OurPlaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services




Abstract
1. Introduction
- (a)
- We propose the OurPlaces crowdsourcing platform to collect cognitive feedback from users regarding similar tourism places.
- (b)
- We built the three-layered architecture to extract the cognitive similarities among users.
- (c)
- We deployed a recommendation system based on the cognitive similarities among users (k-nearest neighbors) extracted from the three-layered architecture.
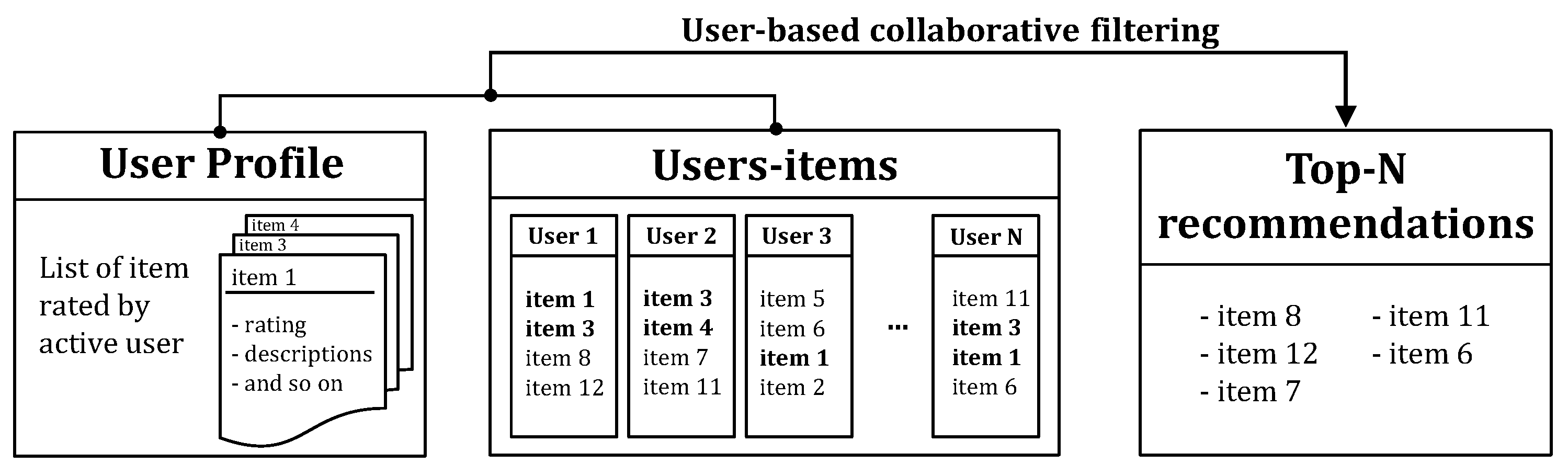
2. Related Work
3. Crowdsourcing Platform for Measuring Cognitive Similarity
3.1. Cognitive Similarity Measurements
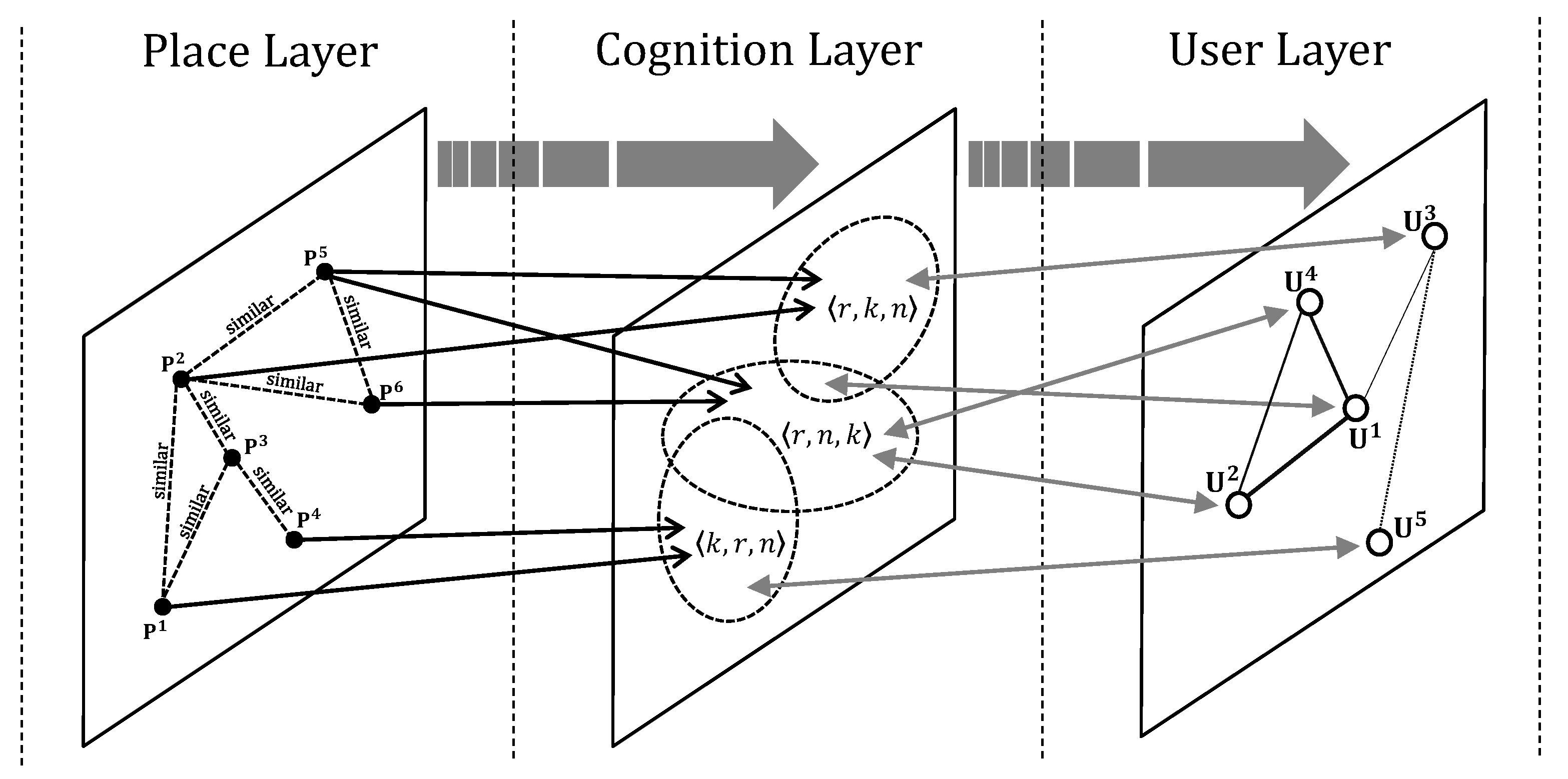
3.2. Three-Layered Architecture for Cognitive Similarity
- Place Layer: In the place network of place layer, the nodes and edges represent tourist places and their relations, respectively. The relations between the nodes are the similarity between tourist places. A place network is a directed graph , where is the set of tourist places and is the set of relations between these tourist places. In this study, the relationship between tourism places was measured by using cosine similarity metric following Equation (1).
- Cognition Layer: In this layer, the cognition network is determined as a network where and are the set of the cognition pattern from groups of users and the relationship between these groups, respectively. These groups are determined and classified based on the cognition pattern of each user as mentioned in Section 3.1. The objective relationship between the and defined through the priority in selecting similar pairs of tourism places by users. These relationship are expressed by a relation: .
- User Layer: In this layer, the user network consists of nodes and relations, which are users and numerous kinds of relationships, respectively. Therefore, the user network is defined as a network , in which is a set of entity of a user and is the relationship between these entities. These relations are extracted through the objective relationship from to based on the extraction of user groups who have cognition pattern similarity. They can be expressed by a relation: .
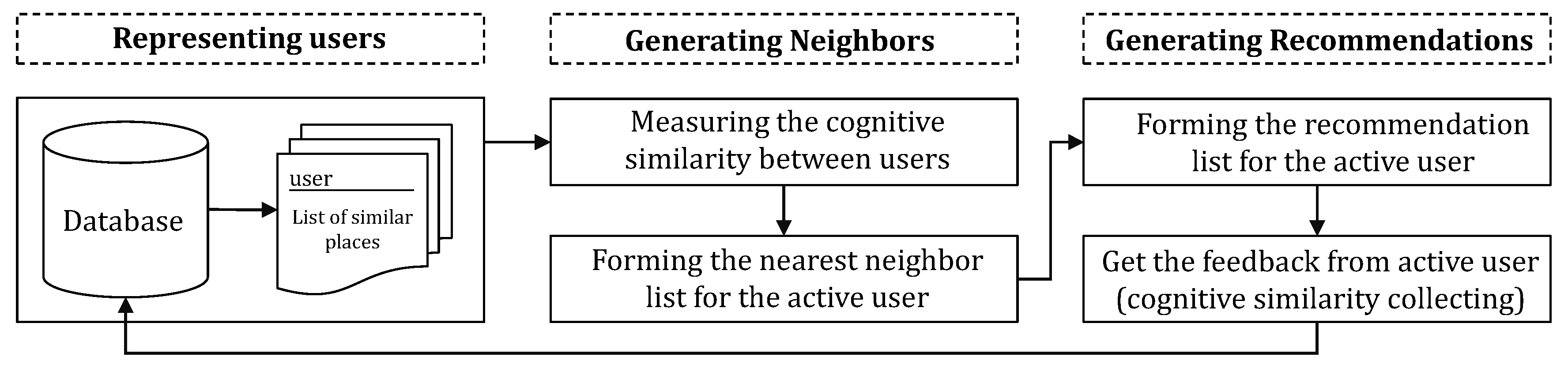
4. Cross-Cultural Recommendation: A Case Study
- Representing the information based on the history of user activities: The priority in selecting similar tourism places of users needs to be analyzed and modeled (user cognition pattern).
- Generating the neighbors of the active user: The cognitive similarities between users can be extracted from the three-layer architecture according to the collected datasets from users and the collaborative filtering algorithm.
- Generating tourism place recommendations: The top-N tourism places are recommended to the active user according to the activity history of the neighbors.
4.1. Users Representation
4.2. Generation of Neighbors
4.3. Generation of Recommendations
5. Experiments
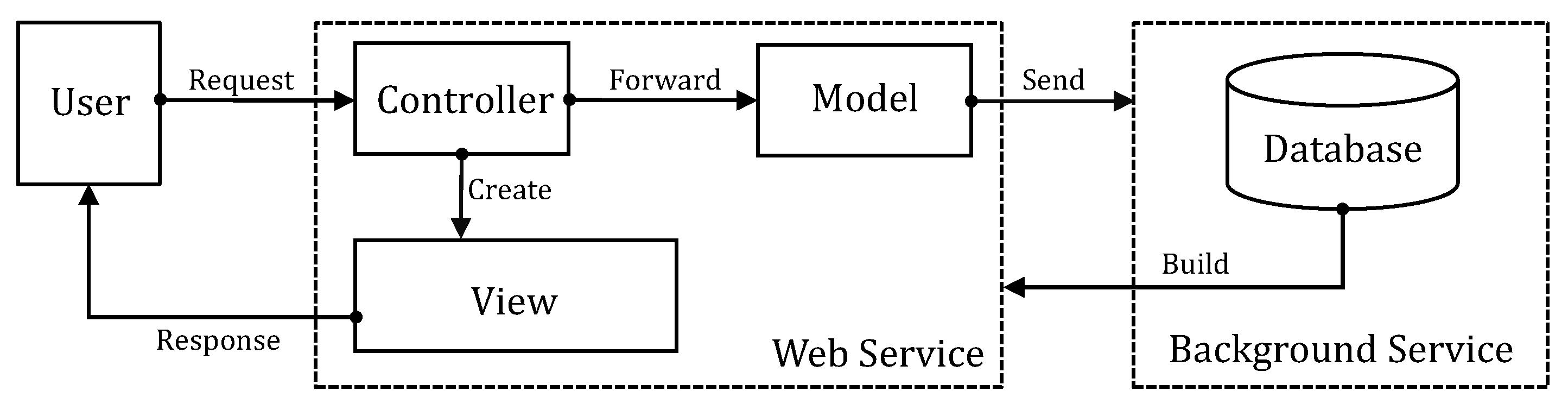
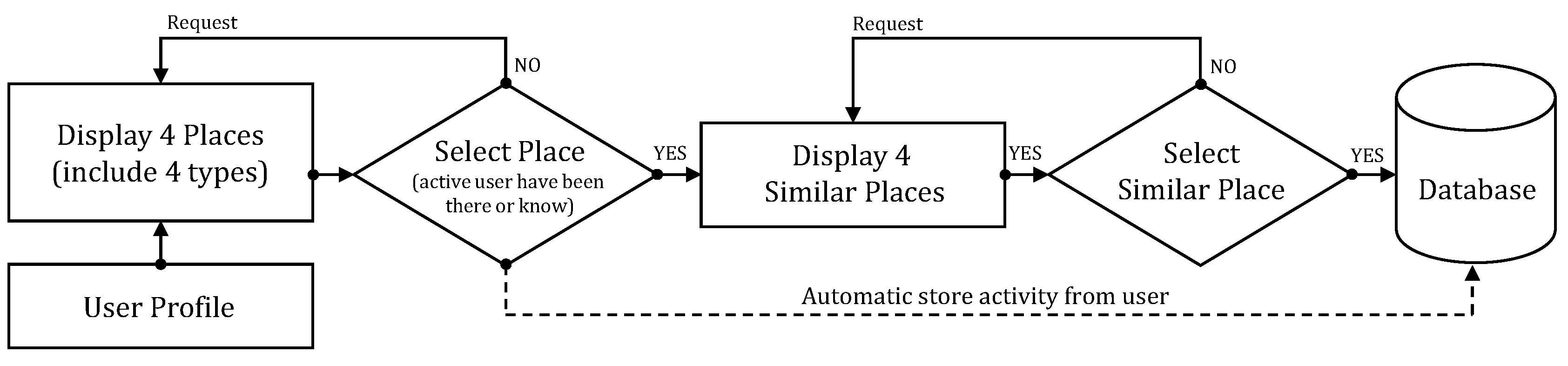
5.1. Overview of OurPlaces Crowdsourcing Platform
- (a)
- During the first step, the OurPlaces platform displays the four types of tourism places (hotels, restaurants, shopping malls, and attractions) based on the country information, and new users then select the tourism places that they are aware of and/or have been to.
- (b)
- During the second step, the platform suggests a list of four similar tourism places (dependent on the type of place and accompanied by an that is initially set to 1 for new users parameter, which is the selecting trend of the user). The user then selects a tourism place they think is similar to the one they have chosen during the first step.
- (c)
- During the final step, the platform stores cognitive feedback from the users in the database and re-calculates the parameter for the suggestion process when the user has a new selection (start a new loop).
5.2. Statistics of Cognitive Feedbacks
5.3. Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Sebastia, L.; Garcia, I.; Onaindia, E.; Guzman, C. e-Tourism: A Tourist Recommendation and Planning Application. Int. J. Artif. Intell. Tools 2009, 18, 717–738. [Google Scholar] [CrossRef]
- Loh, S.; Lorenzi, F.; Salda na, R.; Licthnow, D. A Tourism Recommender System Based on Collaboration and Text Analysis. Inf. Technol. Tour. 2003, 6, 157–165. [Google Scholar] [CrossRef]
- Borràs, J.; Moreno, A.; Valls, A. Intelligent Tourism Recommender Systems: A Survey. Expert Syst. Appl. 2014, 41, 7370–7389. [Google Scholar] [CrossRef]
- Ekstrand, M.D.; Riedl, J.T.; Konstan, J.A. Collaborative Filtering Recommender Systems; Now Publishers Inc.: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Jung, J.J. Crowdsourcing Platform for Collecting Cognitive Feedbacks from Users: A Case Study on Movie Recommender System. In Springer Series in Reliability Engineering; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 139–150. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Hong, M.S.; Jung, J.J.; Sohn, B.S. Cognitive Similarity-Based Collaborative Filtering Recommendation System. Appl. Sci. 2020, 10, 4183. [Google Scholar] [CrossRef]
- Van Pelt, C.; Sorokin, A. Designing a Scalable Crowdsourcing Platform. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; ACM Press: New York, NY, USA, 2012; pp. 765–766. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Zhao, Z.D.; Shang, M.S. User-based Collaborative-Filtering Recommendation Algorithms on Hadoop. In Proceedings of the Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010; pp. 478–481. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized Entity Recommendation: A Heterogeneous Information Network Approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; ACM Press: New York, NY, USA, 2014; pp. 283–292. [Google Scholar] [CrossRef]
- Xue, G.R.; Lin, C.; Yang, Q.; Xi, W.; Zeng, H.J.; Yu, Y.; Chen, Z. Scalable Collaborative Filtering Using Cluster-based Smoothing. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; ACM Press: New York, NY, USA, 2005; pp. 114–121. [Google Scholar] [CrossRef]
- Wang, J.; De Vries, A.P.; Reinders, M.J. Unifying User-based and Item-based Collaborative Filtering Approaches by Similarity Fusion. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; ACM Press: New York, NY, USA, 2006; pp. 501–508. [Google Scholar] [CrossRef]
- Meng, S.; Dou, W.; Zhang, X.; Chen, J. KASR: A Keyword-aware Service Recommendation Method on Mapreduce for Big Data applications. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3221–3231. [Google Scholar] [CrossRef]
- Thakkar, P.; Varma, K.; Ukani, V.; Mankad, S.; Tanwar, S. Combining User-based and Item-based Collaborative Filtering using Machine Learning. Inf. Commun. Technol. Intell. Syst. 2019, 15, 173–180. [Google Scholar]
- Kant, S.; Mahara, T. Merging User and Item based Collaborative Filtering to Alleviate Data Sparsity. Int. J. Syst. Assur. Eng. Manag. 2018, 9, 173–179. [Google Scholar] [CrossRef]
- Quinn, A.J.; Bederson, B.B. Human Computation: A Survey and Taxonomy of a Growing Field. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI’11, New York, NY, USA, 7 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1403–1412. [Google Scholar] [CrossRef]
- Von Ahn, L.; Dabbish, L. Designing Games with a Purpose. Commun. ACM 2008, 51, 58–67. [Google Scholar] [CrossRef]
- Amsterdamer, Y.; Grossman, Y.; Milo, T.; Senellart, P. Crowdminer: Mining Association Rules from The Crowd. Proc. VLDB Endow. 2013, 6, 1250–1253. [Google Scholar] [CrossRef]
- Amsterdamer, Y.; Grossman, Y.; Milo, T.; Senellart, P. Crowd Mining. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 241–252. [Google Scholar] [CrossRef]
- Sheehan, K.B. Crowdsourcing Research: Data Collection with Amazon’s Mechanical Turk. Commun. Monogr. 2018, 85, 140–156. [Google Scholar] [CrossRef]
- Libert, B.; Spector, J.; Tapscott, D. We are Smarter than Me: How to Unleash the Power of Crowds in Your Business; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Brabham, D.C.; Sanchez, T.W.; Bartholomew, K. Crowdsourcing Public Participation in Transit Planning: Preliminary Results from The Next Stop Design Case. In Proceeding of the Transportation Research Board 89th Annual Meeting, Washington, DC, USA, 10–14 January 2010; pp. 10–37. [Google Scholar]
- Budde, A.; Michahelles, F. Towards An Open Product Repository Using Playful Crowdsourcing. In Service Science—Neue Perspektiven für die Informatik. Band 1; INFORMATIK: Lepizig, Germany, 2010; pp. 600–605. [Google Scholar]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A New User Similarity Model to Improve the Accuracy of Collaborative Filtering. Knowl.-Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef]
- Galitz, W.O. The Essential Guide to User Interface Design: An Introduction to GUI Design Principles and Techniques; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Mandel, T. The Elements of User Interface Design Vol. 20; Wiley: New York, NY, USA, 1997. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users | Similar Tourism Place | |||
|---|---|---|---|---|
| , | , | , | , | |
| R = 0.87; K = 0.78; N = 0.67 | R = 0.59; K = 0.64; N = 0.73 | 0 | R = 0.51; K = 0.58; N = 0.43 | |
| R = 0.87; K = 0.78; N = 0.67 | R = 0.59; K = 0.64; N = 0.73 | R = 0.66; K = 0.71; N = 0.66 | 0 | |
| R = 0.87; K = 0.78; N = 0.67 | 0 | 0 | R = 0.51; K = 0.58; N = 0.43 | |
| R = 0.87; K = 0.78; N = 0.67 | R = 0.59; K = 0.64; N = 0.73 | R = 0.66; K = 0.71; N = 0.66 | 0 | |
| 0 | R = 0.59; K = 0.64; N = 0.73 | R = 0.66; K = 0.71; N = 0.66 | R = 0.51; K = 0.58; N = 0.43 | |
| # | Country | (#) Cities | (#) Places |
|---|---|---|---|
| 1 | South Korea | (7) Seoul; Busan; Daegu; Deajeon; Geoje; Incheon; Ulsan | 1306 |
| 2 | Vietnam | (3) Hanoi; Ho Chi Minh; Danang | 670 |
| 3 | Singapore | (1) Singapore | 240 |
| 4 | Thailand | (4) Bangkok; Phuket; Chiang Mai; Pattaya | 750 |
| 5 | India | (2) New Delhi; Mumbai | 334 |
| 6 | Japan | (4) Tokyo; Osaka; Kyoto; Fukuoka | 889 |
| 7 | China | (4) Beijing; Shanghai; Hong Kong; Macau | 1012 |
| 8 | England | (5) London; Manchester; Cambridge; Liverpool; Birmingham | 1211 |
| 9 | Spain | (5) Barcelona; Madrid; Seville; Malaga; Granada | 1128 |
| 10 | Germany | (3) Berlin; Munich; Hamburg | 875 |
| 11 | France | (3) Paris; Nice; Lyon | 768 |
| 12 | Greece | (2) Santorini; Athens | 305 |
| 13 | Austria | (2) Vienna; Langenfeld | 264 |
| 14 | Italy | (4) Rome; Milan; Venice; Turin | 657 |
| 15 | United States | (6) New York; Los Angeles; Miami; Chicago; Washington; San Francisco | 2083 |
| 16 | Brazil | (2) Rio de Janeiro; Sao Paulo | 330 |
| 17 | Argentina | (3) San Carlos de Bariloche; Pinamar; Buenos Aries | 453 |
| 18 | Colombia | (3) Bogota; Pereira; Salento | 450 |
| 19 | Uruguay | (2) Montevideo; La Paloma | 321 |
| 20 | Chile | (2) Santiago; Punta Arenas | 304 |
| 21 | Mexico | (2) Mexico City; Oaxaca | 332 |
| 22 | Canada | (4) Vancouver; Toronto; Montreal; Quebec City | 750 |
| 23 | Australia | (5) Melbourne; Sydney; Brisbane; Newcastle; Adelaide | 1200 |
| 24 | New Zealand | (6) Auckland; Queenstown; Wellington; Paihia; Wanaka; Hamilton | 1654 |
| Total | 84 cities | 18.286 |
| Number of Neighbors | MAE | RMSE | ||
|---|---|---|---|---|
| UBPS | Proposed Method | UBPS | Proposed Method | |
| 5 | 0.809 | 0.784 (+2.5%) | 1.203 | 1.162 (+4.1%) |
| 10 | 0.782 | 0.761 (+2.1%) | 1.145 | 1.108 (+3.7%) |
| 20 | 0.774 | 0.755 (+1.9%) | 0.997 | 0.964 (+3.3%) |
| 30 | 0.771 | 0.757 (+1.4%) | 0.854 | 0.823 (+3.1%) |
| 50 | 0.757 | 0.746 (+1.1%) | 0.791 | 0.769 (+2.2%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, L.V.; Jung, J.J.; Hwang, M. OurPlaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services. ISPRS Int. J. Geo-Inf. 2020, 9, 711. https://doi.org/10.3390/ijgi9120711
Nguyen LV, Jung JJ, Hwang M. OurPlaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services. ISPRS International Journal of Geo-Information. 2020; 9(12):711. https://doi.org/10.3390/ijgi9120711
Chicago/Turabian StyleNguyen, Luong Vuong, Jason J. Jung, and Myunggwon Hwang. 2020. "OurPlaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services" ISPRS International Journal of Geo-Information 9, no. 12: 711. https://doi.org/10.3390/ijgi9120711
APA StyleNguyen, L. V., Jung, J. J., & Hwang, M. (2020). OurPlaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services. ISPRS International Journal of Geo-Information, 9(12), 711. https://doi.org/10.3390/ijgi9120711