrich the history information of the final data products. Process-oriented provenance can prevent barriers to reproduction of the workflow that would otherwise be caused by changes to the code.
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Deep learning of representations: Looking forward. In Proceedings of the International Conference on Statistical Language and Speech Processing, Ljubljana, Slovenias, 14–16 October 2019. [Google Scholar]
- Sun, Z. Some Basics of Deep Learning in Agriculture. 2019. [Google Scholar] [CrossRef]
- Sun, Z. Automatically Recognize Crops from Landsat by U-Net, Keras and Tensorflow. Available online: https://medium.com/artificial-intelligence-in-geoscience/automatically-recognize-crops-from-landsat-by-u-net-keras-and-tensorflow-7c5f4f666231 (accessed on 26 January 2020).
- Sun, Z.; Di, L.; Fang, H. Using long short-term memory recurrent neural network in land cover classification on Landsat and Cropland data layer time series. Int. J. Remote Sens. 2018, 40, 593–614. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; El-Shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial intelligence based models for stream-flow forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195. [Google Scholar] [CrossRef] [PubMed]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Heermann, P.D.; Khazenie, N. Classification of multispectral remote sensing data using a back-propagation neural network. Geosci. Remote Sens. 1992, 30, 81–88. [Google Scholar] [CrossRef]
- Britt, A. Kohonen neural networks and language. Brain Lang. 1999, 70, 86–94. [Google Scholar] [CrossRef]
- Pao, Y. Adaptive Pattern Recognition and Neural Networks; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Frankish, K.; Ramsey, W.M. The Cambridge Handbook of Artificial Intelligence; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef]
- Kök, İ.; Şimşek, M.U.; Özdemir, S. A deep learning model for air quality prediction in smart cities. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017. [Google Scholar]
- Cook, D.J. How smart is your home? Science 2012, 335, 1579–1581. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Dilek, S.; Çakır, H.; Aydın, M. Applications of artificial intelligence techniques to combating cyber crimes: A review. arXiv 2015, arXiv:1502.03552. [Google Scholar] [CrossRef]
- Tsipis, K. 3Q: Machine Learning and Climate Modeling. Available online: http://news.mit.edu/2019/mit-3q-paul-o-gorman-machine-learning-for-climate-modeling-0213 (accessed on 7 June 2019).
- Sattar, A.M.; Ertuğrul, Ö.F.; Gharabaghi, B.; McBean, E.A.; Cao, J. Extreme learning machine model for water network management. Neural Comput. Appl. 2019, 31, 157–169. [Google Scholar] [CrossRef]
- Bergen, K.J.; Johnson, P.A.; Maarten, V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef]
- Watson, G.L.; Telesca, D.; Reid, C.E.; Pfister, G.G.; Jerrett, M. Machine learning models accurately predict ozone exposure during wildfire events. Environ. Pollut. 2019, 254, 112792. [Google Scholar] [CrossRef]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Spina, R. Big Data and Artificial Intelligence Analytics in Geosciences: Promises and Potential. GSA Today 2019, 29, 42–43. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet (accessed on 21 February 2020).
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef]
- Rasp, S.; Pritchard, M.S.; Gentine, P. Deep learning to represent subgrid processes in climate models. Proc. Natl. Acad. Sci. USA 2018, 115, 9684–9689. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Di, L.; Huang, H.; Wu, X.; Tong, D.Q.; Zhang, C.; Virgei, C.; Fang, H.; Yu, E.; Tan, X. CyberConnector: A service-oriented system for automatically tailoring multisource Earth observation data to feed Earth science models. Earth Sci. Inform. 2017, 11, 1–17. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Cash, B.; Gaigalas, J. Advanced cyberinfrastructure for intercomparison and validation of climate models. Environ. Model. Softw. 2019, 123, 104559. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L. CyberConnector COVALI: Enabling inter-comparison and validation of Earth science models. In Proceedings of the AGU Fall Meeting Abstracts, San Francisco, CA, USA, 31 July 2019. [Google Scholar]
- O’Leary, D.E. Artificial intelligence and big data. IEEE Intell. Syst. 2013, 28, 96–99. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.-A.; Yang, S. Service innovation and smart analytics for industry 4.0 and big data environment. Procedia Cirp 2014, 16, 3–8. [Google Scholar] [CrossRef]
- Wikipedia. Big Data. Available online: http://en.wikipedia.org/wiki/Big_data (accessed on 21 September 2014).
- Manyika, J. Big Data: The Next Frontier for Innovation, Competition, and Productivity. Available online: http://www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_The_next_frontier_for_innovation (accessed on 26 January 2020).
- Weiss, R.; Zgorski, L.-J. Obama administration unveils “big data” initiative: Announces $200 million in new R&D investments. Off. Sci. Technol. Policy Exec. Off. Pres. 2012. [Google Scholar]
- Yue, P.; Jiang, L. BigGIS: How big data can shape next-generation GIS. In Proceedings of the 2014 the Third International conference on Agro-Geoinformatics, Beijing, China, 11–14 August 2014; pp. 1–6. [Google Scholar]
- Borthakur, D. The hadoop distributed file system: Architecture and design. Hadoop Proj. Website 2007, 11, 21. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- George, L. HBase: The Definitive Guide: Random Access to Your Planet-Size Data; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2011. [Google Scholar]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Anthony, S.; Liu, H.; Wyckoff, P.; Murthy, R. Hive: A warehousing solution over a map-reduce framework. Proc. VLDB Endow. 2009, 2, 1626–1629. [Google Scholar] [CrossRef]
- Chodorow, K. MongoDB: The Definitive Guide: Powerful and Scalable Data Storage; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2013. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Varia, J.; Mathew, S. Overview of Amazon web Services. Available online: http://cabibbo.dia.uniroma3.it/asw-2014-2015/altrui/AWS_Overview.pdf (accessed on 26 January 2020).
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.E.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.B.; Grout, J.; Corlay, S. Jupyter Notebooks-a publishing format for reproducible computational workflows. In Proceedings of the 20th International Conference on Electronic Publishing, Göttingen, Germany, June 2016; pp. 87–90. [Google Scholar]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Ranjan, R. Streaming big data processing in datacenter clouds. IEEE Cloud Comput. 2014, 1, 78–83. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Rathore, M.M.U.; Paul, A.; Ahmad, A.; Chen, B.W.; Huang, B.; Ji, W. Real-Time Big Data Analytical Architecture for Remote Sensing Application. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4610–4621. [Google Scholar] [CrossRef]
- Sun, Z.; Yue, P.; Lu, X.; Zhai, X.; Hu, L. A Task Ontology Driven Approach for Live Geoprocessing in a Service Oriented Environment. Trans. GIS 2012, 16, 867–884. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Schneider, M. Uncertainty management for spatial datain databases: Fuzzy spatial data types. In Proceedings of the International Symposium on Spatial Databases, Hong Kong, China, 26–28 August 2013. [Google Scholar]
- Camponovo, M.E.; Freundschuh, S.M. Assessing uncertainty in VGI for emergency response. Cartogr. Geogr. Inf. Sci. 2014, 41, 440–455. [Google Scholar] [CrossRef]
- Vatsavai, R.R.; Ganguly, A.; Chandola, V.; Stefanidis, A.; Klasky, S.; Shekhar, S. Spatiotemporal data mining in the era of big spatial data: Algorithms and applications. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Redondo Beach, CA, USA, 6 November 2012. [Google Scholar]
- Couso, I.; Borgelt, C.; Hullermeier, E.; Kruse, R. Fuzzy sets in data analysis: From statistical foundations to machine learning. IEEE Comput. Intell. Mag. 2019, 14, 31–44. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Chen, A.; Yue, P.; Gong, J. The use of geospatial workflows to support automatic detection of complex geospatial features from high resolution images. In Proceedings of the 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Fairfax, VA, USA, 12–16 August 2013. [Google Scholar]
- Sun, Z.; Yue, P. The use of Web 2.0 and geoprocessing services to support geoscientific workflows. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010. [Google Scholar]
- Sun, Z.; Yue, P.; Di, L. GeoPWTManager: A task-oriented web geoprocessing system. Comput. Geosci. 2012, 47, 34–45. [Google Scholar] [CrossRef]
- Cohen-Boulakia, S.; Belhajjame, K.; Collin, O.; Chopard, J.; Froidevaux, C.; Gaignard, A.; Hinsen, K.; Larmande, P.; Le Bras, Y.; Lemoine, F. Scientific workflows for computational reproducibility in the life sciences: Status, challenges and opportunities. Future Gener. Comput. Syst. 2017, 75, 284–298. [Google Scholar] [CrossRef]
- Taylor, I.; Deelman, E.; Gannon, D. Workflows for e-Science: Scientific Workflows for Grids; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Allen, D.W. Getting to Know ArcGIS ModelBuilder; Esri Press: Redlands, CA, USA, 2011. [Google Scholar]
- Heloisa Martins, S.; Tseng, M.M. Workflow technology-based monitoring and control for business process and project management. Int. J. Proj. Manag. 1996, 14, 373–378. [Google Scholar] [CrossRef]
- Yue, P.; Gong, J.Y.; Di, L.P. Automatic Transformation from Semantic Description to Syntactic Specification for Geo-Processing Service Chains. In Proceedings of the Web and Wireless Geographical Information Systems, Naples, Italy, 12–13 April 2012. [Google Scholar]
- Sun, Z.; Di, L.; Gaigalas, J. SUIS: Simplify the use of geospatial web services in environmental modelling. Environ. Model. Softw. 2019, 119, 228–241. [Google Scholar] [CrossRef]
- Juric, M.B.; Krizevnik, M. WS-BPEL 2.0 for SOA Composite Applications with Oracle SOA Suite 11g; Packt Publishing Ltd.: Birmingham, UK, 2010. [Google Scholar]
- Raschka, S. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Sun, Z.; Peng, C.; Deng, M.; Chen, A.; Yue, P.; Fang, H.; Di, L. Automation of Customized and Near-Real-Time Vegetation Condition Index Generation Through Cyberinfrastructure-Based Geoprocessing Workflows. Sel. Top. Appl. Earth Obs. Remote Sens. IEEE J. 2014, 7, 4512–4522. [Google Scholar] [CrossRef]
- WfMC, W.P.D.I.X. Process Definition Language (XPDL), WfMC Standards; WFMC: Washington, DC, USA, 2001. [Google Scholar]
- Moreau, L.; Missier, P.; Belhajjame, K.; B’Far, R.; Cheney, J.; Coppens, S.; Cresswell, S.; Gil, Y.; Groth, P.; Klyne, G. Prov-dm: The prov data model. Retrieved July 2013, 30, W3C. [Google Scholar]
- Goble, C.A.; Bhagat, J.; Aleksejevs, S.; Cruickshank, D.; Michaelides, D.; Newman, D.; Borkum, M.; Bechhofer, S.; Roos, M.; Li, P. myExperiment: A repository and social network for the sharing of bioinformatics workflows. Nucleic Acids Res. 2010, 38, W677–W682. [Google Scholar] [CrossRef] [PubMed]
- Goecks, J.; Nekrutenko, A.; Taylor, J. Galaxy: A comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences. Genome Biol. 2010, 11, R86. [Google Scholar] [CrossRef] [PubMed]
- Ludäscher, B.; Altintas, I.; Berkley, C.; Higgins, D.; Jaeger, E.; Jones, M.; Lee, E.A.; Tao, J.; Zhao, Y. Scientific workflow management and the Kepler system. Concurr. Comput. Pract. Exp. 2006, 18, 1039–1065. [Google Scholar] [CrossRef]
- de Carvalho Silva, J.; de Oliveira Dantas, A.B.; de Carvalho Junior, F.H. A Scientific Workflow Management System for orchestration of parallel components in a cloud of large-scale parallel processing services. Sci. Comput. Program. 2019, 173, 95–127. [Google Scholar] [CrossRef]
- ACM, A. Artifact Review and Badging. Available online: https://www.acm.org/publications/policies/artifact-review-badging (accessed on 19 February 2020).
- Moreau, L. The Foundations for Provenance on the Web; Now Publishers: Hanover, MA, USA, 2010. [Google Scholar]
- McCaney, K. Machine Learning is Creating a Crisis in Science. Available online: https://www.governmentciomedia.com/machine-learning-creating-crisis-science (accessed on 26 January 2020).
- National Academies of Sciences, Engineering and Medicine. Reproducibility and Replicability in Science; The National Academies Press: Washington, DC, USA, 2019. [Google Scholar] [CrossRef]
- Di, L.; Yue, P.; Sun, Z. Ontology-supported complex feature discovery in a web service environment. In Proceedings of the 2012 IEEE International, Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany, 22–27 July 2012; pp. 2887–2890. [Google Scholar]
- Miller, D.D. The medical AI insurgency: What physicians must know about data to practice with intelligent machines. NPJ Digit. Med. 2019, 2, 1–5. [Google Scholar] [CrossRef]
- Tullis, J.A.; Cothren, J.D.; Lanter, D.P.; Shi, X.; Limp, W.F.; Linck, R.F.; Young, S.G.; Alsumaiti, T. Geoprocessing, Workflows, and Provenance. In Remotely Sensed Data Characterization, Classification, and Accuracies, Remote Sens. Handbook; Thenkabail, P., Ed.; CRC Press: Boca Raton, FL, USA, 2015; pp. 401–421. [Google Scholar]
- Tullis, J.A.; Corcoran, K.; Ham, R.; Kar, B.; Williamson, M. Multiuser Concepts and Workflow Replicability in sUAS Applications. In Applications of Small Unmanned Aircraft Systems; Sharma, J.B., Ed.; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Yue, P.; Sun, Z.; Gong, J.; Di, L.; Lu, X. A provenance framework for Web geoprocessing workflows. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium (IGARSS11), Vancouver, BC, Canada, 24–29 July 2011; pp. 3811–3814. [Google Scholar]
- Goodchild, M.; Fotheringham, S.; Li, W.; Kedron, P. Replicability and Reproducibility in Geospatial Research: A SPARC Workshop. Available online: https://sgsup.asu.edu/sparc/RRWorkshop (accessed on 26 January 2020).
- Naseri, M.; Ludwig, S.A. Evaluating workflow trust using hidden markov modeling and provenance data. In Data Provenance and Data Management in eScience; Springer: Berlin/Heidelberg, Germany, 2013; pp. 35–58. [Google Scholar]
- Roemerman, S. Four Reasons Data Provenance is Vital for Analytics and AI. Available online: https://www.forbes.com/sites/forbestechcouncil/2019/05/22/four-reasons-data-provenance-is-vital-for-analytics-and-ai/ (accessed on 23 December 2019).
- Sun, Z.; Di, L.; Tong, D.; Burgess, A.B. Advanced Geospatial Cyberinfrastructure for Deep Learning Posters. In Proceedings of the AGU Fall Meeting, San Francisco, CA, USA, 9–13 December 2019. [Google Scholar]
- Caíno-Lores, S.; Lapin, A.; Carretero, J.; Kropf, P. Applying big data paradigms to a large scale scientific workflow: Lessons learned and future directions. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Oliver, H.J.; Shin, M.; Sanders, O. Cylc: A Workflow Engine for Cycling Systems. J. Open Source Softw. 2018, 3, 737. [Google Scholar] [CrossRef]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Heo, G.; Zhang, C.; Fang, H.; Yue, P.; Jiang, L.; Tan, X.; Guo, L.; Lin, L. GeoFairy: Towards a one-stop and location based Service for Geospatial Information Retrieval. Comput. Environ. Urban Syst. 2017, 62, 156–167. [Google Scholar] [CrossRef]
- Tan, X.; Di, L.; Deng, M.; Huang, F.; Ye, X.; Sha, Z.; Sun, Z.; Gong, W.; Shao, Y.; Huang, C. Agent-as-a-service-based geospatial service aggregation in the cloud: A case study of flood response. Environ. Model. Softw. 2016, 84, 210–225. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Jain, L.; Jain, S. Cloud computing: A study of infrastructure as a service (IAAS). Int. J. Eng. Inf. Technol. 2010, 2, 60–63. [Google Scholar]
- Reed, D.A.; Dongarra, J. Exascale computing and big data. Commun. ACM 2015, 58, 56–68. [Google Scholar] [CrossRef]
- Contributors, W. Big Data. Available online: https://en.wikipedia.org/w/index.php?title=Big_data&oldid=925811014 (accessed on 14 November 2019).
- Arendt, A.A.; Hamman, J.; Rocklin, M.; Tan, A.; Fatland, D.R.; Joughin, J.; Gutmann, E.D.; Setiawan, L.; Henderson, S.T. Pangeo: Community tools for analysis of Earth Science Data in the Cloud. In Proceedings of the AGU Fall Meeting Abstracts, San Francisco, CA, USA, 31 July 2019. [Google Scholar]
- Ketkar, N. Introduction to pytorch. In Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; pp. 195–208. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the OSDI, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Sun, Z.; Di, L. Geoweaver: A Web-Based Prototype System for Managing Compound Geospatial Workflows of Large-Scale Distributed Deep Networks. 2019. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Fang, H.; Burgess, A.B.; Singh, N. Deep Learning Cyberinfrastructure for Crop Semantic Segmentation. In Proceedings of the AGU Fall Meetin, San Francisco, CA, USA, 31 July 2019. [Google Scholar]
- Sun, Z.; Fang, H.; Di, L.; Yue, P.; Tan, X.; Bai, Y. Developing a web-based system for supervised classification of remote sensing images. GeoInformatica 2016, 20, 629–649. [Google Scholar] [CrossRef]
- Sun, Z.; Fang, H.; Di, L.; Yue, P. Realizing parameterless automatic classification of remote sensing imagery using ontology engineering and cyberinfrastructure techniques. Comput. Geosci. 2016, 94, 56–67. [Google Scholar] [CrossRef]
- Sun, Z.; Fang, H.; Deng, M.; Chen, A.; Yue, P.; Di, L. Regular Shape Similarity Index: A Novel Index for Accurate Extraction of Regular Objects from Remote Sensing Images. Geosci. Remote Sens. 2015, 53, 3737–3748. [Google Scholar] [CrossRef]
- You, M.C.; Sun, Z.; Di, L.; Guo, Z. A web-based semi-automated method for semantic annotation of high schools in remote sensing images. In Proceedings of the Third International Conference on Agro-geoinformatics (Agro-geoinformatics 2014), Beijing, China, 11–14 August 2014; pp. 1–4. [Google Scholar]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Di, L.; Fang, H.; Guo, L.; Yu, E.; Tang, J.; Zhao, H.; Gaigalas, J.; Zhang, C.; Lin, L. Advanced Cyberinfrastructure for Agricultural Drought Monitoring. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; pp. 1–5. [Google Scholar]
- Han, W.; Yang, Z.; Di, L.; Mueller, R. CropScape: A Web service based application for exploring and disseminating US conterminous geospatial cropland data products for decision support. Comput. Electron. Agric. 2012, 84, 111–123. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Sun, Z.; Lin, L.; Eugene, G.Y.; Gaigalas, J. Exploring cloud-based Web Processing Service: A case study on the implementation of CMAQ as a service. Environ. Model. Softw. 2019, 113, 29–41. [Google Scholar] [CrossRef]
- Gaigalas, J.; Di, L.; Sun, Z. Advanced Cyberinfrastructure to Enable Search of Big Climate Datasets in THREDDS. ISPRS Int. J. Geo Inf. 2019, 8, 494. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Sun, Z.; Eugene, G.Y.; Hu, L.; Lin, L.; Tang, J.; Rahman, M.S. Integrating OGC Web Processing Service with cloud computing environment for Earth Observation data. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–4. [Google Scholar]
- Tan, X.; Guo, S.; Di, L.; Deng, M.; Huang, F.; Ye, X.; Sun, Z.; Gong, W.; Sha, Z.; Pan, S. Parallel Agent-as-a-Service (P-AaaS) Based Geospatial Service in the Cloud. Remote Sens. 2017, 9, 382. [Google Scholar] [CrossRef]
- Roy, D.P.; Wulder, M.; Loveland, T.; Woodcock, C.; Allen, R.; Anderson, M.; Helder, D.; Irons, J.; Johnson, D.; Kennedy, R. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Zhang, C.; Fang, H.; Yu, E.; Lin, L.; Tan, X.; Guo, L.; Chen, Z.; Yue, P. Establish cyberinfrastructure to facilitate agricultural drought monitoring. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–4. [Google Scholar]
- Sun, Z.; Yue, P.; Hu, L.; Gong, J.; Zhang, L.; Lu, X. GeoPWProv: Interleaving Map and Faceted Metadata for Provenance Visualization and Navigation. Geosci. Remote Sens. 2013, 51, 5131–5136. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Atomic Process | Workflow Language | License |
|---|---|---|---|
| ArcGIS Model Builder | ArcGIS toolbox | Self-Defined | Commercial |
| QGIS Processing Builder | GDAL, QGIS, GRASS, SAGA | Self-Defined | GNU GPL (General Public License) |
| Apache Taverna | Local Java code SOAP web services RESTful services R processor Shell scripts Xpath scripts | SCUFL2 | Apache v2.0 |
| Kepler | Web services Unix commands Shell scripts | Kepler Archive | BSD (Berkeley Software Distribution) |
| Cylc | Shell scripts | Directed Acyclic Graph | GPL v3.0 |
| Galaxy | Built-in bio process | Gxformat2 | AFL (Academic Free License) |
| Pegasus-WMS | Local shell scripts Built-in processes | DAX | Apache v2.0 |
| Apache Airflow | Bash, Python | Directed Acyclic Graph | Apache v2.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Di, L.; Burgess, A.; Tullis, J.A.; Magill, A.B. Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows. ISPRS Int. J. Geo-Inf. 2020, 9, 119. https://doi.org/10.3390/ijgi9020119
Sun Z, Di L, Burgess A, Tullis JA, Magill AB. Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows. ISPRS International Journal of Geo-Information. 2020; 9(2):119. https://doi.org/10.3390/ijgi9020119
Chicago/Turabian StyleSun, Ziheng, Liping Di, Annie Burgess, Jason A. Tullis, and Andrew B. Magill. 2020. "Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows" ISPRS International Journal of Geo-Information 9, no. 2: 119. https://doi.org/10.3390/ijgi9020119
APA StyleSun, Z., Di, L., Burgess, A., Tullis, J. A., & Magill, A. B. (2020). Geoweaver: Advanced Cyberinfrastructure for Managing Hybrid Geoscientific AI Workflows. ISPRS International Journal of Geo-Information, 9(2), 119. https://doi.org/10.3390/ijgi9020119